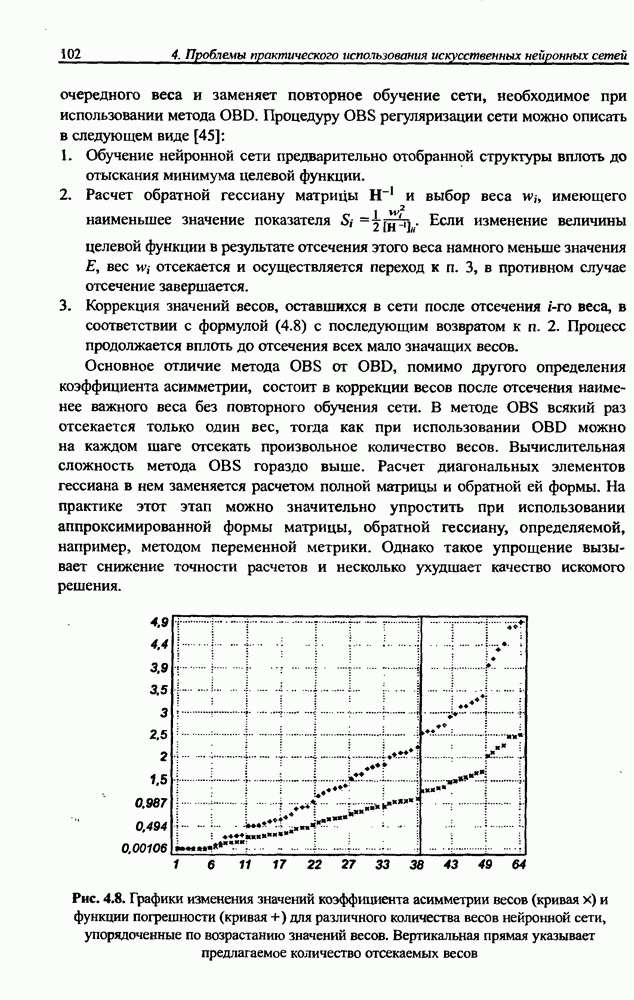
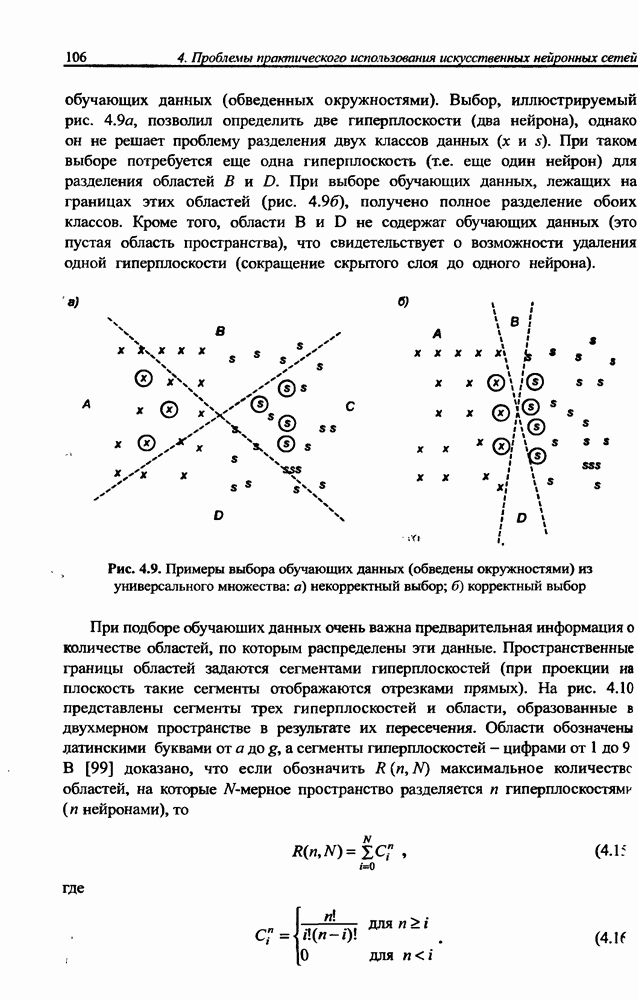
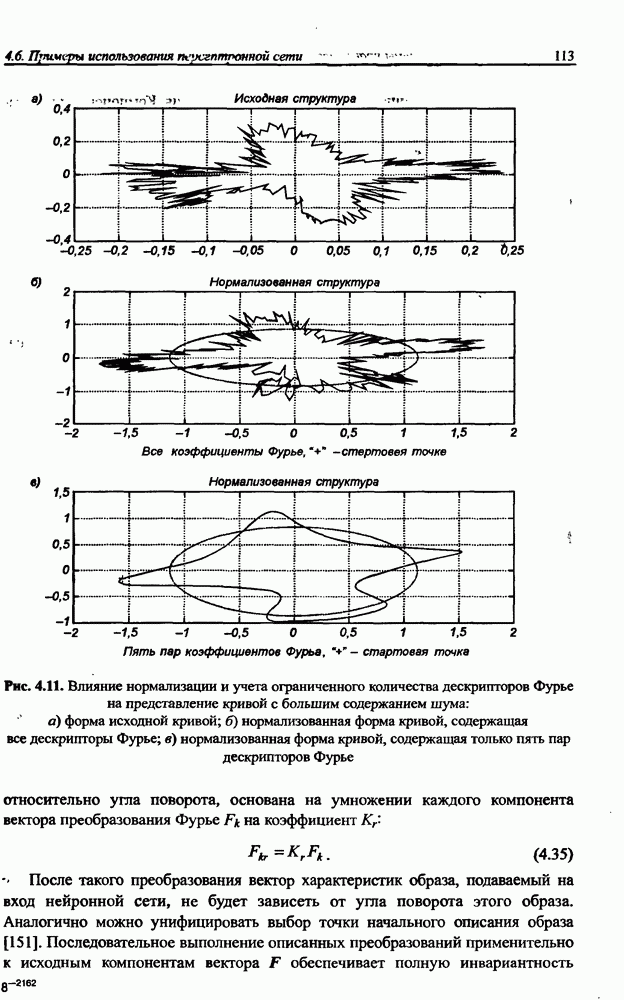
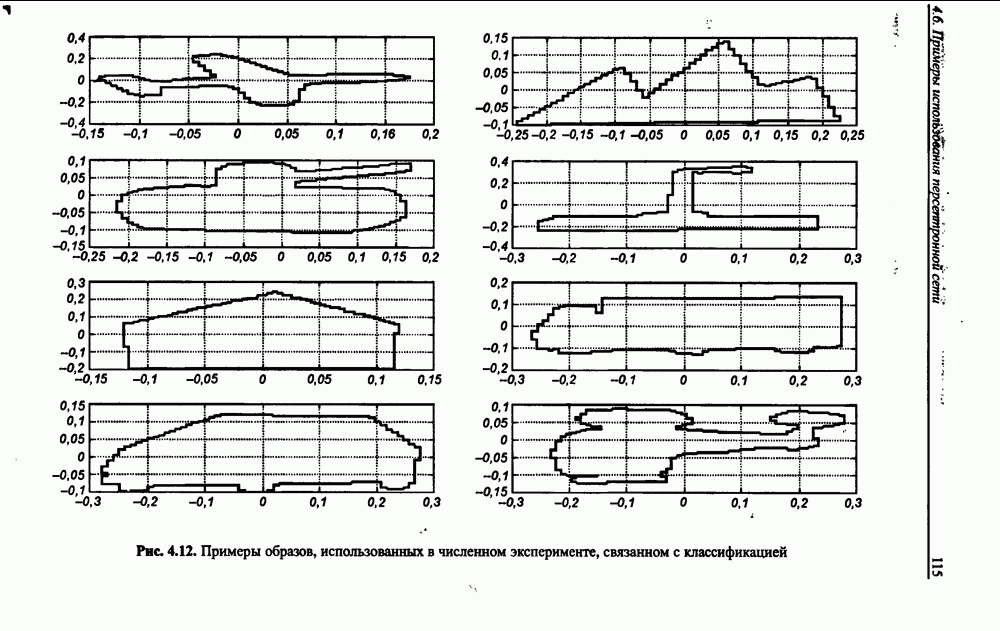
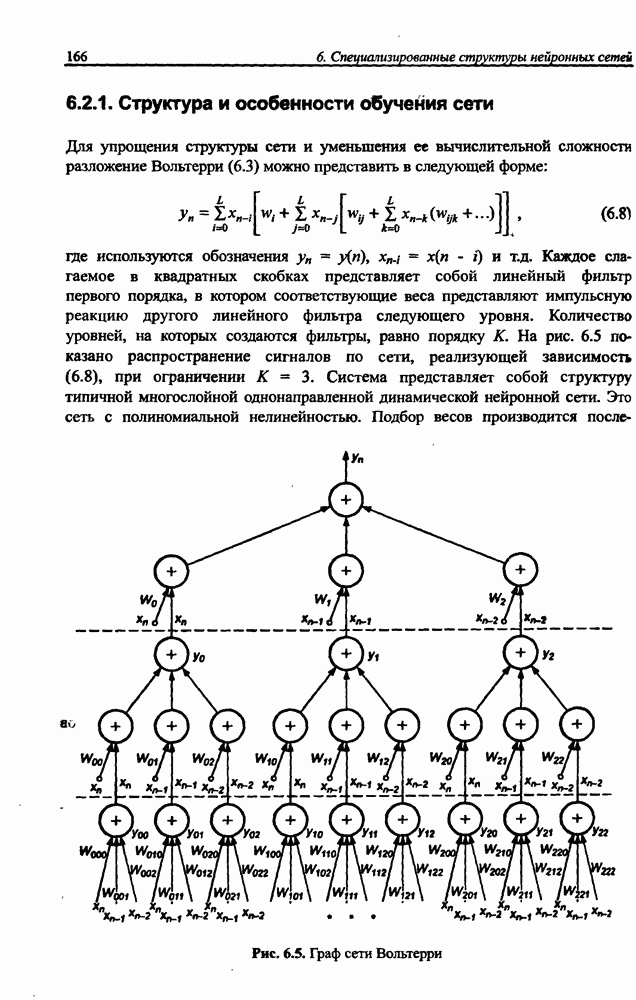
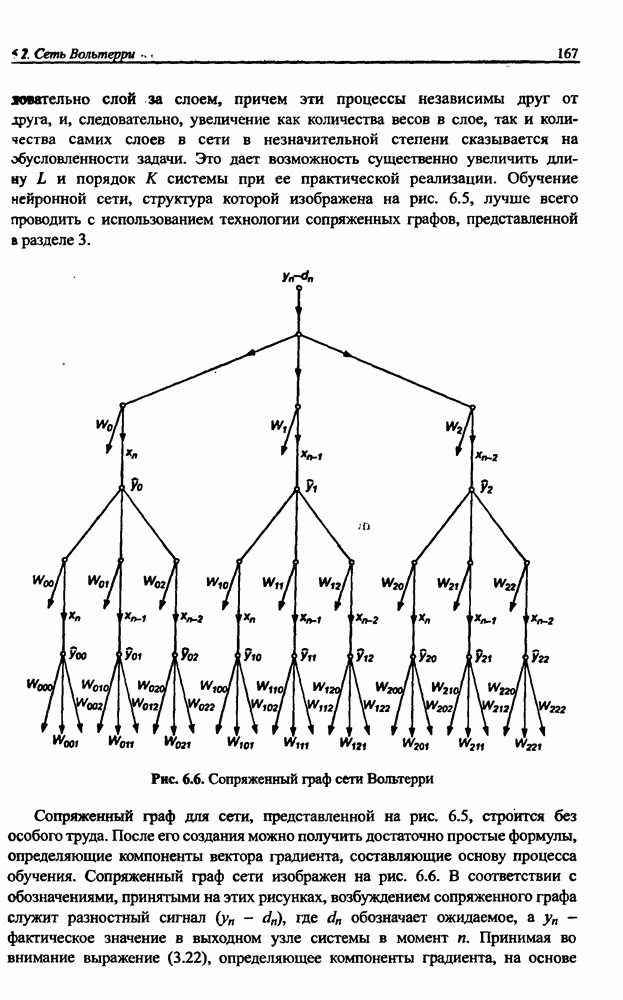
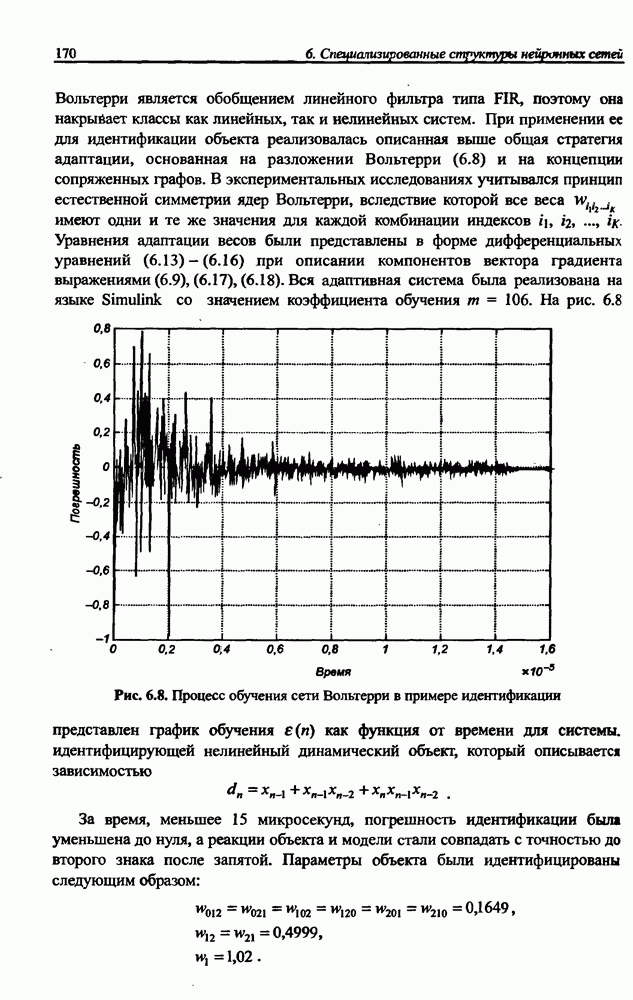
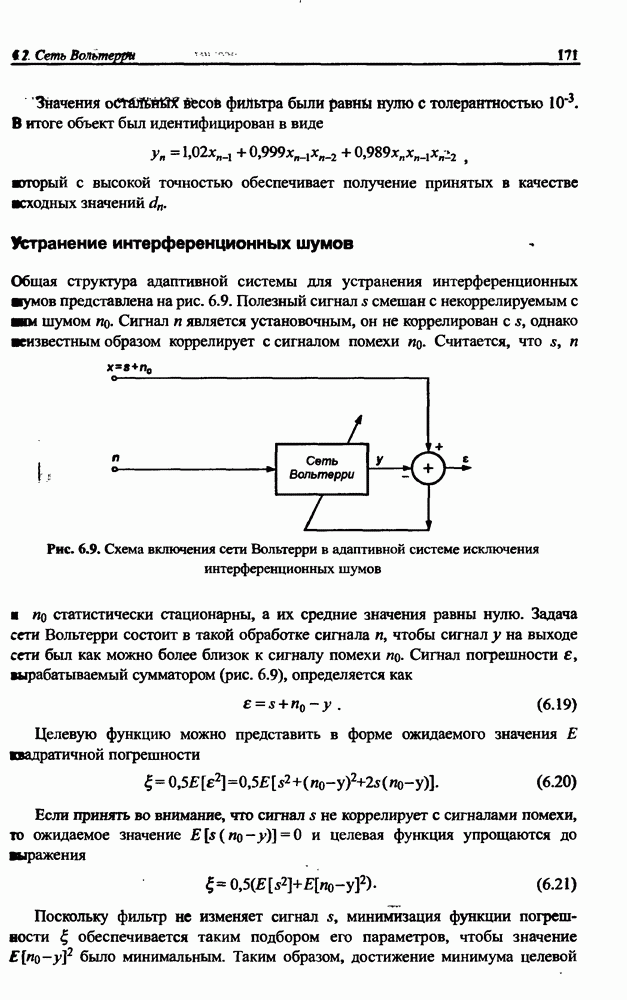
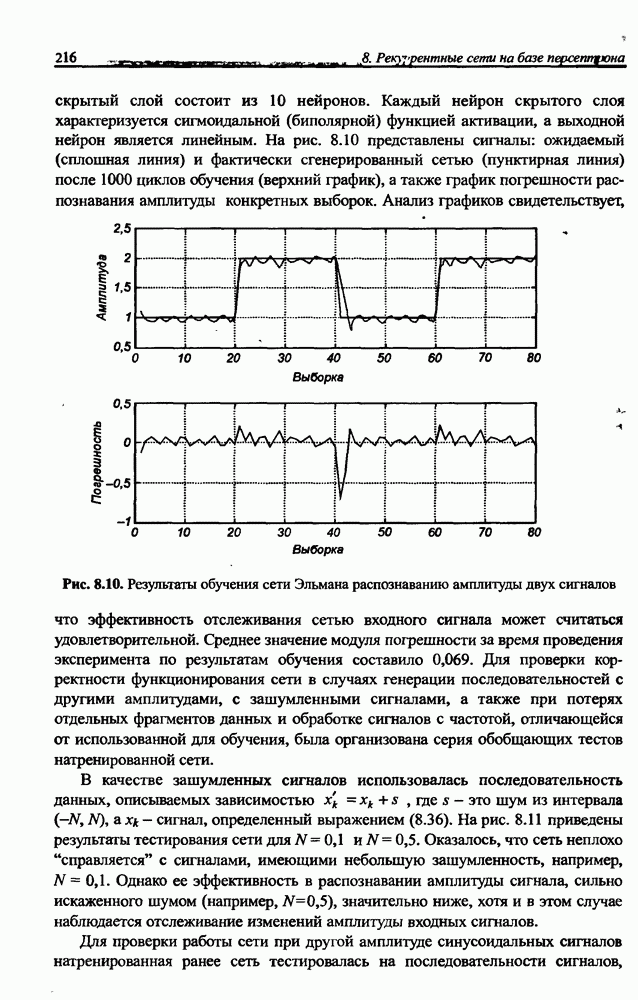
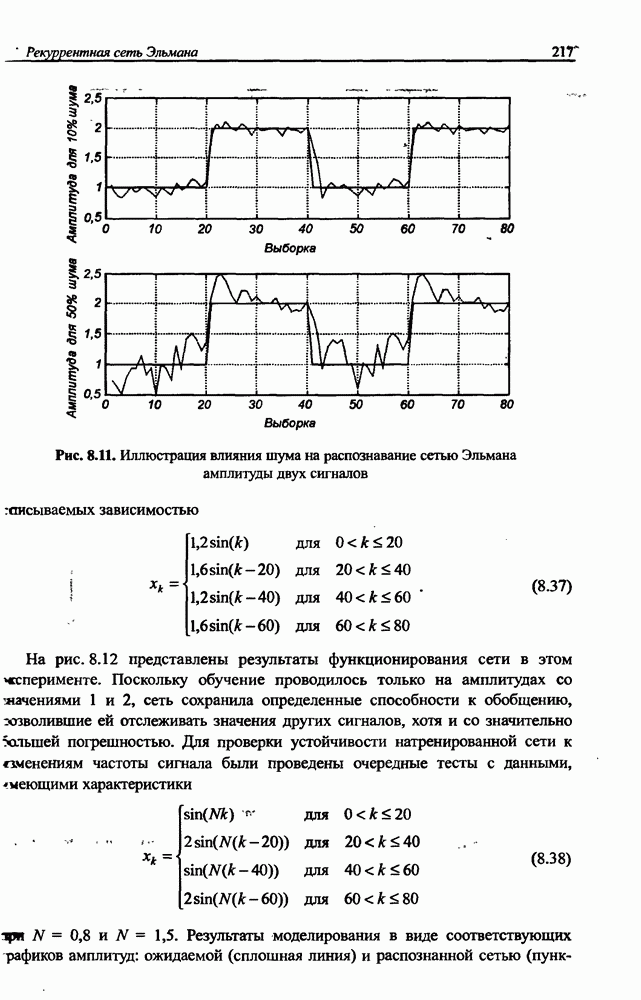
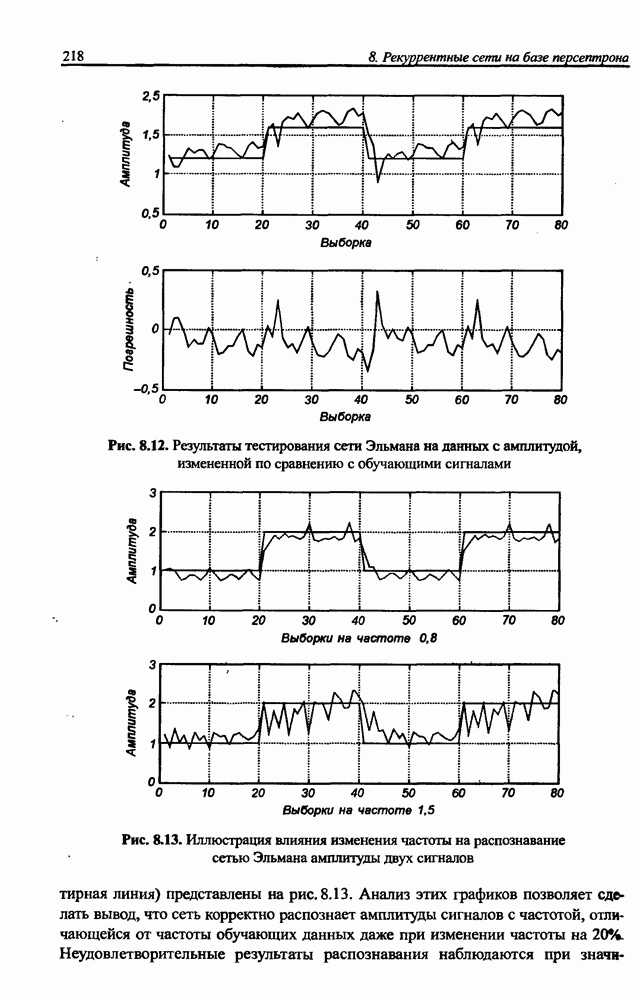
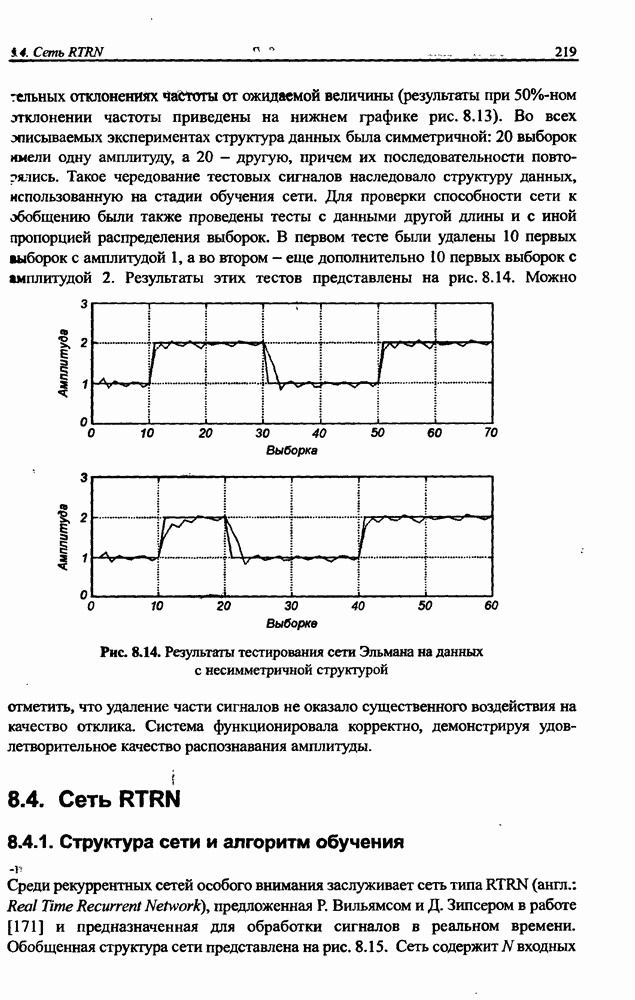
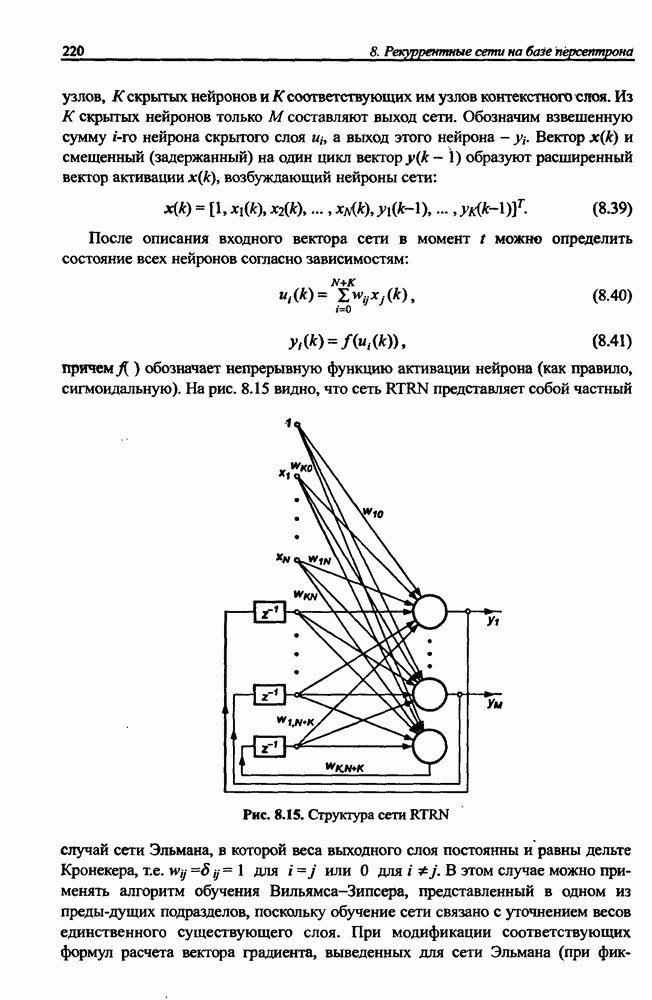
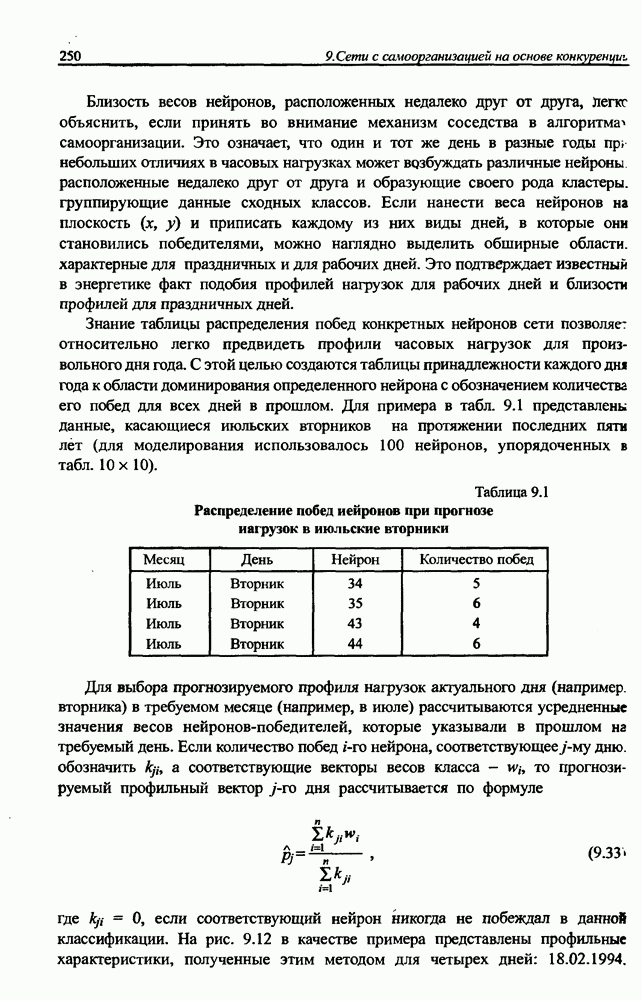
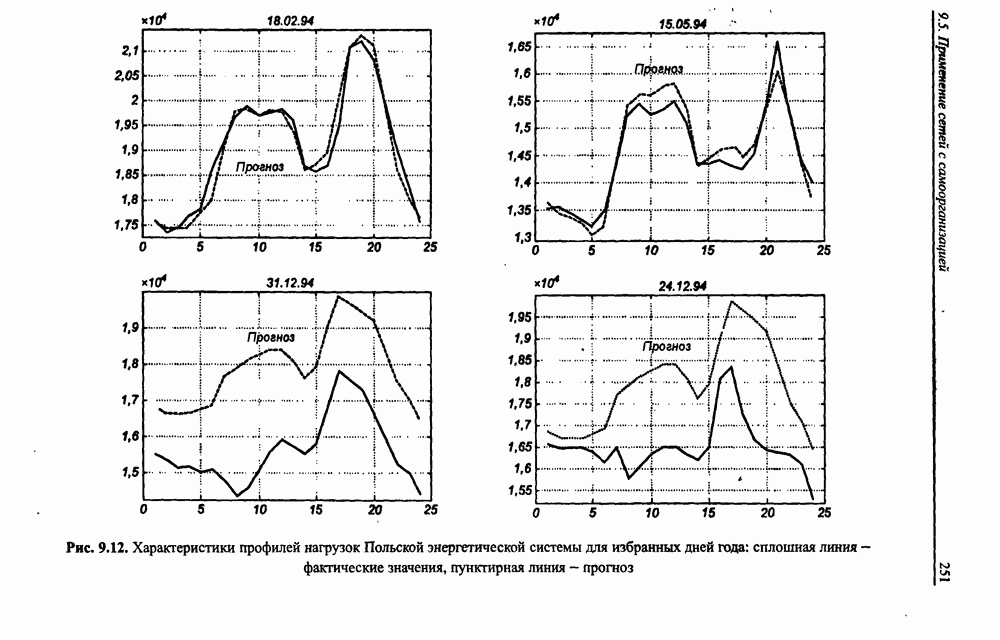
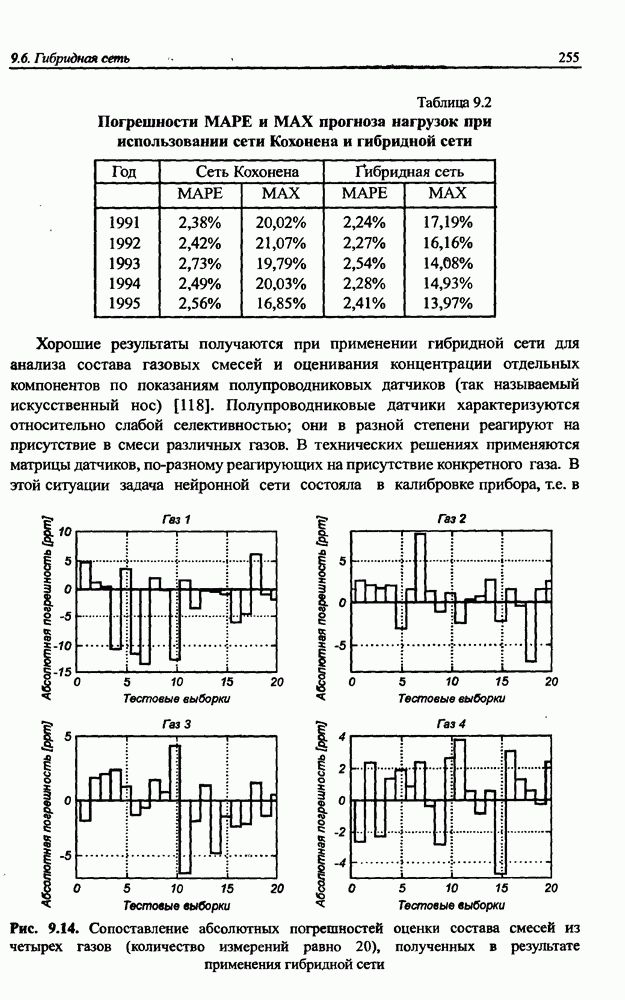
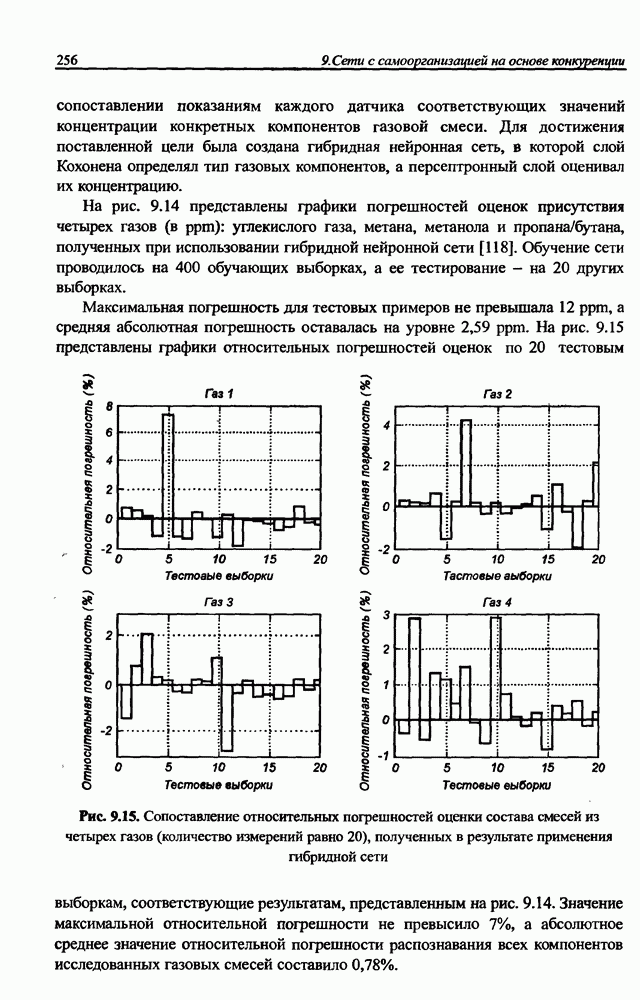
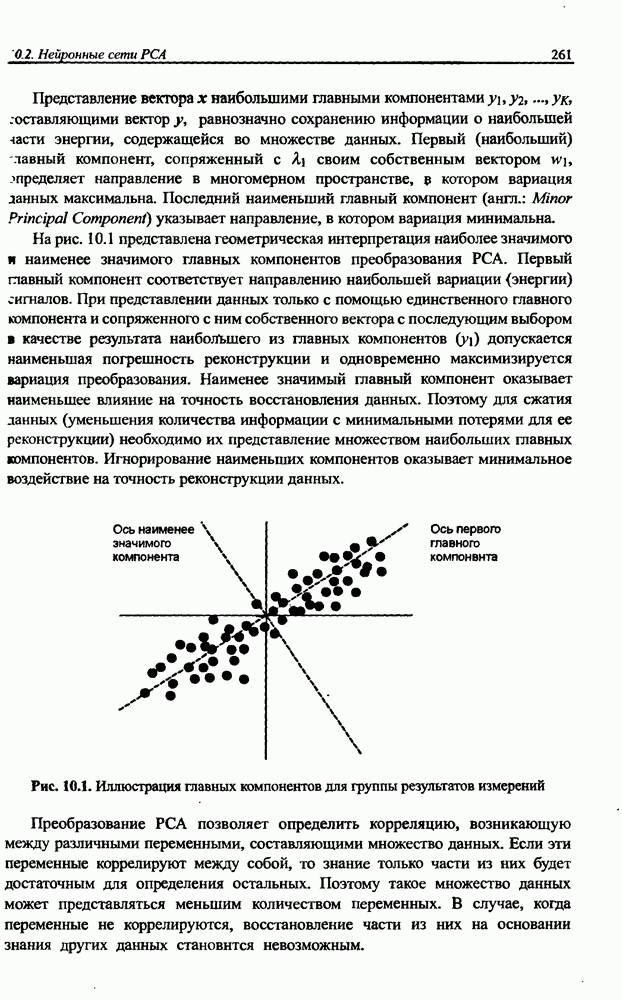
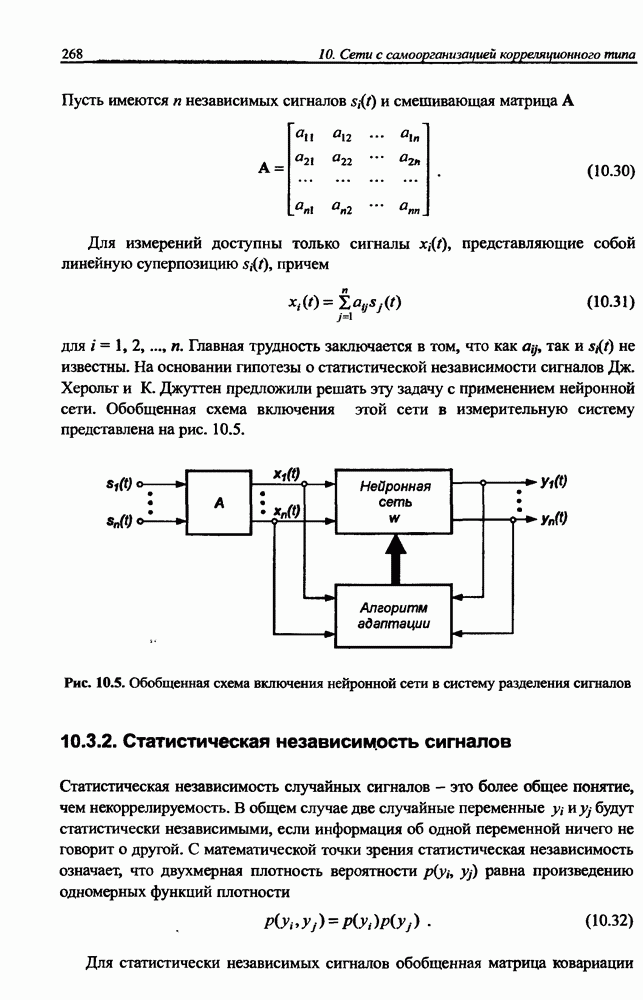
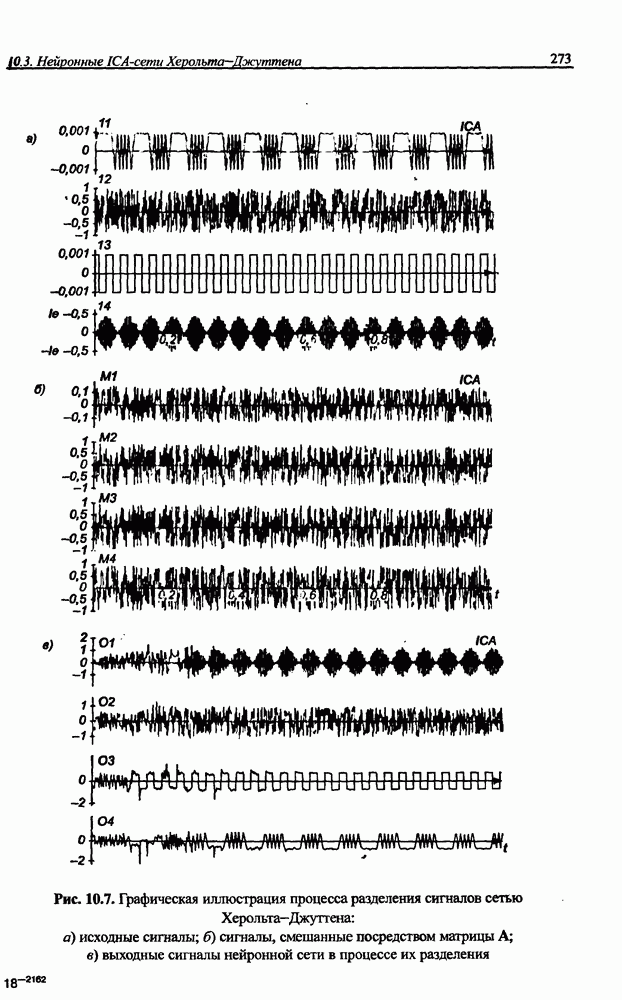
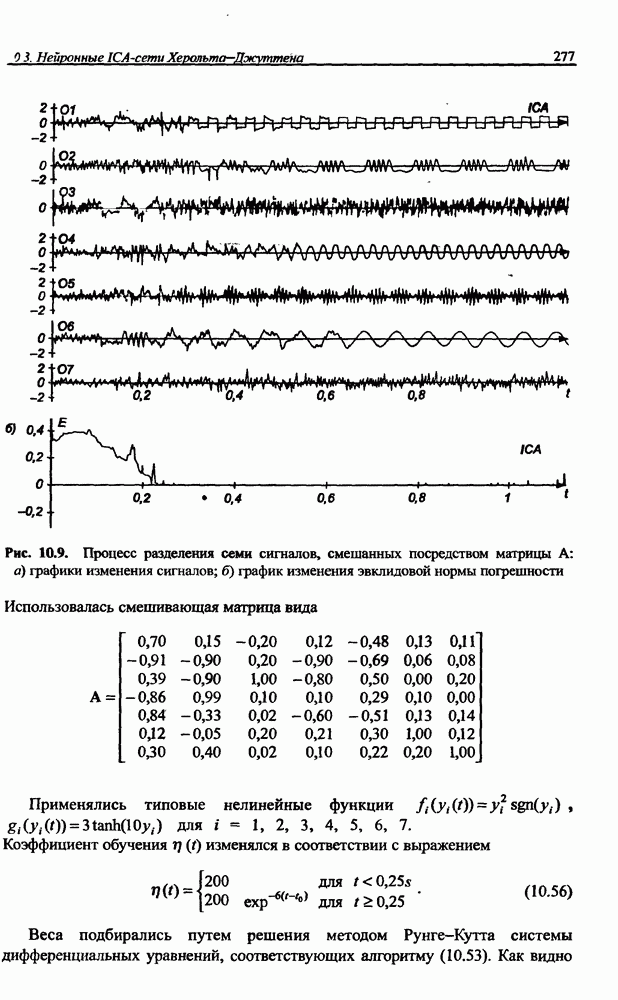
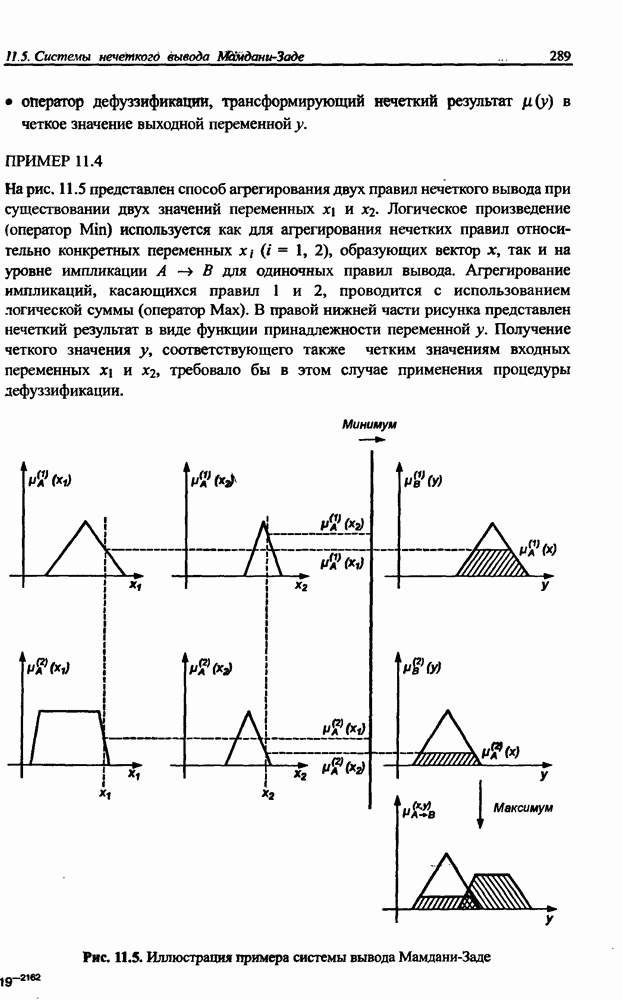
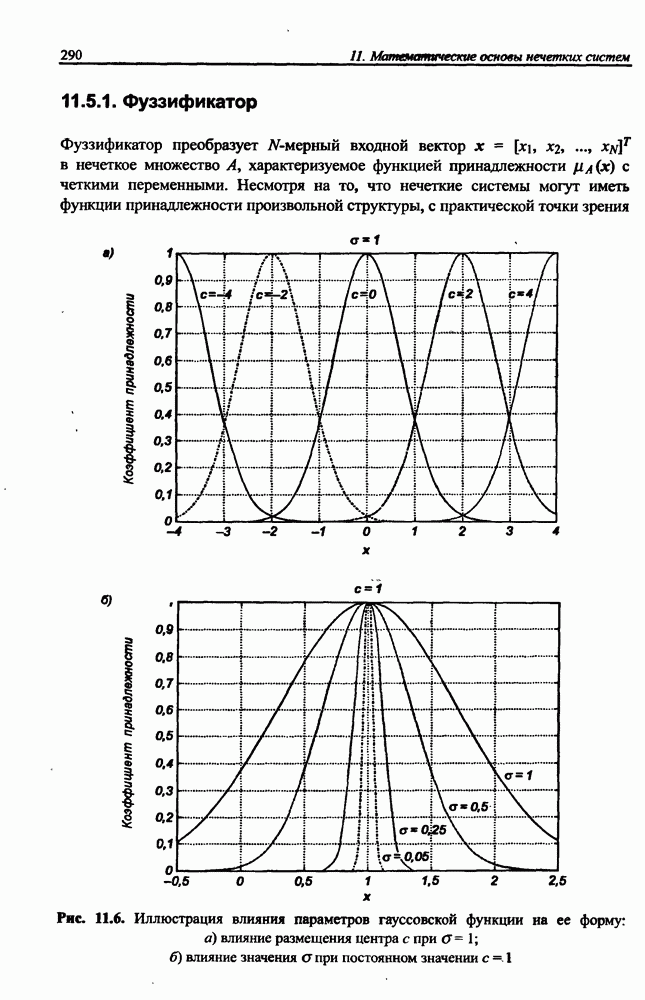
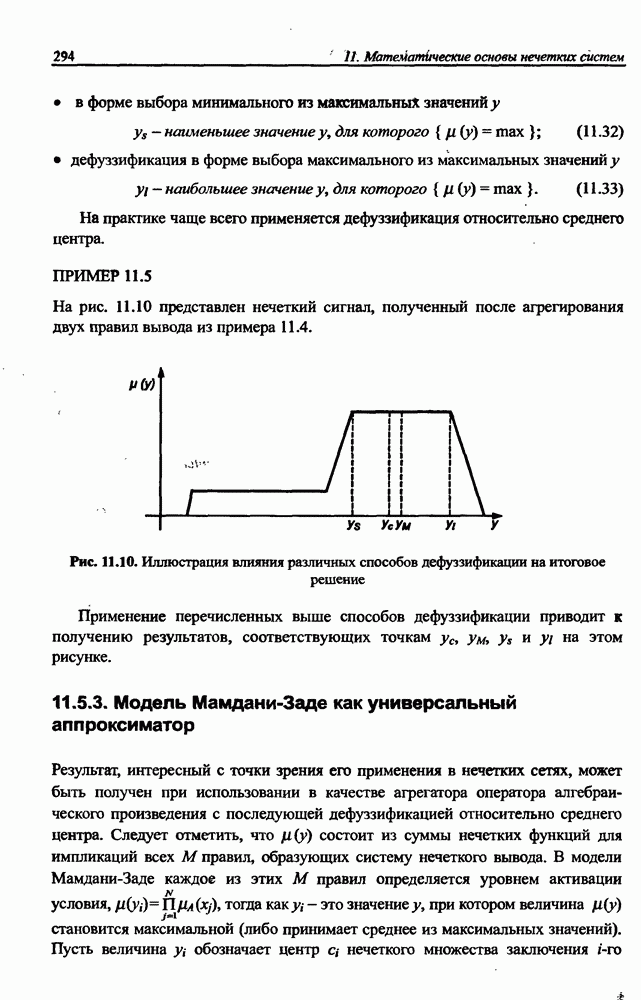
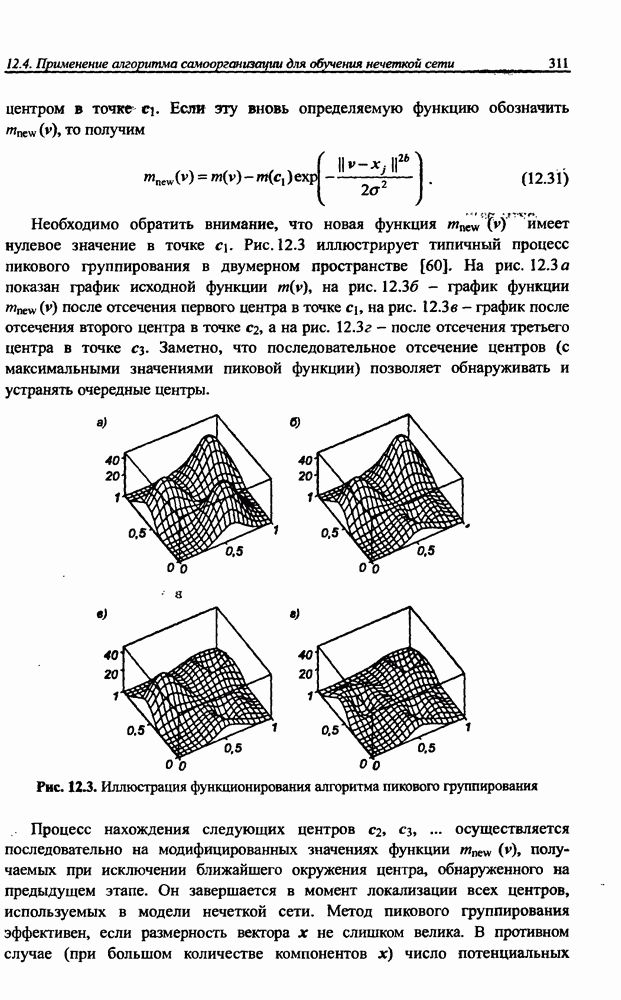
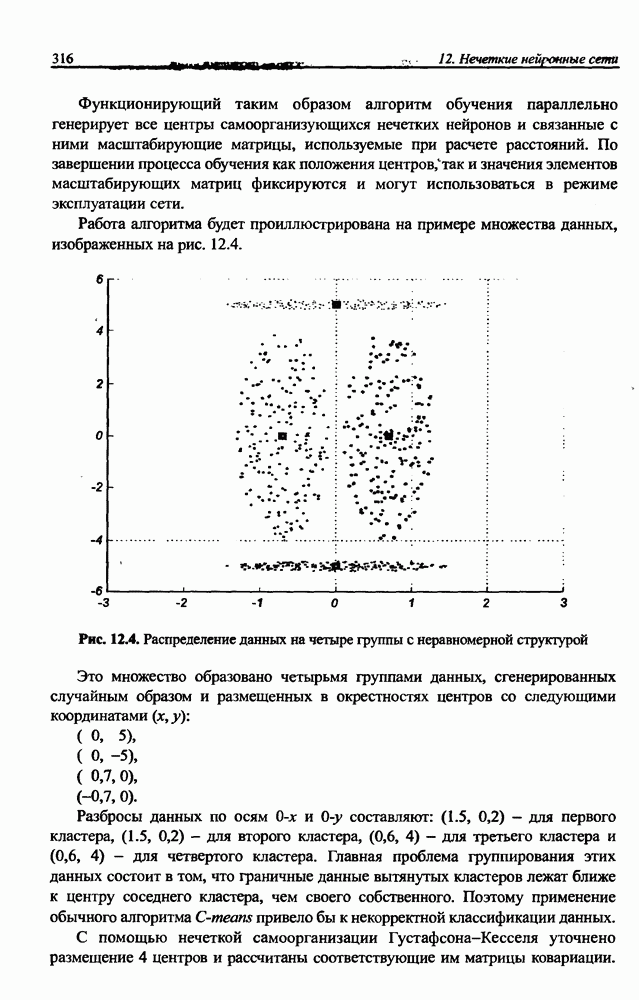
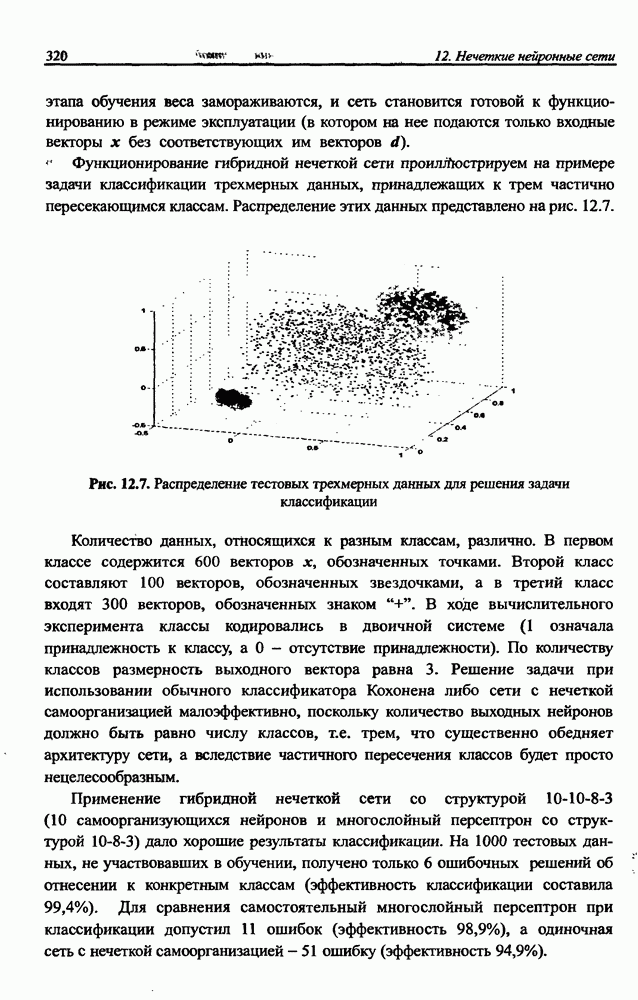
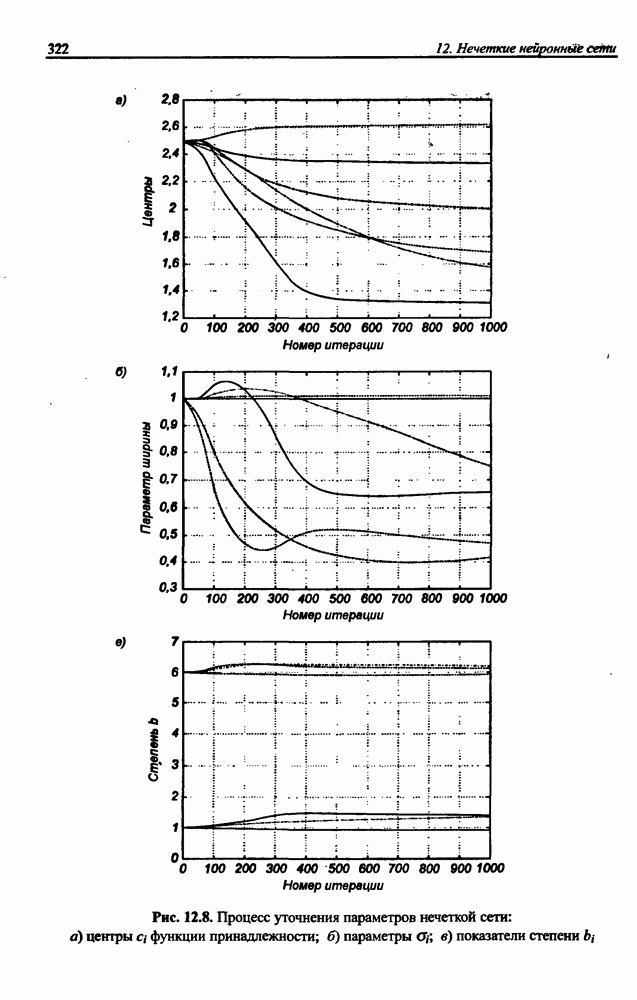
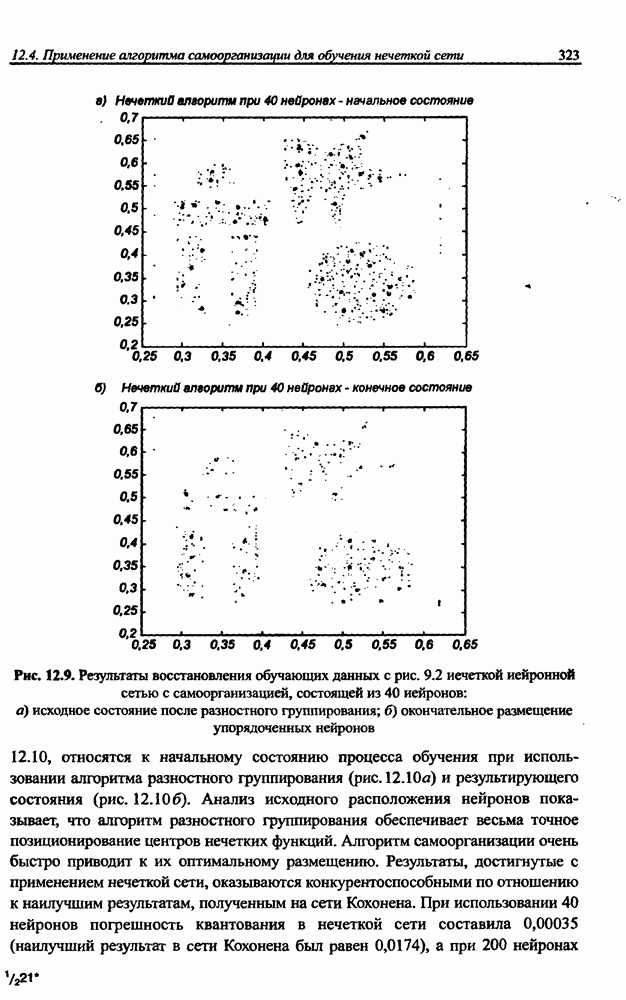
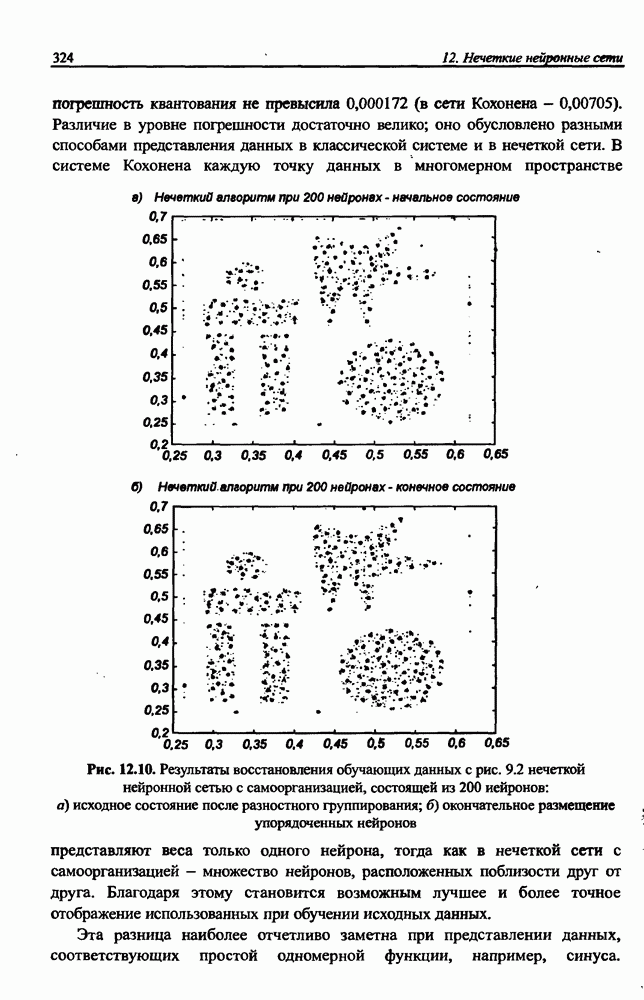
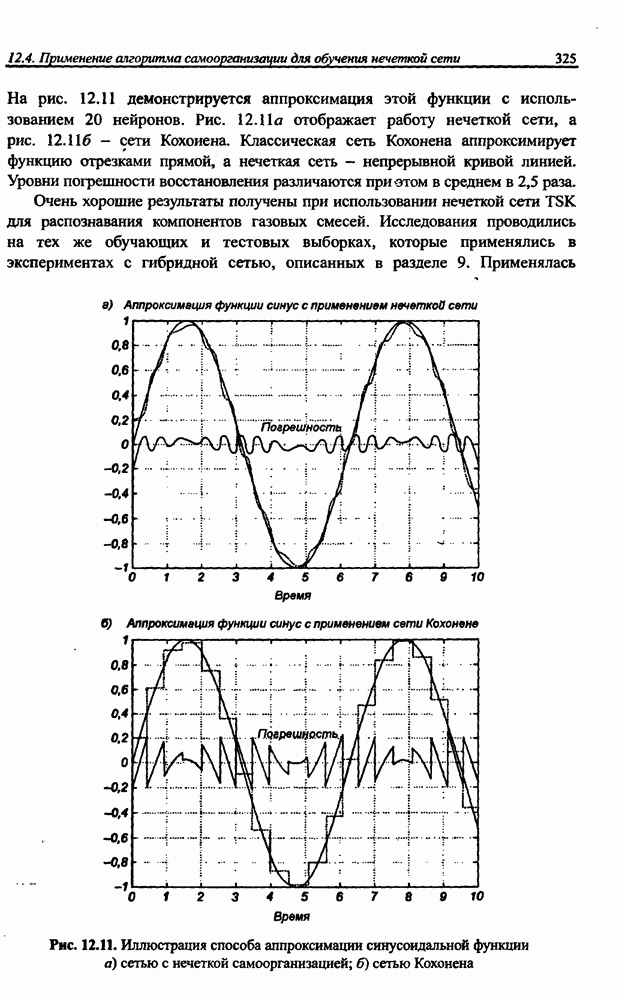
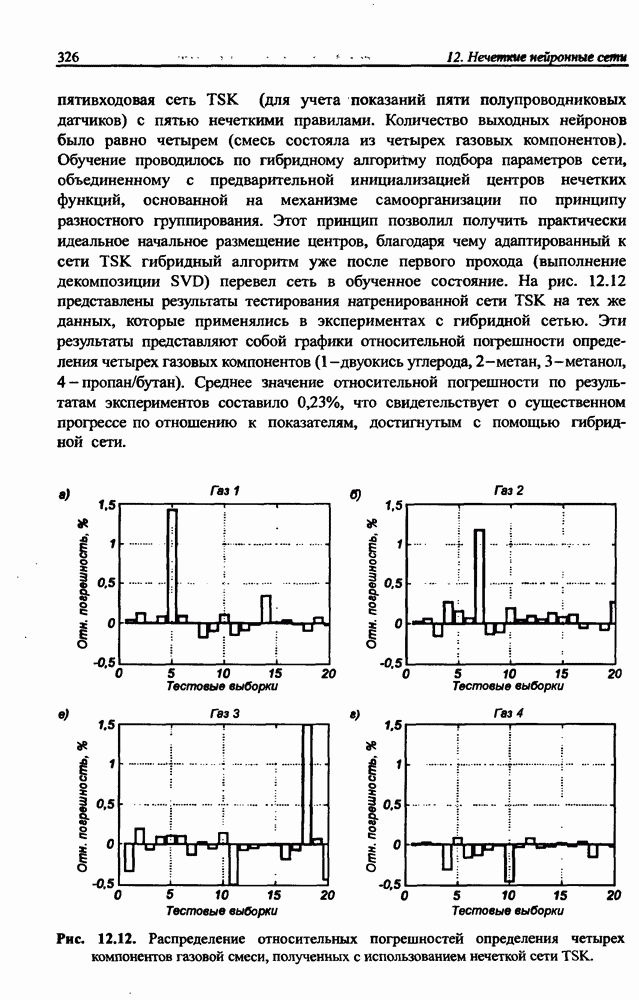
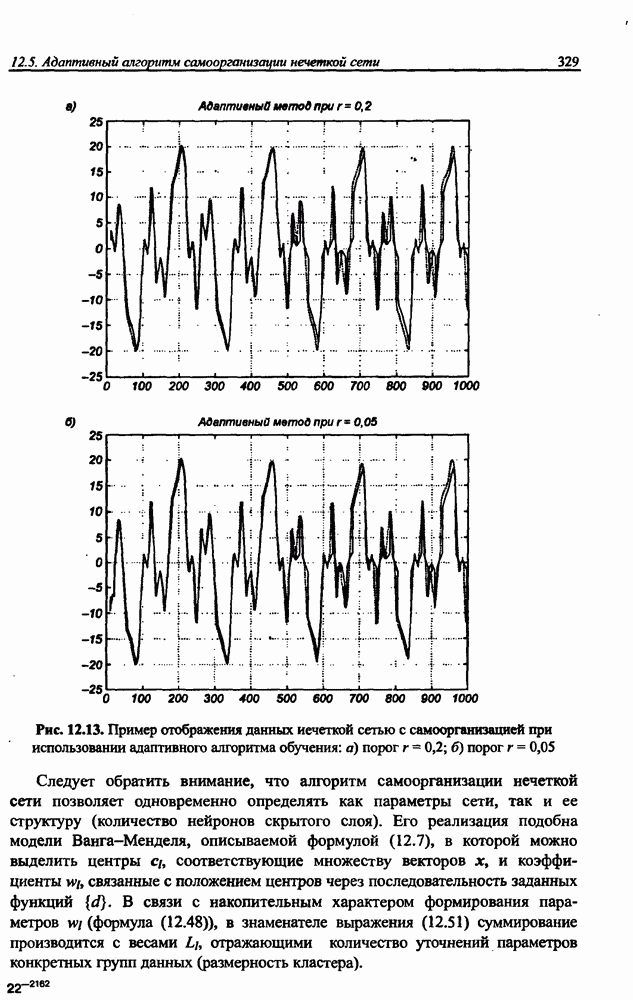
12.4.3. Алгоритм разностного группирования
Алгоритм разностного группирования данных - это модификация предыдущего алгоритма, в которой обучающие векторы х, рассматриваются в качестве потенциальных центров  Пиковая функция
Пиковая функция  в этом алгоритме задается в виде
в этом алгоритме задается в виде

Значение коэффициента  определяет сферу соседства. На значение
определяет сферу соседства. На значение  существенным образом влияют только те векторы
существенным образом влияют только те векторы  которые расположены в пределах этой сферы. При большой плотности точек вокруг х, - (потенциального центра) значение функции
которые расположены в пределах этой сферы. При большой плотности точек вокруг х, - (потенциального центра) значение функции  велико. Напротив, малое ее значение свидетельствует о том, что в окрестности
велико. Напротив, малое ее значение свидетельствует о том, что в окрестности  находится незначительное количество данных. Такая точка считается “неудачным” кандидатом в центры. После расчета значений пиковой функции для каждой точки
находится незначительное количество данных. Такая точка считается “неудачным” кандидатом в центры. После расчета значений пиковой функции для каждой точки  отбирается вектор х, для которого мера плотности
отбирается вектор х, для которого мера плотности  оказалась наибольшей. Именно эта точка становится первым отобранным центром
оказалась наибольшей. Именно эта точка становится первым отобранным центром  Выбор следующего центра возможен после исключения предыдущего и всех точек, лежащих в его окрестности. Так же, как и в методе пикового группирования, пиковая функция переопределяется в виде
Выбор следующего центра возможен после исключения предыдущего и всех точек, лежащих в его окрестности. Так же, как и в методе пикового группирования, пиковая функция переопределяется в виде

При новом определении функции  коэффициент
коэффициент  обозначает новое значение константы, задающей сферу соседства очередного центра. Обычно соблюдается условие
обозначает новое значение константы, задающей сферу соседства очередного центра. Обычно соблюдается условие  Пиковая функция
Пиковая функция  принимает нулевое значение при
принимает нулевое значение при  и близка к нулю в ближайшей окрестности этой точки.
и близка к нулю в ближайшей окрестности этой точки.
После модификации значений пиковой функции отыскивается следующая точка х, для которой величина  оказывается максимальной. Эта точка становится следующим центром
оказывается максимальной. Эта точка становится следующим центром  Процесс поиска очередного центра возобновляется после исключения компонентов, соответствующих уже отобранным точкам. Инициализация завершается в момент фиксации всех центров, предусмотренных начальными условиями.
Процесс поиска очередного центра возобновляется после исключения компонентов, соответствующих уже отобранным точкам. Инициализация завершается в момент фиксации всех центров, предусмотренных начальными условиями.
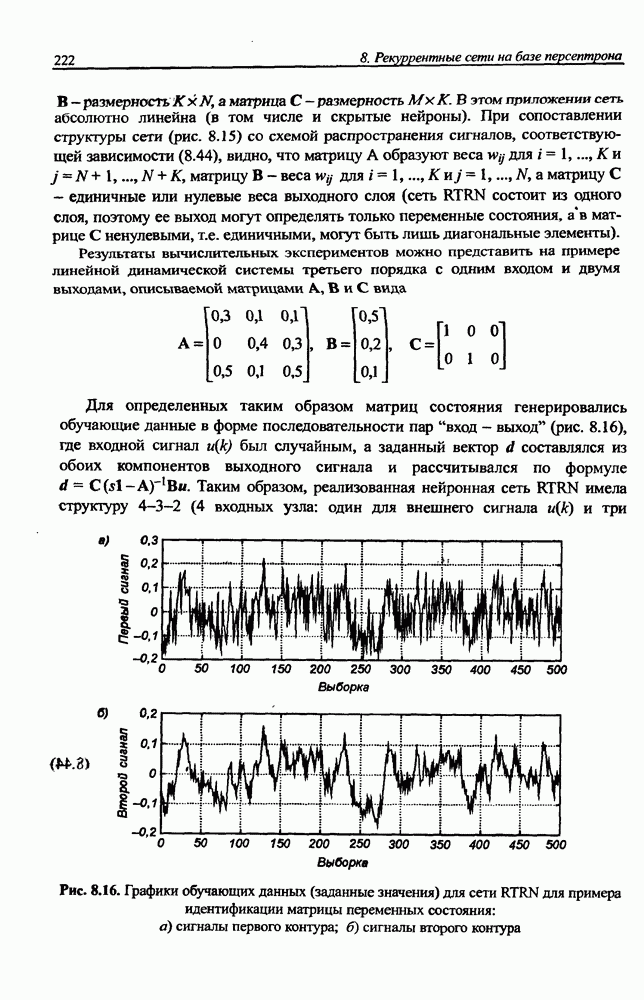
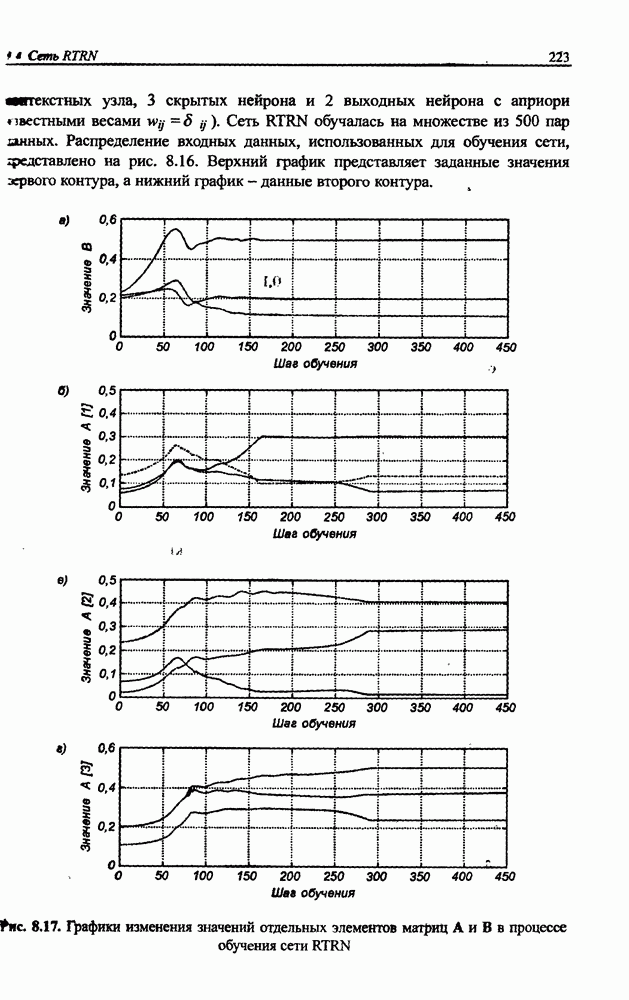
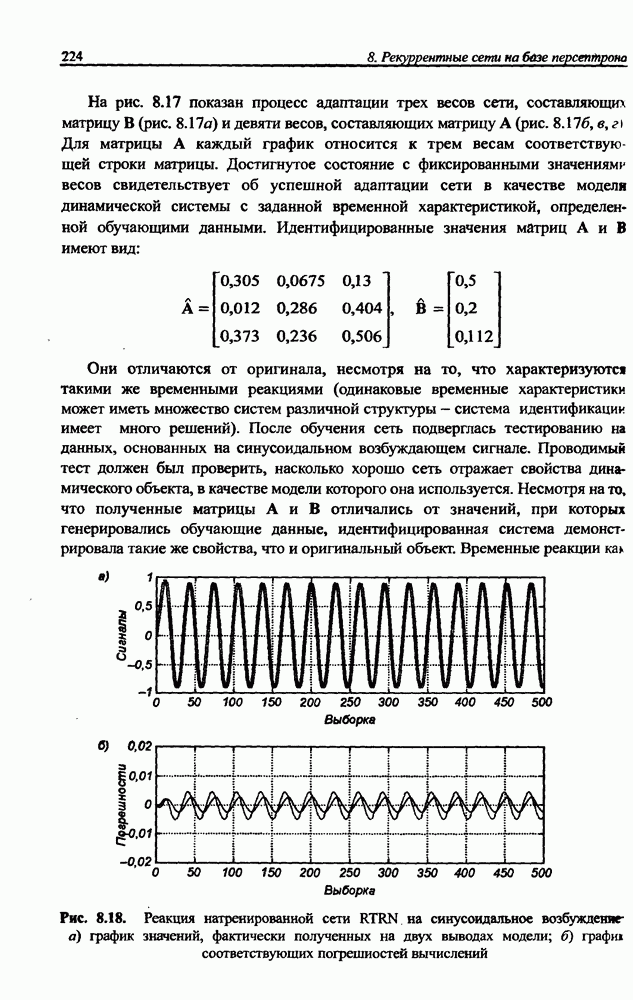
В соответствии с описанным алгоритмом происходит самоорганизация множества векторов  состоящая в нахождении оптимальных значений
состоящая в нахождении оптимальных значений
центров, представляющих множество данных с минимальной погрешностью. Если мы имеем дело с множеством обучающих данных в виде пар векторов  так, как это происходит при обучении с учителем, то для нахождения центров, соответствующих множеству векторов достаточно сформировать расширенную версию векторов х в форме
так, как это происходит при обучении с учителем, то для нахождения центров, соответствующих множеству векторов достаточно сформировать расширенную версию векторов х в форме

Процесс группирования, проводимый с предъявлением расширенных векторов  позволяет определить также расширенные версии центров
позволяет определить также расширенные версии центров  Если принять во внимание, что размерность каждого нового центра равна сумме размерностей векторов х и
Если принять во внимание, что размерность каждого нового центра равна сумме размерностей векторов х и  то в описании этого центра можно легко выделить часть
то в описании этого центра можно легко выделить часть  соответствующую векторам х (первые
соответствующую векторам х (первые  компонентов), и остаток
компонентов), и остаток  соответствующий вектору
соответствующий вектору  Таким образом можно получить центры как входных переменных, так ожидаемых выходных значений
Таким образом можно получить центры как входных переменных, так ожидаемых выходных значений

для  . В случае применения нечетких правил с одним выходом векторы
. В случае применения нечетких правил с одним выходом векторы  сводятся к скалярным величинам
сводятся к скалярным величинам  и
и  соответственно. Таким образом, при использовании правила вывода Ванга-Менделя процесс самоорганизации позволяет восстановить функцию
соответственно. Таким образом, при использовании правила вывода Ванга-Менделя процесс самоорганизации позволяет восстановить функцию  аппроксимирующую множество данных
аппроксимирующую множество данных  для
для  . В частности, при введенных выше обозначениях формула (12.7) принимает вид:
. В частности, при введенных выше обозначениях формула (12.7) принимает вид:

Согласно которому все центры подбираются оптимальным образом. При этом остальные параметры  менее критичные для сходимости алгоритма, могут эффективно подбираться гибридным методом при небольшом количестве итераций. Конечно, итерационный процесс при реализации гибридного метода охватывает также и расчеты координат центров, однако с учетом их удачного начального размещения изменения, вносимые в процессе обучения, обычно оказываются очень незначительными.
менее критичные для сходимости алгоритма, могут эффективно подбираться гибридным методом при небольшом количестве итераций. Конечно, итерационный процесс при реализации гибридного метода охватывает также и расчеты координат центров, однако с учетом их удачного начального размещения изменения, вносимые в процессе обучения, обычно оказываются очень незначительными.