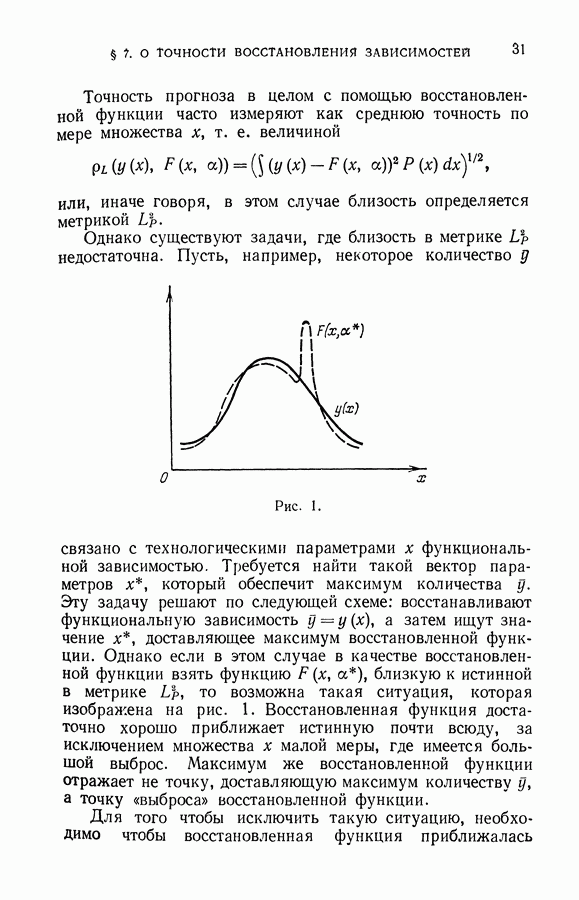
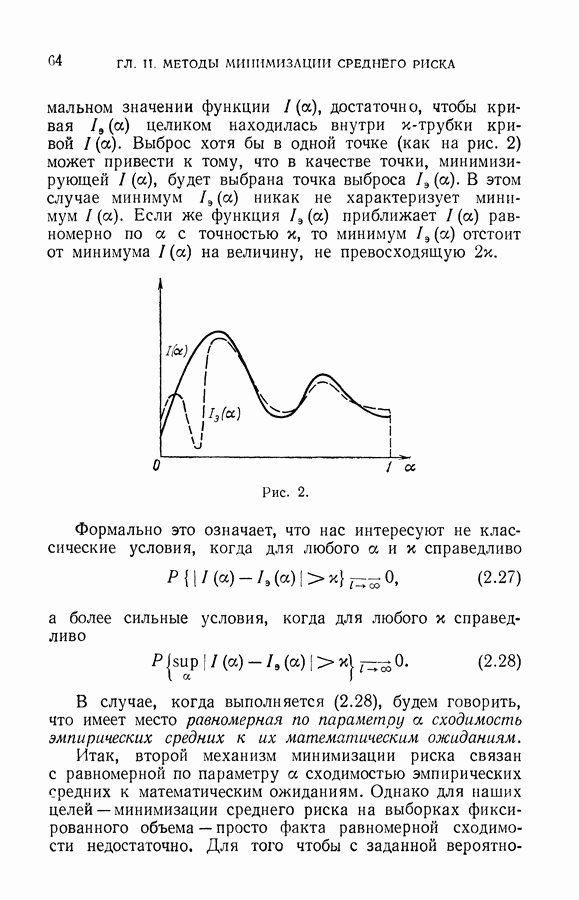
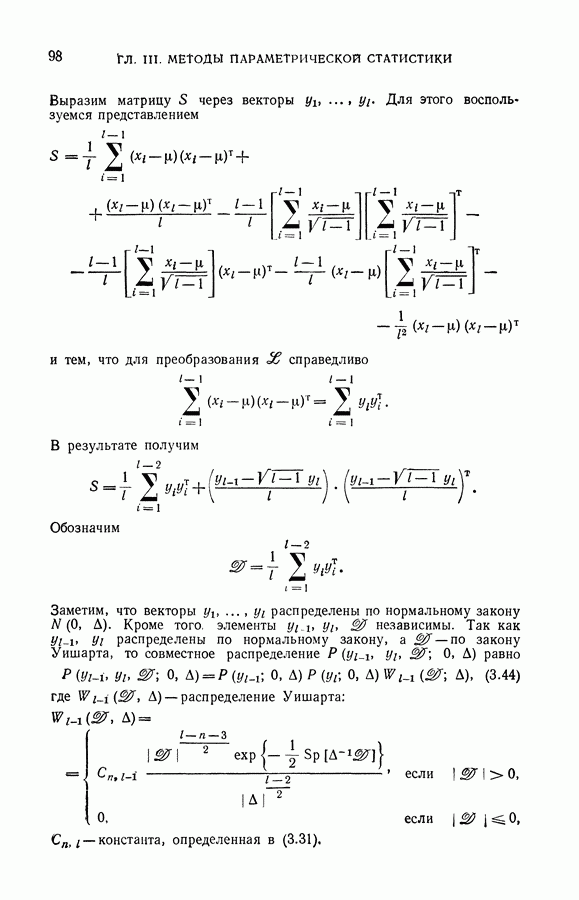
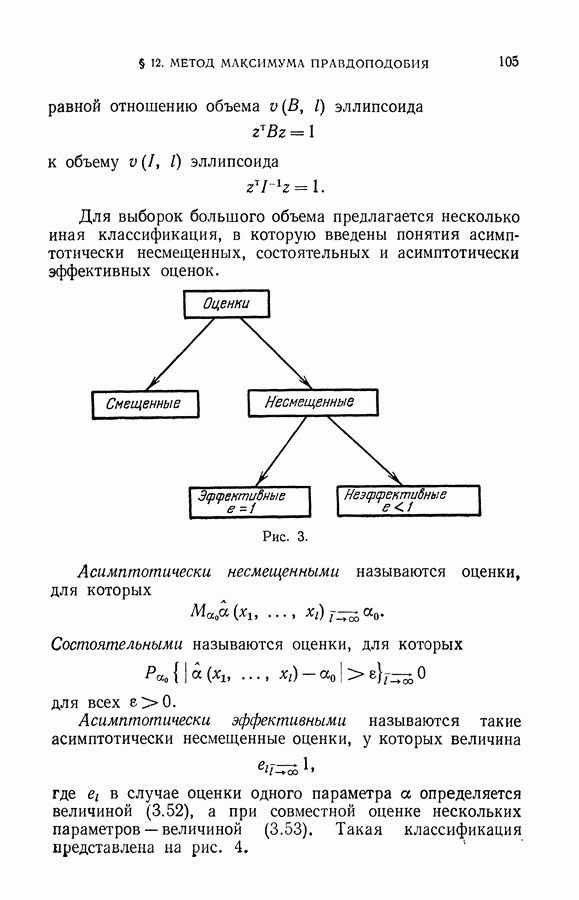
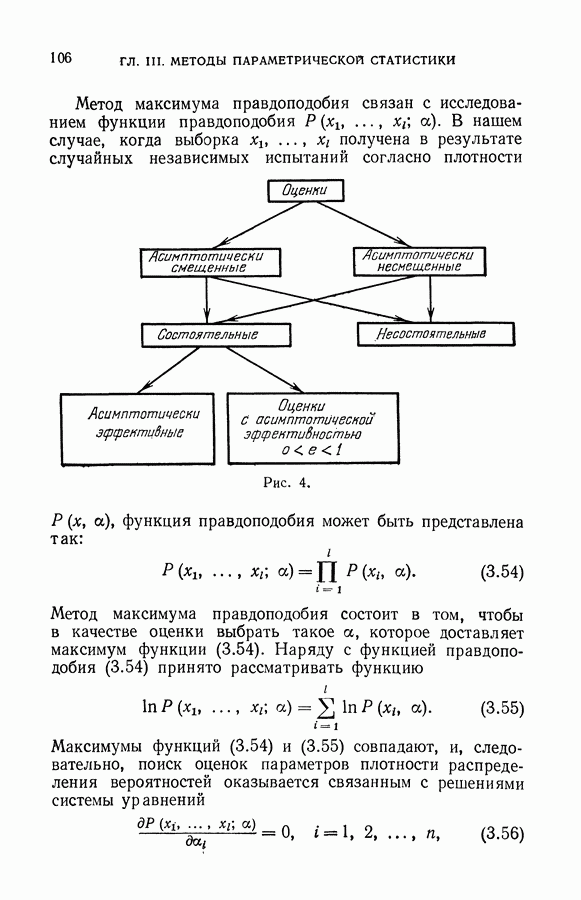
§ 2. Задача дискриминантного анализа
Итак, пусть требуется найти минимум функционала (3.3) для заданной плотности распределения вероятностей (заданных состава объединения  и пропорции объединения
и пропорции объединения 
Рассмотрим сначала простой случай: класс возможных решающих правил  никак не ограничен. В этой ситуации легко может быть построено решающее правило, минимизирующее функционал (3.3).
никак не ограничен. В этой ситуации легко может быть построено решающее правило, минимизирующее функционал (3.3).
В самом деле, согласно формуле Байеса вероятность того, что вектор х принадлежит первому (второму) классу, определяется так:

Минимальные потери (минимум вероятности ошибки) будут получены при такой классификации, при которой вектор х относят к первому классу, если более вероятной оказывается его принадлежность к первому классу, чем ко второму, т. е. если

В противном случае вектор х относят ко второму классу.
Иначе говоря, учитывая (3.6), вектор х должен быть отнесен к первому классу, если выполнится неравенство

или, что то же самое, оптимальная классификация векторов осуществляется с помощью характеристической функции

где

Таким образом, знание плотности распределения вероятностей (состава и пропорции объединения (3.5))
позволяет немедленно построить оптимальное решающее правило.
Однако задача отыскания оптимального решающего правила значительно усложняется, если класс возможных решающих правил  ограничен. В частности, трудной оказывается задача отыскания оптимального линейного решающего правила, т. е. правила вида
ограничен. В частности, трудной оказывается задача отыскания оптимального линейного решающего правила, т. е. правила вида

Вектор  определяет направление линейной дискриминантной функции, а параметр
определяет направление линейной дискриминантной функции, а параметр  пороговое значение. Задача отыскания минимума (3.3) в классе (3.8) получила название задачи линейного дискриминантного анализа.
пороговое значение. Задача отыскания минимума (3.3) в классе (3.8) получила название задачи линейного дискриминантного анализа.
В 30-х годах Р. Фишер предложил в качестве направления линейной дискриминантной функции выбирать направление, на котором достигается максимум величины относительного расстояния между математическими ожиданиями проекций векторов различных классов, т. е. направление а, на котором достигается максимум величины

где

Отыскание максимума (3.9) для произвольных плотностей — задача чрезвычайно трудная. Поэтому основные исследования в области линейного дискриминантного анализа были направлены на то, чтобы установить для определенных типов плотностей, что, во-первых, линейная дискриминантная функция Фишера действительно определяет решение задачи линейного дискриминантного анализа, а во-вторых, найти алгоритмы вычисления дискриминантной функции. Основной результат здесь заключается в том, что для объединения двух нормальных законов

 вектор средних, — матрица ковариации для первого многомерного нормального закона;
вектор средних, — матрица ковариации для первого многомерного нормального закона;  — аналогичные элементы для второго закона), взятых в пропорции
— аналогичные элементы для второго закона), взятых в пропорции  оптимальная линейная дискриминантная функция задается вектором
оптимальная линейная дискриминантная функция задается вектором
направления

где  Значение
Значение  определяется из условия обращения в нуль так называемой резольвентной функции
определяется из условия обращения в нуль так называемой резольвентной функции

При  направление (3.10) линейной дискриминантной функции максимизирует функционал
направление (3.10) линейной дискриминантной функции максимизирует функционал

Вычисление нулей резольвентного уравнения (3.8) — задача достаточно трудная. Поэтому на практике при построении линейной дискриминантной функции полагают  Тем самым в качестве решения задачи принимается линейная дискриминантная функция Фишера. (Подробнее смотри
Тем самым в качестве решения задачи принимается линейная дискриминантная функция Фишера. (Подробнее смотри 
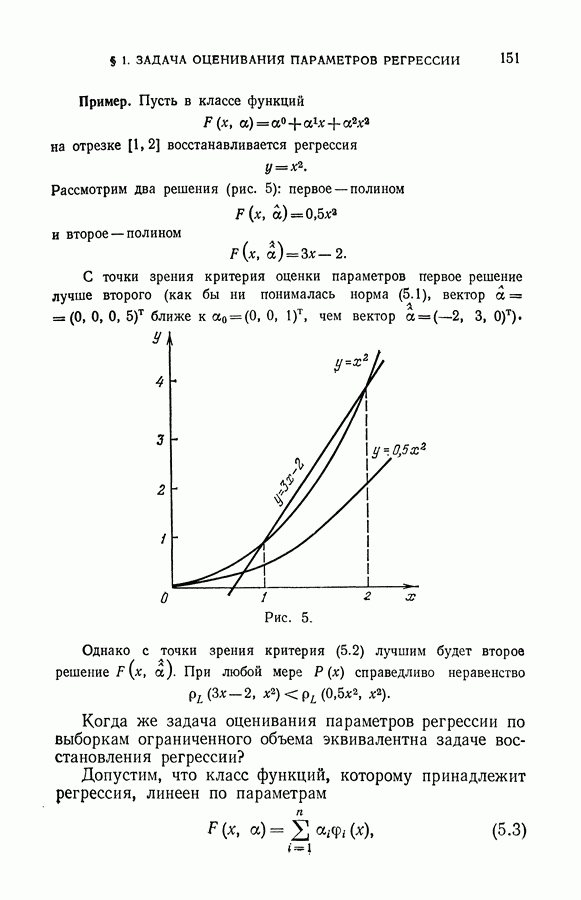
Таким образом, проблемы, которые возникают в дискриминантном анализе, связаны с тем, что класс возможных решающих правил, на котором ищется минимум функционала (3.3), ограничен. Поэтому может показаться, что задача дискриминантного анализа надумана. В самом деле, если уж удается восстановить плотность распределения вероятностей, то для чего отыскивать решающее правило, доставляющее функционалу условный минимум, когда легко можно найти решающее правило (см. (3.7)), доставляющее функционалу (3.3) абсолютный минимум?
Суть, однако, заключается в том, что если плотность восстанавливается неточно, то величина гарантированного уклонения минимума эмпирического функционала от минимума функционала среднего риска будет большей для функции, выбранной из более широкого класса. Поэтому может оказаться, что меньшее гарантированное значение среднего риска будет достигнуто не на функции, доставляющей абсолютный минимум эмпирическому функционалу, а на функции, принадлежащей более узкому классу и доставляющей условный минимум.
Такой результат связан с эффектом второго механизма минимизации среднего риска (см. § 4 гл. II). Идеи сужения класса решающих правил для получения меньшей гарантированной величины среднего риска будут реализованы ниже в главах VIII—IX. В этой же главе мы рассмотрим параметрические методы восстановления
плотностей. Согласно (3.7) знание плотности распределения вероятностей немедленно приводит к построению решающего правила, доставляющего абсолютный минимум (3.3).