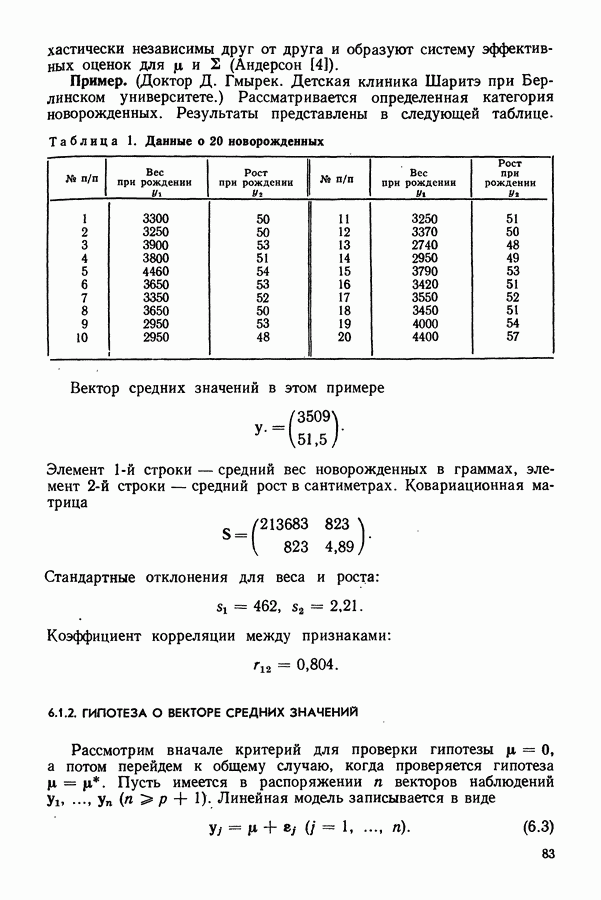
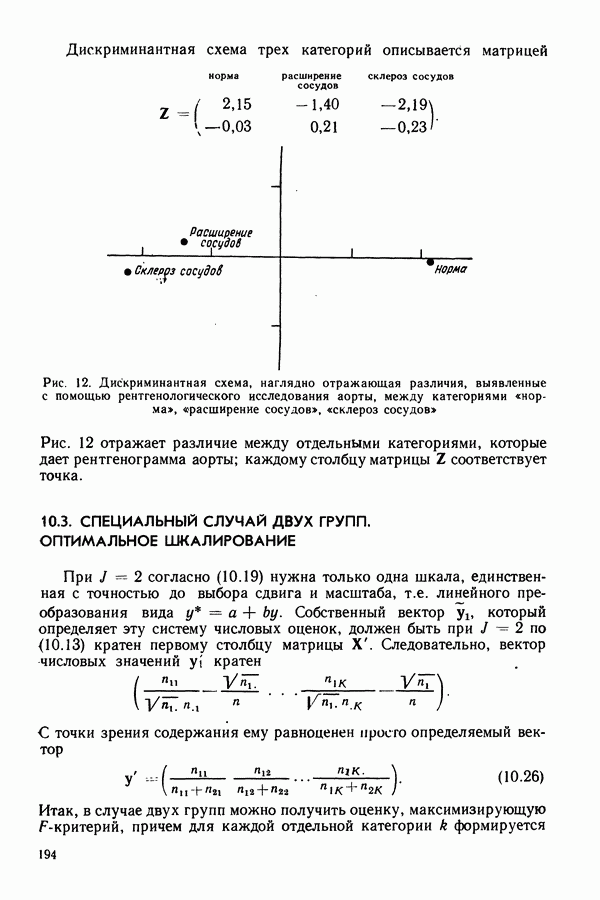
7.4. МНОГОМЕРНЫЙ ДИСТАНТ
У специалистов, работающих в области биологии, медицины и т. д., часто возникает необходимость объективно оценить информационное содержание одной или нескольких измеряемых величин. Применительно к обсуждаемому здесь однофакторному многомерному дисперсионному анализу это означает, что должна быть найдена мера, показывающая, насколько  -мерные векторы средних значений отражают разделение индивидов на группы. В данном разделе вводится подобный показатель информации, который мы называем многомерным дистантом. В своих рассуждениях будем опираться на теоремы, доказанные в разделе 5.1. В частном случае при разделении индивидов на две группы многомерный дистант уже рассматривался нами в разделе 6.2.2.
-мерные векторы средних значений отражают разделение индивидов на группы. В данном разделе вводится подобный показатель информации, который мы называем многомерным дистантом. В своих рассуждениях будем опираться на теоремы, доказанные в разделе 5.1. В частном случае при разделении индивидов на две группы многомерный дистант уже рассматривался нами в разделе 6.2.2.
Определение дистанта
Чтобы найти выражение для разделительной способности либо диагностического содержания признака или совокупности признаков, надо помнить, что подобные функции могут выполнять статистики  и
и  из разделов 7.2 и 7.3. Эти статистики, однако, неудобны, так как не дают сравнимых значений при различных
из разделов 7.2 и 7.3. Эти статистики, однако, неудобны, так как не дают сравнимых значений при различных  и различных гипотезах; кроме того, их значения обычно возрастают по мере роста
и различных гипотезах; кроме того, их значения обычно возрастают по мере роста  Применяемый же нами многомерный дистант свободен от этих недостатков.
Применяемый же нами многомерный дистант свободен от этих недостатков.
В соответствии с главой 5 определим многомерный дистант совокупности признаков  как
как

Его можно также представить в виде

Величина этого дистанта зависит от случайностей, присущих используемым выборкам. Случайность можно устранить, рассматривая «истинный дистант»

где

Поскольку значение истинного дистанта при решении практических задач неизвестно, далее для многомерной классификации возьмем  Как было показано в разделе
Как было показано в разделе  является состоятельной
является состоятельной
оценкой  т. е. с ростом объема выборки
т. е. с ростом объема выборки  приближается к истинной величине
приближается к истинной величине  Понятие истинного дистанта в этом разделе не рассматривается; оно было необходимо для определения «истинно избыточного признака» (раздел 5.1) и для вывода критерия значимости при доказательстве избыточности (разделы 5.4 и 7.8).
Понятие истинного дистанта в этом разделе не рассматривается; оно было необходимо для определения «истинно избыточного признака» (раздел 5.1) и для вывода критерия значимости при доказательстве избыточности (разделы 5.4 и 7.8).
Всегда  При этом
При этом  означает, что
означает, что  признаков полностью непригодны для разделения
признаков полностью непригодны для разделения  групп. Чем больше величина
групп. Чем больше величина  тем лучше проходит разделение
тем лучше проходит разделение  групп с помощью данных
групп с помощью данных  признаков.
признаков.
Пример. Для данных о гипертиреозе из раздела 7.1 получаем следующее значение многомерного дистанта:

Согласно многомерному критерию из раздела 7.2 эта величина значимо отличается от нуля.
Инвариантность относительно невырожденного преобразования
Чрезвычайно важное свойство  его инвариантность относительно любого невырожденного линейного преобразования признаков. А именно, если вместо первоначально заданного вектора признаков
его инвариантность относительно любого невырожденного линейного преобразования признаков. А именно, если вместо первоначально заданного вектора признаков  используем новый вектор признаков
используем новый вектор признаков  полученный из первого путем невырожденного преобразования
полученный из первого путем невырожденного преобразования

то

Таким образом, многомерный дистант может рассматриваться как характеристика всего линейного пространства признаков, а не только как характеристика различных  -мерных комбинаций признаков. Если, например, при медицинском обследовании измеряют систолическое
-мерных комбинаций признаков. Если, например, при медицинском обследовании измеряют систолическое  и диастолическое
и диастолическое  кровяное давление индивида, а затем путем вычитания и суммирования находят новые признаки
кровяное давление индивида, а затем путем вычитания и суммирования находят новые признаки  то все возможные комбинации из пар признаков, а именно
то все возможные комбинации из пар признаков, а именно  имеют одинаковые дистанты и поэтому с точки зрения диагностики эквивалентны. Этот вывод важен, так как свидетельствует о независимости многомерного дистанта от произвола в выборе признаков.
имеют одинаковые дистанты и поэтому с точки зрения диагностики эквивалентны. Этот вывод важен, так как свидетельствует о независимости многомерного дистанта от произвола в выборе признаков.
Дистант произвольного множества признаков
Многомерный дистант можно вычислить для любого подпространства исходного  -мерного пространства признаков. Допустим, что из заданных
-мерного пространства признаков. Допустим, что из заданных  признаков с помощью линейного преобразования
признаков с помощью линейного преобразования

образовано и новых признаков  В таком случае для них, точнее для
В таком случае для них, точнее для  -мерного пространства, натянутого на них (в предположении, что
-мерного пространства, натянутого на них (в предположении, что  значение дистанта можно получить следующим образом. Находим выражение векторов средних значений и ковариационную матрицу
значение дистанта можно получить следующим образом. Находим выражение векторов средних значений и ковариационную матрицу  -вектора:
-вектора:

С помощью (7.30) получаем

Естественно, таким образом можно определить дистант любого подмножества призраков  в частности, дистант
в частности, дистант  одного признака и дистант
одного признака и дистант  пары признаков, а также показать, что
пары признаков, а также показать, что

Здесь  диагональные элементы матрицы
диагональные элементы матрицы  и
и

До сих пор при определении многомерного дистанта для совокупности признаков мы предполагали (из-за обращения матрицы в (7.30) и (7.31)), что между рассматриваемыми признаками отсутствуют линейные зависимости. Можно отказаться от этого условия, если договориться, что в случае линейной зависимости признаков излишние признаки будут исключаться. После чего возможно использование формул (7.30) или (7.31). Таким образом,

Рассмотрим свойство монотонности. Если два пространства признаков содержатся одно в другом, то охватывающее пространство дает большее (или по крайней мере не меньшее) значение дистанта. Иными словами, если число признаков увеличивается, то многомерная классификация облегчается в смысле увеличения дистанта. Например,

Естественно, эти соотношения выполняются, когда в основе дистантов лежат одна и та же модель, одна и та же гипотеза, и одни и те же выборки.
Пример. Для данных о гипертиреозе из раздела 7.1 для пар признаков  получаем значения дистантов:
получаем значения дистантов:

Так как матрица симметричная, то приводится только ее верхняя, наддиагональная, часть. Диагональные элементы — это дистанты десяти отдельных признаков 
Отсюда видно, что признак  (белковосвязанный
(белковосвязанный  во втором тесте с радиоактивным йодом) обладает наилучшей индивидуальной разделительной способностью и что наилучшей разделительной способностью среди пар обладает пара признаков
во втором тесте с радиоактивным йодом) обладает наилучшей индивидуальной разделительной способностью и что наилучшей разделительной способностью среди пар обладает пара признаков  регистрируемый через 3 часа после начала второго теста с радиоактивным йодом).
регистрируемый через 3 часа после начала второго теста с радиоактивным йодом).
Бросается в глаза, что при объединении двух признаков в пару значение дистанта иногда увеличивается незначительно (например, при объединении признаков  С другой стороны, скачок в величине дистанта может быть чрезвычайно высоким (например, при объединении
С другой стороны, скачок в величине дистанта может быть чрезвычайно высоким (например, при объединении  По формулам
По формулам  получаем
получаем  для
для  Отсюда в случае одного признака (диагональные элементы) критическое значение статистики
Отсюда в случае одного признака (диагональные элементы) критическое значение статистики  равно 0,349, а в случае пары признаков (внедиагональные элементы) критическое значение составляет 0.602. В матрице значения дистантов, значимо отличающиеся от нуля, выделены жирным шрифтом (уровень значимости а
равно 0,349, а в случае пары признаков (внедиагональные элементы) критическое значение составляет 0.602. В матрице значения дистантов, значимо отличающиеся от нуля, выделены жирным шрифтом (уровень значимости а 
Связи между двумя множествами признаков
Для понимания многомерного дисперсионного и дискриминантного анализов полезно более обстоятельно исследовать возможные связи между двумя совокупностями признаков и  состоящими соответственно из и
состоящими соответственно из и  признаков. Как для так и для
признаков. Как для так и для  наконец, для их объединения
наконец, для их объединения  можно определить многомерные дистанты
можно определить многомерные дистанты  Представляют интерес следующие частные случаи:
Представляют интерес следующие частные случаи:

В этом случае добавление множества признаков  к множеству не приводит к увеличению дистанта. Следовательно, множество по сравнению с множеством избыточно. При классификации признаки из множества
к множеству не приводит к увеличению дистанта. Следовательно, множество по сравнению с множеством избыточно. При классификации признаки из множества  не оказывают влияния на результаты.
не оказывают влияния на результаты.

Здесь множество  избыточно относительно но и избыточно относительно
избыточно относительно но и избыточно относительно  Оба множества признаков по своему диагностическому значению эквивалентны и полностью взаимозаменимы.
Оба множества признаков по своему диагностическому значению эквивалентны и полностью взаимозаменимы.

В этом случае оба множества признаков вносят свой вклад в разделение групп независимо друг от друга.

Объединение обоих множеств признаков приводит к увеличению многомерного дистанта. Возможно, что оба множества признаков, рассматриваемых по отдельности, дают относительно небольшие значения дистанта, однако  комбинация обладает неожиданно высоким диагностическим значением. Лишь комбинация множеств признаков полностью эффективна; отдельные множества в этом отношении могут оказаться несущественными.
комбинация обладает неожиданно высоким диагностическим значением. Лишь комбинация множеств признаков полностью эффективна; отдельные множества в этом отношении могут оказаться несущественными.
Вид связи между обоими множествами  можно выразить через аффинный коэффициент
можно выразить через аффинный коэффициент

который измеряется в пределах

При  множества
множества  полностью взаимозаменимы. При
полностью взаимозаменимы. При  имеет место независимое действие и
имеет место независимое действие и  Случай
Случай  означает, что комбинация
означает, что комбинация  по сравнению с отдельными множествами имеет большее диагностическое значение. Аффинный коэффициент применяется в кластерном анализе (см. раздел 7.11.2).
по сравнению с отдельными множествами имеет большее диагностическое значение. Аффинный коэффициент применяется в кластерном анализе (см. раздел 7.11.2).
Пример. По данным о гипертиреозе из раздела 7.1 аффинные коэффициенты  между каждыми двумя признаками суть
между каждыми двумя признаками суть

Так как матрица симметричная, то приводится только ее верхняя, наддиагональная часть.
Сразу бросается в глаза, что признаки  вносят вклад в диагностику независимо от других признаков (аффинный коэффициент
вносят вклад в диагностику независимо от других признаков (аффинный коэффициент  близок к 1). Далее можно увидеть, что пары признаков
близок к 1). Далее можно увидеть, что пары признаков  возможно,
возможно,  в смысле диагностики подобны одна другой
в смысле диагностики подобны одна другой
(небольшие значения  Следовательно, использовать для классификации каждую из этих пар нет необходимости. Наконец, ясно, что путем многомерной композиции признаков
Следовательно, использовать для классификации каждую из этих пар нет необходимости. Наконец, ясно, что путем многомерной композиции признаков  может быть достигнут более значительный диагностический эффект, чем при независимом использовании этих признаков (аффинные коэффициенты
может быть достигнут более значительный диагностический эффект, чем при независимом использовании этих признаков (аффинные коэффициенты  существенно выше 1). Это означает, что информационное содержание этих признаков раскрывается только при многомерном подходе. Это, вероятно, связано с тем, что увеличение или уменьшение значения одного признака на фоне других дает больше для классификации, чем значения признаков по отдельности. Детальный анализ вычисленных коэффициентов
существенно выше 1). Это означает, что информационное содержание этих признаков раскрывается только при многомерном подходе. Это, вероятно, связано с тем, что увеличение или уменьшение значения одного признака на фоне других дает больше для классификации, чем значения признаков по отдельности. Детальный анализ вычисленных коэффициентов  можно провести по методу, изложенному в разделе 7.11.2.
можно провести по методу, изложенному в разделе 7.11.2.
Нормированный дистант
Для сравнения одних дистантов с другими в задачах с различным числом групп следует вместо  пользоваться нормированным дистантом (см. также (5.8)):
пользоваться нормированным дистантом (см. также (5.8)):

Чтобы получить довод в пользу такого подхода, рассмотрим дистант  в задаче (7.20) о проверке гипотезы Нцто
в задаче (7.20) о проверке гипотезы Нцто  в случае
в случае  групп. Он равен:
групп. Он равен:

При постоянных  зависит весьма существенно от числа групп
зависит весьма существенно от числа групп  Напротив, дистант
Напротив, дистант

относительно независим от У, так как при  для любого
для любого  получаем
получаем

Пример. Для данных о гипертиреозе из раздела 7.1 для каждой пары групп получаем значения дистантов

Следовательно, нормированные дистанты суть

Для разделения всех трех групп совместно  Эти значения получаем при использовании всех десяти признаков.
Эти значения получаем при использовании всех десяти признаков.