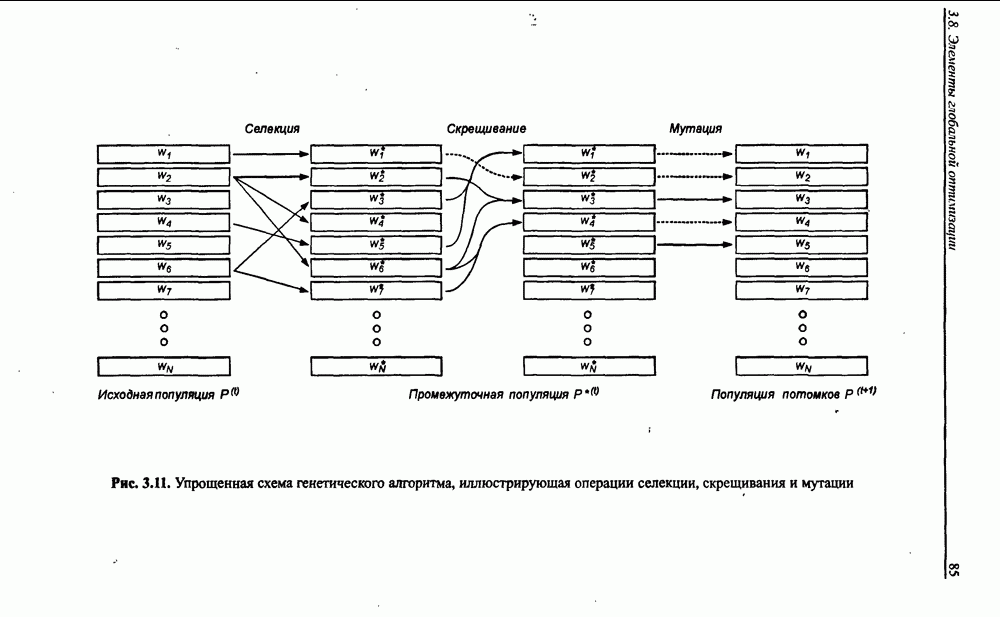
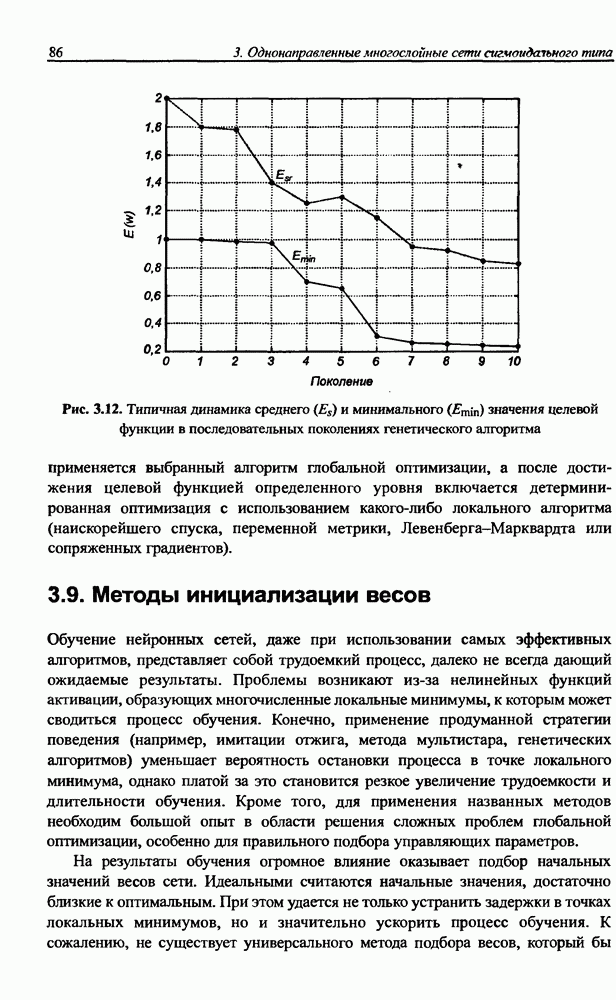
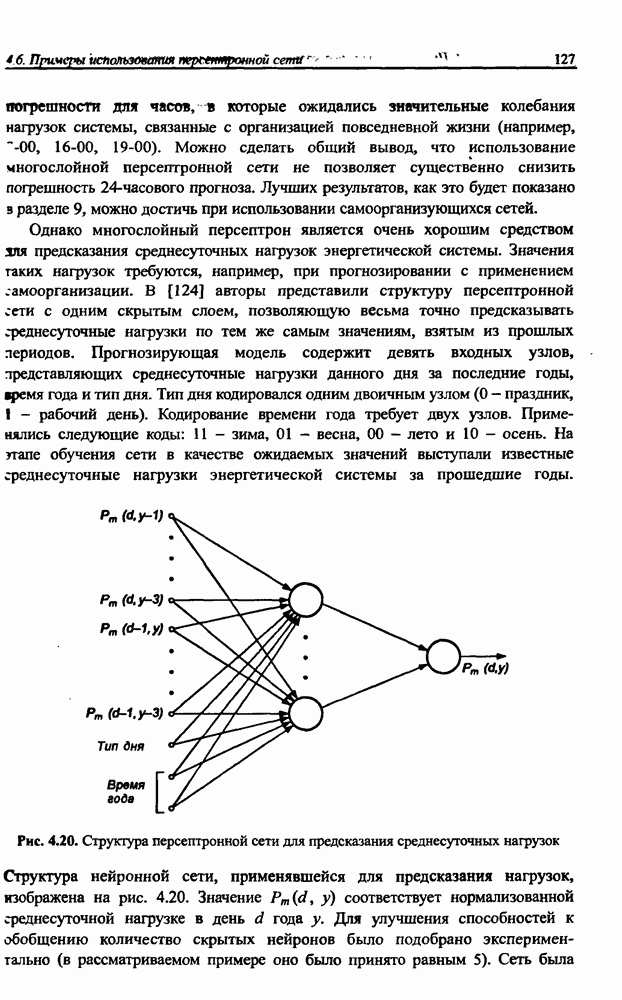
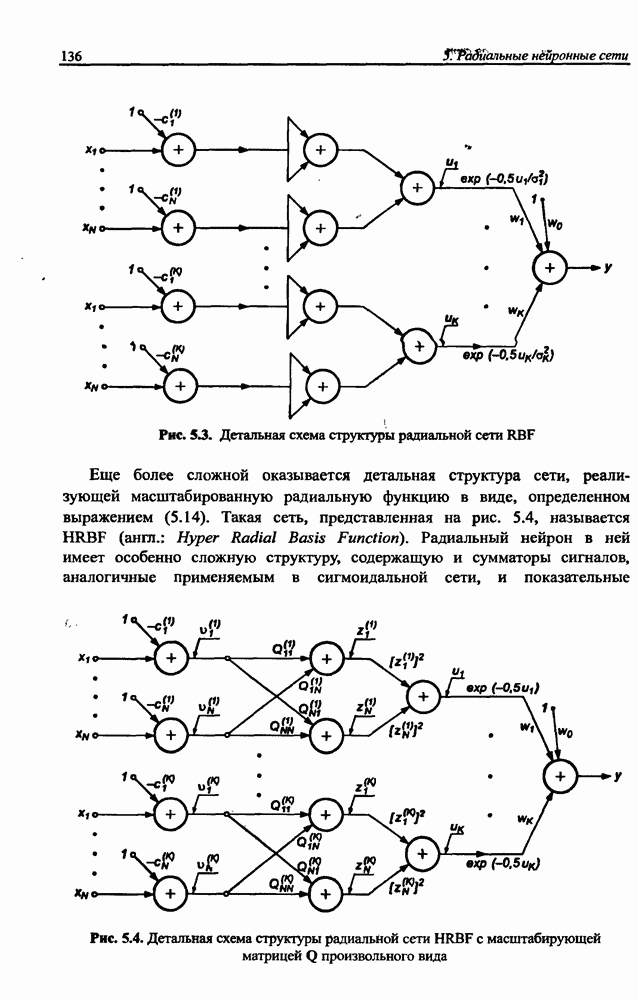
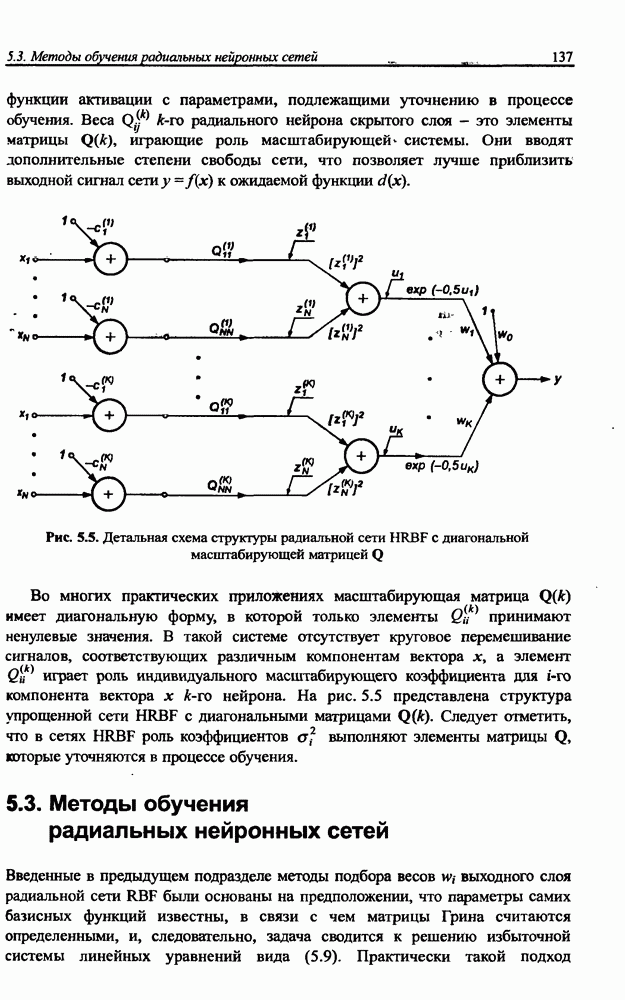
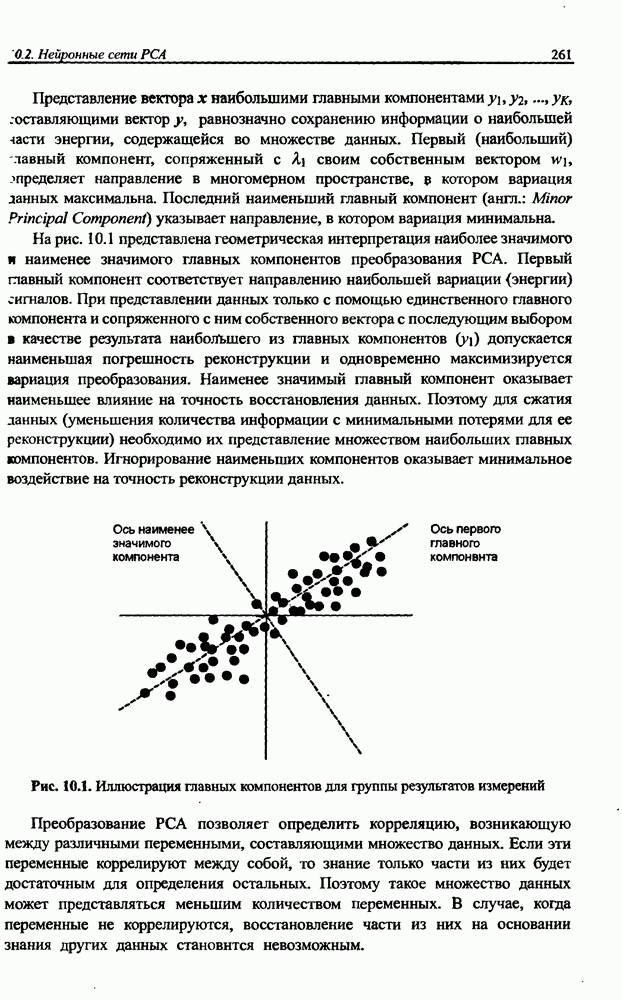
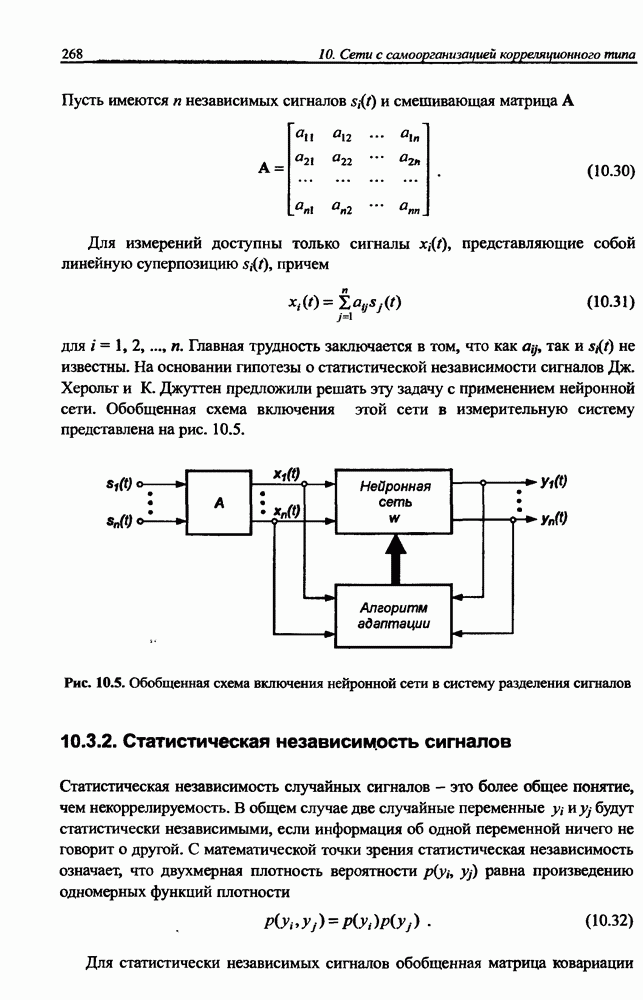
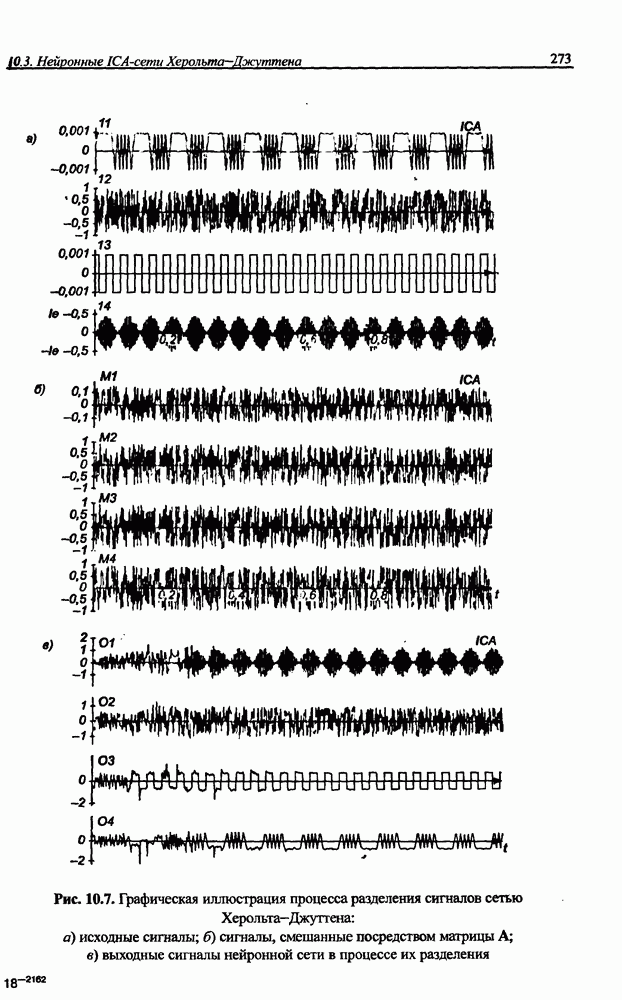
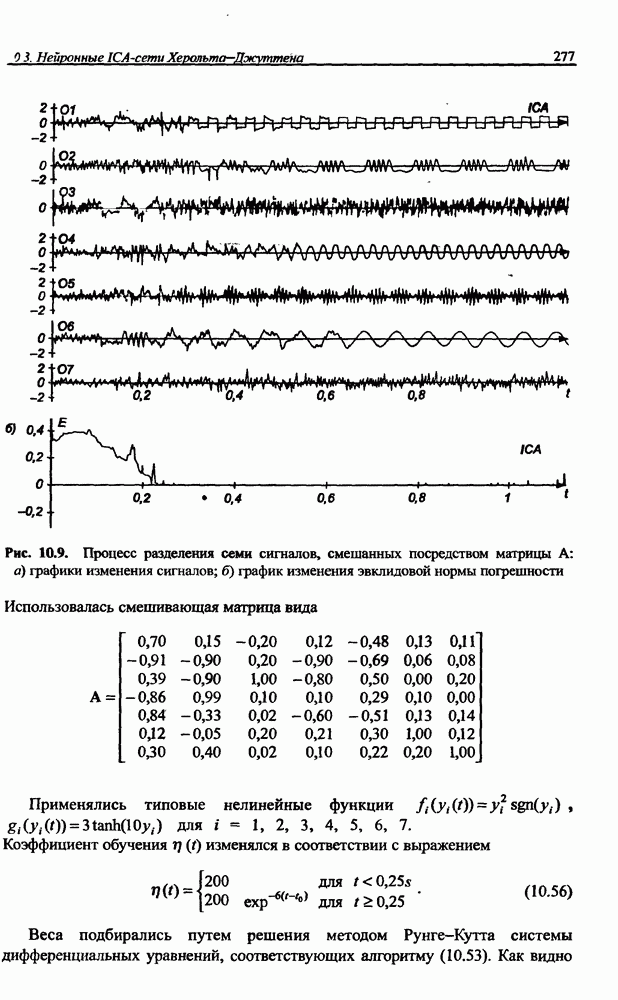
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
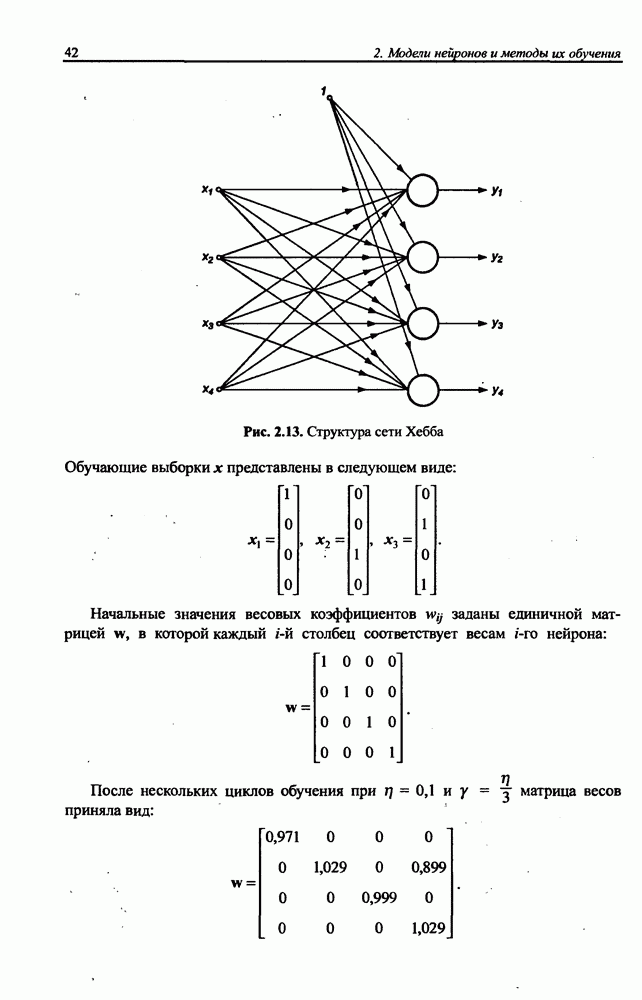
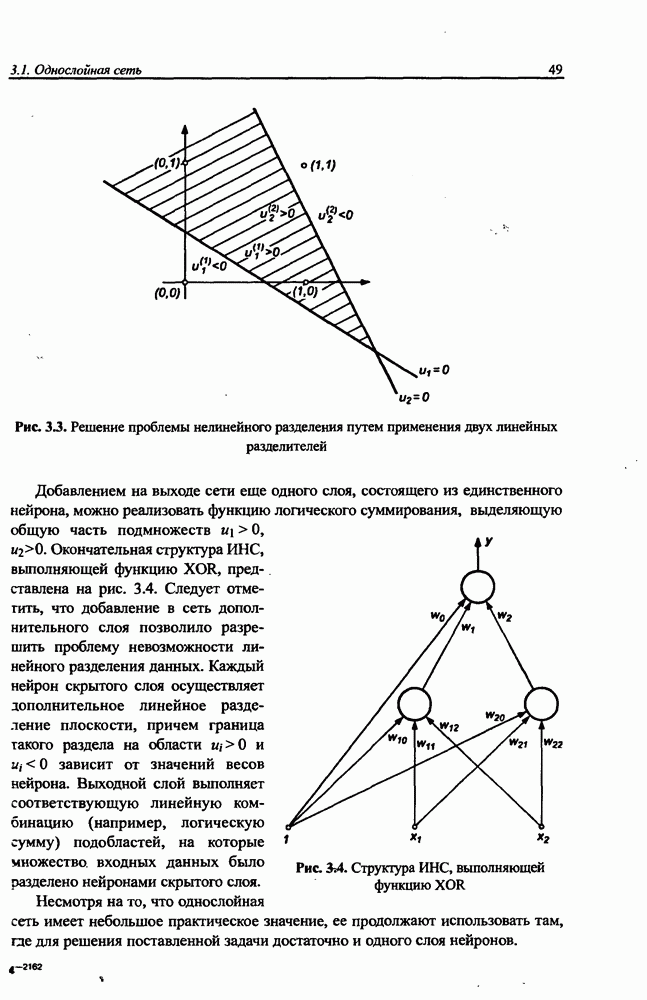
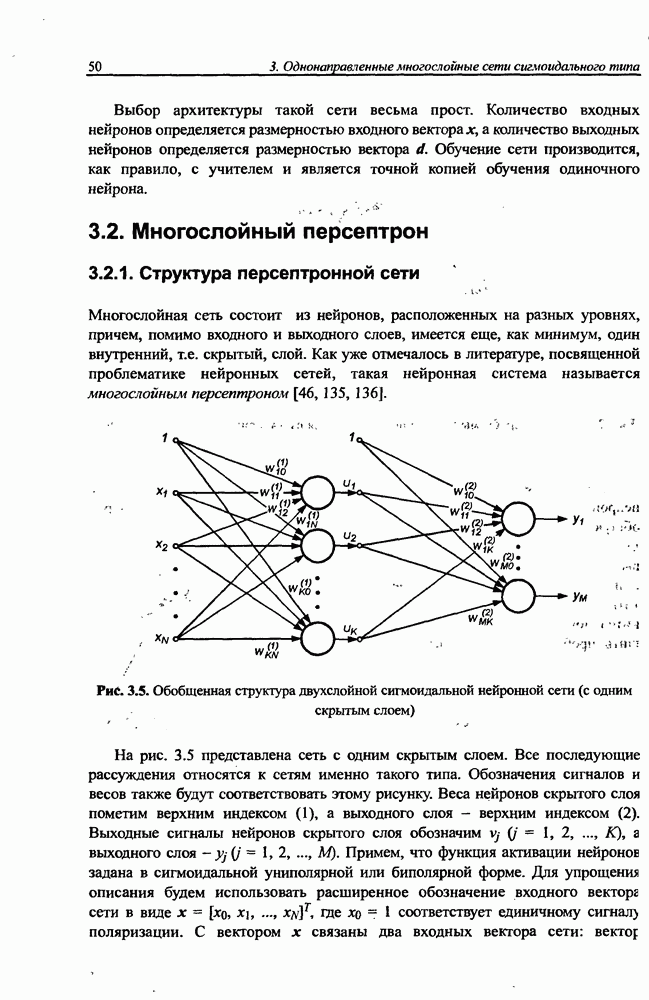
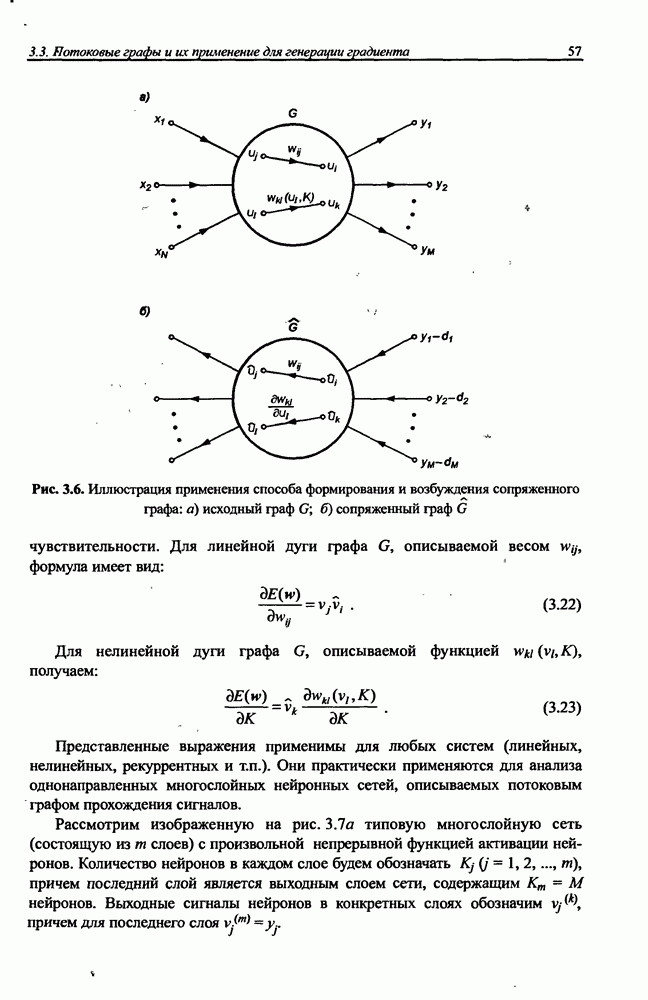
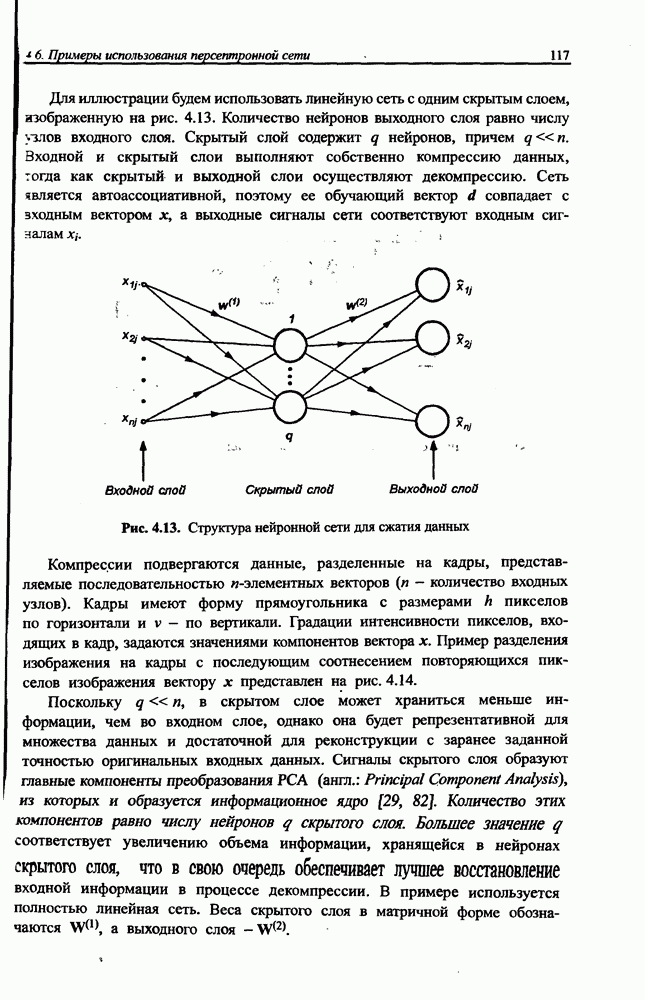
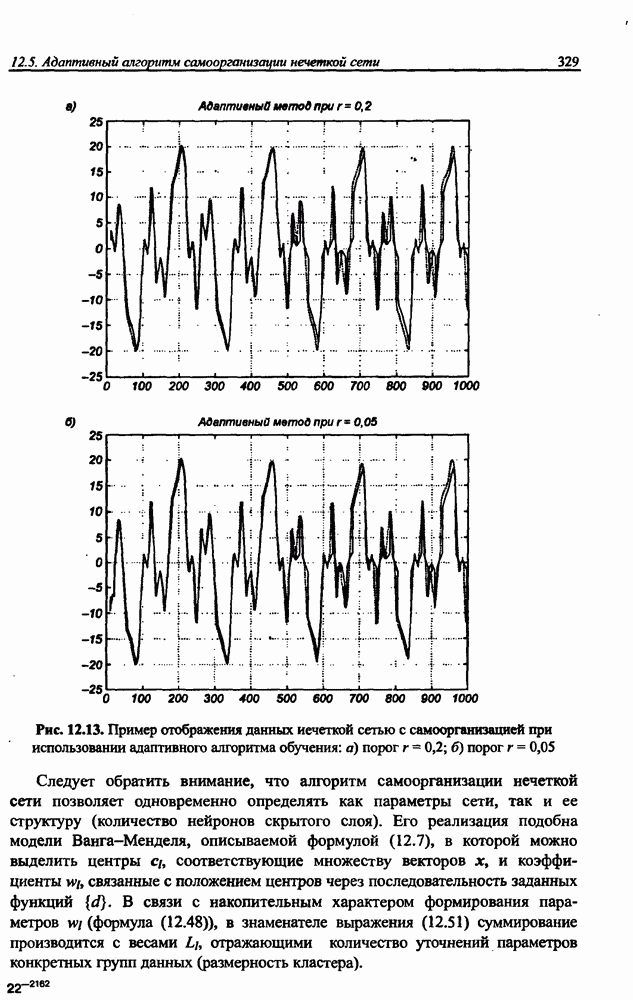
5.3.1. Применение процесса самоорганизации для уточнения параметров радиальных функцийНеплохие результаты уточнения параметров радиальных функций можно получить при использовании алгоритма самоорганизации. Процесс самоорганизации обучающих данных автоматически разделяет пространство на так называемые области Вороного, определяющие различающиеся группы данных. Пример такого разделения двухмерного пространства показан на рис. 5.6. Данные, сгруппированные внутри кластера, представляются центральной точкой, определяющей среднее значение всех его элементов. Центр кластера в дальнейшем будем отождествлять с центром соответствующей радиальной функции. По этой причине количество таких функций равно количеству кластеров и может корректироваться алгоритмом самоорганизации. Разделение данных на кластеры можно выполнить с использованием одной из версий алгоритма Линде-Бузо-Грея [89], называемого также алгоритмом К-усреднений (англ.: K-means). В прямой (онлайн) версии этого алгоритма уточнение центров производится после предъявления каждого очередного вектора х из множества обучающих данных. В накопительной версии (оффлайн) центры уточняются одновременно после предъявления всех элементов множества. В обоих случаях предварительный выбор центров выполняется чаще всего случайным образом с использованием равномерного распределения.
Рис. 5.6. Иллюстрация способа разделения пространства данных на сферы влияния отдельных радиальных функций Если обучающие данные представляют непрерывную функцию, начальные значения центров в первую очередь размещают в точках, соответствующих всем максимальным и минимальным значениям функции. Данные об этих центрах и их ближайшем окружении впоследствии удаляются из обучающего множества, а оставшиеся центры равномерно распределяются в сфере, образованной оставшимися элементами этого множества. В прямой версии после предъявления
где Также применяется разновидность алгоритма, в соответствии с которой значение центра-победителя уточняется в соответствии с формулой (5.20), а один или несколько ближайших к нему центров отодвигаются в противоположном направлении [83], и этот процесс реализуется согласно выражению
Такая модификация алгоритма позволяет отдалить центры, расположенные близко друг к другу, что обеспечивает лучшее обследование всего пространства данных В накопительной версии предъявляются все обучающие векторы х, и каждый из них сопоставляется какому-либо центру. Множество векторов, приписанных одному и тому же центру, образует кластер, новый центр которого определяется как среднее соответствующих векторов:
В этом выражении Другой подход состоит в использовании взвешенной меры расстояния от каждого конкретного центра до предъявляемого вектора х. Весовая норма делает “фаворитами” те центры, которые реже всего становились победителями. Оба подхода не гарантируют 100%-ную оптимальность решения, поскольку представляют собой фактически процедуры возмущения предопределенного процесса локальной оптимизации [11]. Трудность состоит также в подборе коэффициента обучения Г). При использовании постоянного значения
Коэффициент Т обозначает постоянную времени, подбираемую индивидуально для каждой задачи. При После фиксации местоположения центров проводится подбор значений параметров которой значение этой функции не равно нулю (точнее, превышает определенное пороговое значение Проще всего в качестве значения
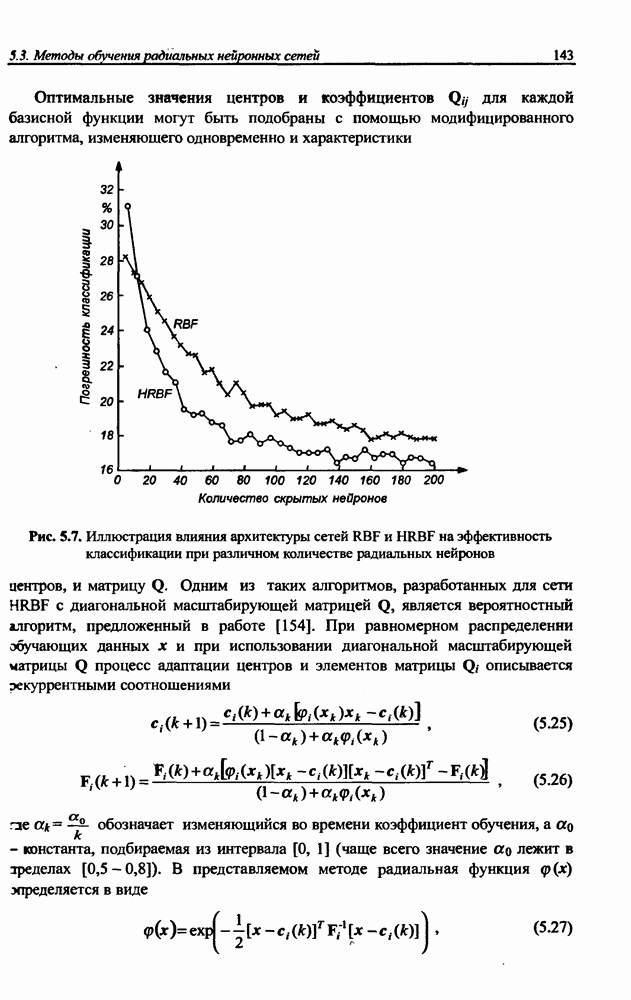
На практике значение Р обычно лежит в интервале [3 - 5]. При решении любой задачи ключевая проблема, определяющая качество отображения, состоит в предварительном подборе количества радиальных функций (скрытых нейронов). Как правило, при этом руководствуются общим принципом: чем больше размерность вектора х, тем большее количество радиальных функций необходимо для получения удовлетворительного решения. Детальное описание процесса подбора количества радиальных функций будет представлено в последующих подразделах.
|
 |
Оглавление
|






































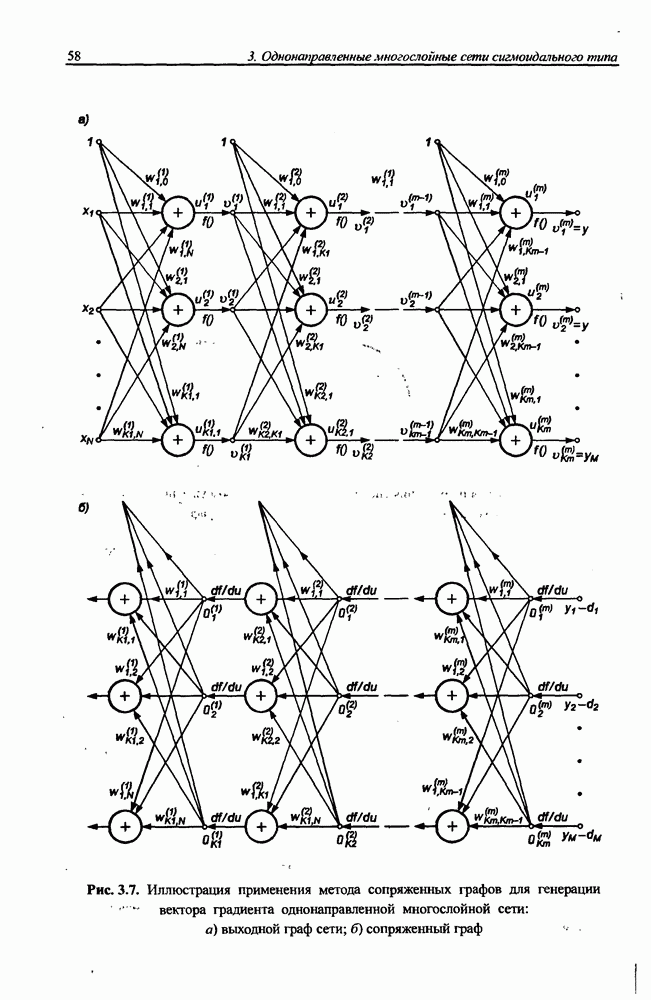


























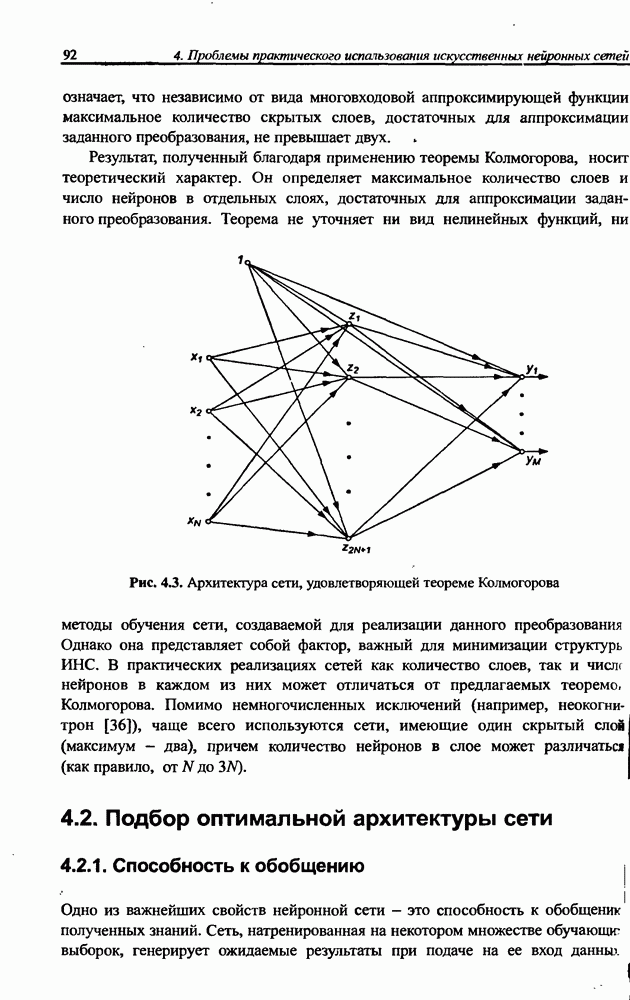



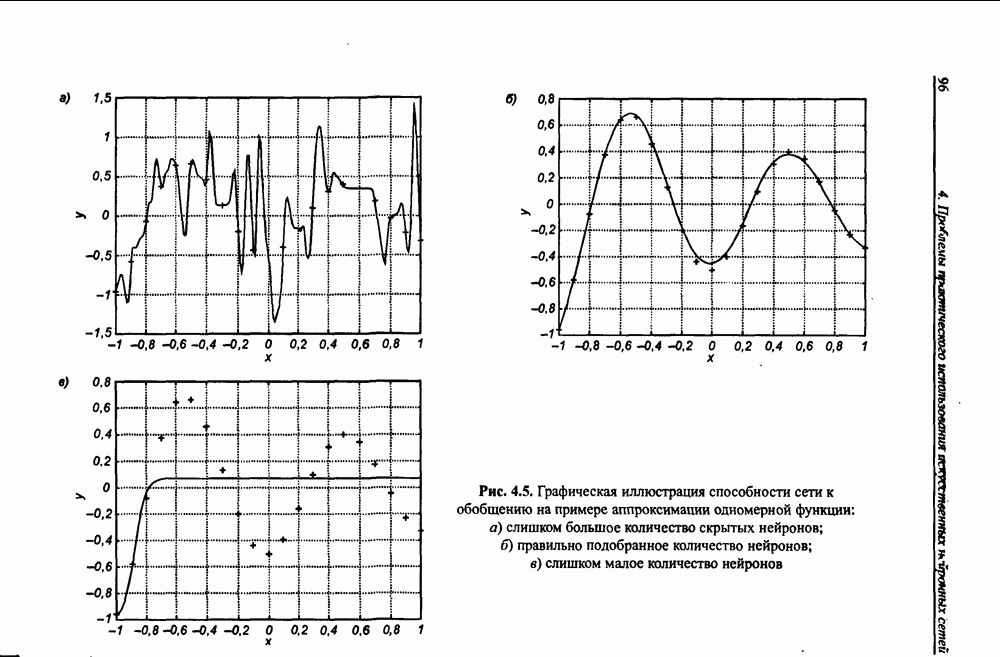

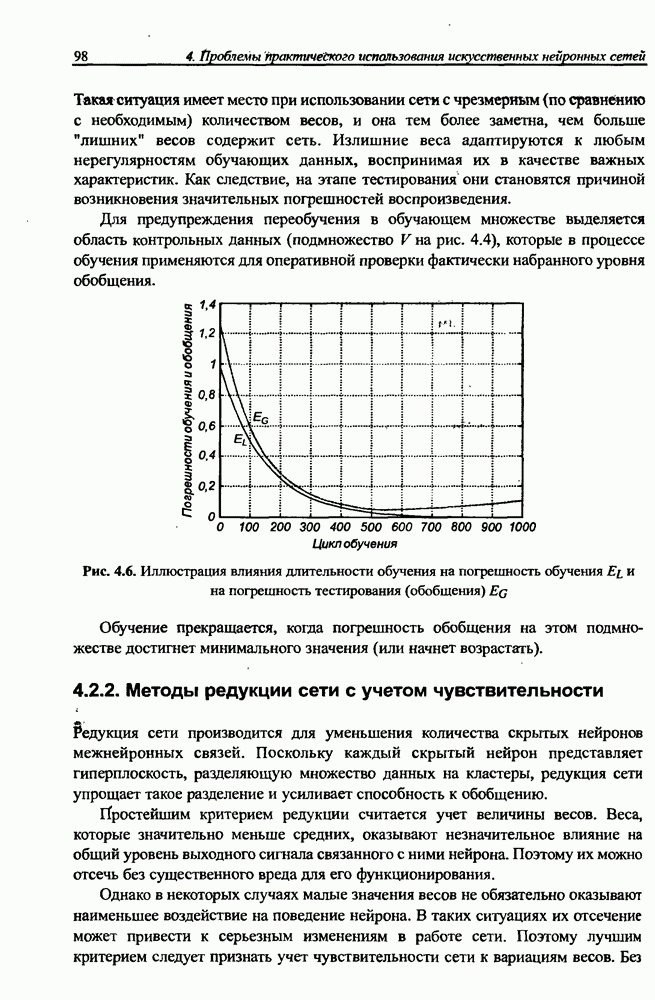


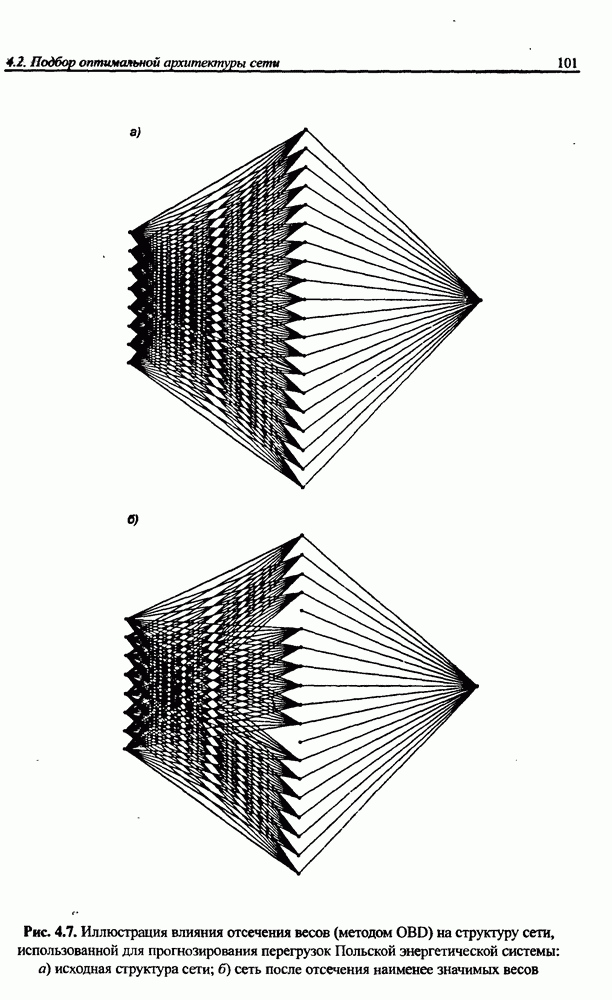

































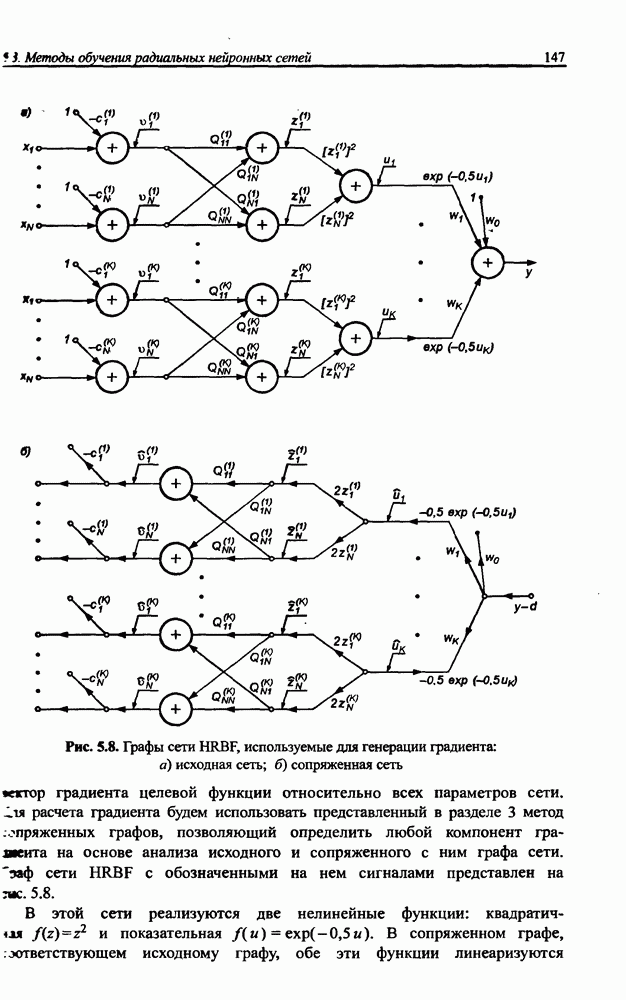

















































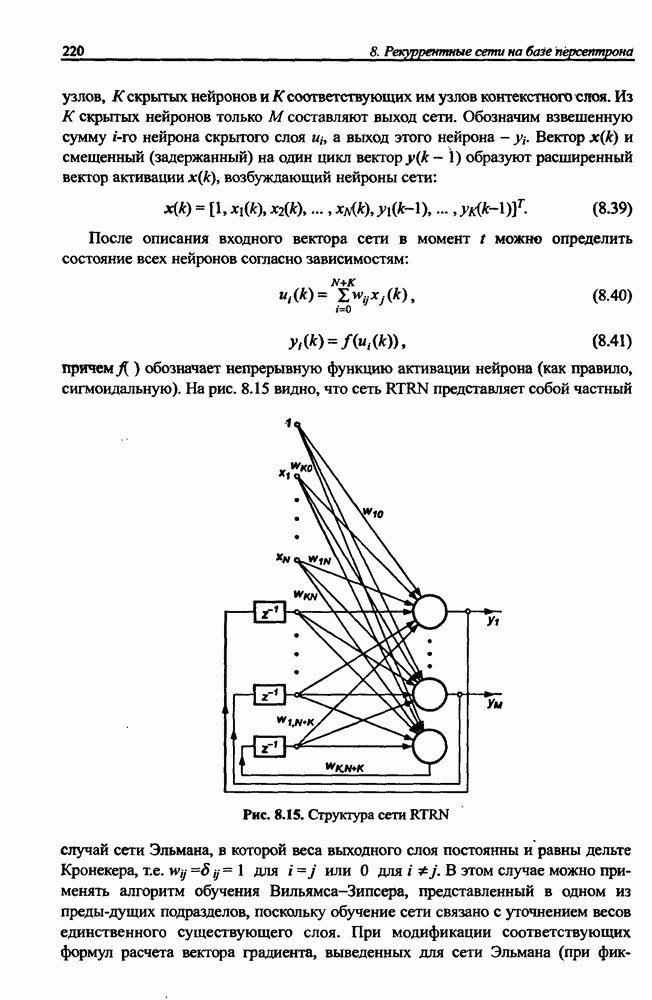

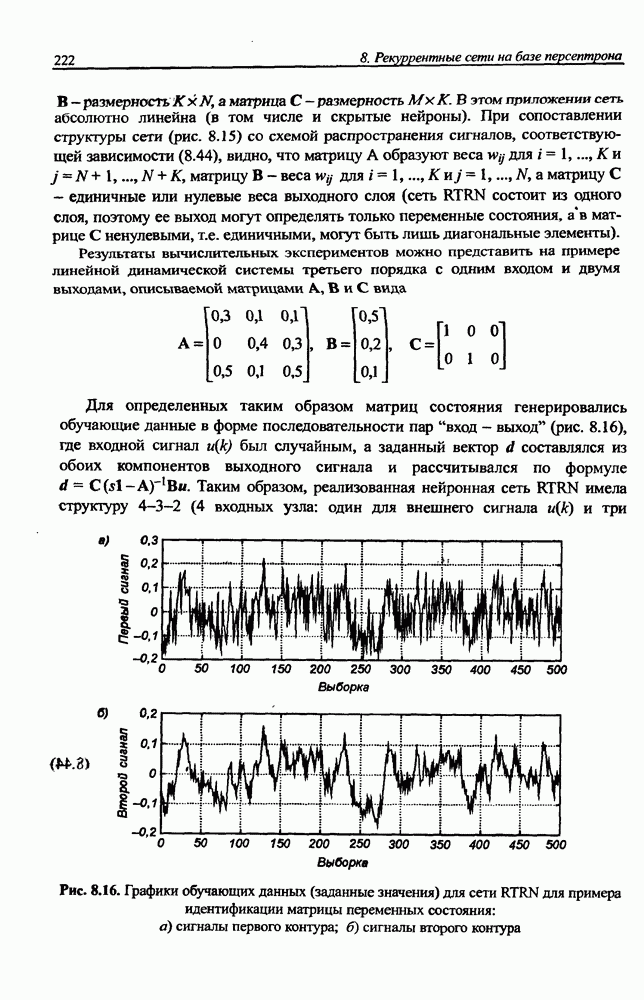
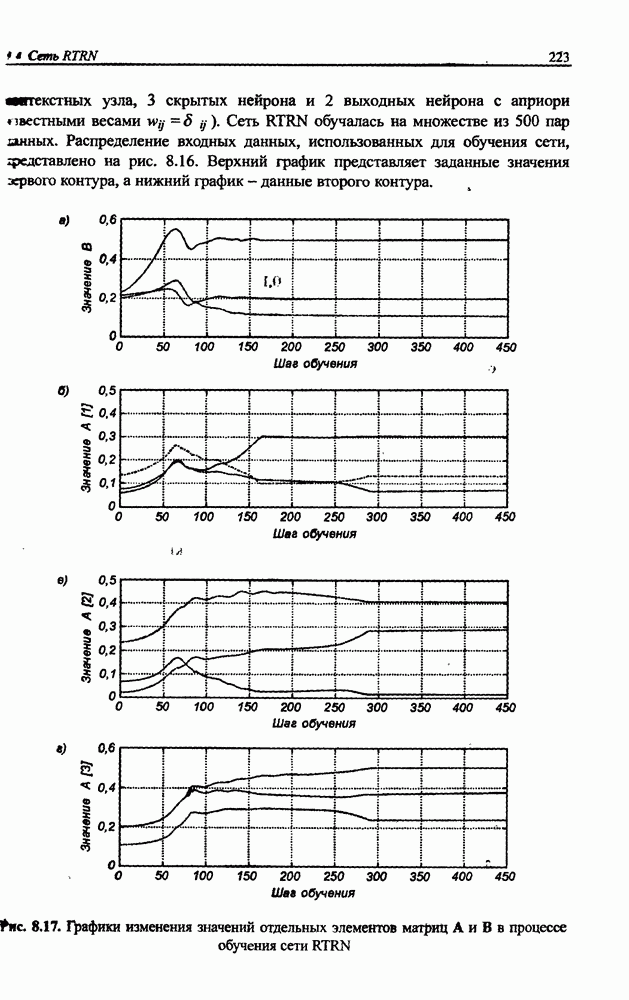
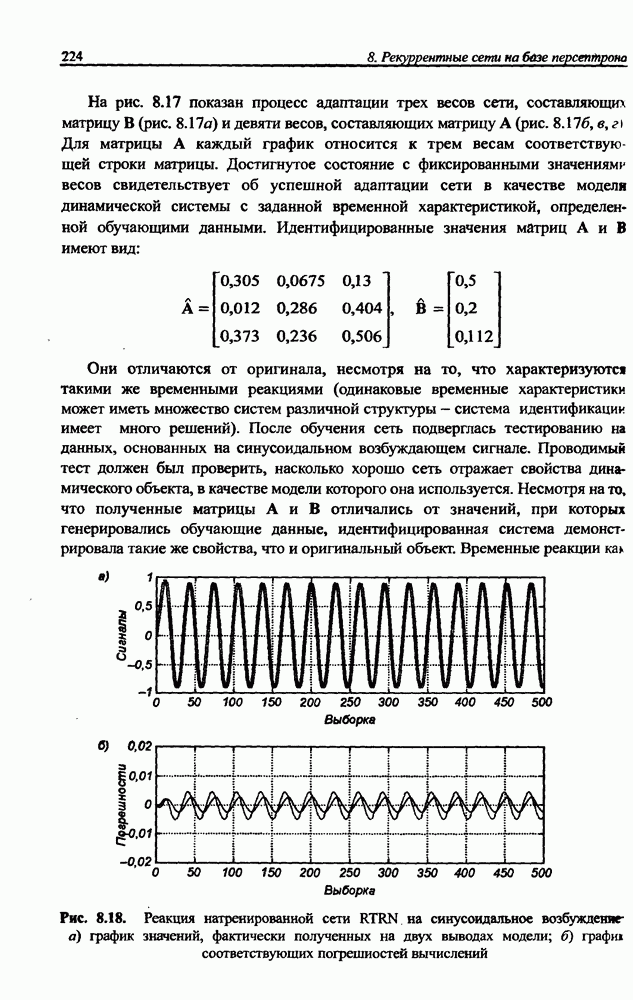






































































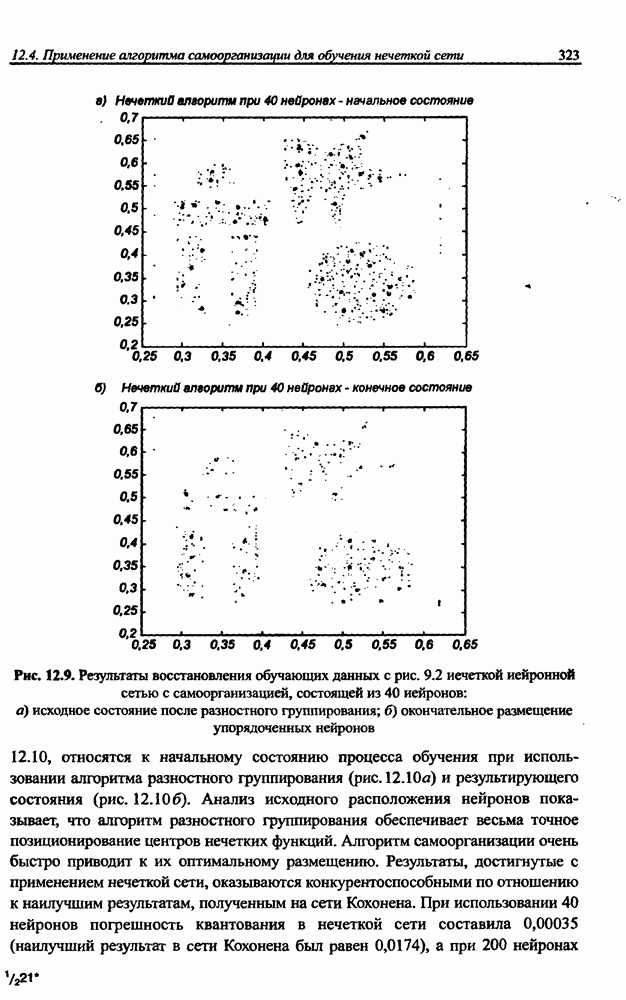
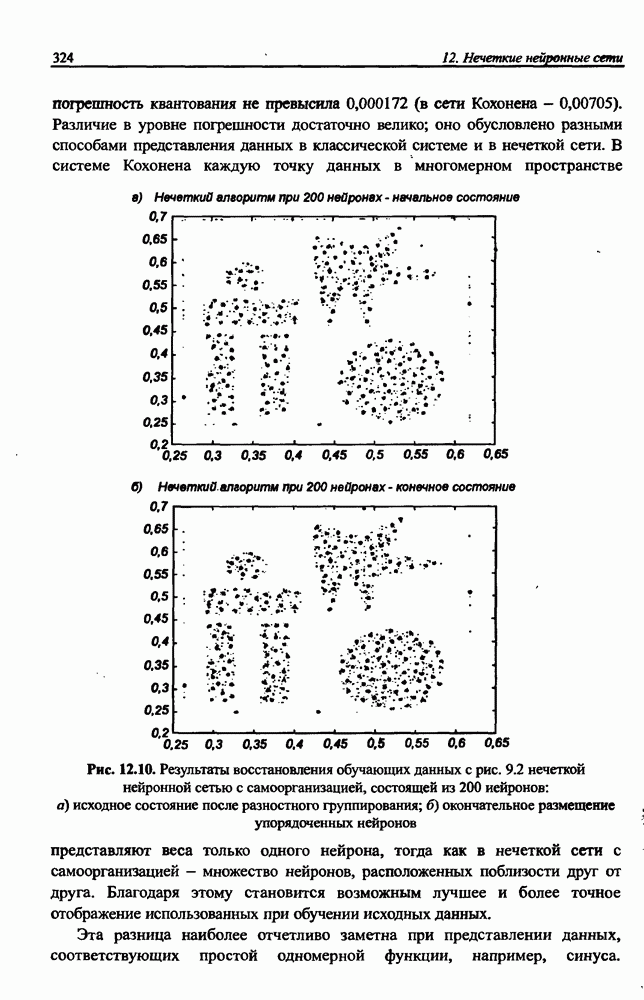
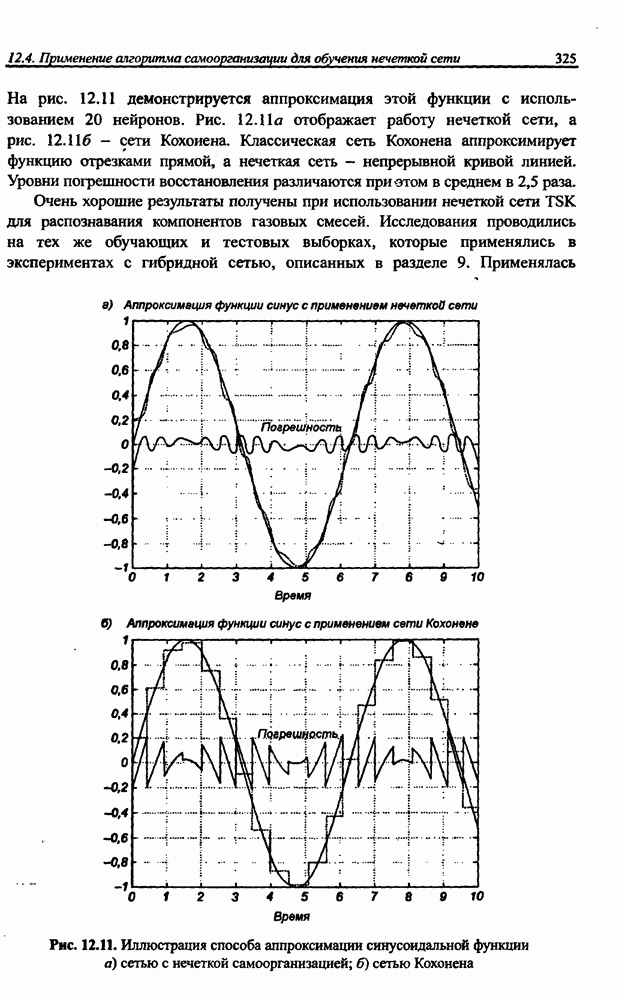
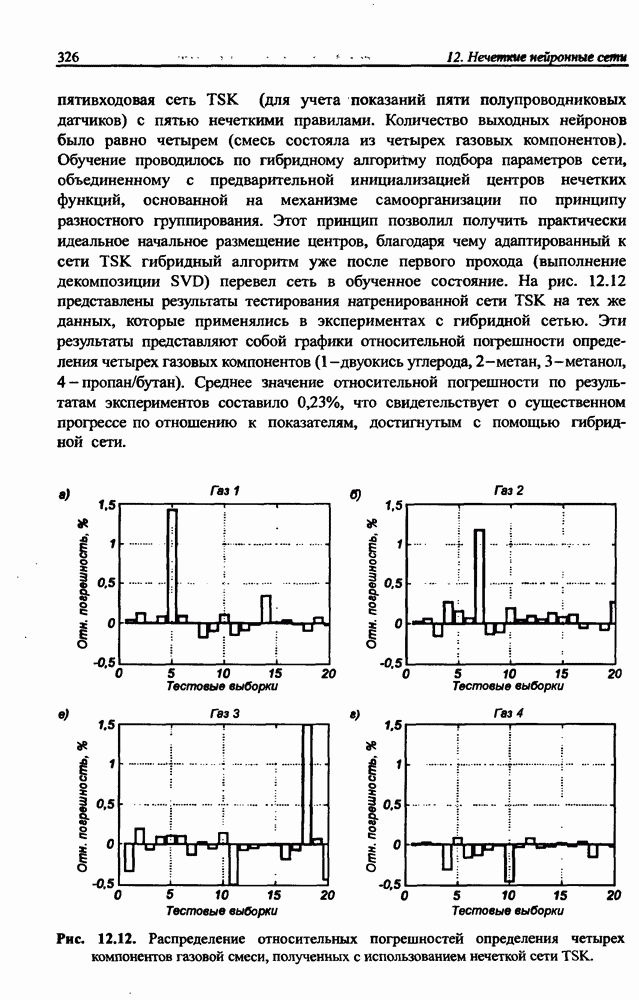













 вектора х, принадлежащего обучающему множеству, выбирается центр, ближайший к х, относительно применяемой метрики. Этот центр подвергается уточнению в соответствии с алгоритмом WTA
вектора х, принадлежащего обучающему множеству, выбирается центр, ближайший к х, относительно применяемой метрики. Этот центр подвергается уточнению в соответствии с алгоритмом WTA

 - коэффициент обучения, имеющий малое значение (обычно
- коэффициент обучения, имеющий малое значение (обычно  ), причем уменьшающееся во времени. Остальные центры не изменяются. Все обучающие векторы х предъявляются по несколько раз, как правило, в случайной последовательности вплоть до стабилизации значений центров.
), причем уменьшающееся во времени. Остальные центры не изменяются. Все обучающие векторы х предъявляются по несколько раз, как правило, в случайной последовательности вплоть до стабилизации значений центров.



 - количество векторов
- количество векторов  приписанных в
приписанных в  цикле к
цикле к  центру. Значения всех центров уточняются параллельно. Процесс предъявления множества векторов х и уточнения значений центров повторяется многократно вплоть до стабилизации значений центров. На практике чаще всего применяется прямой алгоритм, имеющий несколько лучшую сходимость. Однако ни один алгоритм не гарантирует абсолютную сходимость к оптимальному решению в глобальном смысле, а обеспечивает только локальную оптимизацию, зависящую от начальных условий и параметров процесса обучения. При неудачно выбранных начальных условиях некоторые центры могут застрять в области, где количество обучающих данных ничтожно мало либо они вообще отсутствуют, поэтому процесс модификации центров затормозится или остановится. Способом разрешения этой проблемы считается одновременная корректировка размещения большого количества центров с фиксацией значения 77 для каждого из них. Центр, наиболее близкий к текущему вектору х, модифицируется сильнее всего, а остальные - обратно пропорционально их расстоянию до этого текущего вектора.
центру. Значения всех центров уточняются параллельно. Процесс предъявления множества векторов х и уточнения значений центров повторяется многократно вплоть до стабилизации значений центров. На практике чаще всего применяется прямой алгоритм, имеющий несколько лучшую сходимость. Однако ни один алгоритм не гарантирует абсолютную сходимость к оптимальному решению в глобальном смысле, а обеспечивает только локальную оптимизацию, зависящую от начальных условий и параметров процесса обучения. При неудачно выбранных начальных условиях некоторые центры могут застрять в области, где количество обучающих данных ничтожно мало либо они вообще отсутствуют, поэтому процесс модификации центров затормозится или остановится. Способом разрешения этой проблемы считается одновременная корректировка размещения большого количества центров с фиксацией значения 77 для каждого из них. Центр, наиболее близкий к текущему вектору х, модифицируется сильнее всего, а остальные - обратно пропорционально их расстоянию до этого текущего вектора.
 он должен быть очень малым для гарантированной сходимости алгоритма, что непомерно увеличивает время обучения. Адаптивные методы подбора
он должен быть очень малым для гарантированной сходимости алгоритма, что непомерно увеличивает время обучения. Адаптивные методы подбора  позволяют сделать его значение зависимым от времени, т.е. уменьшать по мере роста номера итерации k. Наиболее известным представителем этой группы считается алгоритм Даркена-Муци [11], согласно которому
позволяют сделать его значение зависимым от времени, т.е. уменьшать по мере роста номера итерации k. Наиболее известным представителем этой группы считается алгоритм Даркена-Муци [11], согласно которому

 значение
значение  практически неизменно, но при к
практически неизменно, но при к  оно постепенно уменьшается до нуля. Несмотря на то, что адаптивные методы подбора
оно постепенно уменьшается до нуля. Несмотря на то, что адаптивные методы подбора  более прогрессивны по сравнению с постоянным значением, они тоже не могут считаться наилучшим решением, особенно при моделировании динамических процессов.
более прогрессивны по сравнению с постоянным значением, они тоже не могут считаться наилучшим решением, особенно при моделировании динамических процессов.
 соответствующих конкретным базисным функциям. Параметр
соответствующих конкретным базисным функциям. Параметр  радиальной функции влияет на форму функции и величину области ее охвата, в
радиальной функции влияет на форму функции и величину области ее охвата, в
 ). Подбор
). Подбор  должен проводиться таким образом, чтобы области охвата всех радиальных функций накрывали все пространство входных данных, причем любые две зоны могут перекрываться только в незначительной степени. При такой организации подбора значения
должен проводиться таким образом, чтобы области охвата всех радиальных функций накрывали все пространство входных данных, причем любые две зоны могут перекрываться только в незначительной степени. При такой организации подбора значения  реализуемое радиальной сетью отображение функции будет относительно монотонным.
реализуемое радиальной сетью отображение функции будет относительно монотонным.
 радиальной функции принять эвклидово расстояние между
радиальной функции принять эвклидово расстояние между  центром
центром  и его ближайшим соседом [154]. В другом алгоритме, учитывающем более широкое соседство, на значение
и его ближайшим соседом [154]. В другом алгоритме, учитывающем более широкое соседство, на значение  влияет расстояние между
влияет расстояние между  центром
центром  и его Р ближайшими соседями. В этом случае значение
и его Р ближайшими соседями. В этом случае значение  определяется по формуле
определяется по формуле
