Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
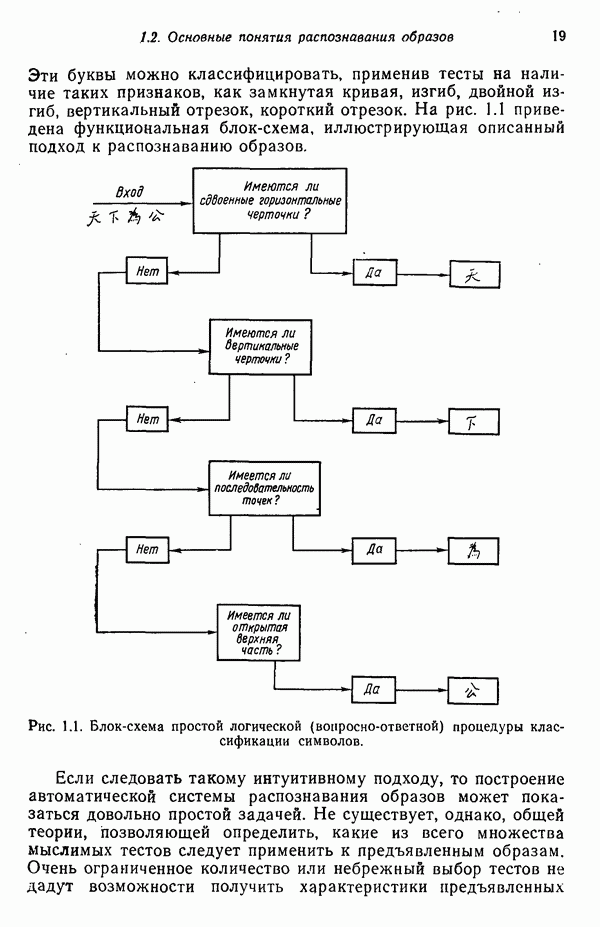
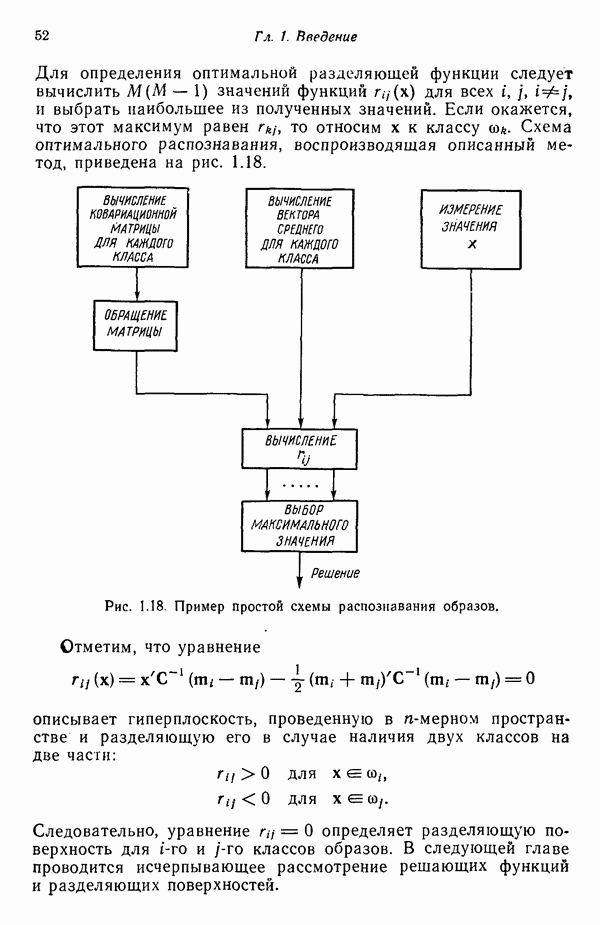
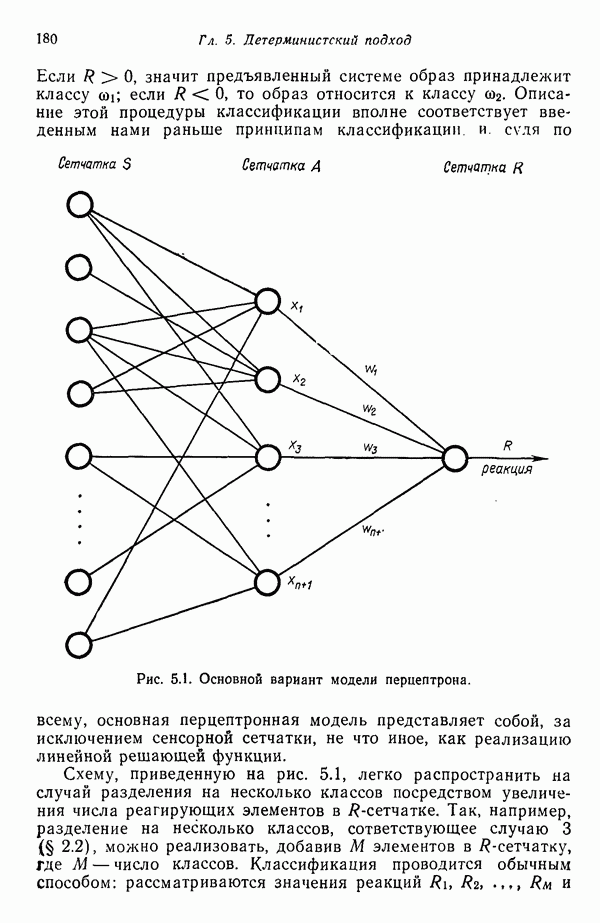
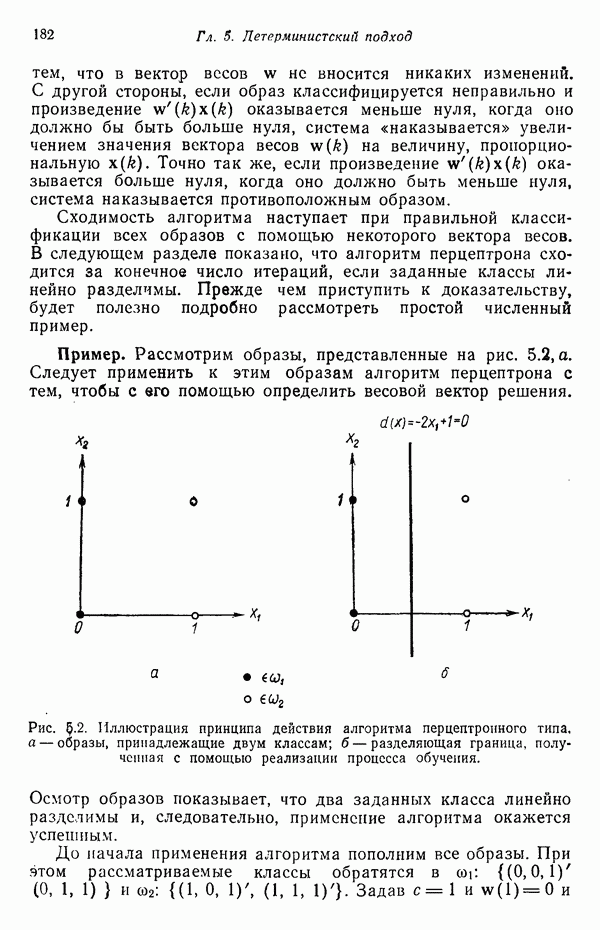
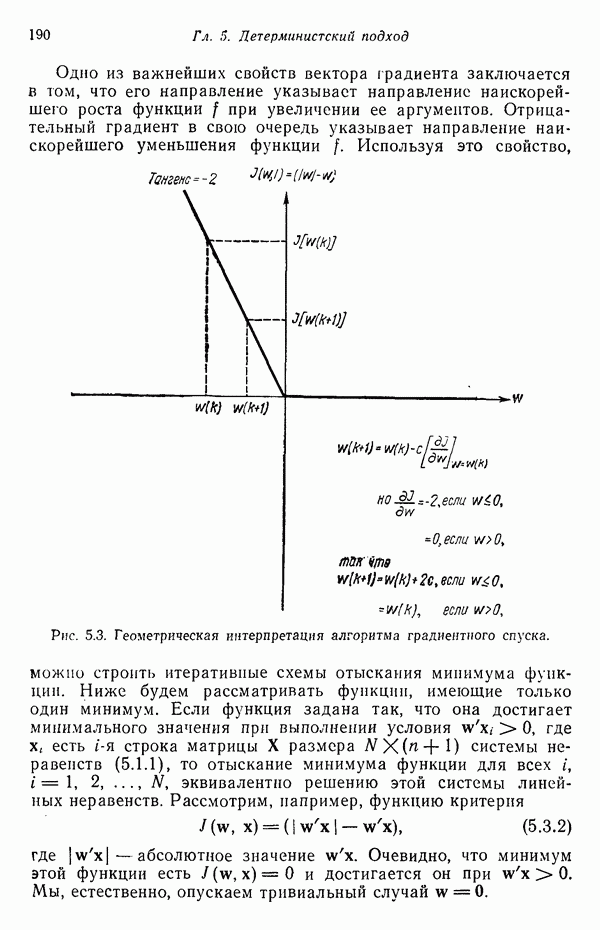
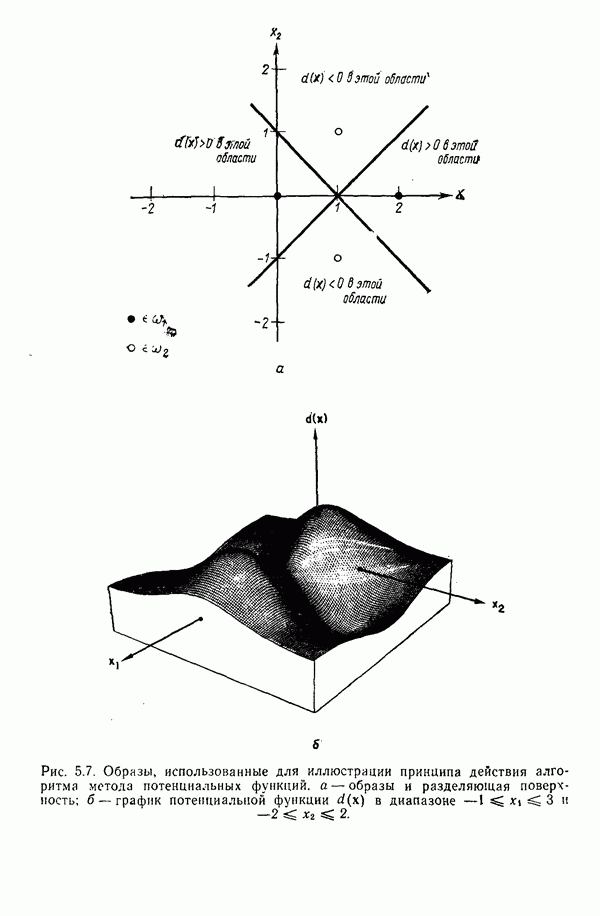
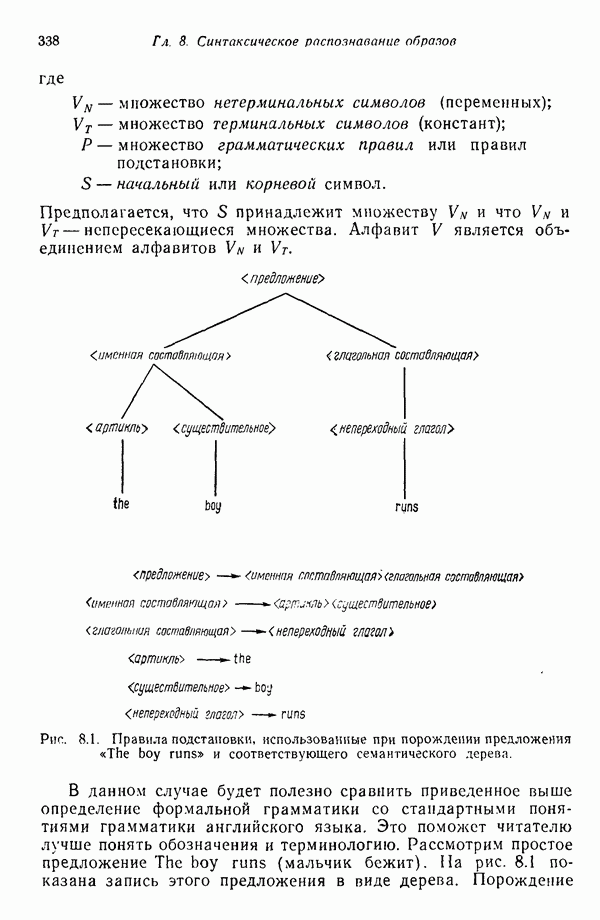
1.3. ОСНОВНЫЕ ЗАДАЧИ, ВОЗНИКАЮЩИЕ ПРИ РАЗРАБОТКЕ СИСТЕМ РАСПОЗНАВАНИЯ ОБРАЗОВЗадачи, возникающие при построении автоматической системы распознавания образов, можно обычно отнести к нескольким основным областям. Первая из них связана с представлением исходных данных, полученных как результаты измерений для "подлежащего распознаванию объекта. Это проблема чувствительности. Каждая измеренная величина является некоторой Характеристикой образа или объекта. Допустим, например, что образами являются буквенно-цифровые символы. В таком случае в датчике может быть успешно использована измерительная сетчатка, подобно приведенной на рис. 1.3, а. Если сетчатка состоит из
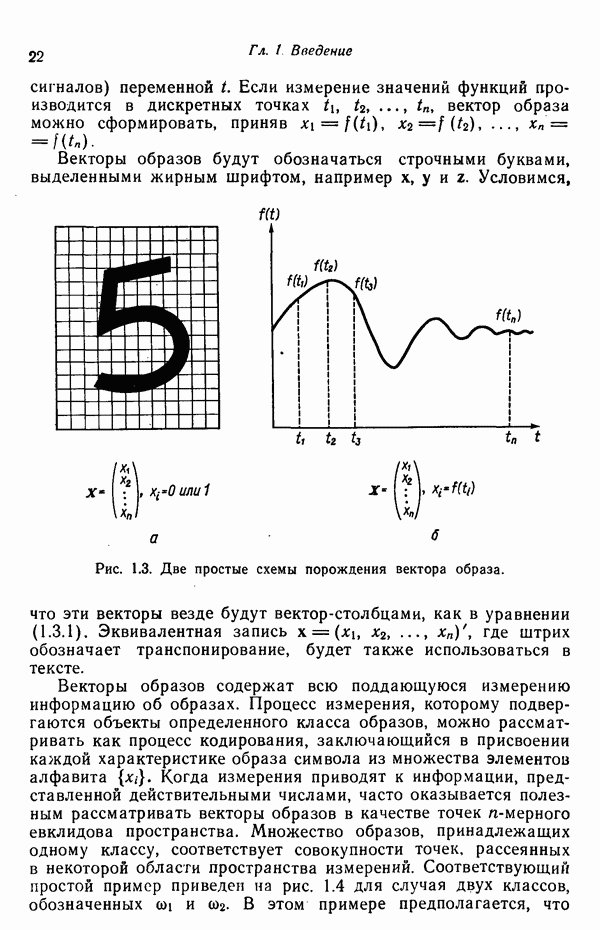
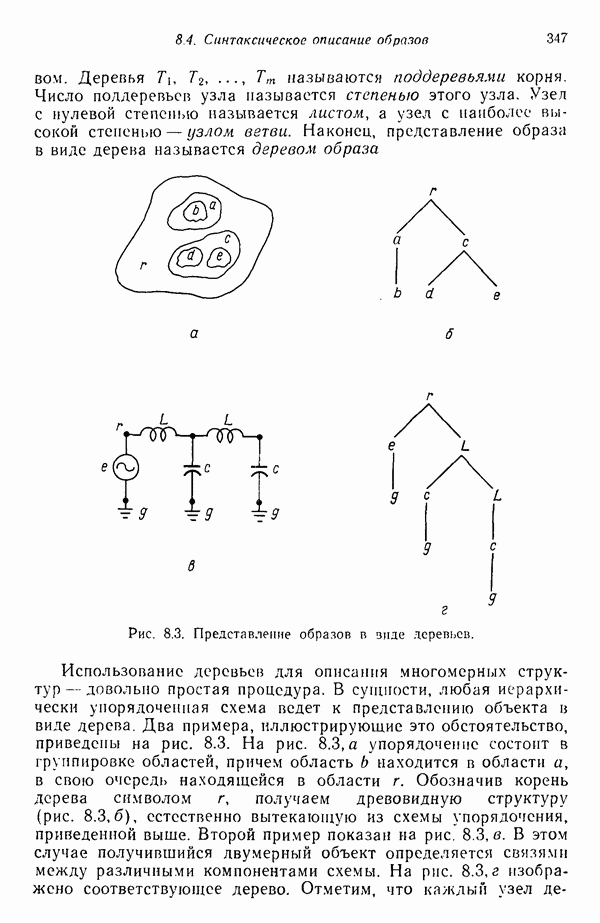
где каждый элемент Второй пример проиллюстрирован на рис. 1.3,б. В этом случае образами служат непрерывные функции (типа звуковых сигналов) переменной t. Если измерение значений функций производится в дискретных точках
Рис. 1.3. Две простые схемы порождения вектора образа. Векторы образов будут обозначаться строчными буквами, выделенными жирным шрифтом, например Векторы образов содержат всю поддающуюся измерению информацию об образах. Процесс измерения, которому подвергаются объекты определенного класса образов, можно рассматривать как процесс кодирования, заключающийся в присвоении каждой характеристике образа символа из множества элементов алфавита классы
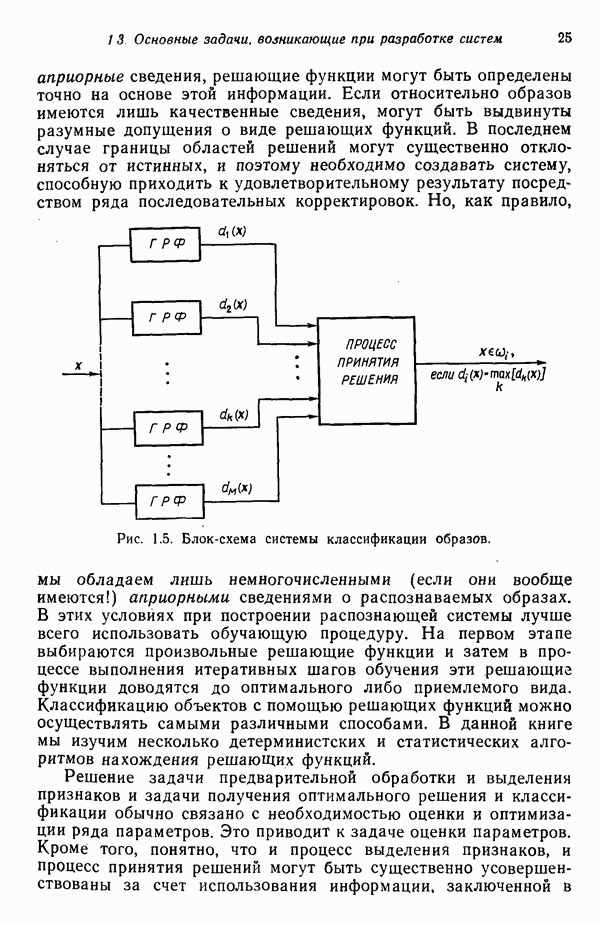
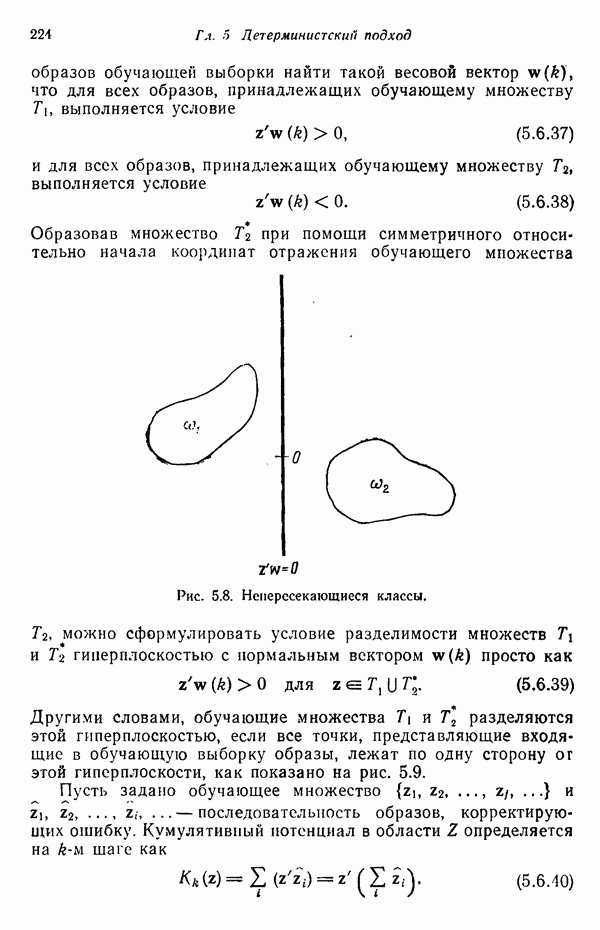
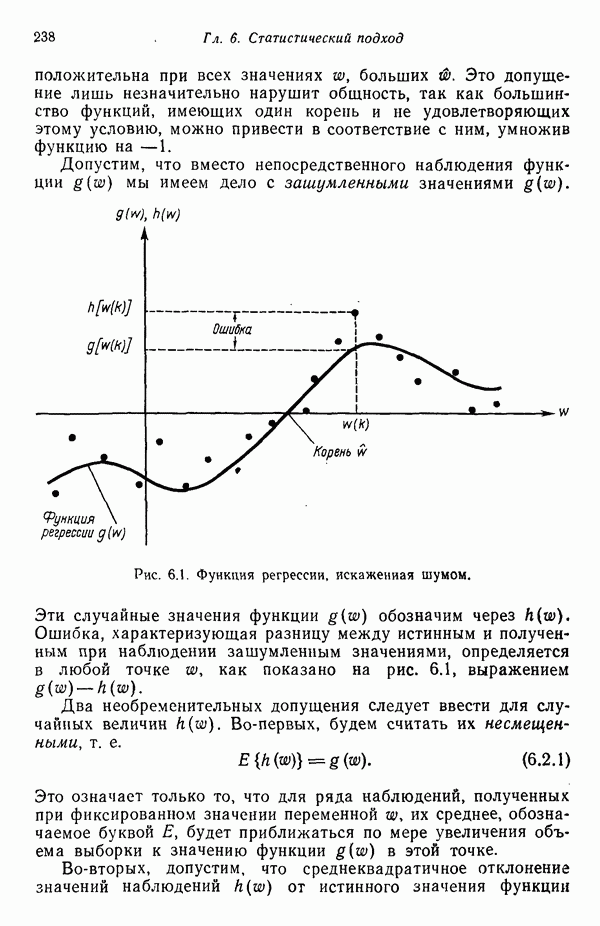
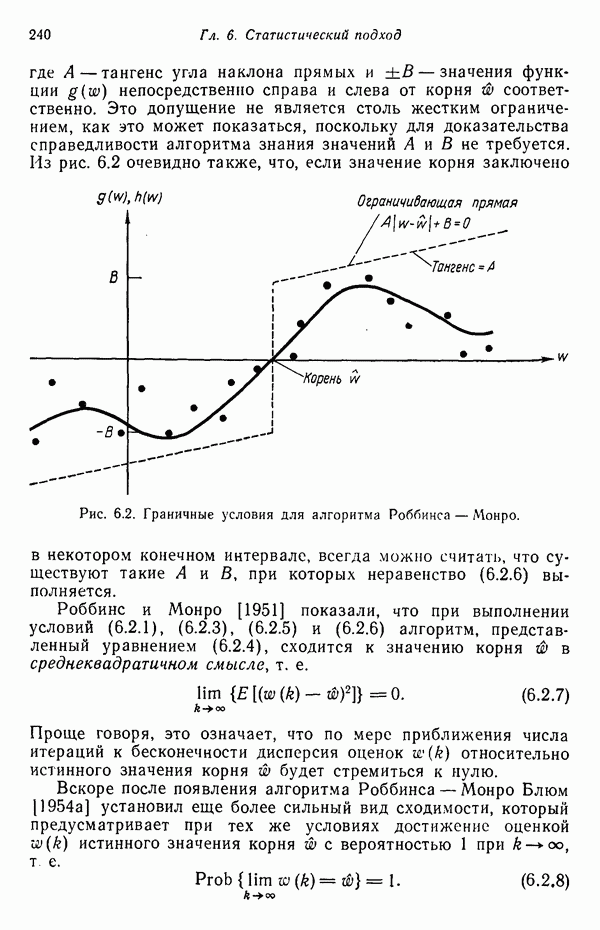
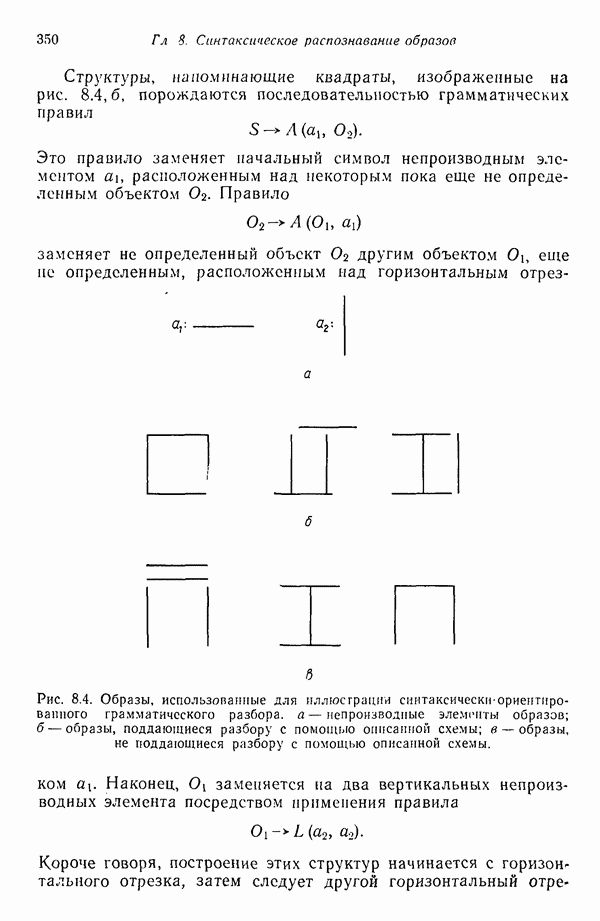
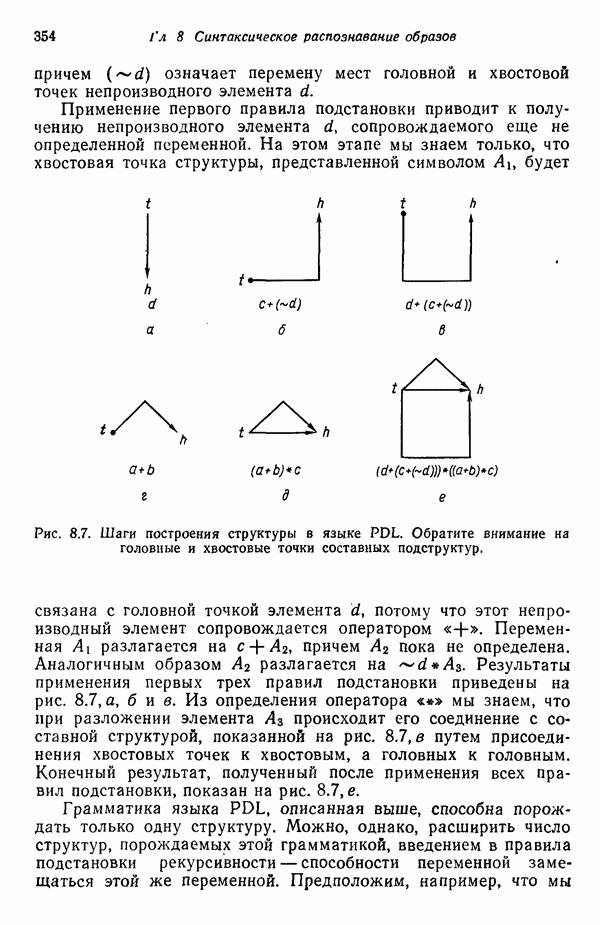
Рис. 1.4. Два непересекающихся класса образов Вторая задача распознавания образов связана с выделением характерных признаков или свойств из полученных исходных данных и снижением размерности векторов образов. Эту задачу часто определяют как задачу предварительной обработки и выбора признаков. При распознавании речи, например, можно отличать гласные и полугласные звуки от фрикативных и некоторых других консонант, измеряя частотное распределение энергии в спектрах. Шире всего при распознавании речи используются такие признаки, как длительность звука, отношения величин энергии в различных диапазонах частот, расположение пиков спектров (или формант) и их смещение во времени. Признаки класса образов представляют собой характерные свойства, общие для всех образов данного класса. Признаки, характеризующие различия между отдельными классами, можно интерпретировать как межклассовые признаки. Внутриклассовые признаки, общие для всех рассматриваемых классов, не несут полезной информации с точки зрения распознавания и могут не приниматься во внимание. Выбор признаков считается одной из важных задач, связанных с построением распознающих систем. Если результаты измерений позволяют получить полный набор различительных признаков для всех классов, собственно распознавание и классификация образов не вызовут особых затруднений. Автоматическое распознавание тогда сведется к процессу простого сопоставления или процедурам типа просмотра таблиц. В большинстве практических задач распознавания, однако, определение полного набора различительных признаков оказывается делом исключительно трудным, если вообще не невозможным. К счастью, из исходных данных обычно удается извлечь, некоторые из различительных признаков и использовать их для упрощения процесса автоматического распознавания образов. В частности, размерность векторов измерений можно снизить с помощью преобразований, обеспечивающих минимизацию потери информации; этот метод обсуждается в гл. 7. Третья задача, связанная с построением систем распознавания образов, состоит в отыскании оптимальных решающих процедур, необходимых при идентификации и классификации. После того как данные, собранные о подлежащих распознаванию образах, представлены точками или векторами измерений в пространстве образов, предоставим машине выяснить, какому классу образов эти данные соответствуют. Пусть машина предназначена для различения М классов, обозначенных Решающие функции можно получать целым рядом способов. В тех случаях, когда о распознаваемых образах имеются полные априорные сведения, решающие функции могут быть определены точно на основе этой информации. Если относительно образов имеются лишь качественные сведения, могут быть выдвинуты разумные допущения о виде решающих функций. В последнем случае границы областей решений могут существенно отклоняться от истинных, и поэтому необходимо создавать систему, способную приходить к удовлетворительному результату посредством ряда последовательных корректировок. Но, как правило, мы обладаем лишь немногочисленными (если они вообще имеются!) априорными сведениями о распознаваемых образах. В этих условиях при построении распознающей системы лучше всего использовать обучающую процедуру. На первом этапе выбираются произвольные решающие функции и затем в процессе выполнения итеративных шагов обучения эти решающие функции доводятся до оптимального либо приемлемого вида. Классификацию объектов с помощью решающих функций можно осуществлять самыми различными способами. В данной книге мы изучим несколько детерминистских и статистических алгоритмов нахождения решающих функций.
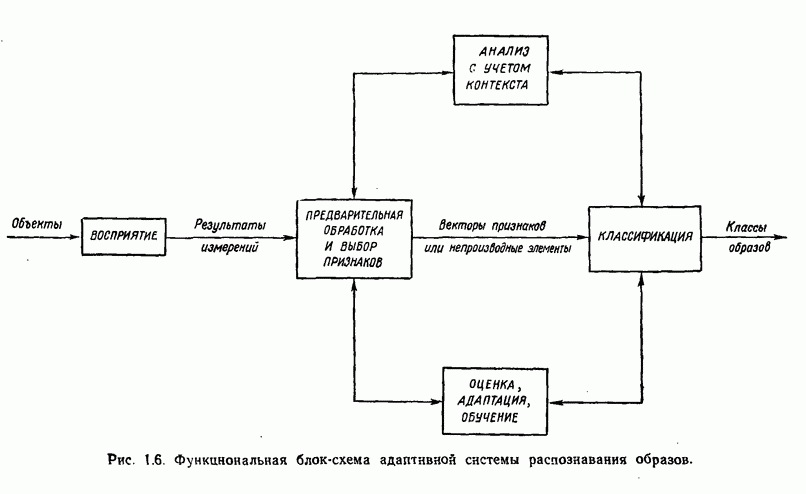
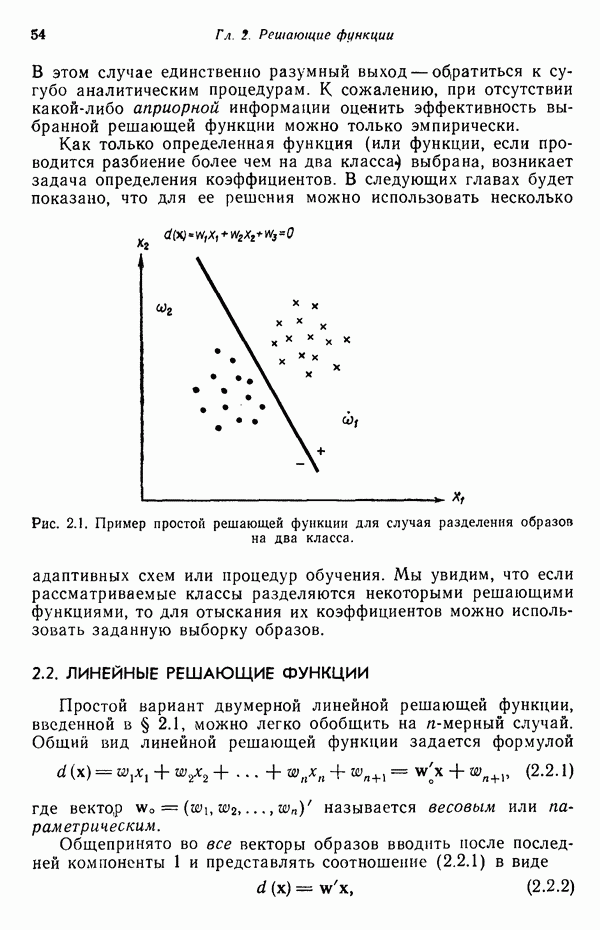
Рис. 1.5. Блок-схема системы классификации образов. Решение задачи предварительной обработки и выделения признаков и задачи получения оптимального решения и классификации обычно связано с необходимостью оценки и оптимизации ряда параметров. Это приводит к задаче оценки параметров. Кроме того, понятно, что и процесс выделения признаков, и процесс принятия решений могут быть существенно усовершенствованы за счет использования информации, заключенной в контексте образов. Информация, содержащаяся в контексте, может быть измерена с помощью условных вероятностей, лингвистических статистик и близких вариантов. В некоторых приложениях просто необходимо использовать контекстуальную информацию для точного распознавания. В частности, полная автоматизация распознавания речи возможна только при наличии контекстуальной и лингвистической информации, дополняющей информацию, содержащуюся в записи звуковых сигналов речи. По аналогичным причинам крайне желательно привлечение контекстуальной информации при распознавании скорописи и классификации отпечатков пальцев. Пытаясь построить распознающую систему, устойчивую по отношению к помехам, способную справиться с существенными отклонениями распознаваемых объектов и обладающую способностью к самонастройке, мы встречаемся с задачей адаптации. Проведенное выше беглое обсуждение основных задач приводит к помещенной на рис. 1.6 функциональной блок-схеме, содержательно иллюстрирующей адаптивную систему распознавания образов. Эта блок-схема показывает, как можно наиболее естественно и разумно разделить функции, которые должна выполнять распознающая система. Функциональные блоки выделены для удобства анализа, что отнюдь не означает их изоляцию и отсутствие межблочного взаимодействия. Хотя различия между получением оптимального решения и предварительной обработкой или выделением признаков несущественны, идея функционального разделения создает четкую картину, поясняющую задачу распознавания образов. Объекты (образы), подлежащие распознаванию и классификации с помощью автоматической системы распознавания образов, должны обладать набором измеримых характеристик. Когда для целой группы образов результаты соответствующих измерений оказываются аналогичными, считается, что эти объекты принадлежат одному классу. Цель работы системы распознавания образов заключается в том, чтобы на основе собранной информации определить класс объектов с характеристиками, аналогичными измеренным у распознаваемых объектов. Правильность распознавания зависит от объема различающей информации, содержащейся в измеряемых характеристиках, и эффективности использования этой информации. Если бы мы были в состоянии измерить все возможные характеристики и обладали неограниченным временем для обработки собранной информации, то можно было бы достичь вполне адекватного уровня распознавания, используя самые примитивные методы. В обычной практике, однако, ограничения по времени, пространству и затратам требуют развития реалистических подходов.
(кликните для просмотра скана)
|
 |
Оглавление
|


















































































































































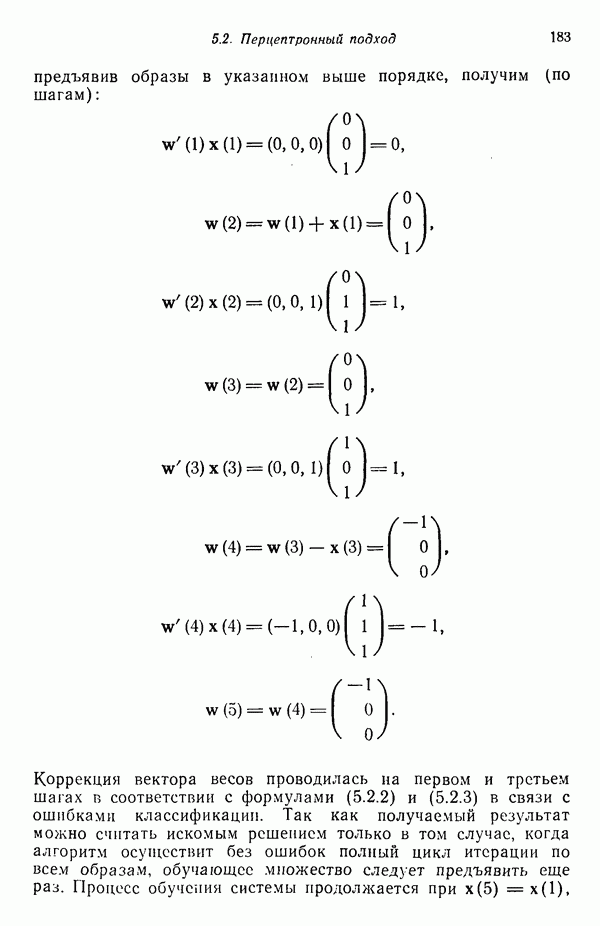





























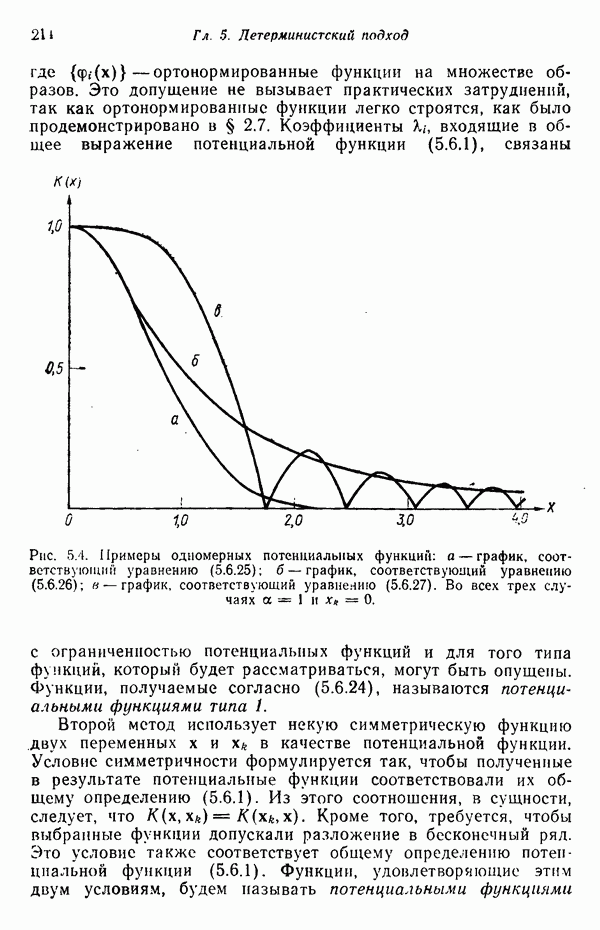

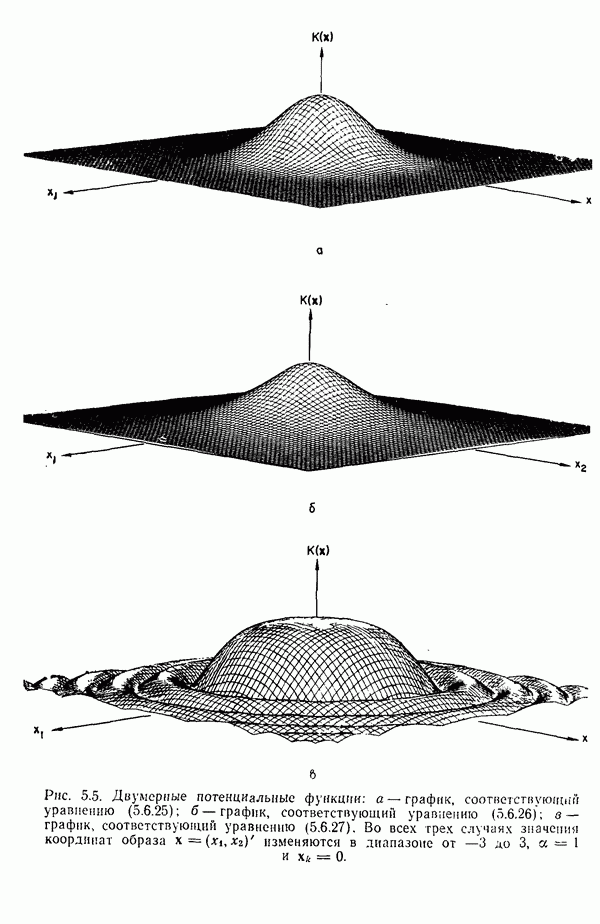
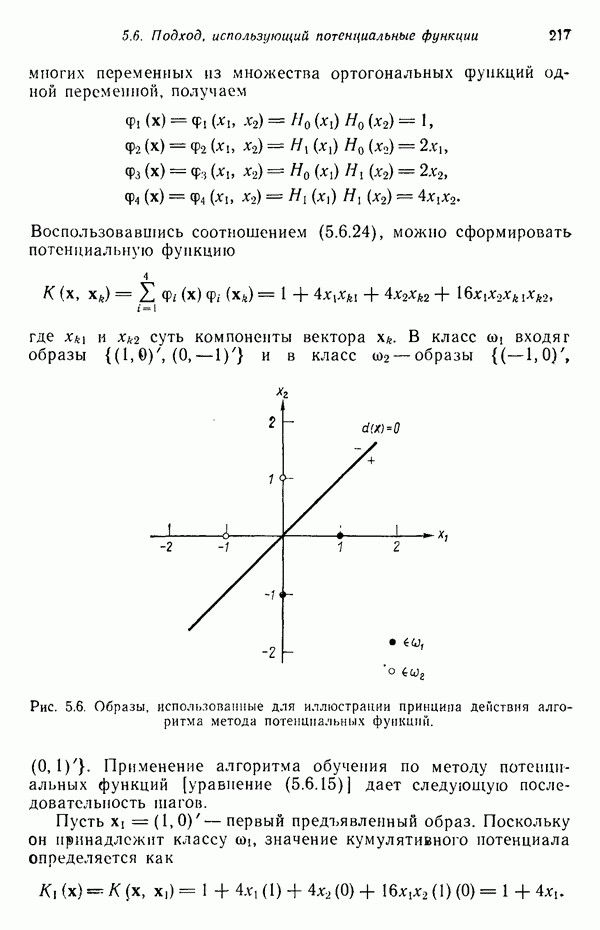
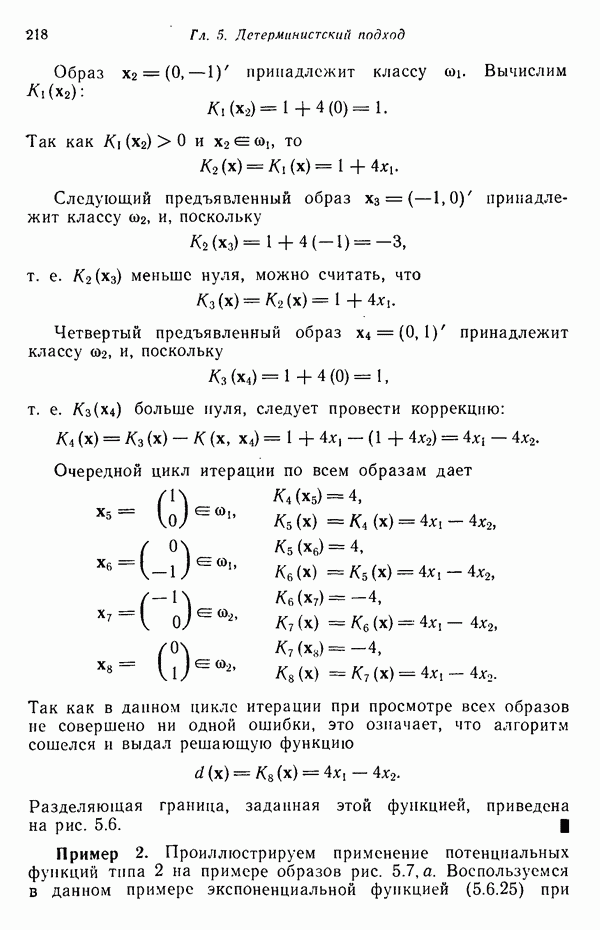


































































































































































 элементов, то результаты измерений можно представить в виде вектора измерений или вектора образа
элементов, то результаты измерений можно представить в виде вектора измерений или вектора образа

 принимает, например, значение 1, если через 1-ю ячейку сетчатки проходит изображение символа, и значение 0 в противном случае. В последующем изложении будем называть векторы образов просто образами в тех случаях, когда это не приводит к изменению смысла.
принимает, например, значение 1, если через 1-ю ячейку сетчатки проходит изображение символа, и значение 0 в противном случае. В последующем изложении будем называть векторы образов просто образами в тех случаях, когда это не приводит к изменению смысла.
 вектор образа можно сформировать, приняв
вектор образа можно сформировать, приняв  .
.

 . Условимся, что эти векторы везде будут вектор-столбцами, как в уравнении (1.3.1). Эквивалентная запись
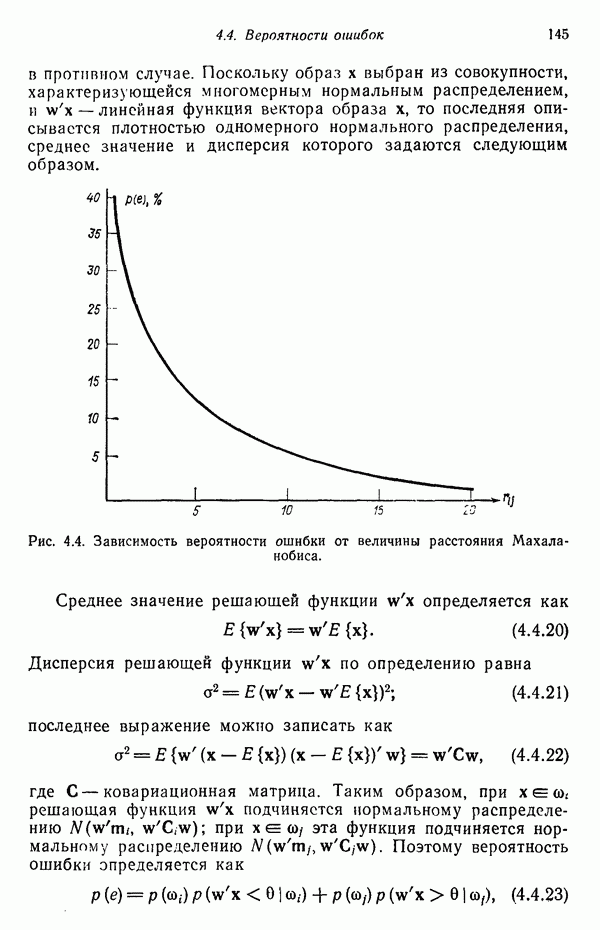
. Условимся, что эти векторы везде будут вектор-столбцами, как в уравнении (1.3.1). Эквивалентная запись  , где штрих обозначает транспонирование, будет также использоваться в тексте.
, где штрих обозначает транспонирование, будет также использоваться в тексте.
 . Когда измерения приводят к информации, представленной действительными числами, часто оказывается полезным рассматривать векторы образов в качестве точек n-мерного евклидова пространства. Множество образов, принадлежащих одному классу, соответствует совокупности точек, рассеянных в некоторой области пространства измерений. Соответствующий простой пример приведен на рис. 1.4 для случая двух классов, обозначенных
. Когда измерения приводят к информации, представленной действительными числами, часто оказывается полезным рассматривать векторы образов в качестве точек n-мерного евклидова пространства. Множество образов, принадлежащих одному классу, соответствует совокупности точек, рассеянных в некоторой области пространства измерений. Соответствующий простой пример приведен на рис. 1.4 для случая двух классов, обозначенных  . В этом примере предполагается, что
. В этом примере предполагается, что
 представляют соответственно группы футболистов-профессионалов и жокеев. Каждый «образ» характеризуется результатами двух измерений: ростом и весом. Векторы образов имеют, следовательно, вид
представляют соответственно группы футболистов-профессионалов и жокеев. Каждый «образ» характеризуется результатами двух измерений: ростом и весом. Векторы образов имеют, следовательно, вид  где параметр
где параметр  — рост, а параметр
— рост, а параметр  — вес. Каждый вектор образа можно считать точкой двумерного пространства. Как следует из рис. 1.4. эти два класса образуют непересекающиеся множеатвдчто объясняется характером изменявшихся параметров. В практических ситуациях, однако, далеко не всегда удается выбрать измеряемые параметры так, чтобы получить строго непересекающиеся множества. В частности, если в качестве критериев разбиения выбран рост и вес, может наблюдаться существенное пересечение классов профессиональных футболистов и баскетболистов.
— вес. Каждый вектор образа можно считать точкой двумерного пространства. Как следует из рис. 1.4. эти два класса образуют непересекающиеся множеатвдчто объясняется характером изменявшихся параметров. В практических ситуациях, однако, далеко не всегда удается выбрать измеряемые параметры так, чтобы получить строго непересекающиеся множества. В частности, если в качестве критериев разбиения выбран рост и вес, может наблюдаться существенное пересечение классов профессиональных футболистов и баскетболистов.

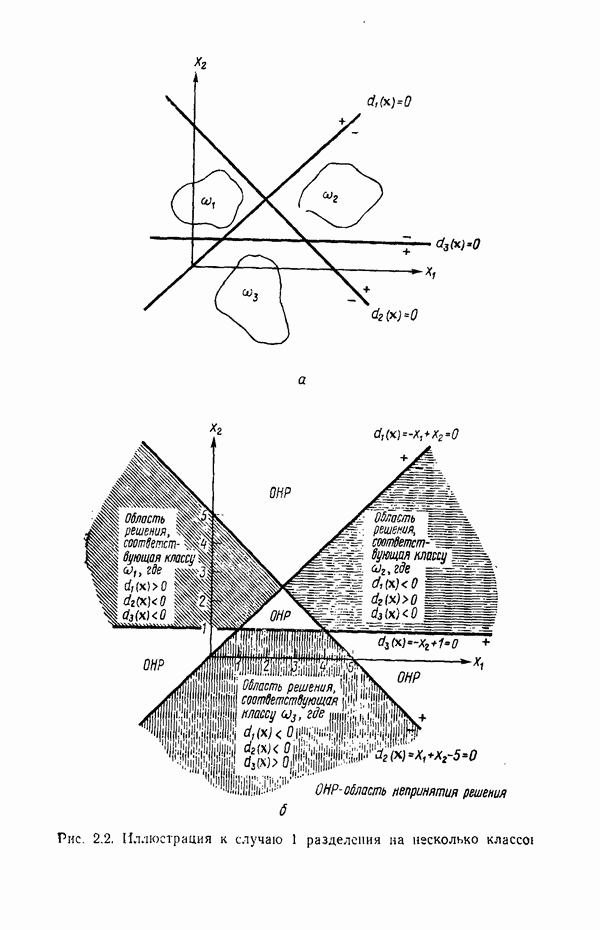
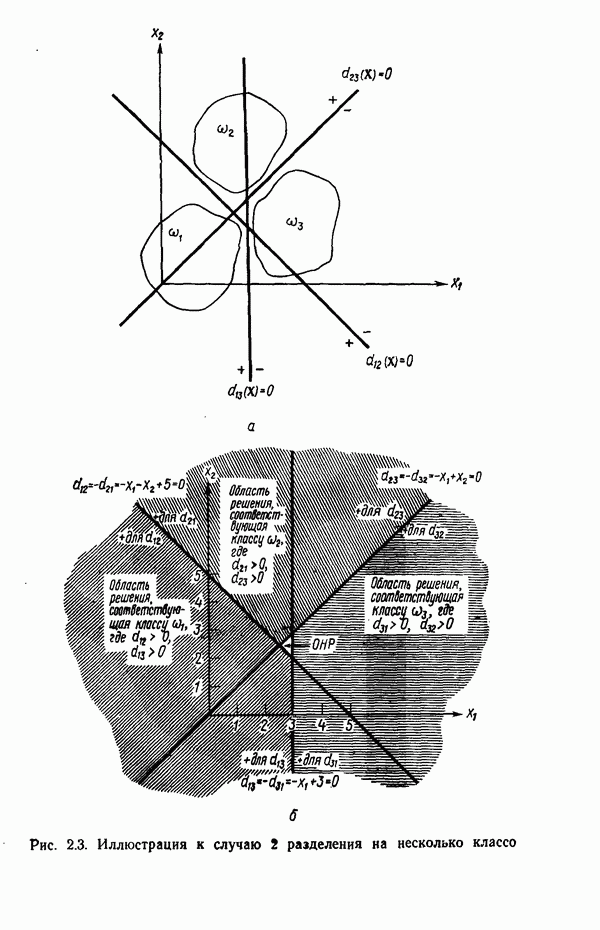
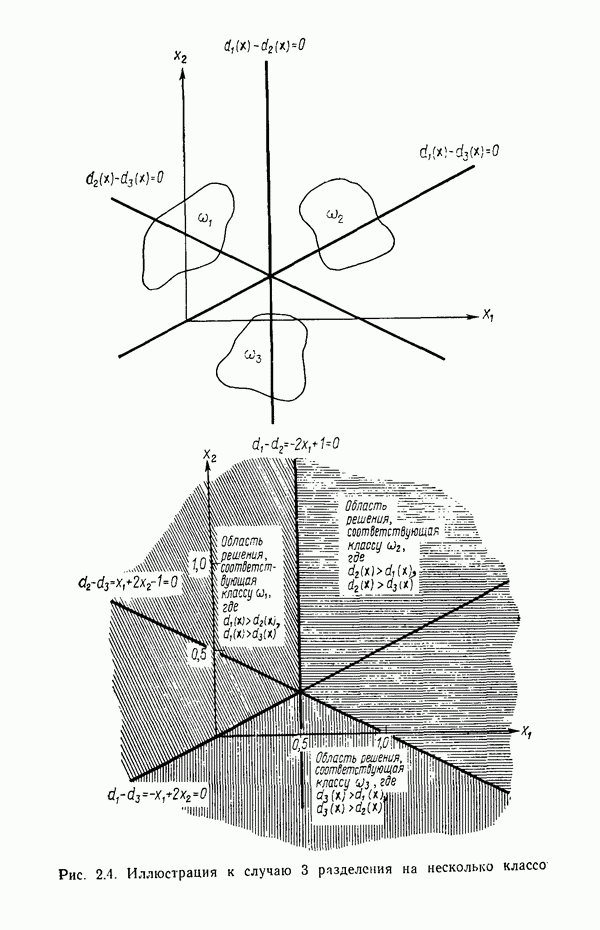
 . В таком случае пространство образов можно считать состоящим из М областей, каждая из которых содержит точки, соответствующие образам из одного класса. При этом задача распознавания может рассматриваться как построение границ областей решений, разделяющих М классов, исходя из зарегистрированных векторов измерений. Пусть эти границы определены, например, решающими функциями
. В таком случае пространство образов можно считать состоящим из М областей, каждая из которых содержит точки, соответствующие образам из одного класса. При этом задача распознавания может рассматриваться как построение границ областей решений, разделяющих М классов, исходя из зарегистрированных векторов измерений. Пусть эти границы определены, например, решающими функциями  . Эти функции, называемые также дискриминантными функциями, представляют собой скалярные и однозначные функции образа
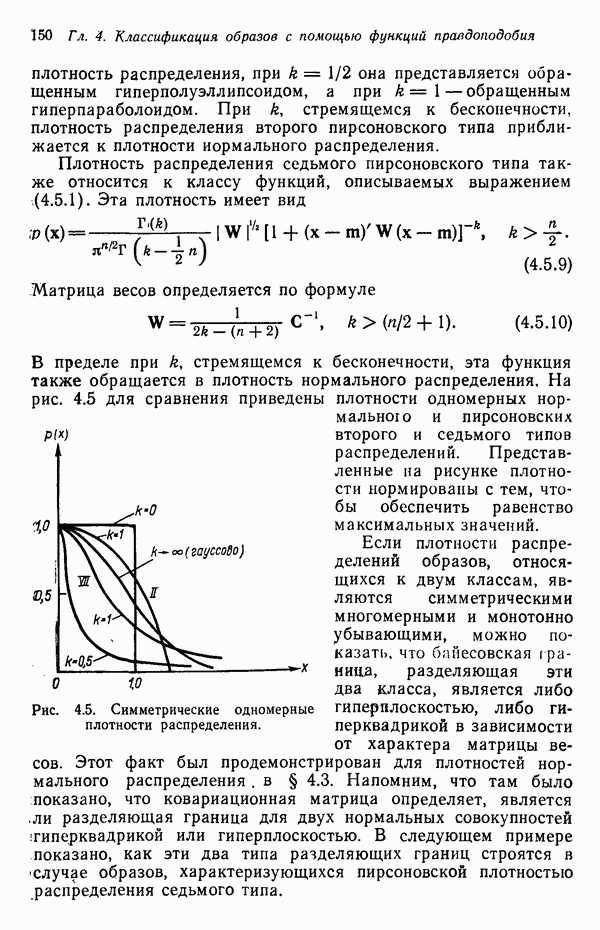
. Эти функции, называемые также дискриминантными функциями, представляют собой скалярные и однозначные функции образа  . Если
. Если  для всех
для всех  , то образ
, то образ  принадлежит классу
принадлежит классу  Другими словами, если i-я решающая функция
Другими словами, если i-я решающая функция  имеет наибольшее значение, то
имеет наибольшее значение, то  . Содержательной иллюстрацией подобной схемы автоматической классификации, основанной на реализации процесса принятия решения, служит приведенная на рис. 1.5 блок-схема (на схеме ГРФ означает «генератор решающих функций»).
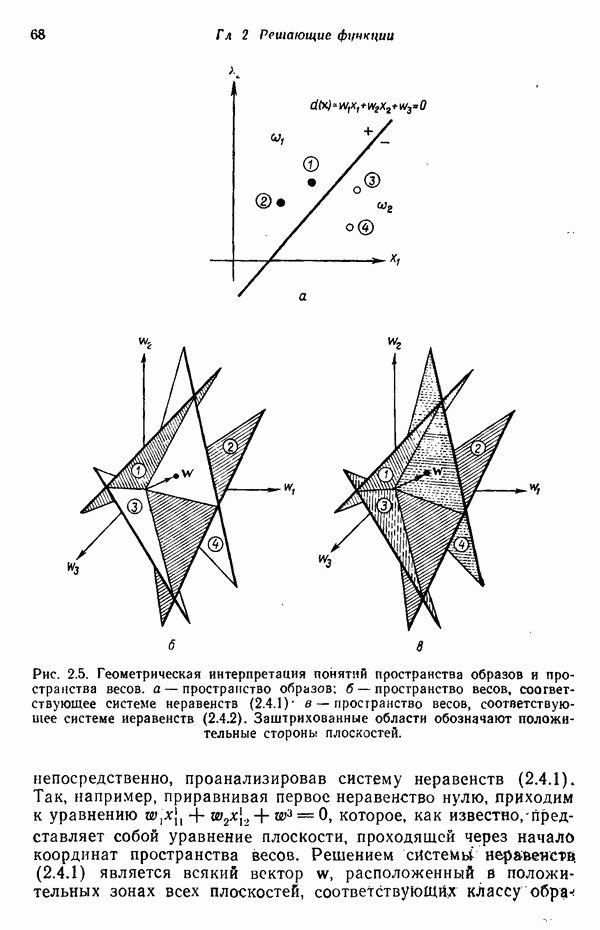
. Содержательной иллюстрацией подобной схемы автоматической классификации, основанной на реализации процесса принятия решения, служит приведенная на рис. 1.5 блок-схема (на схеме ГРФ означает «генератор решающих функций»).

