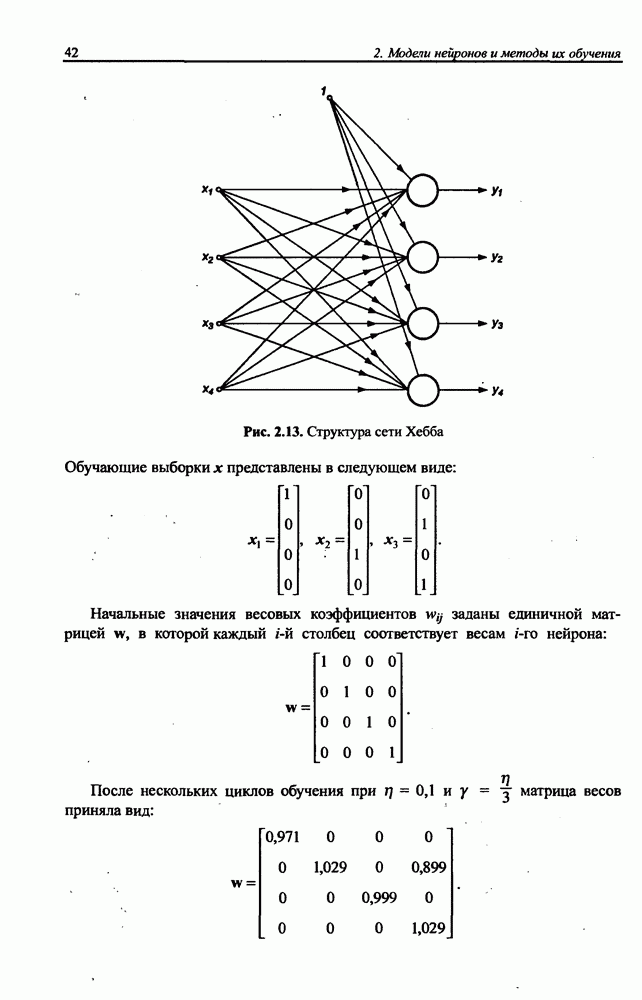
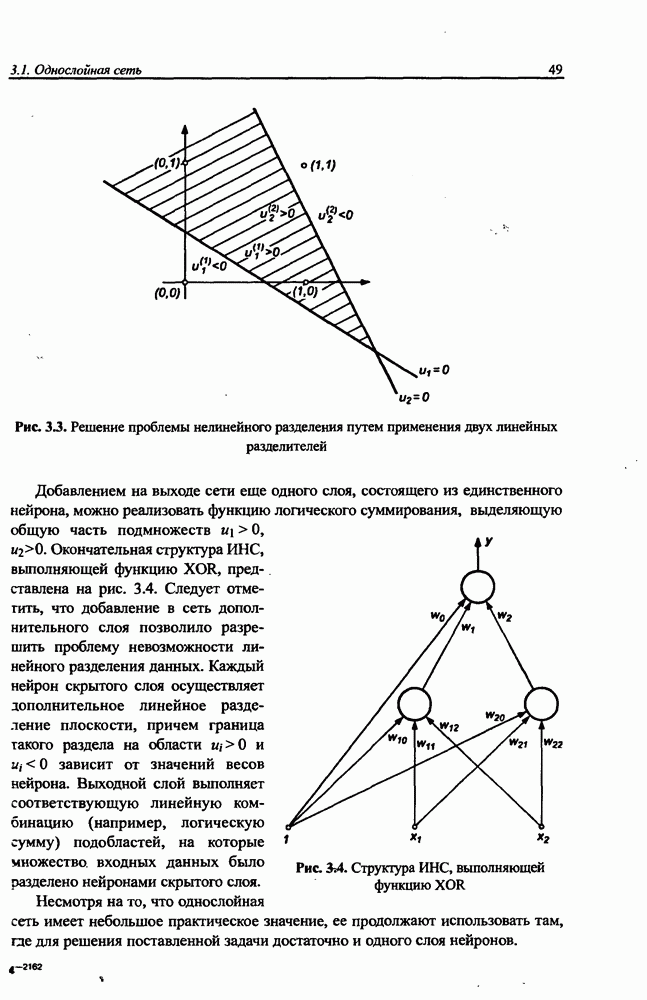
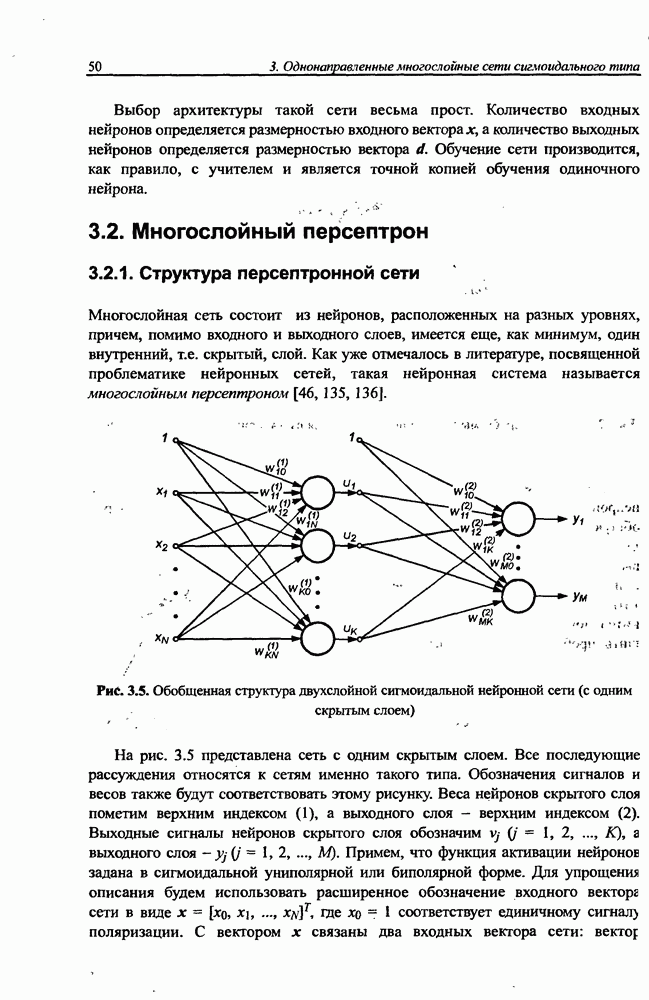
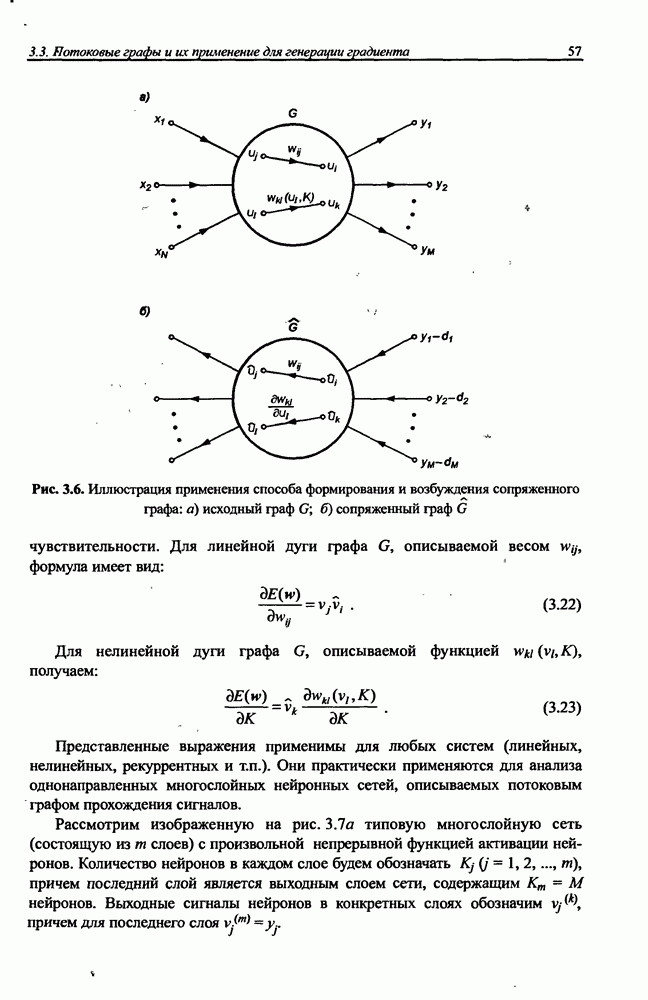
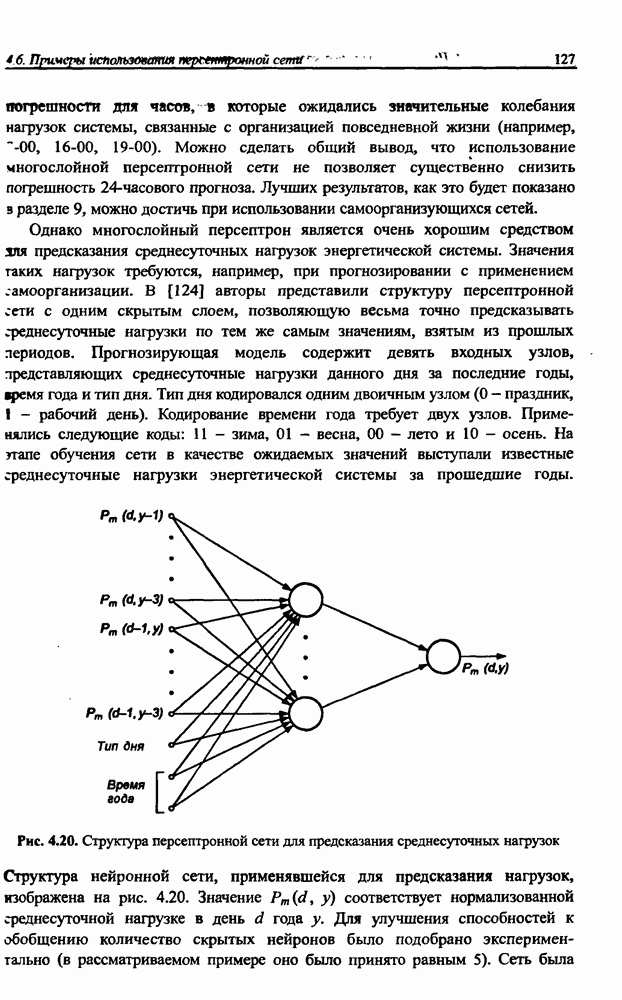
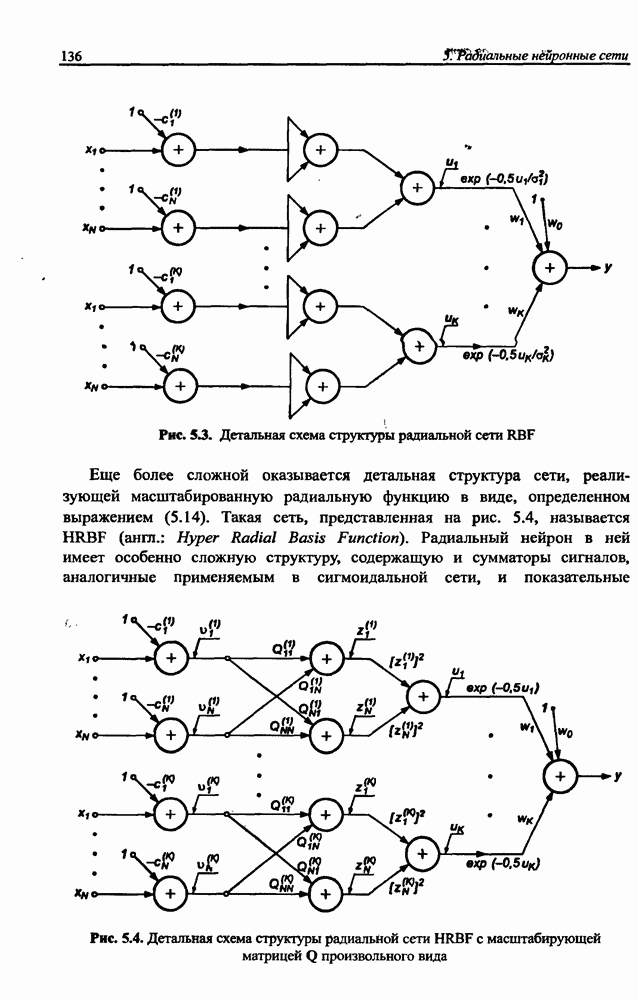
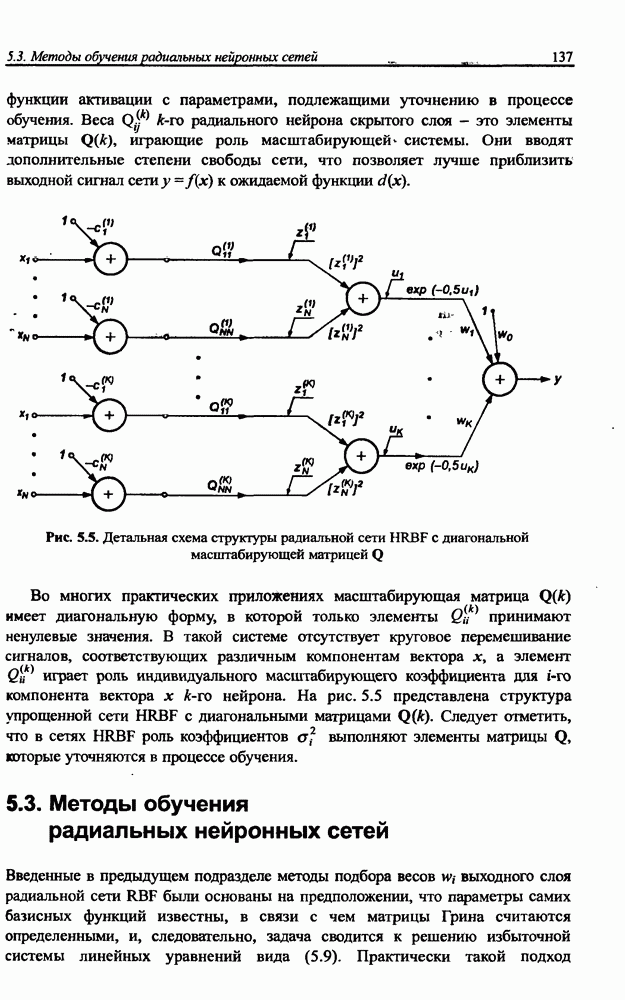
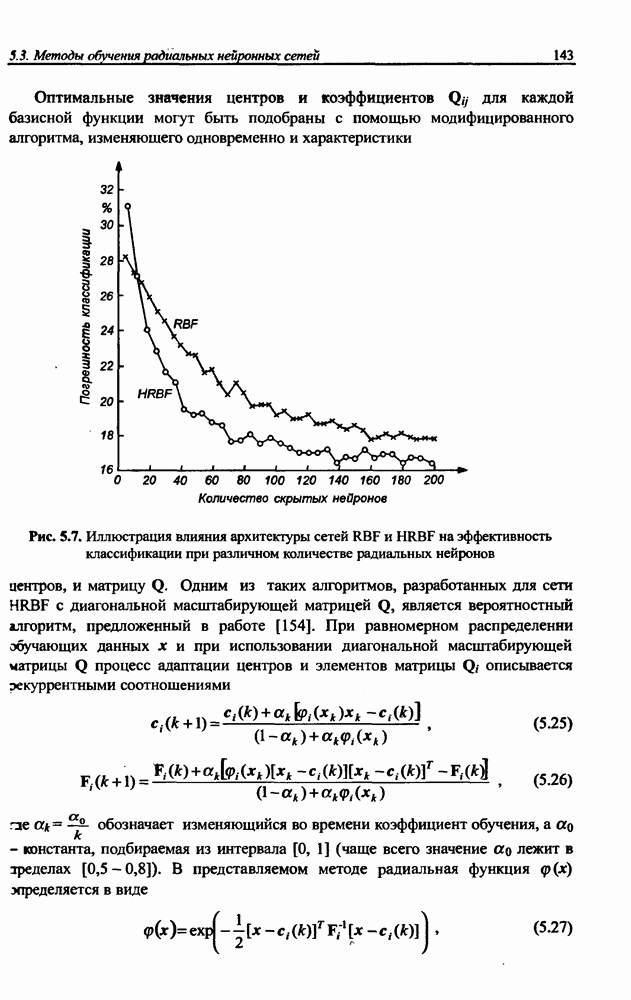
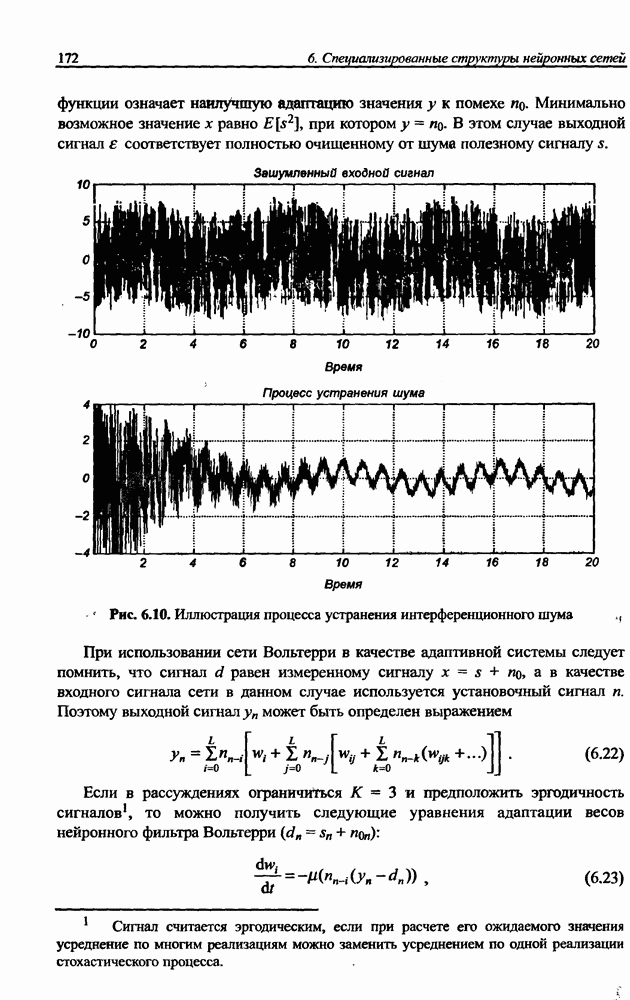
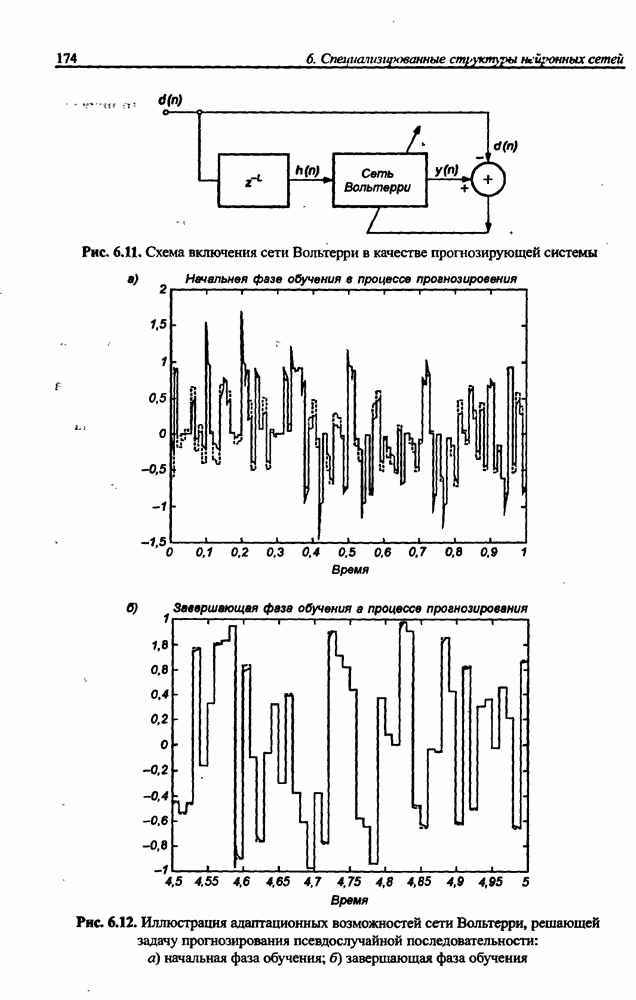
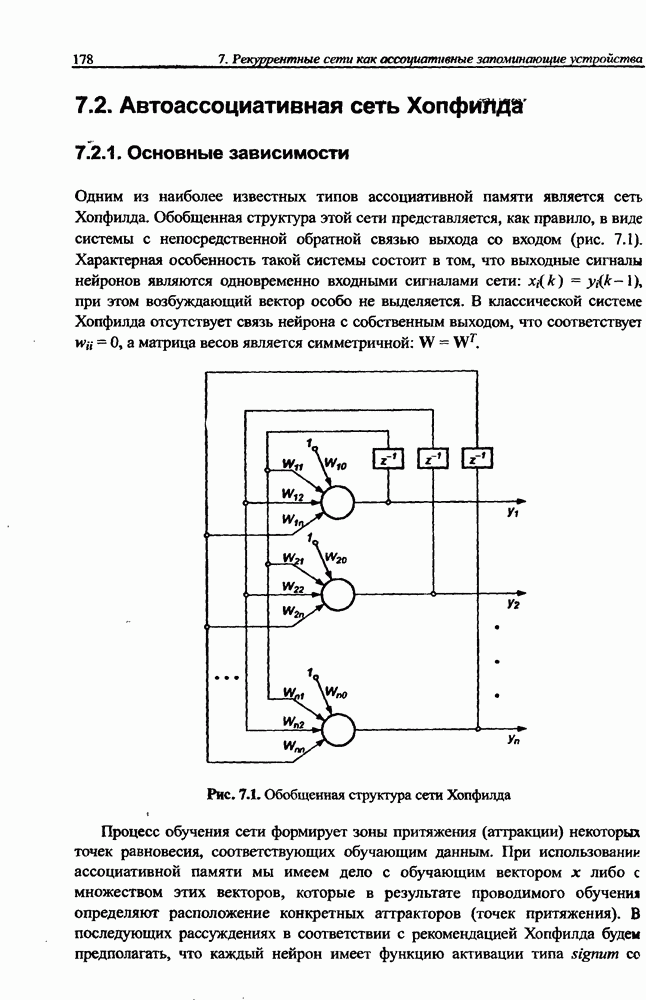
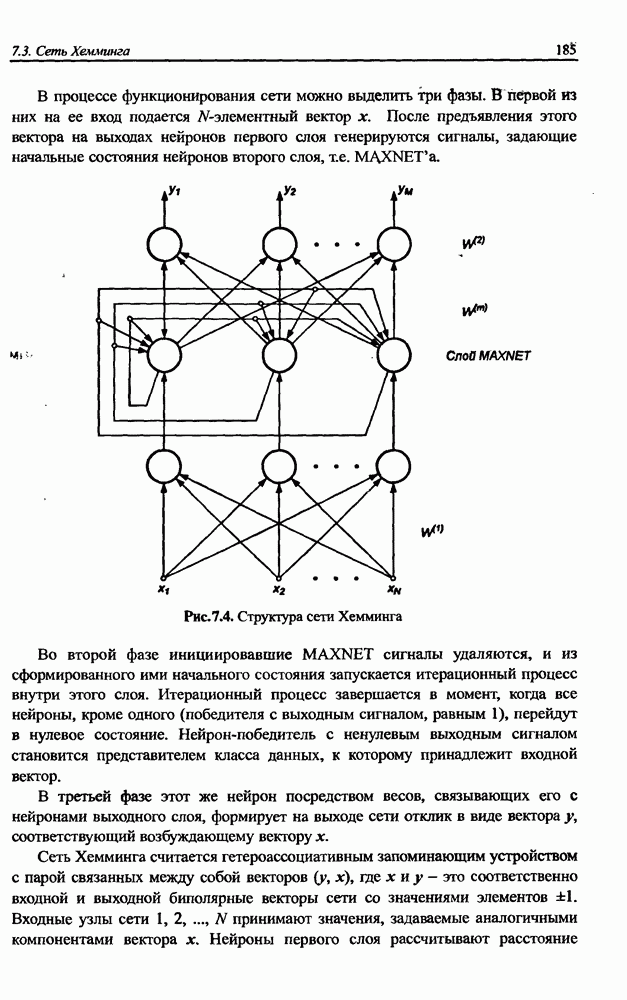
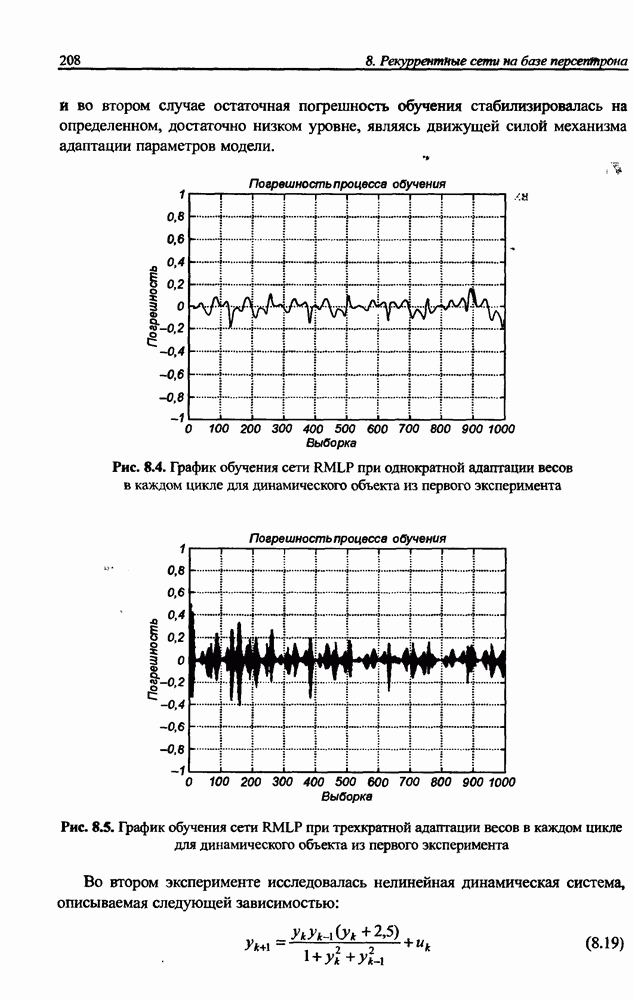
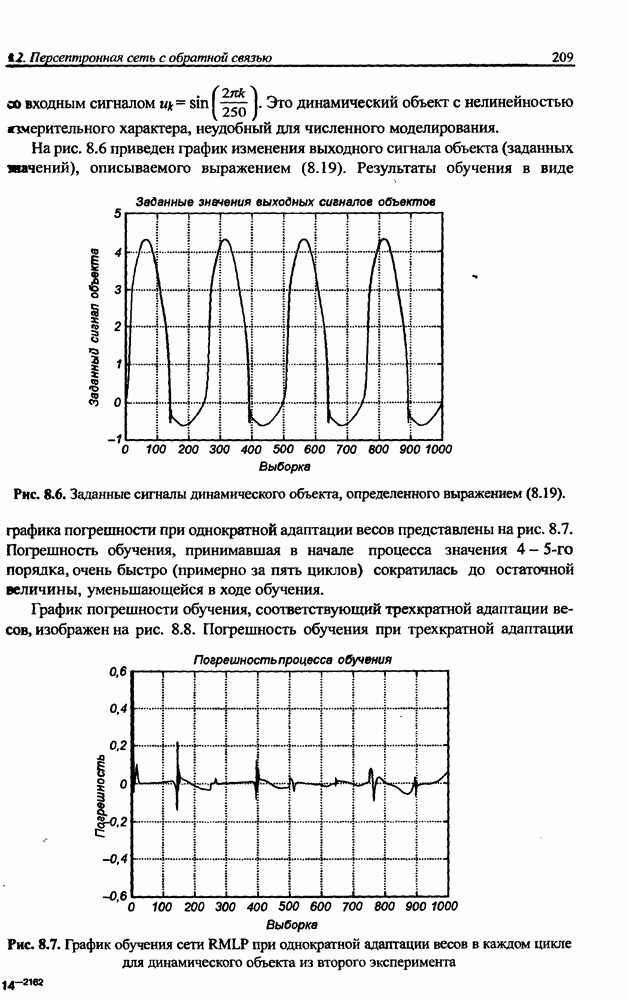
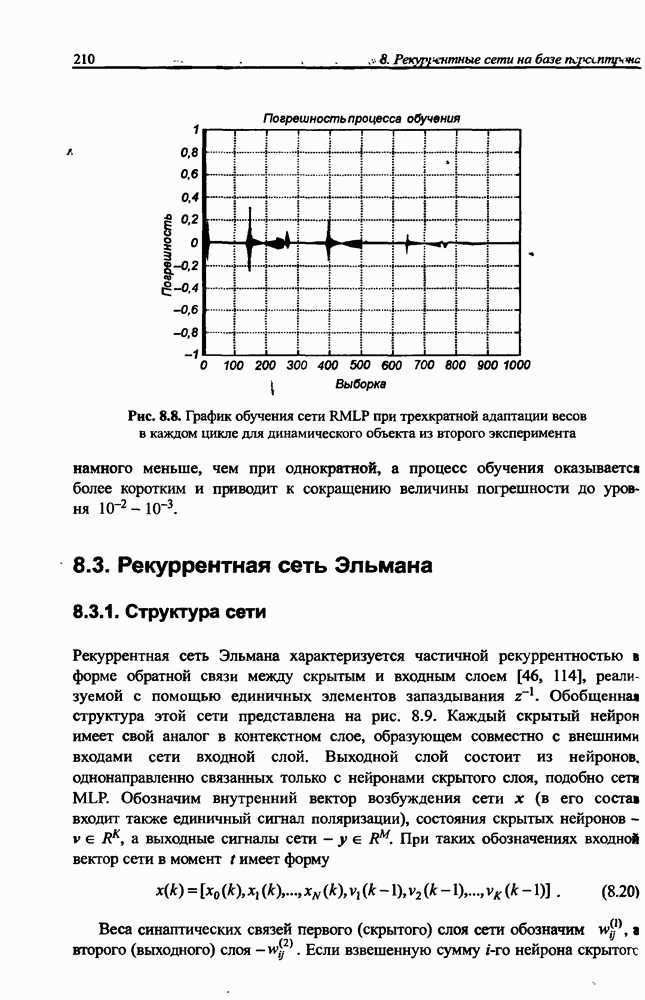
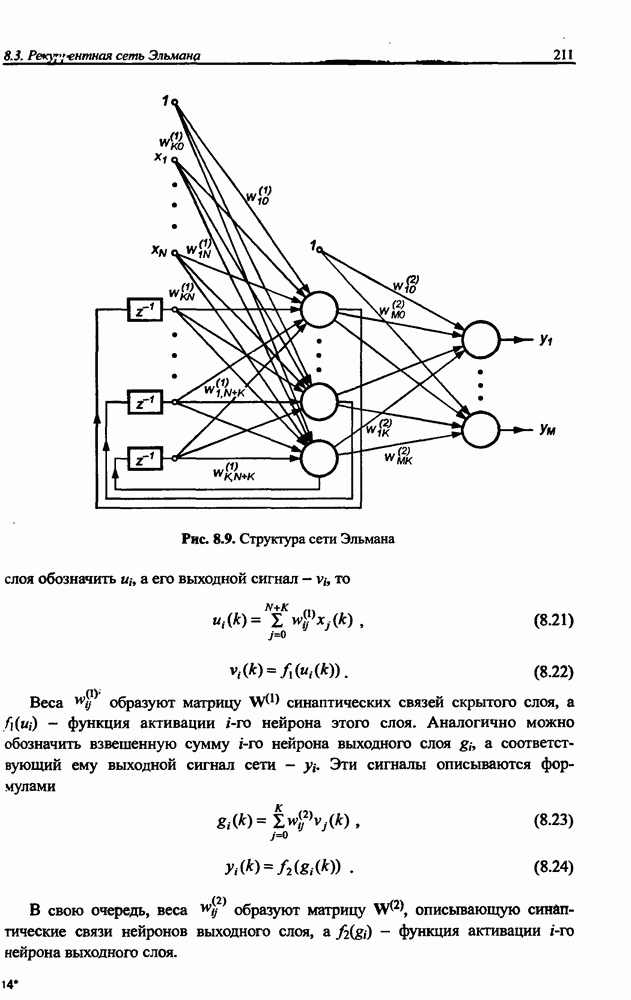
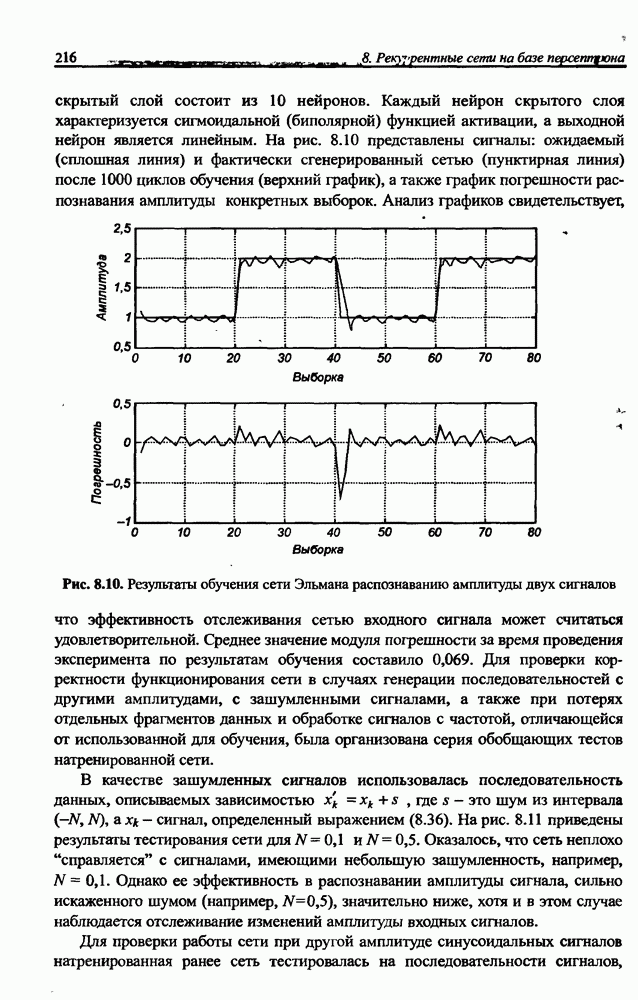
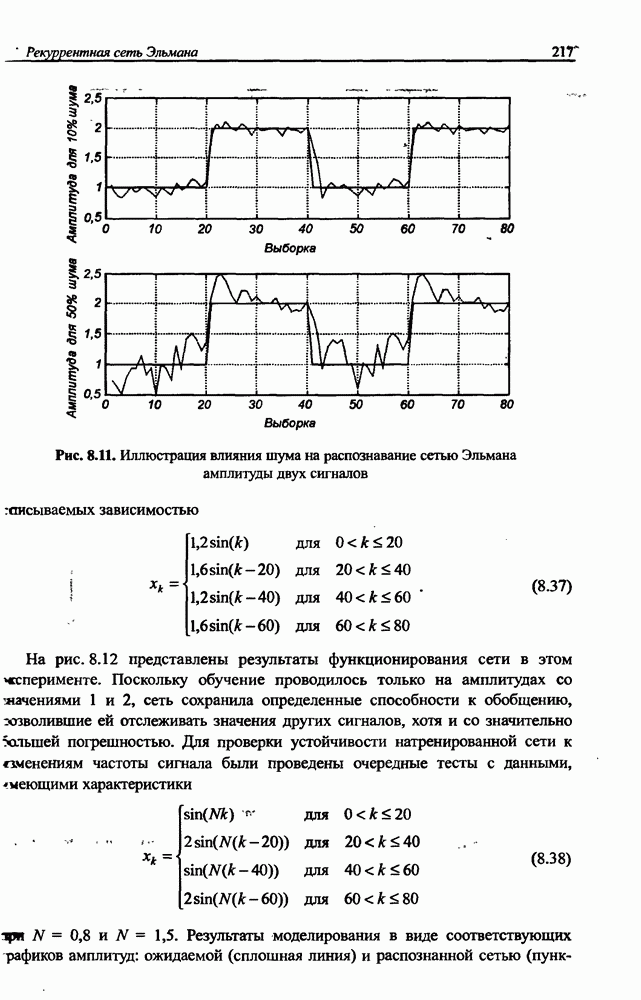
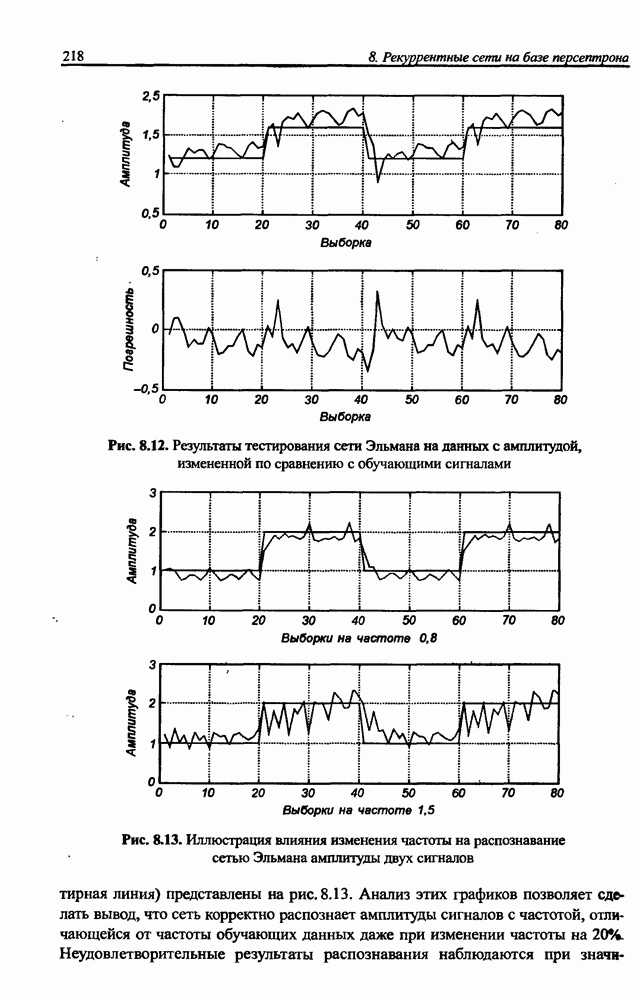
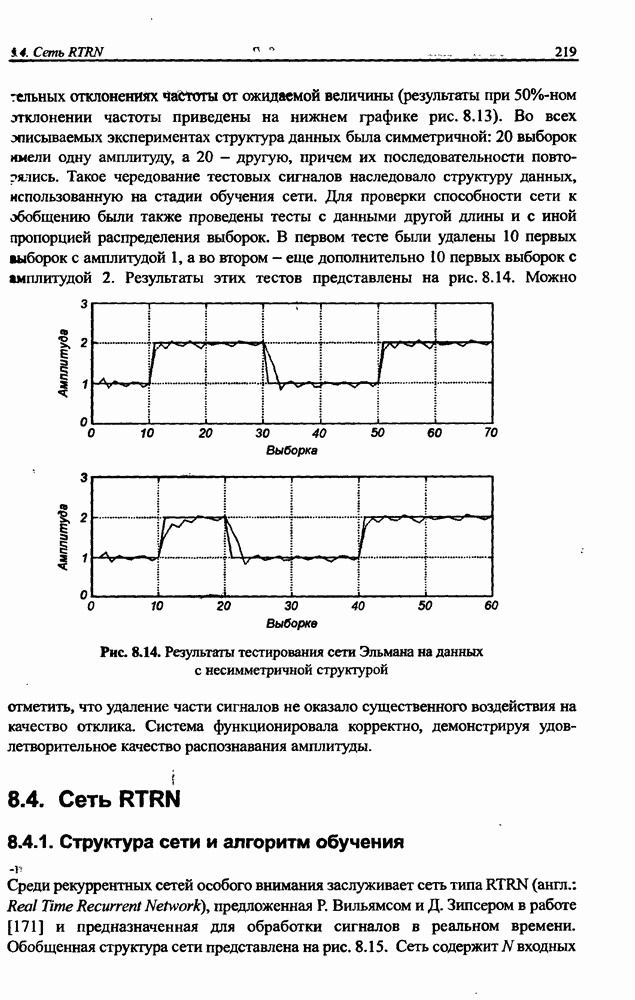
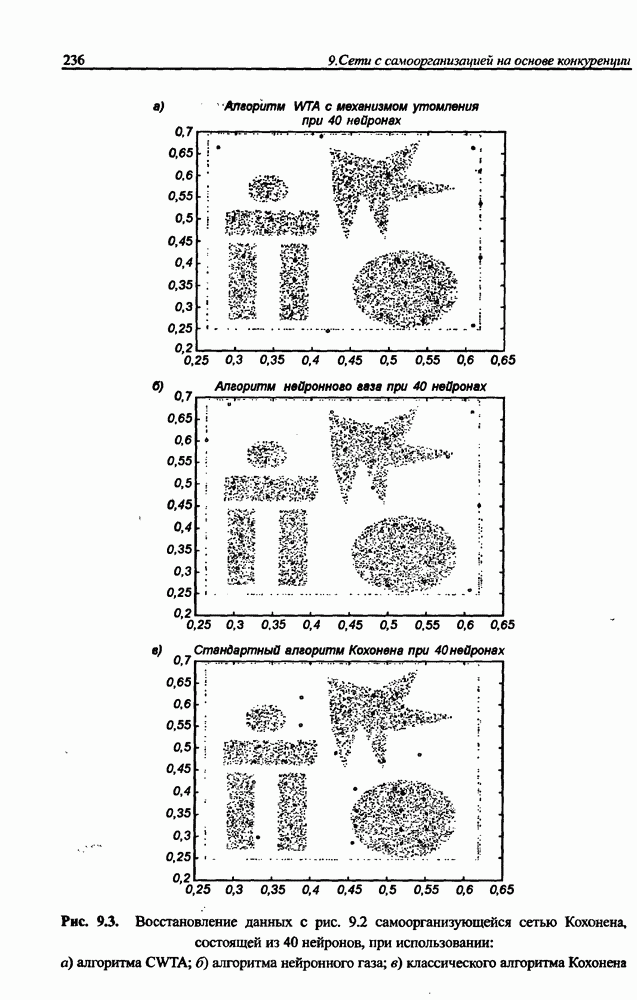
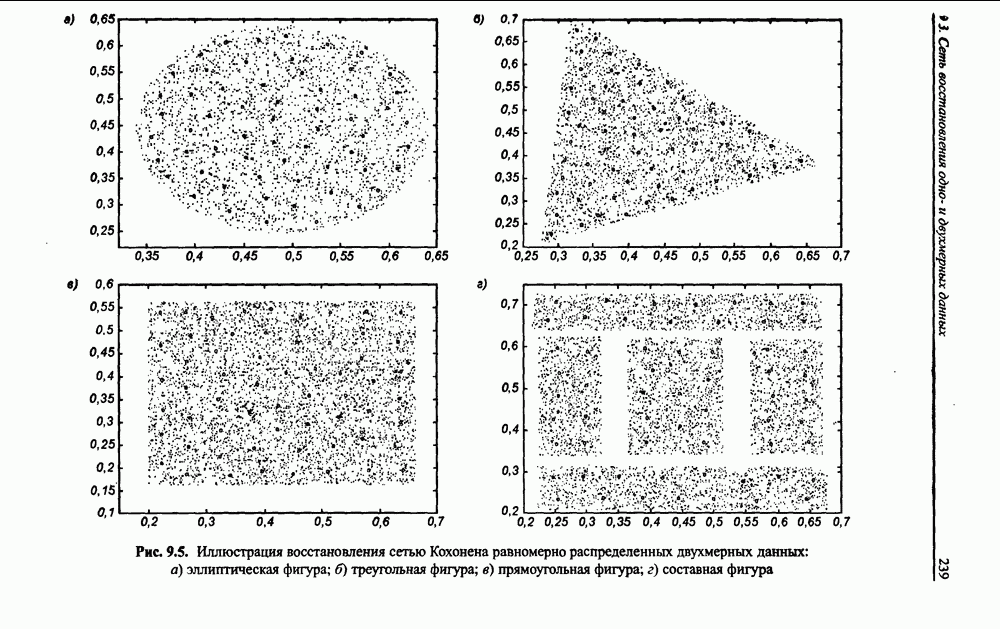
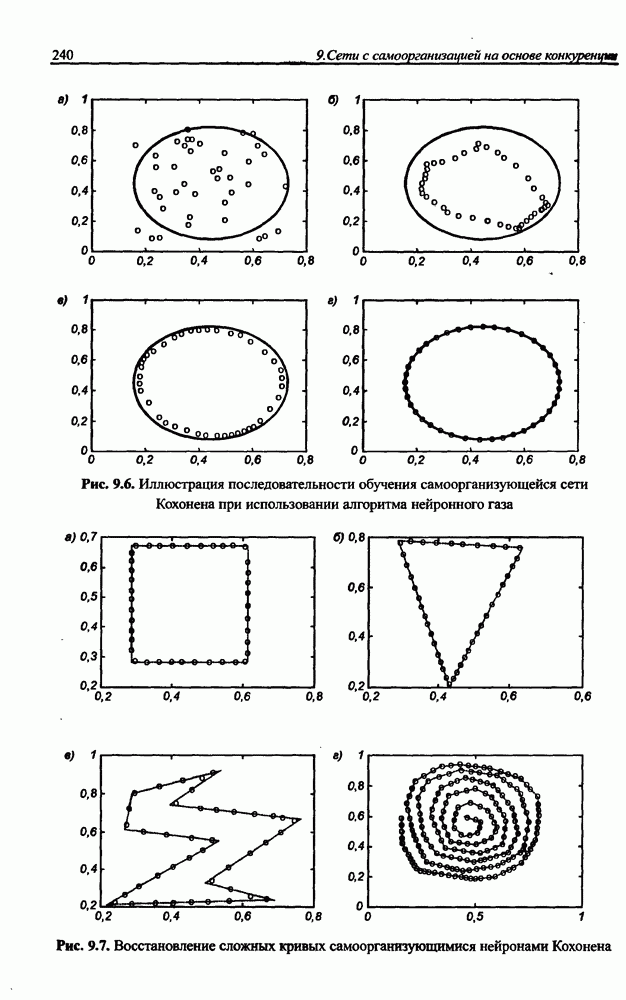
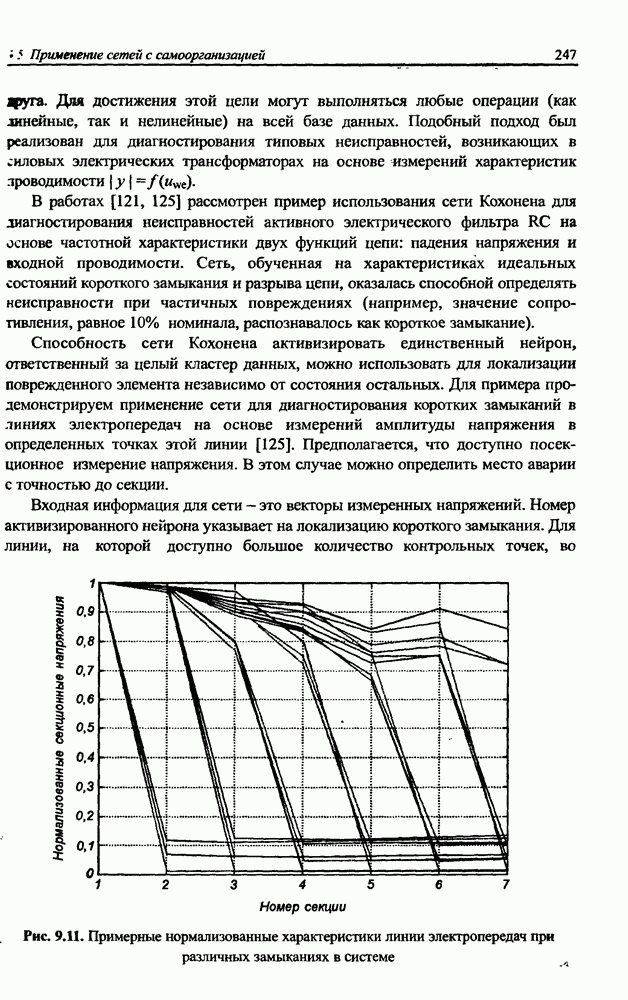
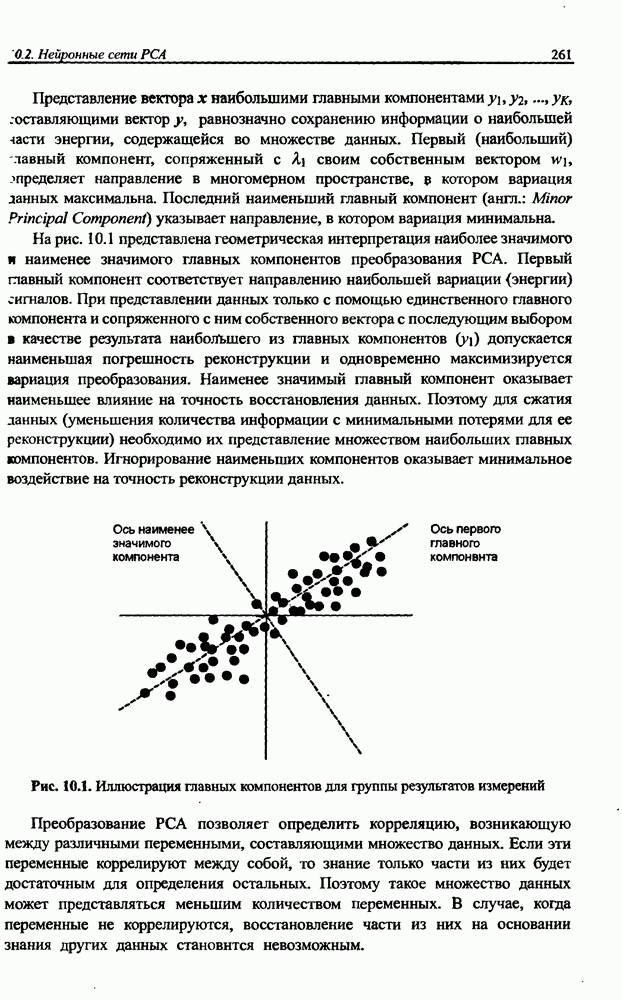
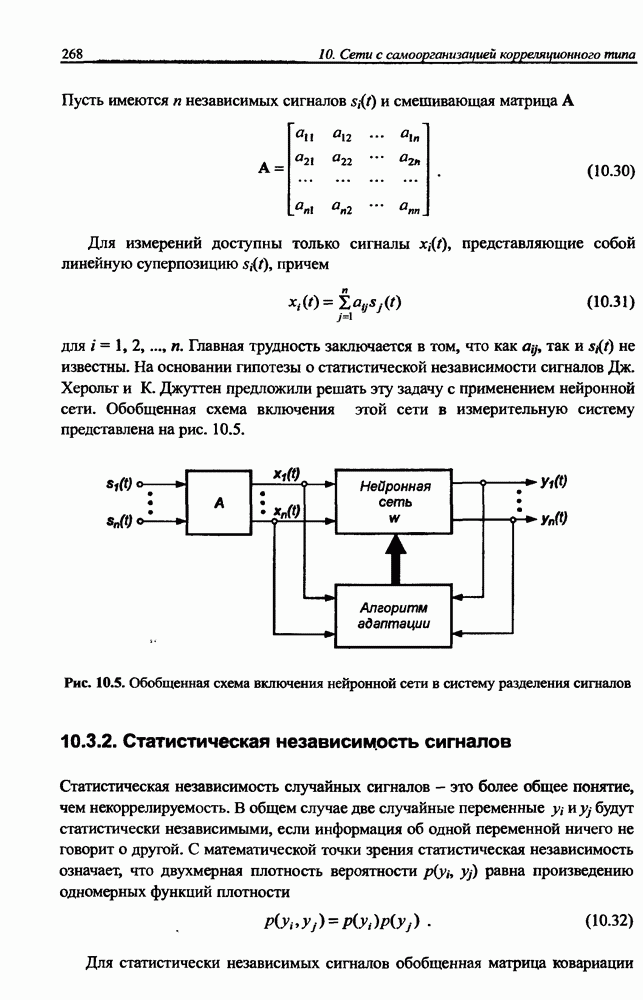
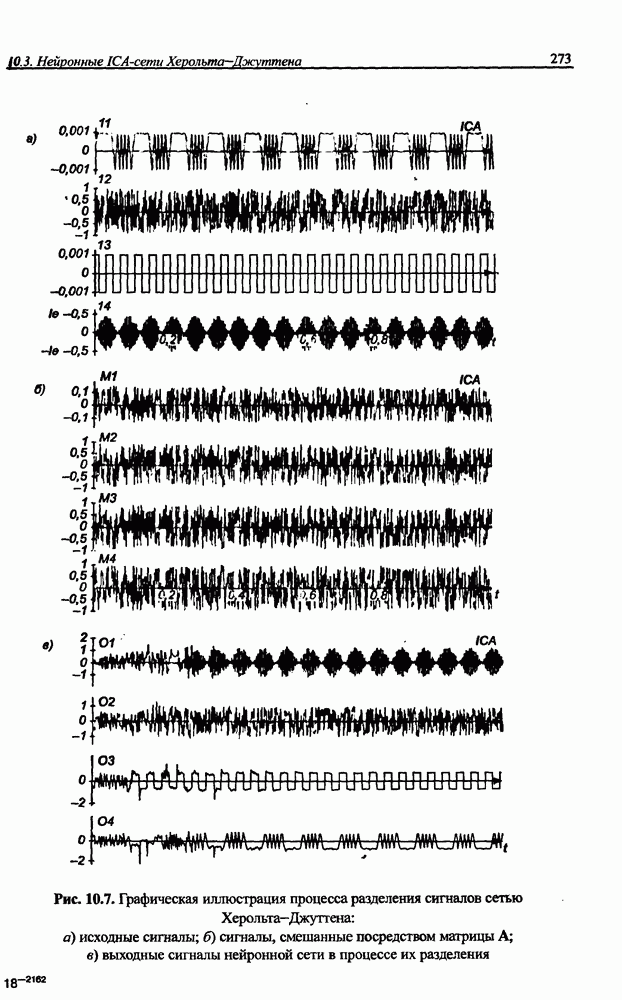
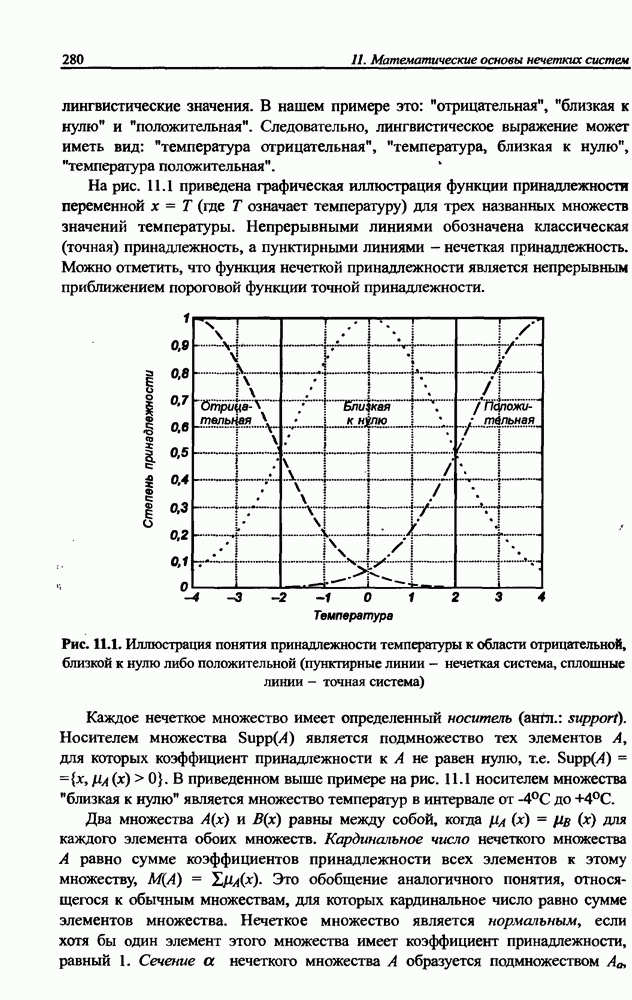
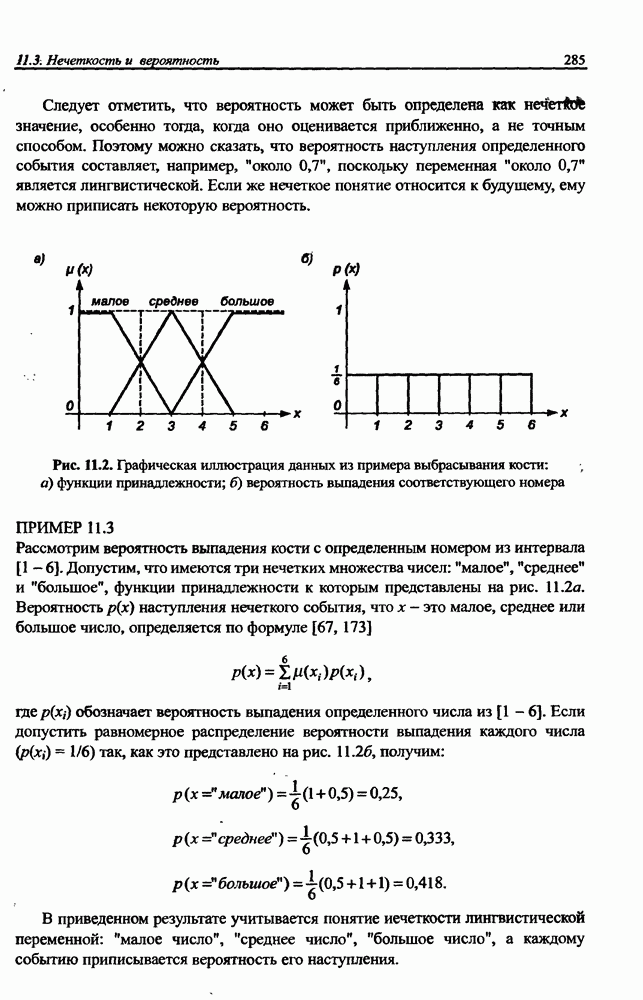
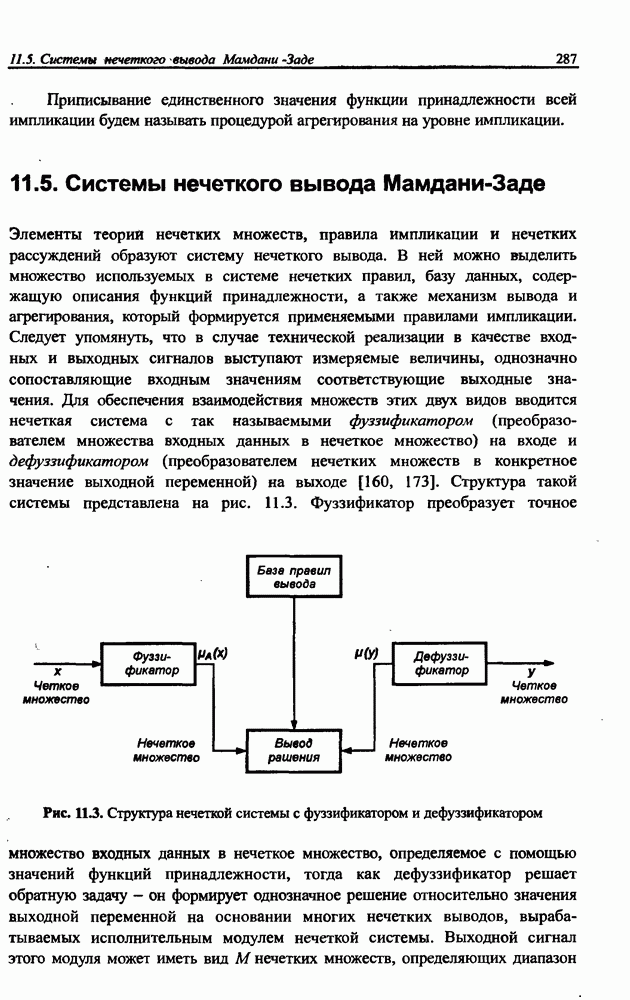
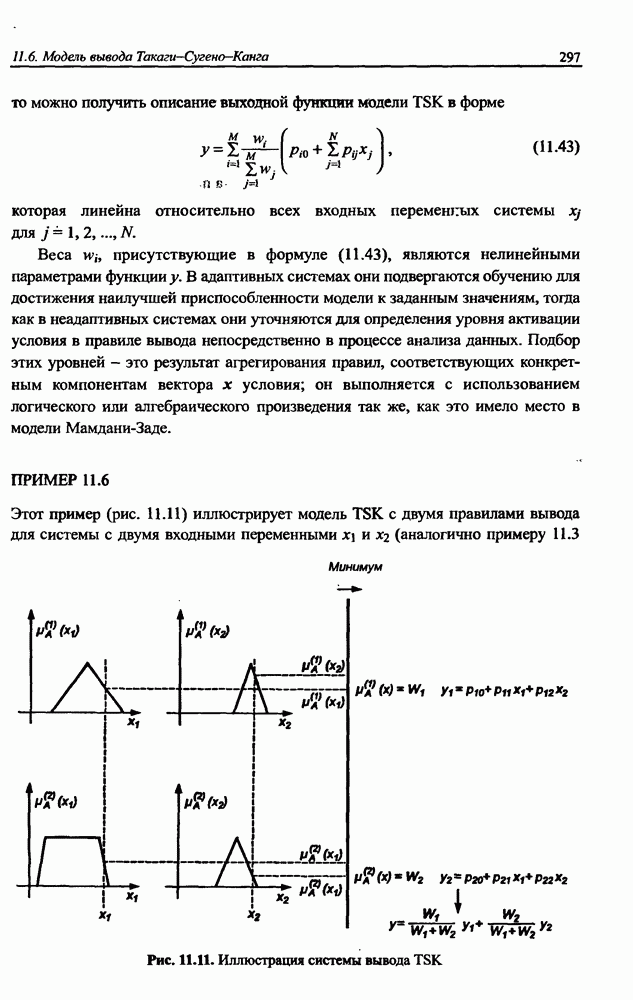
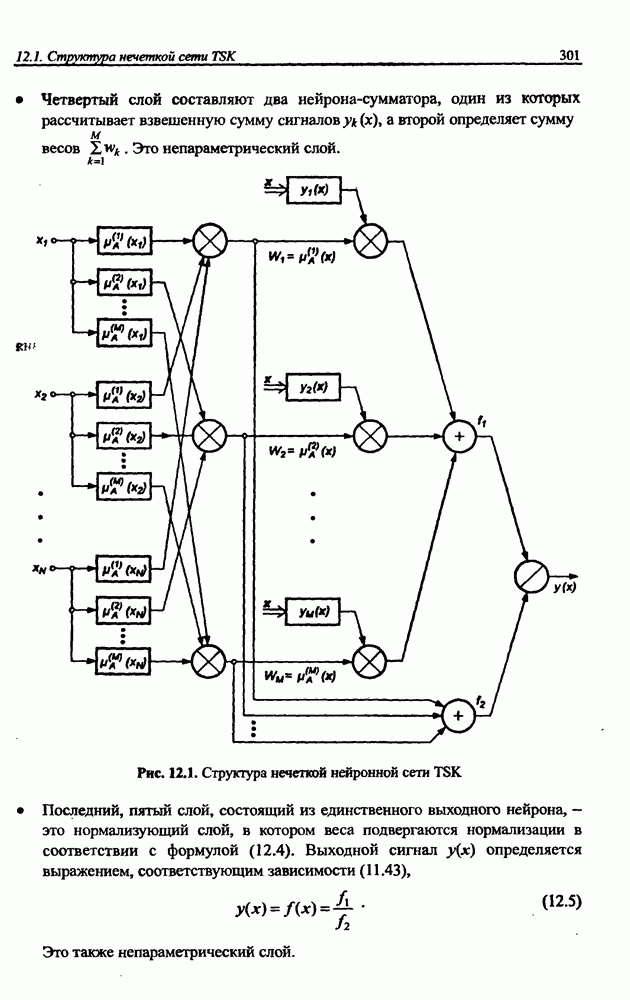
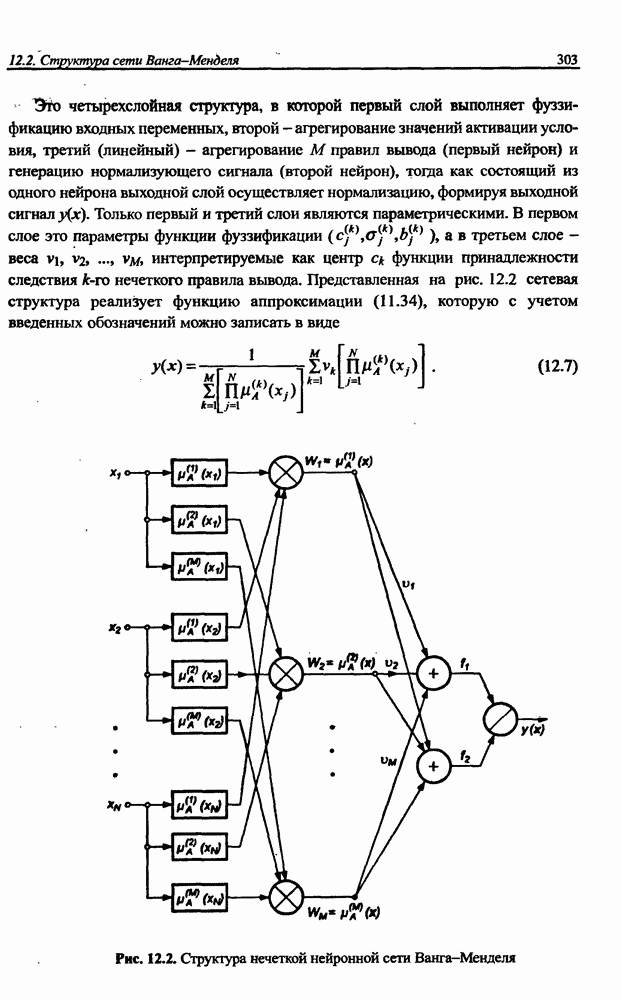
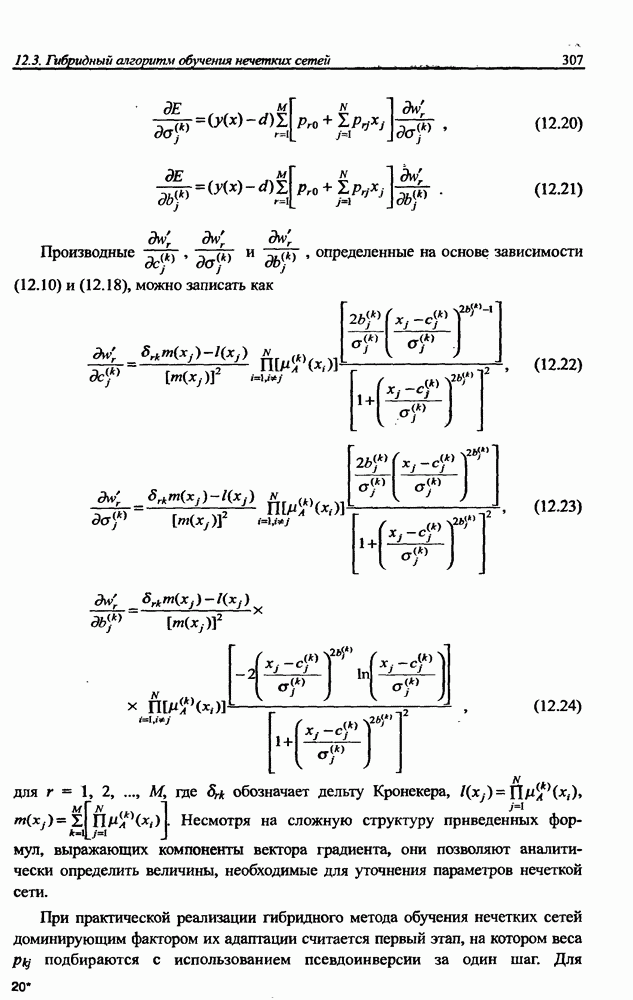
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
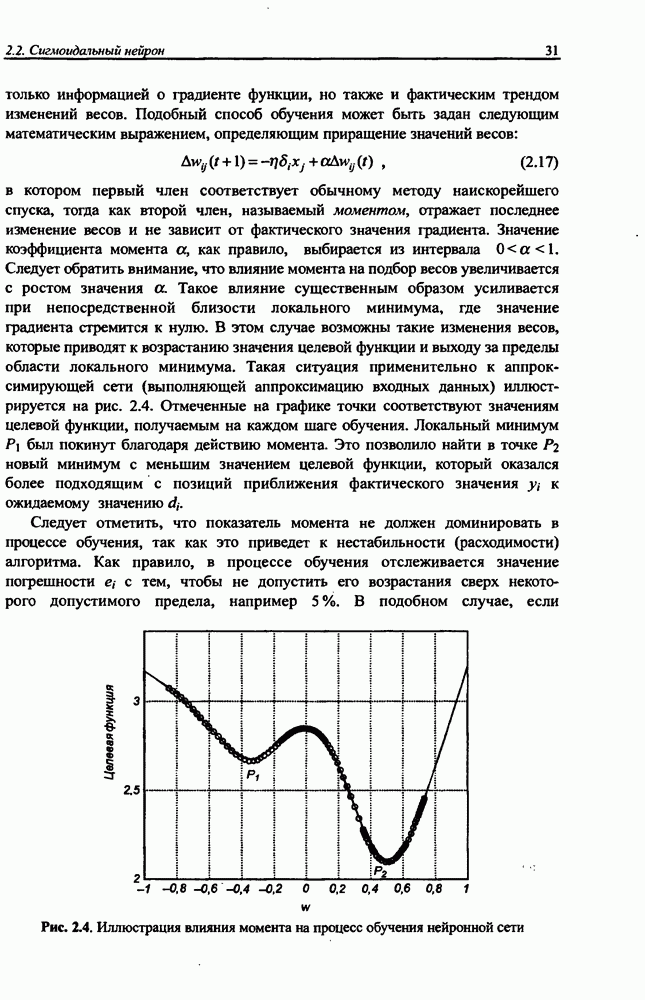
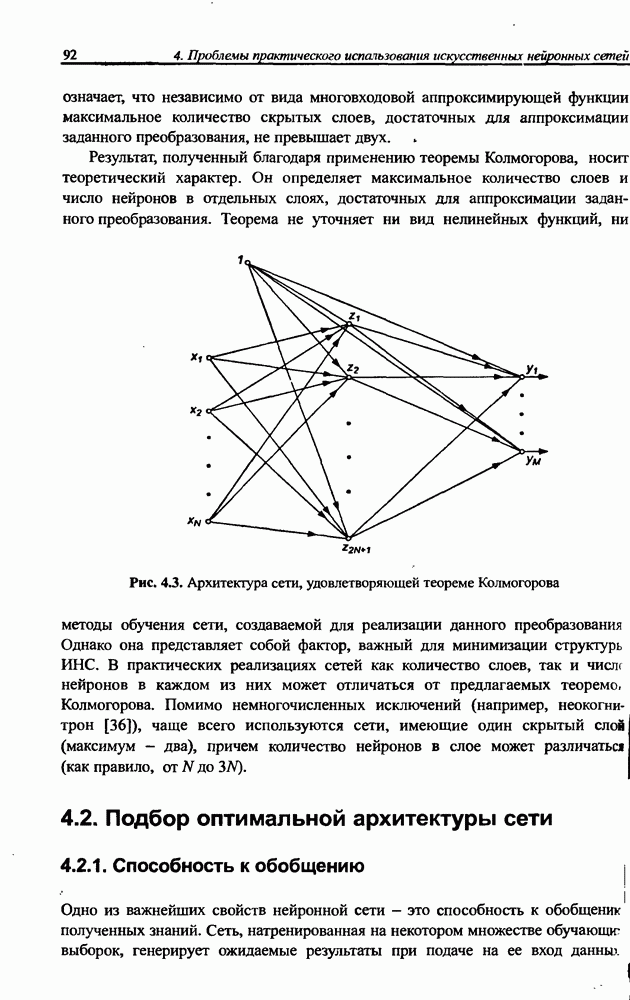
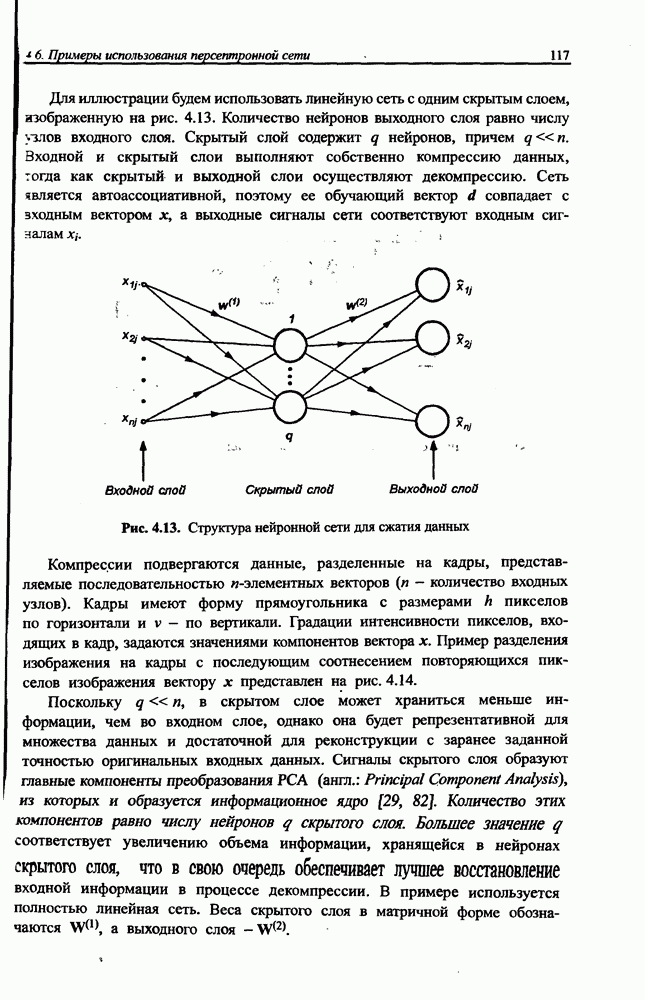
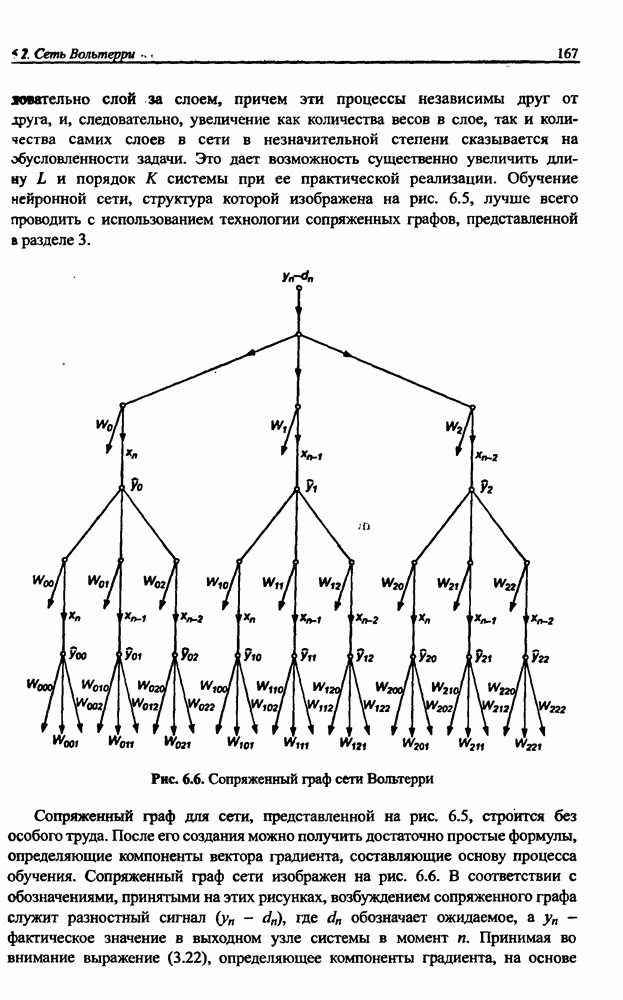
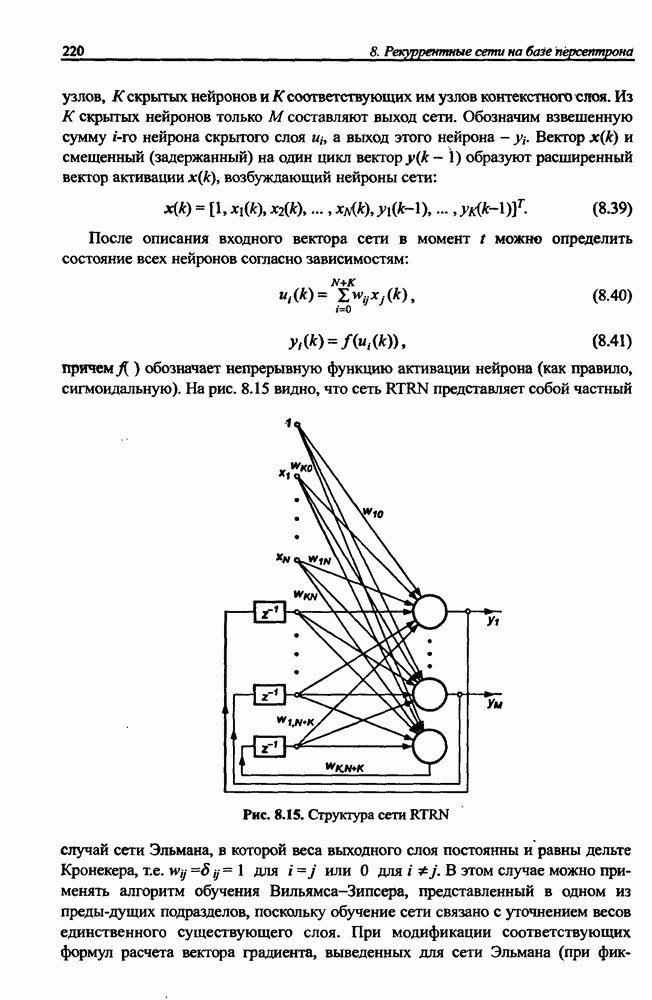
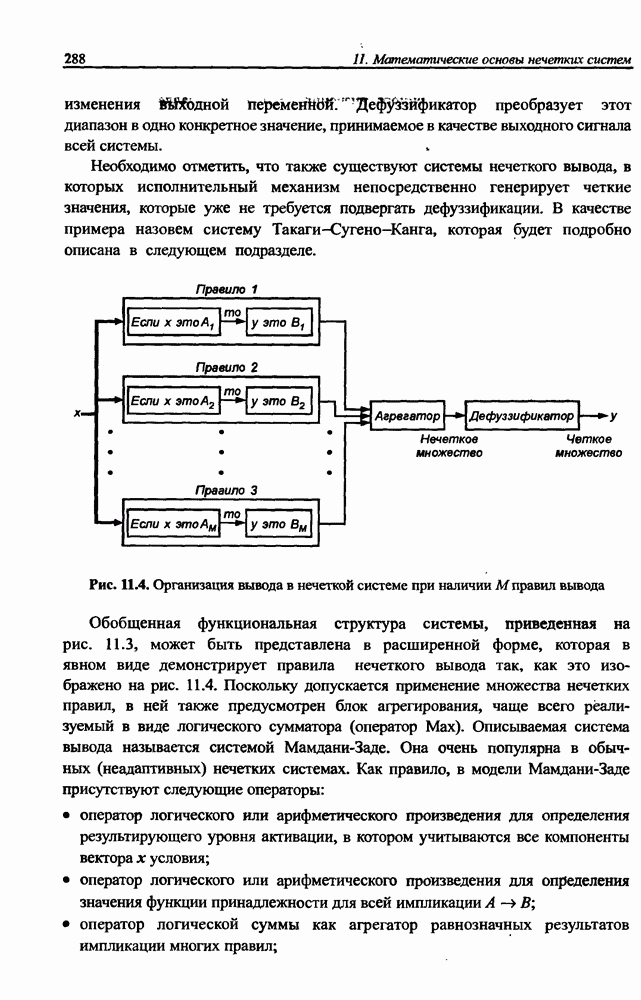
10.3.6. Однонаправленная сеть для разделения сигналов
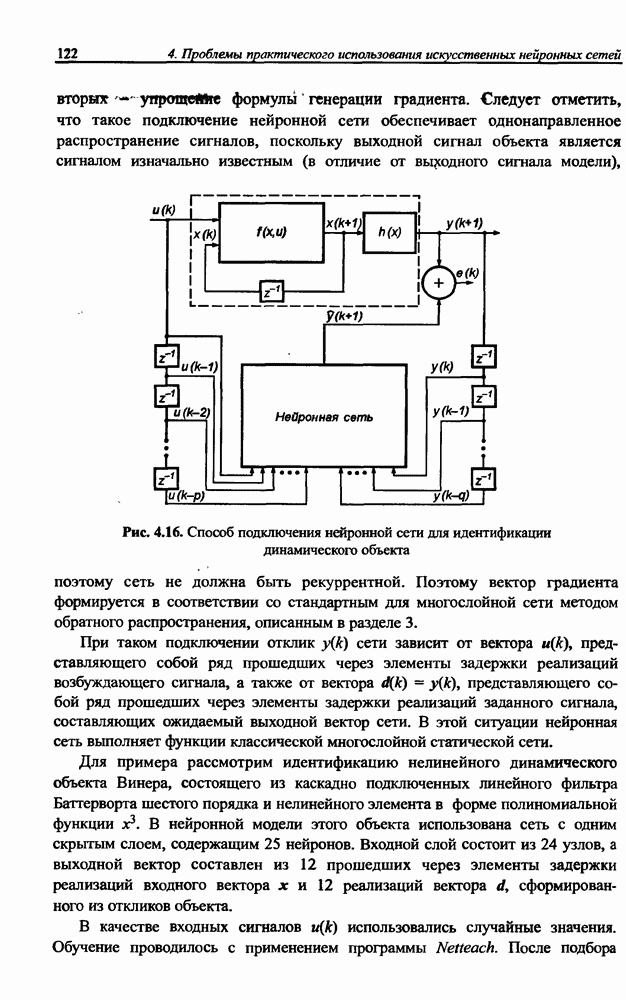
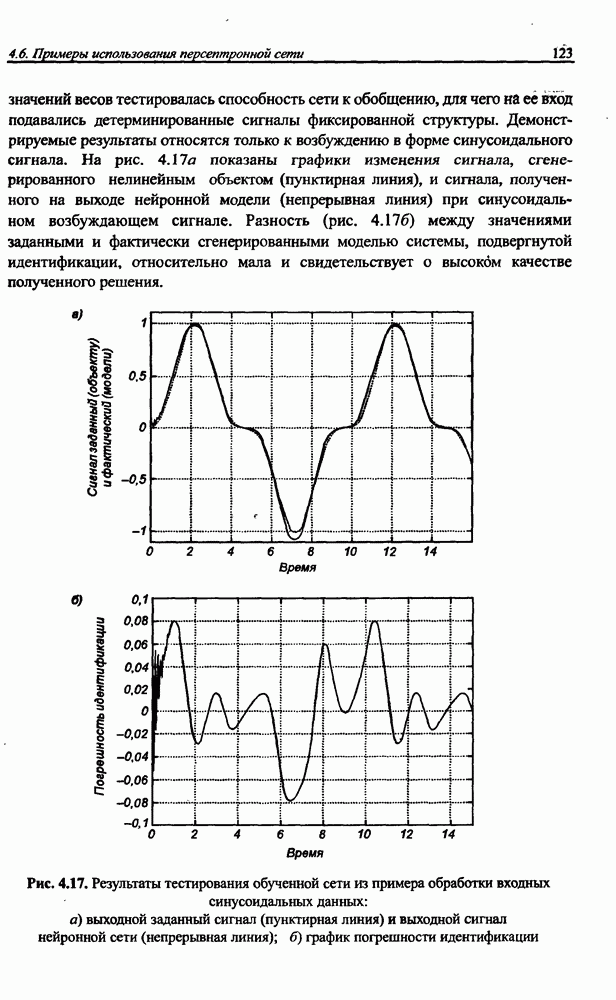
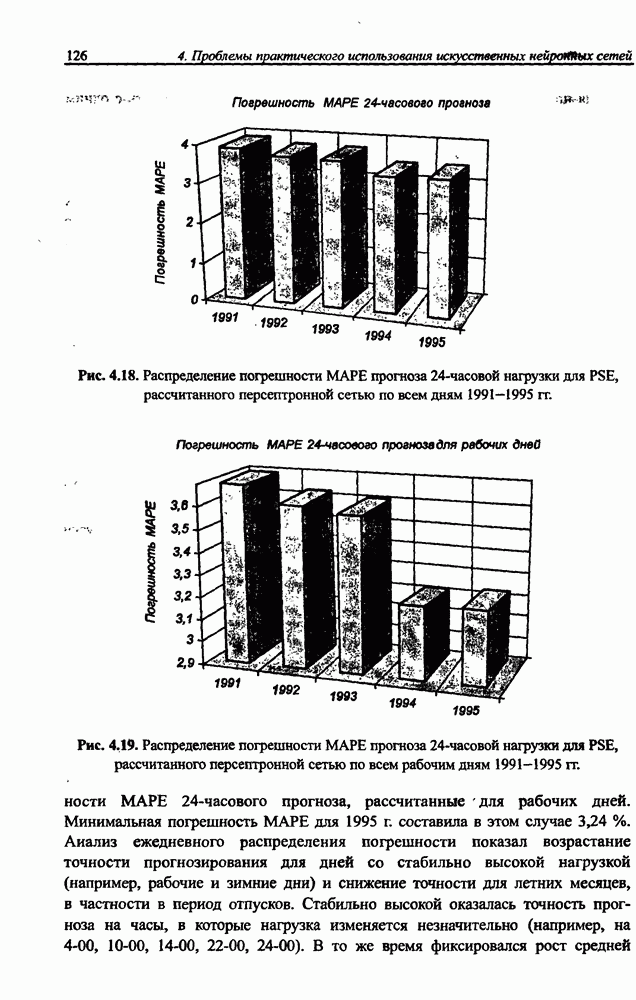
Серьезный недостаток рекуррентной сети Херольта-Джуттена, с трудом устраняемый на практике, состоит в сложности обеспечения стабильности процесса разделения сигналов, особенно тогда, когда матрица А плохо обусловлена, а исходные сигналы сильно отличаются друг от друга по амплитуде. Также следует отметить, что в рекуррентной сети на каждом шаге возникает необходимость инвертировать матрицу весов (формула (10.38)), что заметно увеличивает вычислительную сложность алгоритма. Устранить эти проблемы позволяет применение однонаправленной сети без обратных связей.
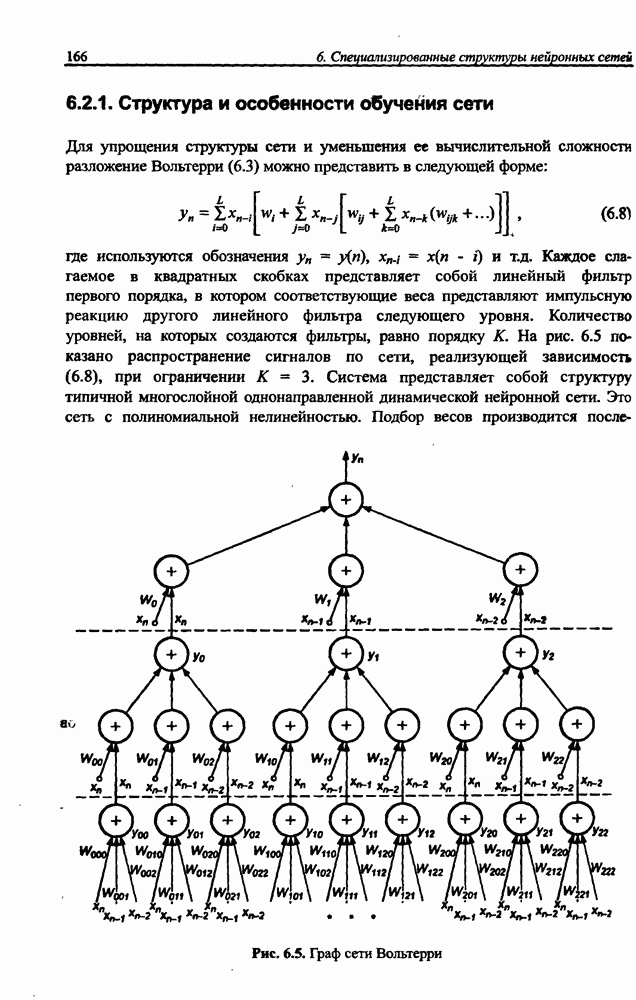
Обобщенная структура такой сети представлена на рис. 10.8. Источниками информации для сети являются только смешанные сигналы  . В результате
. В результате

Рис. 10.8. Структура однонаправленной сети для разделения сигналов
их преобразования линейной системой синаптических весов  формируется вектору
формируется вектору

Матрица  этом выражении является полной. При таком решении однонаправленная сеть равнозначна сети с обратными связями, если матрица весов
этом выражении является полной. При таком решении однонаправленная сеть равнозначна сети с обратными связями, если матрица весов  удовлетворяет условию
удовлетворяет условию

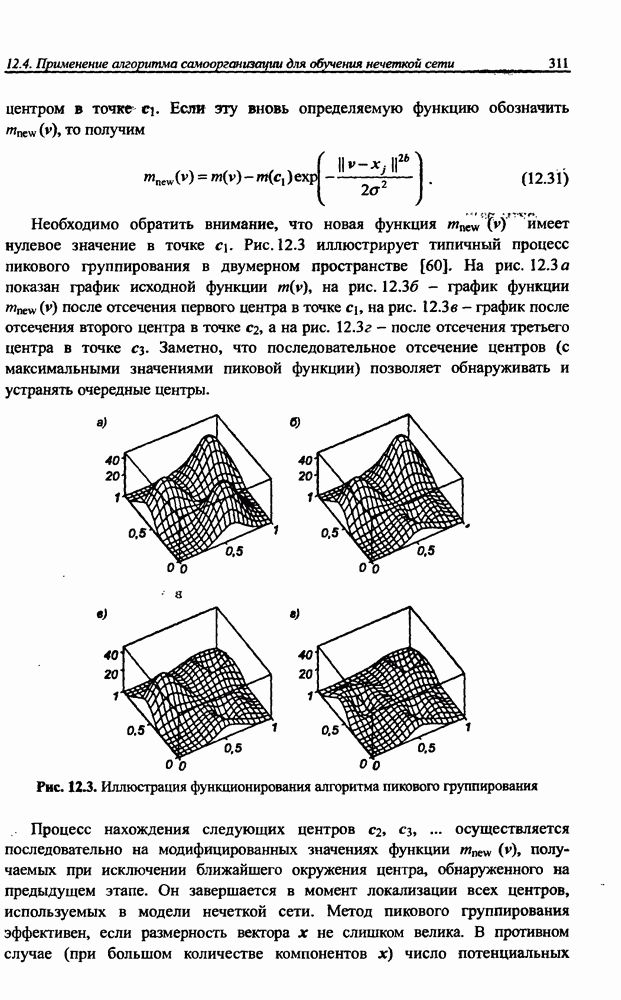
где  обозначена матрица весов рекуррентной сети. В результате простого математического преобразования получаем:
обозначена матрица весов рекуррентной сети. В результате простого математического преобразования получаем:

Алгоритм обучения весов  можно получить непосредственно из обучающих зависимостей для рекуррентных сетей, если принять во внимание, что
можно получить непосредственно из обучающих зависимостей для рекуррентных сетей, если принять во внимание, что

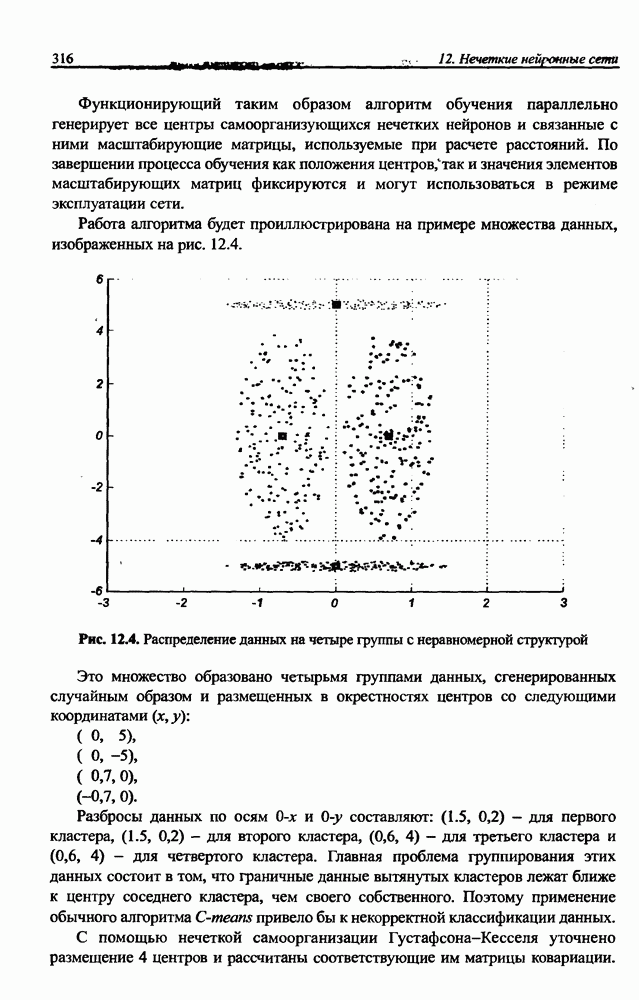
С учётом матричного тождества  получаем
получаем  откуда
откуда

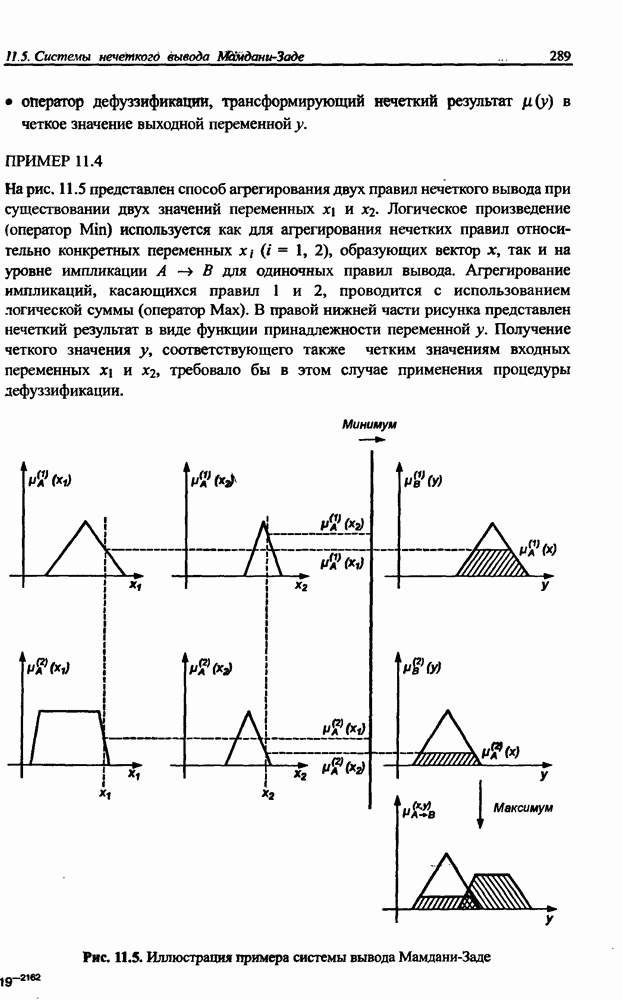
Если выбрать для дальнейшей реализации одно Из правил обучения, сформулированных для рекуррентных сетей, то можно получить его аналог для однонаправленной сети. Например, принимая во внимание модифицированное правило Чихотского [17], строится адаптивная зависимость, представляемая в матричной форме

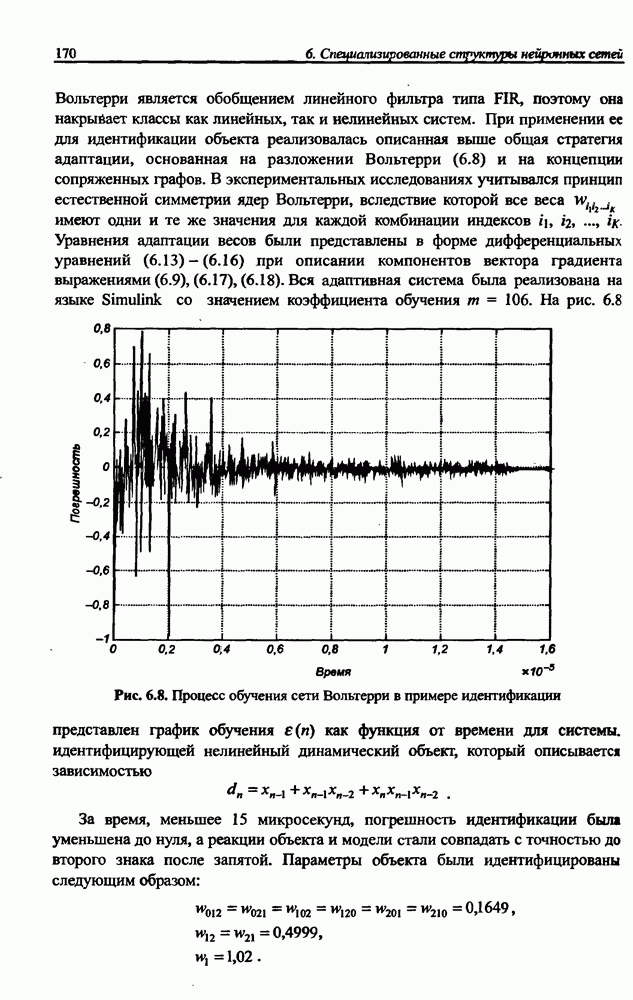
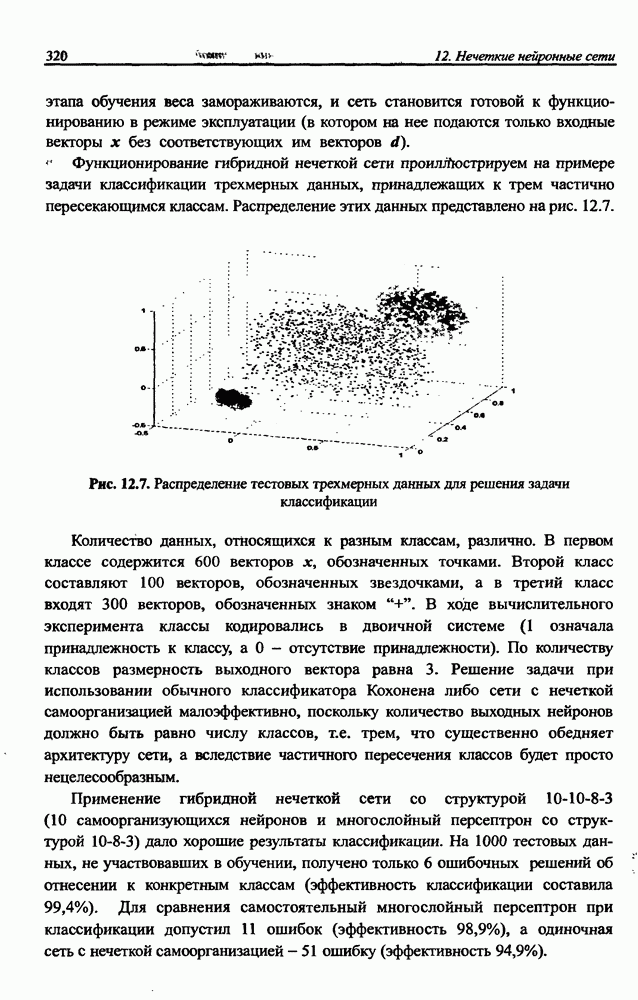
с начальным условием  имеющая свойства, идентичные свойствам алгоритма обучения рекуррентной сети, на базе которого она была создана. В отличие от формулы обучения рекуррентной сети в выражении (10.51) изменения весов обусловлены их фактическими значениями. К настоящему времени известно большое количество вариантов обучающей формулы (10.51), характеризующихся особенно выдающимися качествами при плохой обусловленности матрицы А либо при большой разнице амплитуд исходных сигналов
имеющая свойства, идентичные свойствам алгоритма обучения рекуррентной сети, на базе которого она была создана. В отличие от формулы обучения рекуррентной сети в выражении (10.51) изменения весов обусловлены их фактическими значениями. К настоящему времени известно большое количество вариантов обучающей формулы (10.51), характеризующихся особенно выдающимися качествами при плохой обусловленности матрицы А либо при большой разнице амплитуд исходных сигналов  Среди них можно выделить [12]:
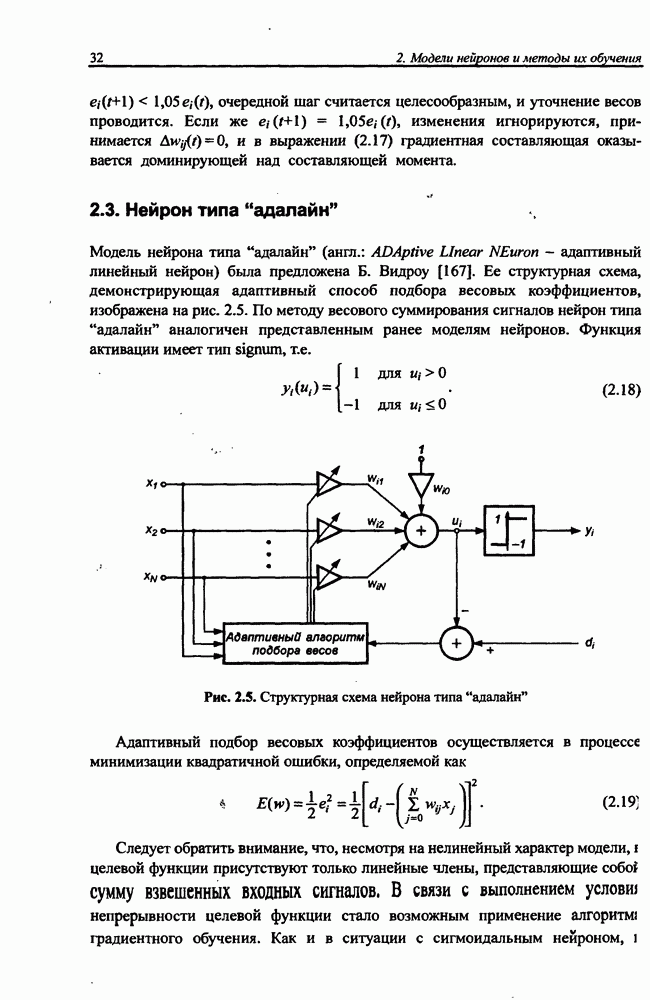
Среди них можно выделить [12]:
• алгоритм Чихотского - Амари - Янга

• алгоритм, основанный на естественном градиенте,

• алгоритмы Кардоссо [3, 12]:

где  это численные коэффициенты из интервала [0, 1].
это численные коэффициенты из интервала [0, 1].
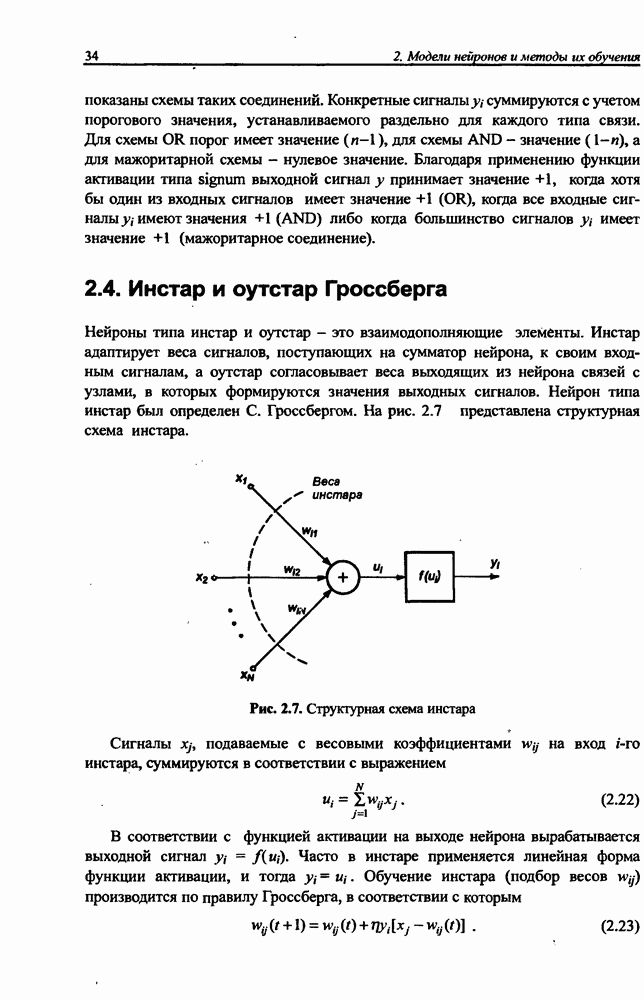
Особенно хорошими качествами характеризуется алгоритм, основанный на естественном градиенте, при реализации которого, как показано в работе [18], процесс сепарации практически не зависит от соотношения амплитуд сигналов  и от степени обусловленности смешивающей матрицы А.
и от степени обусловленности смешивающей матрицы А.
Так же как и в рекуррентных сетях, коэффициент обучения  представляется функцией, значение которой уменьшается с течением времени до нуля. Обычно это показательная функция вида
представляется функцией, значение которой уменьшается с течением времени до нуля. Обычно это показательная функция вида  со значением амплитуды А и постоянной времени, индивидуально подбираемой в каждом конкретном случае.
со значением амплитуды А и постоянной времени, индивидуально подбираемой в каждом конкретном случае.
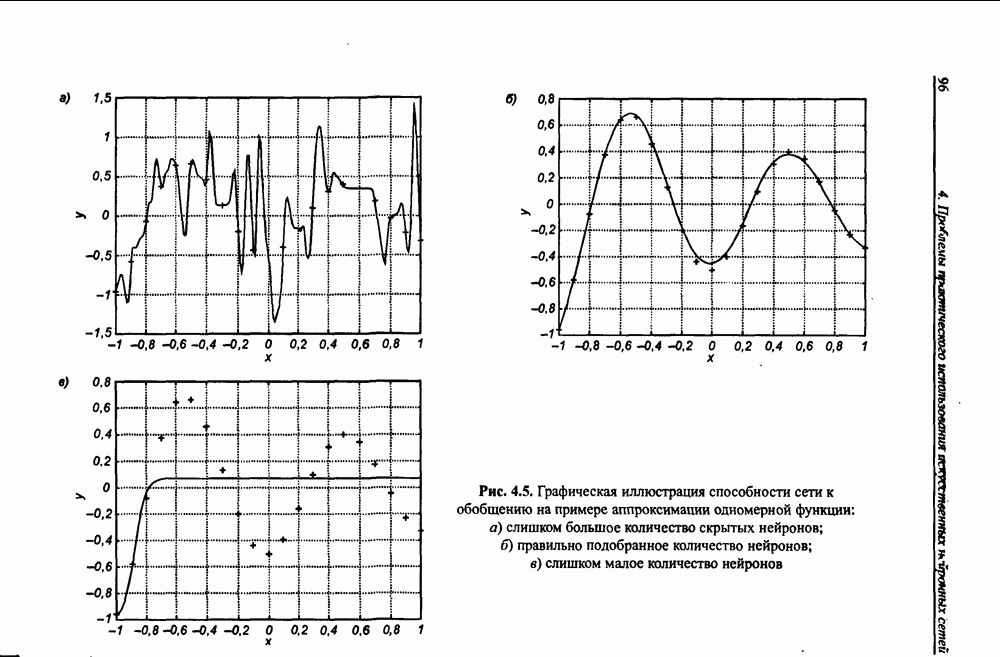
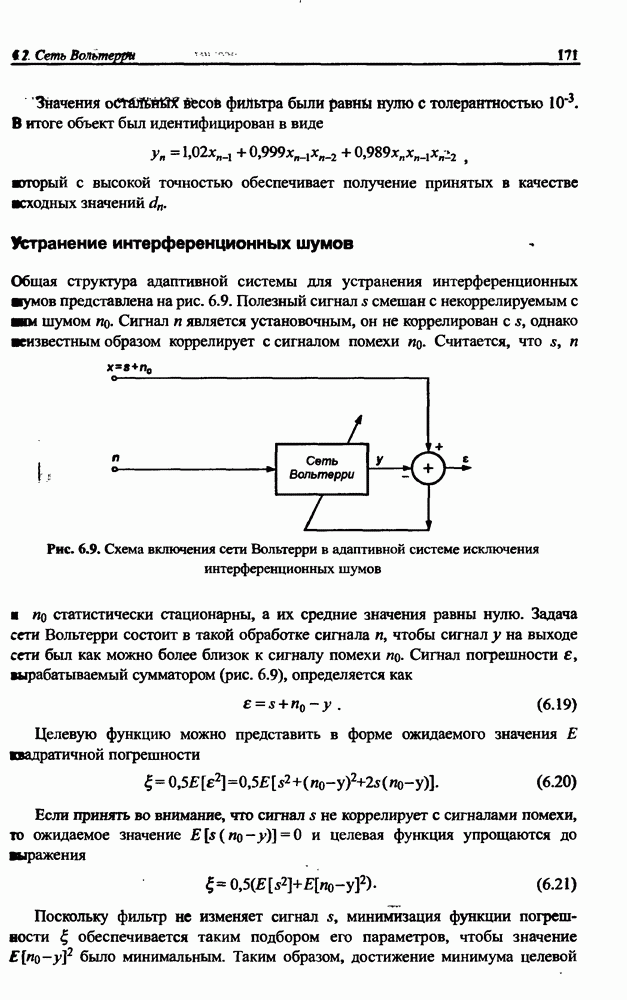
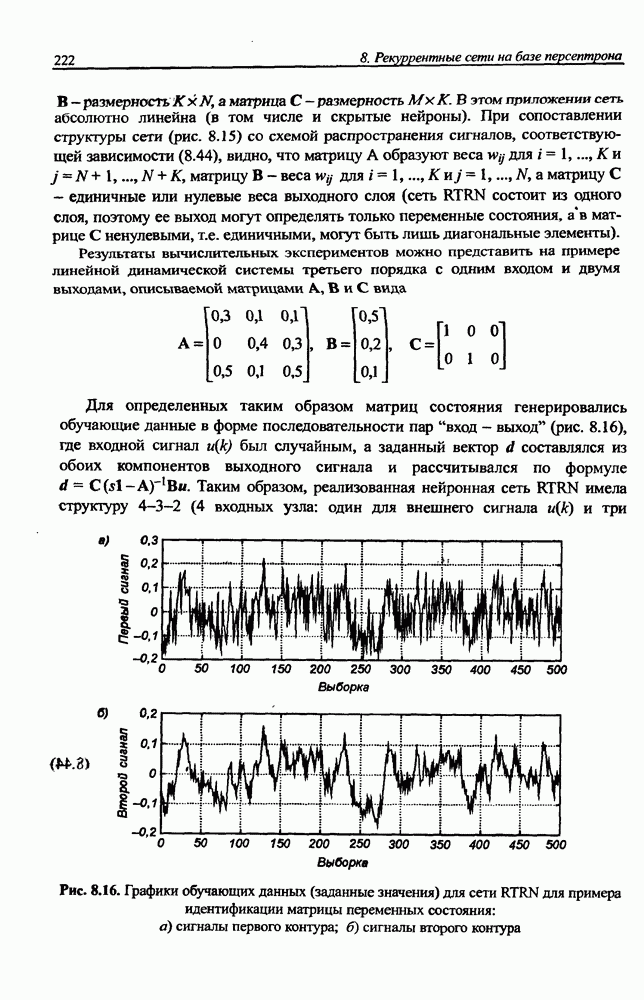
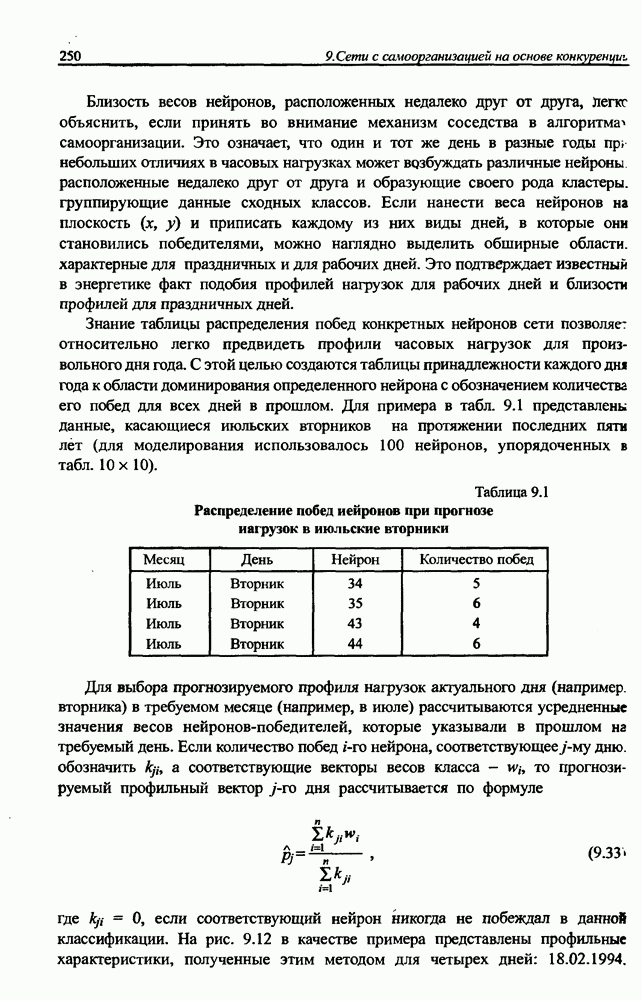
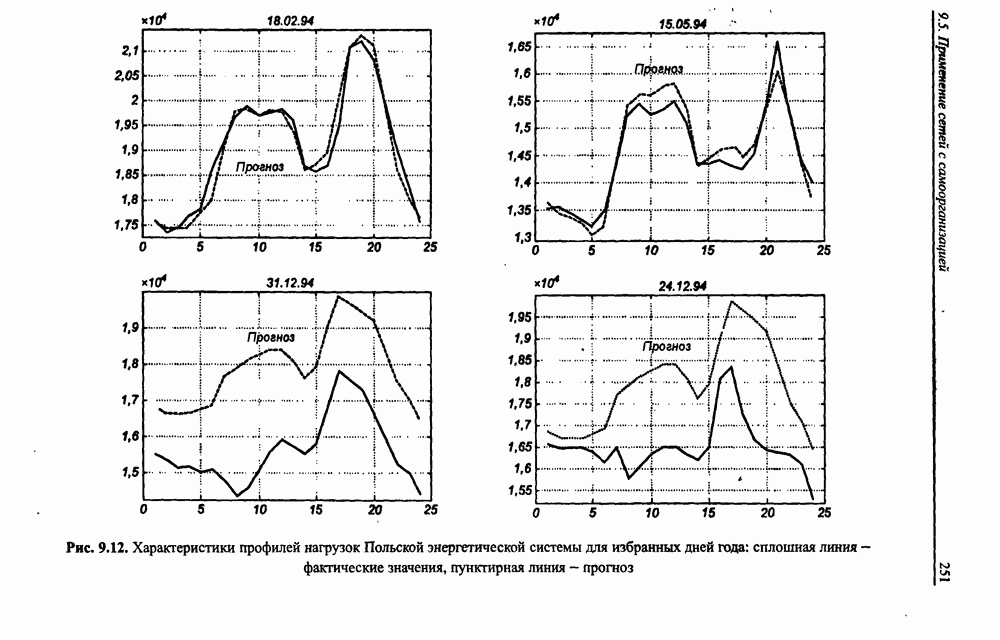
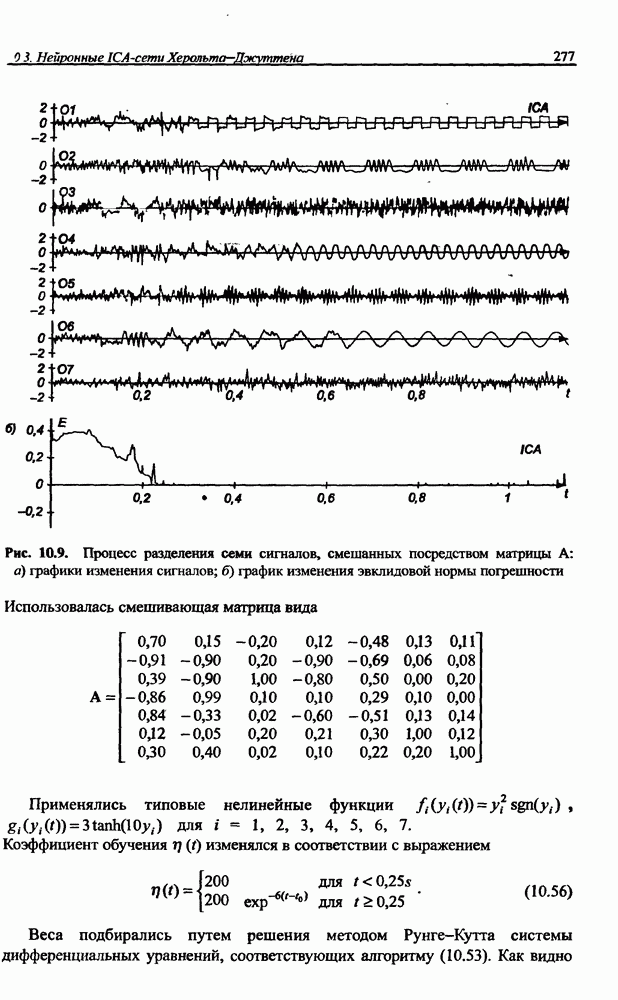
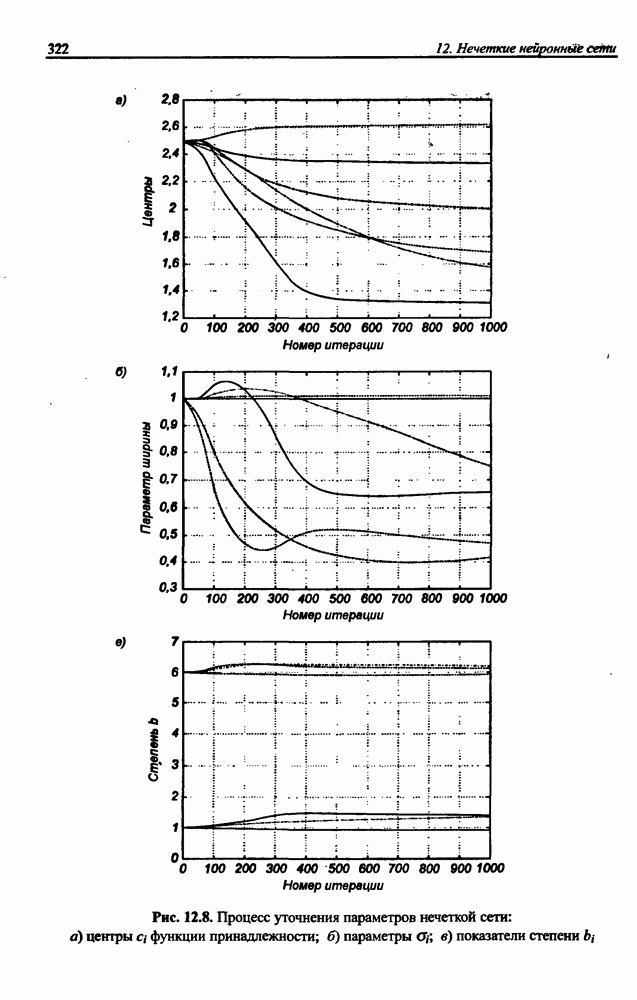
Экспериментальные исследования однонаправленной сети показали высокую эффективность разделения исходных сигналов с большими относительными различиями (доходящими до 1010) амплитуд и плохой обусловленностью смешивающей матрицы А. На рис. 10.9 представлены результаты сепарации семи сигналов со значительно отличающимися уровнями амплитуд:

Рис. 10.9. (см. скан) Процесс разделения семи сигналов, смешанных посредством матрицы А: а) графики изменения сигналов; б) график изменения эвклидовой нормы погрешности
Использовалась смешивающая матрица вида

Применялись типовые нелинейные функции  для
для  .
.
Коэффициент обучения  изменялся в соответствии с выражением
изменялся в соответствии с выражением

Веса подбирались путем решения методом Рунге-Кутта системы дифференциальных уравнений, соответствующих алгоритму (10.53). Как видно
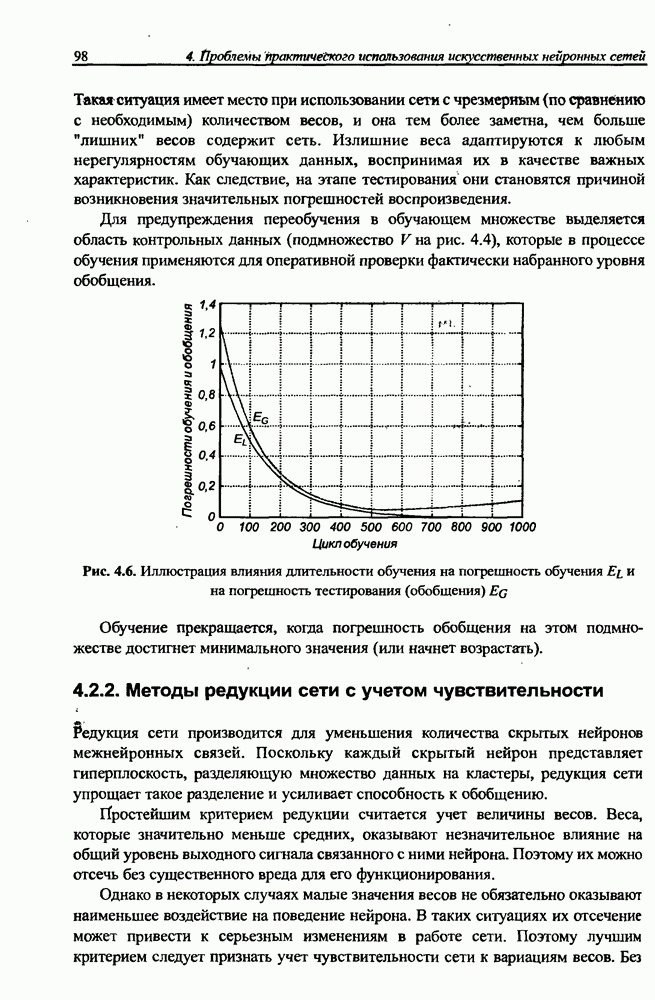
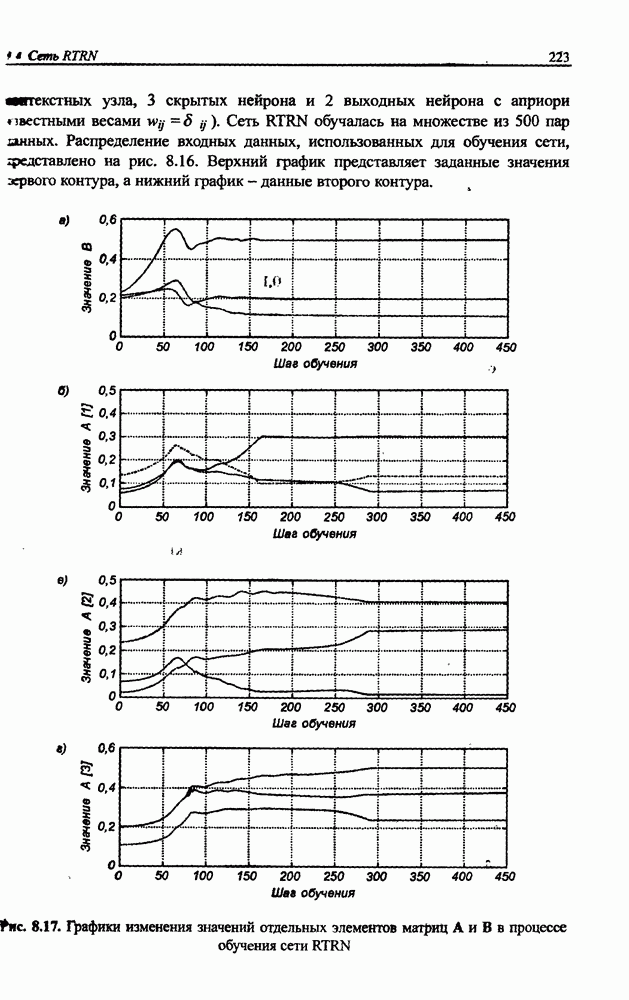
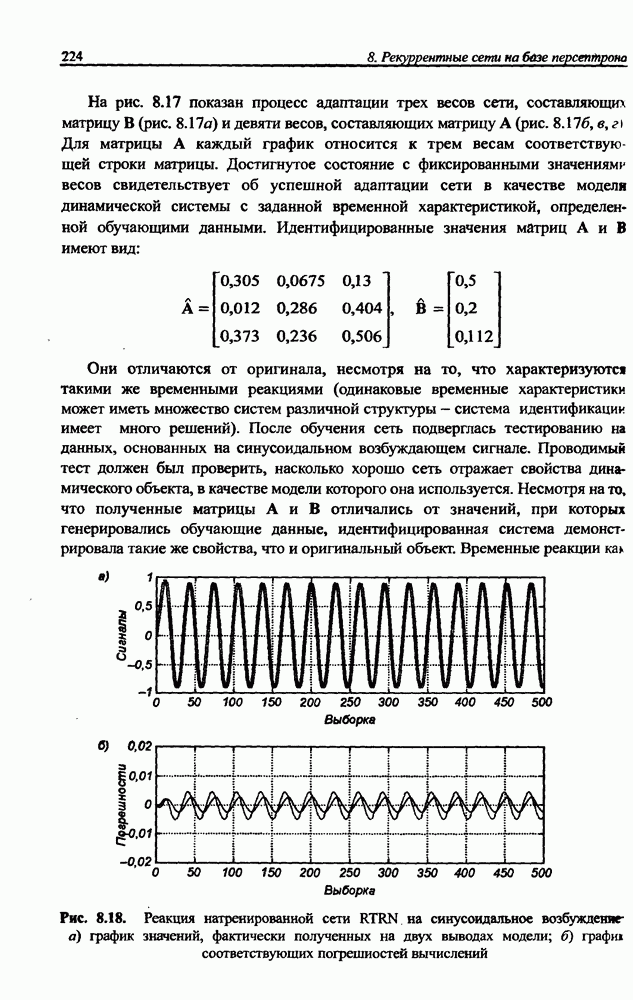
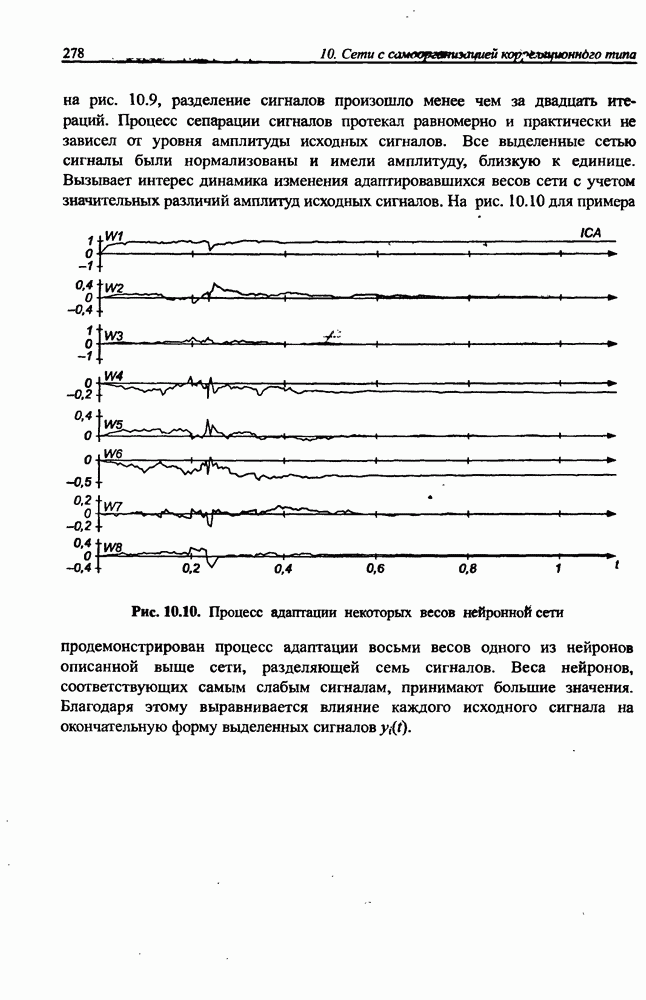
на рис. 10.9, разделение сигналов произошло менее чем за двадцать итераций. Процесс сепарации сигналов протекал равномерно и практически не зависел от уровня амплитуды исходных сигналов. Все выделенные сетью сигналы были нормализованы и имели амплитуду, близкую к единице. Вызывает интерес динамика изменения адаптировавшихся весов сети с учетом значительных различий амплитуд исходных сигналов.
Рис. 10.10. (см. скан) Процесс адаптации некоторых весов нейронной сети
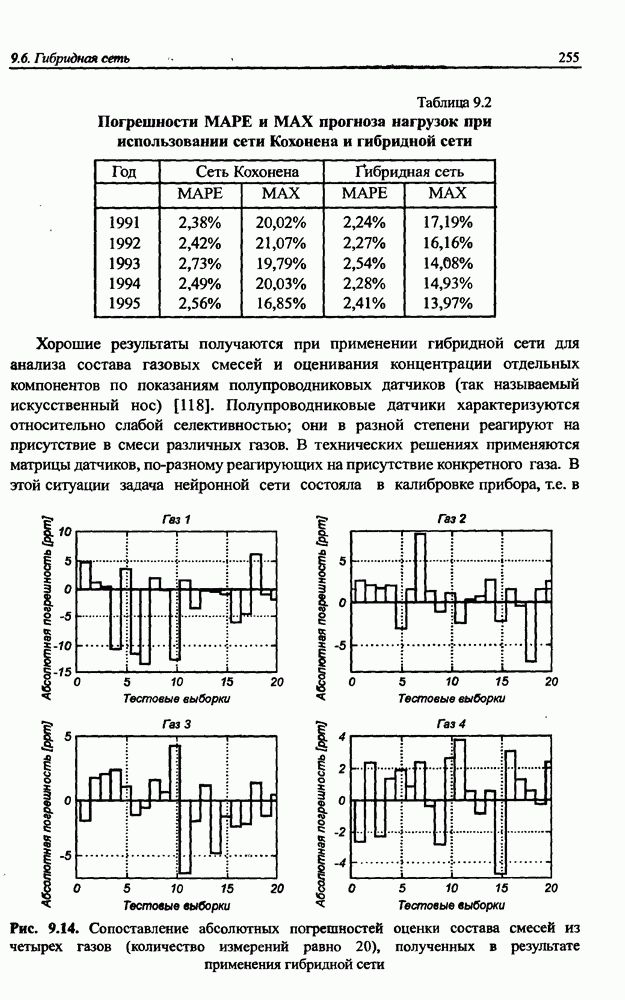
На рис. 10.10 для примера продемонстрирован процесс адаптации восьми весов одного из нейронов описанной выше сети, разделяющей семь сигналов. Веса нейронов, соответствующих самым слабым сигналам, принимают большие значения. Благодаря этому выравнивается влияние каждого исходного сигнала на окончательную форму выделенных сигналов