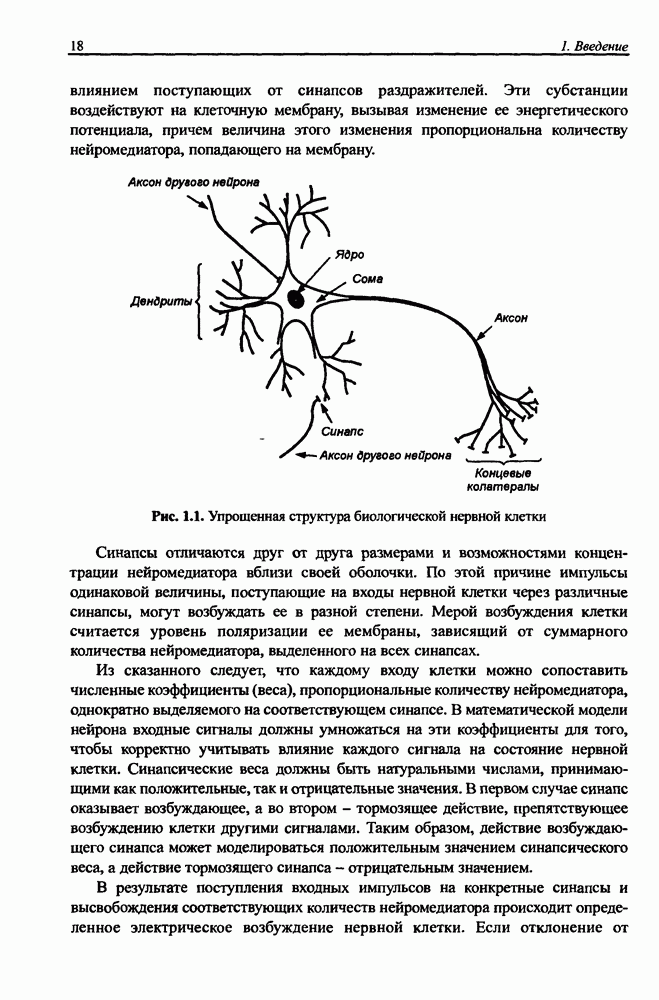
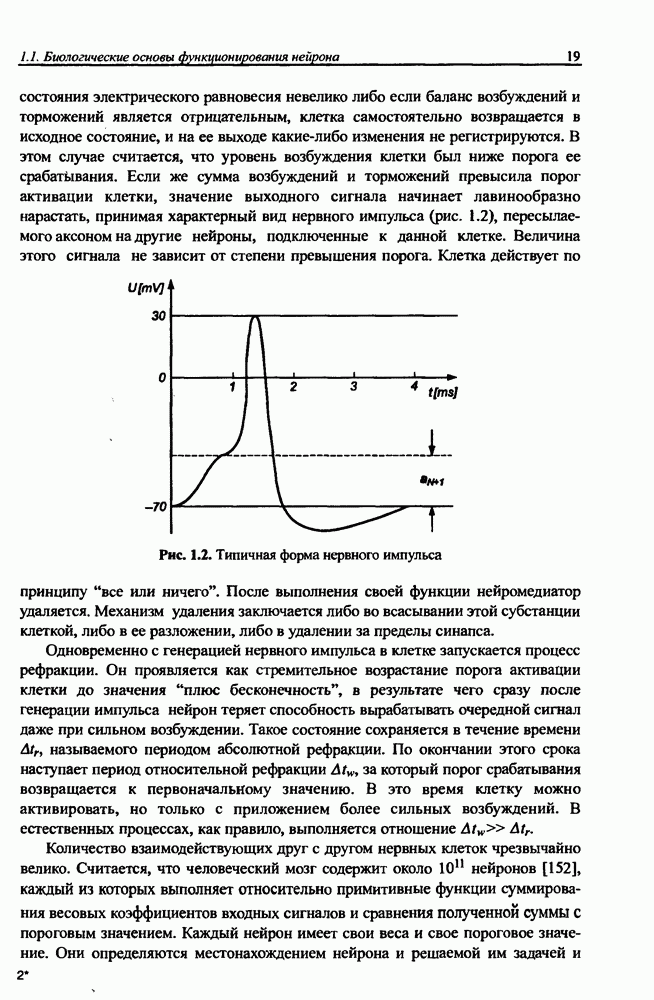
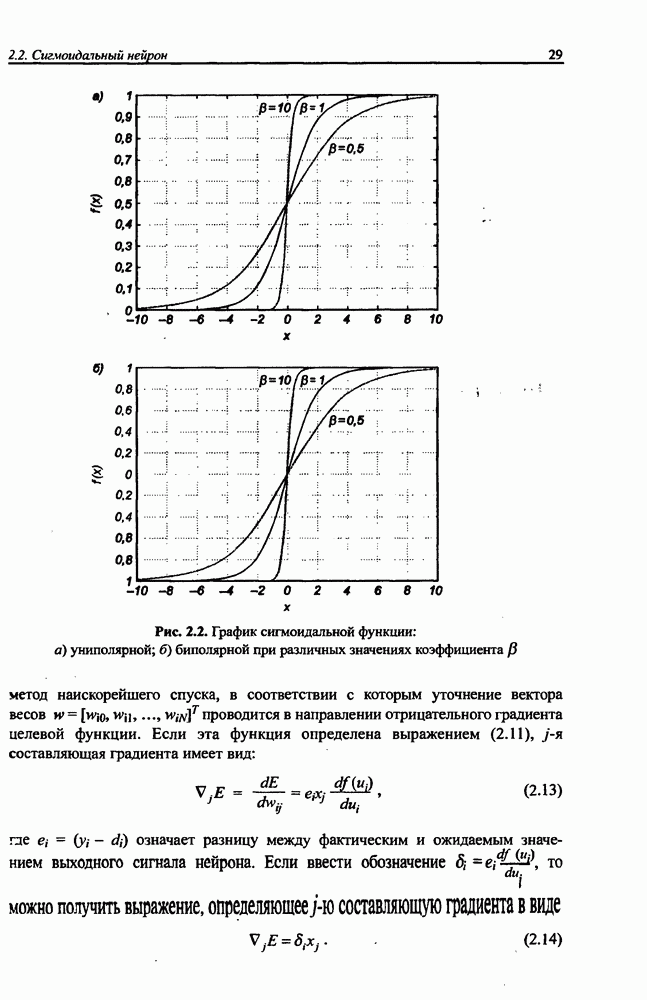
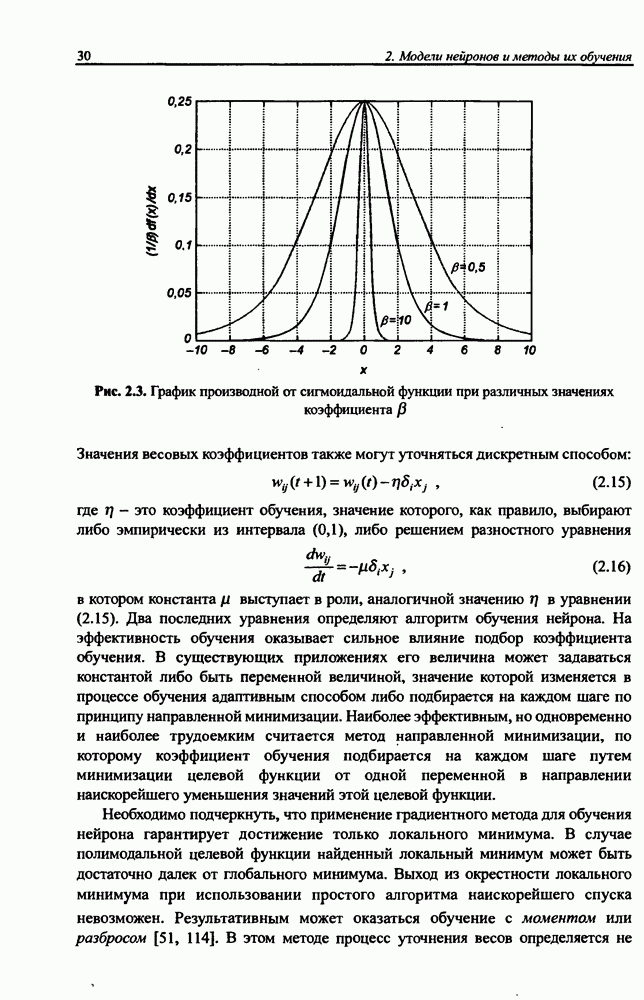
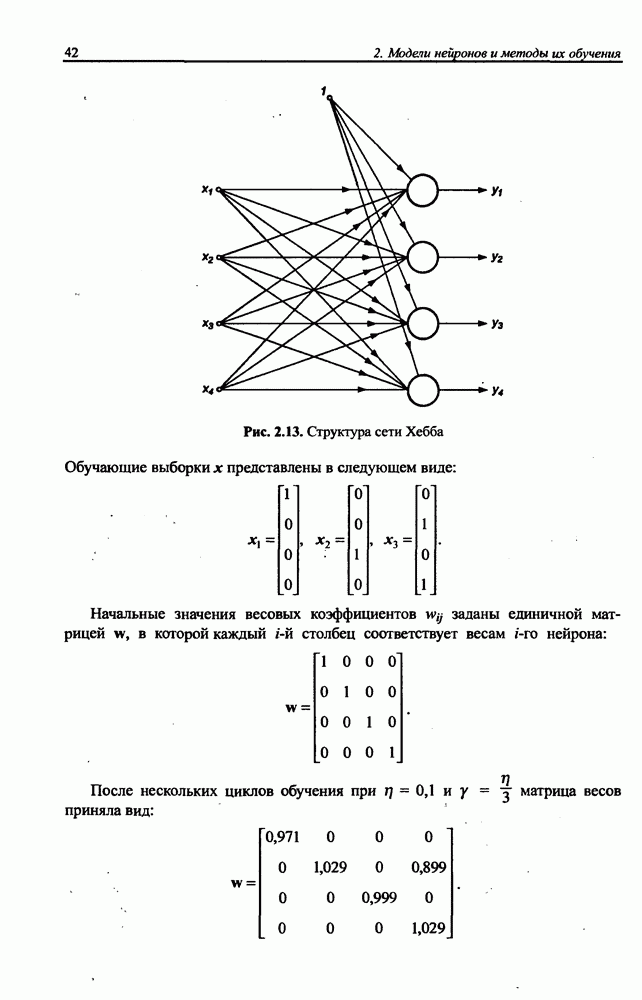
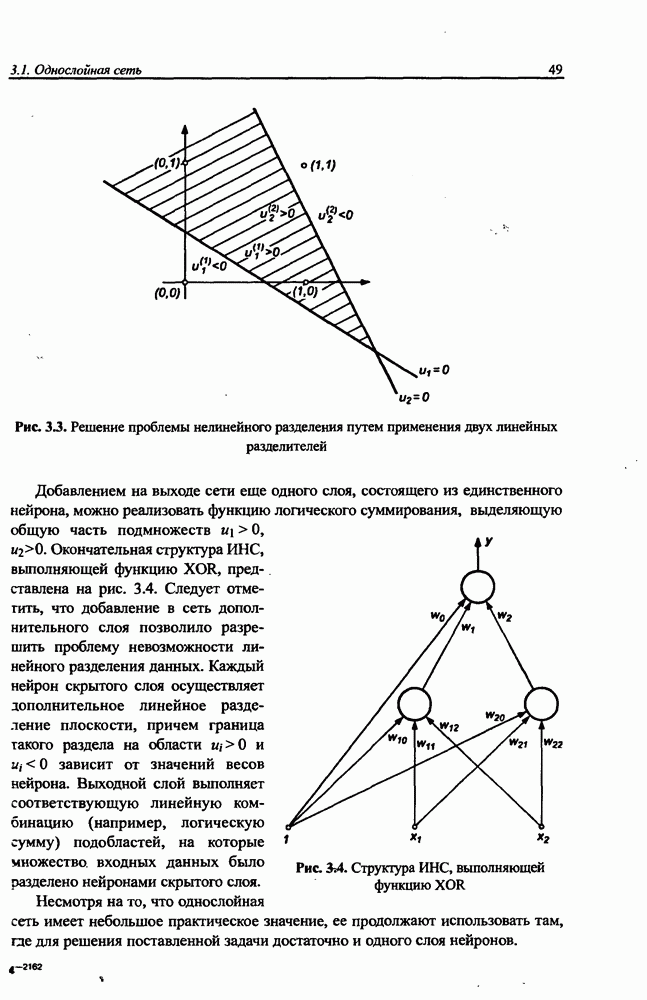
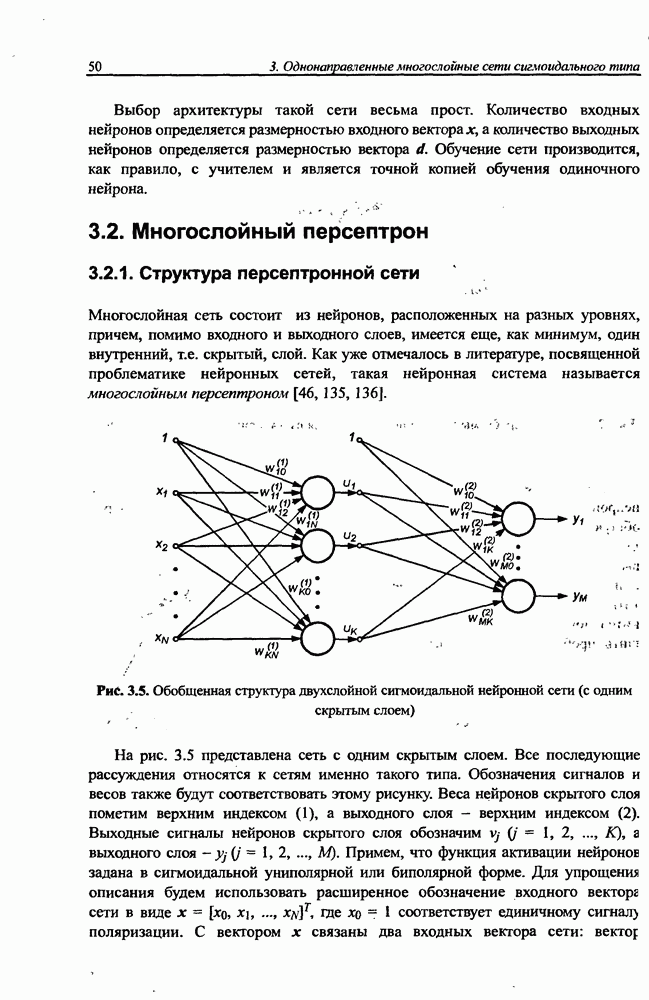
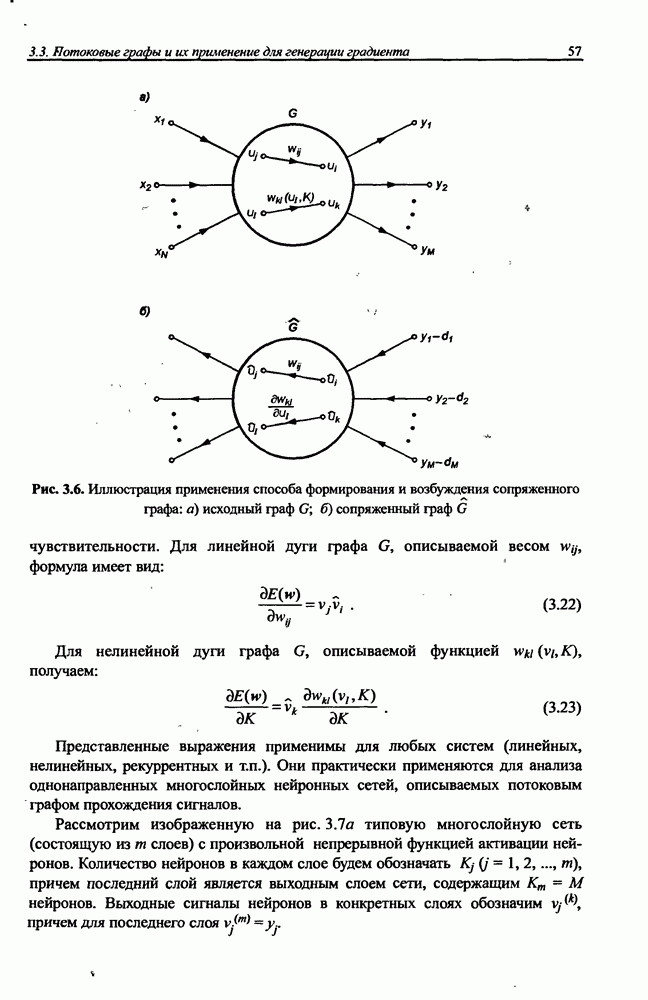
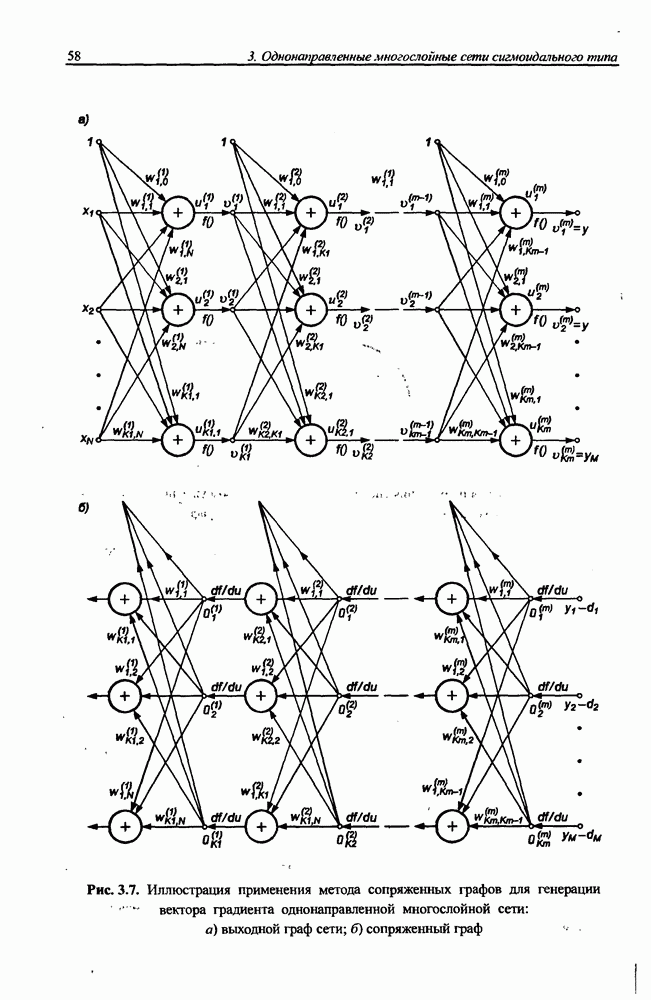
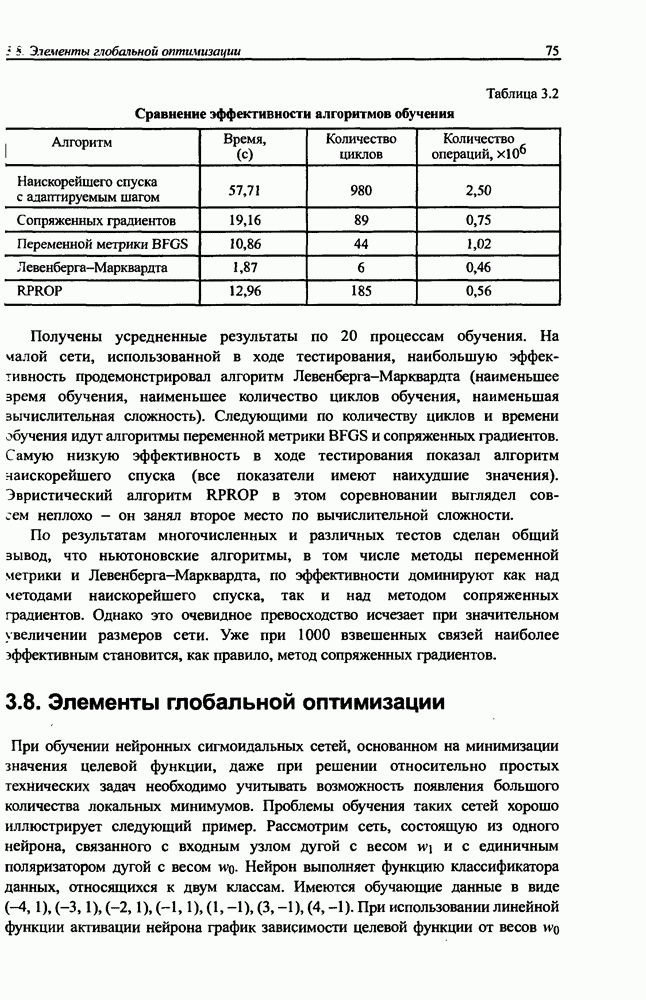
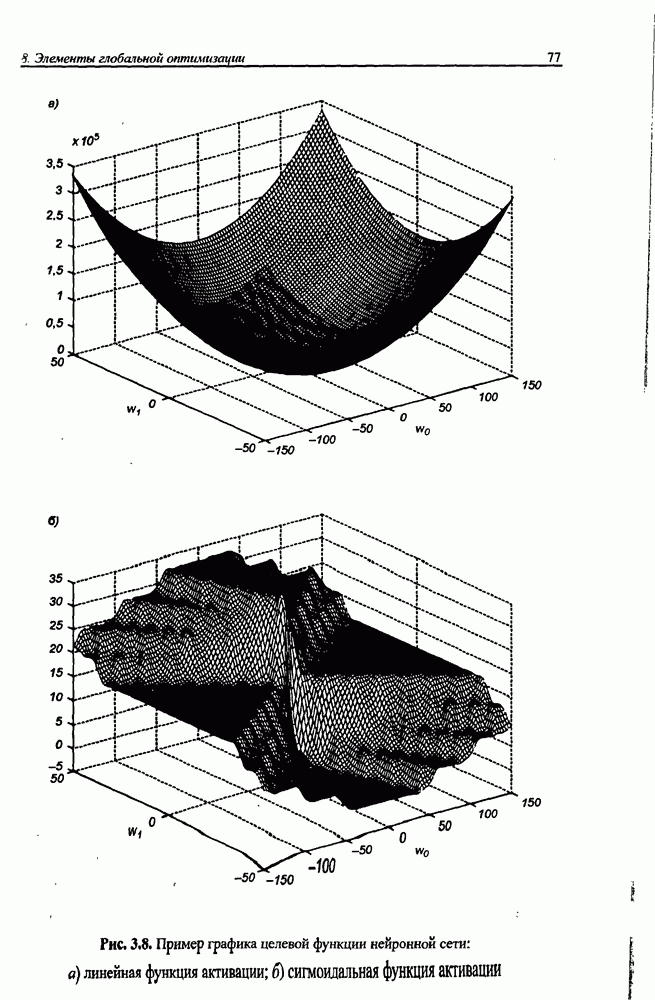
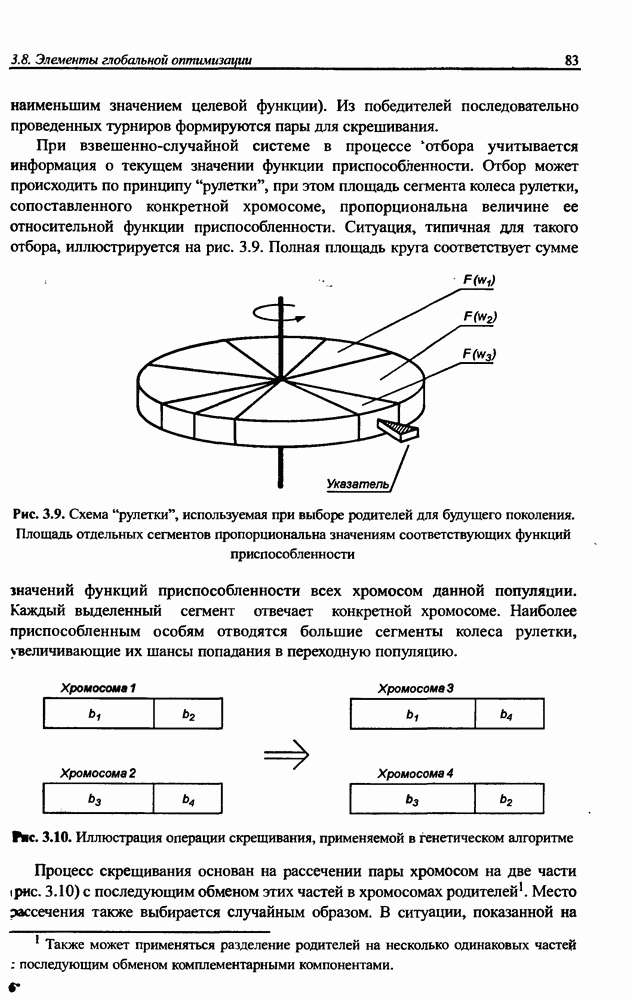
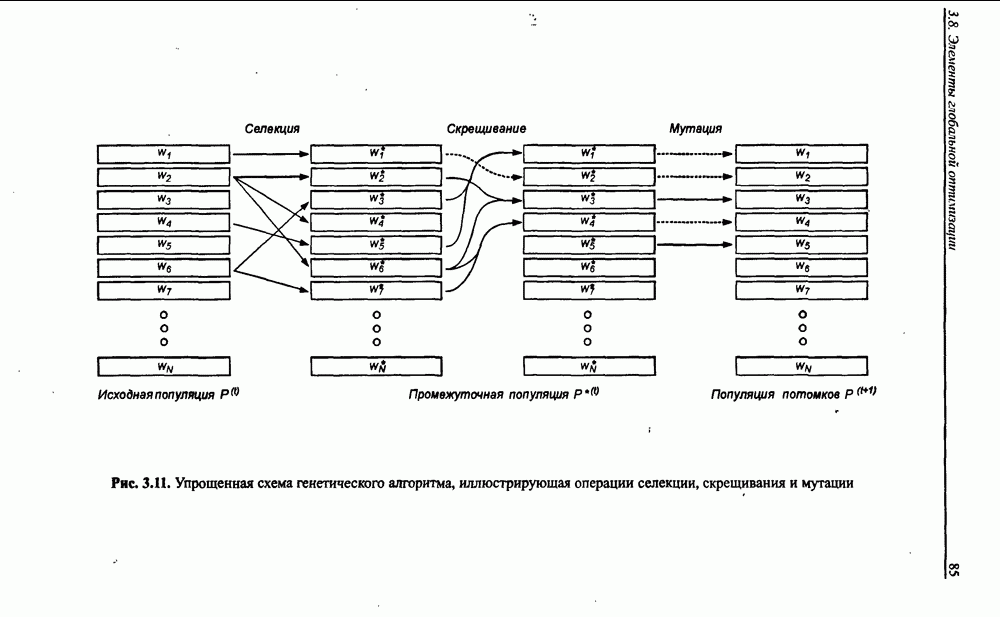
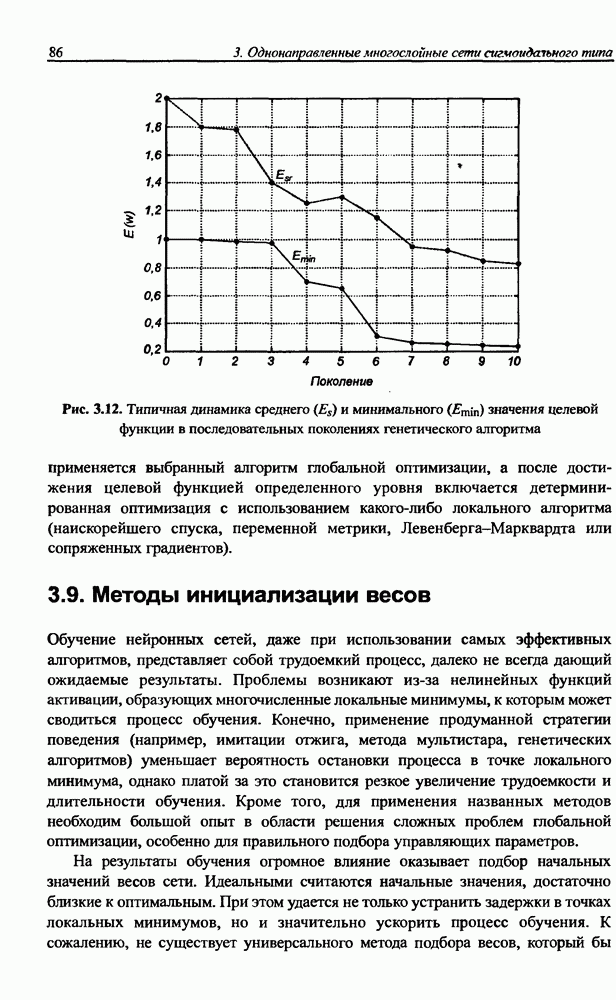
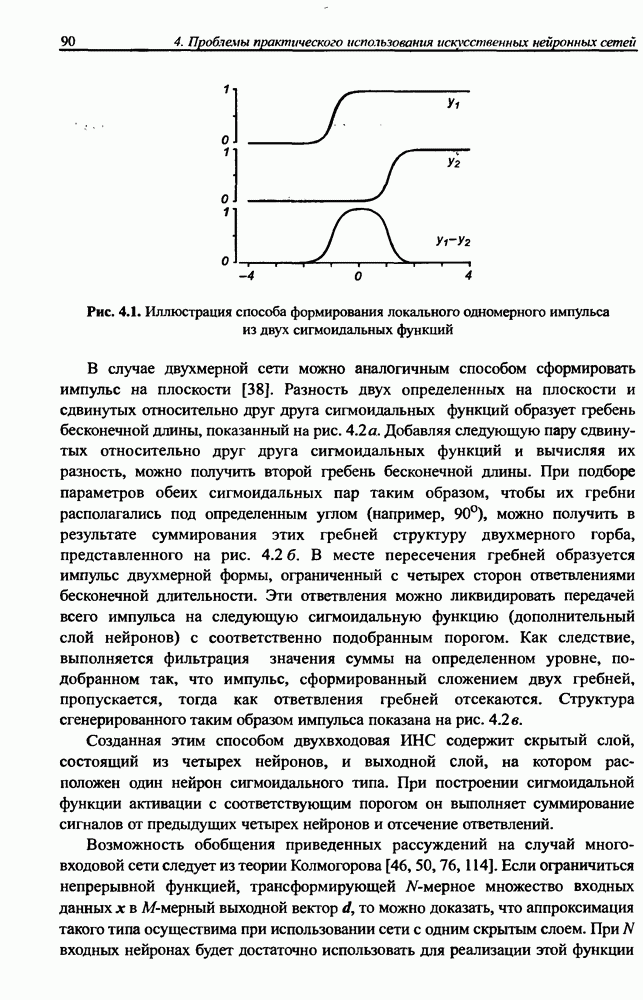
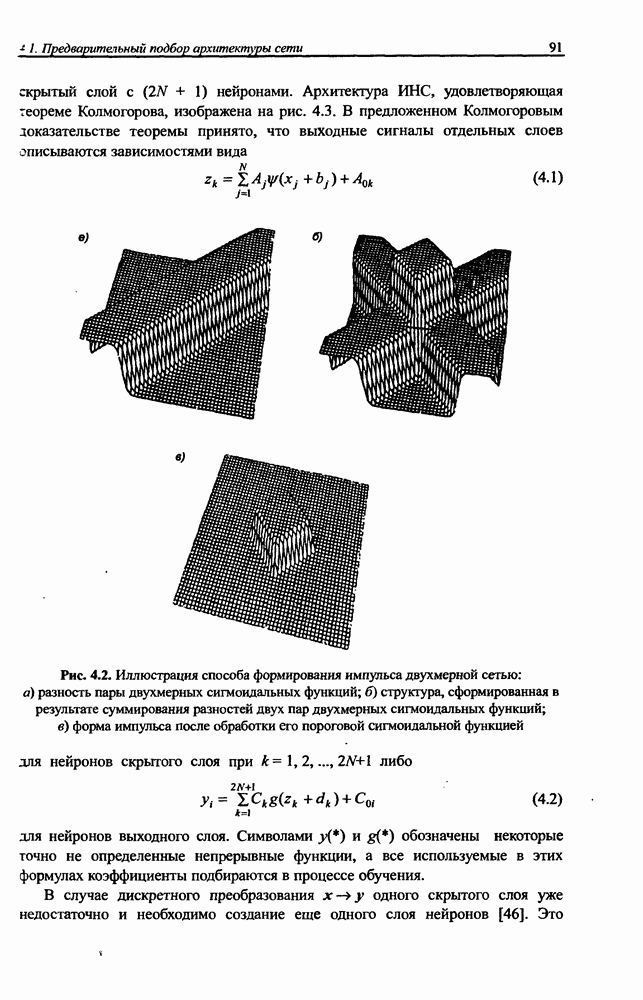
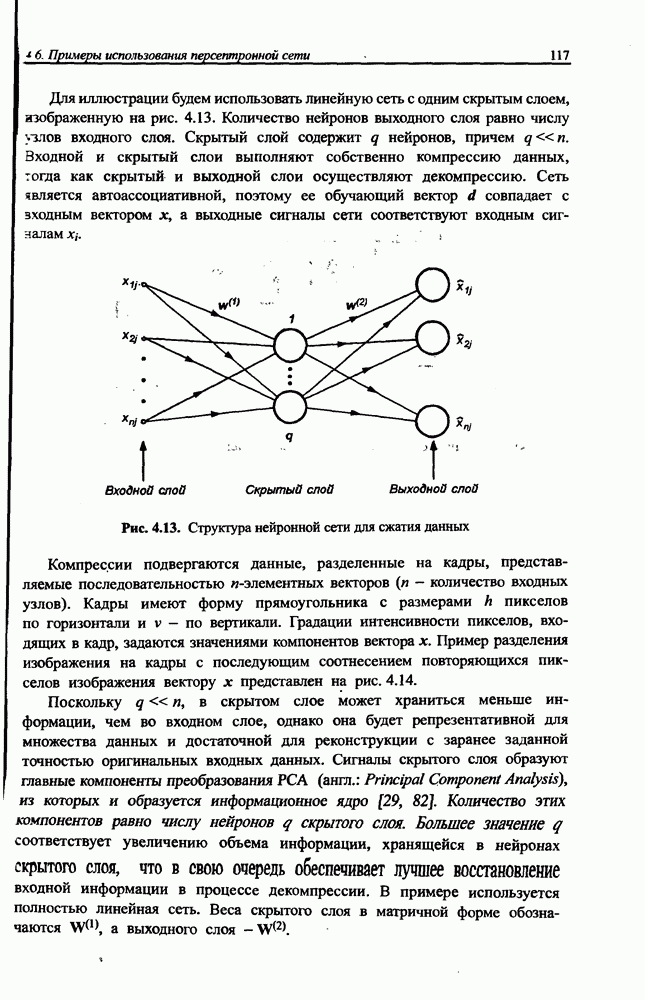
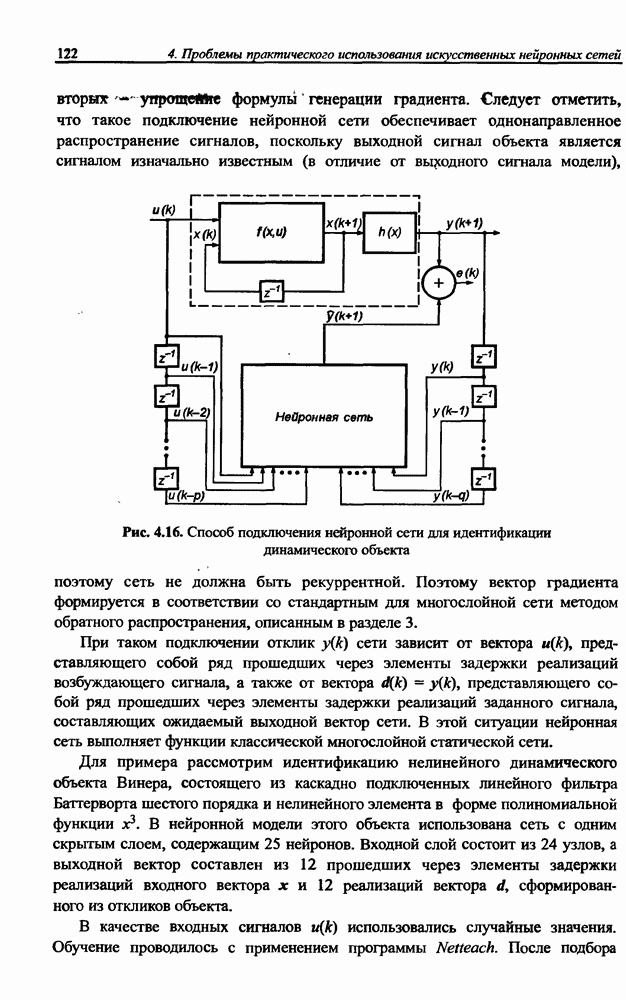
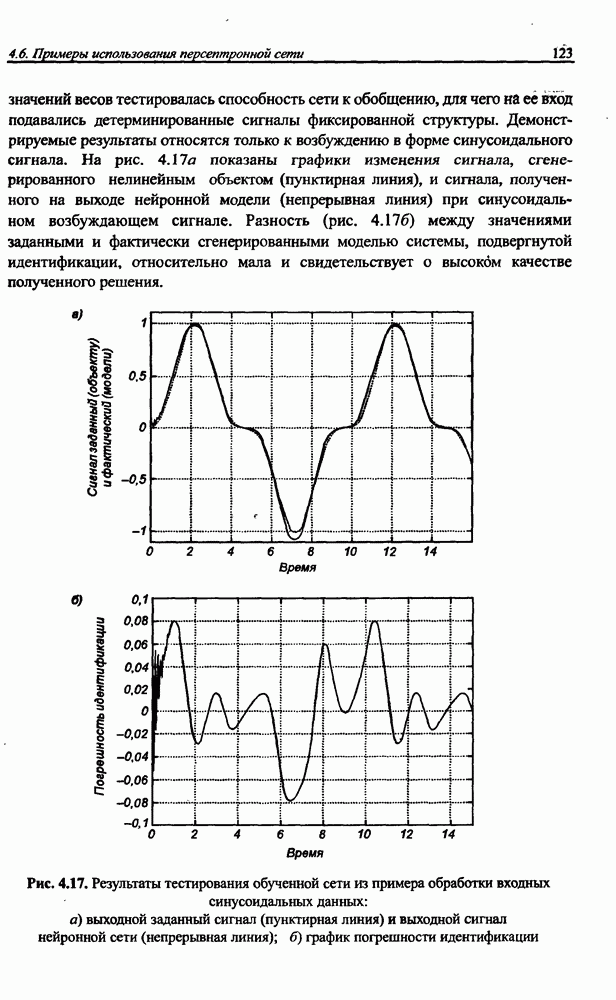
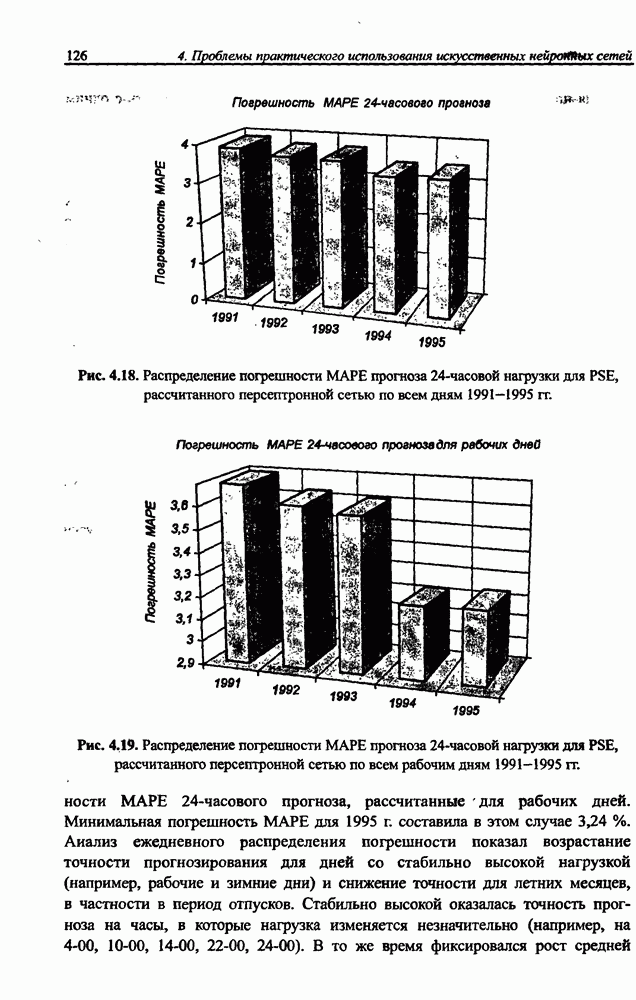
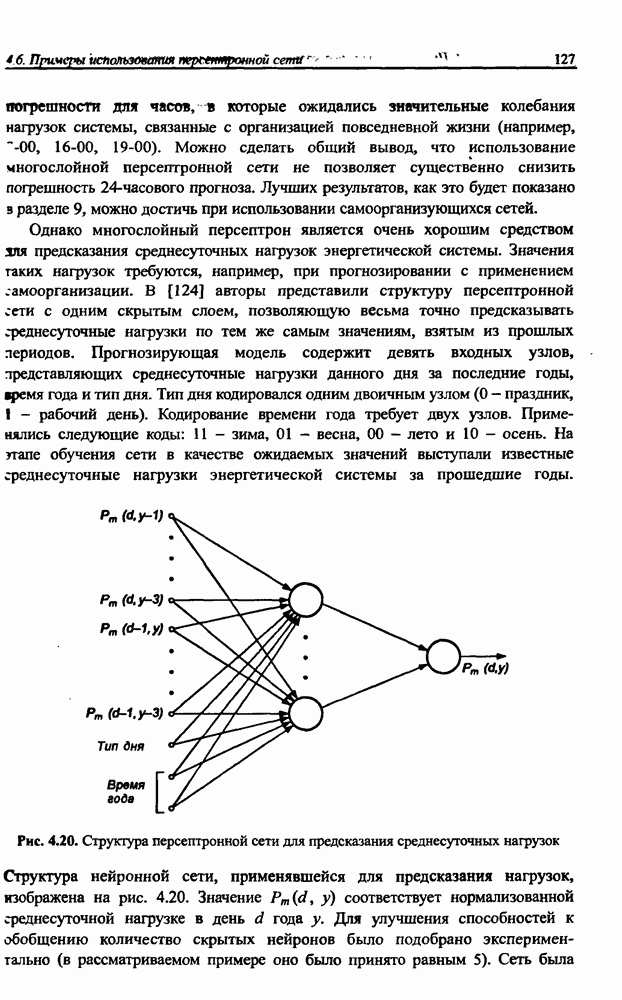
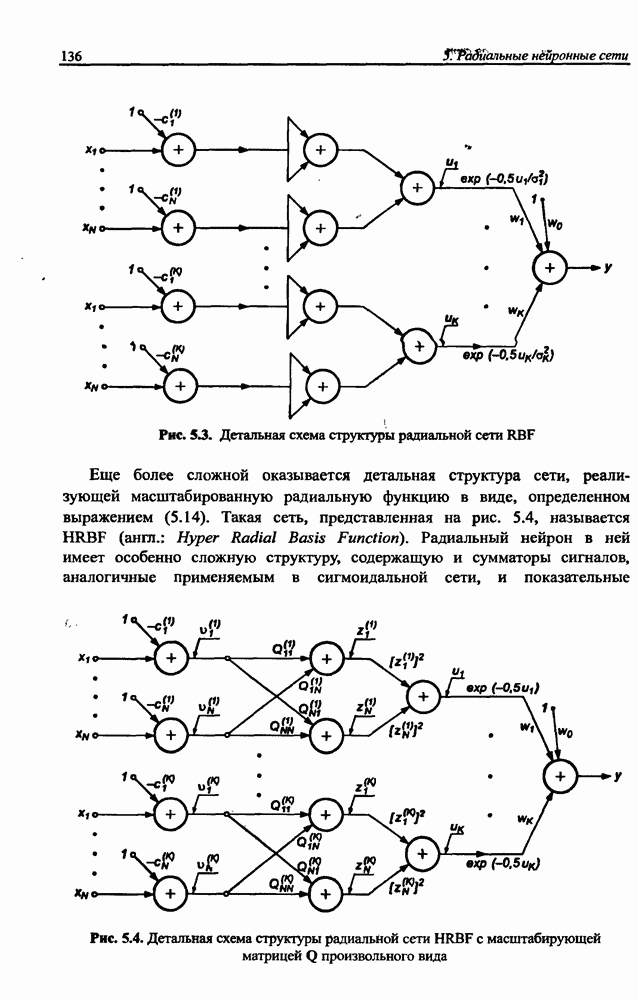
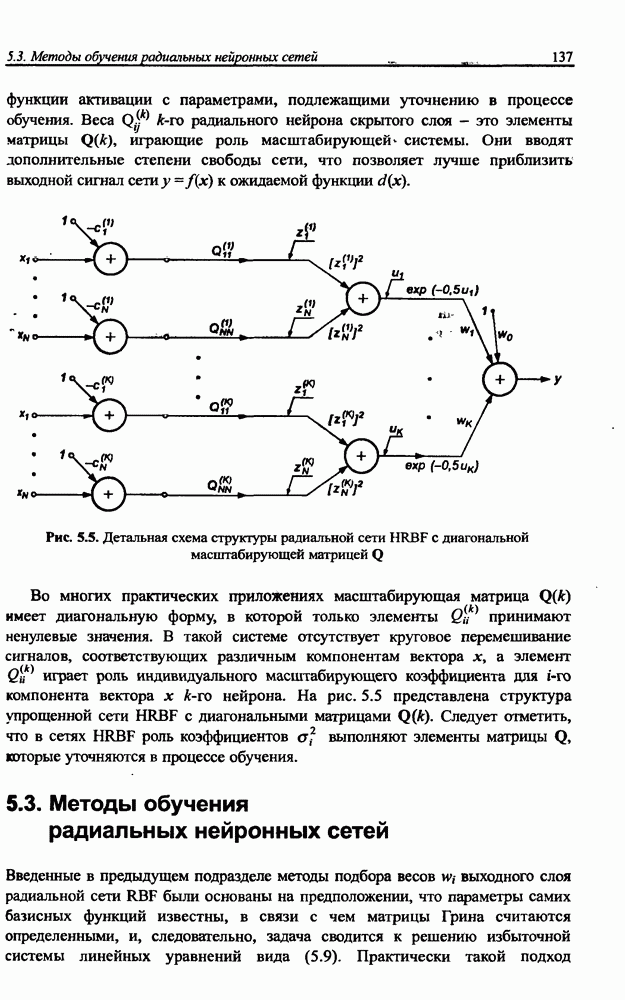
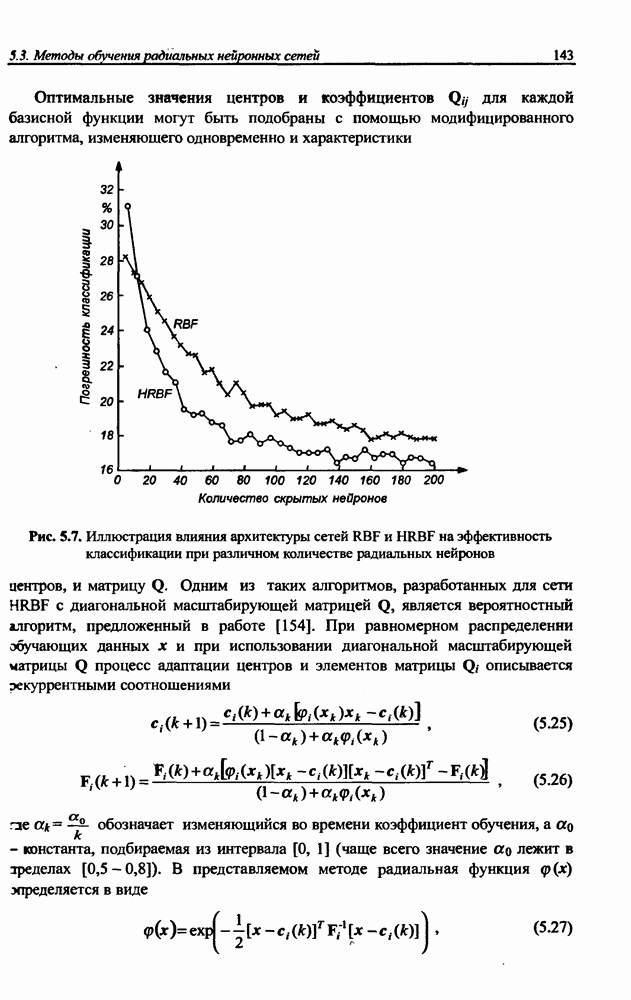
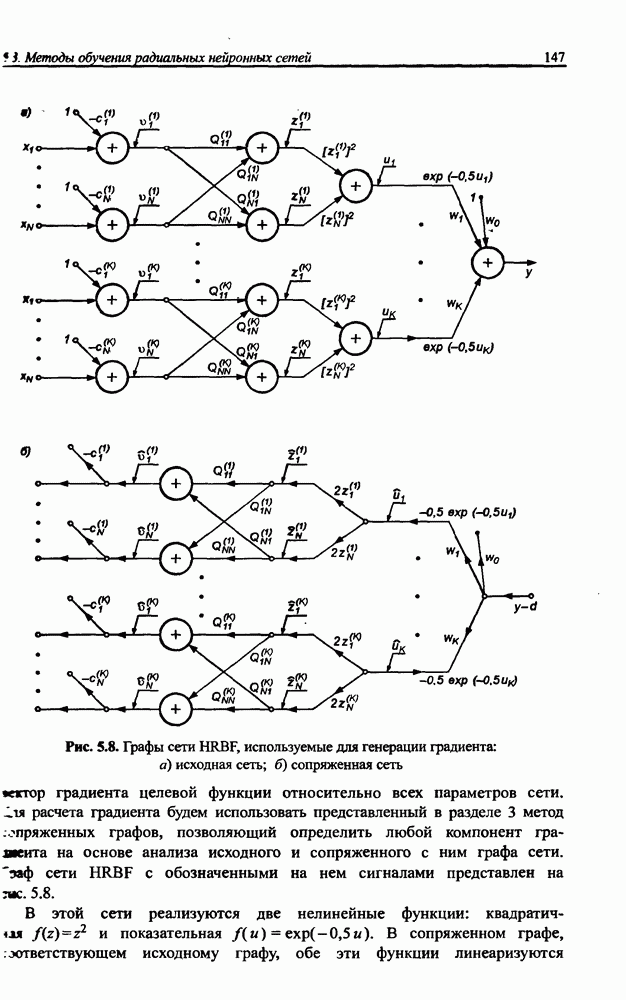
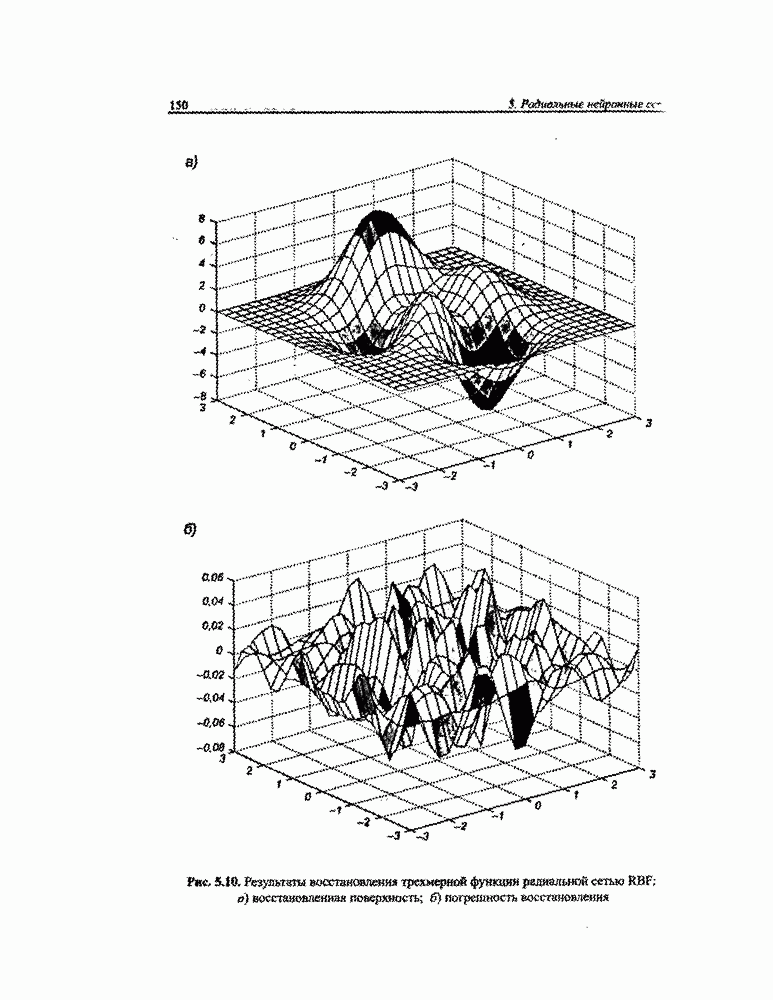
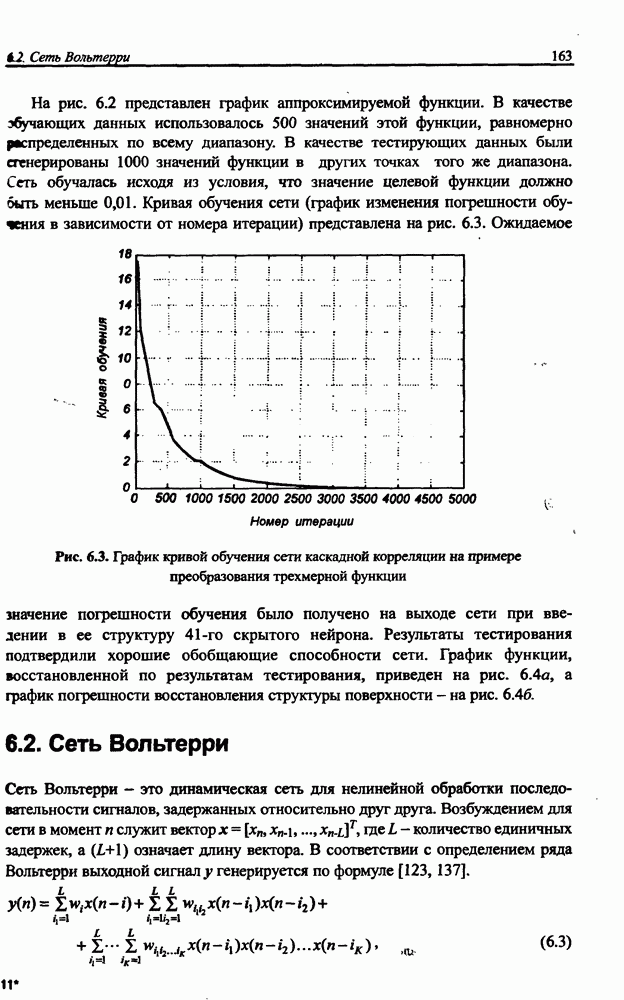
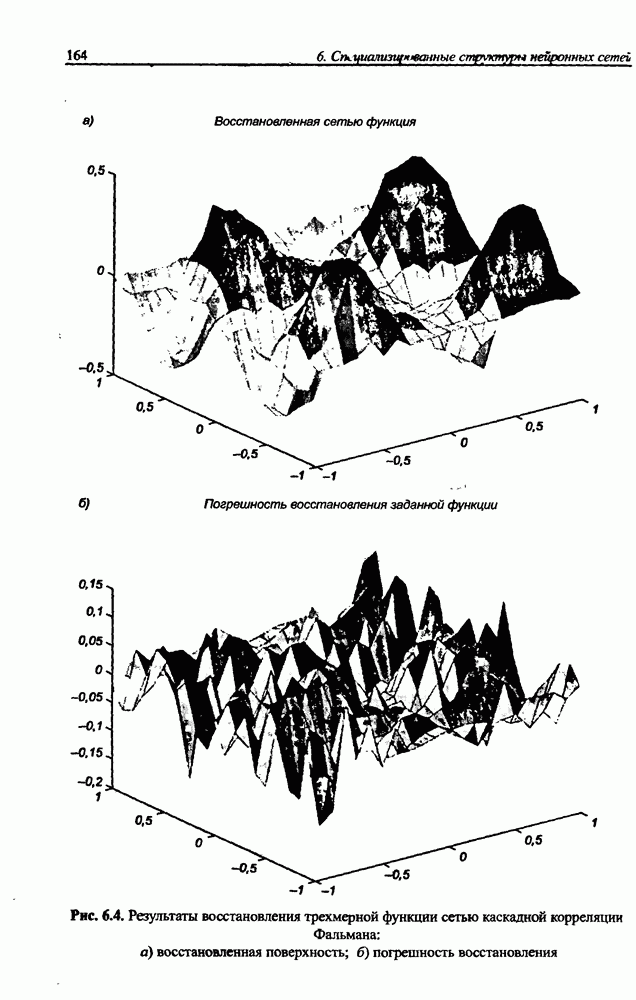
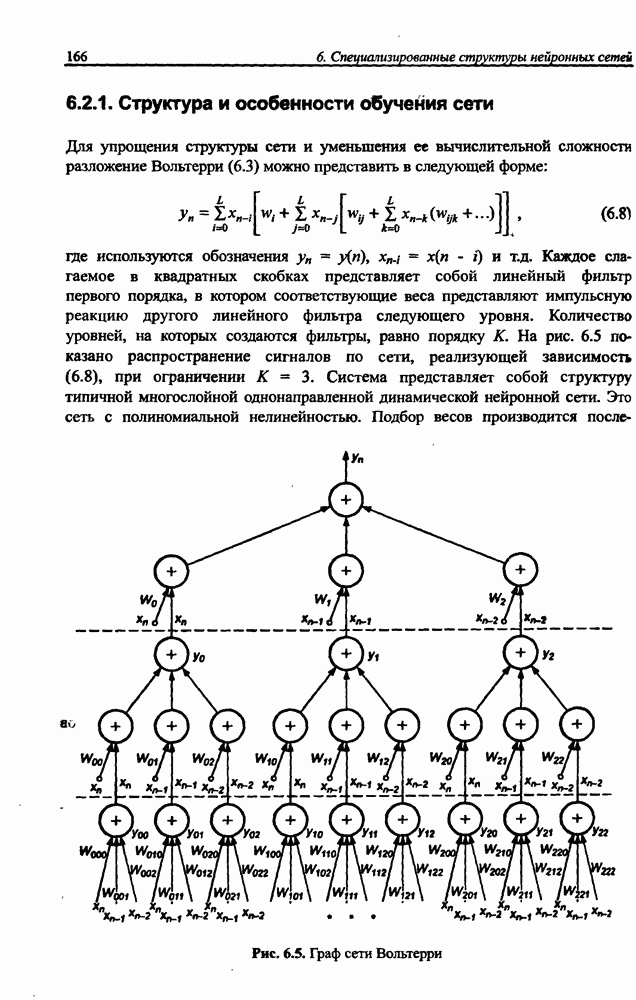
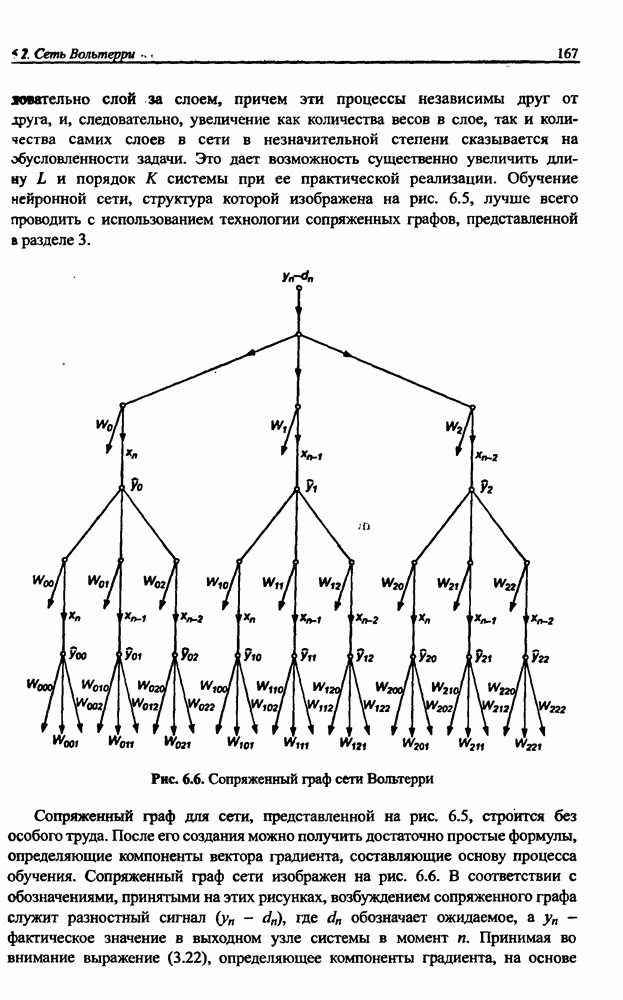
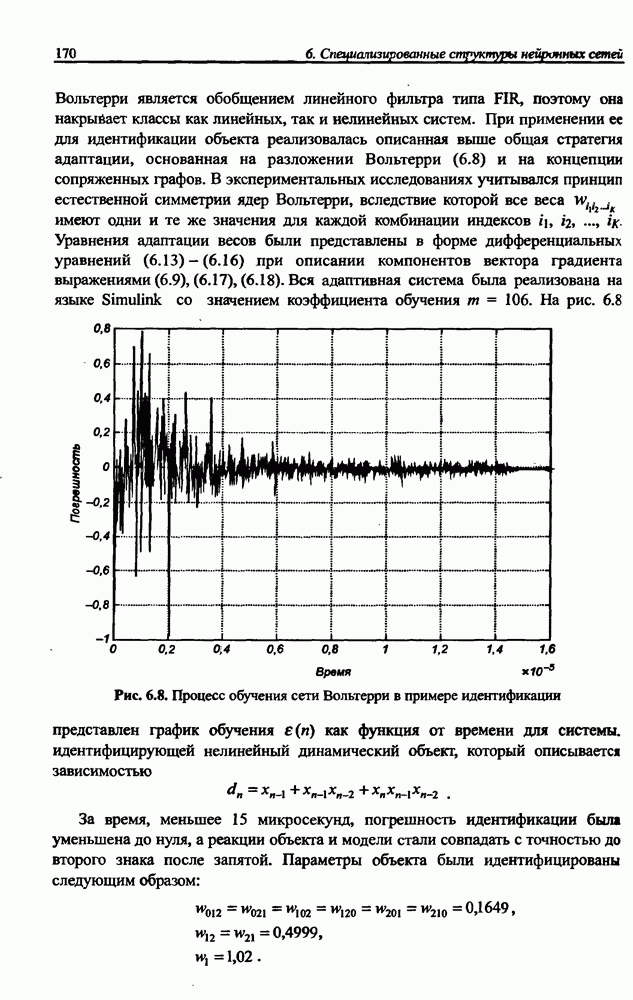
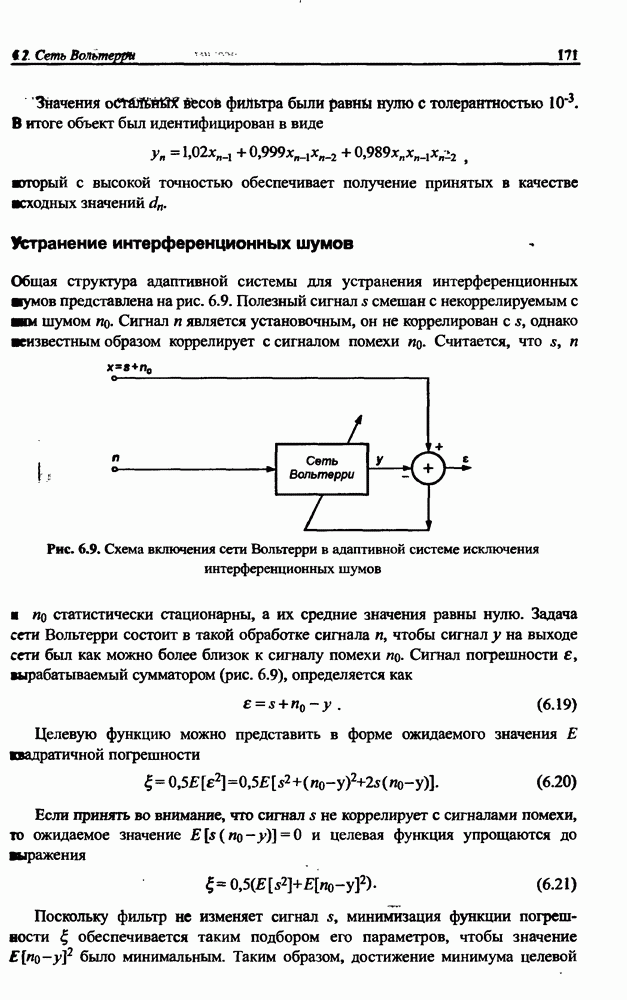
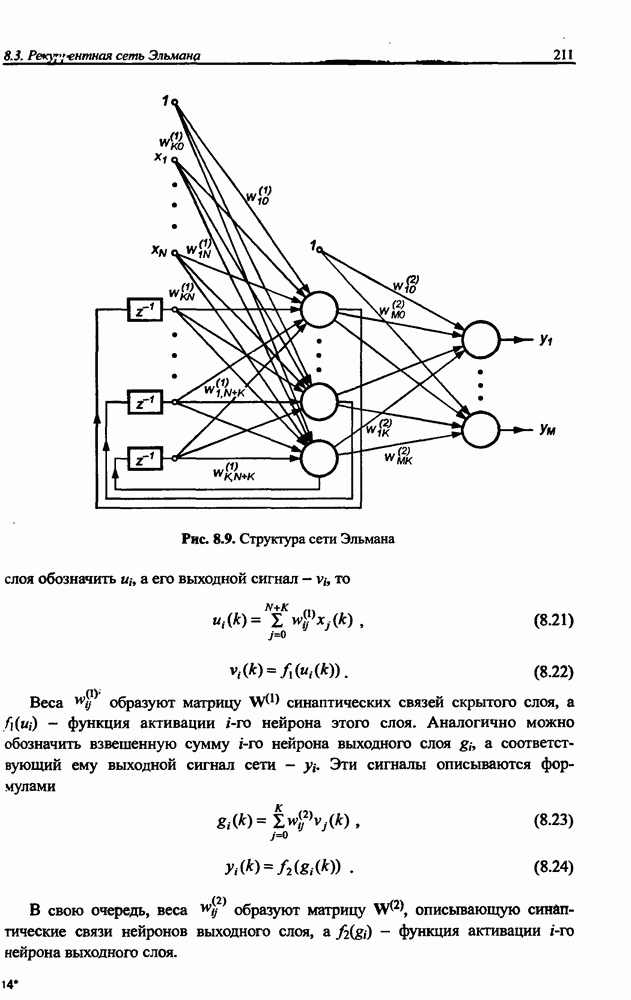
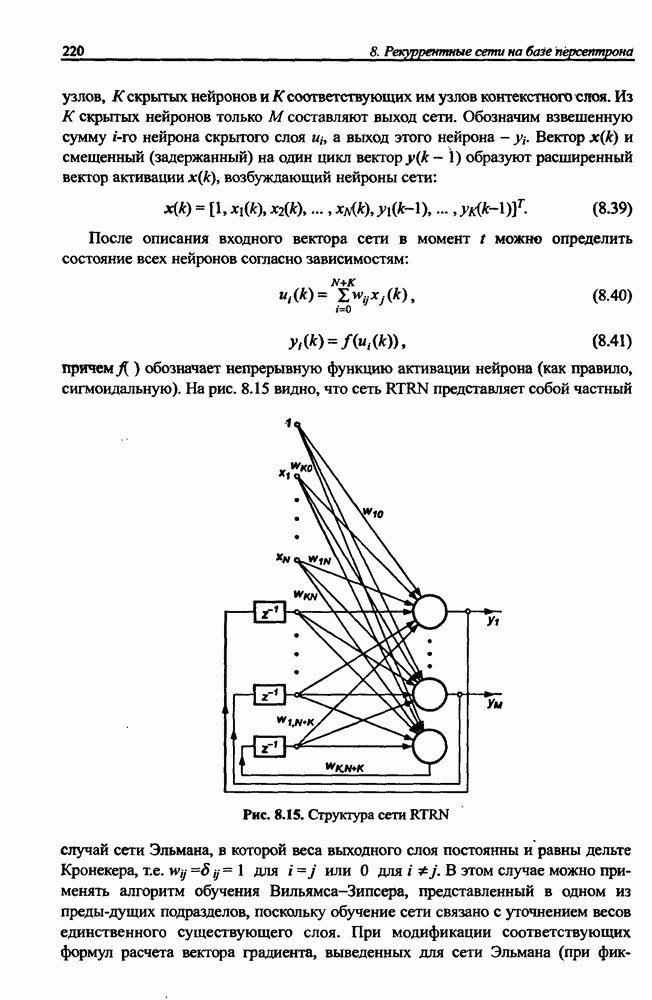
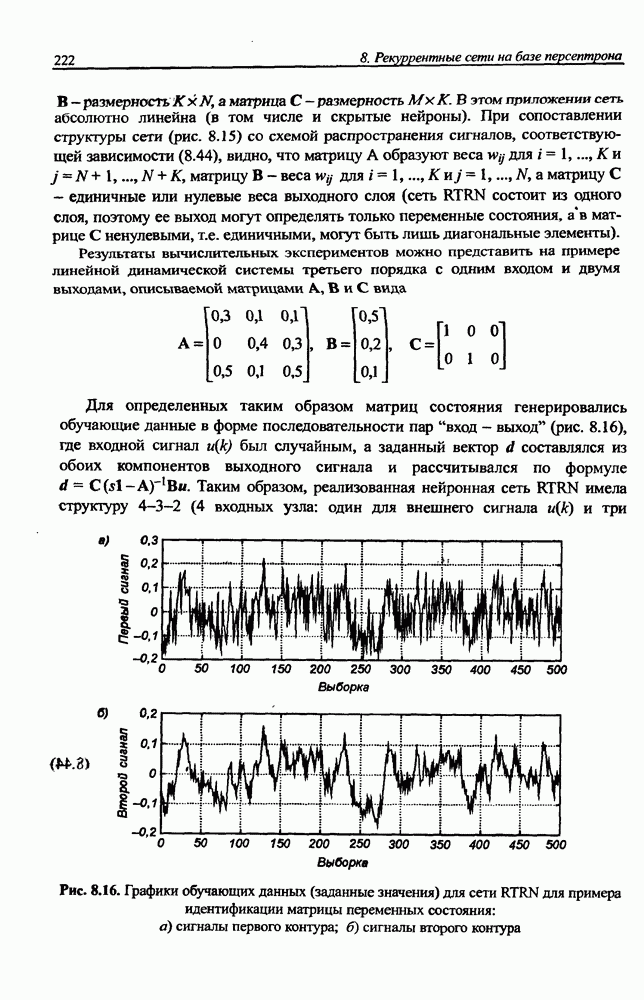
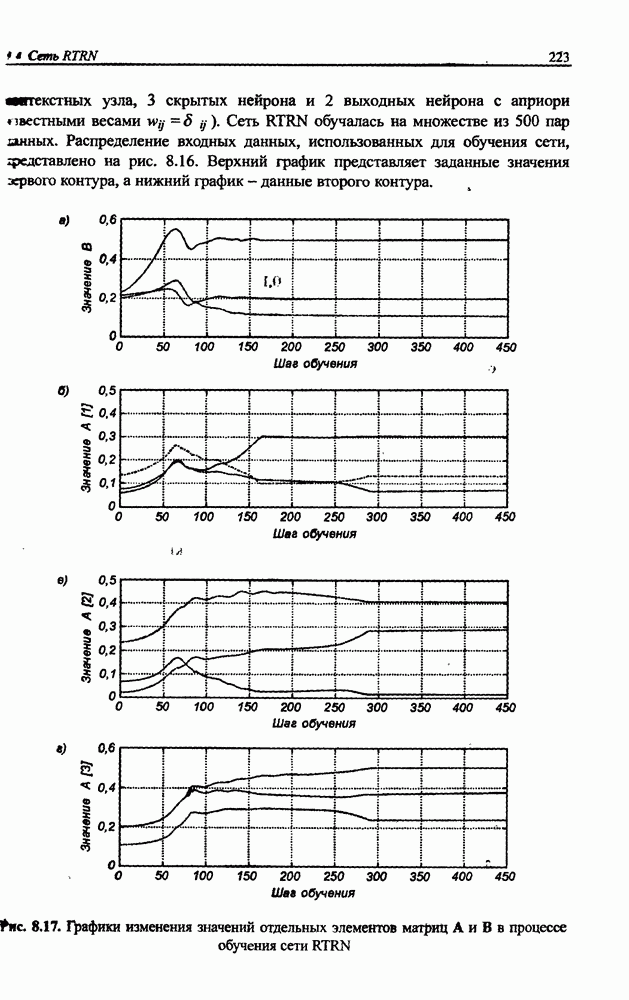
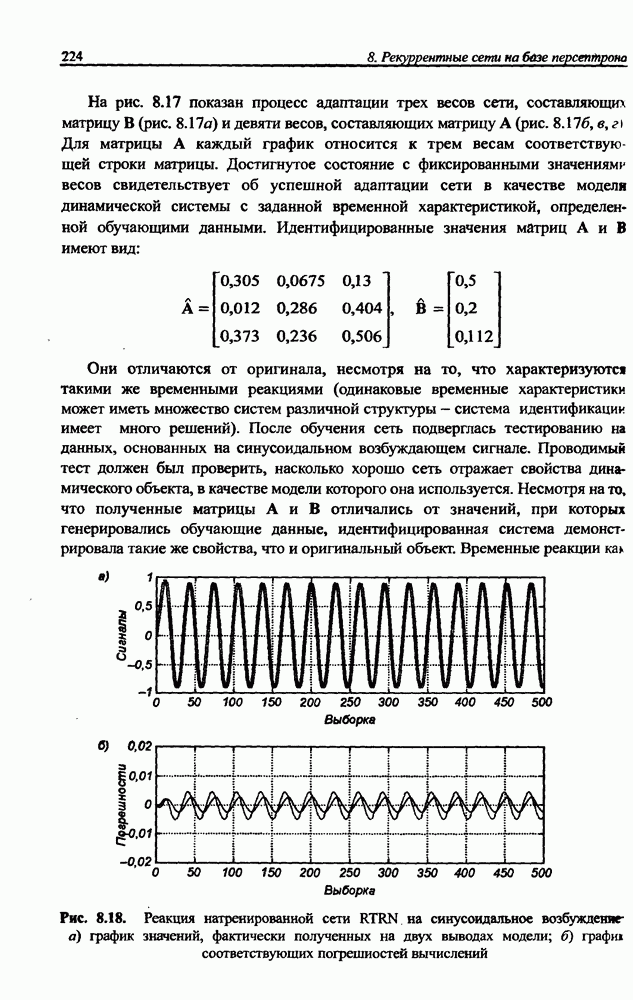
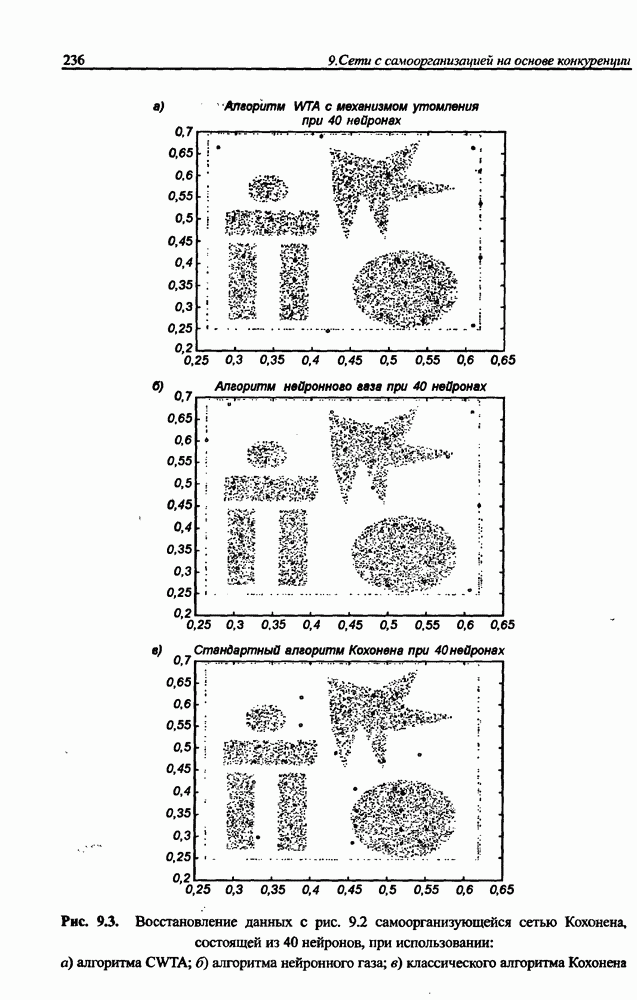
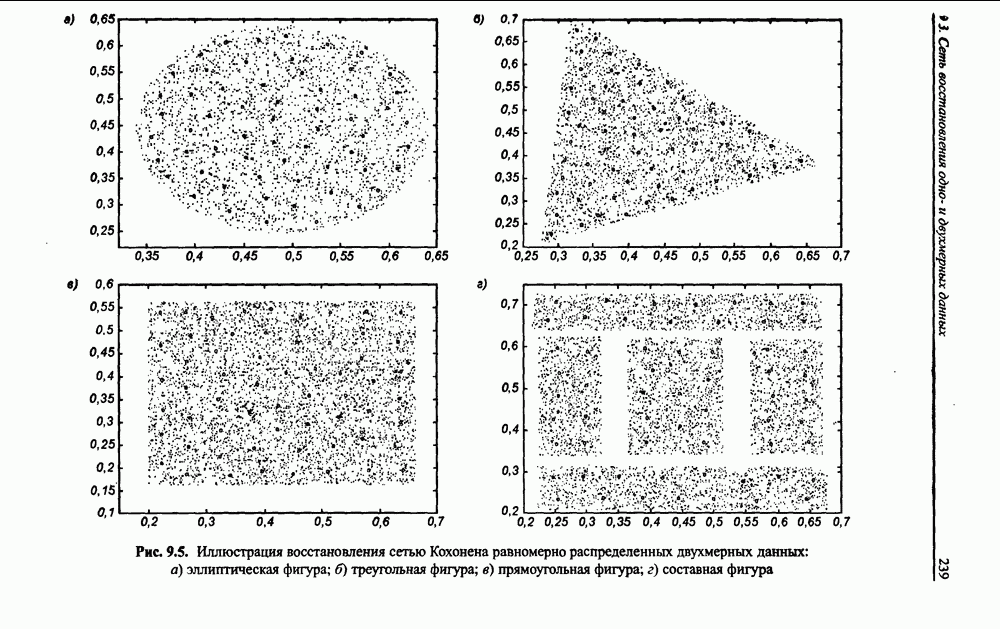
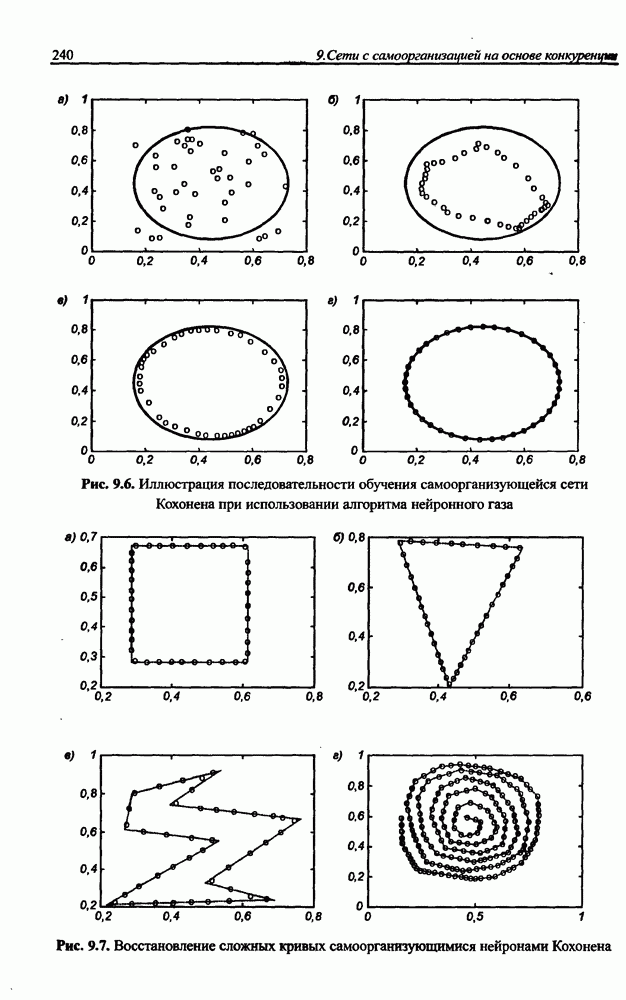
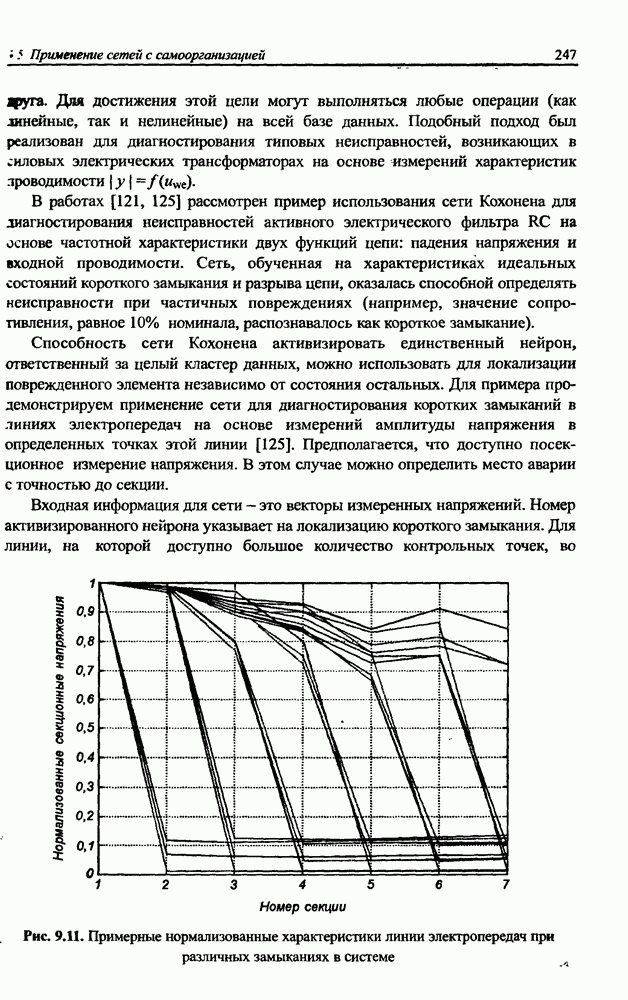
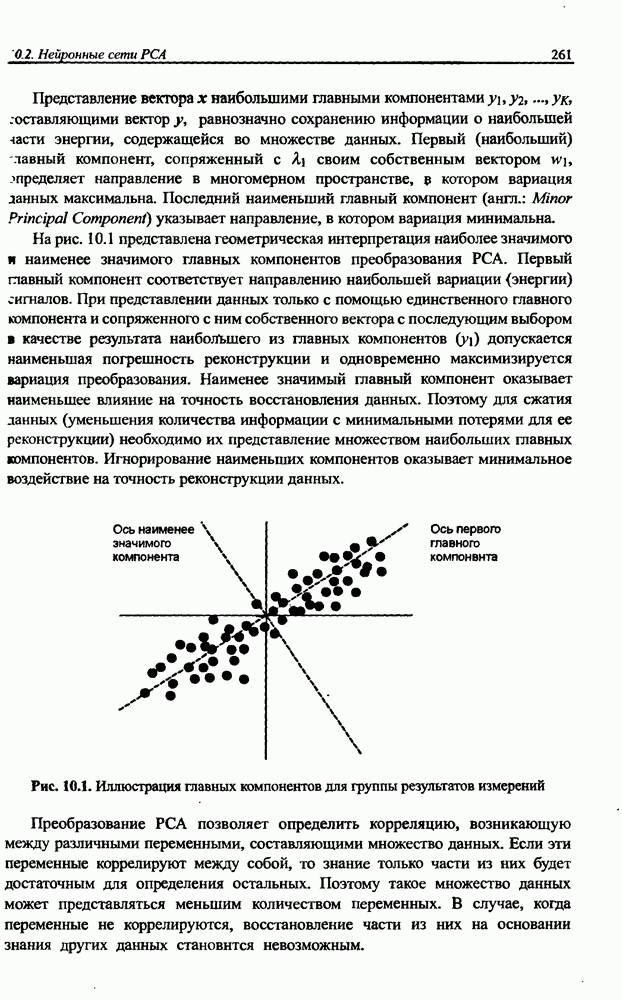
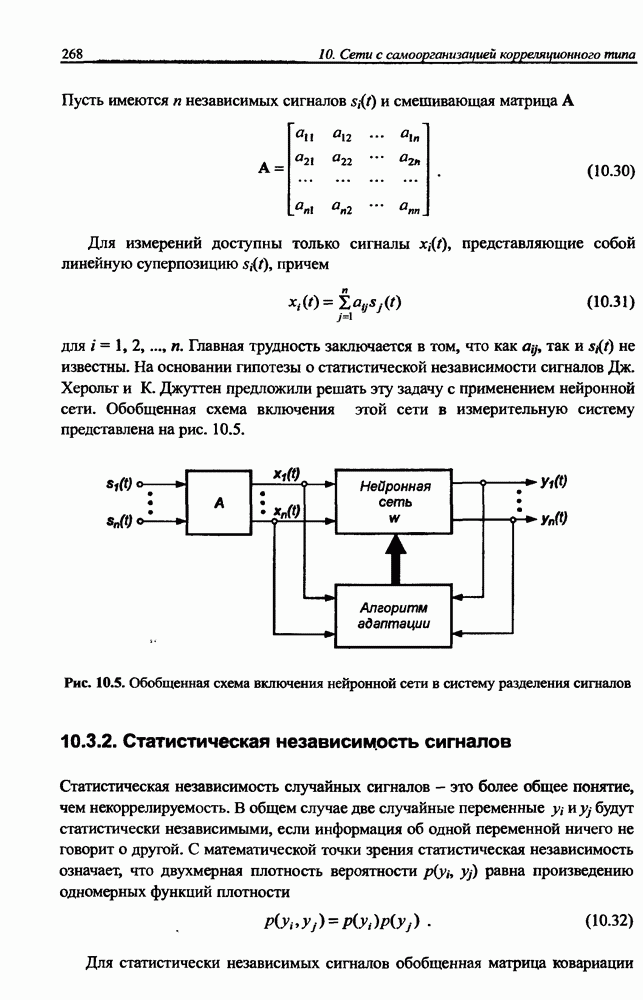
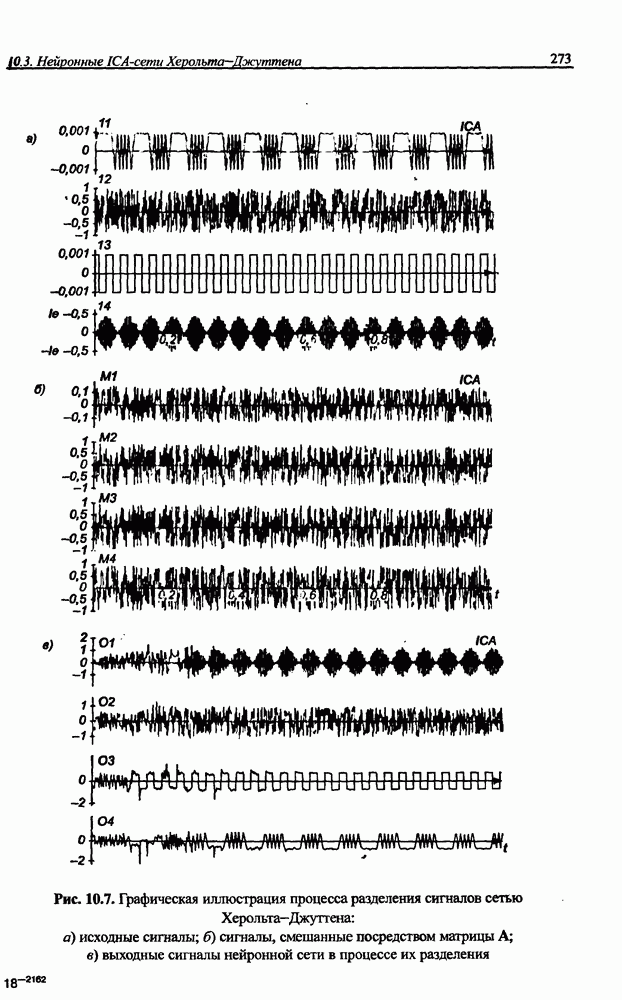
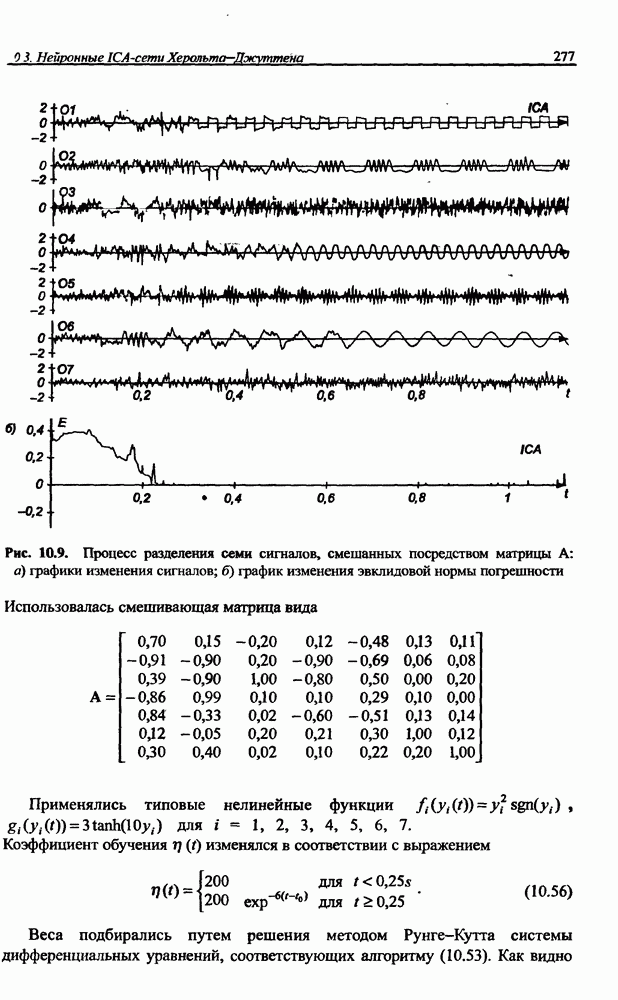
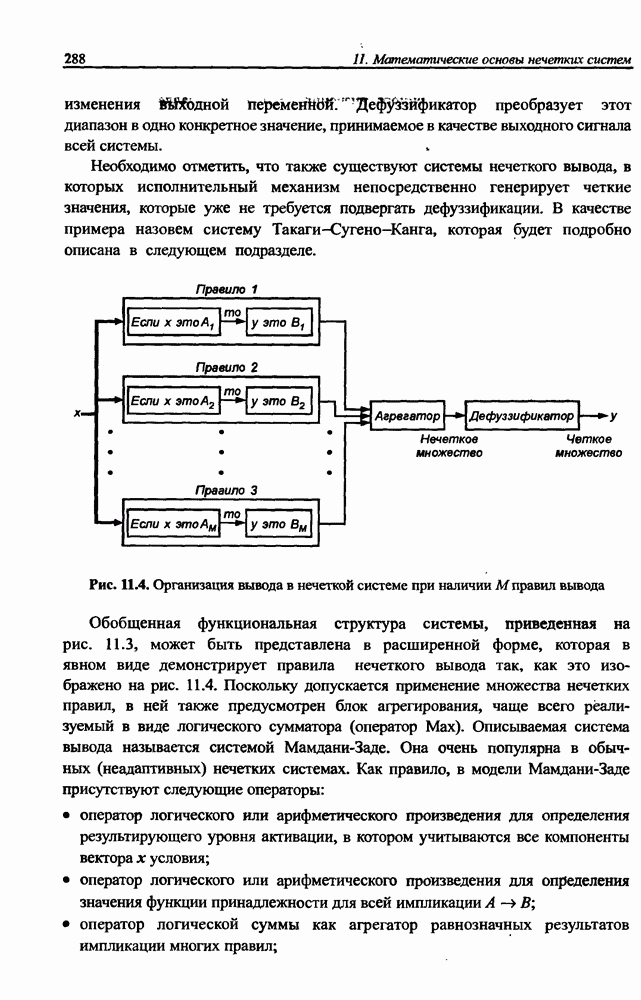
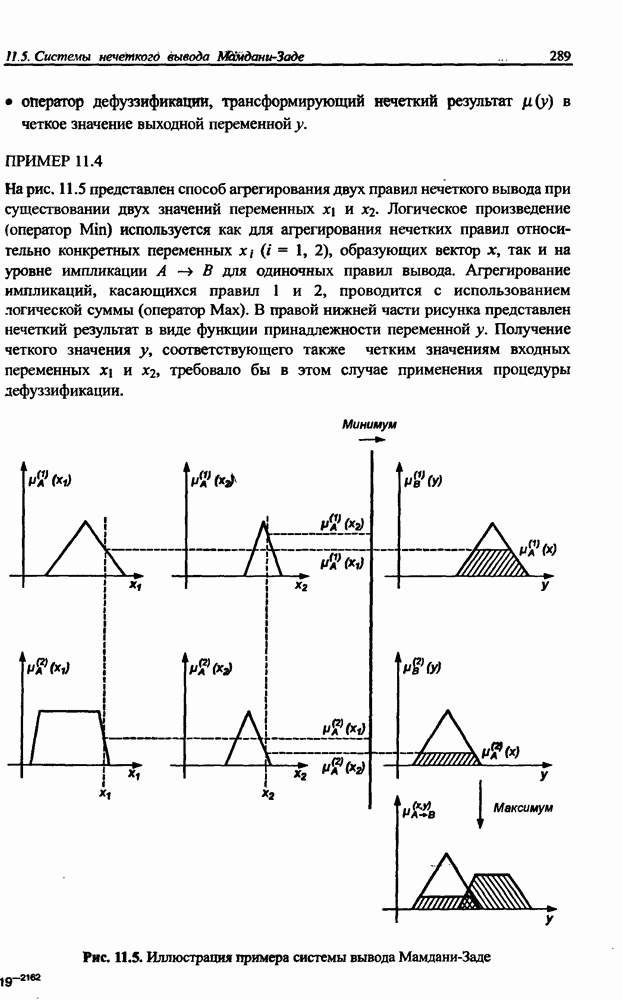
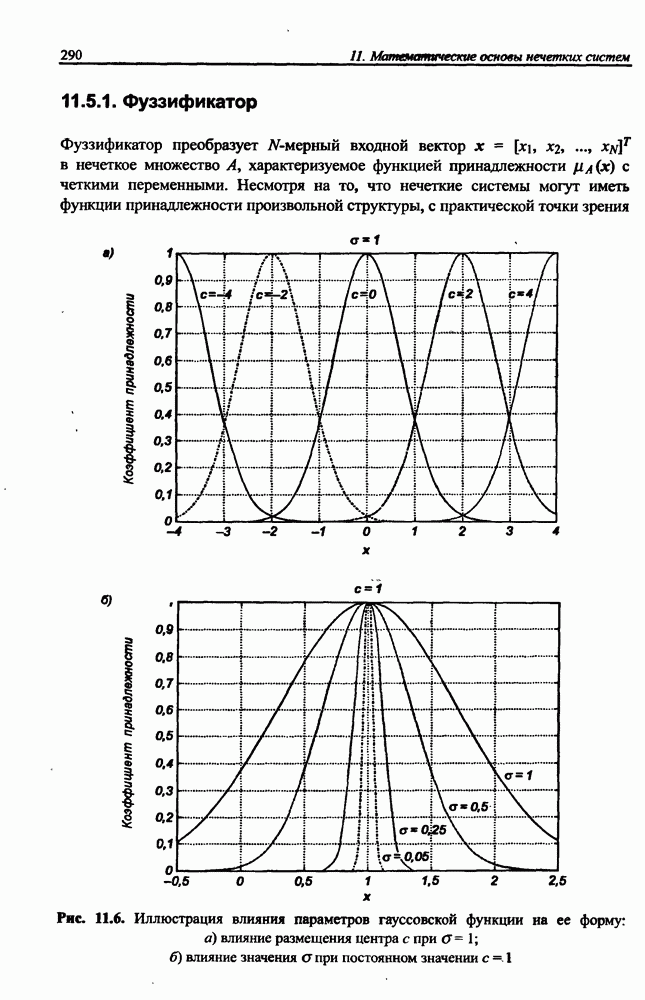
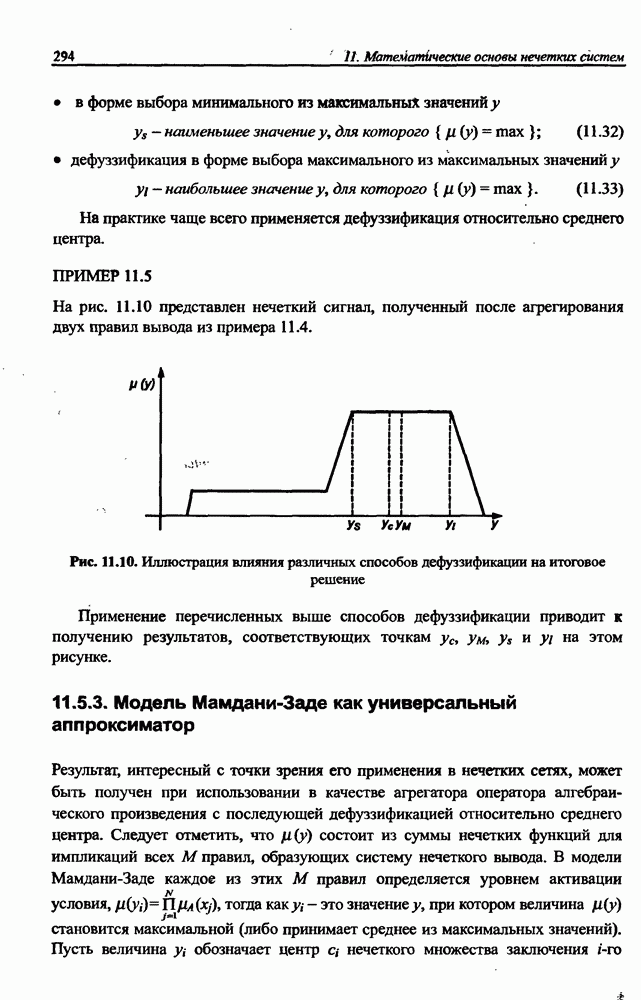
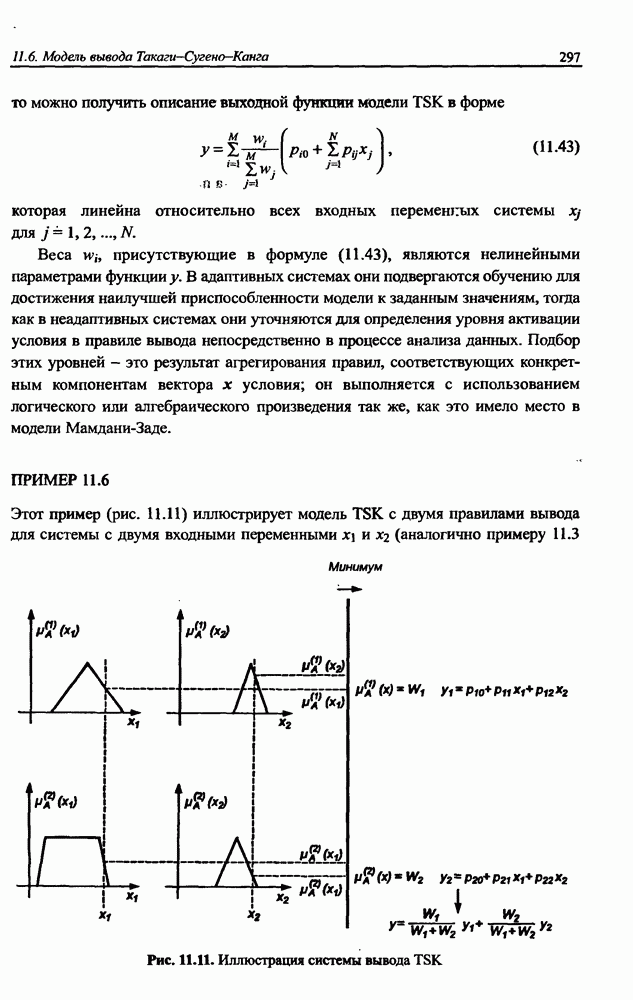
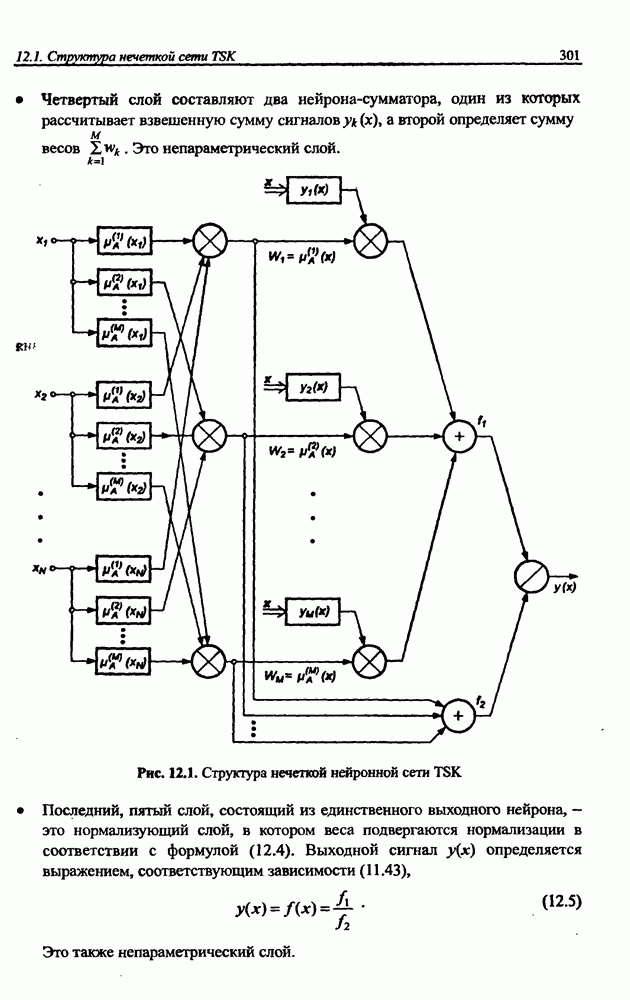
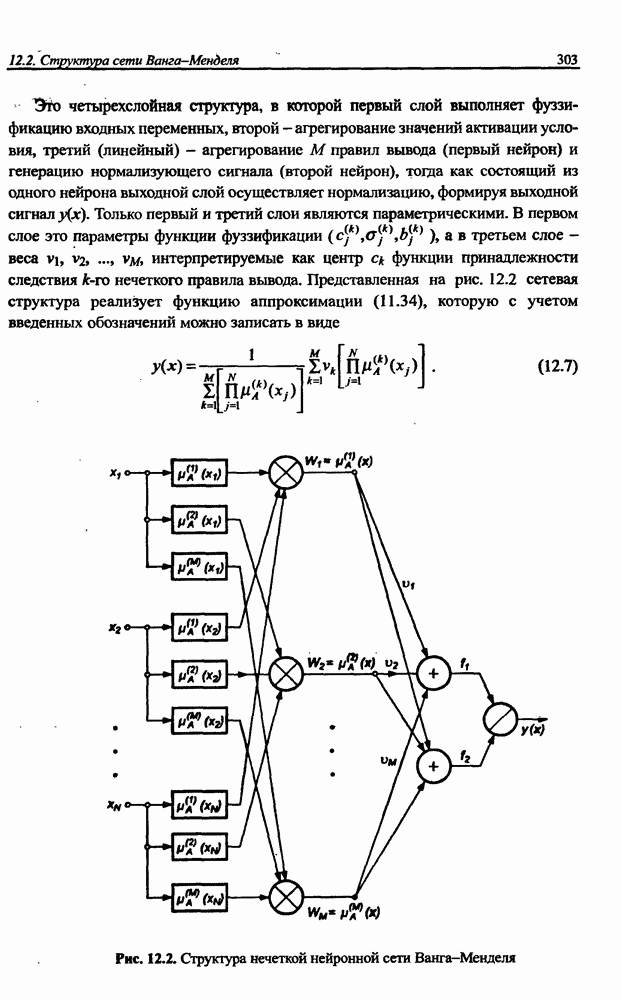
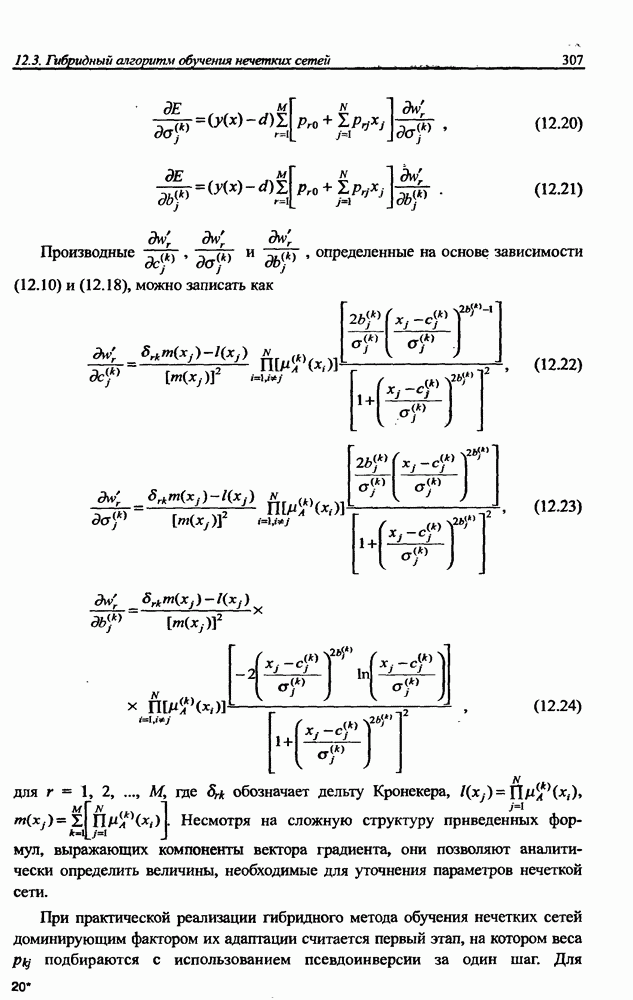
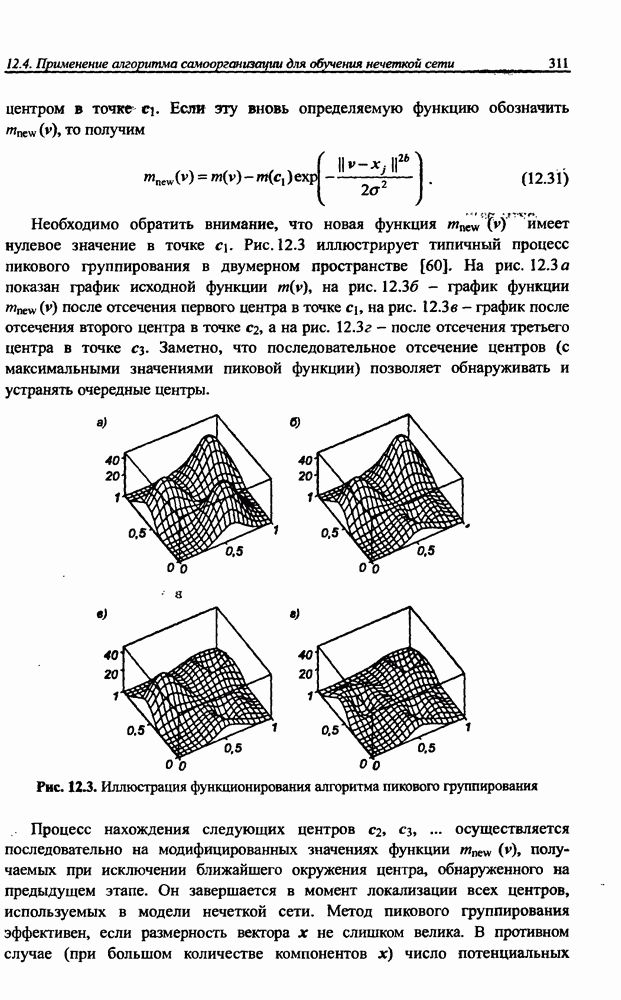
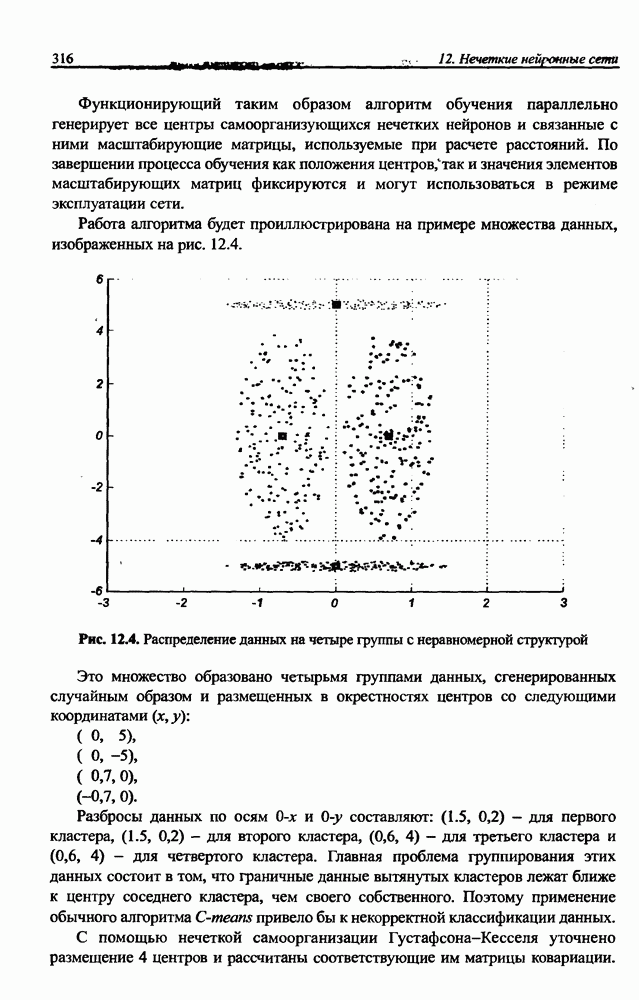
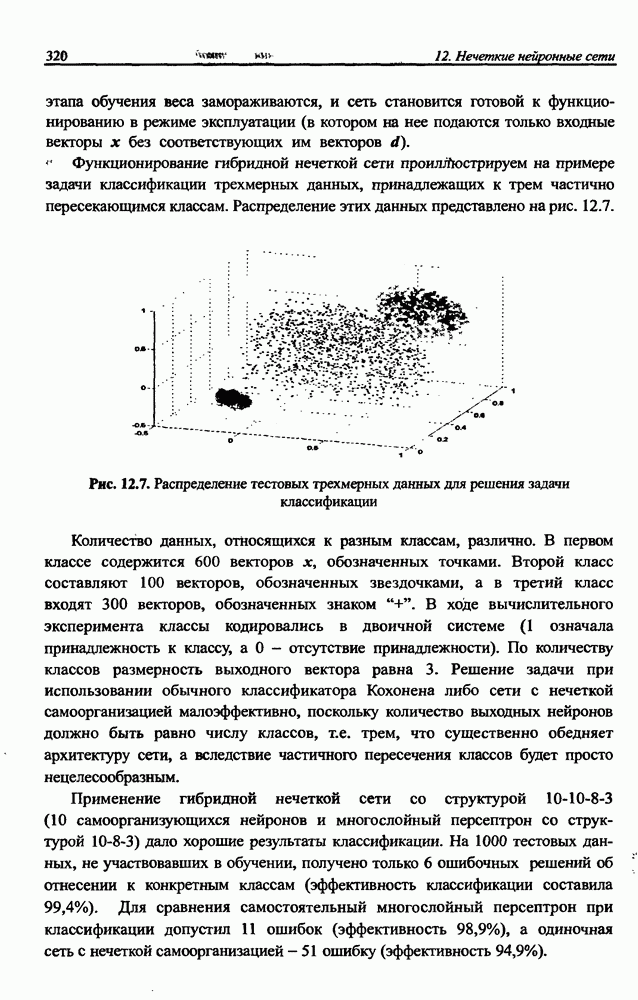
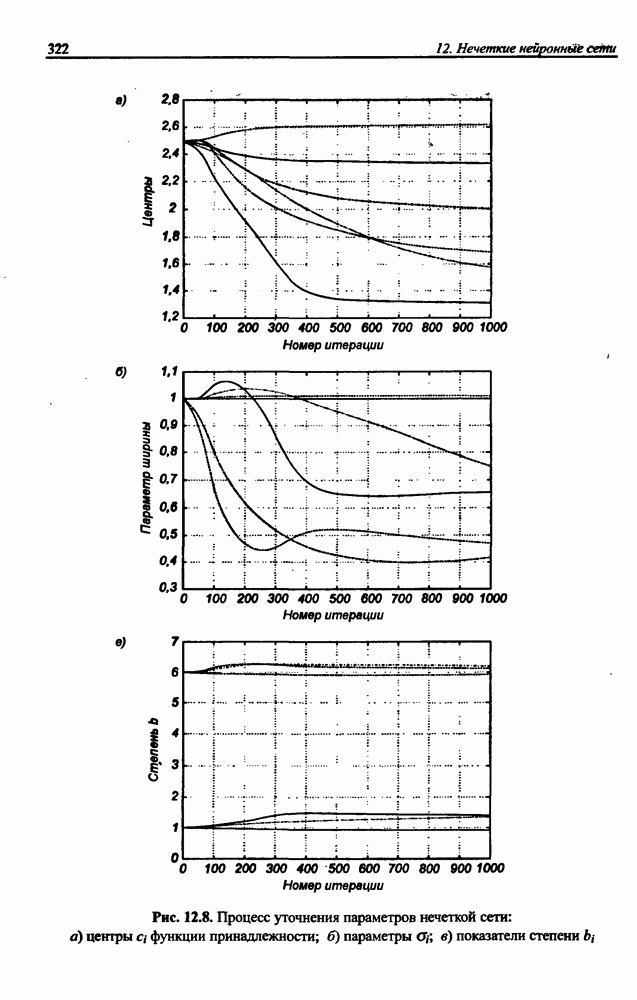
8.3.2. Алгоритм обучения сети Эльмана
Для обучения сети Эльмана будем использовать градиентный метод наискорейшего спуска, основанный на работах Р. Вильямса и Д. Зипсера [171]. Для этого метода необходимо задать формулы, позволяющие рассчитывать градиент целевой функции в текущий момент времени. Целевая функция в момент  определяется как сумма квадратов разностей между значениями выходных сигналов сети и их ожидаемыми значениями для всех М выходных нейронов:
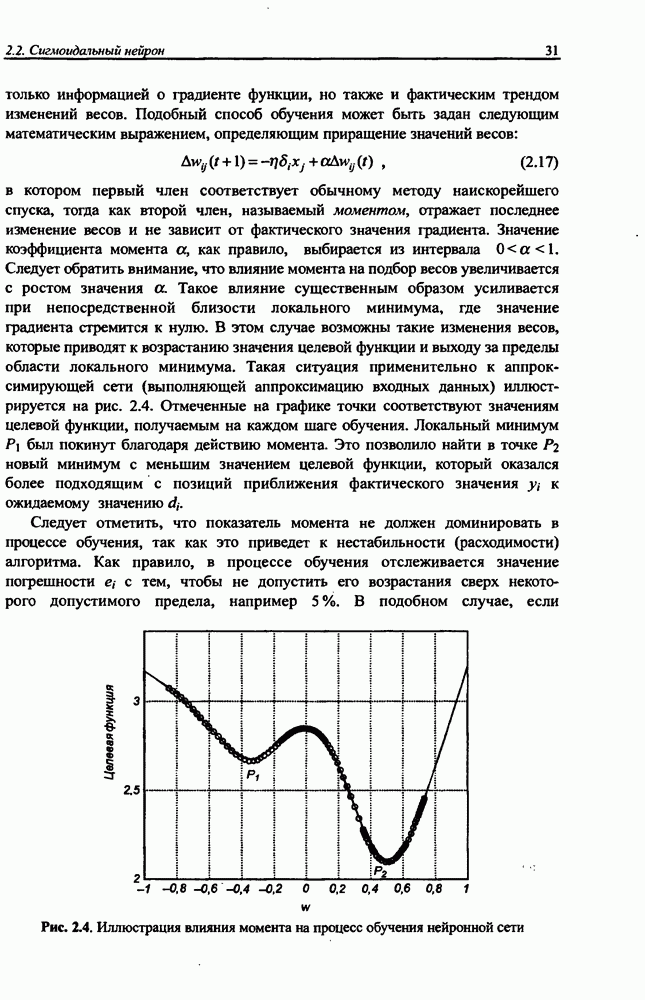
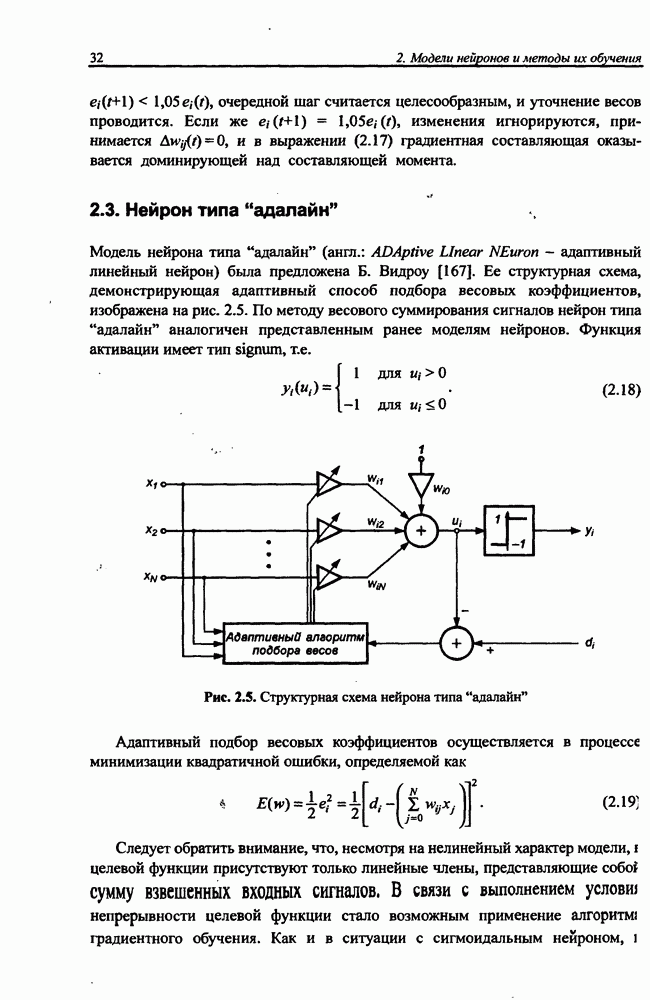
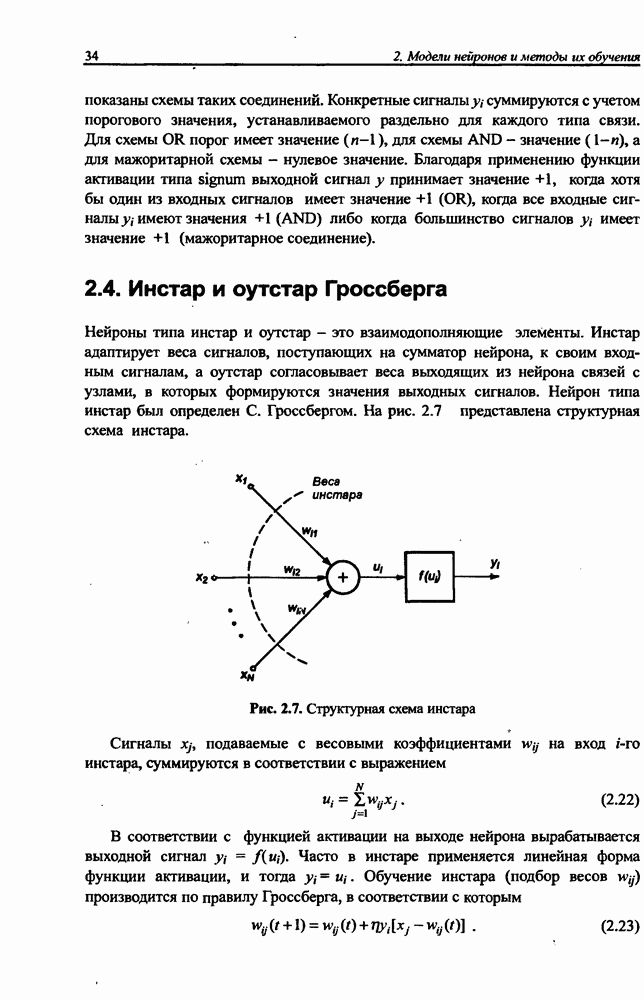
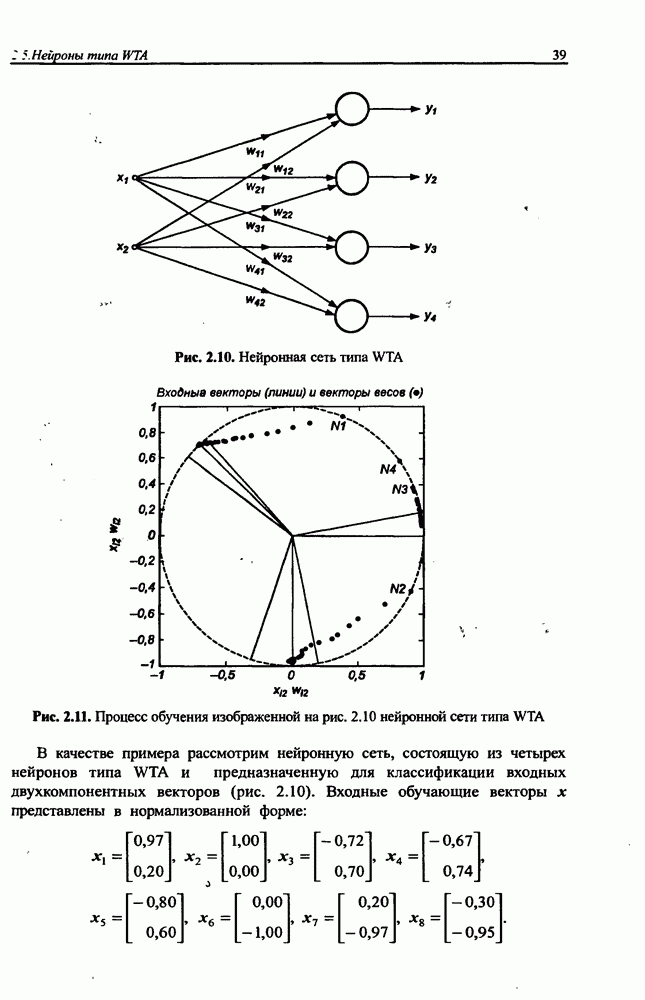
определяется как сумма квадратов разностей между значениями выходных сигналов сети и их ожидаемыми значениями для всех М выходных нейронов:

При дифференцировании целевой функции относительно весов выходного слоя получаем:

С учетом выражений (8.23) и (8.24) зависимость (8.26) можно представить в виде

Связи между скрытым и выходным слоем однонаправленные (см. рис. 8.9), поэтому  . С учетом этого факта
. С учетом этого факта

При использовании метода наискорейшего спуска веса уточняются по формуле  где
где

Простое сравнение с персептронной сетью показывает, что веса выходного слоя сети Эльмана подвергаются точно такой же адаптации, как и веса выходных нейронов персептрона.
Формулы уточнения весов скрытого слоя сети Эльмана более сложны из-за наличия обратных связей между скрытым и контекстным слоями. Расчет компонентов вектора градиента целевой функции относительно весов скрытого слоя требует выполнения значительно большего количества математических операций.
В частности,

С учетом зависимости (8.22) получаем:

Из определения входного вектора  (формула (8.20)) в момент
(формула (8.20)) в момент  следует, что
следует, что 

Это выражение позволяет рассчитать производные целевой функции относительно весов скрытого слоя в момент  Следует отметить, что это рекуррентная формула, определяющая производную в момент
Следует отметить, что это рекуррентная формула, определяющая производную в момент  в зависимости от ее значения в предыдущий момент
в зависимости от ее значения в предыдущий момент  Начальные значения производных в
Начальные значения производных в  исходный момент
исходный момент  считаются нулевыми:
считаются нулевыми:  Таким образом, алгоритм обучения сети Эльйана можно представить в следующем виде.
Таким образом, алгоритм обучения сети Эльйана можно представить в следующем виде.
1. Начать обучение с присвоения весам случайных начальных значений, имеющих, как правило, равномерное распределение в определенном интервале (например, между -1 и 1).
2. Для очередного момента  определить состояние всех нейронов сети (сигналы
определить состояние всех нейронов сети (сигналы  и
и  ). На этой основе можно сформировать входной вектор
). На этой основе можно сформировать входной вектор  для произвольного момента
для произвольного момента 
3. Определить вектор погрешности обучения  для нейронов выходного слоя как разность между фактическим и ожидаемыми значениями сигналов выходных нейронов.
для нейронов выходного слоя как разность между фактическим и ожидаемыми значениями сигналов выходных нейронов.
4. Сформировать вектор градиента целевой функции относительно весов выходного и скрытого слоя с использованием формул (8.28), (8.30) и (8.32).
5. Уточнить значения весов сети согласно правилам метода наискорейшего спуска:
• для нейронов выходного слоя сети

• для нейронов скрытого слоя сети

После уточнения значений весов вернуться к пункту 2 алгоритма для расчетов в очередной момент 
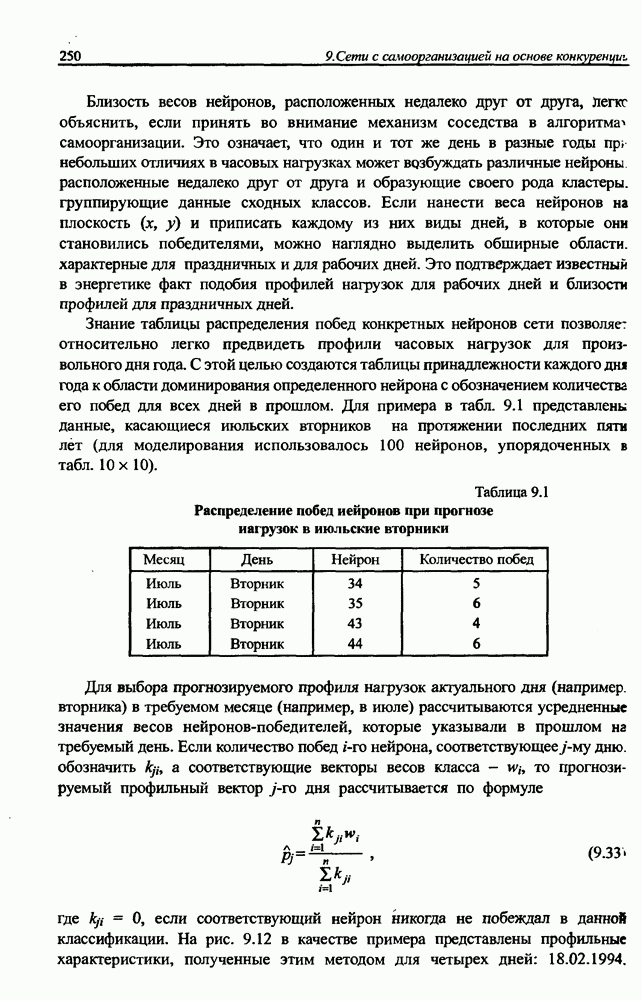
Для упрощения вычислений при выводе формул (8.33) и (8.34) была предложена онлайн-версия алгоритма обучения, согласно которой значения весов уточнялись после предъявления каждой обучающей пары  Обычный офф-лайн-алгоритм несколько более эффективен, поскольку при его выполнении значения весов уточняются только после предъявления всех обучающих пар. Реализация такой версии алгоритма аналогична рассмотренной выше с той разницей, что в ней суммируются компоненты градиента последовательно предъявляемых обучающих пар, а процесс изменения весов выполняется
Обычный офф-лайн-алгоритм несколько более эффективен, поскольку при его выполнении значения весов уточняются только после предъявления всех обучающих пар. Реализация такой версии алгоритма аналогична рассмотренной выше с той разницей, что в ней суммируются компоненты градиента последовательно предъявляемых обучающих пар, а процесс изменения весов выполняется  каждом цикле только один раз.
каждом цикле только один раз.
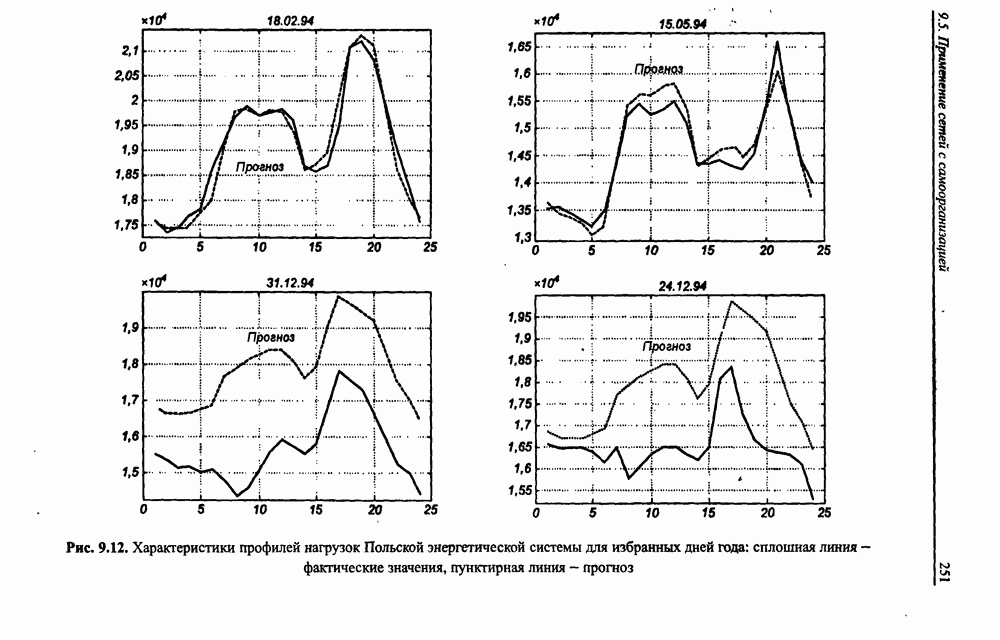
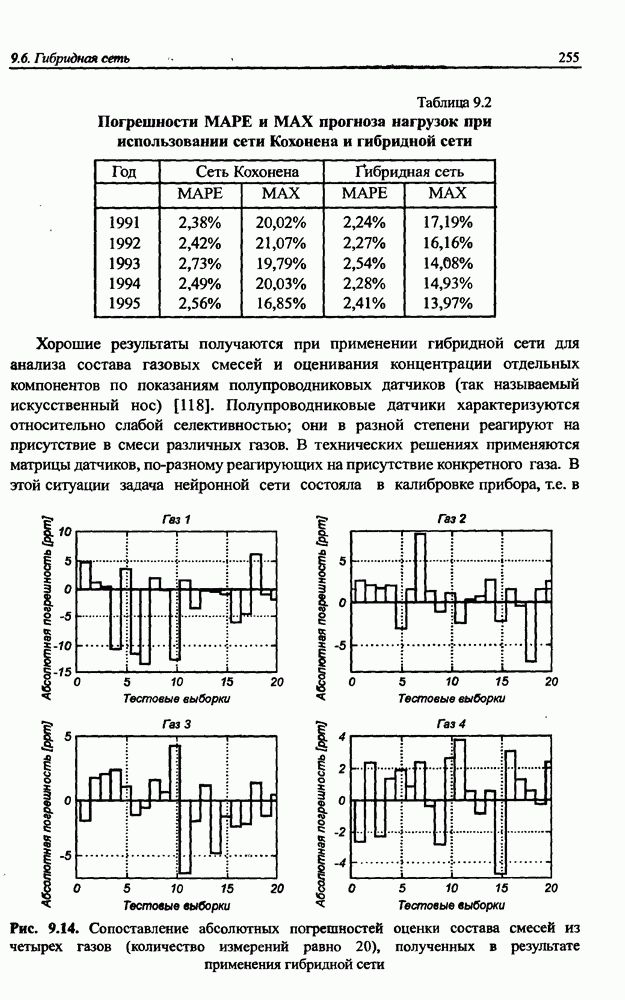
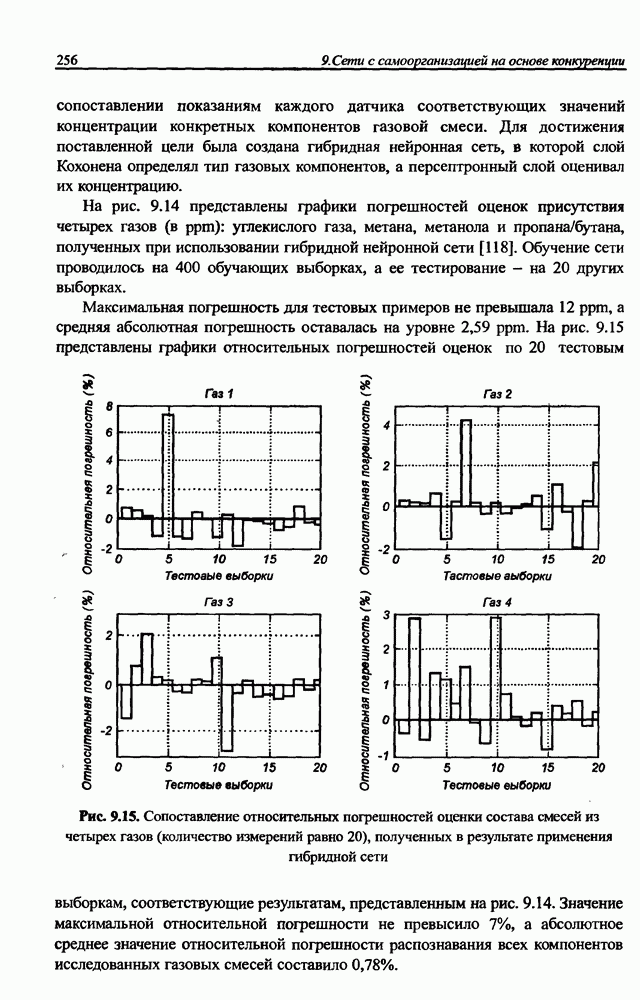
Представленный алгоритм считается нелокальным, поскольку уточнение каждого отдельного веса требует знания значений всех остальных весов сети и сигналов конкретных нейронов. Его требования к размерам памяти компьютер дополнительно повышаются в связи с необходимостью хранить все значения