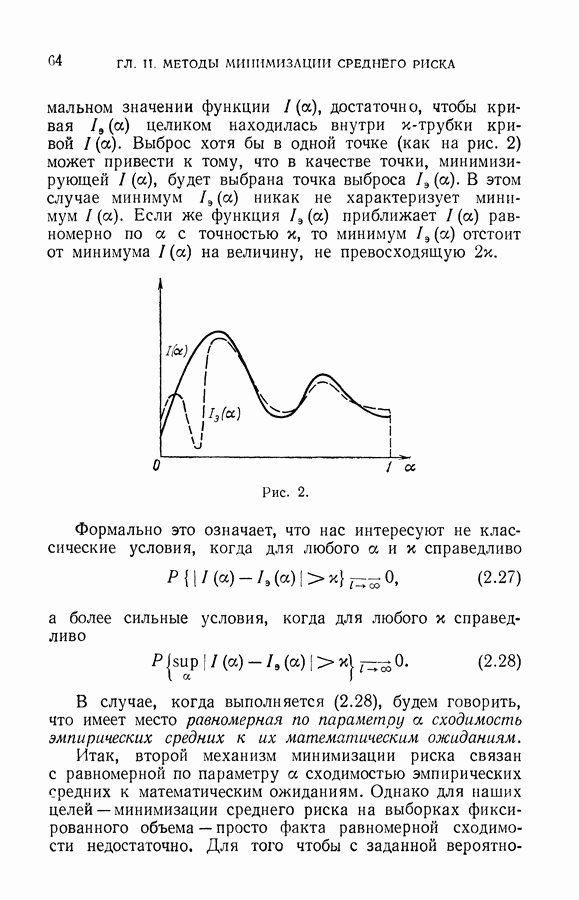
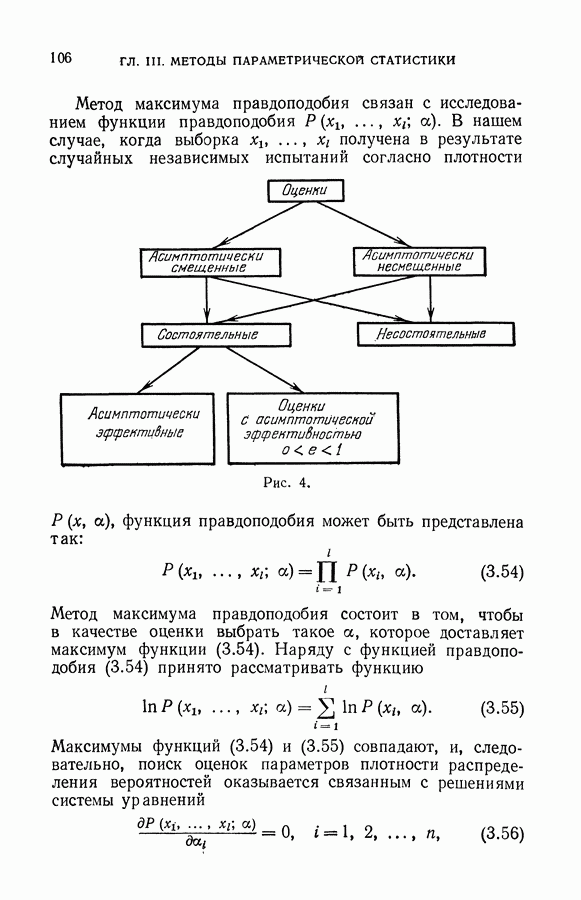
§ 5. Восстановление значений характеристической функции в классе линейных решающих правил
Пусть дана полная выборка

На полной выборке множество решающих правил распадается на конечное число  классов эквивалентности
классов эквивалентности  Два решающих правила
Два решающих правила  попадают в один класс эквивалентности, если они одинаково делят выборку (10.24) на две подвыборки.
попадают в один класс эквивалентности, если они одинаково делят выборку (10.24) на две подвыборки.
Всего возможно  разделений выборки (10.24) на два класса с помощью правил
разделений выборки (10.24) на два класса с помощью правил  и, следовательно, существует
и, следовательно, существует  классов эквивалентности.
классов эквивалентности.
Согласно определению (см. § 7 гл. VI)

Для линейных решающих правил в пространстве размерности  справедлива оценка (см. § 8 гл. VI)
справедлива оценка (см. § 8 гл. VI)

Таким образом, на полной выборке (10.24) множество линейных решающих правил  распадается на
распадается на  классов эквивалентности
классов эквивалентности 
Заметим, что классы эквивалентности не равнозначны по объему. Одни из них содержат «больше» решающих правил, другие — «меньше». Поставим в соответствие каждому классу эквивалентности величину, характеризующую долю линейных решающих правил, принадлежащих этому классу по отношению ко всем линейным решающим правилам. Такую величину можно сконструировать. Действительно, поставим в соответствие каждой функции

направляющий вектор (рис. 19)

Тогда множеству всех гиперплоскостей соответствует в пространстве параметров а единичная сфера, каждому классу эквивалентности  соответствует на поверхности сферы своя область. (Множество из
соответствует на поверхности сферы своя область. (Множество из  классов эквивалентности разбивают сферу на
классов эквивалентности разбивают сферу на  областей.) Отношение площади, соответствующей области к площади сферы X и характеризует долю функций из класса эквивалентности
областей.) Отношение площади, соответствующей области к площади сферы X и характеризует долю функций из класса эквивалентности  отношению ко всем возможным линейным решающим правилам.
отношению ко всем возможным линейным решающим правилам.

Рис. 19.
Упорядочим теперь классы эквивалентности по убыванию величин  и введем следующую структуру:
и введем следующую структуру:

где элементу  принадлежат лишь те классы эквивалентности, для которых
принадлежат лишь те классы эквивалентности, для которых

Таким образом, мы построили структуру, каждый элемент  которой обладает экстремальным свойством: для данного числа классов эквивалентности он содержит максимальную долю всех решающих правил. Однако на практике вычислить величину
которой обладает экстремальным свойством: для данного числа классов эквивалентности он содержит максимальную долю всех решающих правил. Однако на практике вычислить величину  и, следовательно, построить структуру (10.25) трудно. Поэтому мы рассмотрим другую характеристику объема класса эквивалентности, которая близка по смыслу к и может быть найдена на практике.
и, следовательно, построить структуру (10.25) трудно. Поэтому мы рассмотрим другую характеристику объема класса эквивалентности, которая близка по смыслу к и может быть найдена на практике.
Обозначим через  величину расстояния между выпуклыми оболочками векторов полной выборки, отнесенных решающими правилами из
величину расстояния между выпуклыми оболочками векторов полной выборки, отнесенных решающими правилами из  к разным классам, и поставим в соответствие классу эквивалентности
к разным классам, и поставим в соответствие классу эквивалентности  число
число

где  радиус минимальной сферы, содержащей множество (10.24), т. е.
радиус минимальной сферы, содержащей множество (10.24), т. е.

Зададим на множестве классов эквивалентности структуру

где в  включены лишь такие классы эквивалентности
включены лишь такие классы эквивалентности  для которых
для которых

Множество  в (10.27) пусто.
в (10.27) пусто.
Для того чтобы построить метод упорядоченной минимизации суммарного риска на структуре (10.27), оценим число  классов эквивалентности, принадлежащих элементу структуры
классов эквивалентности, принадлежащих элементу структуры 
Справедлива
Лемма. Число  классов эквивалентности в
классов эквивалентности в  оценивается величиной
оценивается величиной

где  — минимум двух величин:
— минимум двух величин:

 размерность пространства,
размерность пространства,  целая часть числа а.
целая часть числа а.
Доказательство. Заметим, что число  равно максимальному числу разбиений выборки
равно максимальному числу разбиений выборки

на два таких класса, что расстояние между их выпуклыми оболочками больше  т. е.
т. е.

Число таких решающих правил не превосходит

где  максимальное число точек выборки, для которых любое разбиение на два класса удовлетворяет условию (10.31). Заметим, что если условие (10.31)
максимальное число точек выборки, для которых любое разбиение на два класса удовлетворяет условию (10.31). Заметим, что если условие (10.31)
близки (различаются менее чем на 0,001). Поэтому примем

(Оценкой сверху  было бы выражение
было бы выражение

Из неравенств (10.32) и (10.33) следует, что для целых 

Окончательно, учитывая, что разбиение осуществляется гиперплоскостью, т. е.  получаем
получаем

И следовательно, согласно теореме 6.6

Лемма доказана.
Из теоремы 10.2 и леммы следует, что с вероятностью 1—г] одновременно для всех решающих правил из  будет выполнено неравенство
будет выполнено неравенство

где k — наименьшее решение неравенства

Метод упорядоченной минимизации суммарного риска состоит в том, чтобы индексировать рабочую выборку с помощью правила  которое минимизирует по
которое минимизирует по  и а функционал (10.35). Пусть минимум равен
и а функционал (10.35). Пусть минимум равен  Для такой индексации справедливо утверждение
Для такой индексации справедливо утверждение

В главе XI мы приведем описание алгоритмов, минимизирующих суммарный риск в классе линейных решающих
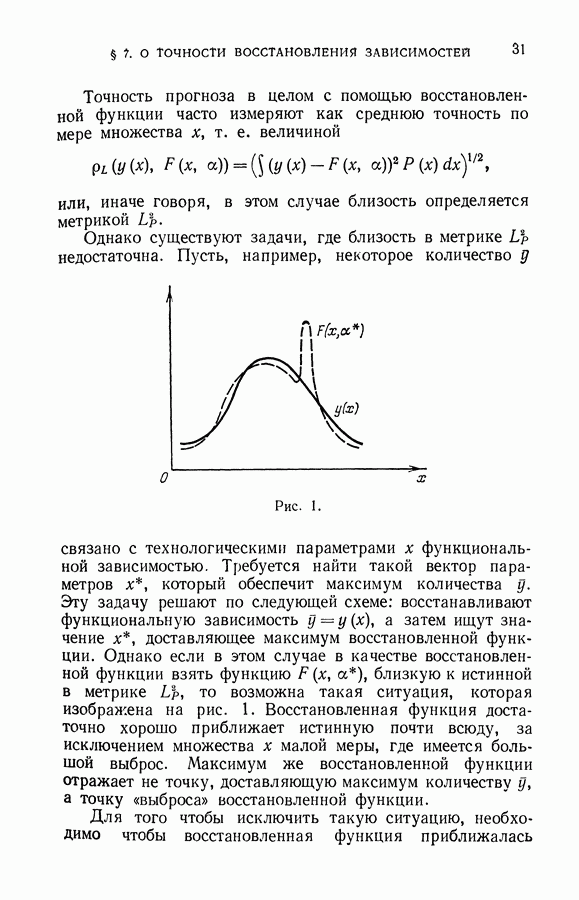
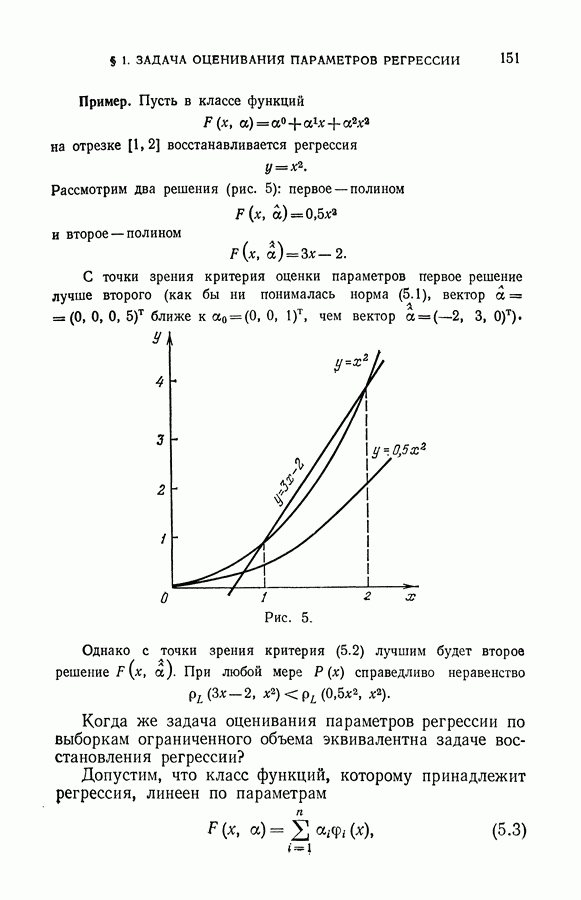
правил. Здесь же рассмотрим пример, иллюстрирующий разницу в решении задачи классификации векторов рабочей выборки методом минимизации суммарного риска и с помощью решающего правила минимизирующего эмпирический риск на обучающей последовательности.
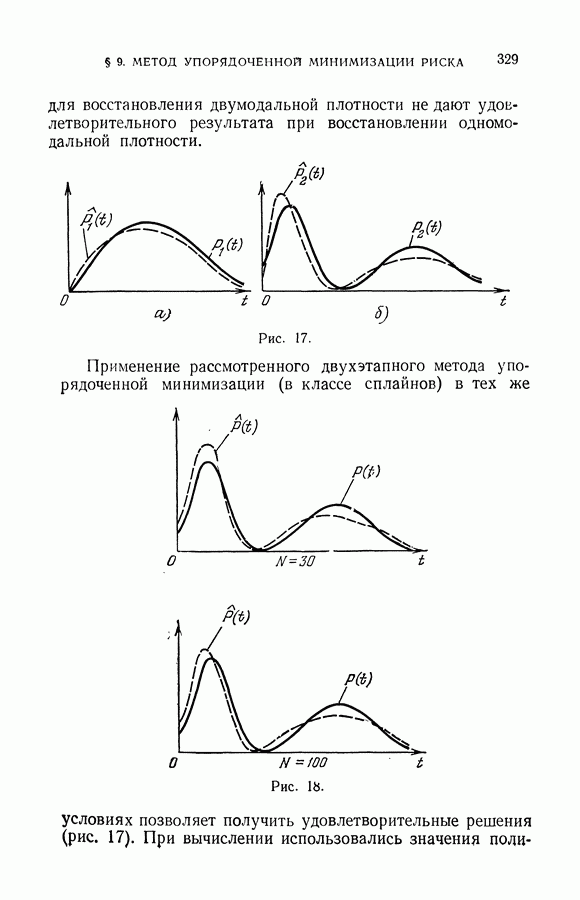
На рис. 20 векторы первого класса обучающей последовательности обозначены крестиками, векторы второго класса — кружочками. Черными точками показаны векторы экзаменационной выборки.

Рис. 20.
Решение этой задачи в схеме минимизации среднего риска заключается в том, чтобы построить разделяющую гиперплоскость, гарантирующую минимальную вероятность ошибки. Пусть решение выбирается среди гиперплоскостей, безошибочно делящих векторы обучающей последовательности. В этом случае минимальную гарантированную вероятность ошибок обеспечит оптимальная разделяющая гиперплоскость (такая, которая наиболее удалена от элементов обучающей последовательности). Те векторы, которые лежат по разные стороны гиперплоскости  относятся к различным классам. Таково решение задачи методом минимизации среднего риска. Решение задачи методом минимизации суммарного риска
относятся к различным классам. Таково решение задачи методом минимизации среднего риска. Решение задачи методом минимизации суммарного риска
определяется гиперплоскостью  максимизирующей расстояние между выпуклыми оболочками разделяемых множеств. Векторы, находящиеся по одну сторону гиперплоскости, относятся к первому классу, а по другую сторону гиперплоскости — ко второму классу.
максимизирующей расстояние между выпуклыми оболочками разделяемых множеств. Векторы, находящиеся по одну сторону гиперплоскости, относятся к первому классу, а по другую сторону гиперплоскости — ко второму классу.
На рисунке выделены (заштрихованы) точки рабочей выборки, которые классифицируются гиперплоскостями  по-разному.
по-разному.






































































































































































































































































































































































































































 размерность пространства.
размерность пространства.
 точек
точек

 всевозможных разбиений этих точек на два подмножества
всевозможных разбиений этих точек на два подмножества

 расстояние между выпуклыми оболочками векторов, принадлежащих разным подмножествам при разбиении
расстояние между выпуклыми оболочками векторов, принадлежащих разным подмножествам при разбиении 
 можно записать как
можно записать как

 не превосходит максимального числа векторов, при котором еще выполняется неравенство
не превосходит максимального числа векторов, при котором еще выполняется неравенство

 достигается, когда векторы
достигается, когда векторы  располагаются в вершинах правильного
располагаются в вершинах правильного  -мерного симплекса, вписанного в шар радиуса
-мерного симплекса, вписанного в шар радиуса  разбиение на два подсимплекса размерности
разбиение на два подсимплекса размерности  для четных
для четных  и два подсимплекса размерности
и два подсимплекса размерности  для нечетных
для нечетных  При этом путем элементарных расчетов может быть найдено, что
При этом путем элементарных расчетов может быть найдено, что

 величины
величины

