Пред.
След.
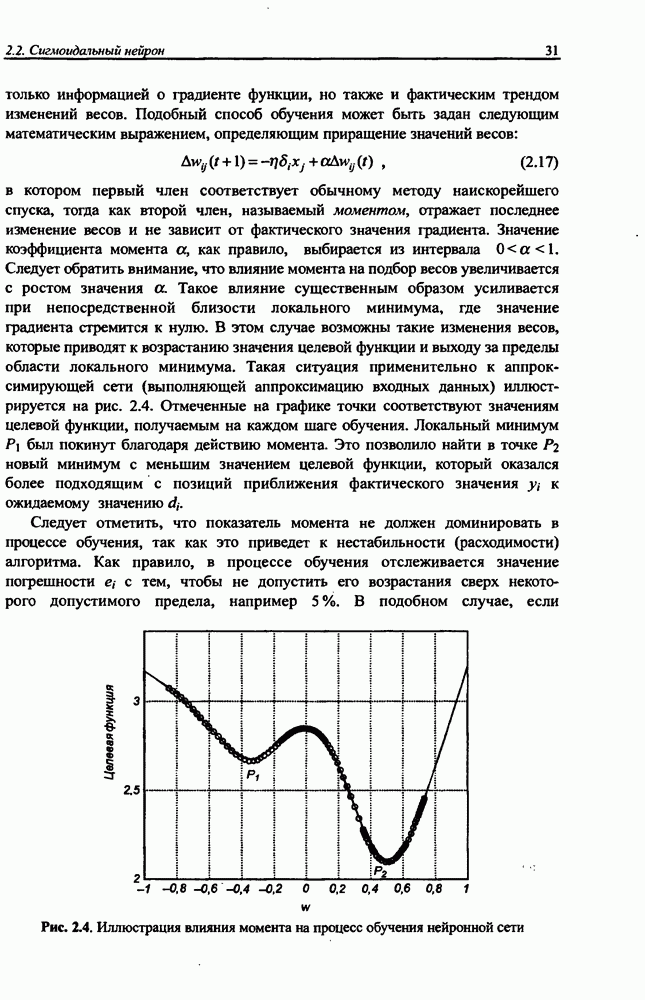
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
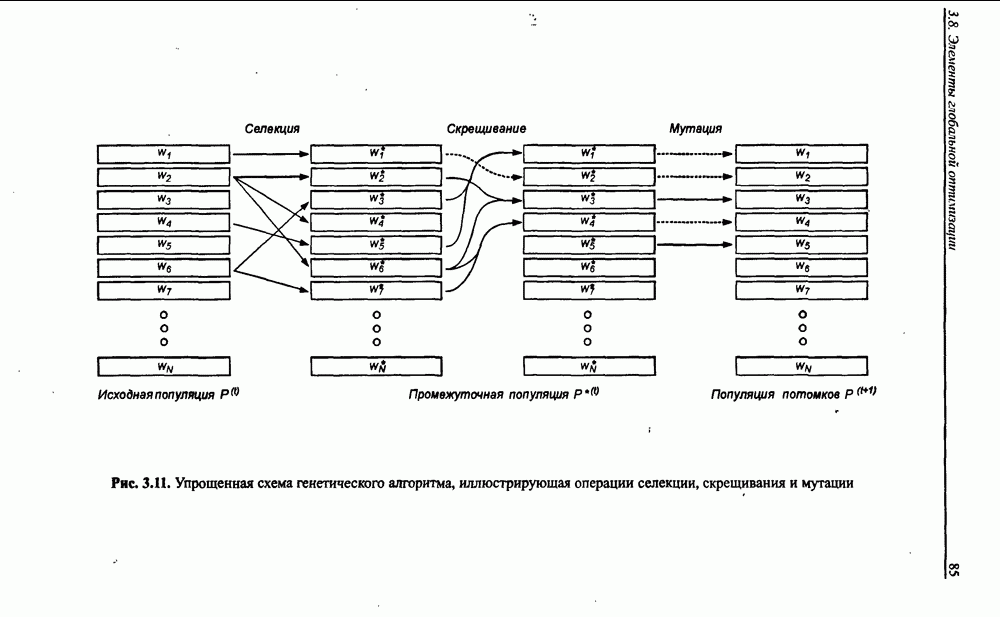
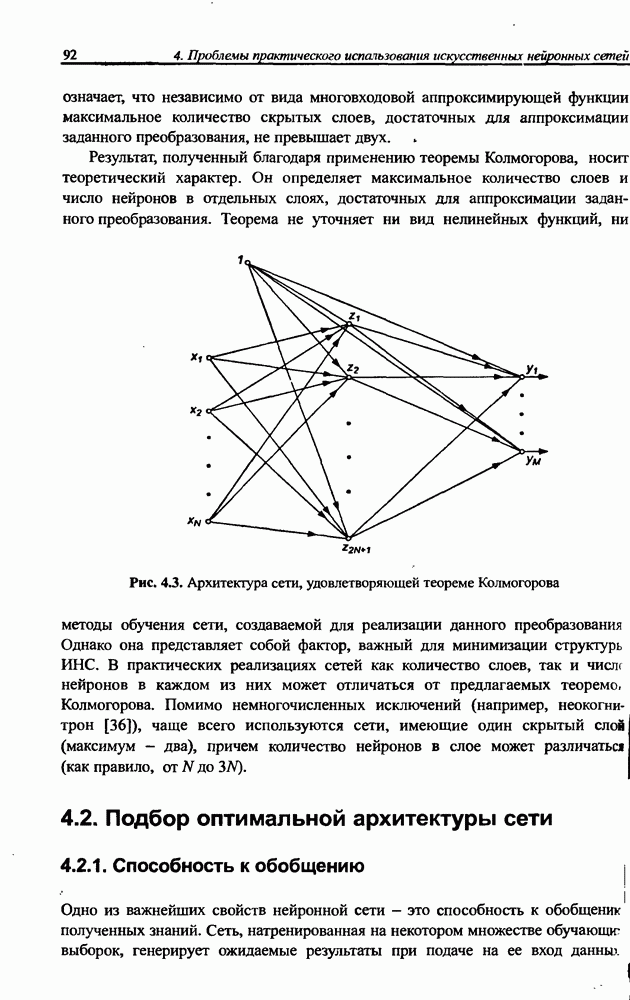
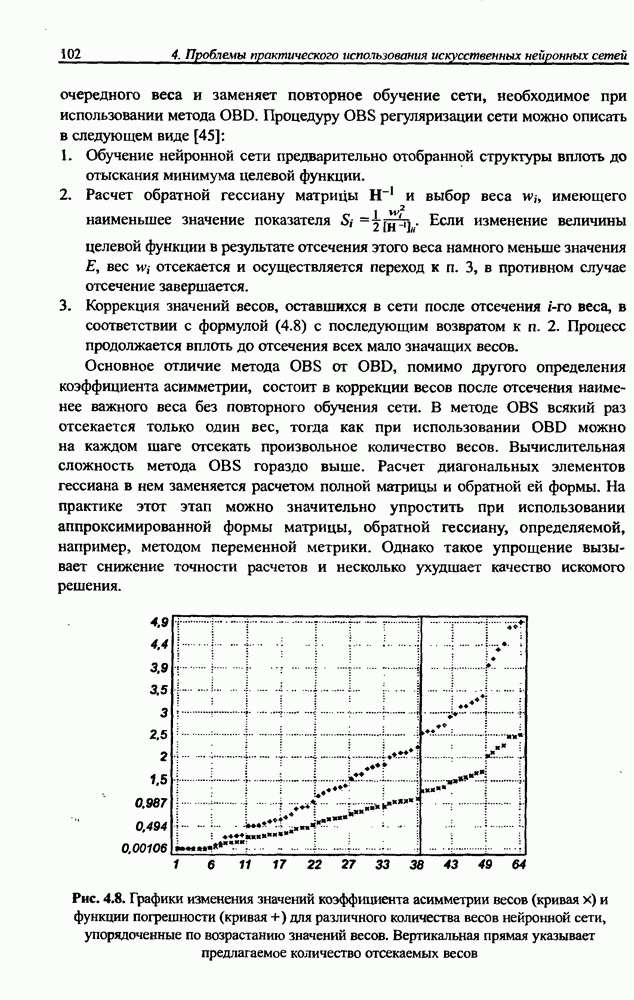
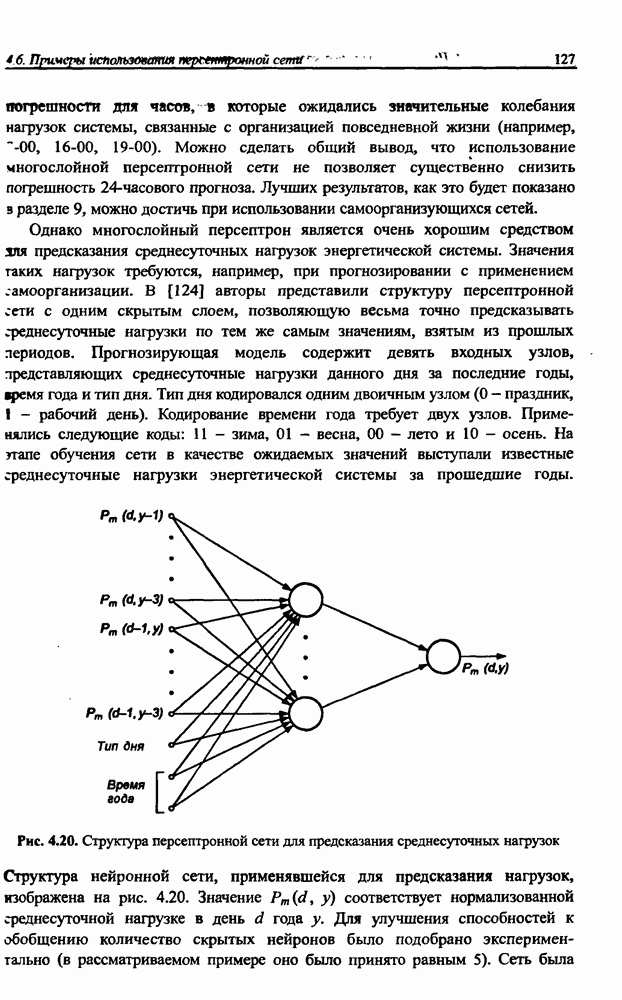
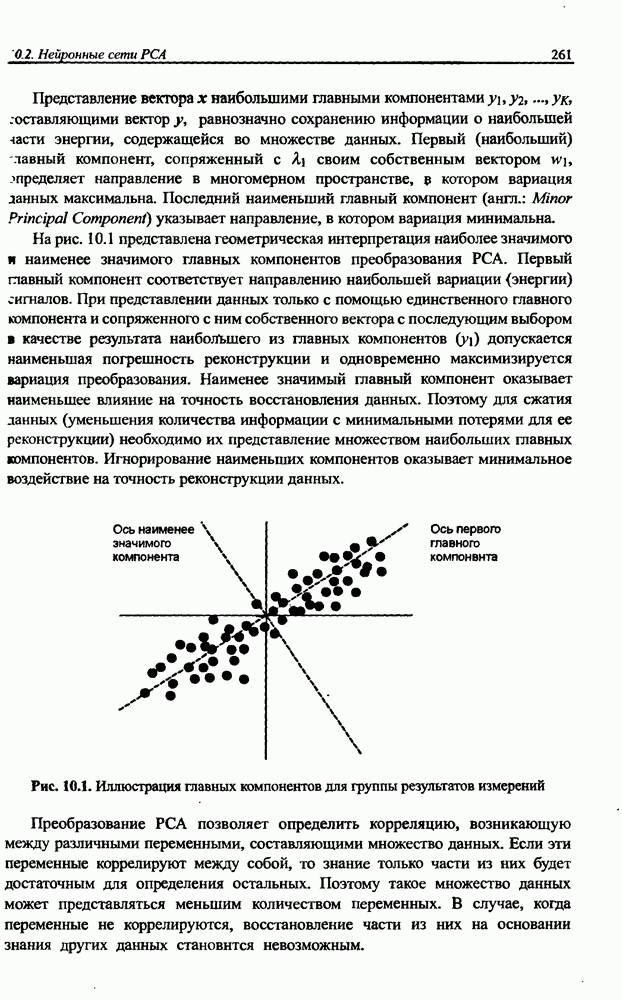
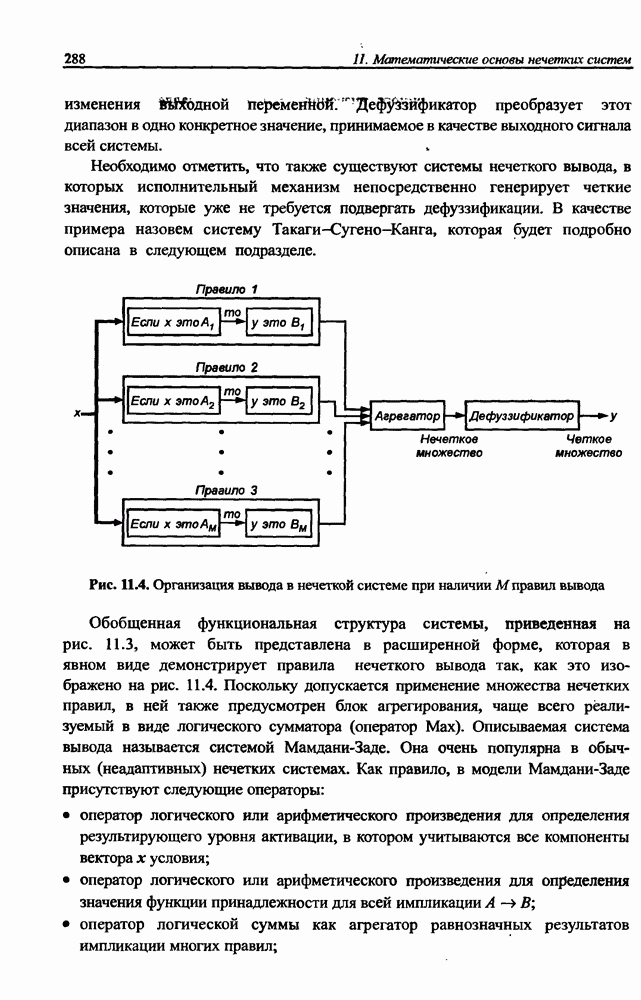
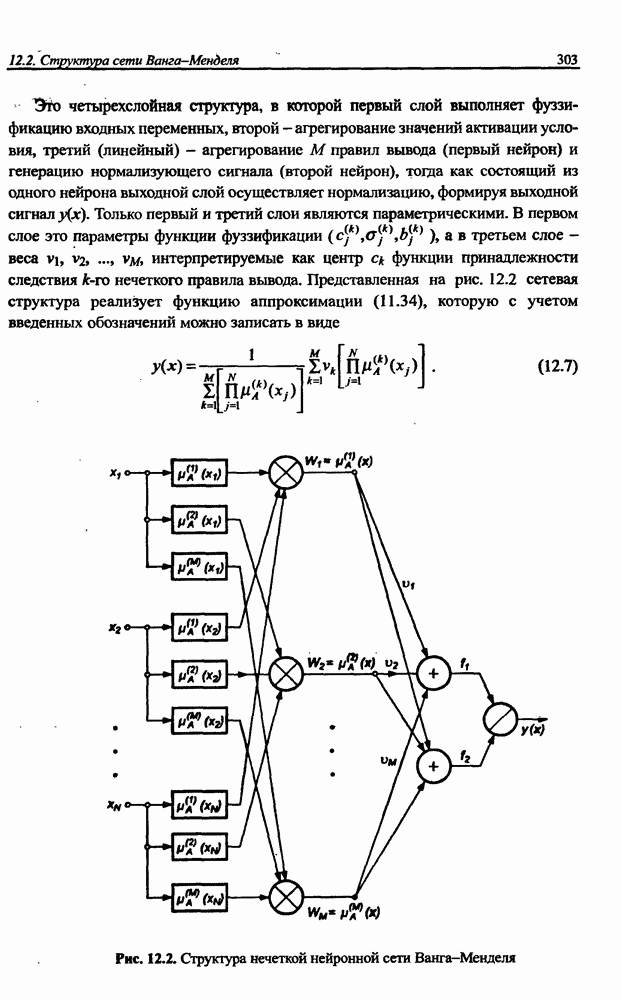
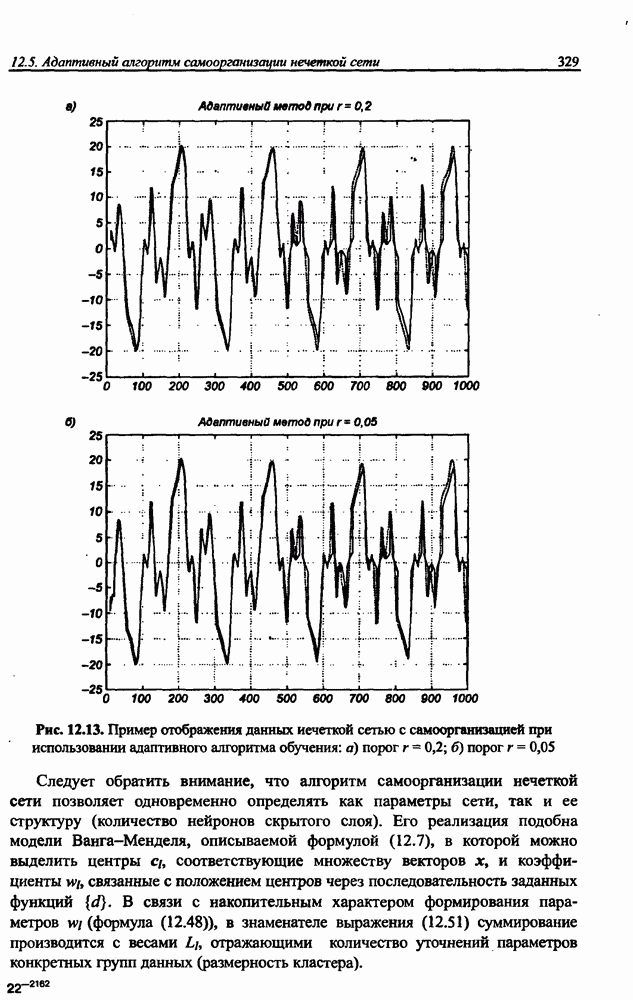
Раздел 12. НЕЧЕТКИЕ НЕЙРОННЫЕ СЕТИПредставленные в предыдущем разделе модели вывода Мамдани-Заде и TSK позволяют описать выходной сигнал многомерного процесса как нелинейную функцию входных переменных 12.1. Структура нечеткой сети TSKОбобщенную схему вывода в модели TSK при использовании М правил и N переменных
Условие
где
При М правилах вывода агрегирование выходного результата сети производится по формуле (11.43), которую можно представить в виде
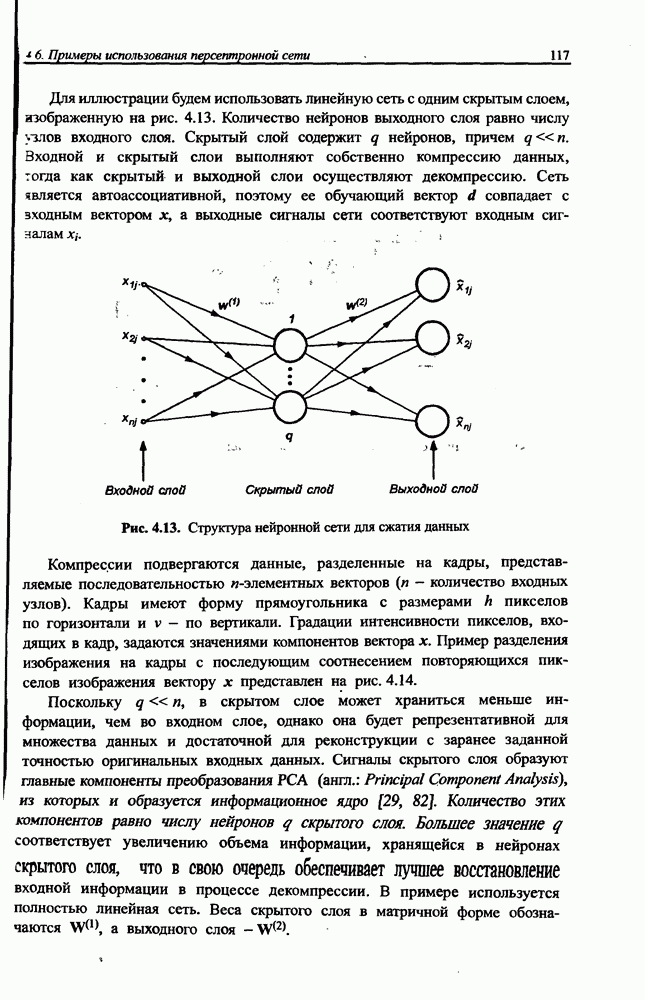
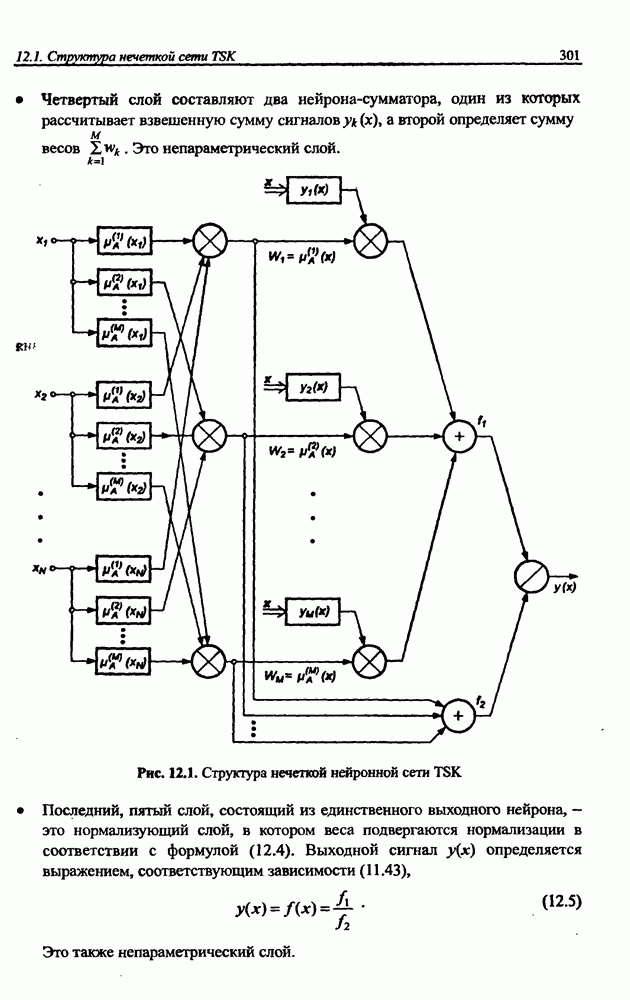
где • Первый слой выполняет раздельную фуззификацию каждой переменной • Второй слой выполняет агрегирование отдельных переменных • Третий слой представляет собой генератор функции TSK, рассчитывающий значения • Четвертый слой составляют два нейрона-сумматора, один из которых рассчитывает взвешенную сумму сигналов у к Рис. 12.1. (см. скан) Структура нечеткой нейронной сети TSK • Последний, пятый слой, состоящий из единственного выходного нейрона, - это нормализующий слой, в котором веса подвергаются нормализации в соответствии с формулой (12.4). Выходной сигнал
Это также непараметрический слой. Из приведенного описания следует, что нечеткая сеть TSK содержит только два параметрических слоя (первый и третий), параметры которых уточняются в процессе обучения. Параметры первого слоя будем называть нелинейными параметрами, поскольку они относятся к нелинейной функции (12.2), а параметры третьего слоя - линейными весами, так как они относятся к параметрам При уточнении функциональной зависимости (12.4) для сети TSK получаем:
Если принять, что в конкретный момент времени параметры условия зафиксированы, то функция При наличии На практике для уменьшения количества адаптируемых параметров оперируют меньшим количеством независимых функций принадлежности для отдельных переменных, руководствуясь правилами, в которых комбинируются функции принадлежности различных переменных. Если принять, что каждая переменная
|
 |
Оглавление
|










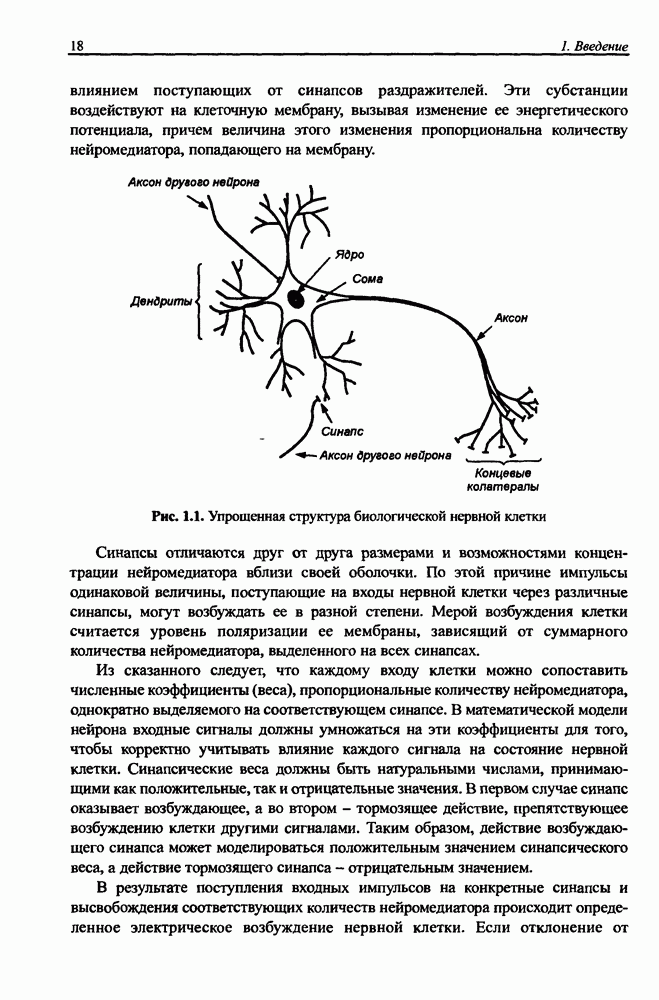
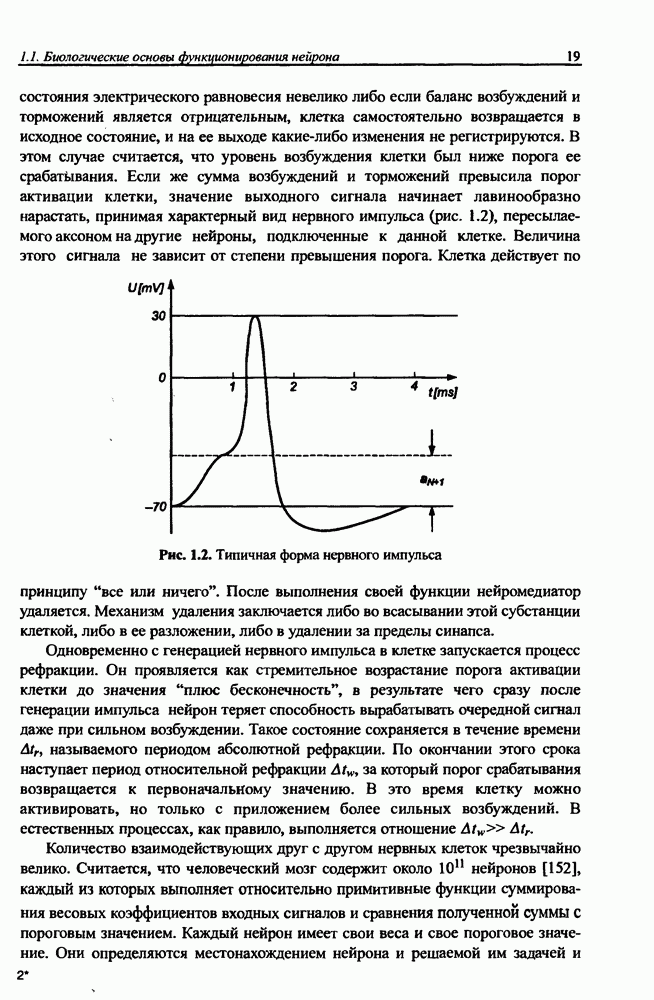









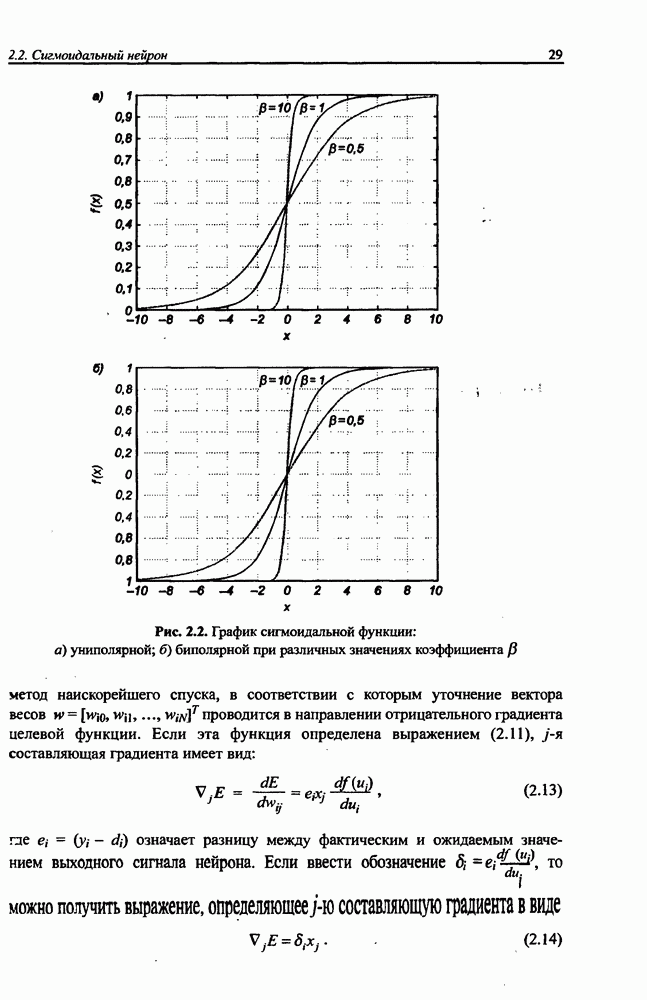
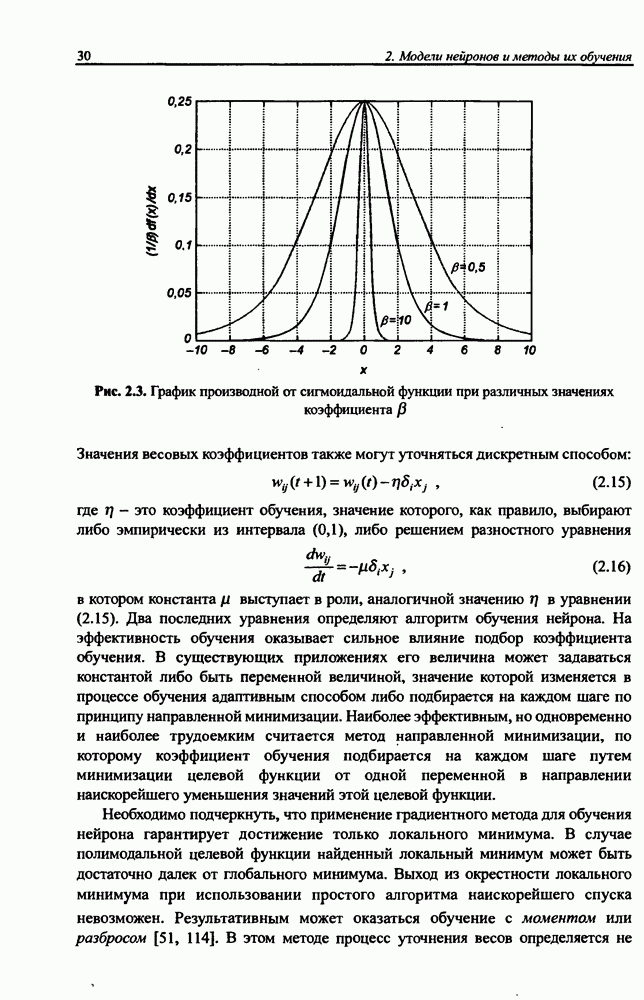
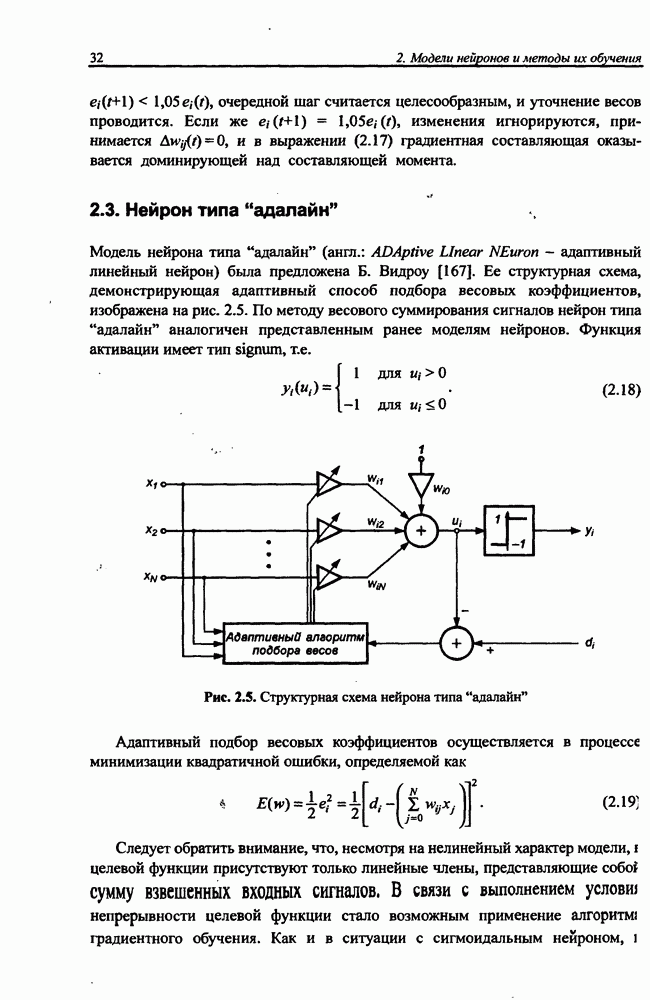



















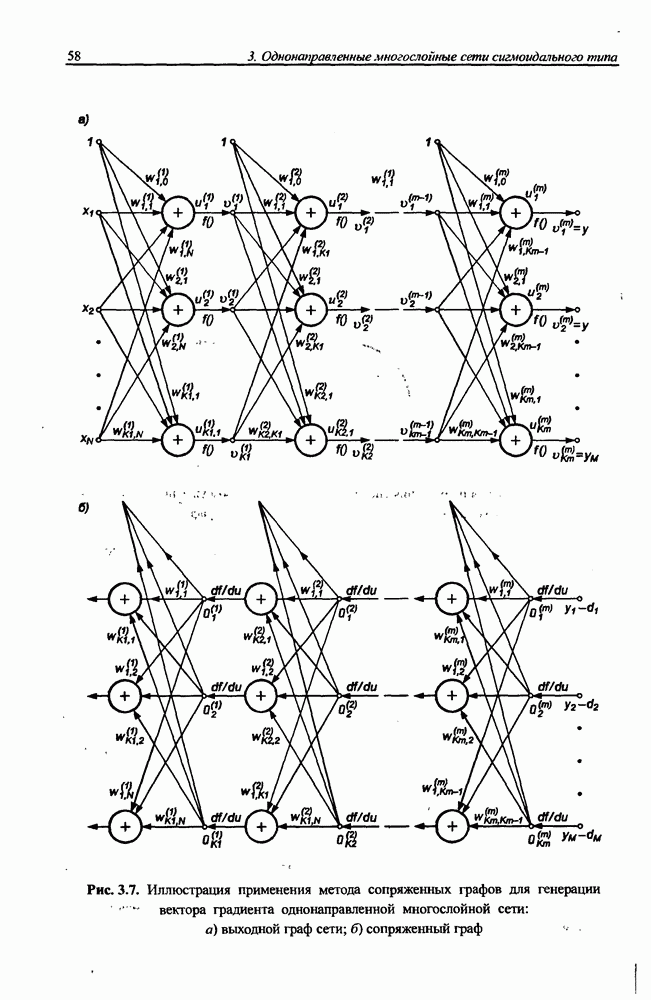
















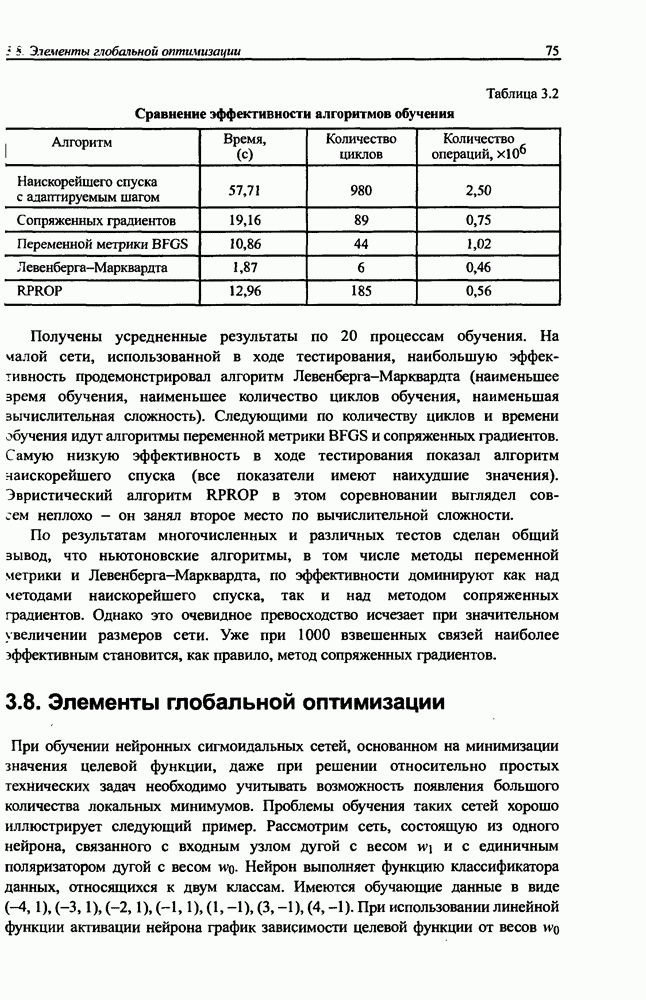

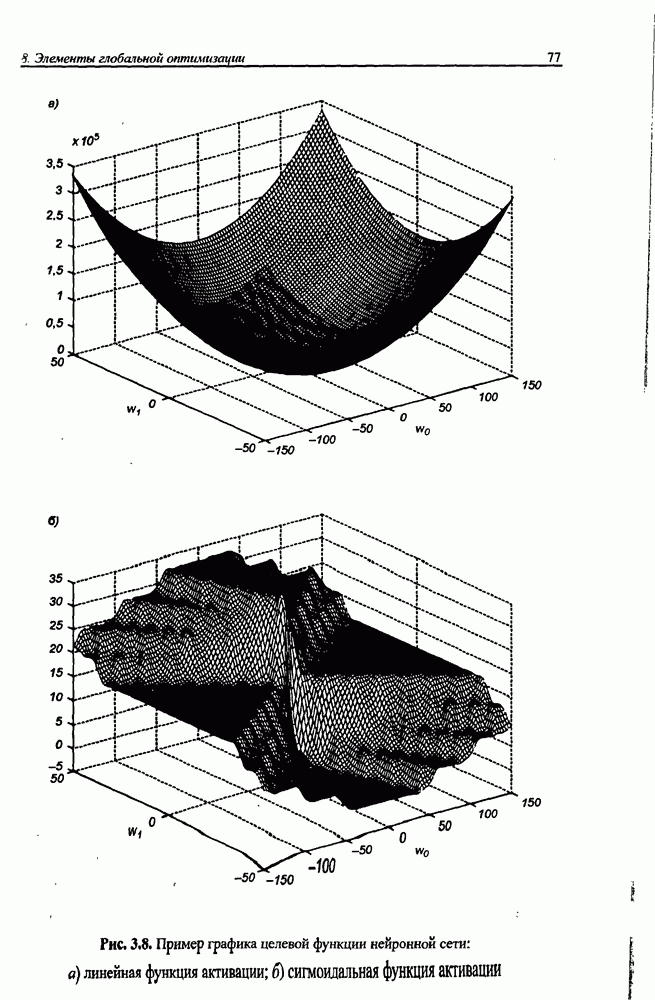





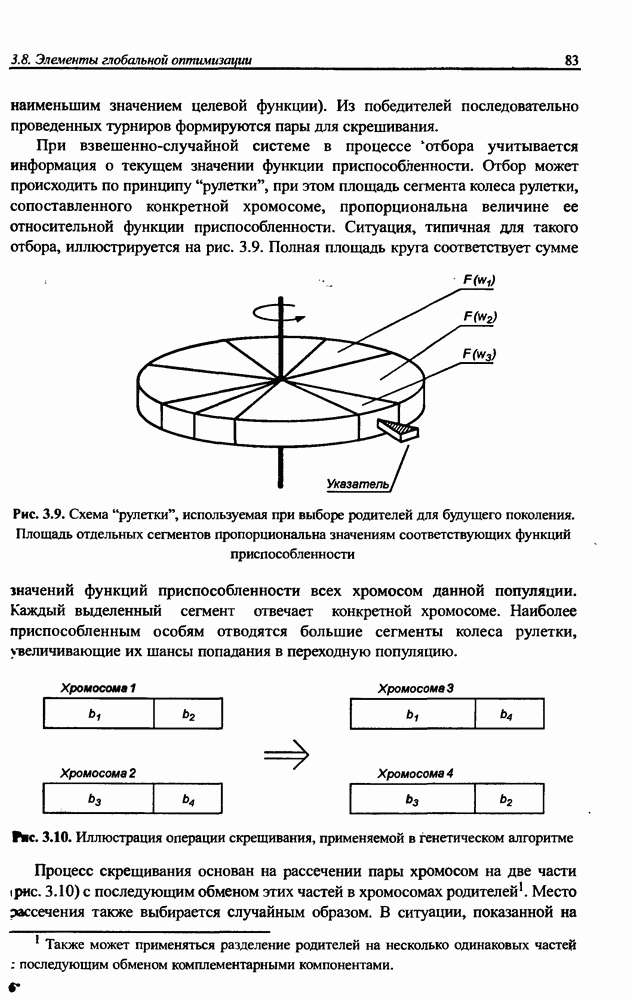

























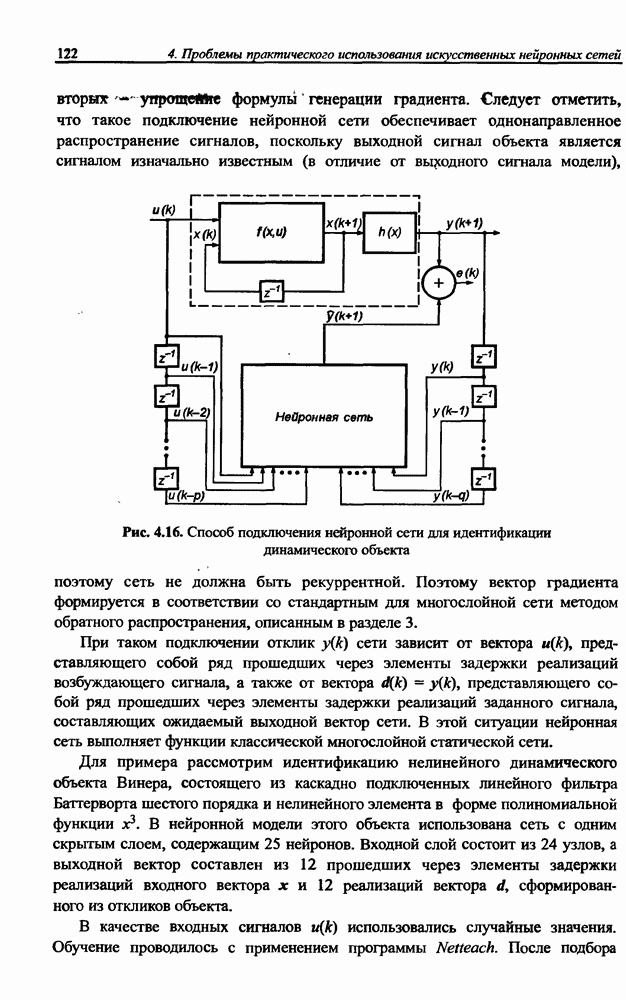
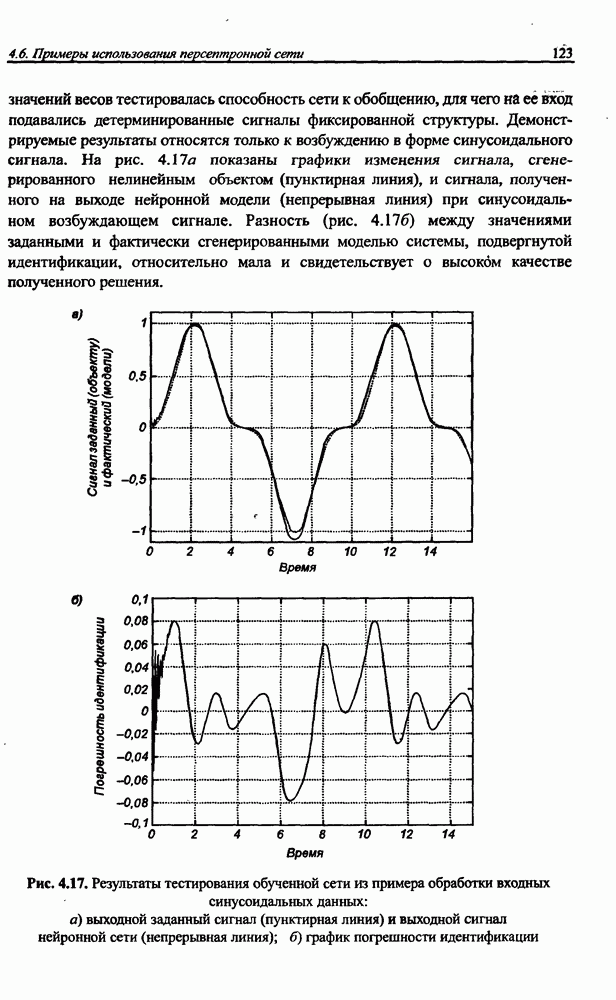


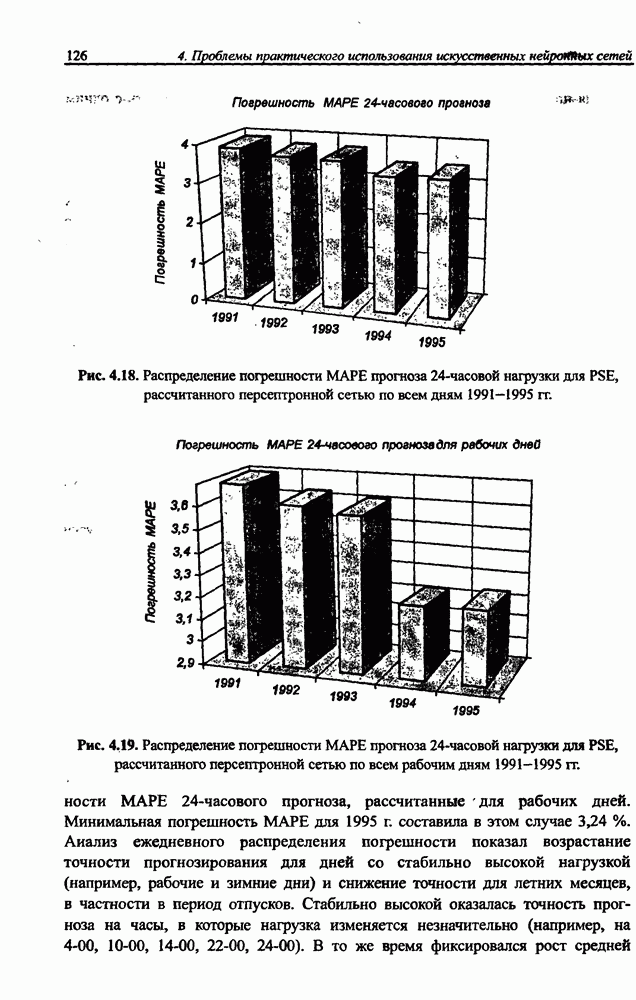








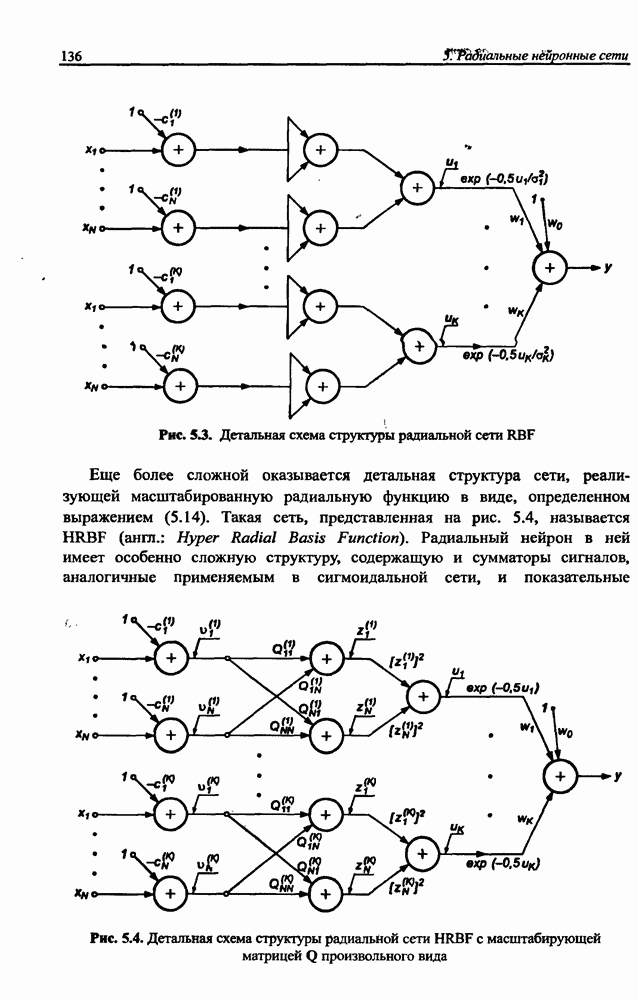
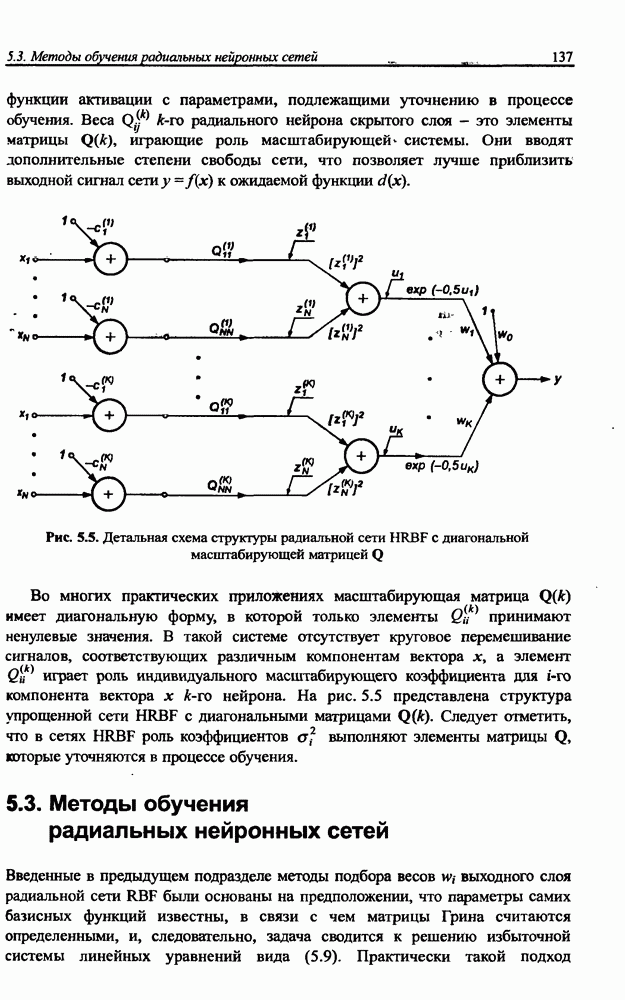





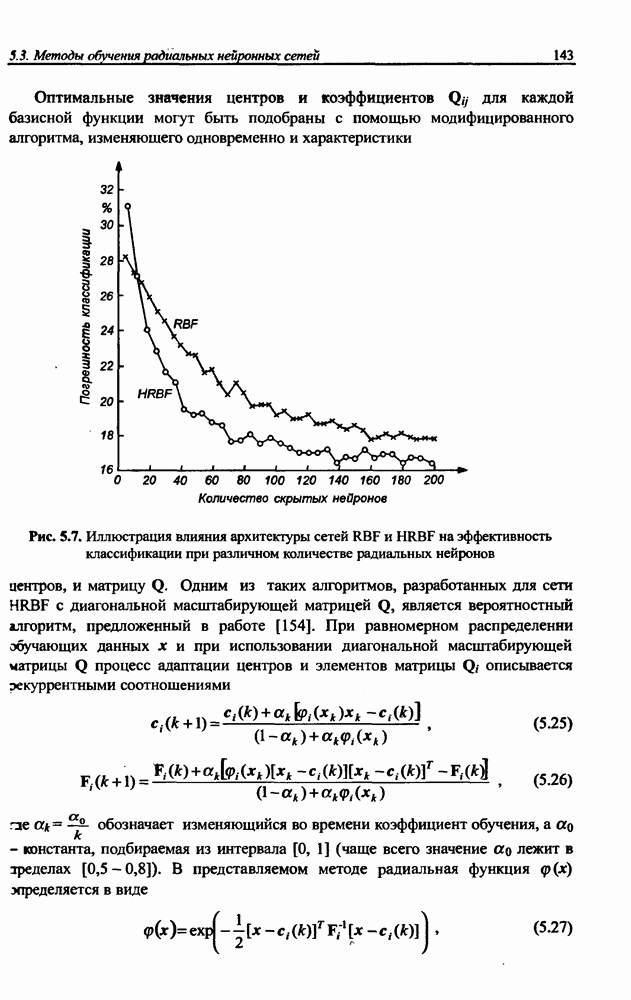


















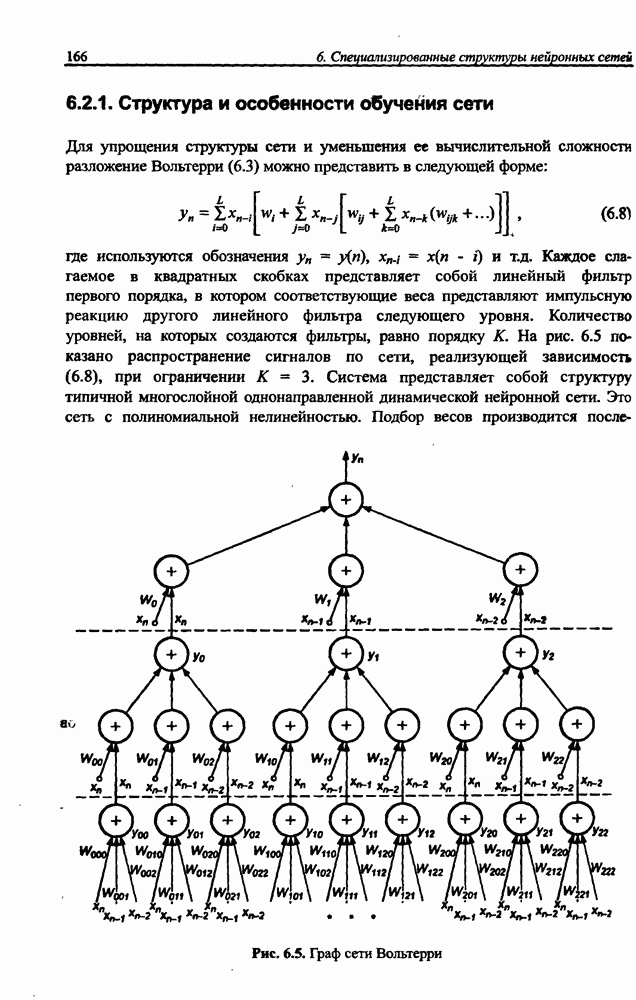
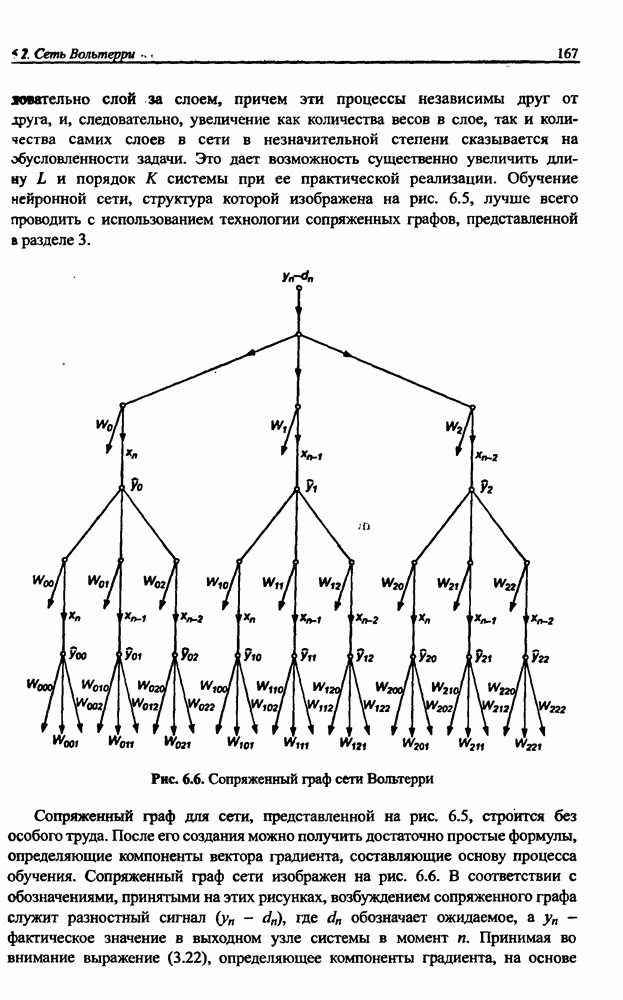


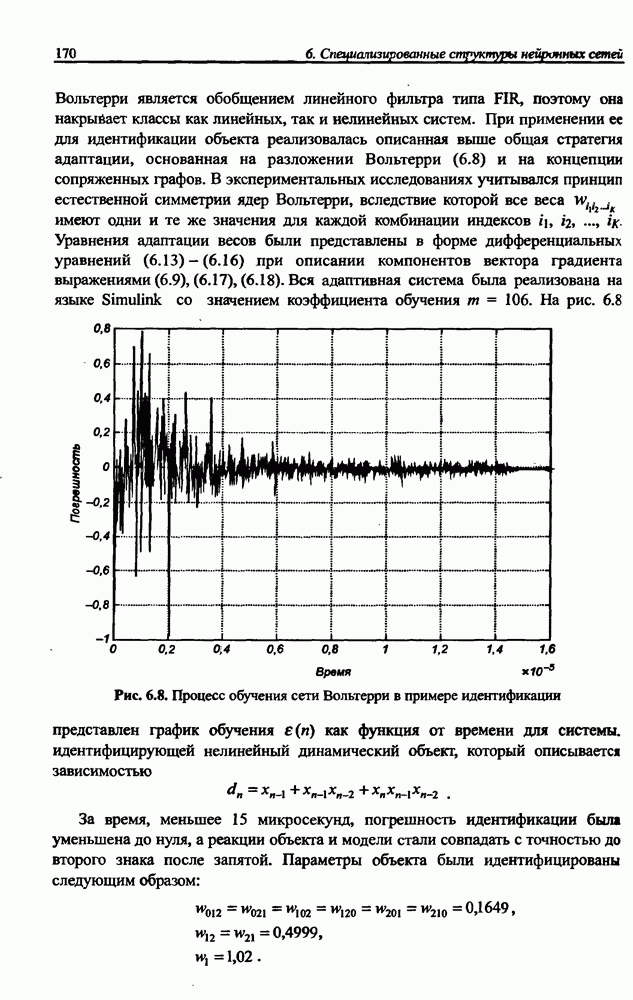
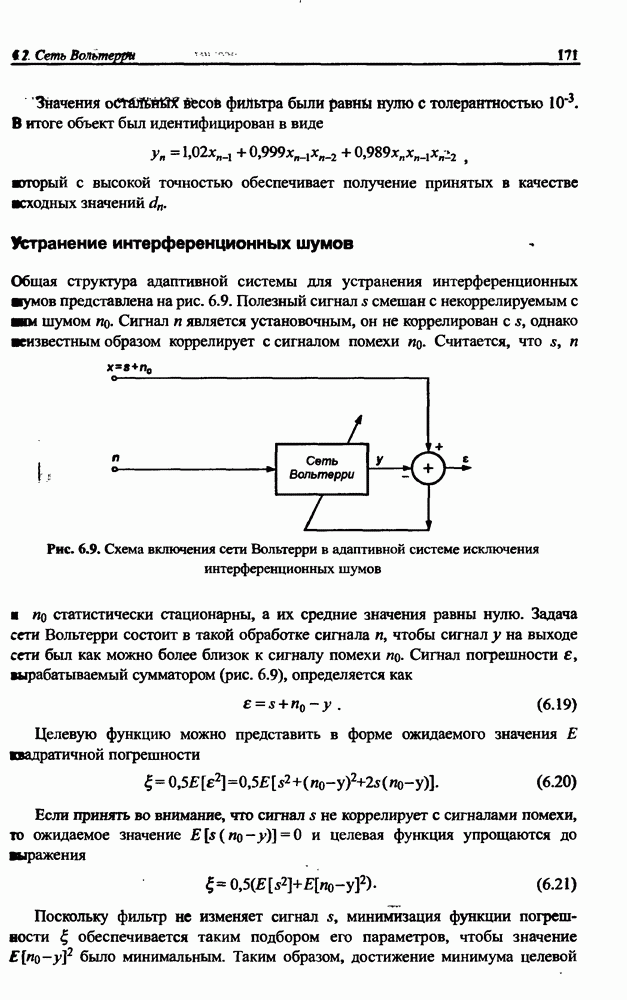













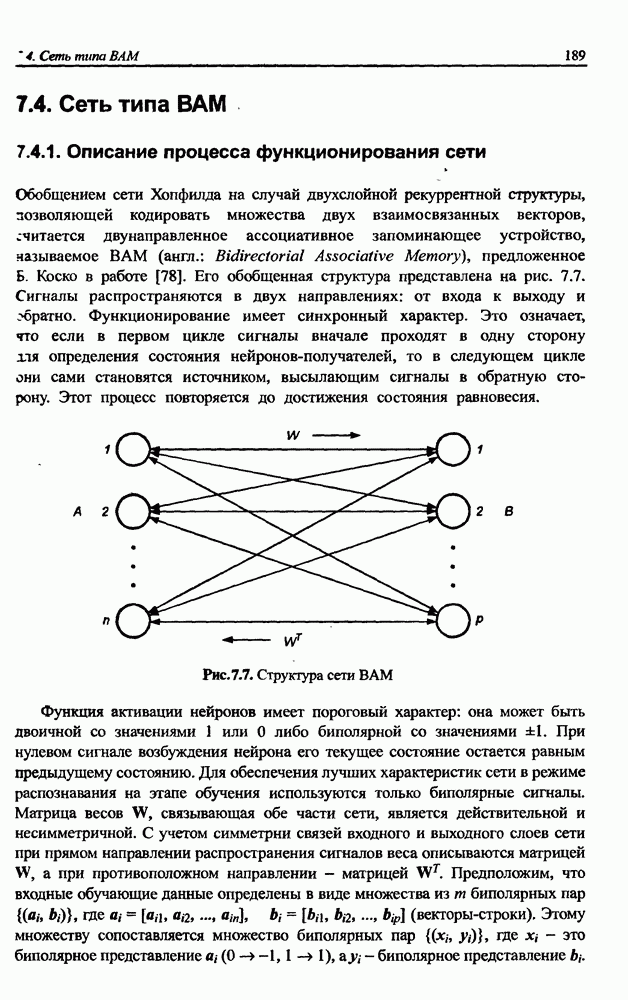




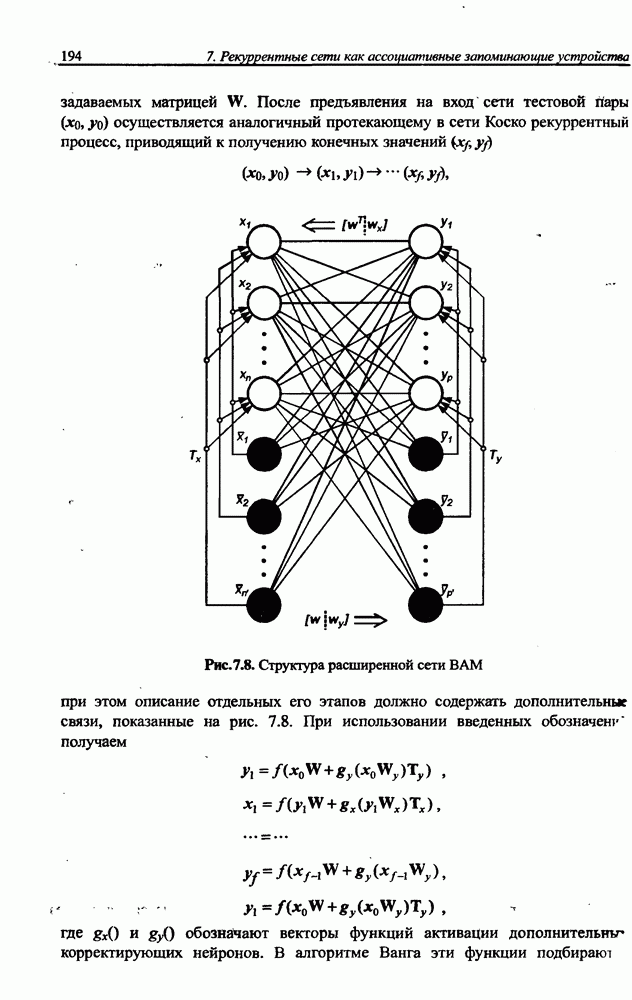






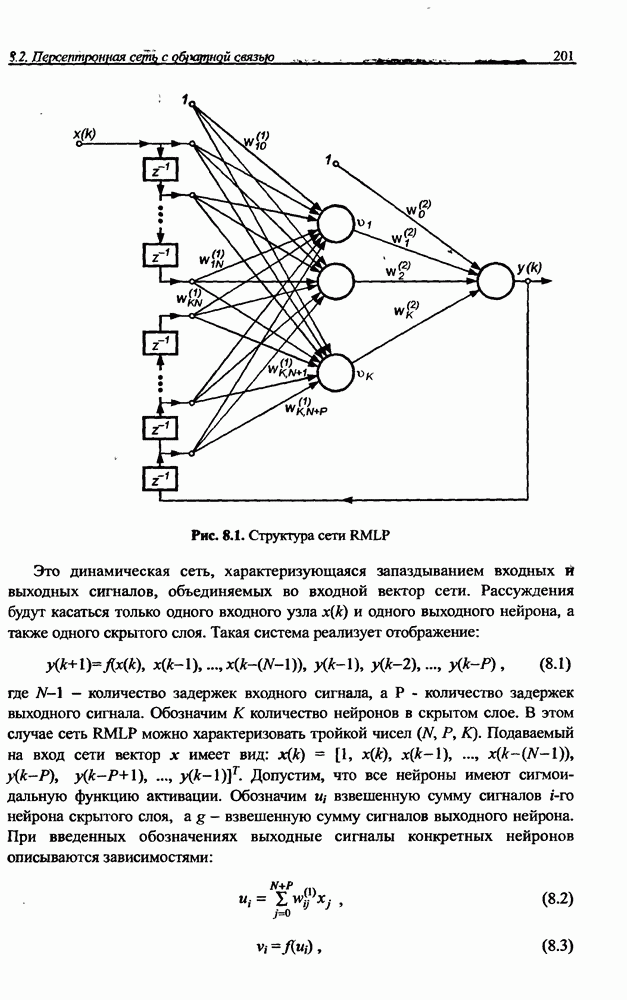





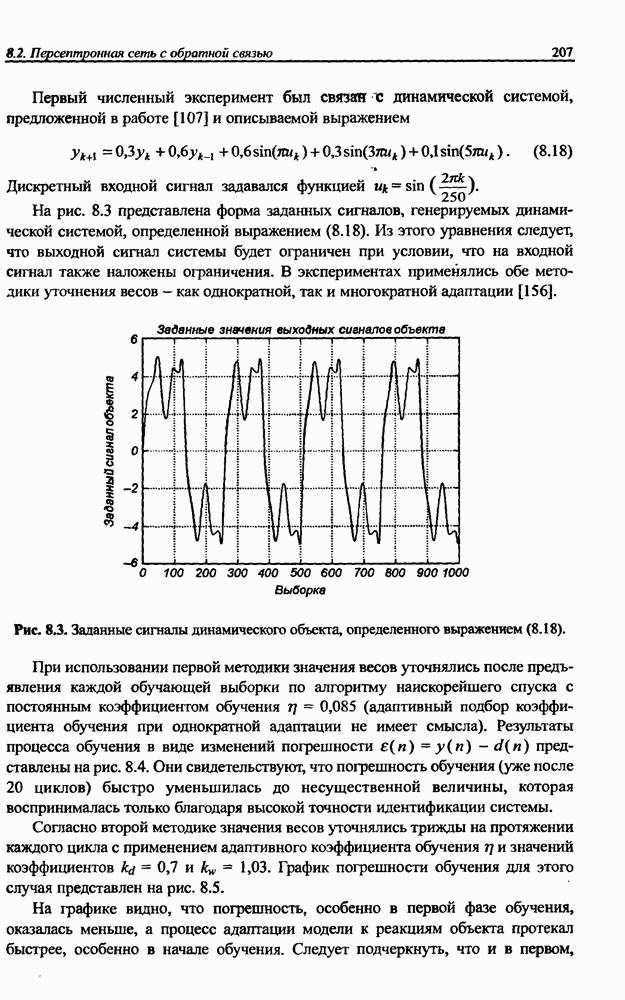




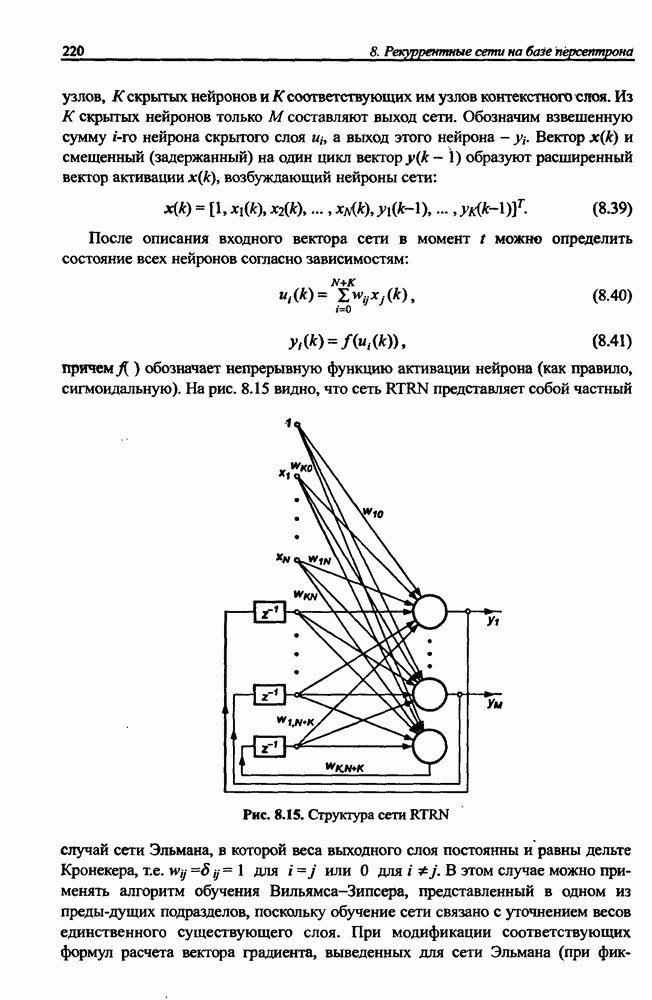

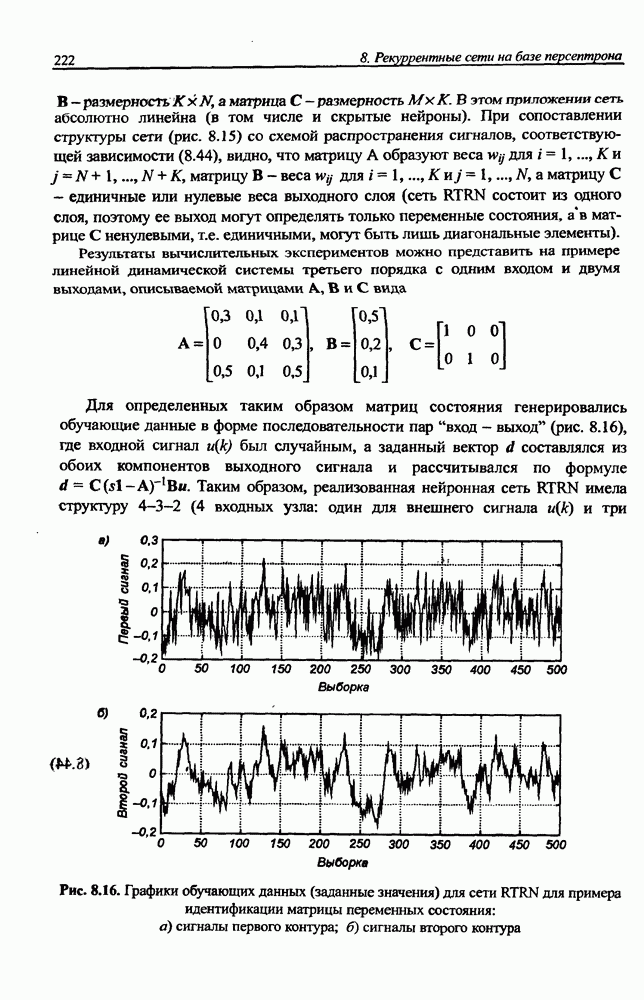
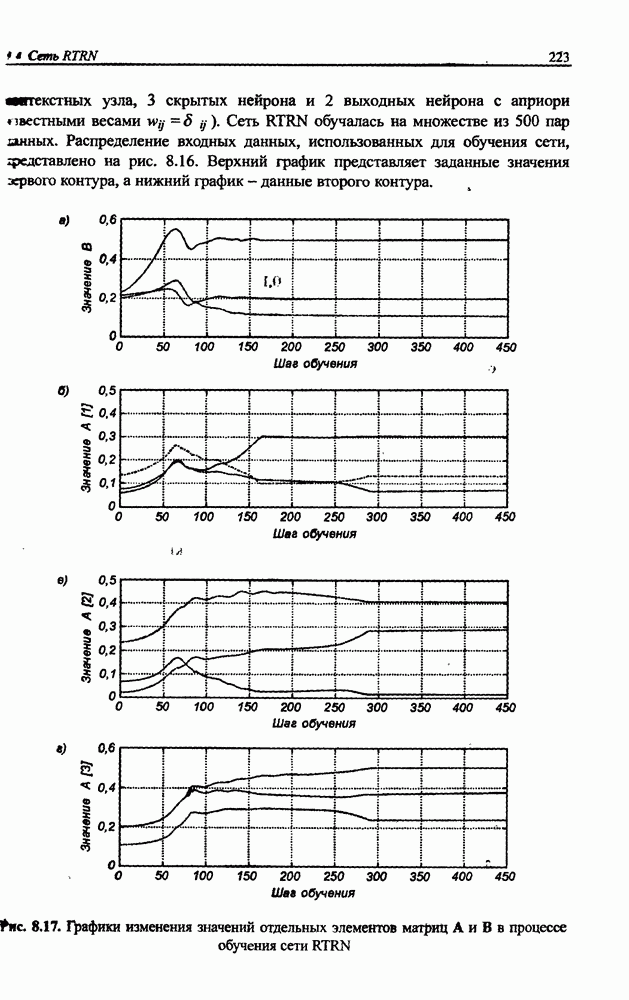
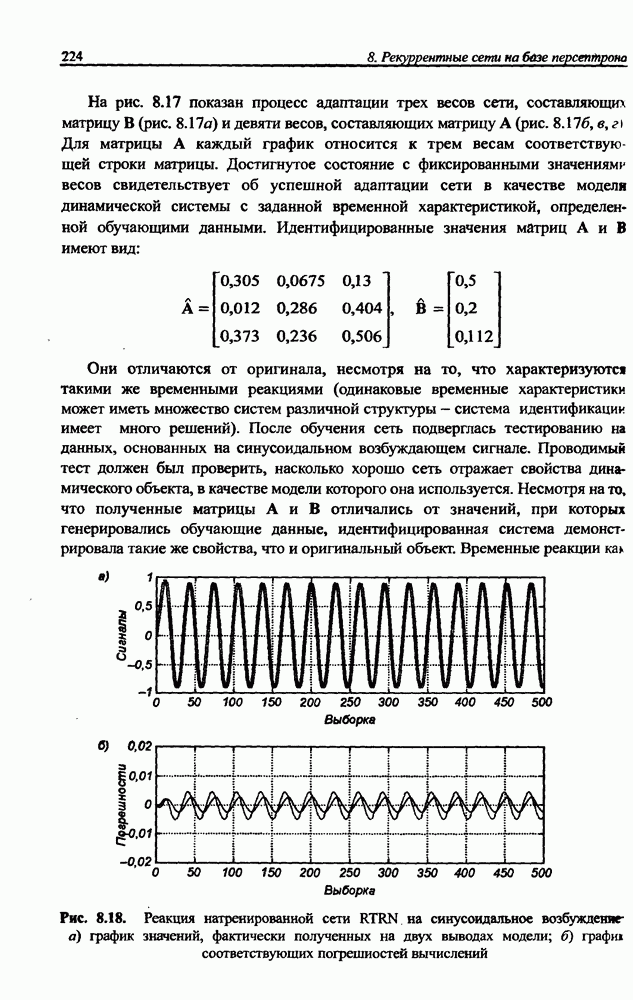





















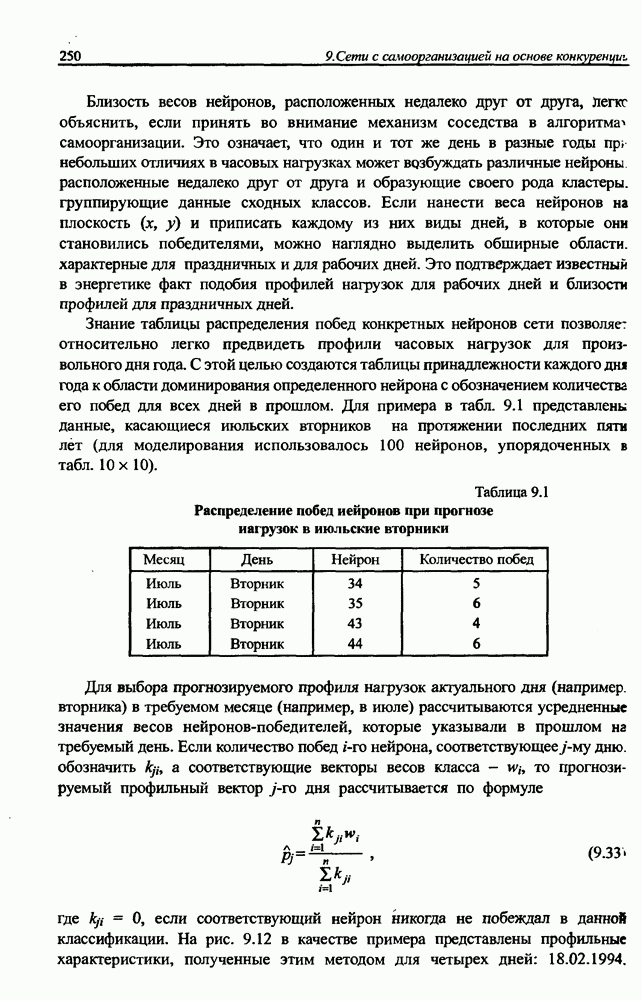



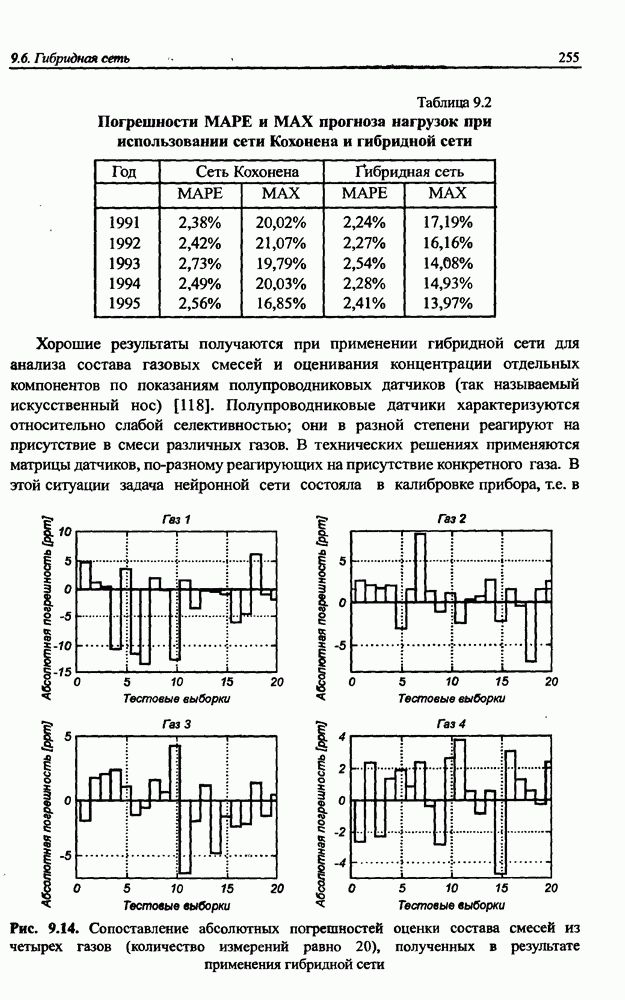
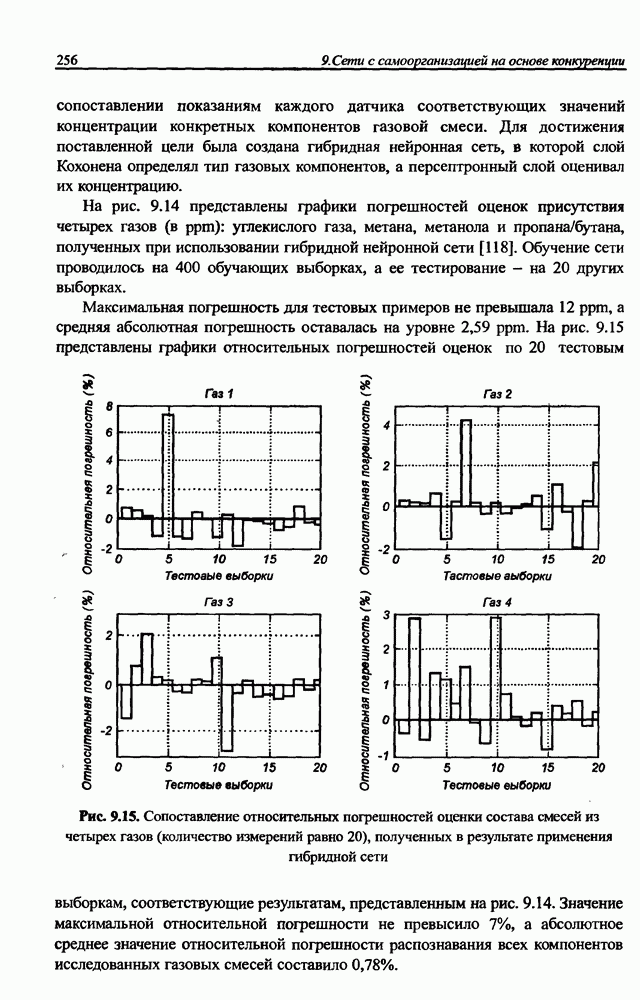























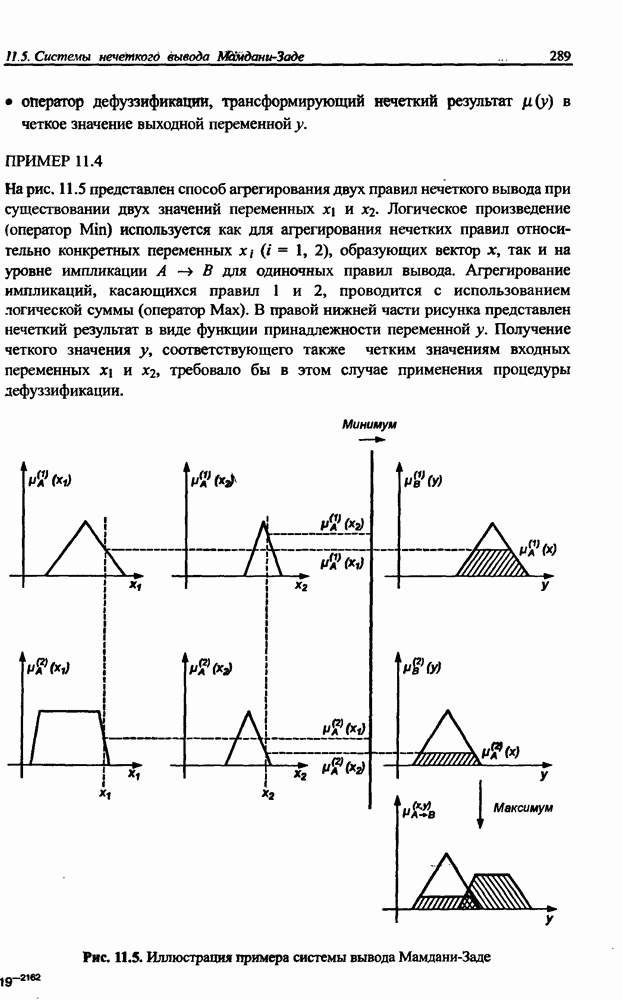





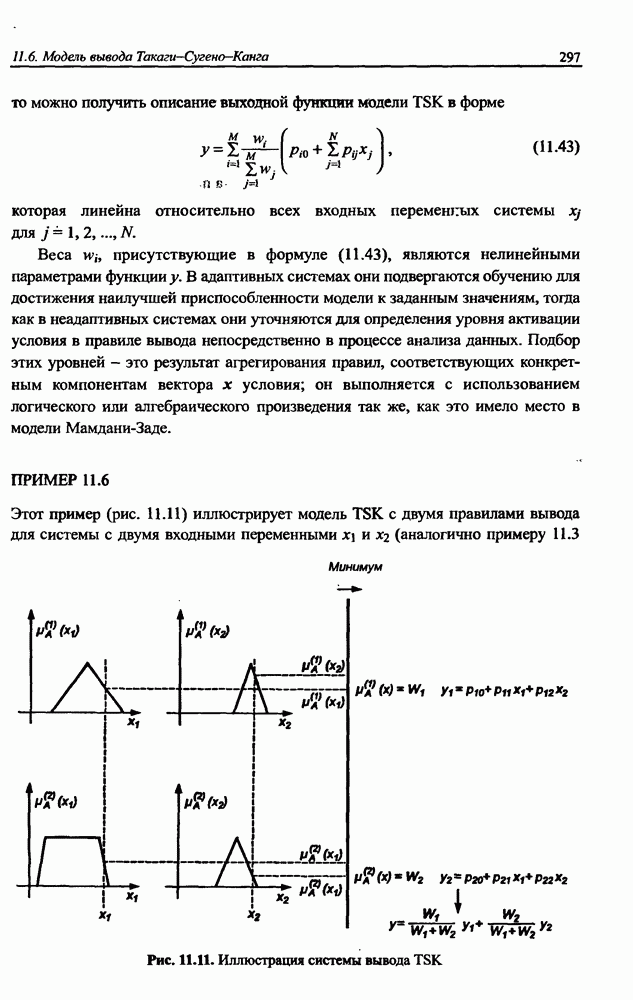










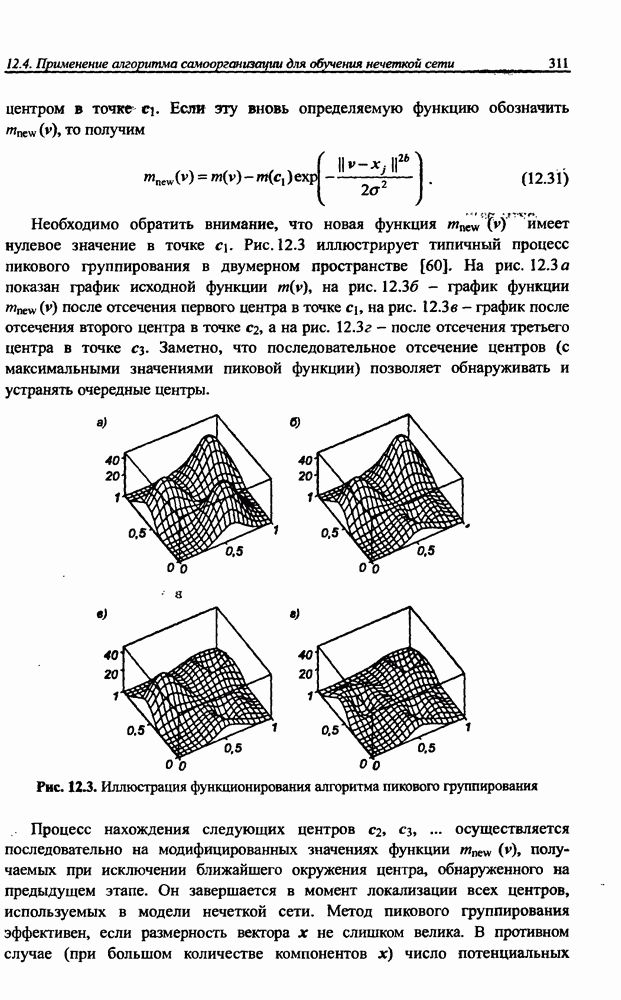




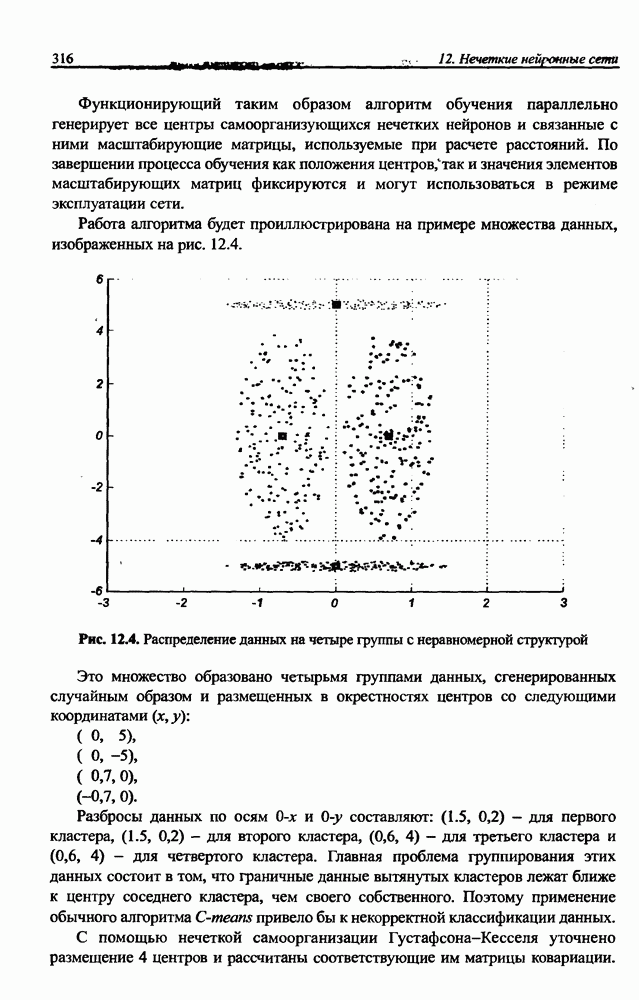



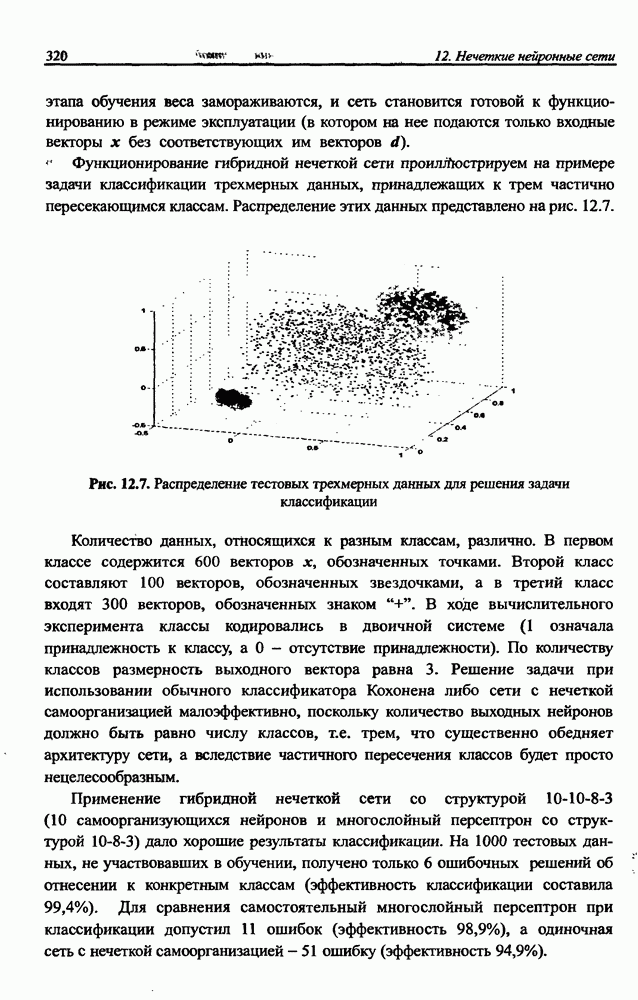

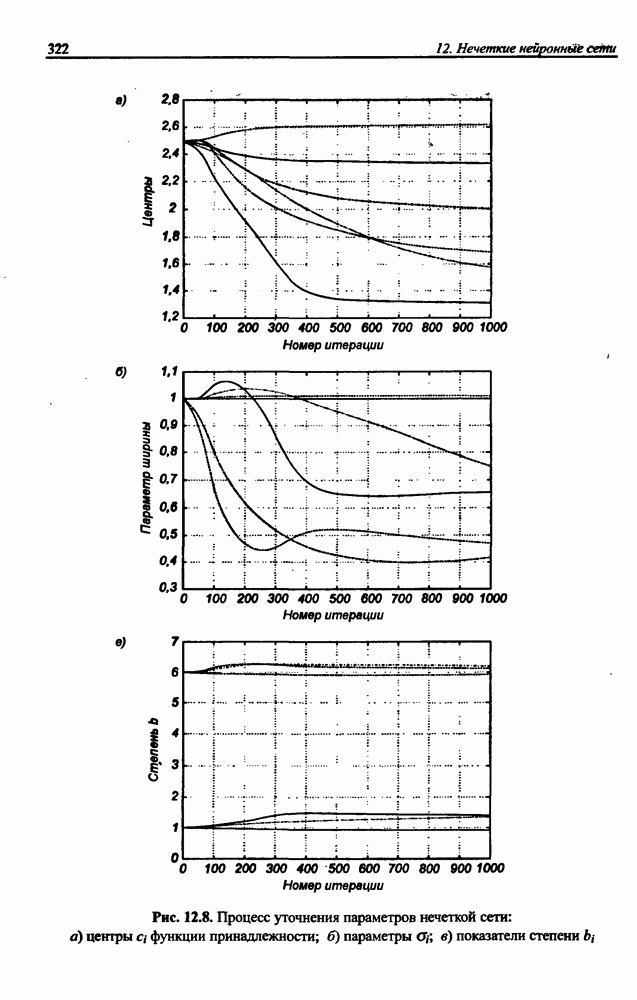
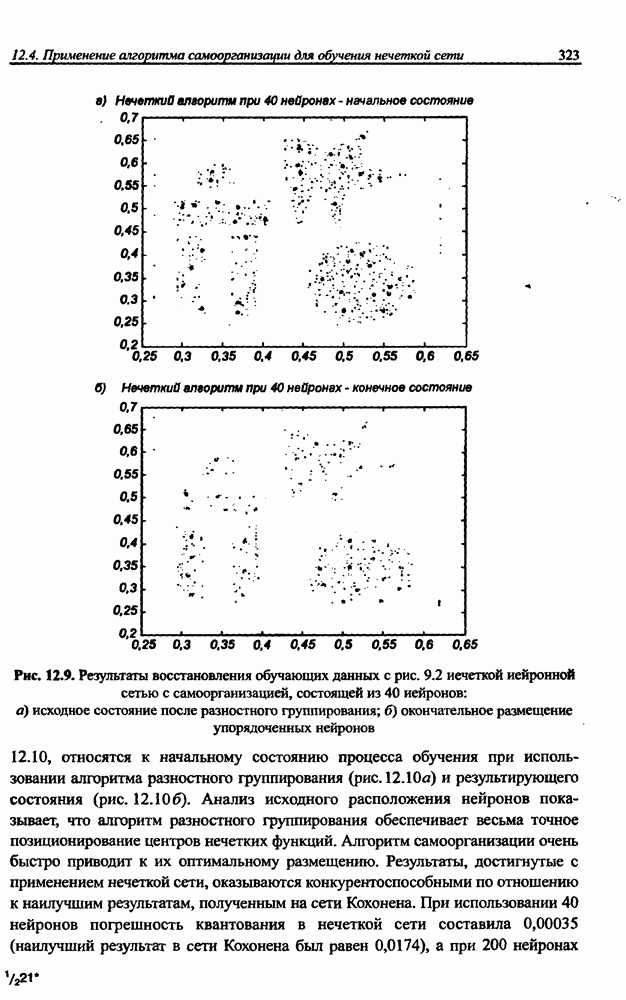
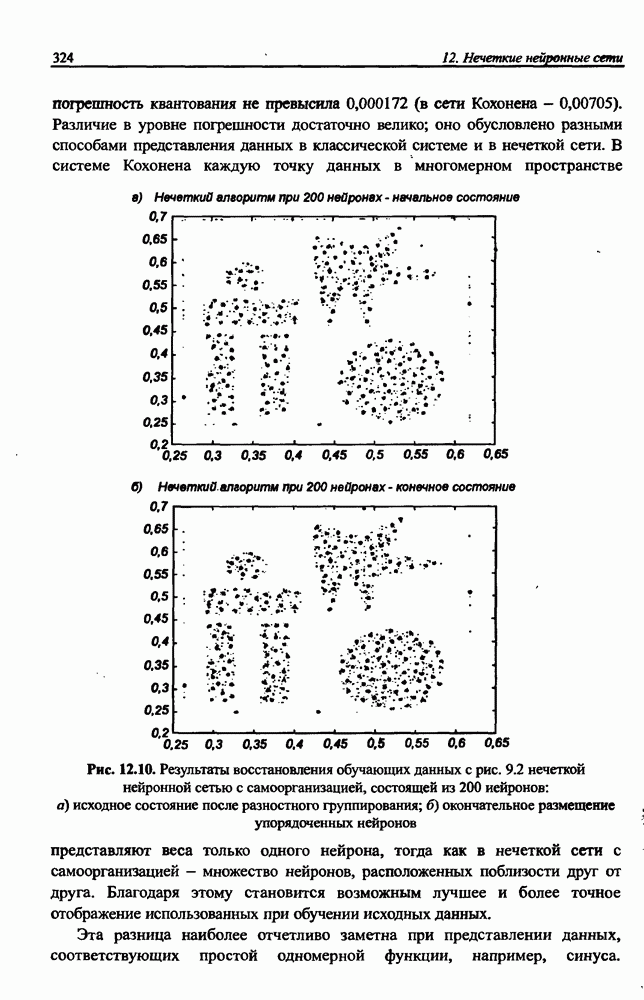
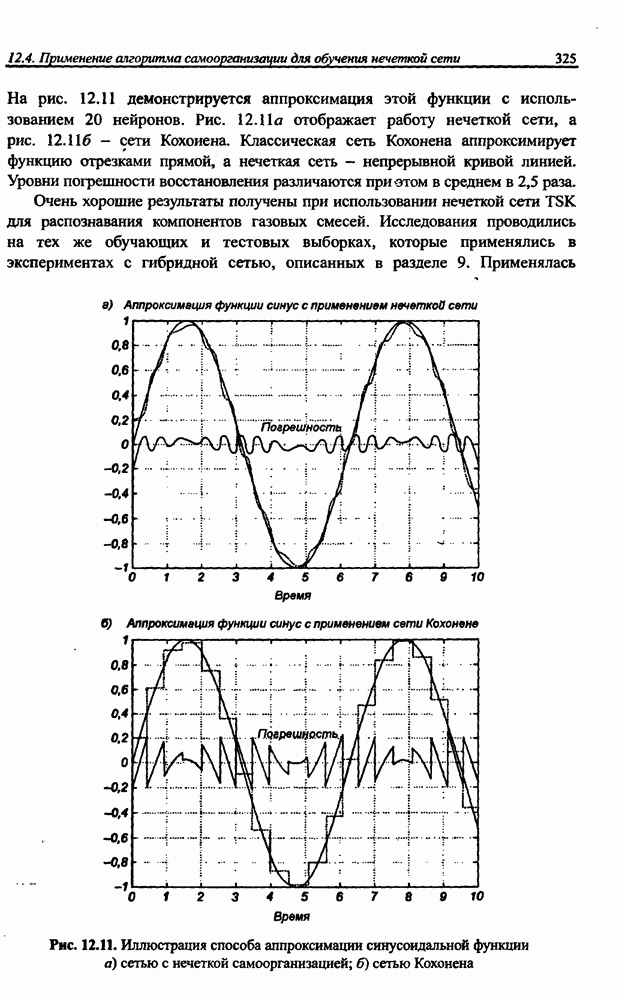
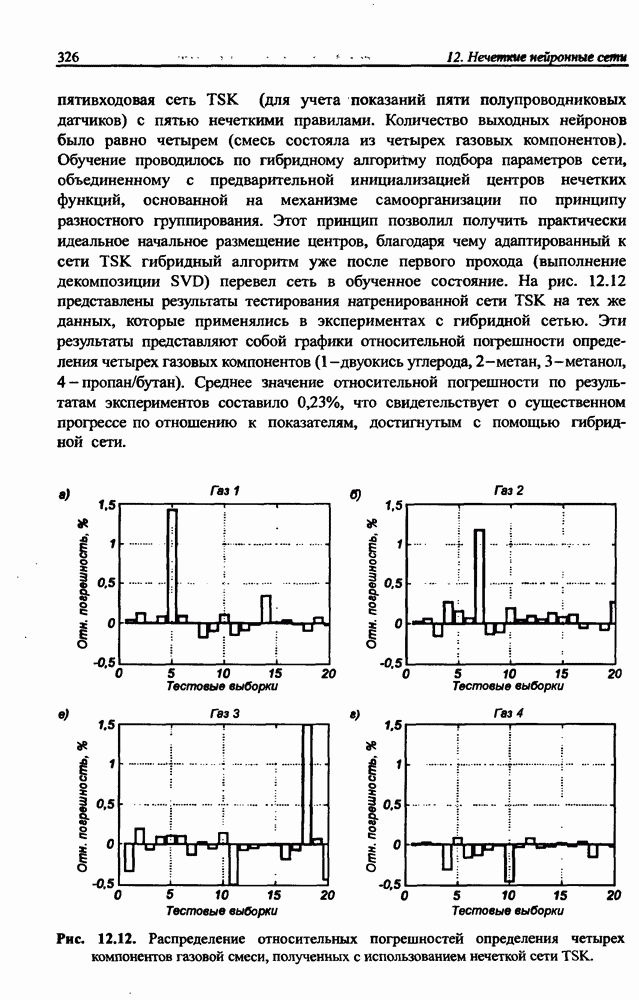












 и параметров нечеткой системы (формула (11.34) в модели Мамдани-Заде и (11.43) в модели TSK). В литературе [67, 160] отмечается, что эти выражения позволяют аппроксимировать с произвольной точностью любую нелинейную функцию многих переменных суммой нечетких функций одной переменной. Формулы (11.34) и (11.43) имеют модульную структуру, идеально подходящую для системного представления в виде равномерной многослойной структуры, напоминающей структуру классических нейронных сетей. В дальнейшем мы будем называть их нечеткими нейронными сетями (англ.: neurofuzzy networks). Характерной особенностью этих сетей является возможность использования нечетких правил вывода для расчета выходного сигнала. В отличие от классических нечетких систем (англ.: fuzzy logic) в них вместо непосредственного расчета уровня активации конкретных правил вывода выполняется адаптивный подбор параметров функции фуззификации. Мы обсудим структуру таких сетей, а также алгоритмы обучения, способные адаптировать и линейные веса (аналогично тому, как это производилось в классических сетях), и параметры нечетких функций фуззификатора (аналогично параметрам гауссовской функции в сетях RBF).
и параметров нечеткой системы (формула (11.34) в модели Мамдани-Заде и (11.43) в модели TSK). В литературе [67, 160] отмечается, что эти выражения позволяют аппроксимировать с произвольной точностью любую нелинейную функцию многих переменных суммой нечетких функций одной переменной. Формулы (11.34) и (11.43) имеют модульную структуру, идеально подходящую для системного представления в виде равномерной многослойной структуры, напоминающей структуру классических нейронных сетей. В дальнейшем мы будем называть их нечеткими нейронными сетями (англ.: neurofuzzy networks). Характерной особенностью этих сетей является возможность использования нечетких правил вывода для расчета выходного сигнала. В отличие от классических нечетких систем (англ.: fuzzy logic) в них вместо непосредственного расчета уровня активации конкретных правил вывода выполняется адаптивный подбор параметров функции фуззификации. Мы обсудим структуру таких сетей, а также алгоритмы обучения, способные адаптировать и линейные веса (аналогично тому, как это производилось в классических сетях), и параметры нечетких функций фуззификатора (аналогично параметрам гауссовской функции в сетях RBF).
 можно представить в виде
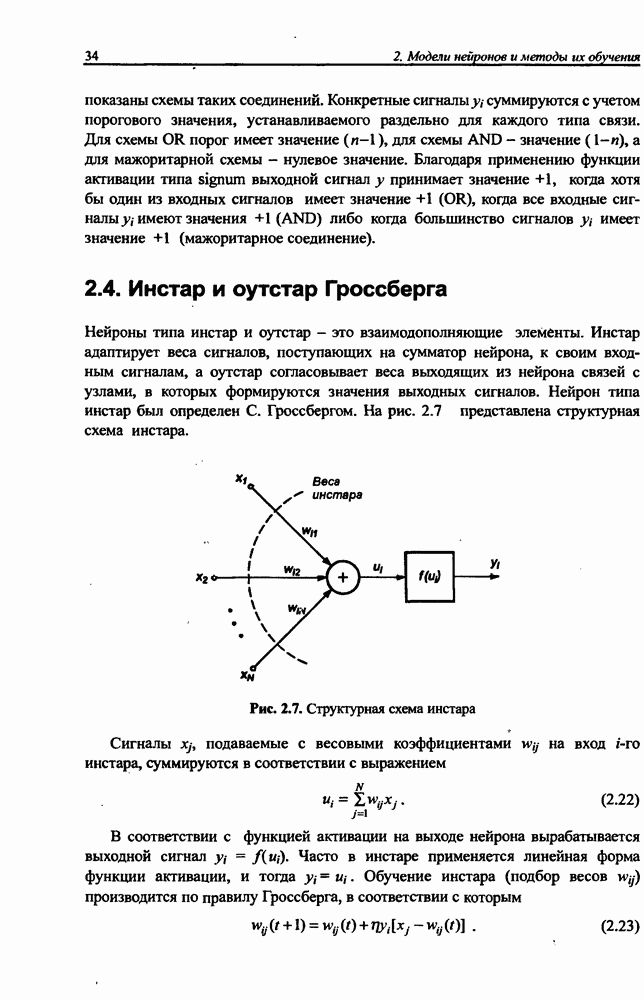
можно представить в виде

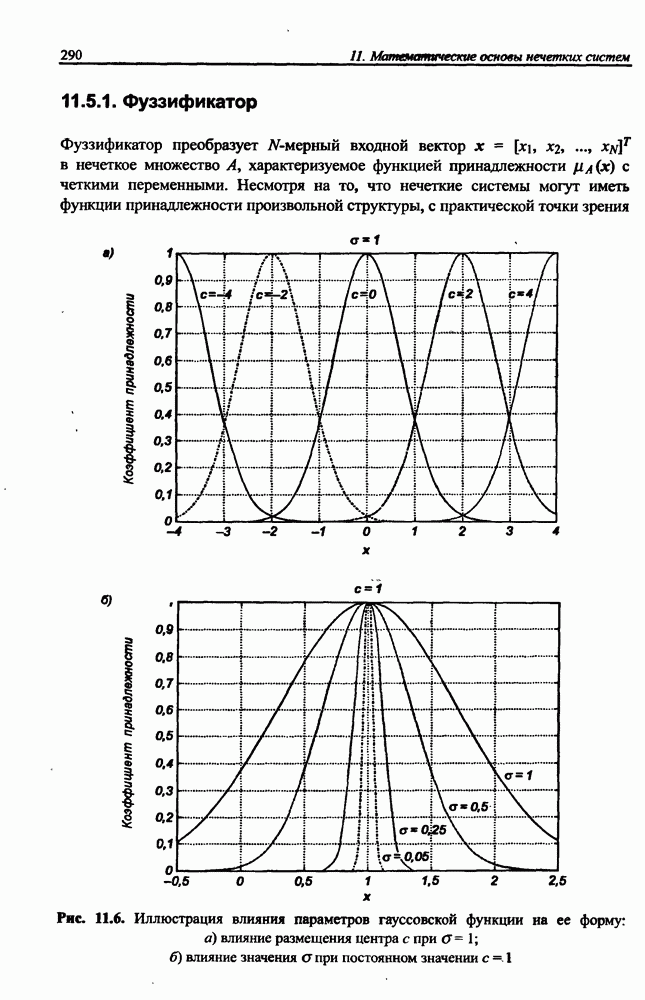
 реализуется функцией фуззифнкации, которая представляется обобщенной функцией Гаусса отдельно для каждой переменной
реализуется функцией фуззифнкации, которая представляется обобщенной функцией Гаусса отдельно для каждой переменной 

 представляет оператор
представляет оператор  . В нечетких сетях целесообразно задавать это условие в форме алгебраического произведения, из которой следует, что для
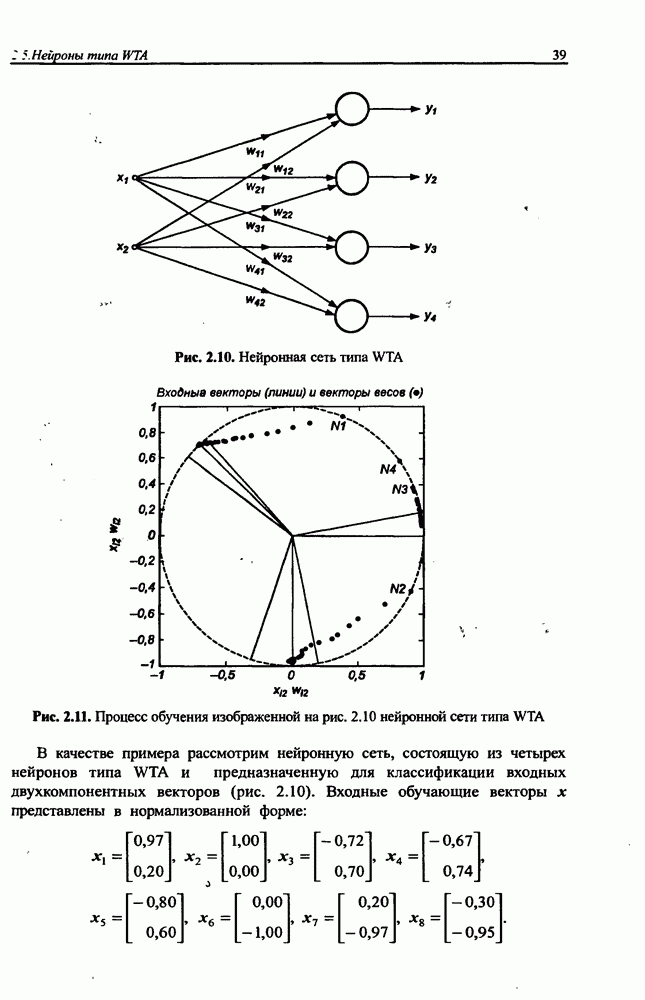
. В нечетких сетях целесообразно задавать это условие в форме алгебраического произведения, из которой следует, что для  правила вывода
правила вывода


 Присутствующие в этом выражении веса
Присутствующие в этом выражении веса  интерпретируются как значимость компонентов
интерпретируются как значимость компонентов  определенных формулой (12.3). При этом условии формуле (12.4) можно сопоставить многослойную структуру сети, изображенную на рис. 12.1. В такой сети выделяется пять слоев.
определенных формулой (12.3). При этом условии формуле (12.4) можно сопоставить многослойную структуру сети, изображенную на рис. 12.1. В такой сети выделяется пять слоев.
 определяя для каждого
определяя для каждого  правила вывода значение коэффициента принадлежности в соответствии с применяемой функцией фуззифнкации (например,
правила вывода значение коэффициента принадлежности в соответствии с применяемой функцией фуззифнкации (например,  Это параметрический слой с параметрами
Это параметрический слой с параметрами  подлежащими адаптации в процессе обучения.
подлежащими адаптации в процессе обучения.
 определяя результирующее значение коэффициента принадлежности
определяя результирующее значение коэффициента принадлежности  вектора
вектора  (уровень активации правила вывода) в соответствии с формулой (12.3). Это слой непараметрический.
(уровень активации правила вывода) в соответствии с формулой (12.3). Это слой непараметрический.
 . В этом слое также производится умножение сигналов
. В этом слое также производится умножение сигналов  на значения
на значения  сформированные в предыдущем слое. Это параметрический слой, в котором адаптации подлежат линейные веса
сформированные в предыдущем слое. Это параметрический слой, в котором адаптации подлежат линейные веса  для
для  определяющие функцию следствия модели TSK.
определяющие функцию следствия модели TSK.
 а второй определяет сумму весов
а второй определяет сумму весов  Это непараметрический слой.
Это непараметрический слой.
 определяется выражением, соответствующим зависимости (11.43),
определяется выражением, соответствующим зависимости (11.43),

 линейной функции TSK.
линейной функции TSK.

 является линейной относительно переменных
является линейной относительно переменных 
 входных переменных каждое правило формирует
входных переменных каждое правило формирует  переменных
переменных  линейной зависимости TSK. При М правилах вывода это дает
линейной зависимости TSK. При М правилах вывода это дает  линейных параметров сети. В свою очередь, каждая функция принадлежности использует три параметра
линейных параметров сети. В свою очередь, каждая функция принадлежности использует три параметра  подлежащих адаптации. Если принять, что каждая переменная х, характеризуется собственной функцией принадлежности, то при М правилах вывода мы получим 3MN нелинейных параметров. В сумме это дает
подлежащих адаптации. Если принять, что каждая переменная х, характеризуется собственной функцией принадлежности, то при М правилах вывода мы получим 3MN нелинейных параметров. В сумме это дает  линейных и нелинейных параметров, значения которых должны подбираться в процессе обучения сети.
линейных и нелинейных параметров, значения которых должны подбираться в процессе обучения сети.
 имеет
имеет  различных функций принадлежности, то максимальное количество правил, которые можно создать при их комбинировании, составит:
различных функций принадлежности, то максимальное количество правил, которые можно создать при их комбинировании, составит:  (при трех функциях принадлежности, распространяющихся на две переменные, это
(при трех функциях принадлежности, распространяющихся на две переменные, это  правил вывода). Таким образом суммарное количество нелинейных параметров сети при М правилах вывода уменьшается с
правил вывода). Таким образом суммарное количество нелинейных параметров сети при М правилах вывода уменьшается с  в общем случае до
в общем случае до  Количество линейных параметров при подобной модификации остается без изменений, т.е.
Количество линейных параметров при подобной модификации остается без изменений, т.е. 