Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
11. ОБЩИЕ ЗАМЕЧАНИЯ О ПРЕДПОСЫЛКАХ МНОГОМЕРНОГО ДИСПЕРСИОННОГО АНАЛИЗАМногомерный дисперсионный анализ, как впрочем, любая математическая теория основывается на предпосылках, ограничивающих область его применений. Речь идет о многомерном нормальном распределении векторов наблюдений, о равенстве ковариационных матриц, стохастической независимости векторов наблюдений и о том, что для каждого индивида известны результаты измерения всех Эти предпосылки не только не всегда точно выполняются на практике, но часто даже нарушаются. Означает ли это, что многомерный дисперсионный анализ не представляет интереса для практического применения или же можно найти достаточно аргументов в его пользу? С теоретической точки зрения такая постановка вопроса касается прежде всего устойчивости (робастности) критерия значимости. Известно, что Соответствующие исследования устойчивости критериев многомерного дисперсионного анализа находятся еще в начальной стадии, так что с теоретической точки зрения в настоящее время нельзя вынести окончательного приговора. Математическая теория многомерного дисперсионного анализа должна учитывать, что распределения встречающиеся на практике, весьма разнообразны, во-первых, из-за большого числа признаков и, во-вторых, из-за их взаимосвязей. С точки зрения практики в дискуссии о выполнении предпосылок следует учитывать другую сторону дела. В первую очередь важно решить, какие выводы позволяет сделать статистический метод; в какой мере на основе информации, полученной с помощью анализа данных приобретаются новые знания о структуре многомерных наблюдений. Применяя дисперсионный анализ, не следует опасаться, что любое нарушение предпосылок приведет к резкому искажению выводов. Напротив, многое за то, что основные результаты анализа, по крайней мере в своей существенной части, остаются правильными и при наличии отклонений. Невыполнение предпосылок может привести к тому, что критерий значимости, вычисленный по обычному либо описанному в данной книге алгоритму для уровня значимости Многочисленные исследования с применением многомерного дисперсионного анализа подтверждают, что преувеличенная осторожность и сдержанность в решении этого вопроса неуместны. На практике в большинстве случаев многомерный дисперсионный анализ применяют не проводя подробного исследования многомерного распределения признаков, если они непрерывны. Иногда имеет смысл перед началом анализа преобразовывать некоторые признаки, например прологарифмировать их. Путем шкалирования, описанного в гл. 10, мы получаем возможность работать также с качественными признаками. Однако это шкалирование следует использовать лишь тогда, когда на передний план выдвигается не сравнение векторов средних с помощью критерия значимости, а другие многомерные рассмотрения. Вообще шкалирование хорошо себя зарекомендовало в дискриминантном анализе. Что касается равенства ковариационных матриц, то мы считаем правильным проводить дисперсионный анализ исходя из этого предположения. Благодаря такой предпосылке значительно упрощается математическая теория и появляется больше возможностей понизить размерность и наглядно интерпретировать результаты. Однако в тех задачах, где требуется особая точность, или если решения имеют особую важность, следует учитывать неравенство ковариации. В случае неравных ковариационных матриц имеются кое-какие приближенные результаты. К стохастической независимости векторов наблюдений предъявляются высокие требования. Должна соблюдаться независимость «индивидов», что большей частью не вызывает особых затруднений. При нарушении независимости степени свободы, фигурирующие в критериях значимости, становятся совершенно нереальными. Если в исходном числовом материале отсутствуют некоторые наблюдения, но в не слишком большом количестве, то можно воспользоваться некоторыми существующими методами оценивания для вычисления заменяющих их значений, а после этого начинать собственно анализ данных. Но этот подход становится сомнительным, если отсутствует много значений или если их отсутствие носит не случайный, а систематический характер. В частности, еще не ясно, стоит ли при классификации отдельных индивидов замещать значения пропущенного признака его оценкой, полученной с помощью значений других признаков, и далее использовать это число в дискриминантной функции, поскольку при этом, вероятно, недостаточно принимается в расчет многомерная связь признаков. Поэтому мы рекомендуем либо совсем избегать пропуска данных, либо, если это не удается, проводить анализ последовательно в нескольких вариантах, используя каждый раз только определенное множество всех Следует также упомянуть, что в последние два десятилетия в рамках многомерного анализа возникла специальная теория обработки данных с пропущенными наблюдениями, на которую можно опираться в определенных практических случаях (см. например, [78]). Все приведенные выше указания нельзя рассматривать как непреложное предписание, отступления от них в зависимости от реальной ситуации возможны. Использование многомерного метода обеспечивает большую надежность результатам анализа. В заключение нам хотелось бы отметить, что в последнее время в одномерном и многомерном анализах начинают применяться и непараметрические методы. Планирование объема выборки для критерия T^2Планирование объема выборки для критерия (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) Формулы для приближенного вычисления вероятности ошибки:
Отклонение от точного значения а при
|
 |
Оглавление
|




























































































































































































































 признаков (нет пропущенных измерений).
признаков (нет пропущенных измерений).
 -критерий в определенной степени устойчив к отклонениям от нормальности распределения наблюдаемых значений. Устойчивость этого критерия относительно нарушения равенства дисперсий тем выше, чем ближе один к другому объемы выборок.
-критерий в определенной степени устойчив к отклонениям от нормальности распределения наблюдаемых значений. Устойчивость этого критерия относительно нарушения равенства дисперсий тем выше, чем ближе один к другому объемы выборок.
 в действительности при настоящем, но неизвестном распределении критериальной статистики имеет уровень значимости, например
в действительности при настоящем, но неизвестном распределении критериальной статистики имеет уровень значимости, например  или
или  Любой статистик по опыту знает, как мало обоснован выбор того или иного конкретного уровня значимости и поэтому понимает, что подобные срывы выбора уровня значимости не означают крушения всего анализа. И даже если встать на пессимистическую точку зрения и не верить в пользу критериев значимости, можно заключить, что многомерный анализ имеет смысл, так как он стандартным образом производит уплотнение экспериментальных данных.
Любой статистик по опыту знает, как мало обоснован выбор того или иного конкретного уровня значимости и поэтому понимает, что подобные срывы выбора уровня значимости не означают крушения всего анализа. И даже если встать на пессимистическую точку зрения и не верить в пользу критериев значимости, можно заключить, что многомерный анализ имеет смысл, так как он стандартным образом производит уплотнение экспериментальных данных.
 признаков, имея в распоряжении соответствующие результаты для всех ожидаемых комбинаций фактически встречающихся признаков без искажения.
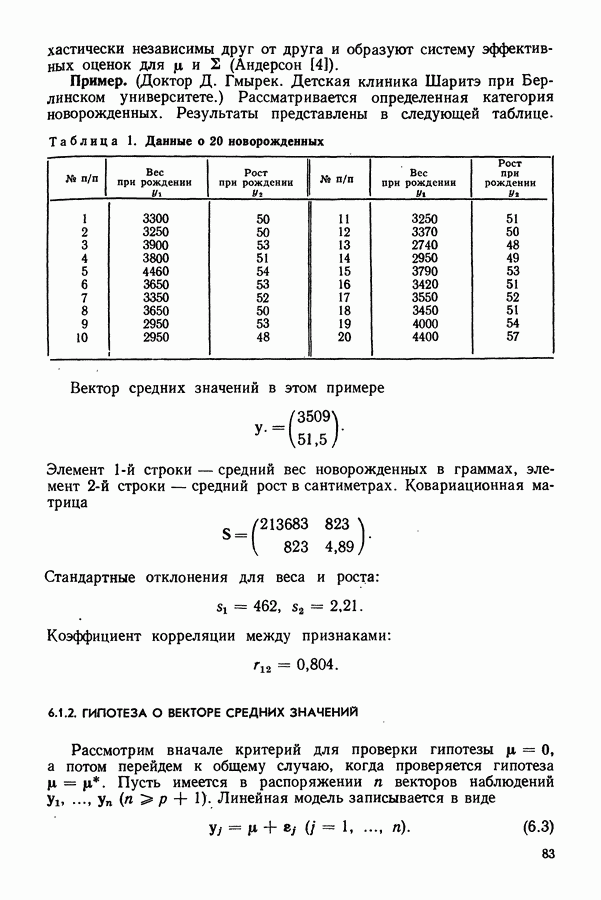
признаков, имея в распоряжении соответствующие результаты для всех ожидаемых комбинаций фактически встречающихся признаков без искажения.
 при сравнении средних двух групп. В таблице указан объем выборки, используемый для каждой группы,
при сравнении средних двух групп. В таблице указан объем выборки, используемый для каждой группы,  число признаков, а — ошибка I рода,
число признаков, а — ошибка I рода,  ошибка II рода, наименьшее отклонение от гипотезы о равенстве средних: для одного признака
ошибка II рода, наименьшее отклонение от гипотезы о равенстве средних: для одного признака 
 степени свободы
степени свободы  -распределения:
-распределения:

 меньше 0,005.
меньше 0,005.
