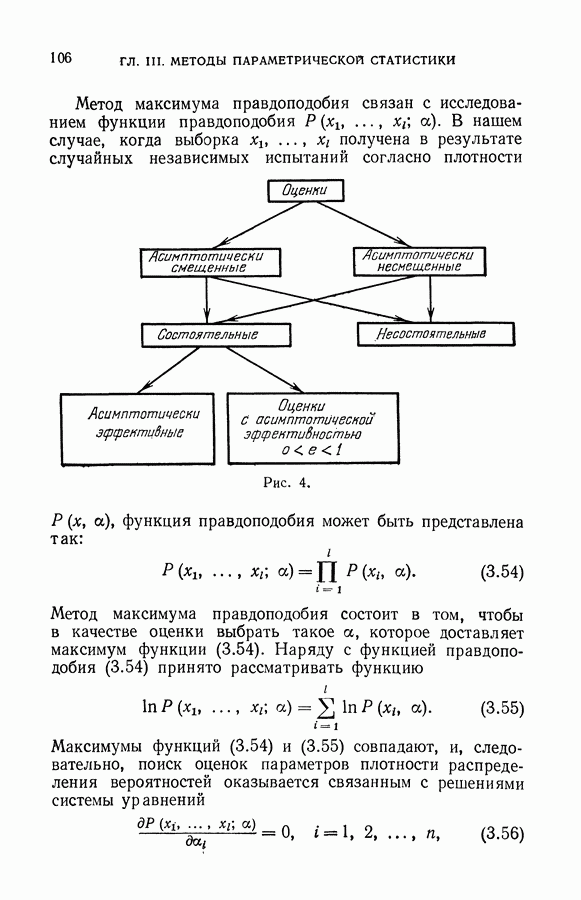
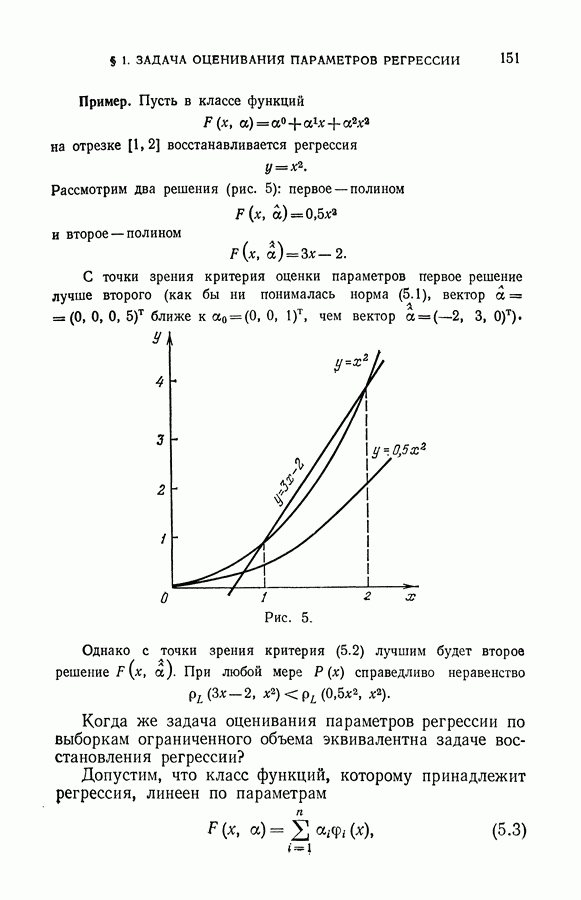
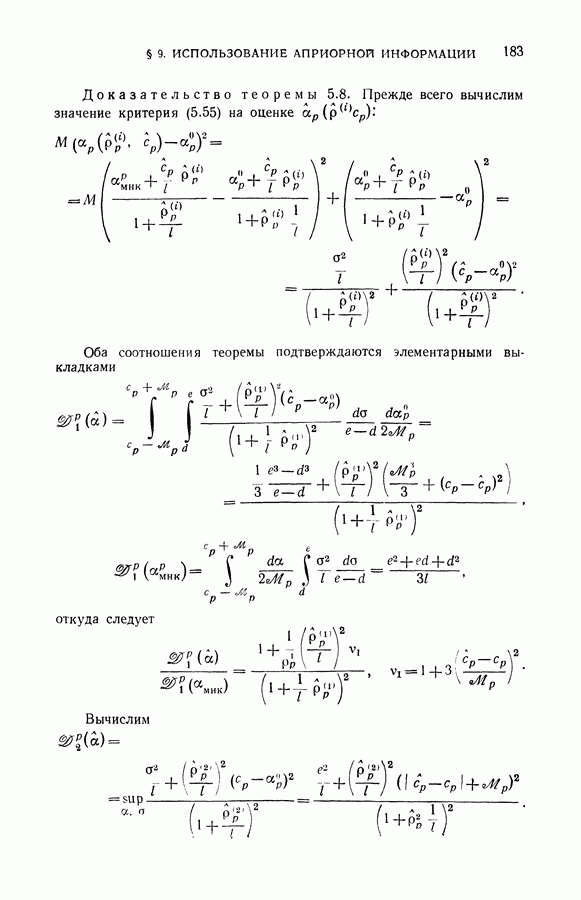
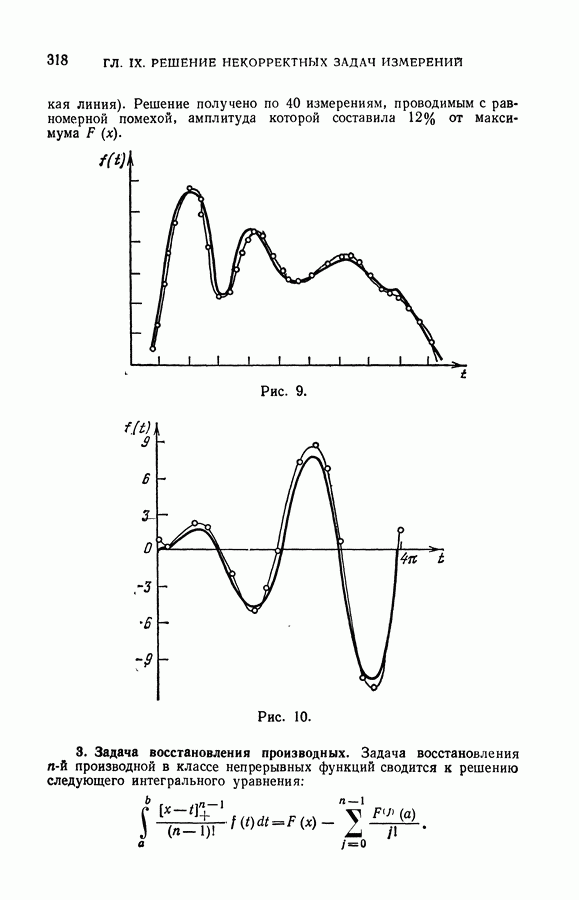
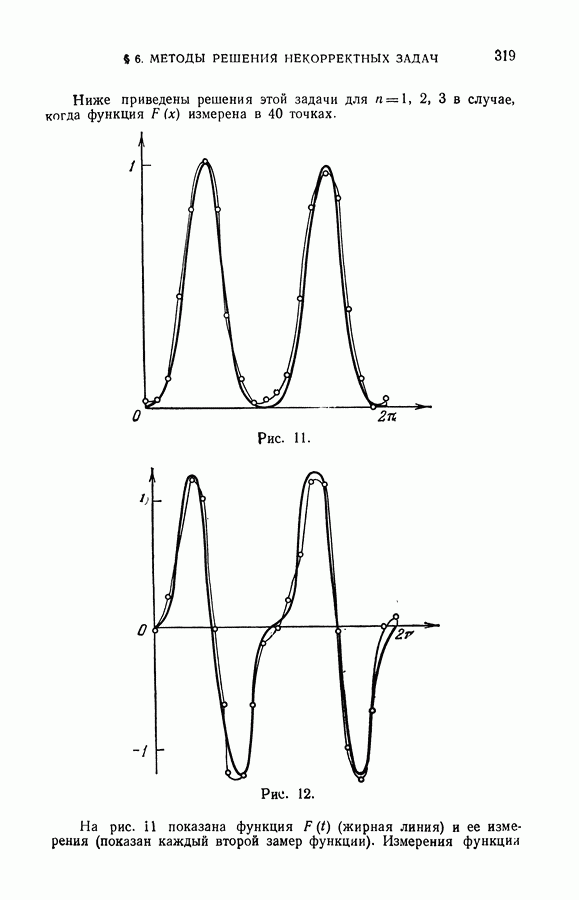
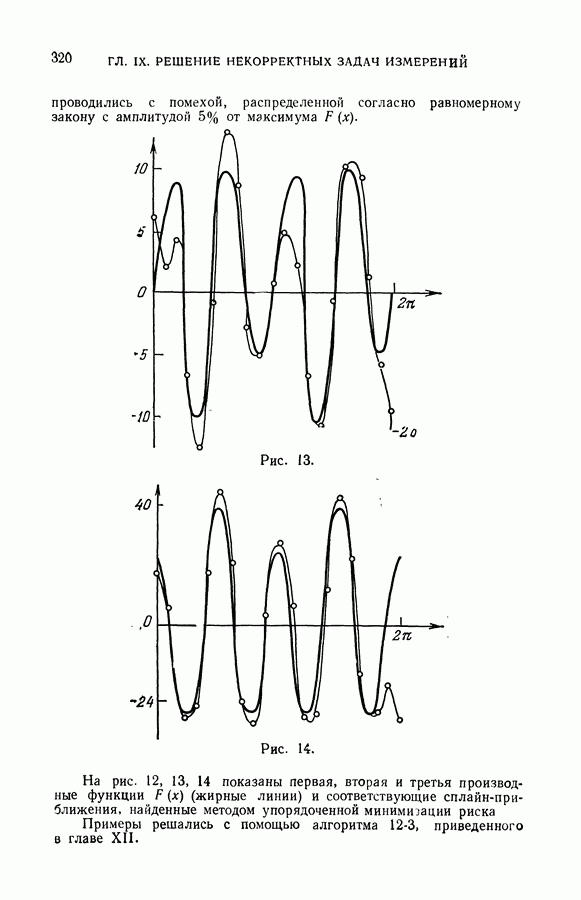
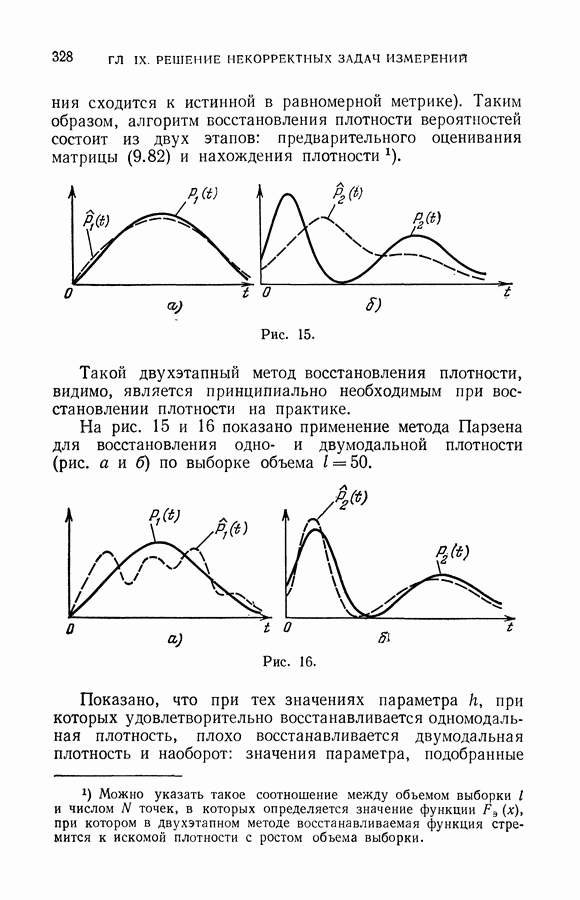
ГЛАВА VIII. МЕТОД УПОРЯДОЧЕННОЙ МИНИМИЗАЦИИ РИСКА В ЗАДАЧАХ ВОССТАНОВЛЕНИЯ ЗАВИСИМОСТЕЙ
§ 1. Идея метода упорядоченной минимизации риска
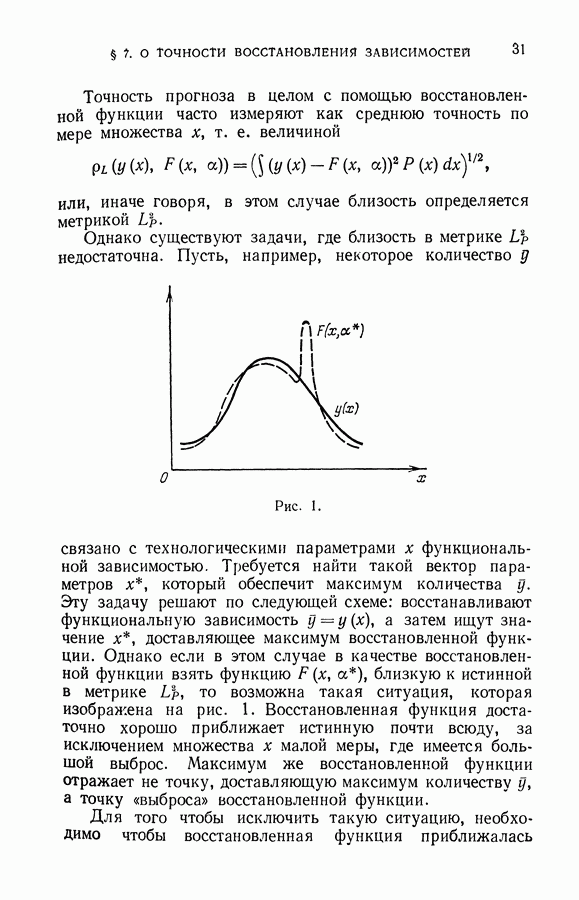
До сих пор при исследовании методов восстановления зависимостей по эмпирическим данным количество данных играло второстепенную роль: принципы, которые определяли выбор искомой зависимости из заданного множества возможных зависимостей, непосредственно не учитывали объема имеющейся информации.
Начиная с этой главы, мы будем рассматривать методы восстановления, позволяющие для фиксированного объема эмпирических данных получать наилучший в определенном смысле результат. Здесь учет объема имеющейся информации, особенно в случае малой обучающей выборки

окажется существенным. Однако, прежде чем приступить к изложению методов восстановления зависимостей, рассчитанных на использование малой выборки, договоримся о том, какую выборку мы будем называть малой.
Определение. Будем говорить, что для восстановления функции из заданного класса  выборка объема I является малой, если отношение
выборка объема I является малой, если отношение  мало (например,
мало (например,  ), где
), где  емкость класса функций.
емкость класса функций.
Величина  определяет относительный объем выборки (объем выборки на единицу емкости класса).
определяет относительный объем выборки (объем выборки на единицу емкости класса).
Заметим, что оценки величины среднего риска, полученные в главах VI и VII, зависели не от абсолютной величины объема выборки, а от относительной величины.
Основной результат главы VI состоял в том, что с вероятностью  одновременно для всех характеристических функций
одновременно для всех характеристических функций  выполняются неравенства
выполняются неравенства

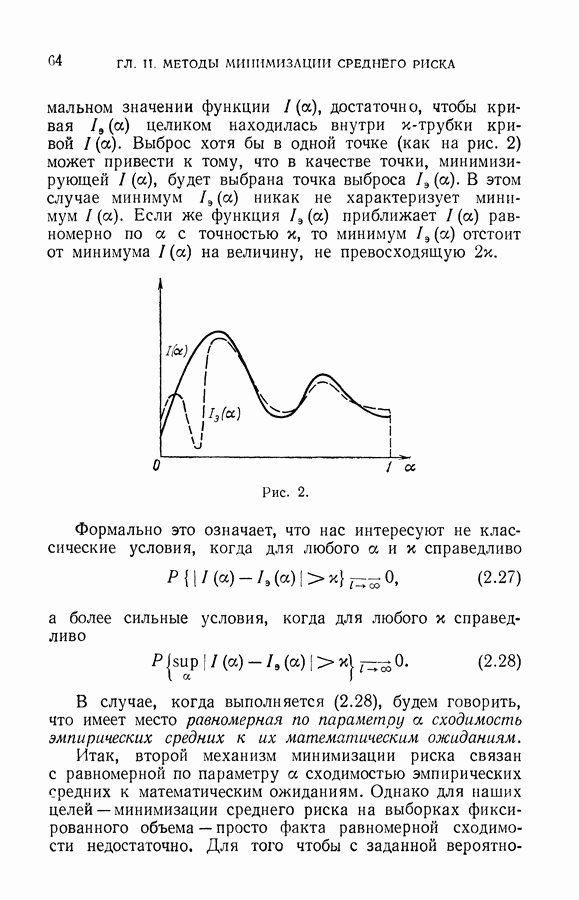
В этой главе мы рассмотрим метод минимизации риска, который, в отличие от метода минимизации эмпирического риска, минимизирует верхнюю оценку риска (8.2) или  не по одному слагаемому
не по одному слагаемому  (сомножителю
(сомножителю  ), а сразу по обоим:
), а сразу по обоим:

Реализует эту идею метод, который мы будем называть методом упорядоченной минимизации риска.
Пусть на множестве функций  задана структура, т. е. выделено минимальное подмножество элементов
задана структура, т. е. выделено минимальное подмножество элементов  затем подмножество
затем подмножество  содержащее
содержащее  и, наконец, подмножество
и, наконец, подмножество  совпадающее со всем множеством:
совпадающее со всем множеством:

Упорядочение (8.4) на множестве  задано априорно (до появления обучающей последовательности).
задано априорно (до появления обучающей последовательности).
Пусть структура задана так, что емкость  подмножества функций
подмножества функций  меньше емкости
меньше емкости  подмножества
подмножества  т. е.
т. е.

Для каждого подмножества  с вероятностью
с вероятностью  справедлива оценка
справедлива оценка

если упорядочению подлежало множество характеристических функций, и с вероятностью  справедлива оценка
справедлива оценка

если упорядочивалось множество произвольных функций;  элемент, доставляющий минимум эмпирическому риску в
элемент, доставляющий минимум эмпирическому риску в 
В выражении  величина первого слагаемого (сомножителя) правой части падает с ростом
величина первого слагаемого (сомножителя) правой части падает с ростом  а величина второго слагаемого (сомножителя) растет.
а величина второго слагаемого (сомножителя) растет.
Метод упорядоченной минимизации риска состоит в том, чтобы найти подмножество  в котором функция
в котором функция  минимизирующая эмпирический риск, доставит
минимизирующая эмпирический риск, доставит
минимальную оценку среднему риску, и принять эту функцию за решение.
Заметим, что так как для каждого элемента  справедлива оценка (8.5) (оценка (8.6)), а всего в структуре
справедлива оценка (8.5) (оценка (8.6)), а всего в структуре  элементов, то с вероятностью
элементов, то с вероятностью  оценки справедливы одновременно для всех
оценки справедливы одновременно для всех  функций, минимизирующих эмпирический риск (каждая в своем
функций, минимизирующих эмпирический риск (каждая в своем  Поэтому найденное с помощью метода упорядоченной минимизации риска решение
Поэтому найденное с помощью метода упорядоченной минимизации риска решение  доставит гарантированную с вероятностью
доставит гарантированную с вероятностью  минимальную оценку риску. Иначе говоря, неравенство
минимальную оценку риску. Иначе говоря, неравенство

неравенство

будет справедливо с вероятностью 
При реализации метода упорядоченной минимизации нам будет важно, чтобы гарантия полученной оценки риска была велика (равнялась  Поэтому, положив
Поэтому, положив  вместо
вместо  получим, что с вероятностью
получим, что с вероятностью  имеет место неравенство
имеет место неравенство

неравенство

Для структуры, состоящей из небольшого числа элементов  , вообще говоря, полученное увеличение верхней оценки для
, вообще говоря, полученное увеличение верхней оценки для  а (по отношению к (8.5) и
а (по отношению к (8.5) и  незначительно. (Число
незначительно. (Число  элементов структуры находится под знаком логарифма). Это означает, что при самом неблагоприятном стечении обстоятельств гарантированная величина риска для решения, полученного методом упорядоченной минимизации, может оказаться лишь на малую величину хуже гарантированной величины риска для решения, полученного методом минимизации эмпирического риска, в то время как в обычных
элементов структуры находится под знаком логарифма). Это означает, что при самом неблагоприятном стечении обстоятельств гарантированная величина риска для решения, полученного методом упорядоченной минимизации, может оказаться лишь на малую величину хуже гарантированной величины риска для решения, полученного методом минимизации эмпирического риска, в то время как в обычных
ситуациях, как мы увидим ниже, выигрыш от применения метода упорядоченной минимизации риска может оказаться значительным.
В дальнейшем нам удобно будет считать, что метод упорядоченной минимизации риска реализует двухуровневую процедуру минимизации: сначала на каждом элементе  структуры (8.4) выбирается функция
структуры (8.4) выбирается функция  минимизирующая величину эмпирического риска, а затем из
минимизирующая величину эмпирического риска, а затем из  отобранных функций выбирается такая, которая доставляет величине риска гарантированный минимум.
отобранных функций выбирается такая, которая доставляет величине риска гарантированный минимум.
Таким образом, при реализации метода упорядоченной минимизации риска возникают две проблемы:
1) Как задать структуру на исходном множестве функций 
2) Каким должен быть алгоритм выбора второго уровня?
Задание структуры на множестве функций  является неформальным моментом в реализации метода. В структуре должна быть отражена априорная информация о задачах, которая имеется у исследователя. Те функции, которые, по мнению исследователя, более вероятно приближают искомую, следует относить к классу
является неформальным моментом в реализации метода. В структуре должна быть отражена априорная информация о задачах, которая имеется у исследователя. Те функции, которые, по мнению исследователя, более вероятно приближают искомую, следует относить к классу  с меньшим номером. При этом чем больше имеется априорной информации, тем более узкими следует задавать классы с малыми номерами.
с меньшим номером. При этом чем больше имеется априорной информации, тем более узкими следует задавать классы с малыми номерами.
Задание алгоритма выбора второго уровня отражает умение оценивать качество каждого из отобранных на первом уровне решающих правил.
Ниже при построении алгоритмов выбора второго уровня мы используем оценку среднего риска (6.48)

если выбор осуществляется среди характеристических функций (решается задача распознавания образов), и оценку (7.27)

если выбор осуществляется среди функций произвольной природы (решается задача восстановления регрессии).
Использование этих оценок позволит получить наилучшее для заданной структуры гарантированное решение. Другая идея построения алгоритмов второго уровня связана с использованием процедуры «скользящий контроль».



























































































































































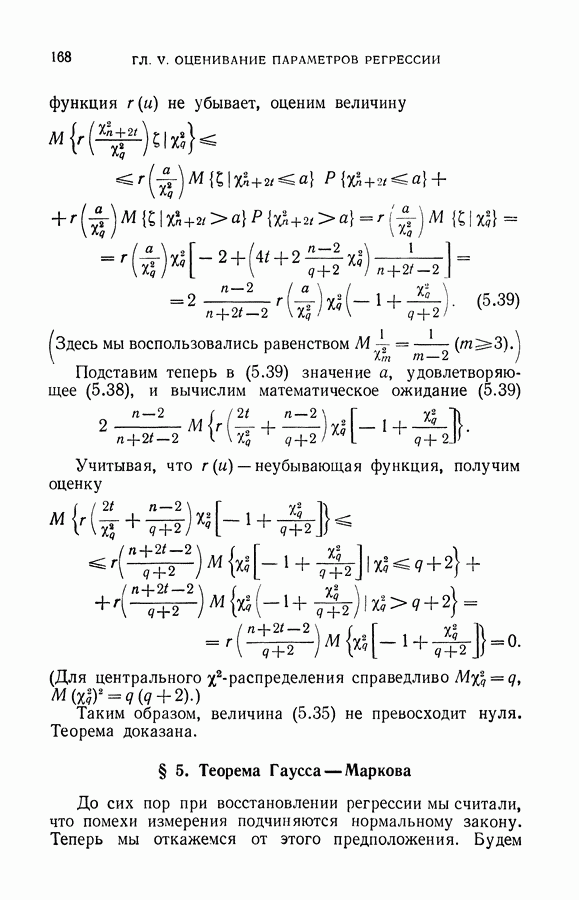










































































































































































































































































 одновременно для всего множества произвольных функций
одновременно для всего множества произвольных функций  выполняются неравенства
выполняются неравенства

 ни конкретный вид сомножителя
ни конкретный вид сомножителя  Важно другое — полученные оценки были таковы, что с ростом величина
Важно другое — полученные оценки были таковы, что с ростом величина  стремилась к нулю, а величина
стремилась к нулю, а величина  к единице.
к единице.
 найдется такая величина
найдется такая величина  что как только
что как только  с вероятностью
с вероятностью  одновременно для всего множества
одновременно для всего множества  выполнятся неравенства
выполнятся неравенства

 характеристические функции, и неравенства
характеристические функции, и неравенства

 произвольные функции.
произвольные функции.
 малую величину среднего риска.
малую величину среднего риска.
 может значительно отличаться от нуля, а сомножитель
может значительно отличаться от нуля, а сомножитель  единицы. В этом случае функция, доставляющая малую величину эмпирическому риску, может не обеспечить малую величину среднему риску.
единицы. В этом случае функция, доставляющая малую величину эмпирическому риску, может не обеспечить малую величину среднему риску.
 но и величину слагаемого сомножителя
но и величину слагаемого сомножителя 
