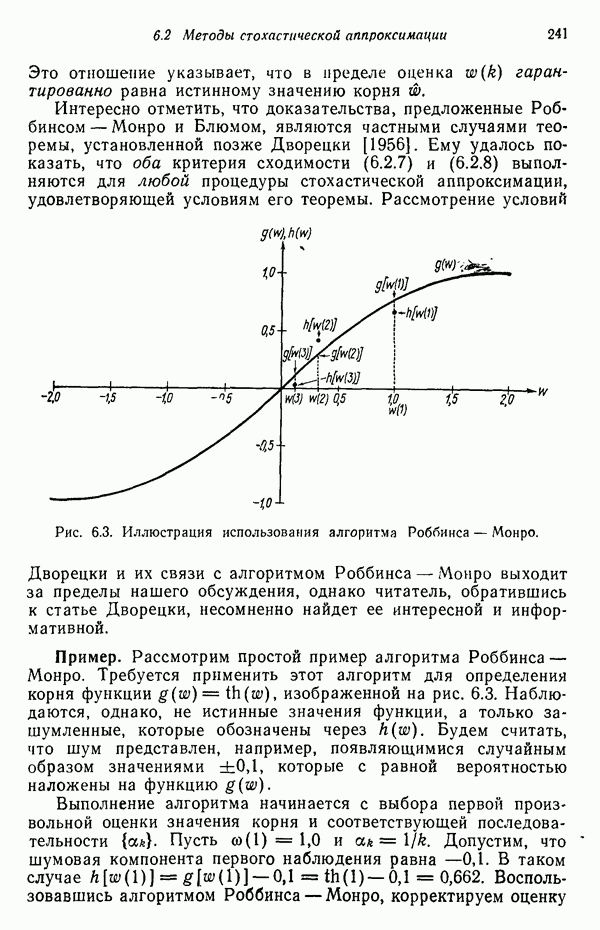
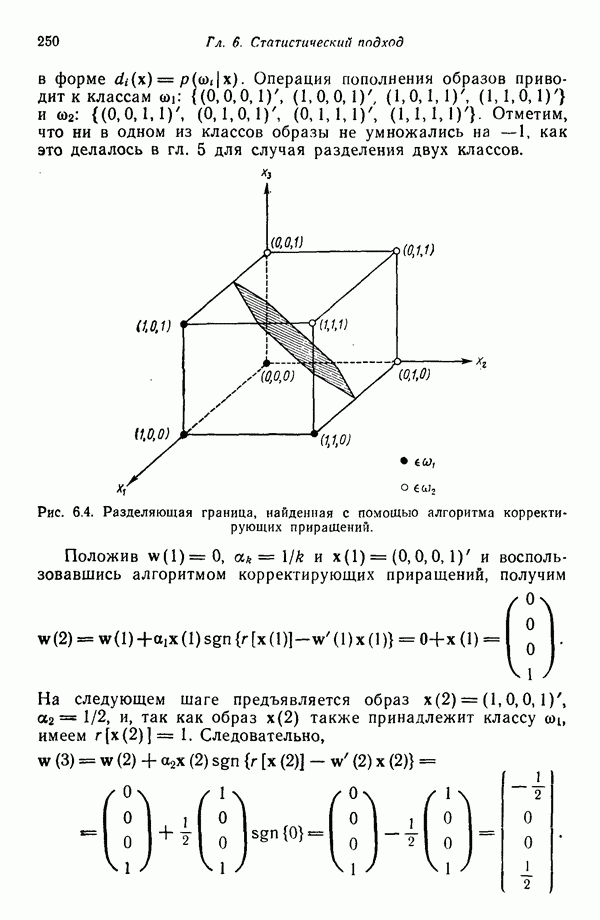
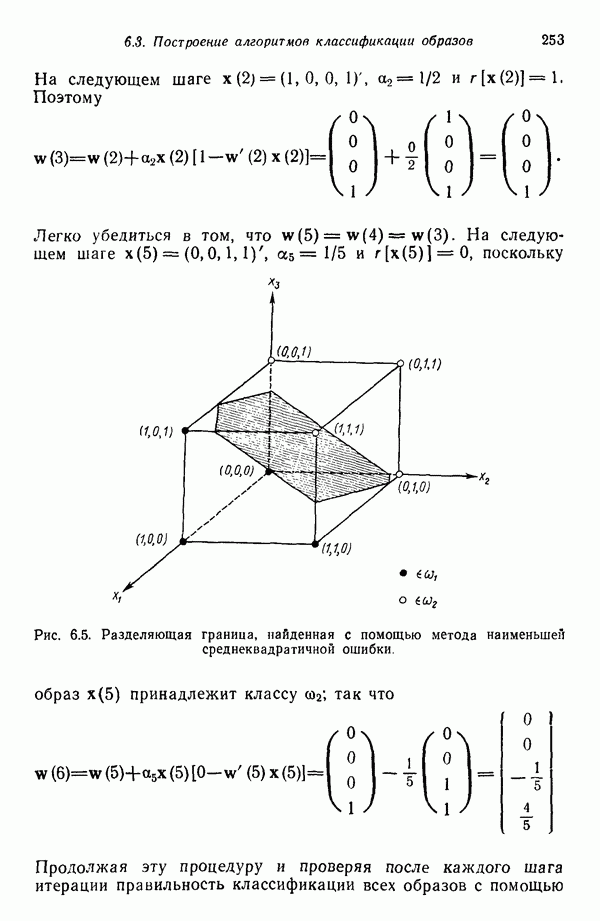
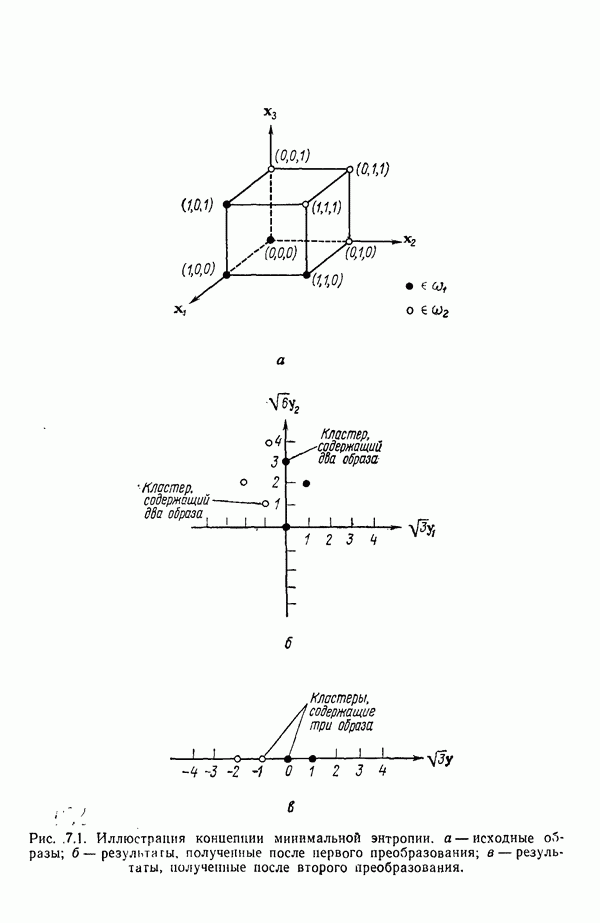
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
8.6. СТАТИСТИЧЕСКИЙ АНАЛИЗДля определения и описания переменных, представляющих случайную среду, должны быть привлечены статистические понятия и методология. В распознавании образов случайность появляется в основном в результате воздействия двух принципиальных факторов: шума, возникающего при измерении характеристик объекта, и неполноты информации о характеристиках классов образов. В этом разделе внимание сосредотачивается на обобщении основной модели формальной грамматики 8.6.1. Стохастические грамматики и языкиДля придания статистического характера нашим моделям грамматик весьма целесообразно воспользоваться следующим приемом — считать недетерминированными правила подстановки и ставить в соответствие каждому из них некоторую вероятностную меру. Основываясь на этом приеме, мы определяем стохастическую грамматику следующим образом:
где Рассмотрим следующий процесс порождения терминальной цепочки
где
где Если различных путей порождения цепочки х, характеризующихся вероятностями
Множество
Стохастический язык
где Пример. Рассмотрим стохастическую бесконтекстную грамматику
где
Заметим, что каждому правилу подстановки поставлена в соответствие вероятность его применения. В данном случае первое правило применяется с вероятностью Дважды применив первое правило, а затем один раз второе, получим последовательность
Обозначив терминальную цепочку
Язык, порожденный грамматикой
Каждая цепочка В стохастических языках используются те же методы грамматического разбора, что были рассмотрены в предыдущем параграфе. Однако для облегчения процесса разбора могут привлекаться знания о вероятности применения правил подстановки. Предположим, например, что на определенном шаге процедуры восходящего грамматического разбора имеется несколько правил-кандидатов, одно из которых следует выбрать и применить. Очевидно, что правилом, имеющим наибольшую вероятность успешного применения, будет правило с наибольшей вероятностью применения для порождения анализируемой терминальной цепочки. В общем случае вероятности применения грамматических правил должны использоваться в грамматическом разборе для увеличения скорости распознавания стохастических систем.
|
 |
Оглавление
|















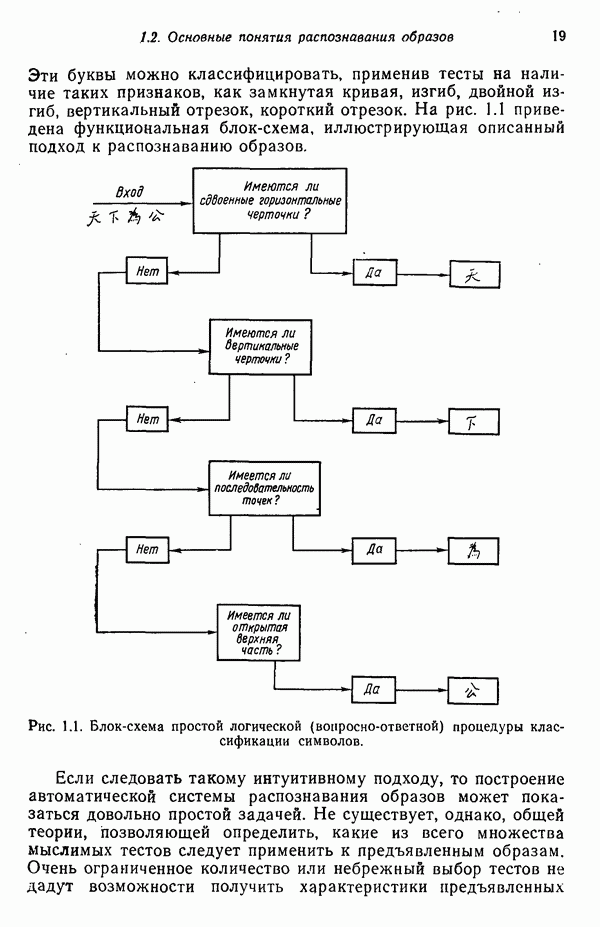
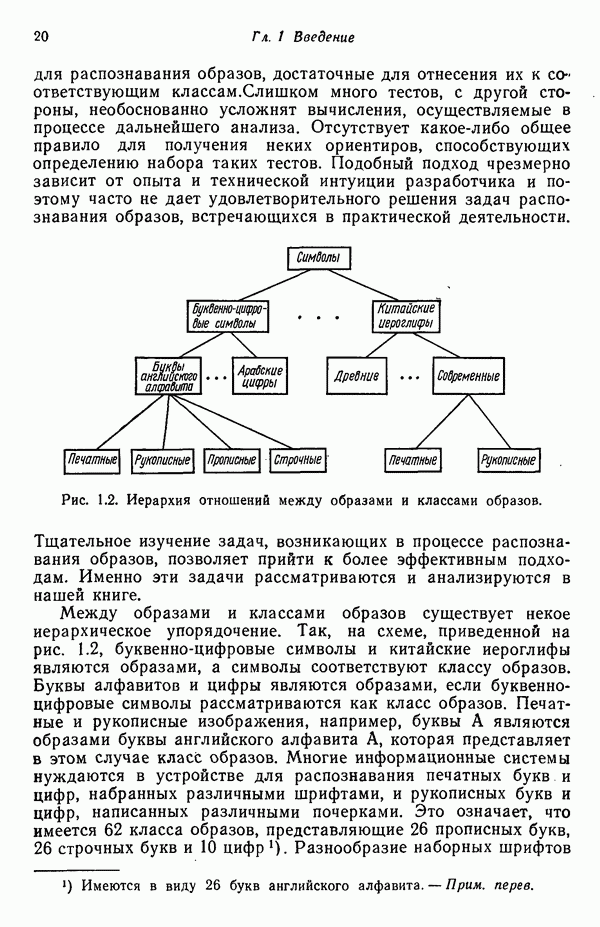

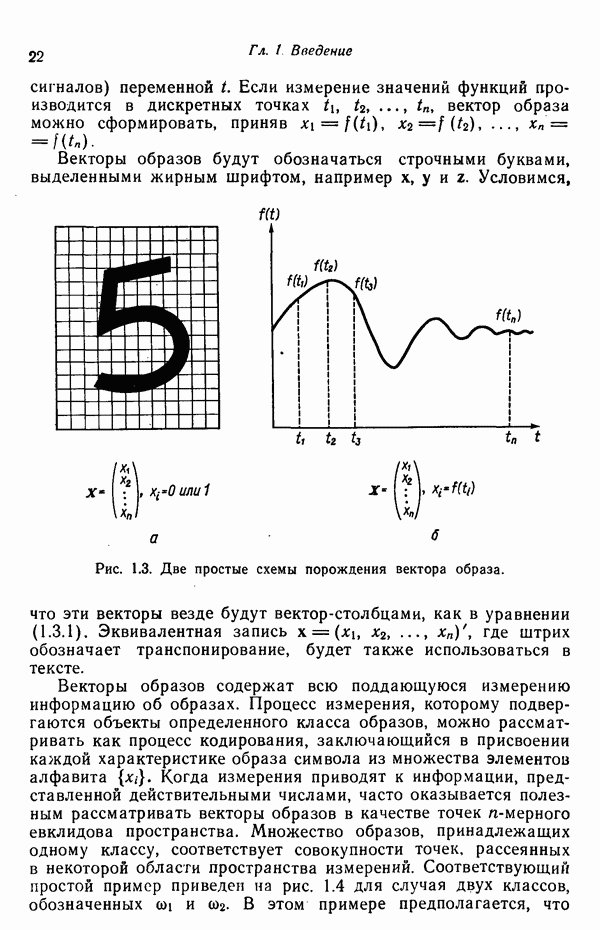


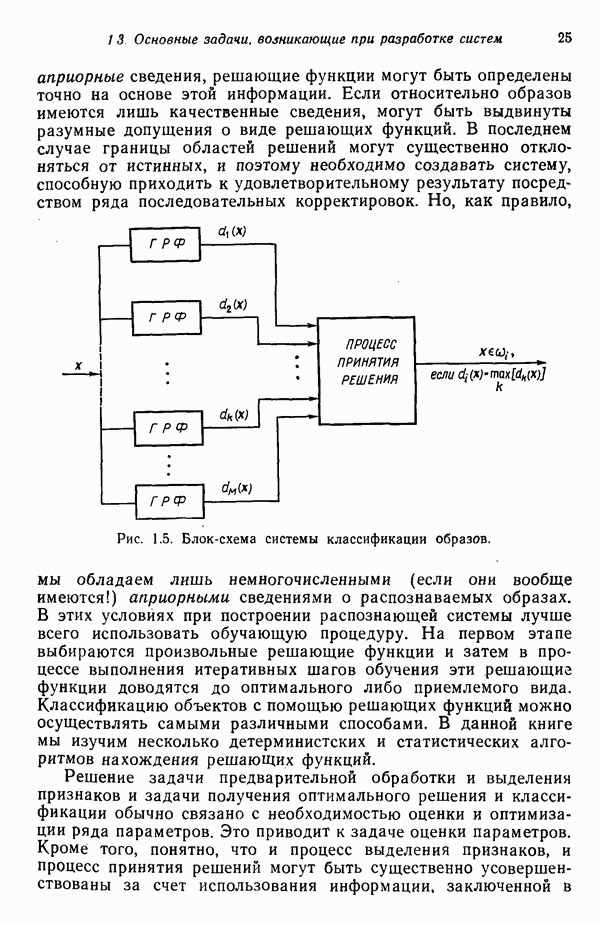

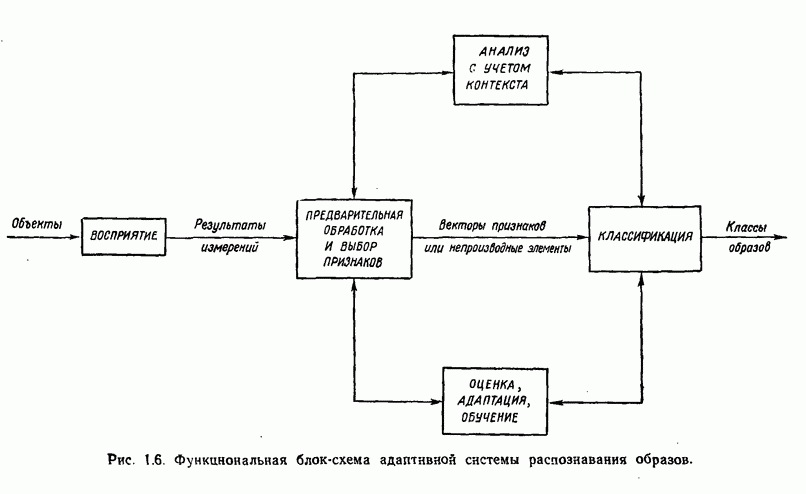













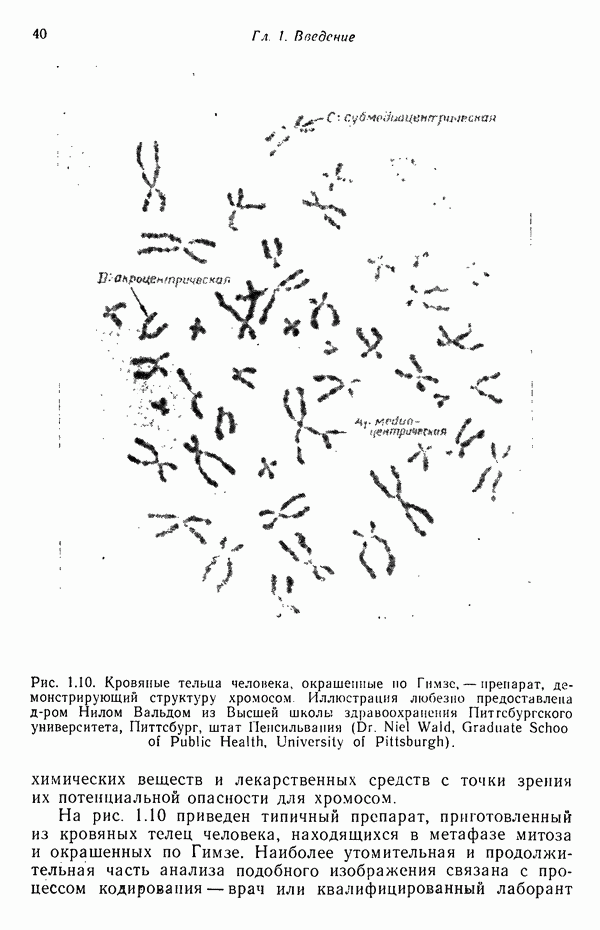


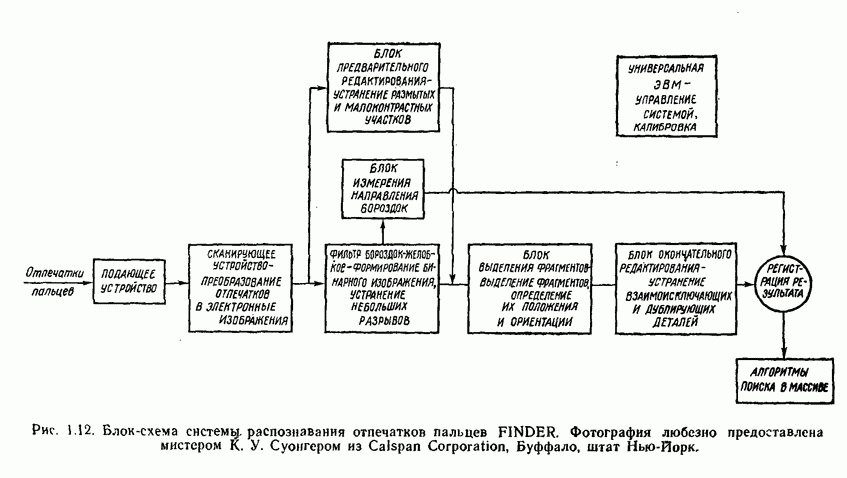




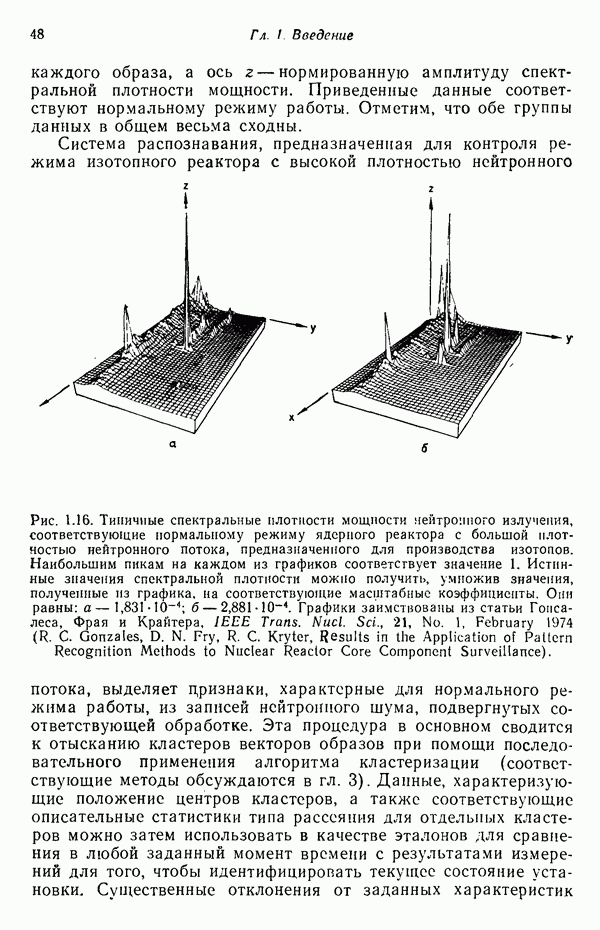



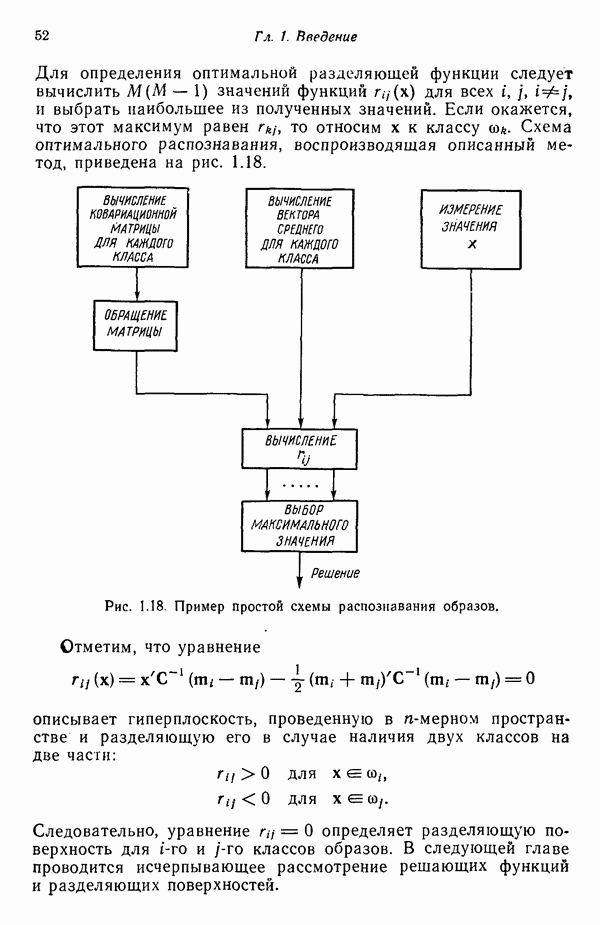

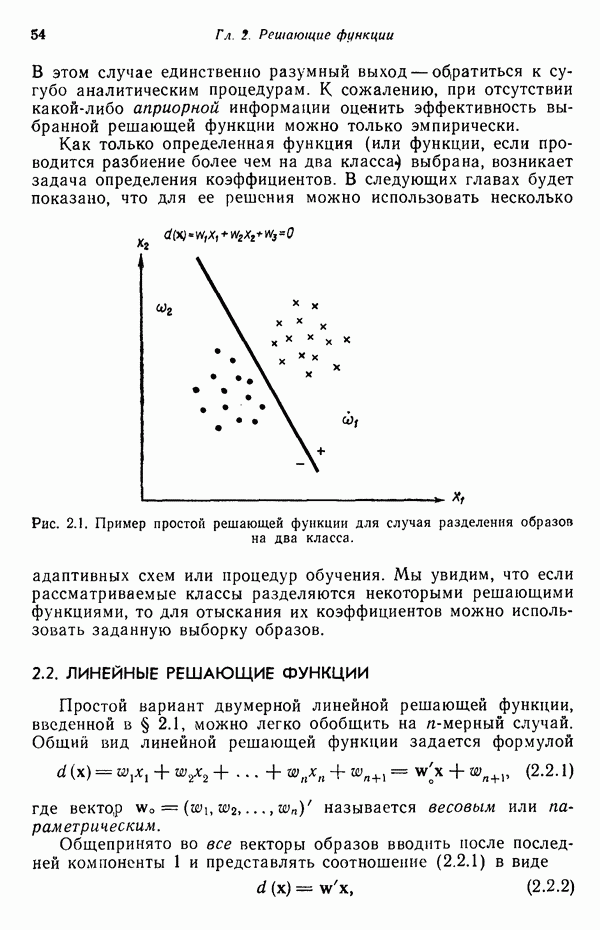

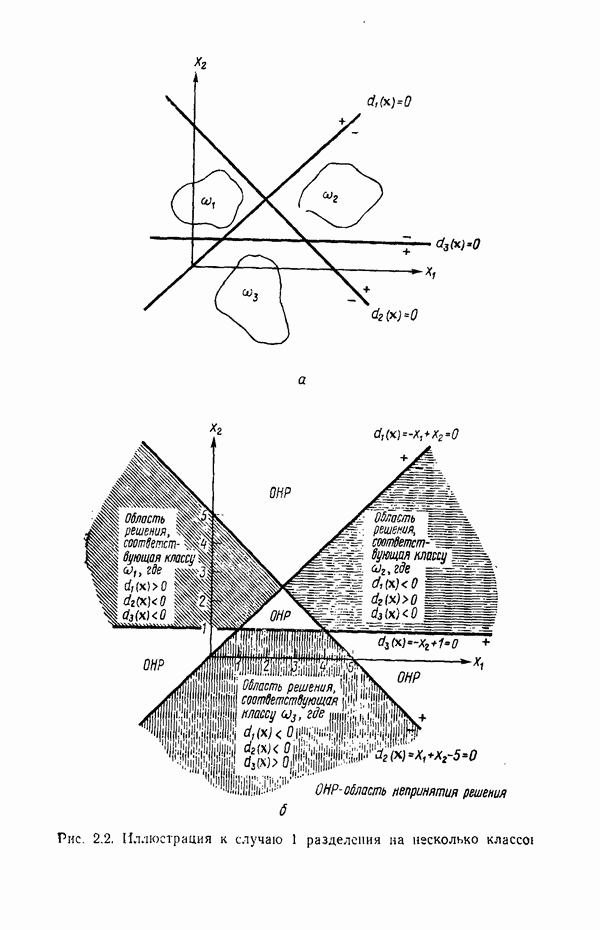

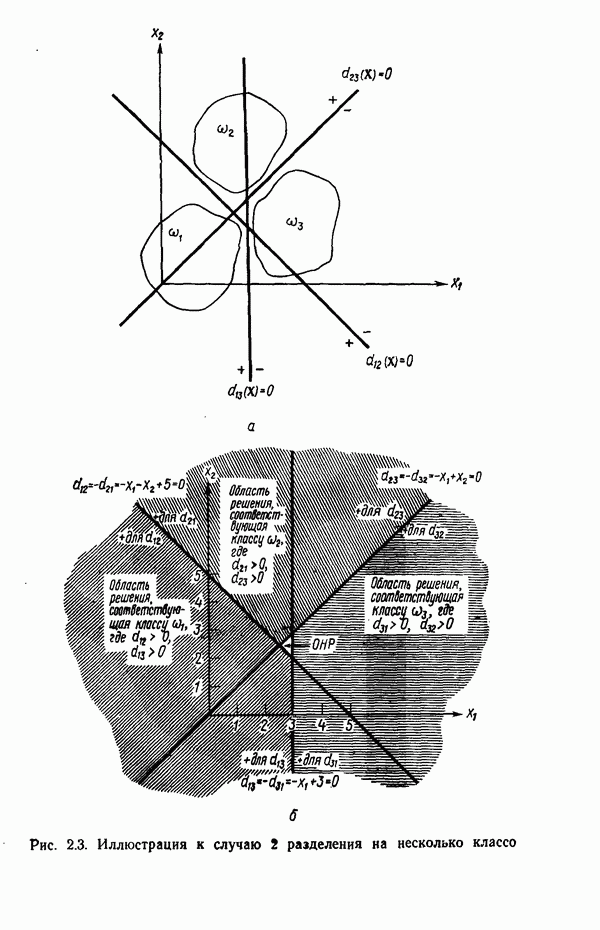












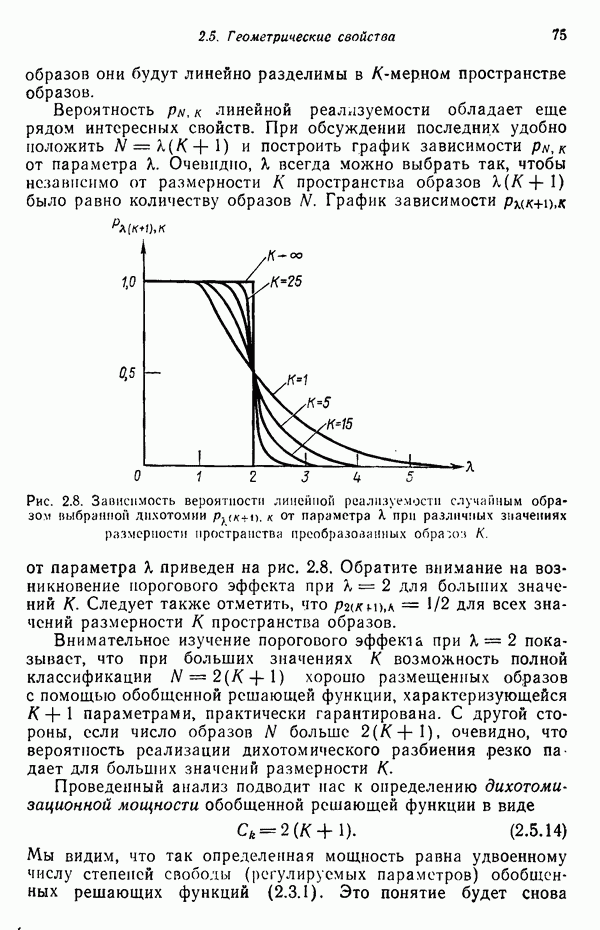

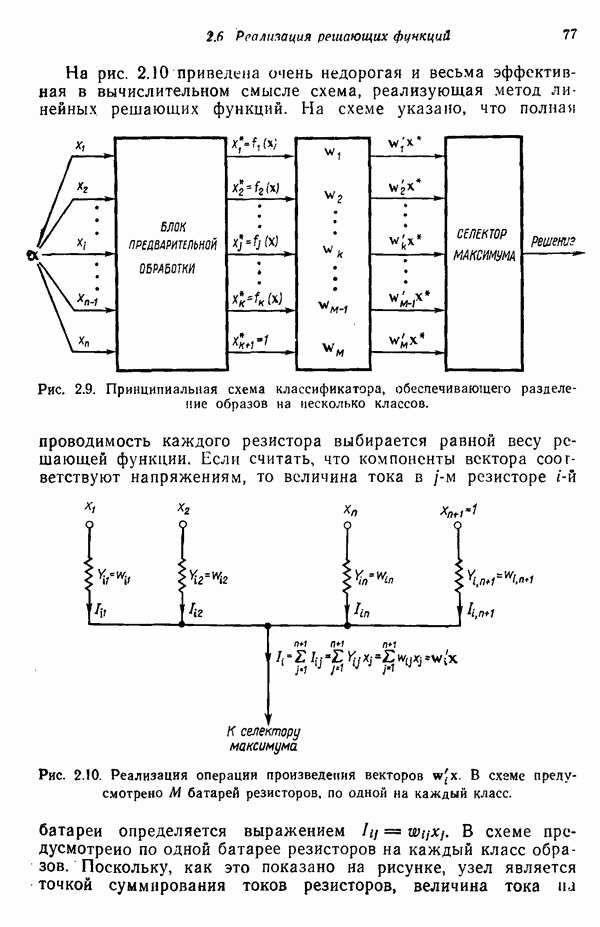












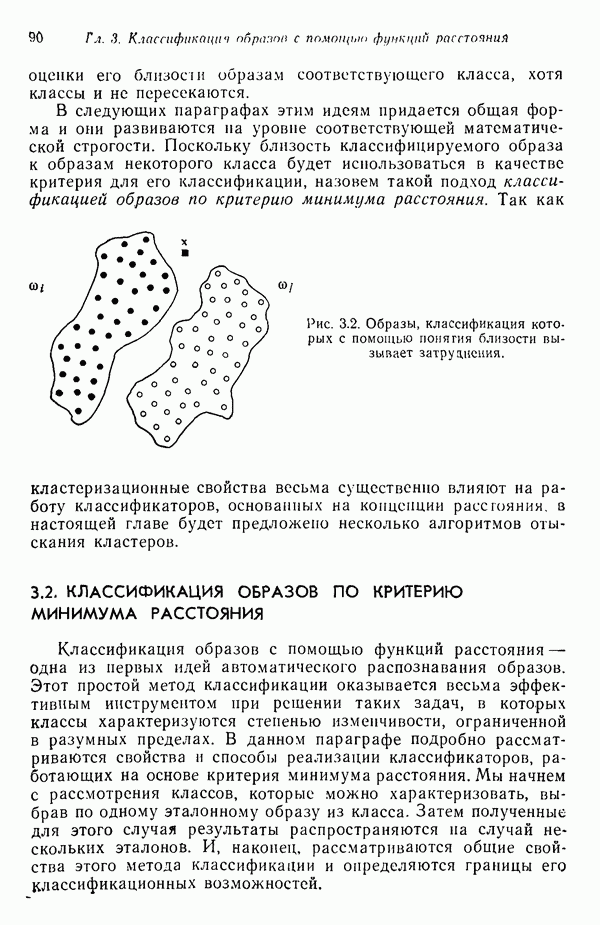

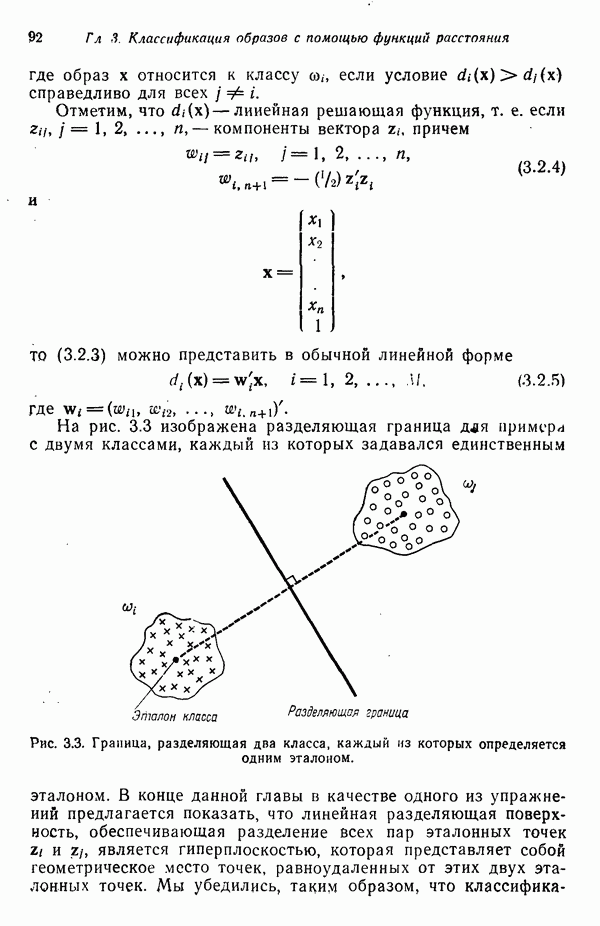









































































































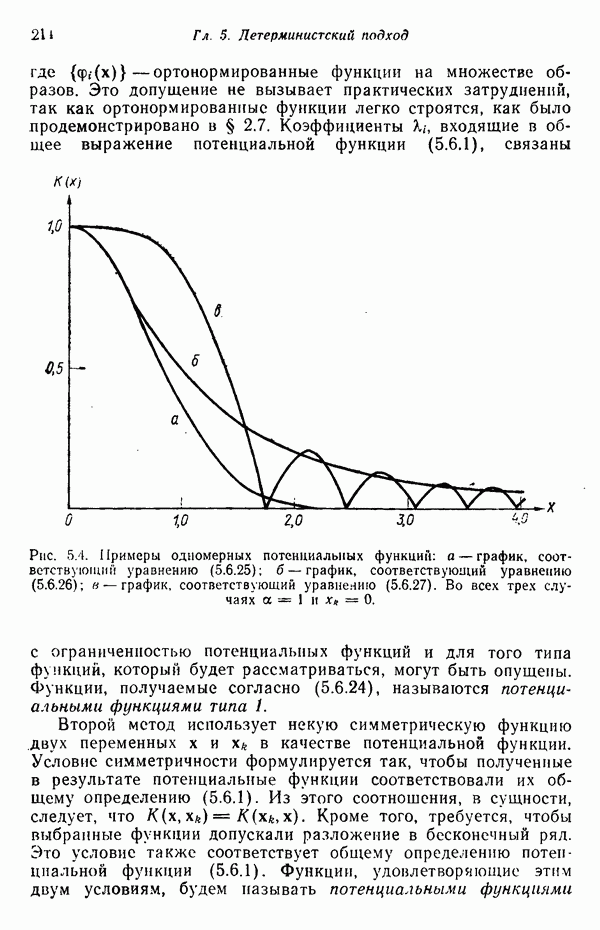

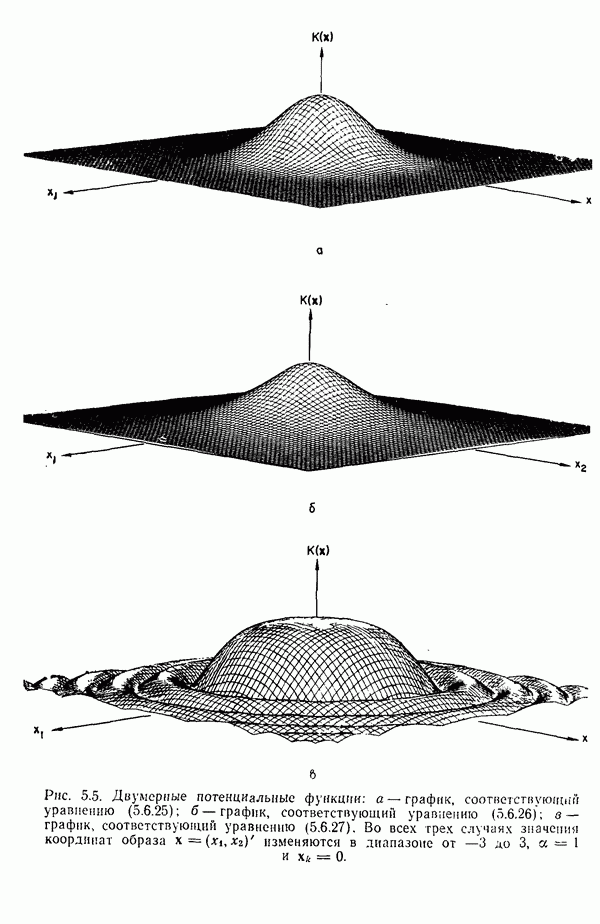
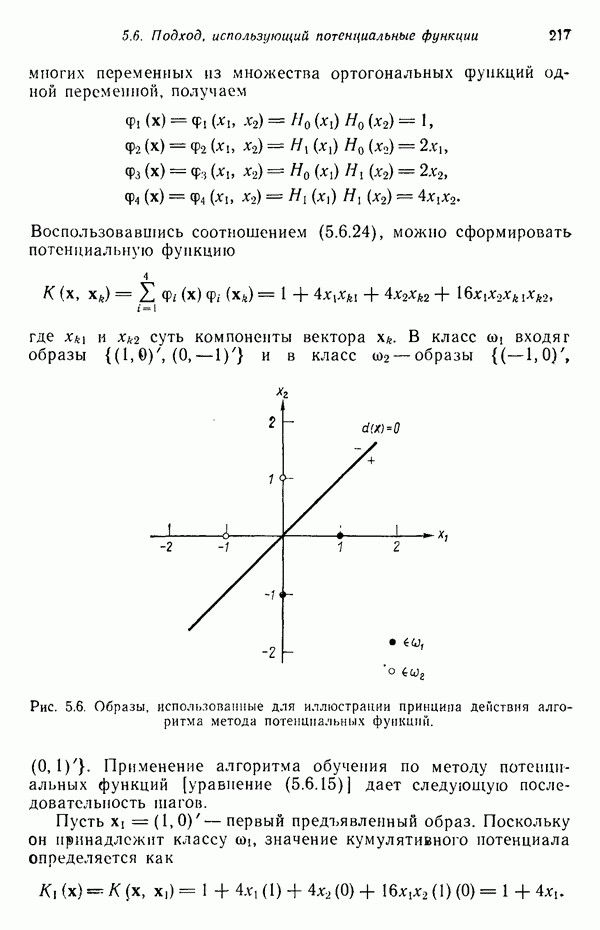
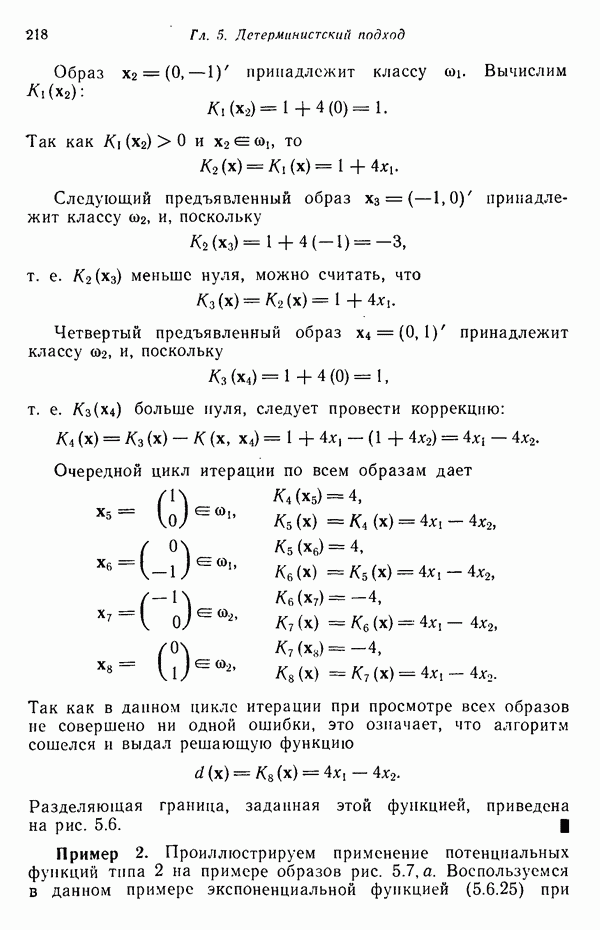



























































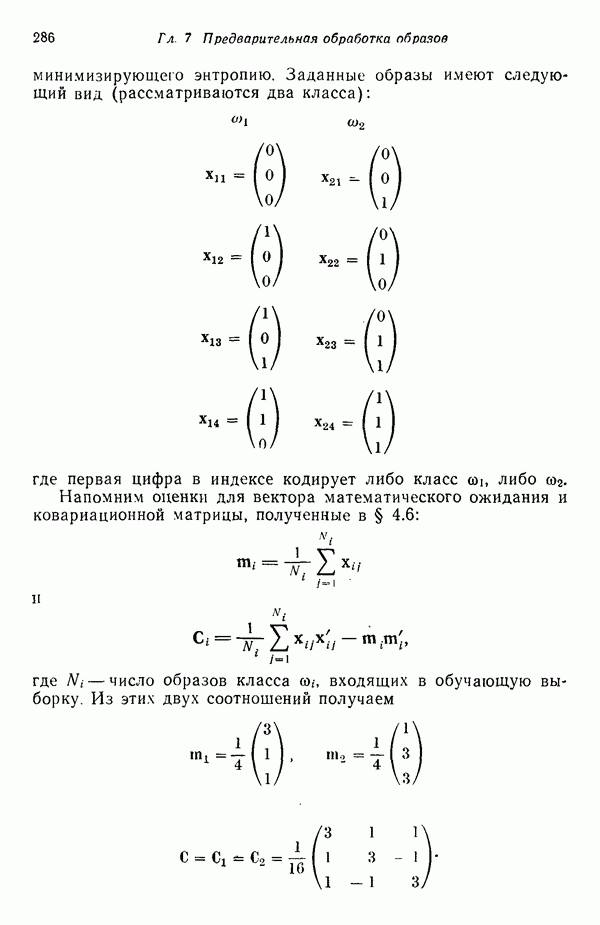













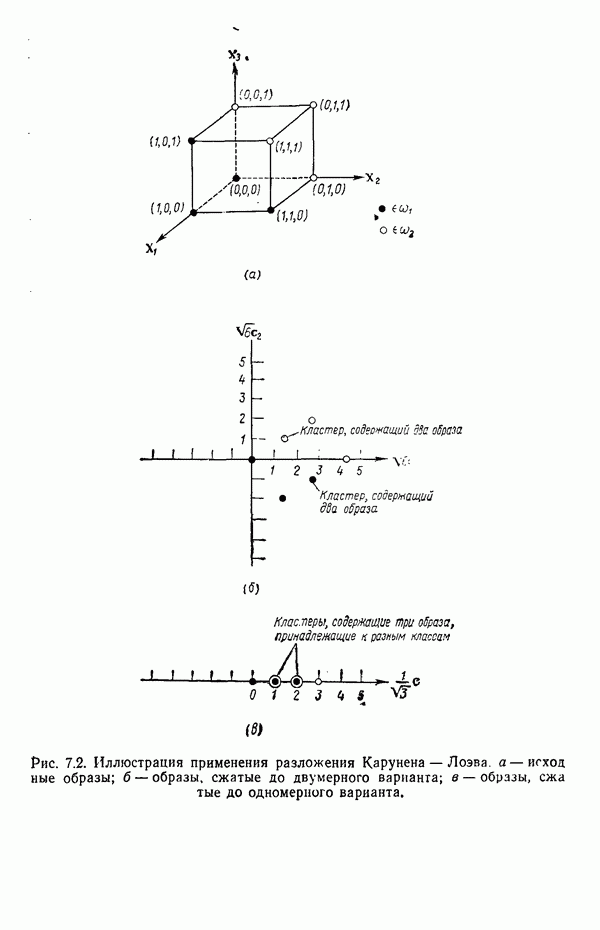



























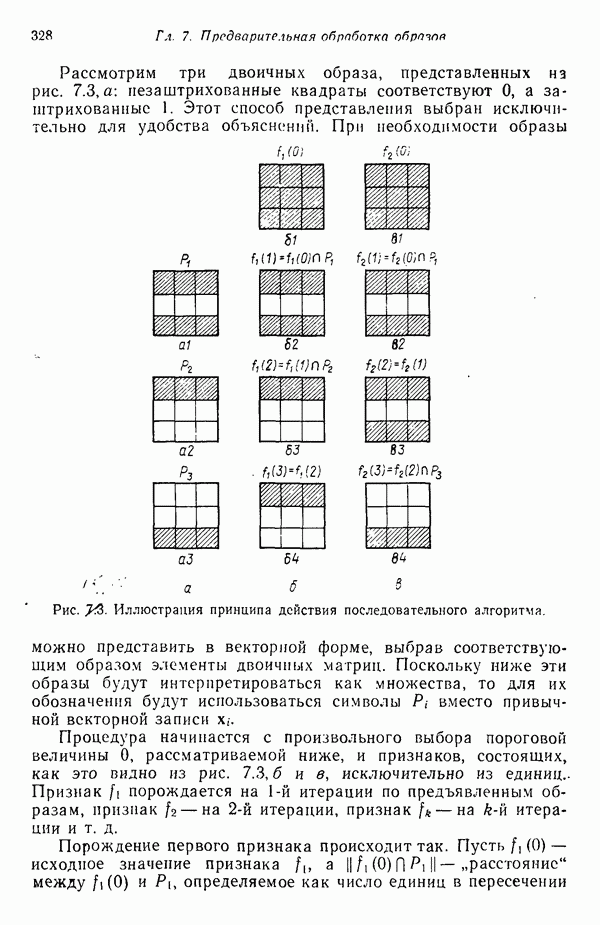



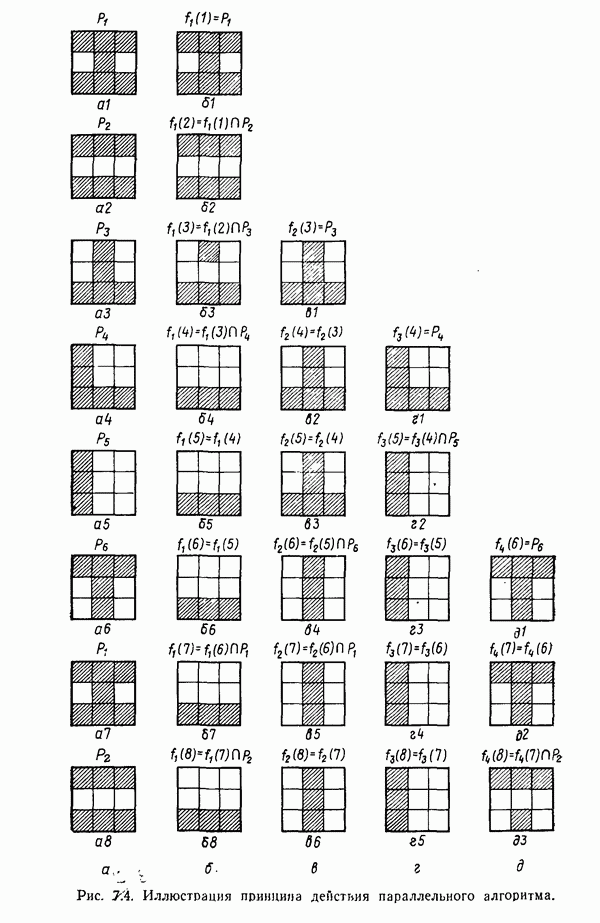




























































 распространением ее на ситуации статистического характера. Полученная в результате стохастическая модель грамматики затем может быть использована в качестве статистического аппарата в процессе распознавания.
распространением ее на ситуации статистического характера. Полученная в результате стохастическая модель грамматики затем может быть использована в качестве статистического аппарата в процессе распознавания.

 как и прежде, — множества нетерминалов, терминалов, правил подстановки и начальный символ соответственно,
как и прежде, — множества нетерминалов, терминалов, правил подстановки и начальный символ соответственно,  множество вероятностных мер, заданных на множестве правил подстановки Р. Основные определения неограниченной грамматики, грамматики непосредственно составляющих, бесконтекстной и регулярной грамматик остаются в силе также и для стохастических грамматик. Как и прежде, тип грамматики зависит от типа допустимых правил подстановки из множества Р.
множество вероятностных мер, заданных на множестве правил подстановки Р. Основные определения неограниченной грамматики, грамматики непосредственно составляющих, бесконтекстной и регулярной грамматик остаются в силе также и для стохастических грамматик. Как и прежде, тип грамматики зависит от типа допустимых правил подстановки из множества Р.
 начинающийся с
начинающийся с 

 представляют любые
представляют любые  правил подстановки из множества Р и ось
правил подстановки из множества Р и ось  промежуточные цепочки. Пусть различные правила подстановки применяются с вероятностями
промежуточные цепочки. Пусть различные правила подстановки применяются с вероятностями  Тогда вероятность порождения цепочки
Тогда вероятность порождения цепочки  определяется как
определяется как

 — условная вероятность, поставленная в соответствие правилу
— условная вероятность, поставленная в соответствие правилу  при предварительном применении правил
при предварительном применении правил 
 распределение вероятностей, поставленных в соответствие правилу
распределение вероятностей, поставленных в соответствие правилу  называется неограниченным; множество
называется неограниченным; множество  неограниченно, если все составляющие его распределения вероятностей неограниченны. Стохастическую грамматику называют неоднозначной, если существует
неограниченно, если все составляющие его распределения вероятностей неограниченны. Стохастическую грамматику называют неоднозначной, если существует 
 . Таким образом, вероятность порождения цепочки
. Таким образом, вероятность порождения цепочки  неоднозначной стохастической грамматикой определяется как
неоднозначной стохастической грамматикой определяется как

 совместно, если
совместно, если

 — это язык, порожденный стохастической грамматикой
— это язык, порожденный стохастической грамматикой  . Каждая терминальная цепочка
. Каждая терминальная цепочка  языка
языка  должна обладать вероятностью
должна обладать вероятностью  порождения данной цепочки. Стохастический язык, порожденный стохастической грамматикой
порождения данной цепочки. Стохастический язык, порожденный стохастической грамматикой  формально можно определить так:
формально можно определить так:

 — множество всех терминальных цепочек, исключая пустую, порожденных грамматикой
— множество всех терминальных цепочек, исключая пустую, порожденных грамматикой  обозначение
обозначение  используется для обозначения выводимости цепочки
используется для обозначения выводимости цепочки  из начального символа
из начального символа  посредством соответствующего применения правил подстановки из множества Р. Короче говоря, выражение (8.6.6) означает, что стохастический язык — это множество всех терминальных цепочек, каждой из которых поставлена в соответствие вероятность ее порождения, причем все цепочки выводимы из начального символа
посредством соответствующего применения правил подстановки из множества Р. Короче говоря, выражение (8.6.6) означает, что стохастический язык — это множество всех терминальных цепочек, каждой из которых поставлена в соответствие вероятность ее порождения, причем все цепочки выводимы из начального символа  . Вероятность порождения
. Вероятность порождения  задается суммированием вероятностей всех различных способов порождения цепочки
задается суммированием вероятностей всех различных способов порождения цепочки  Заметим, однако, что при
Заметим, однако, что при  стохастический язык становится неоднозначным. Рассмотренные выше понятия иллюстрируются следующим примером.
стохастический язык становится неоднозначным. Рассмотренные выше понятия иллюстрируются следующим примером.


 в то время как второе — с вероятностью
в то время как второе — с вероятностью 

 через
через  и используя (8.6.3), имеем
и используя (8.6.3), имеем

 задается в данном случае следующим образом:
задается в данном случае следующим образом:

 имеет, как мы видим, связанную с ней вероятность
имеет, как мы видим, связанную с ней вероятность  . Отметим также, что эта стохастическая грамматика не является неоднозначной, так как существует всего одна последовательность правил подстановки, ведущая к каждой терминальной цепочке. В качестве упражнения в конце этой главы предлагается доказать, что множество
. Отметим также, что эта стохастическая грамматика не является неоднозначной, так как существует всего одна последовательность правил подстановки, ведущая к каждой терминальной цепочке. В качестве упражнения в конце этой главы предлагается доказать, что множество  в данном случае совместно.
в данном случае совместно.