§ 5. Алгоритм экстремального разбиения значений признака на градации
В задачах обучения распознаванию образов приняты два способа представления информации — непрерывный и дискретный.
При непрерывном способе представления информации координаты вектора х могут принимать любые значения. При дискретном способе каждая координата вектора принимает фиксированное число значений. Дискретным способом удобно кодировать качественные признаки. Например, следующие характеристики в задачах медицинской дифференциальной диагностики: «бледность кожных покровов не выражена», «выражена умеренно», «сильно выражена», могут иметь коды 
Однако в задачах обучения распознаванию образов принято дискретно кодировать не только признаки, отражающие качественную характеристику объекта, но и признаки, принимающие числовые значения.
При этом пользуются следующим способом представления информации. Весь диапазон значений параметра разбивается на ряд градаций. Единицей кодируется  разряд кода, если значение параметра принадлежит
разряд кода, если значение параметра принадлежит  градации, если же значение параметра не принадлежит
градации, если же значение параметра не принадлежит  градации, то в
градации, то в  разряде ставится нуль.
разряде ставится нуль.
Пример. Пусть значение параметра  принадлежит отрезку
принадлежит отрезку  и этот отрезок разбивается на пять градаций:
и этот отрезок разбивается на пять градаций:

Кодом 10 000 обозначаются величины  , кодом
, кодом  — величины
— величины  кодом 00100 — величины
кодом 00100 — величины  кодом 00010 — величины
кодом 00010 — величины  и, наконец, кодом
и, наконец, кодом  -величины
-величины 
Рассмотренный способ представления информации замечателен не только тем, что позволяет компактно записывать информацию (для приведенного примера вместо одной ячейки памяти в ЦВМ — пять разрядов ячейки).
Дискретизация координат вектора есть нелинейная операция, с помощью которой вектор х переводится в бинарный вектор х с большим числом координат.
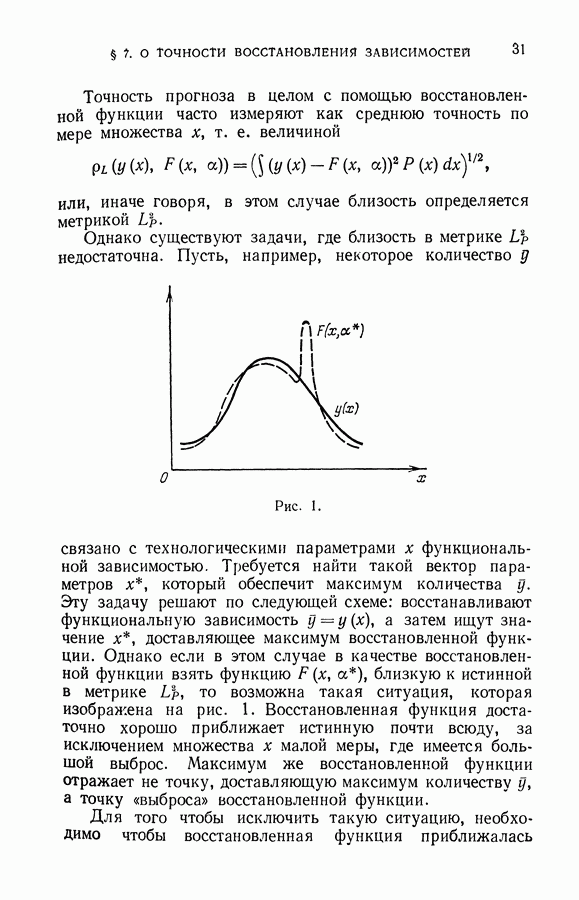
Использование большого числа градации при кодировке параметра эквивалентно использованию более разнообразного класса разделяющих поверхностей в пространстве  чем линейные. Однако, как было установлено в главе VIII, чрезмерно большая емкость класса решающих правил при ограниченном объеме обучающей последовательности недопустима, и поэтому возникает проблема экстремальной разбивки на градации непрерывных признаков.
чем линейные. Однако, как было установлено в главе VIII, чрезмерно большая емкость класса решающих правил при ограниченном объеме обучающей последовательности недопустима, и поэтому возникает проблема экстремальной разбивки на градации непрерывных признаков.
В этом параграфе будет приведен алгоритм экстремального разбиения значений признака на градации. Принцип, который реализует алгоритм, заключается в следующем: необходимо так разбить значения параметра на конечное число градаций, чтобы оценка неопределенности (энтропии) при классификации с помощью этого признака была минимальной (или близка к минимальной).
Итак, пусть признак (координата) х может принимать значения из интервала  и пусть вектор, обладающий этим признаком, принадлежит одному из К классов. Пусть существуют условные вероятности принадлежности к каждому классу
и пусть вектор, обладающий этим признаком, принадлежит одному из К классов. Пусть существуют условные вероятности принадлежности к каждому классу

Для каждого фиксированного значения признака х может быть определена мера неопределенности (энтропия) принадлежности к тому или иному классу

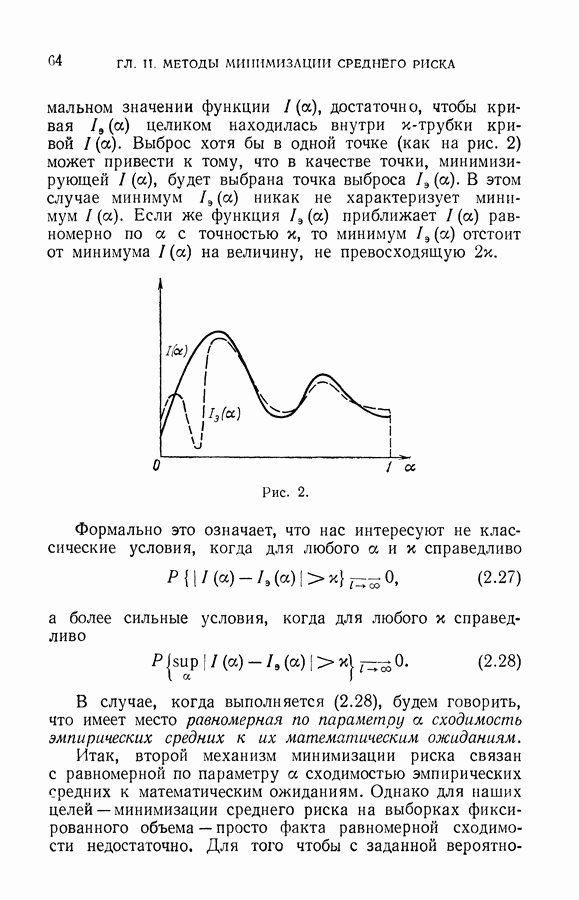
Среднее значение по мере  энтропии вычисляется так:
энтропии вычисляется так:

Пусть теперь параметр х разбит на  градаций, т. е. принимает одно из
градаций, т. е. принимает одно из  значений
значений  Тогда средняя энтропия может быть записана в виде
Тогда средняя энтропия может быть записана в виде


























































































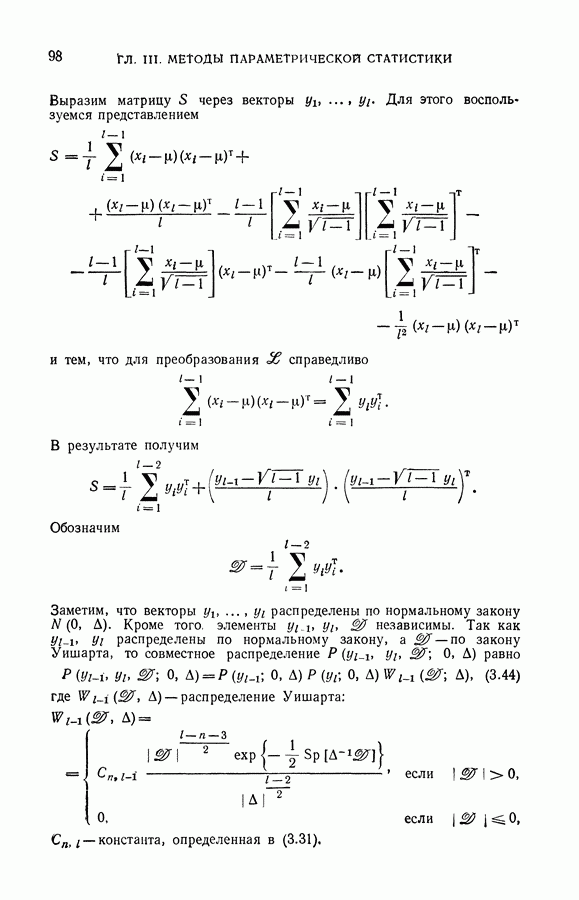






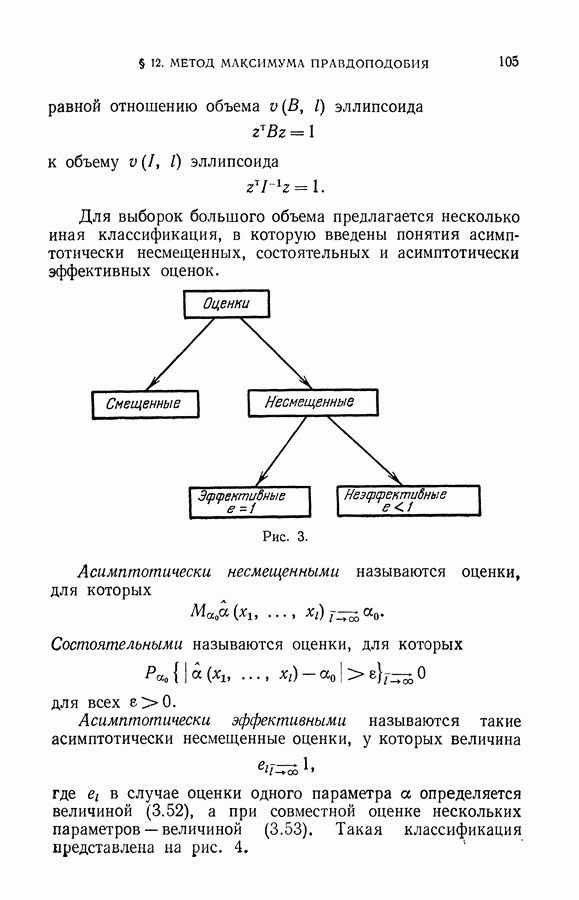








































































































































































































































































































































 по обучающей последовательности. Воспользуемся байесовыми оценками (см. § 6 гл. III):
по обучающей последовательности. Воспользуемся байесовыми оценками (см. § 6 гл. III):

 число элементов
число элементов  класса в обучающей выборке,
класса в обучающей выборке,  число векторов
число векторов  класса, у которых
класса, у которых  длина выборки.
длина выборки.
 Алгоритм удобно реализовать в следующей форме: сначала разбить интервал на достаточно большое число градаций, а затем, «склеивая» соседние градации (и тем самым уменьшая число градаций
Алгоритм удобно реализовать в следующей форме: сначала разбить интервал на достаточно большое число градаций, а затем, «склеивая» соседние градации (и тем самым уменьшая число градаций  добиться минимизации
добиться минимизации  по
по  Для этого сначала склеивают такую пару соседних градаций, чтобы величина
Для этого сначала склеивают такую пару соседних градаций, чтобы величина  уменьшилась на наибольшую величину. Затем среди оставшихся
уменьшилась на наибольшую величину. Затем среди оставшихся  градации «склеивают» две соседние, чтобы минимизировать
градации «склеивают» две соседние, чтобы минимизировать  и т. д. Пусть минимум достигается при разбивке на
и т. д. Пусть минимум достигается при разбивке на  градаций.
градаций.
 которые доставляют сведения о значениях параметра
которые доставляют сведения о значениях параметра


 функции
функции  но лишь до тех пор, пока величина
но лишь до тех пор, пока величина  не уменьшится в
не уменьшится в  раз (
раз ( — параметр алгоритма, обычно
— параметр алгоритма, обычно  ).
).
