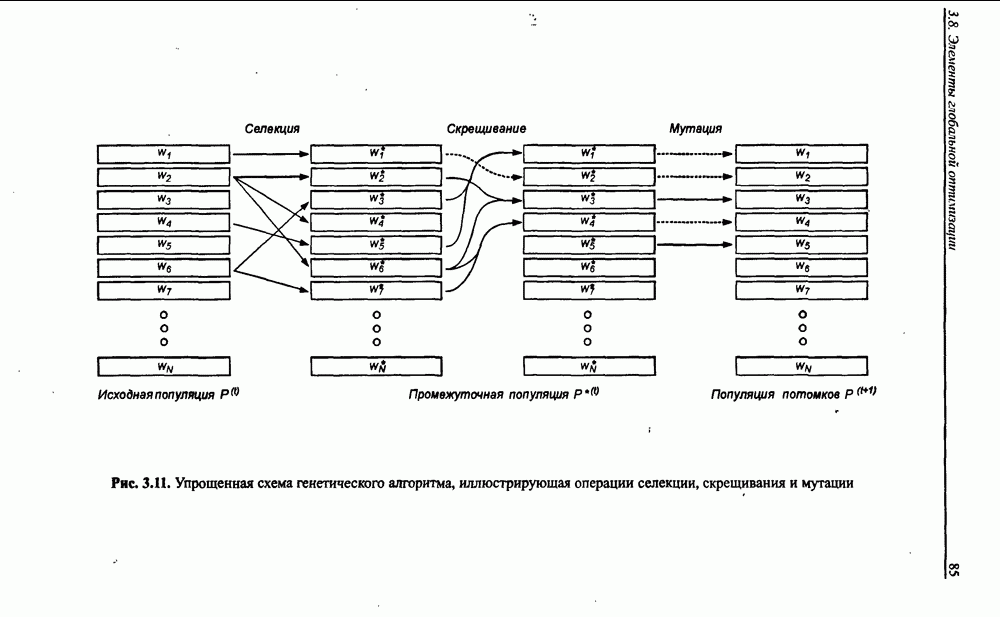
Пред.
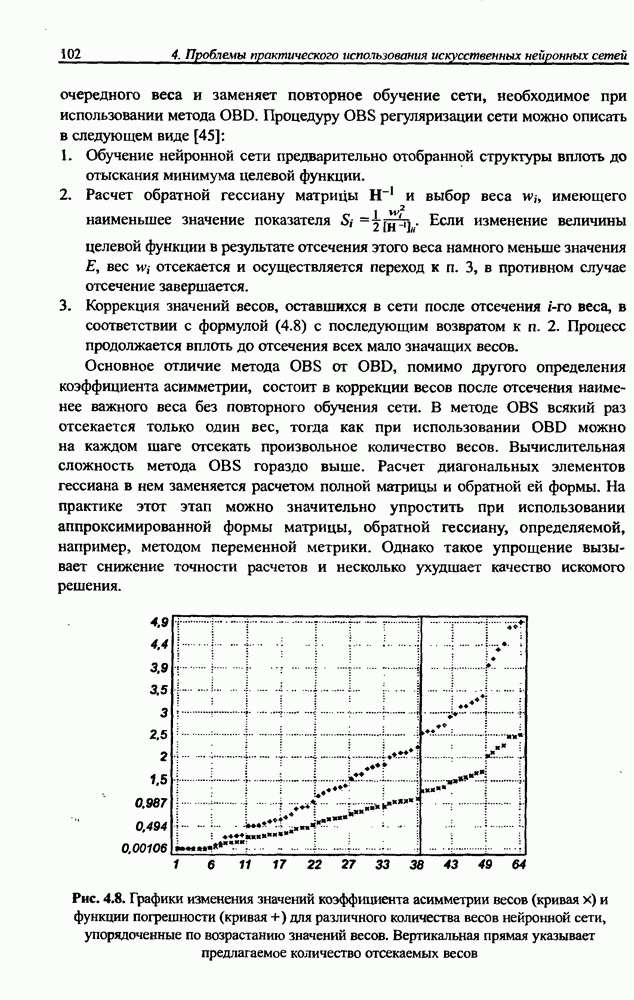
След.
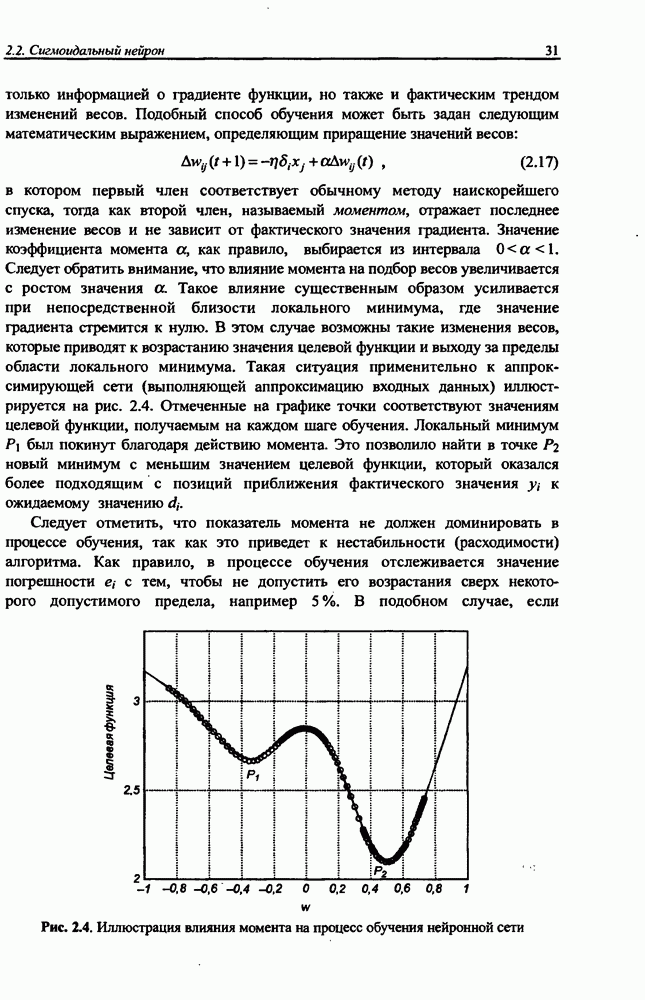
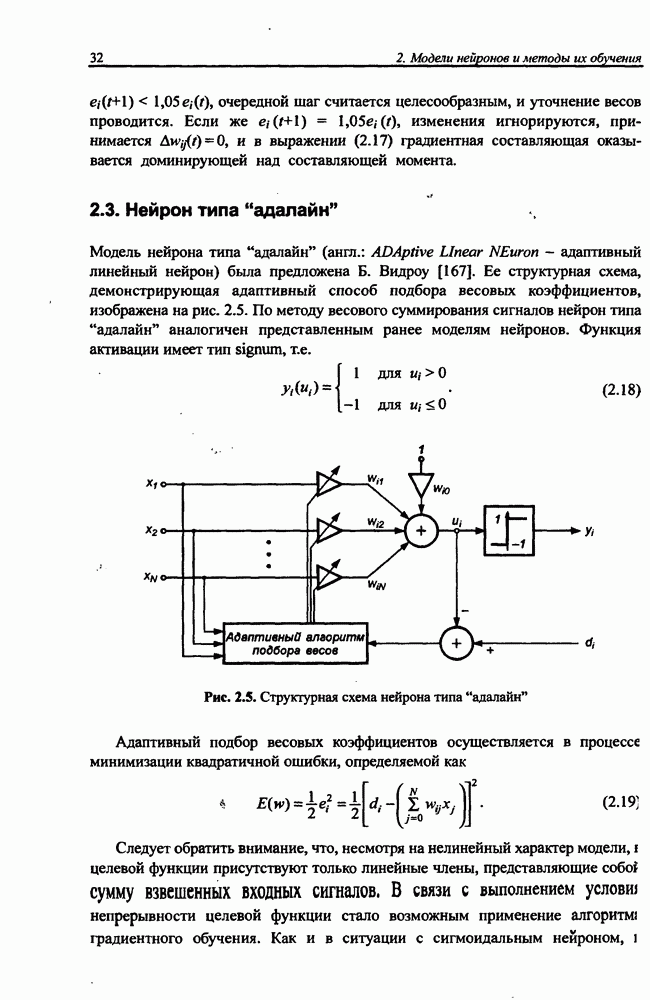
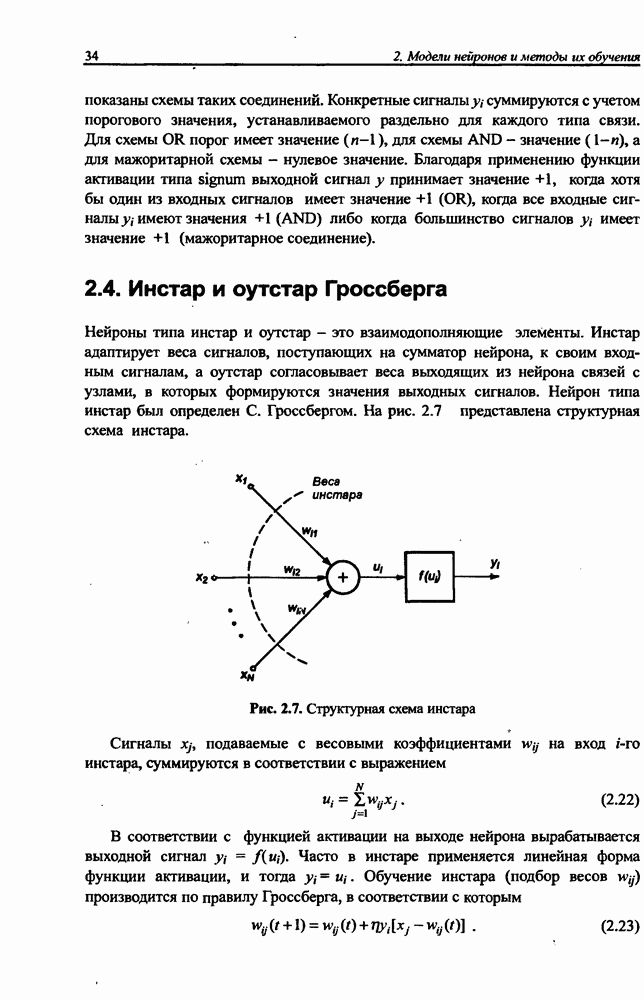
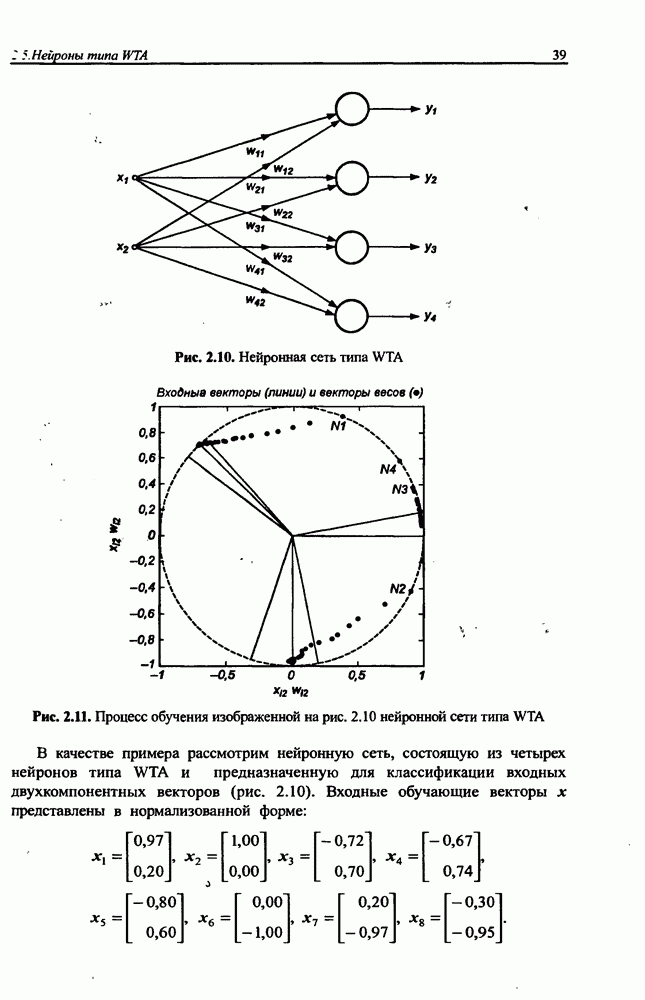
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
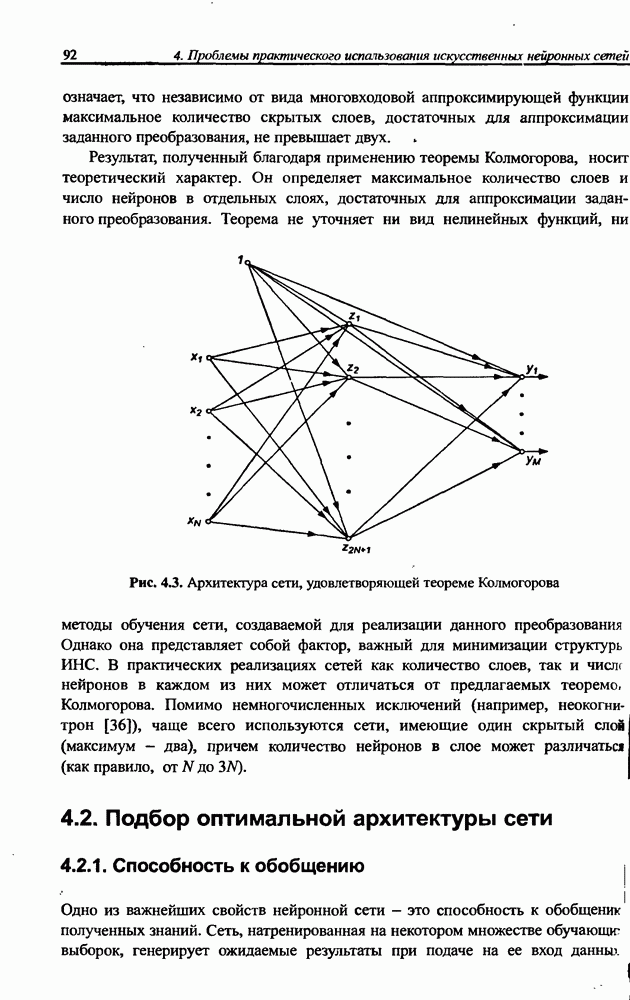
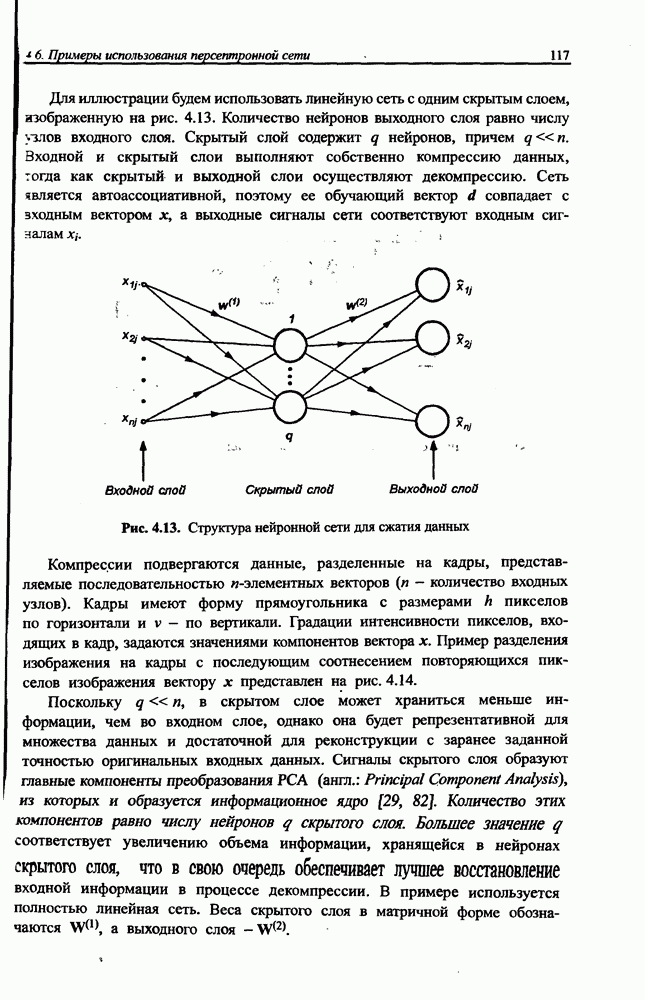
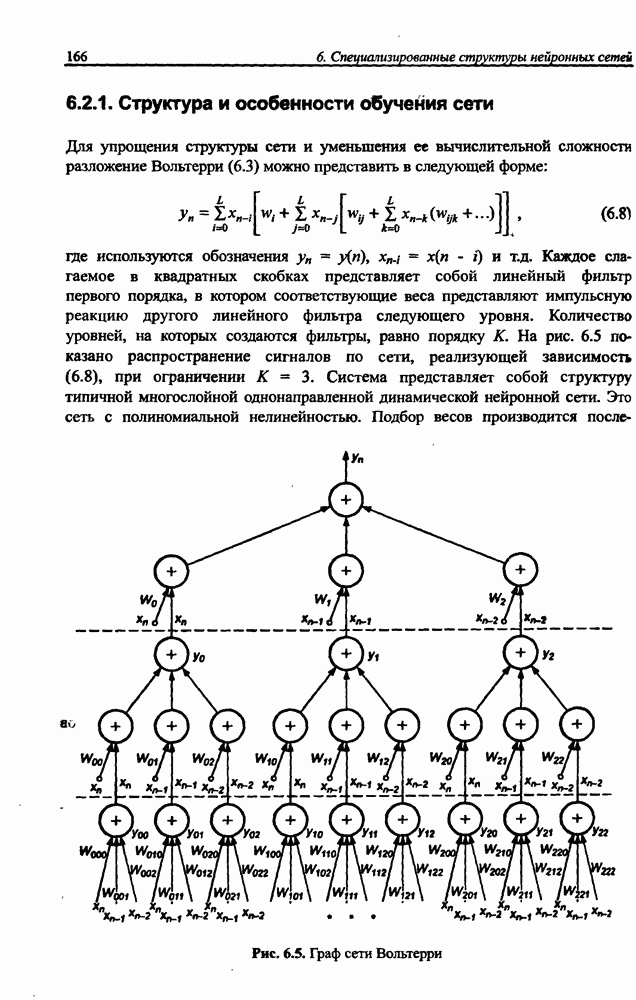
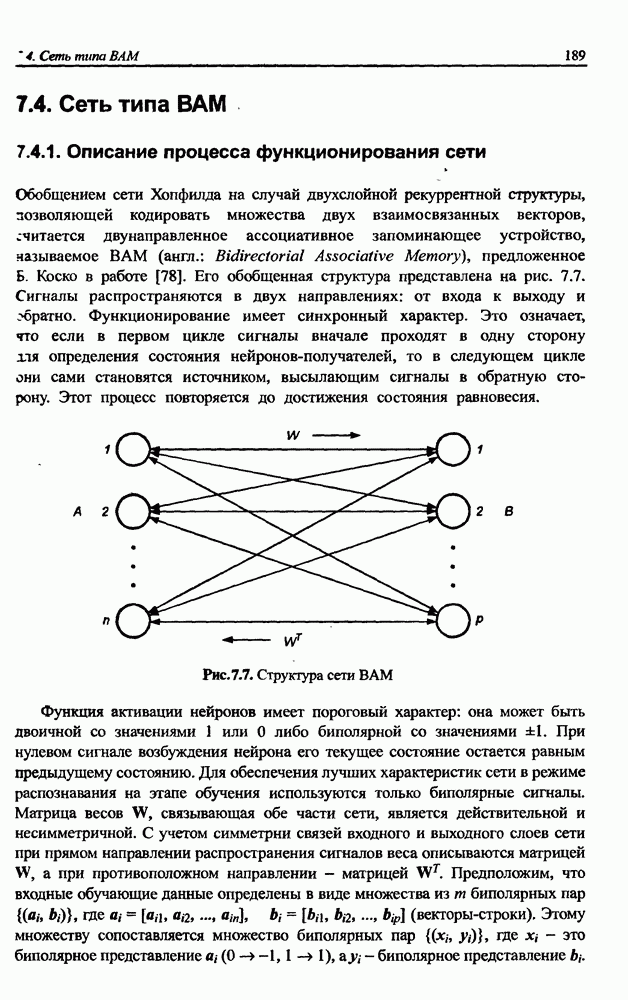
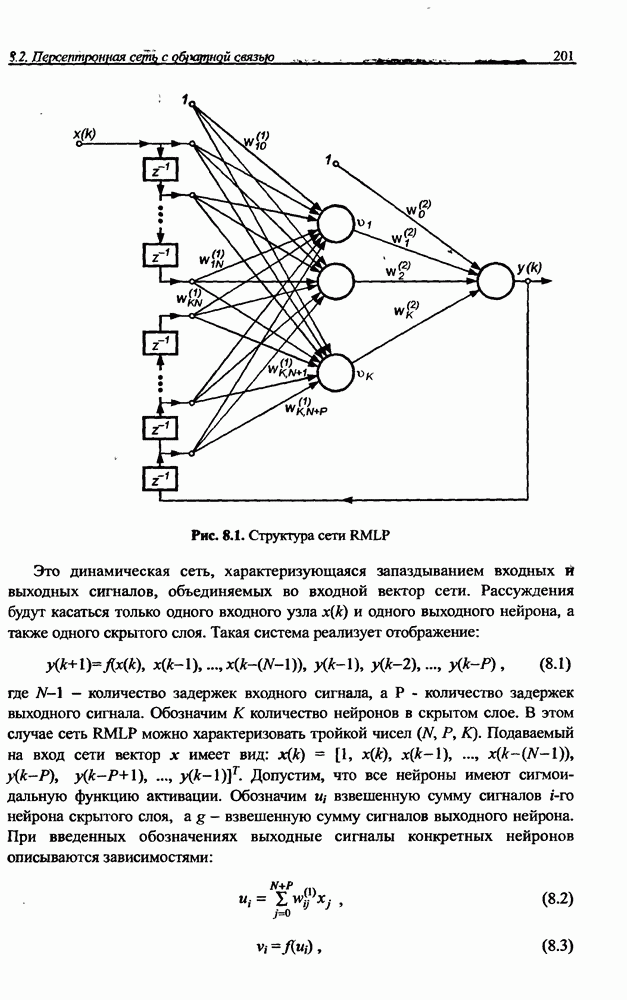
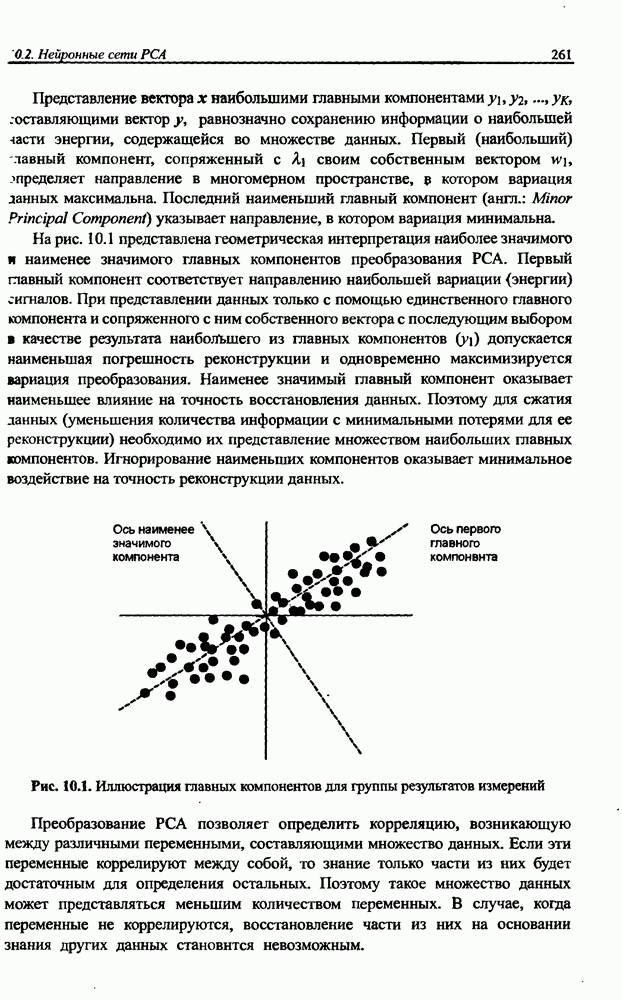
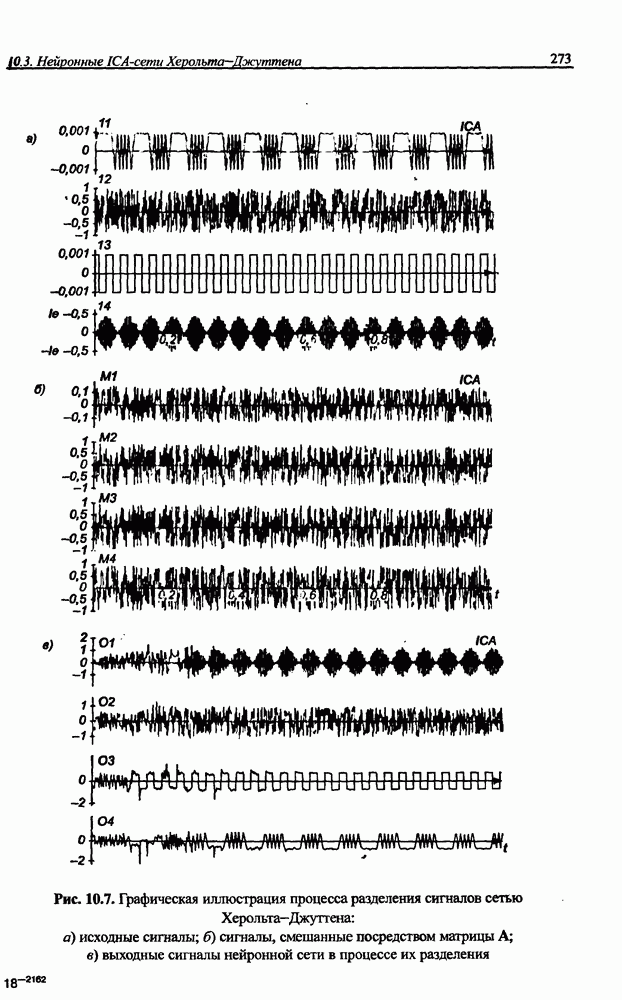
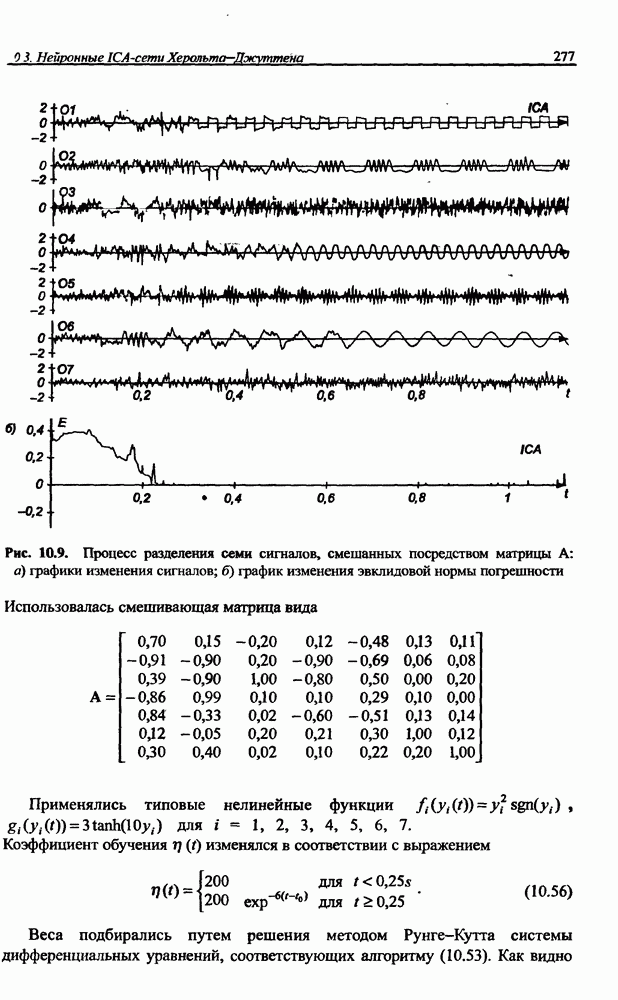
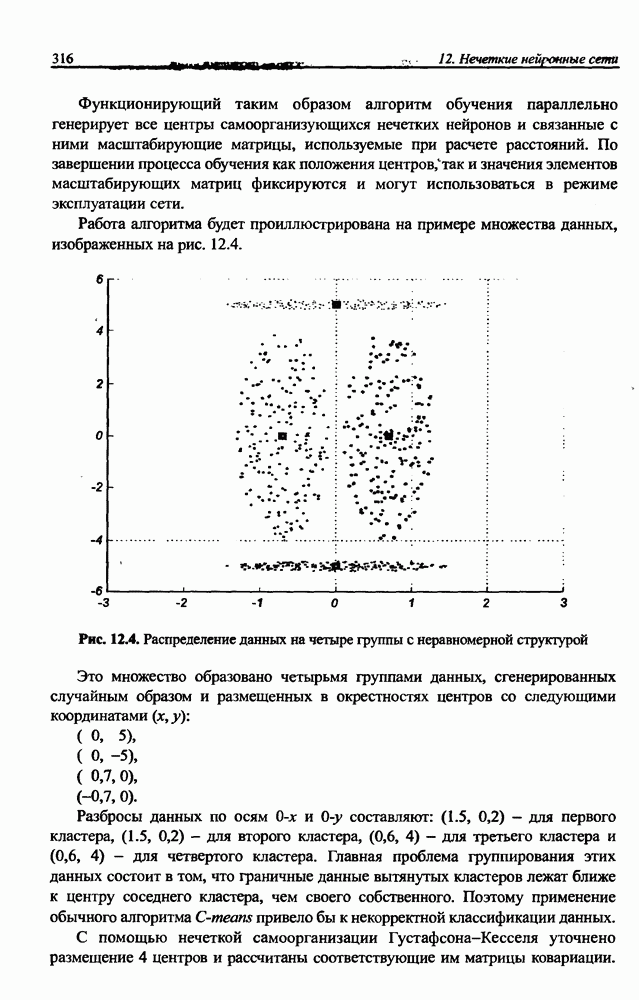
4.2. Подбор оптимальной архитектуры сети4.2.1. Способность к обобщениюОдно из важнейших свойств нейронной сети - это способность к обобщение полученных знаний. Сеть, натренированная на некотором множестве обучающих выборок, генерирует ожидаемые результаты при подаче на ее вход данных, относящихся к тому же множеству, но не участвовавших непосредственно в процессе обучения. Разделение данных на обучающее и тестовое подмножества представлено на рис. 4.4. Множество данных, на котором считается истинным некоторое правило
Рис. 4.4. Иллюстрация разделения данных, подчиняющихся правилу Феномен обобщения возникает вследствие большого количества комбинаций входных данных, которые могут кодироваться в сети с Подбор весов сети в процессе обучения имеет целью найти такую комбинацию их значений, которая наилучшим образом воспроизводила бы последовательность ожидаемых обучающих пар статистически усредненным совокупностям. Следовательно, для усиления способности к обобщению необходимо не только оптимизировать структуру сети в направлении ее минимизации, но и оперировать достаточно большим объемом обучающих данных. Обратим внимание на определенную непоследовательность процесса обучения сети. Собственно обучение ведется путем минимизации целевой функции - вектор реакции сети на возбуждение Истинная цель обучения состоит в таком подборе архитектуры и параметров сети, которые обеспечат минимальную погрешность распознавания тестового подмножества данных, не участвовавших в обучении. Эту погрешность будем называть погрешностью обобщения
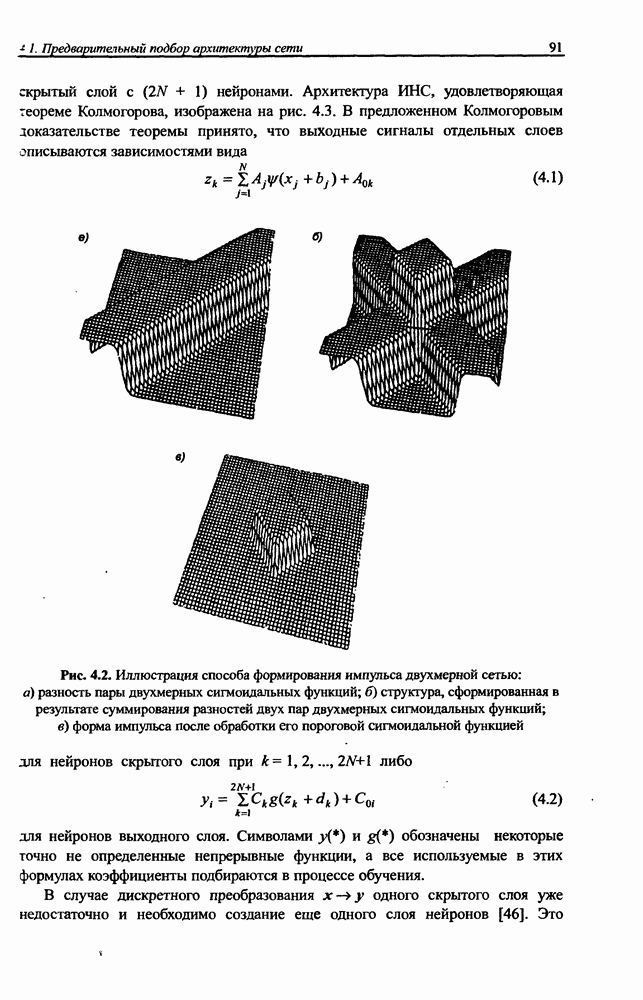
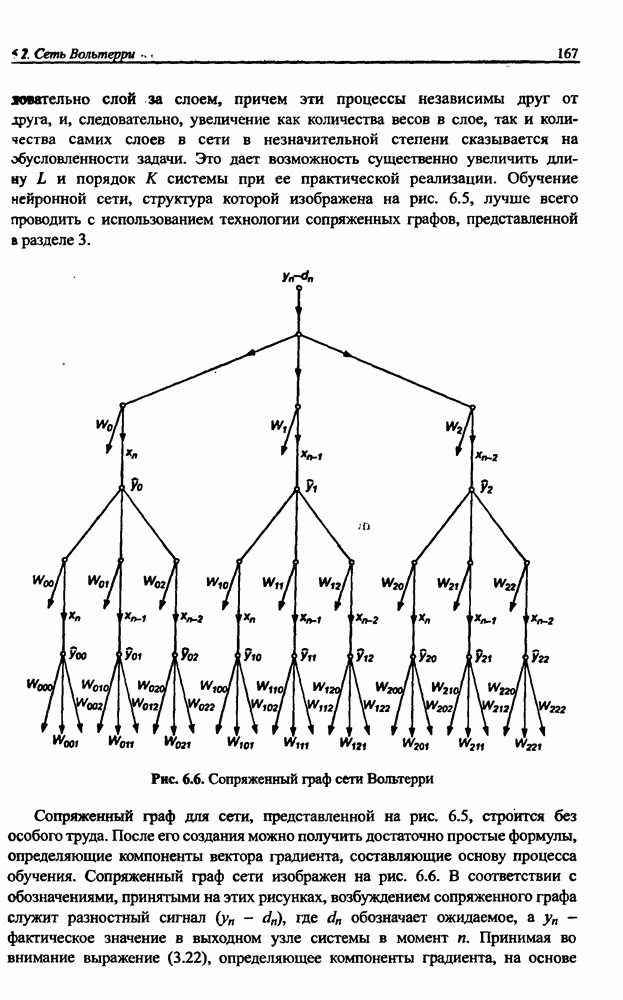
В работе [46] показано, что значение По этой причине обязательным условием выработки хороших способностей к обобщению считается грамотное определение меры Вапника-Червоненкиса для сети заданной структуры. Метод точного определения этой меры не известен, о нем можно лишь сказать, что ее значение функционально зависит от количества синаптических весов, связывающих нейроны между собой. Чем больше количество различных весов, тем больше сложность сети и соответственно значение меры
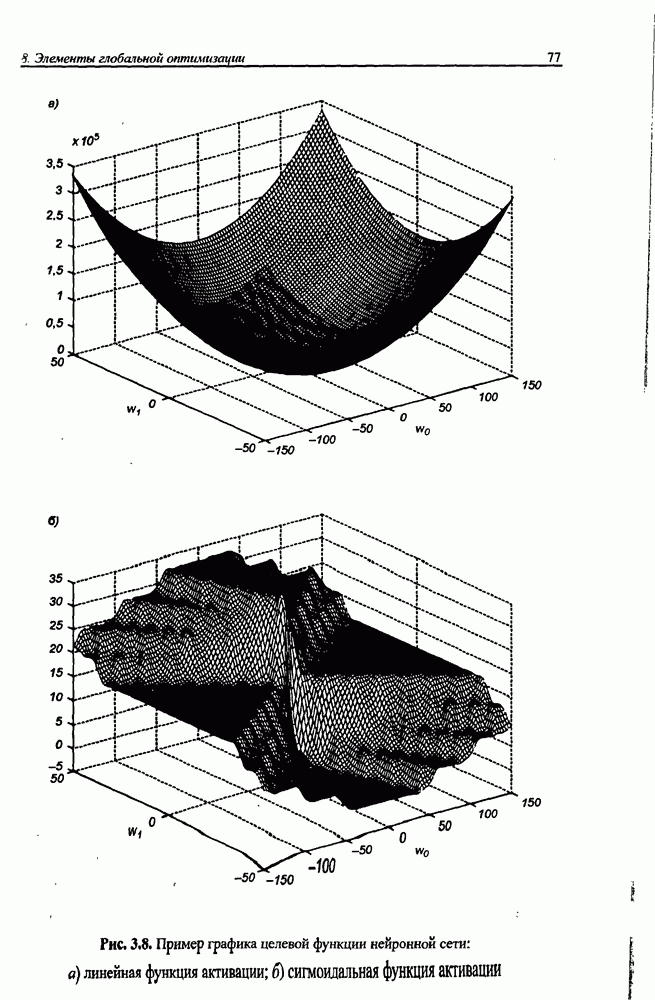
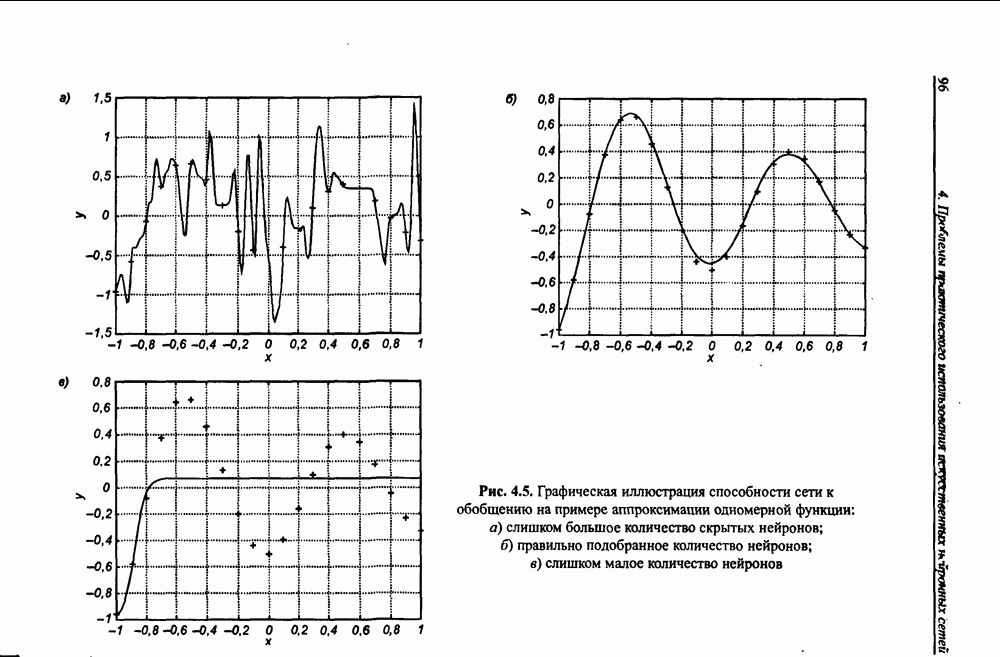
где Из выражения (4.4) следует, что нижняя граница диапазона приблизительно равна количеству весов, связывающих входной и скрытый слои, тогда как верхняя граница превышает двукратное суммарное количество всех весов сети. В связи с невозможностью точного определения меры FCdim в качестве ее приближенного значения используется общее количество весов нейронной сети. Таким образом, на погрешность обобщения оказывает влияние отношение количества обучающих выборок к количеству весов сети. Небольшой объем обучающего подмножества при фиксированном количестве весов вызывает хорошую адаптацию сети к его элементам, однако не усиливает способности к обобщению, так как в процессе обучения наблюдается относительное превышение числа подбираемых параметров (весов) над количеством пар фактических и ожидаемых выходных сигналов сети. Эти параметры адаптируются с чрезмерной (а вследствие превышения числа параметров над объемом обучающего множества - и неконтролируемой) точностью к значениям конкретных выборок, а не к диапазонам, которые эти выборки должны представлять. Фактически задача аппроксимации подменяется в этом случае задачей приближенной интерполяции. В результате всякого рода нерегулярности обучающих данных и измерительные шумы могут восприниматься как существенные свойства процесса. Функция, воспроизводимая в точках обучения, будет хорошо восстанавливаться только при соответствующих этим точкам значениях. Даже минимальное отклонение от этих точек вызовет значительное увеличение погрешности, что будет восприниматься как ошибочное обобщение. По результатам разнообразных численных экспериментов установлено, что высокие показатели обобщения достигаются в случае, когда количество обучающих выборок в несколько раз превышает меру FCdim [57]. На рис. 4.5 а представлена графическая иллюстрация эффекта гиперразмерности сети (слишком большого количества нейронов и весов). Аппроксимирующая сеть, скрытый слой которой состоит из 80 нейронов, на основе интерполяции в 21-й точке адаптировала свои выходные сигналы с нулевой погрешностью обучения. Минимизация этой погрешности на слишком малом (относительно количества весов) количестве обучающих выборок спровоцировала случайный характер значений многих весов, что при переходе от обучающих выборок к тестовым стало причиной значительных отклонений фактических значений у от ожидаемых значений
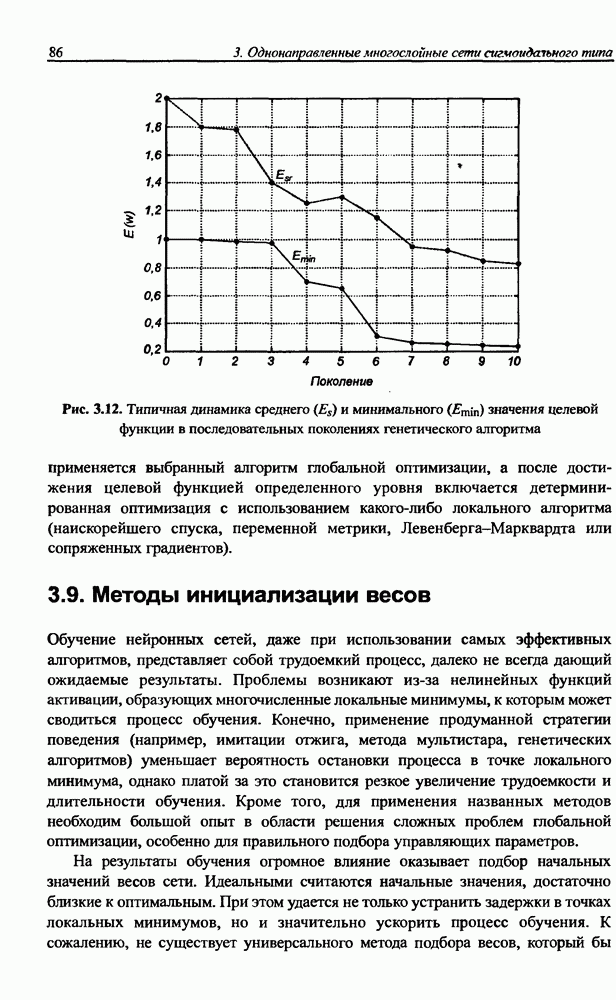
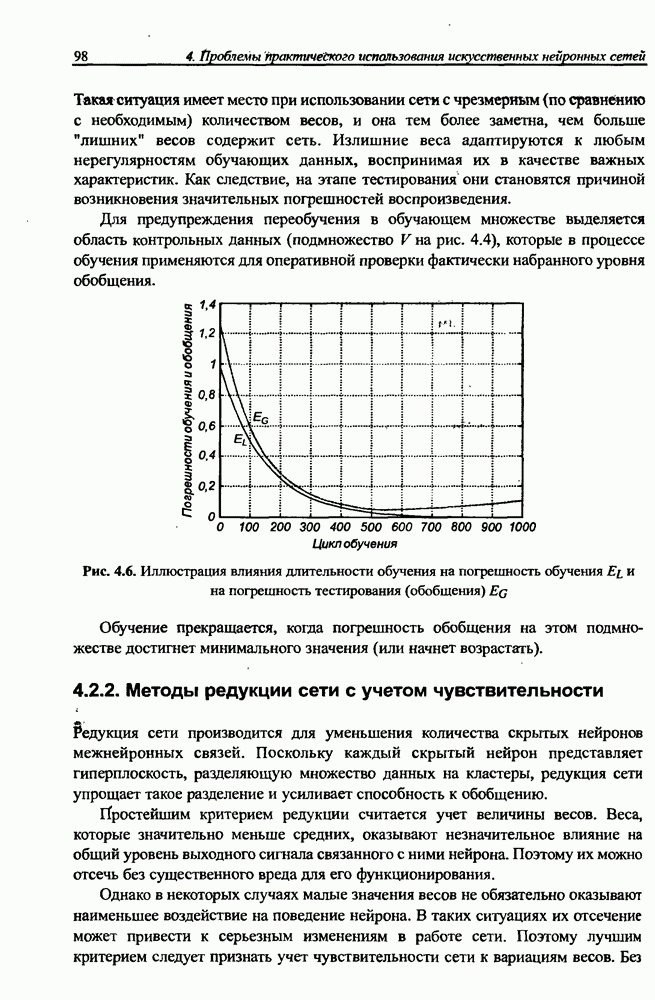
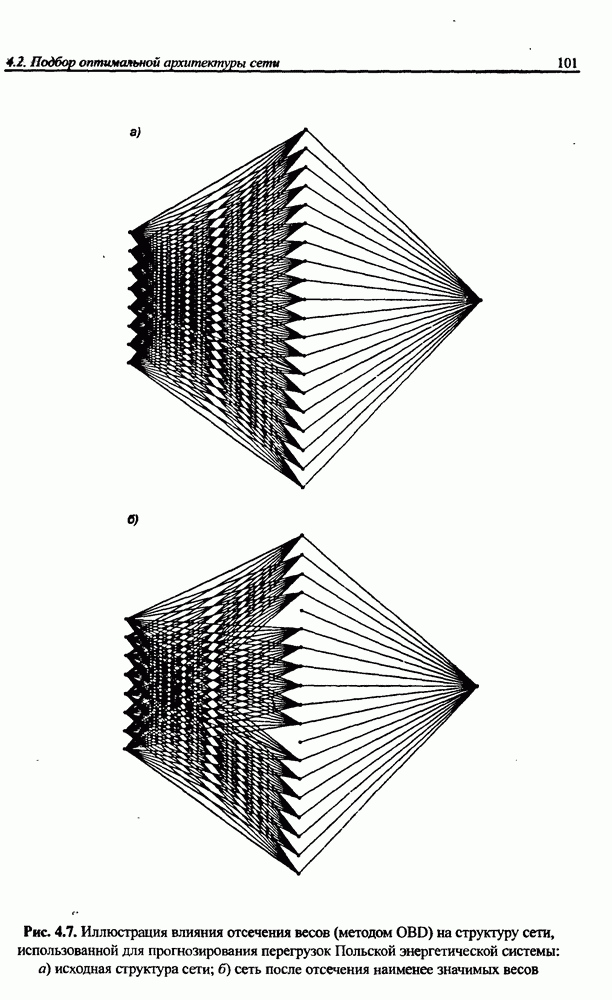
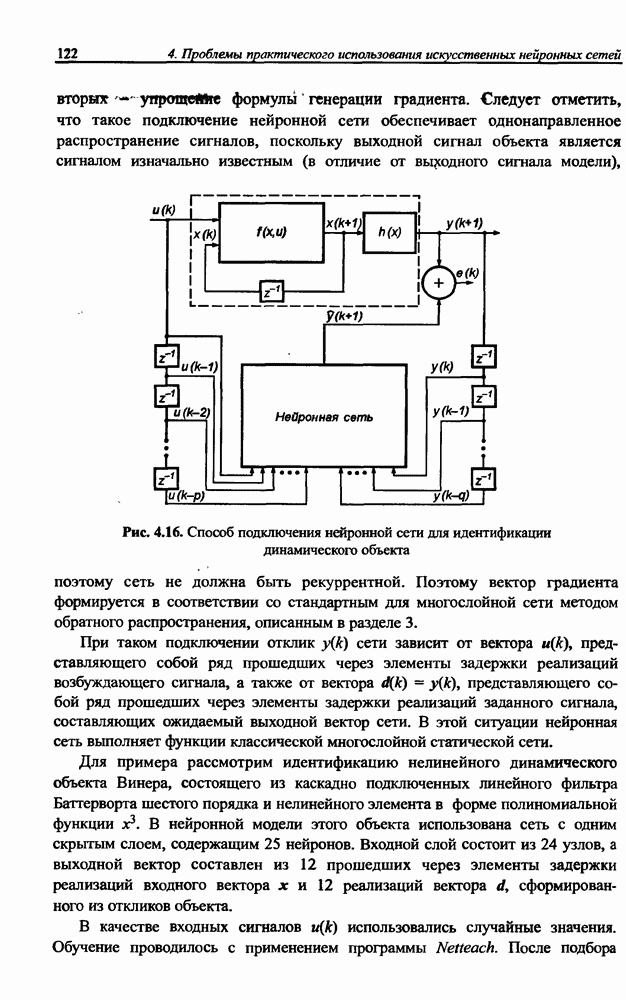
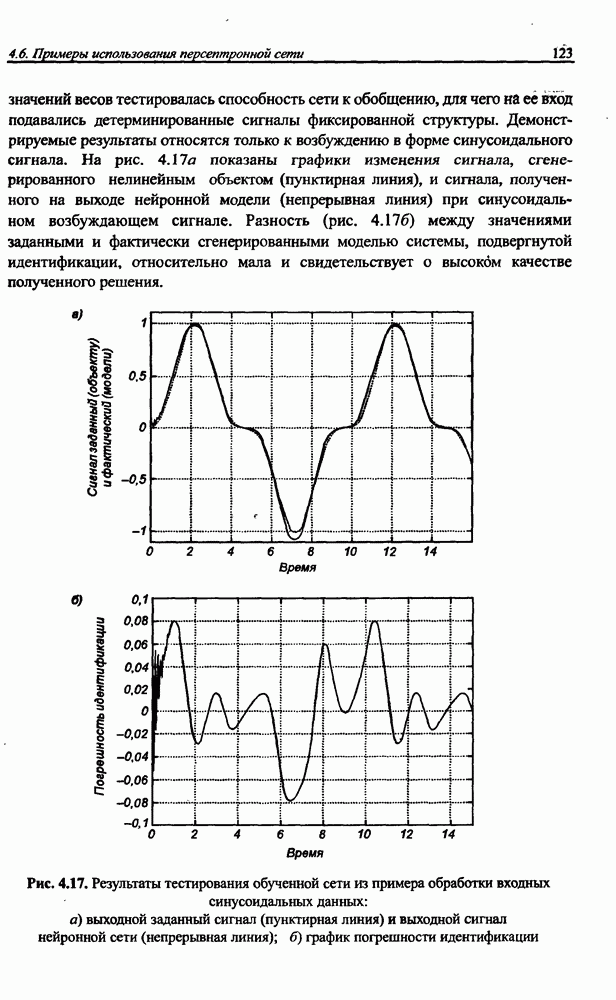
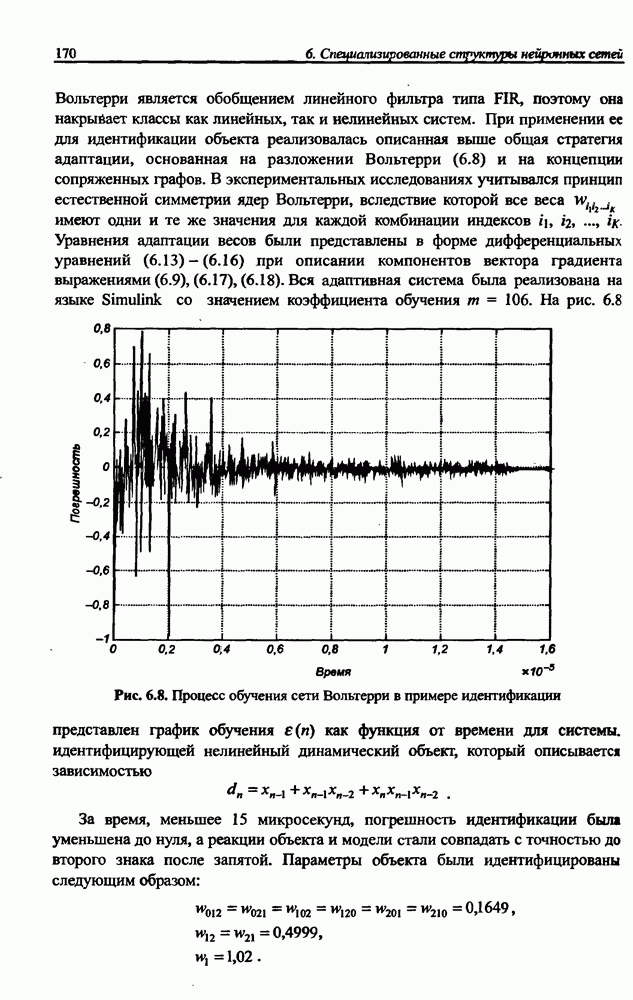
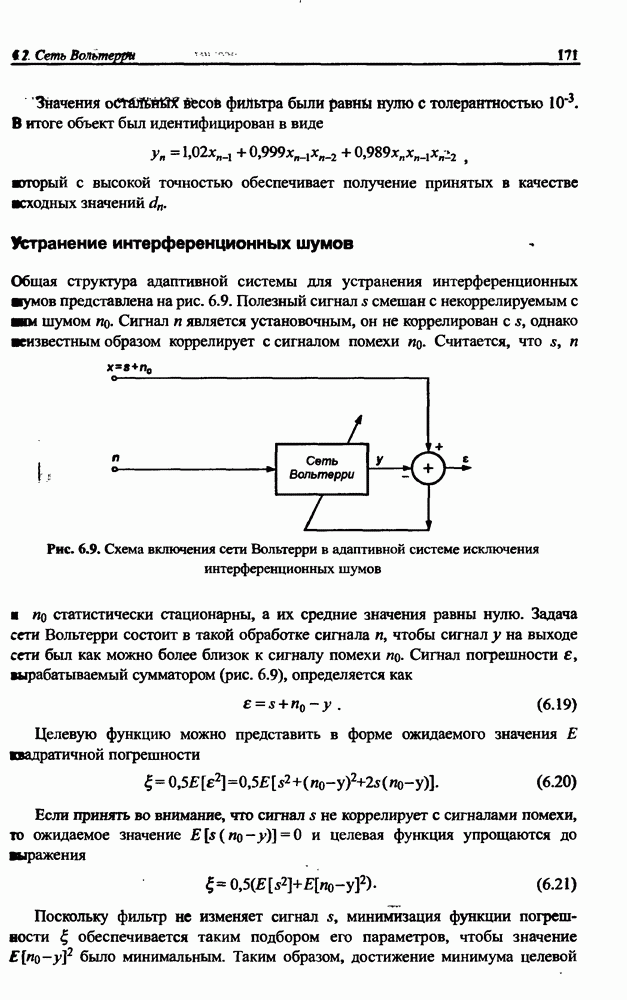
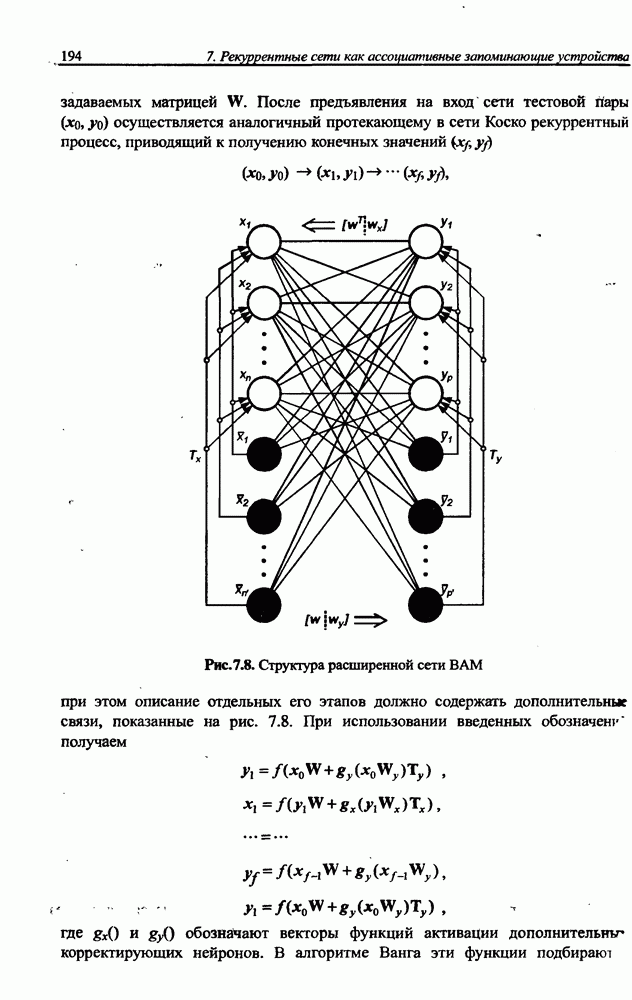
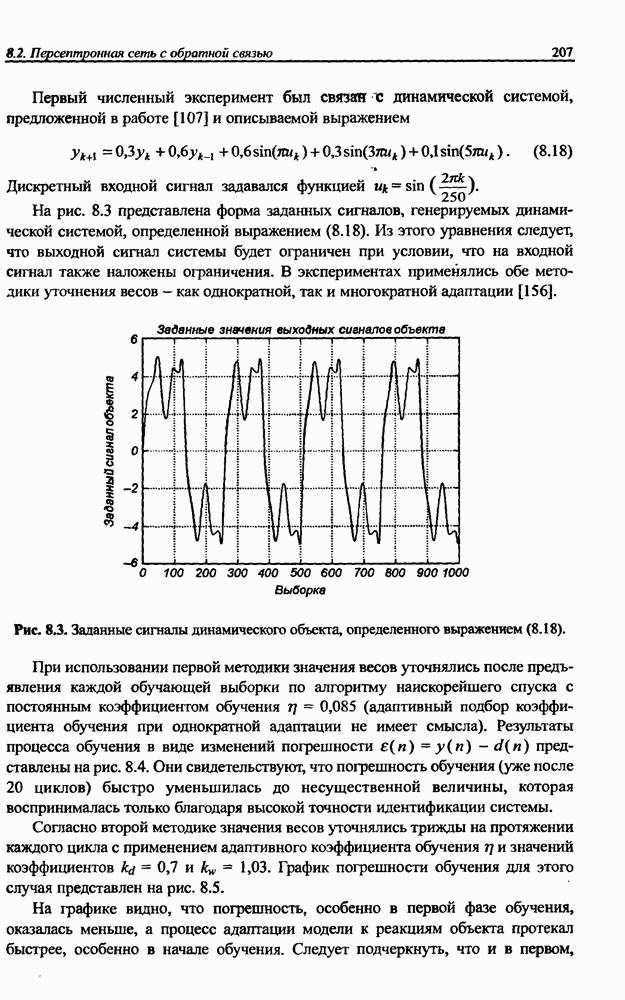
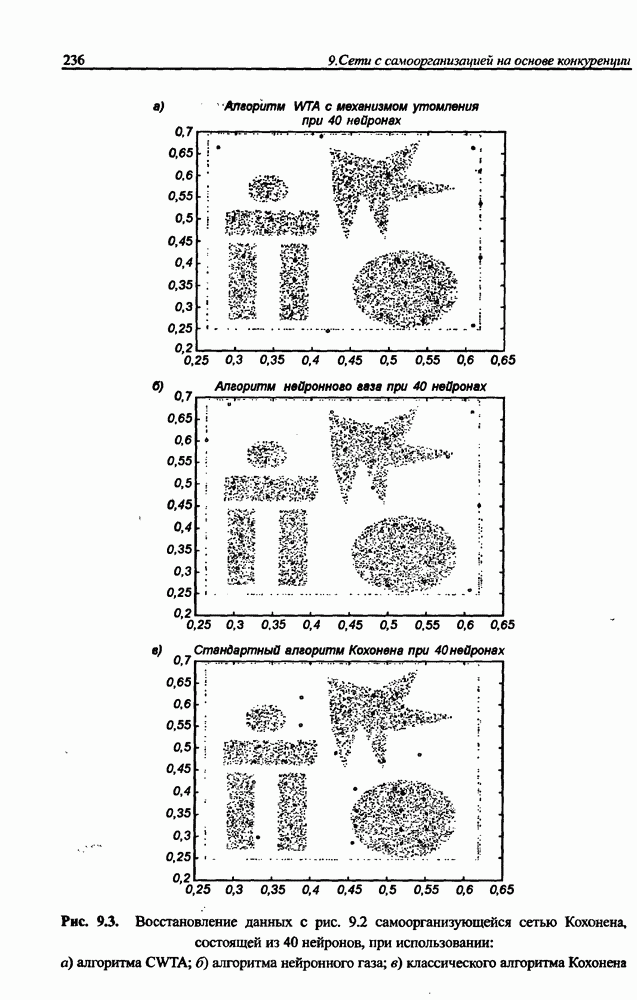
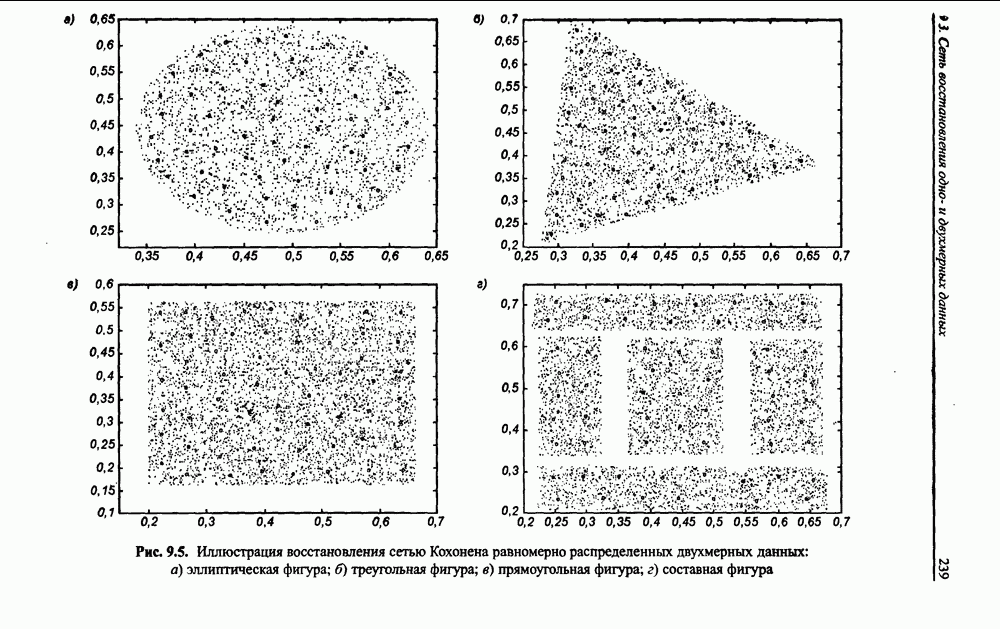
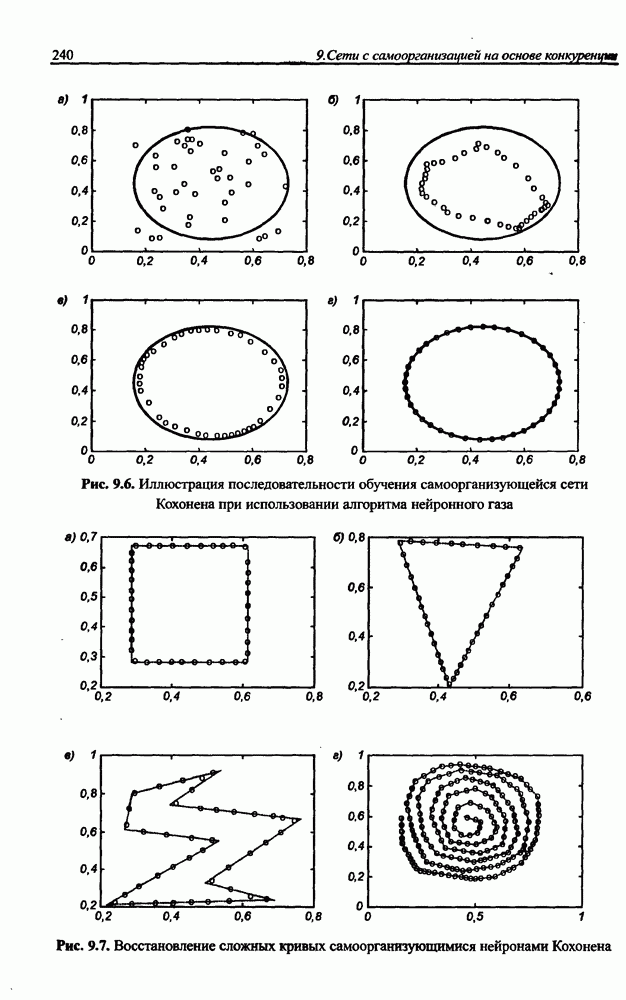
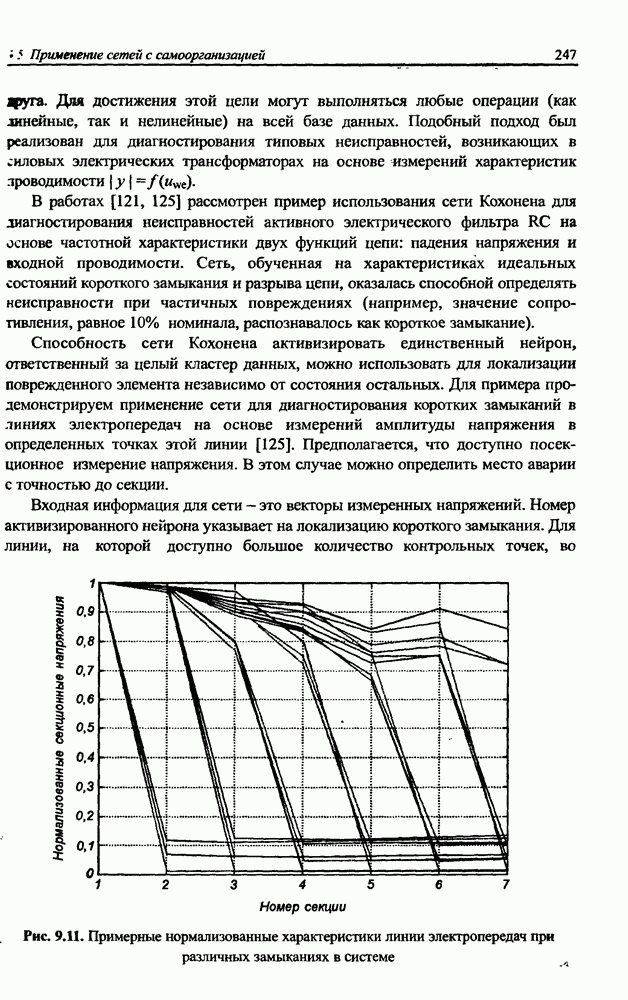
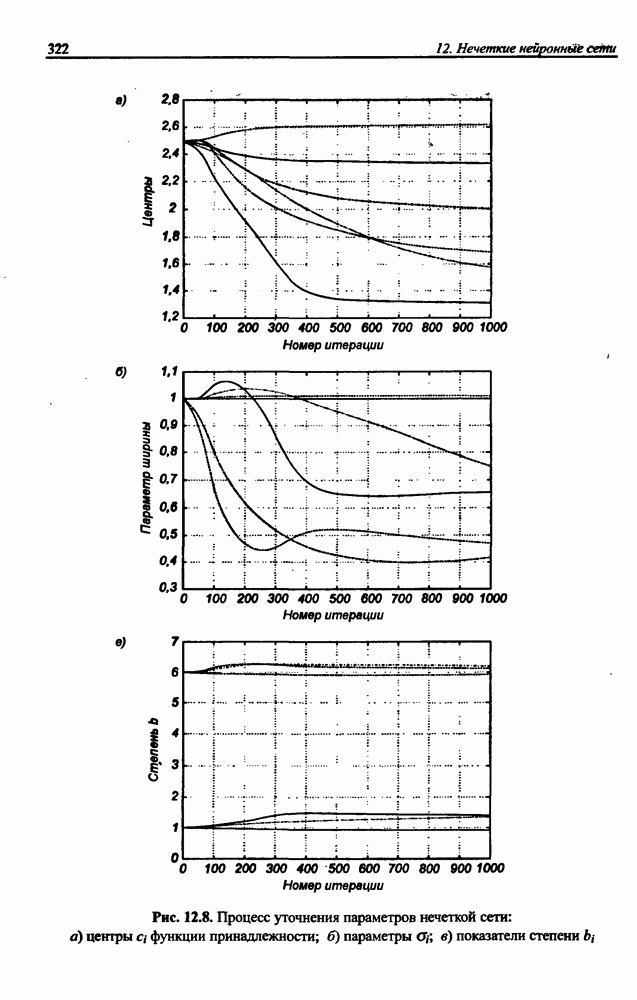
(кликните для просмотра скана) сетей с последующим выбором той из них, которая содержит наименьшее количество скрытых нейронов при допустимой погрешности обучения. Решение по выбору окончательной схемы сети может быть принято только после полноценного обучения (с уменьшением погрешности до уровня, признаваемого удовлетворительным) различных вариантов ее структуры. Однако нет никакой уверенности в том, что этот выбор будет оптимальным, поскольку тренируемые сети могут отличаться различной чувствительностью к подбору начальных значений весов и параметров обучения. По этой причине базу для редукции сети (англ. pruning) составляют алгоритмы отсечения взвешенных связей либо исключения нейронов в процессе обучения или после его завершения. Как правило, методы непосредственного отсечения связей, основанные на временном присвоении им нулевых значений, с принятием решения о возобновлении их обучения по результатам наблюдаемых изменений величины целевой функции (если это изменение слишком велико, следует восстановить отсеченную связь), оказываются неприменимыми из-за слишком высокой вычислительной сложности. Большинство применяемых в настоящее время алгоритмов редукции сети можно разбить на две категории. Методы первой группы исследуют чувствительность целевой функции к удалению веса или нейрона. С их помощью устраняются веса с наименее заметным влиянием, оказывающие минимальное воздействие на величину целевой функции, и процесс обучения продолжается уже на редуцированной сети. Методы второй группы связаны с модификацией целевой функции, в которую вводятся компоненты, штрафующие за неэффективную структуру сети. Чаще кего это бывают элементы, усиливающие малые значения амплитуды весов. Такой способ менее эффективен по сравнению с методами первой группы, поскольку малые значения весов не обязательно ослабляют их влияние на функционирование сети. Принципиально иной подход состоит в начале обучения при минимальном обычно нулевом) количестве скрытых нейронов и последовательном их убавлении вплоть до достижения требуемого уровня натренированности сети на исходном множестве обучающих выборок. Добавление нейронов, как правило, производится по результатам оценивания способности сети к обобщению после определенного количества циклов обучения. В частности, именно такой прием реализован в алгоритме каскадной корреляции Фальмана. При обсуждении способности сети к обобщению невозможно обойти вниманием влияние на ее уровень длительности обучения. Численные эксперименты показали, что погрешность обучения при увеличении количества иттераций монотонно уменьшается, тогда как погрешность обобщения снижается только до определенного момента, после чего начинает расти. Типичная динамика этих показателей представлена на рис. 4.6, где погрешность обучения Такая ситуация имеет место при использовании сети с чрезмерным (по сравнению с необходимым) количеством весов, и она тем более заметна, чем больше "лишних" весов содержит сеть. Излишние веса адаптируются к любым нерегулярностям обучающих данных, воспринимая их в качестве важных характеристик. Как следствие, на этапе тестирования они становятся причиной возникновения значительных погрешностей воспроизведения. Для предупреждения переобучения в обучающем множестве выделяется область контрольных данных (подмножество V на рис. 4.4), которые в процессе обучения применяются для оперативной проверки фактически набранного уровня обобщения.
Рис. 4.6. Иллюстрация влияния длительности обучения на погрешность обучения Обучение прекращается, когда погрешность обобщения на этом подмножестве достигнет минимального значения (или начнет возрастать).
|
 |
Оглавление
|


























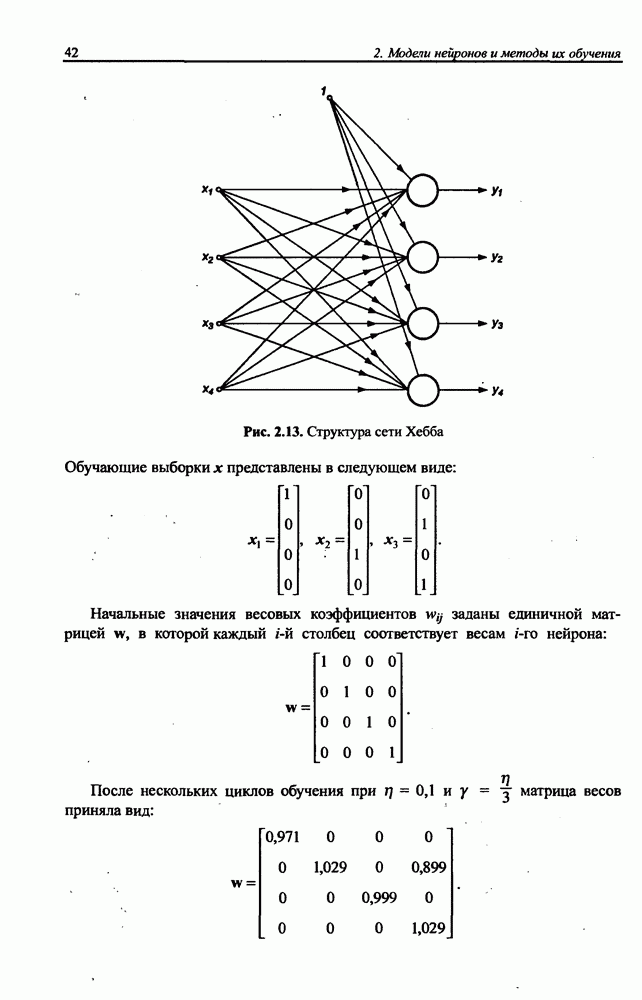





























































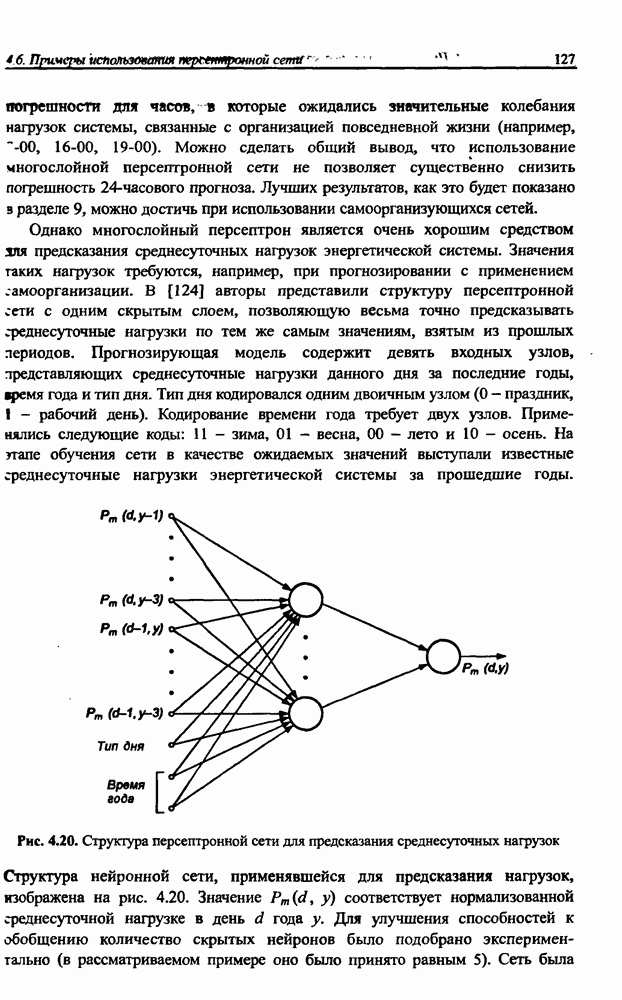








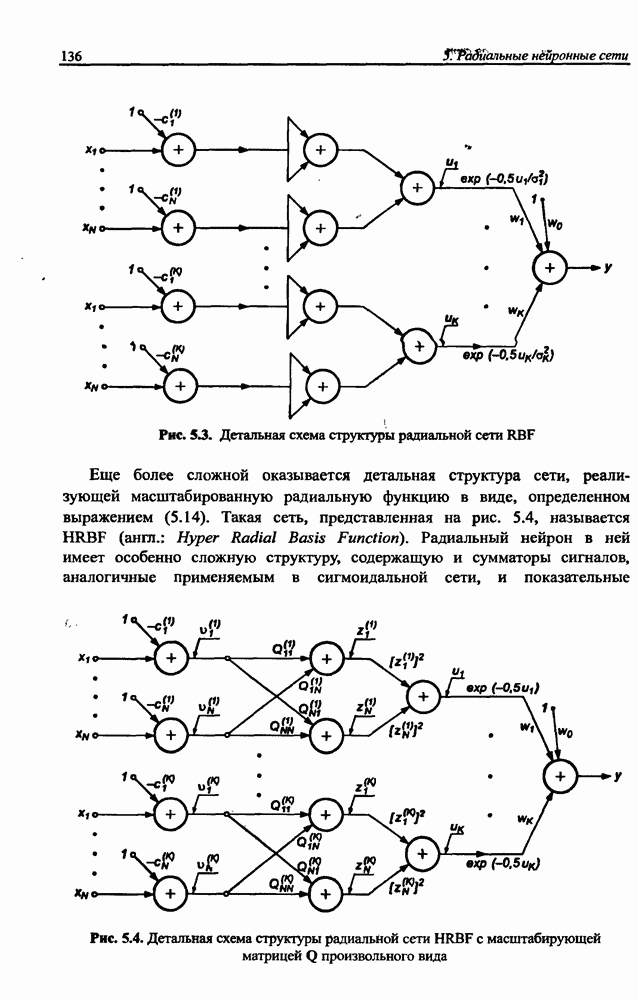
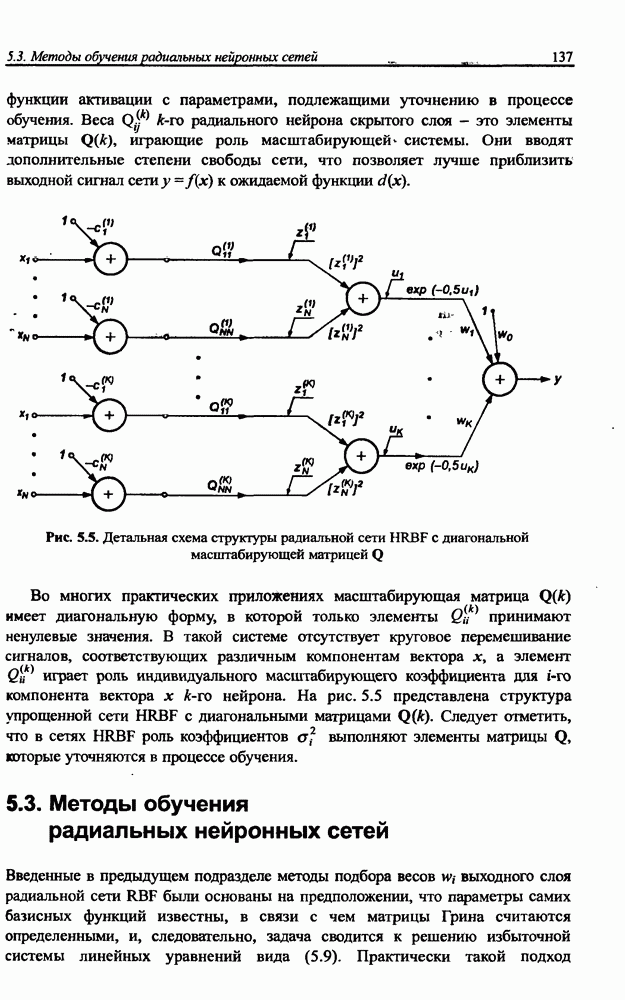





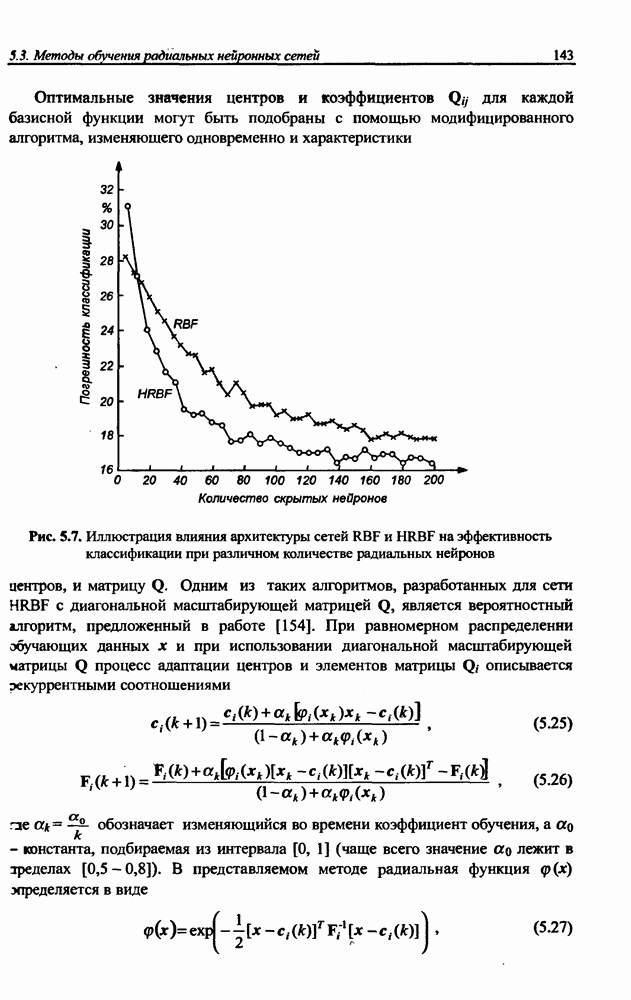










































































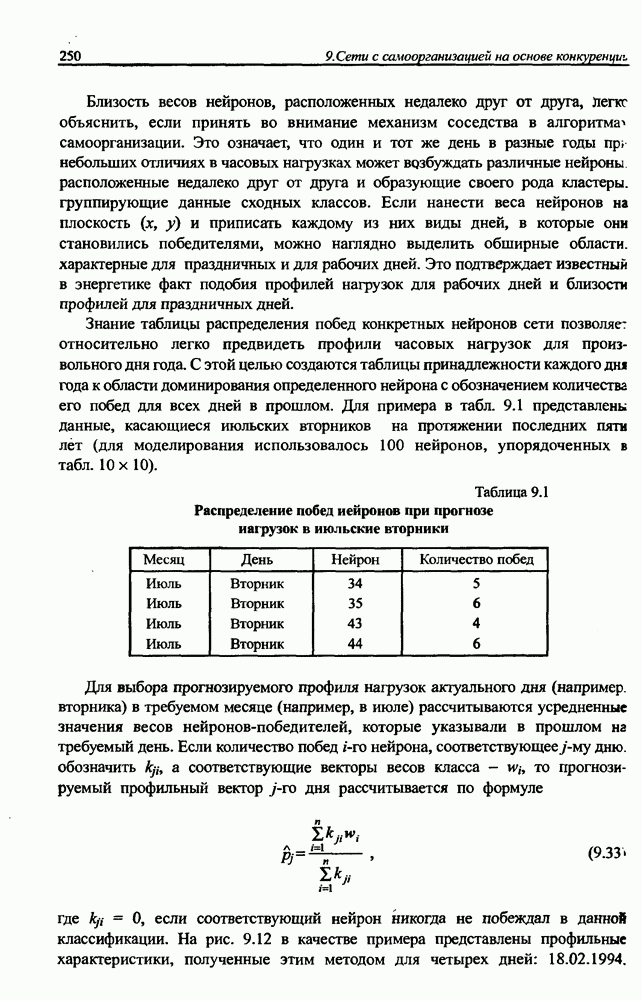
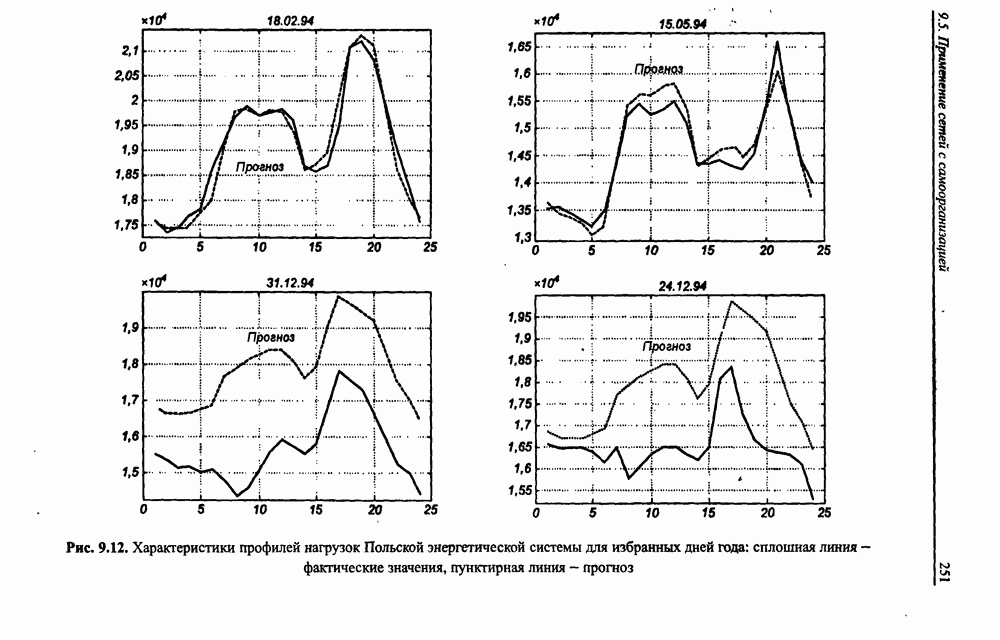



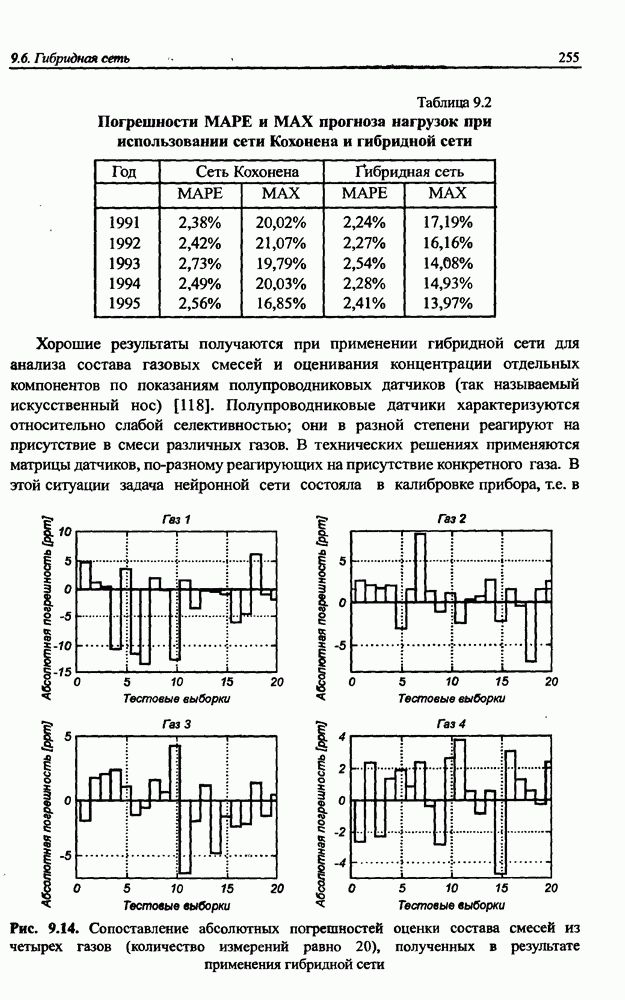
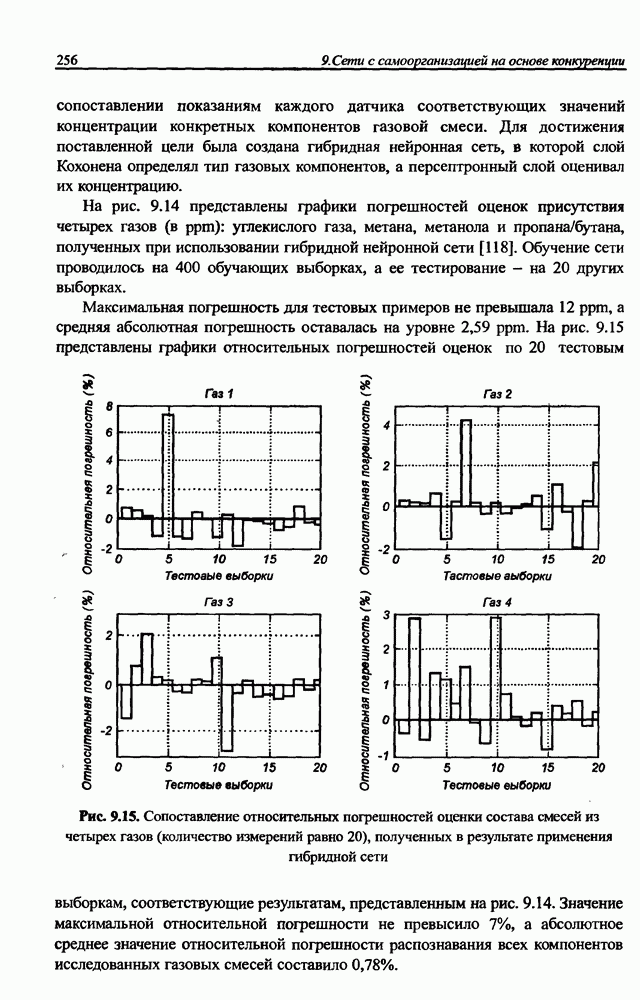























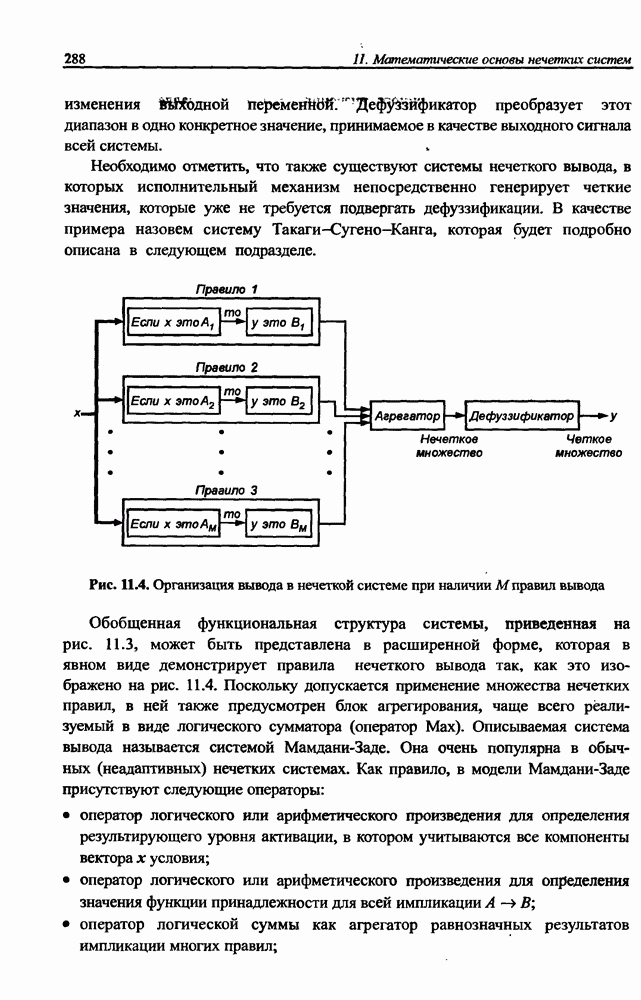
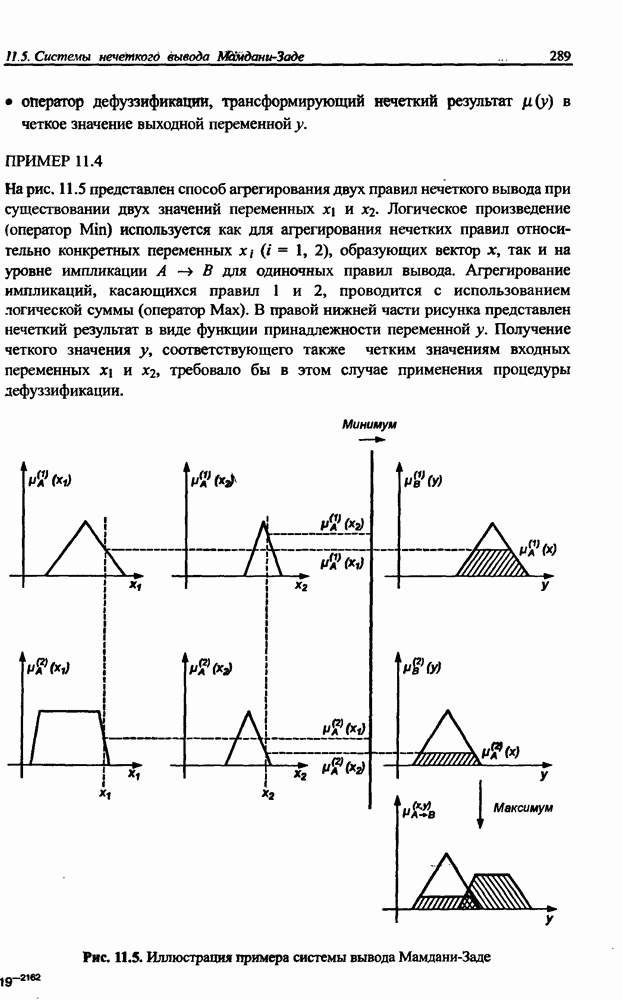
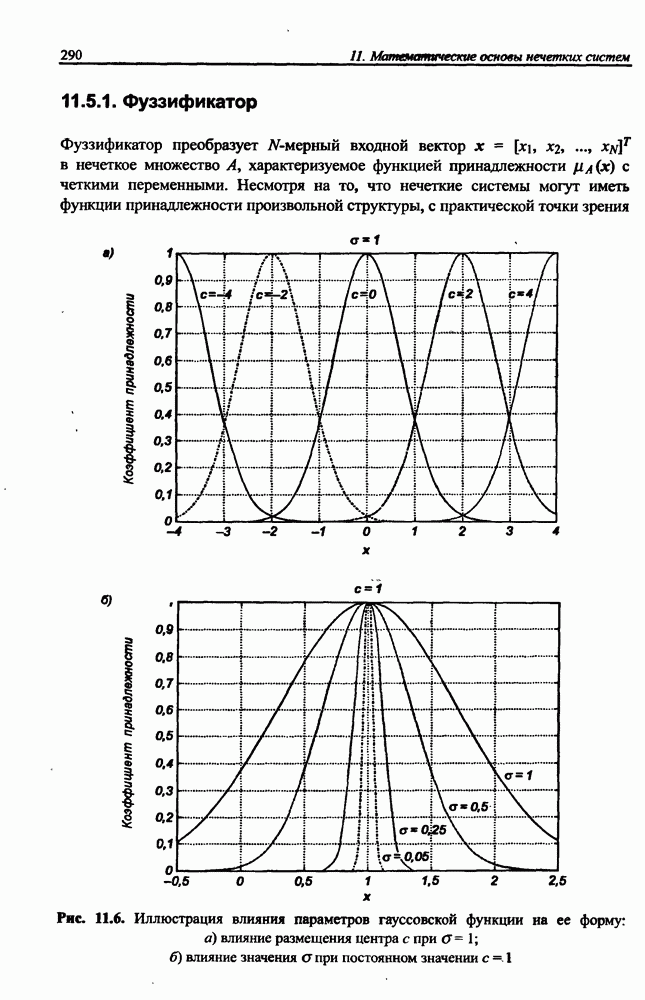



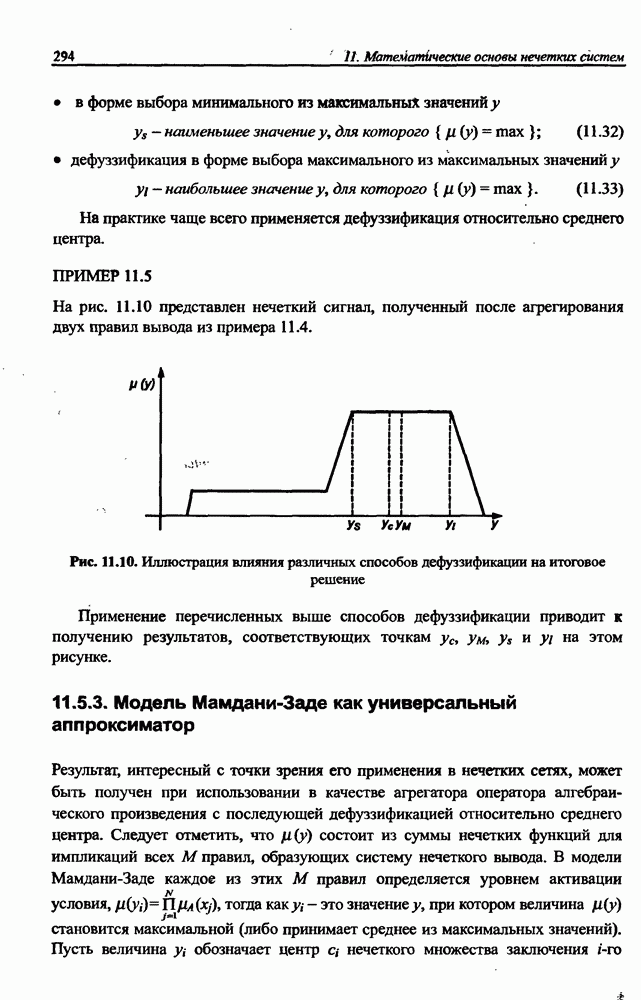












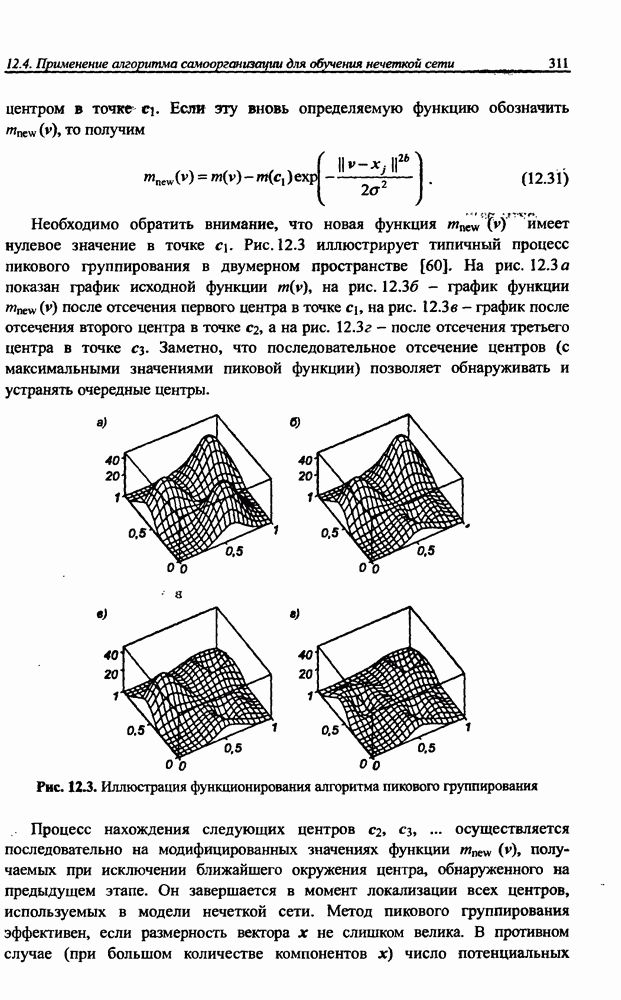




















 разбито на подмножества
разбито на подмножества  и
и  при этом в составе
при этом в составе  в свою очередь, можно выделить определенное подмножество контрольных данных V, используемых для верификации степени обучения сети. Обучение проводится на данных, составляющих подмножество
в свою очередь, можно выделить определенное подмножество контрольных данных V, используемых для верификации степени обучения сети. Обучение проводится на данных, составляющих подмножество  Способность отображения сетью элементов
Способность отображения сетью элементов  может считаться показателем степени накопления обучающих данных, тогда как способность распознавания данных, входящих во множество
может считаться показателем степени накопления обучающих данных, тогда как способность распознавания данных, входящих во множество  и не использованных для обучения, характеризует ее возможности обобщения (генерализации) знаний. Данные, входящие и в
и не использованных для обучения, характеризует ее возможности обобщения (генерализации) знаний. Данные, входящие и в  и в
и в  должны быть типичными элементами множества R. В обучающем подмножестве не должно быть уникальных данных, свойства которых отличаются от ожидаемых типичных) значений.
должны быть типичными элементами множества R. В обучающем подмножестве не должно быть уникальных данных, свойства которых отличаются от ожидаемых типичных) значений.

 не обучающее подмножество
не обучающее подмножество  тестовое подмножество
тестовое подмножество  и контрольное подмножество V
и контрольное подмножество V
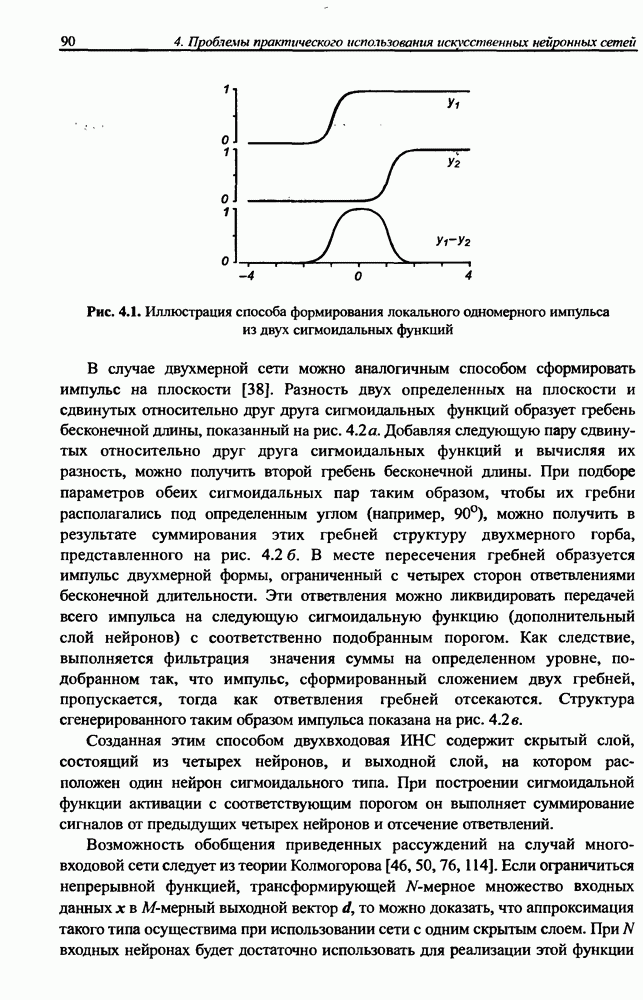
 входами. Если в качестве простого примера рассмотреть однослойную сеть с одним выходным нейроном, то для нее может быть составлено
входами. Если в качестве простого примера рассмотреть однослойную сеть с одним выходным нейроном, то для нее может быть составлено  входных выборок. Каждой выборке может соответствовать единичное или нулевое состояние выходного нейрона. Таким образом, общее количество различаемых сигналов составит
входных выборок. Каждой выборке может соответствовать единичное или нулевое состояние выходного нейрона. Таким образом, общее количество различаемых сигналов составит  Если для обучения сети используются
Если для обучения сети используются  из общего числа
из общего числа  входных выборок, то оставшиеся незадействованными
входных выборок, то оставшиеся незадействованными  допустимых комбинаций характеризуют потенциально возможный уровень обобщения знаний.
допустимых комбинаций характеризуют потенциально возможный уровень обобщения знаний.
 При этом наблюдается тесная связь между количеством весов сети (числом степеней свободы) и количеством обучающих выборок. Если бы целью обучения было только запоминание обучающих выборок, их количество могло быть равным числу весов. В таком случае каждый вес соответствовал бы единственной обучающей паре. К сожалению, такая сеть не будет обладать свойством обобщения и сможет только восстанавливать данные. Для обретения способности обобщать информацию сеть должна тренироваться на избыточном множестве данных, поскольку тогда веса будут адаптироваться не к уникальным выборкам, а к их
При этом наблюдается тесная связь между количеством весов сети (числом степеней свободы) и количеством обучающих выборок. Если бы целью обучения было только запоминание обучающих выборок, их количество могло быть равным числу весов. В таком случае каждый вес соответствовал бы единственной обучающей паре. К сожалению, такая сеть не будет обладать свойством обобщения и сможет только восстанавливать данные. Для обретения способности обобщать информацию сеть должна тренироваться на избыточном множестве данных, поскольку тогда веса будут адаптироваться не к уникальным выборкам, а к их
 определяемой только на обучающем подмножестве
определяемой только на обучающем подмножестве  при этом
при этом  где
где  обозначено количество обучающих пар
обозначено количество обучающих пар 
 Минимизация этой функции обеспечивает достаточное соответствие выходных сигналов сети ожидаемым значениям из обучающих выборок.
Минимизация этой функции обеспечивает достаточное соответствие выходных сигналов сети ожидаемым значениям из обучающих выборок.
 . Со статистической точки зрения погрешность обобщения зависит от уровня погрешности обучения
. Со статистической точки зрения погрешность обобщения зависит от уровня погрешности обучения  и от доверительного интервала
и от доверительного интервала  . Она характеризуется отношением [46]
. Она характеризуется отношением [46]

 функционально зависит от уровня погрешности обучения
функционально зависит от уровня погрешности обучения  и от отношения количества обучающих выборок
и от отношения количества обучающих выборок  к фактическому значению
к фактическому значению  параметра, называемого мерой Вапника-Червоненкиса и обозначаемого
параметра, называемого мерой Вапника-Червоненкиса и обозначаемого  Мера
Мера  отражает уровень сложности нейронной сети и тесно связана с количеством содержащихся в ней весов. Значение
отражает уровень сложности нейронной сети и тесно связана с количеством содержащихся в ней весов. Значение  уменьшается по мере возрастания отношения количества обучающих выборок к уровню сложности сети.
уменьшается по мере возрастания отношения количества обучающих выборок к уровню сложности сети.
 . В [158] предложено определять верхнюю и нижнюю границы этой меры в виде
. В [158] предложено определять верхнюю и нижнюю границы этой меры в виде

 обозначена целая часть числа,
обозначена целая часть числа,  - размерность входного вектора, К - количество нейронов скрытого слоя,
- размерность входного вектора, К - количество нейронов скрытого слоя,  - общее количество весов сети,
- общее количество весов сети,  - общее количество нейронов сети.
- общее количество нейронов сети.
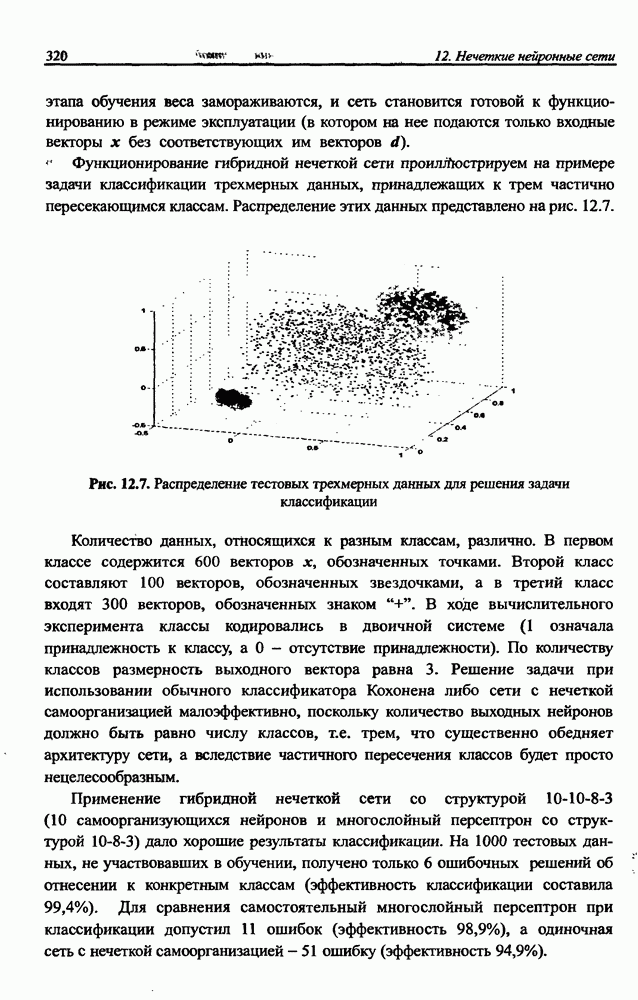
 Уменьшение количества скрытых нейронов до
Уменьшение количества скрытых нейронов до  при неизменном объеме обучающего множества позволило обеспечить и малую погрешность обучения, и высокий уровень обобщения (рис. 4.56). Дальнейшее уменьшение количества скрытых нейронов может привести к потере сетью способности восстанавливать обучающие данные (т.е. к слишком большой погрешности обучения
при неизменном объеме обучающего множества позволило обеспечить и малую погрешность обучения, и высокий уровень обобщения (рис. 4.56). Дальнейшее уменьшение количества скрытых нейронов может привести к потере сетью способности восстанавливать обучающие данные (т.е. к слишком большой погрешности обучения  Подобная ситуация иллюстрируется на рис. 4.5 в, где задействован только один скрытый нейрон. Сеть оказалась не в состоянии корректно воспроизвести обучающие данные, поскольку количество ее степеней свободы слишком мало по сравнению с необходимым для такого воспроизведения. Очевидно, что в этом случае невозможно достичь требуемого уровня обобщения, поскольку он явно зависит от погрешности обучения
Подобная ситуация иллюстрируется на рис. 4.5 в, где задействован только один скрытый нейрон. Сеть оказалась не в состоянии корректно воспроизвести обучающие данные, поскольку количество ее степеней свободы слишком мало по сравнению с необходимым для такого воспроизведения. Очевидно, что в этом случае невозможно достичь требуемого уровня обобщения, поскольку он явно зависит от погрешности обучения  На практике подбор количества скрытых нейронов (и связанный с ним подбор количества весов) может, в частности, выполняться путем тренинга нескольких
На практике подбор количества скрытых нейронов (и связанный с ним подбор количества весов) может, в частности, выполняться путем тренинга нескольких

 обозначена сплошной, а погрешность обобщения
обозначена сплошной, а погрешность обобщения  - пунктирной линией. Приведенный график однозначно свидетельствует, что слишком долгое обучение может привести к "переобучению" сети, которое выражается в слишком детальной адаптации весов к несущественным флуктуациям обучающих данных.
- пунктирной линией. Приведенный график однозначно свидетельствует, что слишком долгое обучение может привести к "переобучению" сети, которое выражается в слишком детальной адаптации весов к несущественным флуктуациям обучающих данных.

 и на погрешность тестирования (обобщения)
и на погрешность тестирования (обобщения) 