Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
7.8. ИСКЛЮЧЕНИЕ ИЗЛИШНИХ ПРИЗНАКОВДля применения многомерного дисперсионного и дискриминантного анализов особое значение приобретают высокоэффективные комбинации признаков. При этом стремятся достигнуть возможно большего значения дистанта с возможно меньшим числом признаков. Пошаговое сокращение числа признаковСократить число признаков можно шаг за шагом, от
Используя (5.29) и (7.58), получим
где логично можно выполнить следующий шаг, исключая очередной признак. На каждом шаге вычисляются заново показатели необходимости. Как уже подробно обсуждалось в разделе 5.4 при исключении признака можно ориентироваться также на критериальную Статистику
Это неравенство следует из (5.43) и (5.46). Если признак
Прекращение процесса сокращения признаковНа вопрос, когда следует прервать процесс исключения признаков, т. е. другими словами, когда будет принято компромиссное решение о величине дистанта и числе признаков, можно ответить по-разному. Аналогично процедуре, изложенной в разделе 7.7.2, окончание процесса исключения можно поставить в зависимость от того, насколько отдельные признаки дают значимое увеличение дистанта; можно также опираться на эвристический принцип оценки подмножества признаков. Если исключать все признаки с недостаточно значимым статистическим влиянием, то процесс сокращения можно продолжать на основе (7.82) и (7.83) до тех пор, пока все остающиеся признаки
Можно также продолжать сокращение до тех пор, пока (по соответствующему критерию) совокупность всех исключенных признаков не окажется избыточной по сравнению с оставшимися. В таком случае в соответствии с (5.43) процедура может быть прервана, если ни для одного из оставшихся признаков
Здесь так же, как в (7.84), — показатель необходимости признака
В основу формул (7.85)-(7.87) здесь (в отличие от раздела 5.4) для облегчения расчетов положена упрощенная форма критерия значимости. При этих критериях значимости результат процесса сокращения сильно зависит от объема выборки Само собой разумеется, прекращение процедуры исключения признаков в конкретных случаях можно сделать зависимым от теоретико-содержательных соображений. На этом аспекте процедуры мы не будем подробно останавливаться. Пример. Для данных о гипертиреозе из раздела 7.1 при учете всех 10 признаков получаем следующие показатели необходимости: Сравнивая эти значения со значениями дистанта для отдельных признаков (см. раздел 7.4), видим, что упорядочения признаков по одномерному разделительному свойству и по показателю необходимости не согласуются. Так, признак Все приведенные нами показатели необходимости по критерию (7.84) (при Причина отсутствия значимости заключается в том, что каждый из 10 признаков может быть заменен прочими девятью и, следовательно, специфическое влияние определенного признака остается сомнительным. Напротив, если исключаются излишние признаки, то появляется большая надежда на то, что показатели необходимости оставшихся признаков будут значимо отличаться от нуля. Другими словами, эти признаки будут оказывать существенное влияние на разделение групп. По табл. 8 можно проследить весь процесс исключения Признаков применительно к данным о гипертиреозе. Процесс начинается с 10 признаков и оканчивается одним признаком (столбец 2). в столбце 3 указан признак, исключаемый на данном шаге. В столбце 4 приведены значения дистанта В столбце 8 даны значения показателей необходимости
вычисленные в соответствии с формулой (7.84). В столбцах 10 и 11 приведены соответствующие степени свободы и квантиль По окончании процесса сокращения остается лишь признак Если сокращать признаки до тех пор, пока не будут исключены все незначимо влияющие на разделение групп, то в нашем распоряжении останется тройка признаков Подобная надежность для других совокупностей признаков, возникающих в процессе сокращения (см. в столбце 9 табл. 8), не достигается Таблица 8. (см. скан) Процедура сокращения признаков на примере идентификации больных гипертиреозом Пошаговое расширение совокупности признаковИзложенный выше пошаговый метод сокращения признаков оптимален в том смысле, что на каждом шаге оставляет из всех возможных комбинаций признаков - обладающую наибольшим дистантом. В результате же нескольких таких шагов мы не обязательно получаем наилучшую совокупность признаков. При известных обстоятельствах может найтись другое множество такого же числа признаков, превосходящее первое значением своего дистанта. Поэтому на практике наряду с методом исключения используют и метод последовательного пополнения множества признаков, а также их комбинации. При включении признака в уже имеющееся множество останавливаются на признаке, дающем наибольшее приращение значению дистанта. Так же как метод последовательного исключения, метод последовательного пополнения совокупности признаков не всегда дает наилучшую комбинацию. Б. Визорке [86] провел сравнение обоих методов применительно к регрессионному анализу. По его мнению, наилучшие комбинации большого числа признаков можно получить скорее методом последовательного исключения, а наилучшие комбинации малого числа призраков — скорее методом последовательного пополнения. В целом метод последовательного исключения эффективнее. Во избежание затруднений Визорке предлагает при применении любого из этих методов проверять, возможно ли улучшение за счет замены признака из множества оставленных на уже исключенный. Мы также за комбинированное применение обоих методов: вначале, по нашему мнению, можно применить метод исключения по принципу наименьшей вероятности ошибки, а затем найденное множество признаков оптимизировать с помощью пошаговых методов включения и исключения. Из следующего раздела мы увидим, что при использовании метода пошагового пополнения требуется тот же самый математический аппарат и такм же объем вычислений, как и при методе исключения.
|
 |
Оглавление
|




























































































































































































































 до
до  затем до
затем до  и т. д. Признак на каждом шаге отбрасывается так, чтобы менее всего уменьшался многомерный дистант. Исходя из
и т. д. Признак на каждом шаге отбрасывается так, чтобы менее всего уменьшался многомерный дистант. Исходя из  признаков исключают признак с наименьшим показателем необходимости
признаков исключают признак с наименьшим показателем необходимости


 весовые коэффициенты элементарных дискриминантных функций,
весовые коэффициенты элементарных дискриминантных функций,  диагональные элементы матрицы
диагональные элементы матрицы 
 соответствующую критерию избыточности для признака
соответствующую критерию избыточности для признака  Исключения признаков по этому методу не всегда идентичны исключениям на основе показателей необходимости (7.81). Но так как точное вычисление
Исключения признаков по этому методу не всегда идентичны исключениям на основе показателей необходимости (7.81). Но так как точное вычисление  затруднительно, мы не хотим вступать на этот второй путь. Ограничимся лишь указанием неравенства для упомянутой статистики
затруднительно, мы не хотим вступать на этот второй путь. Ограничимся лишь указанием неравенства для упомянутой статистики

 избыточен, величина
избыточен, величина  точно распределена по закону
точно распределена по закону  со степенями свободы
со степенями свободы

 не будут удовлетворять неравенству
не будут удовлетворять неравенству

 не выполняется неравенство
не выполняется неравенство

 среди множества признаков
среди множества признаков  а степени свободы определяется как
а степени свободы определяется как

 Чем больше
Чем больше  тем меньше признаков исключается. Как эвристический способ отбора признаков может быть использован уже упомянутый в разделе 7.7.2 принцип наименьшей вероятности ошибки. Причем из всей совокупности признаков, оставшихся после нескольких исключений, выделяем те, для которых многомерные критерии, вычисляемые по формулам (7.12)- (7.14) или (7.15)-(7.19), дают наименьший критический уровень. Из нашего опыта следует, что этот эвристический принцип дает вполне осмысленные результаты.
тем меньше признаков исключается. Как эвристический способ отбора признаков может быть использован уже упомянутый в разделе 7.7.2 принцип наименьшей вероятности ошибки. Причем из всей совокупности признаков, оставшихся после нескольких исключений, выделяем те, для которых многомерные критерии, вычисляемые по формулам (7.12)- (7.14) или (7.15)-(7.19), дают наименьший критический уровень. Из нашего опыта следует, что этот эвристический принцип дает вполне осмысленные результаты.
 .
.
 обладает очень малой одномерной разделительной способностью; однако в комбинации с другими признаками, в частности с
обладает очень малой одномерной разделительной способностью; однако в комбинации с другими признаками, в частности с  оказывается чрезвычайно полезным. Это обусловлено, в частности, высокой корреляцией между
оказывается чрезвычайно полезным. Это обусловлено, в частности, высокой корреляцией между  и другими признаками (см. раздел 7.2).
и другими признаками (см. раздел 7.2).
 ) незначимо отличаются от нуля. Наименьшее значение
) незначимо отличаются от нуля. Наименьшее значение  требуемое для подтверждения значимости, равно 4,47.
требуемое для подтверждения значимости, равно 4,47.
 для остающихся на каждом этапе
для остающихся на каждом этапе  признаков. Значения критериальной статистики
признаков. Значения критериальной статистики  (раздел 7.2), соответствующие степени свободы
(раздел 7.2), соответствующие степени свободы  и критические уровни а (т. е. уровни, при которых многомерные критерии становятся значимыми) указаны в столбцах 5, 6 и 7.
и критические уровни а (т. е. уровни, при которых многомерные критерии становятся значимыми) указаны в столбцах 5, 6 и 7.
 исключа-ёмых признаков, в столбце 9 — значения статистики
исключа-ёмых признаков, в столбце 9 — значения статистики

 -распределения на уровне значимости
-распределения на уровне значимости 
 уже известный нам из раздела 7.4 как единичный признак с наилучшей разделяющей способностью. Пара признаков
уже известный нам из раздела 7.4 как единичный признак с наилучшей разделяющей способностью. Пара признаков  что идут последними в процессе сокращения, еще в разделе 7.4 была выявлена как наиболее благоприятная комбинация.
что идут последними в процессе сокращения, еще в разделе 7.4 была выявлена как наиболее благоприятная комбинация.
 Влияние на разделение каждого признака из этой тройки статистически значимо (значение статистики превышает 3,55).
Влияние на разделение каждого признака из этой тройки статистически значимо (значение статистики превышает 3,55).
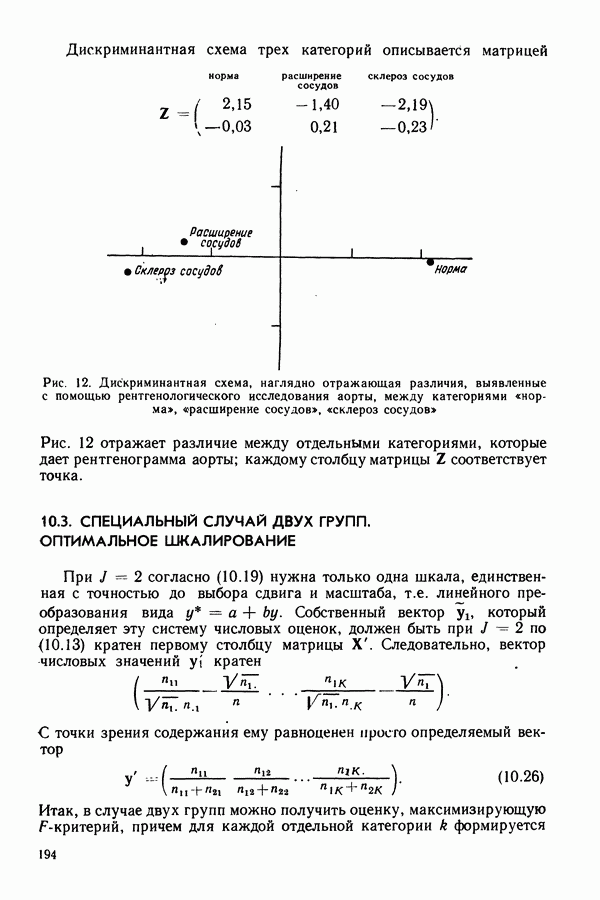
 В табл. 5 и 6 содержатся также результаты классификации, которые получаются при использовании этой тройки признаков. Дискриминантная схема представлена на рис. 6. Эвристический принцип классификации по наименьшему критическому уровню в данном примере также указывает как оптимальную тройку признаков
В табл. 5 и 6 содержатся также результаты классификации, которые получаются при использовании этой тройки признаков. Дискриминантная схема представлена на рис. 6. Эвристический принцип классификации по наименьшему критическому уровню в данном примере также указывает как оптимальную тройку признаков  Такой результат может вызвать удивление, если сравнить дискриминантную схему на рис. 6 с аналогичной схемой для всех 10 признаков на рис. 5; разделение групп 1 и 3 проходит значительно хуже по трем избранным признакам, чем по всем десяти. Дело в том, что в этом примере главную роль играет различие между группой 2 и двумя прочими группами. Значит, при исключении признаков мало учитывается взаимное разделение групп 1 и 3. В других примерах редко наблюдается подобное ухудшение классификации при переходе к оптимальному множеству признаков.
Такой результат может вызвать удивление, если сравнить дискриминантную схему на рис. 6 с аналогичной схемой для всех 10 признаков на рис. 5; разделение групп 1 и 3 проходит значительно хуже по трем избранным признакам, чем по всем десяти. Дело в том, что в этом примере главную роль играет различие между группой 2 и двумя прочими группами. Значит, при исключении признаков мало учитывается взаимное разделение групп 1 и 3. В других примерах редко наблюдается подобное ухудшение классификации при переходе к оптимальному множеству признаков.