Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ПРЕДИСЛОВИЕЗадача восстановления зависимостей по эмпирическим данным была и, вероятно, всегда будет центральной в прикладном анализе. Эта задача является математической интерпретацией одной из основных проблем естествознания: как найти существующую закономерность по разрозненным фактам. В наиболее простой постановке, той, которой и посвящена книга, проблема состоит в восстановлении функции по ее значениям в некоторых точках. Необходимо сформулировать общие принципы восстановления функциональных зависимостей, а затем в соответствии с ними построить алгоритмы восстановления. Обычно, когда ищется общий принцип, предназначенный для решения широкого класса задач, выделяется наиболее простая, базовая задача. Эта задача подвергается тщательному теоретическому анализу, а полученная для нее схема решения распространяется на все задачи класса. При изучении проблемы восстановления функциональных зависимостей по существу принята следующая базовая задача — восстановить функцию, принимающую лишь одно значение (восстановить константу). Считается, что константа измеряется с ошибками. Требуется, имея ряд измерений, определить ее. Существуют различные варианты конкретизации постановки этой задачи. Они основаны на разных моделях «измерения с ошибками». Однако каковы бы ни были эти модели, изучение базовой задачи приводит к утверждению следующего классического принципа восстановления функциональных зависимостей по эмпирическим данным: — Следует из допустимого множества функций выбирать такую функцию, которая наилучшим образом приближается к совокупности имеющихся эмпирических данных. Этот принцип является достаточно общим. Он оставляет свободу в толковании того, что является мерой качества приближения функции к совокупности эмпирических данных. Возможны различные определения меры, такие, например, как величина среднеквадратичного уклонения значений функции, величина среднего уклонения, величина наибольшего уклонения и т. д. Каждое определение меры порождает свой метод восстановления зависимостей (метод наименьших квадратов, наименьших модулей и т. д.). Однако во всех случаях принцип отыскания решения — поиск функции, наилучшим образом приближающейся к эмпирическим данным, — остается неизменным. Основное содержание книги связано с исследованием другого, неклассического принципа восстановления зависимостей: — Следует из допустимого множества функций выбирать такую, которая удовлетворяет определенному соотношению между величиной, характеризующей качество приближения функции к заданной совокупности эмпирических данных, и величиной, характеризующей «сложность» приближающей функции. Этот принцип нуждается в пояснении. Дело в том, что с увеличением «сложности» приближающей функции удается получать все лучшие и лучшие приближения к имеющимся эмпирическим данным и даже, может быть, построить функцию, проходящую через заданные точки. Сформулированный принцип, в отличие от классического, утверждает, что не следует добиваться приближения к эмпирическим данным любыми средствами (т. е. за счет выбора чрезмерно «сложной» приближающей функции). Для каждого объема эмпирических данных существует свое соотношение между «сложностью» приближающей функции и достигнутым качеством приближения, при соблюдении которого восстановленная зависимость наиболее точно характеризует истинную. Дальнейшее приближение к эмпирическим данным за счет «усложнения» приближающей функции может привести к тому, что восстановленная функция будет лучше приближать эти конкретные эмпирические данные, но хуже — искомую функцию. Неклассический принцип восстановления отражает попытку учесть то обстоятельство, что зависимость восстанавливается в условиях ограниченного объема эмпирических данных. Мысль о том, что в условиях ограниченного объема эмпирических данных выбранная функция должна не просто приближать эмпирические данные, но и обладать некоторыми экстремальными свойствами, существовала давно. Однако впервые она получила теоретическое обоснование при исследовании задачи обучения распознаванию образов. Дело в том, что математическая постановка задачи обучения распознаванию образов приводит к необходимости восстанавливать функцию, которая принимает не одно, как в базовой задаче, а два значения. Такое усложнение по сравнению с базовой задачей неожиданно оказалось принципиальным. Множество функций, принимающих два значения, намного «разнообразнее» множества констант (т. е. функций, принимающих лишь одно значение). Важным здесь оказалось то, что «структура» функций-констант «простая и однородная», в то время как «структура» множества функций, принимающих два значения, достаточно богатая и допускает упорядочение по степени «сложности». Учет упорядоченности функций и оказался существенным при восстановлении зависимостей в условиях ограниченного объема эмпирических данных. Таким образом, исследование задачи обучения распознаванию образов показало, что классическая базовая задача не содержит всех проблем восстановления зависимостей — класс функций, в котором ведется восстановление константы, настолько беден, что вопрос о его расслоении просто не возникает. В книге в качестве базовой принята задача обучения распознаванию образов. Для ее решения используются разные методы: как те, которые основаны на классических идеях статистического анализа, так и те, которые связаны с неклассическим принципом восстановления. Все эти методы перенесены на две другие задачи восстановления: задачу восстановления регрессии и задачу интерпретации результатов косвенных экспериментов. Для новой базовой задачи оказалось возможным различать две постановки: восстановление функции и восстановление значений функции в заданных точках. (При восстановлении констант эти постановки совпадают.) Различать эти две постановки целесообразно потому, что в условиях ограниченного объема эмпирических данных имеющейся информации может не хватить, чтобы удовлетворительно восстановить функцию в целом, но в то же время оказаться достаточно, чтобы восстановить Итак, книга посвящена проблемам восстановления зависимостей в условиях ограниченного объема эмпирических данных. Основная ее мысль состоит в следующем: попытка учесть ограниченность объема эмпирических данных приводит к утверждению неклассического принципа восстановления зависимостей. Использование же этого принципа позволяет решать «тонкие» задачи восстановления, такие, как определение экстремального набора, признаков при распознавании образов, определение структуры приближающей функции при восстановлении регрессии, построение регуляризующего функционала при решении некорректных задач интерпретации косвенных экспериментов, т. е. задачи, которые возникают вследствие ограниченности объема эмпирических данных и которые не могут быть решены в рамках классических схем. Книга содержит двенадцать глав. Первые две главы носят вводный характер. В них разные задачи восстановления зависимостей рассматриваются с единых позиций минимизации среднего риска по эмпирическим данным и обсуждаются различные возможные пути минимизации риска. Следующие три главы (III, IV, V) посвящены исследованию классических идей минимизации риска: восстановлению функции плотности распределения вероятностей с помощью параметрических методов и использованию восстановленной плотности для минимизации риска. В главе III эти идеи реализованы на задаче обучения распознаванию образов, а в главах IV и V — на задаче восстановления регрессии. Начиная с главы VI, в книге исследуются неклассические пути минимизации риска. В главах VI и VII устанавливаются условия применимости метода минимизации эмпирического риска для решения задачи минимизации среднего риска на выборках ограниченного объема, а в главах VIII —X на базе полученных условий конструируется новый метод минимизации риска — метод упорядоченной минимизации, который существенно учитывает ограниченность объема эмпирических данных. Этот метод и реализует неклассический принцип восстановления зависимостей. В главе VIII рассмотрено применение метода упорядоченной минимизации риска к задачам распознавания образов и восстановления регрессии, а в главе IX —к решению некорректных задач интерпретации результатов косвенных экспериментов. В главе X на основе метода упорядоченной минимизации исследована задача восстановления значений функции в заданных точках. Наконец, в главах XI и XII приведено описание алгоритмов упорядоченной минимизации риска. Книга рассчитана на широкий круг читателей: студентов старших курсов, аспирантов, инженеров, научных работников. В ней изложение ведется так, чтобы доказательства не заслоняли основного хода рассуждений и вместе с тем, чтобы все принципиальные утверждения были доказаны полностью. Автор старался избегать возможно и важных, но малосодержательных с точки зрения развития основных идей книги обобщений. Поэтому всюду рассматриваются наиболее простые случаи: квадратичная функция потерь, равноточность измерений, независимость помех и т. д. Как правило, соответствующие обобщения осуществимы и могут быть получены по стандартным схемам. Чтение основной части книги не требует знания специальных разделов математики. Однако при разборе доказательств от читателя потребуется определенный навык в обращении с математическими понятиями. Книга не является обзором принятой теории, она во многом тенденциозна. Тем не менее автор надеется, что она будет интересна и полезна читателю. В. Вапник Москва, 1978
|
 |
Оглавление
|
























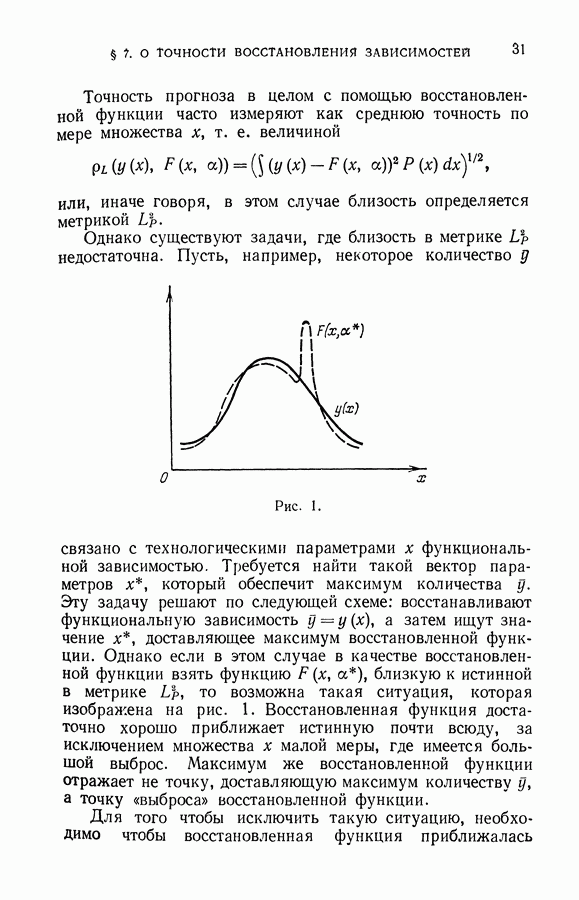
































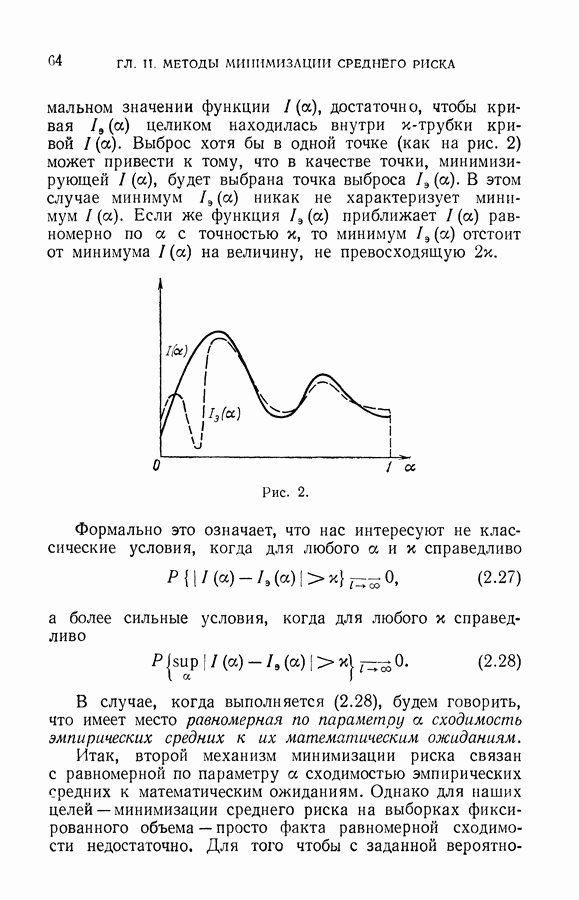

































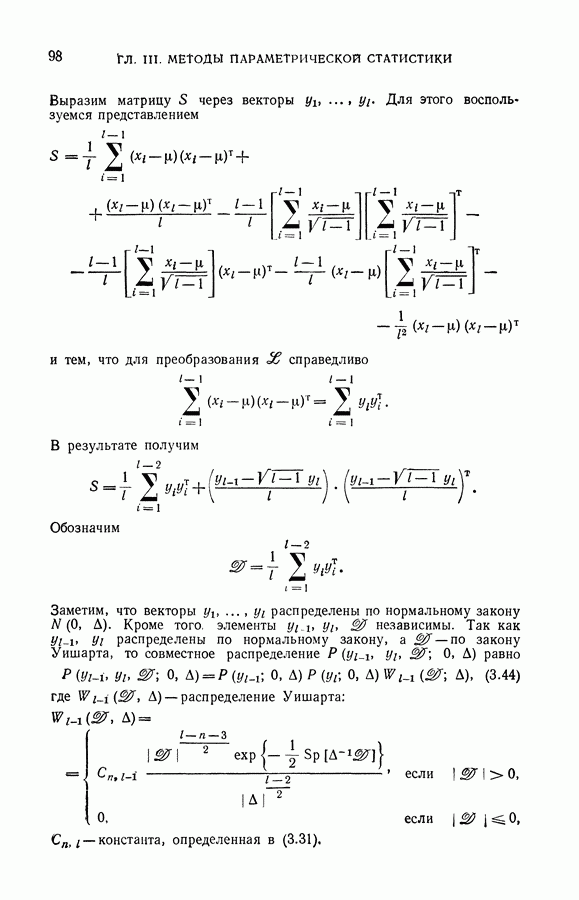






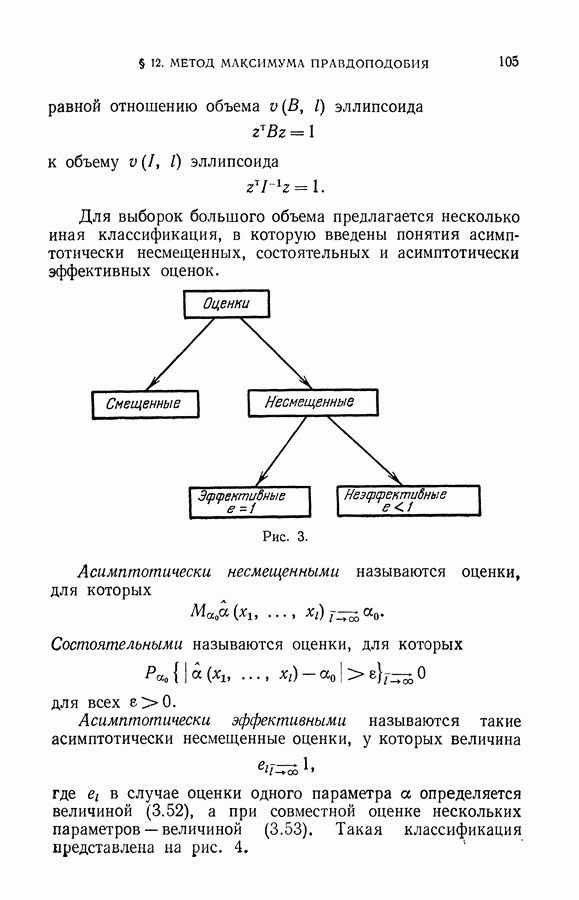
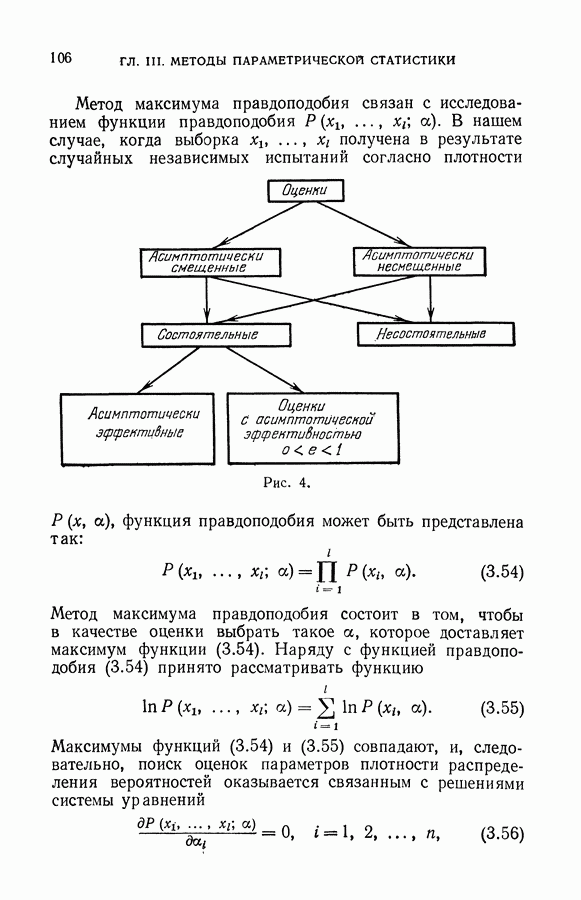












































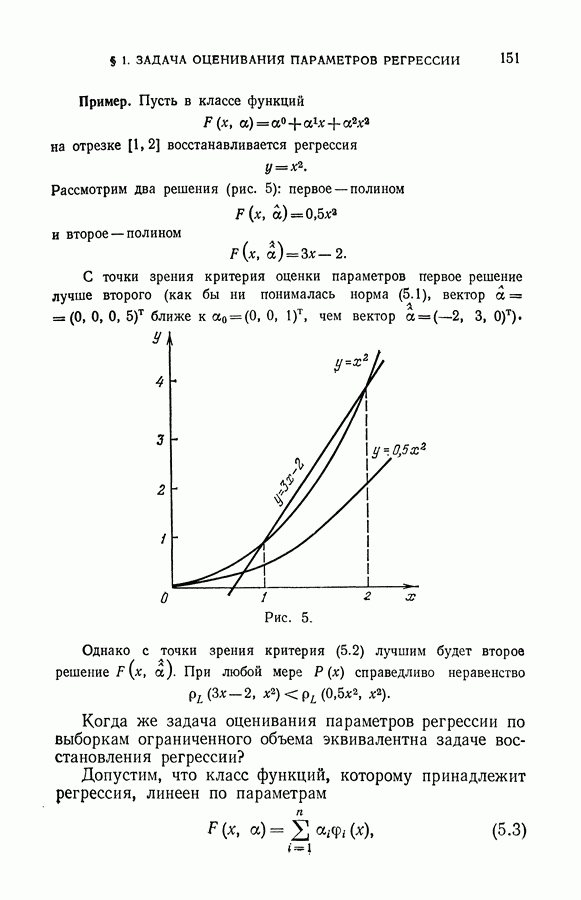
































































































































































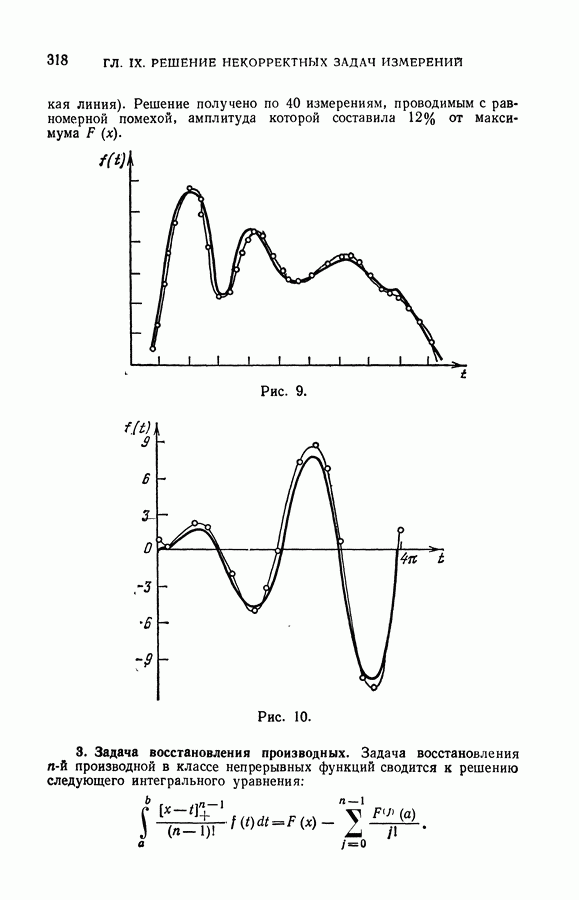
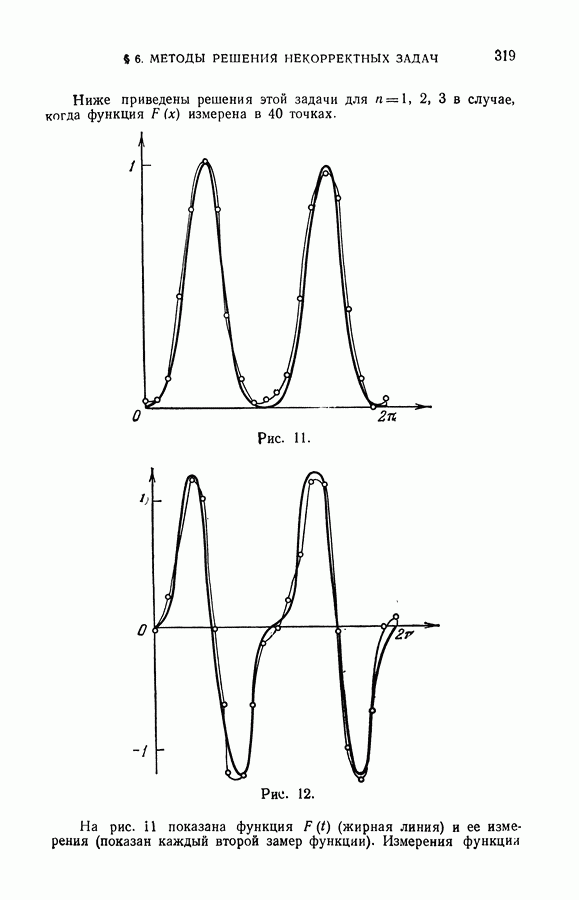
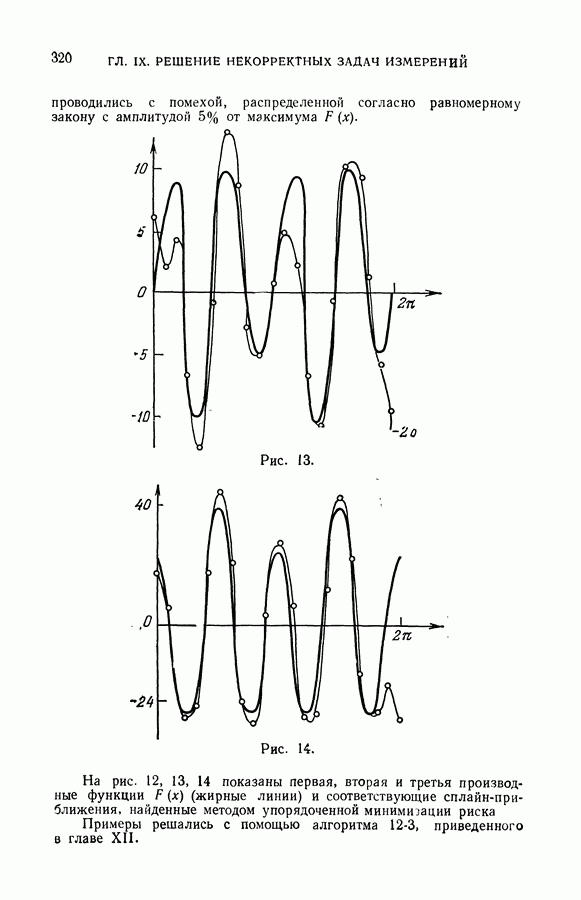







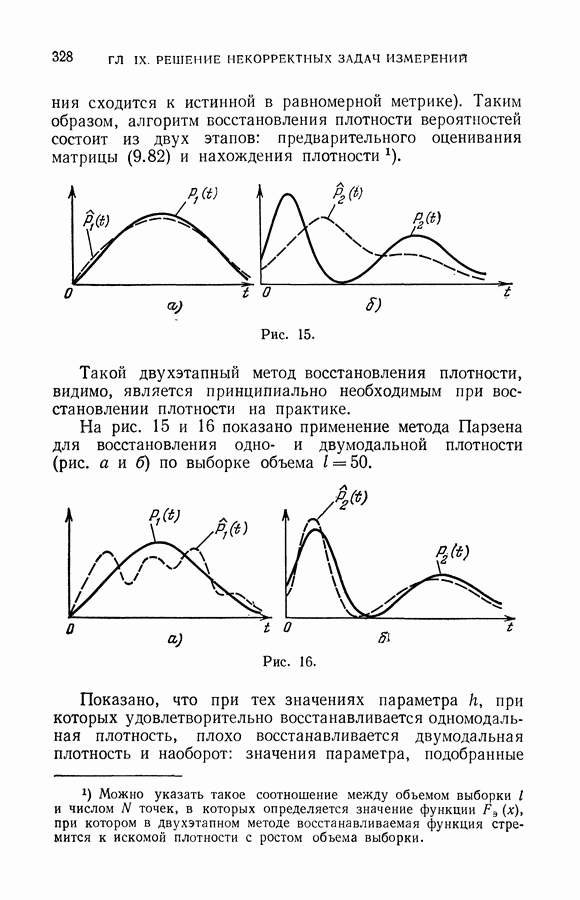
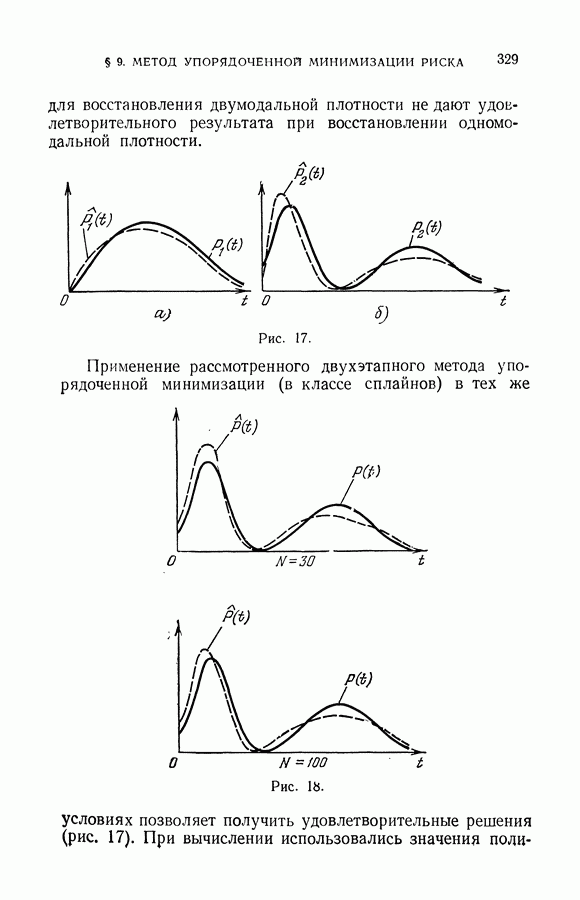









































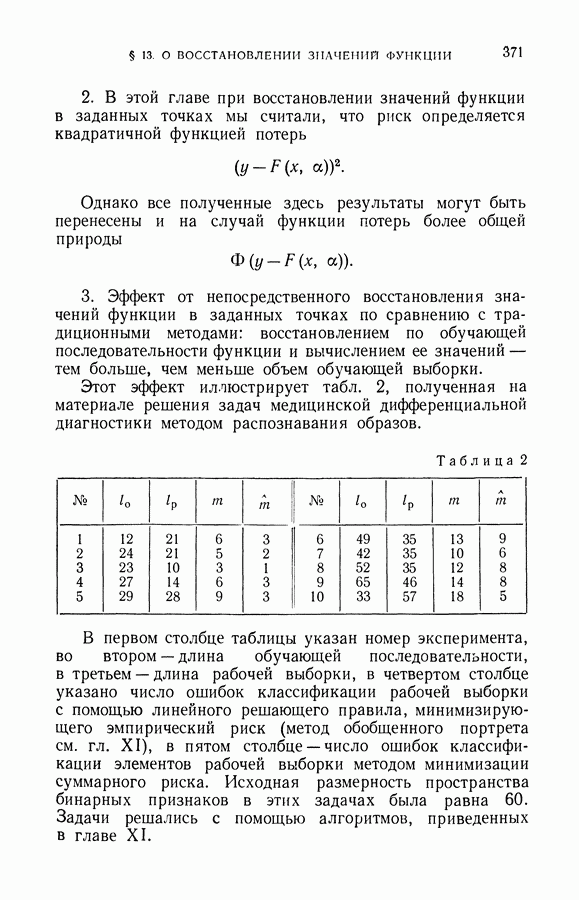













































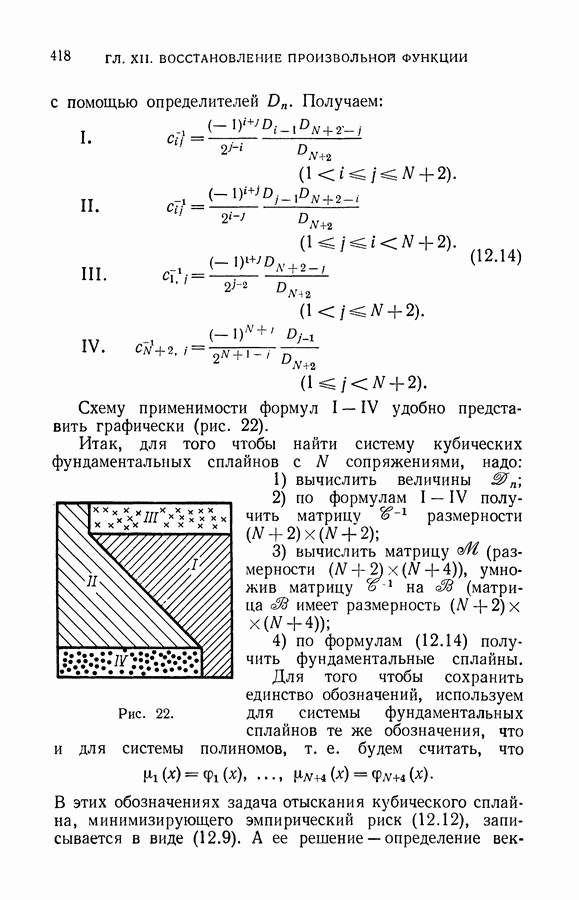





























 чисел — значений функции в заданных точках.
чисел — значений функции в заданных точках.