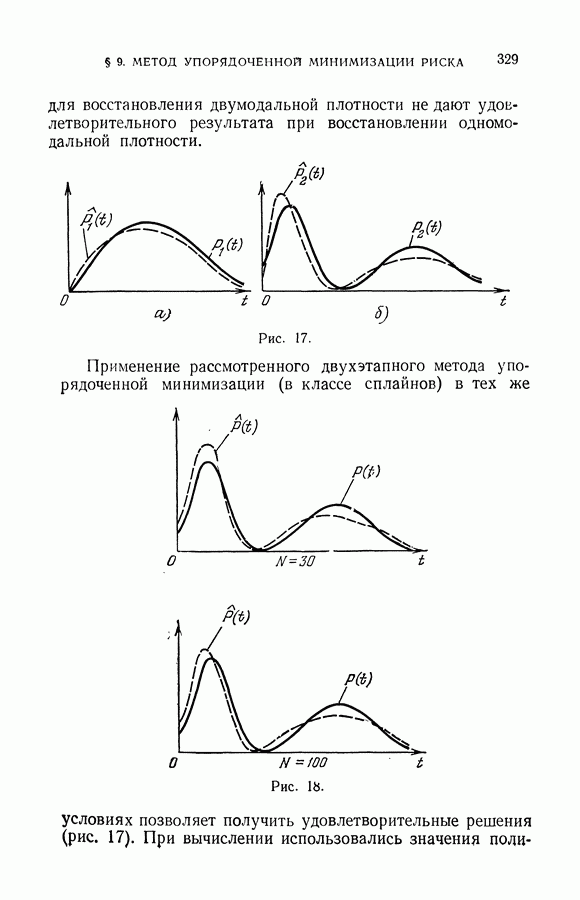
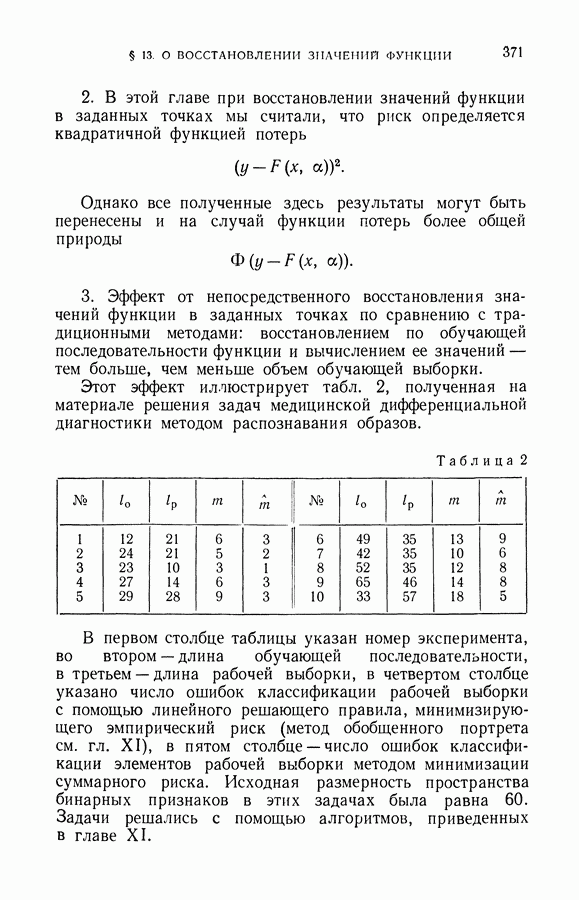
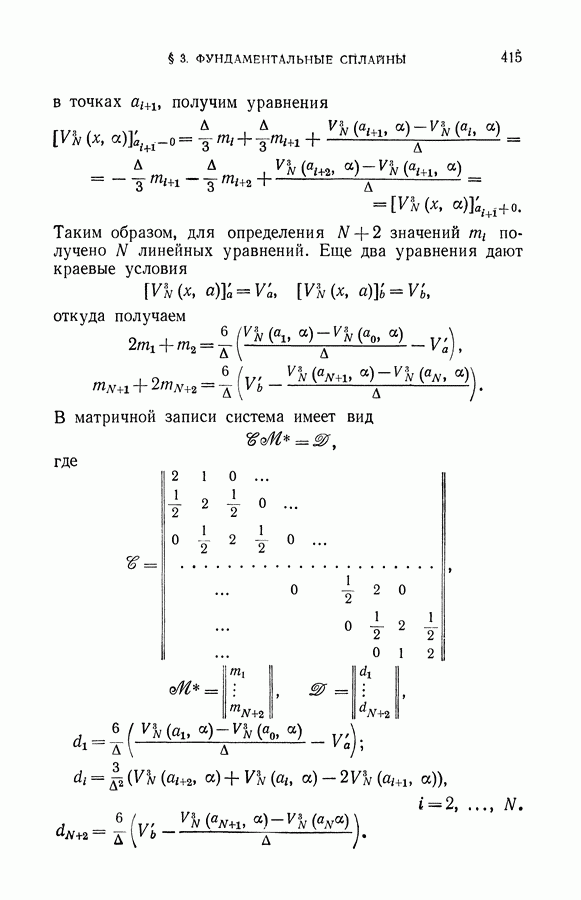
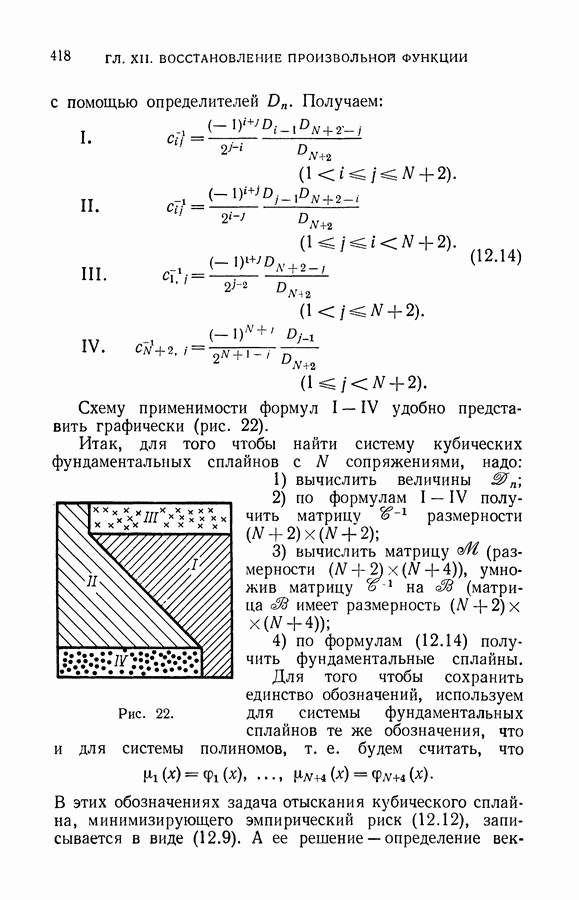
§ 9. Алгоритмы восстановления значений функции в классе линейных решающих правил
Рассмотрим алгоритмы восстановления значений функции в классе линейных решающих правил. Согласно постановке этой задачи наряду с обучающей последовательностью

задается рабочая выборка

Требуется с помощью линейного решающего правила  так индексировать точки рабочей выборки, чтобы минимизировать число ошибок классификации.
так индексировать точки рабочей выборки, чтобы минимизировать число ошибок классификации.
Рассмотрим сначала частную постановку. Будем считать, что индексация точек рабочей выборки должна быть проведена с помощью линейного решающего правила,
которое безошибочно делит векторы обучающей последовательности.
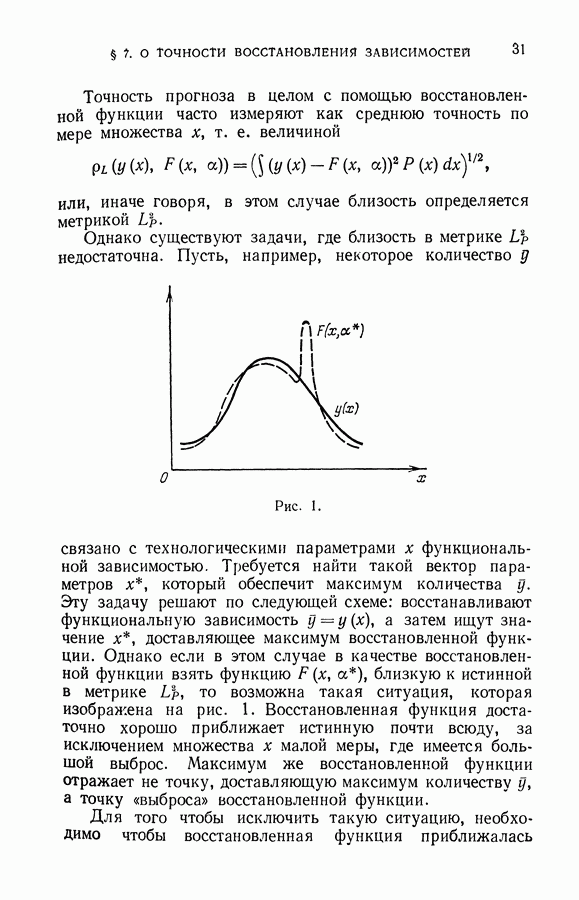
Решение этой частной задачи состоит в том, чтобы так индексировать точки рабочей выборки первым и вторым классом, чтобы расстояние между выпуклыми оболочками множества векторов обучающей и рабочей выборок первого класса и множества векторов обучающей и рабочей выборок второго класса было максимальным.
Принципиально эта задача решается так. Существует  различных способов индексации рабочей выборки длины
различных способов индексации рабочей выборки длины  Для каждого способа индексации с помощью алгоритма 11-1 может быть определено расстояние между выпуклыми оболочками векторов различных классов. С помощью алгоритма 11-1 будет найдена оптимальная разделяющая гиперплоскость и с ее помощью вычислена величина
Для каждого способа индексации с помощью алгоритма 11-1 может быть определено расстояние между выпуклыми оболочками векторов различных классов. С помощью алгоритма 11-1 будет найдена оптимальная разделяющая гиперплоскость и с ее помощью вычислена величина  либо будет установлено, что разделяющей гиперплоскости не существует, т. е.
либо будет установлено, что разделяющей гиперплоскости не существует, т. е. 
Перебором по всем способам индексаций может быть найдена такая индексация, при которой достигает максимума расстояние между выпуклыми оболочками векторов первого и второго класса.
Такая схема решения задачи опирается на полный перебор всех вариантов индексации векторов рабочей выборки. Для очень малых длин рабочей выборки  этот путь допустим. Однако уже при объеме выборки
этот путь допустим. Однако уже при объеме выборки  перебор становится настолько большим, что реализация его оказывается невозможной. В этом случае приходится применять методы, направленные на сокращение перебора.
перебор становится настолько большим, что реализация его оказывается невозможной. В этом случае приходится применять методы, направленные на сокращение перебора.
Выше при выборе информативного пространства признаков для сокращения перебора мы пользовались эвристическим методом последовательного улучшения оценки. Этот же принцип можно использовать и для отыскания наилучшего варианта индексации векторов рабочей выборки. Идею последовательного улучшения оценок при индексации векторов рабочей выборки реализует алгоритм 11-5.
Реализуется следующая последовательность действий:
1) По элементам обучающей последовательности строится оптимальная разделяющая гиперплоскость.
2) Точки рабочей выборки индексируются в соответствии с положением относительно этой гиперплоскости.
3) Строится оптимальная гиперплоскость, разделяющая всю выборку, в которой точки рабочей выборки взяты с индексацией, полученной в п. 2).
4) Поочередно меняется индексация точек рабочей выборки и выясняется, для какой из точек произойдет наибольшее увеличение 
5) Если для найденной точки  такое увеличение положительно, то перейдем к новой индексации, в которой изменено значение
такое увеличение положительно, то перейдем к новой индексации, в которой изменено значение  и снова будем действовать в соответствии с
и снова будем действовать в соответствии с  . Если же любое изменение индексации не приводит к увеличению
. Если же любое изменение индексации не приводит к увеличению  то считается, что оптимальная индексация найдена. Более глубокий минимум может быть достигнут с помощью методов сокращения полного перебора (например, метода ветвей и границ [29, 97]).
то считается, что оптимальная индексация найдена. Более глубокий минимум может быть достигнут с помощью методов сокращения полного перебора (например, метода ветвей и границ [29, 97]).
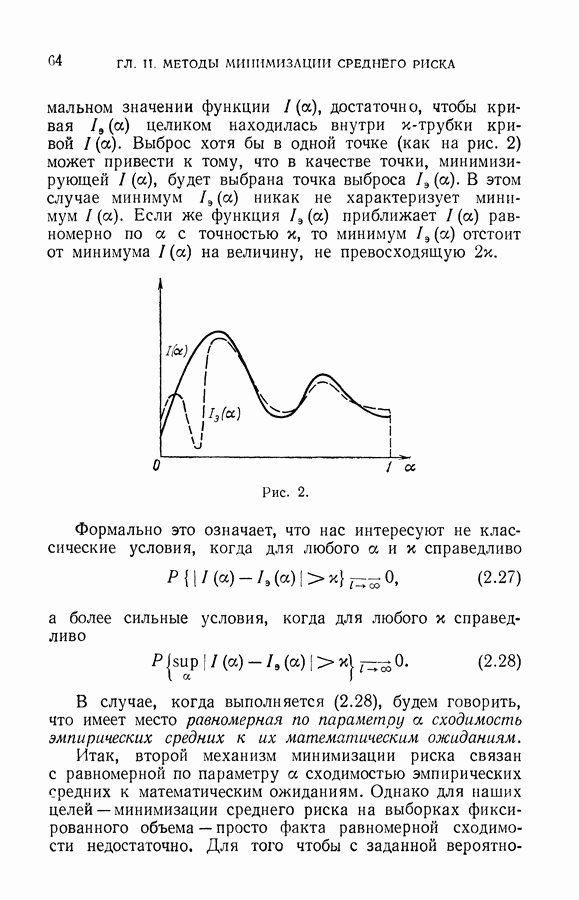
При проведении индексации векторов рабочей выборки дальнейшее уменьшение числа ошибок классификации с помощью линейных решающих правил может быть достигнуто за счет селекции выборки и отыскания информативного пространства признаков.
Алгоритм 11-6 минимизирует в классе линейных решающих правил, безошибочно делящих обучающую выборку, функционал

где  наименьшее решение неравенства
наименьшее решение неравенства

 — общее число исключенных векторов,
— общее число исключенных векторов,  число исключенных векторов обучающей выборки,
число исключенных векторов обучающей выборки,  число исключенных векторов рабочей выборки,
число исключенных векторов рабочей выборки,

В (11.38) расстояние между выпуклыми оболочками  определяется для множества векторов, из которого исключено
определяется для множества векторов, из которого исключено  элементов, за величину
элементов, за величину  принимается диаметр этого множества.
принимается диаметр этого множества.
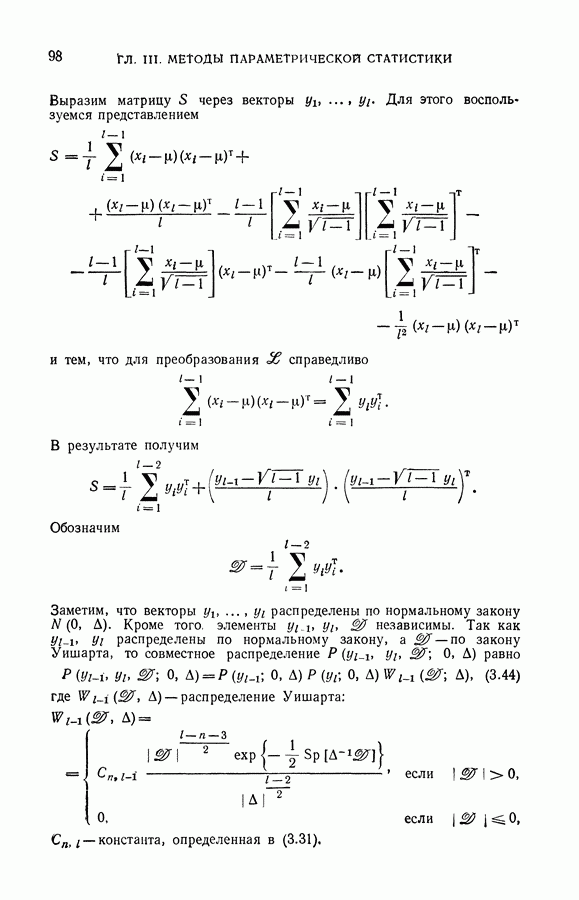
Требуется исключить такое число векторов  и так индексировать оставшиеся векторы рабочей выборки, чтобы векторы первого и второго классов были разделимы гиперплоскостью и, кроме того, достигался минимум функционала (11.36).
и так индексировать оставшиеся векторы рабочей выборки, чтобы векторы первого и второго классов были разделимы гиперплоскостью и, кроме того, достигался минимум функционала (11.36).
Как обычно в подобных случаях, отыскание точного минимума функционала требует полного перебора по всем способам индексации и всем возможным способам исключения векторов. Поэтому при поиске минимума (11.36) используется метод последовательного уменьшения значения (11.36).
Сначала отыскивается наилучшее решение на всех элементах обучающей и рабочей выборки, а затем делается попытка максимально улучшить полученную оценку, исключив один элемент. Если такая попытка оказывается удачной, то предпринимается попытка уменьшить (11.36), исключив еще один элемент, и т. д.
Процесс исключения векторов продолжается до тех пор, пока в результате его уменьшается величина оценки (11.36).