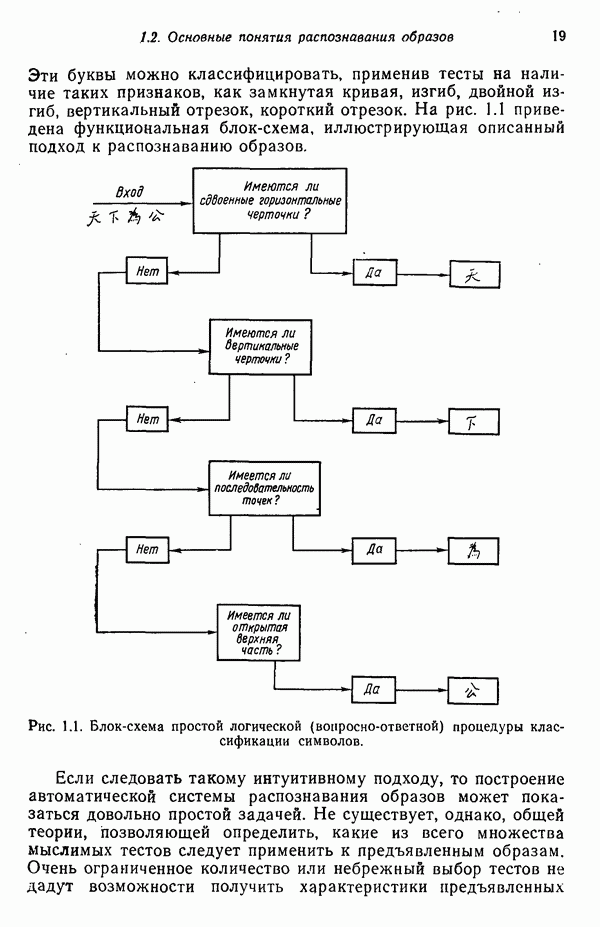
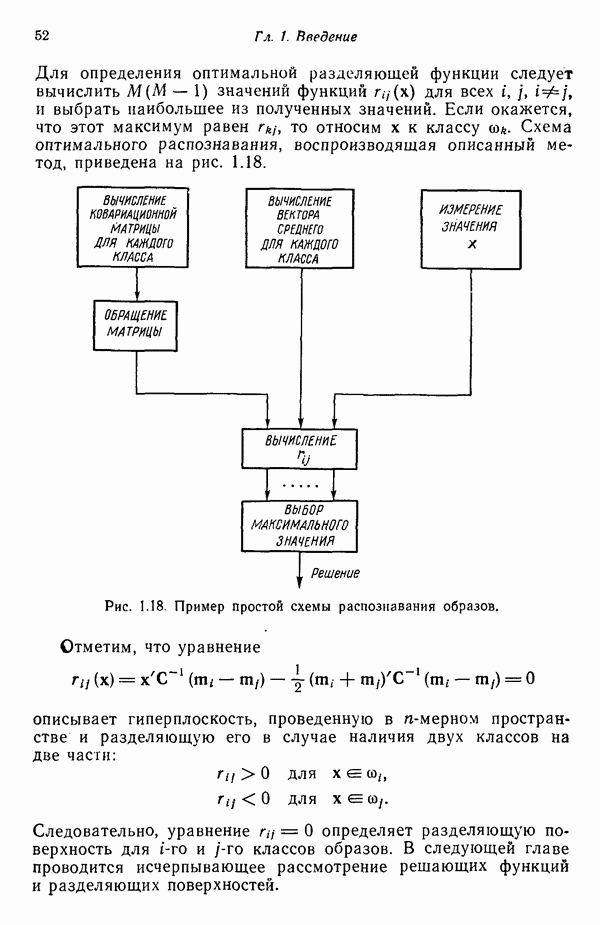
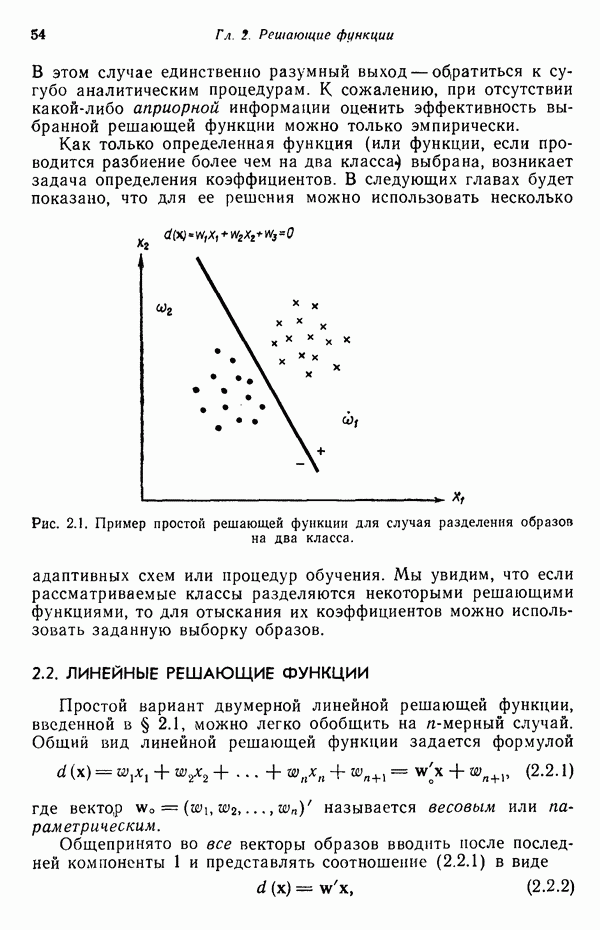
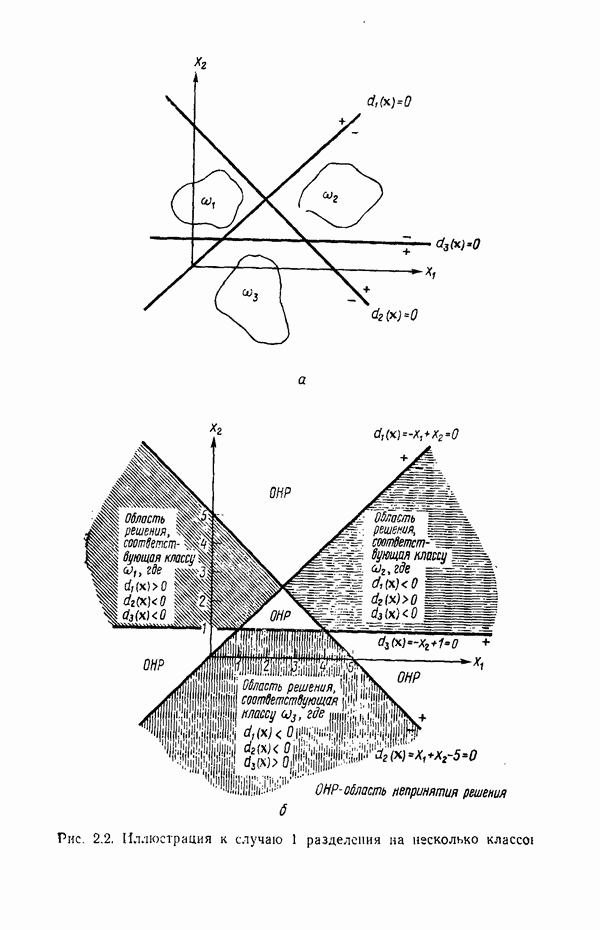
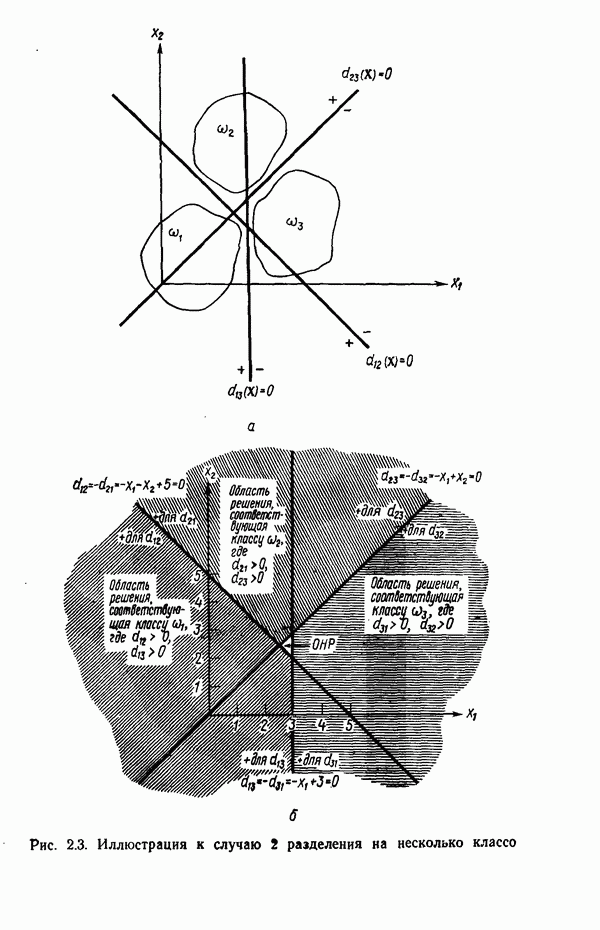
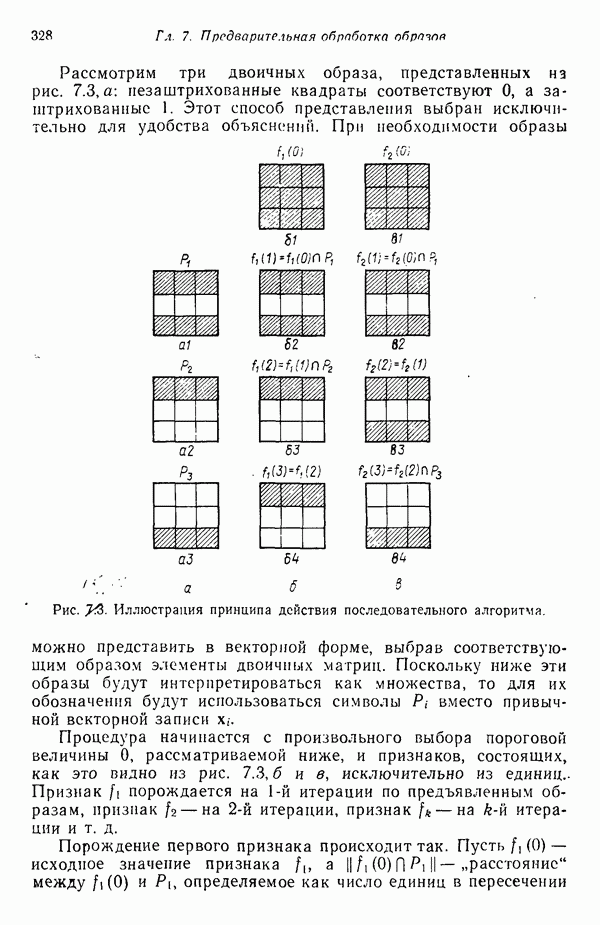
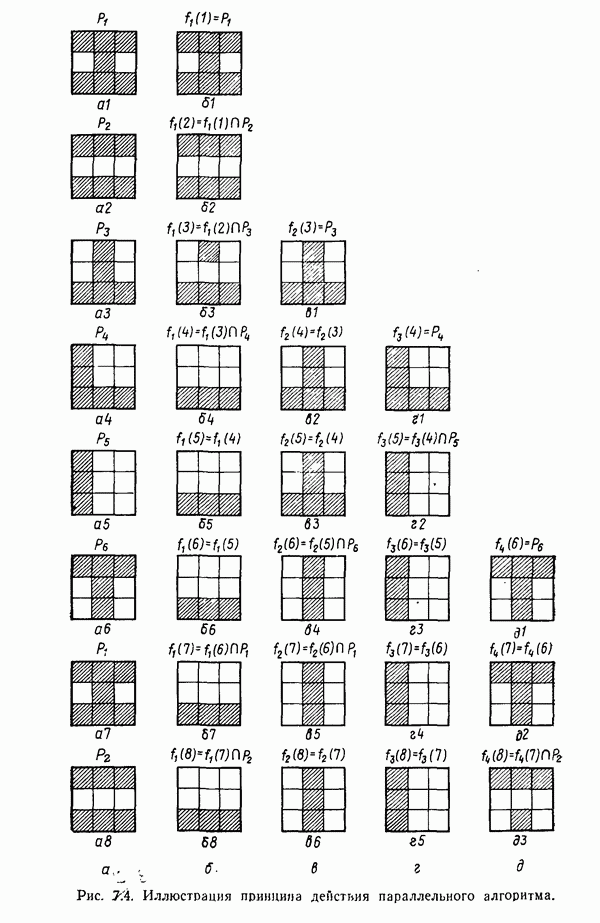
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
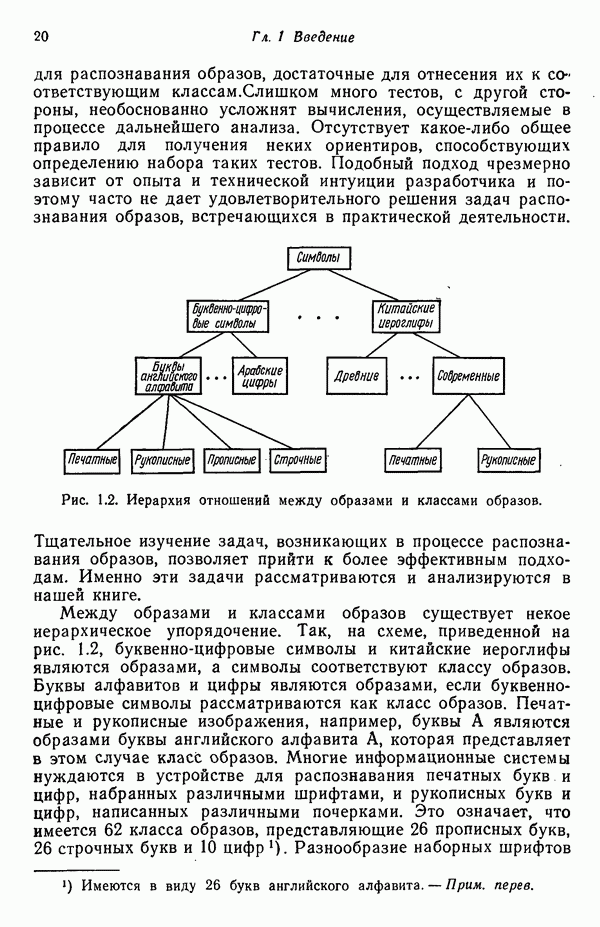
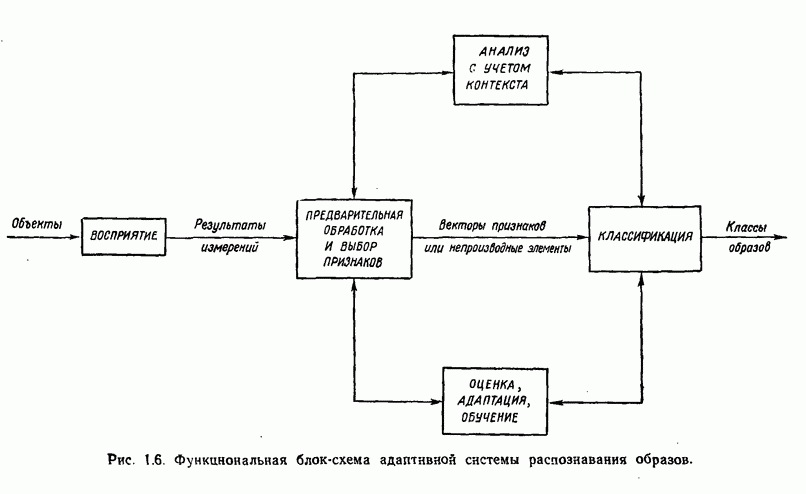
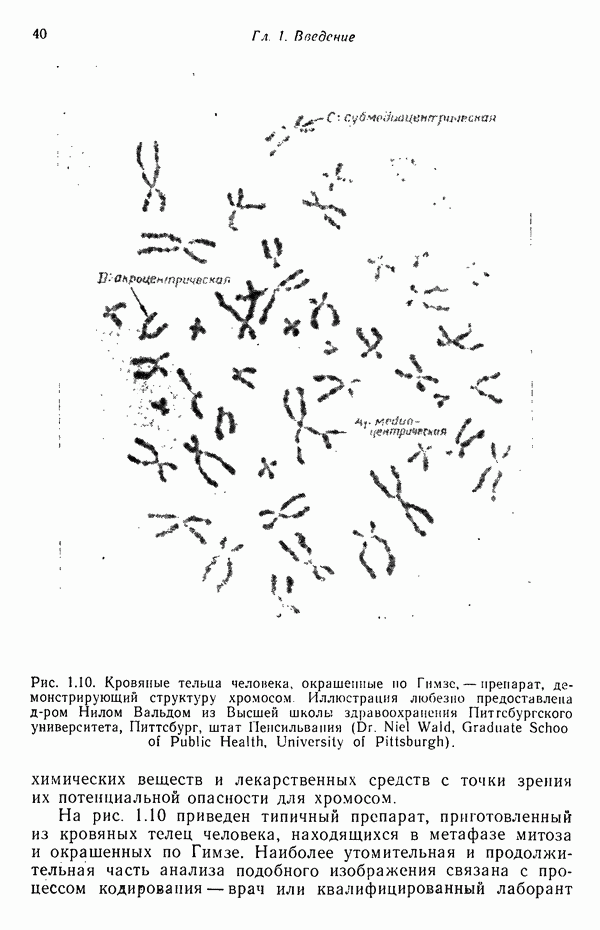
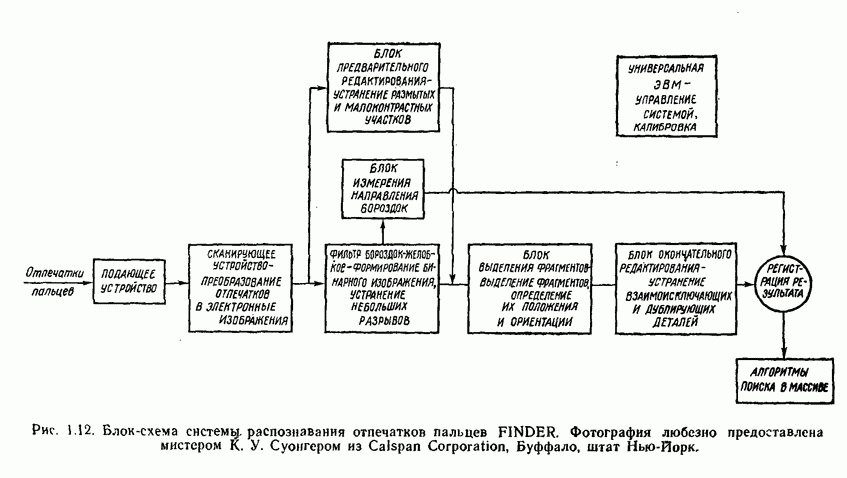
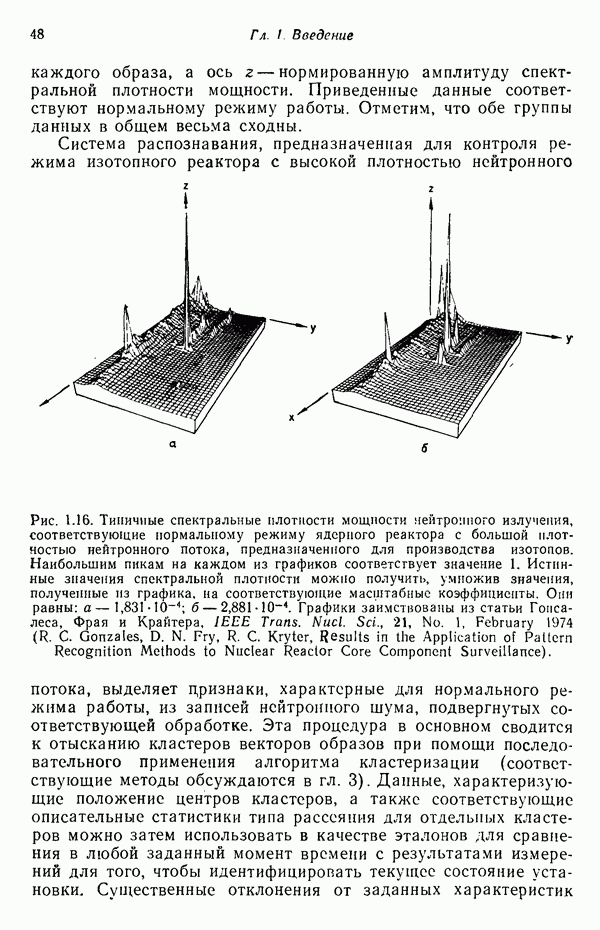
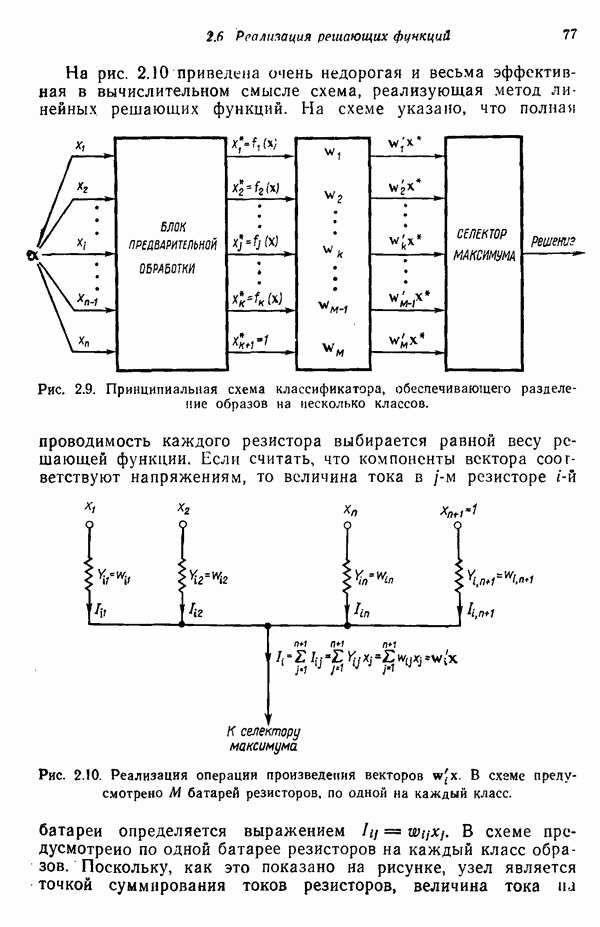
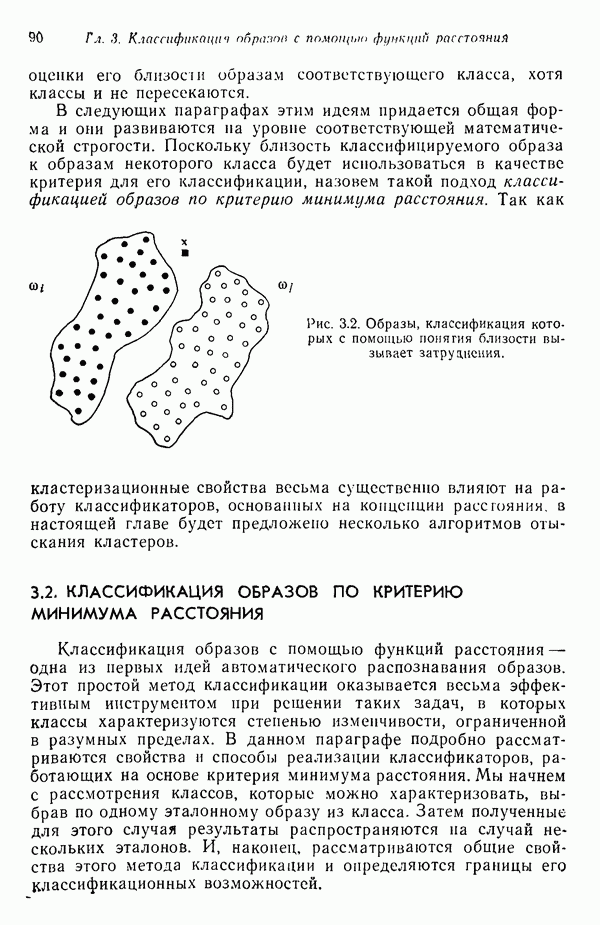
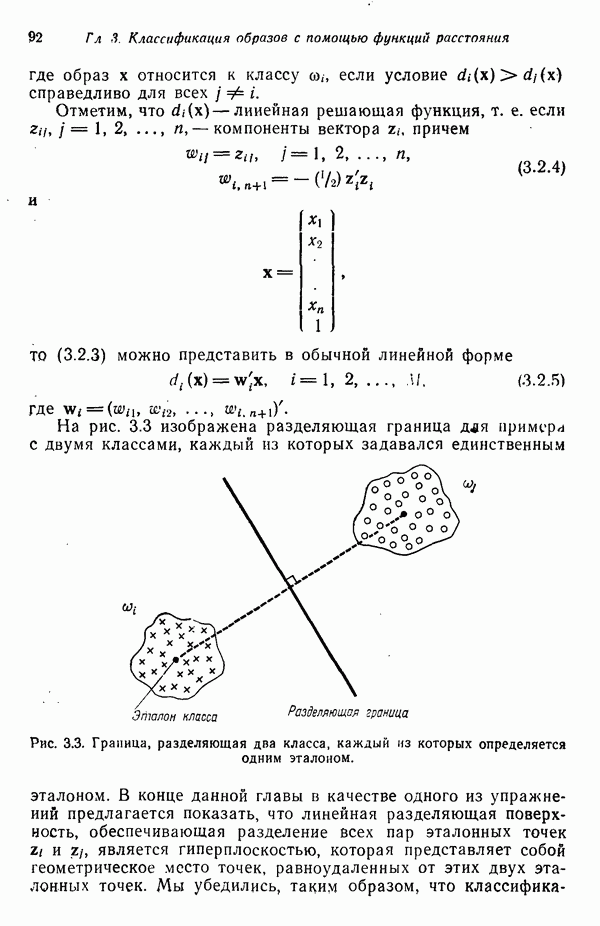
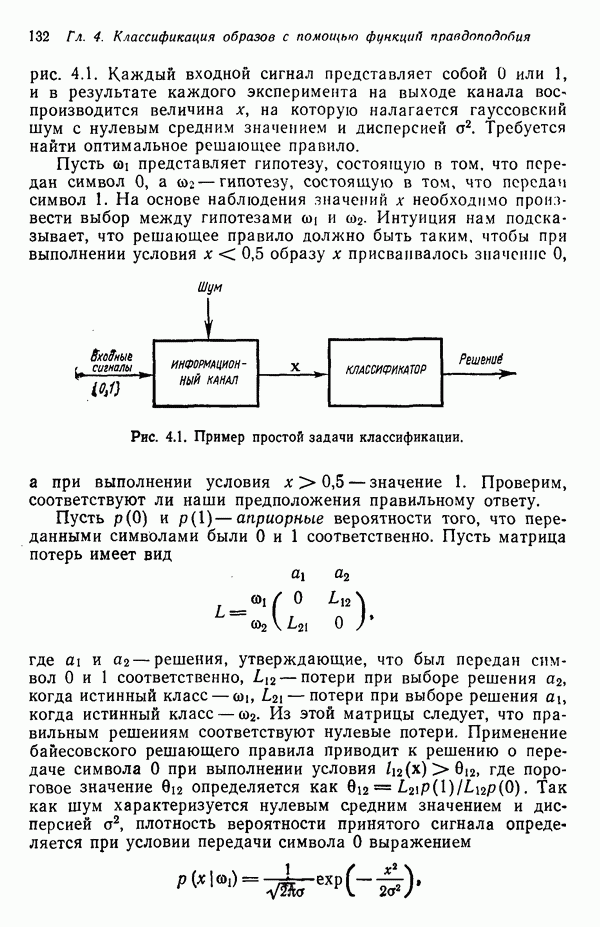
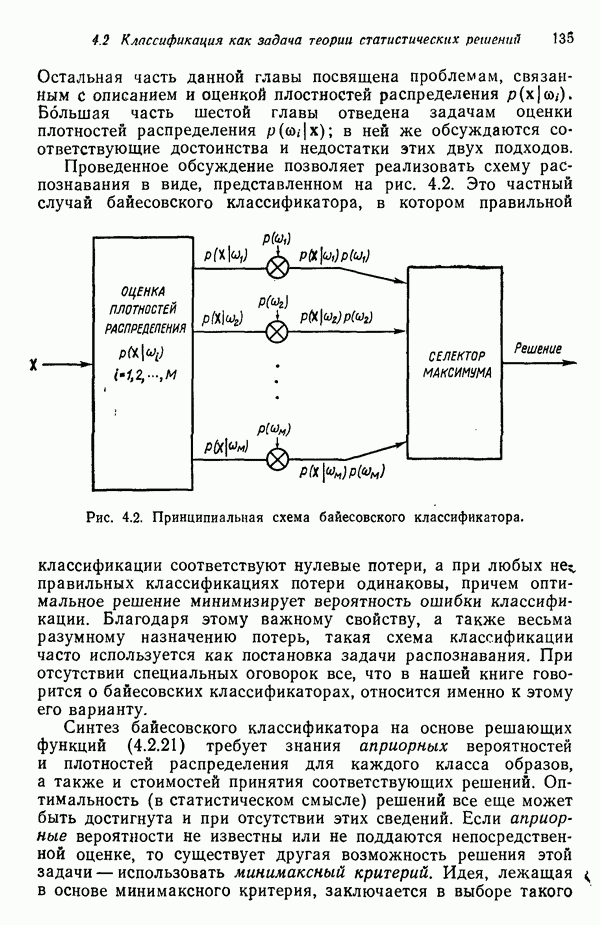
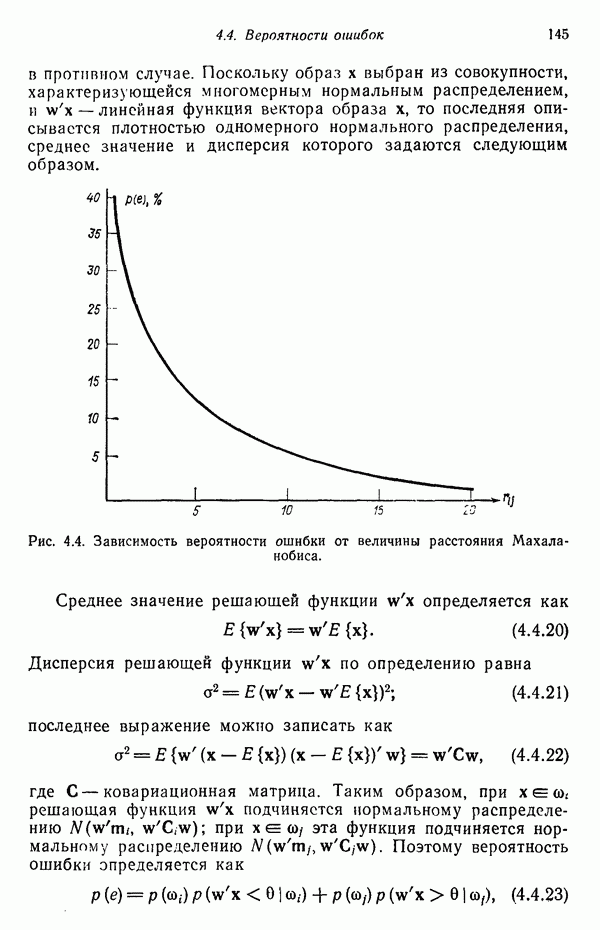
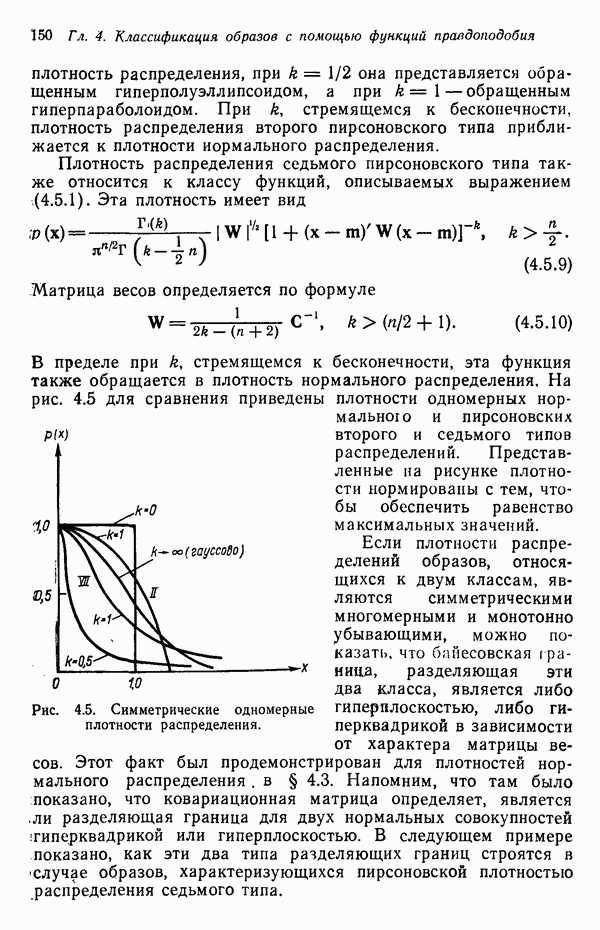
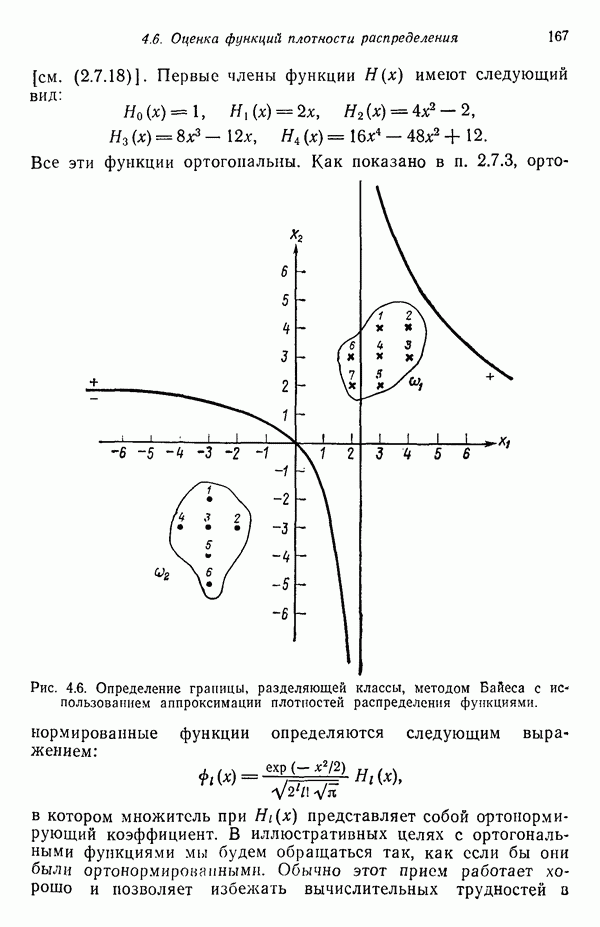
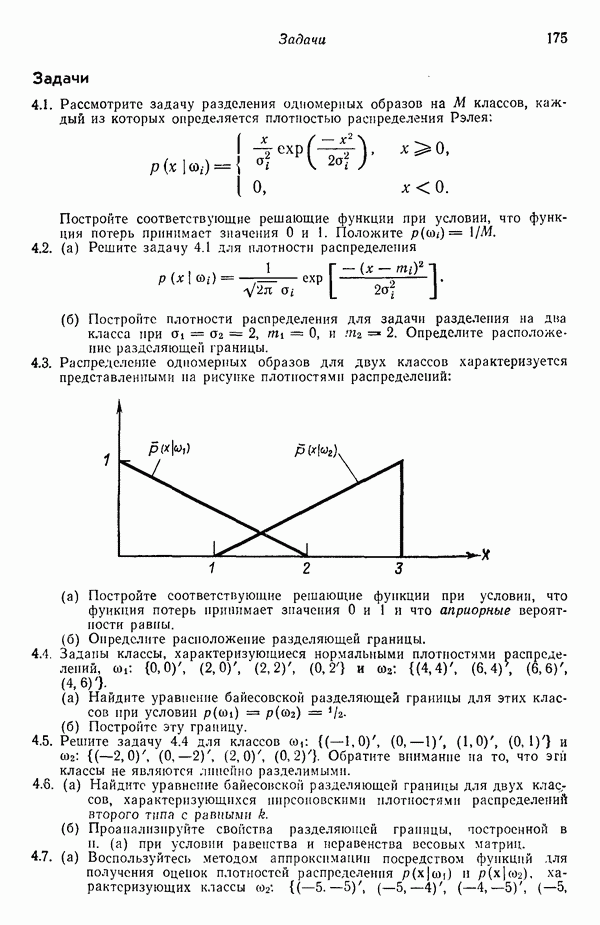
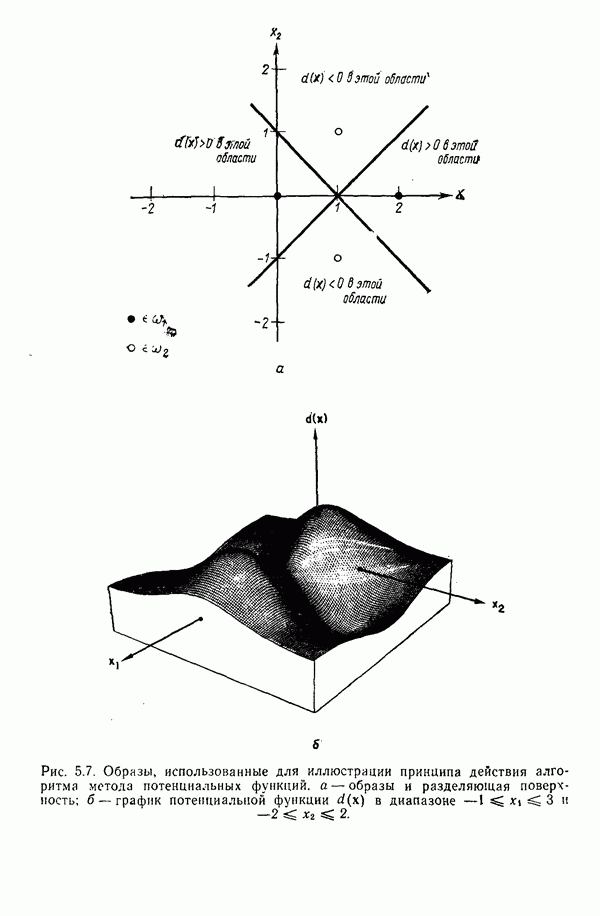
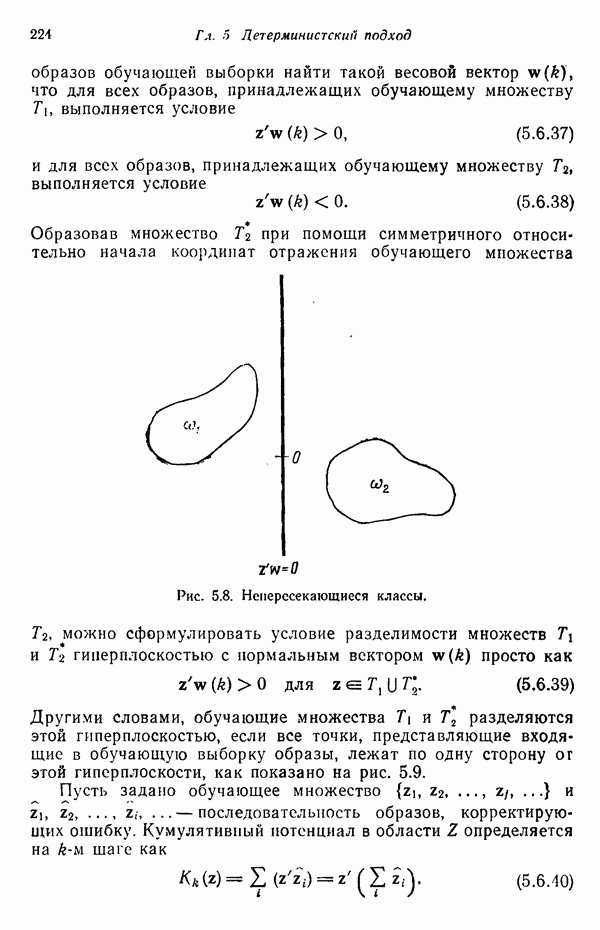
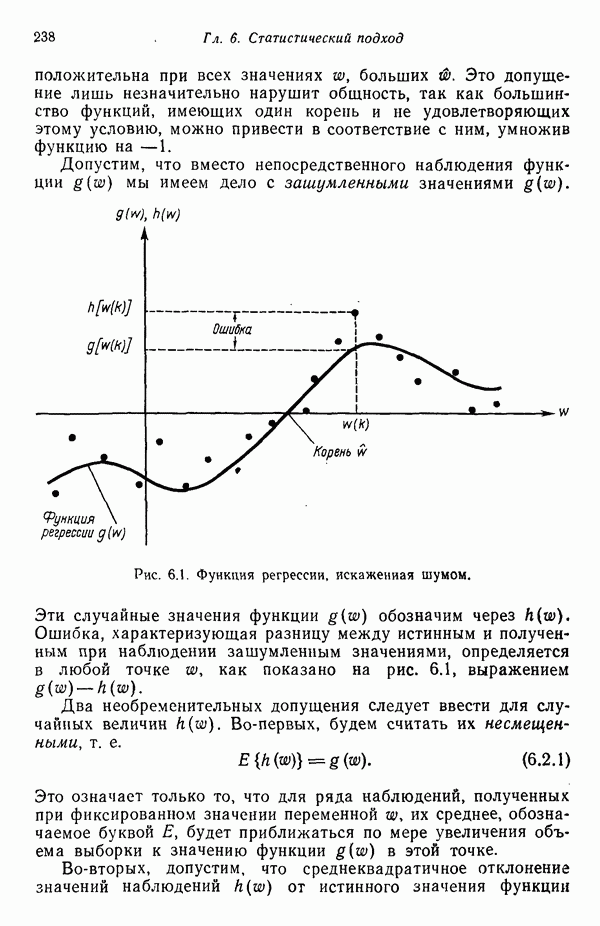
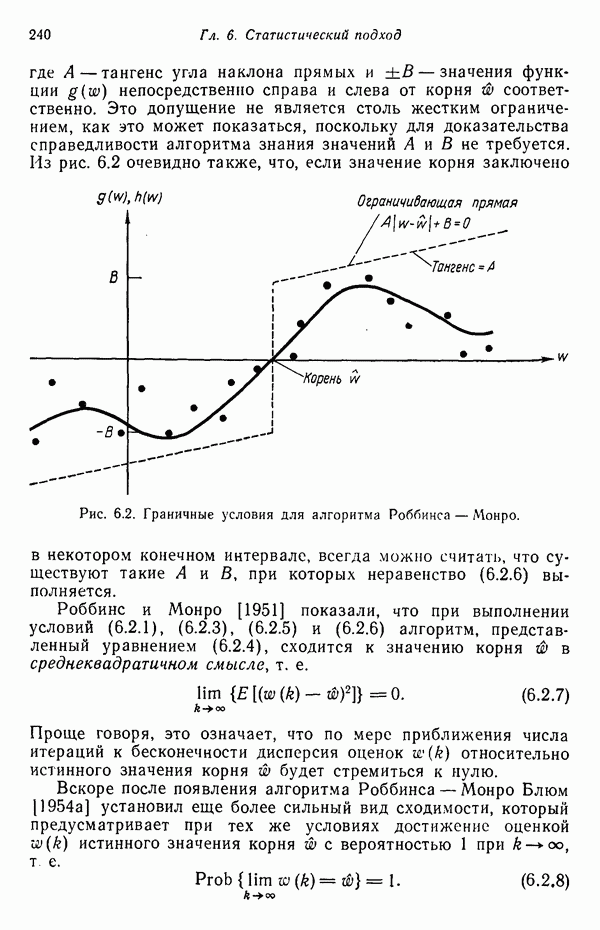
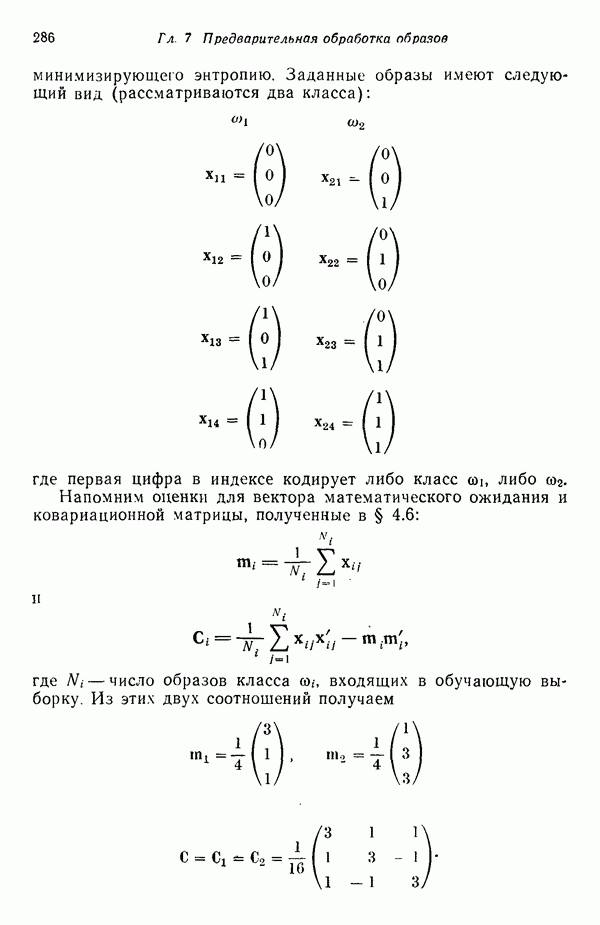
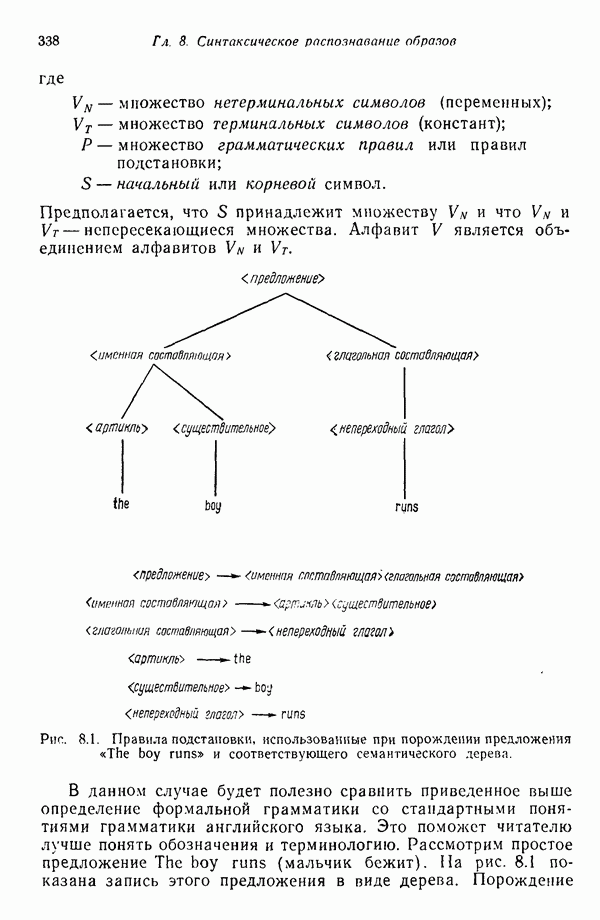
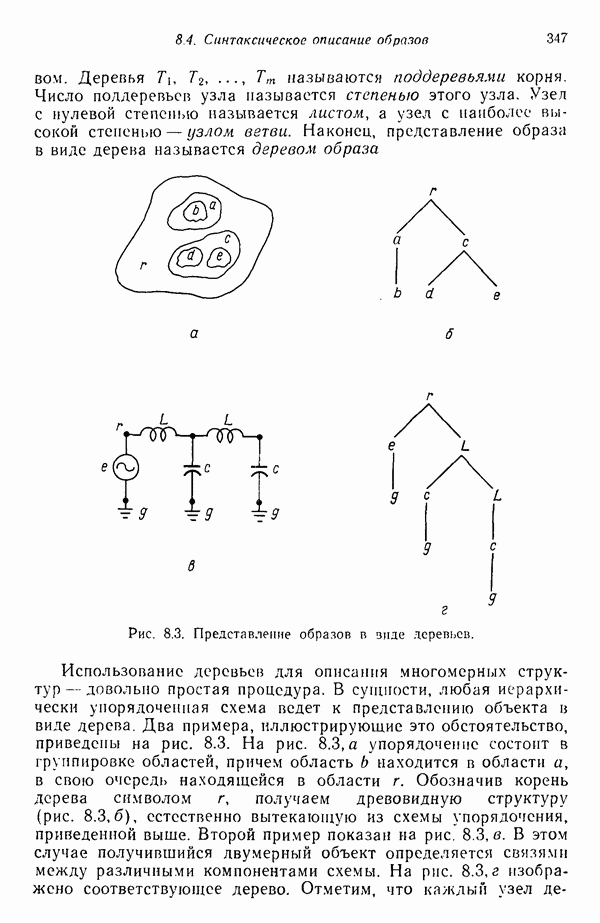
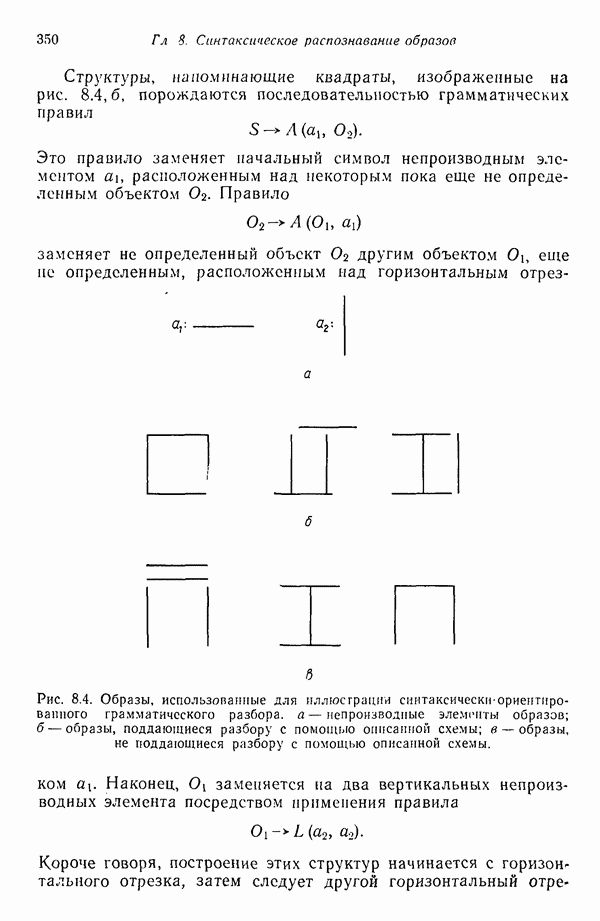
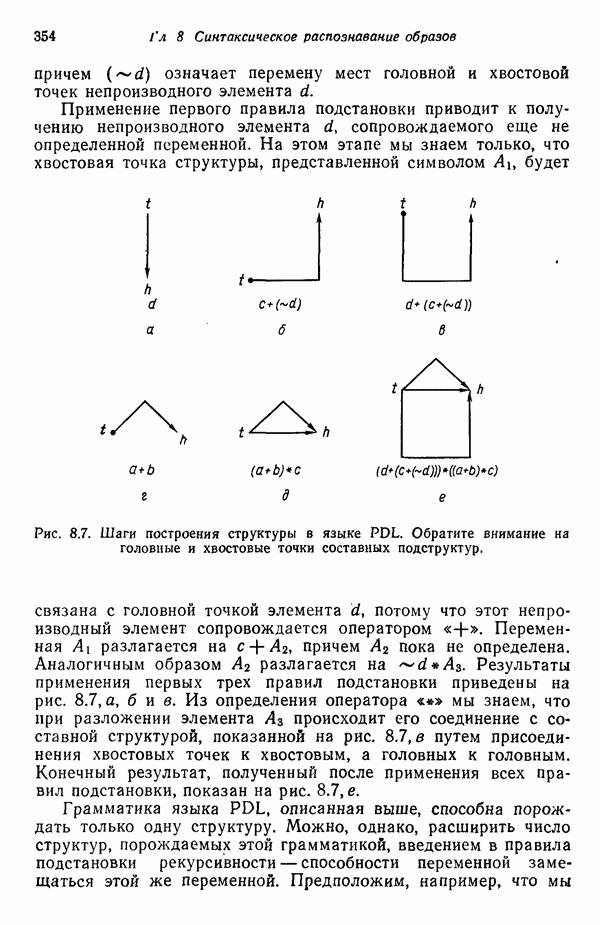
7.5. ВЫБОР ПРИЗНАКОВ ПРИ ПОМОЩИ МИНИМИЗАЦИИ ЭНТРОПИИЭнтропия представляет собой статистическую меру неопределенности. Хорошей мерой внутреннего разнообразия для заданного семейства векторов образов служит энтропия совокупности, определяемая как
где результату. Таким образом, если считать энтропию мерой неопределенности, то разумным правилом является выбор признаков, обеспечивающих минимизацию энтропии рассматриваемых классов. Поскольку это правило эквивалентно минимизации дисперсии в различных совокупностях образов, то вполне можно ожидать, что соответствующая процедура будет обладать кластеризационными свойствами. Рассмотрим М классов, соответствующие совокупности образов которых характеризуются плотностями распределения
где интегрирование осуществляется по пространству образов. Очевидно, что при Далее будет предполагаться, что каждая из М совокупностей образов характеризуется плотностью нормального распределения Основная идея, лежащая в основе рассматриваемых в данном параграфе методов, с учетом введенных допущений заключается в определении матрицы линейного преобразования А, переводящей заданные векторы образов в новые векторы меньшей размерности — изображения. Это преобразование можно представить как
причем матрица преобразования отыскивается при помощи минимизации энтропий совокупностей образов, входящих в рассматриваемые классы. Здесь собой вектор-строки. Таким образом, матрица А имеет вид
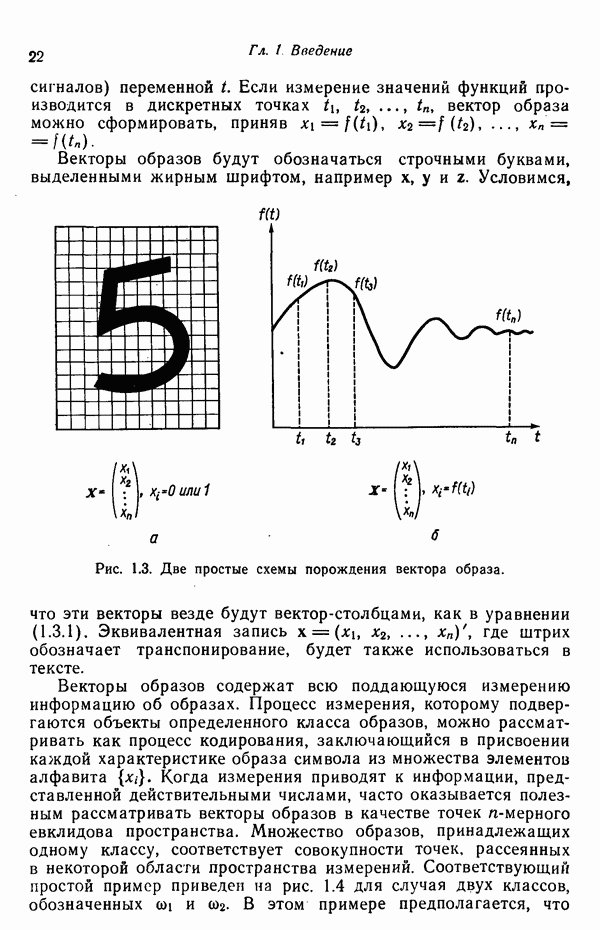
Задача состоит в определении такого способа выбора Многомерное нормальное распределение полностью определяется вектором математического ожидания и ковариационной матрицей. Эта матрица в свою очередь определяется характеристическими числами и собственными векторами. Последние можно рассматривать как векторы, представляющие свойства рассматриваемых образов. Часть из этих векторов свойств содержит меньше информации, ценной для распознавания, чем другие векторы, и поэтому ими можно пренебречь. Это явление приводит к процедуре выбора признаков, предусматривающей использование наиболее важных векторов свойств в качестве векторов-признаков. Такие векторы-признакн можно затем использовать для формирования матрицы преобразования А. Один из подходов к выбору векторов-признаков, использующий принцип минимума энтропии, состоит в следующем. В силу предположения о равенстве всех ковариационных матриц положим
Вектор математического ожидания для изображений у, обозначенный через
Положив
В таком случае ковариационная матрица для изображений равна
так как Плотность распределения для изображений определяется, исходя из (7.5.6) и (7.5.9), как
Энтропия изображений равна
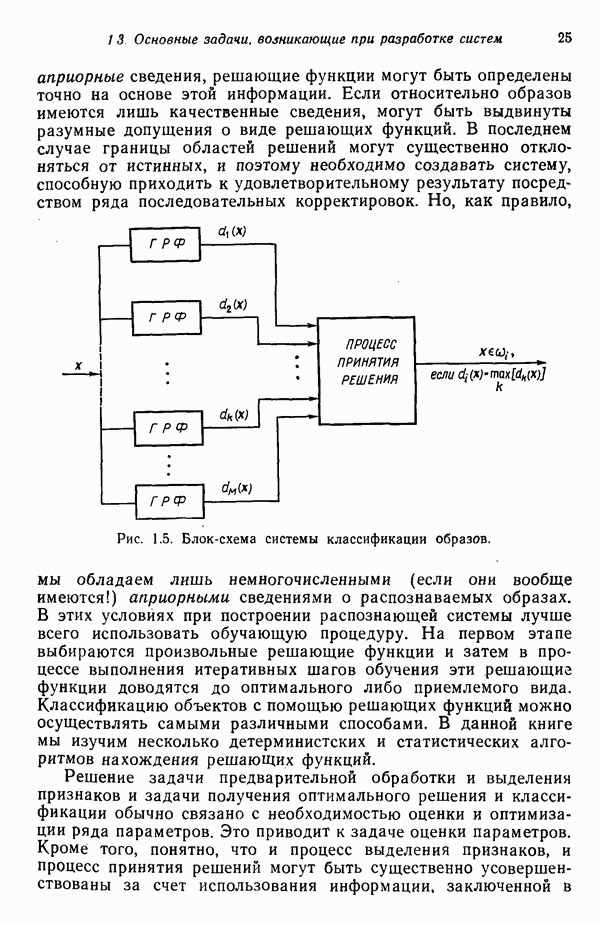
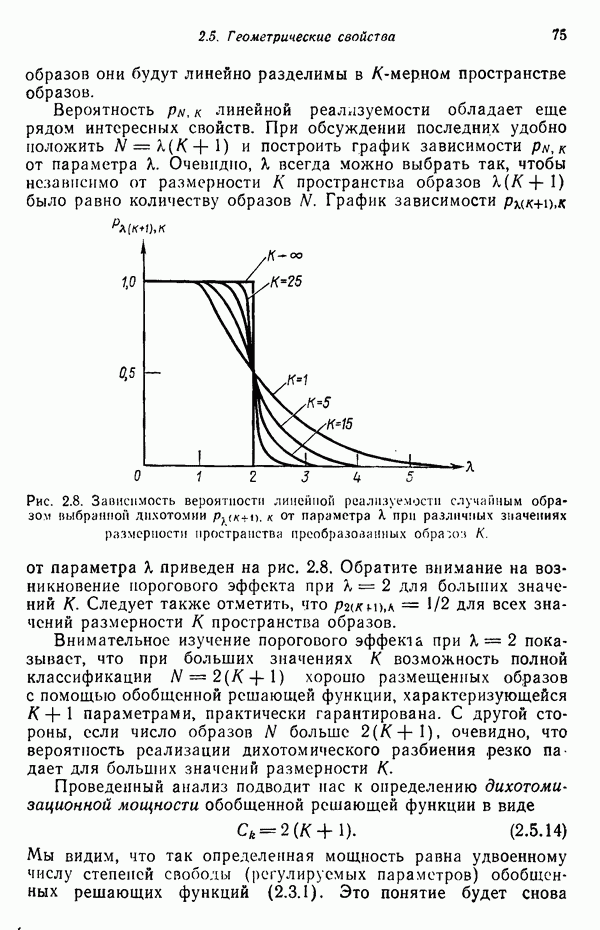
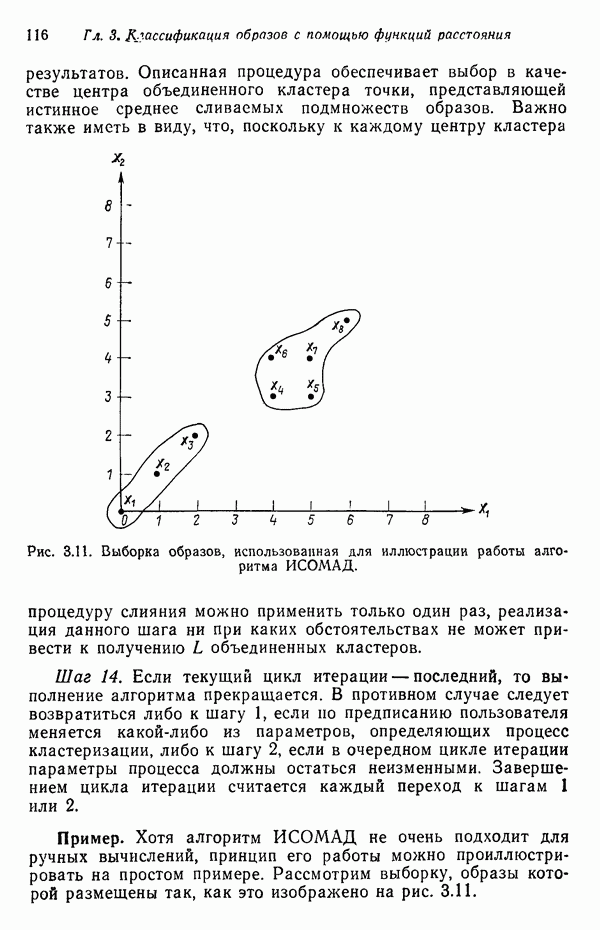
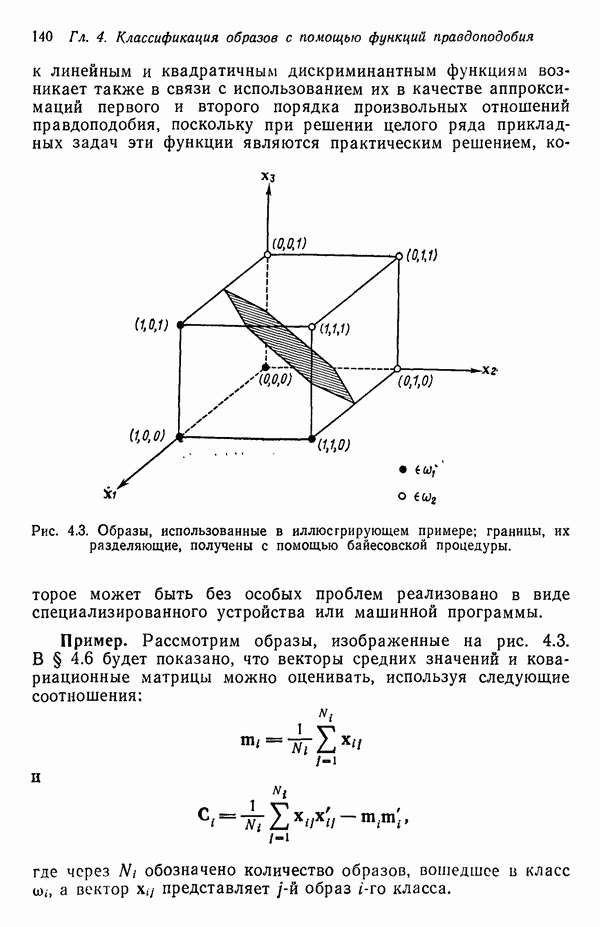
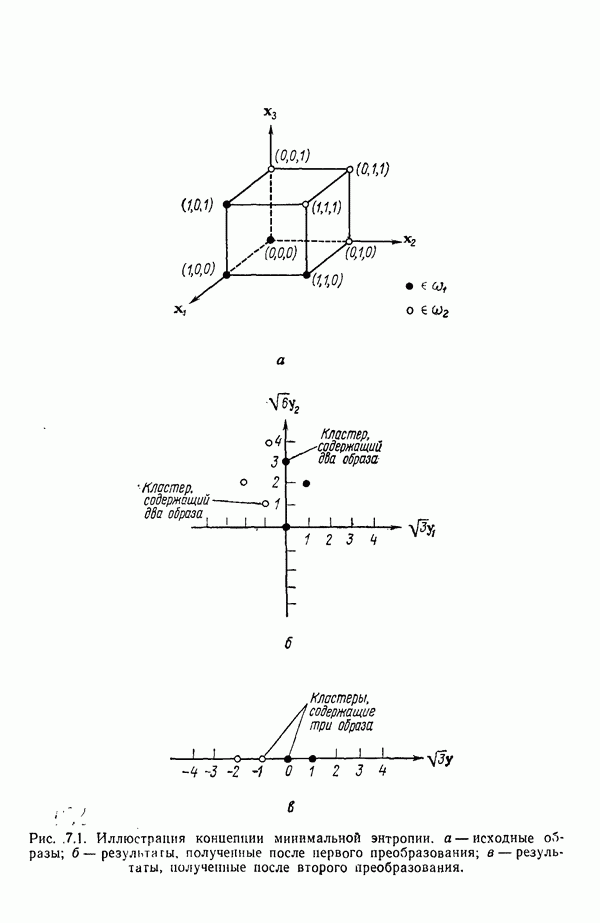
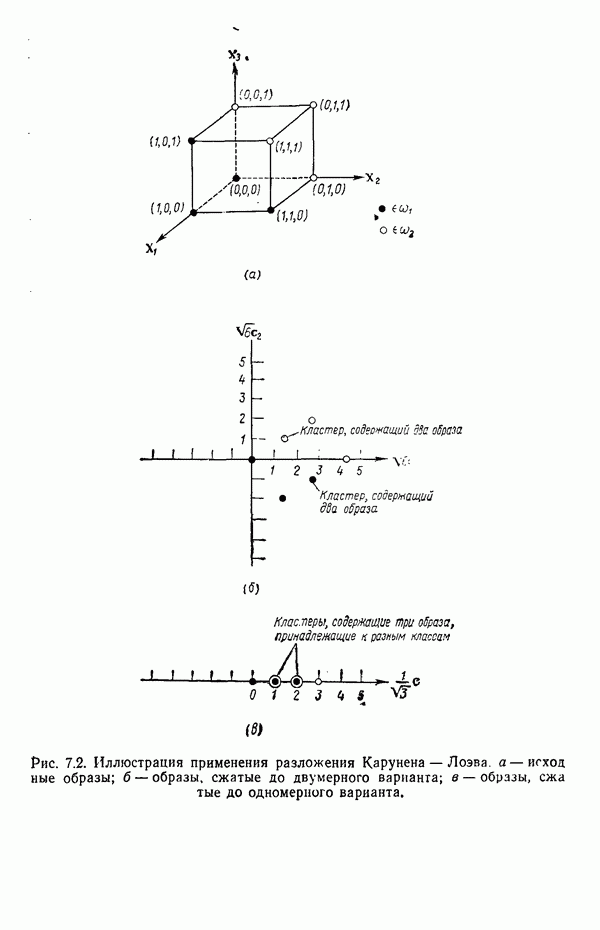
Подстановка выражения для плотности распределения (7.5.10) в выражение для энтропии (7.5.11) и минимизация относительно собственных векторов ковариационной матрицы С позволяют сформулировать следующий результат: Функция энтропии Применяя этот результат, надо иметь в виду, что число векторов, используемых для формирования матрицы А, должно быть достаточно большим, чтобы изображения несли достаточное количество различительной информации. Следует четко представлять себе разницу между выбором и выделением признаков. В данном параграфе процедура выбора признаков сводится к выбору в качестве признаков Пример. Проиллюстрируем описанную процедуру простым примером. Допустим, что требуется понизить размерность образов, представленных на рис. 7.1, а, с помощью преобразования,
(кликните для просмотра скана)
(кликните для просмотра скана) Характеристические числа ковариационной матрицы С равны
Поскольку ковариационная матрица — симметрическая, то всегда можно определить набор действительных ортогональных собственных векторов независимо от кратности характеристических чисел. Нормированные собственные векторы, соответствующие этим характеристическим числам, имеют вид
где собственные векторы
Выбор собственных векторов Изображения, полученные в результате преобразования
Образы с пониженной размерностью представлены на рис. 7.1,б. Интересно отметить эффект кластеризации, полученный после этого преобразования. Читатель может без труда убедиться в том, что при перестановке собственных векторов Дальнейшего понижения размерности можно добиться, используя для матрицы А только собственный вектор
Применение этого преобразования к исходным образам приводит к новым изображениям:
Образы пониженной размерности представлены на рис. 7.1, в. На этом рисунке снова отчетливо виден эффект кластеризации, возникающий в результате преобразования, минимизирующего энтропию.
|
 |
Оглавление
|



















































































































































































































































































































































 — плотность вероятности совокупности образов, а
— плотность вероятности совокупности образов, а  — оператор математического ожидания плотности
— оператор математического ожидания плотности  . Понятие энтропии удобно использовать в качестве критерия при организации оптимального выбора признаков. Признаки, уменьшающие неопределенность заданной ситуации, считаются более информативными, чем те, которые приводят к противоположном.
. Понятие энтропии удобно использовать в качестве критерия при организации оптимального выбора признаков. Признаки, уменьшающие неопределенность заданной ситуации, считаются более информативными, чем те, которые приводят к противоположном.
 . В силу (7.5.1) энтропия
. В силу (7.5.1) энтропия  совокупности образов определяется как
совокупности образов определяется как

 т. е. при отсутствии неопределенности, имеем
т. е. при отсутствии неопределенности, имеем  в полном соответствии с данной выше интерпретацией понятия энтропии.
в полном соответствии с данной выше интерпретацией понятия энтропии.
 , где
, где  и
и  — соответственно вектор математического ожидания и ковариационная матрица
— соответственно вектор математического ожидания и ковариационная матрица  совокупности образов (см. гл. 4). Кроме того, будет предполагаться, что ковариационные матрицы, описывающие статистические характеристики всех М классов, идентичны. Этот случай возникает, если каждый образ, принадлежащий некоторому классу, является случайным вектором, полученным в результате наложения случайного вектора на неслучайный. Наложенные случайные векторы, что характерно для многих приложений, выбираются из одной и той же нормально распределенной совокупности.
совокупности образов (см. гл. 4). Кроме того, будет предполагаться, что ковариационные матрицы, описывающие статистические характеристики всех М классов, идентичны. Этот случай возникает, если каждый образ, принадлежащий некоторому классу, является случайным вектором, полученным в результате наложения случайного вектора на неслучайный. Наложенные случайные векторы, что характерно для многих приложений, выбираются из одной и той же нормально распределенной совокупности.

 — вектор размерности
— вектор размерности  — отображенный вектор, имеющий размерность
— отображенный вектор, имеющий размерность  и А — матрица размерности
и А — матрица размерности  . Строками матрицы А служат
. Строками матрицы А служат  выбранных векторов признаков
выбранных векторов признаков  представляющих
представляющих

 векторов признаков, чтобы вектор
векторов признаков, чтобы вектор  преобразовывался в изображение у и одновременно минимизировалась величина энтропии, определяемой формулой (7.5.2).
преобразовывался в изображение у и одновременно минимизировалась величина энтропии, определяемой формулой (7.5.2).
 и получим следующее выражение для плотности нормального распределения образов
и получим следующее выражение для плотности нормального распределения образов  класса:
класса:

 определяется, согласно (7.5.3), как
определяется, согласно (7.5.3), как

 из (7.5.6) получаем, что
из (7.5.6) получаем, что





 принимает минимальное значение, если матрица преобразования А составлена из
принимает минимальное значение, если матрица преобразования А составлена из  нормированных собственных векторов, соответствующих наименьшим характеристическим числам ковариационной матрицы С.
нормированных собственных векторов, соответствующих наименьшим характеристическим числам ковариационной матрицы С.
 собственных векторов ковариационной матрицы С, удовлетворяющих сформулированным выше условиям. Процедура выделения признаков состоит в определении характеристических чисел и собственных векторов ковариационной матрицы С по обучающей выборке.
собственных векторов ковариационной матрицы С, удовлетворяющих сформулированным выше условиям. Процедура выделения признаков состоит в определении характеристических чисел и собственных векторов ковариационной матрицы С по обучающей выборке.




 соответствуют характеристическим числам
соответствуют характеристическим числам  в указанной последовательности. Выбор собственных векторов
в указанной последовательности. Выбор собственных векторов  приводит к матрице преобразования
приводит к матрице преобразования

 столь же оправдан, так как собственные векторы
столь же оправдан, так как собственные векторы  соответствуют одинаковым характеристическим числам.
соответствуют одинаковым характеристическим числам.
 имеют следующий вид:
имеют следующий вид:

 в матрице А мы придем к тому же результату. Единственным отличием будет соответствующая перестановка компонент вектора у.
в матрице А мы придем к тому же результату. Единственным отличием будет соответствующая перестановка компонент вектора у.


