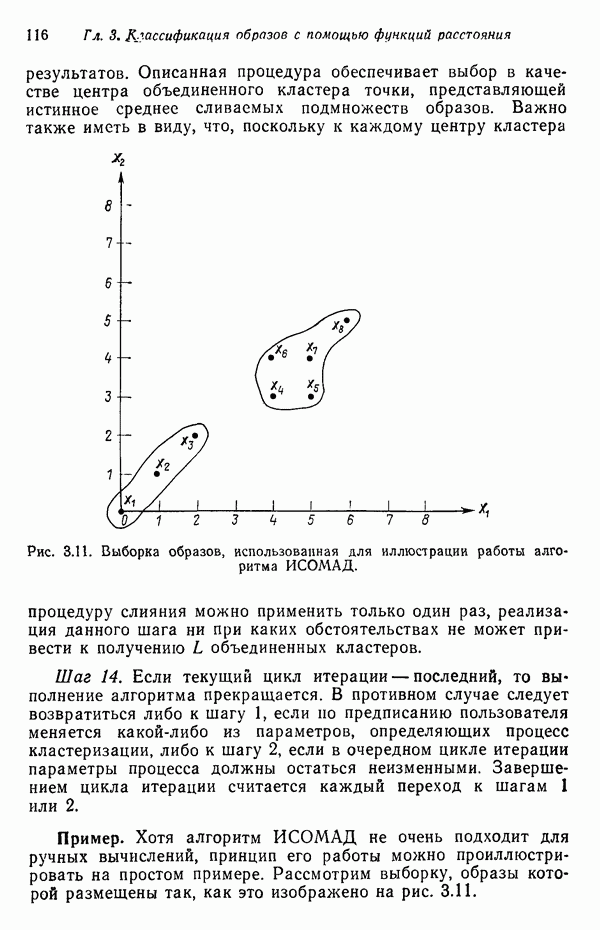
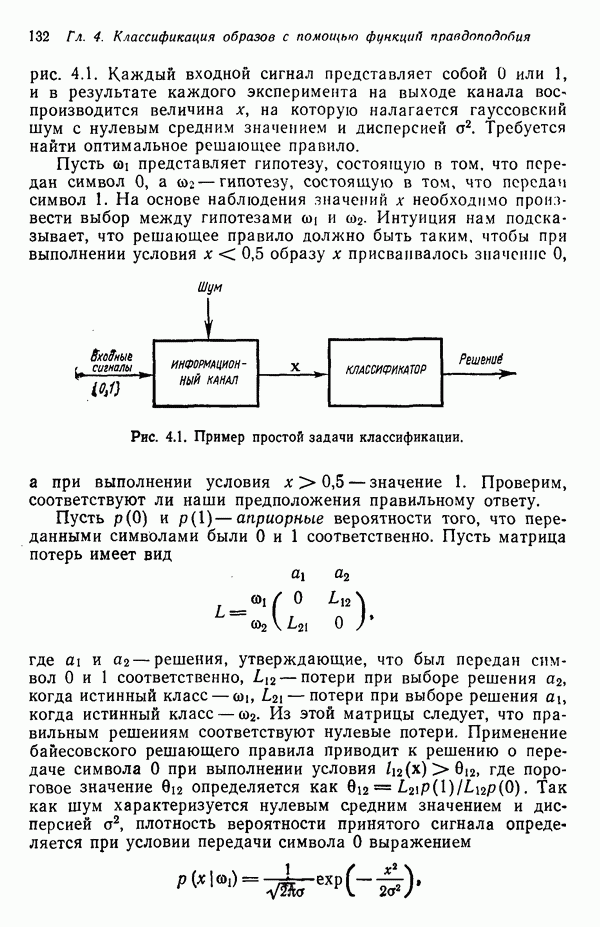
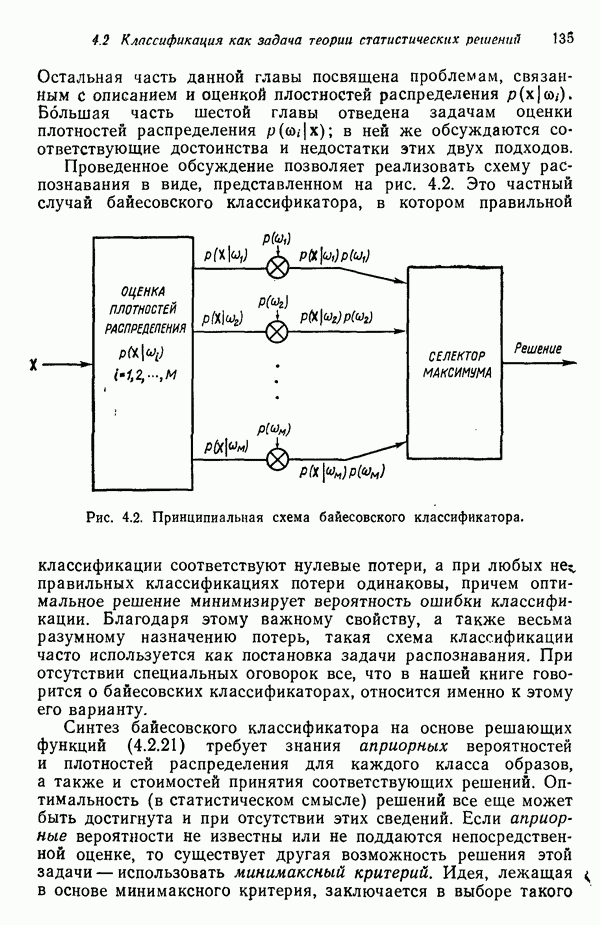
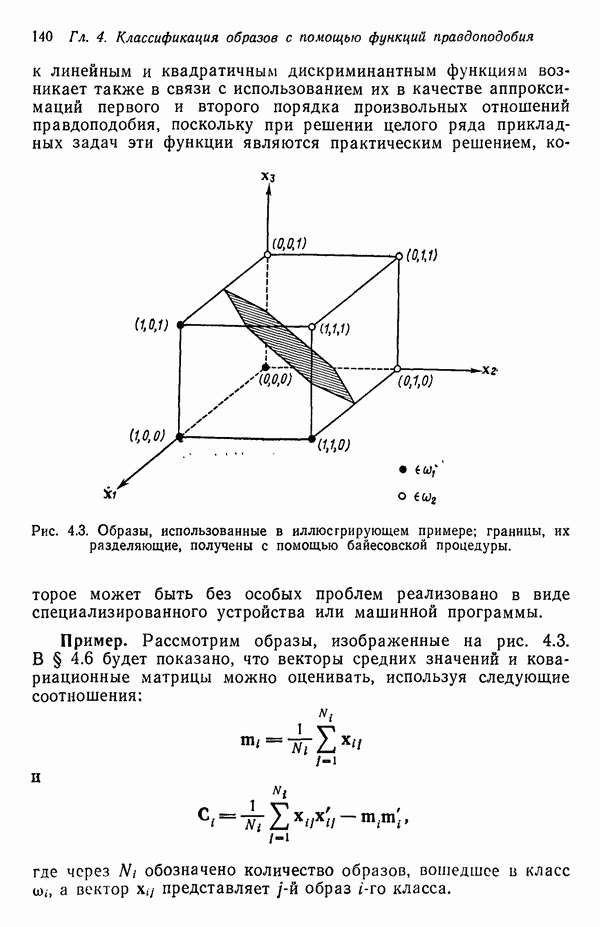
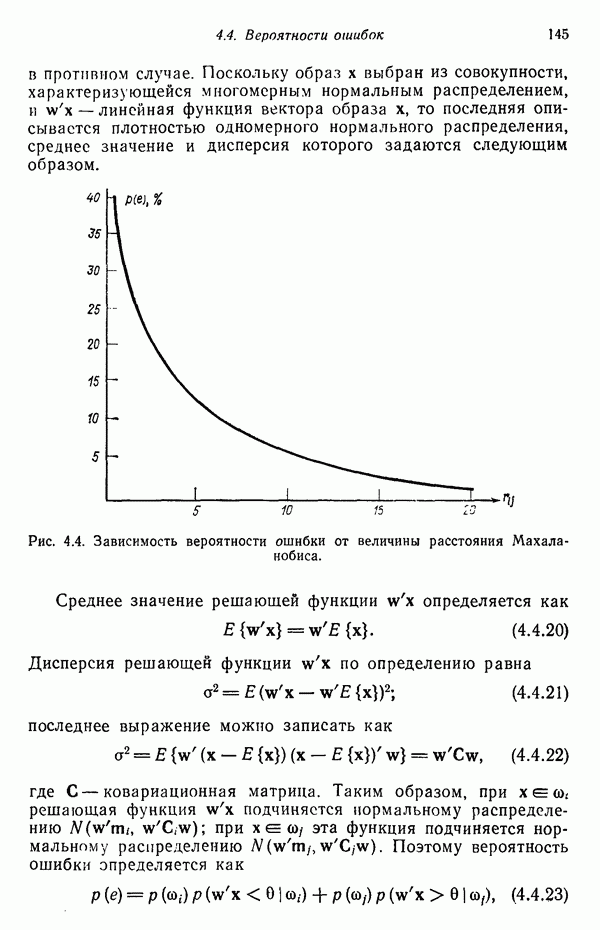
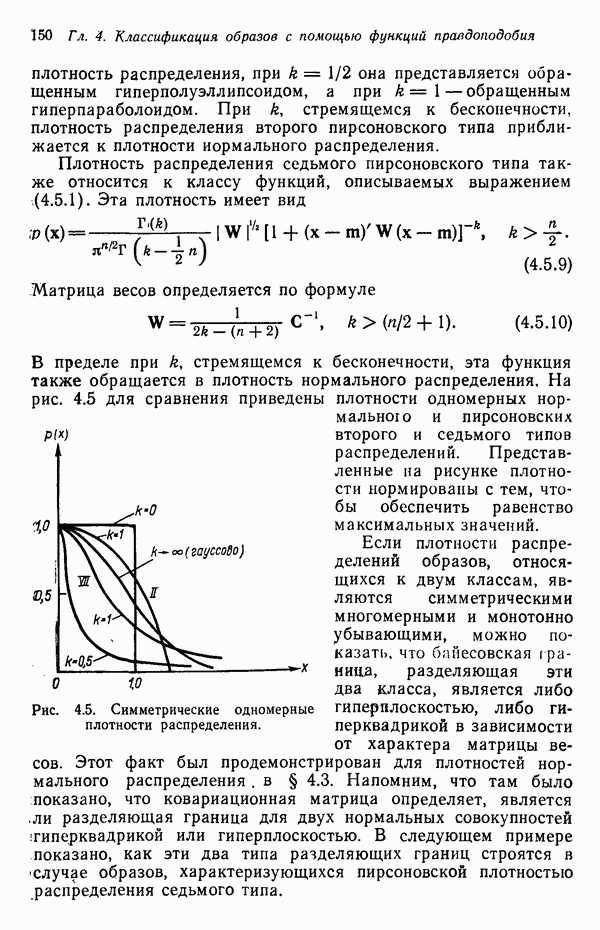
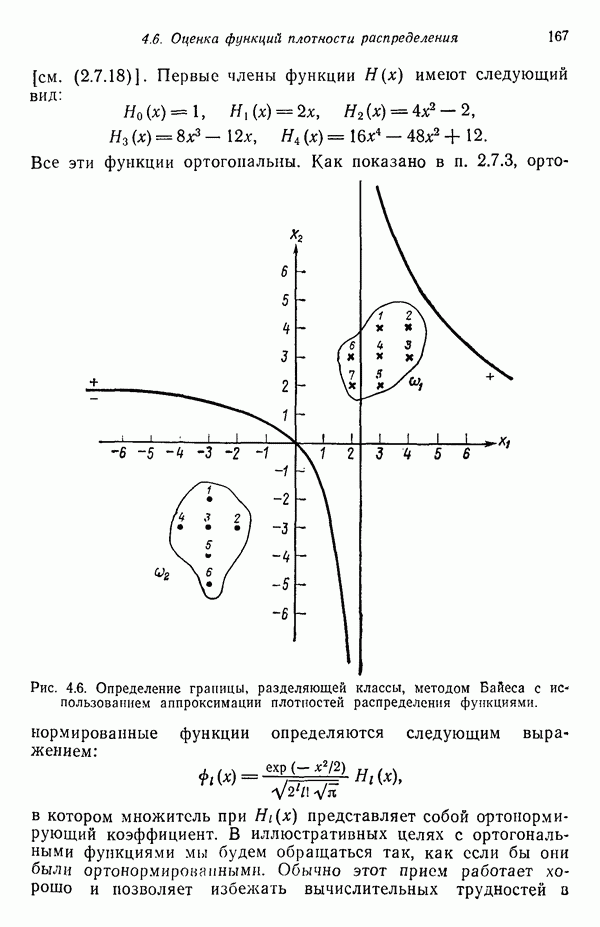
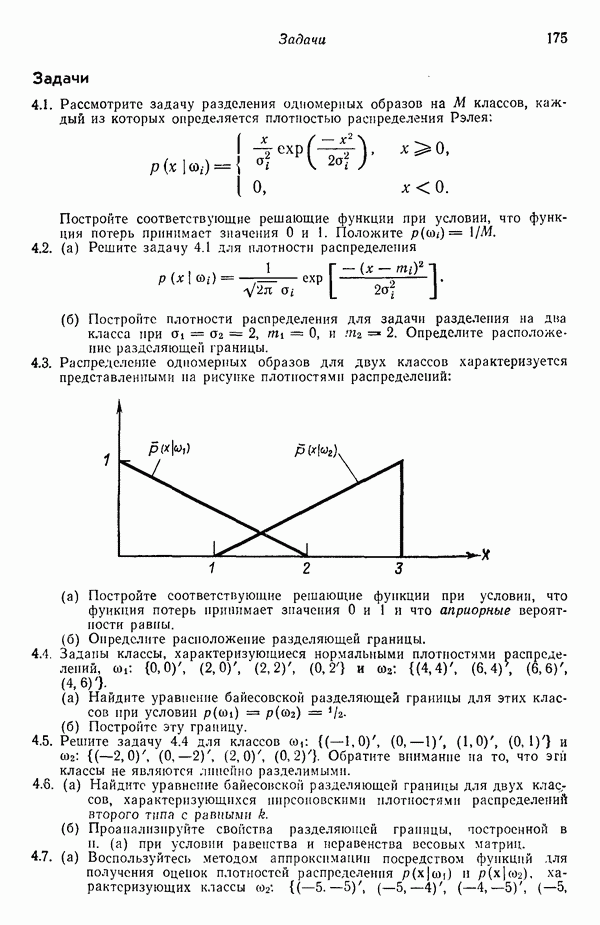
Пред.
След.
Макеты страниц
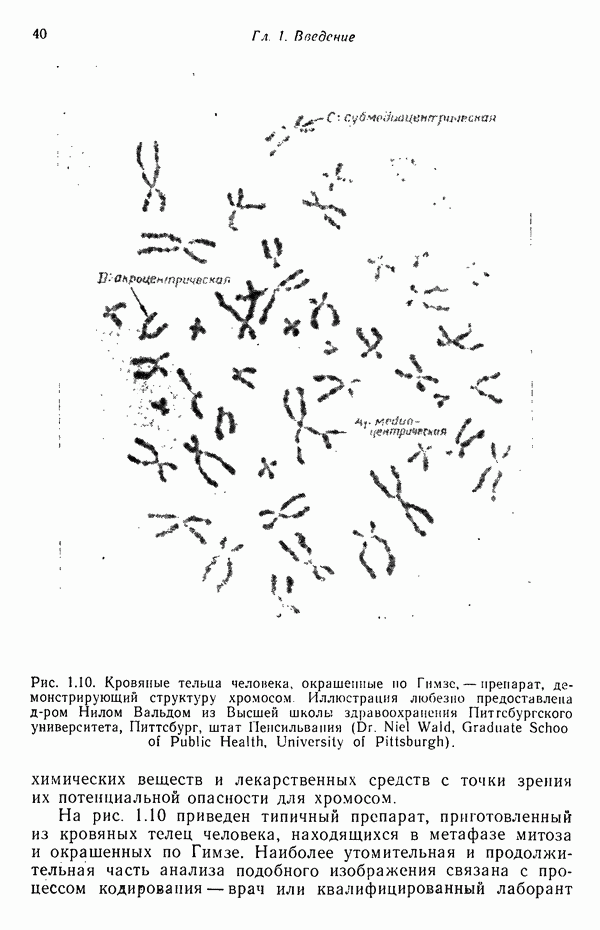
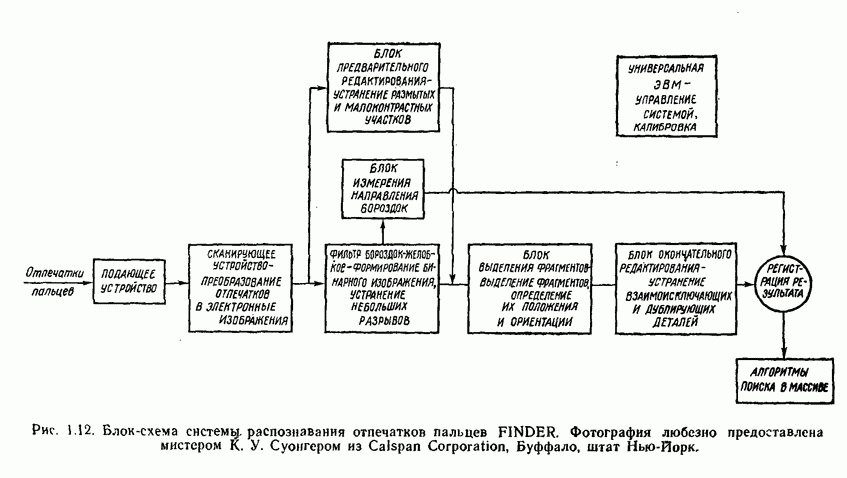
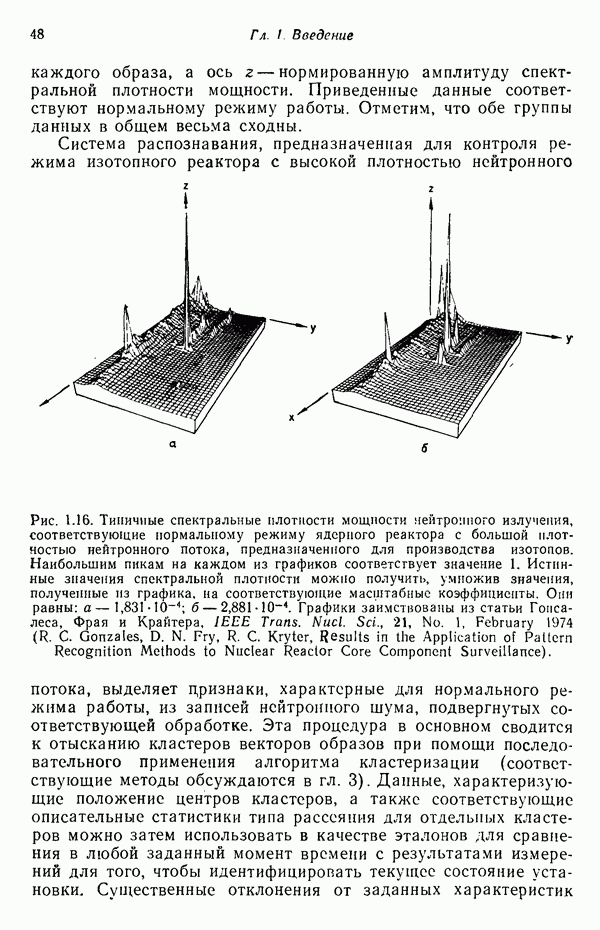
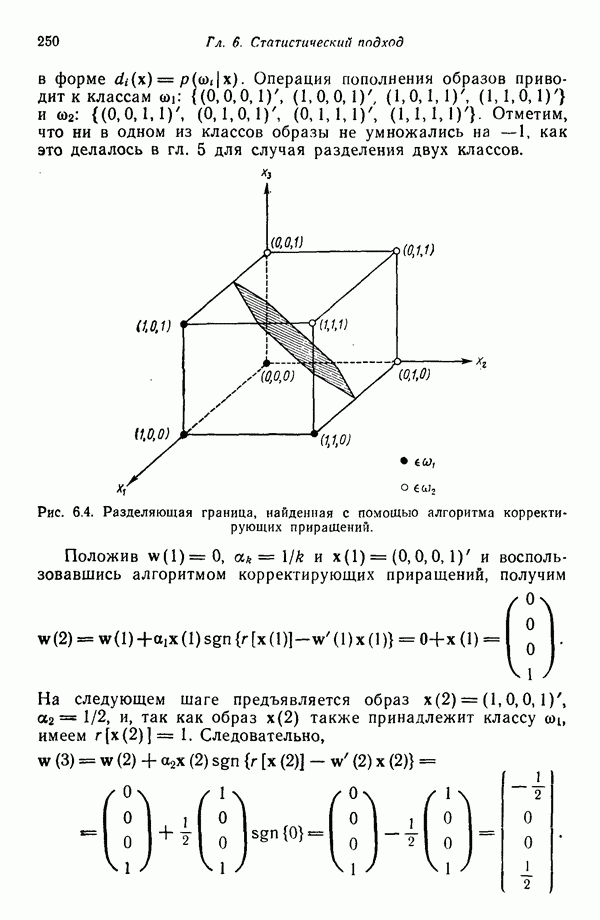
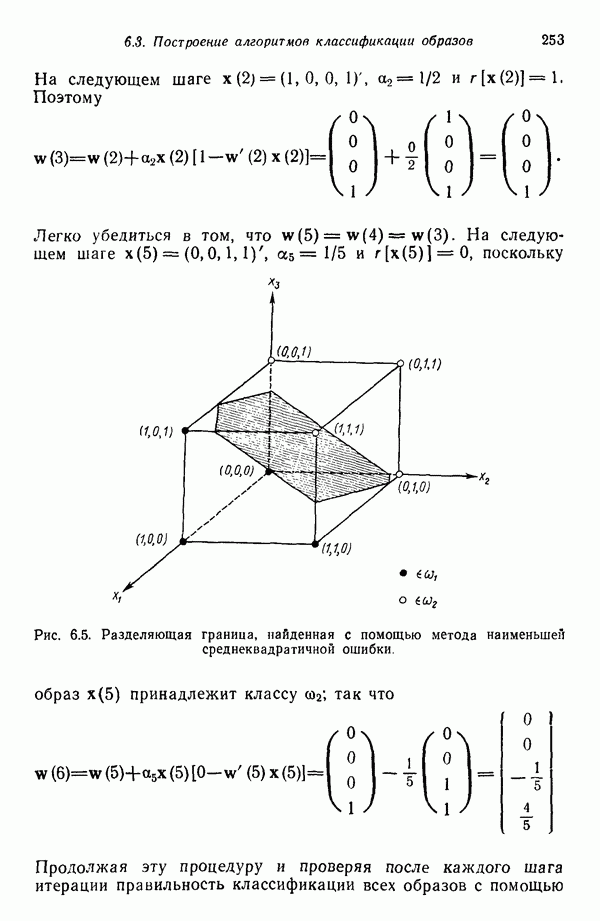
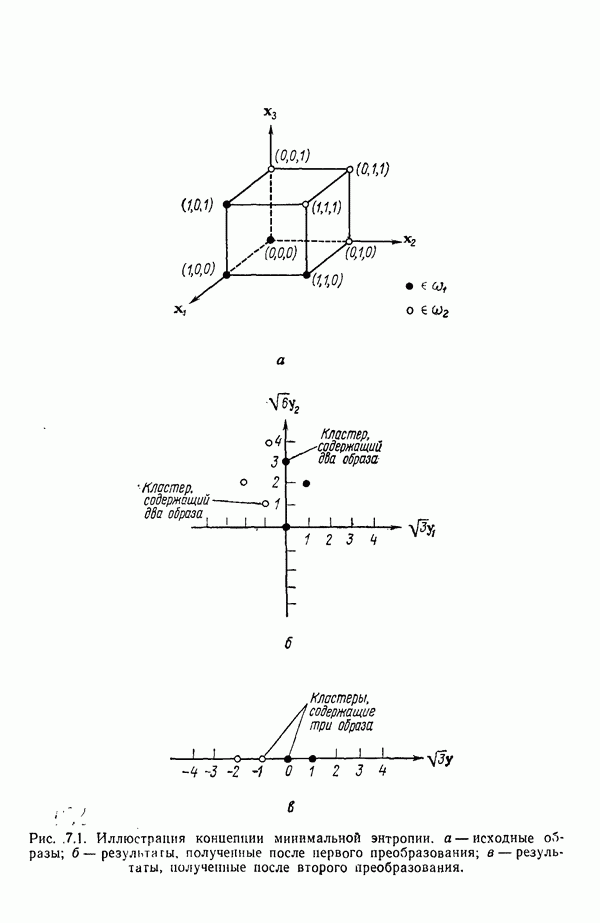
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
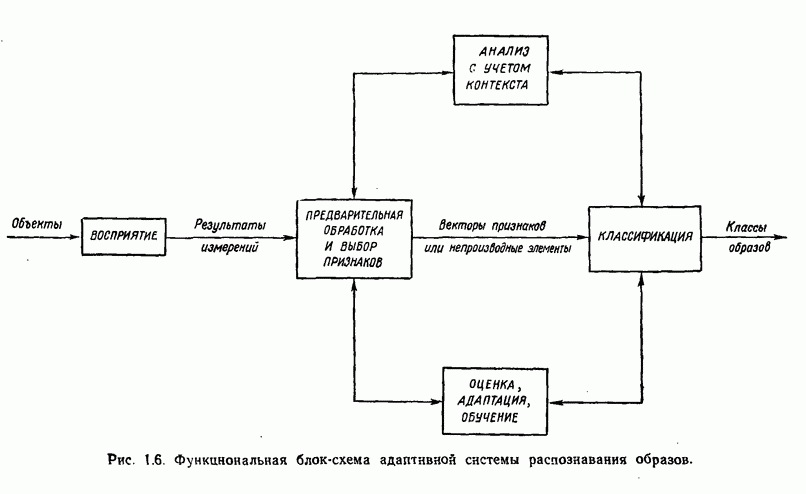
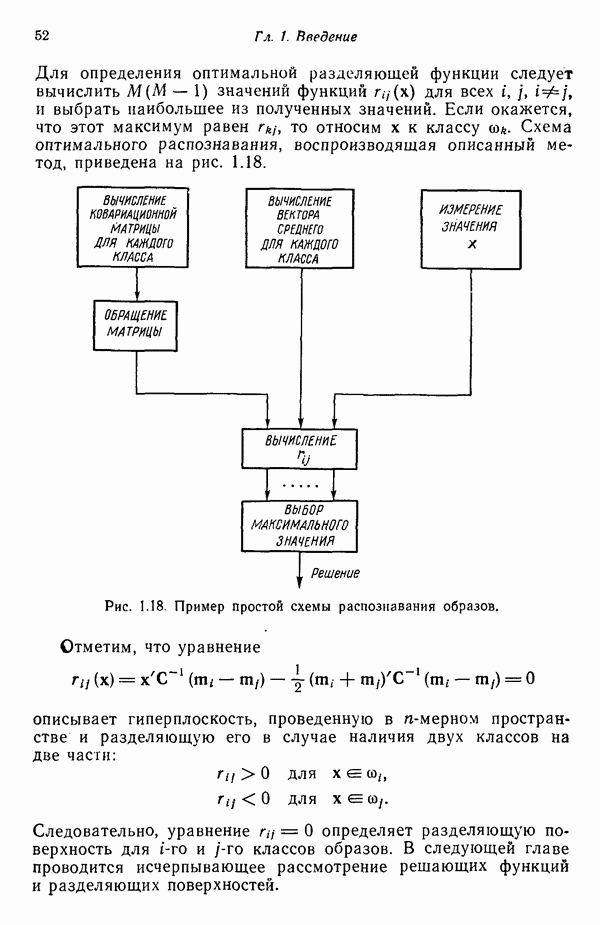
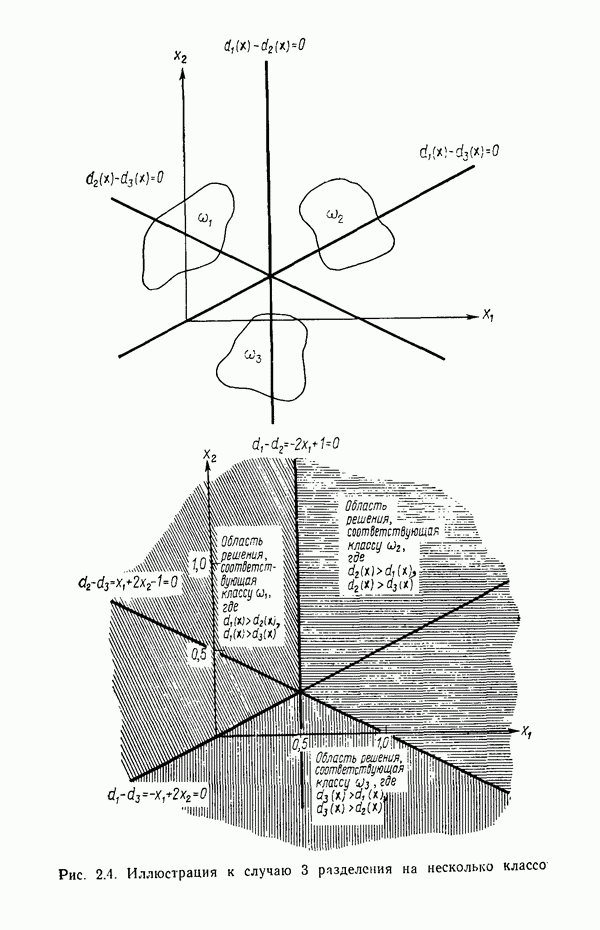
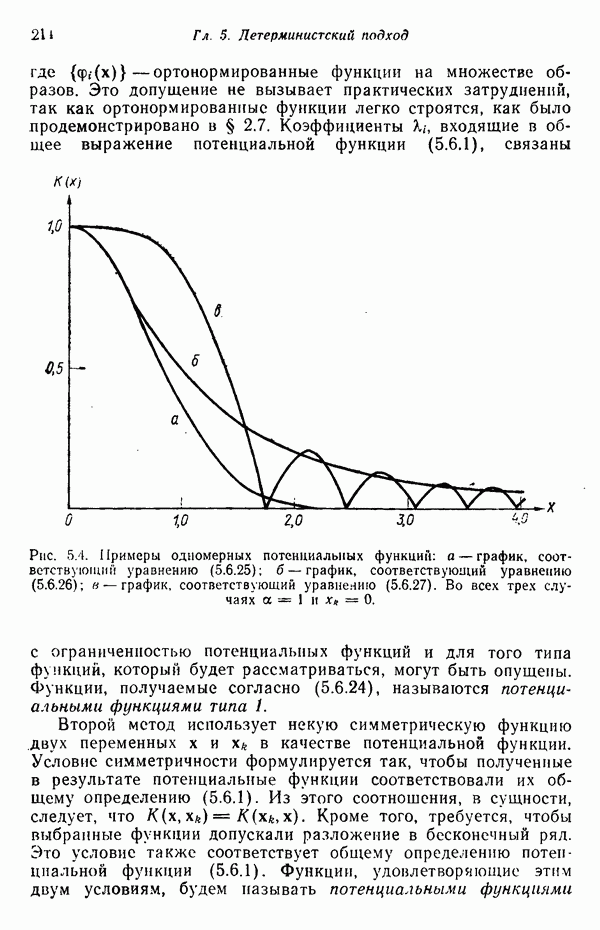
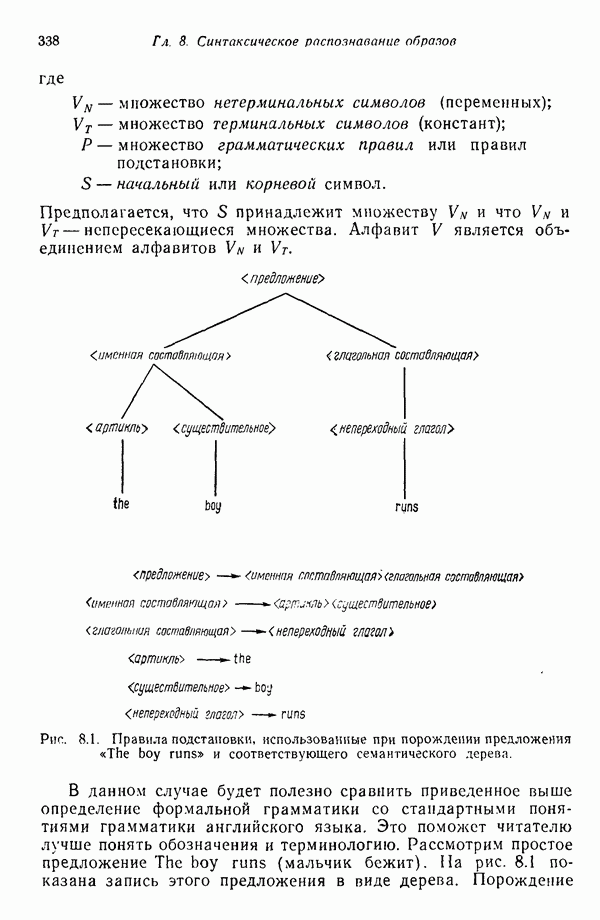
6.2. МЕТОДЫ СТОХАСТИЧЕСКОЙ АППРОКСИМАЦИИПрежде чем переходить к изучению статистических алгоритмов классификации образов, необходимо ввести несколько концепций, которые позволят должным образом описывать построение этих алгоритмов. Методы, используемые в этой главе, весьма сходны с градиентными методами, рассматривавшимися в гл. 5. Вместо детерминистских функций критерия мы сталкиваемся теперь со статистическими функциями, которые статистики обычно называют функциями регрессии. Для определения корней функции регрессии воспользуемся методами так называемой стохастической аппроксимации. Если функция регрессии представляет производную от должным образом заданной функции критерия, то определение корня этой производной обеспечивает отыскание минимума функции критерия. При помощи соответствующего выбора функций критерия можно построить итеративные алгоритмы обучения, аппроксимирующие в некотором смысле байесовский классификатор. Для того чтобы упростить изложение, в начале мы сосредоточим внимание на одномерных задачах. Затем обобщим полученные результаты на многомерный случай. 6.2.1. Алгоритм Роббинса — МонроРассмотрим функцию положительна при всех значениях Допустим, что вместо непосредственного наблюдения функции
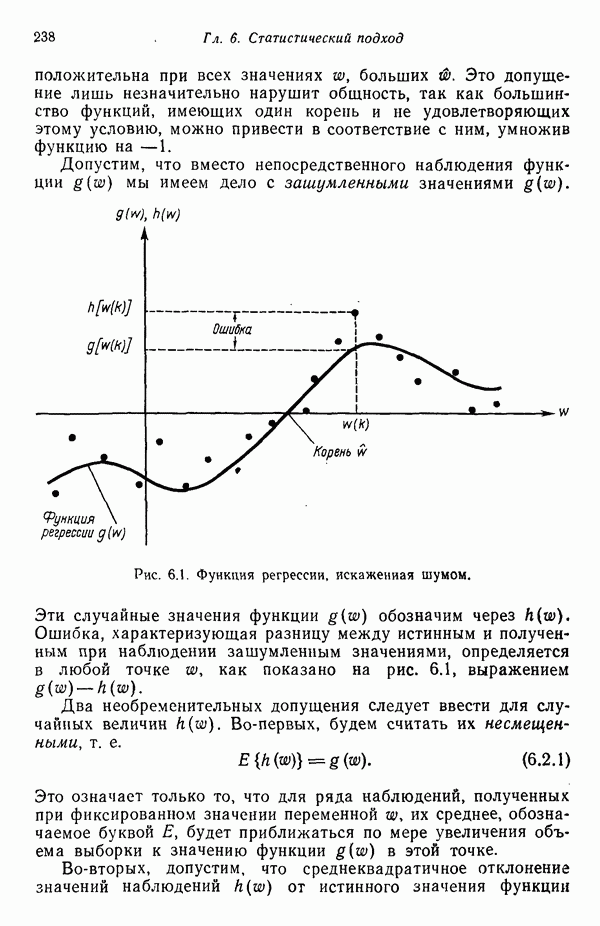
Рис. 6.1. Функция регрессии, искаженная шумом. Эти случайные значения функции Два необременительных допущения следует ввести для случайных величин
Это означает только то, что для ряда наблюдений, полученных при фиксированном значении переменной Во-вторых, допустим, что среднеквадратичное отклонение значений наблюдений
должно выполняться неравенство
при всех значениях переменной Если слабые условия (6.2.1) и (6.2.2) выполняются, то алгоритм, предложенный Роббинсом и Монро, можно применить для итеративного определения корня
где
Примером последовательности, удовлетворяющей этим условиям, служит гармонический ряд Отметим, что коррекции оценок, вводимые алгоритмом Роббинса — Монро, пропорциональны значению предыдущего наблюдения
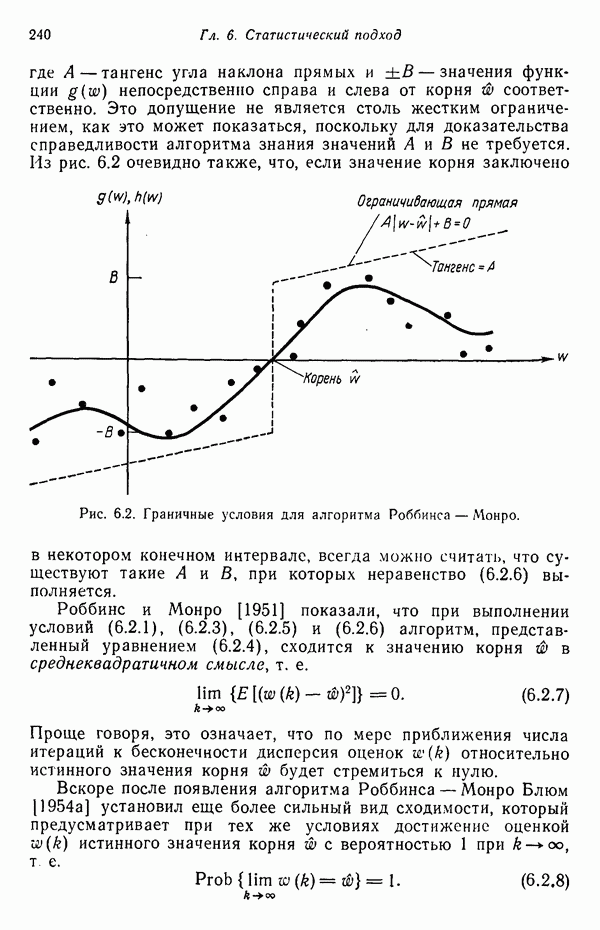
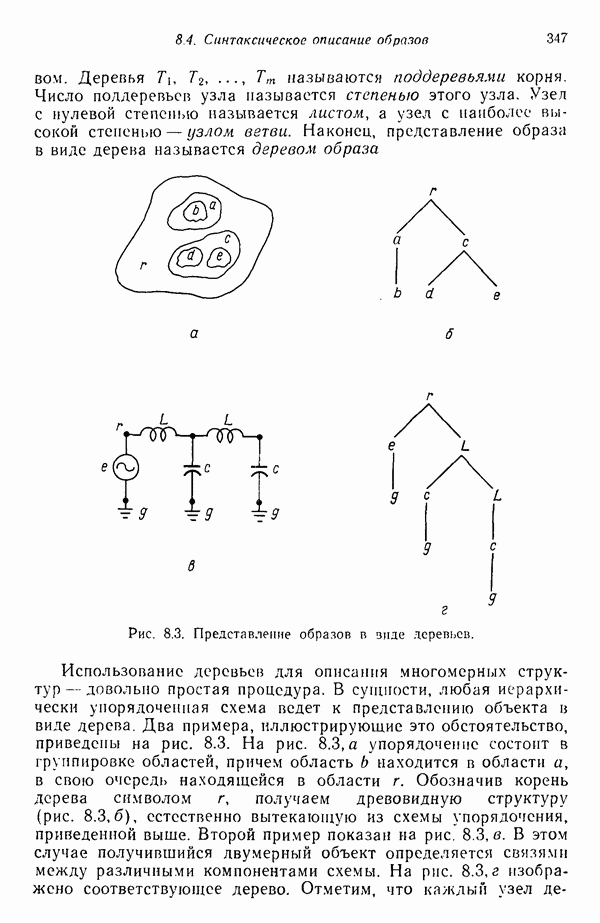
где А — тангенс угла наклона прямых и
Рис. 6.2. Граничные условия для алгоритма Роббинса — Монро. Роббинс и Монро [1951] показали, что при выполнении условий (6.2.1), (6.2.3), (6.2.5) и (6.2.6) алгоритм, представленный уравнением (6.2.4), сходится к значению корня
Проще говоря, это означает, что по мере приближения числа итераций к бесконечности дисперсия оценок Вскоре после появления алгоритма Роббинса — Монро Блюм [1954а] установил еще более сильный вид сходимости, который предусматривает при тех же условиях достижение оценкой
Это отношение указывает, что в пределе оценка Интересно отметить, что доказательства, предложенные Роббинсом — Монро и Блюмом, являются частными случаями теоремы, установленной позже Дворецки [1956]. Ему удалось показать, что оба критерия сходимости (6.2.7) и (6.2.8) выполняются для любой процедуры стохастической аппроксимации, удовлетворяющей условиям его теоремы. Рассмотрение условий
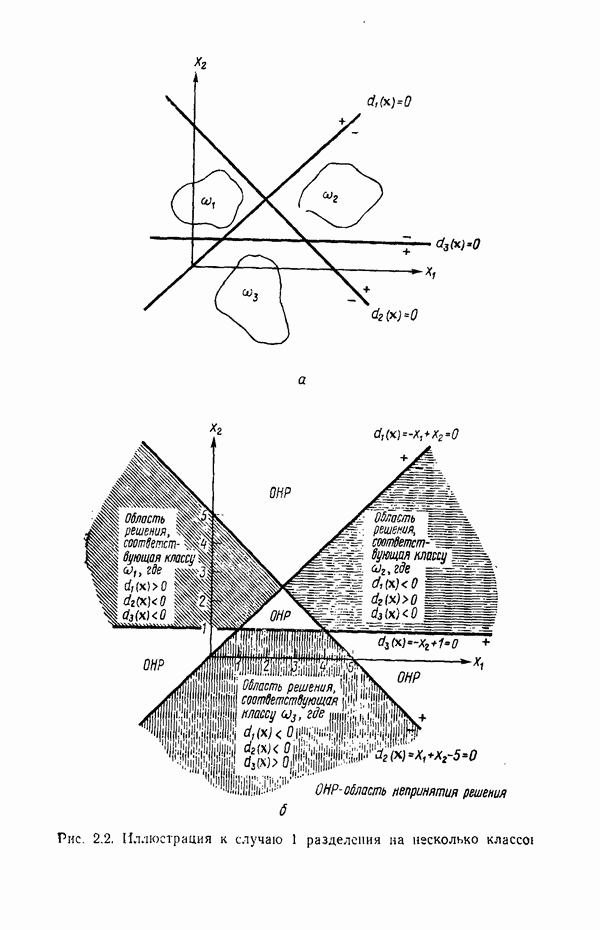
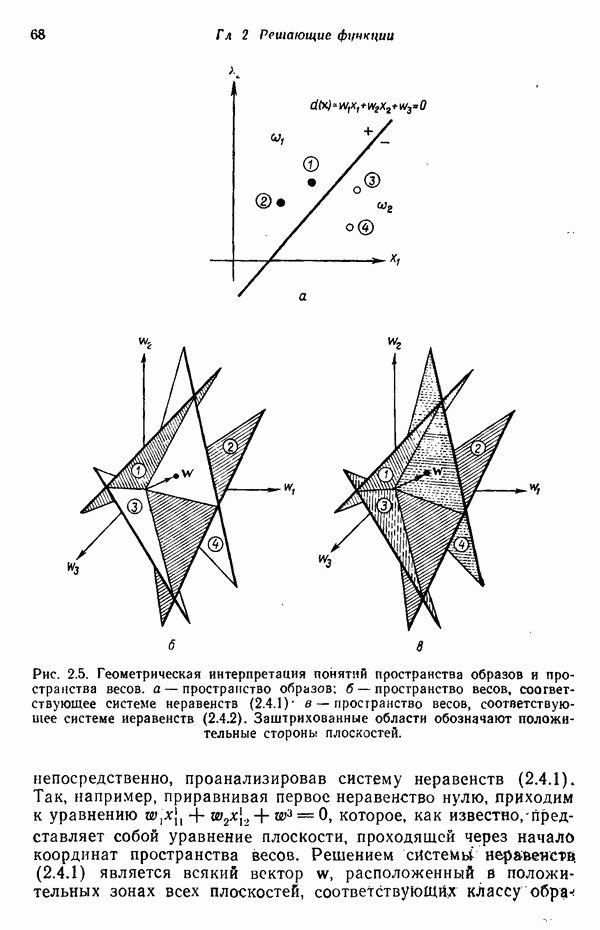
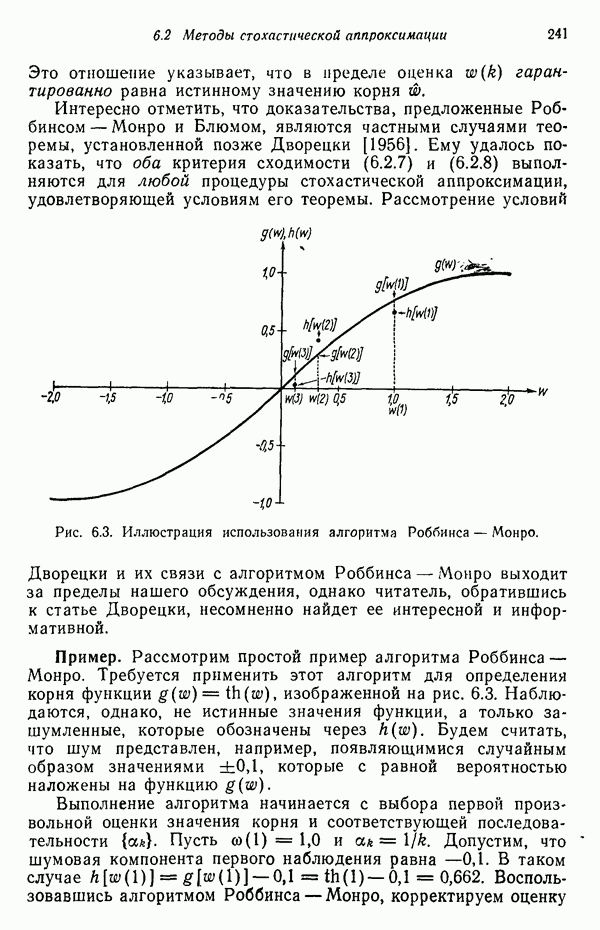
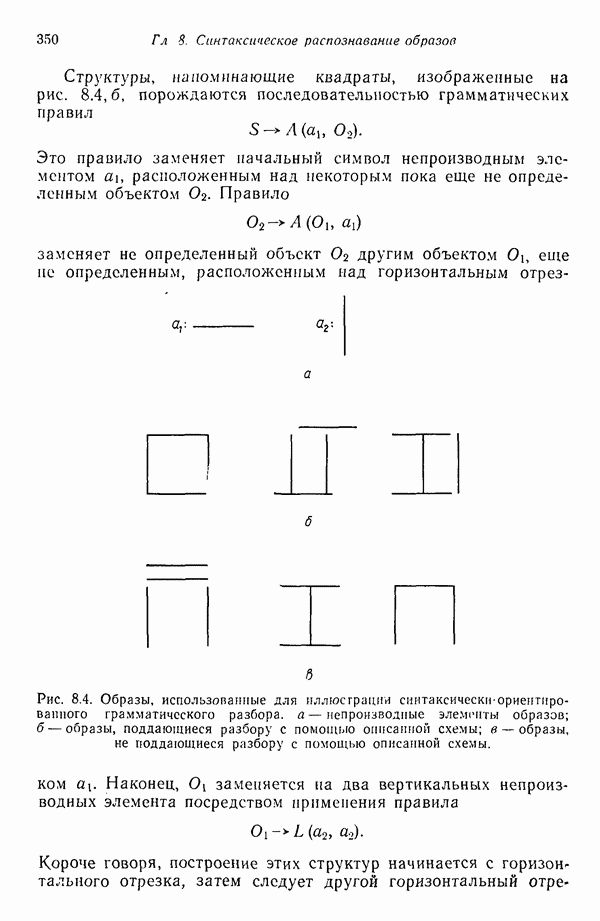
Рис. 6.3. Иллюстрация использования алгоритма Роббинса — Монро. Дворецки и их связи с алгоритмом Роббинса — Монро выходит за пределы нашего обсуждения, однако читатель, обратившись к статье Дворецки, несомненно найдет ее интересной и информативной. Пример. Рассмотрим простой пример алгоритма Роббинса — Монро. Требуется применить этот алгоритм для определения корня функции Выполнение алгоритма начинается с выбора первой произвольной оценки значения корня и соответствующей последовательности корня:
Скорректированная оценка приведена на рис. 6.3. Если этому новому значению соответствует шумовая компонента, равная
Это значение явно ближе к истинному значению корня (см. скан) Отметим, что в течение нескольких первых итераций оценка быстро приближается к значению корня, а затем эта скорость уменьшается с увеличением
|
 |
Оглавление
|
























































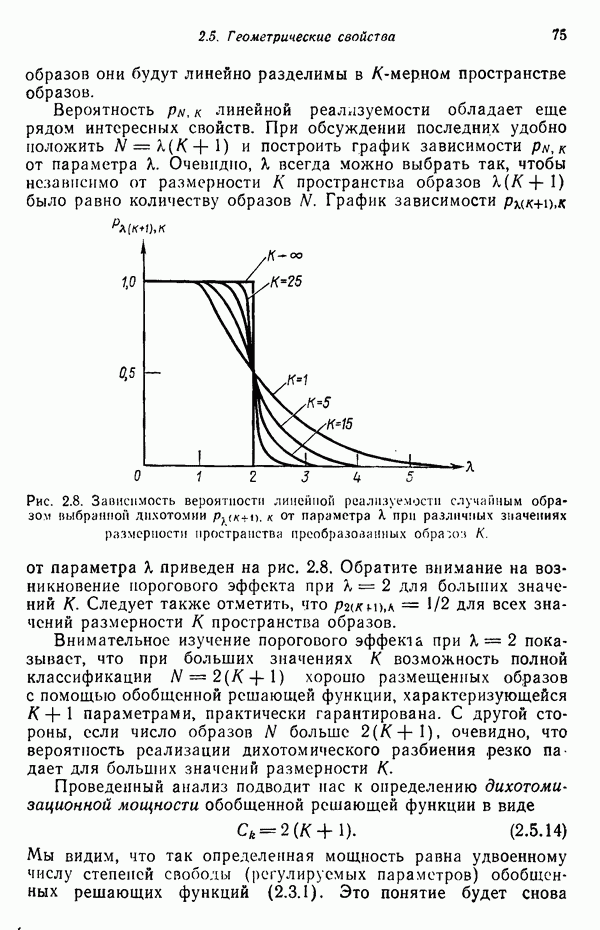

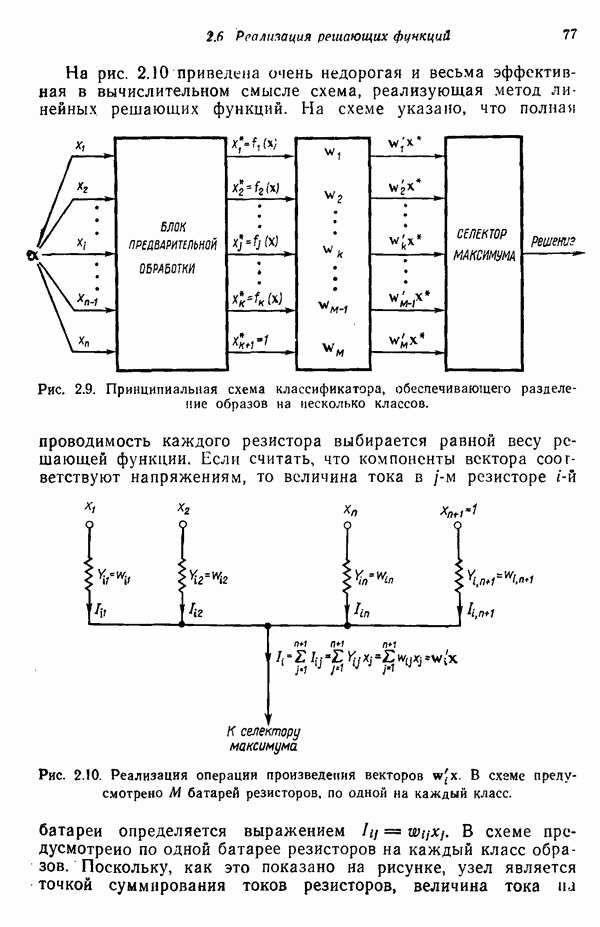












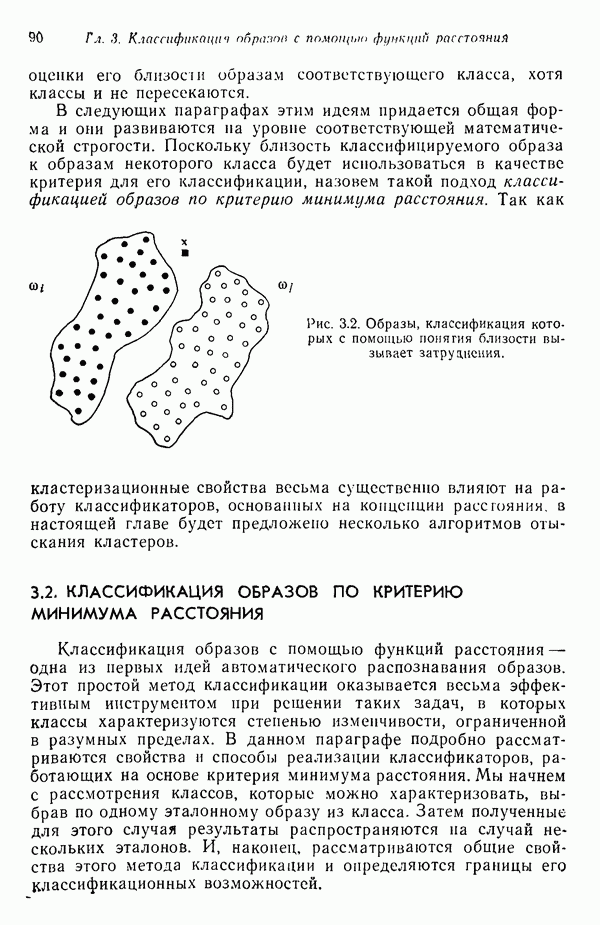











































































































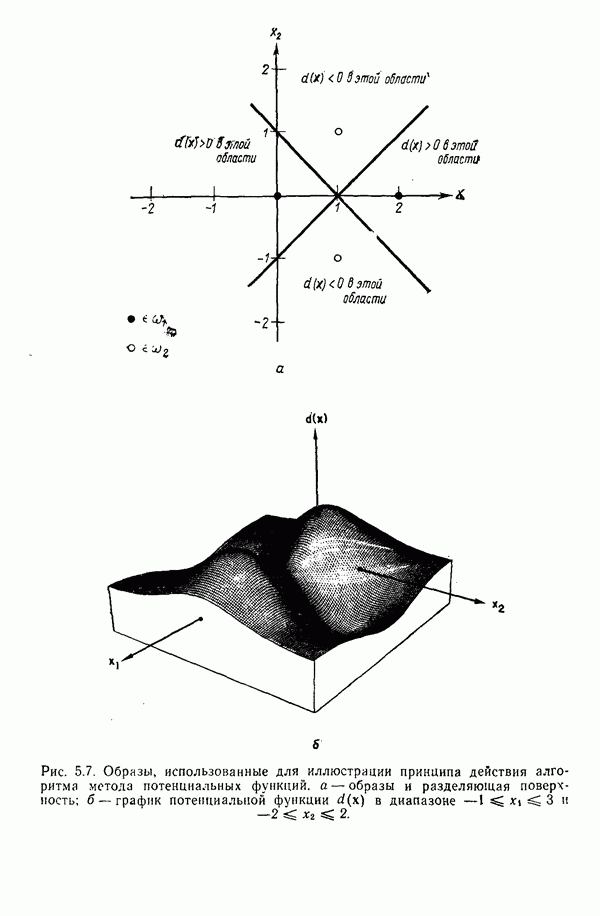




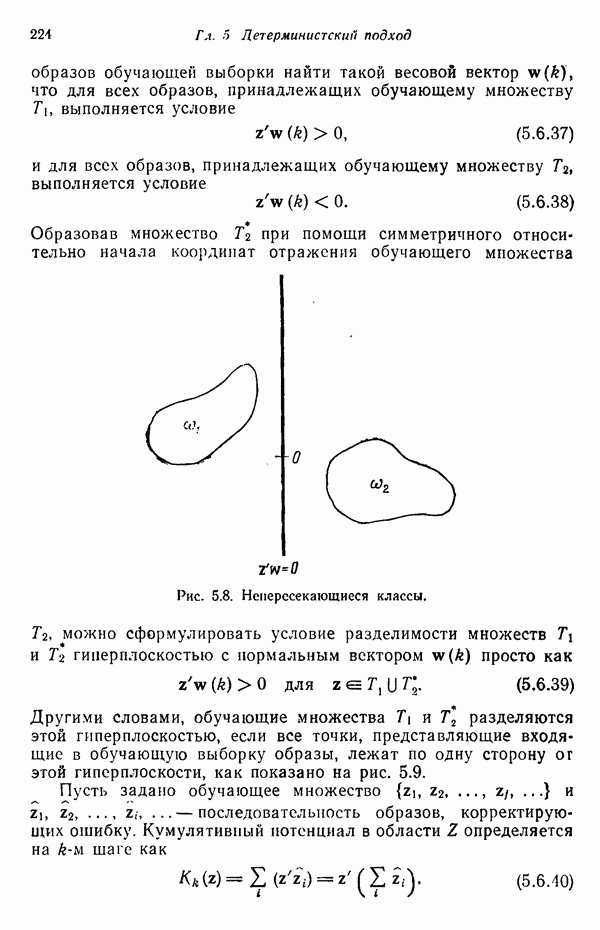






























































































































































 переменной
переменной  , имеющую единственный корень
, имеющую единственный корень  такой, что
такой, что  Пусть функция
Пусть функция  отрицательна при всех значениях переменной
отрицательна при всех значениях переменной  , меньших и
, меньших и
 больших
больших  . Это допущение лишь незначительно нарушит общность, так как большинство функций, имеющих один корень и не удовлетворяющих этому условию, можно привести в соответствие с ним, умножив функцию на —1.
. Это допущение лишь незначительно нарушит общность, так как большинство функций, имеющих один корень и не удовлетворяющих этому условию, можно привести в соответствие с ним, умножив функцию на —1.
 мы имеем дело с затупленными значениями
мы имеем дело с затупленными значениями 

 обозначим через
обозначим через  (до). Ошибка, характеризующая разницу между истинным и полученным при наблюдении зашумленным значениями, определяется в любой точке
(до). Ошибка, характеризующая разницу между истинным и полученным при наблюдении зашумленным значениями, определяется в любой точке  как показано на рис. 6.1, выражением
как показано на рис. 6.1, выражением  .
.
 . Во-первых, будем считать их несмещенными, т. е.
. Во-первых, будем считать их несмещенными, т. е.

 их среднее, обозначаемое буквой Е, будет приближаться по мере увеличения объема выборки к значению функции
их среднее, обозначаемое буквой Е, будет приближаться по мере увеличения объема выборки к значению функции  в этой точке.
в этой точке.
 от истинного значения функции
от истинного значения функции
 конечно для всех значений переменной
конечно для всех значений переменной  . Другими словами, для дисперсии
. Другими словами, для дисперсии


 , где
, где  — положительная константа. Это допущение исключает возможность использования наблюдений, отличающихся от истинных значений функции
— положительная константа. Это допущение исключает возможность использования наблюдений, отличающихся от истинных значений функции  столь сильно, что процедура отыскания корня ни в коем случае не приведет к получению искомого результата. В физическом смысле это означает, что наблюдения должны быть зашумлены в разумных пределах.
столь сильно, что процедура отыскания корня ни в коем случае не приведет к получению искомого результата. В физическом смысле это означает, что наблюдения должны быть зашумлены в разумных пределах.
 функции
функции  Обозначив через
Обозначив через  произвольную начальную оценку корня
произвольную начальную оценку корня  и через
и через  оценку этого корня, полученную на
оценку этого корня, полученную на  шаге итерации, процедуру коррекции оценки с помощью алгоритма Роббинса — Монро выразим в виде соотношения
шаге итерации, процедуру коррекции оценки с помощью алгоритма Роббинса — Монро выразим в виде соотношения

 — элемент последовательности положительных чисел, удовлетворяющей следующим условиям:
— элемент последовательности положительных чисел, удовлетворяющей следующим условиям:


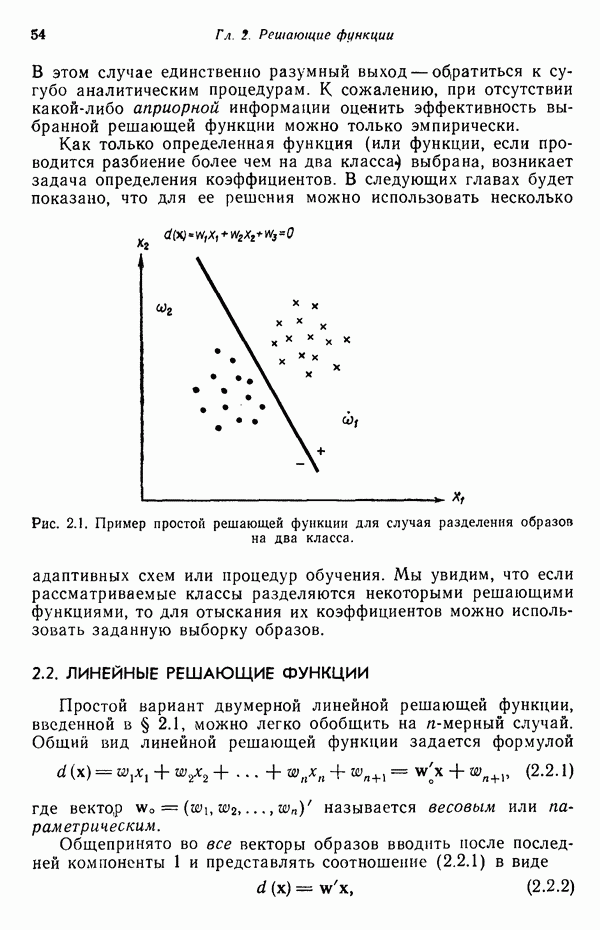
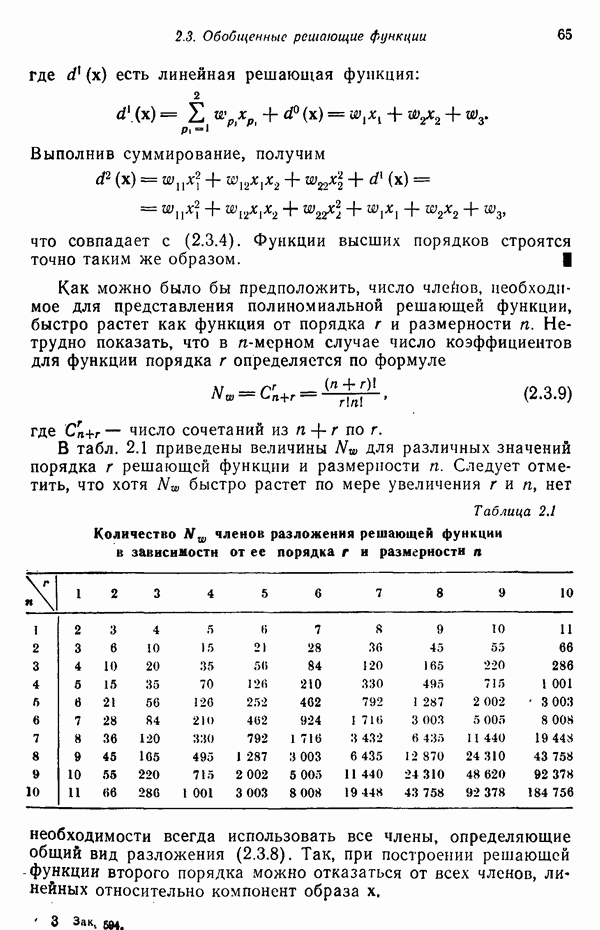
 Чтобы предотвратить введение чрезмерных коррекций, предполагается, что значения функции
Чтобы предотвратить введение чрезмерных коррекций, предполагается, что значения функции  ограничены прямыми в областях значений переменной, больших и меньших значения корня
ограничены прямыми в областях значений переменной, больших и меньших значения корня  как это показано на рис. 6.2. Выбор такой ограничивающей функции обусловлен ее простотой; ограничение при этом задается неравенством
как это показано на рис. 6.2. Выбор такой ограничивающей функции обусловлен ее простотой; ограничение при этом задается неравенством

 значения функции
значения функции  непосредственно справа и слева от корня
непосредственно справа и слева от корня  соответственно. Это допущение не является столь жестким ограничением, как это может показаться, поскольку для доказательства справедливости алгоритма знания значений
соответственно. Это допущение не является столь жестким ограничением, как это может показаться, поскольку для доказательства справедливости алгоритма знания значений  не требуется. Из рис. 6.2 очевидно также, что, если значение корня заключено в некотором конечном интервале, всегда можно считать, что существуют такие
не требуется. Из рис. 6.2 очевидно также, что, если значение корня заключено в некотором конечном интервале, всегда можно считать, что существуют такие  , при которых неравенство (6.2.6) выполняется.
, при которых неравенство (6.2.6) выполняется.

 в среднеквадратичном смысле, т. е.
в среднеквадратичном смысле, т. е.

 относительно истинного значения корня
относительно истинного значения корня  будет стремиться к нулю.
будет стремиться к нулю.
 истинного значения корня
истинного значения корня  с вероятностью 1 при
с вероятностью 1 при  , т. е.
, т. е.

 гарантированно равна истинному значению корня
гарантированно равна истинному значению корня 

 изображенной на рис. 6.3. Наблюдаются, однако, не истинные значения функции, а только зашумленные, которые обозначены через
изображенной на рис. 6.3. Наблюдаются, однако, не истинные значения функции, а только зашумленные, которые обозначены через  . Будем считать, что шум представлен, например, появляющимися случайным образом значениями ±0,1, которые с равной вероятностью наложены на функцию
. Будем считать, что шум представлен, например, появляющимися случайным образом значениями ±0,1, которые с равной вероятностью наложены на функцию
 . Пусть
. Пусть  . Допустим, что шумовая компонента первого наблюдения равна —0,1. В таком случае
. Допустим, что шумовая компонента первого наблюдения равна —0,1. В таком случае  Воспользовавшись алгоритмом Роббинса — Монро, корректируем оценку
Воспользовавшись алгоритмом Роббинса — Монро, корректируем оценку

 то
то  . Следовательно,
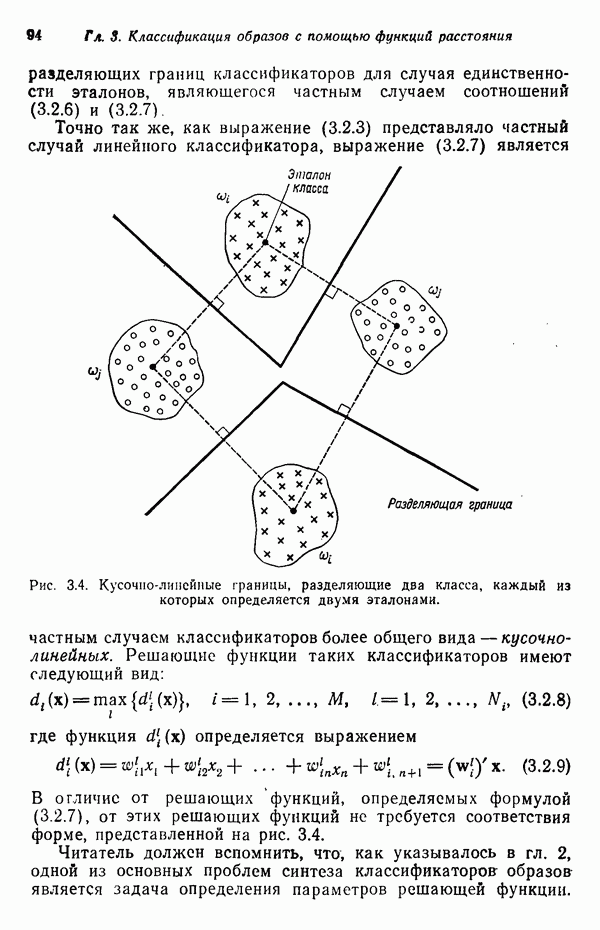
. Следовательно,

 . В приведенной ниже таблице помещены значения последовательных оценок вплоть до
. В приведенной ниже таблице помещены значения последовательных оценок вплоть до  , где через
, где через  обозначена шумовая компонента на k-м шаге.
обозначена шумовая компонента на k-м шаге.
 Во-первых, при увеличении
Во-первых, при увеличении  коэффициент а теряет корректирующую мощность, так как
коэффициент а теряет корректирующую мощность, так как  . Во-вторых, очевидно, что шум оказывает сильное влияние на значения функции
. Во-вторых, очевидно, что шум оказывает сильное влияние на значения функции  соответствующие близким к корню значениям переменной
соответствующие близким к корню значениям переменной  . В связи с этим, обстоятельством приближение к значению корня в этой области в большой степени зависит от случайной природы шума.
. В связи с этим, обстоятельством приближение к значению корня в этой области в большой степени зависит от случайной природы шума.