Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
6.2.2. МНОГОМЕРНЫЙ ДИСТАНТ, ДИСКРИМИНАНТНАЯ ФУНКЦИЯ. ДИСКРИМИНАНТНЫЙ АНАЛИЗ (КЛАССИФИКАЦИЯ)Величина
Эта величина показывает, насколько две данные выборки противоречат гипотезе
Преимущество этой величины по сравнению с (6.22) заключается в том, что она основана только на несмещенных и состоятельных оценках Рассмотрим некоторую линейную комбинацию исходных
где вектор
В (6.23) величины
есть новый признак.
внутригрупповая дисперсия признака
Многомерный дистант для признака
Сравнивая (6.29) с (6.22), убеждаемся, что признак Среди всех линейных комбинаций, которые могут быть образованы из Линейная комбинация признаков Путем классификации (идентификации) решается вопрос о принадлежности каждого индивида к группам 1 или 2. При этом предполагаются известными характеристики Для практического применения отдельными авторами был предложен ряд различных правил классификации. Одна из трудностей заключается в том, что классификация опирается не на точные значения параметров распределений
где Индивид считается принадлежащим к совокупности
При этом следует выбрать какой-либо определенный уровень значимости а, например Чтобы в любом случае иметь однозначную классификацию, можно для данного индивида остановиться на наиболее вероятном решении, а именно выбрать для него группу с наименьшим Если при идентификации учитываются так называемые априорные вероятности
Индивида относят к группе с наименьшим
соответственно
Последними формулами можно воспользоваться при достаточно больших Пример. Продолжим рассмотрение примера, приведенного в разделе 6.2.1. Получаем значение многомерного дистанта
Дискриминантная функция имеет вид
Средние значения признака
т. е. для детей, заболевших желтухой, значения признака исходных признаков), проведем классификацию каждого из 31 указанных индивидов по правилам (6.30)-(6.33) (как без учета априорных вероятностей, так и с их учетом). Полученные результаты отражены в табл. 2 и 3. Априорные вероятности были выбраны пропорциональными объемам выборок:
Таблица 2. (см. скан) Данные по недоношенным детям, отнесенным к двум группам в результате дискриминантного анализа (с учетом и без учета априорной вероятности): а) по всем четырем признакам, б) только по продолжительности беременности матери. При классификации без априорной вероятности первым указано наиболее вероятное решение; вторым — Другая идентификация, если она считается возможной по Таблица 3. (см. скан) Частоты решений при идентификации 31 недоношенного ребенка (приведены результаты, полученные по правилу наиболее вероятного решения) Идентификация прошла довольно удачно. При разделении по наибольшей вероятности был ошибочно классифицирован всего один ребенок. Различие априорных вероятностей не оказало влияния на результаты классификации. Для сравнения в табл. 2 и 3 приведены также результаты идентификации, в основу которой была положена одна лишь продолжительность беременности матери (признак с наибольшим разделительным свойством). Видно, что в каждую группу ошибочно попадают по три индивида (как с учетом априорной вероятности, так и без ее учета). Итак, очевидно, что одномерная идентификация во многом уступает многомерной.
|
 |
Оглавление
|





























































































































































































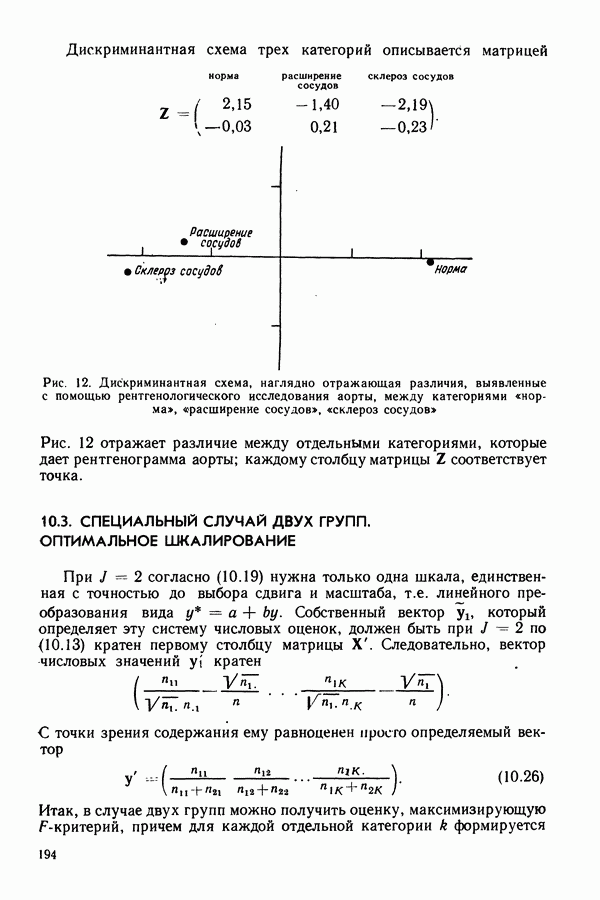































 в гл. 5 рассматривалась как многомерный дистант по совокупности признаков
в гл. 5 рассматривалась как многомерный дистант по совокупности признаков  Для данного конкретного случая двух генеральных совокупностей получим
Для данного конкретного случая двух генеральных совокупностей получим

 или как велико «статистическое расстояние» между обеими генеральными совокупностями. Различие между двумя совокупностями часто выражается и так называемым расстоянием Махаланобиса
или как велико «статистическое расстояние» между обеими генеральными совокупностями. Различие между двумя совокупностями часто выражается и так называемым расстоянием Махаланобиса

 параметров
параметров  Для единообразия мы в своем изложении будем пользоваться дистантом
Для единообразия мы в своем изложении будем пользоваться дистантом 
 признаков
признаков  именно пусть
именно пусть

 с компонентами
с компонентами  определяется как
определяется как

 следует рассматривать как переменные. Итак,
следует рассматривать как переменные. Итак, 

 значения для каждого индивида определяются с помощью равенства (6.25). Средние значения этого признака
значения для каждого индивида определяются с помощью равенства (6.25). Средние значения этого признака  в обеих совокупностях суть
в обеих совокупностях суть





 имеет тот же самый дистант, что и вся совокупность исходных
имеет тот же самый дистант, что и вся совокупность исходных  признаков.
признаков.
 исходных признаков,
исходных признаков,  дает дистанту наивысшее значение.
дает дистанту наивысшее значение.
 в виде (6.23) и (6.25) называется дискриминантной функцией, а признак
в виде (6.23) и (6.25) называется дискриминантной функцией, а признак  дискриминантным признаком. Результат (6.29) означает, что разделение групп с помощью дискриминантного признака
дискриминантным признаком. Результат (6.29) означает, что разделение групп с помощью дискриминантного признака  можно выполнить с таким же успехом, как и с помощью всей совокупности
можно выполнить с таким же успехом, как и с помощью всей совокупности  исходных признаков
исходных признаков  Поэтому, решая вопрос о том, к какой из двух имеющихся групп надо отнести данного индивида (как его классифицировать), вместо
Поэтому, решая вопрос о том, к какой из двух имеющихся групп надо отнести данного индивида (как его классифицировать), вместо  исходных признаков мы будем брать исключительно дискриминантный признак
исходных признаков мы будем брать исключительно дискриминантный признак 
 обеих выборок. Дискриминантный анализ — это непосредственное использование статистического метода.
обеих выборок. Дискриминантный анализ — это непосредственное использование статистического метода.
 и 2 (они нам неизвестны), а на их оценки по выборкам. В избранном нами правиле мы связали задачу классификации с проверкой статистических гипотез. А именно: при
и 2 (они нам неизвестны), а на их оценки по выборкам. В избранном нами правиле мы связали задачу классификации с проверкой статистических гипотез. А именно: при  проверяется гипотеза о принадлежности индивида (с вектором признаков
проверяется гипотеза о принадлежности индивида (с вектором признаков  к совокупности
к совокупности  (с векторов средних значений
(с векторов средних значений  Для этого вычисляются две статистики:
Для этого вычисляются две статистики:

 определяются по формулам
определяются по формулам 
 если
если

 С помощью этого метода индивид может быть отнесен либо к одной из двух совокупностей, либо к обеим совокупностям сразу, либо не отнесен ни к одной из них. Это многообразие ответов соответствует действительным условиям приложений, так как при идентификации имеет смысл как многозначный, так и однозначный ответ — что индивид не входит ни в одну из имеющихся групп. С помощью (6.32) вокруг каждого из двух центров
С помощью этого метода индивид может быть отнесен либо к одной из двух совокупностей, либо к обеим совокупностям сразу, либо не отнесен ни к одной из них. Это многообразие ответов соответствует действительным условиям приложений, так как при идентификации имеет смысл как многозначный, так и однозначный ответ — что индивид не входит ни в одну из имеющихся групп. С помощью (6.32) вокруг каждого из двух центров  и
и  устанавливаются области рассеяния.
устанавливаются области рассеяния.  них с вероятностью
них с вероятностью  попадают индивиды, действительно относящиеся к соответствующим группам. Итак, при
попадают индивиды, действительно относящиеся к соответствующим группам. Итак, при  приблизительно 95% индивидов, действительно принадлежащих к 1-й группе, будут отнесены к этой группе с помощью нашего правила.
приблизительно 95% индивидов, действительно принадлежащих к 1-й группе, будут отнесены к этой группе с помощью нашего правила.
 если
если  то группу 1, если
то группу 1, если  то группу 2, если
то группу 2, если  то группу 1 или 2.
то группу 1 или 2.
 обеих групп, указывающие, с какой вероятностью данный индивид можно отнести к группе 1 или к группе 2, то рекомендуется использовать величины
обеих групп, указывающие, с какой вероятностью данный индивид можно отнести к группе 1 или к группе 2, то рекомендуется использовать величины

 При
При  это решающее правило совпадает с правилом, приведенным выше. Если объемы выборок стремятся к бесконечности, то из (6.33) получаем
это решающее правило совпадает с правилом, приведенным выше. Если объемы выборок стремятся к бесконечности, то из (6.33) получаем


 Индивида относят к группе с наименьшим
Индивида относят к группе с наименьшим 


 в обеих группах
в обеих группах

 в среднем меньше, чем для здоровых. При взгляде на знак коэффициентов дискриминантной функции бросается в глаза, что коэффициент при переменной
в среднем меньше, чем для здоровых. При взгляде на знак коэффициентов дискриминантной функции бросается в глаза, что коэффициент при переменной  (вес ребенка при рождении) отрицателен, т. е. с увеличением веса ребенка при рождении (при остальных неизменяющихся признаках) возрастает опасность заболевания желтухой. Исходя же из средних значений веса ребенка при рождении (см. раздел 6.2.1), а также опыта врачей следовало бы ожидать обратной тенденции. Детальное обсуждение вида дискриминантной функции (см. [21]) привело к убеждению, что отрицательное влияние переменной
(вес ребенка при рождении) отрицателен, т. е. с увеличением веса ребенка при рождении (при остальных неизменяющихся признаках) возрастает опасность заболевания желтухой. Исходя же из средних значений веса ребенка при рождении (см. раздел 6.2.1), а также опыта врачей следовало бы ожидать обратной тенденции. Детальное обсуждение вида дискриминантной функции (см. [21]) привело к убеждению, что отрицательное влияние переменной  имеет глубокий смысл. Этот пример показывает, как многомерный анализ открывает новые связи, невидимые при исследовании отдельных показателей. Чтобы непосредственно проверить способность к разделению дискриминантного признака
имеет глубокий смысл. Этот пример показывает, как многомерный анализ открывает новые связи, невидимые при исследовании отдельных показателей. Чтобы непосредственно проверить способность к разделению дискриминантного признака  (образованного из четырех
(образованного из четырех

