Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
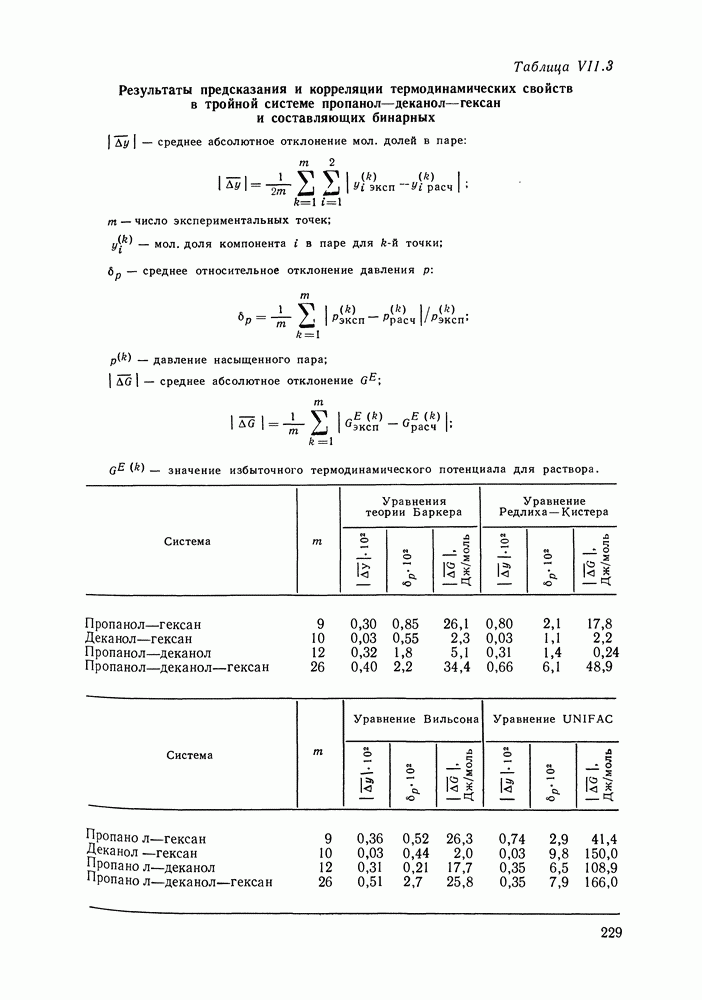
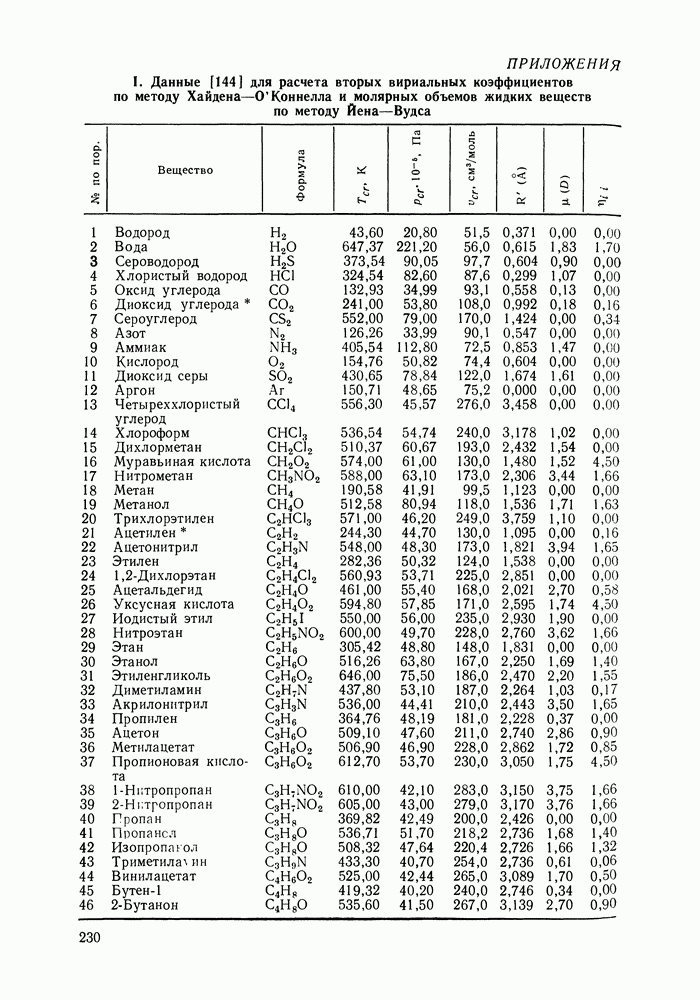
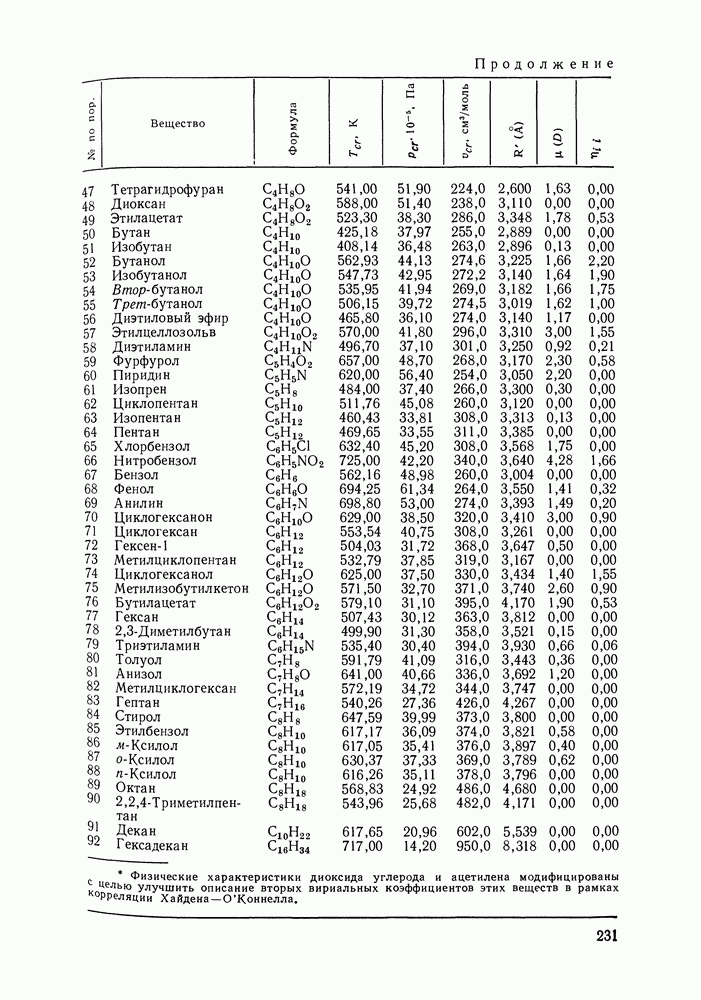
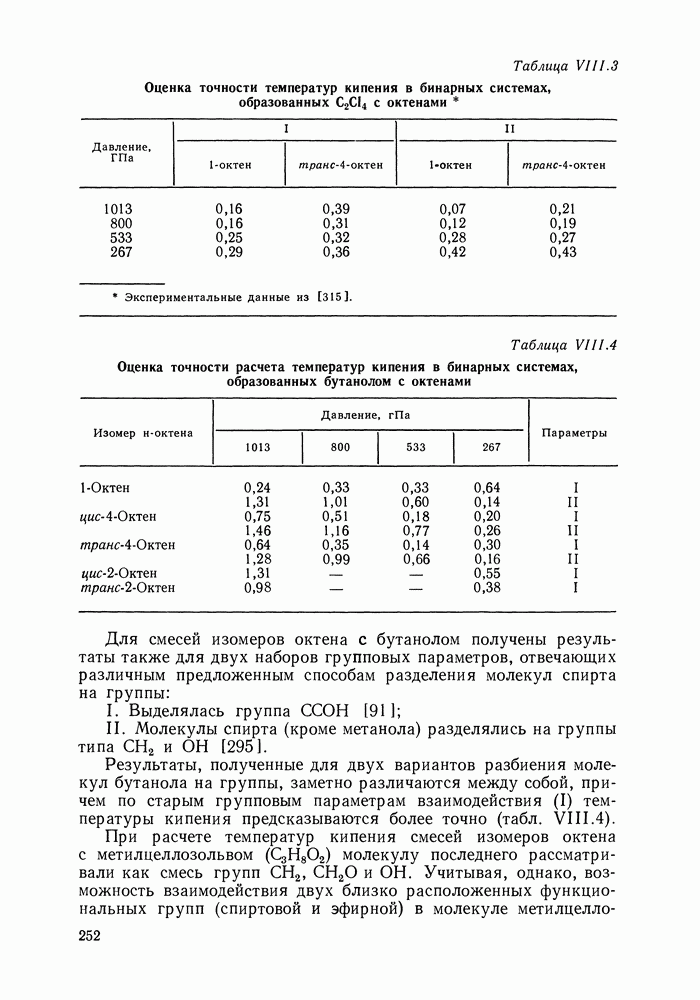
VI.6. СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБРАБОТКИ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ О РАВНОВЕСИИ ЖИДКОСТЬ—ПАРЛюбые экспериментальные данные, содержащие или не содержащие систематическую ошибку, неизбежно подвержены случайным ошибкам. Поэтому рассмотренные выше термодинамические соотношения не могут быть удовлетворены точно, а систематическая ошибка оказывается замаскированной случайными колебаниями экспериментальных значений. Термодинамическим уравнениям должны удовлетворять не сами значения наблюдаемых в эксперименте величин, а их значения, исправленные от случайных ошибок или, как говорят, оценки их истинных значений. Причем точность получения этих оценок, а следовательно и точность выполнения термодинамических соотношений определяется погрешностью исходных экспериментальных данных. Необходимо оценить величину случайной ошибки и определить, являются ли отклонения от указанных термодинамических зависимостей значимыми, т. е. указывающими на действительное систематическое уклонение измеренных величин, или это уклонение носит чисто случайный характер. Приведенные выше количественные характеристики, используемые как критерий согласованности данных (см. разд. VI.4), имели значения, которые устанавливались эмпирическим путем. Последовательным можно назвать подход, основанный на применении формулы Оценка истинных значений и случайных ошибок (дисперсий) при многократном повторении измерений может быть выполнена стандартными методами [116]. Однако экспериментальное исследование равновесия жидкость — пар трудоемко, данные обычно приводятся для единичных измерений в каждой точке фазовой диаграммы. Оценка истинных значений величин, когда в каждой точке имеется по одному измерению, представляет собою задачу регрессионного анализа и выполнима только тогда, когда есть точная модель, способная скоррелировать зависимость истинных значений измеряемых свойств. Моделью здесь и далее будем называть некоторую аналитическую зависимость, аппроксимирующую экспериментальные данные. Нужна также определенная информация о случайных ошибках. Помимо определения погрешности экспериментальных данных часто необходимым оказывается решение задачи интерполяции, т. е. определения значений параметров модели. Далее, необходим статистический анализ полученных значений параметров, оценка их надежности, связанной с погрешностью исходных экспериментальных данных, их значимости, взаимной зависимости и проч. Перечисленные проблемы (оценка случайных ошибок, истинных значений измеряемых свойств, поиск параметров модели) можно свести к одной и той же задаче математической статистики — к проблеме оценки неизвестных параметров закона распределения случайной величины. Бурное развитие прикладной статистики в 40—60-х гг. и широкое распространение быстродействующих ЭВМ стимулировали использование статистических методов при обработке разнообразного экспериментального материала. В последнее десятилетие эти методы стали привлекаться и для исследования фазовых равновесий [120, 122—128]. Практически во всех цитированных работах проводят статистический анализ экспериментальных данных о равновесии жидкость—пар, который включает оценку параметров модели, определение случайных погрешностей экспериментальных данных, различные тесты на систематические ошибки. Такая полная статистическая обработка экспериментальных данных (в западной литературе принято выражение data reduction) включает как составную часть и проверку термодинамической согласованности данных. Наиболее часто обработку проводят на основе принципа максимального правдоподобия, который позволяет определить неизвестные параметры функции распределения случайной величины, если вид этой функции известен (обычно предполагается нормальность распределения наблюдаемых в эксперименте величин). Согласно принципу максимального правдоподобия наиболее вероятной считается именно та совокупность значений измеряемых свойств, которая была в эксперименте. Общую формулировку принципа для нормально распределенных случайных величин дают следующим образом. Полагая измерения в различных точках фазовой диаграммы независимыми (зависимость между измерениями разных переменных в одной точке не исключается), для совместной плотности вероятности осуществления наблюдаемых значений можем записать:
Здесь Функция
В общем виде [129] обсуждаются возможности определения различных комбинаций параметров допущения. При обработке данных о фазовых равновесиях наиболее типичными являются следующие предположения: случайные ошибки измеряемых величин считаются известными, их определяют на основании эксперимента; измерения всех определяемых экспериментально величин предполагаются независимыми. При этих условиях применение принципа максимального правдоподобия для оценки параметров модели приводит к методу наименьших квадратов со взвешиванием. В качестве модели может быть выбрана любая аналитическая зависимость, в частности сплайн-полином, уравнения Редлиха-Кистера, Вильсона и др. Параметры модели и оценки истинных значений измеряемых величин определяются минимизацией суммы
при условии, что модель с параметрами
Здесь Если данные о равновесии жидкость—пар не полные, то соответствующие слагаемые формулы Чаще всего ошибки для различных измерений предполагаются одинаковыми: Уравнения
где в качестве независимых переменных выбраны Неоднократно ставился вопрос о том, по каким экспериментальным данным лучше определять параметры модели. Действительно, для определения параметров можно использовать косвенно определяемые в эксперименте величины; коэффициенты активности, измеряемых величин эквивалентна минимизации уклонений
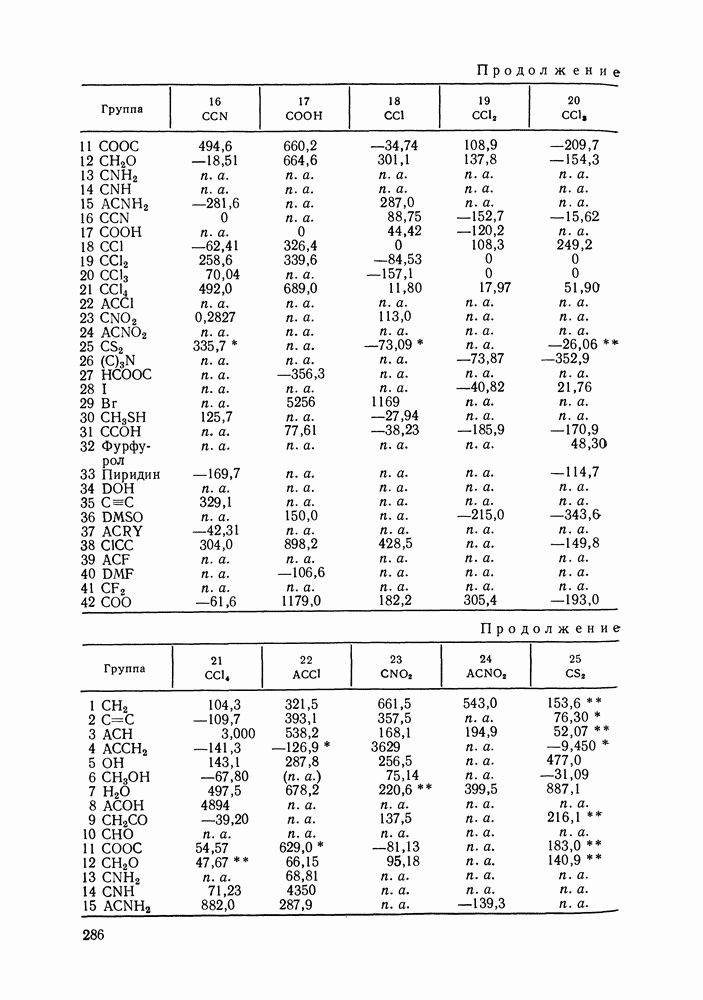
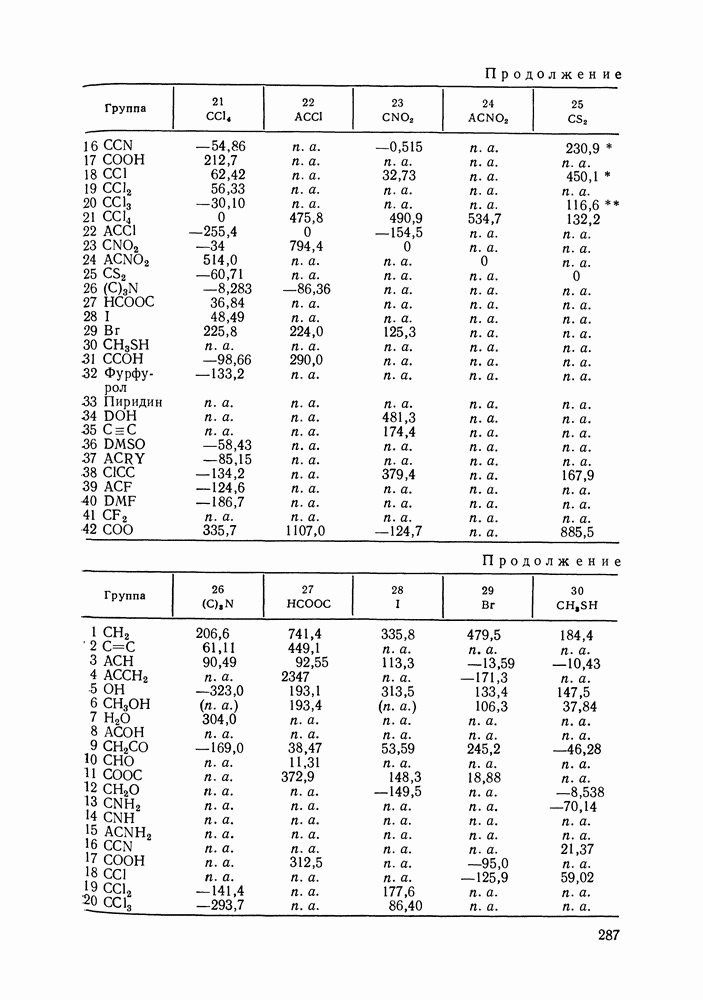
где Однако в формуле Минимизации Реализация процедур статистического оценивания параметров очень громоздка в вычислительном отношении. Пусть, например, имеется 30 экспериментальных точек Казалось бы, второй метод, предложенный Кемени [126], менее трудоемкий, так как не требует оценки истинных значений независимых переменных. Однако в этом методе при минимизации После того, как параметры модели определены, рассчитывают ковариационную матрицу параметров. Затем может быть вычислена погрешность любого рассчитанного с помощью модели свойства, проведен статистический анализ полученных параметров. Иногда, как отмечалось выше, случайные ошибки считались известными, их устанавливали до проведения обработки данных. В другом варианте метода случайная ошибка заранее не фиксируется, ее пытаются оценить в ходе статистической обработки данных. Это возможно лишь, если сделаны дополнительные допу щения, например, если независимые переменные измерены точно, или случайные ошибки для этих переменных известны. В целом, удается определить не значения случайных ошибок отдельных переменных, а лишь некоторые их агрегаты, так что потом трудно установить, какая величина случайной ошибки приходится, скажем, на долю давления, на долю состава пара и т. д. В то же время достаточно разумные оценки дисперсий измеряемых величин могут быть предложены экспериментаторами на основании накопленного опыта работы. Поэтому большее значение имеет не непосредственное вычисление случайных ошибок, а проверка соответствия значений погрешностей представленным экспериментальным данным. Сами по себе оценки случайных ошибок и истинных значений измеряемых величин еще ничего не говорят о надежности, с которой эти оценки могут быть приняты, не позволяют построить их доверительные интервалы, проверить различные гипотезы об их значении, а следовательно, и получить статистически обоснованный критерий термодинамической согласованности данных. Для того, чтобы справиться с этими задачами, необходимо знать распределение соответствующих оценок. Для обработки данных о равновесии жидкость—пар применяется набор тестов, основанных на точных выборочных распределениях [125, 126, 128]. Хорошо известно, что величина
имеет распределение Заметим, что независимость означает здесь статистическую независимость ошибок измерений, а не независимость термодинамических переменных. Таким образом, наблюдаемые на опыте значения зависимых термодинамических величин часто могут считаться независимо распределенными, это определяется методикой их измерения. Предполагают, что имеется гибкая модель, способная практически точно связать истинные значения величин (х, величин Однако, если в формуле
Здесь величины в правой и левой частях неравенства — квантили распределения Если хотя бы для одного из поднаборов неравенство Критерий
то экспериментальные данные согласованы, т. е. они подчиняются уравнению Гиббса-Дюгема в пределах объявленной экспериментальной погрешности Невыполнение этого неравенства указывает на то, что данные содержат дополнительную систематическую ошибку, которая не входит в величины Аналогичный критерий для
Рис. VI.4. Зависимость остатков также представляет собой тест согласованности и эквивалентен тесту Редлиха-Кистера (см. выше). Для обнаружения систематических ошибок часто исследуют поведение остатков, т. е. разностей между наблюдаемыми экспериментально переменными и оценками их истинных значений [120; 125, первая ссылка; 126—128]. Эти оценки получают обычно методом максимального правдоподобия как описано выше. Если используемая модель точна, а экспериментальные данные не содержат систематических ошибок, то остатки представляют собой случайные величины с нулевым средним. Эффективен графический анализ остатков. Строят графики остаток—свойство, и по этим графикам могут быть замечены систематические ошибки (рис. VI.4). Применяют и количественные критерии для остатков [120, 126—128]. Систематическое отклонение независимых, нормально распределенных остатков
Систематическая ошибка появляется, если
где Такие систематические тенденции остатков к смещению, как на рис. VI.4, б могут быть обнаружены с помощью критерия Аббе, основанного на сравнении последовательных разностей остатков с оценкой их рассеяния:
Если Рассмотренные выше критерии применяют для анализа данных о равновесии жидкость—пар в бинарных системах; они позволяют уточнить значения экспериментальных погрешностей, объявленные экспериментаторами. Для ряда систем обнаружены систематические ошибки в экспериментальных данных. При этом различные критерии дополняют друг друга, систематические ошибки, не замеченные с помощью одного критерия, выявляются при использовании другого. В заключение сделаем несколько замечаний об ограничениях, обсуждаемых статистических методов. Эти методы основаны на предположении, что модель, использованная для описания экспериментальных данных, точна. Поэтому невозможно разделить систематические ошибки в данных и ошибки, вносимые моделью. Невозможно определить источник систематических ошибок (например, переменную, которая ее содержит), можно лишь установить их присутствие, и то, если оно оказывается заметным на фоне случайных ошибок Принцип максимального правдоподобия эффективен для оценки параметров точной модели по экспериментальным данным, содержащим лишь случайные ошибкиг Естественно, что этот метод, так же как и любой другой, не позволяет надежно определить параметры модели по данным, содержащим систематическую ошибку. Еще раз отметим, что применяемая при обработке данных модель должна быть точнее, поэтому предпочтительнее использовать гибкие аппроксимирующие зависимости типа полиномов Редлиха-Кистера, сплайн-полиномов, а не корреляционные уравнения NRTL, UNIQUAC и другие [см. разд. VII.5], которые, несмотря на большую обоснованность, как правило, хуже аппроксимируют экспериментальные данные.
|
 |
Оглавление
|













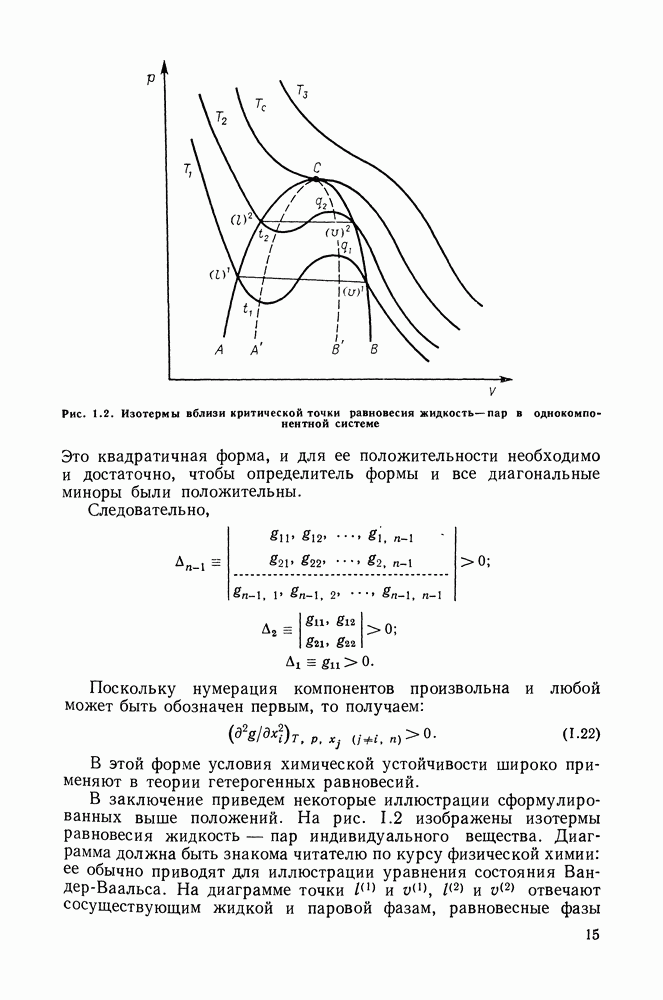
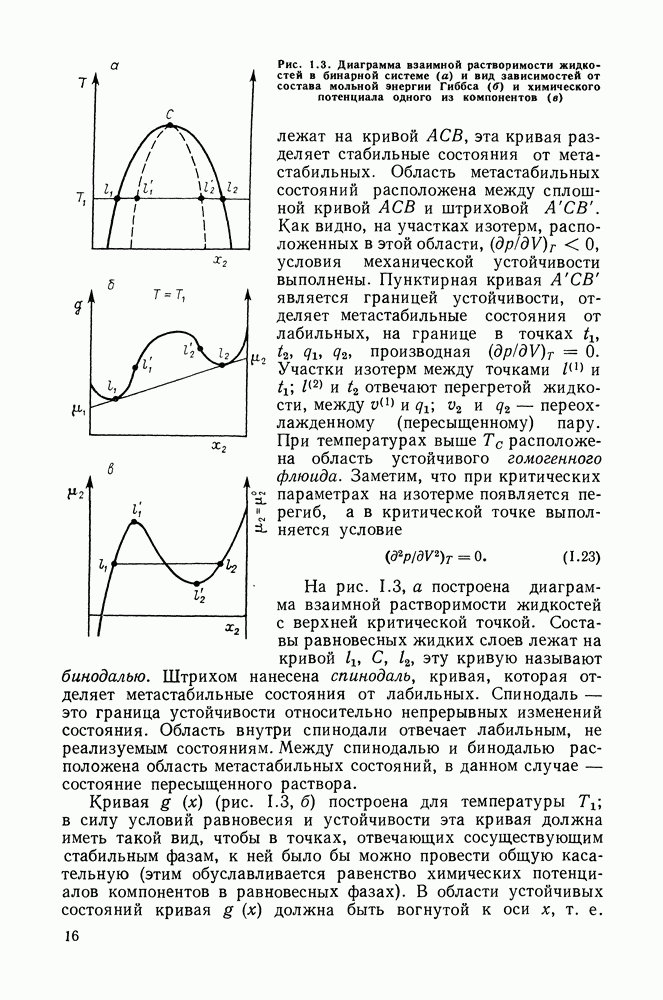













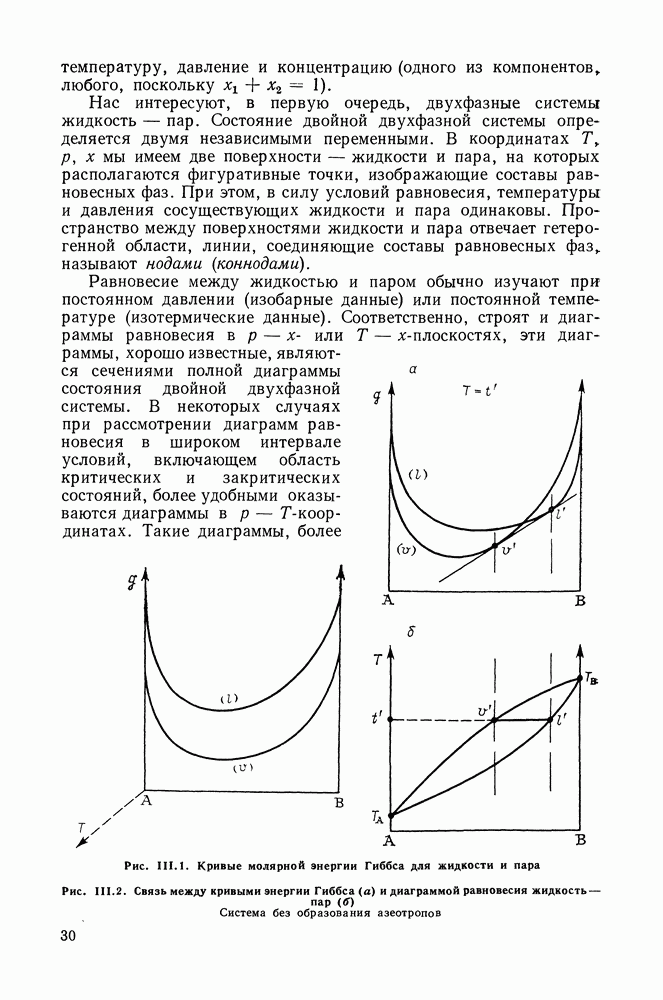
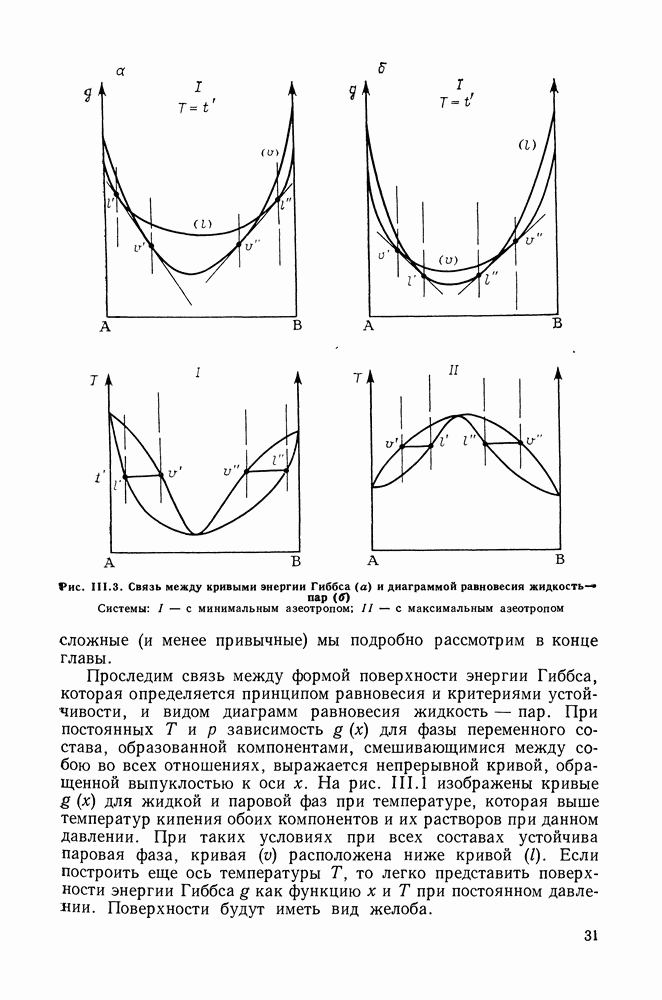




















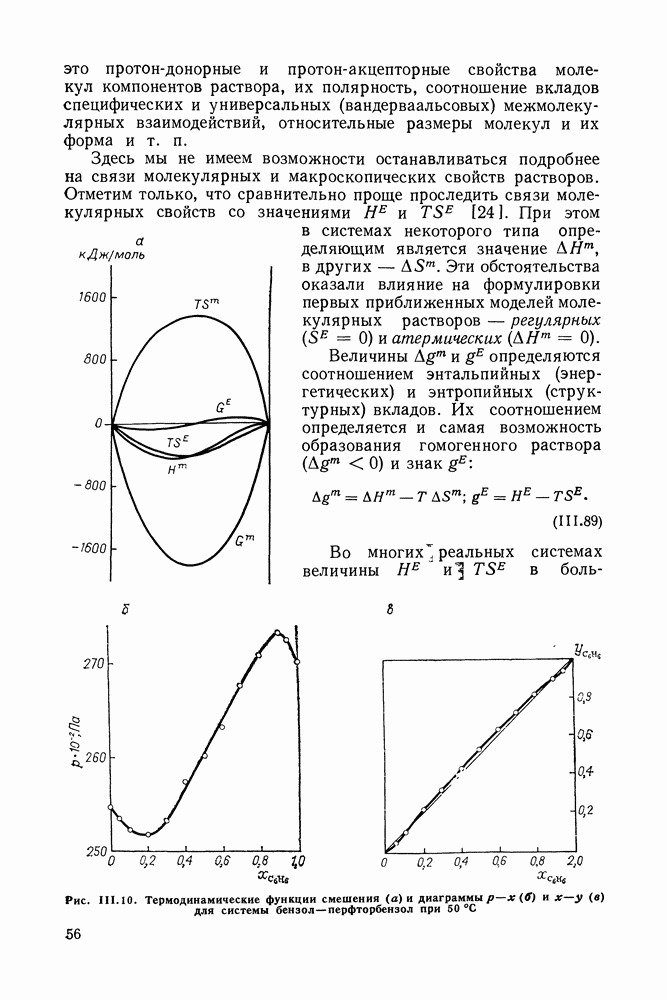



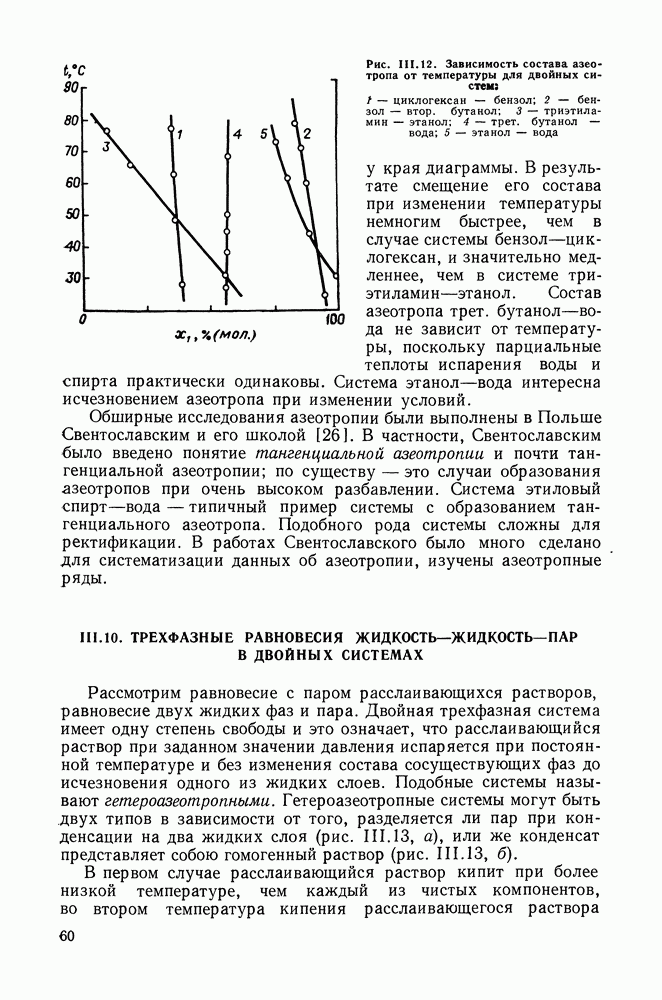





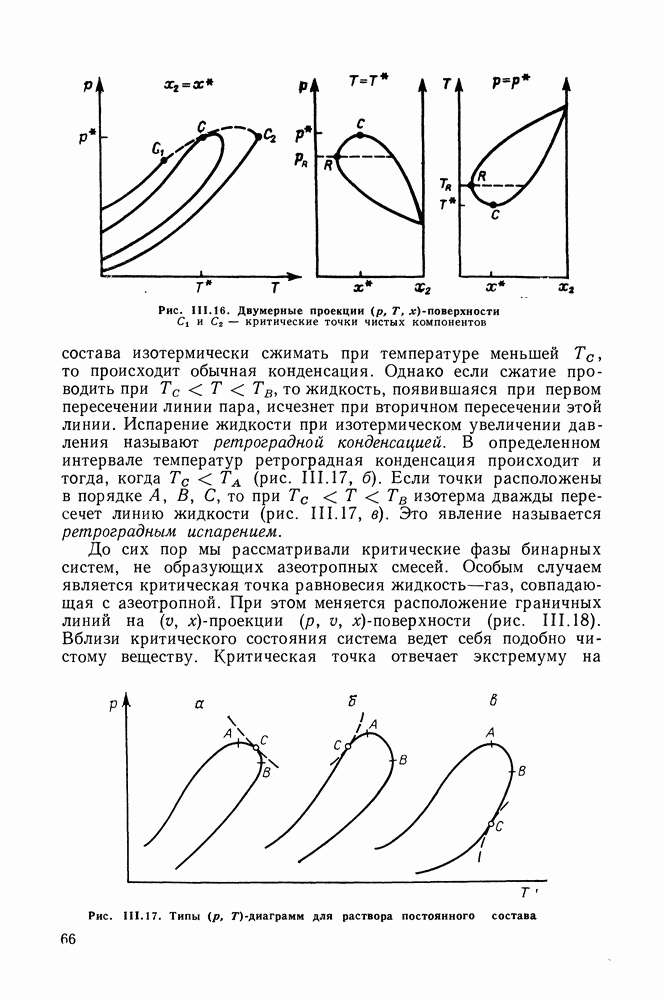
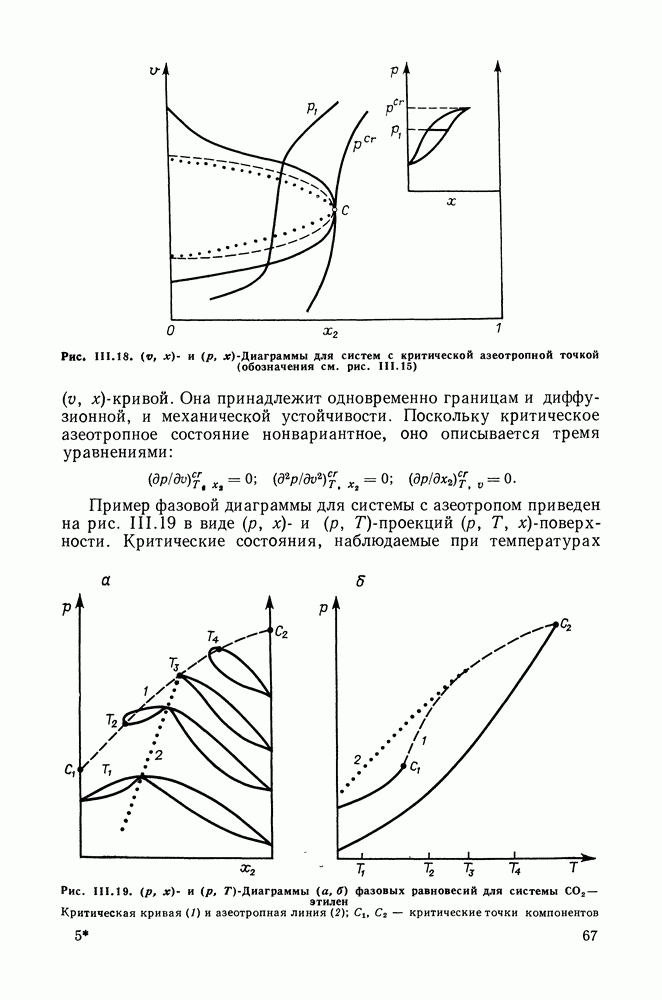


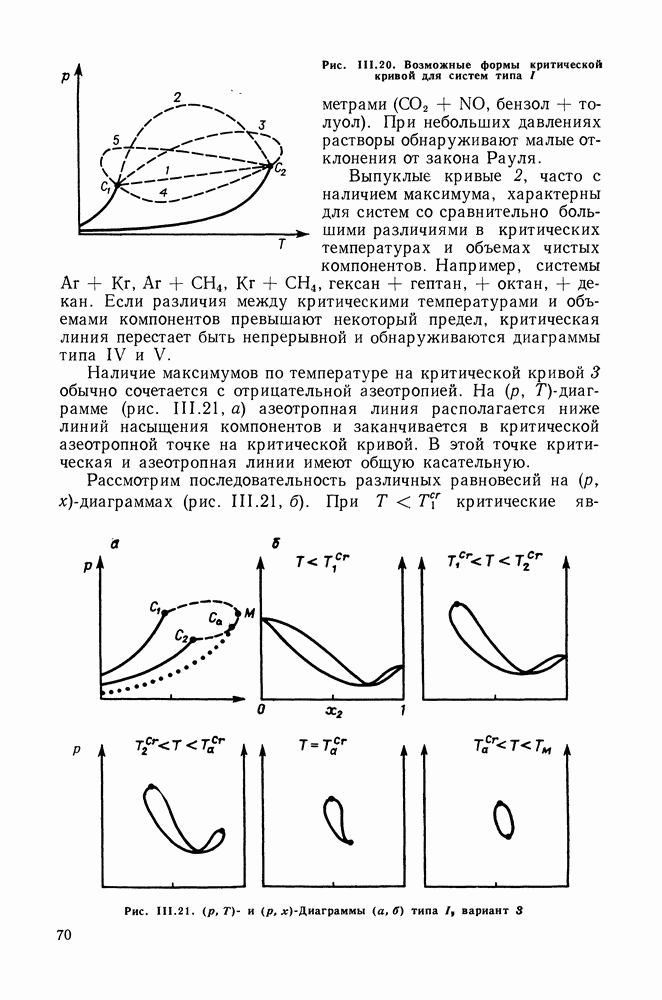

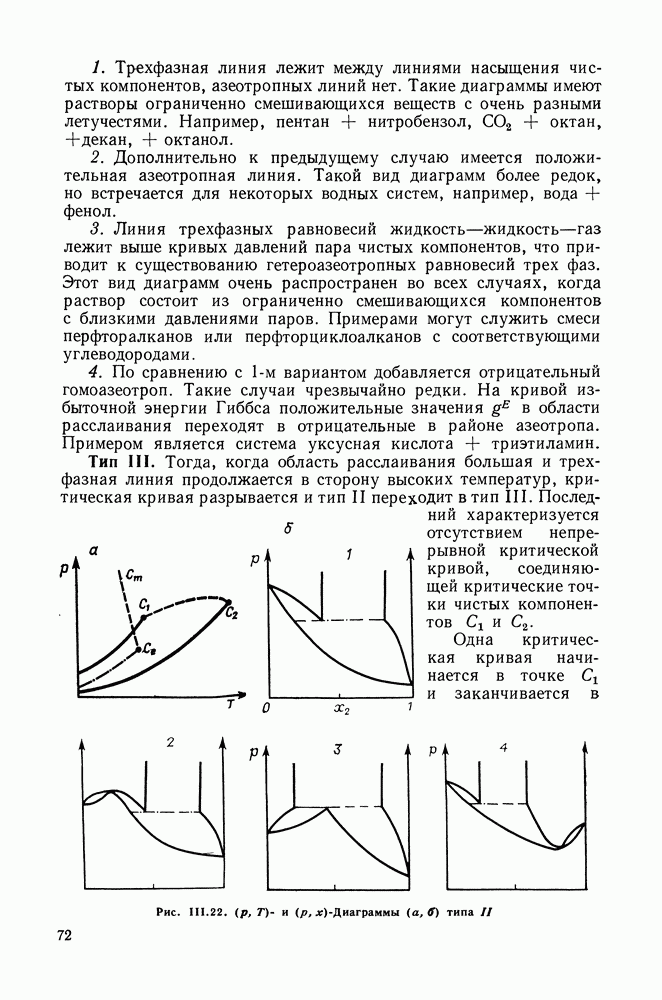
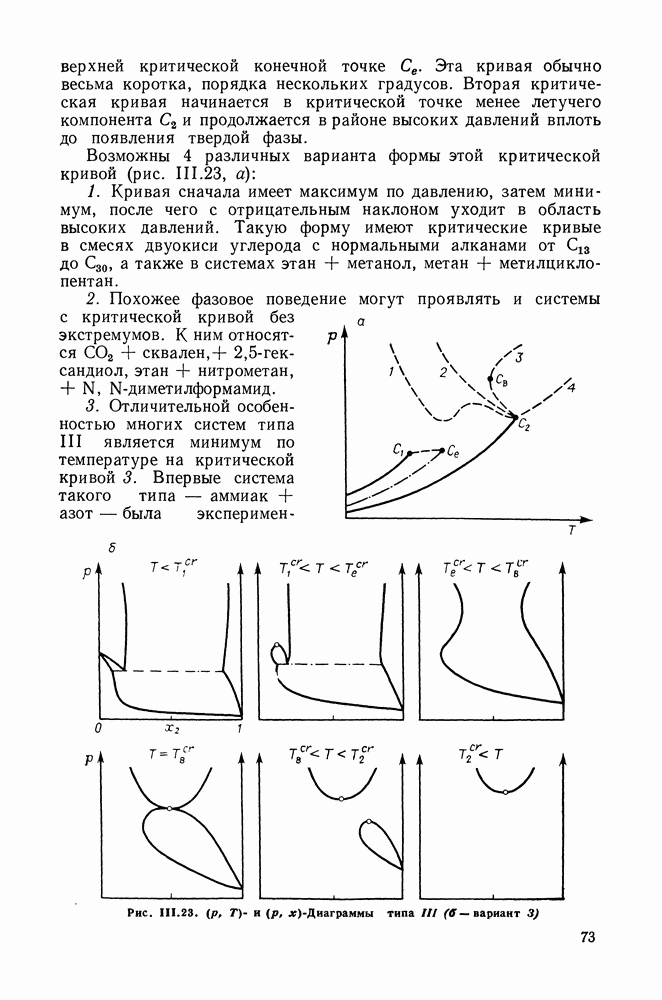
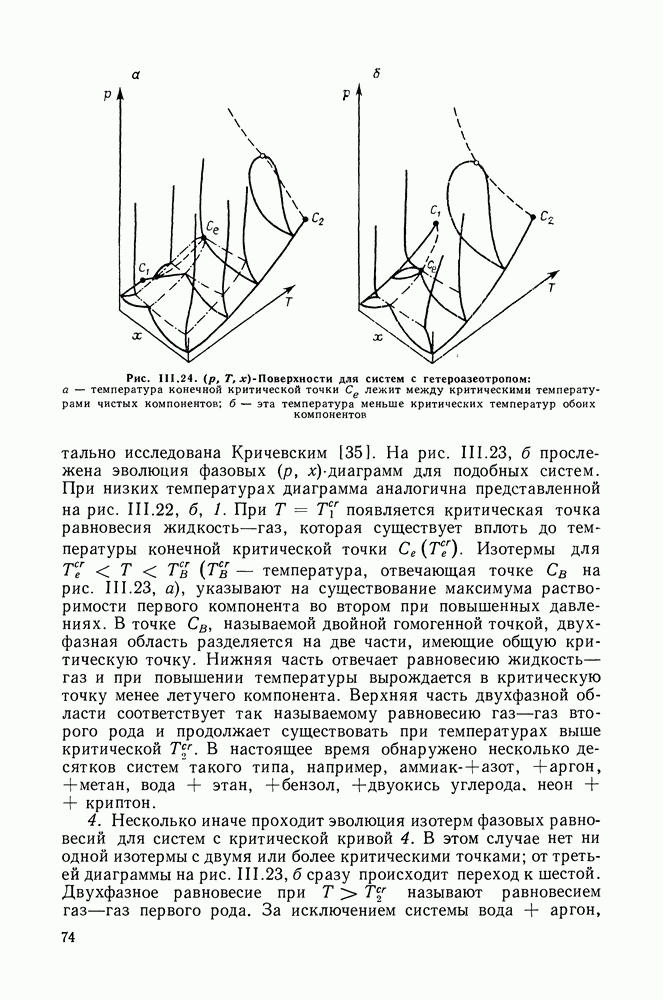



















































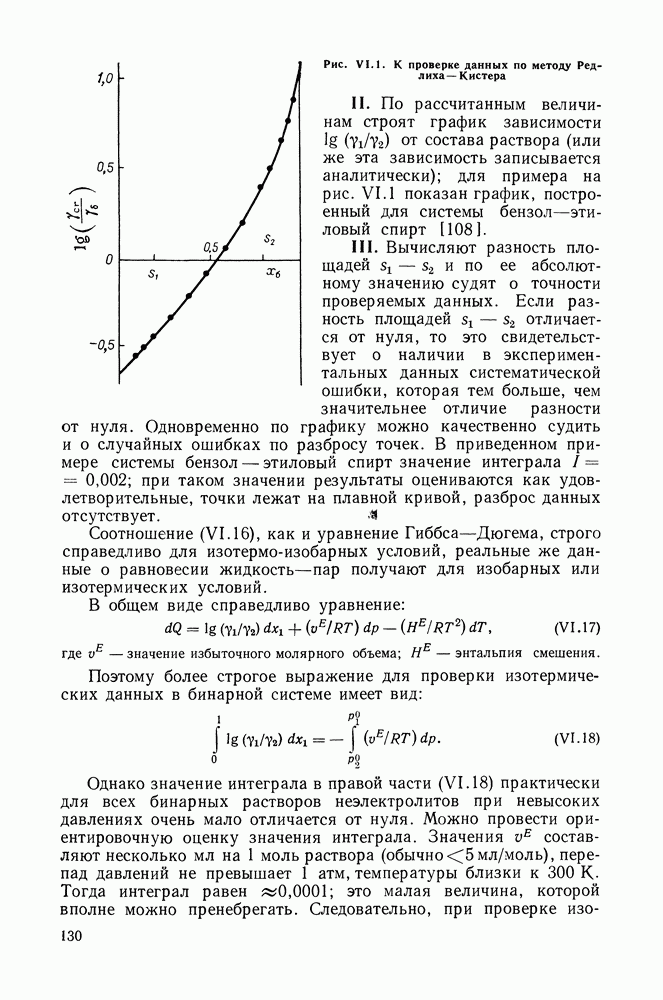



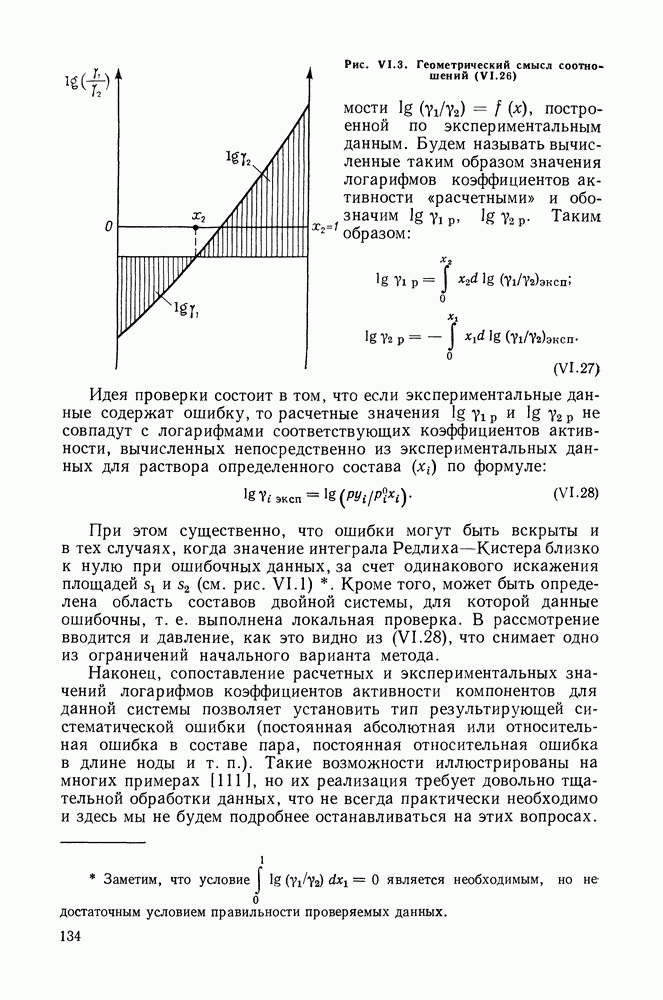











































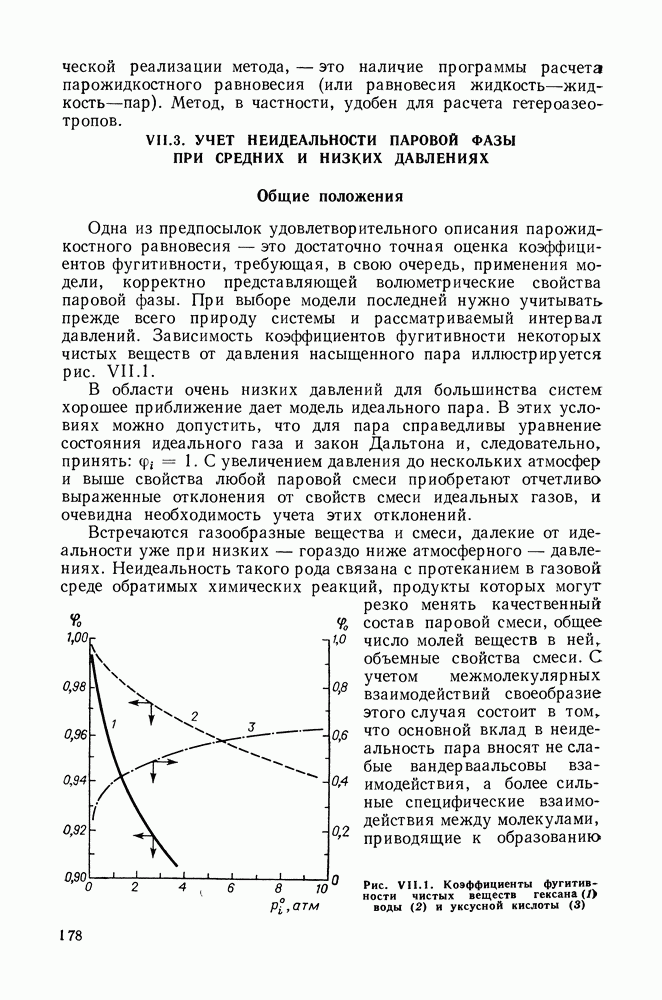





















































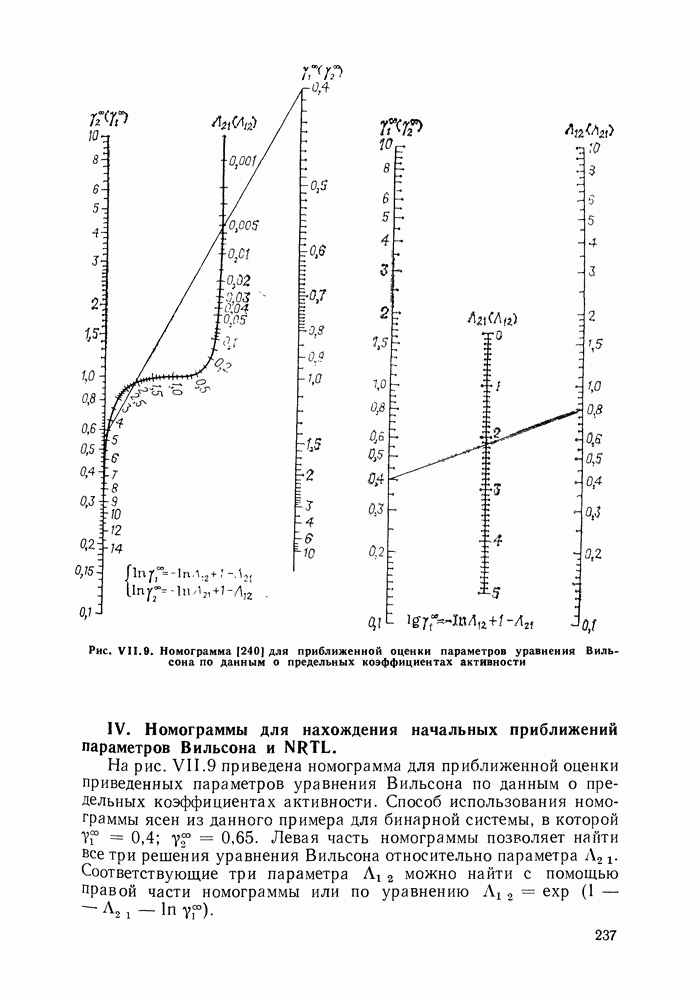
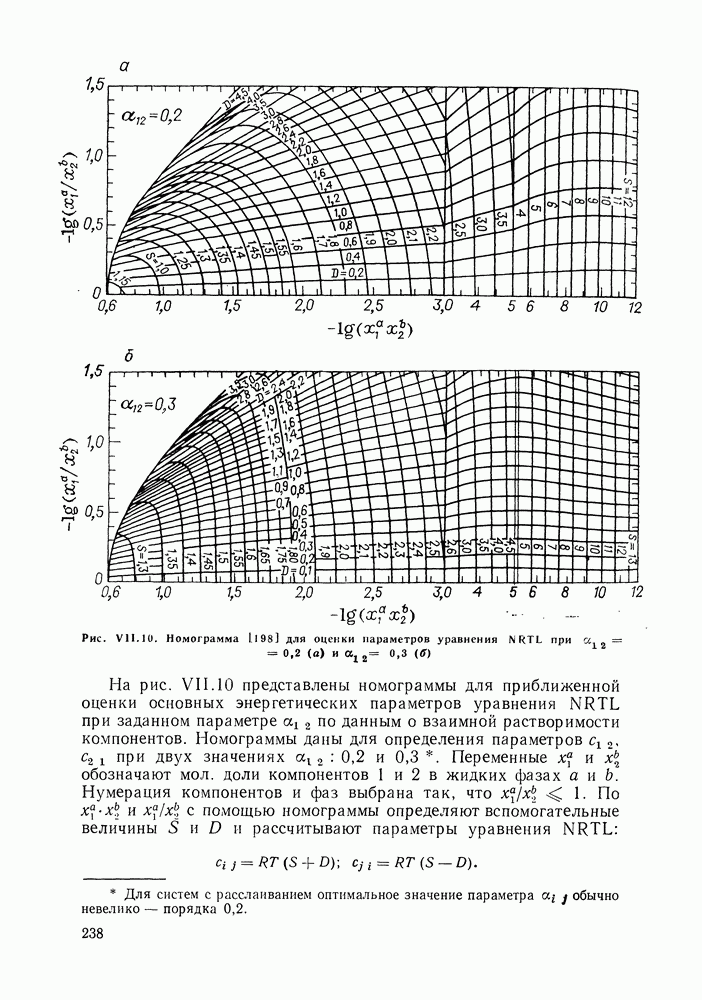











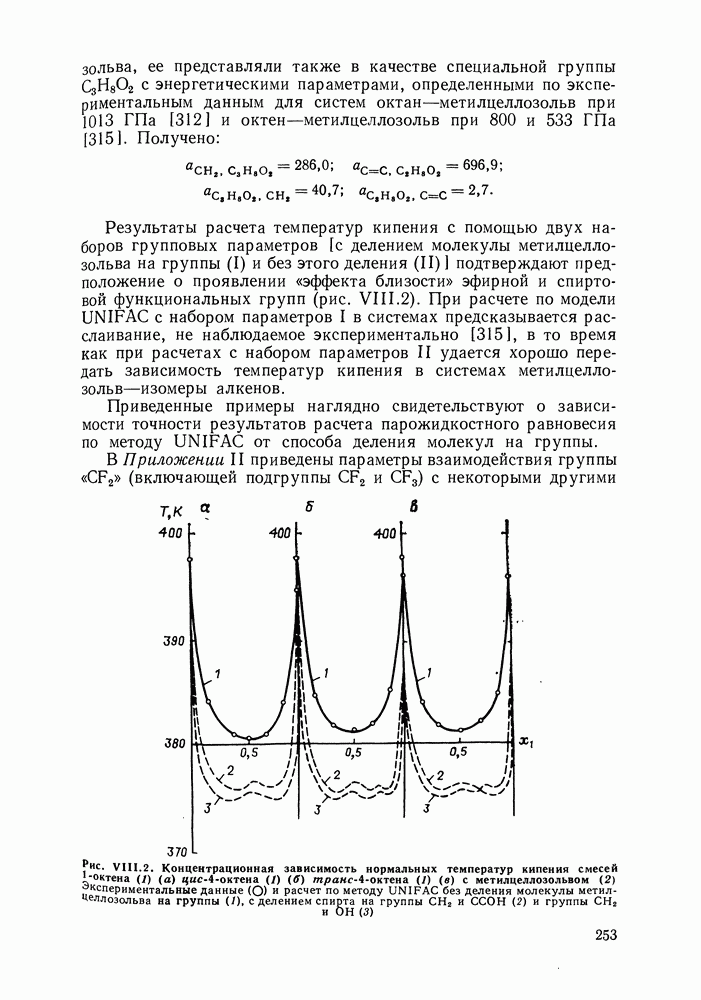

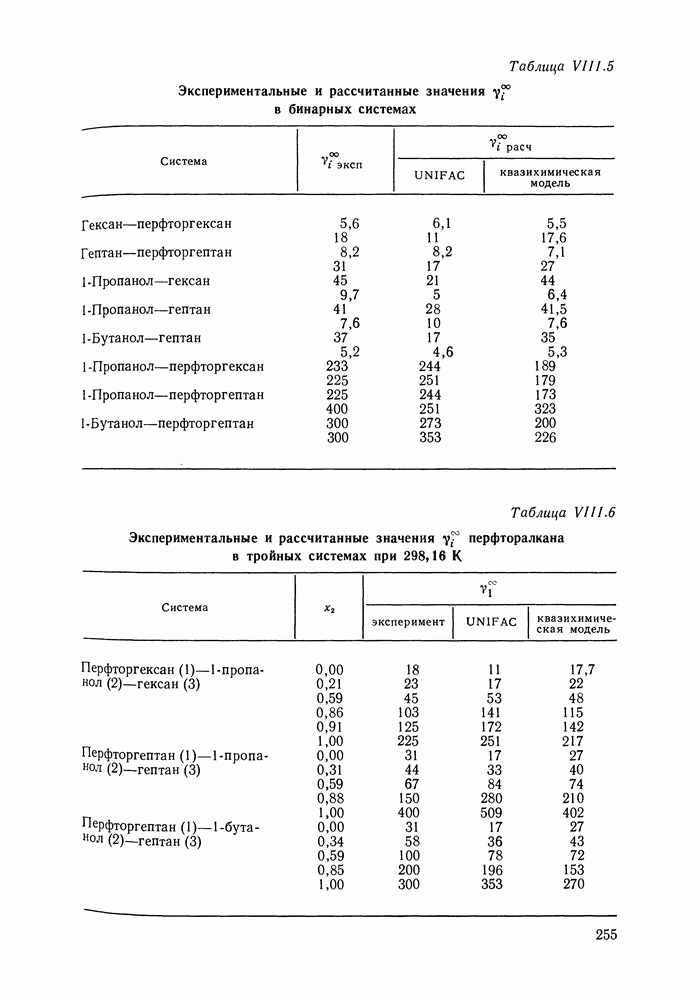


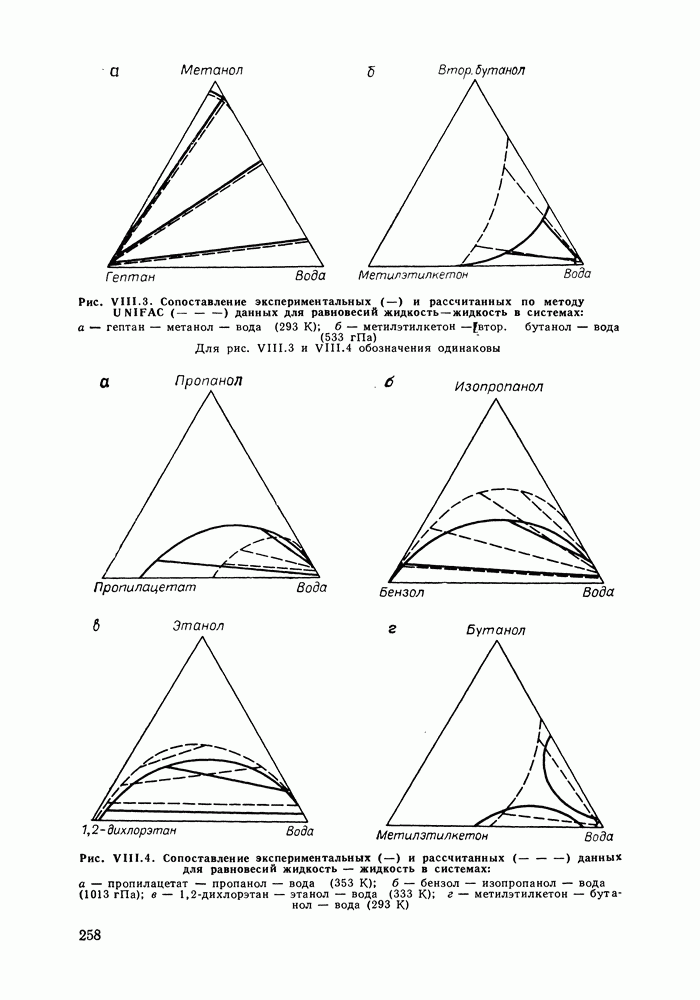












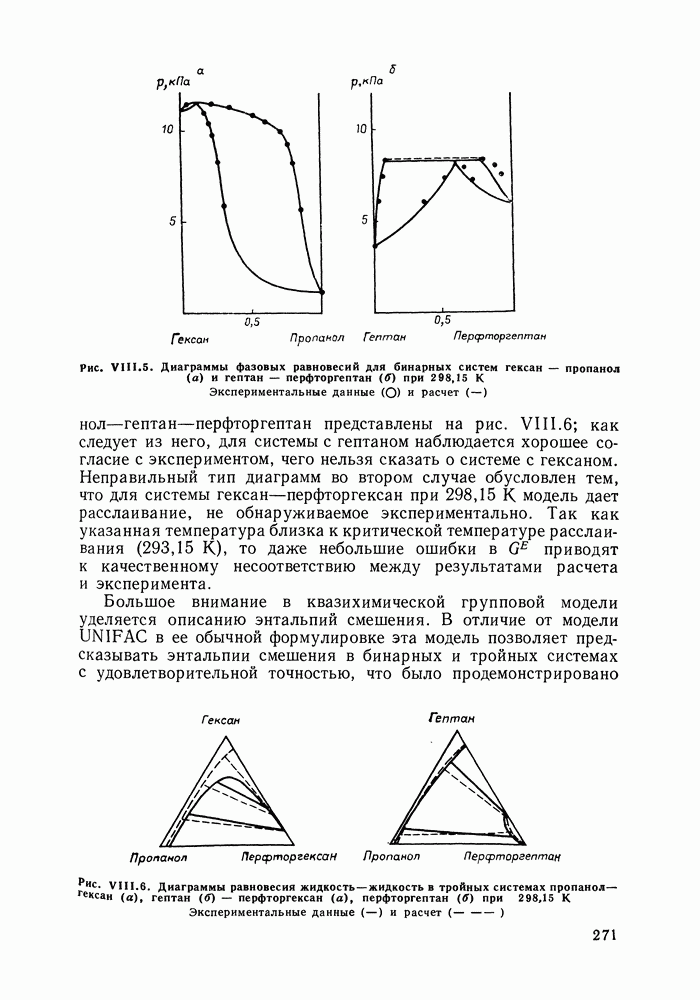
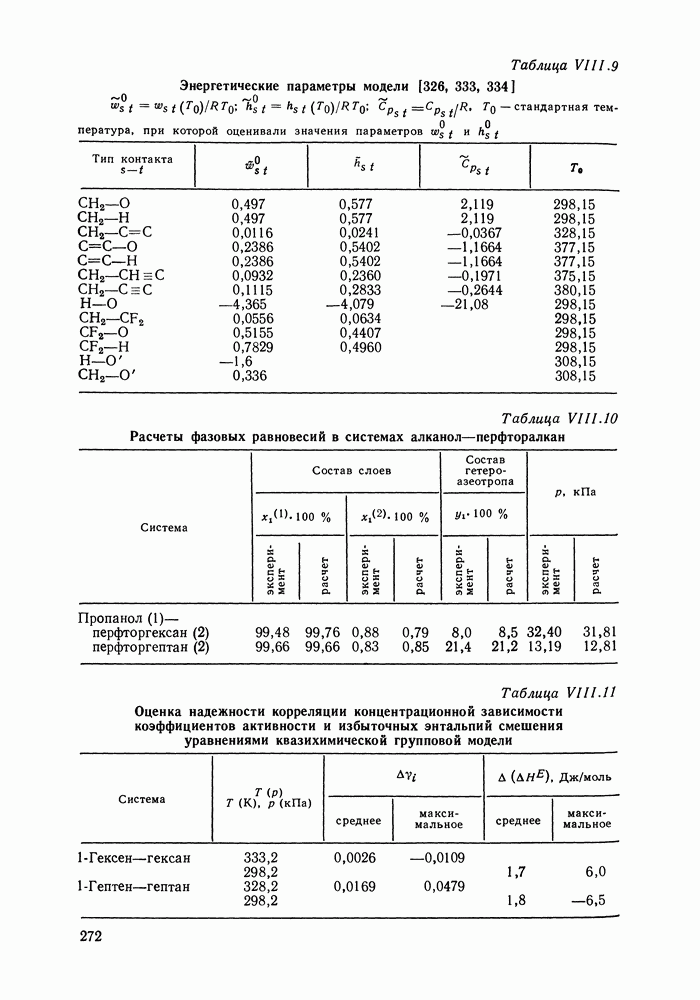
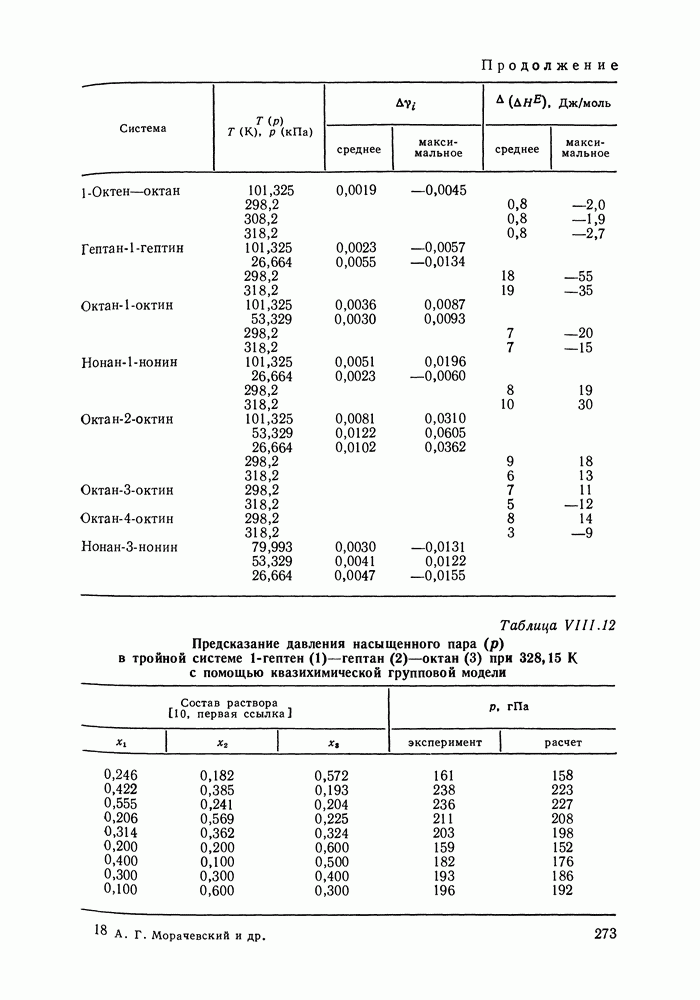
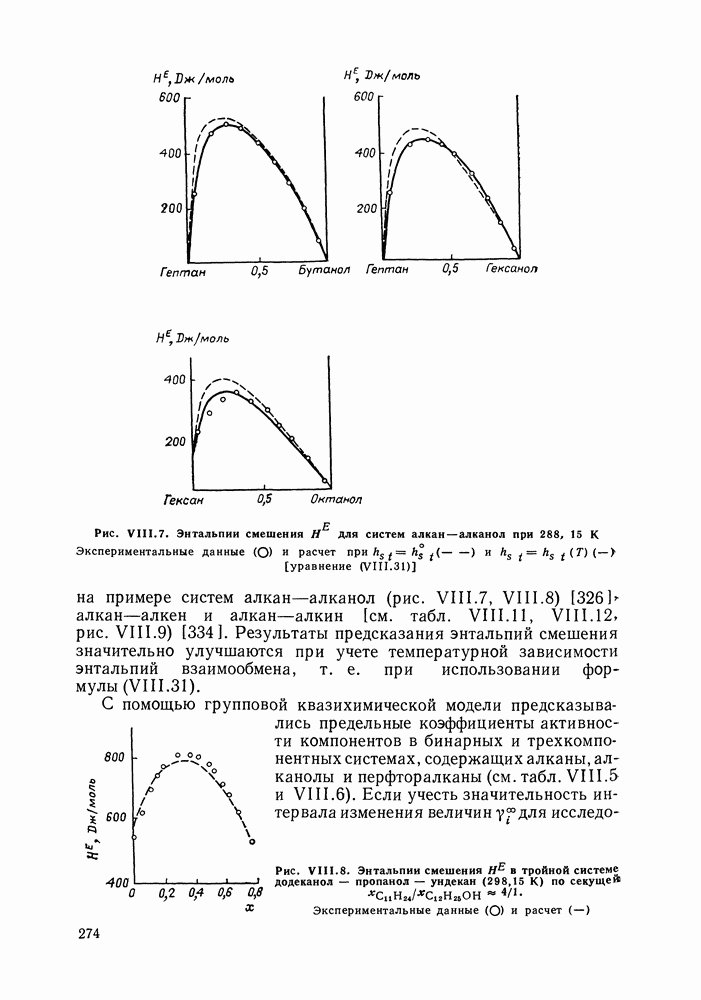
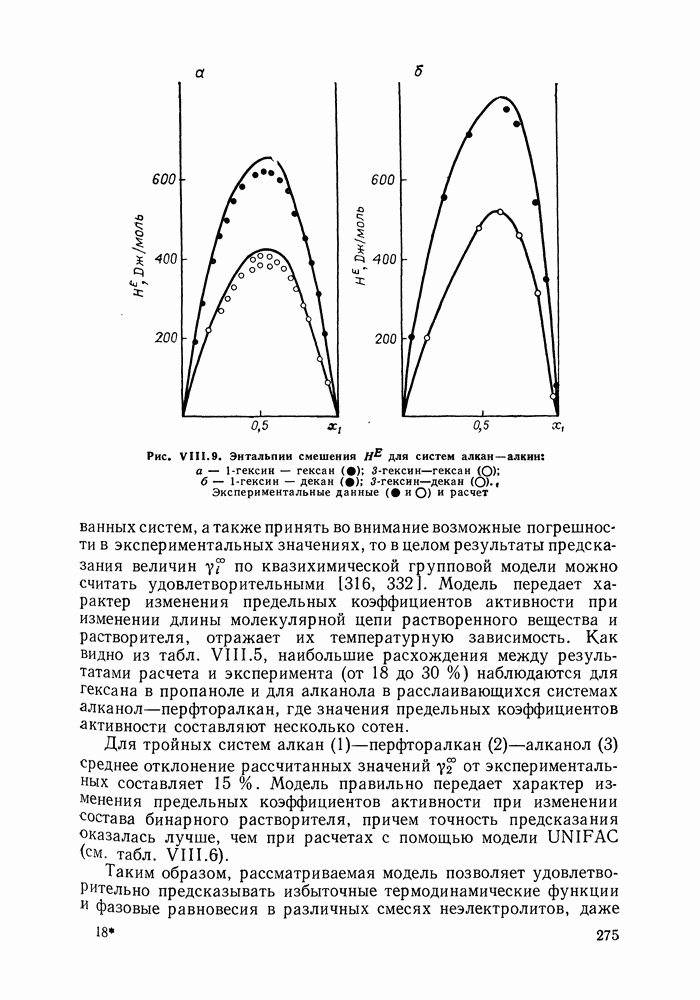


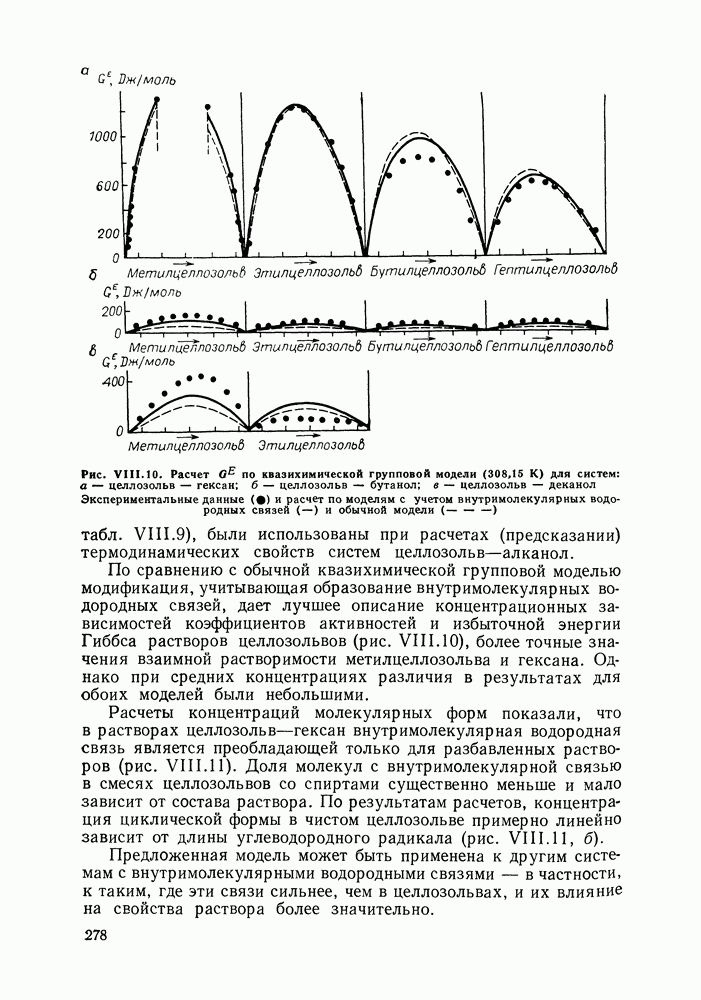
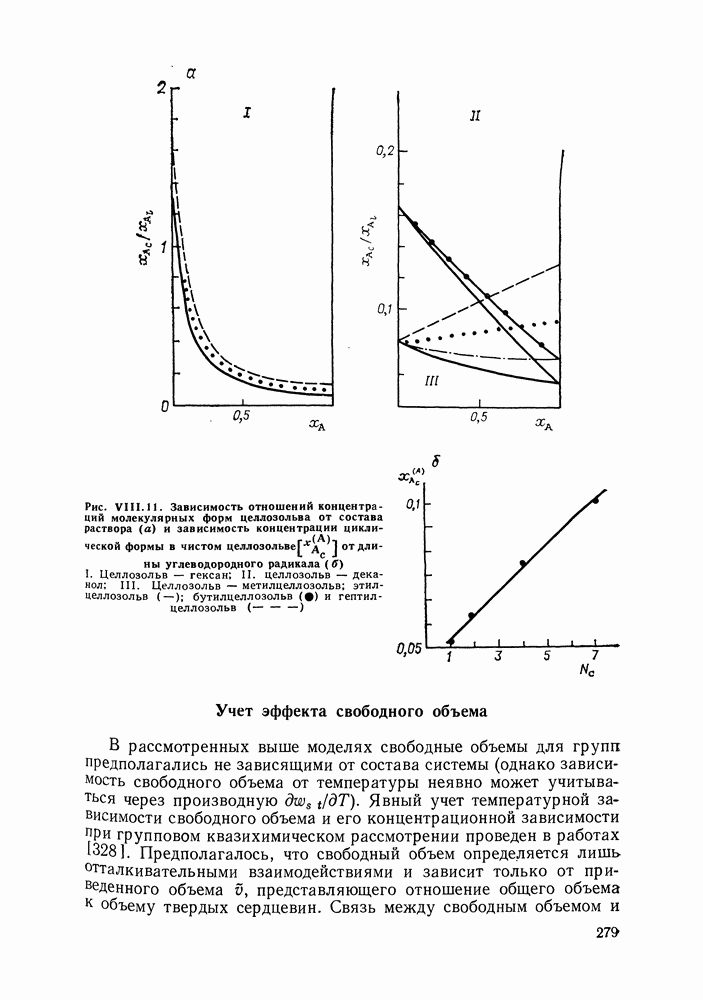
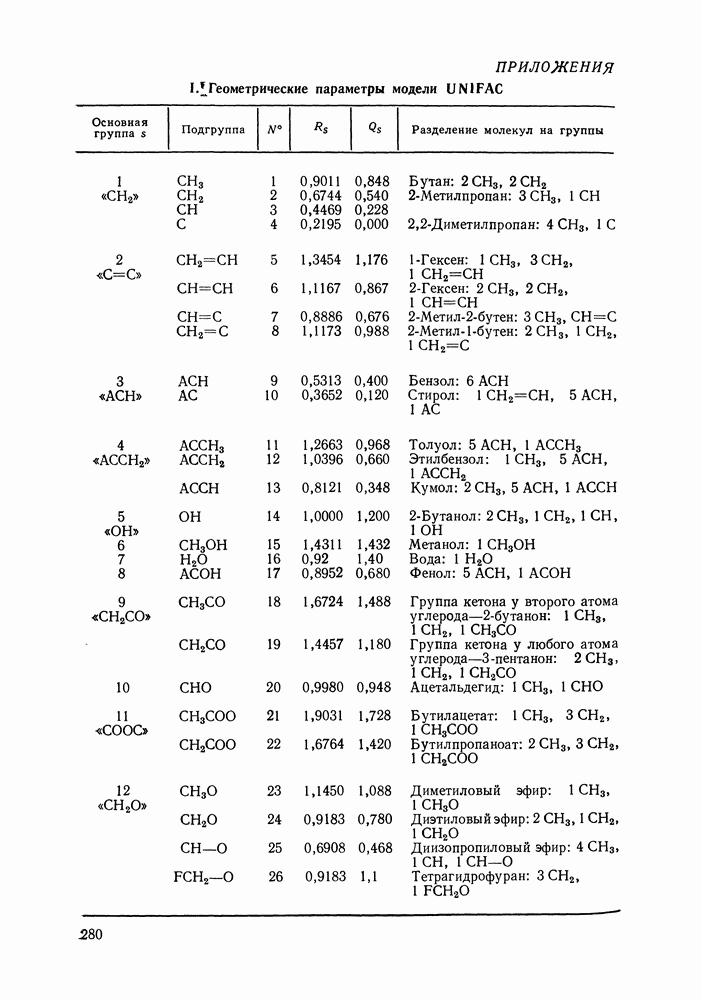
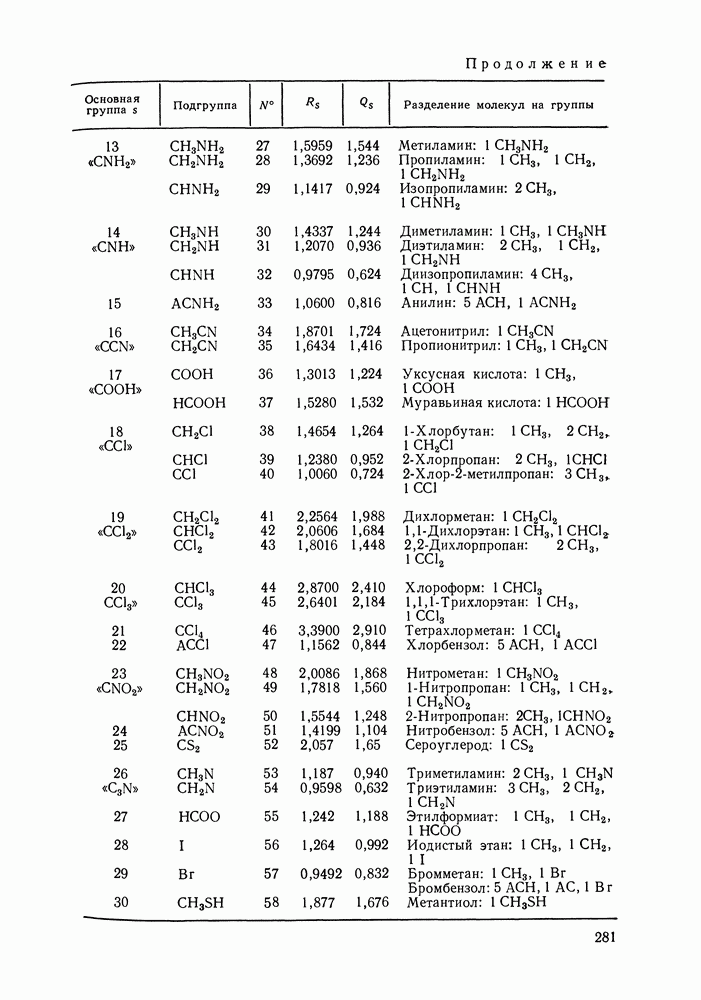

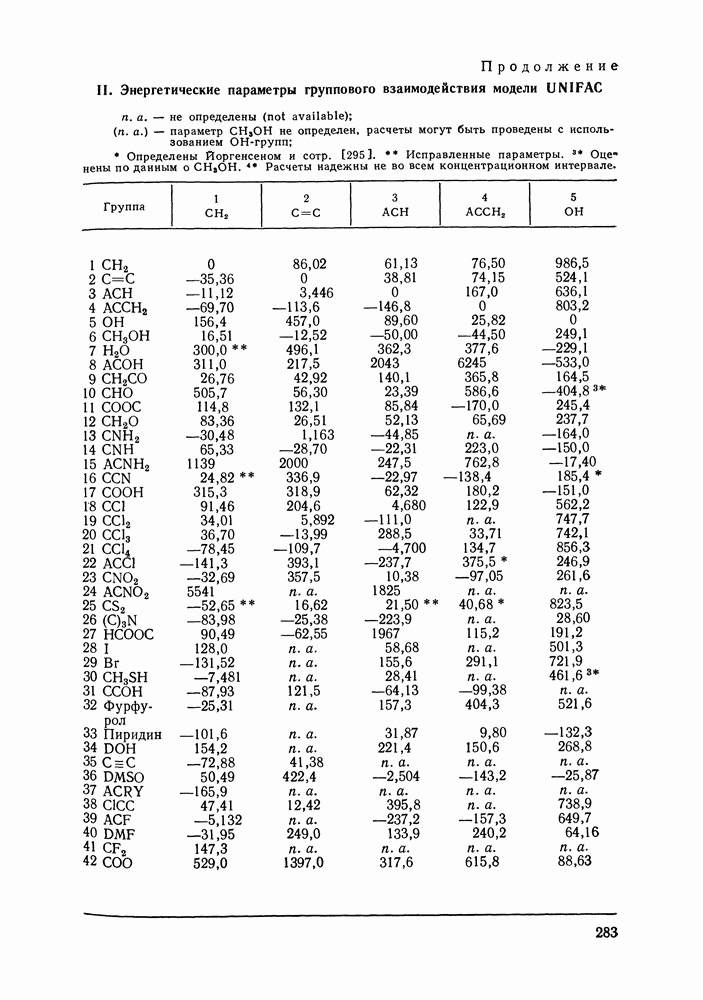
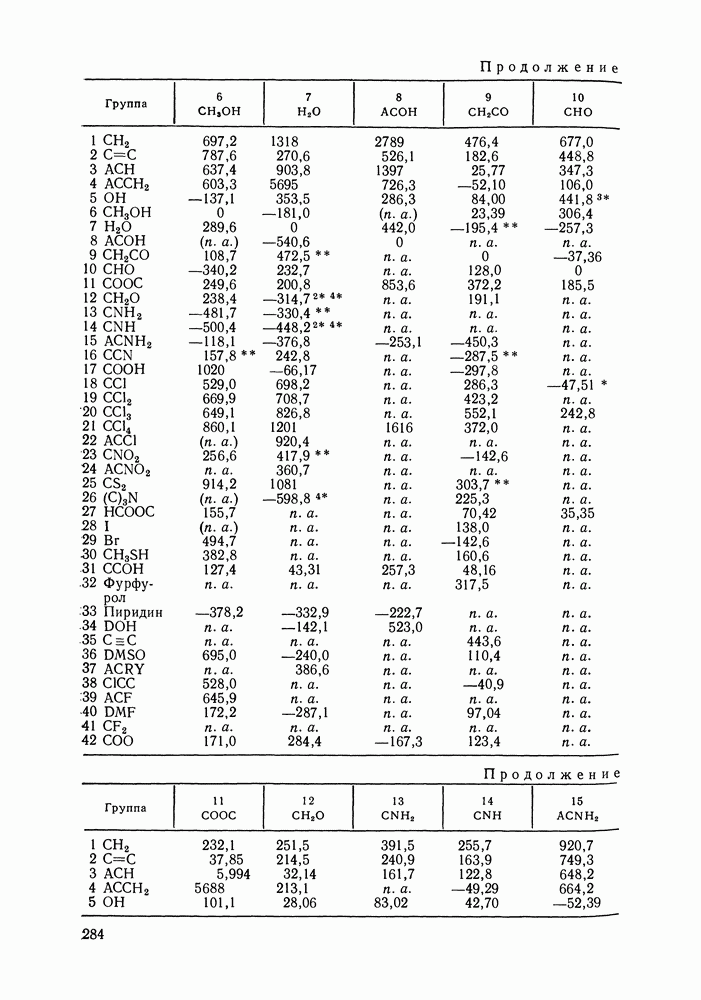
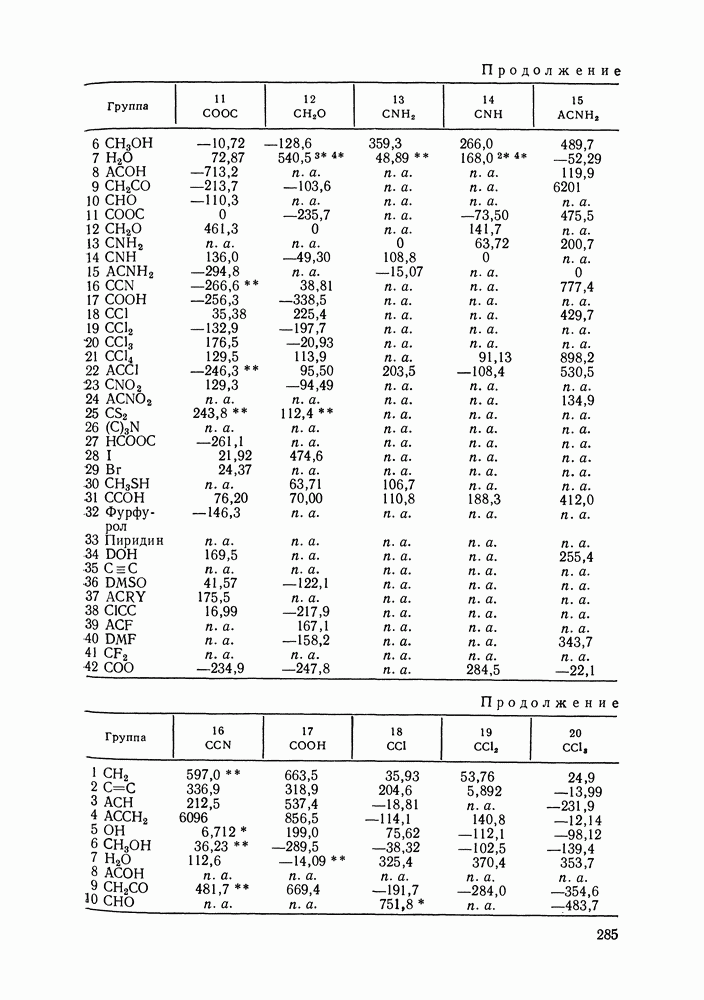
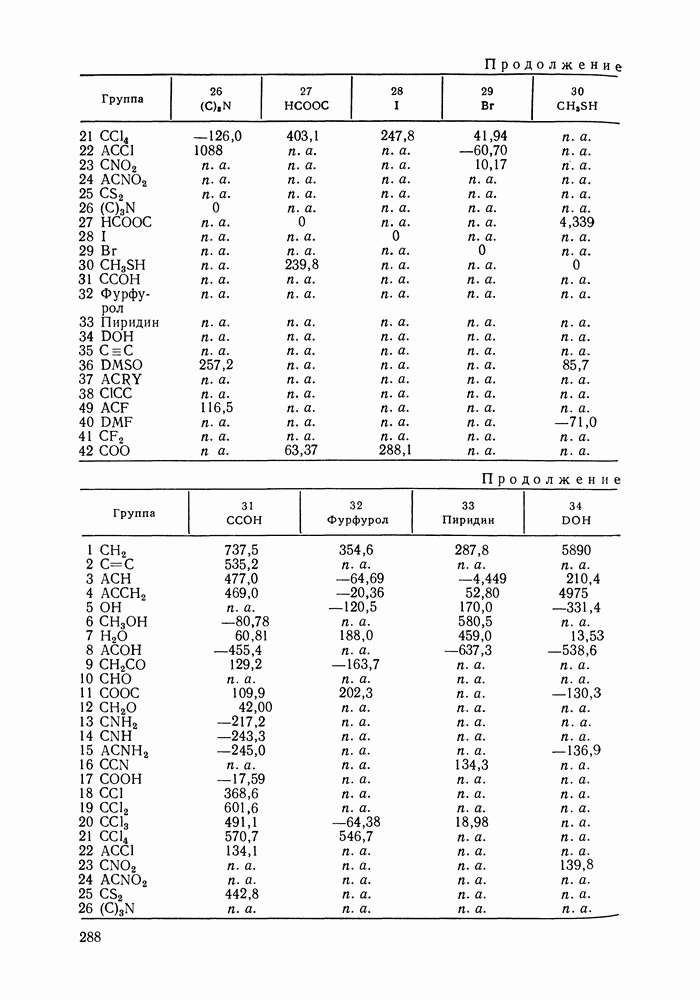




















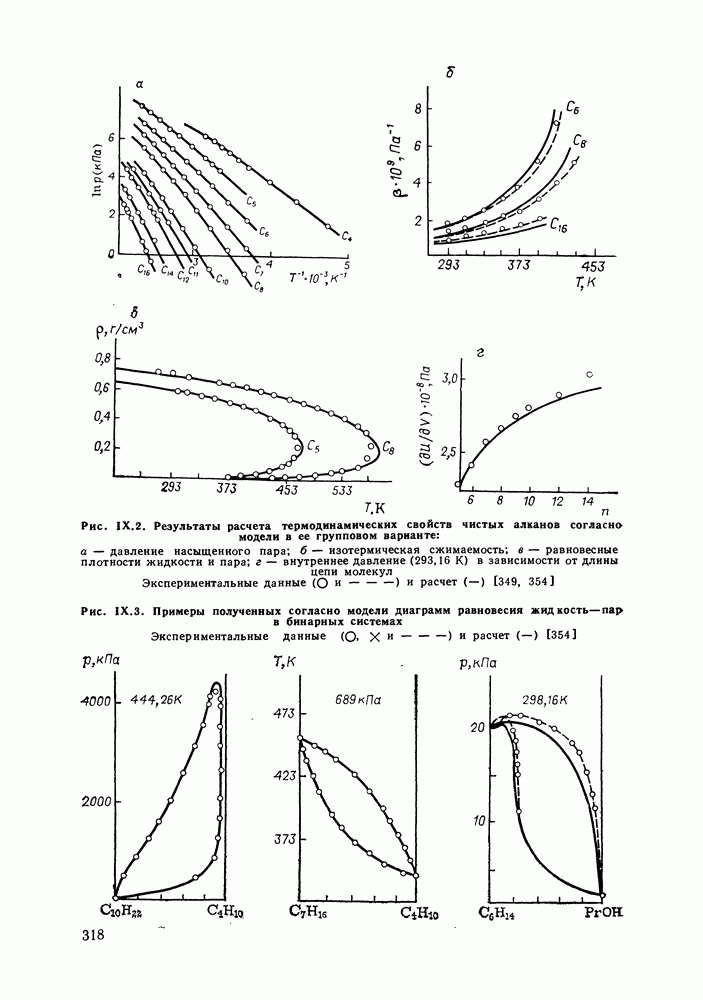
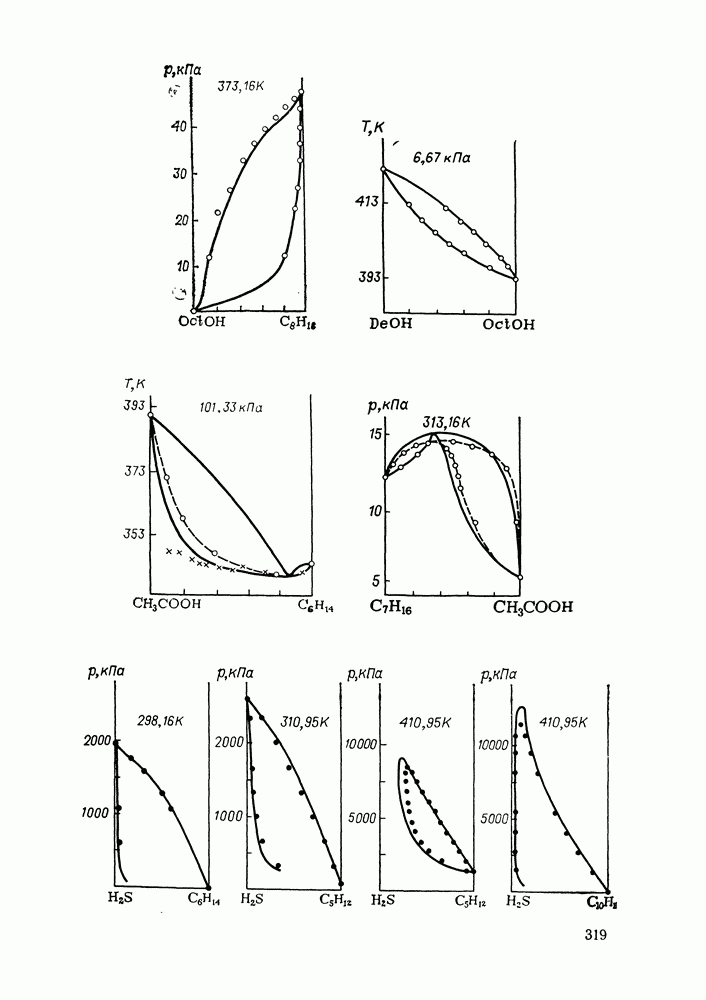

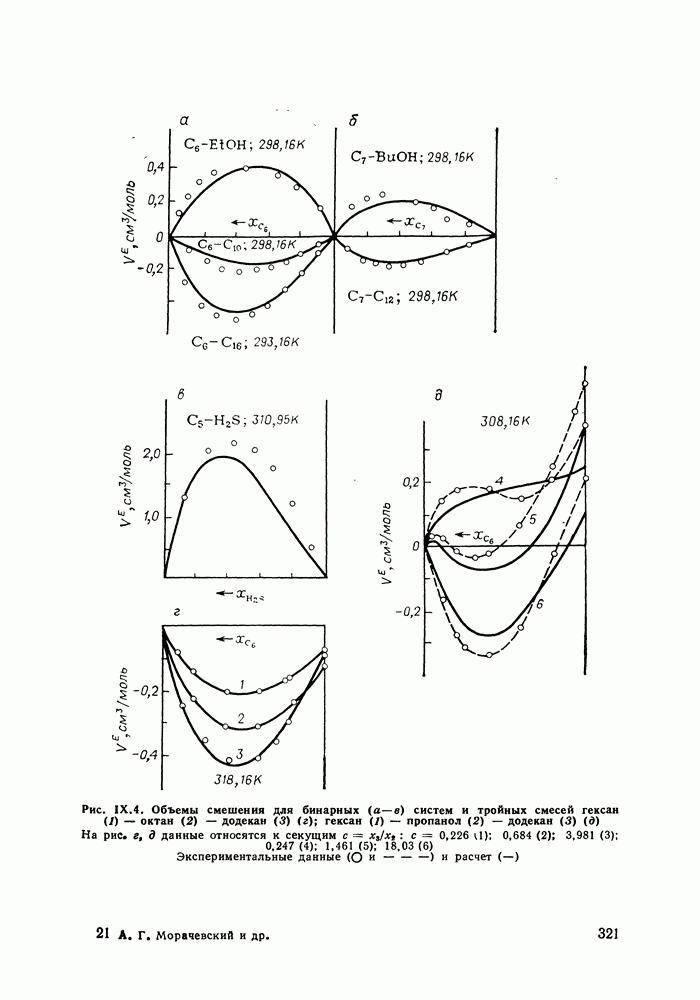
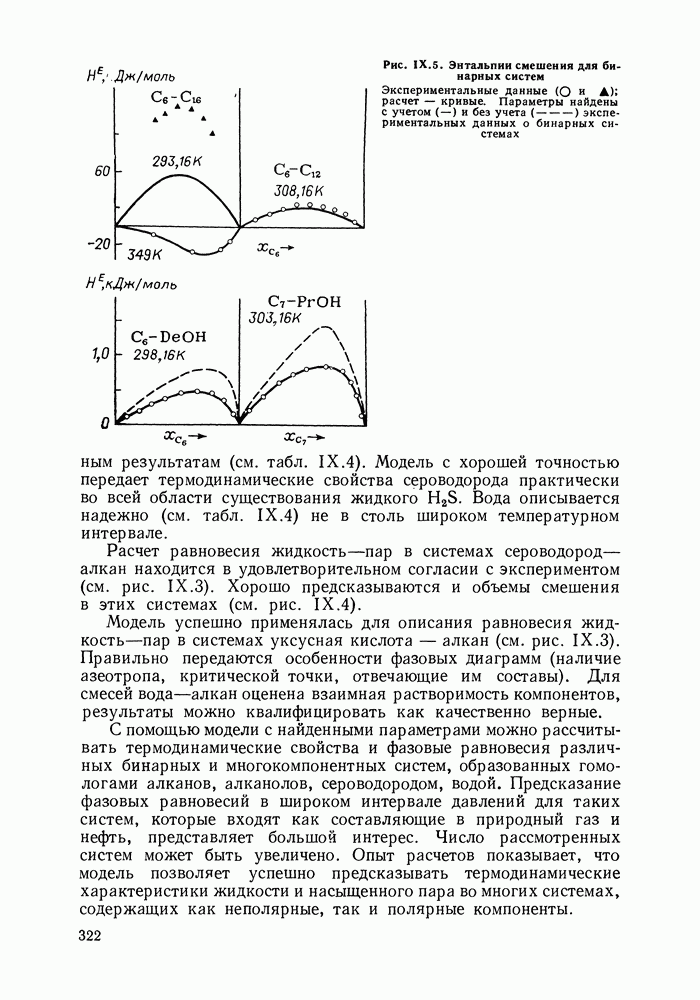
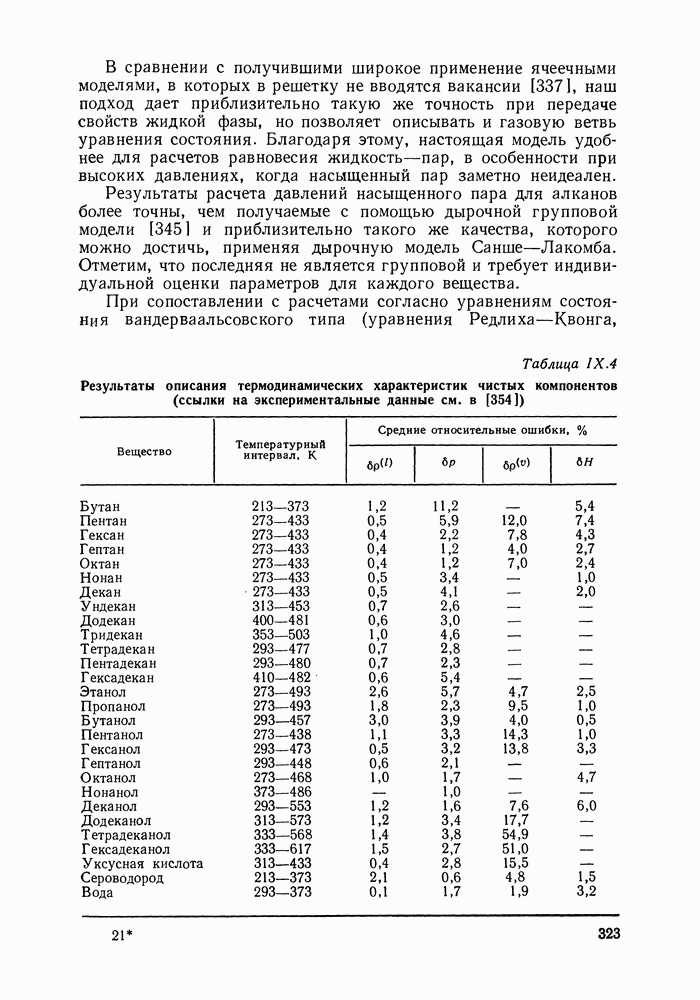



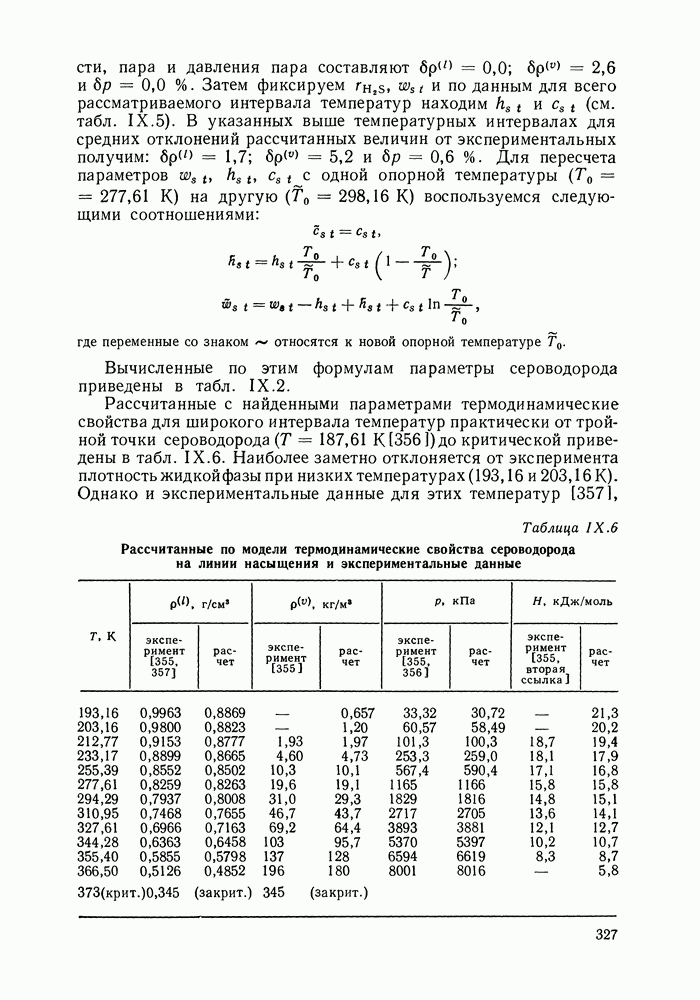
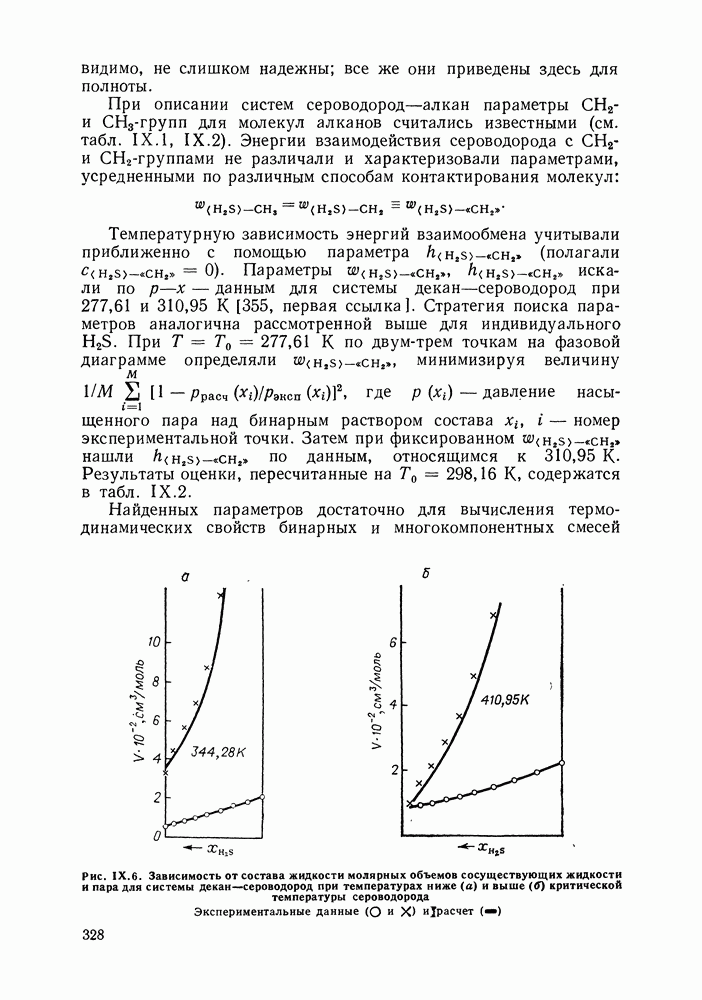













 однако, этот подход использует предельные ошибки и потому способен давать лишь грубые оценки. Желательно иметь более обоснованные статистические критерии.
однако, этот подход использует предельные ошибки и потому способен давать лишь грубые оценки. Желательно иметь более обоснованные статистические критерии.

 плотность вероятности совместного осуществления наблюдаемых значений всех переменных
плотность вероятности совместного осуществления наблюдаемых значений всех переменных  экспериментальной точке;
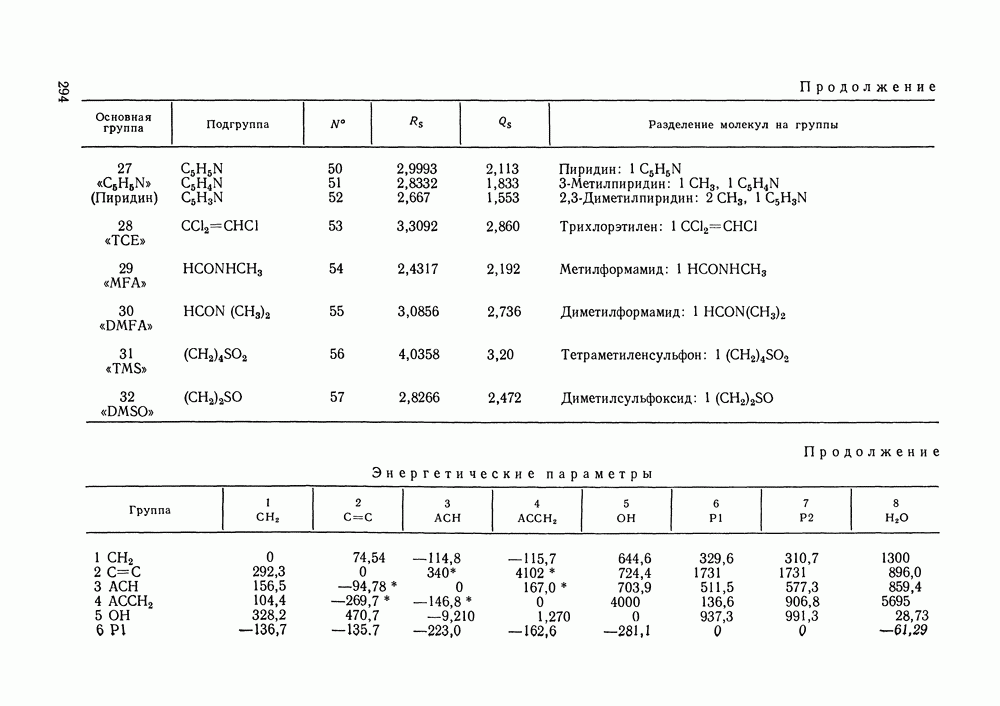
экспериментальной точке;  номер экспериментальной точки;
номер экспериментальной точки;  их число;
их число;  число измеряемых в каждой экспериментальной точке переменных;
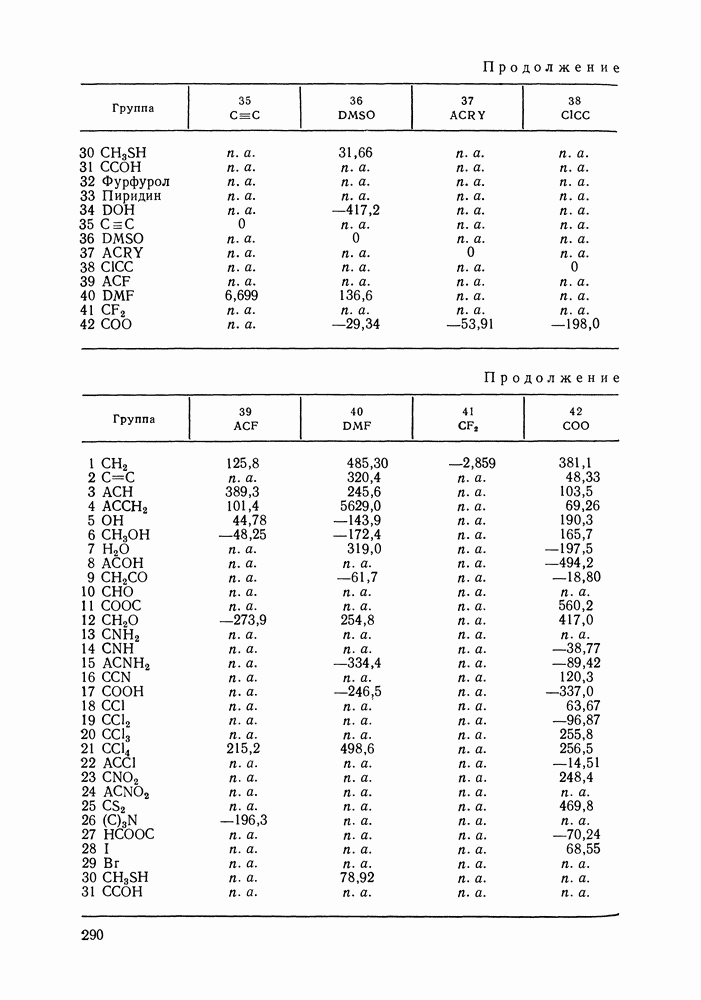
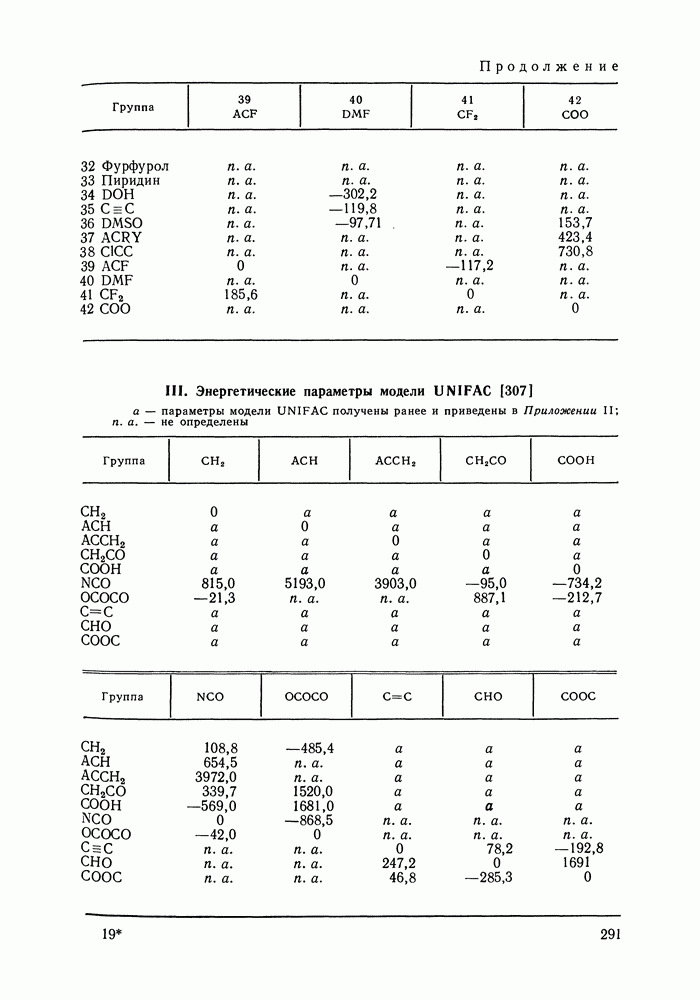
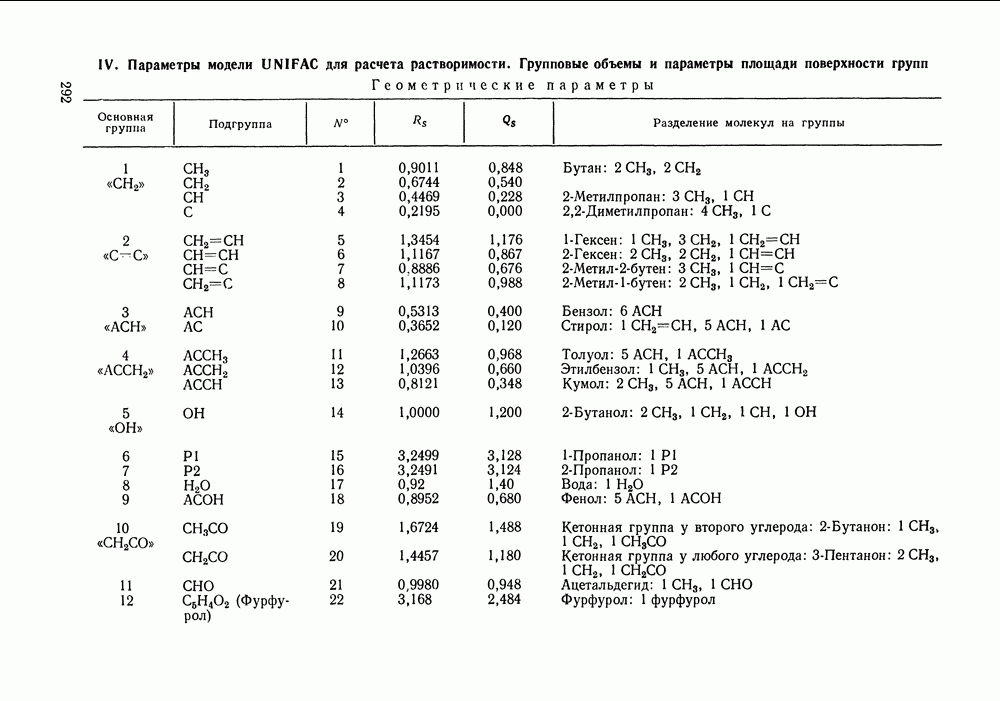
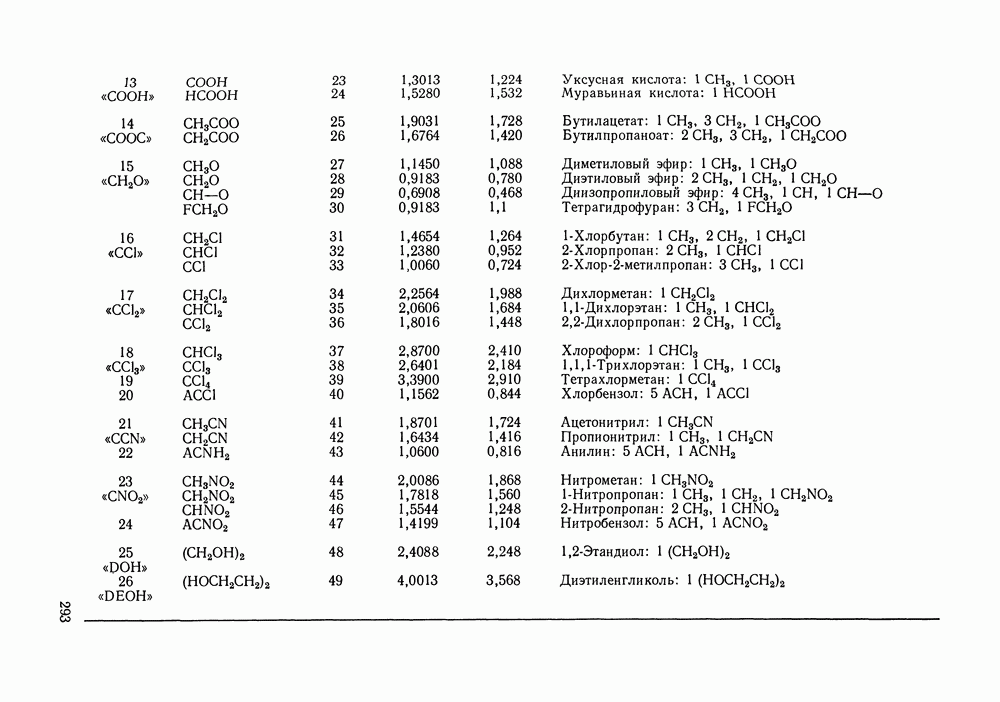
число измеряемых в каждой экспериментальной точке переменных;  вектор наблюдаемых значений переменных в
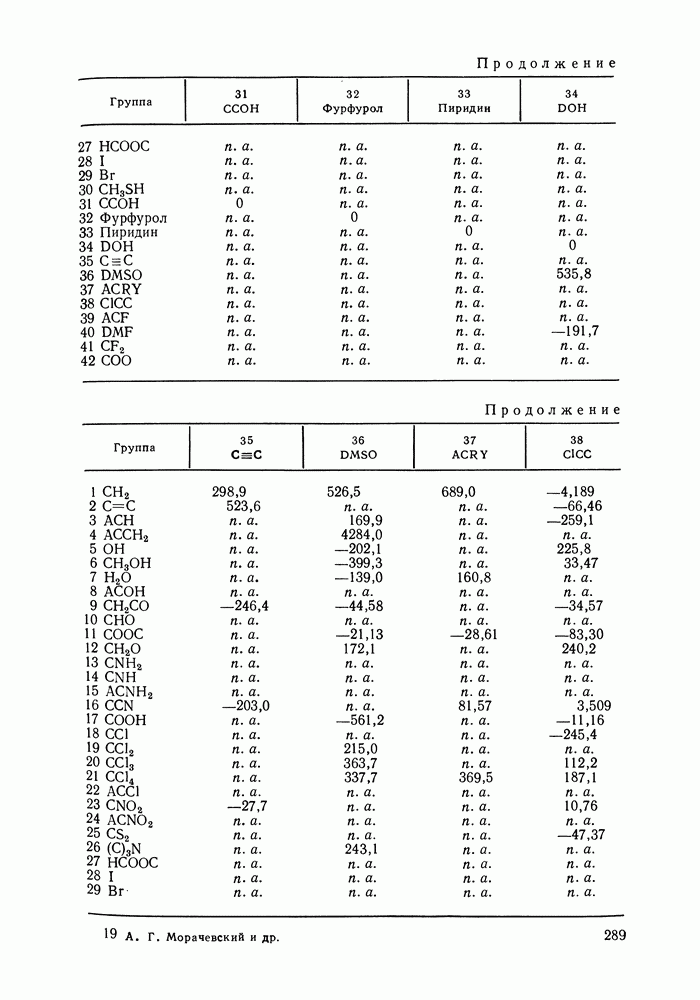
вектор наблюдаемых значений переменных в  экспериментальной точке; — вектор их истинных значений; — ковариационная матрица, которая содержит информацию о случайных ошибках экспериментальных данных и о зависимости ошибок измеряемых величин в
экспериментальной точке; — вектор их истинных значений; — ковариационная матрица, которая содержит информацию о случайных ошибках экспериментальных данных и о зависимости ошибок измеряемых величин в  экспериментальной точке;
экспериментальной точке;  означает определитель,
означает определитель,  транспонирование.
транспонирование.
 зависит от вектора искомых параметров
зависит от вектора искомых параметров  которые могут быть трех типов. Это могут быть параметры модели, применяемой для аппроксимации экспериментальных данных; тогда с помощью этих параметров оцениваются истинные значения измеряемых величин
которые могут быть трех типов. Это могут быть параметры модели, применяемой для аппроксимации экспериментальных данных; тогда с помощью этих параметров оцениваются истинные значения измеряемых величин  это могут быть сами истинные значения (например, для независимых паременных) и, наконец, это могут быть неизвестные элементы ковариационной матрицы
это могут быть сами истинные значения (например, для независимых паременных) и, наконец, это могут быть неизвестные элементы ковариационной матрицы  Значения
Значения  максимизирующие
максимизирующие  находятся решением системы уравнений правдоподобия:
находятся решением системы уравнений правдоподобия:

 и необходимые для этого
и необходимые для этого

 связывает истинные значения переменных
связывает истинные значения переменных

 стандартные уклонения состава раствора, состава пара, температуры и давления;
стандартные уклонения состава раствора, состава пара, температуры и давления;  уравнения модели.
уравнения модели.
 опускаются.
опускаются.
 при
при 
 для каждого состава бинарного раствора могут быть записаны в следующем виде:
для каждого состава бинарного раствора могут быть записаны в следующем виде:

 параметры зависимости
параметры зависимости 
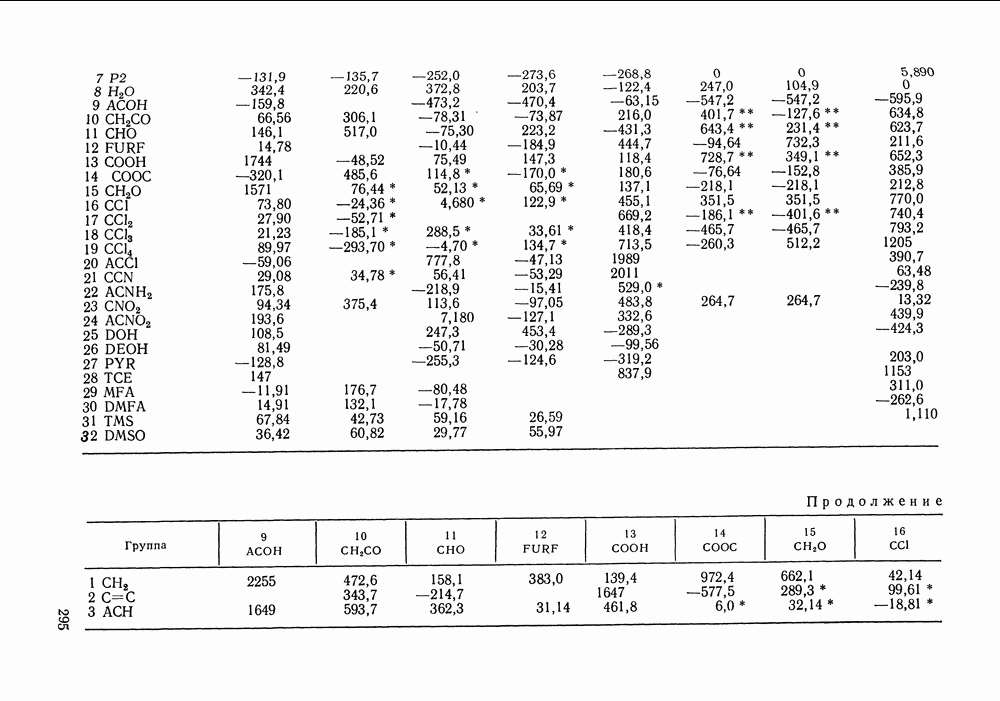
 Наиболее важный результат получен Кемени и сотр. [126], которые показали, что в условии малости случайных ошибок минимизация
Наиболее важный результат получен Кемени и сотр. [126], которые показали, что в условии малости случайных ошибок минимизация  уклонений непосредственно
уклонений непосредственно
 произвольных функций этих величин,
произвольных функций этих величин, 

 вектор этих произвольных функций в
вектор этих произвольных функций в  экспериментальной точке;
экспериментальной точке;  значения переменных, непосредственно измеренных в эксперименте; индекс
значения переменных, непосредственно измеренных в эксперименте; индекс  означает рассчитанные по модели значения,
означает рассчитанные по модели значения,  параметры модели;
параметры модели;  ковариационная матрица для величин
ковариационная матрица для величин 
 величины
величины  не могут уже более рассматриваться как независимые, даже в условии независимости всех измеряемых
не могут уже более рассматриваться как независимые, даже в условии независимости всех измеряемых  Ковариационную матрицу
Ковариационную матрицу  вычисляют по обычным правилам переноса ошибок для каждой экспериментальной точки на фазовой диаграмме. Соотношения для расчета
вычисляют по обычным правилам переноса ошибок для каждой экспериментальной точки на фазовой диаграмме. Соотношения для расчета  содержатся в работах [126, 127].
содержатся в работах [126, 127].
 и
и  приводят к одинаковым в пределах случайной ошибки параметрам модели [126]. Однако для такой эквивалентности необходимо, чтобы критерии
приводят к одинаковым в пределах случайной ошибки параметрам модели [126]. Однако для такой эквивалентности необходимо, чтобы критерии  и
и  содержали одинаковую экспериментальную информацию. Например, если выбрать
содержали одинаковую экспериментальную информацию. Например, если выбрать  то сведения о давлении пара в
то сведения о давлении пара в  не содержатся. Тогда этот критерий не эквивалентен
не содержатся. Тогда этот критерий не эквивалентен  для непосредственно измеренных
для непосредственно измеренных  и он не дает тот же набор параметров.
и он не дает тот же набор параметров.
 для бинарной системы. Тогда, пользуясь методом работы [125, первая ссылка], нам придется искать минимум функции
для бинарной системы. Тогда, пользуясь методом работы [125, первая ссылка], нам придется искать минимум функции  по 302 — истинным значениям независимых переменных и по
по 302 — истинным значениям независимых переменных и по  -вектору параметров модели.
-вектору параметров модели.
 по параметрам модели
по параметрам модели  приходится в каждой экспериментальной точке при текущих значениях параметров модели рассчитывать матрицу Обычно это связано с численным дифференцированием, что сопряжено с большим объемом работы; поэтому оба метода приблизительно одинаковы по трудоемкости.
приходится в каждой экспериментальной точке при текущих значениях параметров модели рассчитывать матрицу Обычно это связано с численным дифференцированием, что сопряжено с большим объемом работы; поэтому оба метода приблизительно одинаковы по трудоемкости.

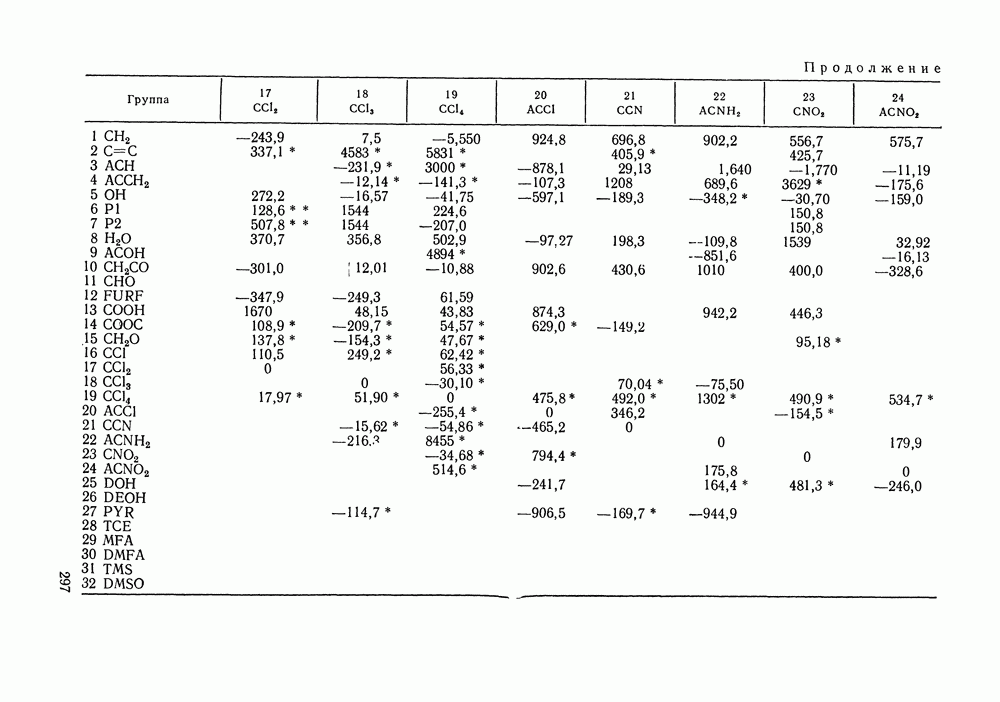
 [20], если
[20], если  независимые, нормально распределенные случайные величины со средними
независимые, нормально распределенные случайные величины со средними  и дисперсиями
и дисперсиями  Здесь коэффициенты
Здесь коэффициенты  равны единицам для полных данных
равны единицам для полных данных  и соответствующие
и соответствующие  равны нулю, если набор данных не полный.
равны нулю, если набор данных не полный.
 Согласно методу максимального правдоподобия, поиск параметров
Согласно методу максимального правдоподобия, поиск параметров  этой модели, как говорилось выше, проводится миниминизацией
этой модели, как говорилось выше, проводится миниминизацией  где вместо истинных значений зависимых переменных стоят их значения вычисленные по модели. Тогда распределение
где вместо истинных значений зависимых переменных стоят их значения вычисленные по модели. Тогда распределение
 в минимуме
в минимуме  близко к распределению
близко к распределению  Возникающее при этом смещение распределения учитывается изменением его числа степеней свободы.
Возникающее при этом смещение распределения учитывается изменением его числа степеней свободы.
 вместо дисперсий или истинных значений, поставить их грубые оценки, то распределение
вместо дисперсий или истинных значений, поставить их грубые оценки, то распределение  будет отклоняться от
будет отклоняться от  На этом основаны многие критерии надежности данных. Согласно [128] полный набор данных
На этом основаны многие критерии надежности данных. Согласно [128] полный набор данных  для бинарной системы разбивается на 4 поднабора данных:
для бинарной системы разбивается на 4 поднабора данных:  Затем принимаются некоторые пробные значения погрешностей
Затем принимаются некоторые пробные значения погрешностей  и ищутся параметры модели для каждого поднабора в отдельности и для полного набора данных. Гипотеза о равенстве дисперсий
и ищутся параметры модели для каждого поднабора в отдельности и для полного набора данных. Гипотеза о равенстве дисперсий  их предполагаемым значениям верна, если для каждого» поднабора значение
их предполагаемым значениям верна, если для каждого» поднабора значение  лежит в интервале:
лежит в интервале:

 для уровня значимости а с
для уровня значимости а с  степенями свободы;
степенями свободы;  число параметров модели.
число параметров модели.
 нарушено, гипотеза отвергается. Однако такой тест не позволяет разделить случайные и систематические ошибки в экспериментальных данных. Величины
нарушено, гипотеза отвергается. Однако такой тест не позволяет разделить случайные и систематические ошибки в экспериментальных данных. Величины  удовлетворяющие неравенству
удовлетворяющие неравенству  отражают суммарный вклад ошибок обоих типов. Может случиться, что из-за систематических ошибок тест
отражают суммарный вклад ошибок обоих типов. Может случиться, что из-за систематических ошибок тест  приведет к завышенным оценкам дисперсий. И наоборот, выполнение
приведет к завышенным оценкам дисперсий. И наоборот, выполнение  для всех поднаборов не гарантирует отсутствия систематических ошибок и, в частности, термодинамической согласованности данных.
для всех поднаборов не гарантирует отсутствия систематических ошибок и, в частности, термодинамической согласованности данных.
 дополняют разнообразными тестами на систематические ошибки. Как отмечалось выше, при описании полного набора данных с помощью модели уравнение Гиббса-Дюгема учитывается автоматически, ему удовлетворяют оценки истинных значений переменных. Поэтому
дополняют разнообразными тестами на систематические ошибки. Как отмечалось выше, при описании полного набора данных с помощью модели уравнение Гиббса-Дюгема учитывается автоматически, ему удовлетворяют оценки истинных значений переменных. Поэтому  для полного набора используют для проверки термодинамической согласованности данных [122, вторая ссылка; 128]. Если
для полного набора используют для проверки термодинамической согласованности данных [122, вторая ссылка; 128]. Если

 на уровне значимости
на уровне значимости 
 проверенные для поднаборов.
проверенные для поднаборов.
 -поднабора:
-поднабора:


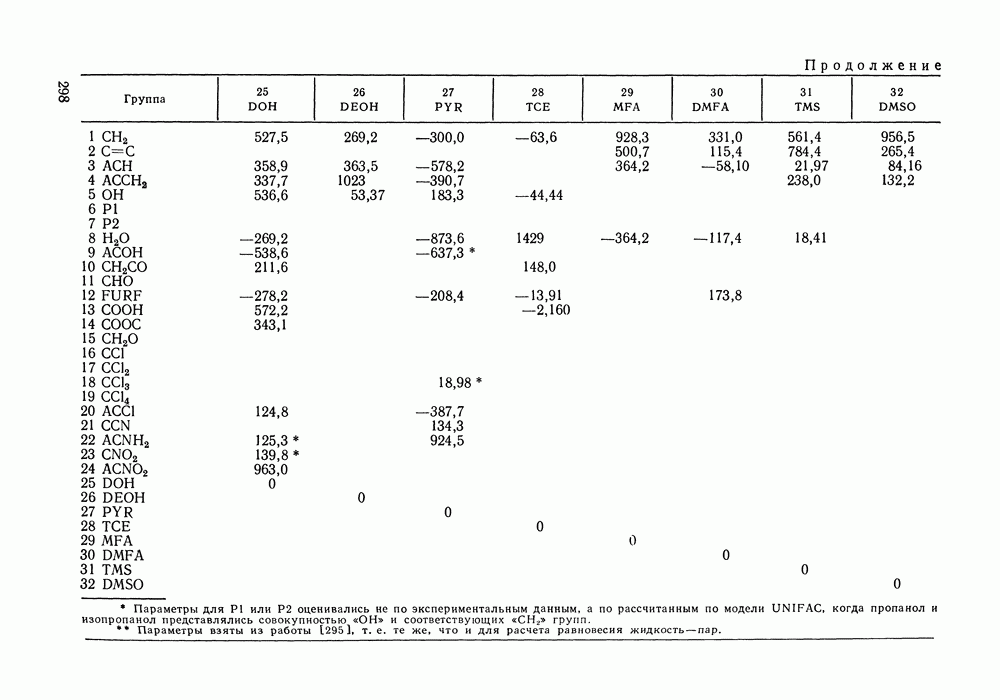
 составе пара) от мол. доли в бинарных системах бутанол—гексан;
составе пара) от мол. доли в бинарных системах бутанол—гексан;  и этанол—бензол;
и этанол—бензол;  Данные содержат систематические ошибки
Данные содержат систематические ошибки
 от нуля (рис. VI.4, а) может быть обнаружено с помощью статистики
от нуля (рис. VI.4, а) может быть обнаружено с помощью статистики 


 квантиль распределения Стьюдента с
квантиль распределения Стьюдента с  степенями свободы.
степенями свободы.

 где
где  -квантиль соответствующего распределения, то данные подвержены систематическому смещению. Используются и другие статистические критерии, например, критерий перемены знаков остатков.
-квантиль соответствующего распределения, то данные подвержены систематическому смещению. Используются и другие статистические критерии, например, критерий перемены знаков остатков.