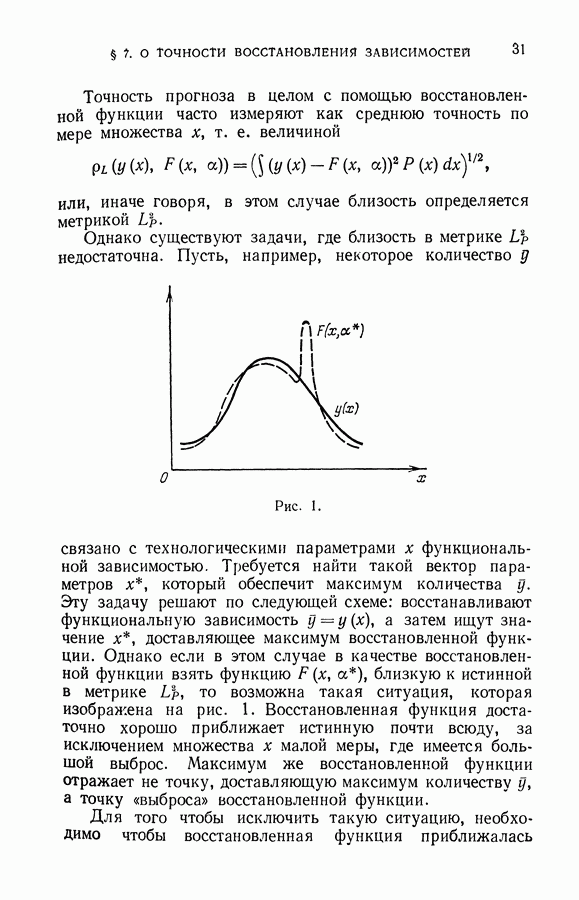
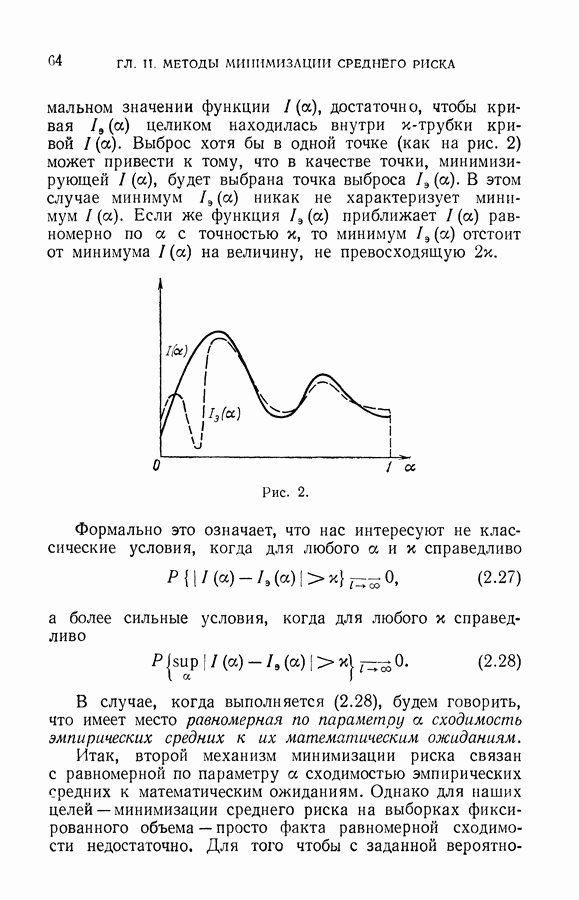
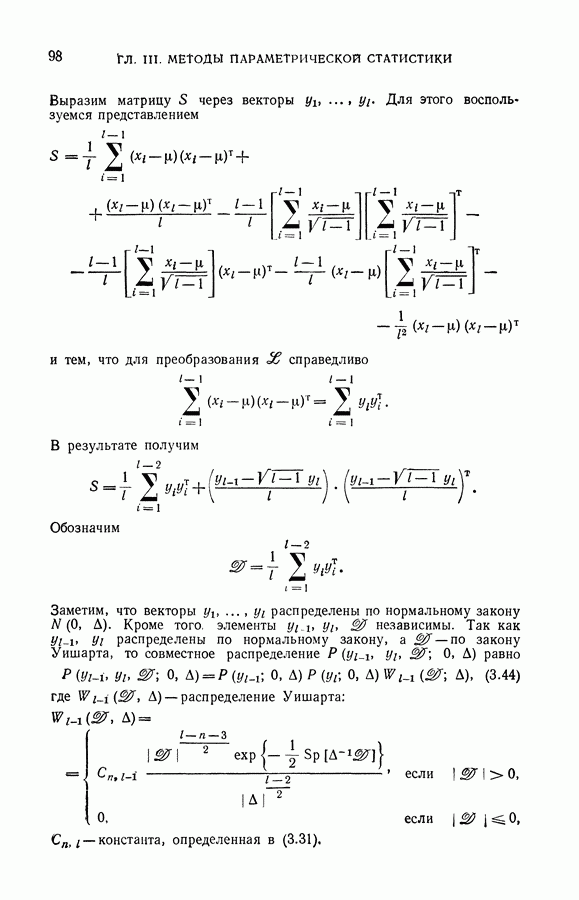
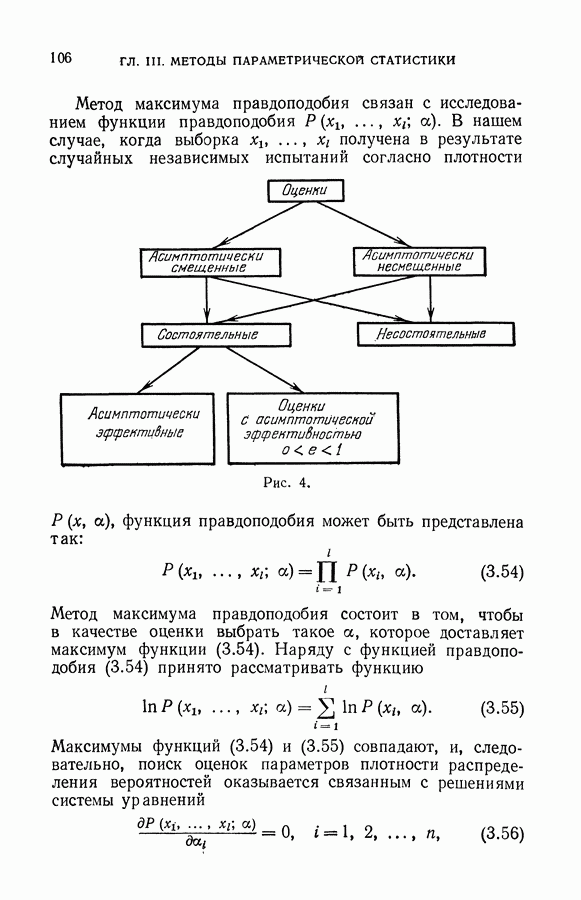
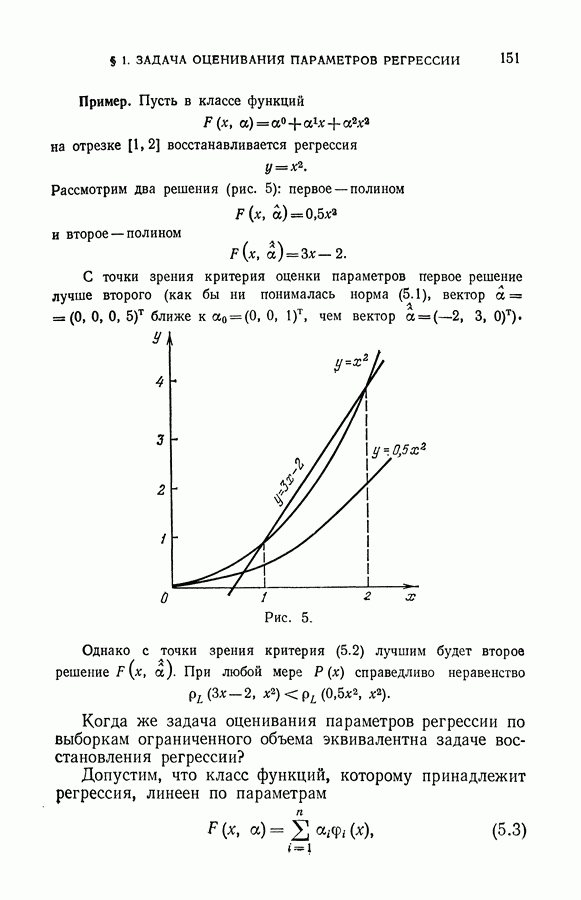
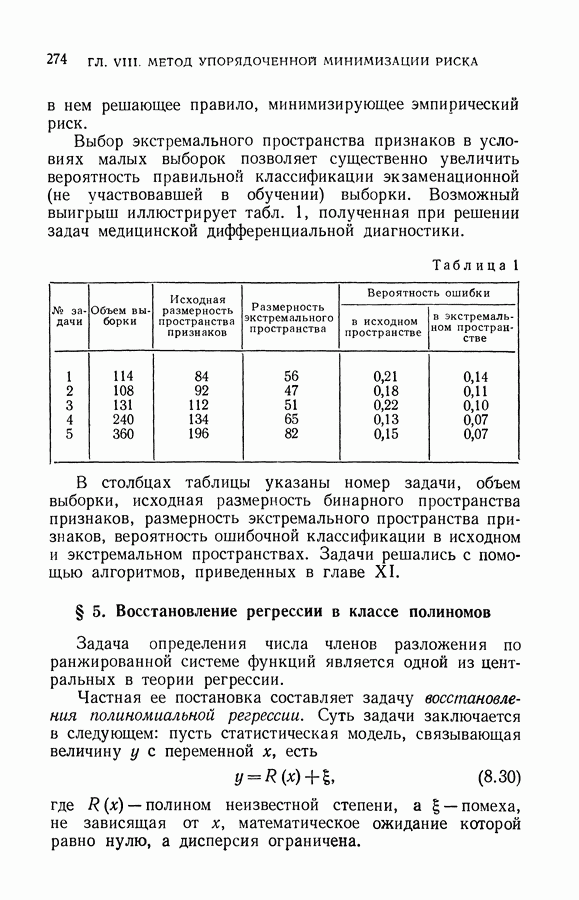
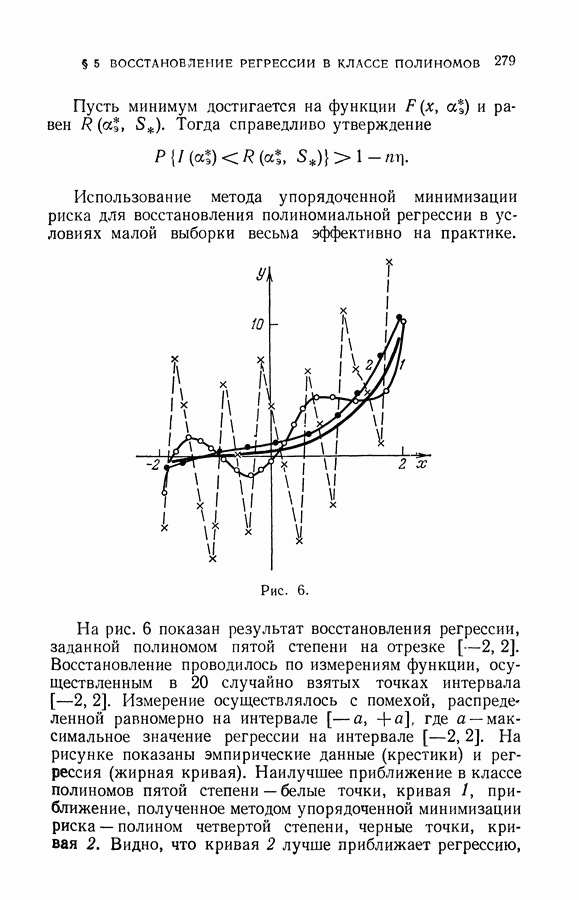
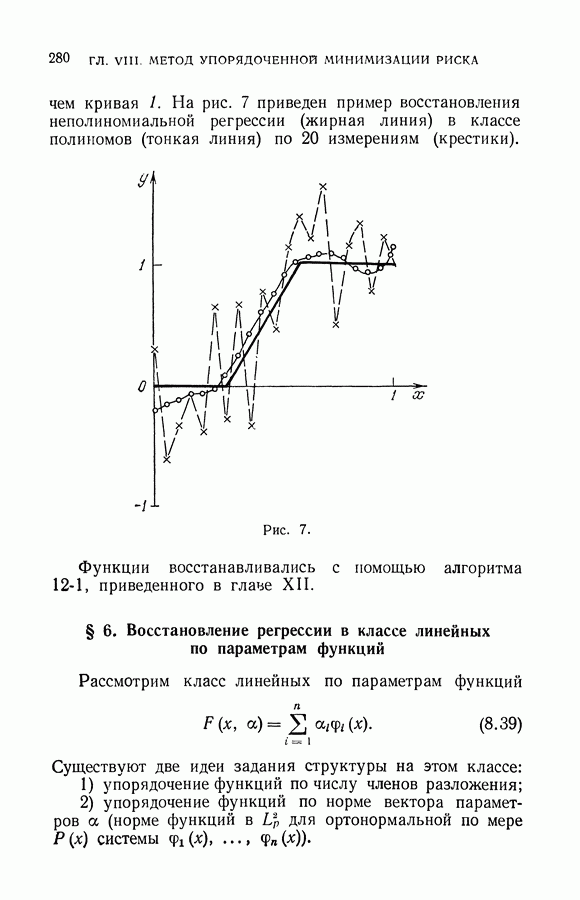
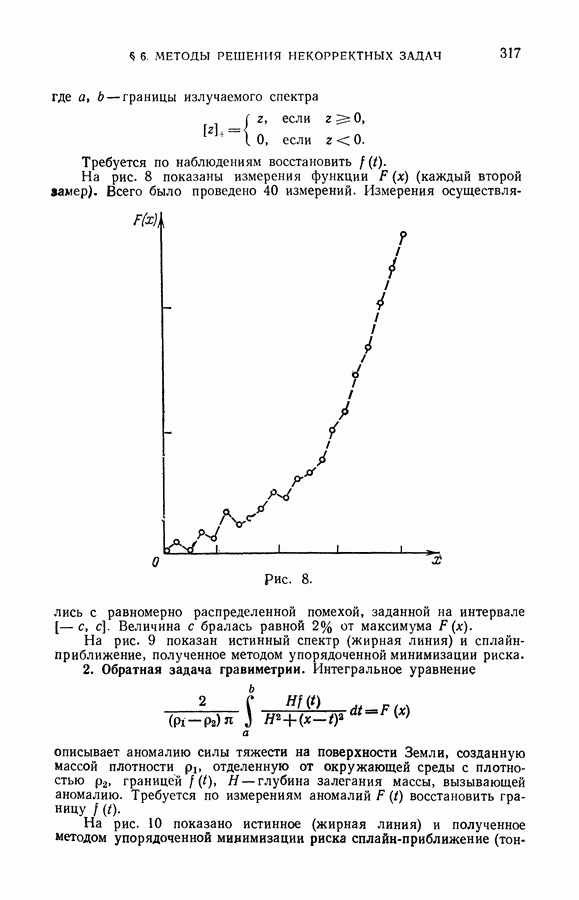
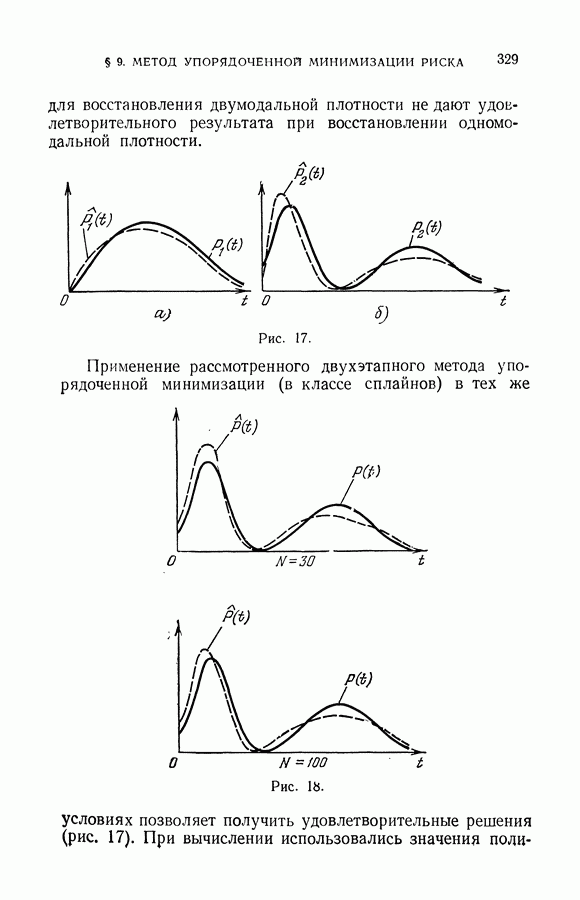
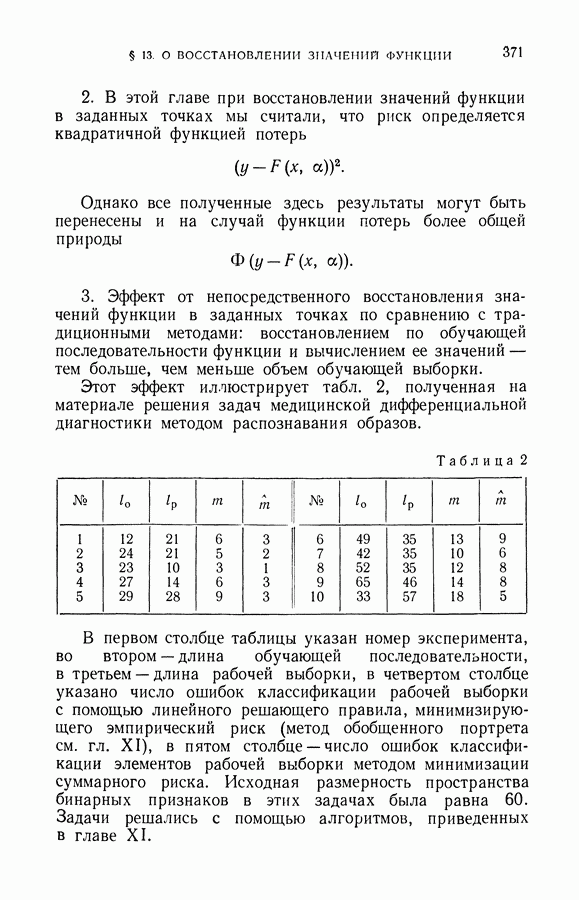
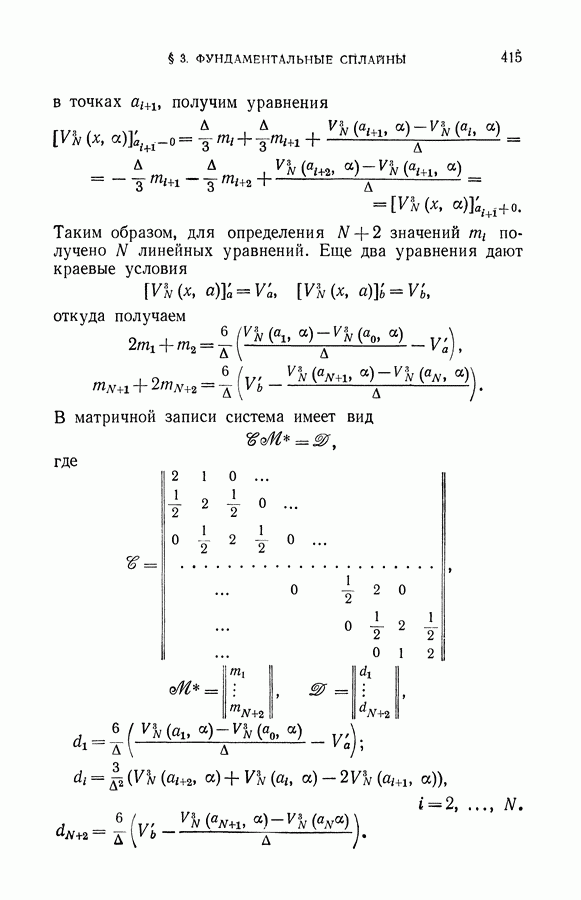
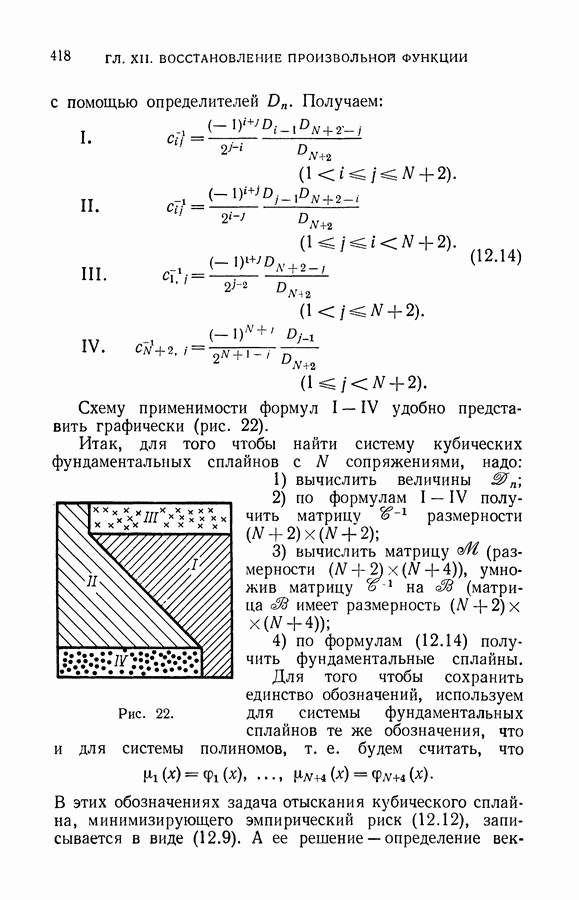
§ 14. Замечания о различных методах приближения плотности
В этой главе мы рассмотрели три типа приближения плотностей, заданных с точностью до параметров: байесовы приближения, наилучшие несмещенные приближения и приближения, задаваемые параметрами, найденными методом максимума правдоподобия. Для наших частных задач восстановления плотностей двух конкретных классов (3.58) и (3.59) удалось получить все эти приближения. Какое же из приближений лучше использовать на практике, какое из них следует подставить в выражение (3.7) для получения решающих правил в задаче обучения распознаванию образов?
С теоретической точки зрения, безусловно, байесово. Это приближение экстремизирует функционал, который разумно определяет качество, предъявляемое к приближению. Однако для того, чтобы получить байесово приближение, необходимо знать априорное распределение параметров плотности, т. е. знать закон, определяющий, как часто на практике придется восстанавливать ту или иную конкретную плотность. Обычно этот закон неизвестен.
В §§ 6, 7 были получены байесовы приближения для таких априорных законов, которые, с одной стороны, содержат достаточно неопределенную информацию, а с
другой стороны, способствуют максимальному упрощению вычислений. Насколько же можно доверять байесовому приближению, полученному по одному априорному закону, если на практике будет реализован другой закон? На этот вопрос существует лишь качественный ответ. С ростом объема выборки влияние априорной информации на байесово приближение падает (теорема Бернштейна).
Таким образом, выбор байесова приближения определяется верой в то, что на практике несоответствие в задании априорного закона скажется мало.
При конструировании наилучшей несмещенной оценки плотности нет необходимости учитывать априорную информацию. В этом классе оценок существует наилучшая оценка, которая не зависит от того, какие плотности из заданного класса придется восстанавливать. Казалось бы, в такой ситуации выбор наилучшей несмещенной оценки не связан ни с каким риском. На самом деле это не так. Ни откуда не следует, что в классе несмещенных оценок плотности имеются достаточно хорошие оценки. Ведь, как уже отмечалось, само свойство несмещенности оценки не имеет никакой самостоятельной ценности и вводится исключительно в целях ограничения класса оценок. Класс же несмещенных оценок узок (так, несмещенная оценка нормального закона, выраженная через достаточные статистики, единственна).
Не исключено, что сравнительно узкий класс несмещенных оценок состоит лишь из достаточно «плохих» оценок, и тогда выбор в нем наилучшей не гарантирует того, что оценка будет хорошей.
Подтверждением того, что такая ситуация вполне реальна, служит пример, приведенный Стейном: при оценке вектора средних  -мерного
-мерного  нормального закона с единичной ковариационной матрицей
нормального закона с единичной ковариационной матрицей  равномерно лучшей оценкой, чем среднее арифметическое (наилучшая несмещенная оценка)
равномерно лучшей оценкой, чем среднее арифметическое (наилучшая несмещенная оценка)

является смещенная оценка

(Подробнее оценки стейновского типа будут рассмотрены в главе V.)
Пример Стейна замечателен тем, что он построен для самых простых задач оценивания параметров, и уже здесь существуют равномерно лучшие смещенные оценки.
Таким образом, выбор наилучшей несмещенной оценки определяется верой в то, что класс несмещенных оценок содержит достаточно хорошую.
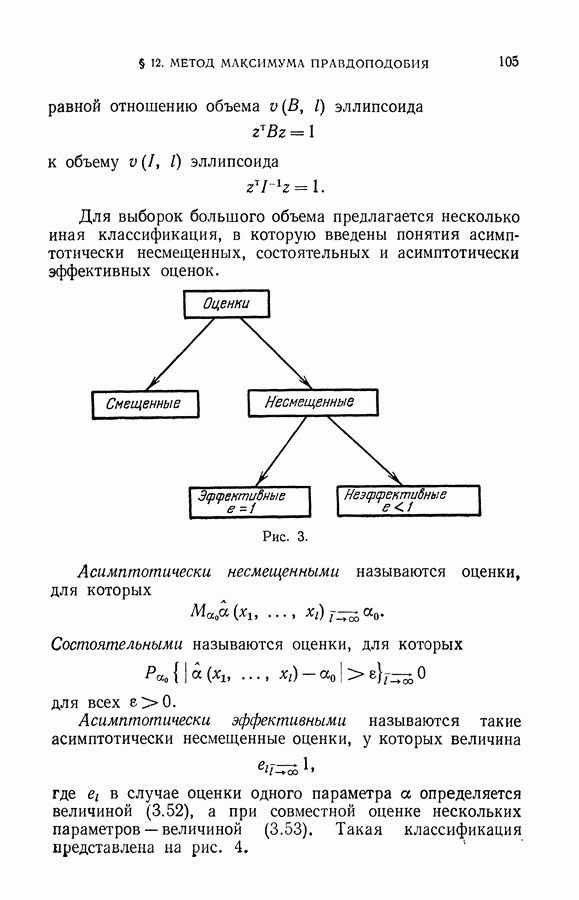
Наконец, теория оценок максимального правдоподобия не дает никакого ответа на вопрос о том, каковы свойства оценок на конечных выборках. Теория лишь гарантирует приближение к эффективным оценкам с ростом объема выборки, т. е. что качество оценки максимального правдоподобия с ростом объема выборки приблизится к качеству наилучшей несмещенной оценки параметров.
Получилось так, что благодаря счастливому стечению обстоятельств, в этой главе нам удалось найти байесовы оценки — провести аналитическое интегрирование многократного интеграла (численное интегрирование в силу высокой кратности интеграла затруднительно), получить наилучшую несмещенную оценку плотности — найти аналитическое решение уравнения Фредгольма I рода (численное решение является некорректно поставленной задачей).
Однако такой результат связан с особенностью рассмотренного параметрического класса плотностей.
В общем случае вряд ли можно рассчитывать на получение подобных приближений. В этом отношении метод максимума правдоподобия имеет преимущество — он может быть применен для различных классов плотностей. Регулярность метода максимума правдоподобия связана с тем, что он сводится к решению алгебраических уравнений, т. е. к задаче, которая может эффективно решаться на вычислительных машинах.
И еще одно замечание. Рассмотренные в этой главе методы восстановления плотностей имеют смысл лишь при условии, что искомая плотность принадлежит заданному параметрическому семейству плотностей.
На практике же мы никогда не располагаем такой априорной информацией, которая позволяет выделить параметрическое семейство функций, заведомо содержащее искомую. Таким образом, оказывается, что не только
выбор того или иного метода приближения плотности, но и выбор самой постановки задачи восстановления зависимости по эмпирическим данным как параметрической во многом является вопросом веры.