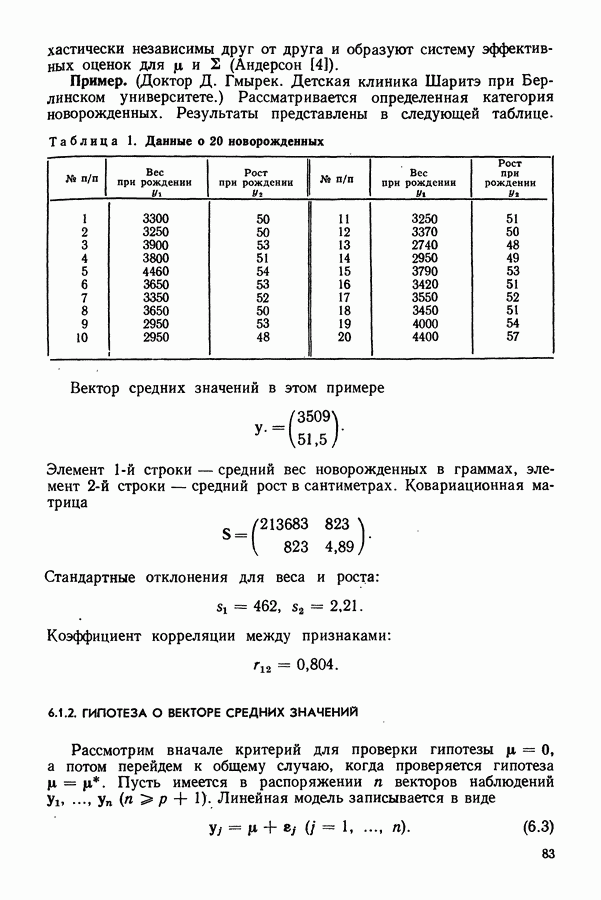
4. ЛИНЕЙНАЯ МОДЕЛЬ МНОГОМЕРНОГО ДИСПЕРСИОННОГО АНАЛИЗА
В этой главе мы кратко расскажем о проверке линейных гипотез в задачах одномерного дисперсионного анализа, что приведет нас к известному  -критерию. С помощью одномерного дисперсионного анализа мы перейдем к многомерному случаю. Читателю, знакомому с одномерным дисперсионным анализом, данная глава все же будет полезна, так как позволит увидеть аналогии в ходе рассуждений, а также убедиться в возникновении новых аспектов при изучении многомерного дисперсионного анализа.
-критерию. С помощью одномерного дисперсионного анализа мы перейдем к многомерному случаю. Читателю, знакомому с одномерным дисперсионным анализом, данная глава все же будет полезна, так как позволит увидеть аналогии в ходе рассуждений, а также убедиться в возникновении новых аспектов при изучении многомерного дисперсионного анализа.
4.1. ОДНОМЕРНЫЙ СЛУЧАЙ
Подвергнем  наблюденных величин
наблюденных величин  дисперсионному анализу. Предположим, что каждое наблюдение
дисперсионному анализу. Предположим, что каждое наблюдение  принадлежит нормально распределенной генеральной совокупности
принадлежит нормально распределенной генеральной совокупности  и отдельные наблюдения взаимно независимы.
и отдельные наблюдения взаимно независимы.
Предположим, что вектор-столбец  с компонентами удовлетворяет линейному соотношению
с компонентами удовлетворяет линейному соотношению

При этом элементы  будут неизвестными параметрами и, напротив, элементы X — известными числами. Матрицу X называют матрицей плана, или блок-схемой. Она определяется соответствующим экспериментом. Далее мы примем, что все нормально распределенные совокупности имеют одинаковую дисперсию, т. е.
будут неизвестными параметрами и, напротив, элементы X — известными числами. Матрицу X называют матрицей плана, или блок-схемой. Она определяется соответствующим экспериментом. Далее мы примем, что все нормально распределенные совокупности имеют одинаковую дисперсию, т. е.  для всех
для всех  Чтобы Дисперсионный анализ оказался возможным, потребуем, чтобы ранг
Чтобы Дисперсионный анализ оказался возможным, потребуем, чтобы ранг  матрицы плана X был отличен от
матрицы плана X был отличен от  и число
и число  наблюдаемых значений превосходило
наблюдаемых значений превосходило 

Составленный из наблюдений  вектор-столбец у в силу сделанных выше предположений есть реализация
вектор-столбец у в силу сделанных выше предположений есть реализация  -мерной нормально распределенной
-мерной нормально распределенной  случайной величины (I — единичная матрица). Отсюда следует уравнение модели
случайной величины (I — единичная матрица). Отсюда следует уравнение модели

где вектор  обозначает случайные составляющие измеренных значений.
обозначает случайные составляющие измеренных значений.
Цель дисперсионного анализа — нахождение оценок неизвестных параметров и проверка определенных гипотез. Гипотезы мы выдвигаем в виде 

а их альтернативы — в виде

где К — заданная неслучайная матрица положительного ранга, относительно которой мы предполагаем, что число строк совпадает с ее рангом:

Все это в целом составляет линейную модель для одномерного случая.
Для проверки гипотезы  используется известный
используется известный  -критерий, Его можно вывести из критерия отношения правдоподобия (см, также [1]). В дальнейшем мы приведем выражение статистики.
-критерий, Его можно вывести из критерия отношения правдоподобия (см, также [1]). В дальнейшем мы приведем выражение статистики.
В отличие от модели регрессионного анализа для модели дисперсионного анализа типично то, что столбцы матрицы плана X не являются линейно-независимыми. Из-за этого построение критерия несколько усложняется.
Допустим, что в X можно найти  линейно-независимых столбцов. Путем перенумерации столбцов можно достигнуть того, что первые
линейно-независимых столбцов. Путем перенумерации столбцов можно достигнуть того, что первые  столбцов окажутся линейно-независимыми. Соответствующую перенумерацию произведем и для
столбцов окажутся линейно-независимыми. Соответствующую перенумерацию произведем и для  После этой предварительной подготовки мы разобьем матрицу X на две подматрицы
После этой предварительной подготовки мы разобьем матрицу X на две подматрицы 

Расчленению X соответствует также разбиение К:

В этих обозначениях статистика  -критерия имеет вид
-критерия имеет вид

Это выражение можно вычислить в каждом конкретном случае, поскольку в него наряду с заданными наблюдениями входят только матрицы  которые определяются соответствующей матрицей плана X и гипотезой, подлежащей проверке. Если гипотеза
которые определяются соответствующей матрицей плана X и гипотезой, подлежащей проверке. Если гипотеза  верна, отношение (4.7) имеет
верна, отношение (4.7) имеет  степенями свободы. Гипотеза отклоняется на уровне значимости а, если
степенями свободы. Гипотеза отклоняется на уровне значимости а, если

В противном случае гипотеза принимается. Вывод выражения (4.7) читатель может найти, например,  [74]. Заметим, что при
[74]. Заметим, что при  критерий применим не для каждой выдвинутой гипотезы
критерий применим не для каждой выдвинутой гипотезы  Указанный
Указанный  -итерий может быть использован для проверки гипотезы
-итерий может быть использован для проверки гипотезы  лишь при выполнении равенства
лишь при выполнении равенства

Для краткости положим

С учетом (4.10) и  -статистику запишем в виде
-статистику запишем в виде

Можно показать, что  и однозначно определяются матрицей плана X и матрицей гипотезы
и однозначно определяются матрицей плана X и матрицей гипотезы  в частности, они не зависят от выбора в X «базисной матрицы»
в частности, они не зависят от выбора в X «базисной матрицы» 
На основании (4.3) квадратичная форма  в знаменателе (4.12) распределена по закону
в знаменателе (4.12) распределена по закону  При справедливости нулевой гипотезы (4.4) и условия (4.3) квадратичная форма в числителе выражения (4.12) имеет
При справедливости нулевой гипотезы (4.4) и условия (4.3) квадратичная форма в числителе выражения (4.12) имеет  -распределение, причем числитель и знаменатель стохастически независимы друг от друга.
-распределение, причем числитель и знаменатель стохастически независимы друг от друга.
При анализе широко известных блок-схем  -факторной классификации, иерархической классификации и т.д.) при проверке нулевых гипотез о группах главных эффектов либо взаимодействий квадратичные формы в числителе и знаменателе (4.12) превращаются в привычные суммы квадратов из соответствующих таблиц дисперсионного анализа.
-факторной классификации, иерархической классификации и т.д.) при проверке нулевых гипотез о группах главных эффектов либо взаимодействий квадратичные формы в числителе и знаменателе (4.12) превращаются в привычные суммы квадратов из соответствующих таблиц дисперсионного анализа.
Проблема оценки неизвестных параметров и их линейных комбинаций  тесно связана с проверкой гипотез. Предположим, мы хотим оценить вектор
тесно связана с проверкой гипотез. Предположим, мы хотим оценить вектор

Как не для любой произвольно выдвинутой гипотезы вида (4.4) можно сконструировать критерий проверки, так и не для каждого
вектора у может быть найдена оценка. По аналогии с К указанную матрицу С расчленяем на две подматрицы 

Вектор у допускает оценку при условии, что

В этом случае искомой оценкой  является
является

Среди всех линейных оценок у оценка у имеет наименьшую дисперсию.
Кроме того, она несмещенная.
При использовании оценок параметров  -критерий можно представить в другом виде. Оценкой вектора средних значений
-критерий можно представить в другом виде. Оценкой вектора средних значений  (см. формулу (4.1)) является
(см. формулу (4.1)) является

Условие возможности построения оценки в этом случае выполняется, так как столбцы  могут быть представлены в виде линейных комбинаций столбцов
могут быть представлены в виде линейных комбинаций столбцов  т. е. существует такая матрица
т. е. существует такая матрица  что
что

благодаря чему получаем

Используя (4.16) с учетом того, что матрица  симметричная и идемпотентная, получаем в знаменателе
симметричная и идемпотентная, получаем в знаменателе  -критерия (4.12) выражения:
-критерия (4.12) выражения:

Соотношение такого рода большинству читателей известно: в правой части стоит сумма квадратов отклонений измеренных значений  от оценок
от оценок  соответствующих средних значений. В этом месте нам хотелось бы подчеркнуть, что
соответствующих средних значений. В этом месте нам хотелось бы подчеркнуть, что

— несмещенная оценка дисперсии  ошибки измерения.
ошибки измерения.
В данном случае символ  означает стандартное отклонение. В других формулах
означает стандартное отклонение. В других формулах  используется для обозначения ранга матрицы гипотезы.
используется для обозначения ранга матрицы гипотезы.
Чтобы можно было преобразовать числитель  -критерия, нужно найти оценку вектора параметров
-критерия, нужно найти оценку вектора параметров

При условии, что гипотеза проверяема, т. е. выполняется (4.9), параметр  допускает оценку
допускает оценку

так что

Отсюда видно, что чем меньше  тем больше оценка 6 соответствует гипотезе
тем больше оценка 6 соответствует гипотезе 
Используя (4.18) и (4.21), получим выражения для  -критерия:
-критерия: