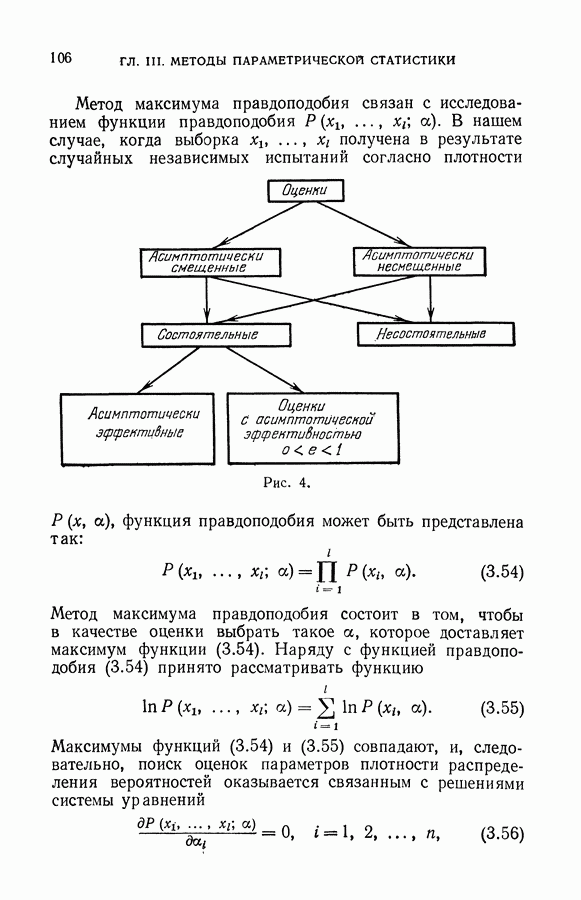
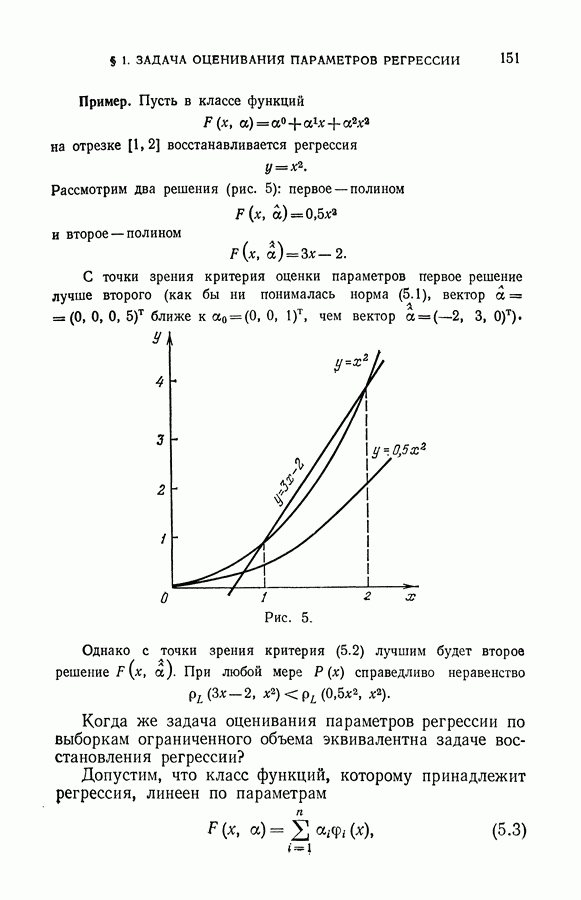
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
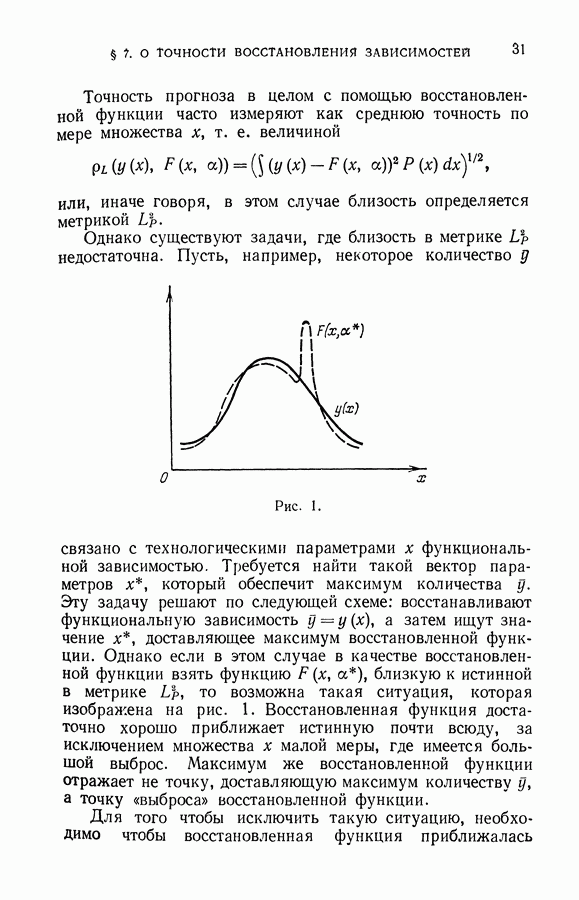
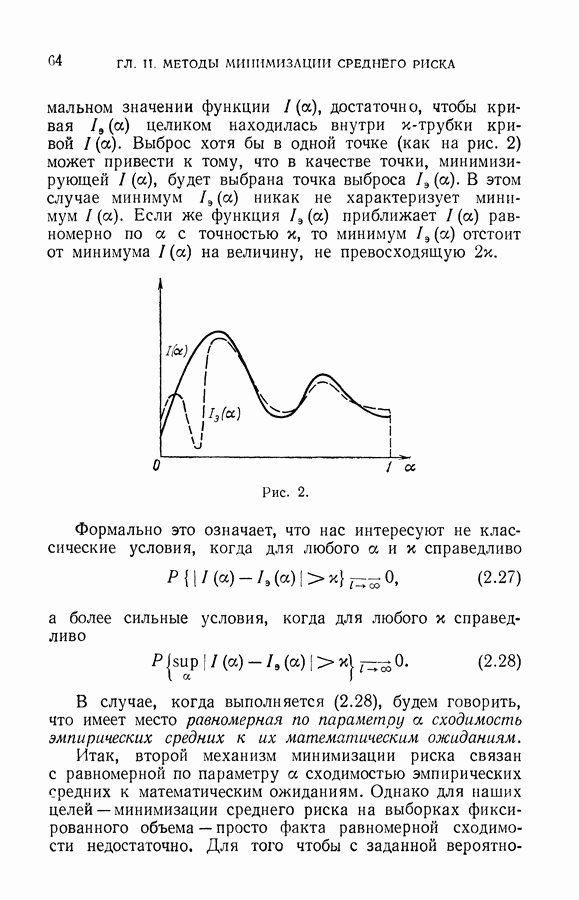
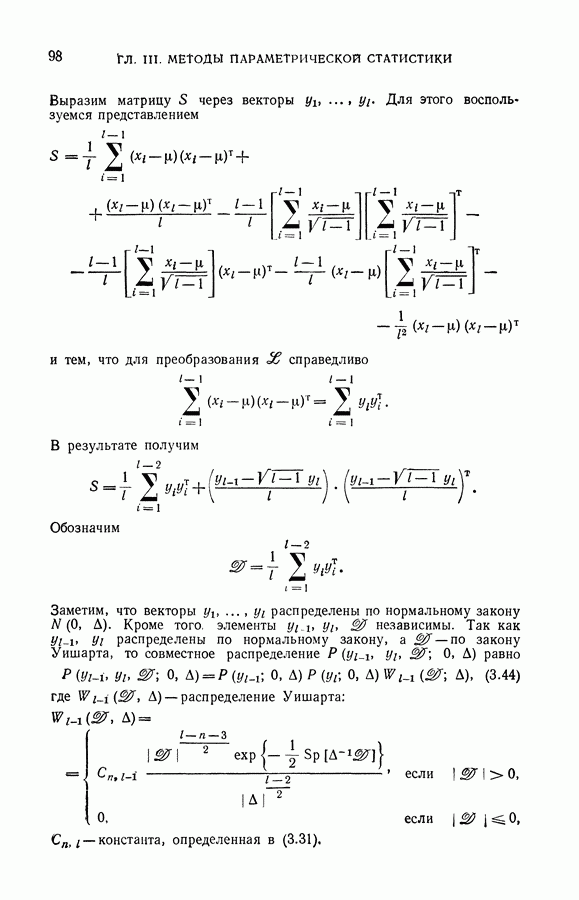
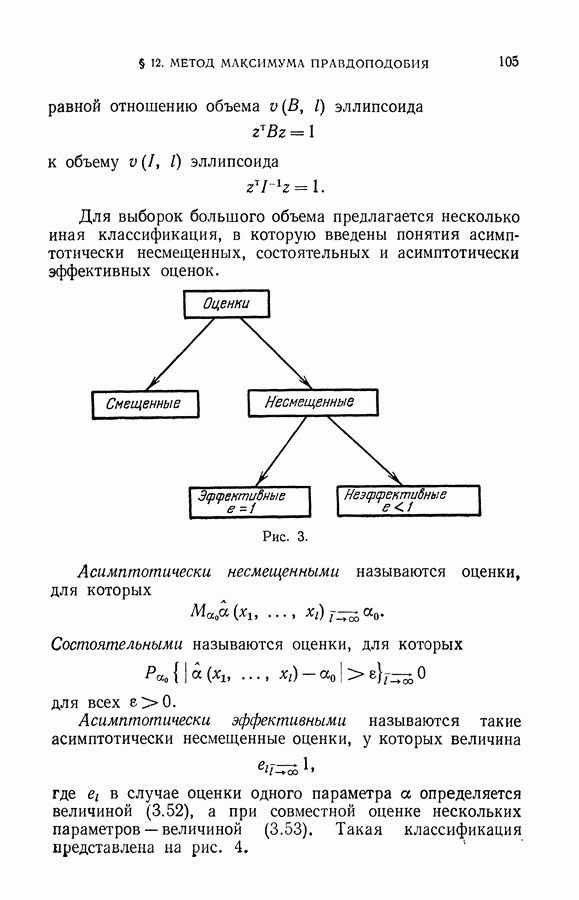
§ 6. Селекция выборки для восстановления значений характеристической функции
Итак, решение задачи восстановления значений характеристической функции в заданных точках, полученное методом упорядоченной минимизации суммарного риска, может приводить к результатам, отличным от тех, которые следуют из классификации векторов рабочей выборки

решающим правилом  минимизирующим эмпирический риск на элементах обучающей последовательности
минимизирующим эмпирический риск на элементах обучающей последовательности

Эффект этот был получен потому, что полная выборка

состояла из сравнительно небольшого числа элементов, расположение которых в пространстве могло быть изучено и связано с конкретным способом упорядочения класса решающих правил 
Способ упорядочения и определил разницу в классификации. Таким образом, геометрия векторов полной выборки (10.38) предопределила возможность более точного решения задачи восстановления значений функции в заданных точках.
Если это так, то возникает вопрос, нельзя ли, исключив из полной выборки (10.38) несколько элементов (изменив геометрию расположения векторов полной выборки в пространстве), так повлиять на задание структуры на классе решающих правил, чтобы увеличить
гарантированное число правильных классификаций элементов рабочей выборки? Оказывается, можно.
Реализуем идею селекции полной выборки. Рассмотрим наряду с множеством X векторов полной выборки  различных подмножеств
различных подмножеств  к полученных из (10.38) исключением не более
к полученных из (10.38) исключением не более  векторов. Пусть теперь на исходном множестве векторов (10.38) определена обучающая последовательность (10.37) и рабочая выборка (10.36). Обучающая и рабочая выборки индуцируют на каждом из множеств
векторов. Пусть теперь на исходном множестве векторов (10.38) определена обучающая последовательность (10.37) и рабочая выборка (10.36). Обучающая и рабочая выборки индуцируют на каждом из множеств  свою обучающую и рабочую подвыборки.
свою обучающую и рабочую подвыборки.
Рассмотрим  задач восстановления значений функции в заданных точках. Каждая из этих задач определяется обучающей последовательностью
задач восстановления значений функции в заданных точках. Каждая из этих задач определяется обучающей последовательностью

и рабочей выборкой

 означает, что элемент х исключен из последовательности).
означает, что элемент х исключен из последовательности).
Для каждой задачи в соответствии с ее полной выборкой

определим классы эквивалентности линейных решающих правил. Зададим структуру на классах эквивалентности, используя принцип упорядочения по относительным расстояниям, рассмотренный в предыдущем параграфе.
Из теоремы 10.2 и леммы следует, что с вероятностью  в каждой задаче (в отдельности) для правила
в каждой задаче (в отдельности) для правила  минимизирующего эмпирический риск в
минимизирующего эмпирический риск в  справедливо неравенство
справедливо неравенство 

тем неравенством (той задачей), для которого величина, оценивающая число ошибок на  элементах рабочей выборки наименьшая.
элементах рабочей выборки наименьшая.
Однако число векторов, исключенных из рабочей выборки для разных задач разное. Поэтому будем считать наилучшим решением то, которое максимизирует число правильных классификаций элементов рабочей выборки, т. е. определяется той задачей, для которой достигает минимума величина

определяющая число ошибок плюс число исключенных векторов рабочей выборки.
Теперь перебором по  найдем векторы, которые следует исключить, чтобы гарантировать наибольшее число правильно классифицированных векторов рабочей выборки. Задача минимизации по
найдем векторы, которые следует исключить, чтобы гарантировать наибольшее число правильно классифицированных векторов рабочей выборки. Задача минимизации по  функционала (10.44) достаточно трудна в вычислительном отношении. Точное ее решение требует большого перебора вариантов. Однако использование некоторых эвристических приемов позволяет найти удовлетворительное решение в приемлемое время. Подробно об алгоритмах упорядоченной минимизации суммарного риска см. главу XI.
функционала (10.44) достаточно трудна в вычислительном отношении. Точное ее решение требует большого перебора вариантов. Однако использование некоторых эвристических приемов позволяет найти удовлетворительное решение в приемлемое время. Подробно об алгоритмах упорядоченной минимизации суммарного риска см. главу XI.
Заметим, что при селекции полной выборки подбираются как элементы обучающей, так и элементы рабочей выборок.
Селекция элементов рабочей выборки позволяет за счет отказа от классификации некоторых элементов увеличить общее число правильно классифицируемых векторов.
До сих пор мы исходили из того, что пространство, в котором строится структура, фиксировано. Однако процедура упорядочения по относительным расстояниям может быть проведена в любом подпространстве  исходного пространства
исходного пространства  При этом минимальное значение соответствующей оценки будет достигнуто не обязательно в исходном пространстве
При этом минимальное значение соответствующей оценки будет достигнуто не обязательно в исходном пространстве 
Это обстоятельство открывает возможность достичь еще более глубокого минимума оценки риска за счет дополнительной минимизации по подпространствам.





































































































































































































































































































































































































































 корень уравнения
корень уравнения

 — число исключенных элементов обучающей последовательности,
— число исключенных элементов обучающей последовательности,  число исключенных элементов рабочей выборки
число исключенных элементов рабочей выборки 
 элементов структур всех
элементов структур всех  задач с вероятностью
задач с вероятностью  выполнятся неравенства
выполнятся неравенства



 меняется от 1 до
меняется от 1 до 
 — число элементов обучающей и рабочей выборок, исключенных из (10.37) и (10.36) при образовании
— число элементов обучающей и рабочей выборок, исключенных из (10.37) и (10.36) при образовании  задачи
задачи  частоты ошибочной классификации рабочей и обучающей выборок в
частоты ошибочной классификации рабочей и обучающей выборок в  задаче.
задаче.
 результате для каждой задачу получим оценку числа ошибок
результате для каждой задачу получим оценку числа ошибок  на
на  элементах ее рабочей выборки
элементах ее рабочей выборки

 то наилучшее гарантированное решение задачи классификации
то наилучшее гарантированное решение задачи классификации  векторов рабочей выборки определялось бы
векторов рабочей выборки определялось бы
