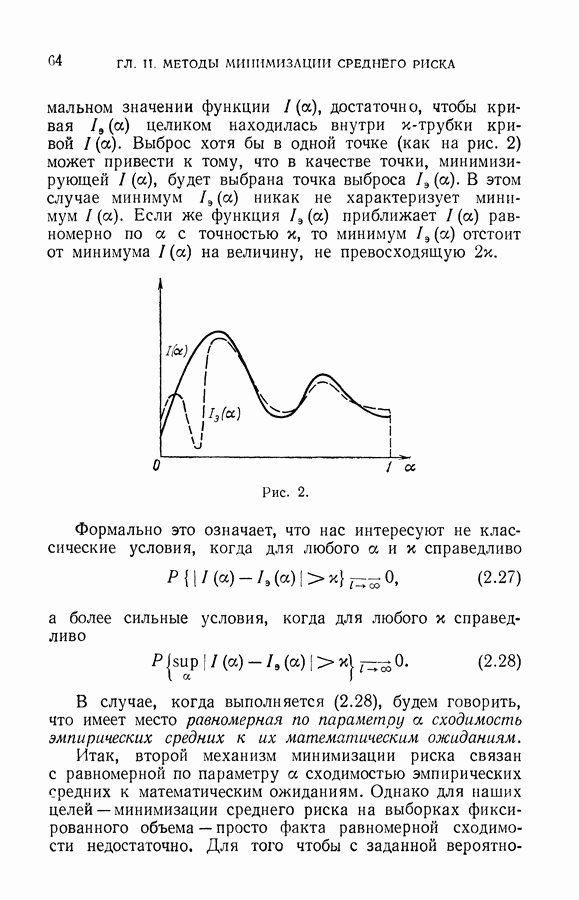
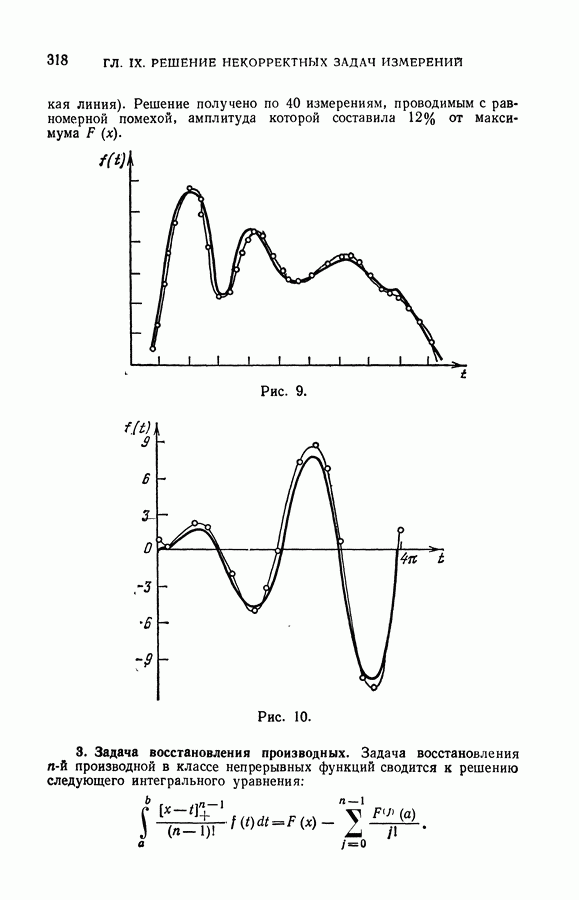
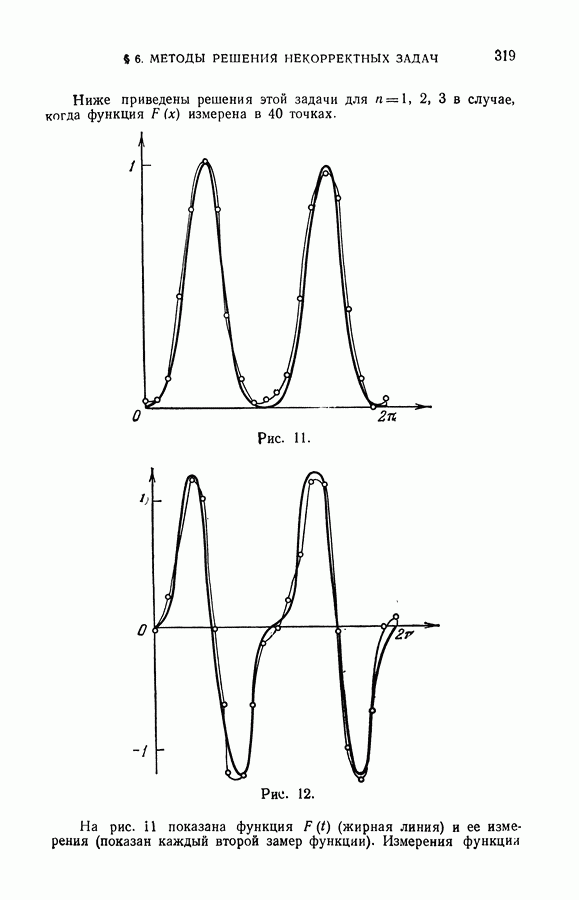
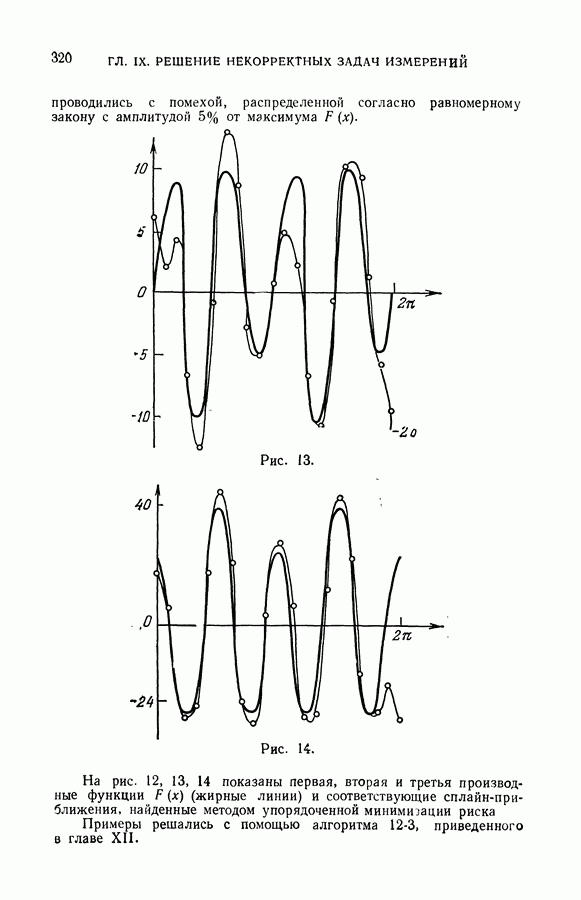
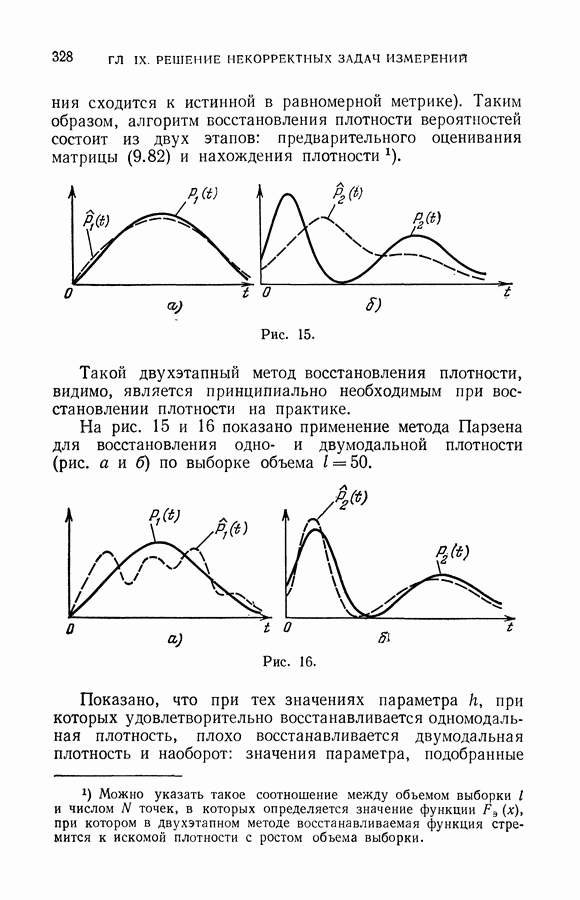
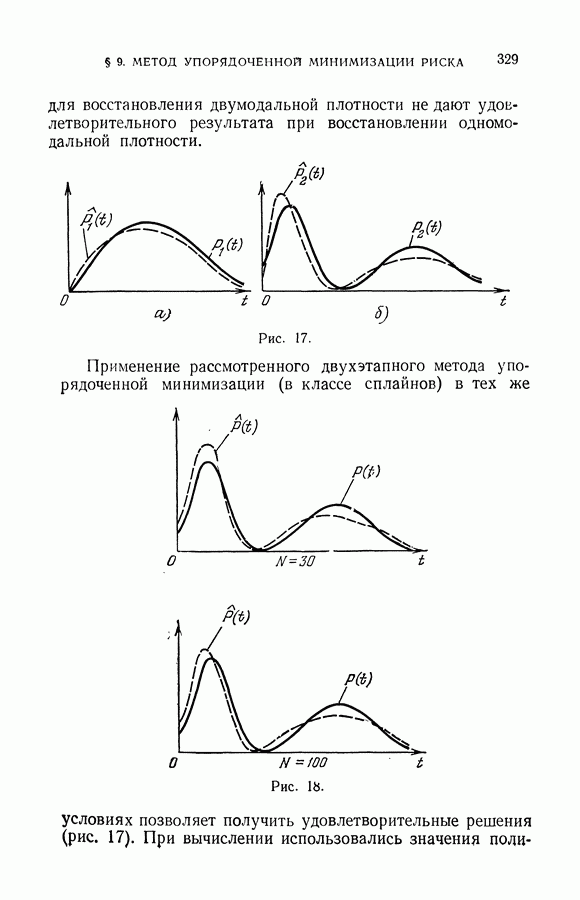
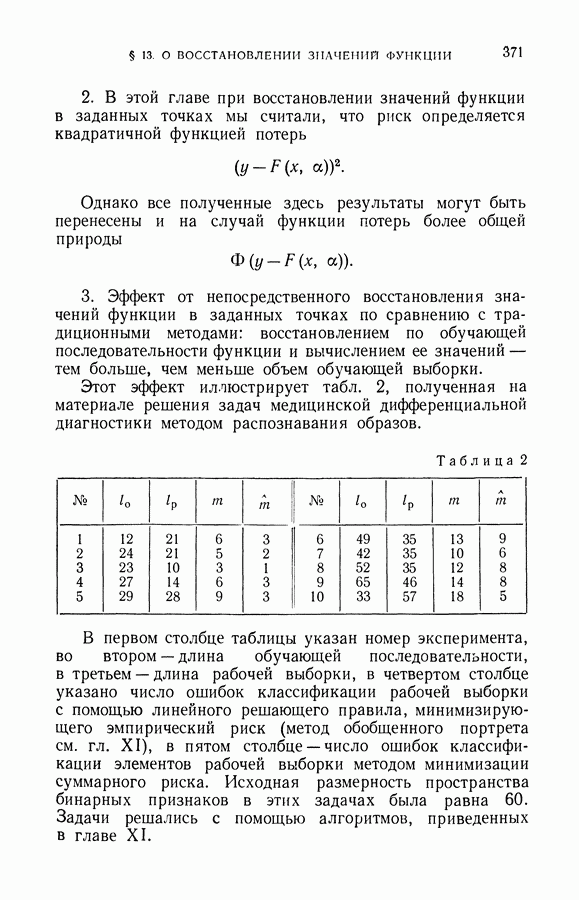
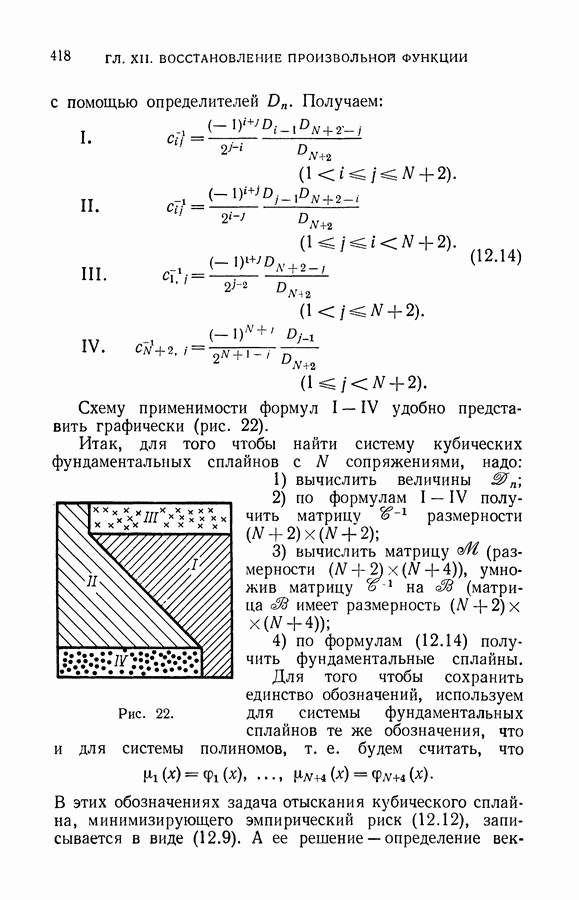
§ 7. О точности восстановления зависимостей по эмпирическим данным
В конце предыдущего параграфа была сформулирована цель исследования: найти алгоритмы, которые гарантировали бы достижение риска, близкого к минимальному. Построению и обоснованию таких алгоритмов посвящена эта книга. Однако при формулировке цели исследования была по существу подменена задача. В самом деле, нашей
исходной целью было восстановление функциональных зависимостей. В §§ 2, 3, 4 было показано, что функция, доставляющая точный минимум соответствующему функционалу среднего риска, определяет искомую зависимость. С другой стороны, найти точный минимум по выборке фиксированного объема — задача малореальная. Поэтому-то и предлагалось искать функцию, доставляющую среднему риску значение, близкое к минимальному.
Однако ниоткуда не следует, что близким значениям функционала будут соответствовать близкие функции. Отыскание значения функционала, близкого к минимальному, и функции, близкой к искомой, вообще говоря, — задачи разные. Поэтому, прежде чем решать задачу восстановления функциональной зависимости по эмпирическим данным методом минимизации среднего риска, необходимо выяснить, приведет ли такая подмена задач к успеху, т. е. гарантирует ли близость функционалов близость функций.
Для того чтобы начать исследование в этом направлении, надо прежде всего договориться о том, как мы будем понимать близость функций. В отличие от близости функционалов, которая определяется естественным образом как расстояние между двумя точками числовой оси (значениями этих функционалов), близость функций должна быть определена как расстояние между двумя элементами функционального пространства.
В функциональном анализе приняты различные способы метризации (введения понятия расстояния). Мы же будем использовать два таких понятия (две метрики): среднеквадратичное уклонение с весом и равномерное уклонение. Расстояние между двумя функциями  в смысле среднеквадратичного уклонения с весом
в смысле среднеквадратичного уклонения с весом  (метрика
(метрика  определяется функционалом
определяется функционалом

где  неотрицательная функция, такая, что
неотрицательная функция, такая, что  Расстояние же в смысле равномерного уклонения (метрика С) определяется функционалом
Расстояние же в смысле равномерного уклонения (метрика С) определяется функционалом

Таким образом, две функции близки в метрике  если
если

и близки в метрике С, если

Заметим, что требование равномерной близости (1.17) является более сильным, чем среднеквадратичной. Из выполнения неравенства (1.17) следует выполнение неравенства (1.16). Обратное утверждение, вообще говоря, неверно.
Итак, будем использовать понятия близости в следующих смыслах:
1) близость качества функций (значений функционалов),
2) близость функций в метрике 
3) близость функций в метрике С.
Выбор понятия близости определяется не формальной, а содержательной постановкой задачи.
Как же задается близость в различных задачах восстановления зависимостей?
В задаче распознавания образов требуется в заданном классе характеристических функций найти такую, которая минимизирует вероятность ошибочной классификации (т. е. по постановке требуется минимизировать функционал). Поэтому здесь естественно считать две функции близкими, если их качества близки; здесь близость определяется близостью функционалов.
При восстановлении регрессии проблема состоит не в том, чтобы минимизировать функционал, а в том, чтобы найти функцию, близкую к регрессии. В этой задаче близость определяется с помощью метрики  или метрики С в зависимости от того, как в дальнейшем предполагается использовать восстановленную функцию.
или метрики С в зависимости от того, как в дальнейшем предполагается использовать восстановленную функцию.
Пусть, например, решается задача восстановления регрессии  в схеме интерпретации прямых экспериментов. Восстановленную зависимость
в схеме интерпретации прямых экспериментов. Восстановленную зависимость  а при этом предполагается использовать для целей прогноза величины у в зависимости от ситуации
а при этом предполагается использовать для целей прогноза величины у в зависимости от ситуации  Точность прогноза для всякой фиксированной ситуации х естественно измерять величиной
Точность прогноза для всякой фиксированной ситуации х естественно измерять величиной

Точность прогноза в целом с помощью восстановленной функции часто измеряют как среднюю точность по мере множества х, т. е. величиной

или, иначе говоря, в этом случае близость определяется метрикой 
Однако существуют задачи, где близость в метрике  недостаточна.
недостаточна.

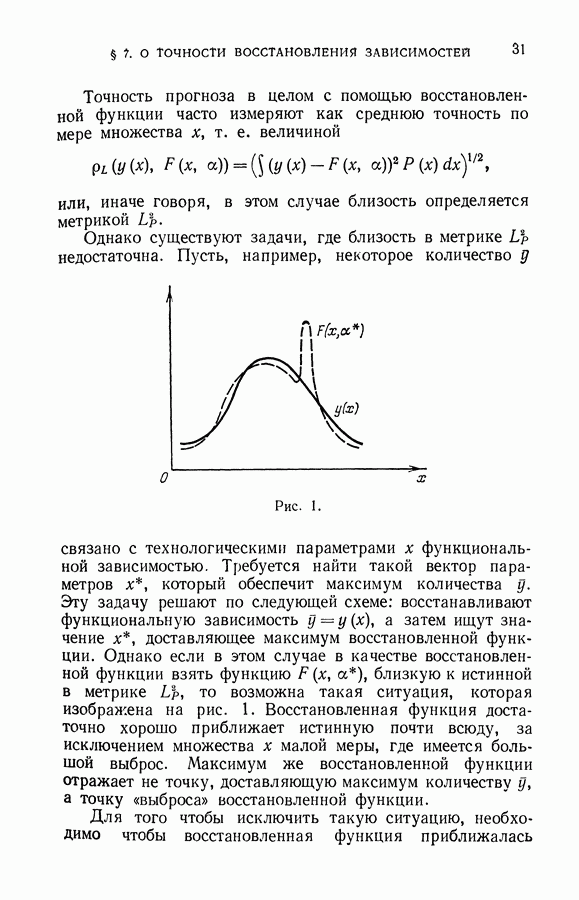
Рис. 1.
Пусть, например, некоторое количество у связано с технологическими параметрами х функциональной зависимостью. Требуется найти такой вектор параметров х, который обеспечит максимум количества у. Эту задачу решают по следующей схеме: восстанавливают функциональную зависимость  а затем ищут значение х, доставляющее максимум восстановленной функции. Однако если в этом случае в качестве восстановленной функции взять функцию
а затем ищут значение х, доставляющее максимум восстановленной функции. Однако если в этом случае в качестве восстановленной функции взять функцию  а, близкую к истинной в метрике
а, близкую к истинной в метрике  то возможна такая ситуация, которая изображена на рис. 1. Восстановленная функция достаточно хорошо приближает истинную почти всюду, за исключением множества х малой меры, где имеется большой выброс. Максимум же восстановленной функции отражает не точку, доставляющую максимум количеству у, а точку «выброса» восстановленной функции.
то возможна такая ситуация, которая изображена на рис. 1. Восстановленная функция достаточно хорошо приближает истинную почти всюду, за исключением множества х малой меры, где имеется большой выброс. Максимум же восстановленной функции отражает не точку, доставляющую максимум количеству у, а точку «выброса» восстановленной функции.
Для того чтобы исключить такую ситуацию, необходимо чтобы восстановленная функция приближалась
к истинной равномерно во всей области задания функции, т. е. в метрике С

Таким образом, в задаче восстановления регрессии используется понятие близость как в метрике  так и в метрике С.
так и в метрике С.
В задаче интерпретации данных косвенного эксперимента также используются два понятия близости: близость в метрике  с весом
с весом 

и близость в метрике С:

Как и при восстановлении регрессии, здесь выбор метрики определяется тем, как в дальнейшем предполагается использовать восстановленную функцию.