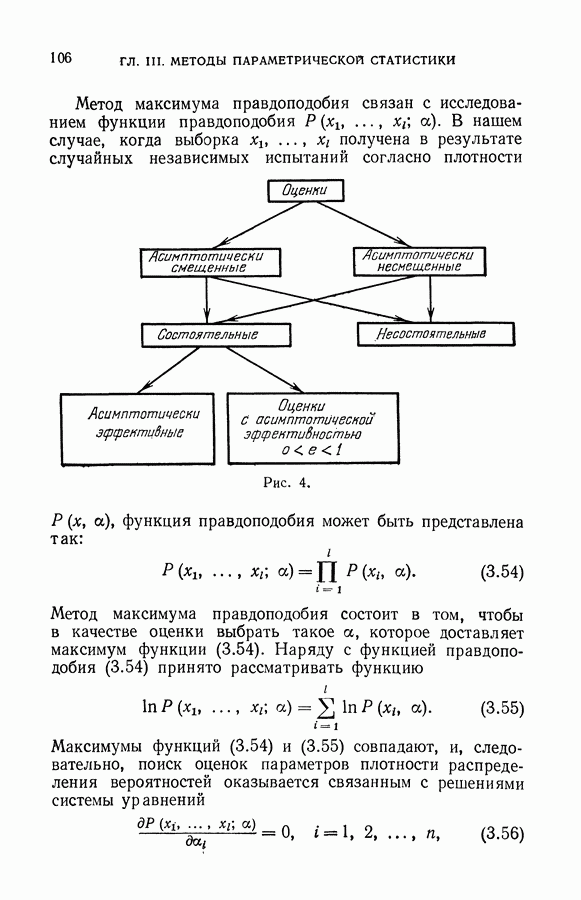
§ 11. Локальные алгоритмы восстановления значений характеристической функции
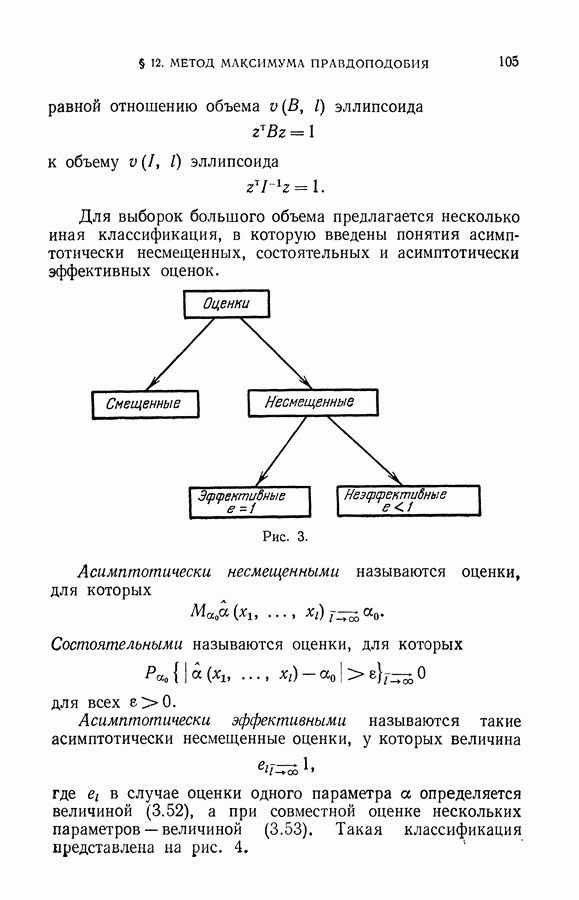
Наконец, рассмотрим третью идею построения алгоритмов восстановления значений функции.
Определим для каждого вектора х полной выборки систему окрестностей:

минимум достигается на окрестности  — полученная классификация векторов рабочей! выборки из этой окрестности. Очевидно, что с вероятностью
— полученная классификация векторов рабочей! выборки из этой окрестности. Очевидно, что с вероятностью  эта классификация содержит меньше
эта классификация содержит меньше  ошибок.
ошибок.
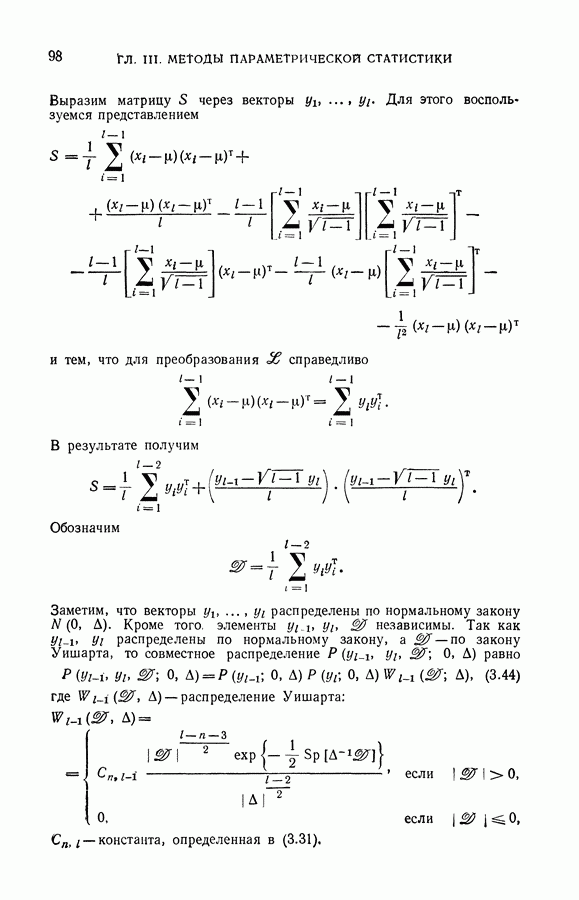
Аналогично могут быть найдены решения для окрестностей всех векторов генеральной совокупности. В результате получим табл. 1.
Таблица 1

В первом столбце таблицы указаны векторы, задающие систему окрестностей, затем наилучшая по данной системе окрестностей классификация векторов и, наконец, гарантированная оценка числа ошибок классификации.
Заметим, что одни и те же векторы рабочей выборки принадлежат окрестностям различных векторов, а классификация некоторых векторов рабочей выборки, данная в разных строках второго столбца таблицы, может не совпадать.
Обозначим через  истинную классификацию векторов рабочей выборки
истинную классификацию векторов рабочей выборки  .
.
Тогда содержание таблицы может быть переписано в виде

Здесь  означает, что суммирование ведется лишь по классификациям тех векторов рабочей выборки, которые принадлежат выбранной окрестности точки
означает, что суммирование ведется лишь по классификациям тех векторов рабочей выборки, которые принадлежат выбранной окрестности точки 
Каждое из неравенств (10.56) выполняется с вероятностью  Следовательно, система совместна (все не?
Следовательно, система совместна (все не?
























































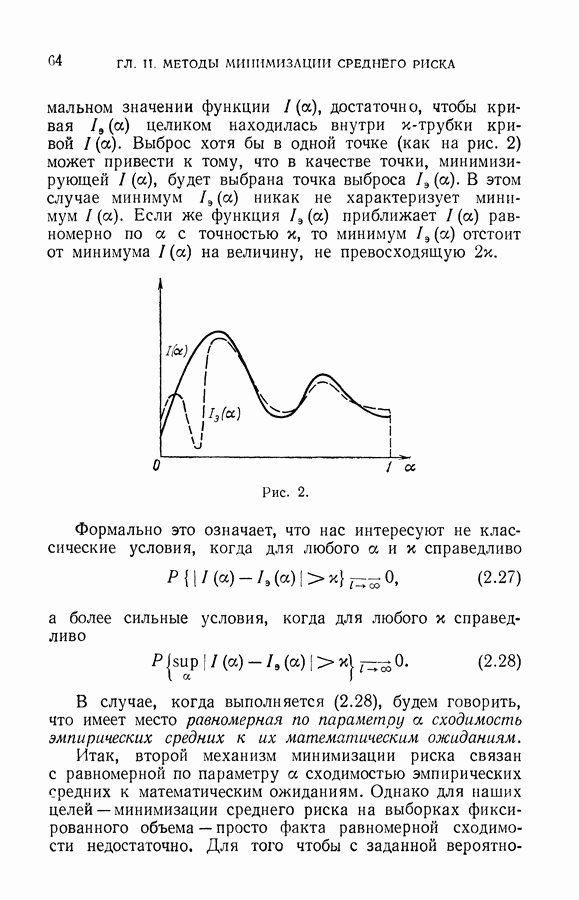













































































































































































































































































































































































 систем окрестностей, своя для каждого вектора полной выборки:
систем окрестностей, своя для каждого вектора полной выборки:

 точки
точки  содержащую как элементы обучающей, так и элементы рабочей выборок. Согласно теореме 10.2 с вероятностью
содержащую как элементы обучающей, так и элементы рабочей выборок. Согласно теореме 10.2 с вероятностью  можно утверждать, что одновременно для всех линейных решающих правил будет выполнено неравенство
можно утверждать, что одновременно для всех линейных решающих правил будет выполнено неравенство

 есть величина суммарного риска классификации элементов из окрестности XI с помощью решающего правила
есть величина суммарного риска классификации элементов из окрестности XI с помощью решающего правила  величина эмпирического риска, вычисленная для правила
величина эмпирического риска, вычисленная для правила  по элементам обучающей последовательности, принадлежащим окрестности
по элементам обучающей последовательности, принадлежащим окрестности  наименьшее решение неравенства
наименьшее решение неравенства

 размерность пространства
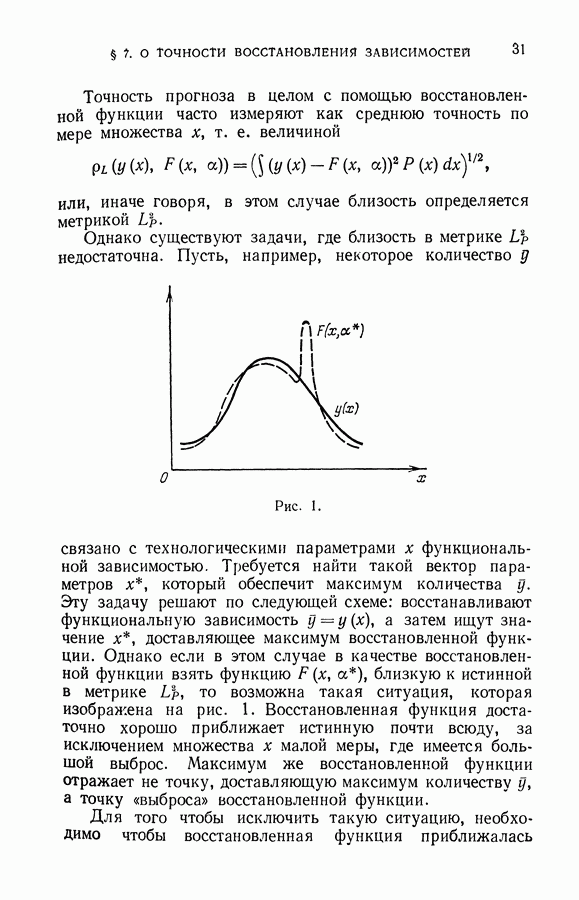
размерность пространства 
 число элементов обучающей и рабочей выборок из окрестности
число элементов обучающей и рабочей выборок из окрестности  Пусть
Пусть  решающее правило, минимизирующее на обучающей последовательности из
решающее правило, минимизирующее на обучающей последовательности из  величину эмпирического риска.
величину эмпирического риска.
 для элементов из
для элементов из  справедлива оценка
справедлива оценка

 для которой достигается минимум (по
для которой достигается минимум (по  ) величины
) величины  Пусть
Пусть

 векторов
векторов  решений системы неравенств (8.56). В принципе в качестве окончательного вектора классификации может быть выбран любой вектор из
решений системы неравенств (8.56). В принципе в качестве окончательного вектора классификации может быть выбран любой вектор из  Однако целесообразнее в подобных случаях выбирать такое решение, которое обладает некоторыми дополнительными экстремальными свойствами.
Однако целесообразнее в подобных случаях выбирать такое решение, которое обладает некоторыми дополнительными экстремальными свойствами.
 минимаксный —
минимаксный —  т. е. наименее удаленный от самого далекого вектора из допустимого множества
т. е. наименее удаленный от самого далекого вектора из допустимого множества  :
:

 мы и примем за окончательное решение задачи классификации векторов рабочей выборки.
мы и примем за окончательное решение задачи классификации векторов рабочей выборки.
 оптимальную окрестность для построения линейного решающего правила. Полученное правило использовалось лишь для классификации векторов, принадлежащих оптимальной окрестности. Такие алгоритмы иногда называют локальными.
оптимальную окрестность для построения линейного решающего правила. Полученное правило использовалось лишь для классификации векторов, принадлежащих оптимальной окрестности. Такие алгоритмы иногда называют локальными.
 вектора
вектора  может быть определена по метрической близости (множество
может быть определена по метрической близости (множество  содержит векторы полной выборки, для которых
содержит векторы полной выборки, для которых  , где с — константа. Набор констант
, где с — константа. Набор констант  определяет систему окрестностей).
определяет систему окрестностей).
