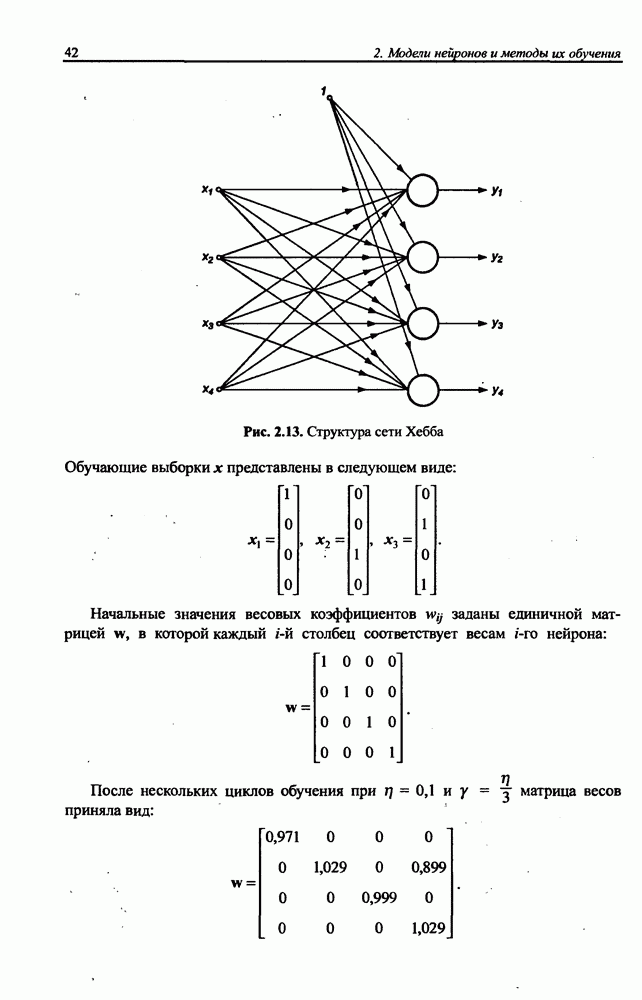
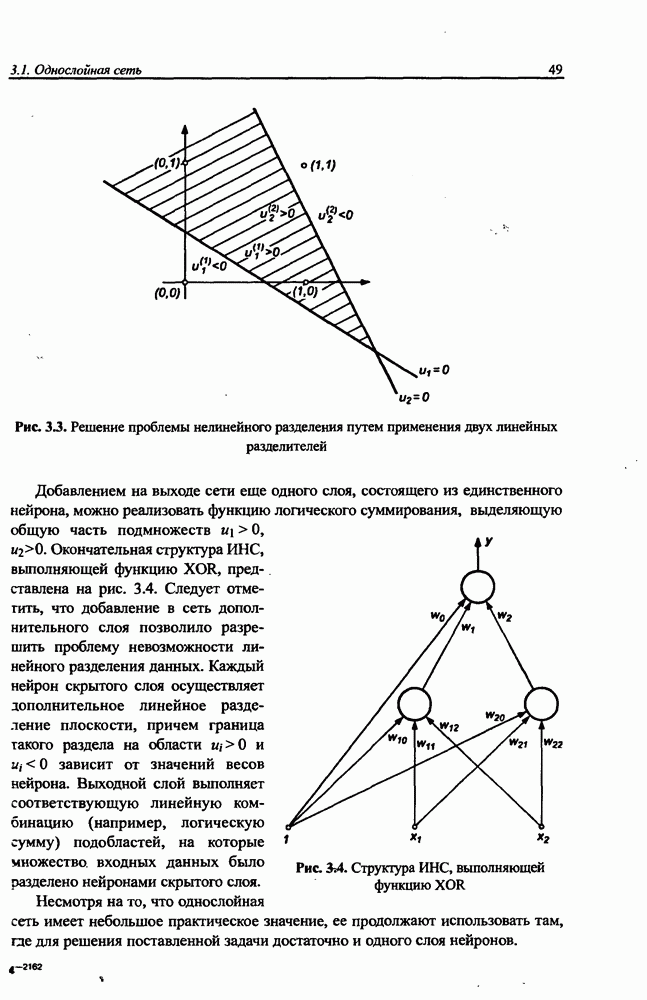
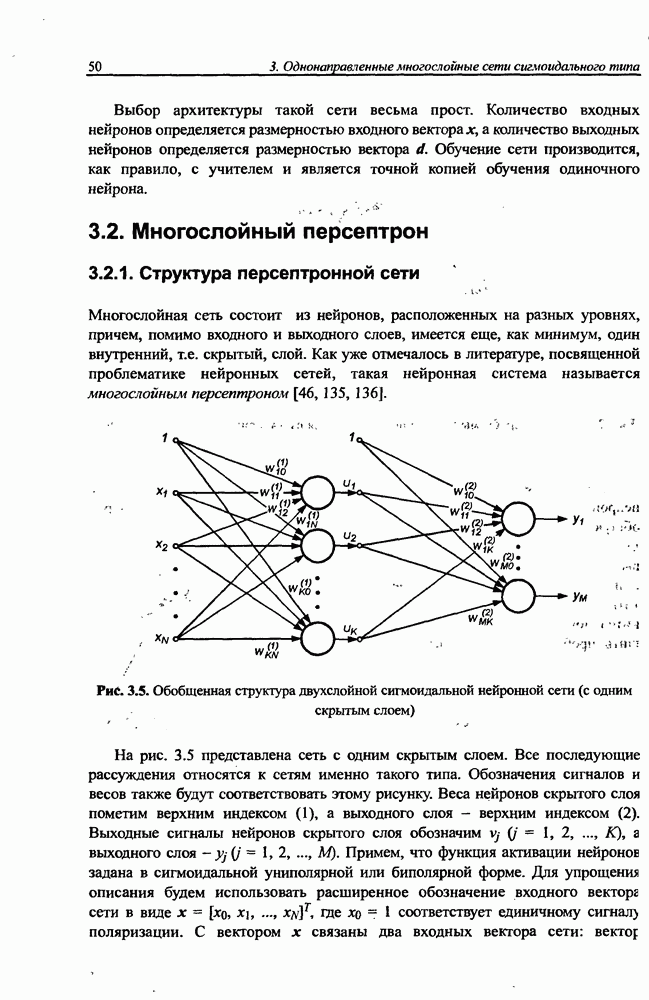
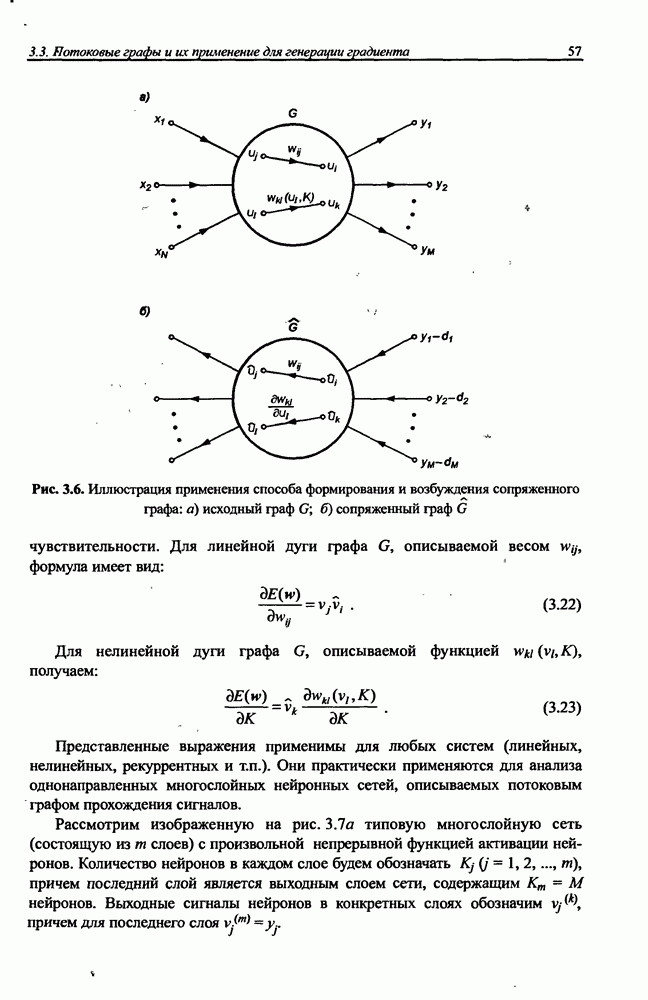
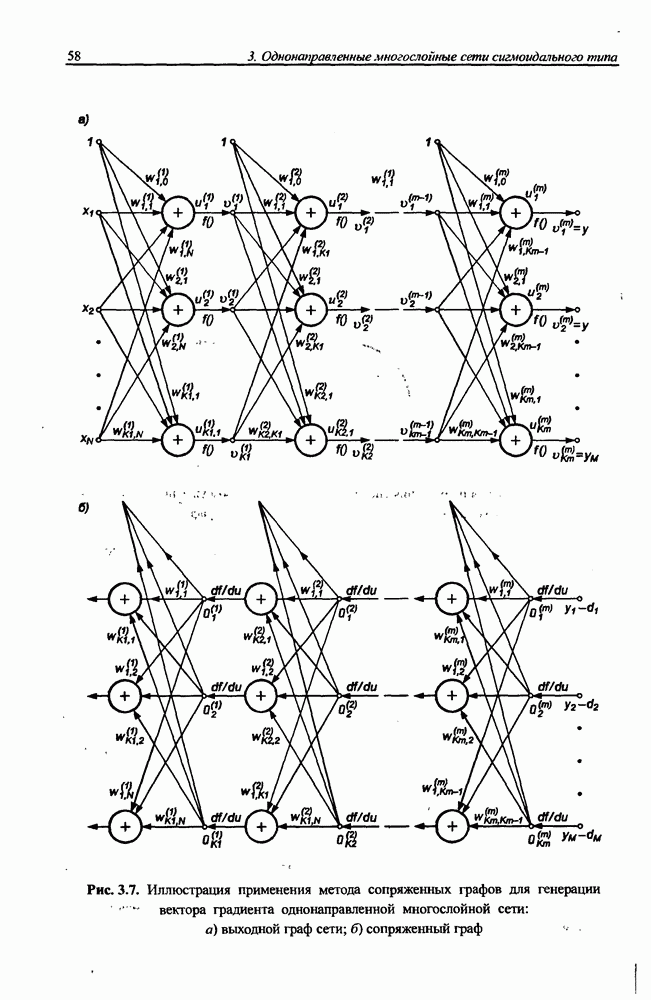
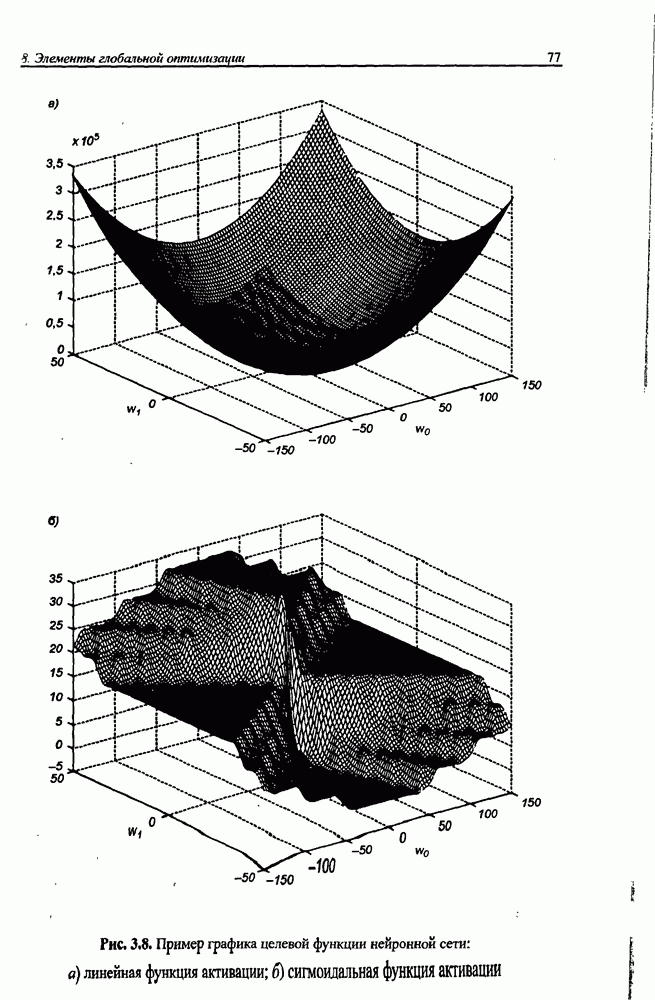
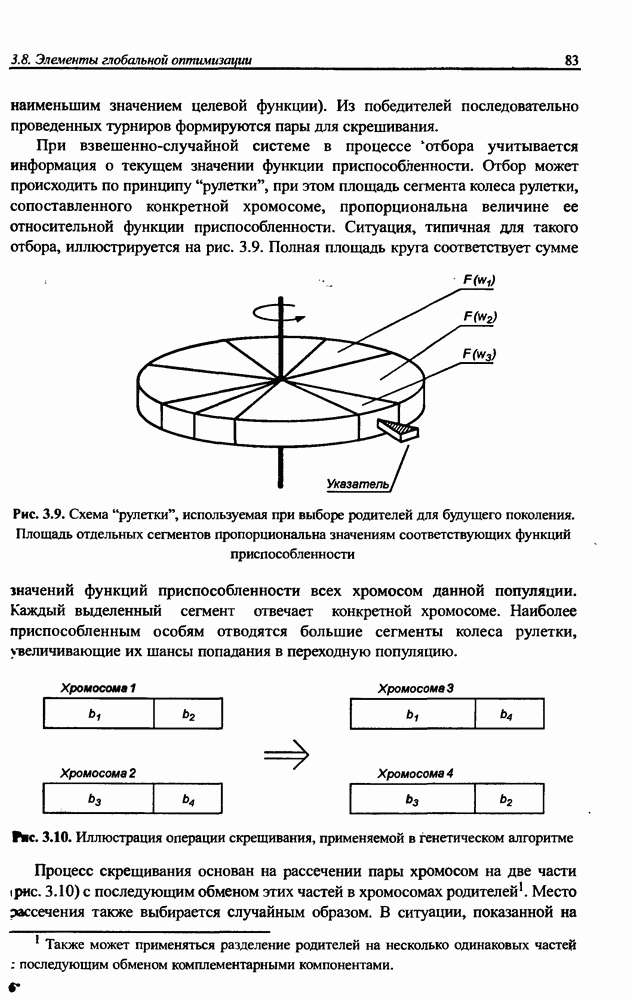
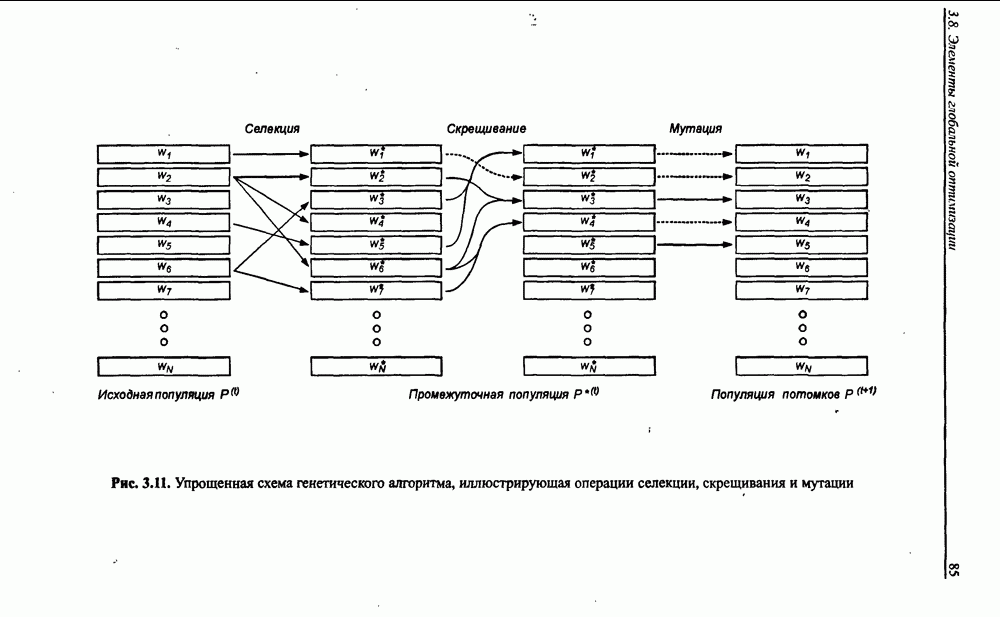
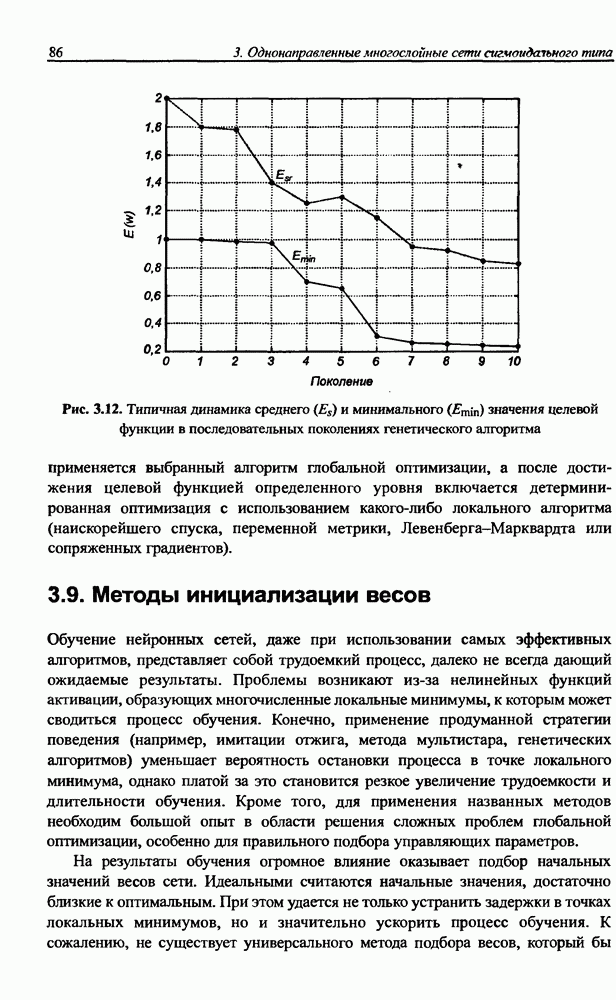
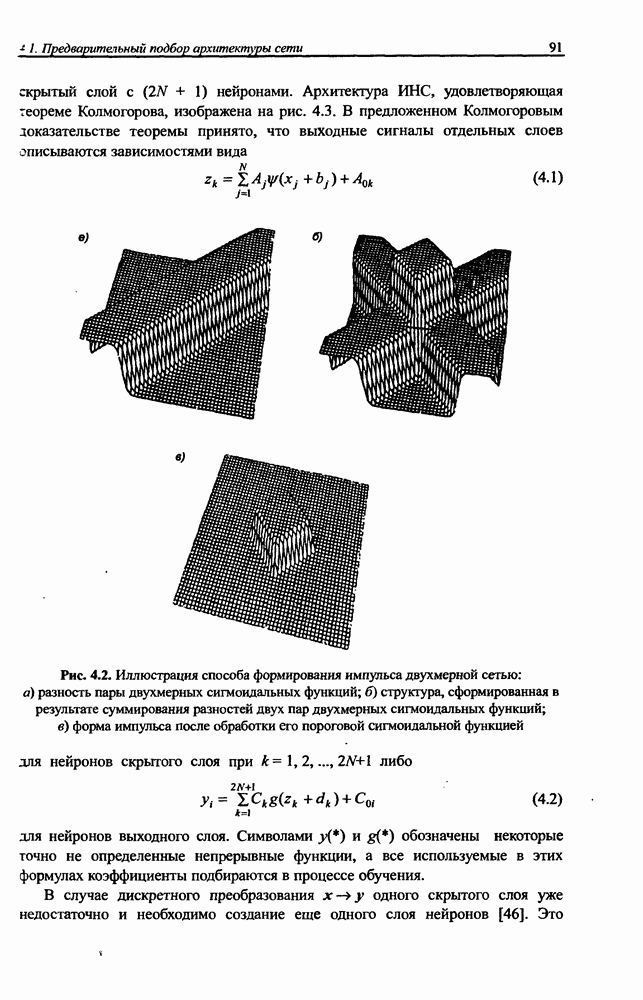
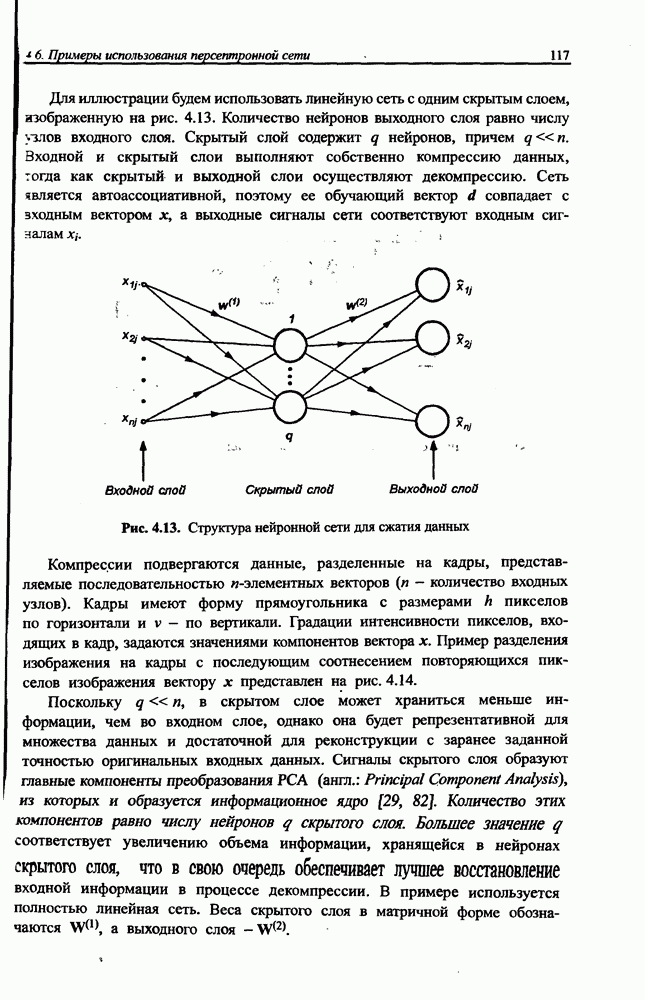
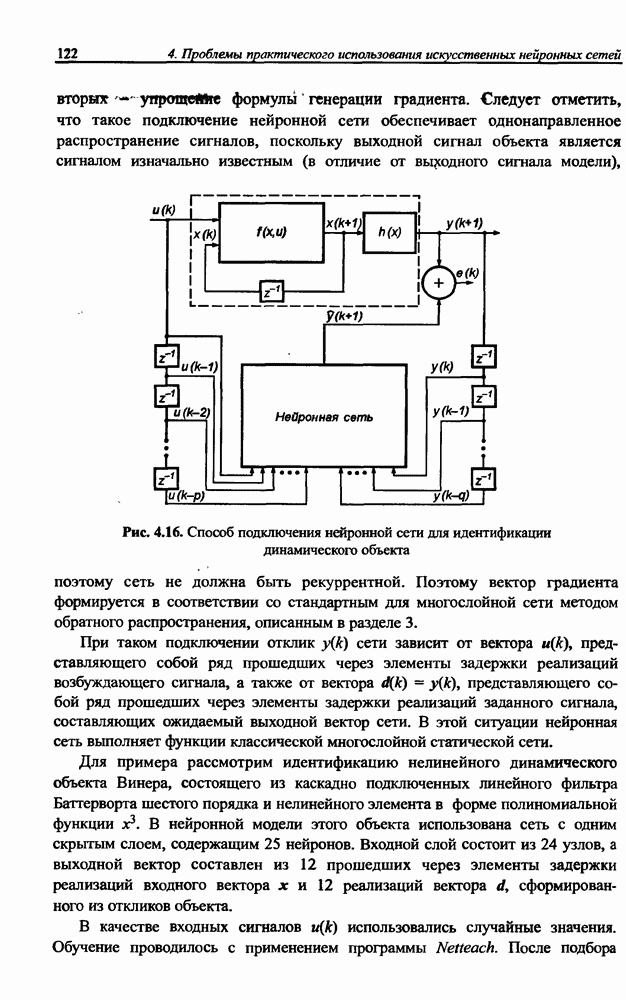
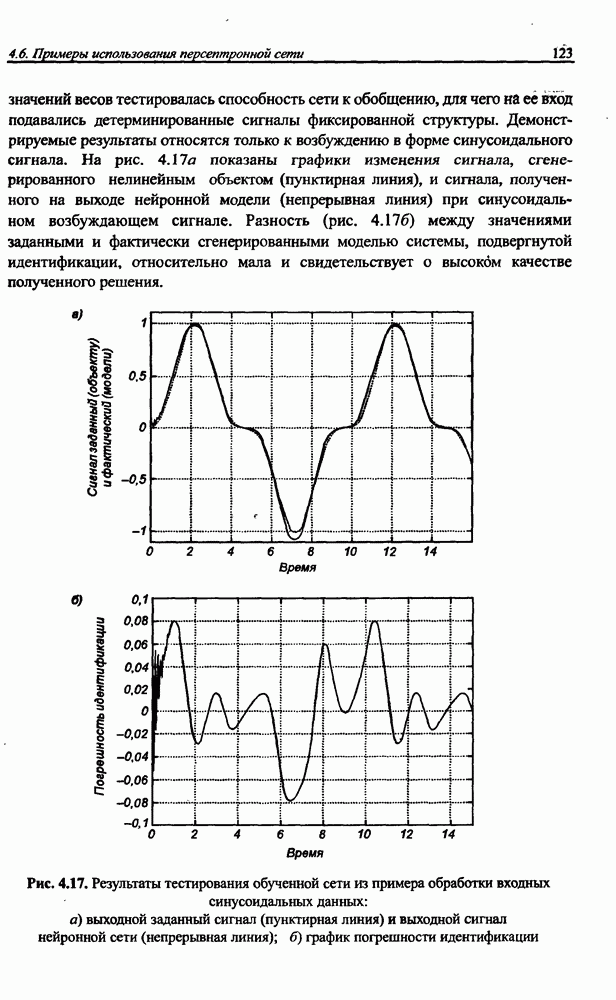
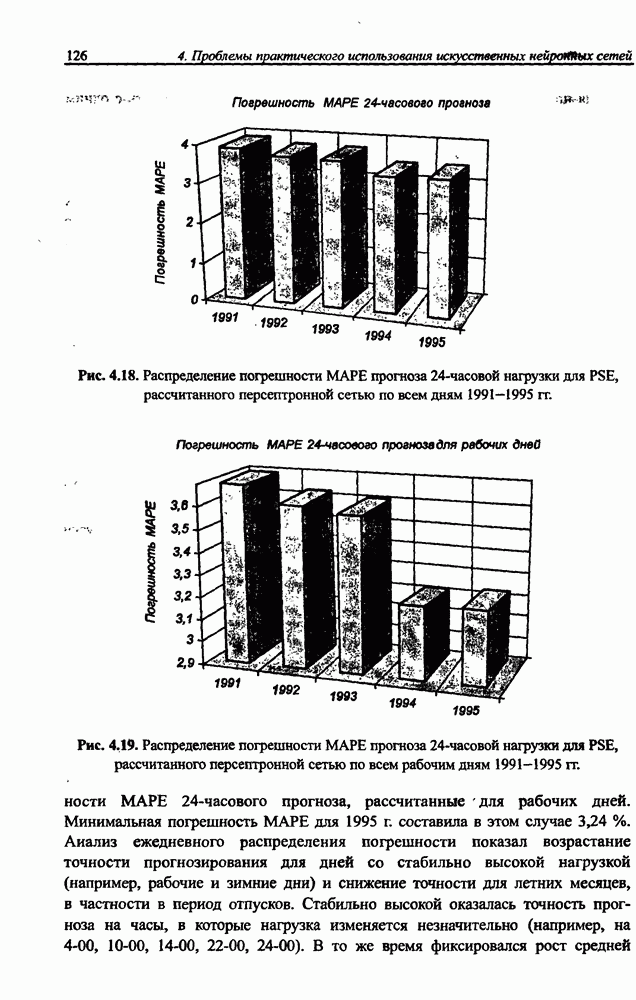
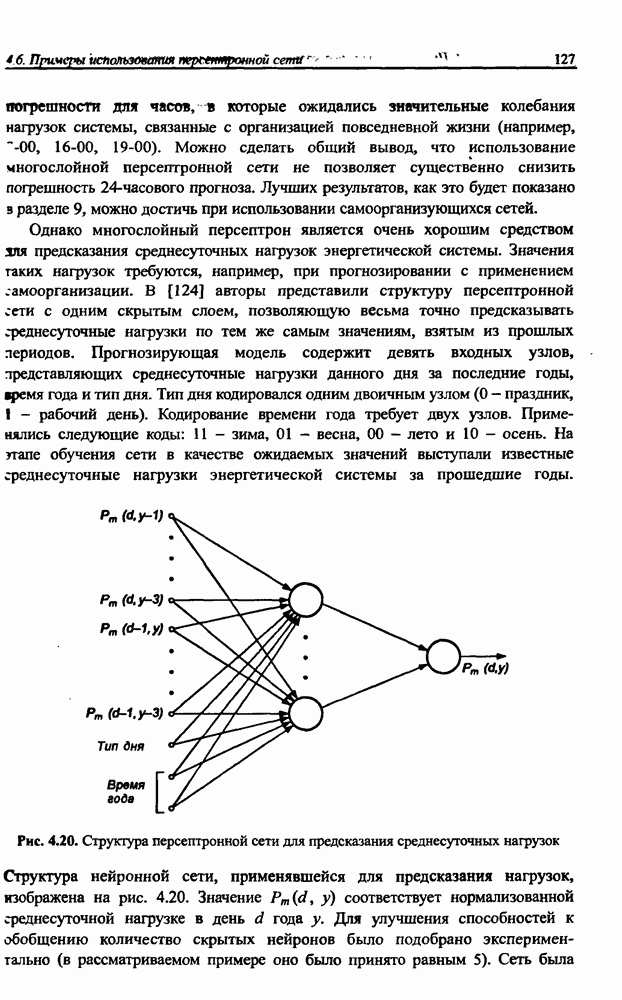
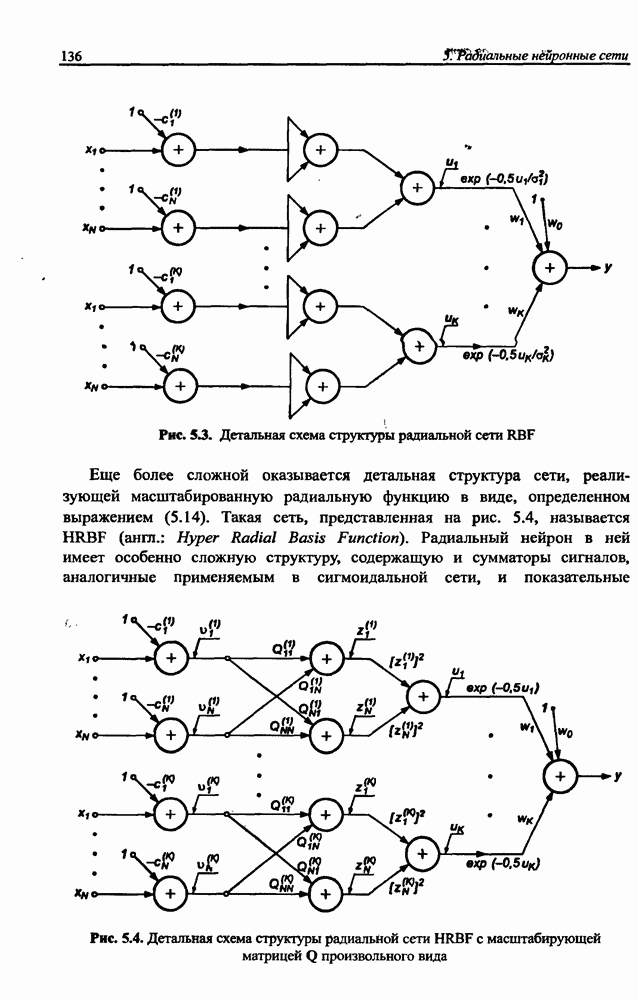
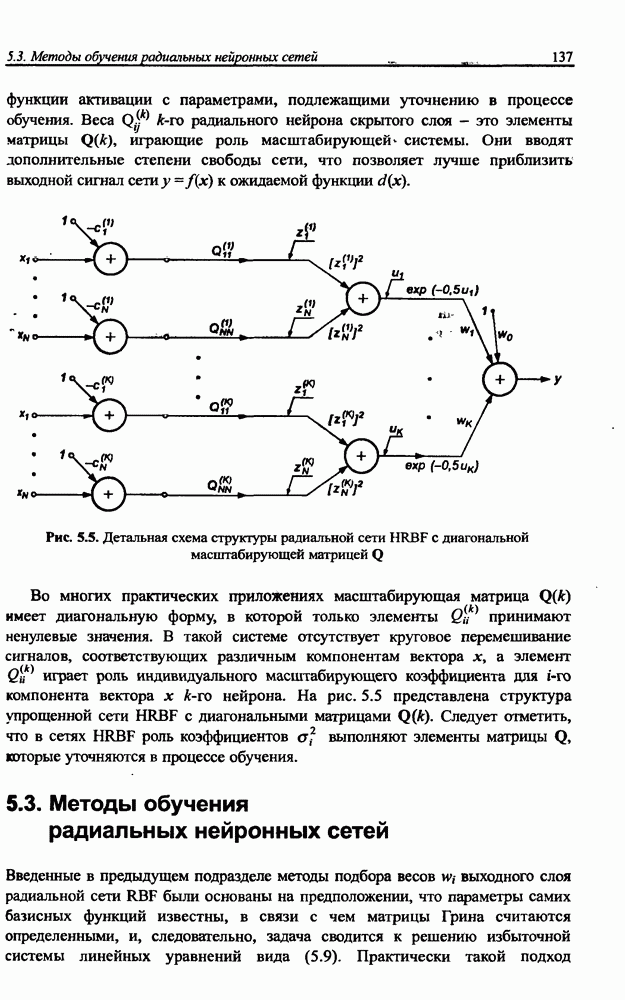
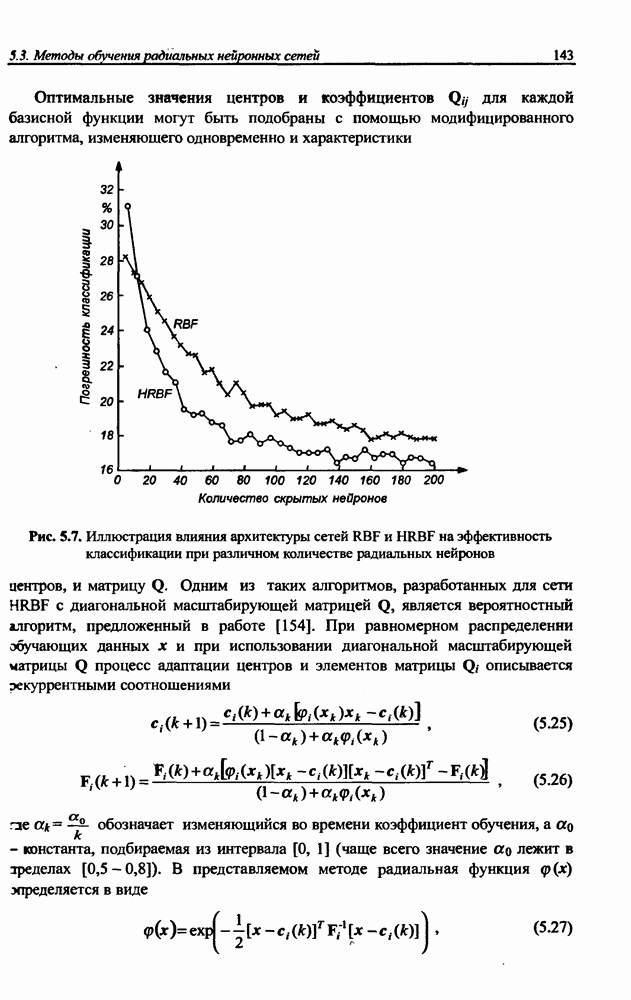
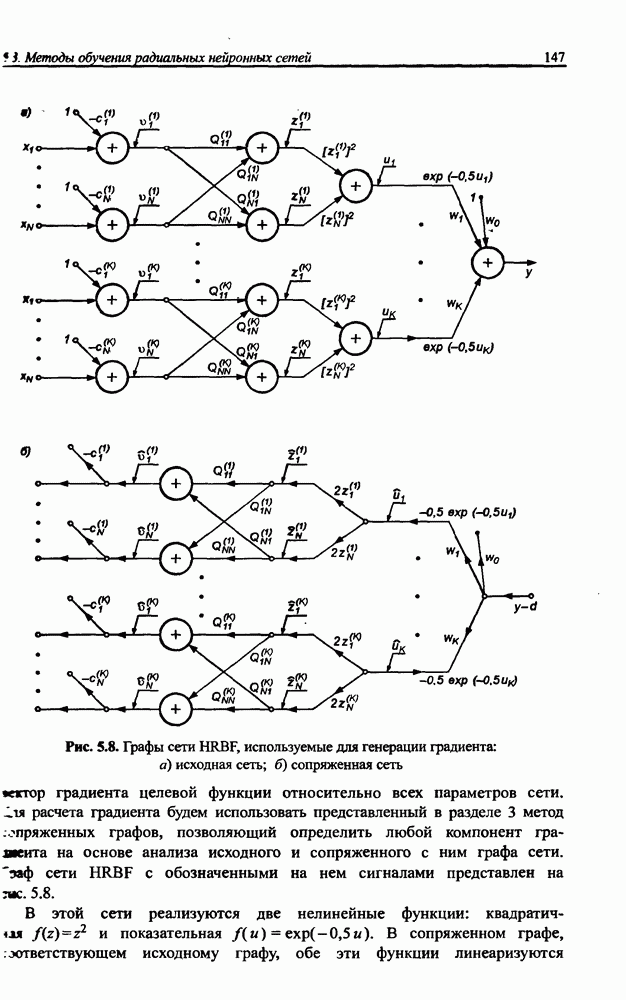
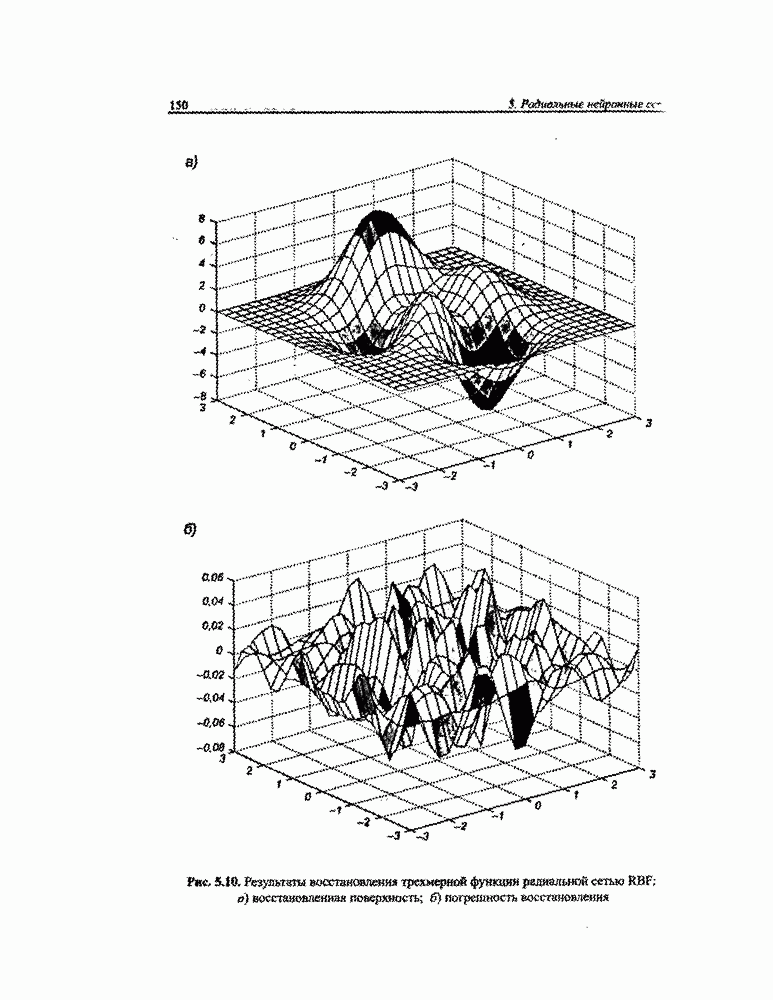
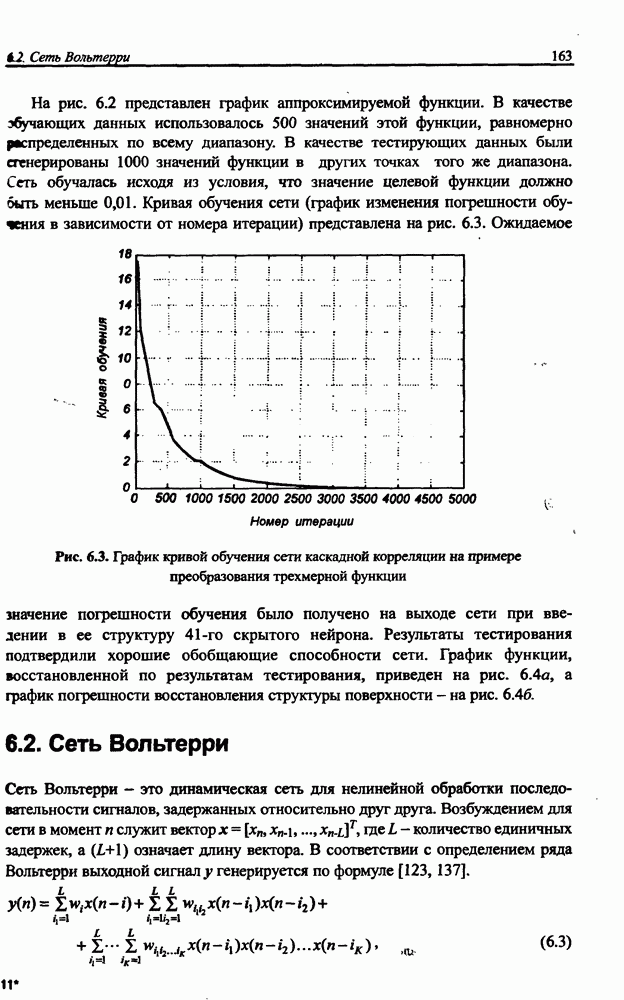
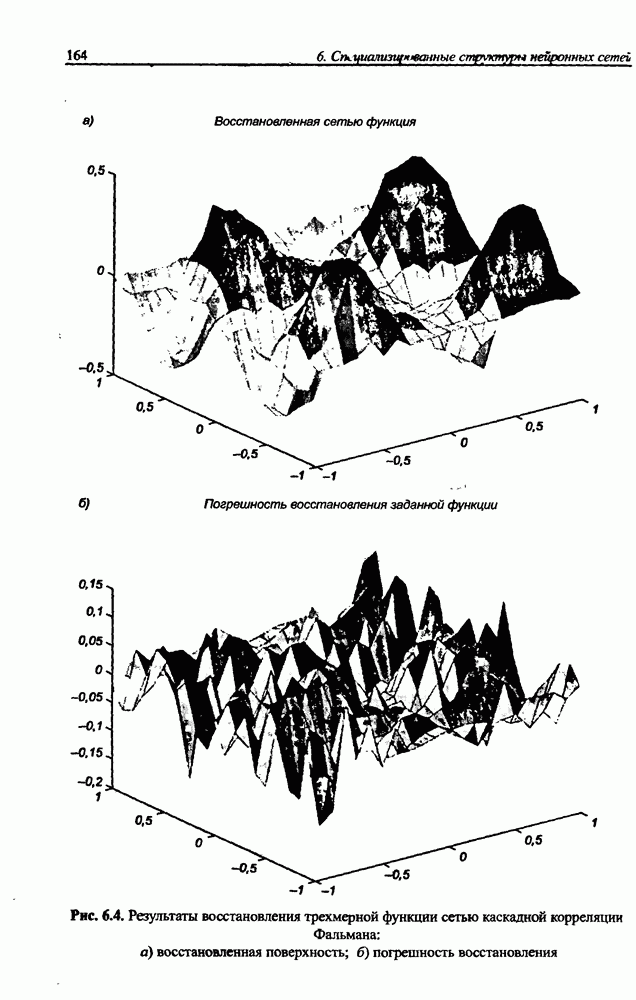
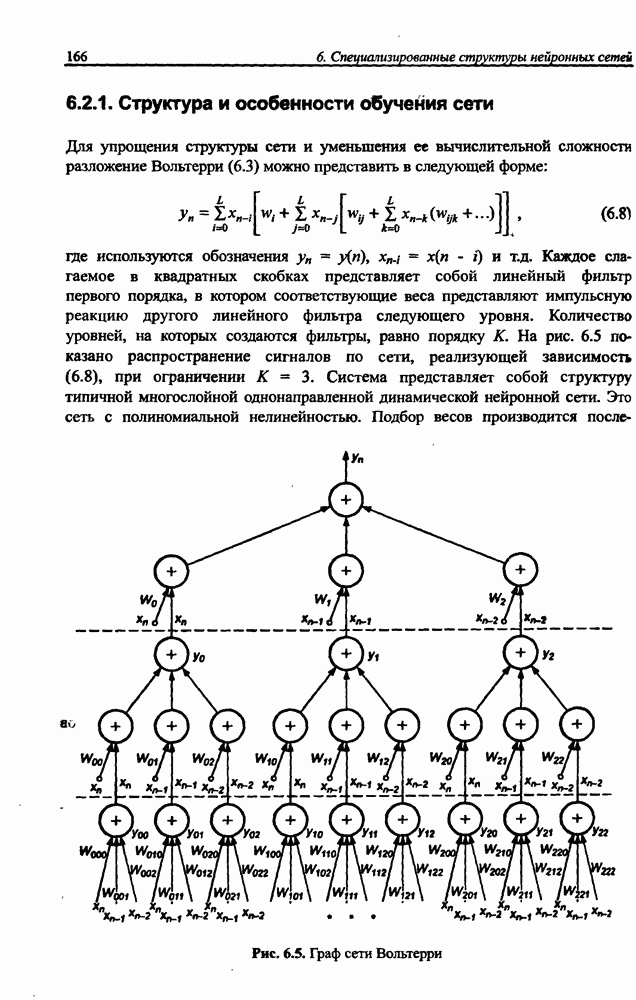
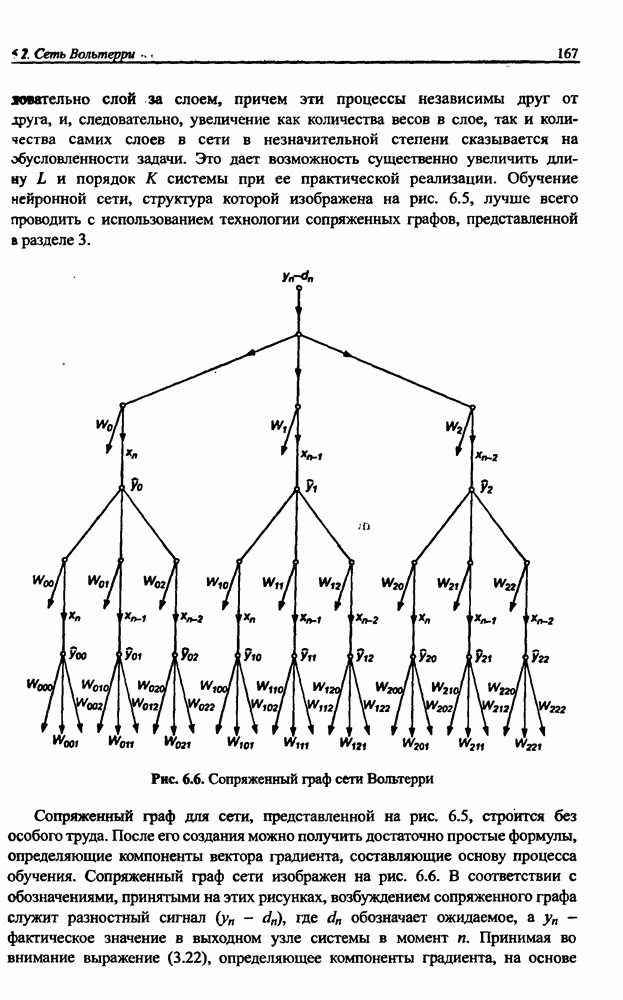
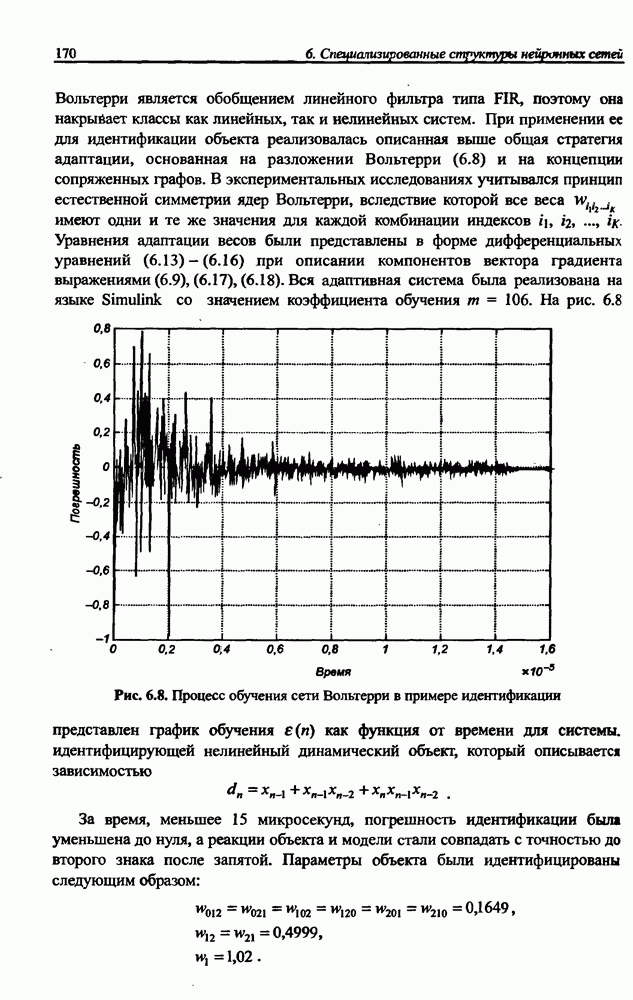
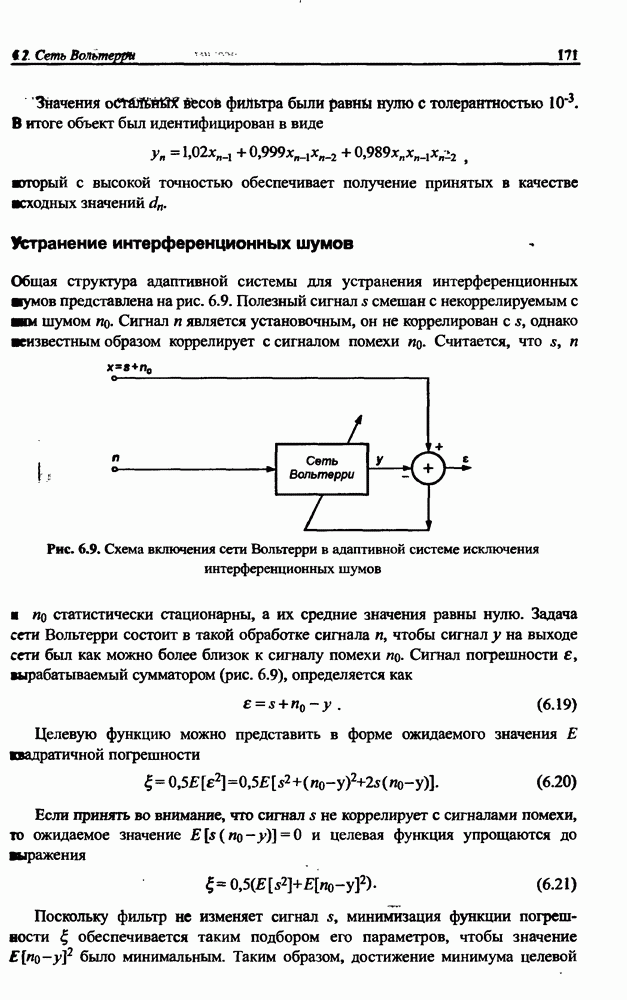
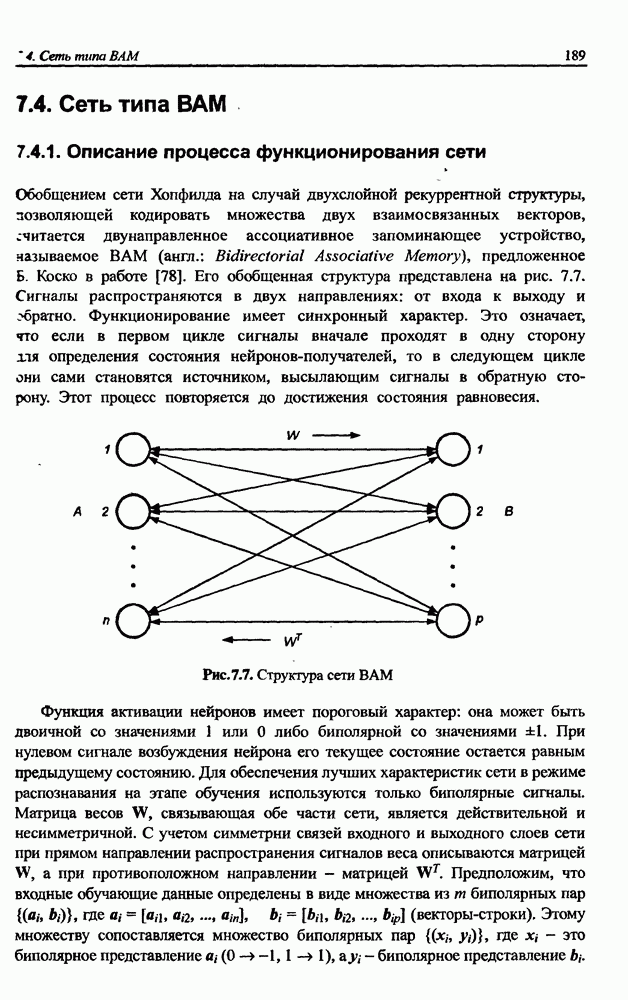
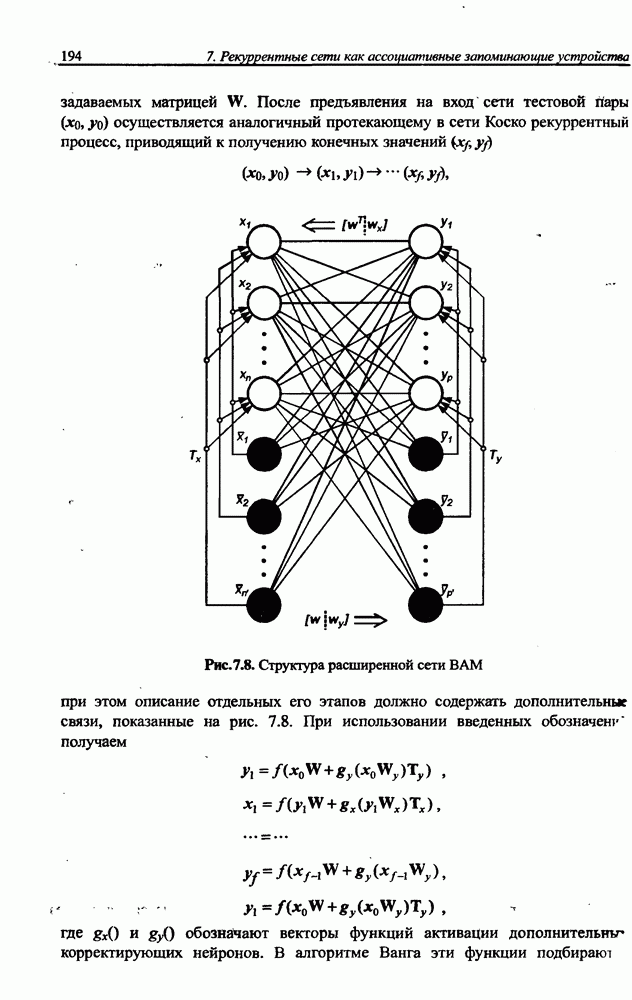
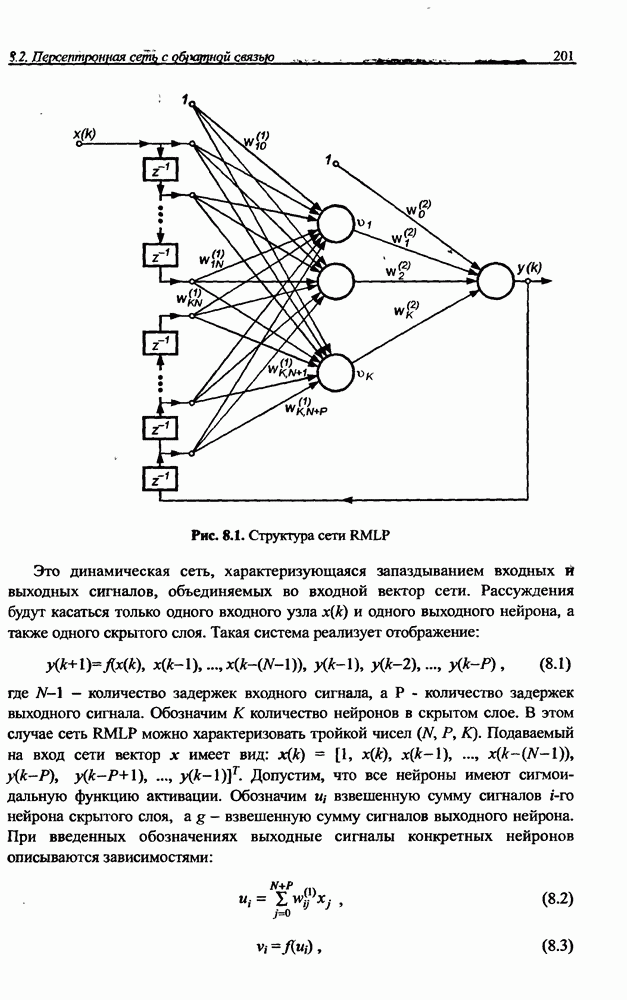
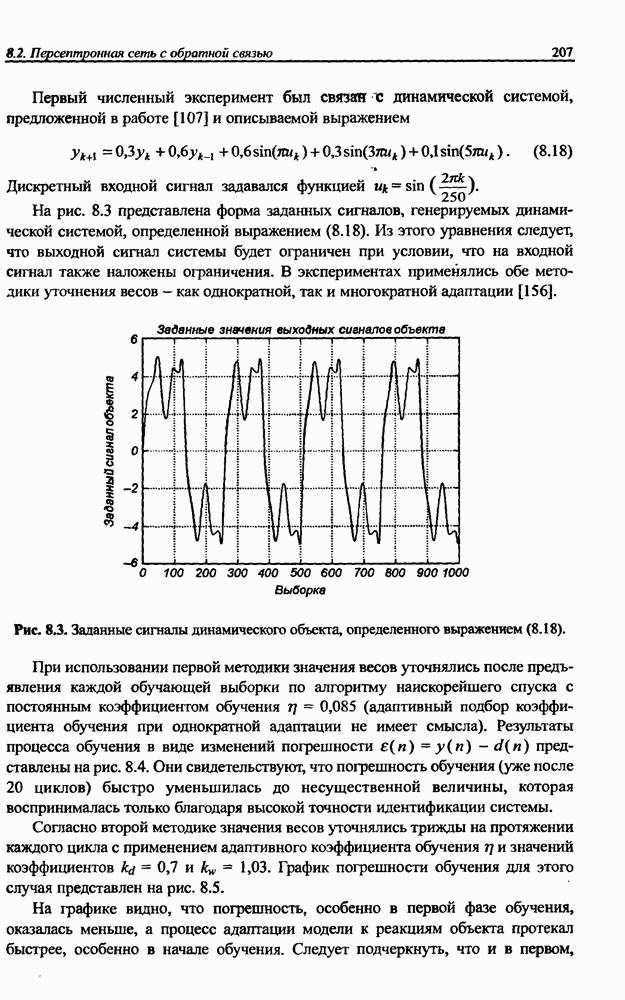
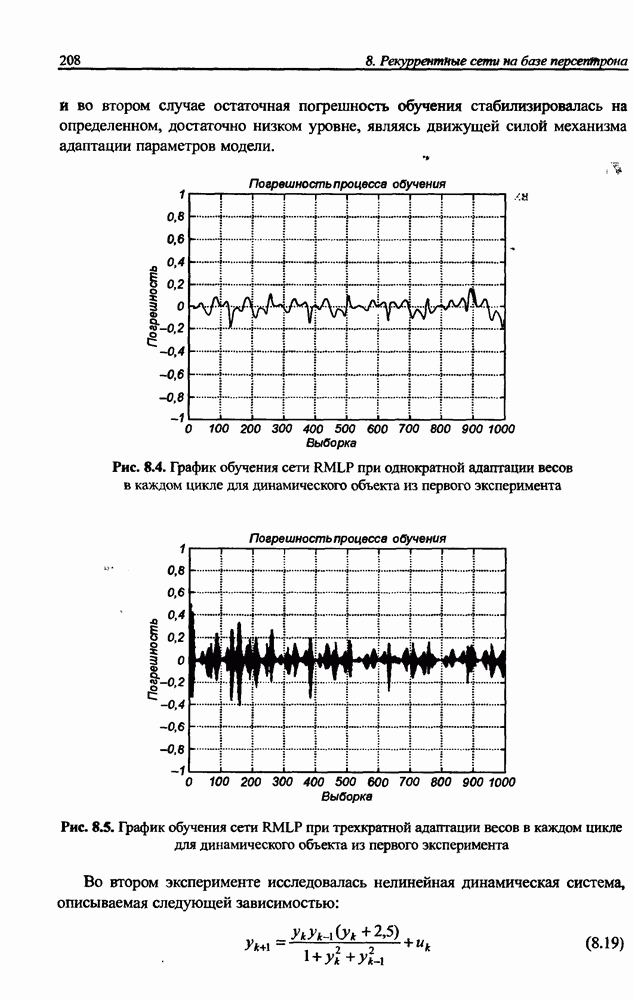
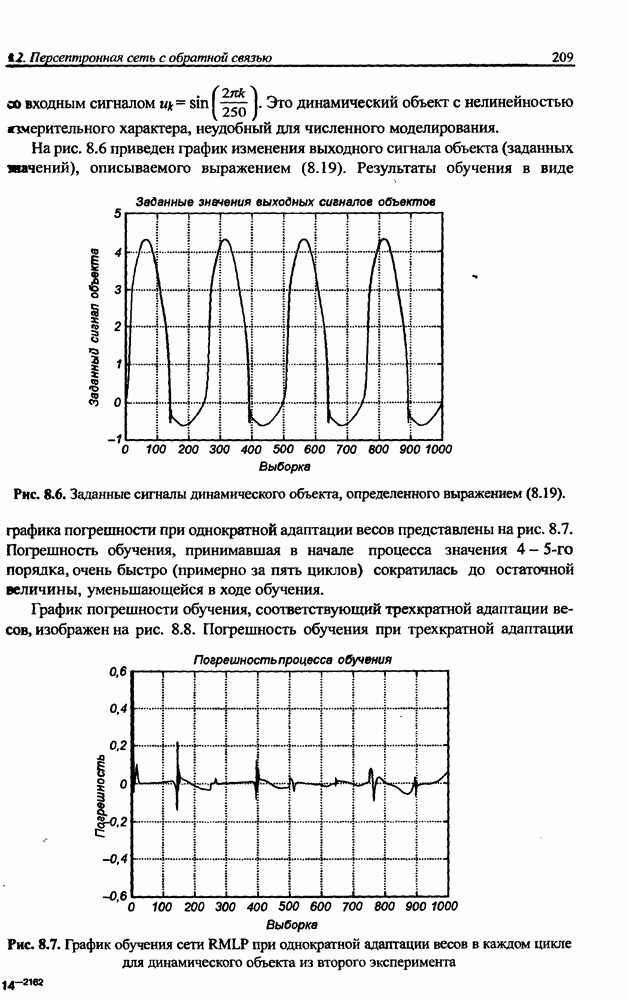
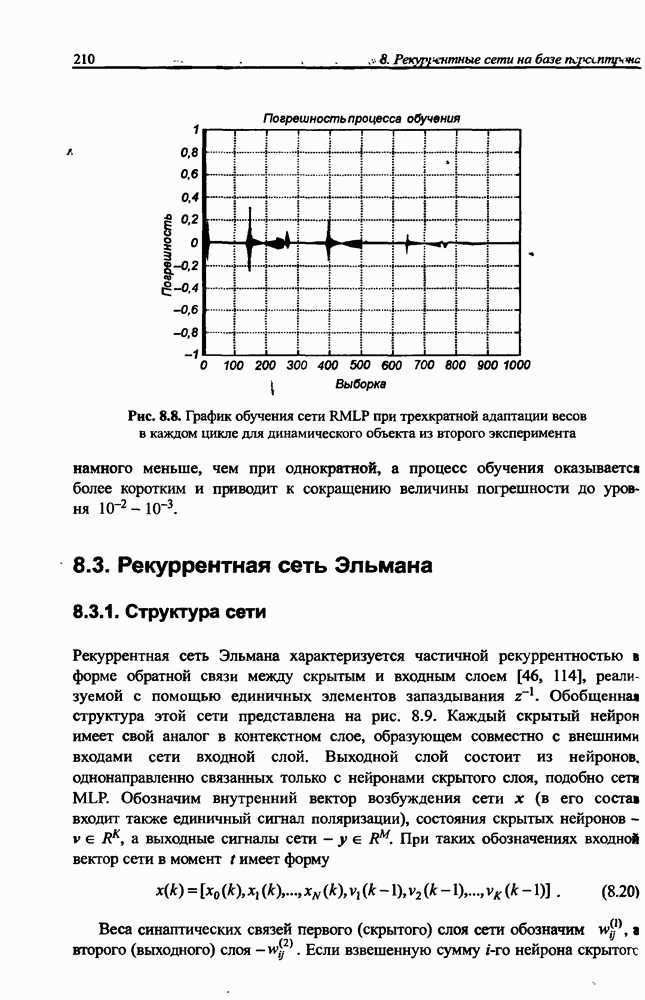
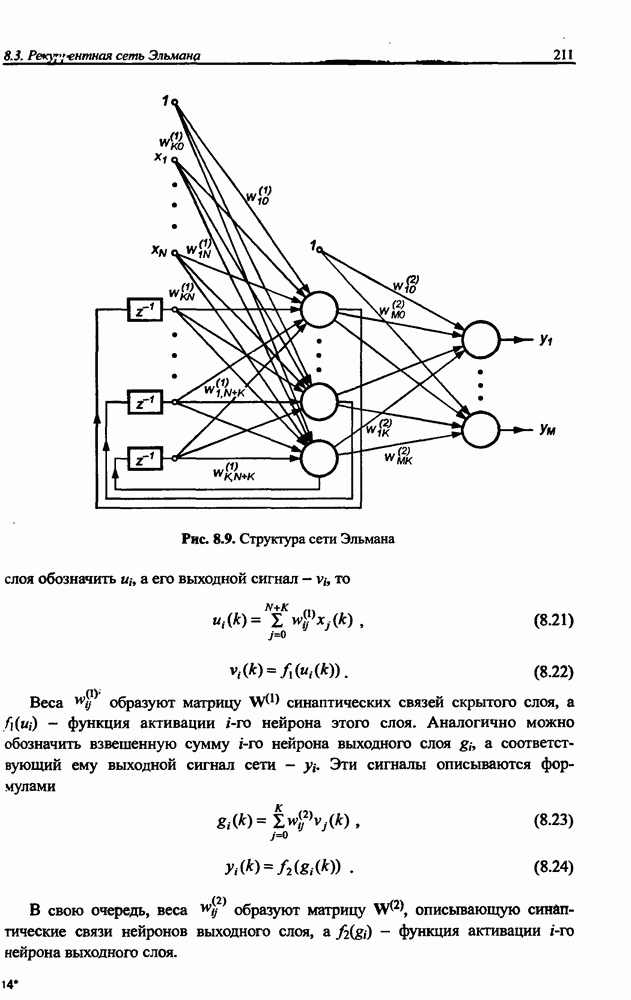
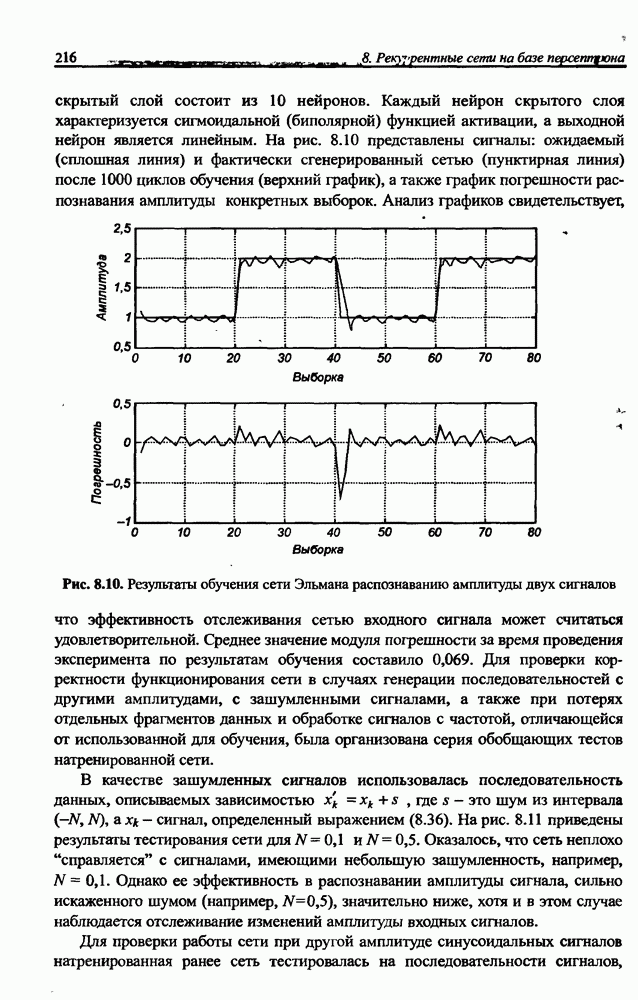
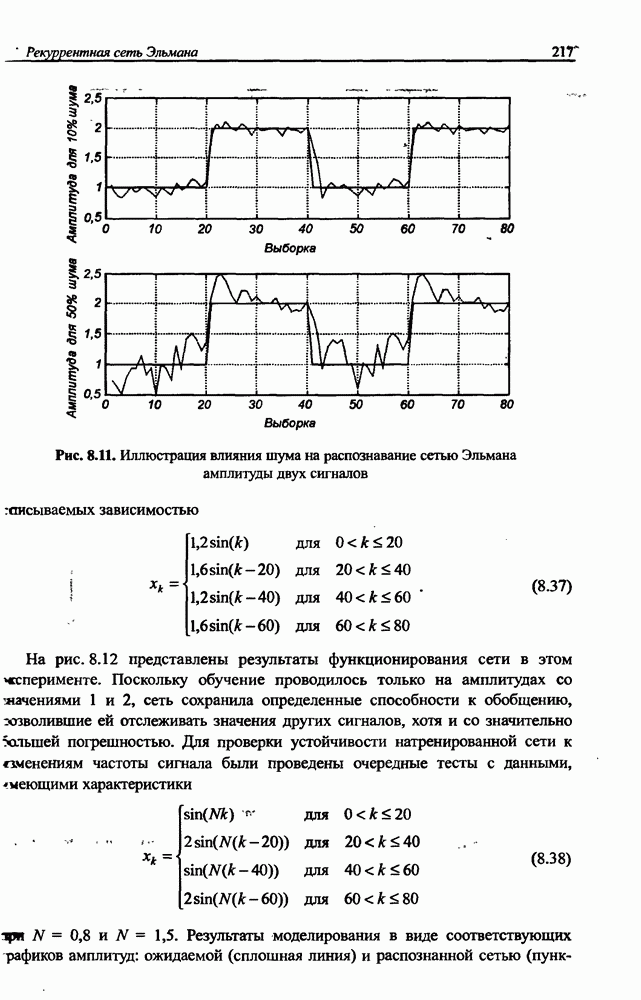
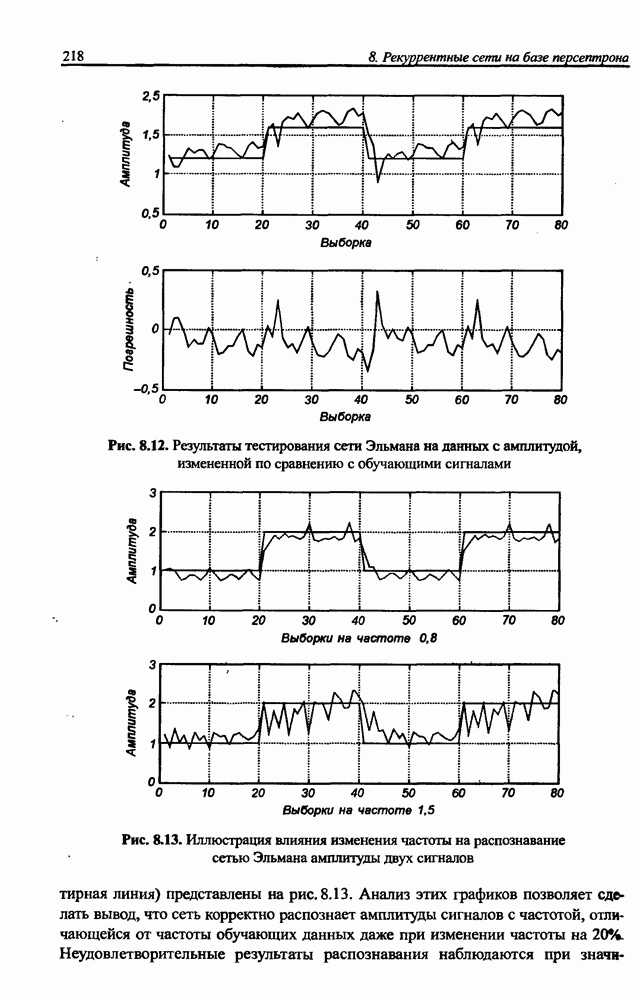
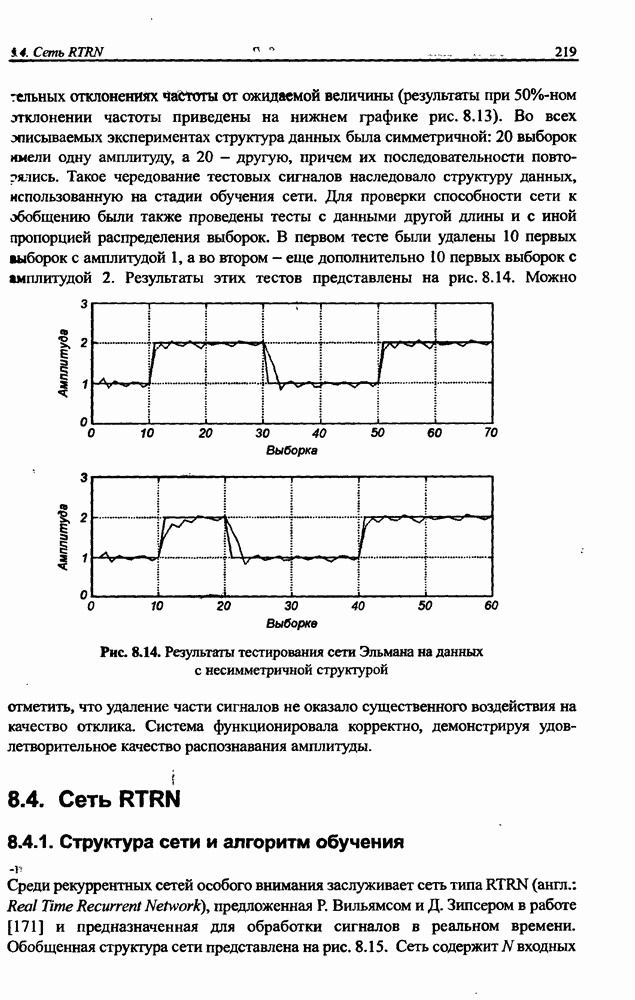
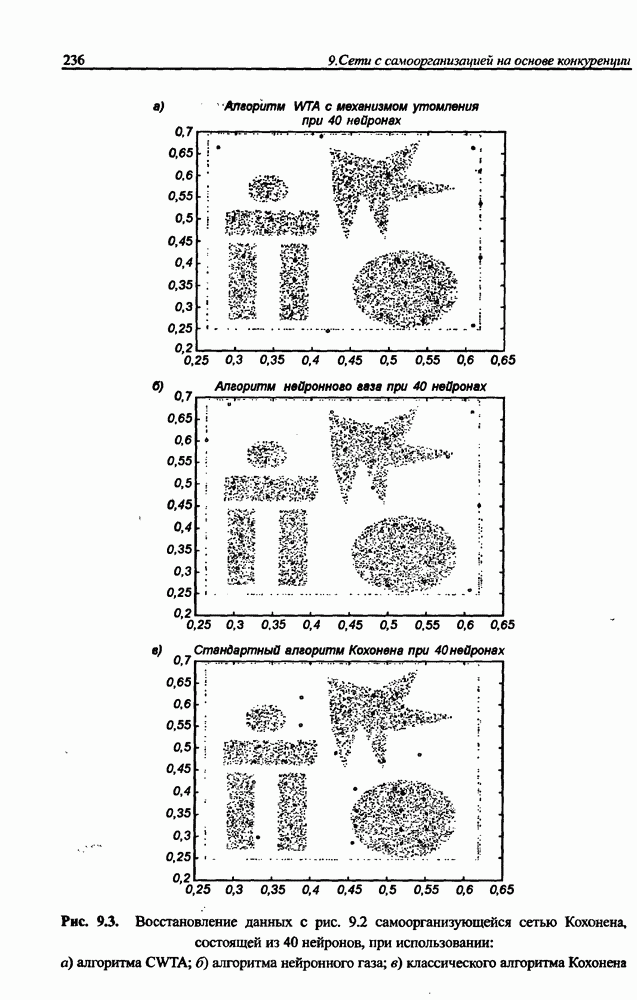
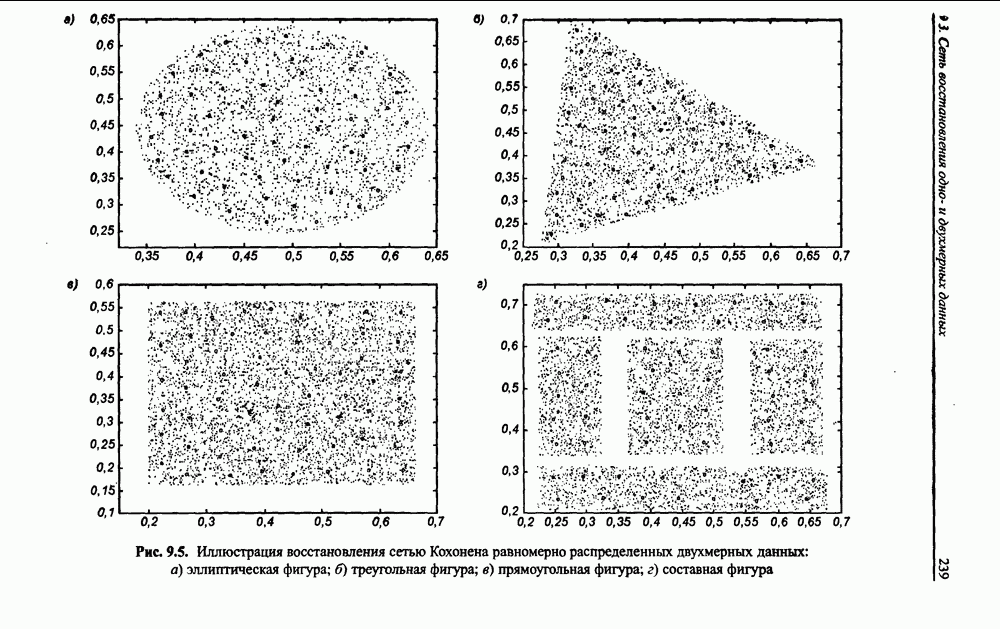
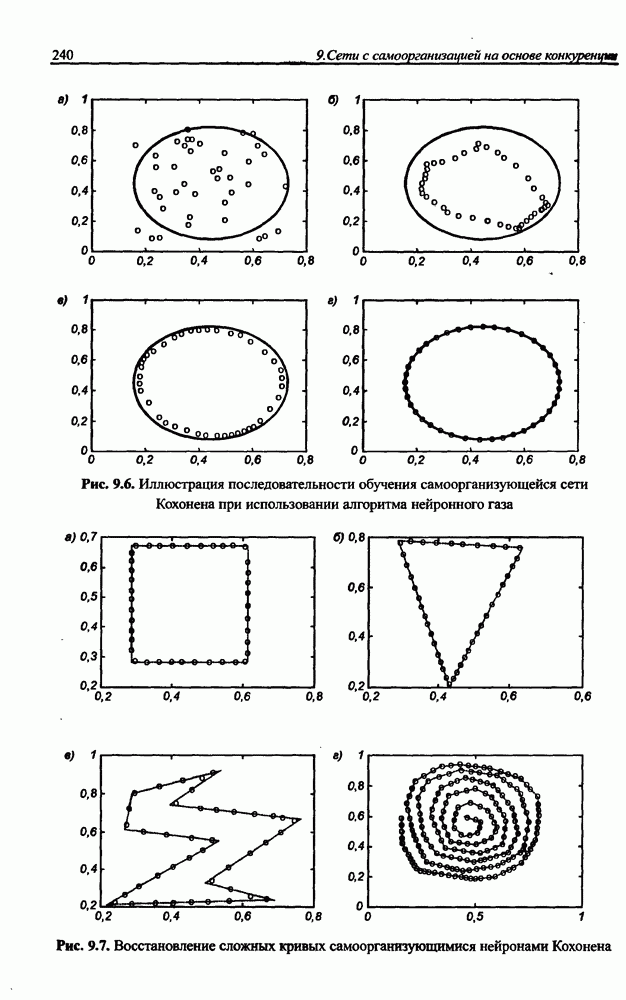
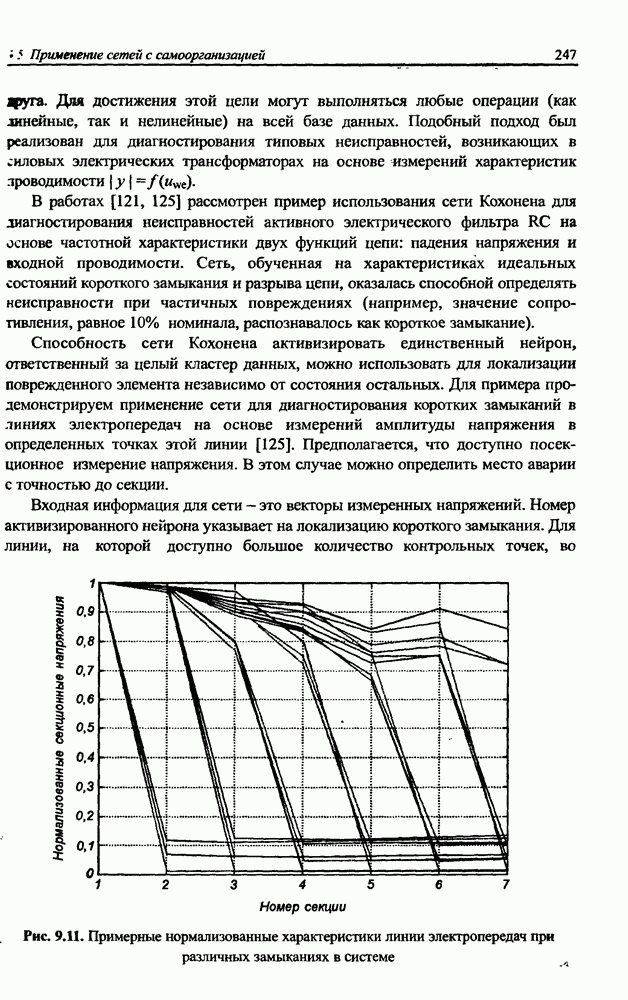
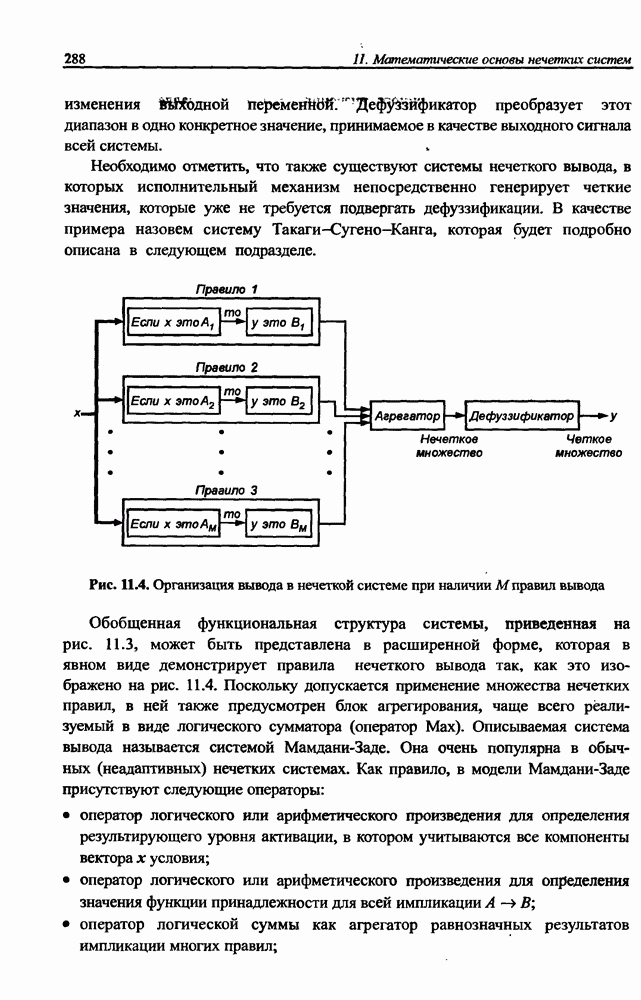
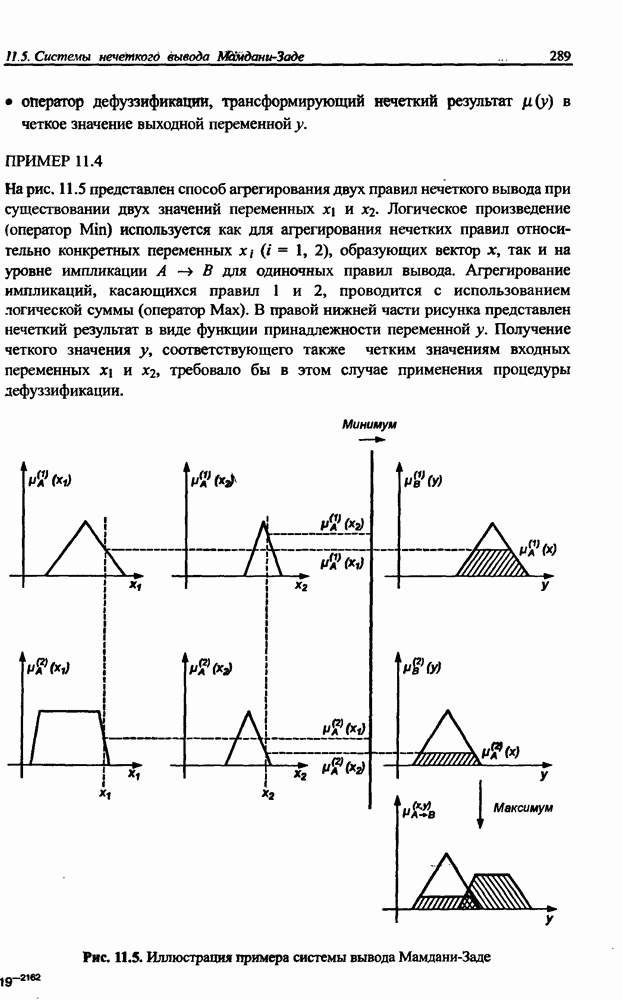
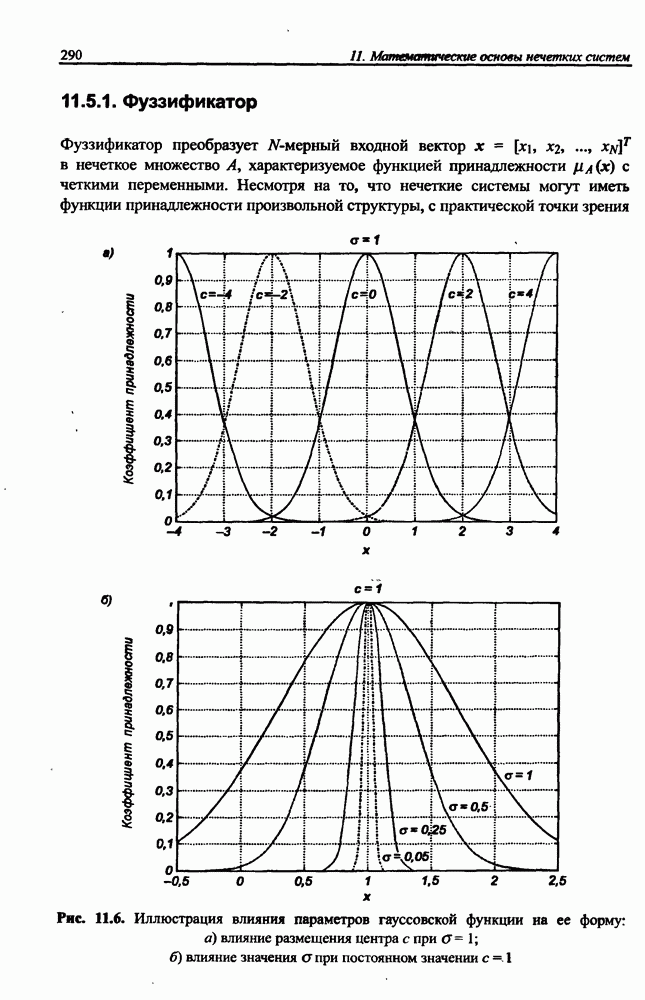
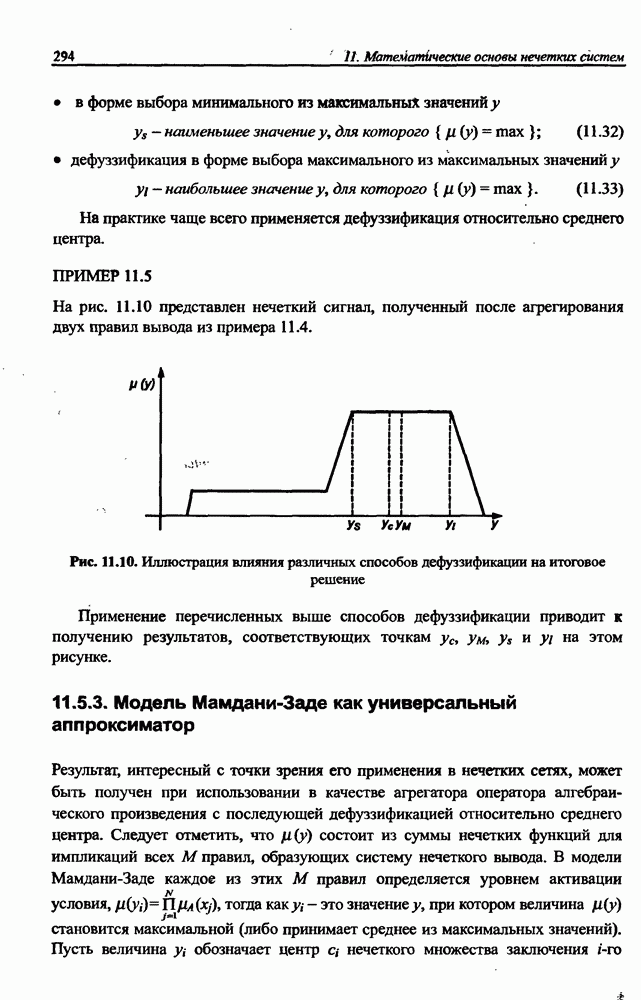
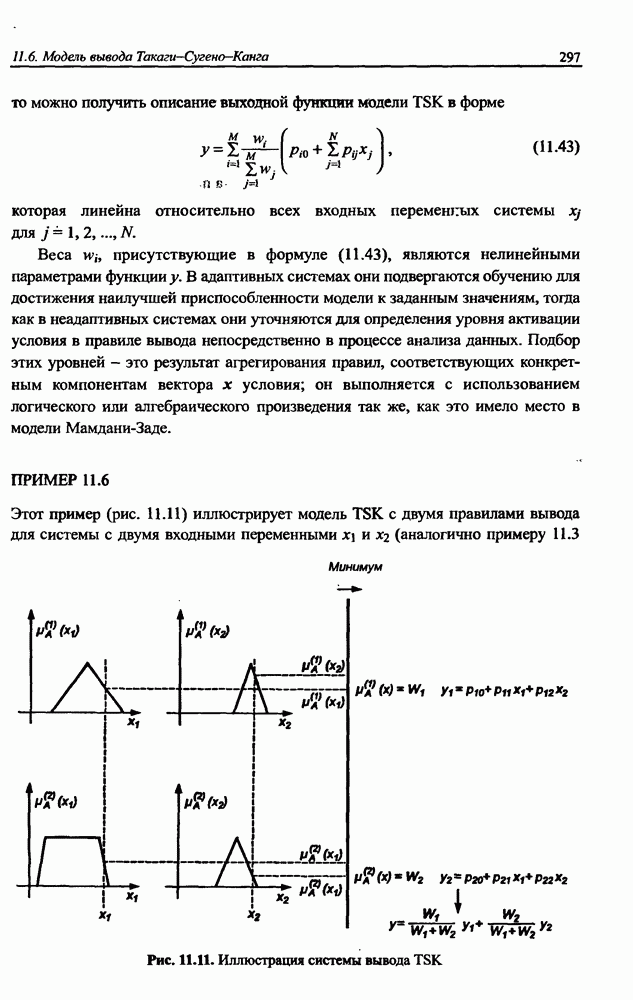
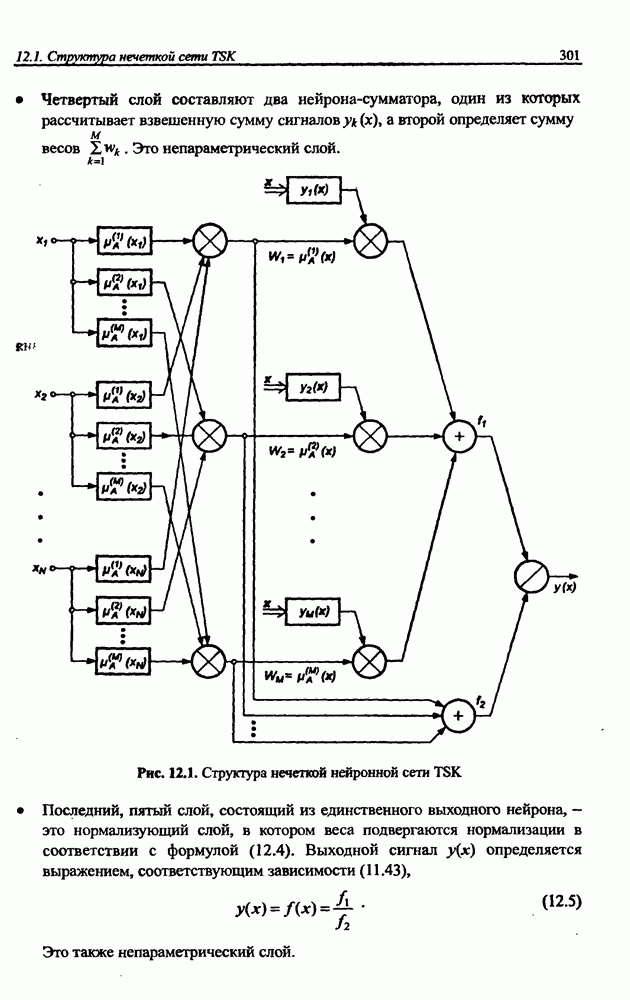
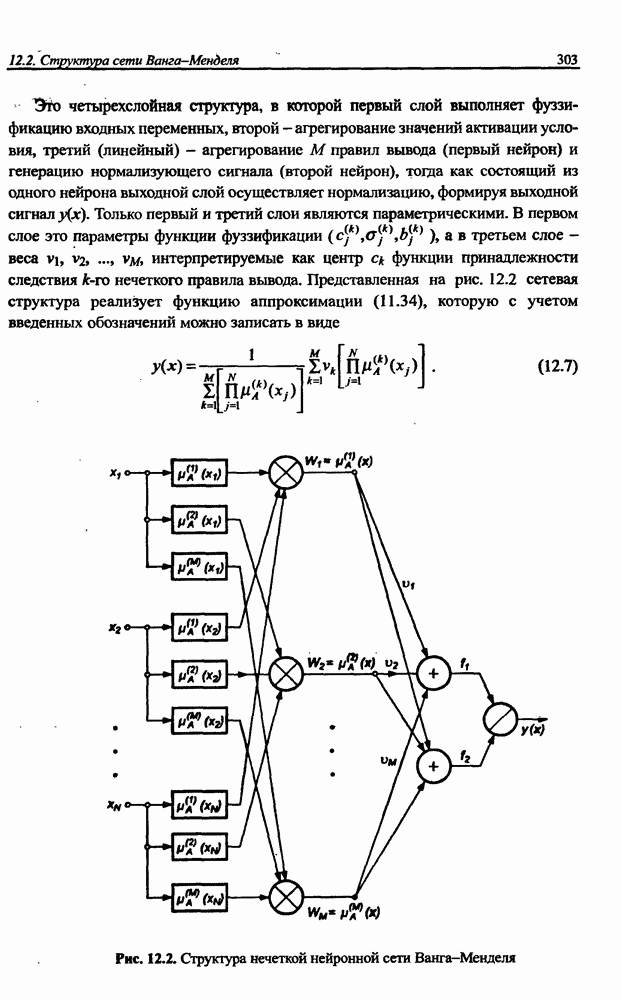
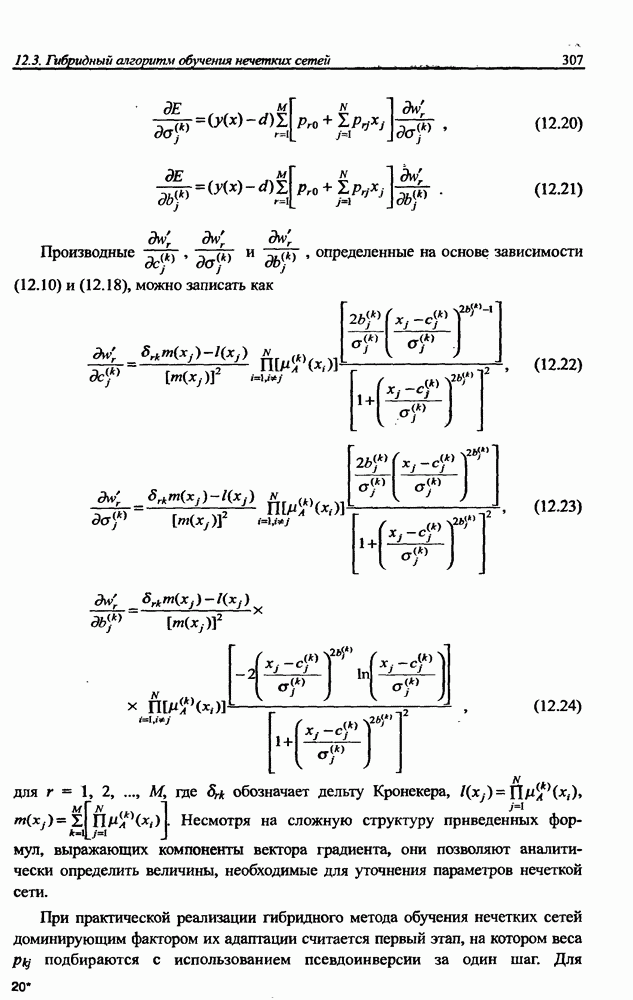
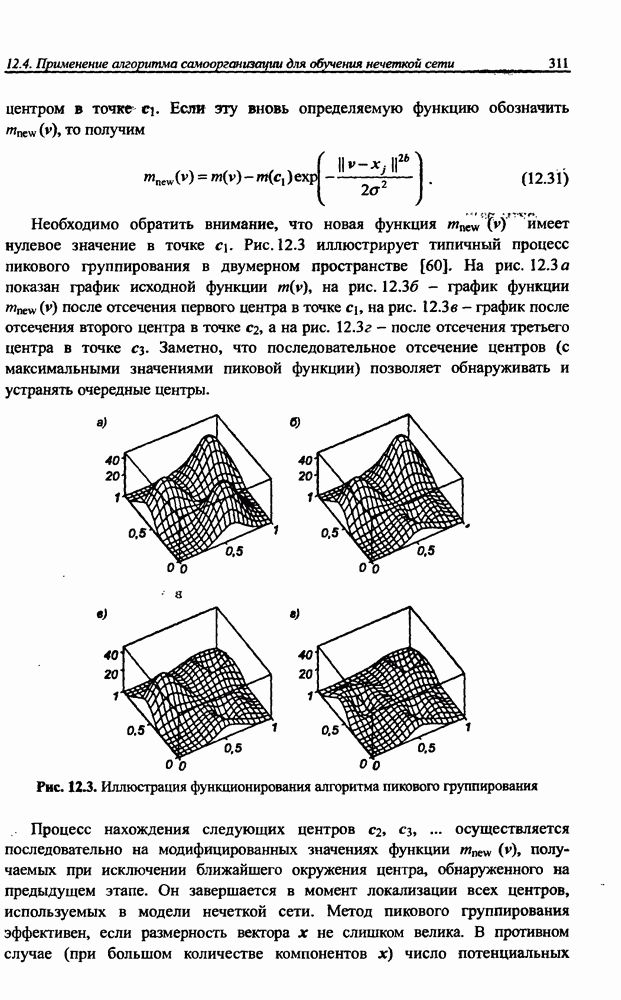
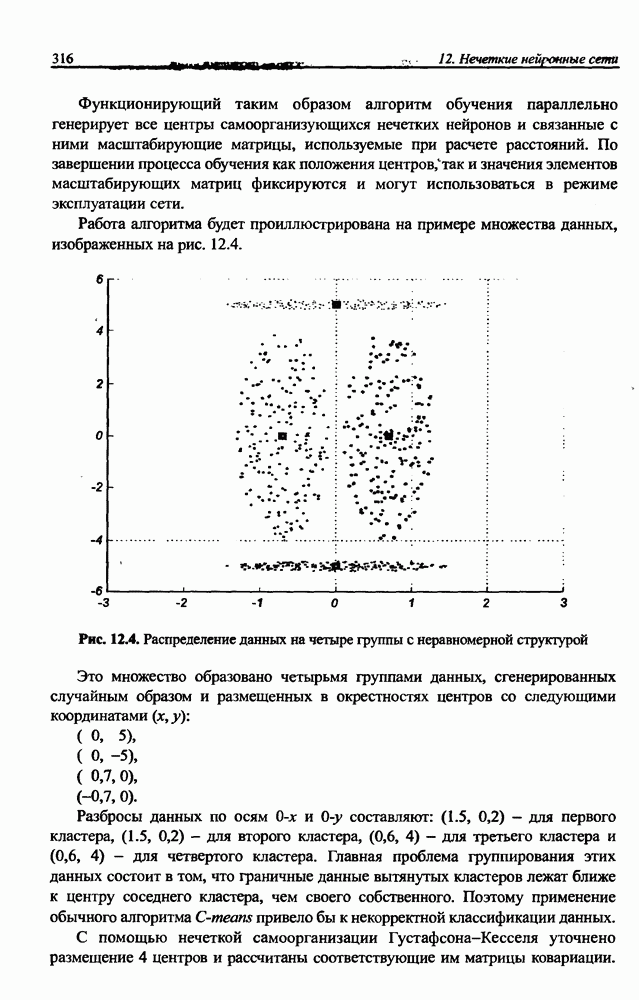
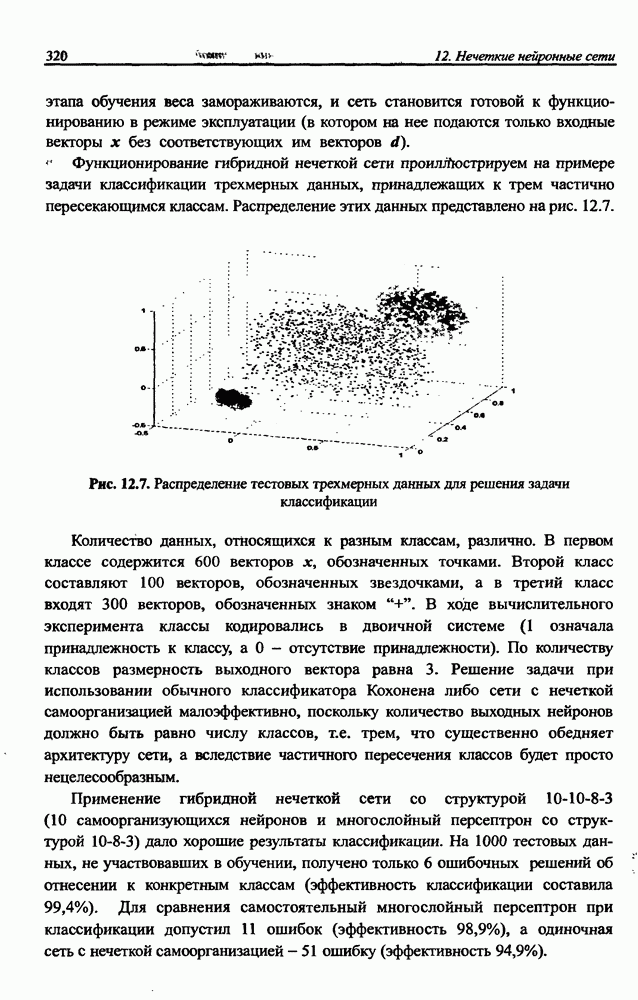
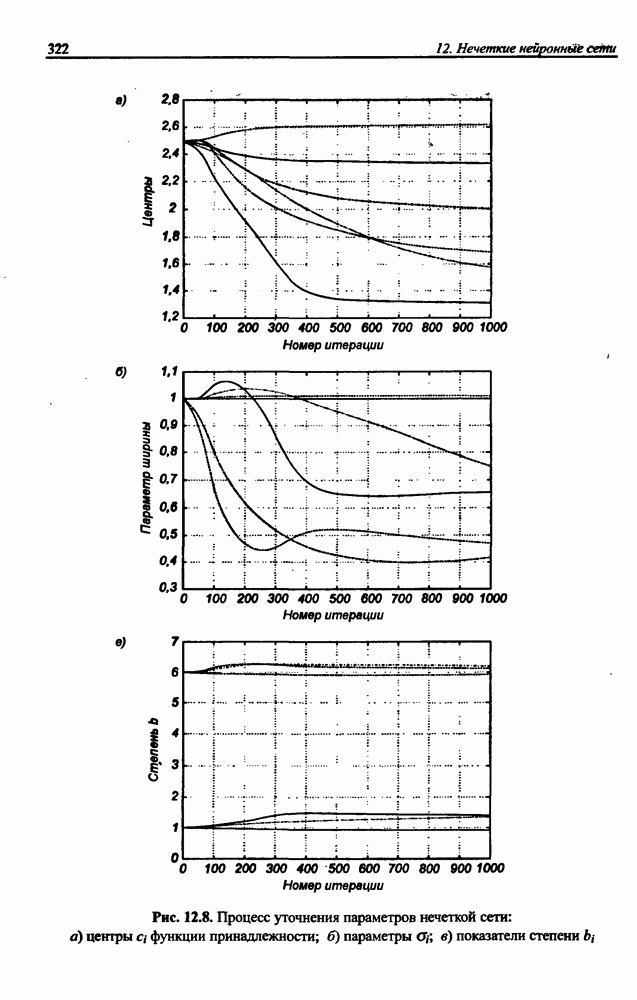
3.6. Эвристические методы обучения сети
Помимо алгоритмов обучения, реализующих апробированные методы оптимизации нелинейной целевой функции (такие, как методы переменной метрики, Левенберга-Марквардта либо сопряженных градиентов), создано огромное количество алгоритмов эвристического типа, представляющих собой в основном модификацию методов наискорейшего спуска или сопряженных градиентов. Подобные модификации широко известных алгоритмов связаны с внесением в них некоторых изменений, ускоряющих (по мнению авторов) процесс обучения. Как правило, такие методы не имеют серьезного теоретического обоснования, особенно это относится к процедуре подбора управляющих параметров. Однако в таких алгоритмах реализуется личный опыт работы авторов с нейронными сетями. К наиболее известным эвристическим алгоритмам относится Quickprop С. Фальмана [33] (использованный среди прочих и в программе  а также RPROP М. Ридмиллера и X. Брауна [133], реализованный в программе SNNS [178].
а также RPROP М. Ридмиллера и X. Брауна [133], реализованный в программе SNNS [178].
3.6.1. Алгоритм Quickprop
Quickprop содержит элементы, предотвращающие зацикливание в точке неглубокого локального минимума, возникающего в результате работы нейрона на фазе насыщения сигмоидальной кривой, где из-за близости к нулю производной функции активации процесс обучения практически прекращается.
Вес  на
на  шаге алгоритма изменяется согласно правилу
шаге алгоритма изменяется согласно правилу

Первое слагаемое соответствует оригинальному алгоритму наискорейшего спуска, последнее слагаемое, - фактору момента, а средний член  предназначен для минимизации абсолютных значений весов. Коэффициент у, имеющий обычно малую величину (типовое значение
предназначен для минимизации абсолютных значений весов. Коэффициент у, имеющий обычно малую величину (типовое значение  ), - это фактор, приводящий к уменьшению весов вплоть до возможного разрыва соответствующих взвешенных связей. Константа
), - это фактор, приводящий к уменьшению весов вплоть до возможного разрыва соответствующих взвешенных связей. Константа  это коэффициент обучения, который в данном алгоритме может иметь ненулевое значение
это коэффициент обучения, который в данном алгоритме может иметь ненулевое значение  (как правило,
(как правило,  на старте процесса обучения, когда
на старте процесса обучения, когда  либо когда
либо когда  или нулевое значение - в противном случае.
или нулевое значение - в противном случае.
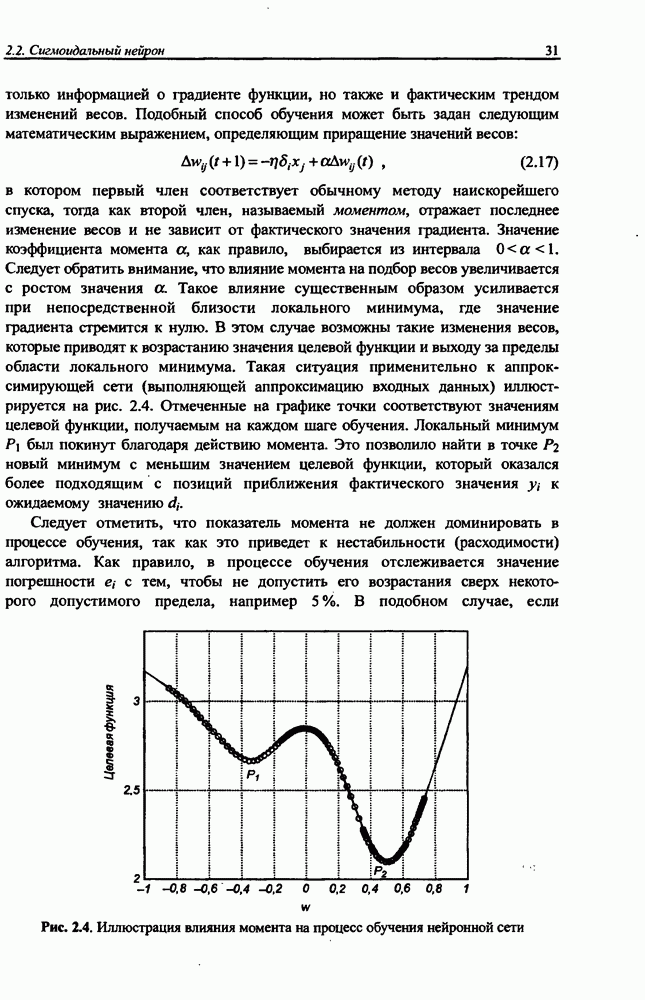
Важную роль в алгоритме Quickprop играет фактор момента, который адаптируется к текущим результатам процесса обучения. В соответствии с алгоритмом Фальмана коэффициент момента  подбирается индивидуально для каждого веса по правилу
подбирается индивидуально для каждого веса по правилу

причем

Константа  - это максимальное значение коэффициента момента, которая по предложению Фальмана принимается равной
- это максимальное значение коэффициента момента, которая по предложению Фальмана принимается равной 
Также известна упрощенная версия алгоритма  в которой значения весов изменяются в соответствии с правилом
в которой значения весов изменяются в соответствии с правилом

где  нем уменьшено количество управляющих параметров и упрощена сама формула уточнения значений весов. Согласно представленным в [159] результатам эффективность модифицированного алгоритма сравнима с оригинальным алгоритмом Фальмана.
нем уменьшено количество управляющих параметров и упрощена сама формула уточнения значений весов. Согласно представленным в [159] результатам эффективность модифицированного алгоритма сравнима с оригинальным алгоритмом Фальмана.
3.6.2. Алгоритм RPROP
Другой простой эвристический алгоритм, демонстрирующий высокую эффективность обучения, - это алгоритм М. Ридмиллера и X. Брауна, называемый RPROP (англ.: Resilient back PROPagation) [133, 178]. В этом алгоритме при уточнении весов учитывается только знак градиентной составляющей, а ее значение игнорируется:

Коэффициент обучения подбирается индивидуально для каждого веса  с учетом изменения значения градиента:
с учетом изменения значения градиента:

где  - константы:
- константы:  Минимальное и максимальное значения коэффициента обучения обозначены соответственно
Минимальное и максимальное значения коэффициента обучения обозначены соответственно  и
и  для алгоритма RPROP они составляют
для алгоритма RPROP они составляют  и
и  Функция
Функция  принимает значение, равное знаку градиента.
принимает значение, равное знаку градиента.
Алгоритм RPROP, в котором игнорируется информация о значении градиента, позволяет значительно ускорить процесс обучения в тех случаях, когда угол наклона целевой функции невелик. В соответствии со стратегией подбора весов, если на двух последовательных шагах знак градиента не изменяется, предусматривается увеличение коэффициента обучения. Если же знак градиента изменяется, то коэффициент обучения уменьшается.