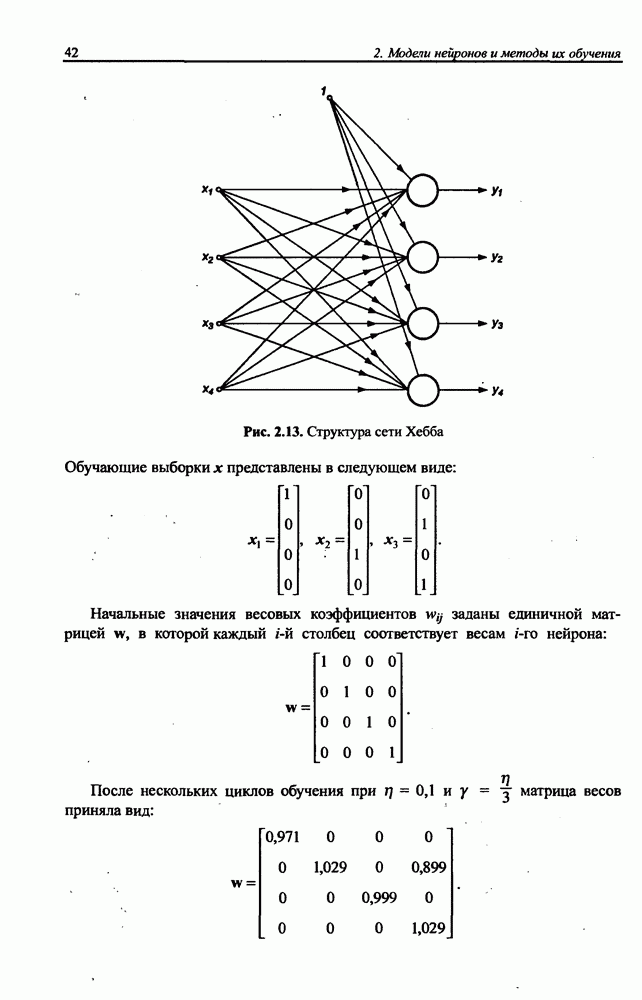
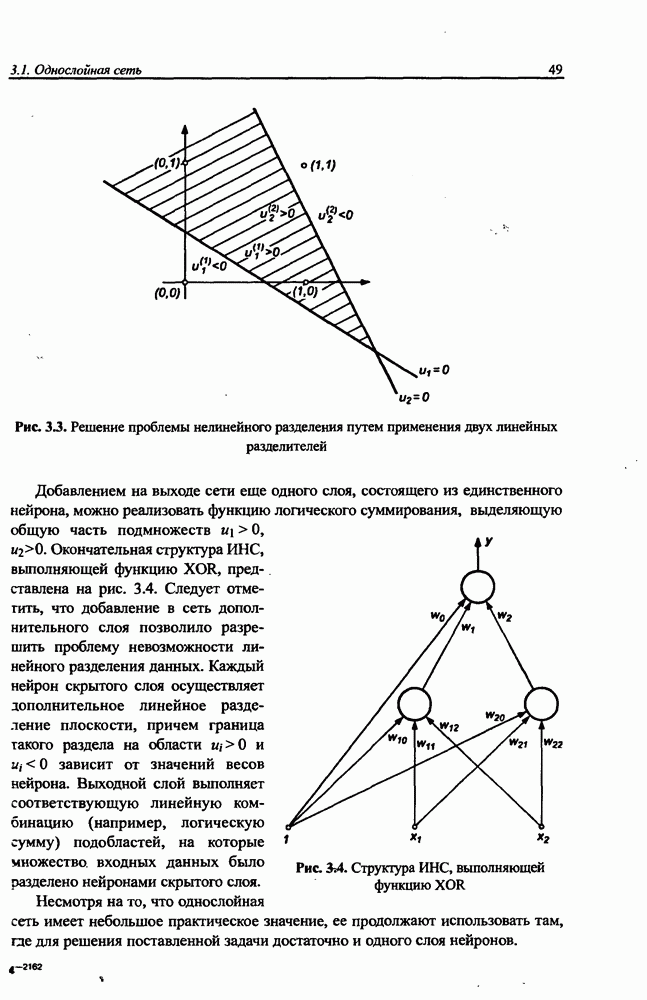
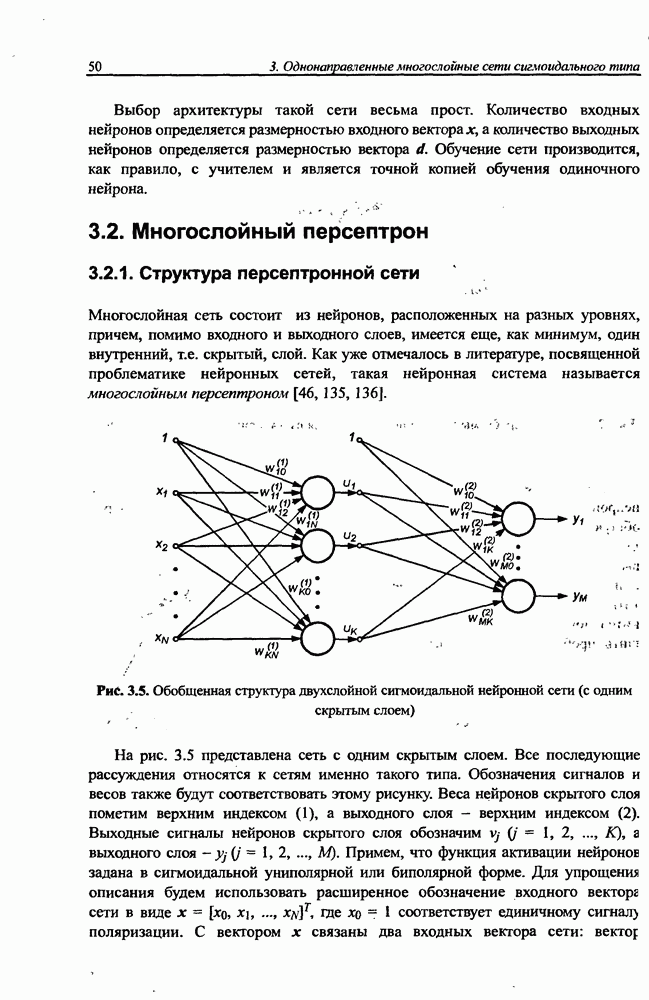
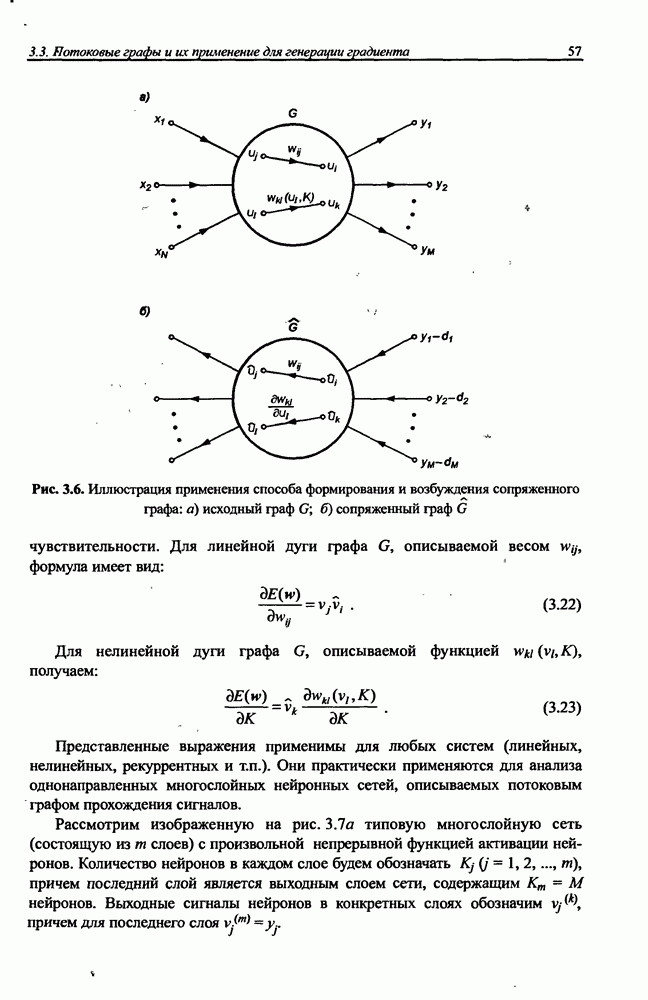
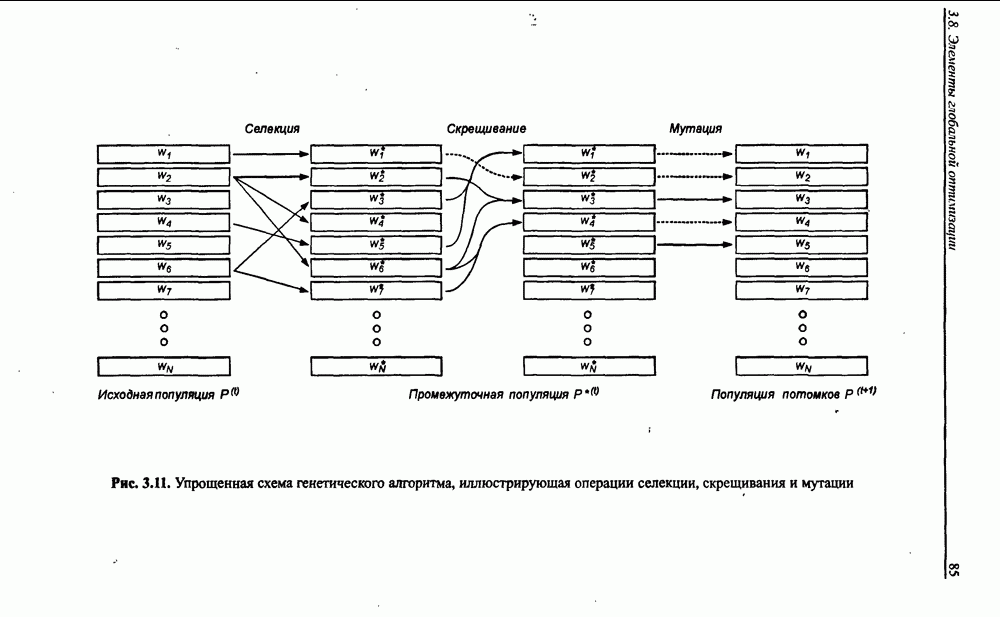
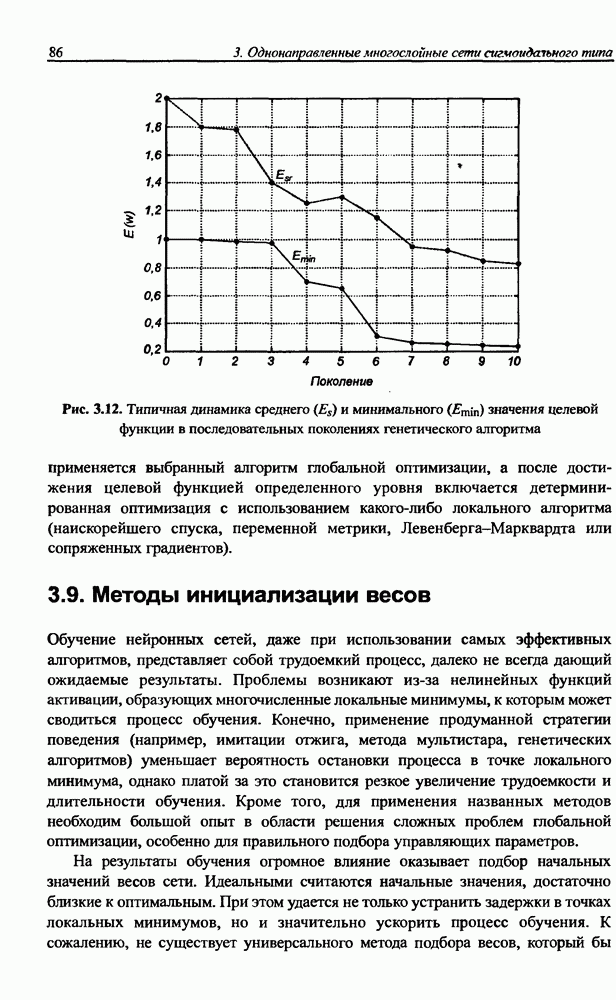
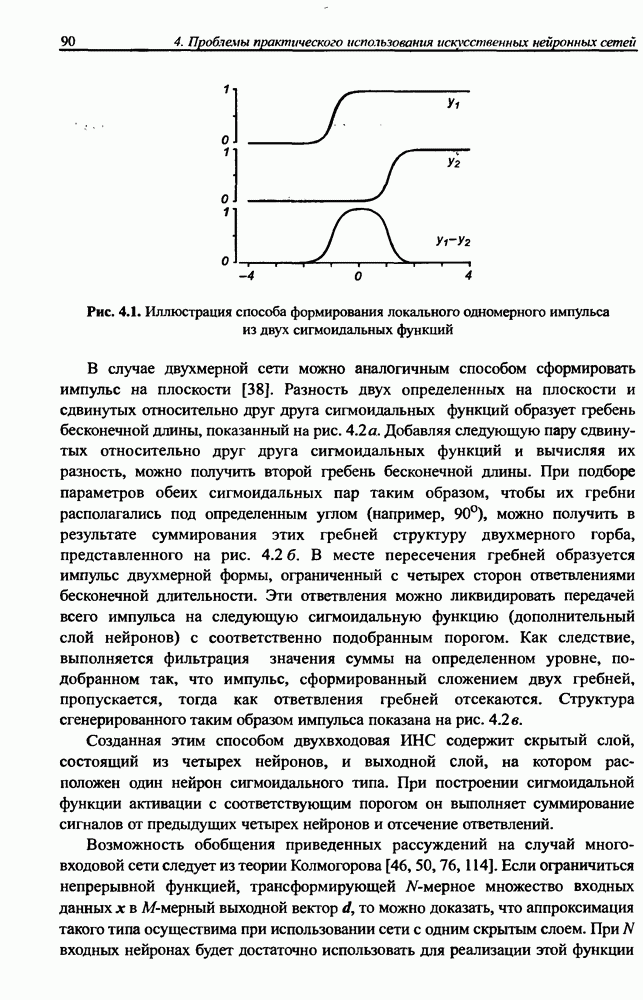
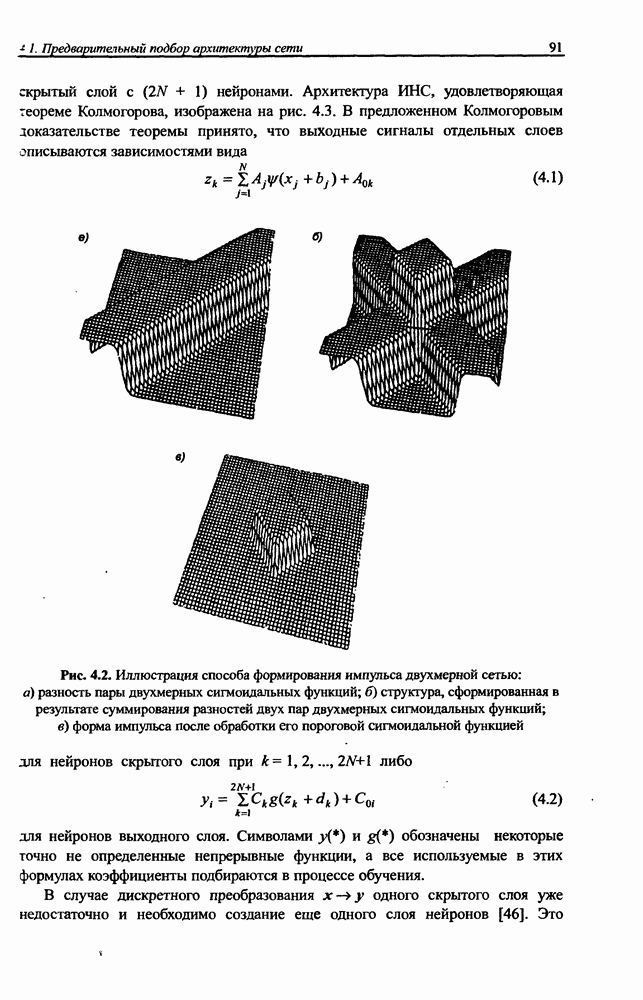
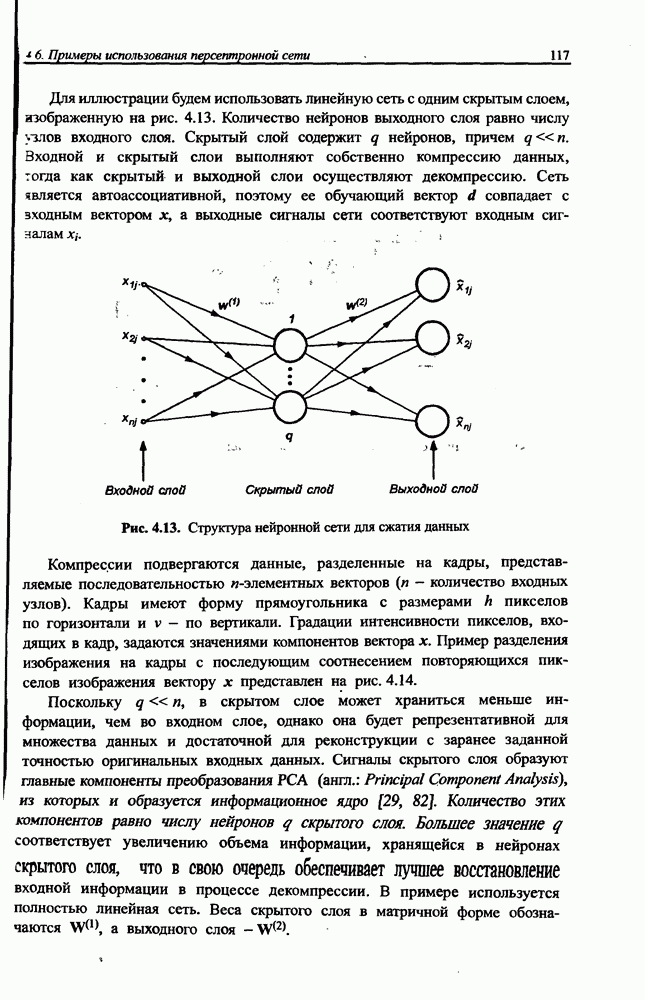
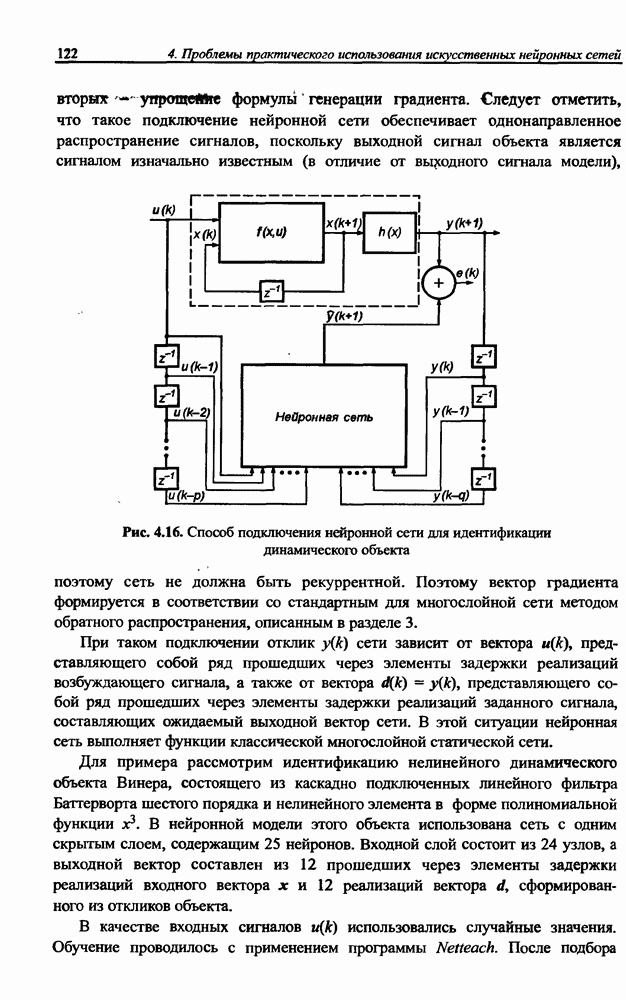
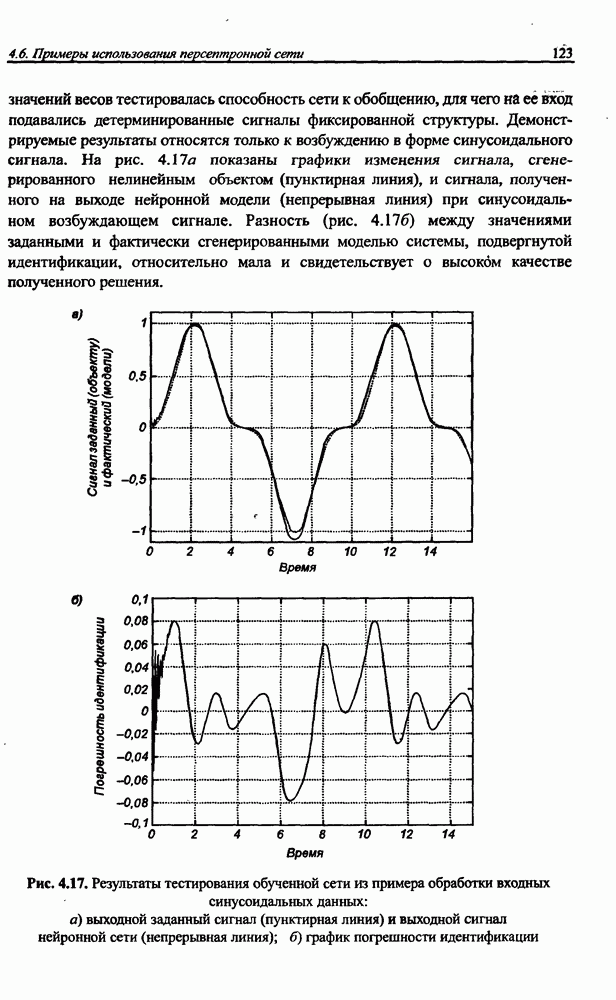
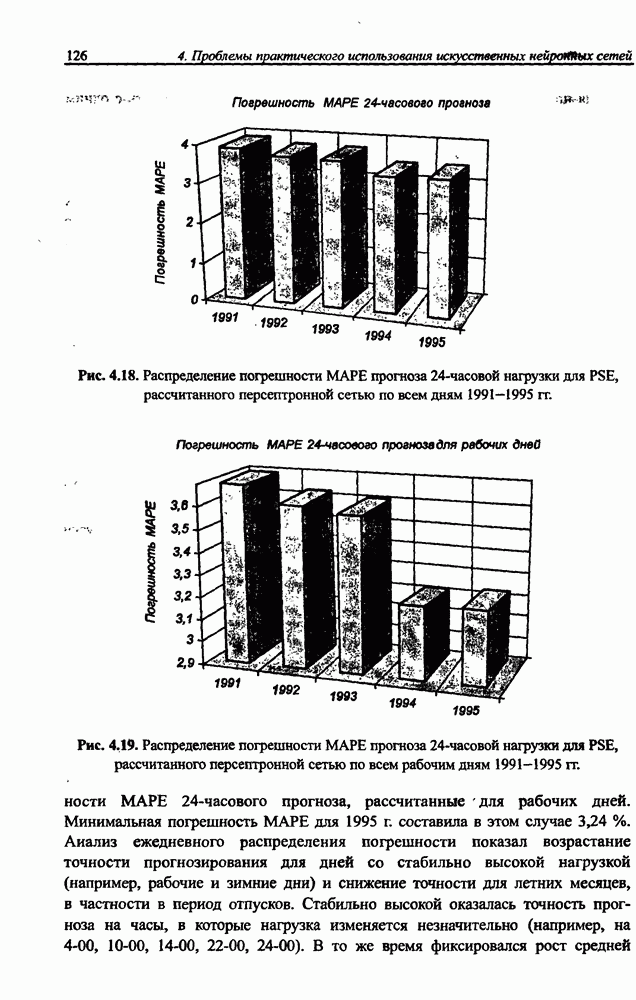
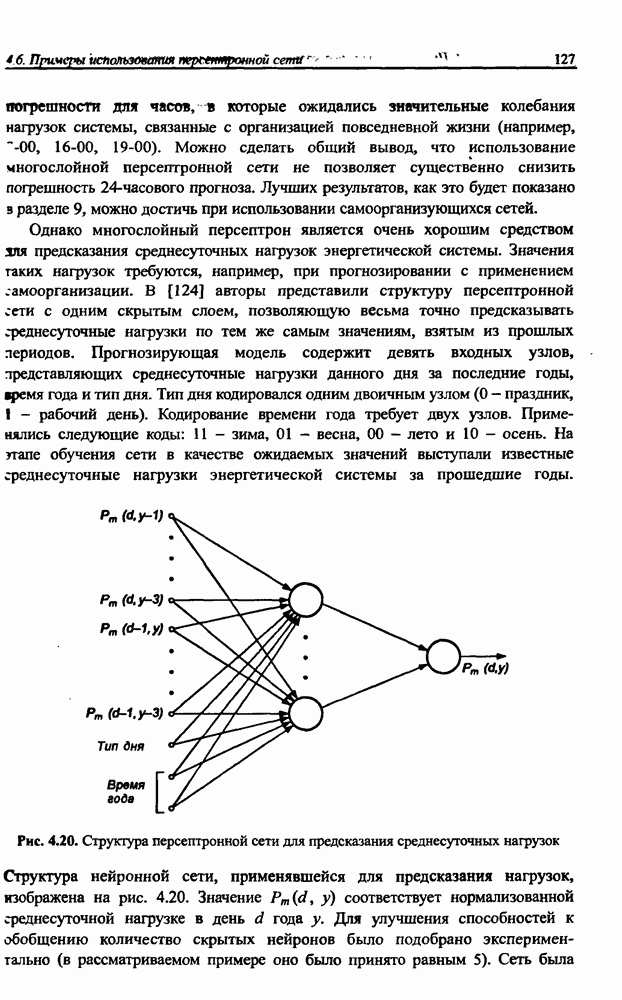
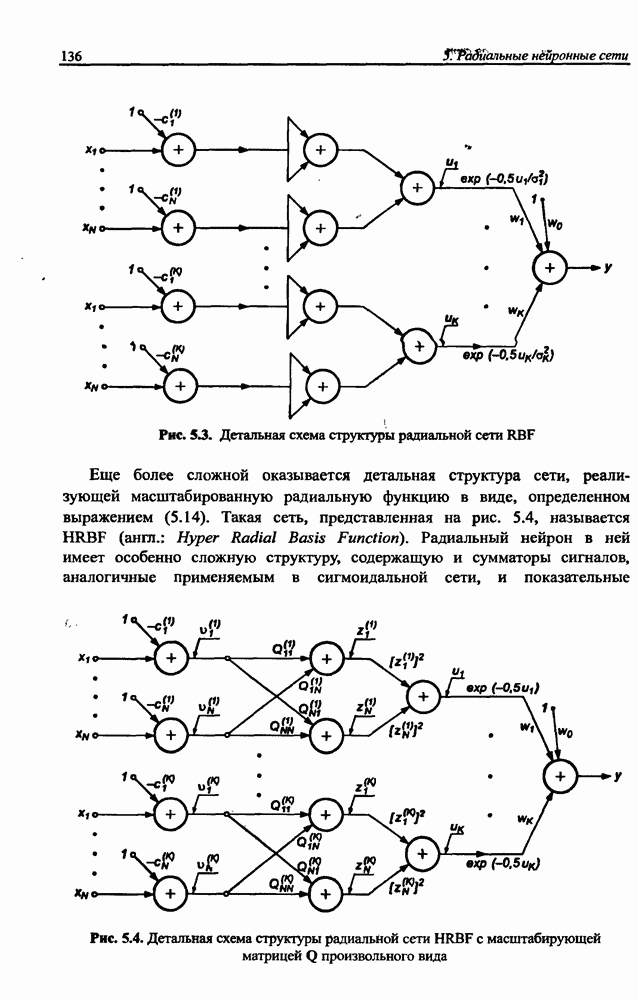
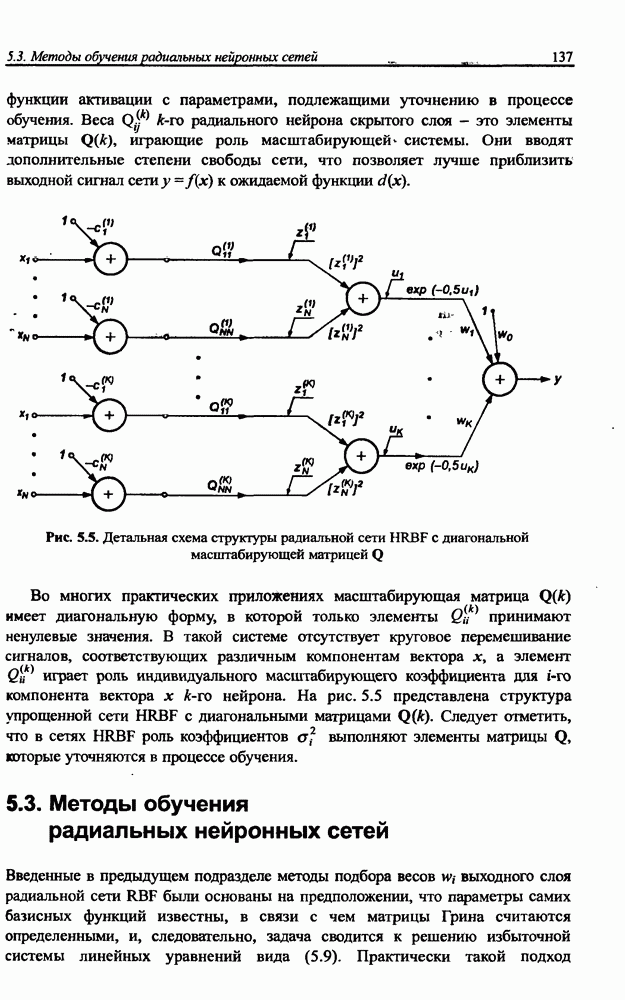
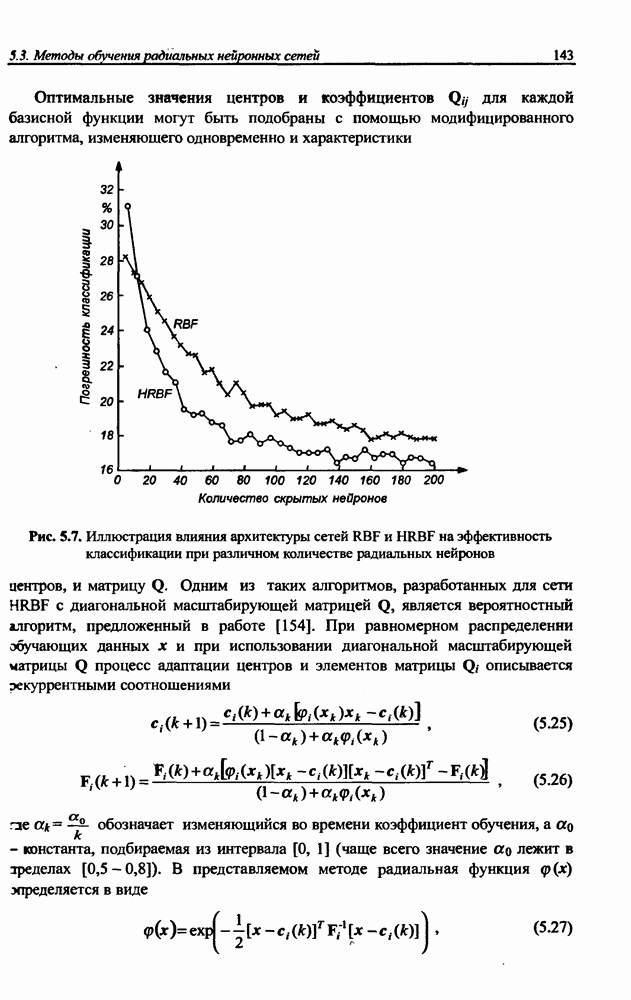
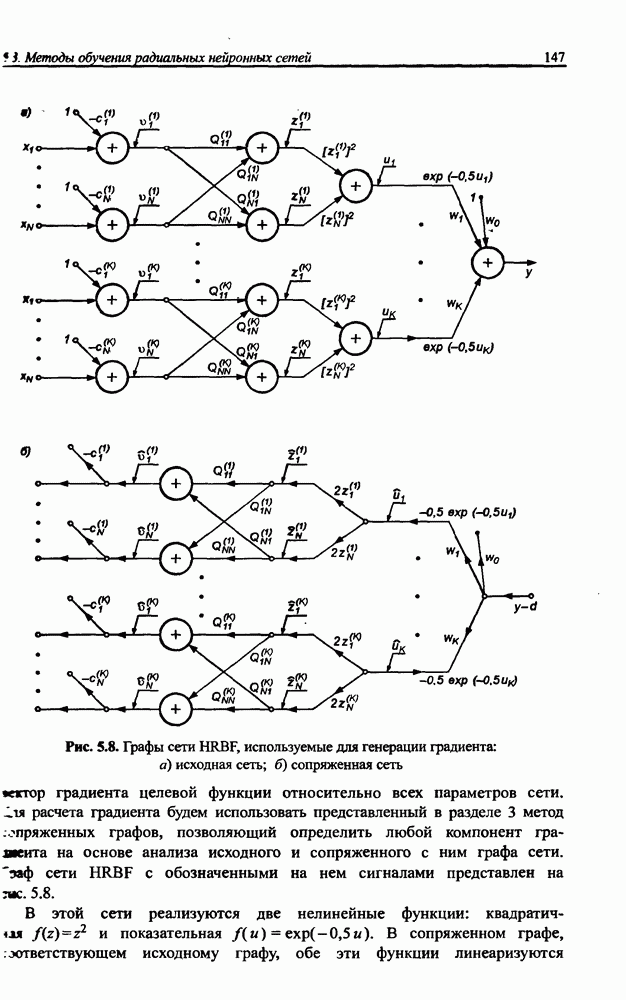
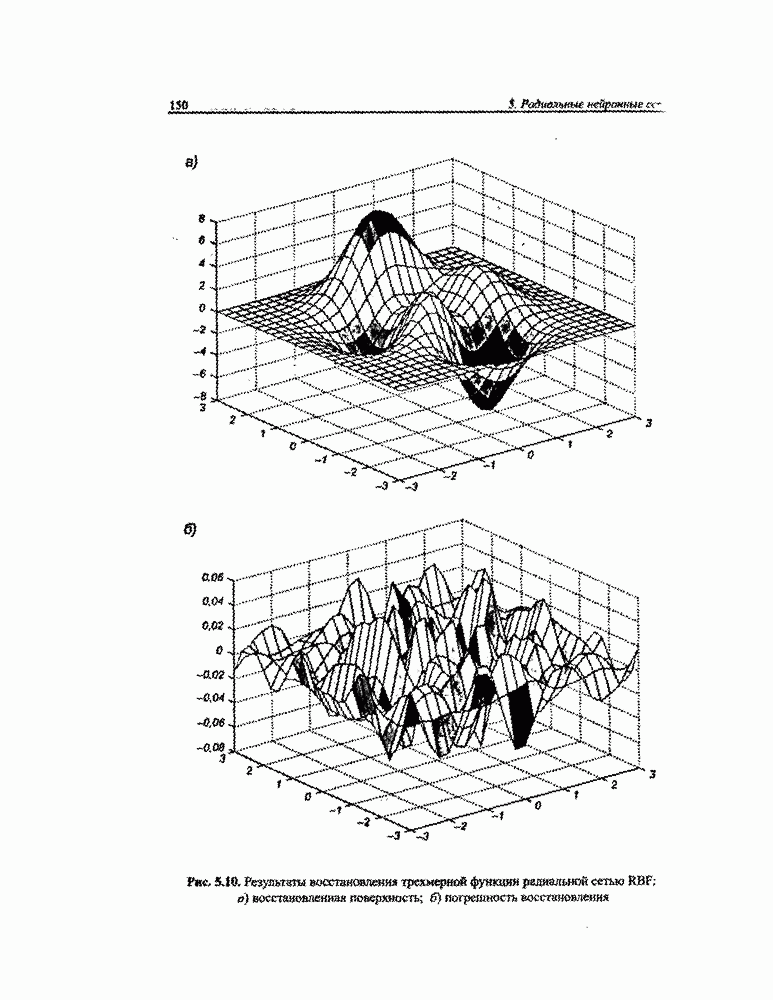
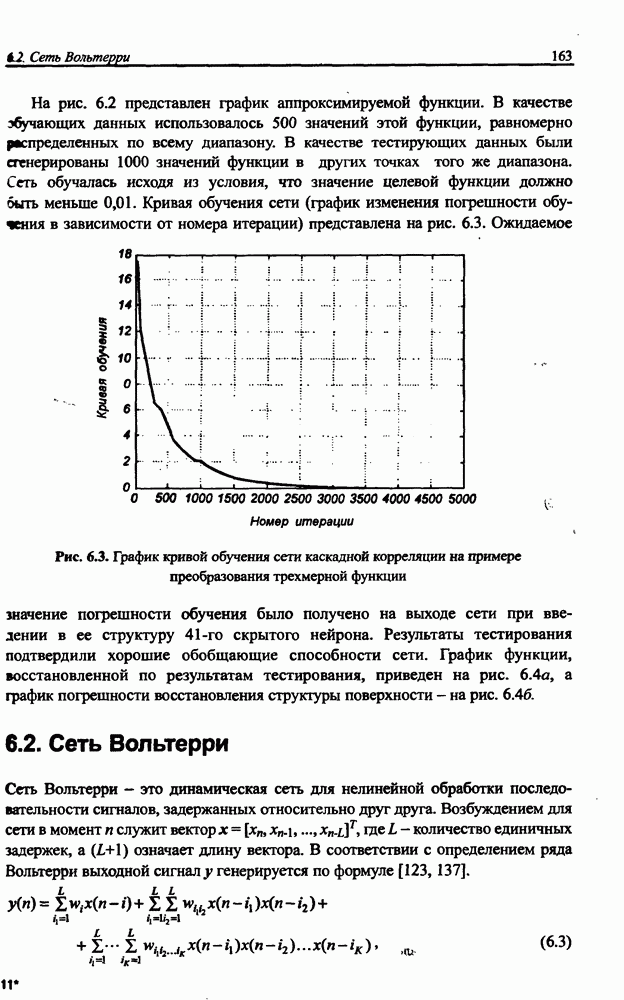
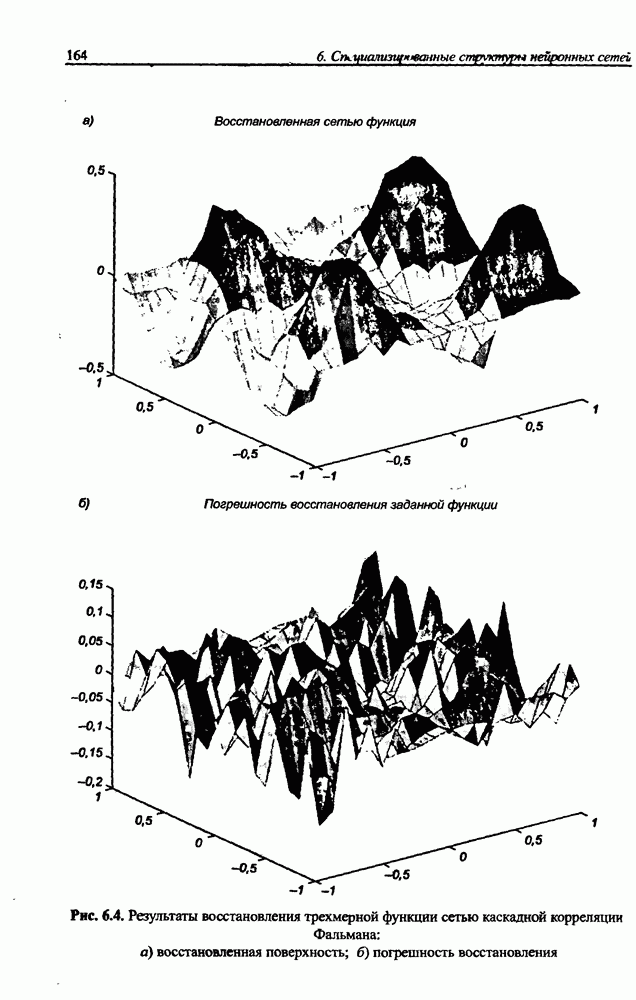
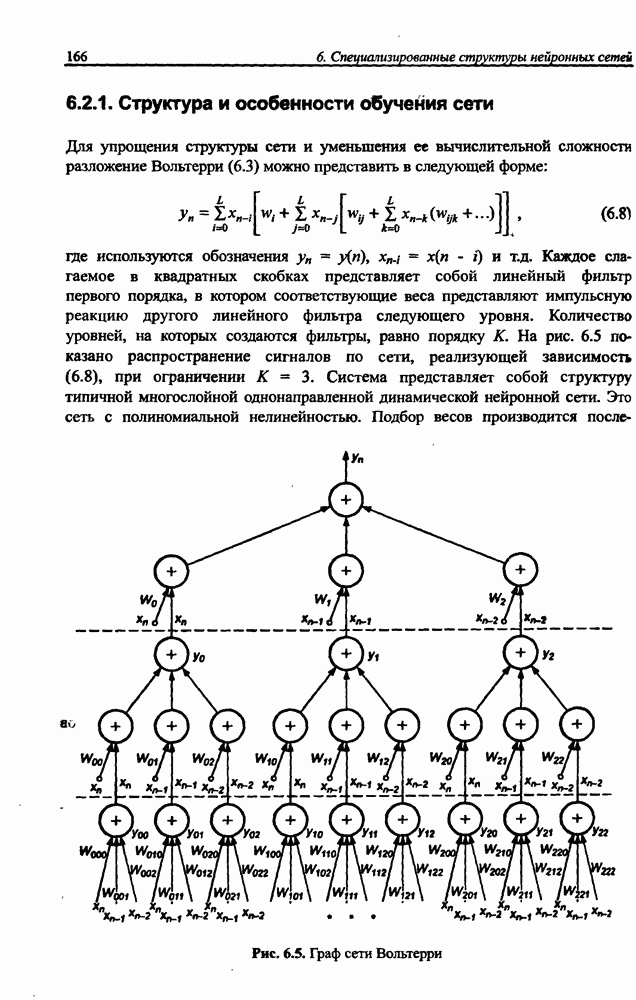
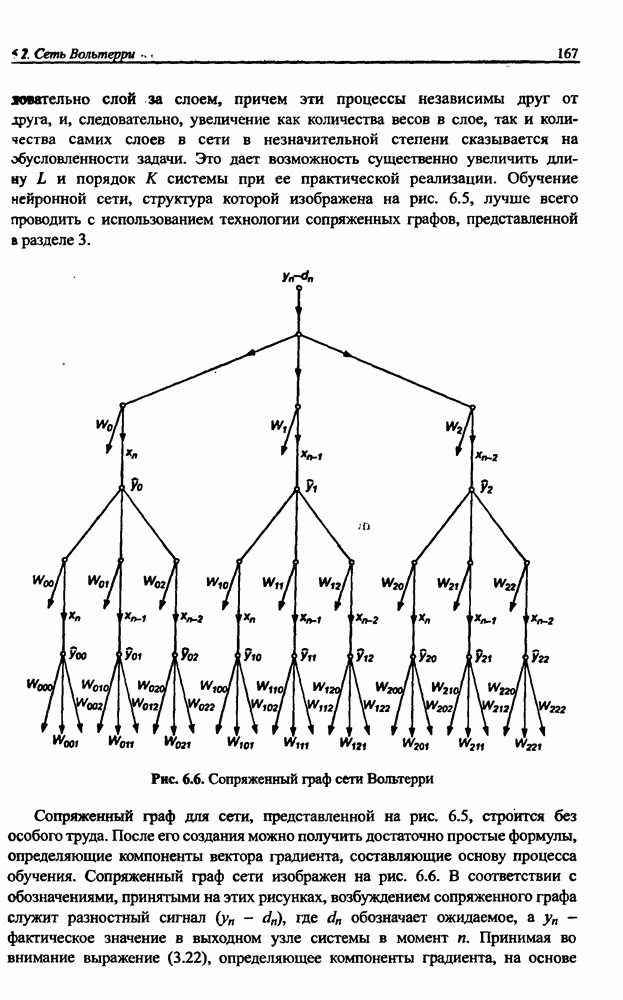
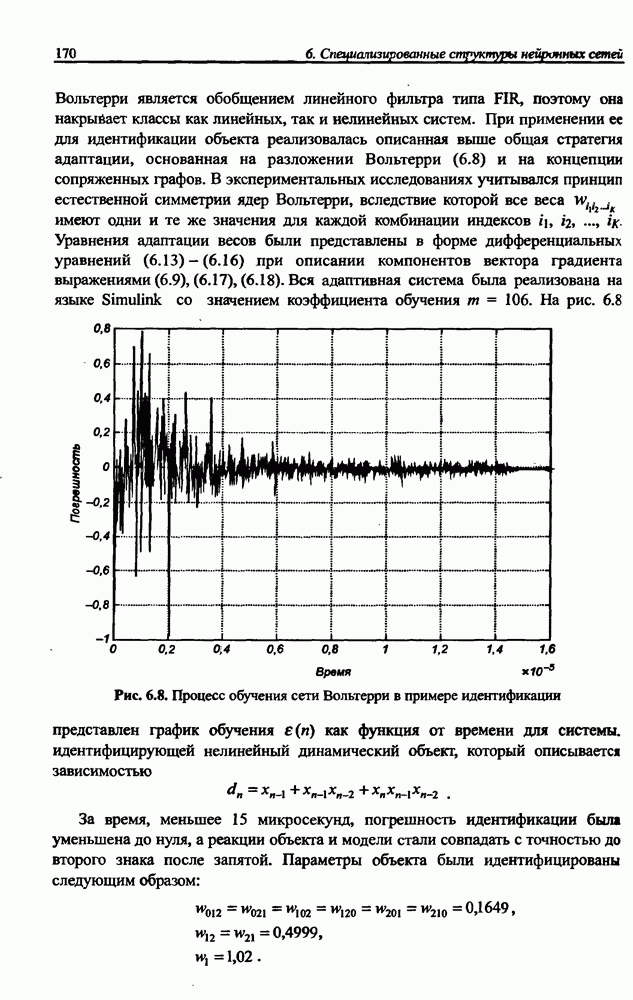
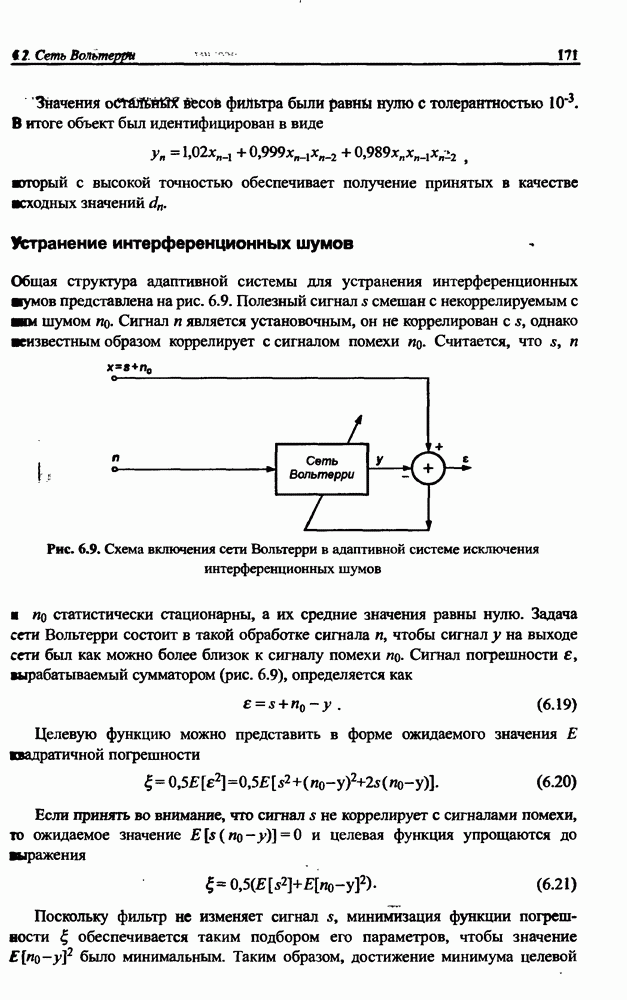
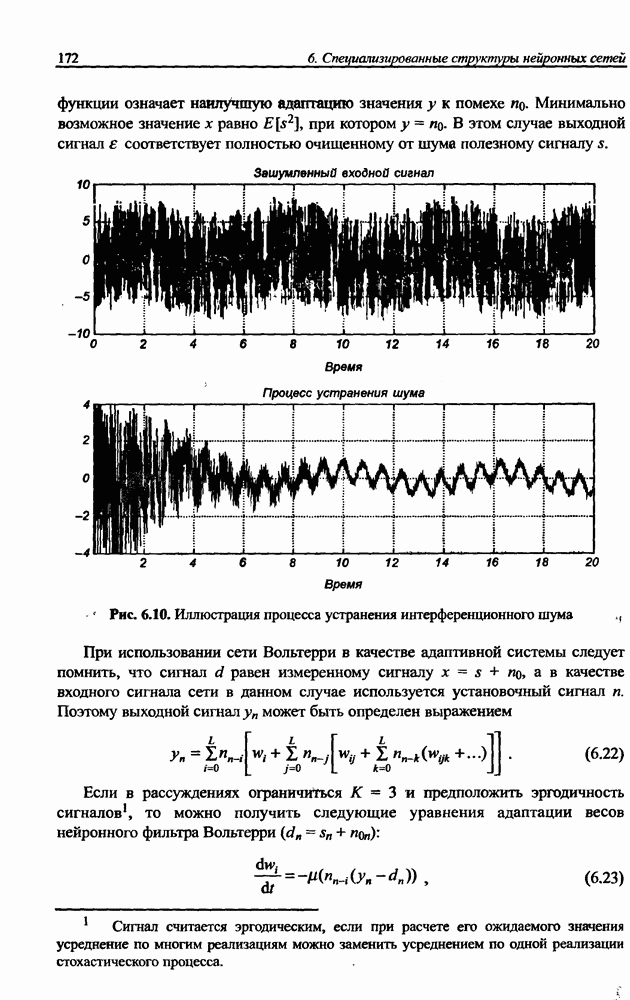
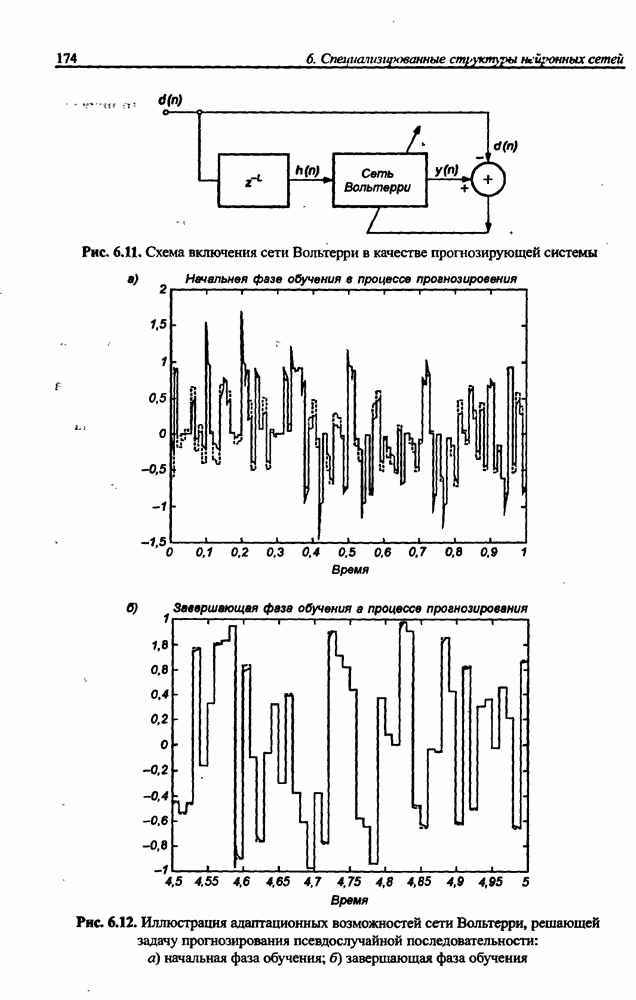
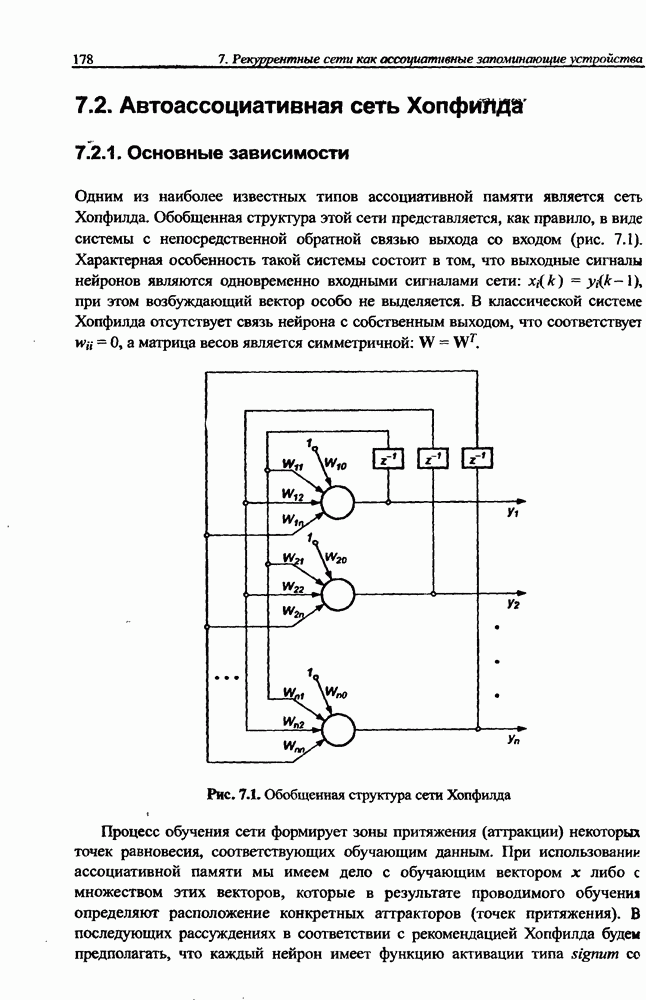
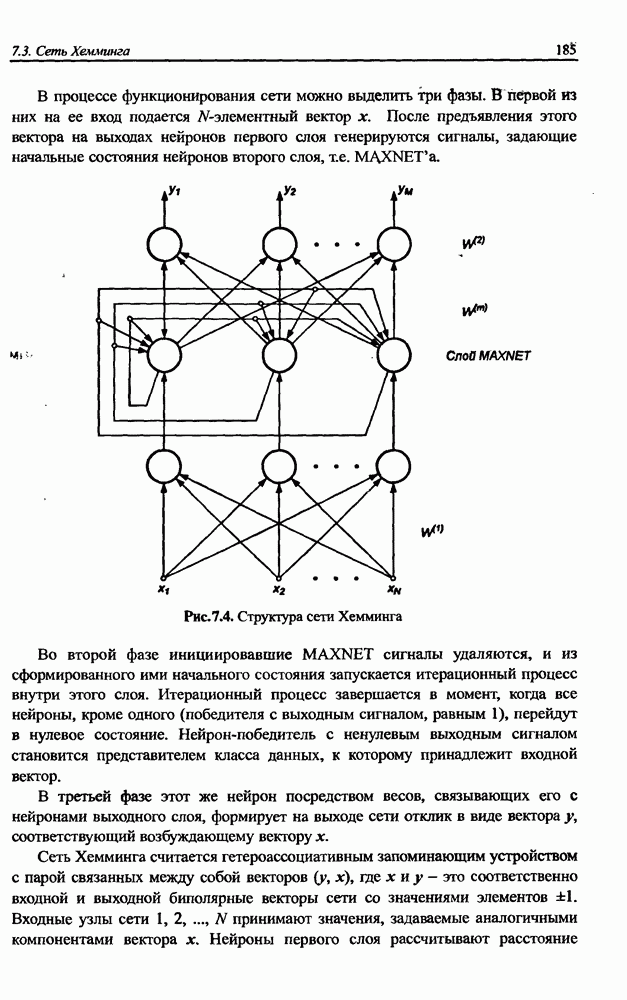
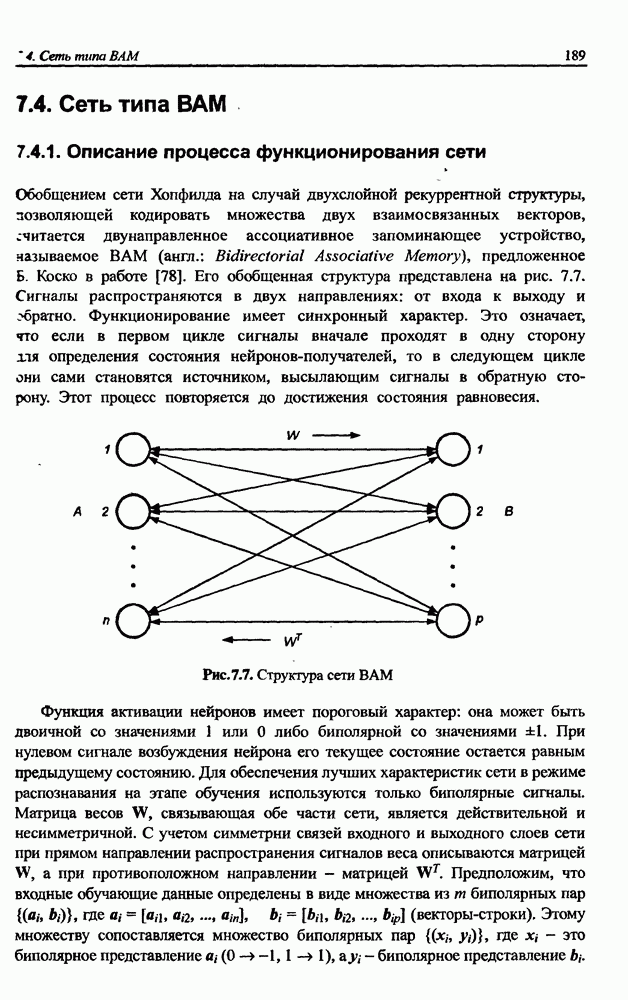
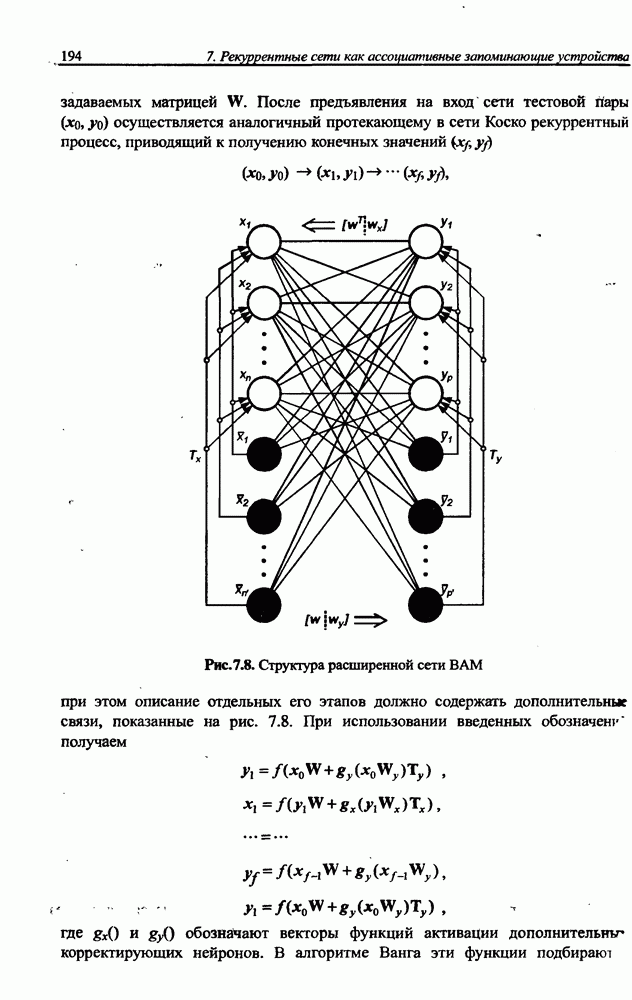
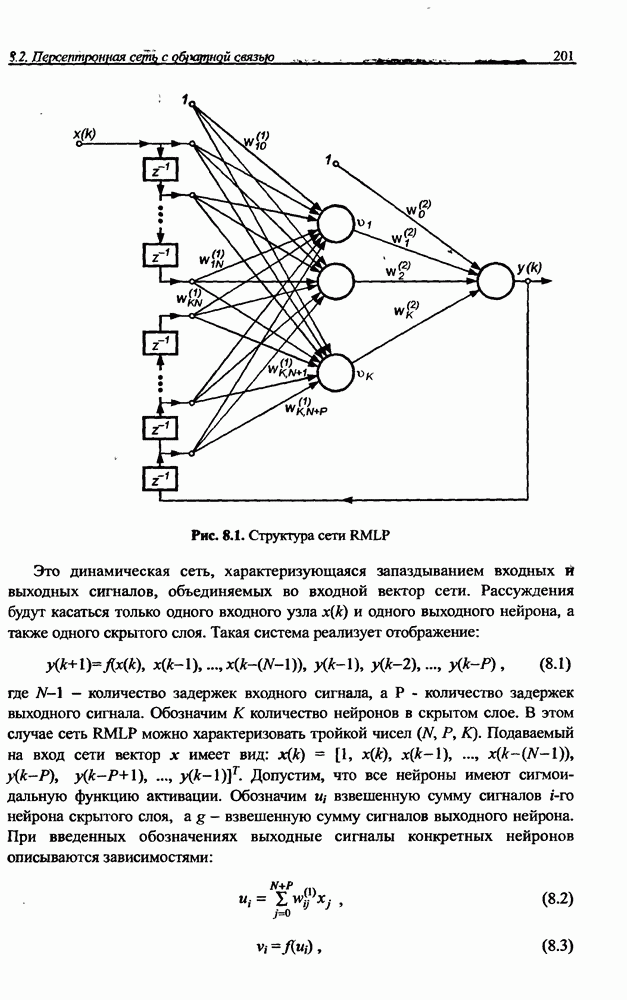
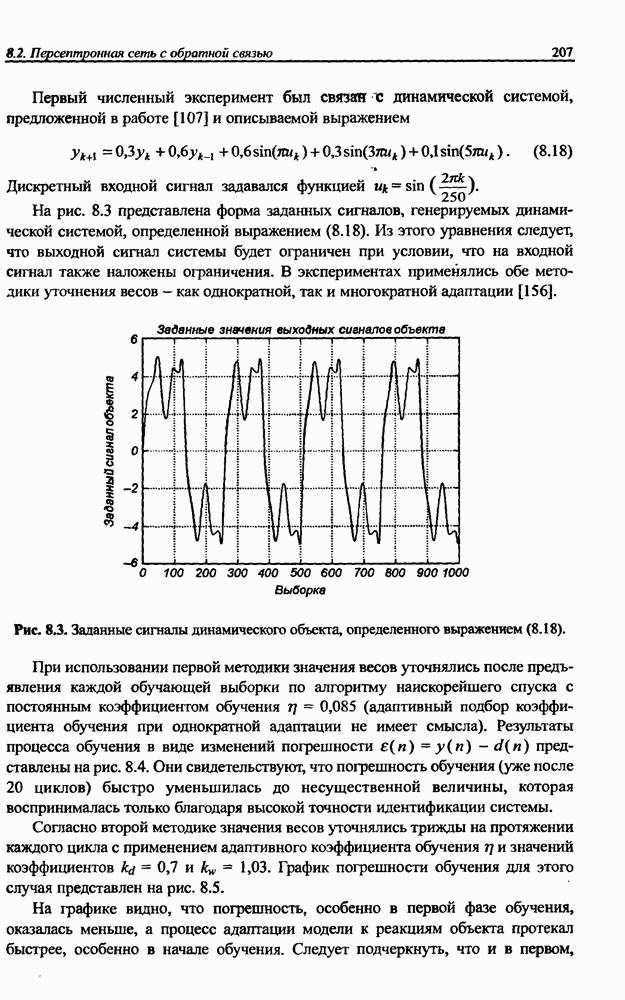
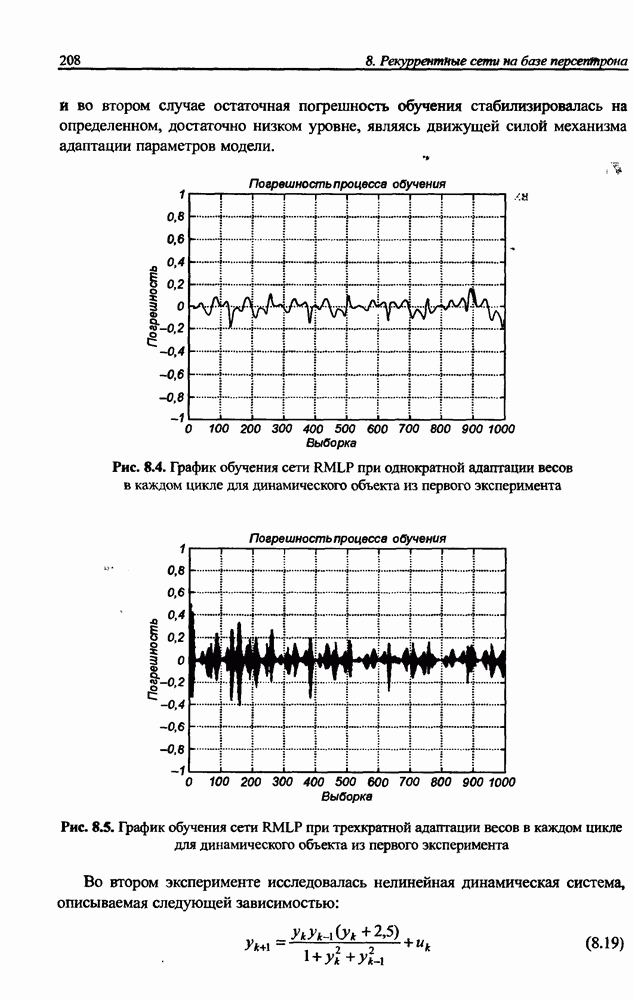
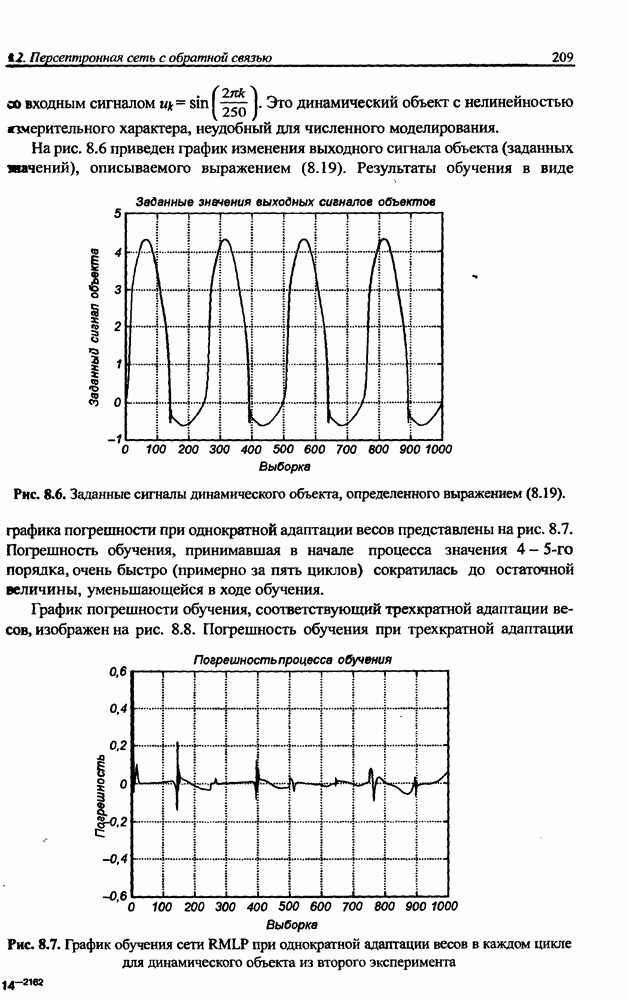
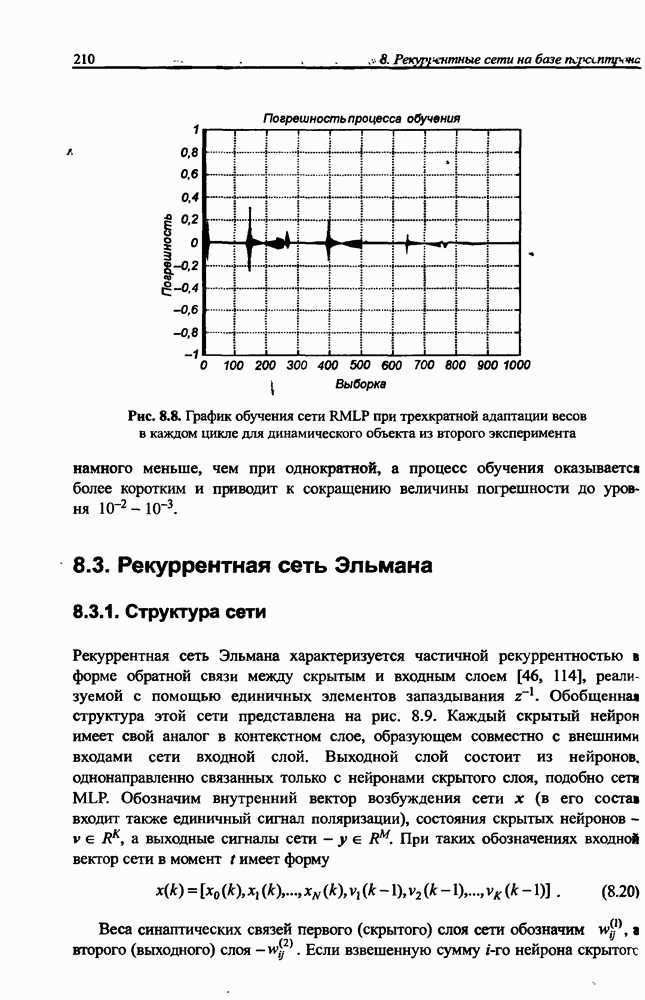
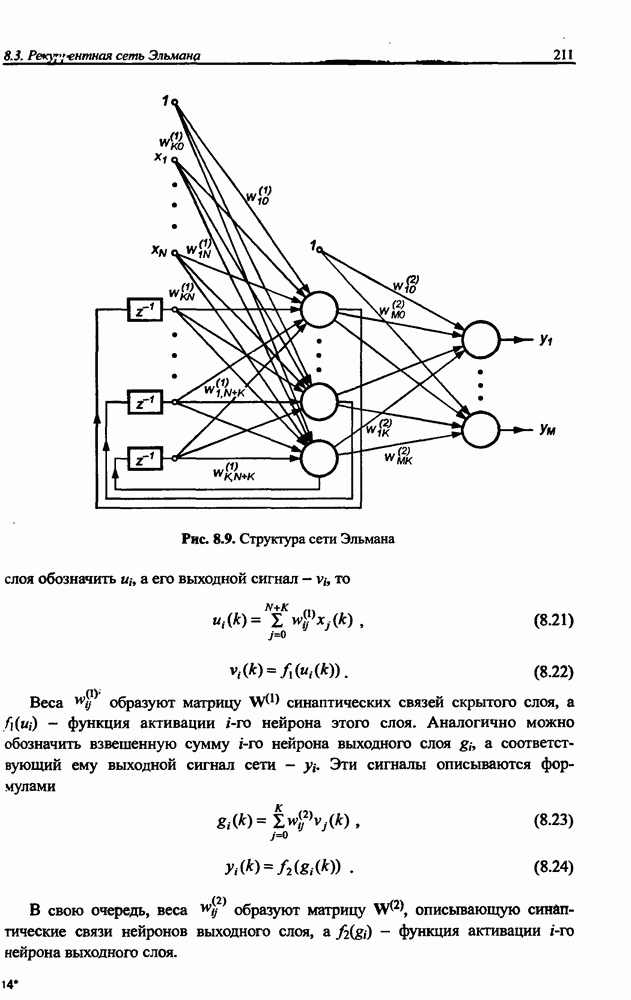
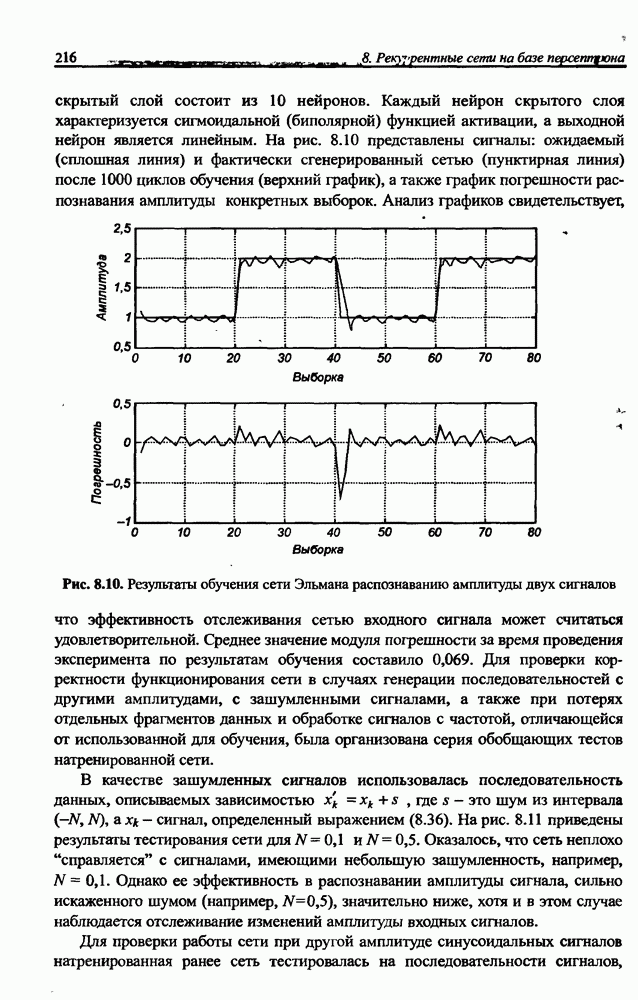
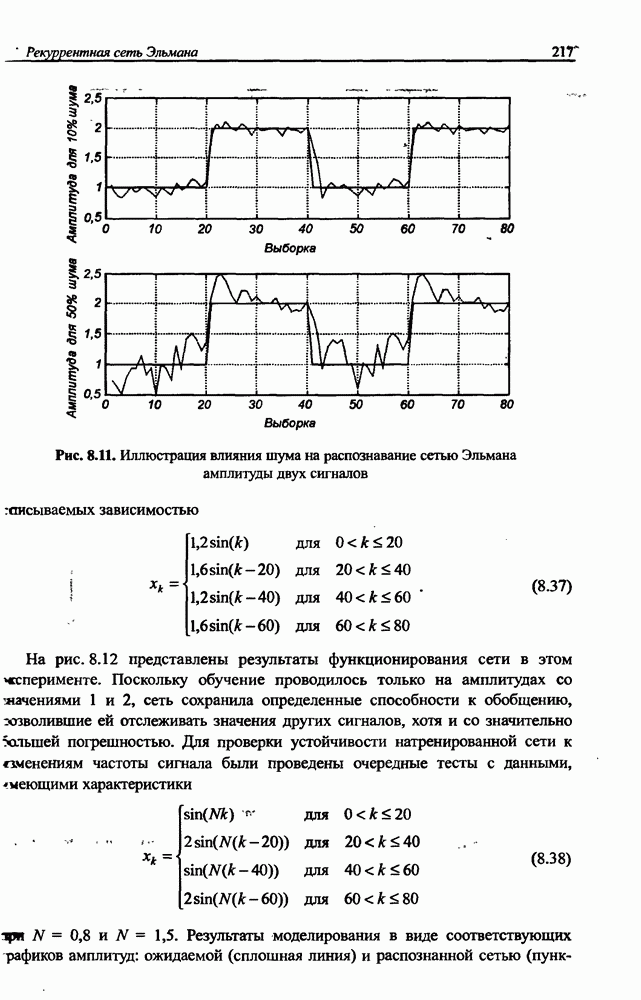
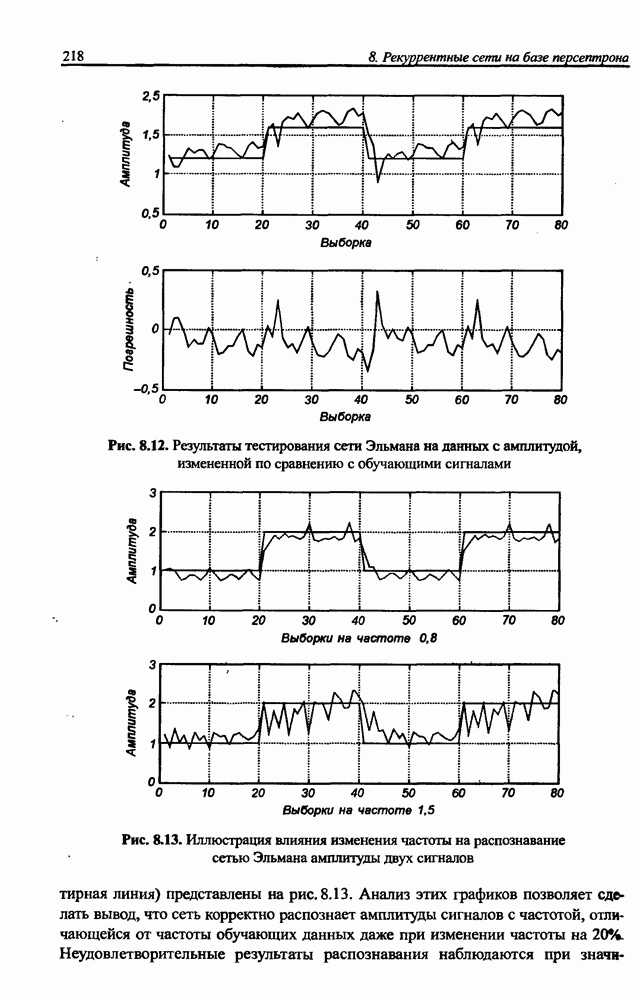
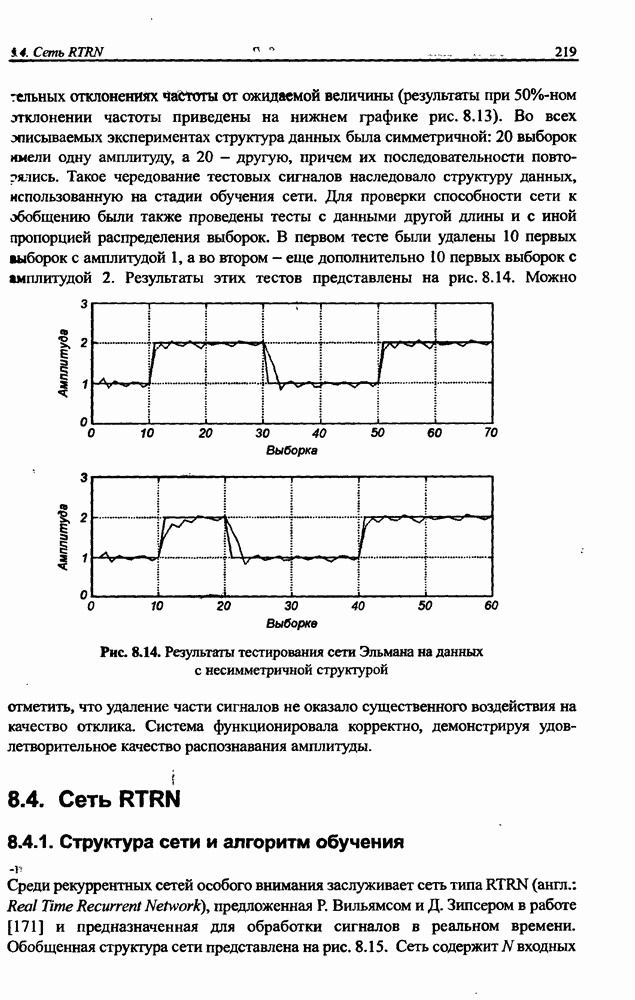
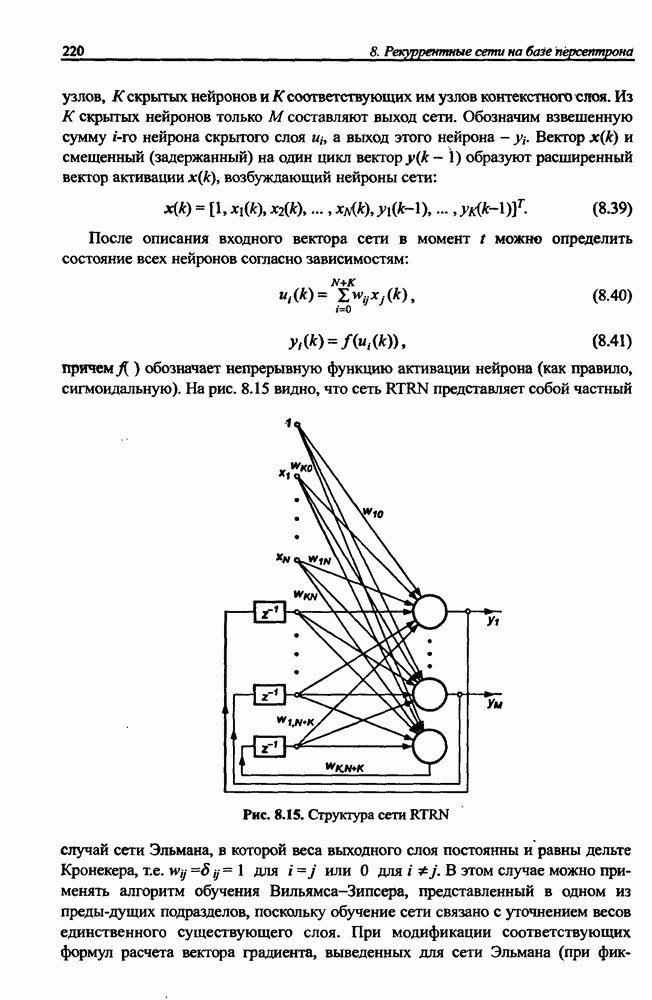
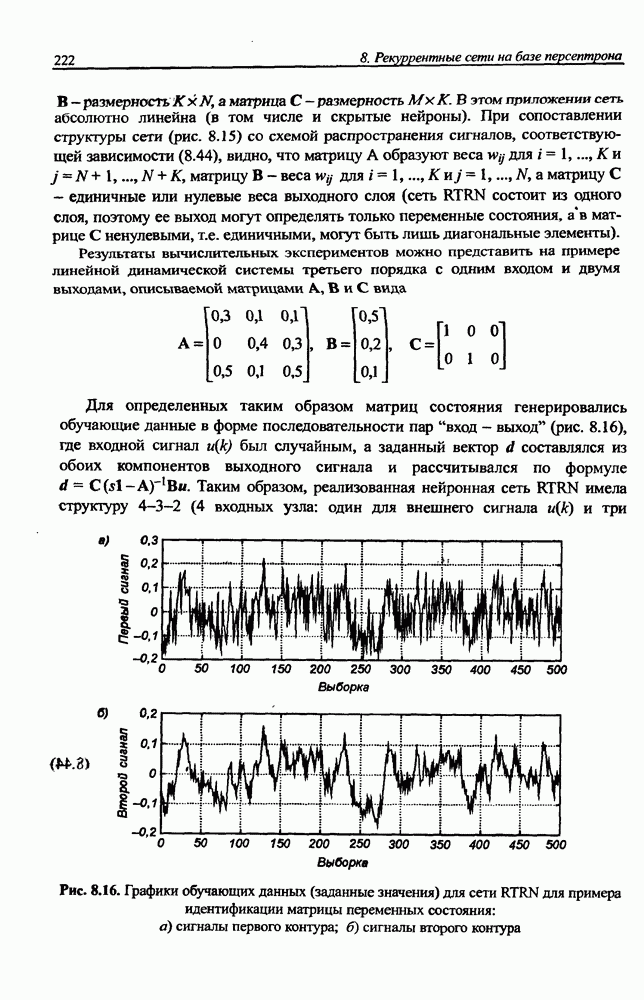
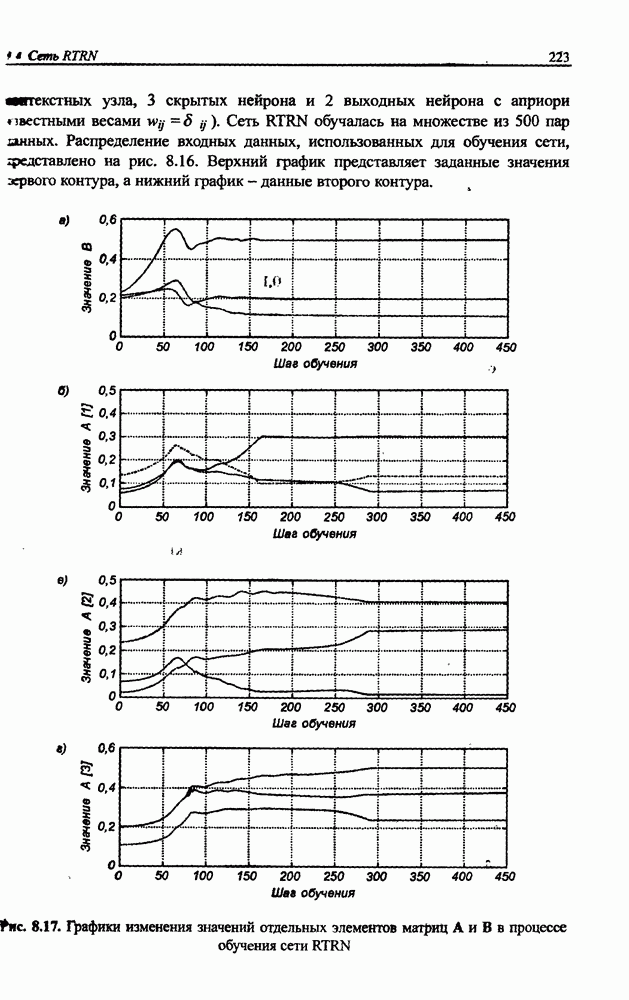
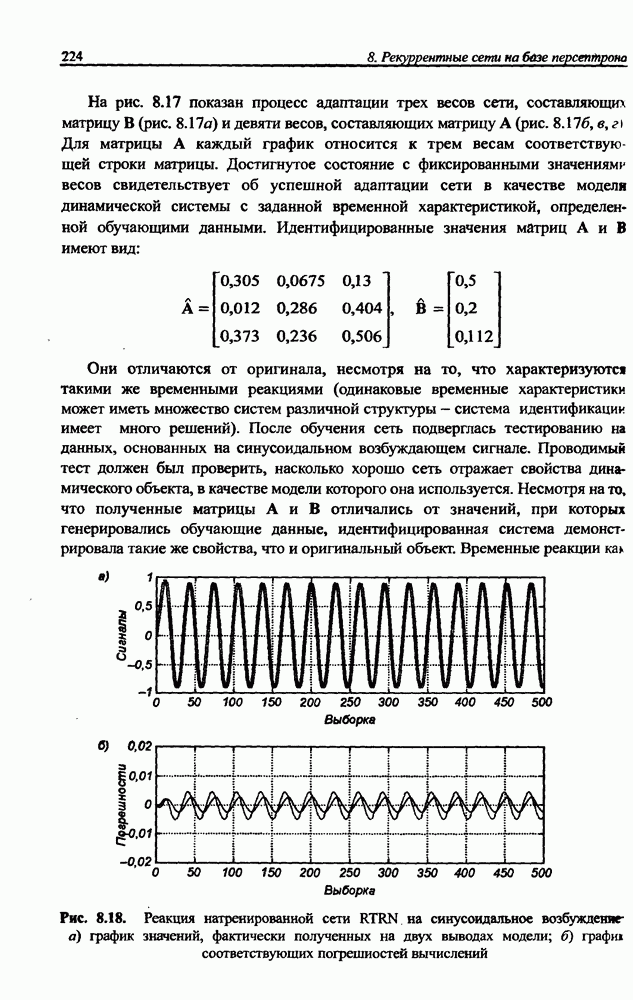
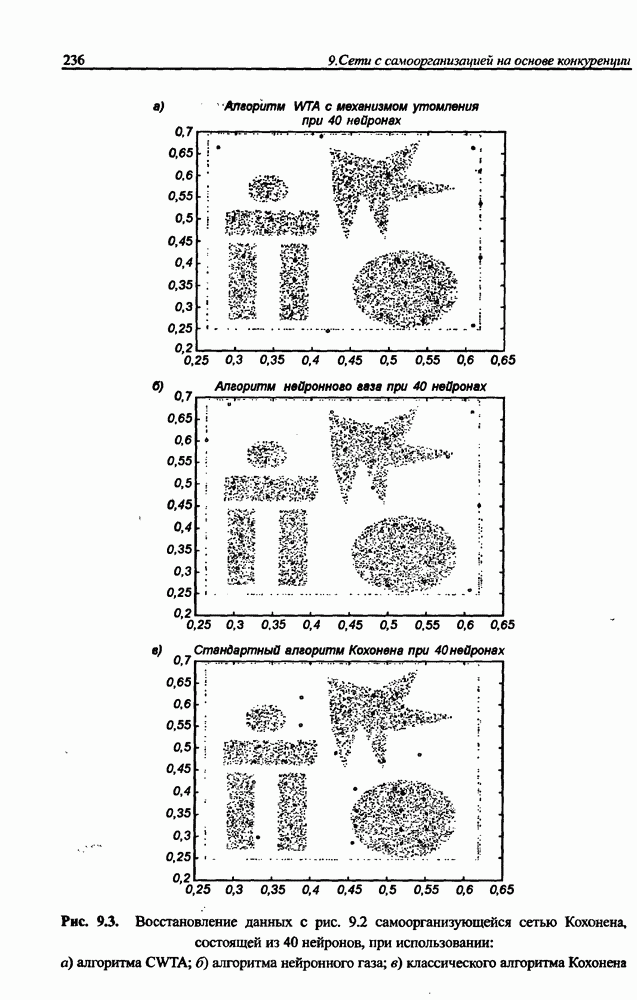
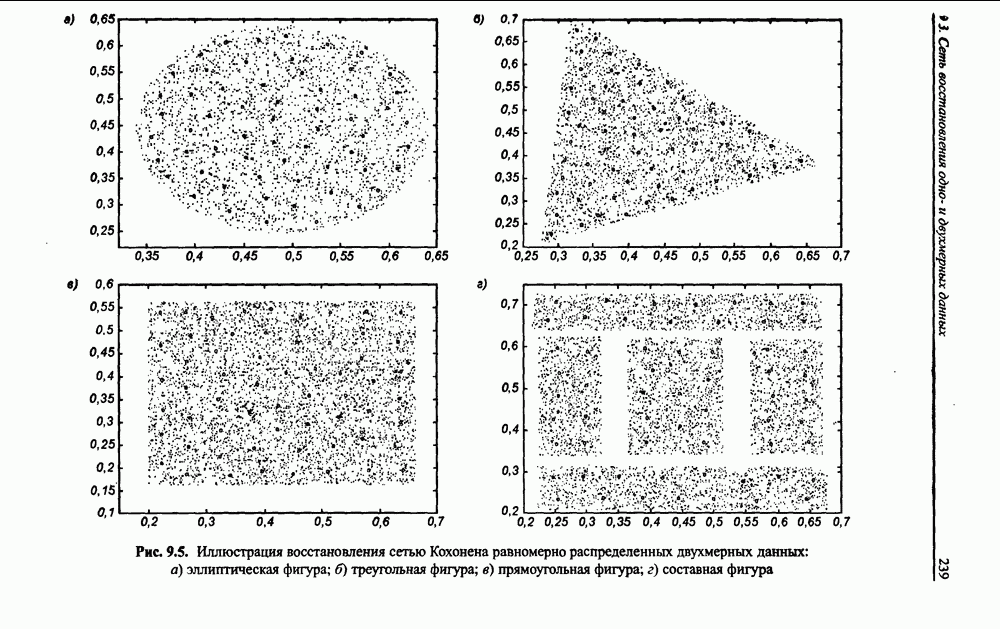
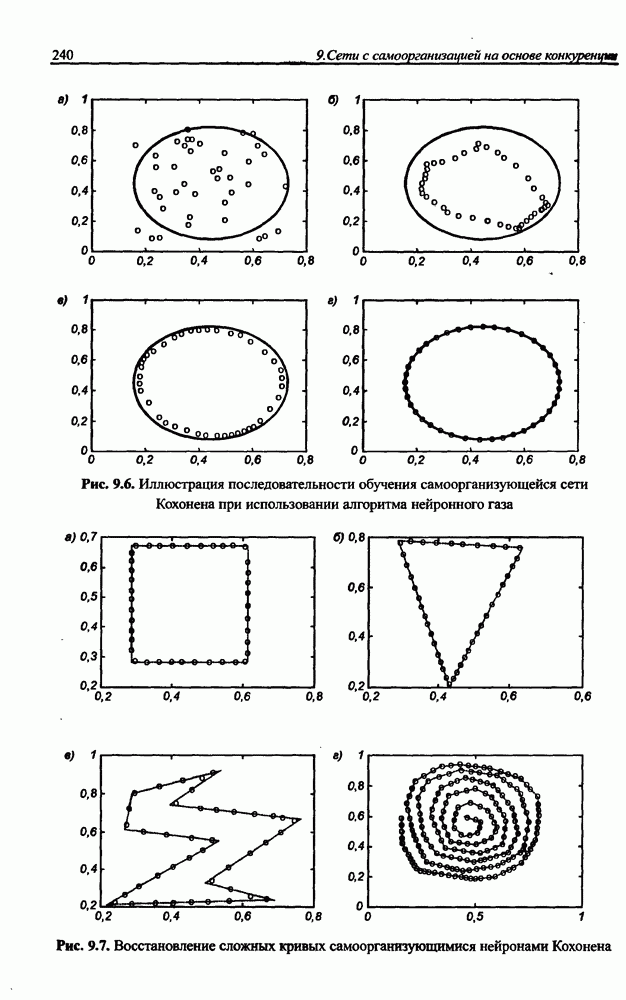
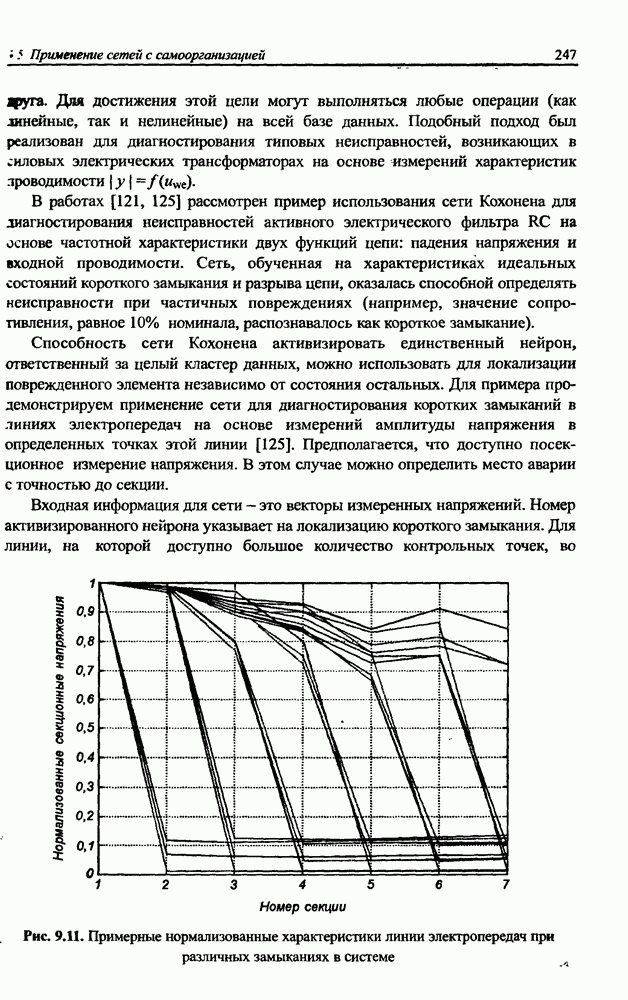
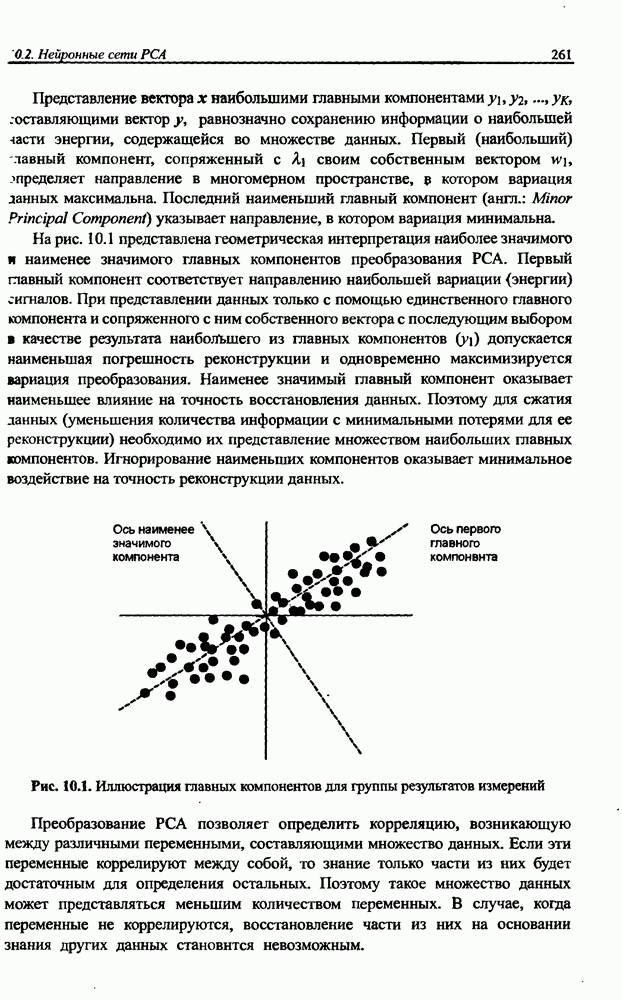
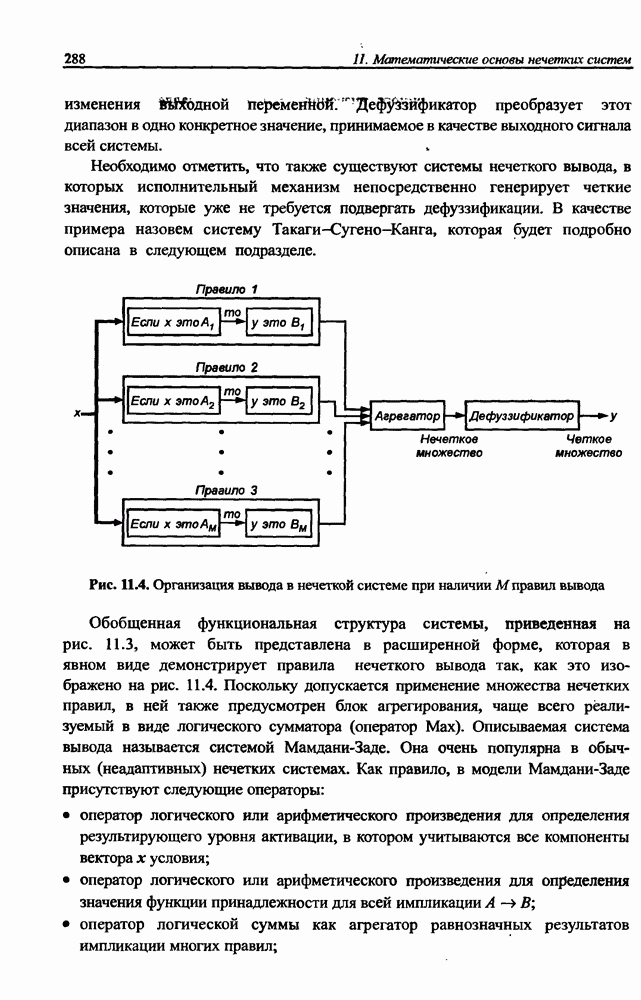
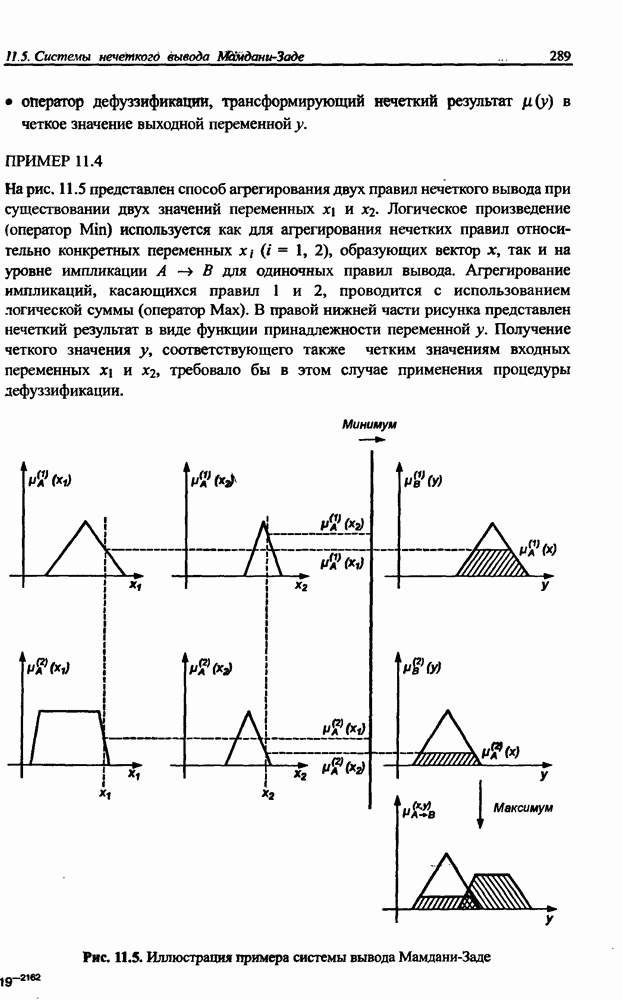
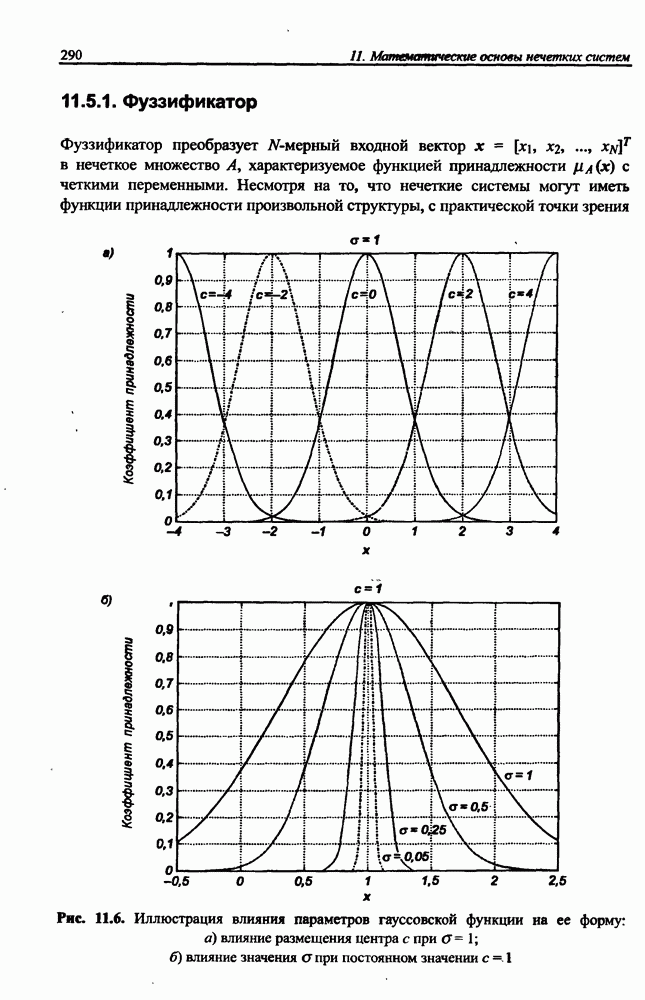
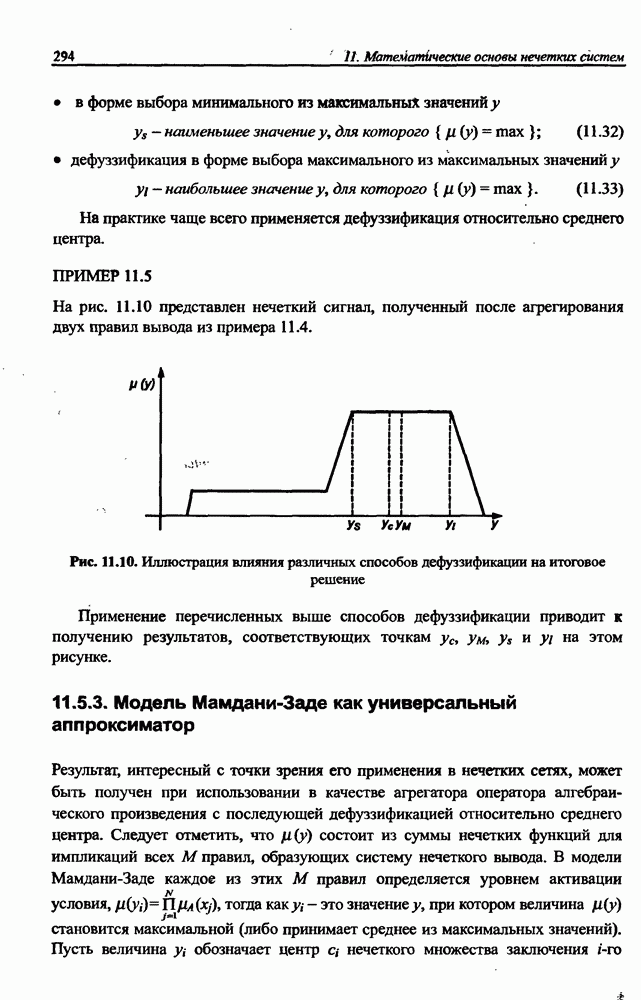
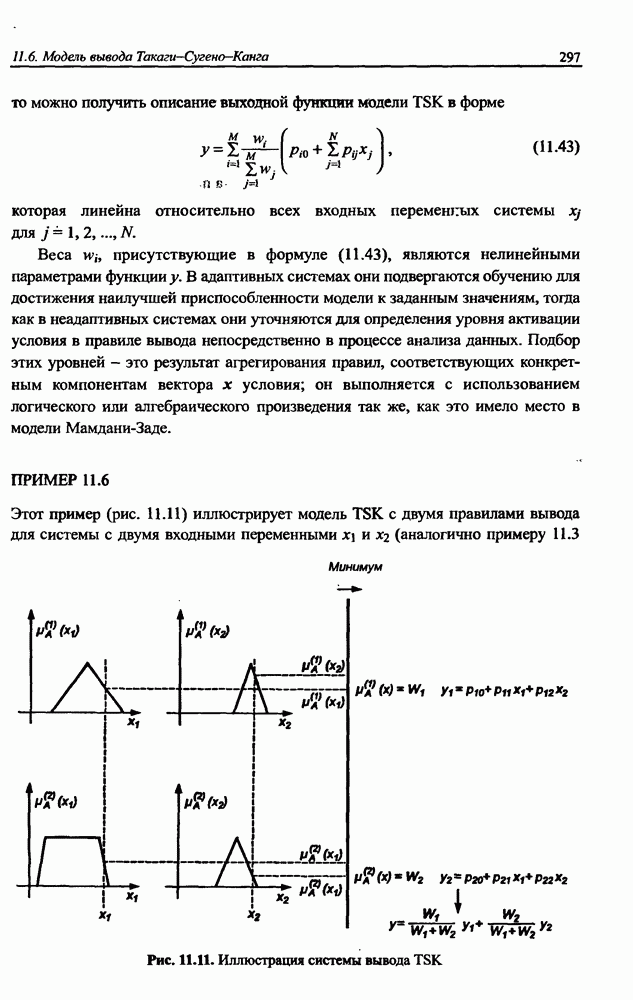
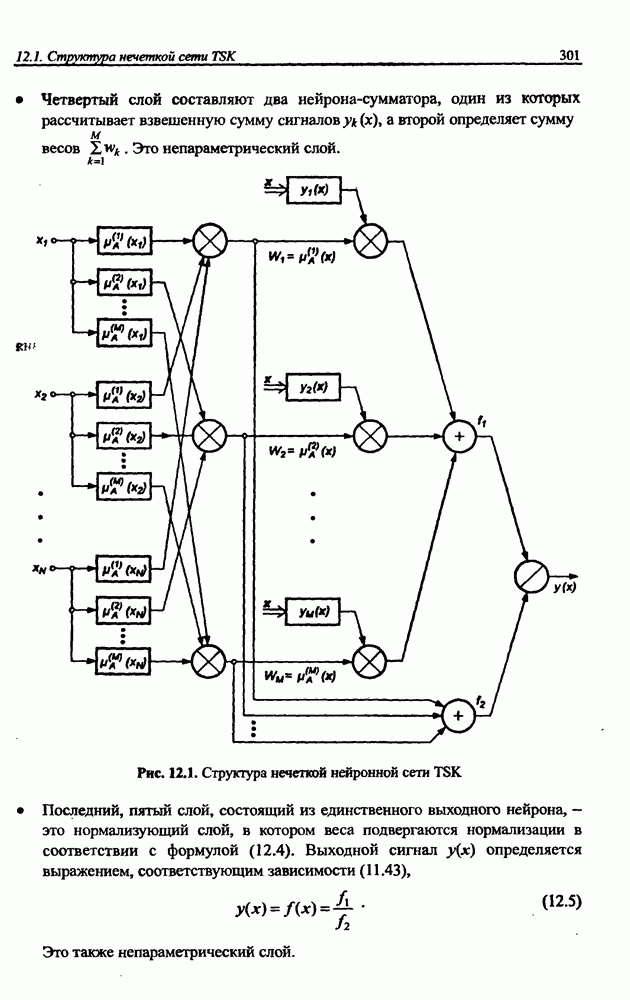
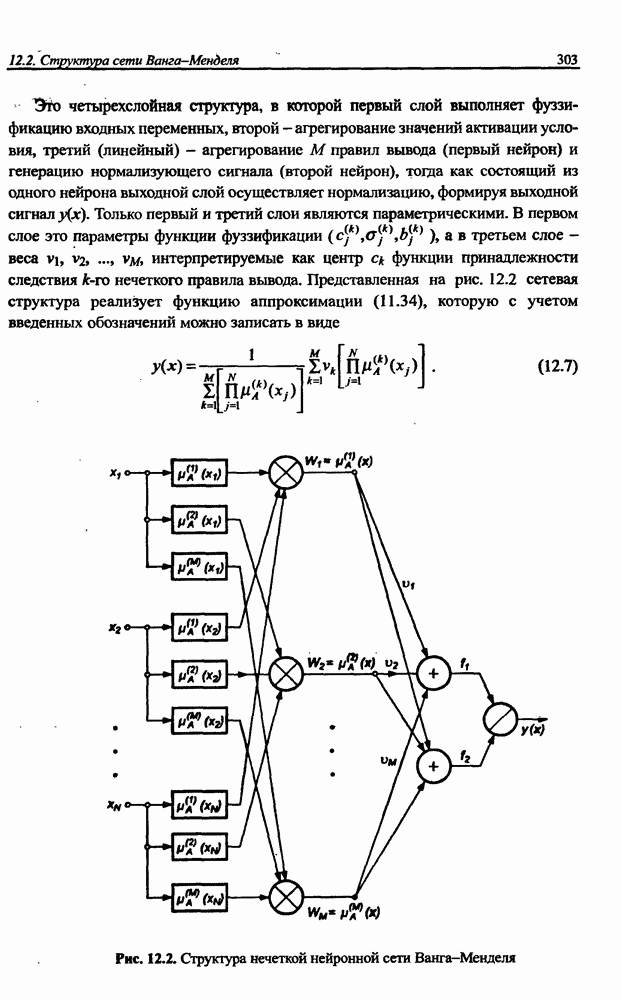
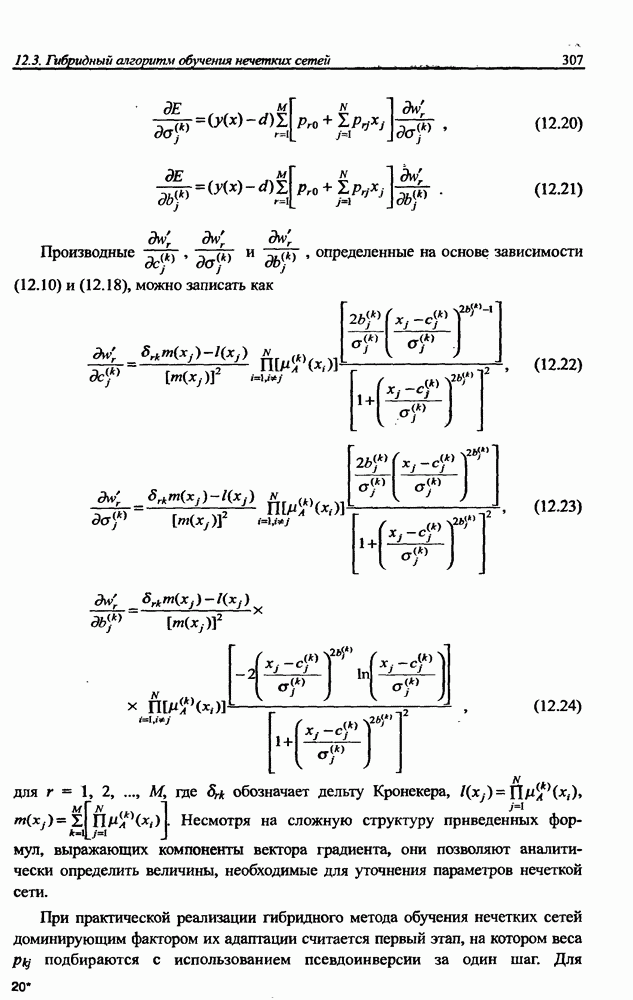
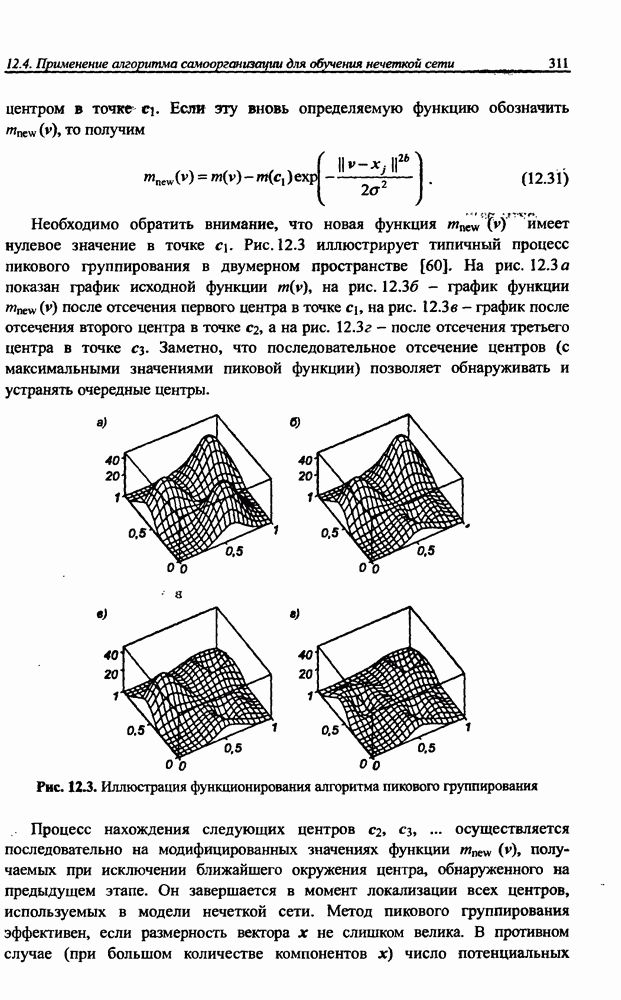
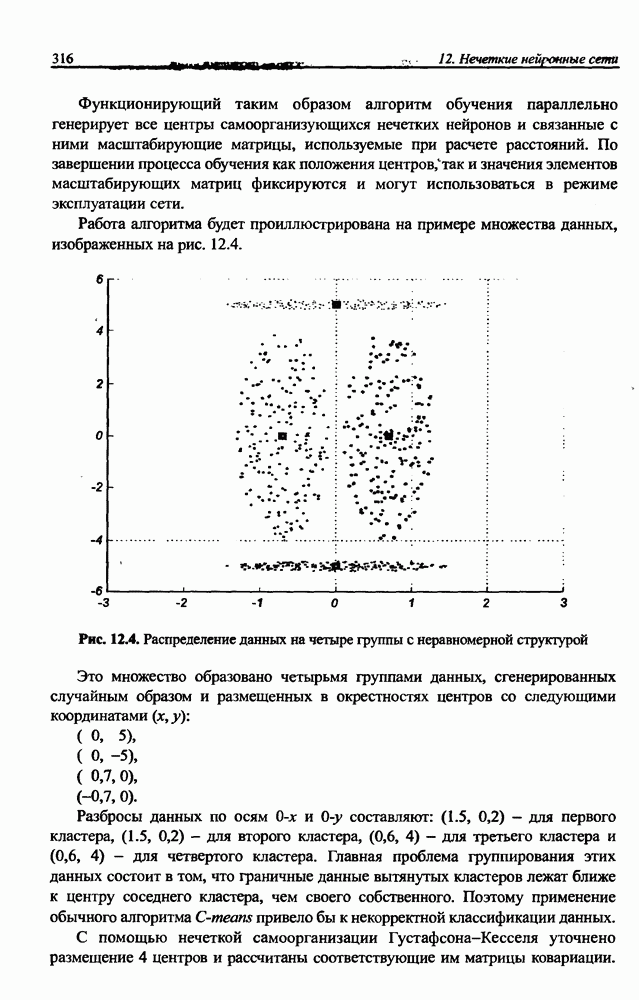
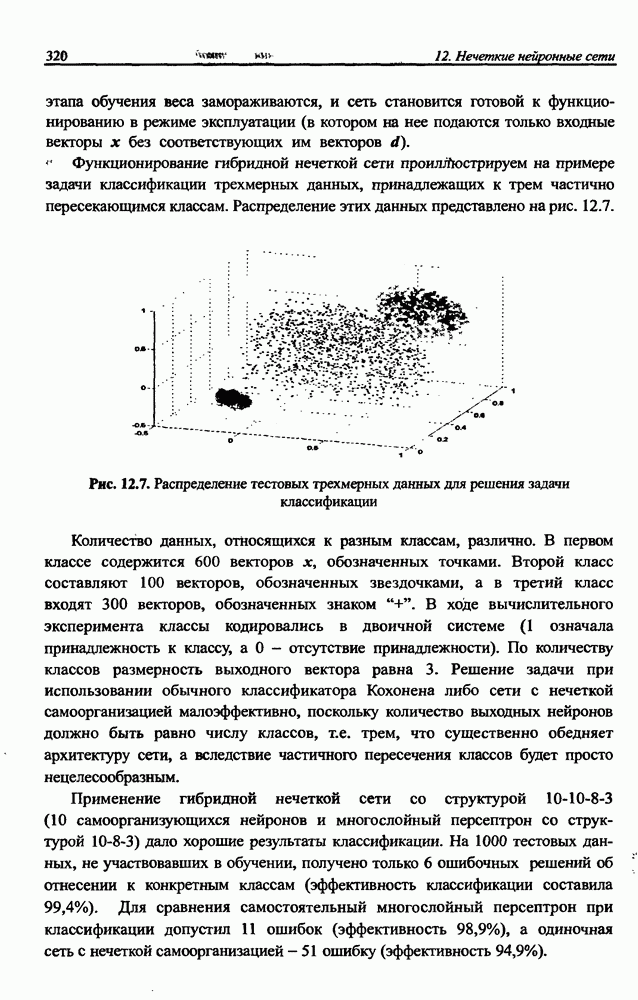
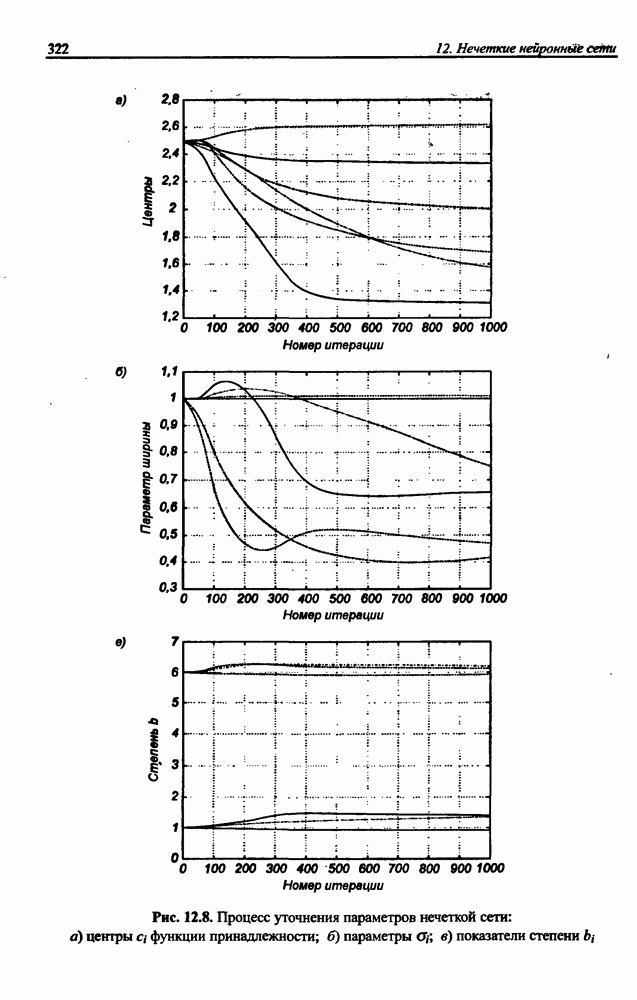
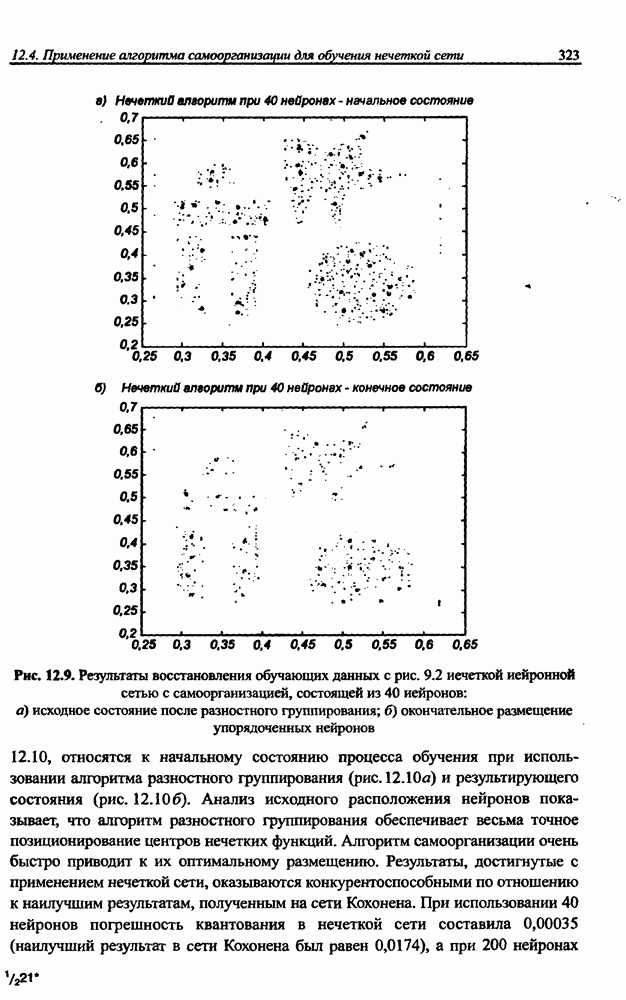
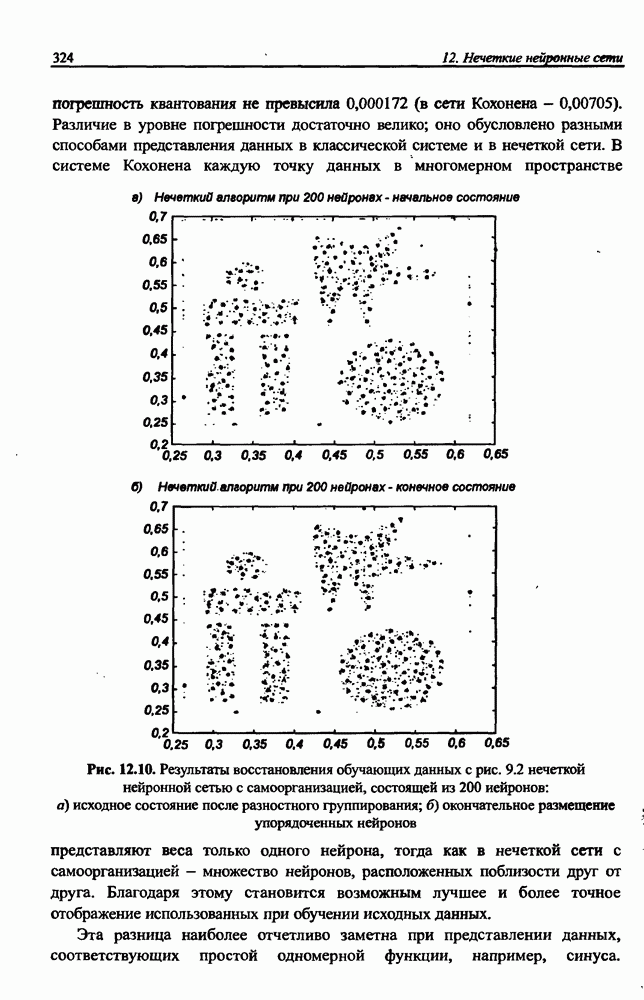
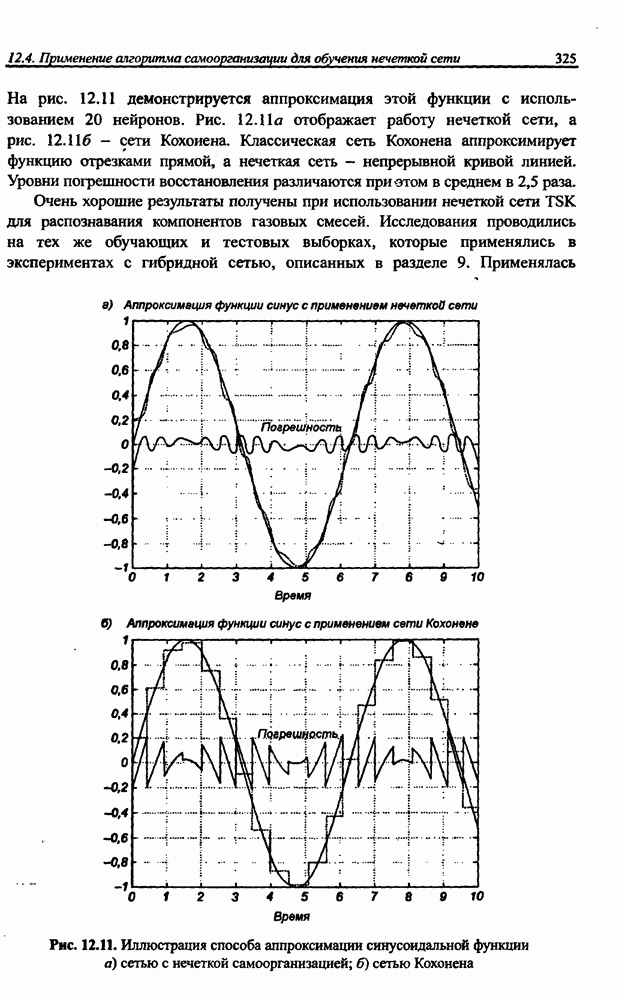
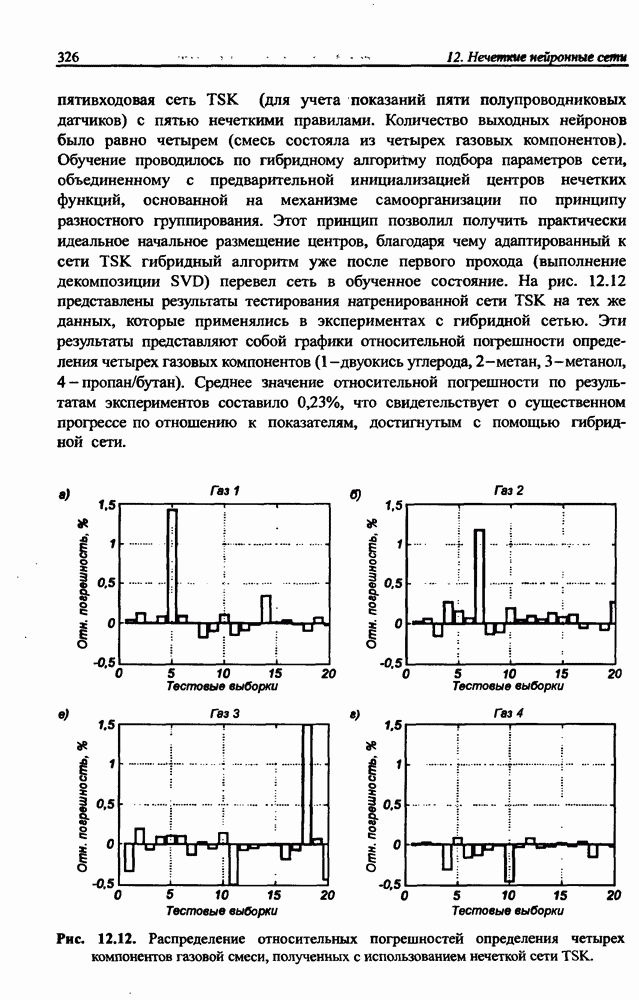
3.5. Подбор коэффициента обучения
Алгоритмы, представленные в предыдущем подразделе, позволяют определить только направление, в котором уменьшается целевая функция, но не говорят ничего о величине шага, при котором эта функция может получить минимальное значение. После выбора правильного направления  следует определить на нем новую точку решения
следует определить на нем новую точку решения  в которой будет выполняться условие
в которой будет выполняться условие  Необходимо подобрать такое значение
Необходимо подобрать такое значение  чтобы новое решение
чтобы новое решение  лежало как можно ближе к минимуму функции
лежало как можно ближе к минимуму функции  в направлении
в направлении  Грамотный подбор коэффициента
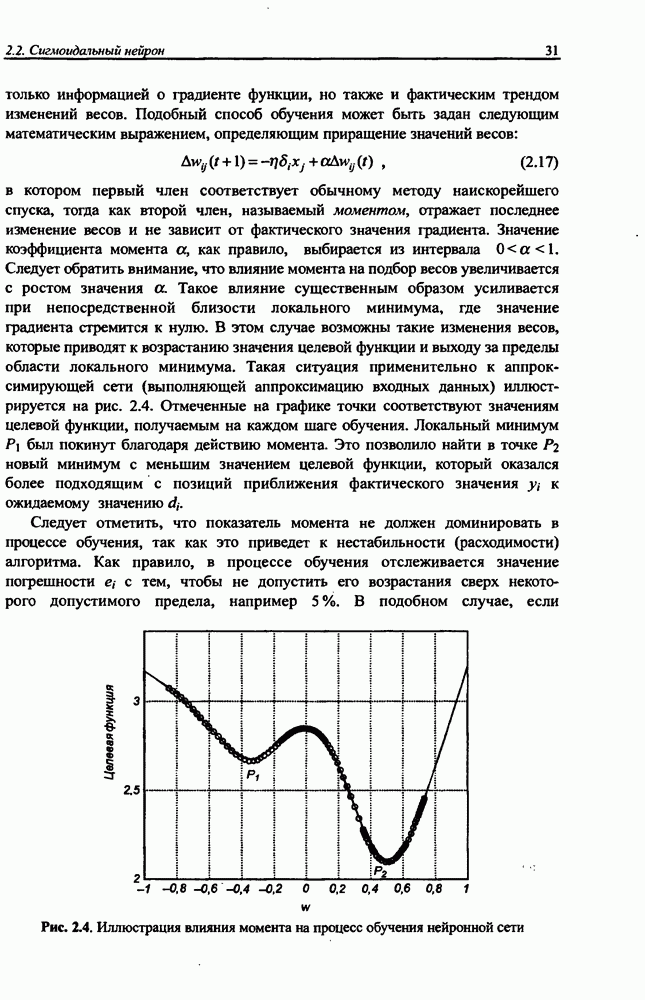
Грамотный подбор коэффициента  оказывает огромное влияние на сходимость алгоритма оптимизации к минимуму целевой функции. Чем сильнее величина
оказывает огромное влияние на сходимость алгоритма оптимизации к минимуму целевой функции. Чем сильнее величина  отличается от значения, при котором
отличается от значения, при котором  достигает минимума в выбранном направлении
достигает минимума в выбранном направлении  тем большее количество итераций потребуется для поиска оптимального решения. Слишком малое значение
тем большее количество итераций потребуется для поиска оптимального решения. Слишком малое значение  не позволяет минимизировать целевую функцию за один шаг и вызывает необходимость повторно двигаться в том же направлении. Слишком большой шаг приводит к “перепрыгиванию” через минимум функции и фактически заставляет возвращаться к нему.
не позволяет минимизировать целевую функцию за один шаг и вызывает необходимость повторно двигаться в том же направлении. Слишком большой шаг приводит к “перепрыгиванию” через минимум функции и фактически заставляет возвращаться к нему.
Существуют различные способы подбора значения  называемого в теории нейронных сетей коэффициентом обучения. Простейший из них (относительно редко применяемый в настоящее время, главным образом для обучения в режиме “онлайн”) основан на фиксации постоянного значения
называемого в теории нейронных сетей коэффициентом обучения. Простейший из них (относительно редко применяемый в настоящее время, главным образом для обучения в режиме “онлайн”) основан на фиксации постоянного значения  на весь период оптимизации. Этот способ практически используется только совместно с методом наискорейшего спуска. Он имеет низкую эффективность, поскольку значение коэффициента обучения никак не зависит от вектора фактического градиента и, следовательно, от направления
на весь период оптимизации. Этот способ практически используется только совместно с методом наискорейшего спуска. Он имеет низкую эффективность, поскольку значение коэффициента обучения никак не зависит от вектора фактического градиента и, следовательно, от направления  на данной итерации. Величина
на данной итерации. Величина  подбирается, как правило, раздельно для каждого слоя сети с использованием различных эмпирических зависимостей. Один из подходов состоит в определении минимального значения коэффициента Г) для каждого слоя по формуле [72]
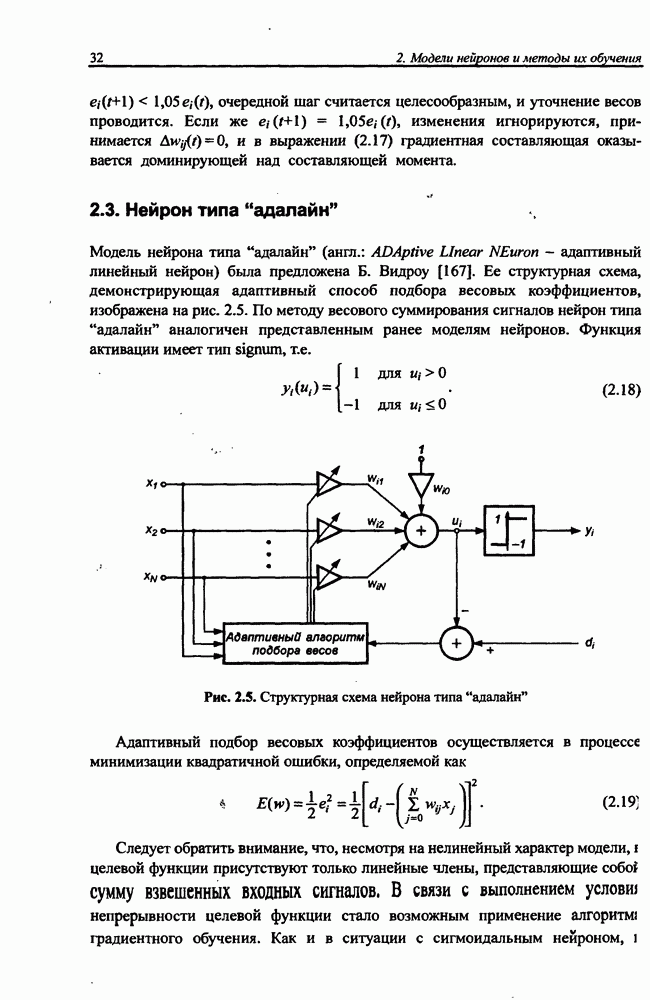
подбирается, как правило, раздельно для каждого слоя сети с использованием различных эмпирических зависимостей. Один из подходов состоит в определении минимального значения коэффициента Г) для каждого слоя по формуле [72]

где  обозначает количество входов
обозначает количество входов  нейрона в слое.
нейрона в слое.
Другой более эффективный метод основан на адаптивном подборе коэффициента  с учетом фактической динамики величины целевой функции в результате обучения. В соответствии с этим методом стратегия изменения
с учетом фактической динамики величины целевой функции в результате обучения. В соответствии с этим методом стратегия изменения
значения  определяется путем сравнения суммарной погрешности
определяется путем сравнения суммарной погрешности  на
на  итерации с ее предыдущим значением, причем
итерации с ее предыдущим значением, причем  рассчитывается по формуле
рассчитывается по формуле

Для ускорения процесса обучения следует стремиться к непрерывному увеличению  при одновременном контроле прироста погрешности
при одновременном контроле прироста погрешности  по сравнению с ее значением на предыдущем шаге. Незначительный рост этой погрешности считается допустимым.
по сравнению с ее значением на предыдущем шаге. Незначительный рост этой погрешности считается допустимым.
Если погрешности на  итерациях обозначить соответственно
итерациях обозначить соответственно  а коэффициенты обучения на этих же итерациях -
а коэффициенты обучения на этих же итерациях -  то в случае
то в случае  - коэффициент допустимого прироста погрешности) значение
- коэффициент допустимого прироста погрешности) значение  должно уменьшаться в соответствии с формулой
должно уменьшаться в соответствии с формулой

где  - коэффициент уменьшения
- коэффициент уменьшения  В противном случае, когда
В противном случае, когда  принимается
принимается

где  - коэффициент увеличения
- коэффициент увеличения  Несмотря на некоторое возрастание объема вычислений (необходимых для дополнительного расчета значений
Несмотря на некоторое возрастание объема вычислений (необходимых для дополнительного расчета значений  ), возможно существенное ускорение процесса обучения. Например, реализация представленной стратегии в программе MATLAB [27] со значениями
), возможно существенное ускорение процесса обучения. Например, реализация представленной стратегии в программе MATLAB [27] со значениями  позволила в несколько раз ускорить обучение при решении проблемы аппроксимации нелинейных функций.
позволила в несколько раз ускорить обучение при решении проблемы аппроксимации нелинейных функций.
Интересно проследить характер изменения коэффициента 1) в процессе обучения. Как правило, на начальных этапах доминирует тенденция к его увеличению, однако при достижении некоторого квазистационарного состояния величина  постепенно уменьшается, но не монотонно, а циклически возрастая и понижаясь в следующих друг за другом циклах.
постепенно уменьшается, но не монотонно, а циклически возрастая и понижаясь в следующих друг за другом циклах.
Однако необходимо подчеркнуть, что адаптивный метод подбора  сильно зависит от вида целевой функции и значений коэффициентов
сильно зависит от вида целевой функции и значений коэффициентов  Значения, оптимальные для функции одного вида, могут замедлять процесс обучения при использовании другой функции. Поэтому при практической реализации этого метода следует обращать внимание на механизмы контроля и управления значениями коэффициентов, подбирая их в соответствии со спецификой решаемой задачи.
Значения, оптимальные для функции одного вида, могут замедлять процесс обучения при использовании другой функции. Поэтому при практической реализации этого метода следует обращать внимание на механизмы контроля и управления значениями коэффициентов, подбирая их в соответствии со спецификой решаемой задачи.
Наиболее эффективный, хотя и наиболее сложный, метод подбора коэффициента обучения связан с направленной минимизацией целевой функции в выбранном заранее направлении  Необходимо так подобрать скалярное значение
Необходимо так подобрать скалярное значение  чтобы новое решение
чтобы новое решение  соответствовало минимуму целевой функции в данном направлении
соответствовало минимуму целевой функции в данном направлении  . В действительности получаемое решение
. В действительности получаемое решение  только с определенным приближением может считаться настоящим
только с определенным приближением может считаться настоящим
минимумом. Это результат компромисса между объемом вычислений и влиянием величины  на сходимость алгоритма.
на сходимость алгоритма.
Среди наиболее популярных способов направленной минимизации можно выделить безградиентные и градиентные методы. В безградиентных методах используется только информация о значениях целевой функции, а ее минимум достигается в процессе последовательного уменьшения диапазона значений вектора и». Примерами могут служить методы деления пополам, золотого сечения либо метод Фибоначчи [39,170], различающиеся способом декомпозиции получаемых поддиапазонов.
Заслуживает внимания метод аппроксимации целевой функции  в предварительно выбранном направлении
в предварительно выбранном направлении  с последующим расчетом минимума, получаемого таким образом, функции одной переменной Т]. Выберем для аппроксимации многочлен второго порядка вида
с последующим расчетом минимума, получаемого таким образом, функции одной переменной Т]. Выберем для аппроксимации многочлен второго порядка вида

где  обозначены коэффициенты, определяемые в каждом цикле оптимизации. Выражение (3.53) - это многочлен
обозначены коэффициенты, определяемые в каждом цикле оптимизации. Выражение (3.53) - это многочлен  одной скалярной переменной
одной скалярной переменной  Если для расчета входящих в
Если для расчета входящих в  коэффициентов используются три произвольные точки
коэффициентов используются три произвольные точки  лежащие в направлении
лежащие в направлении  т.е.
т.е.  (в этом выражении и» обозначено предыдущее решение), а соответствующие этим точкам значения целевой функции
(в этом выражении и» обозначено предыдущее решение), а соответствующие этим точкам значения целевой функции  обозначены
обозначены  то
то

Коэффициенты  многочлена
многочлена  рассчитываются в соответствии с системой линейных уравнений, описываемых в (3.54). Для определения минимума этого многочлена его производная
рассчитываются в соответствии с системой линейных уравнений, описываемых в (3.54). Для определения минимума этого многочлена его производная  приравнивается к нулю, что позволяет получить значение
приравнивается к нулю, что позволяет получить значение  в виде
в виде  После подстановки выражений для
После подстановки выражений для  в формулу расчета
в формулу расчета  получаем:
получаем:

Однако лучшим решением считается применение градиентных методов, в которых, кроме значения функции, учитывается также и ее производная вдоль направляющего вектора  Они позволяют значительно ускорить достижение минимума, поскольку используют информацию о направлении уменьшения величины целевой функции. В такой ситуации применяется, как правило, аппроксимирующий многочлен третьего порядка
Они позволяют значительно ускорить достижение минимума, поскольку используют информацию о направлении уменьшения величины целевой функции. В такой ситуации применяется, как правило, аппроксимирующий многочлен третьего порядка

Значения четырех коэффициентов  этого многочлена можно получить исходя из информации о величине функции и ее производной всего лишь в двух
этого многочлена можно получить исходя из информации о величине функции и ее производной всего лишь в двух
точках. Если приравнять к нулю производную многочлена относительно  то можно получить формулу для расчета
то можно получить формулу для расчета  в виде
в виде

Более подробное описание этого подхода можно найти в первоисточниках, посвященных теории оптимизации [39,170].
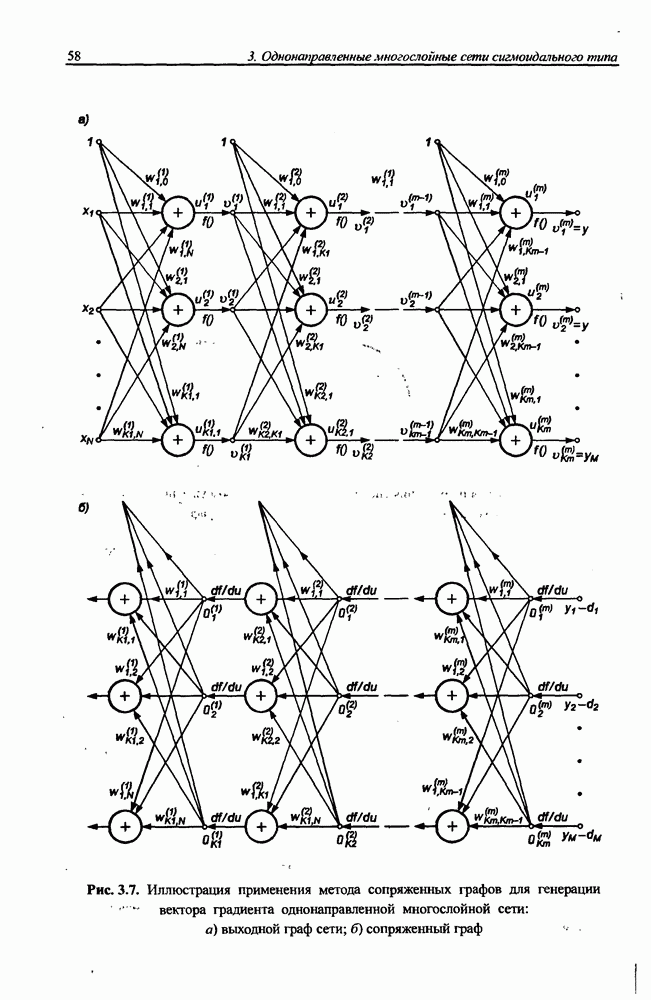
Алгоритм обучения многослойного персептрона реализован в Институте теоретической электротехники и электроизмерений Варшавского политехнического университета на языке C++ в виде программы Netteach [144]. Для выбора направления минимизации в нем применяется метод переменной метрики или классический метод сопряженных градиентов, а для расчета оптимального значения коэффициента обучения - аппроксимация многочленом третьего порядка. Программа позволяет работать с произвольным количеством слоев, причем функция активации нейронов каждого слоя задается индивидуально. На выбор предлагаются функции: сигмоидальная униполярная (Sigm), сигмоидальная биполярная (Bip), а также линейная (Lin). Градиент рассчитывается с применением метода потоковых графов.