Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
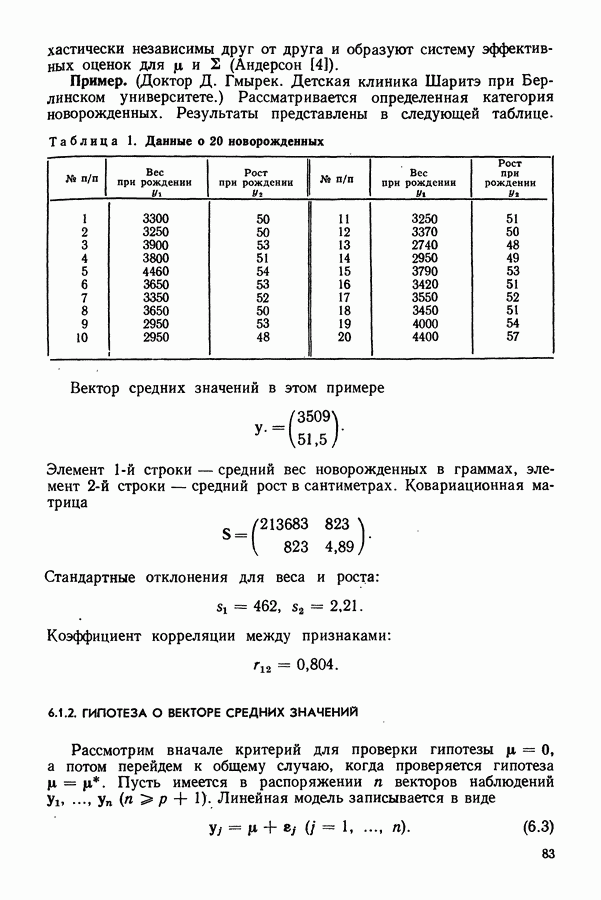
7.10. УКРУПНЕННАЯ БЛОК-СХЕМА РЕАЛИЗАЦИИ ВЫЧИСЛЕНИЙНа рис. 8 (с. 148) представлены важнейшие этапы многомерного дисперсионного и дискриминантного анализов в случае однофакторной классификации. Приведенная блок-схема может иметь множества модификаций. В зависимости от конкретной постановки задачи некоторые шаги позволяется опустить. Для проверки одной лишь гипотезы о равенстве векторов средних значений с помощью многомерного критерия значимости допустимо отказаться от определения неэлементарных дискриминантных функций. Кто не указывает значения для числа используемых признаков, тот не проводит сокращения множества признаков и т. д. 7.11. КАЧЕСТВЕННЫЕ ВЫВОДЫ ОБ ОТДЕЛЬНЫХ ПРИЗНАКАХ И МНОЖЕСТВАХ ПРИЗНАКОВДо сих пор мы излагали точные количественные методы анализа многомерных наблюдений. Но из-за сложности явления получаемые при этом результаты не всегда легко интерпретировать. Может возникнуть желание глубже разобраться в связях признаков. В большинстве случаев практически не удается убедительно объяснить, почему при уменьшении числа признаков именно эти признаки были исключены, а другие оставлены. Желательно получить дополнительные сведения о связях признаков, их взаимозаменяемости и тождественности. Этому вопросу и посвящен данный раздел. 7.11.1. РАЗЛОЖЕНИЕ МНОГОМЕРНОГО ДИСТАНТА НА СОСТАВЛЯЮЩИЕ, СООТВЕТСТВУЮЩИЕ ДИСКРИМИНАНТНЫМ ПРИЗНАКАМПринцип разложения на компоненты Согласно (7.47), (7.58), (7.59) и (7.69) получаем
Итак, матрицу
соответствующие неэлементарным дискриминантным признакам:
Благодаря этому появляется возможность разложить на компоненты многомерный дистант
согласно (7.11) и (7.49) имеем
Подставляя в (7.106) соответствующие подматрицы
где
Из (7.105) для дистанта по любому подмножеству признаков следует выражение
Показатели необходимости также разлагаются на составляющие. По (7.39), (7.58), (7.59) и (7.69) получаем, что
Отсюда по (7.81) следует, что
Здесь Вращение в дискриминантном пространствеПредставления (7.103) родственны соотношениям
или
из (7.69). Из равенства (7.113) следует, что центры групп в исходном пространстве получаются из центров в пространстве дискриминантных признаков
Аналогично в равенстве (7.103) можно перейти к новому базису дискриминантного пространства. Обозначим через
В результате получаем, что
Это дает разложение на компоненты матрицы Мера расстоянияТеперь можно перейти к качественной оценке множества признаков. Два множества признаков считают подобными, если они имеют при всех ортогональных базисах дискриминантного пространства одинаковые или мало различающиеся компоненты Ради более точного определения сходства введем расстояния между двумя множествами признаков
где максимум берем по всевозможным ортонормированным базисам дискриминантного пространства. Величины Векторная диаграмма представления отдельных признаковРассмотрим частный случай, когда совокупности состоят из единственного признака. В этом случае каждому отдельному признаку
В другом ортонормированном базисе, получающемся путем преобразования
Длина Продолжая наши рассуждения, можно показать, что расстояние
Отсюда можно непосредственно заключить, что расстояние Следует заметить, что качественные суждения о признаках, которые дает этот метод, сильно ограничиваются размерностью Приведенные здесь соображения в значительной степени сходны с концепциями факторного анализа. Пример. (Доктор Е. Рихтер-Хайнрих. Центральный институт сердечно-сосудистых заболеваний и регулирования кровообращения Академии наук Рассматриваются
Рис. 9. Векторная диаграмма 28 признаков при психофизиологическом обследовании. Обозначение признаков: В каждый из этих промежутков времени измерялись 4 величины: 5 (систолическое кровяное давление), Вектор наблюдений размерностью 28 для одного индивида записывается в форме группа 1: 30 здоровых индивидов; группа 2: 40 больных гипертонией, степень тяжести I; группа 3: 30 больных гипертонией, степень тяжести II. Мы не будем здесь вдаваться в подробности расчетов многомерного критерия значимости и описания классификации (см. [69] и [44]), а обсудим только вопрос качественной оценки признаков. Векторная диаграмма, отображающая сходство между 28 признаками, представлена на рис. 9. На рисунке 7 признаков Рис. 10. (см. скан) Схема поведения 28 признаков при психофизиологическом обследовании Два признака, этого достаточно поменять знаки Отдельным направлениям векторов на диаграмме соответствуют образцы поведения признаков на рис. 10. Систолическое давление характеризуется сильным наклоном группы 1 к группе 2 и группы 2 к группе 3. Для диастолического давления различие между группами 7.11.2. ИСПОЛЬЗОВАНИЕ АФФИННОГО КОЭФФИЦИЕНТАДругое объяснение диагностическому сходству, отдельных признаков и их совокупностей можно дать с помощью аффинного коэффициента (7.33). Два множества признаков по своему диагностическому содержанию тем больше схожи, чем меньше их аффинный коэффициент а. Чтобы узнать, какие признаки схожи, а какие, напротив, различны, проводят кластерный анализ всей совокупности признаков. При этом возникают кластеры схожих признаков. Процедура заключается в следующем: вначале каждый из Пример. Для данных по гипертонии из раздела 7.11.1 изложенным выше методом получаем следующие кластеры (процедура объединения кластеров была прекращена при
Далее наследующем шаге объединяются в один кластер признаки Если сравнить полученные нами сейчас результаты с результатами из раздела 7.11.1, то увидим практически полное совпадение. Отдельные незначительные отклонения в результатах обоих методов (например, на векторной диаграмме (кожный потенциал
|
 |
Оглавление
|






























































































































































































































 представляющую разности средних значений по
представляющую разности средних значений по  группам, можно разложить на компоненты
группам, можно разложить на компоненты


 совокупности всех
совокупности всех  признаков, а также дистант по любому подмножеству этих признаков. Для составляющих дистанта всех
признаков, а также дистант по любому подмножеству этих признаков. Для составляющих дистанта всех  признаков
признаков


 получим компоненты
получим компоненты  по ограниченному подмножеству признаков. Так, например, для отдельного признака
по ограниченному подмножеству признаков. Так, например, для отдельного признака  компонентами дистанта являются величины
компонентами дистанта являются величины

 элемент матрицы
элемент матрицы  диагональный элемент матрицы
диагональный элемент матрицы  Следует упомянуть, что по (7.56)
Следует упомянуть, что по (7.56)




 весовые коэффициенты неэлементарных дискриминантных функций.
весовые коэффициенты неэлементарных дискриминантных функций.


 за счет умножения на
за счет умножения на  Если к дискриминантным признакам
Если к дискриминантным признакам  применить ортогональное преобразование
применить ортогональное преобразование  то вместо
то вместо  появляется новая матрица
появляется новая матрица  В соответствии с этим
В соответствии с этим

 отдельные столбцы ортогональной матрицы
отдельные столбцы ортогональной матрицы  так что
так что


 относящееся к произвольному ортогональному базису в дискриминантном пространстве. Таким образом, для каждого данного ортогонального базиса получаем соответствующее аддитивное разложение дистанта на компоненты
относящееся к произвольному ортогональному базису в дискриминантном пространстве. Таким образом, для каждого данного ортогонального базиса получаем соответствующее аддитивное разложение дистанта на компоненты 
 .
.


 представляют собой квадратные корни из
представляют собой квадратные корни из  Благодаря расстоянию
Благодаря расстоянию  множество всех наборов признаков превращается в метрическое пространство. Конечно, численное определение
множество всех наборов признаков превращается в метрическое пространство. Конечно, численное определение  при двух любых множествах немного проблематично.
при двух любых множествах немного проблематично.
 соответствует,
соответствует,  -мерный вектор
-мерный вектор  В базисе
В базисе  вектор
вектор  имеет координаты
имеет координаты

 вектор
вектор  имеет координаты
имеет координаты

 равна квадратному корню из соответствующего дистанта
равна квадратному корню из соответствующего дистанта  угол между двумя векторами выражает различные качества признаков.
угол между двумя векторами выражает различные качества признаков.
 между двумя отдельными признаками
между двумя отдельными признаками  равно:
равно:

 это длина вектор-разности
это длина вектор-разности  если векторы
если векторы  образуют острый угол (чтобы использовать это определение, иногда приходится знак одного из признаков изменять на противоположный).
образуют острый угол (чтобы использовать это определение, иногда приходится знак одного из признаков изменять на противоположный).
 дискриминантного пространства. При двух группах
дискриминантного пространства. При двух группах  каждые из двух векторов кратны один относительно другого. При трех группах
каждые из двух векторов кратны один относительно другого. При трех группах  все векторы лежат в двумерном пространстде, и
все векторы лежат в двумерном пространстде, и 

 -мерные векторы наблюдений, каждый из которых относится к одному индивиду. Во время психофизиологических обследований испытуемый в семь последовательных промежутков времени находился в состояниях: 0) покой,
-мерные векторы наблюдений, каждый из которых относится к одному индивиду. Во время психофизиологических обследований испытуемый в семь последовательных промежутков времени находился в состояниях: 0) покой,  готовность,
готовность,  устный счет; 3) покой, II; 4) готовность, II; 5) образование предложений; 6) покой, III.
устный счет; 3) покой, II; 4) готовность, II; 5) образование предложений; 6) покой, III.

 систолическое кровяное давление;
систолическое кровяное давление;  диастолическое кровяное давление;
диастолическое кровяное давление;  частота сердечных сокращений;
частота сердечных сокращений;  кожные потенциалы
кожные потенциалы
 (диастолическое кровяное давление),
(диастолическое кровяное давление),  (частота сокращений сердечной мышцы) и
(частота сокращений сердечной мышцы) и  (кожный потенциал).
(кожный потенциал).
 Цель исследования — диагностика гипертонии. Данные о ста пациентах, обработанные статистическими методами, оказались разделенными на 3 группы:
Цель исследования — диагностика гипертонии. Данные о ста пациентах, обработанные статистическими методами, оказались разделенными на 3 группы:
 (систолическое давление), а также 7 признаков
(систолическое давление), а также 7 признаков  (диастолическое давление) и 7 признаков
(диастолическое давление) и 7 признаков  (частота сердечных сокращений) очень схожи. Признак
(частота сердечных сокращений) очень схожи. Признак  (кожный потенциал покоя I) обладает по сравнению с частотой сердечных сокращений более сильным разделительным свойством, хотя и сходен с ним по направлению вектора
(кожный потенциал покоя I) обладает по сравнению с частотой сердечных сокращений более сильным разделительным свойством, хотя и сходен с ним по направлению вектора  (кожный потенциал) образуют еще одну группу признаков,
(кожный потенциал) образуют еще одну группу признаков,  по своему разделительному свойству немного отличается от остальных.
по своему разделительному свойству немного отличается от остальных.
 (кожный потенциал в двух состояниях нагрузки) направлены противоположно дискриминантному признаку
(кожный потенциал в двух состояниях нагрузки) направлены противоположно дискриминантному признаку  Если рассматривать только направление векторов, а не их длину, то можно заметить определенное сходство
Если рассматривать только направление векторов, а не их длину, то можно заметить определенное сходство  Для
Для
 или, что то же самое, повернуть эти векторы на 180°.
или, что то же самое, повернуть эти векторы на 180°.
 относительно мало, то же самое можно сказать и о признаке
относительно мало, то же самое можно сказать и о признаке  Частота сердечных сокращений сильно увеличивается при переходе от группы 1 к группе 3 и почти не меняется при переходе от группы 2 к группе 3. Поведение признака
Частота сердечных сокращений сильно увеличивается при переходе от группы 1 к группе 3 и почти не меняется при переходе от группы 2 к группе 3. Поведение признака  представляет собой зеркальное отражение изменений в поведении частоты сердечных сокращений. Кожные потенциалы
представляет собой зеркальное отражение изменений в поведении частоты сердечных сокращений. Кожные потенциалы  ведут себя монотонно. Эта интерпретация убеждает, что разложение дистанта на компоненты дает разумные результаты.
ведут себя монотонно. Эта интерпретация убеждает, что разложение дистанта на компоненты дает разумные результаты.
 признаков считается отдельным кластером. Затем для каждых двух кластеров, т. е. для каждых двух отдельных признаков, вычисляется аффинный коэффициент а. Два кластера, соответствующие наименьшему значению а, объединяются в один. Тем самым число кластеров
признаков считается отдельным кластером. Затем для каждых двух кластеров, т. е. для каждых двух отдельных признаков, вычисляется аффинный коэффициент а. Два кластера, соответствующие наименьшему значению а, объединяются в один. Тем самым число кластеров  уменьшается до
уменьшается до  Далее для всех пар кластеров опять вычисляют аффинные коэффициенты а и объединяют кластеры с наименьшим а. Процедура продолжается. Число кластеров на каждом шаге уменьшается на 1. И так, пока все признаки не объединяются в один кластер. Среди всех промежуточных результатов выделяют хорошо интерпретируемые. Процедуру по желанию можно прервать на определенном шаге. Наш опыт свидетельствует, что процедуру можно закончить после того, как все аффинные коэффициенты станут меньше 0,75.
Далее для всех пар кластеров опять вычисляют аффинные коэффициенты а и объединяют кластеры с наименьшим а. Процедура продолжается. Число кластеров на каждом шаге уменьшается на 1. И так, пока все признаки не объединяются в один кластер. Среди всех промежуточных результатов выделяют хорошо интерпретируемые. Процедуру по желанию можно прервать на определенном шаге. Наш опыт свидетельствует, что процедуру можно закончить после того, как все аффинные коэффициенты станут меньше 0,75.


 Это означает, что кожные потенциалы в состоянии покоя и готовности близки один к другому.
Это означает, что кожные потенциалы в состоянии покоя и готовности близки один к другому.
 расположен ближе к частотам сердечных сокращений
расположен ближе к частотам сердечных сокращений  чем к кожным потенциалам
чем к кожным потенциалам  здесь свидетельствуют лишь о том, что кластерный анализ на основе аффинного коэффициента лучше улавливает содержание признаков. Следовательно, в данном случае кластерный анализ полнее отражает многомерность статистического материала, чем векторная диаграмма (рис. 9). С другой стороны, преимущество векторной диаграммы в ее наглядности, так как она позволяет увидеть свойства признаков и тем самым помогает интерпретировать результаты.
здесь свидетельствуют лишь о том, что кластерный анализ на основе аффинного коэффициента лучше улавливает содержание признаков. Следовательно, в данном случае кластерный анализ полнее отражает многомерность статистического материала, чем векторная диаграмма (рис. 9). С другой стороны, преимущество векторной диаграммы в ее наглядности, так как она позволяет увидеть свойства признаков и тем самым помогает интерпретировать результаты.