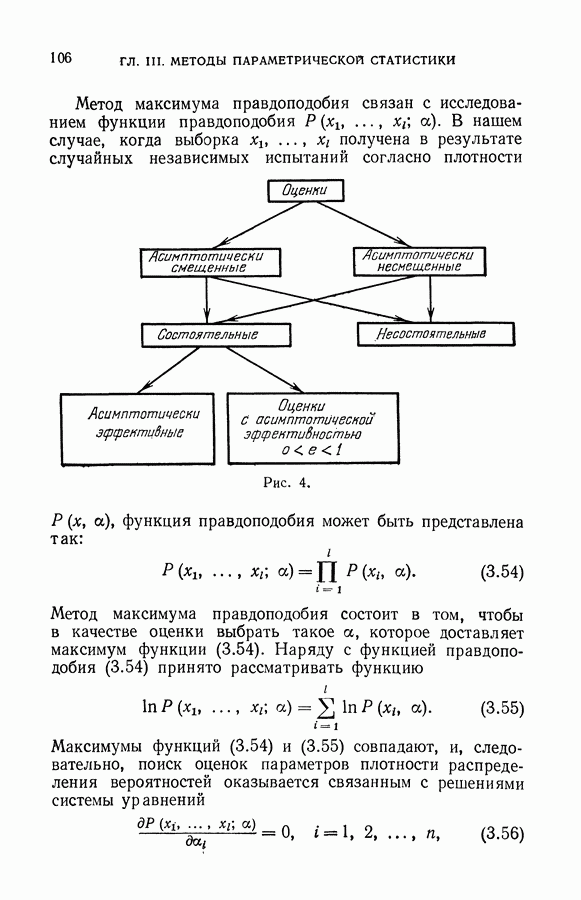
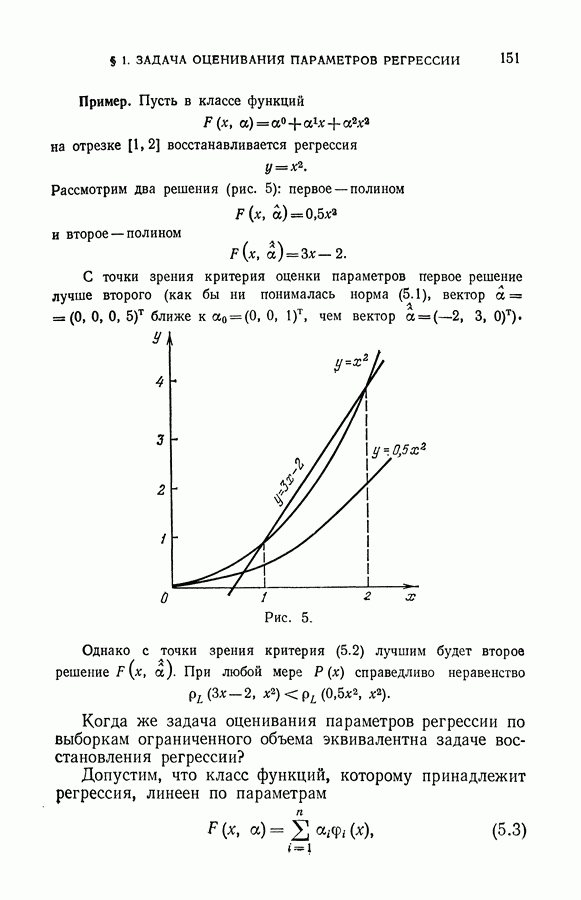
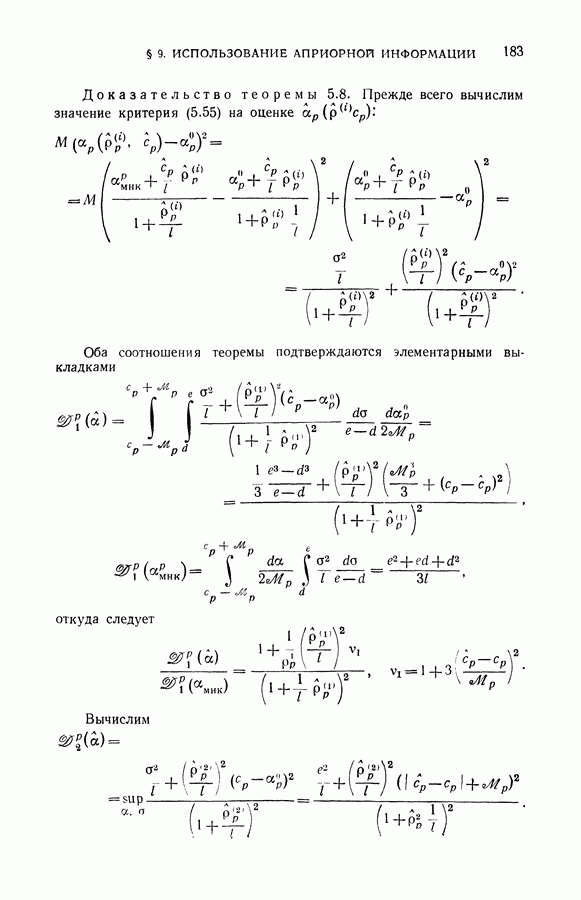
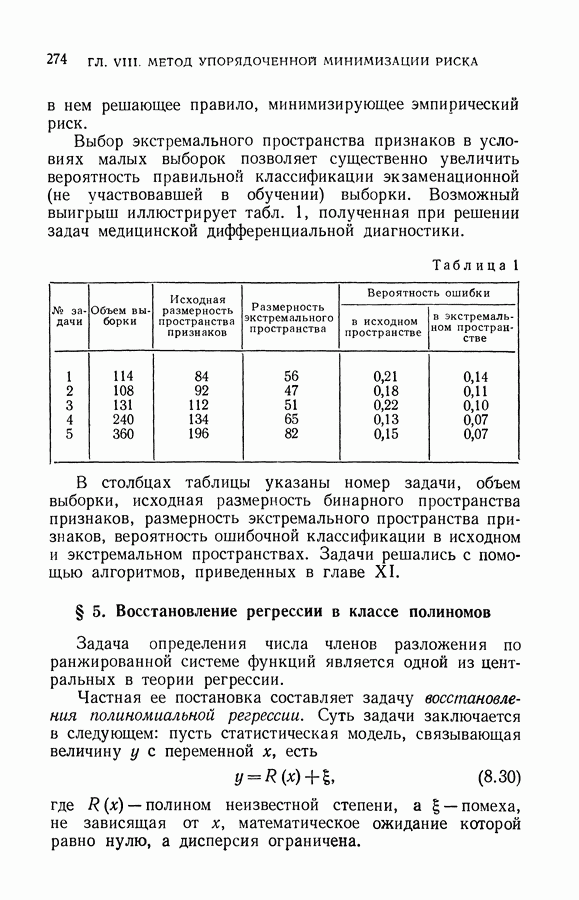
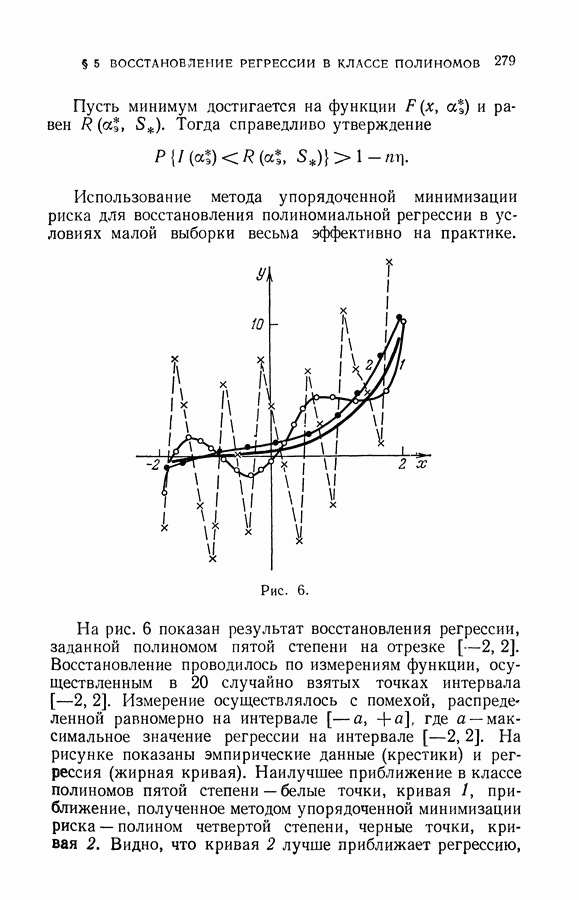
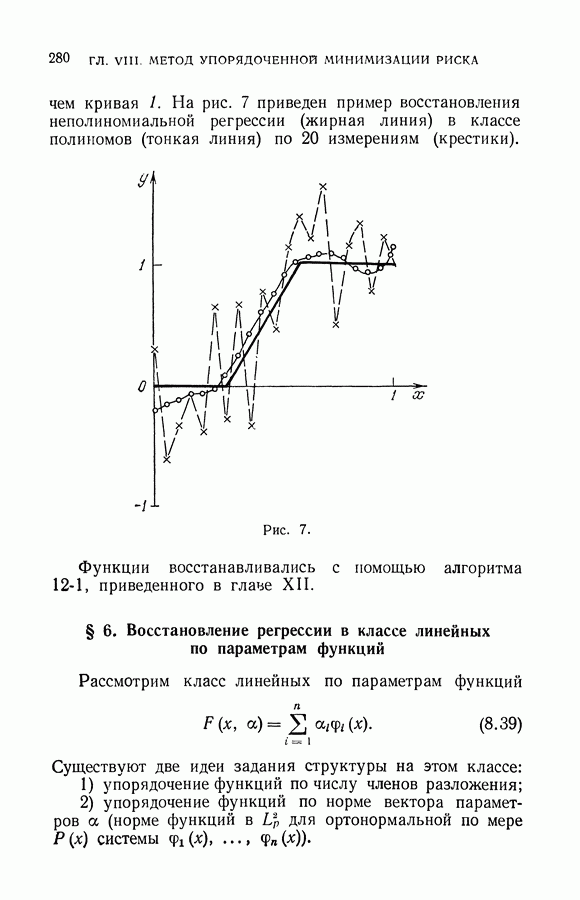
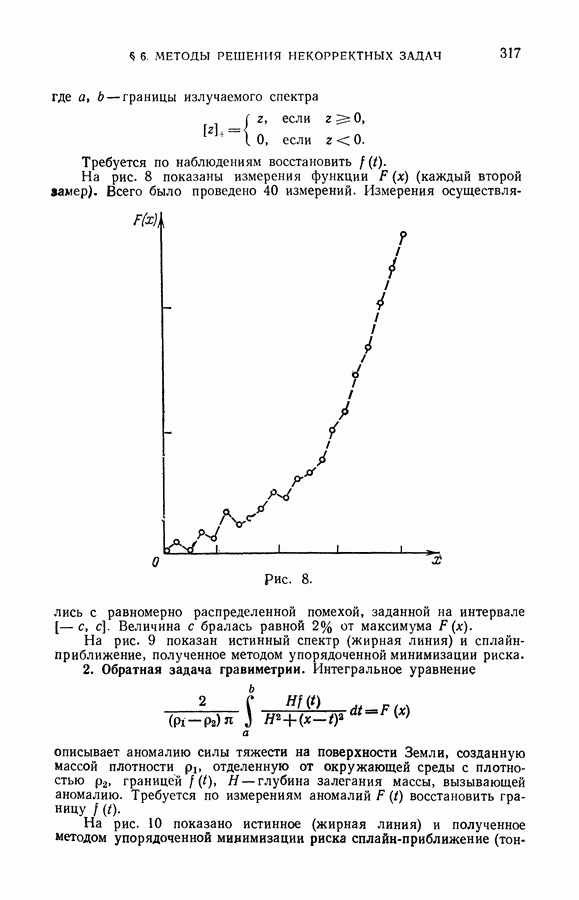
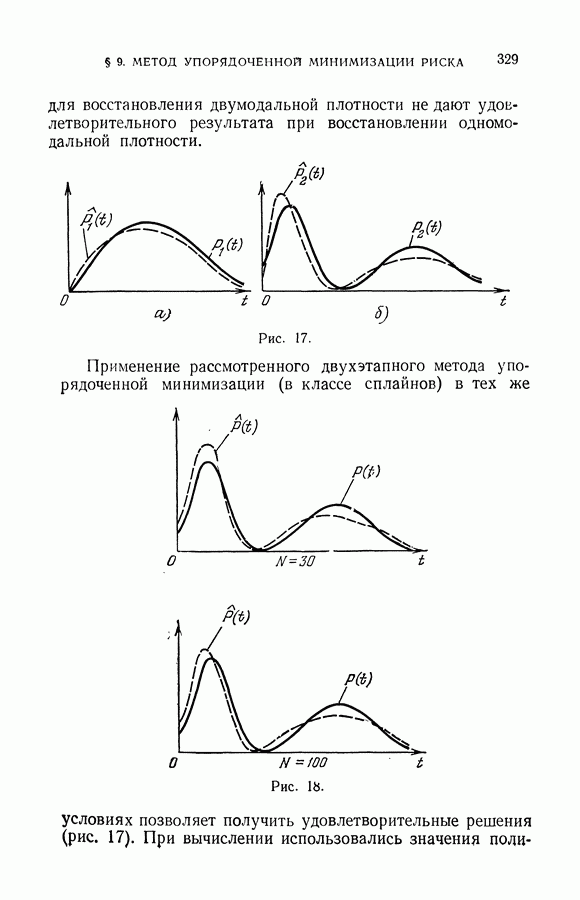
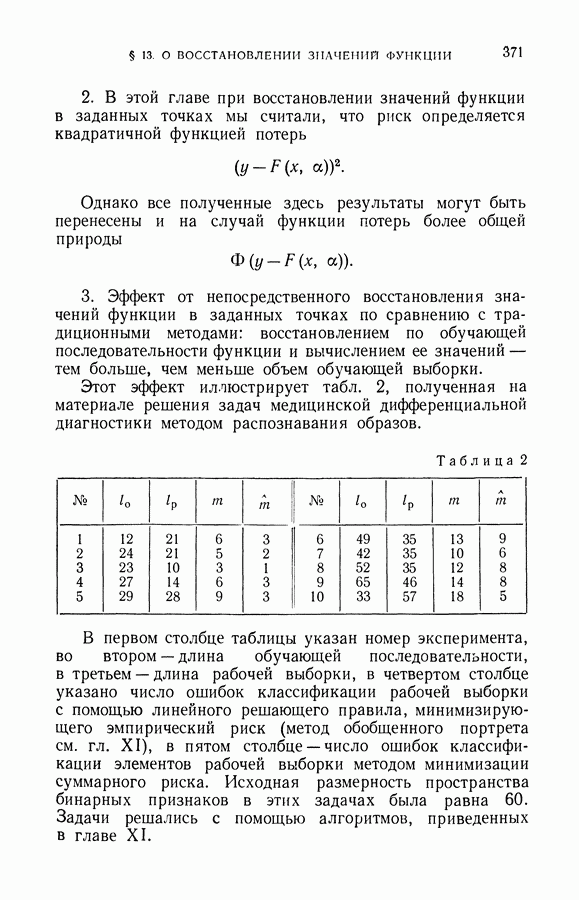
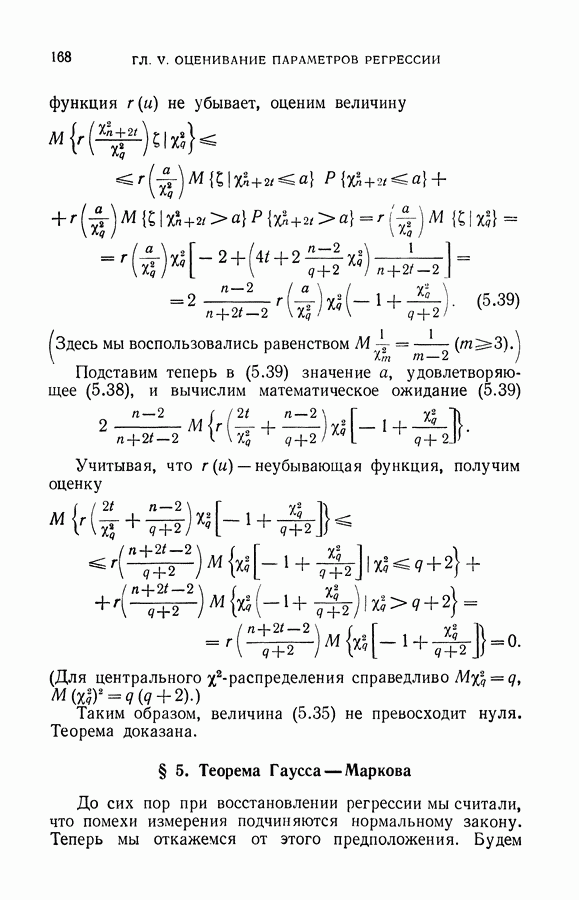§ 2. Равномерная сходимость частот появления событий к их вероятностям
Рассмотрим функционал, минимизация которого составляет суть задачи обучения распознаванию образов:

Как уже указывалось, этот функционал для каждого решающего правила определяет вероятность ошибочной классификации. Эмпирический функционал

вычисленный по обучающей последовательности

для каждого решающего правила определяет частоту неправильной классификации.
Согласно классическим теоремам теории вероятностей частота появления любого события сходится к вероятности этого события при неограниченном увеличении числа испытаний. Формально это означает, что для любых фиксированных а и х имеет место соотношение

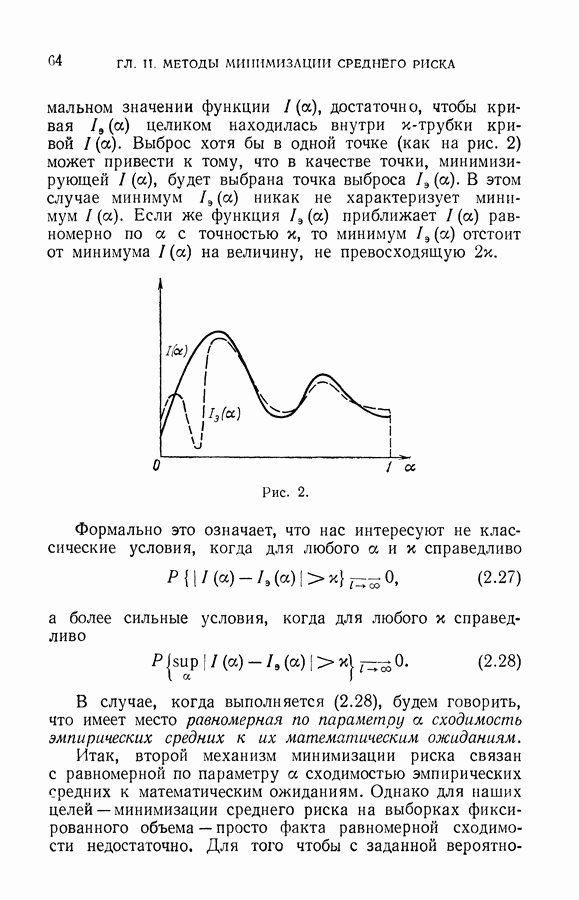
Однако (см. гл. II, § 6) из условия (6.13) не следует, что правило, минимизирующее (6.11), будет доставлять функционалу (6.10) значение, близкое к минимальному. Для
достаточно больших I близость найденного решения к наилучшему следует из более сильного условия, когда для любого х выполняется равенство

В этом случае говорят, что имеет место равномерная сходимость частот появления событий к их вероятностям по классу событий  Каждое событие S (а в классе
Каждое событие S (а в классе  задается решающим правилом
задается решающим правилом  а как множество пар
а как множество пар  на которых выполняется равенство
на которых выполняется равенство 
Ниже мы приведем условия, обеспечивающие равномерную сходимость частот появления событий к их вероятностям, и тем самым укажем область применимости метода минимизации эмпирического риска.
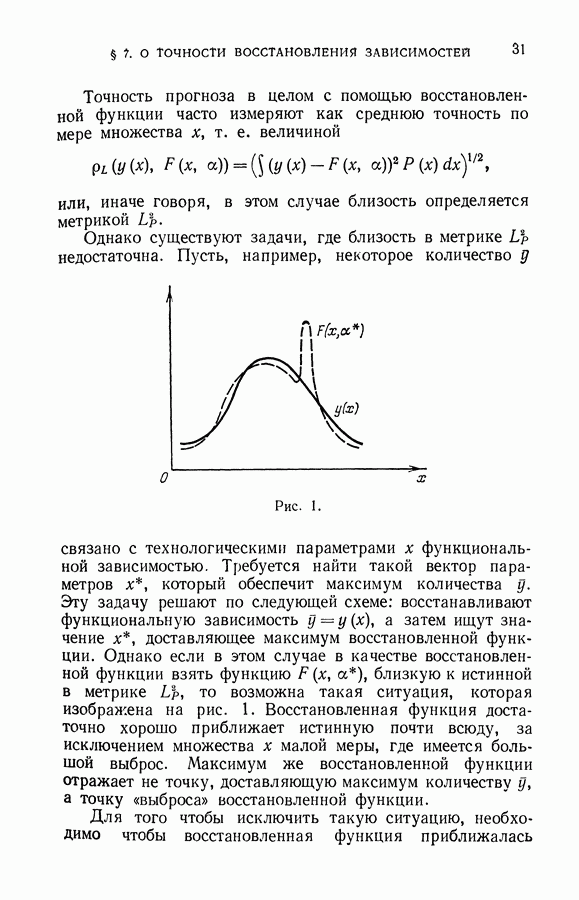
Однако прежде заметим, что применение метода минимизации эмпирического риска само по себе не гарантирует успеха при решении задачи восстановления зависимостей.
Вот пример алгоритма обучения распознаванию образов, который минимизирует эмпирический риск и вместе с тем не способен обучаться (т. е. для которого нельзя гарантировать, что построенное решающее правило близко к наилучшему в классе). Алгоритм заключается в следующем. Запоминаются элементы обучающей последовательности, и каждая ситуация, предъявленная для распознавания, сравнивается с примерами, хранящимися в памяти. Если предъявленная ситуация совпадает с одним из примеров, то она будет отнесена к тому классу, к которому принадлежит пример. Если же в памяти нет аналогичного примера, то ситуацию относят к первому классу. Понятно, что подобное устройство ничему научиться не может, так как обучающую последовательность обычно составляет лишь ничтожная доля ситуаций, которые могут возникнуть при контроле. А вместе с тем такое устройство классифицирует элементы обучающей последовательности безошибочно, т. е. его алгоритм минимизирует (вплоть до нуля) эмпирический риск.
В дальнейшем мы убедимся, что этот алгоритм использует множество решающих правил, образующих систему событий, по которой нет равномерной сходимости.