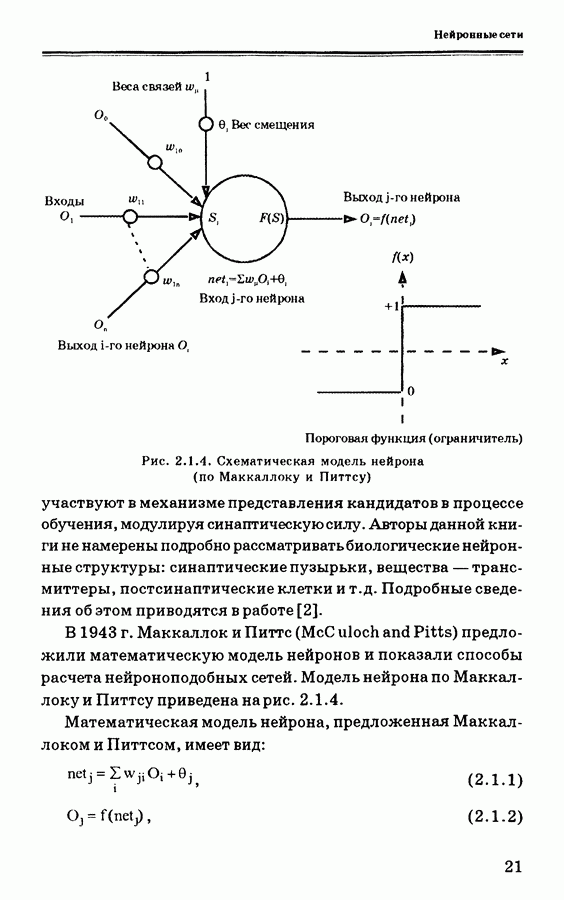
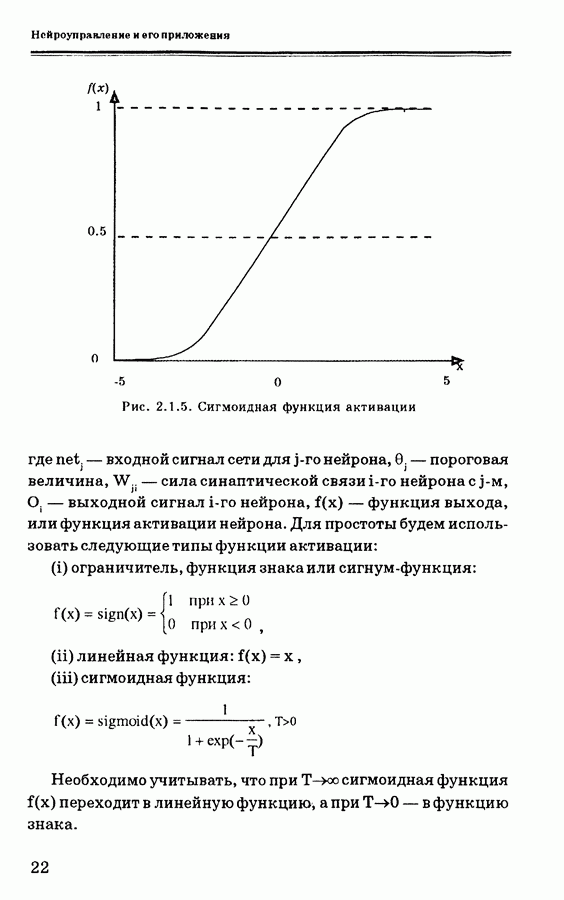
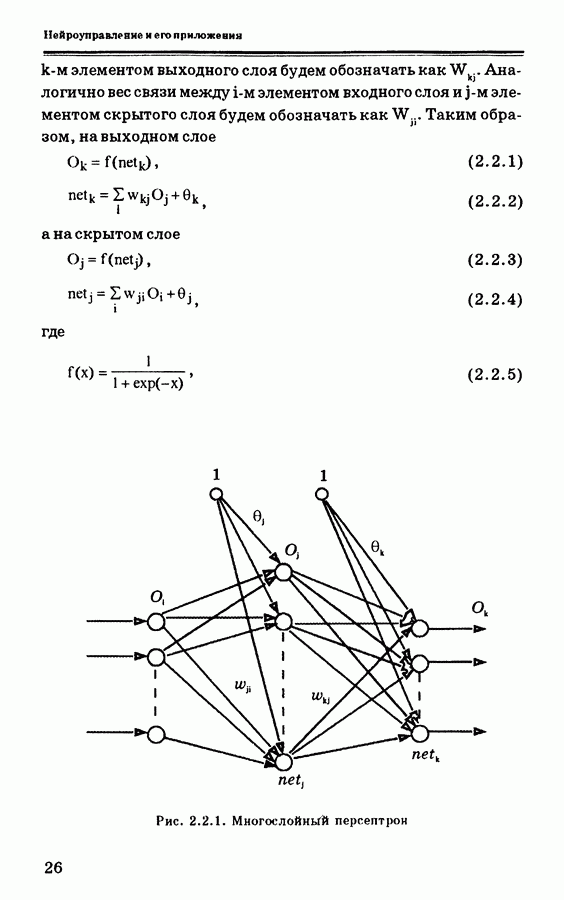
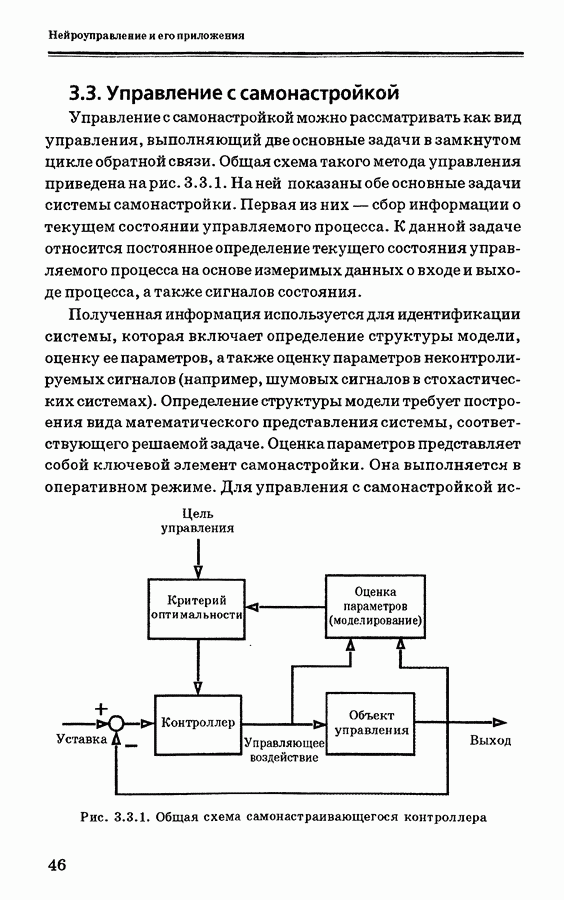
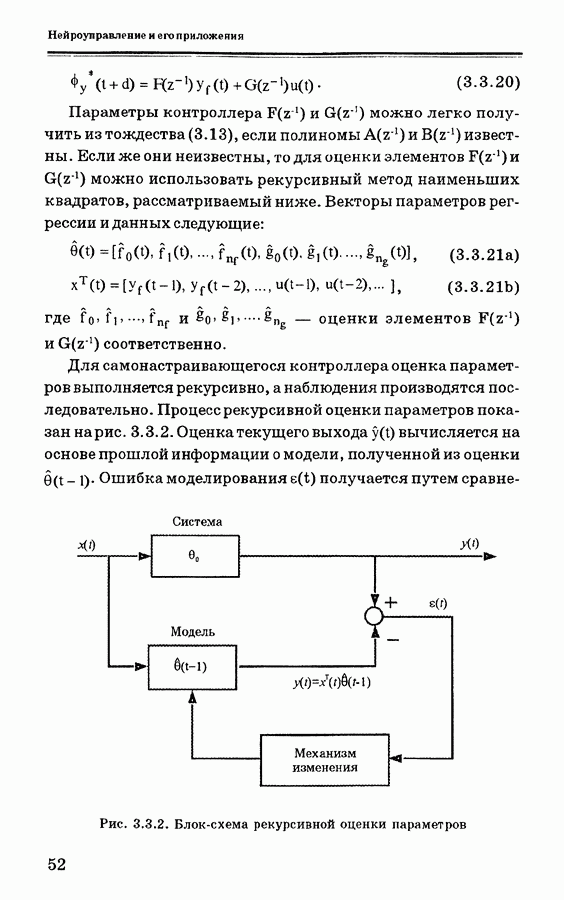
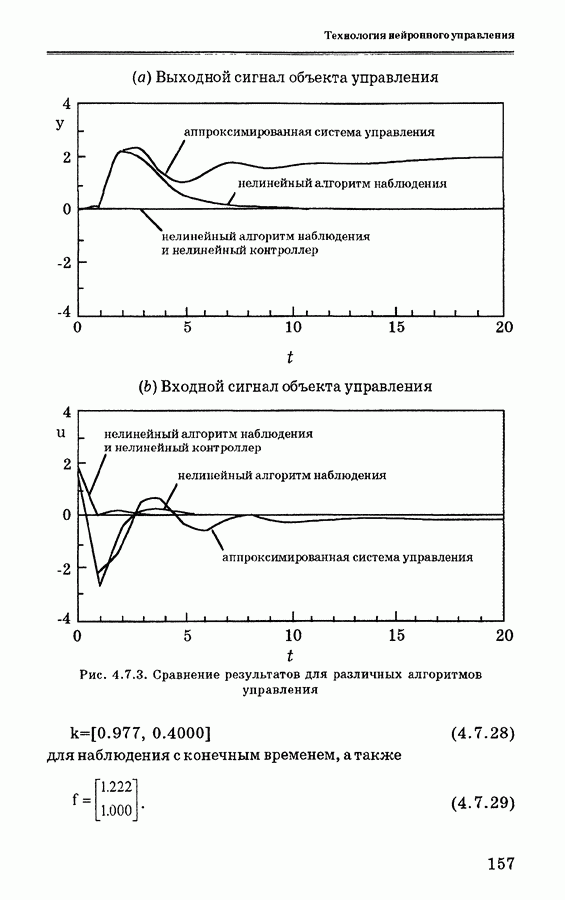
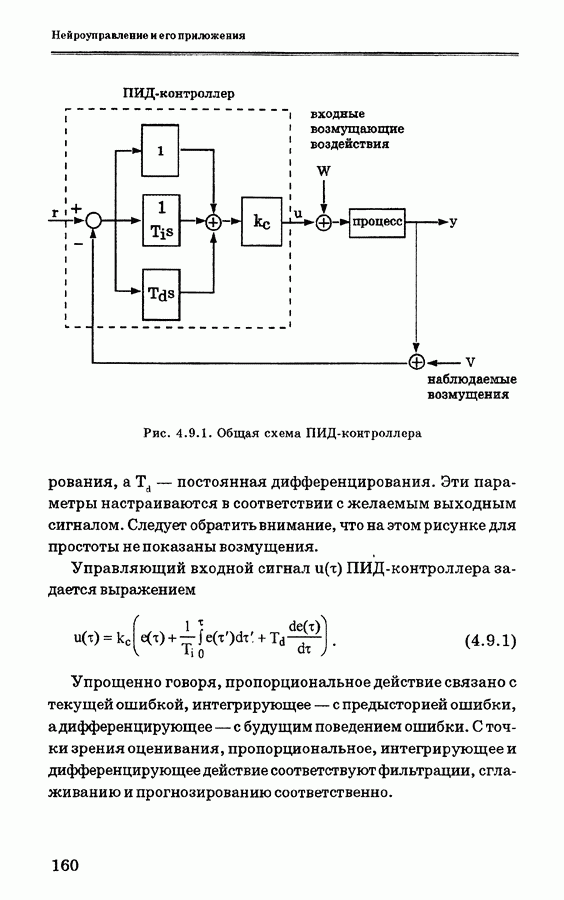
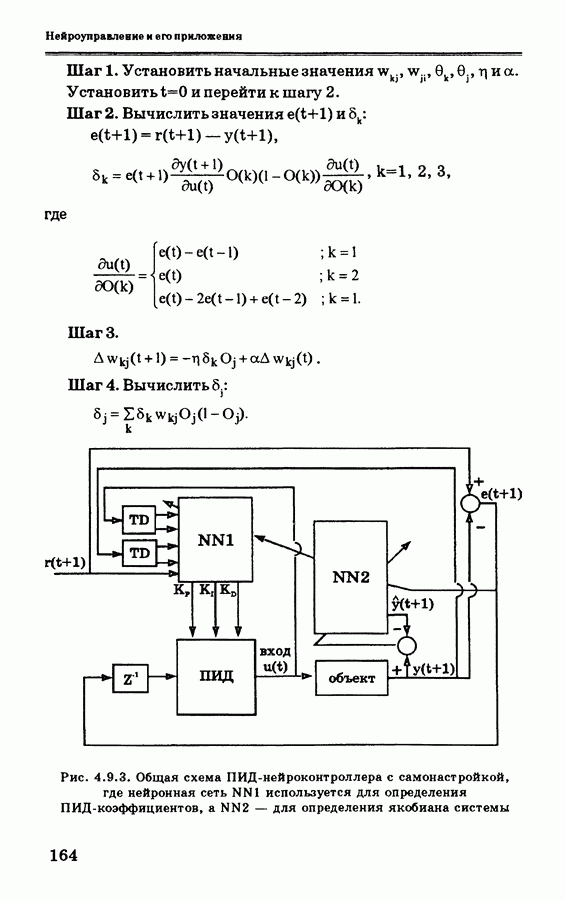
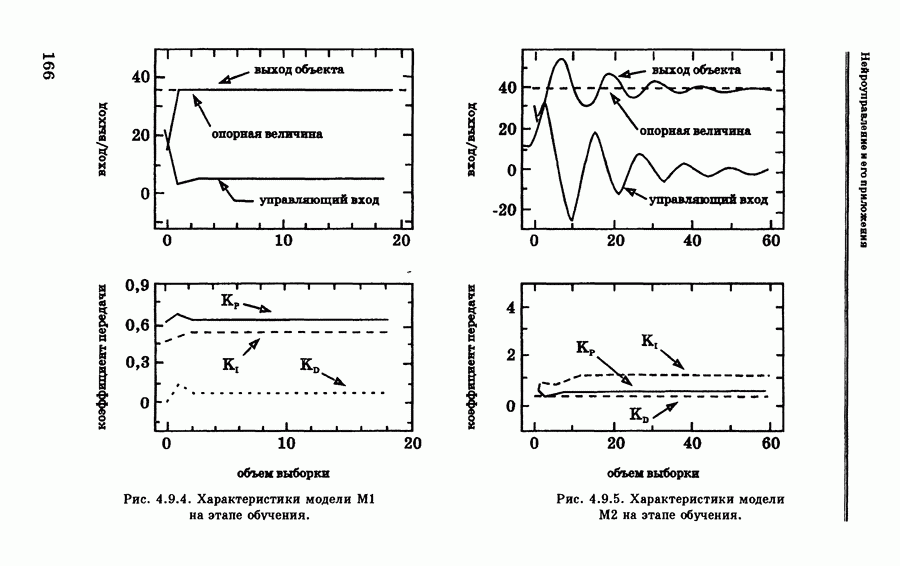
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
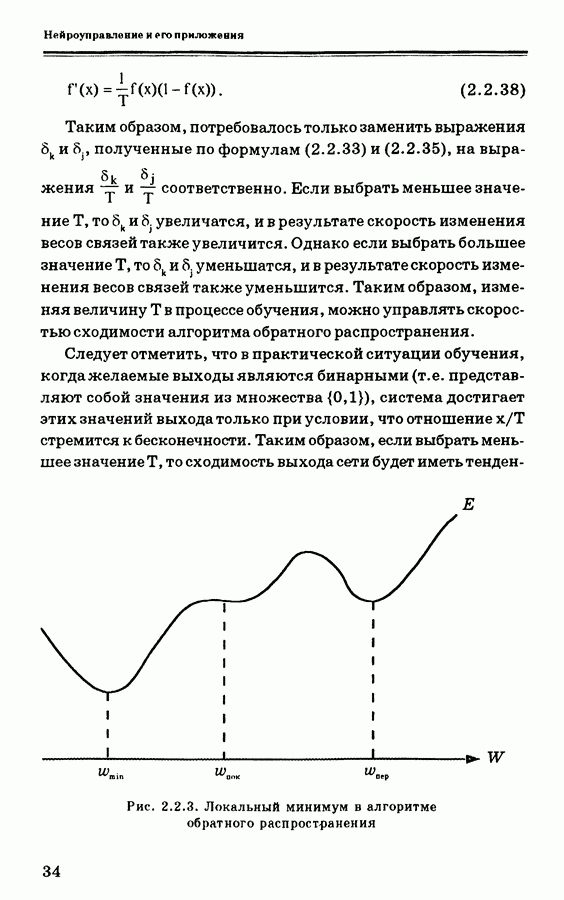
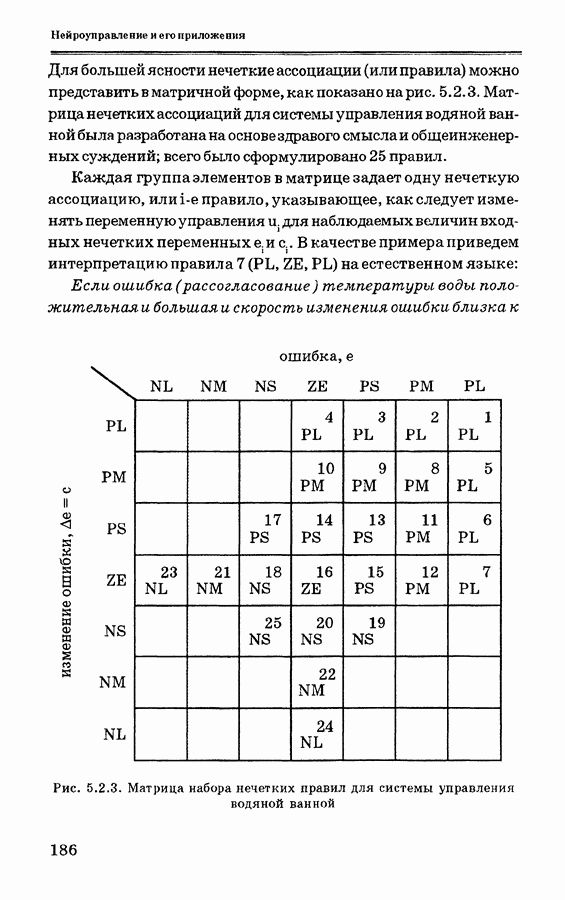
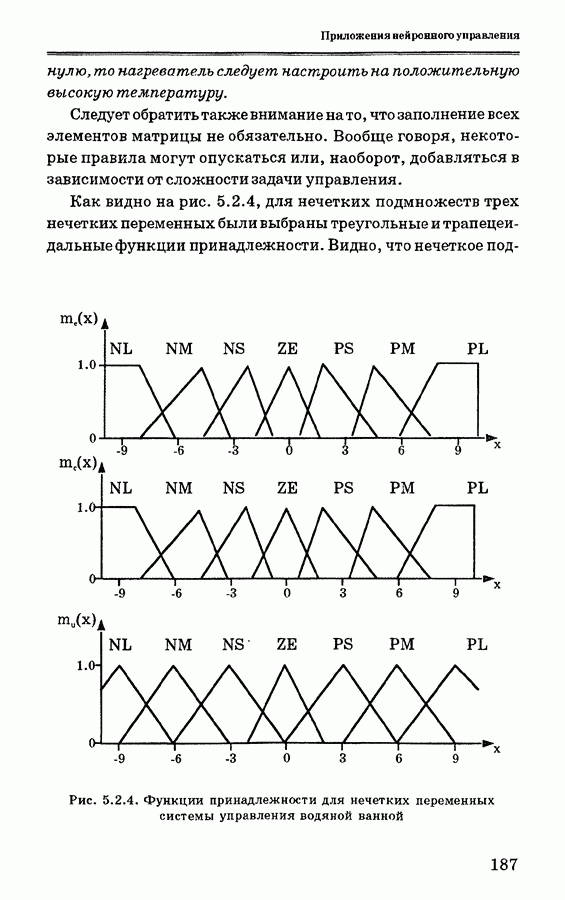
2.2.4. Обсуждение алгоритма обратного распространенияАлгоритм обратного распространения, полученный на основе градиентного метода наискорейшего спуска, предназначен для поиска минимума ошибки, что приводит, однако, к поиску локального минимума или точки перегиба (плато), как показано на рис. 2.2.3. В идеальном случае должен отыскиваться глобальный минимум, представляющий собой нижнюю точку на всей области определения. Так как локальный минимум окружен более высокими точками, стандартный алгоритм обратного распространения обычно не пропускает локальных минимумов. Вид локального минимума не всегда представляет существенный интерес. Можно ожидать, что в ходе обучения в соответствии с алгоритмом обратного распространения ошибка сети будет сходиться к приемлемому значению, если обучающие образцы четко различимы. Чтобы избежать «ловушек» на локальных минимумах, можно изменять параметры обучения, количество скрытых слоев, начальные значения весов связей. Обычно эти методы разрабатываются так, чтобы попытаться изменить сценарий перемещения по участку, содержащему локальные минимумы и максимумы. Для поиска достаточно приемлемых значений параметров алгоритма обратного распространения в последнее время используется генетический алгоритм. Для вывода алгоритма обратного распространения, представленного в разделе 2.2.2, использована сигмоидная функция (2.2.5). Могут использоваться и другие функции активации. Если, например, использовать функцию вида:
то получим:
Таким образом, потребовалось только заменить выражения Следует отметить, что в практической ситуации обучения, когда желаемые выходы являются бинарными (т.е. представляют собой значения из множества
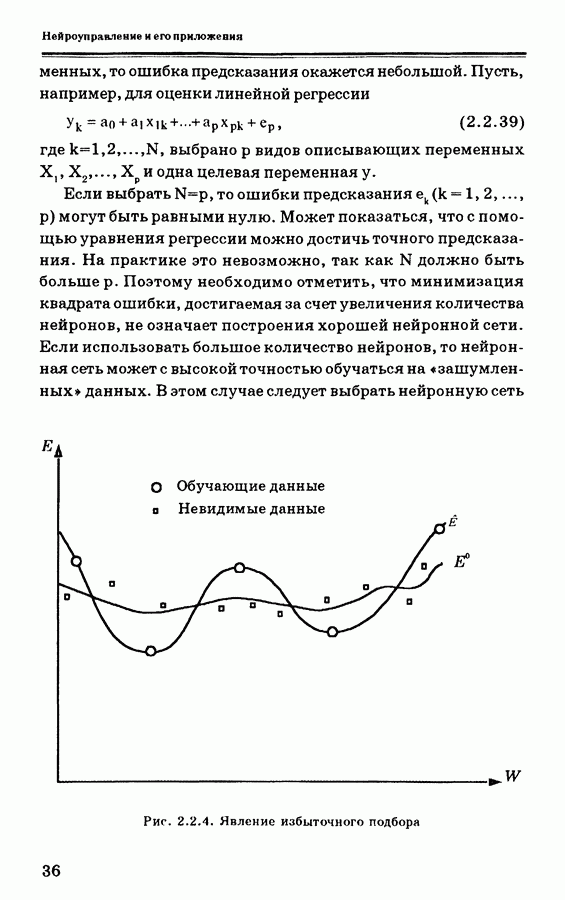
Рис. 2.2.3. Локальный минимум в алгоритме обратного распространения тенденцию к ускорению. При Другое свойство функции активации состоит в том, что нейронная сеть не может достигать предельных значений 0 и 1, если веса связей не являются бесконечно большими. Таким образом, в практической ситуации обучения, когда желаемые выходы являются бинарными Скорость обучения Другой проблемой является выбор количества скрытых узлов или скрытых слоев. Из регрессионного анализа известно, что если выбрать достаточно много видов описывающих переменных, то ошибка предсказания окажется небольшой. Пусть, например, для оценки линейной регрессии
где Если выбрать
Рис. 2.2.4. Явление избыточного подбора меньшего размера, даже если ошибка при этом оказывается не такой малой, как показано на рис. 2.2.4. На этом рисунке Е представляет кривую ошибки, полученную приточном обучении на наблюдаемых данных, а
|
 |
Оглавление
|






































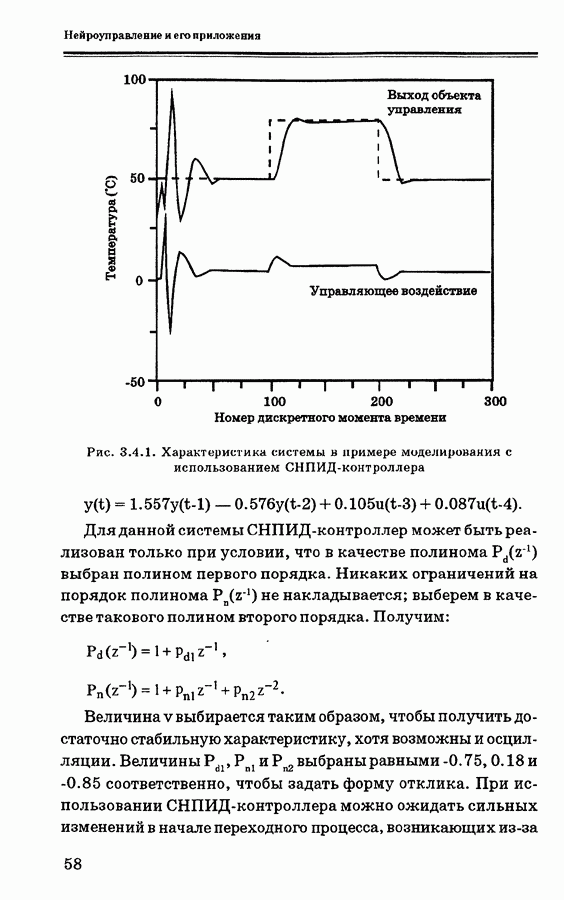
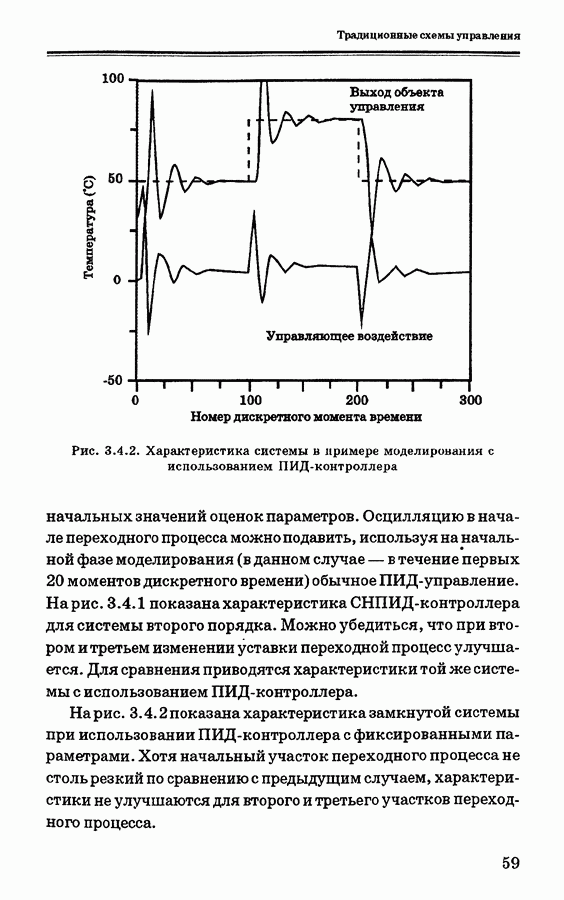
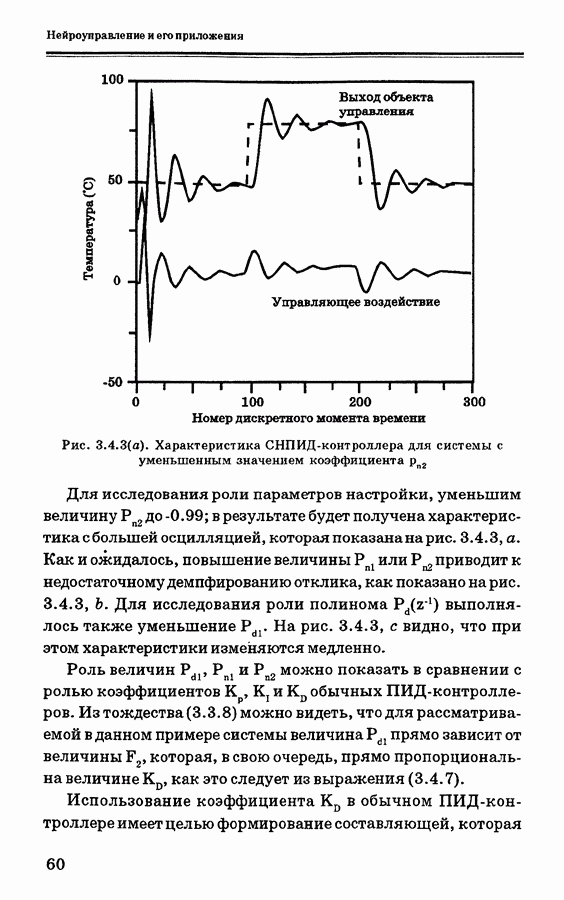
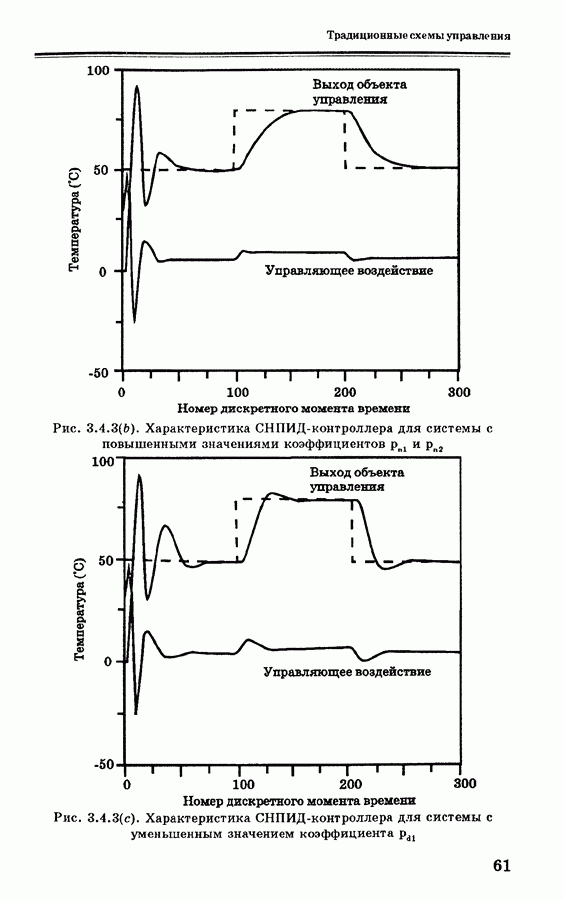
























































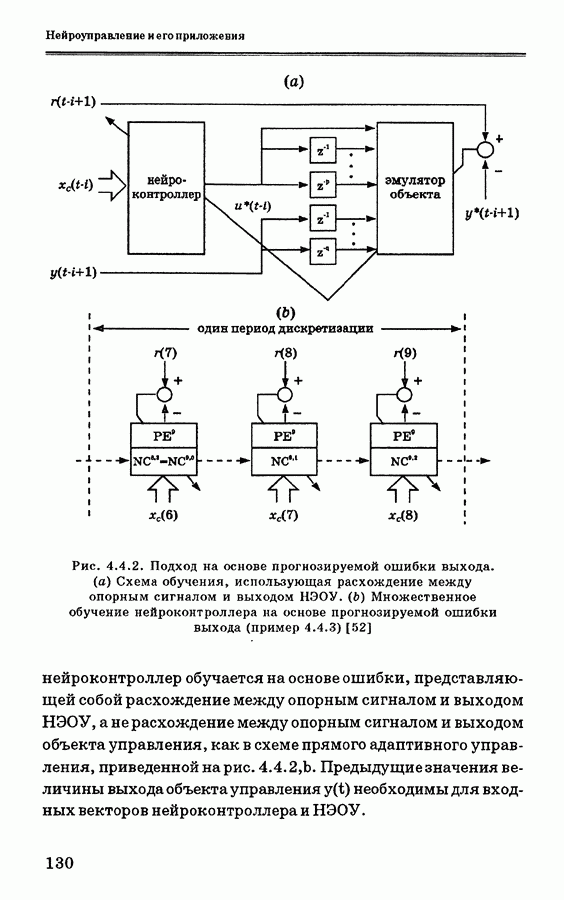







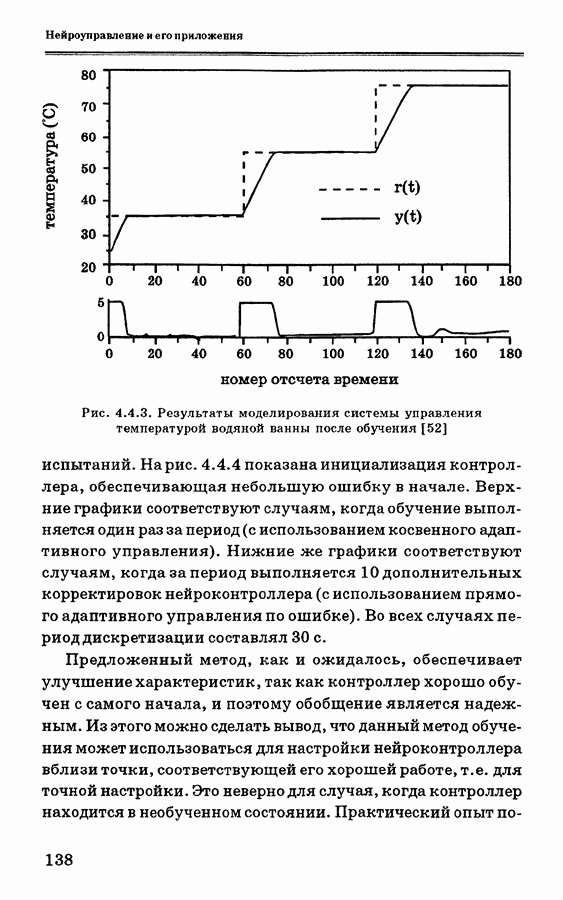
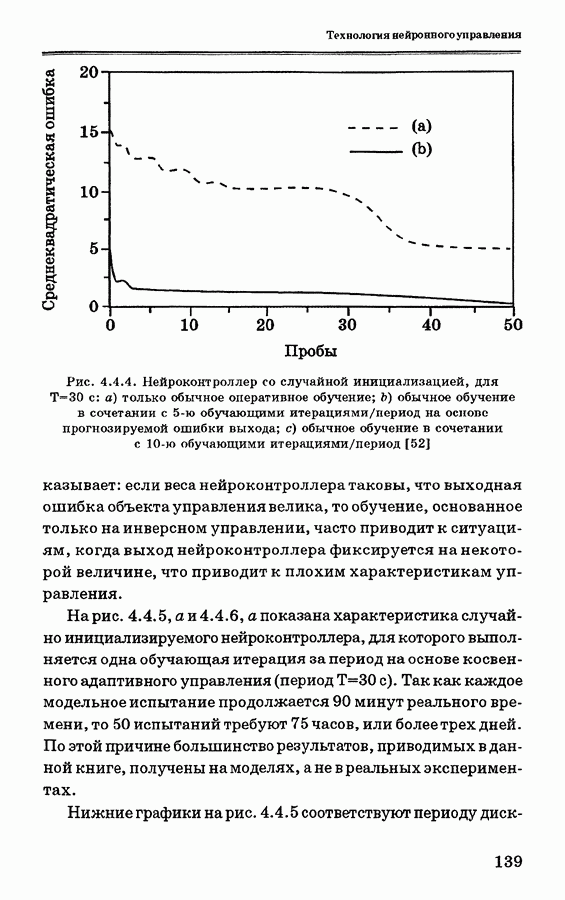
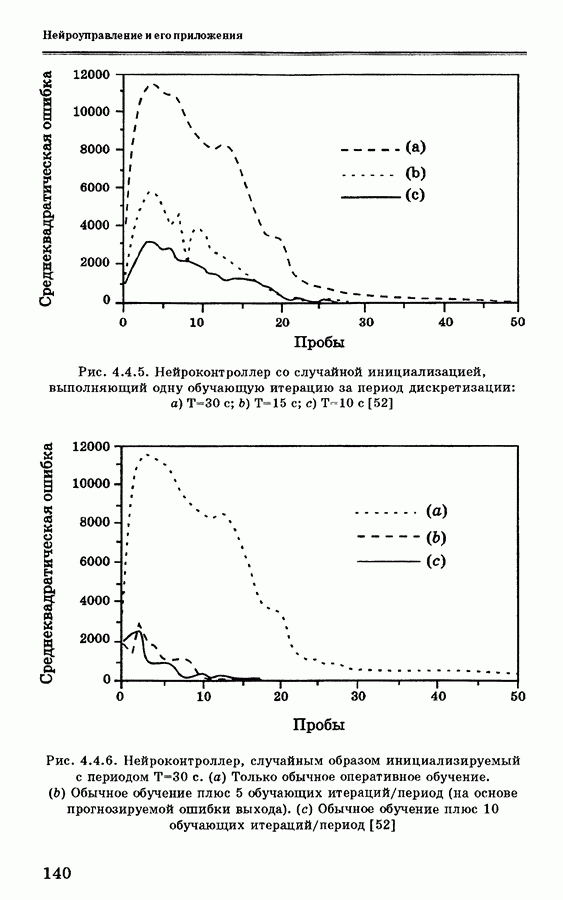


















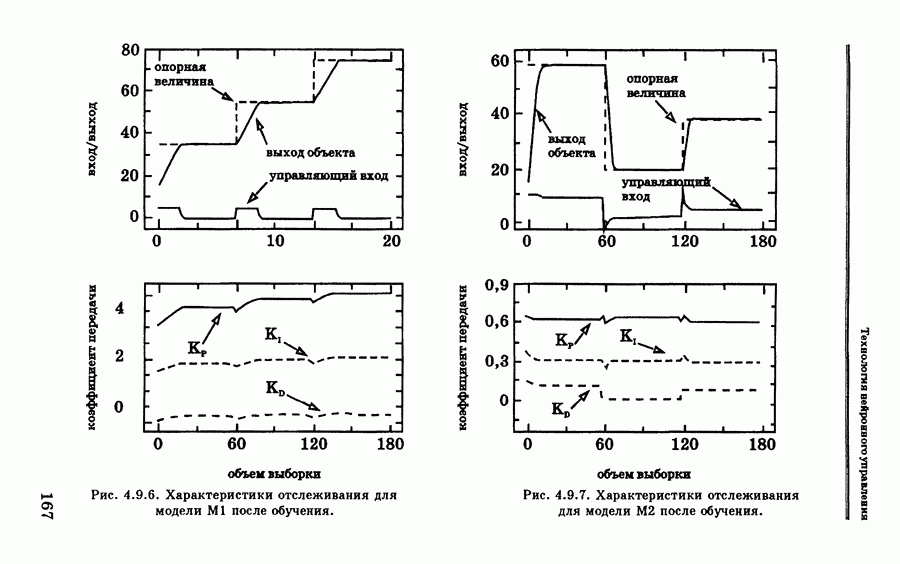


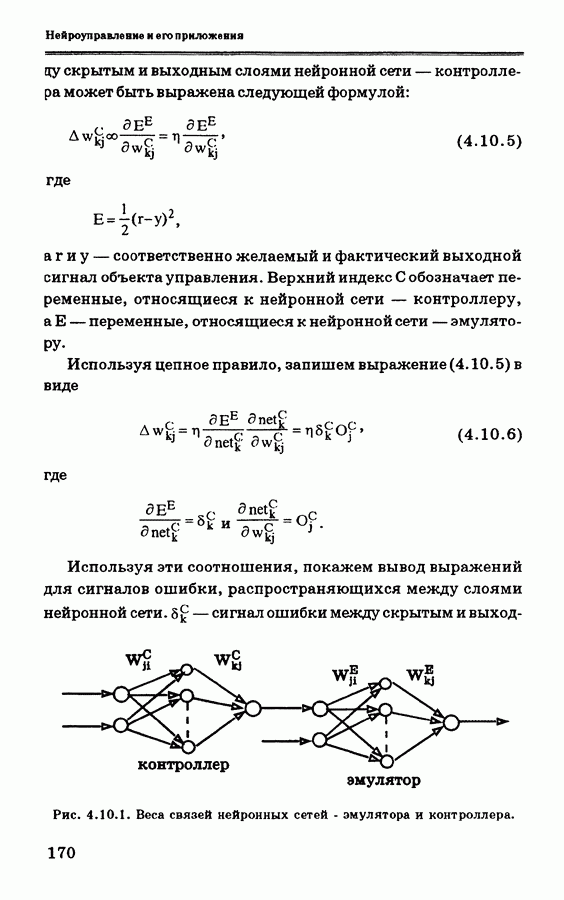







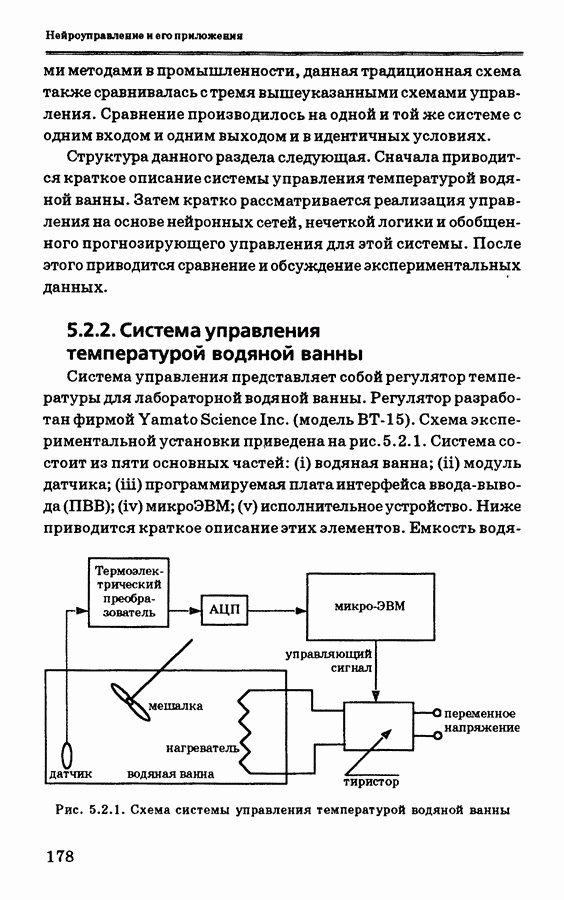



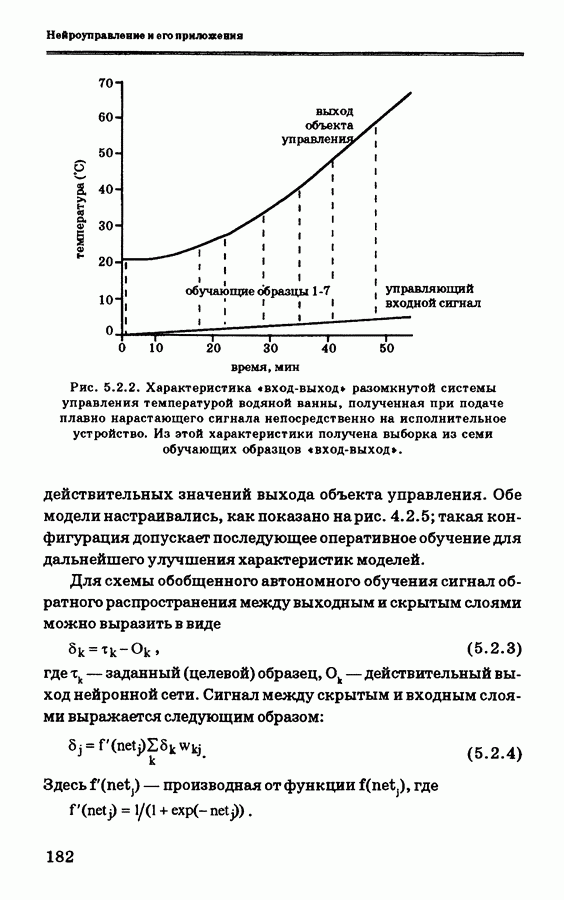









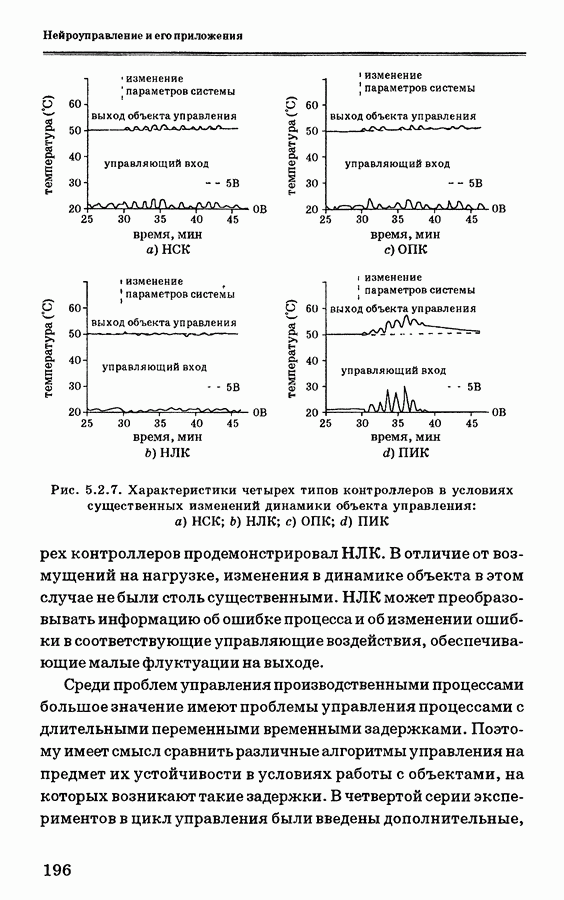

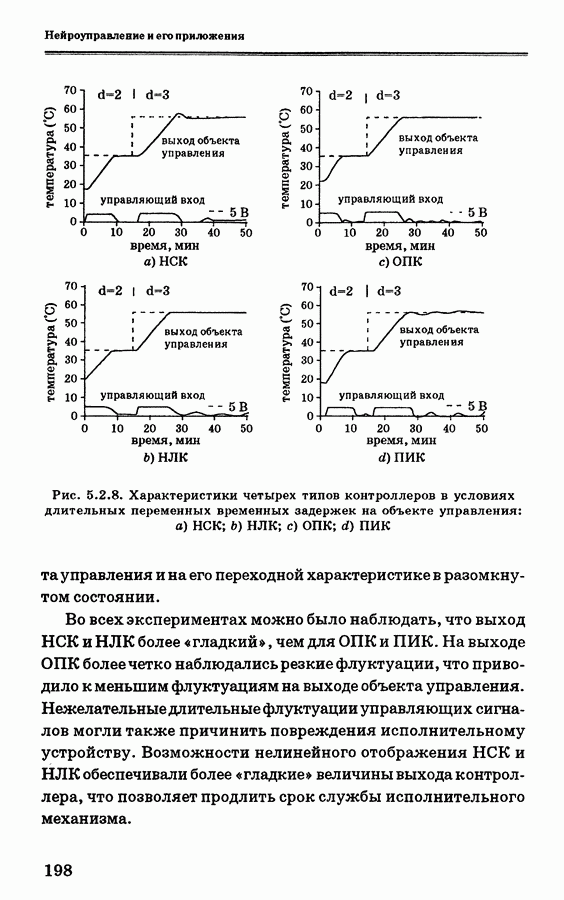





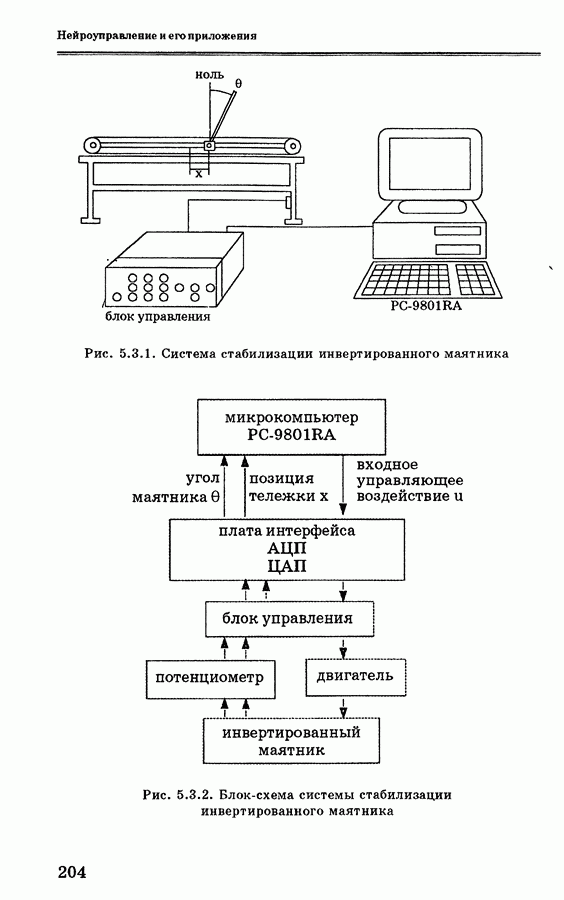



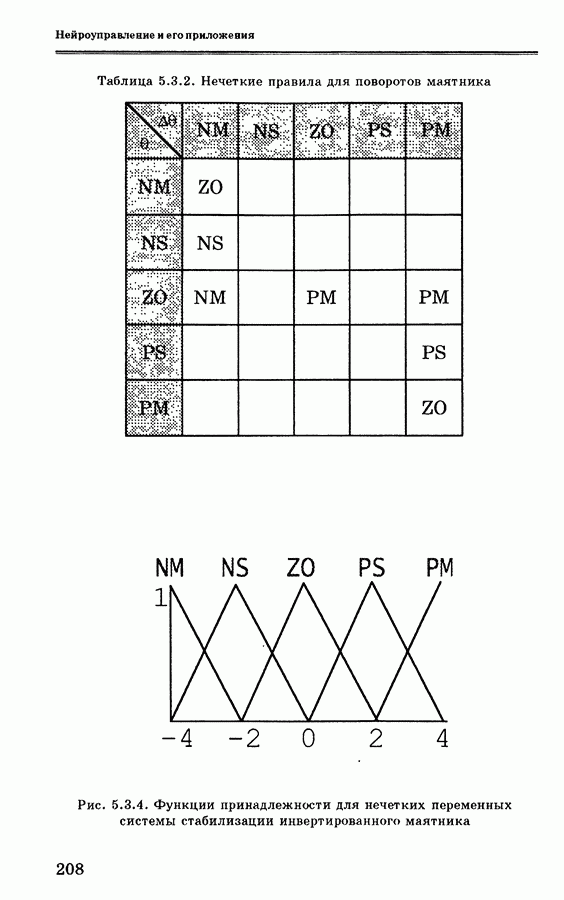














































 и
и  , полученные по формулам (2.2.33) и (2.2.35), на выражения
, полученные по формулам (2.2.33) и (2.2.35), на выражения  и
и  соответственно. Если выбрать меньшее значение Т, то
соответственно. Если выбрать меньшее значение Т, то  . увеличатся, и в результате скорость изменения весов связей также увеличится. Однако если выбрать большее значение Т, то
. увеличатся, и в результате скорость изменения весов связей также увеличится. Однако если выбрать большее значение Т, то  уменьшатся, и в результате скорость изменения весов связей также уменьшится. Таким образом, изменяя величину Т в процессе обучения, можно управлять скоростью сходимости алгоритма обратного распространения.
уменьшатся, и в результате скорость изменения весов связей также уменьшится. Таким образом, изменяя величину Т в процессе обучения, можно управлять скоростью сходимости алгоритма обратного распространения.
 система достигает этих значений выхода только при условии, что отношение
система достигает этих значений выхода только при условии, что отношение  стремится к бесконечности. Таким образом, если выбрать меньшее значение Т, то сходимость выхода сети будет иметь
стремится к бесконечности. Таким образом, если выбрать меньшее значение Т, то сходимость выхода сети будет иметь

 производные
производные  достигают максимальных значений при
достигают максимальных значений при  . В связи с тем, что
. В связи с тем, что  минимумы производных достигаются при приближении этих величин к нулевому или единичному значениям. Так как величина изменения конкретного веса связи пропорциональна производной, эти веса будут изменяться в основном для этих значений.
минимумы производных достигаются при приближении этих величин к нулевому или единичному значениям. Так как величина изменения конкретного веса связи пропорциональна производной, эти веса будут изменяться в основном для этих значений.
 нейронная сеть никогда не достигнет этих значений. Поэтому в качестве желаемых величин можно рассматривать 0,1 и 0,9, даже если в действительности желаемыми величинами являются 0 и 1.
нейронная сеть никогда не достигнет этих значений. Поэтому в качестве желаемых величин можно рассматривать 0,1 и 0,9, даже если в действительности желаемыми величинами являются 0 и 1.
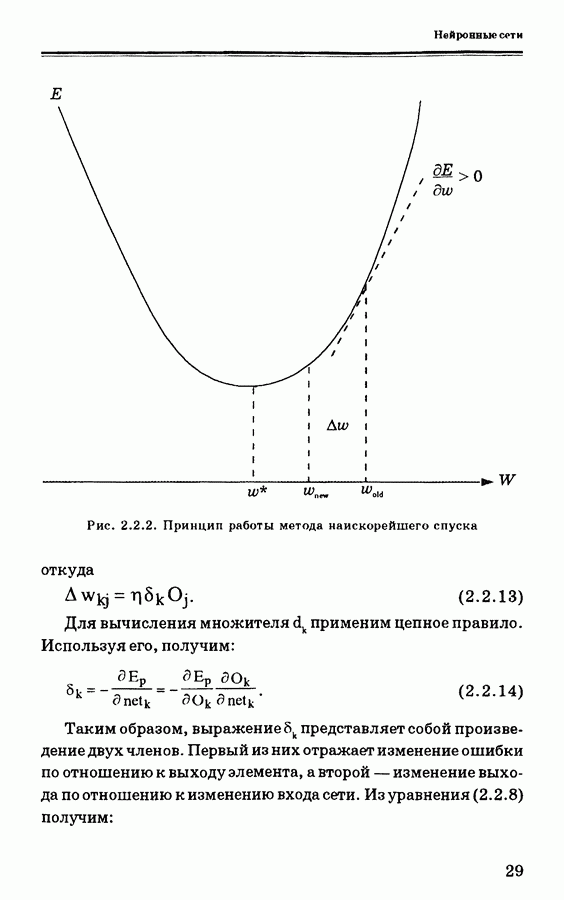
 — это константа, представляющая собой коэффициент пропорциональности между изменением веса связи и градиентом ошибки Е относительно веса. Чем больше данная константа, тем больше изменения в весах связей. Обычно скорость обучения выбирается как можно большей, но такой, чтобы не возникало осцилляции. Так как для исключения осцилляции в формулы был введен момент времени, требуется выбрать подходящее значение а. Введение момента времени «отфильтровывает» высокочастотные изменения поверхности ошибки в пространстве весов связей. Это полезно в случаях, когда пространство весов связей содержит длинные овраги с острыми искривлениями. В связи с тем, что такое искривление вызывает резкие расходящиеся колебания в долине, необходимо выбирать небольшой размер шага, для чего требуется небольшая скорость обучения. В книге Румельхарта (Rumelhart) и др. [11] рекомендуется использовать величину а, приблизительно равную 0,9.
— это константа, представляющая собой коэффициент пропорциональности между изменением веса связи и градиентом ошибки Е относительно веса. Чем больше данная константа, тем больше изменения в весах связей. Обычно скорость обучения выбирается как можно большей, но такой, чтобы не возникало осцилляции. Так как для исключения осцилляции в формулы был введен момент времени, требуется выбрать подходящее значение а. Введение момента времени «отфильтровывает» высокочастотные изменения поверхности ошибки в пространстве весов связей. Это полезно в случаях, когда пространство весов связей содержит длинные овраги с острыми искривлениями. В связи с тем, что такое искривление вызывает резкие расходящиеся колебания в долине, необходимо выбирать небольшой размер шага, для чего требуется небольшая скорость обучения. В книге Румельхарта (Rumelhart) и др. [11] рекомендуется использовать величину а, приблизительно равную 0,9.

 выбрано
выбрано  видов описывающих переменных
видов описывающих переменных  и одна целевая переменная у.
и одна целевая переменная у.
 то ошибки предсказания
то ошибки предсказания  могут быть равными нулю. Может показаться, что с помощью уравнения регрессии можно достичь точного предсказания. На практике это невозможно, так как
могут быть равными нулю. Может показаться, что с помощью уравнения регрессии можно достичь точного предсказания. На практике это невозможно, так как  должно быть больше
должно быть больше  Поэтому необходимо отметить, что минимизация квадрата ошибки, достигаемая за счет увеличения количества нейронов, не означает построения хорошей нейронной сети. Если использовать большое количество нейронов, то нейронная сеть может с высокой точностью обучаться на «зашумленных» данных. В этом случае следует выбрать нейронную сеть
Поэтому необходимо отметить, что минимизация квадрата ошибки, достигаемая за счет увеличения количества нейронов, не означает построения хорошей нейронной сети. Если использовать большое количество нейронов, то нейронная сеть может с высокой точностью обучаться на «зашумленных» данных. В этом случае следует выбрать нейронную сеть

 — кривую ошибки, обеспечивающую наименьшую ошибку предсказания для невидимых данных. Это явление называется проблемой избыточного подбора. Для ее решения предложено несколько методов, которые позволяют уменьшить размер нейронной сети.
— кривую ошибки, обеспечивающую наименьшую ошибку предсказания для невидимых данных. Это явление называется проблемой избыточного подбора. Для ее решения предложено несколько методов, которые позволяют уменьшить размер нейронной сети.