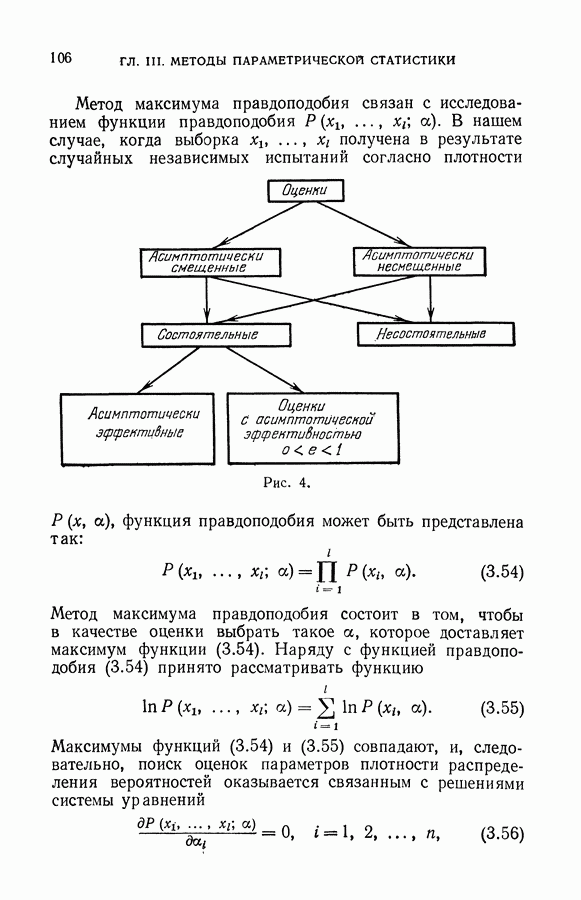
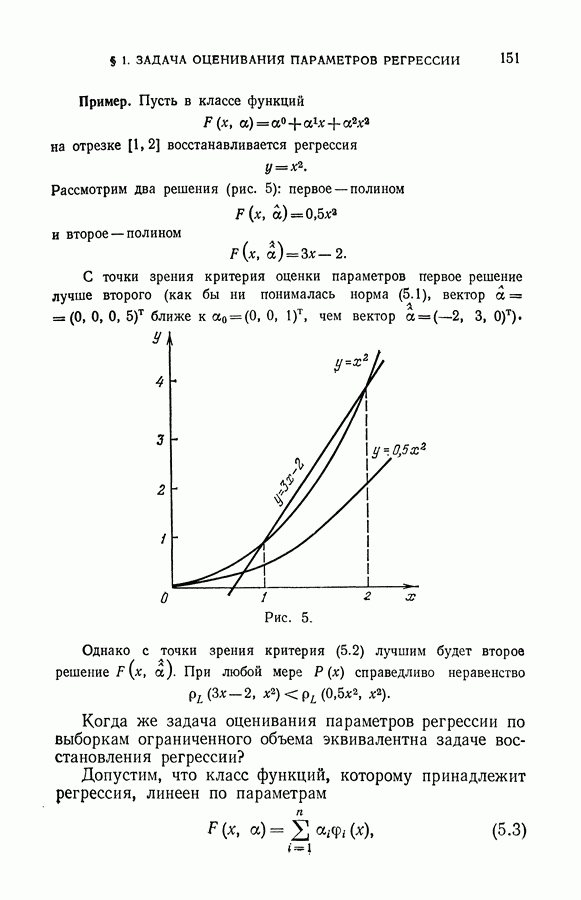
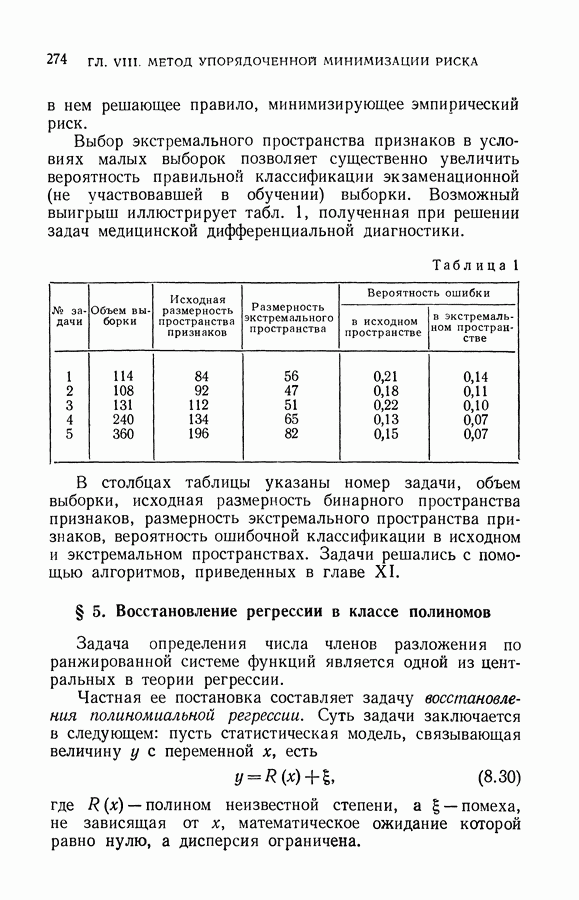
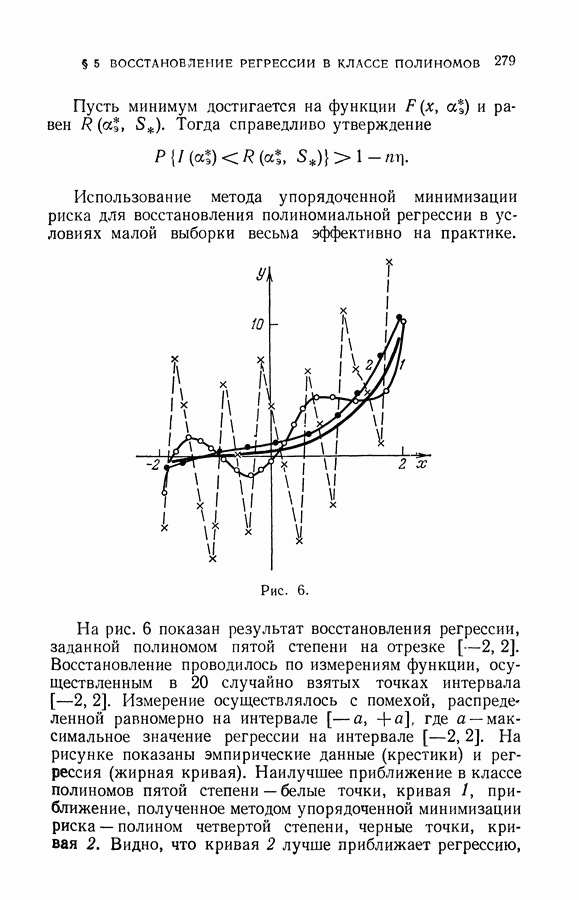
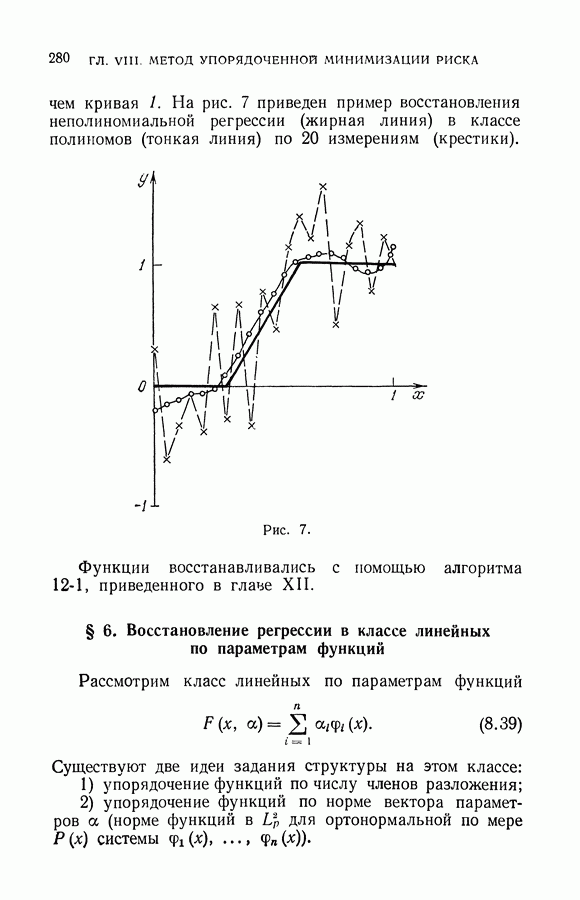
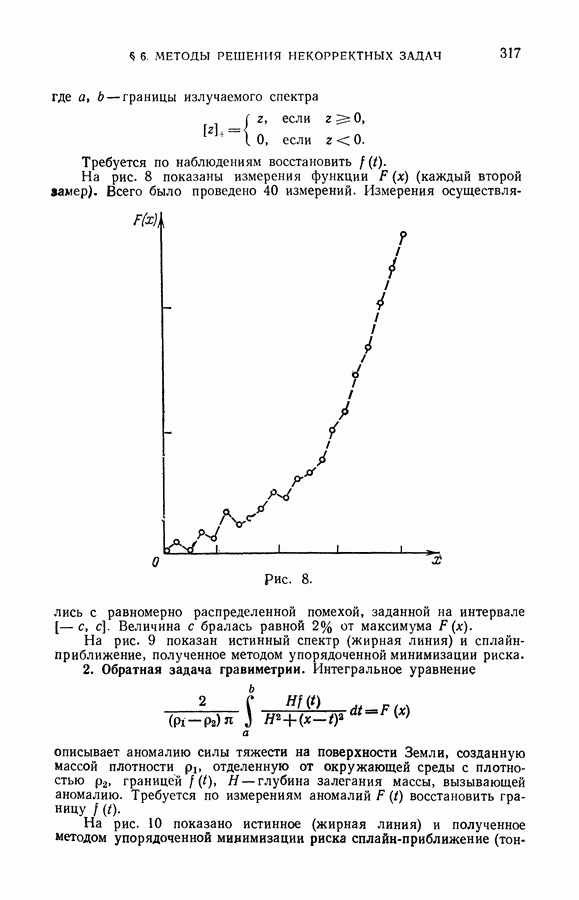
§ 10. Алгоритмы восстановления значений функции в классе кусочно-линейных решающих правил
Алгоритм 11-7 определения значений функции с помощью кусочно-линейных решающих правил построен по схеме:
1. На полной выборке х определяется таксонная структура. Алгоритм построения таксонной структуры тот же, что и раньше.
2. Каждый элемент таксонной структуры  задает разбиение полного множества X на подмножества
задает разбиение полного множества X на подмножества  Для каждого подмножества
Для каждого подмножества  решается задача классификации элементов рабочей выборки, принадлежащей
решается задача классификации элементов рабочей выборки, принадлежащей  с помощью линейных решающих правил. Для этого используются алгоритмы предыдущего параграфа. Далее по формулам
с помощью линейных решающих правил. Для этого используются алгоритмы предыдущего параграфа. Далее по формулам

где  число элементов обучающей последовательности, принадлежащих
число элементов обучающей последовательности, принадлежащих  число векторов рабочей выборки, принадлежащих
число векторов рабочей выборки, принадлежащих  определяется частота ошибок классификации рабочей выборки с помощью линейного решающего правила.
определяется частота ошибок классификации рабочей выборки с помощью линейного решающего правила.
3. По формуле

определяется частота ошибок классификации по всем элементам рабочей выборки.
4. Перебором по  находится такой элемент структуры, а вместе с ним и то решение, для которого оценка (11.39) минимальна.
находится такой элемент структуры, а вместе с ним и то решение, для которого оценка (11.39) минимальна.
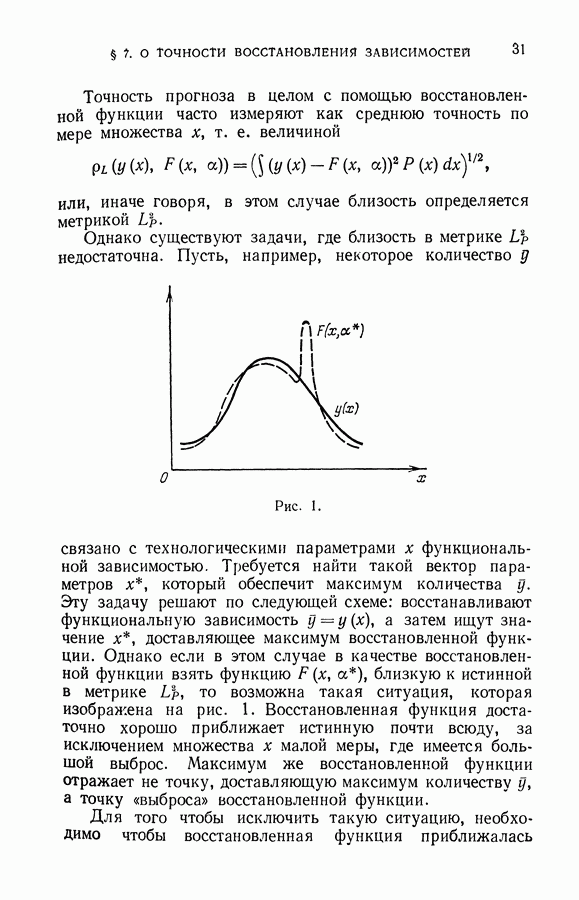
Наконец, рассмотрим алгоритм 11-8, реализующий идеи локальных приближений. Пусть задана полная выборка

Для каждого вектора х, принадлежащего полной выборке (11.40), перенумеруем векторы последовательности (11.40) в соответствии с их расстоянием до этого вектора. Таким образом, задается  систем окрестностей, своя для каждого вектора полной выборки (11.40)
систем окрестностей, своя для каждого вектора полной выборки (11.40)

Будем рассматривать систему окрестностей точки  Пусть
Пусть  некоторая окрестность, содержащая
некоторая окрестность, содержащая  точек обучающей выборки и
точек обучающей выборки и  точек рабочей выборки.
точек рабочей выборки.
Тогда частоту правильной классификации векторов рабочей выборки, принадлежащих этой окрестности, с помощью линейного решающего правила, минимизирующего эмпирический риск, в  оценим с помощью величины
оценим с помощью величины

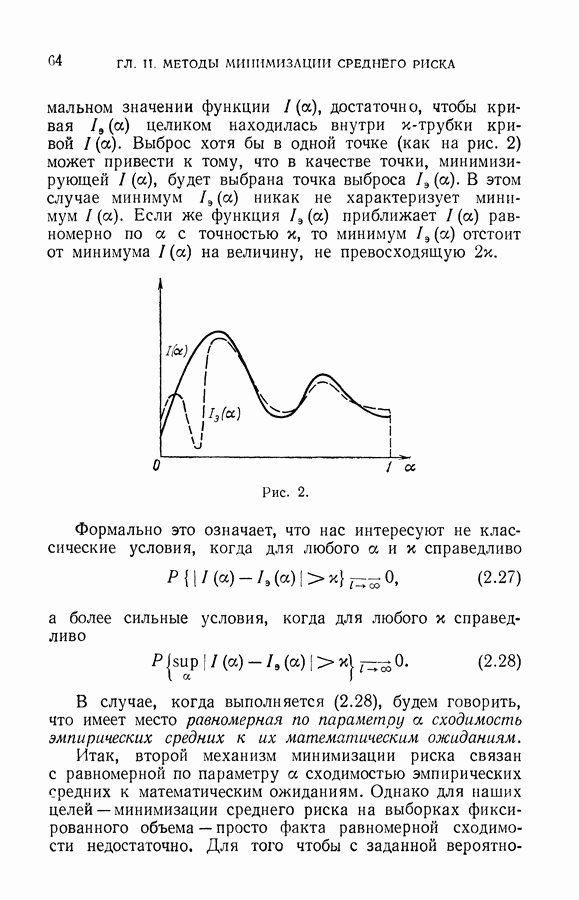
где  наименьшее решение неравенства
наименьшее решение неравенства

Определим такую окрестность, а вместе с ней такую индексацию векторов рабочей выборки, для которой достигается минимум выражения (11.41). Пусть минимум равен 
Таким образом, для каждого вектора  полной выборки (11.40) может быть указана классификация некоторых (попавших в окрестность) векторов рабочей выборки и получена оценка
полной выборки (11.40) может быть указана классификация некоторых (попавших в окрестность) векторов рабочей выборки и получена оценка  числа ошибок классификации.
числа ошибок классификации.
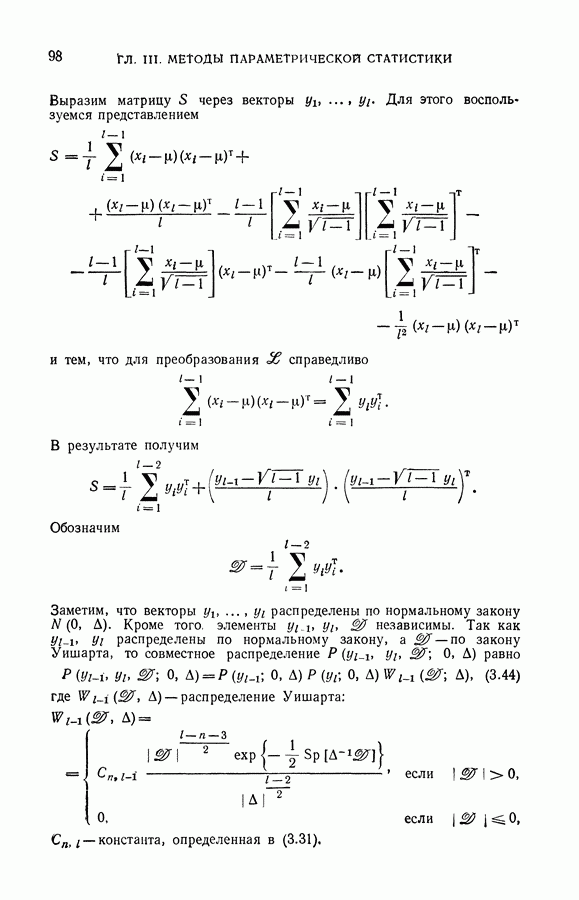
Рассмотрим табл. 1.
Таблица 1

Прочерк в столбце таблицы означает, что соответствующий вектор рабочей выборки не принадлежит окрестности, для которой проведена индексация.
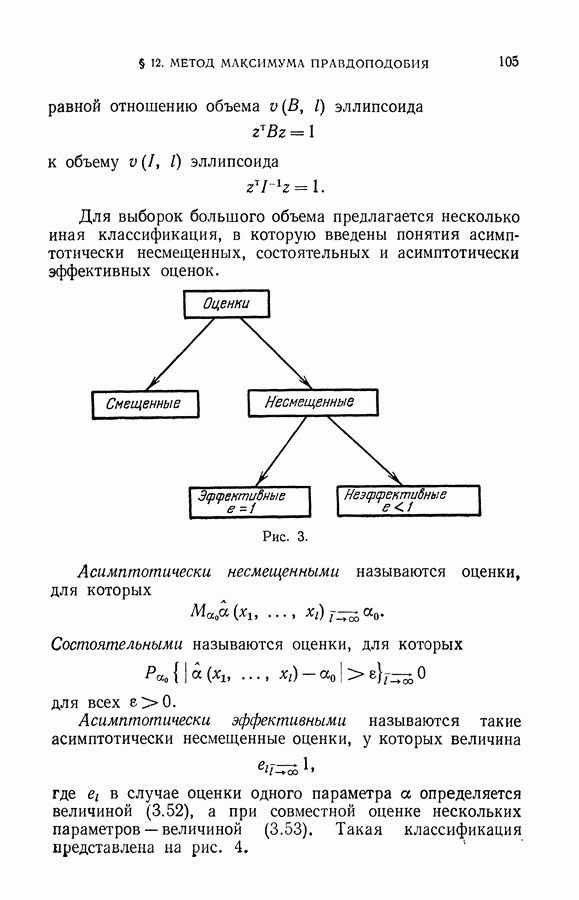
Теория локальных алгоритмов предписывает индексацию с помощью минимаксного допустимого решения (см. § 10 гл. VIII). Отыскание такого минимаксного вектора индексаций есть задача целочисленного программирования, решение которой сопряжено с большим объемом вычислений.
Поэтому при реализации алгоритма 11-8 на ЦВМ в качестве окончательной индексации вектора  выбирается та, которая совпадает с большинством индексаций по столбцу таблицы,
выбирается та, которая совпадает с большинством индексаций по столбцу таблицы,