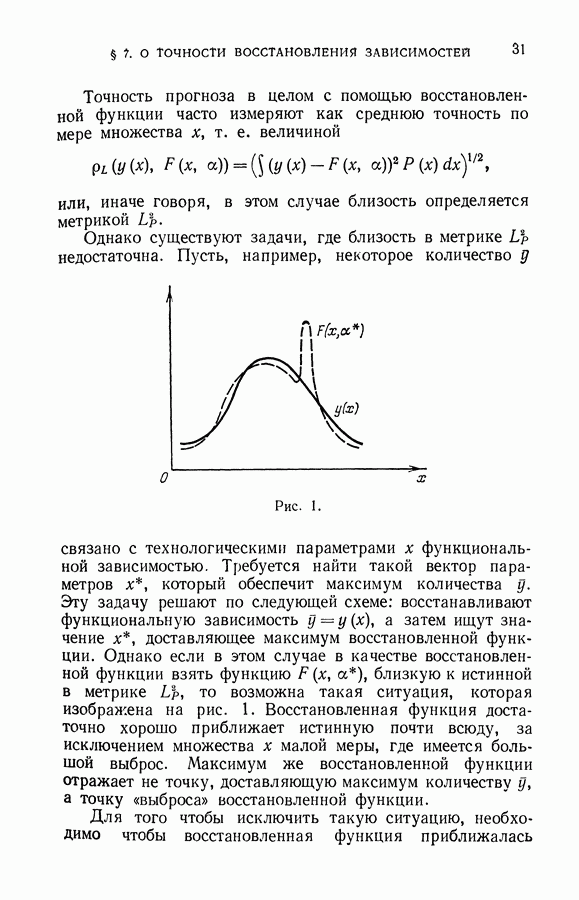
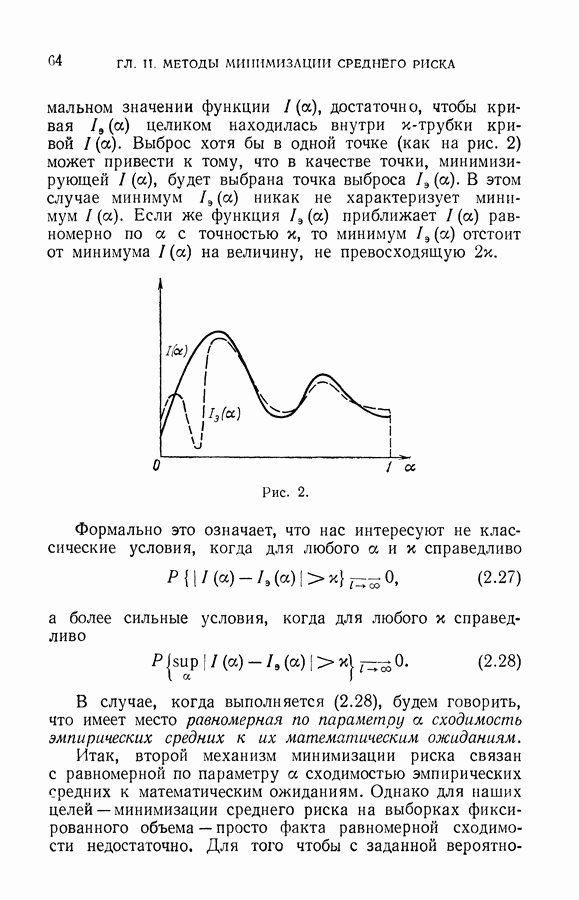
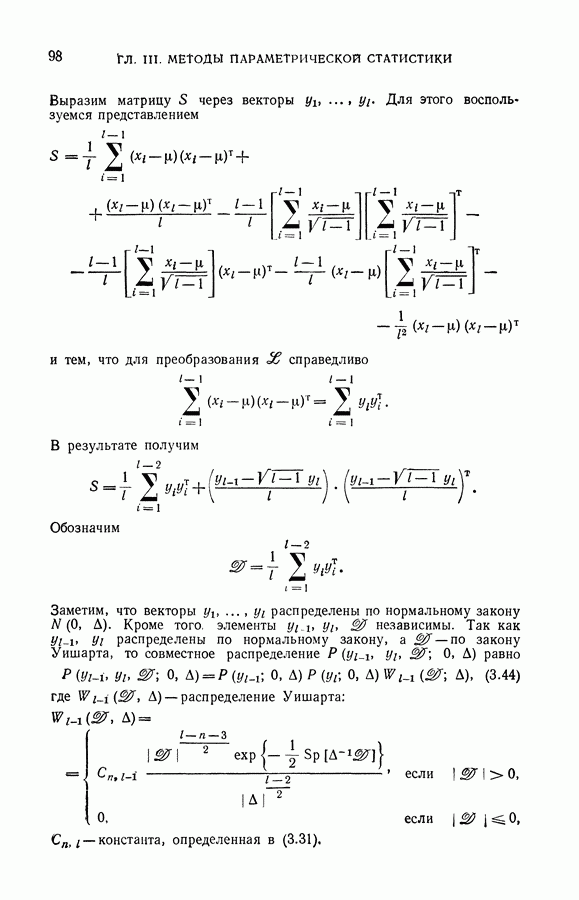
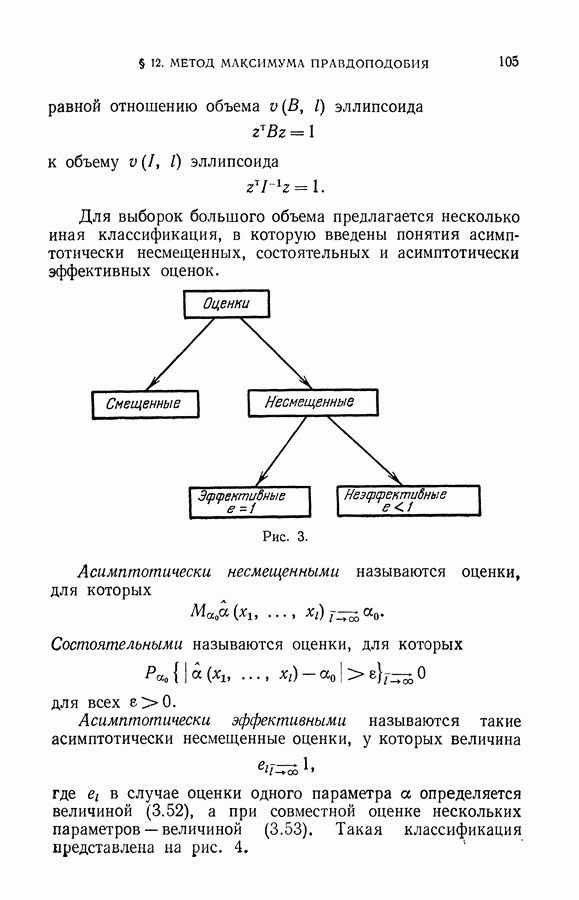
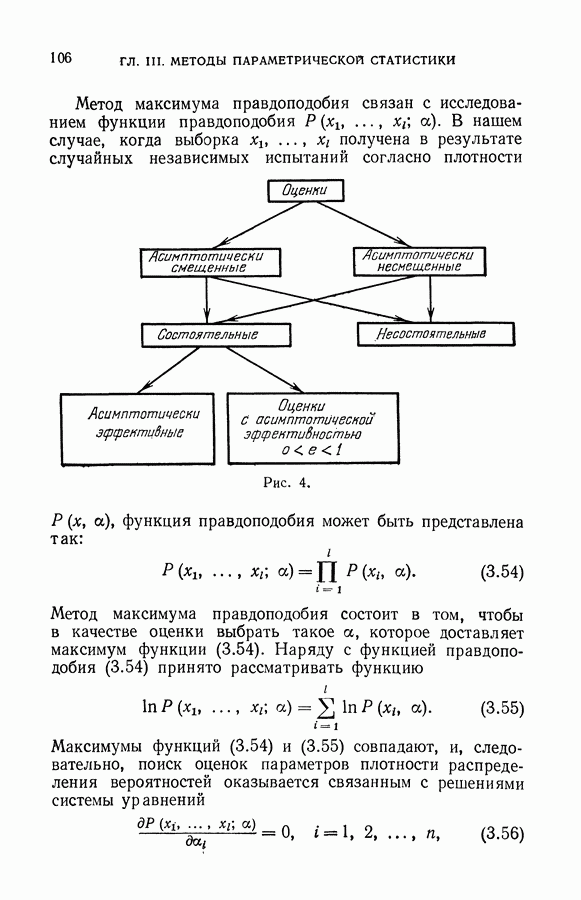
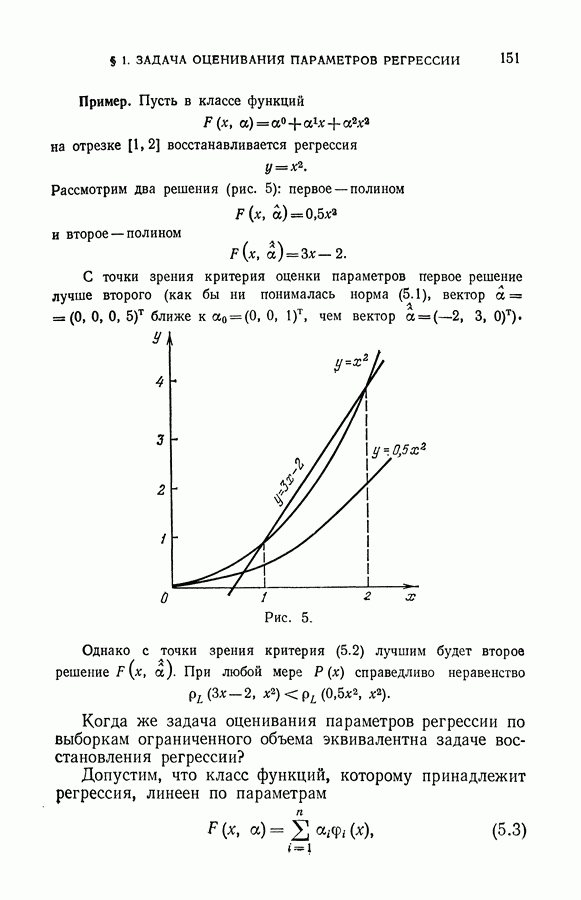
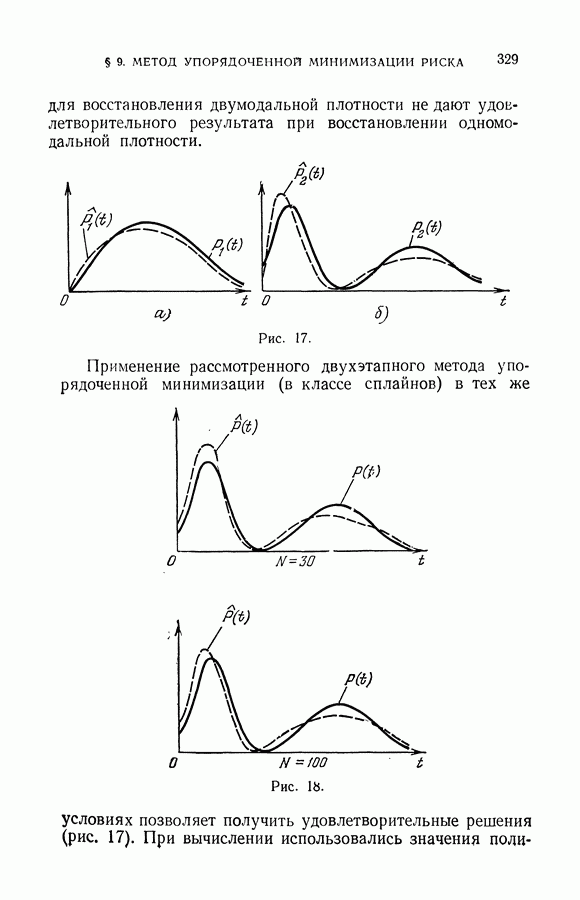
§ 7. Построение разделяющей гиперплоскости в экстремальном пространстве признаков
Алгоритмы 11-1 и 11-2 реализуют идею минимизации эмпирического риска. С их помощью в классе линейных решающих правил отыскивается правило, минимизирующее число ошибок на обучающей последовательности. Начиная с алгоритма 11-3 мы будем строить алгоритмы обучения распознаванию образов, реализующие метод упорядоченной минимизации риска. В этом параграфе мы рассмотрим алгоритмы упорядоченной минимизации риска в классе линейных решающих правил.
Пусть структура класса линейных решающих правил задается по числу используемых при распознавании признаков (см. гл. VIII) исходного пространства
признаков  В этом случае одновременно для всех решающих правил имеет место оценка
В этом случае одновременно для всех решающих правил имеет место оценка

где  — размерность подпространства исходного пространства признаков, в котором строится линейное решающее правило. Таким образом, проблема заключается в том, чтобы, выбрав подходящее подпространство
— размерность подпространства исходного пространства признаков, в котором строится линейное решающее правило. Таким образом, проблема заключается в том, чтобы, выбрав подходящее подпространство  и построив в нем линейное решающее правило, минимизирующее эмпирический риск, добиться минимальной величины оценки среднего риска.
и построив в нем линейное решающее правило, минимизирующее эмпирический риск, добиться минимальной величины оценки среднего риска.
В фиксированном пространстве  поиск решающего правила, минимизирующего эмпирический риск, осуществляется с помощью алгоритма 11-2.
поиск решающего правила, минимизирующего эмпирический риск, осуществляется с помощью алгоритма 11-2.
Алгоритм 11-3 отыскивает в пространстве признаков такое подпространство, в котором гарантируется наилучшее решение задачи с помощью линейных решающих правил (иногда такое подпространство признаков называют информативным).
Принципиально отыскание информативного подпространства может быть осуществлено с помощью полного перебора по всем  подпространствам исходного пространства признаков. Для каждого подпространства с помощью алгоритма 11-2 может быть найдено правило, минимизирующее эмпирический риск, а с помощью оценки (11.32) выбрано такое подпространство и такое решающее правило в нем, для которых гарантируется наименьшая оценка вероятности ошибочной классификации.
подпространствам исходного пространства признаков. Для каждого подпространства с помощью алгоритма 11-2 может быть найдено правило, минимизирующее эмпирический риск, а с помощью оценки (11.32) выбрано такое подпространство и такое решающее правило в нем, для которых гарантируется наименьшая оценка вероятности ошибочной классификации.
Однако осуществление полного перебора по всем подпространствам при вычислениях на ЦВМ требует чрезвычайно больших затрат машинного времени. Поэтому в алгоритме 11-3 используется стандартный эвристический прием последовательного улучшения оценки. Сначала отыскивается такой признак из  возможных признаков, исключение которого в наибольшей степени уменьшает оценку (11.32). Этот признак исключается. Затем из оставшихся
возможных признаков, исключение которого в наибольшей степени уменьшает оценку (11.32). Этот признак исключается. Затем из оставшихся  признаков по тому же правилу снова
признаков по тому же правилу снова
исключается признак и т. д. Исключение признаков продолжается до тех пор, пока оценка вероятности ошибочной классификации не достигнет минимума.
Процедуру исключения признаков удобно проводить по следующей схеме.
1. Найдем решающее правило, минимизирующее эмпирический риск в исходном пространстве  и вычислим для него оценку (11.32).
и вычислим для него оценку (11.32).
Пусть это правило построено с исключением из обучающей последовательности  векторов и соответствует решению двойственной задачи (см. §§ 3 и 4), при
векторов и соответствует решению двойственной задачи (см. §§ 3 и 4), при 
2. Выберем в качестве рабочей группы те векторы обучающей последовательности  для которых
для которых  отличны от нуля, а в качестве начальных значений при максимизации функции
отличны от нуля, а в качестве начальных значений при максимизации функции  соответствующие значения а, Р, и будем последовательно искать в пространствах
соответствующие значения а, Р, и будем последовательно искать в пространствах  решающие правила, делящие обучающую последовательность, состоящую из
решающие правила, делящие обучающую последовательность, состоящую из  векторов (без исключенных в
векторов (без исключенных в  . Для каждого найденного правила вычисляется оценка. Выберем то решение, которое экстремизирует оценку.
. Для каждого найденного правила вычисляется оценка. Выберем то решение, которое экстремизирует оценку.
3. Если найденная величина оценки меньше той, которая была получена для исходного пространства, то в качестве исходного рассматривается пространство  и производятся операции
и производятся операции  Если же экстремальная оценка больше той, которая была получена для
Если же экстремальная оценка больше той, которая была получена для  то пространство
то пространство  считается информативным, а найденное в нем линейное решающее правило, минимизирующее эмпирический риск, — наилучшим.
считается информативным, а найденное в нем линейное решающее правило, минимизирующее эмпирический риск, — наилучшим.