3.3. БАЙЕСОВСКИЙ КЛАССИФИКАТОР
Читателям, знакомым с математической статистикой, известно, что оценка по максимуму правдоподобия для ковариационной матрицы смещена, т. е. ожидаемое значение 2 не равно 2. Несмещенная оценка для 2 задается выборочной ковариационной матрицей

Очевидно, что  так что эти две оценки, по существу, совпадают при большом n. Однако наличие двух сходных и тем не менее разных оценок для ковариационной матрицы смущает многих исследователей, так как, естественно, возникает вопрос: какая же из них «верная»? Ответить на это можно, сказав, что каждая из этих оценок ни верна, ни ложна: они просто различны. Наличие двух различных оценок на деле показывает, что единой оценки, включающей все свойства, которые только можно пожелать, не существует. Для наших целей сформулировать наиболее желательные свойства довольно сложно — нам нужна такая оценка, которая позволила бы наилучшим образом проводить классификацию. Хотя разрабатывать классификатор, используя оценки по максимуму правдоподобия для неизвестных параметров, обычно представляется разумным и логичным, вполне естествен вопрос, а нет ли других оценок, обеспечивающих еще лучшее качество работы. В данном разделе мы рассмотрим этот вопрос с байесовской точки зрения.
так что эти две оценки, по существу, совпадают при большом n. Однако наличие двух сходных и тем не менее разных оценок для ковариационной матрицы смущает многих исследователей, так как, естественно, возникает вопрос: какая же из них «верная»? Ответить на это можно, сказав, что каждая из этих оценок ни верна, ни ложна: они просто различны. Наличие двух различных оценок на деле показывает, что единой оценки, включающей все свойства, которые только можно пожелать, не существует. Для наших целей сформулировать наиболее желательные свойства довольно сложно — нам нужна такая оценка, которая позволила бы наилучшим образом проводить классификацию. Хотя разрабатывать классификатор, используя оценки по максимуму правдоподобия для неизвестных параметров, обычно представляется разумным и логичным, вполне естествен вопрос, а нет ли других оценок, обеспечивающих еще лучшее качество работы. В данном разделе мы рассмотрим этот вопрос с байесовской точки зрения.
3.3.1. ПЛОТНОСТИ, УСЛОВНЫЕ ПО КЛАССУ
Сущность байесовской классификации заложена в расчете апостериорных вероятностей  Байесовское правило позволяет вычислять эти вероятности по априорным вероятностям
Байесовское правило позволяет вычислять эти вероятности по априорным вероятностям  и условным по классу плотностям
и условным по классу плотностям  однако возникает вопрос: как быть, если эти величины неизвестны? Общий ответ таков: лучшее, что мы можем сделать, — это вычислить
однако возникает вопрос: как быть, если эти величины неизвестны? Общий ответ таков: лучшее, что мы можем сделать, — это вычислить  используя всю информацию, имеющуюся в распоряжении. Часть этой информации может быть априорной, как, например, знание о виде неизвестных функций плотности и диапазонах значений неизвестных параметров. Часть этой информации может содержаться в множестве выборок. Пусть
используя всю информацию, имеющуюся в распоряжении. Часть этой информации может быть априорной, как, например, знание о виде неизвестных функций плотности и диапазонах значений неизвестных параметров. Часть этой информации может содержаться в множестве выборок. Пусть  обозначает множество выборок, тогда мы подчеркнем роль выборок, сказав, что цель заключается в вычислении апостериорных вероятностей
обозначает множество выборок, тогда мы подчеркнем роль выборок, сказав, что цель заключается в вычислении апостериорных вероятностей  По этим вероятностям мы можем построить байесовский классификатор.
По этим вероятностям мы можем построить байесовский классификатор.
Согласно байесовскому правилу 

Это уравнение означает, что мы можем использовать информацию, получаемую из выборок, для определения как условных по классу плотностей, так и априорных вероятностей.
Мы могли бы придерживаться этой общности, однако впредь будем предполагать, что истинные значения априорных вероятностей известны, так что  Кроме того, так как в данном случае мы имеем дело с наблюдаемыми значениями, то можно разделить выборки по классам в с подмножеств
Кроме того, так как в данном случае мы имеем дело с наблюдаемыми значениями, то можно разделить выборки по классам в с подмножеств  причем выборки из принадлежат
причем выборки из принадлежат  Во многих случаях, в частности во всех, с которыми мы будем иметь дело, выборки из не оказывают влияния на
Во многих случаях, в частности во всех, с которыми мы будем иметь дело, выборки из не оказывают влияния на  , если
, если  . Отсюда вытекают два упрощающих анализа следствия. Во-первых, это позволяет нам иметь дело с каждым классом в отдельности, используя для определения
. Отсюда вытекают два упрощающих анализа следствия. Во-первых, это позволяет нам иметь дело с каждым классом в отдельности, используя для определения  только выборки из
только выборки из  . Вместе с принятым нами предположением, что априорные вероятности известны, это следствие позволяет записать уравнение (12) в виде
. Вместе с принятым нами предположением, что априорные вероятности известны, это следствие позволяет записать уравнение (12) в виде

Во-вторых, так как каждый класс может рассматриваться независимо, можно отказаться от ненужных различий классов и упростить записи. По существу, здесь имеется с отдельных задач следующего вида: требуется определить  используя множество
используя множество  выборок, взятых независимо в соответствии с фиксированным, но неизвестным вероятностным законом
выборок, взятых независимо в соответствии с фиксированным, но неизвестным вероятностным законом  Это и составляет главную задачу байесовского обучения.
Это и составляет главную задачу байесовского обучения.
3.3.2. РАСПРЕДЕЛЕНИЕ ПАРАМЕТРОВ
Хотя требуемая плотность  неизвестна, предположим, что она имеет известную параметрическую форму. Единственно, что предполагается неизвестным, это величина параметрического вектора в. Тот факт, что
неизвестна, предположим, что она имеет известную параметрическую форму. Единственно, что предполагается неизвестным, это величина параметрического вектора в. Тот факт, что  неизвестна, но имеет известный параметрический вид, выразим утверждением, что функция
неизвестна, но имеет известный параметрический вид, выразим утверждением, что функция  полностью известна. При байесовском подходе предполагается, что неизвестный параметрический вектор есть случайная переменная. Всю информацию о
полностью известна. При байесовском подходе предполагается, что неизвестный параметрический вектор есть случайная переменная. Всю информацию о  до наблюдения выборок дает известная априорная плотность
до наблюдения выборок дает известная априорная плотность  Наблюдение выборок превращает ее в апостериорную плотность
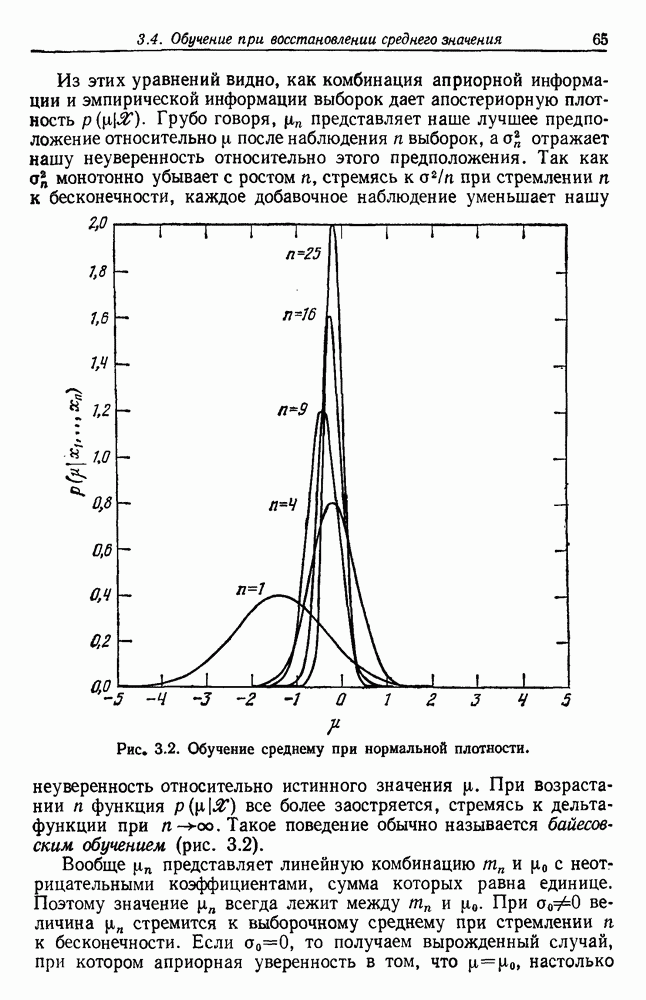
Наблюдение выборок превращает ее в апостериорную плотность  которая, как можно надеяться, имеет крутой подъем вблизи истинного значения
которая, как можно надеяться, имеет крутой подъем вблизи истинного значения  .
.
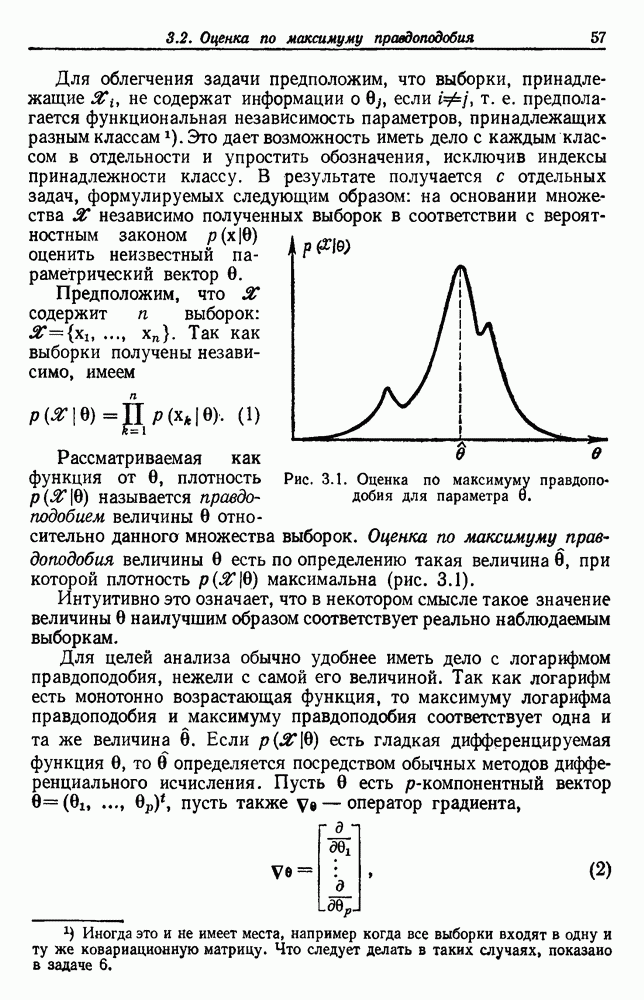
Основная наша цель — это вычисление плотности  достаточно достоверной для того, чтобы прийти к получению неизвестной
достаточно достоверной для того, чтобы прийти к получению неизвестной  Это вычисление мы выполняем посредством интегрирования объединенной плотности
Это вычисление мы выполняем посредством интегрирования объединенной плотности  по 0. Получаем
по 0. Получаем

причем интегрирование производится по всему пространству параметра 1). Теперь  всегда можно представить как произведение
всегда можно представить как произведение  . Так как х и выборки из
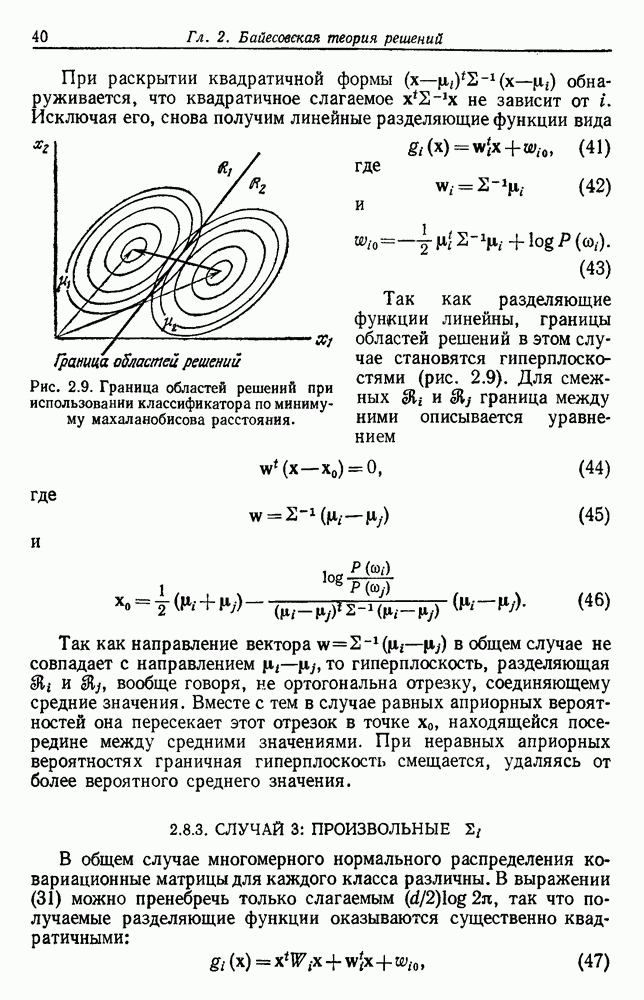
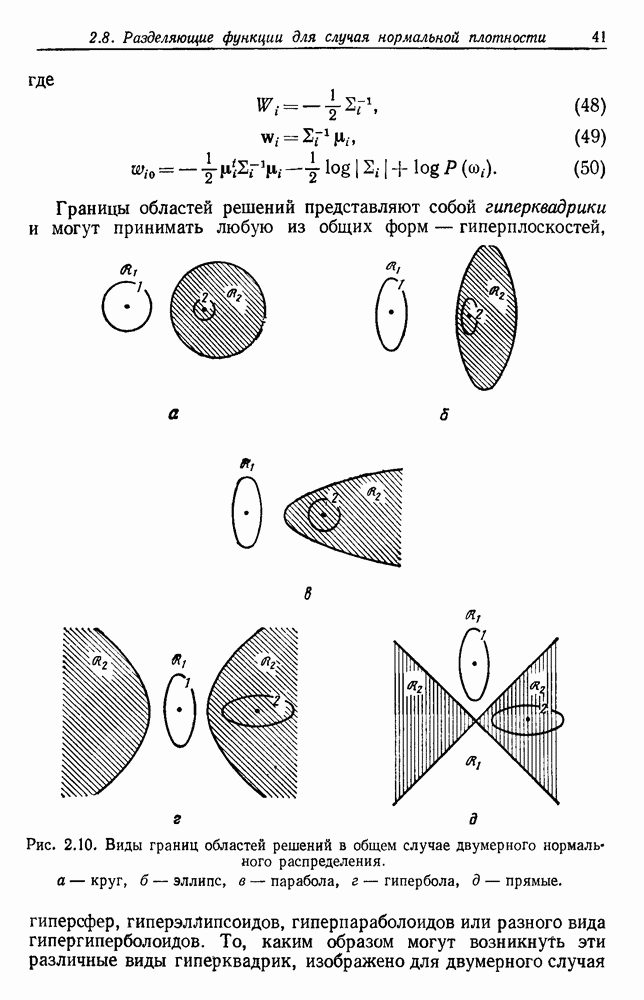
. Так как х и выборки из  получаются независимо, то первый множитель есть просто
получаются независимо, то первый множитель есть просто  Распределение величины х, таким образом, полностью известно, если известна величина параметрического вектора. В результате имеем
Распределение величины х, таким образом, полностью известно, если известна величина параметрического вектора. В результате имеем

Это важнейшее уравнение связывает «условную по классу» плотность  с апостериорной плотностью
с апостериорной плотностью  неизвестного параметрического вектора. Если вблизи некоторого значения
неизвестного параметрического вектора. Если вблизи некоторого значения  функция
функция  имеет острый пик, то
имеет острый пик, то  так что решение может быть получено подстановкой оценки
так что решение может быть получено подстановкой оценки  , в качестве истинной величины вектора параметров. Вообще, если существует большая
, в качестве истинной величины вектора параметров. Вообще, если существует большая









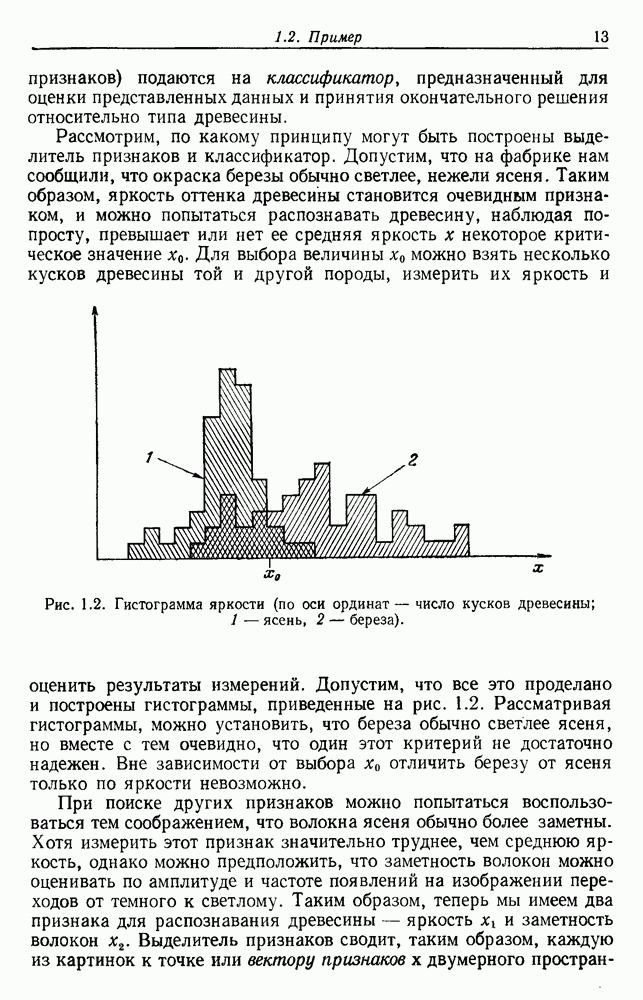







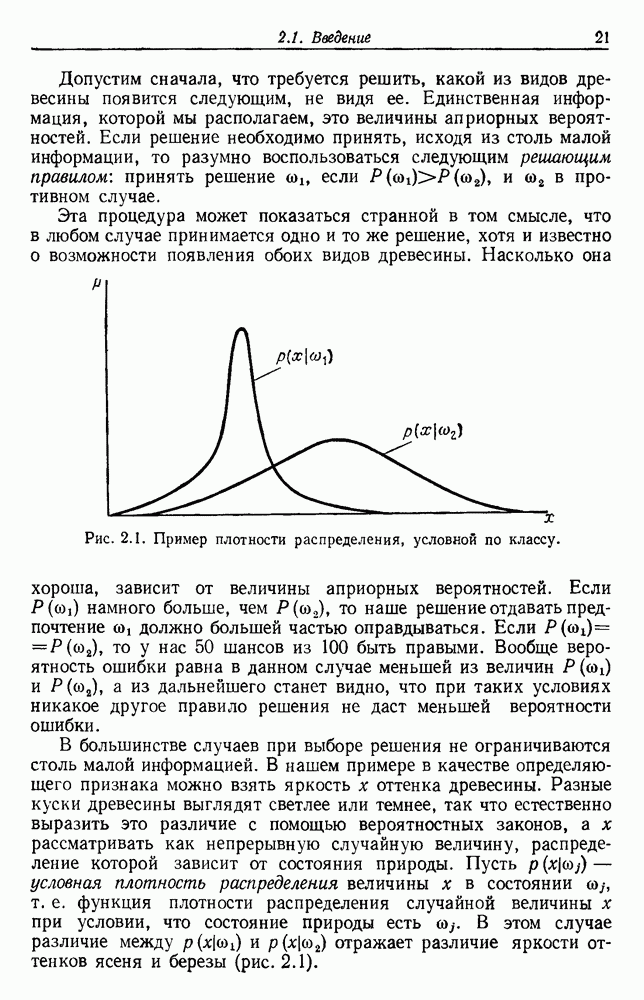
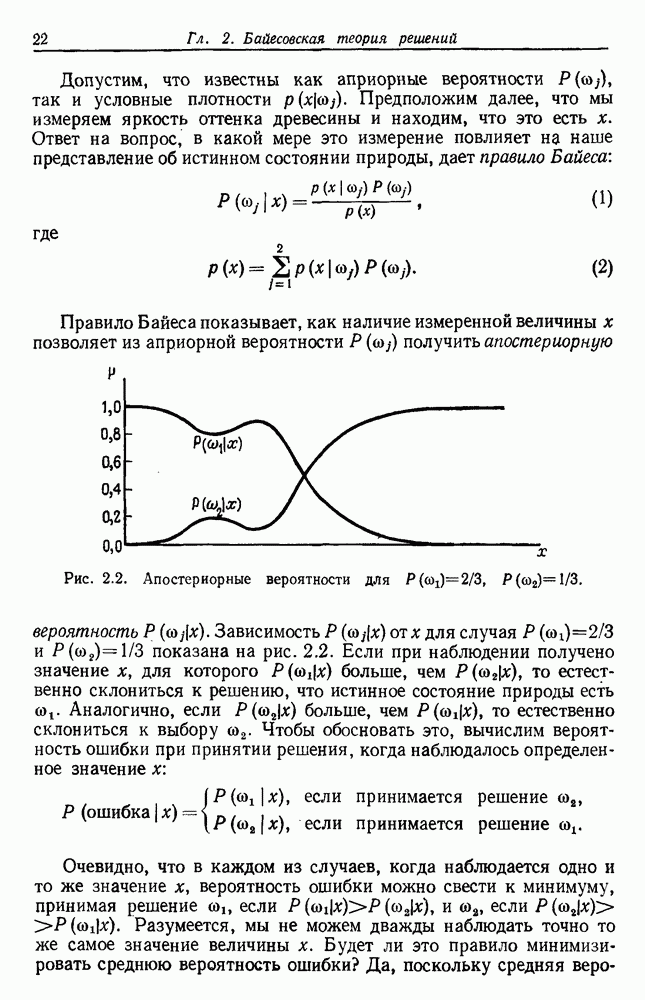





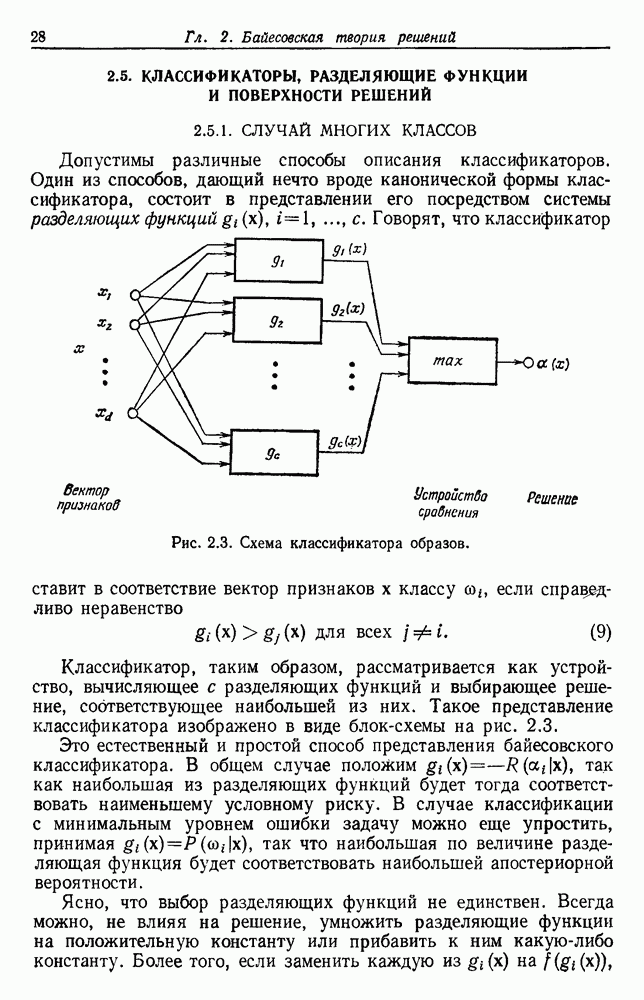













































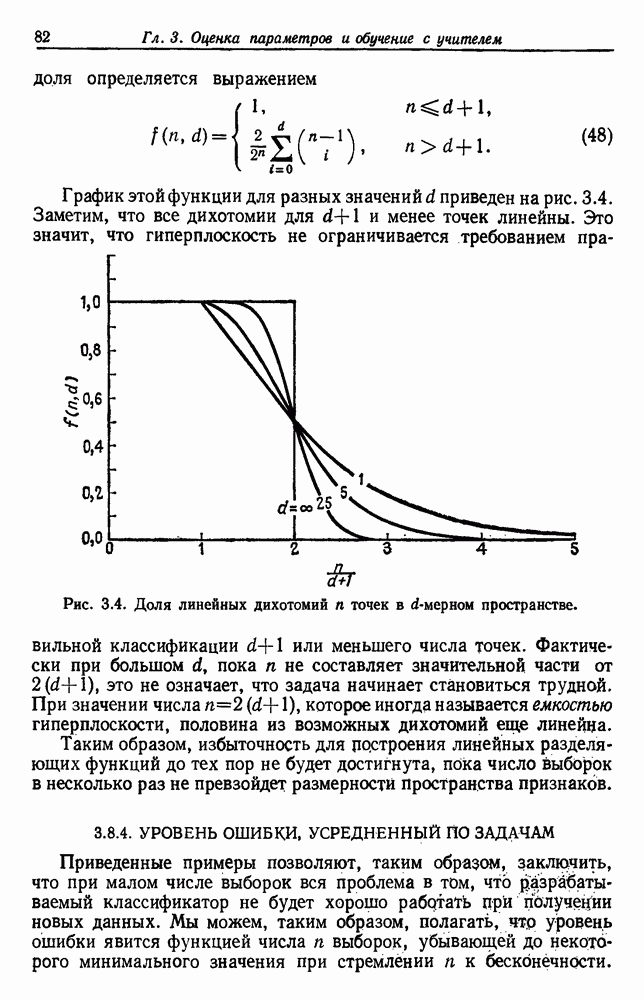


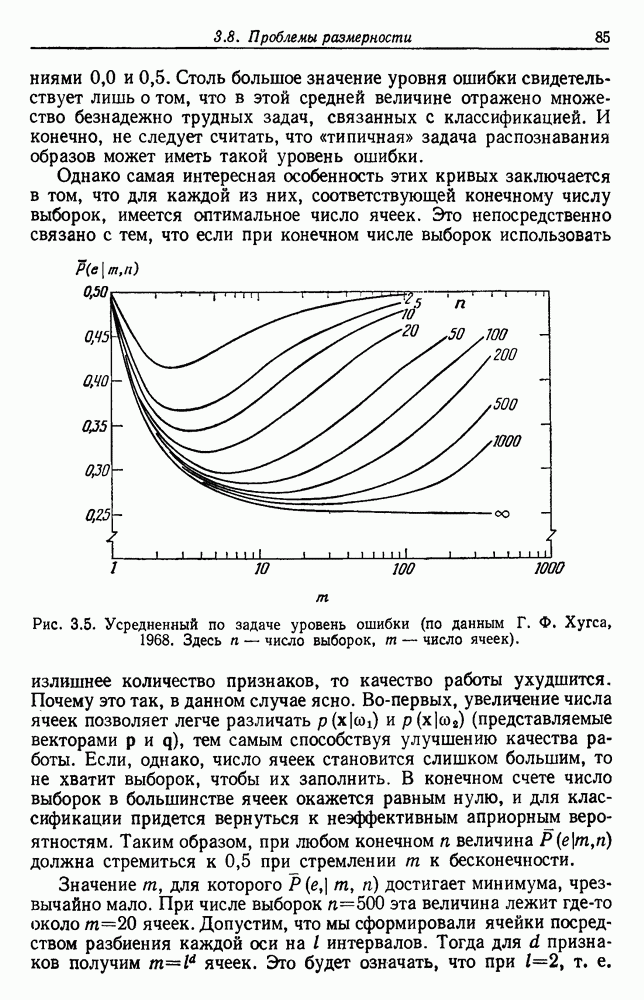


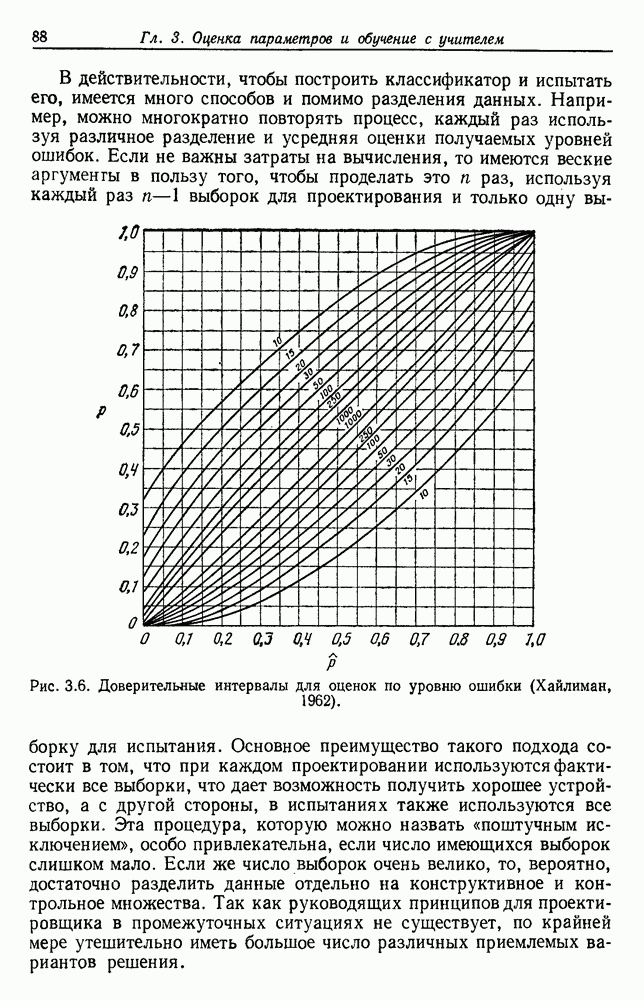

















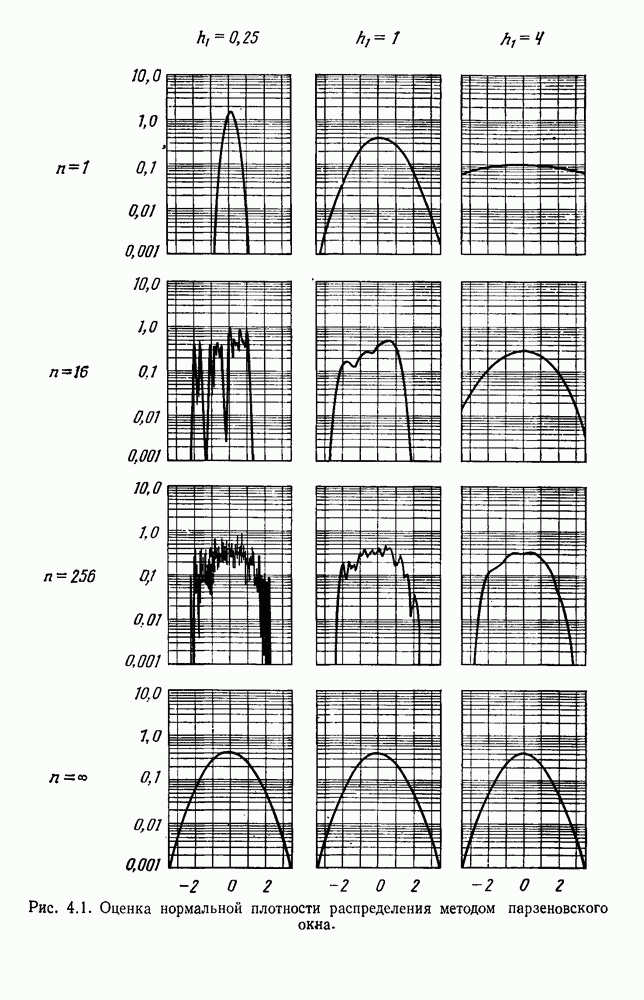
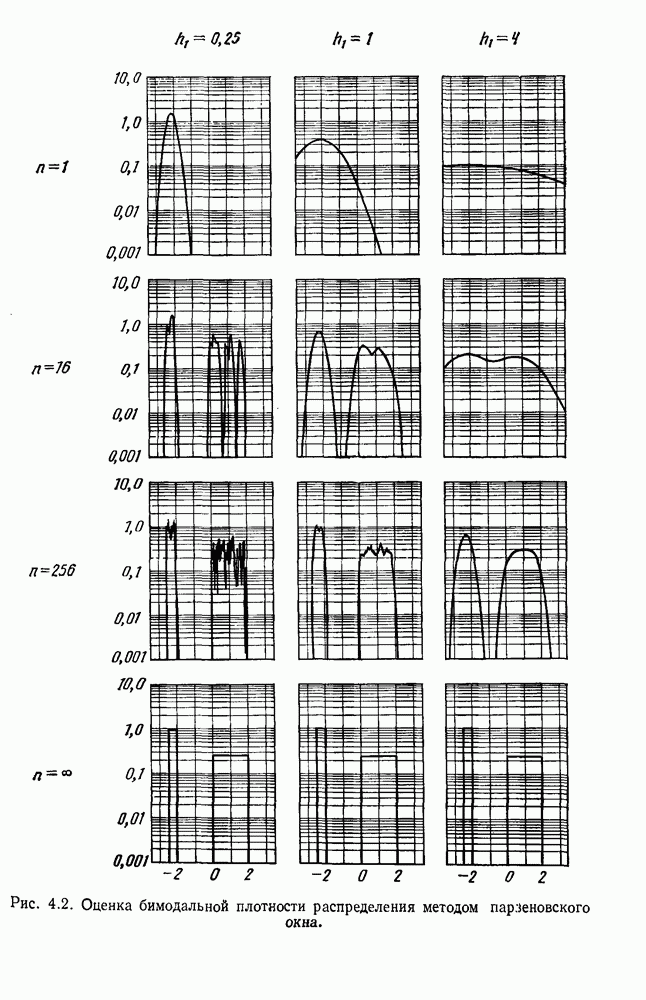

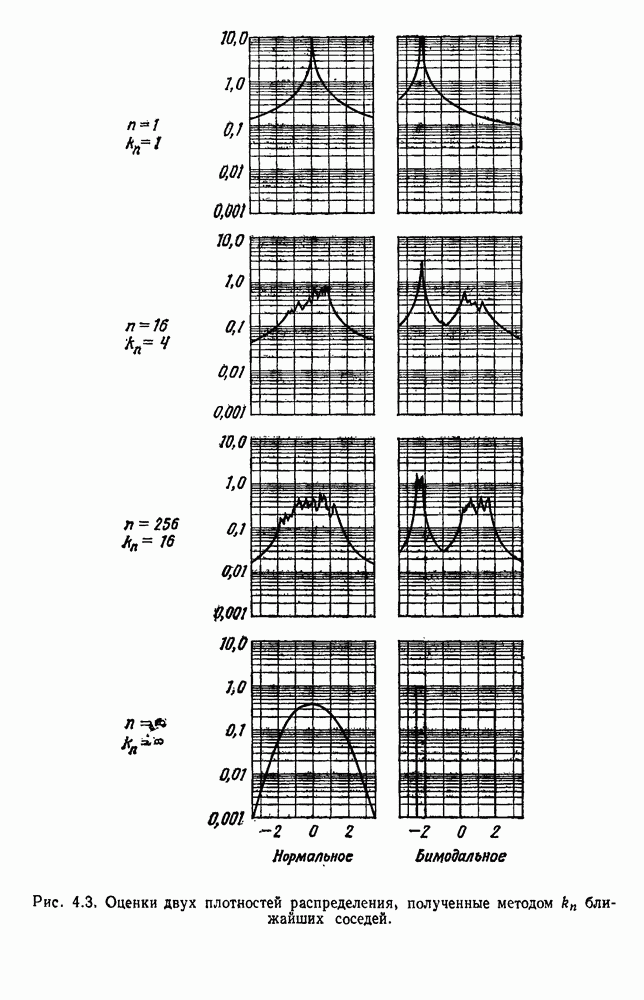








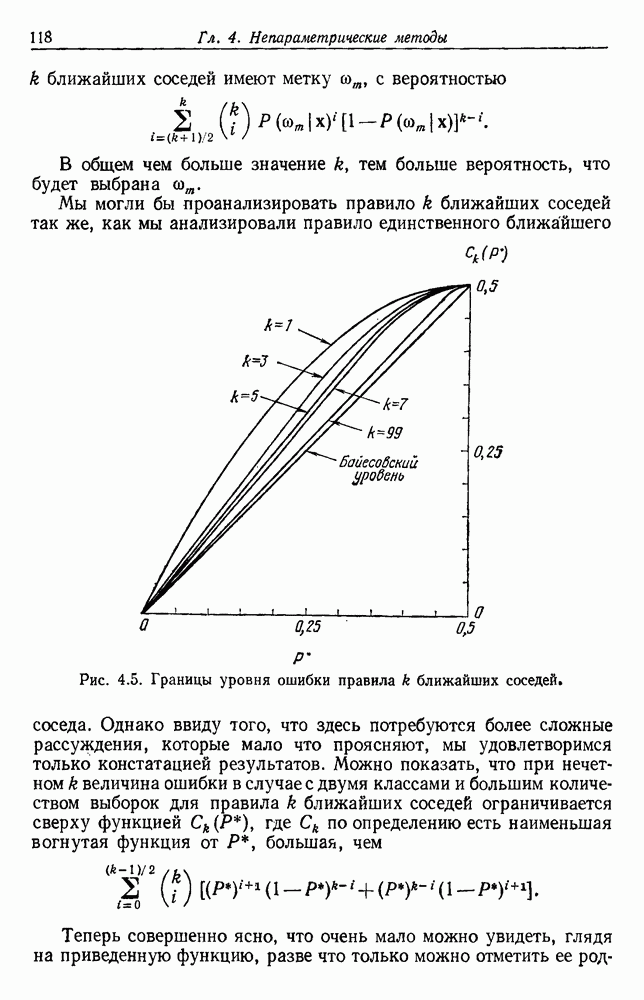



























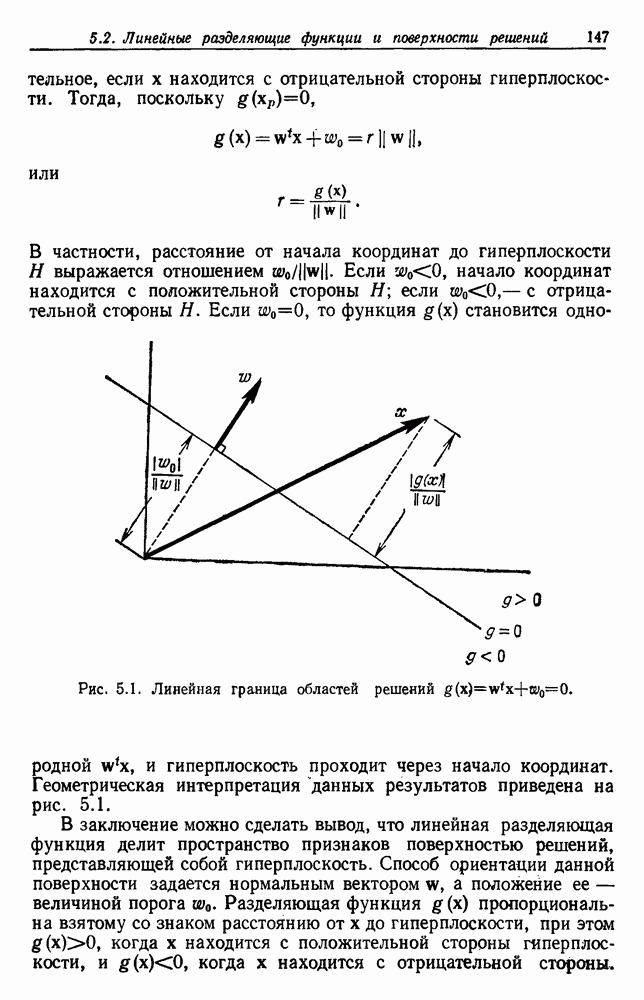
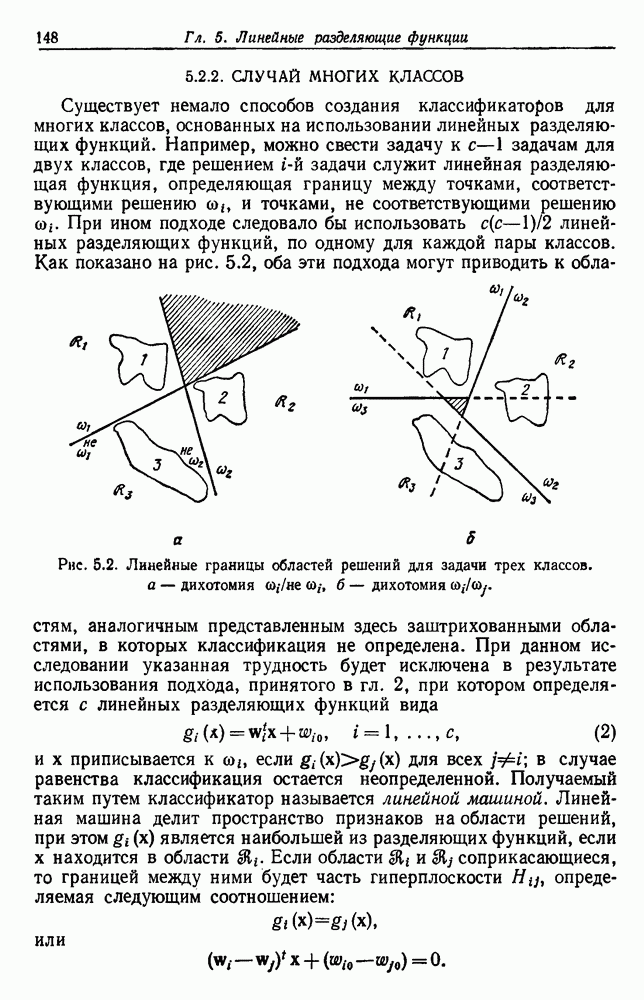


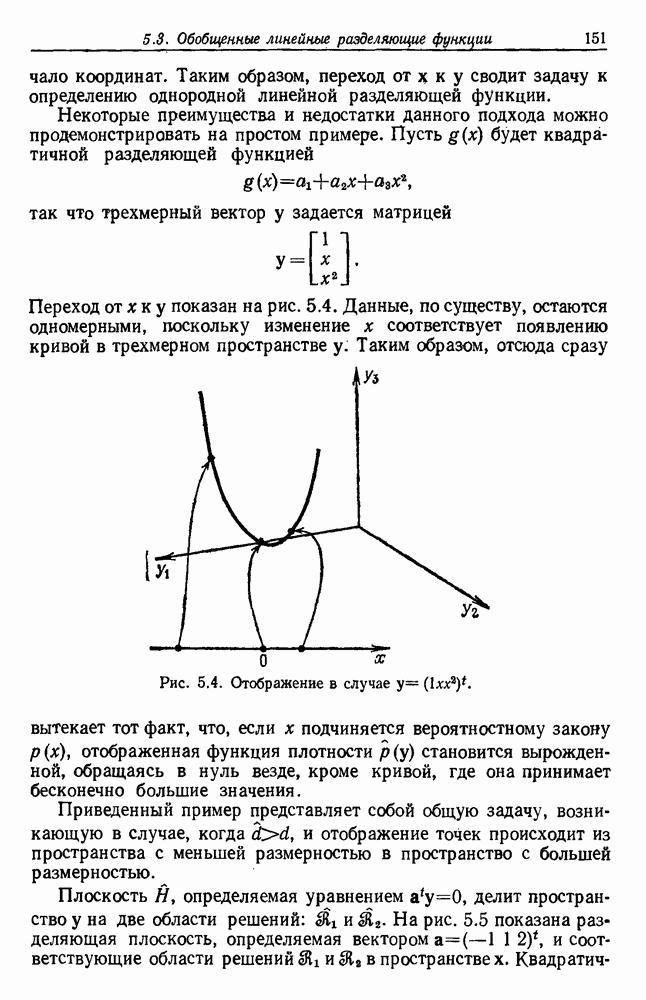
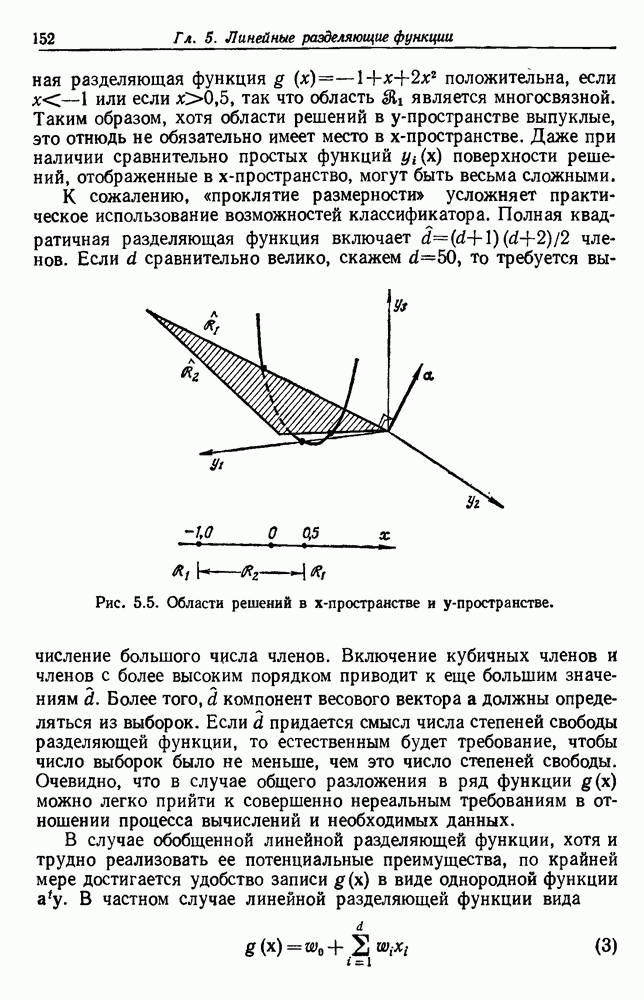



































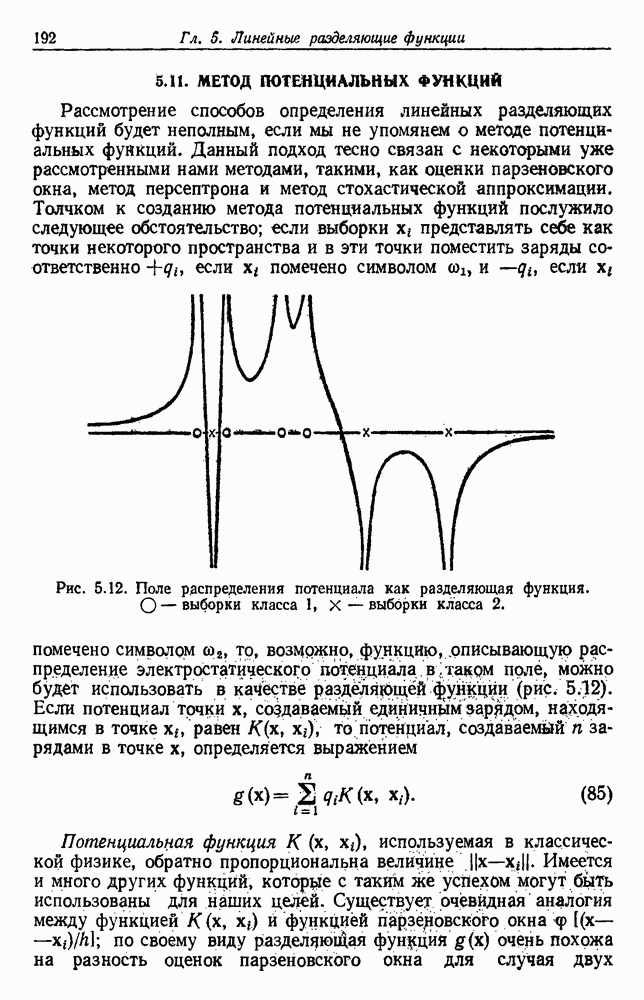

























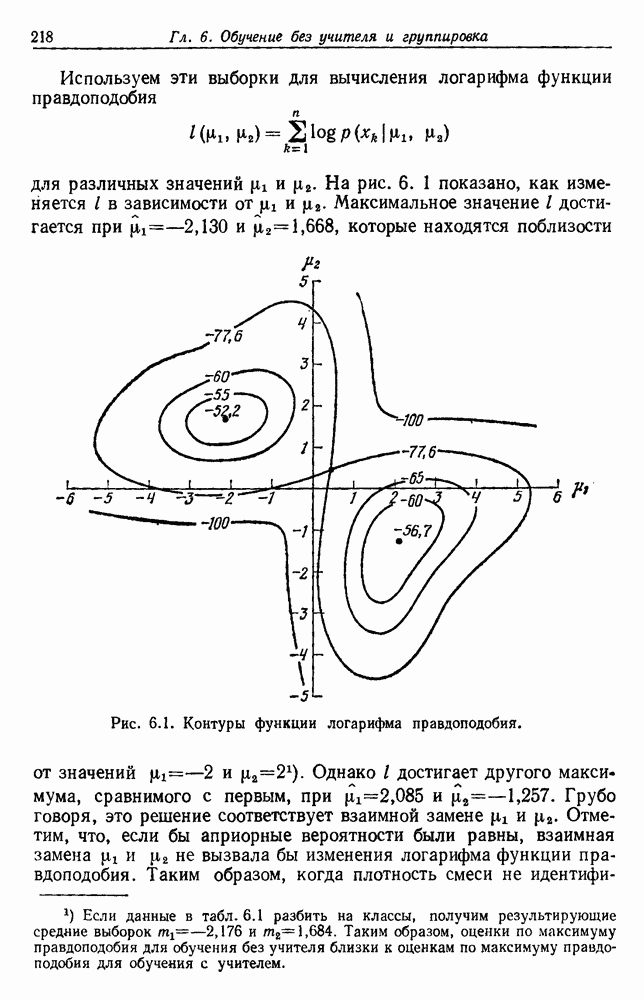
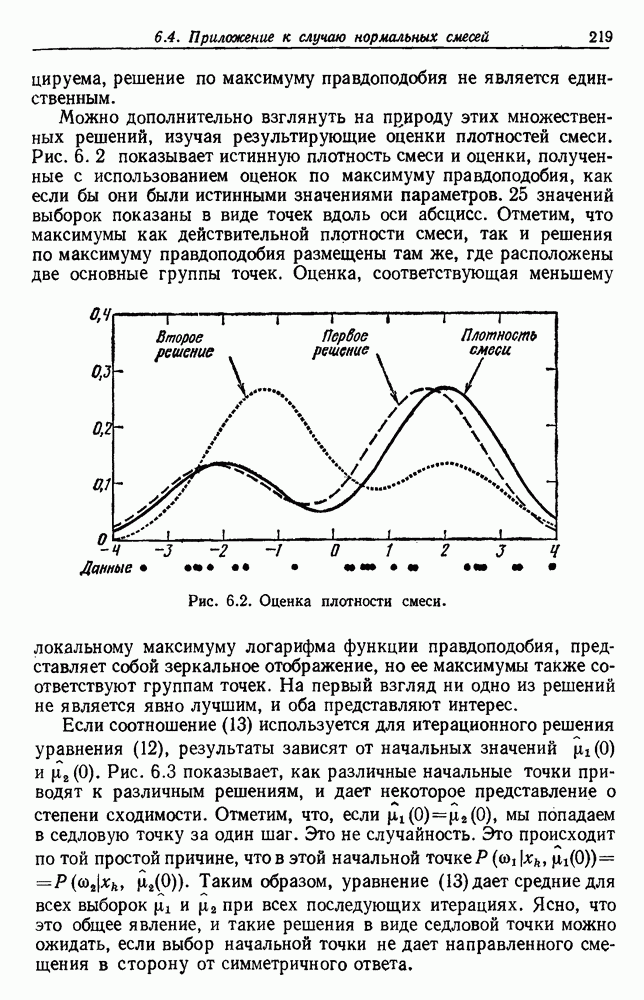
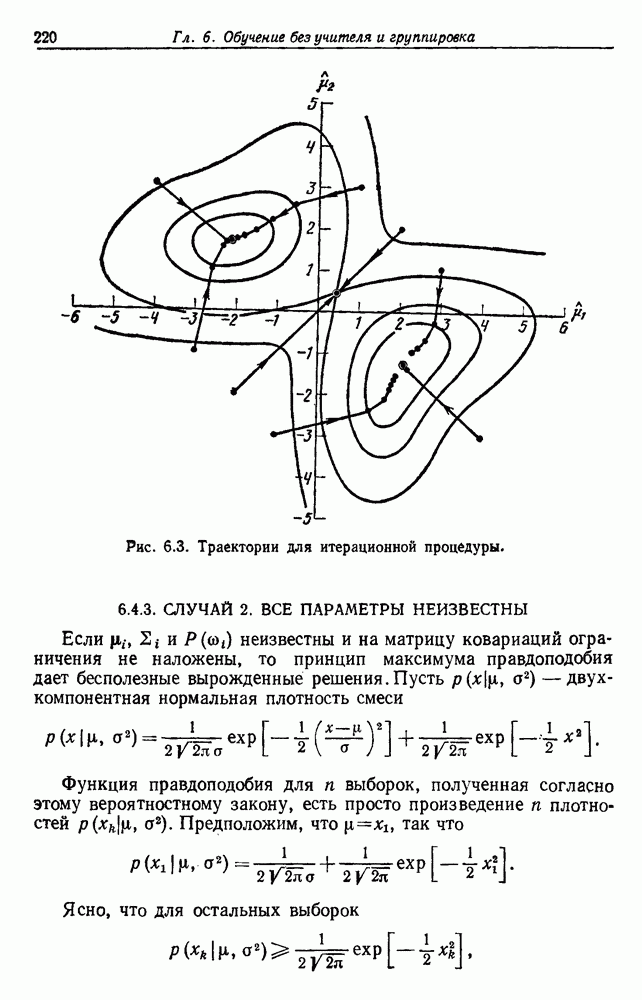



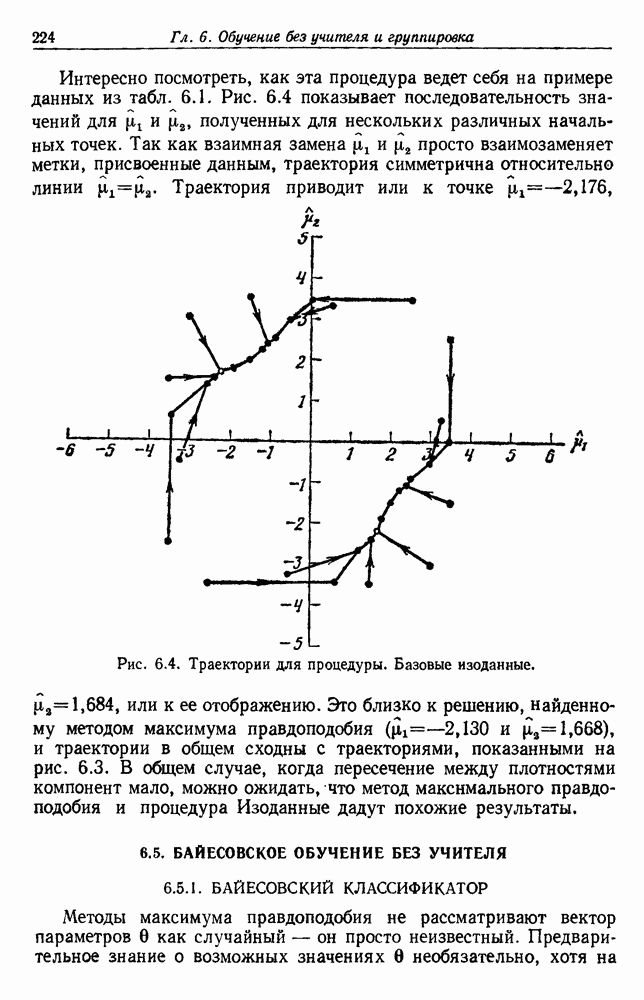





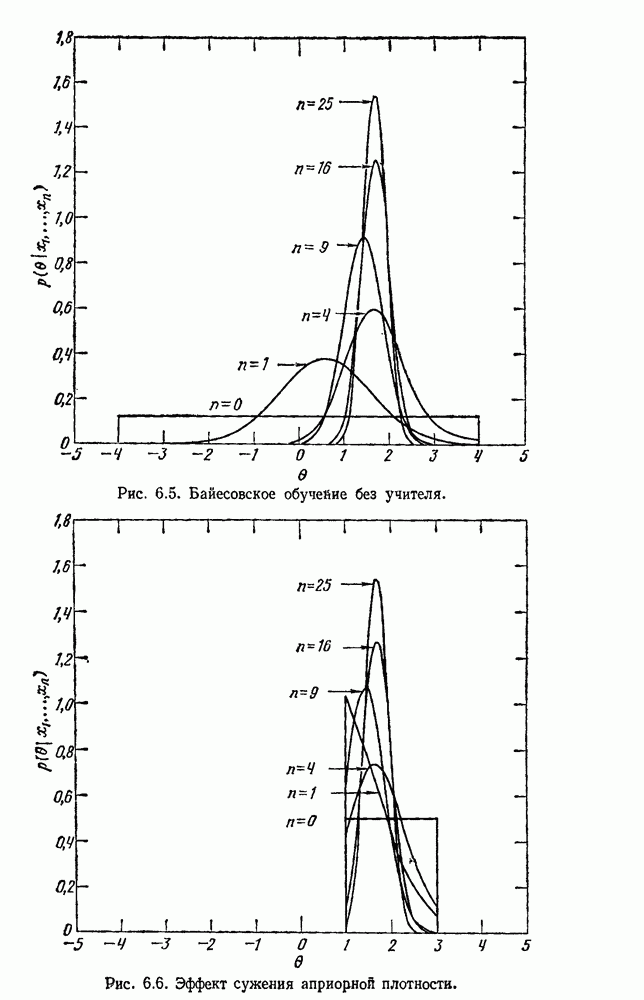





























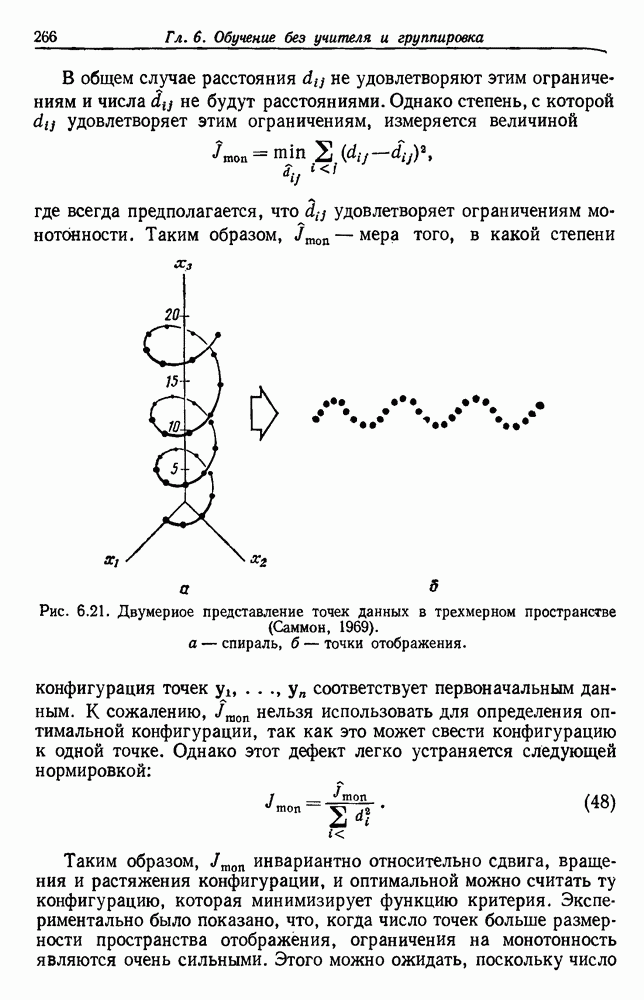




















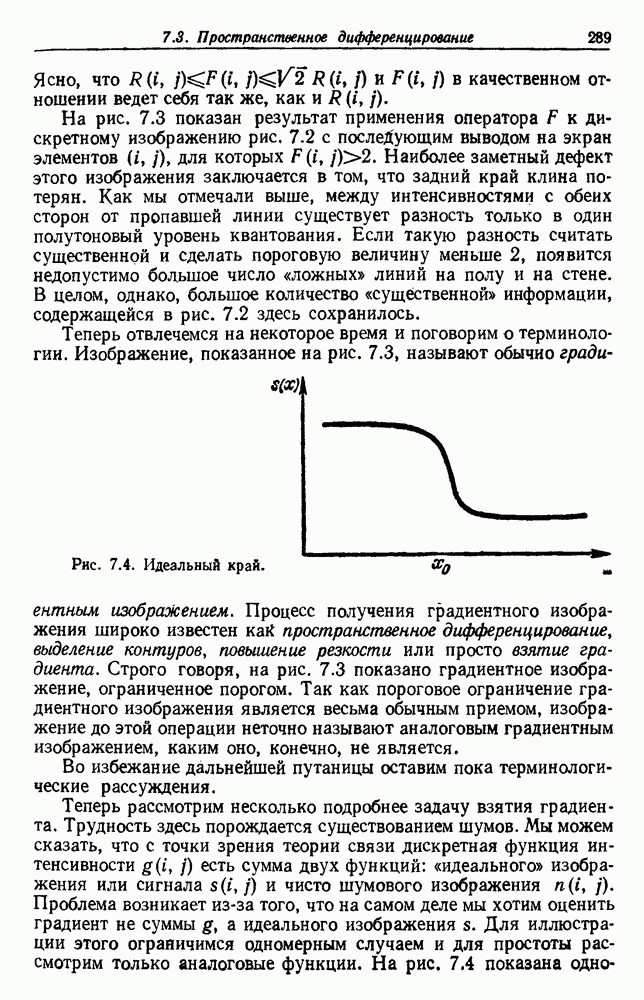
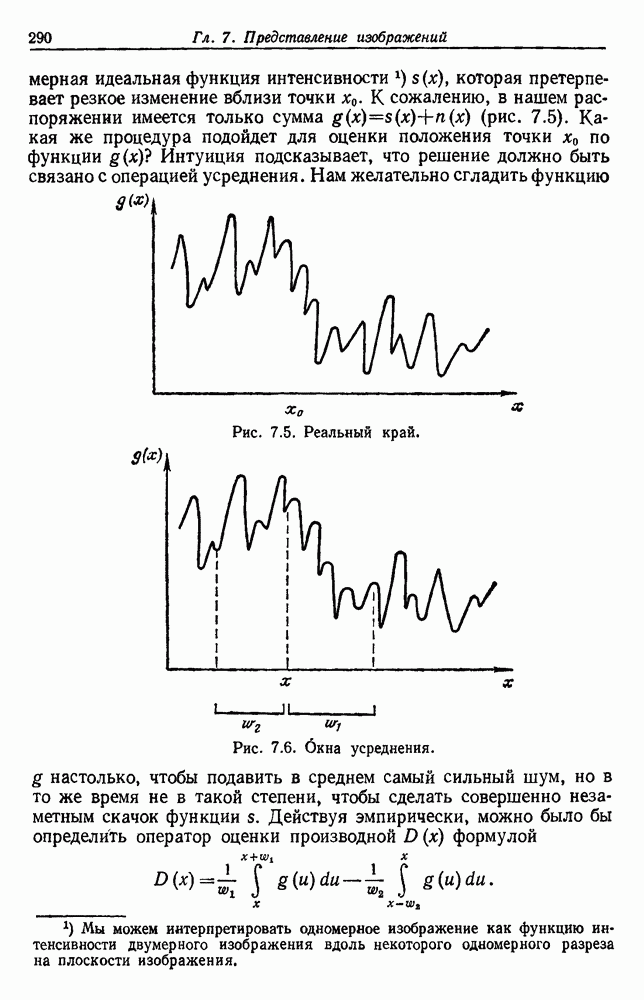

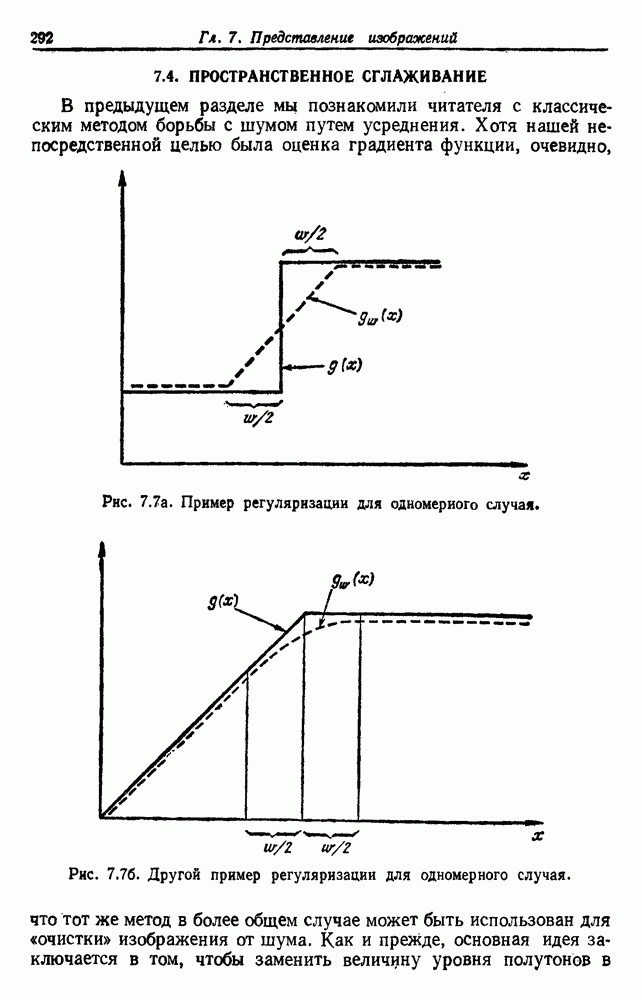
















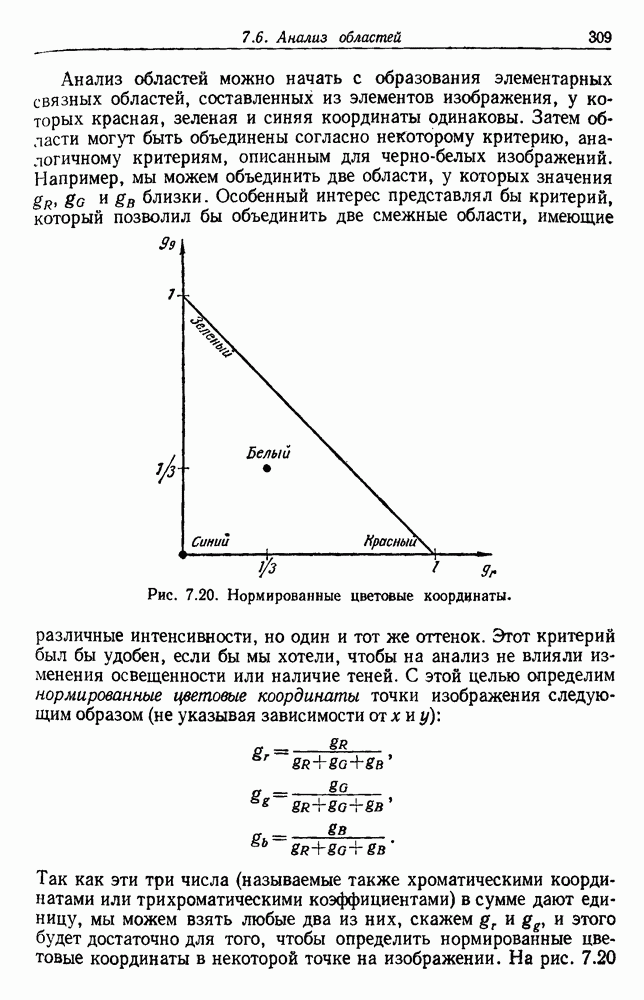






















































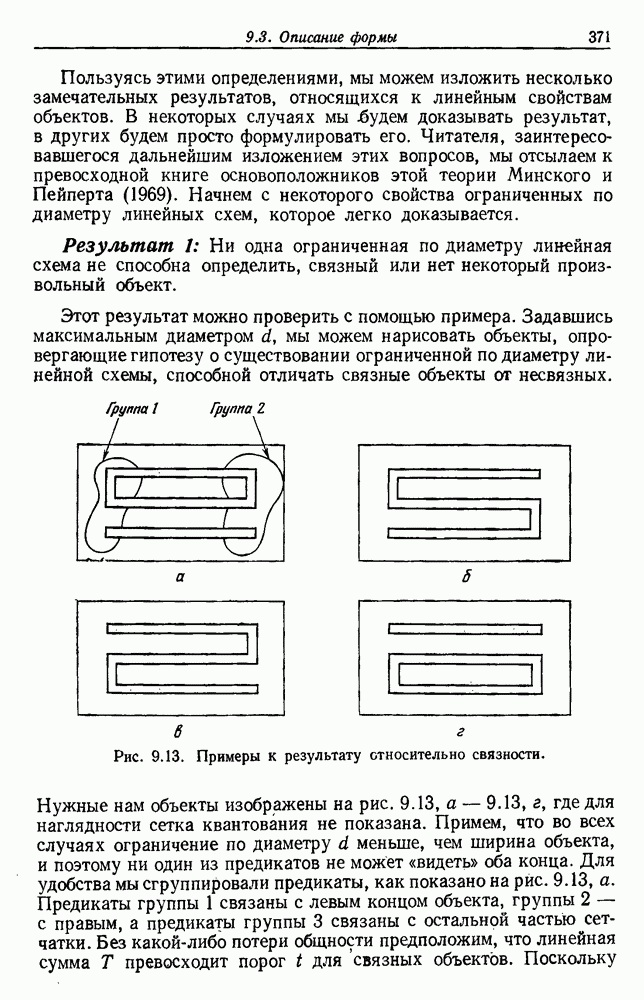





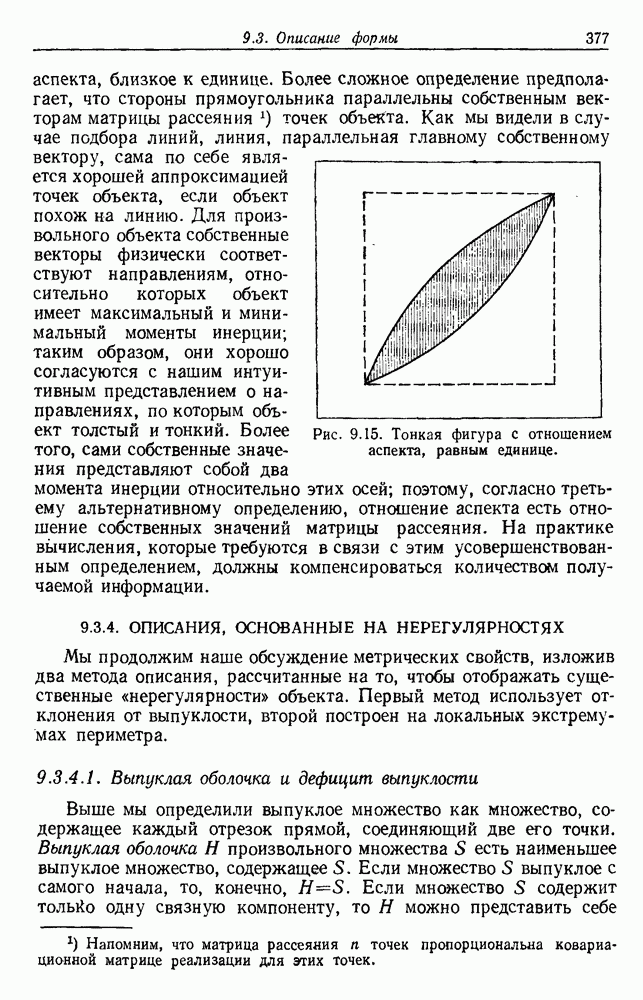


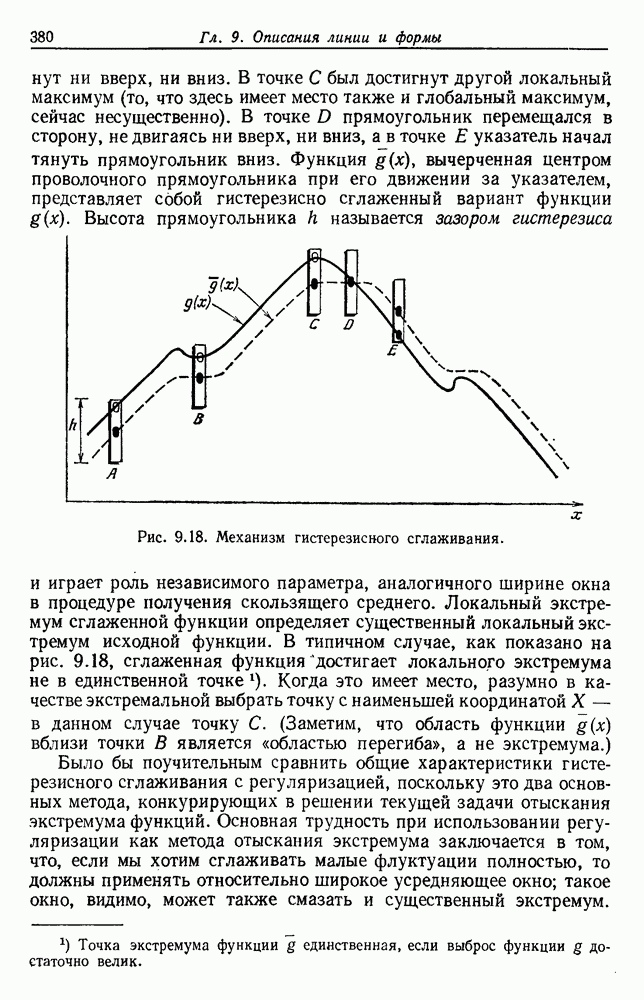
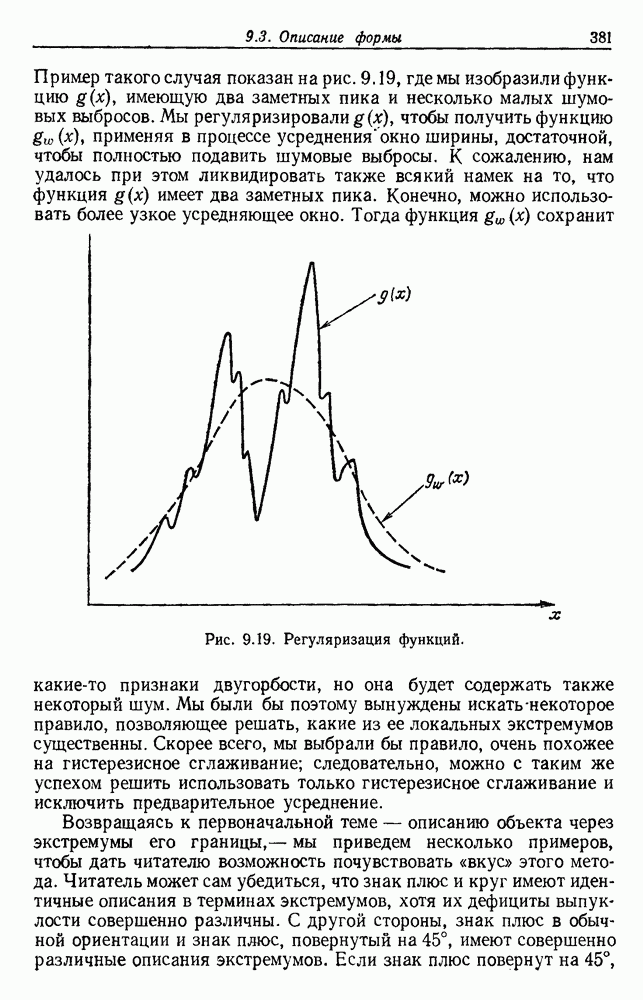





















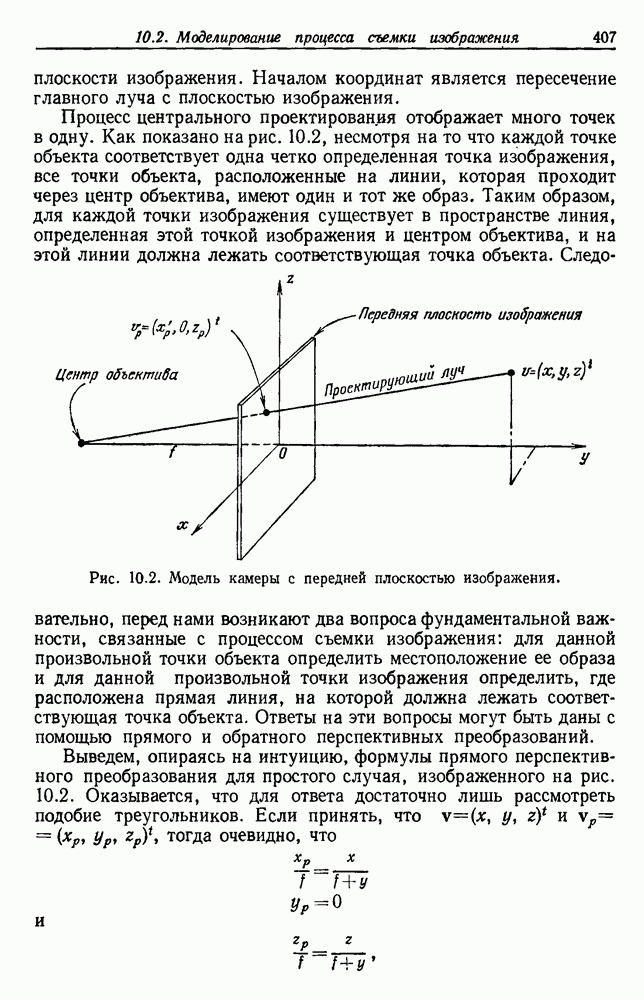





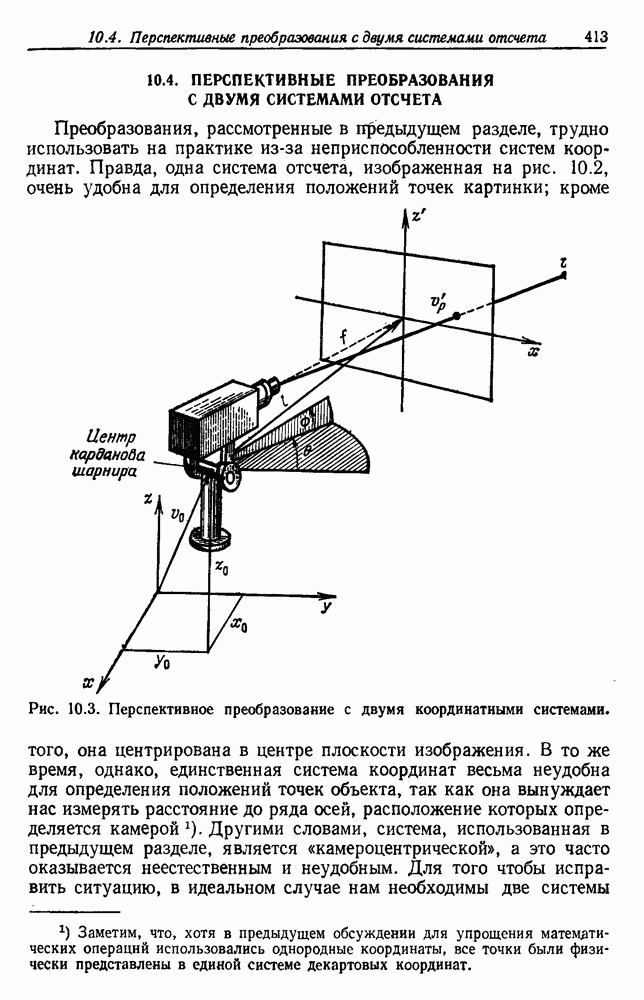








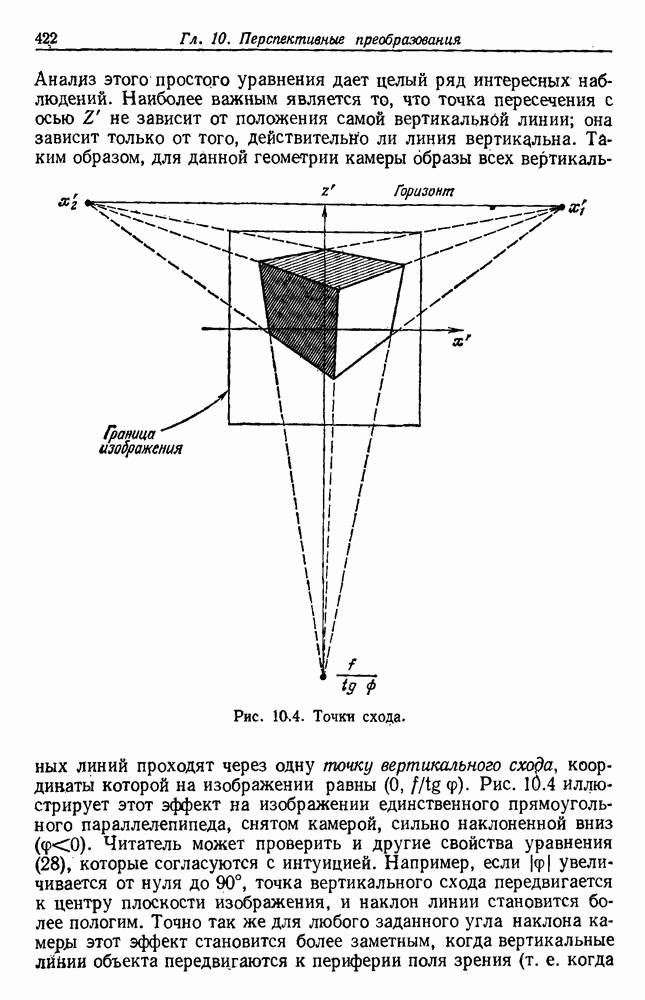

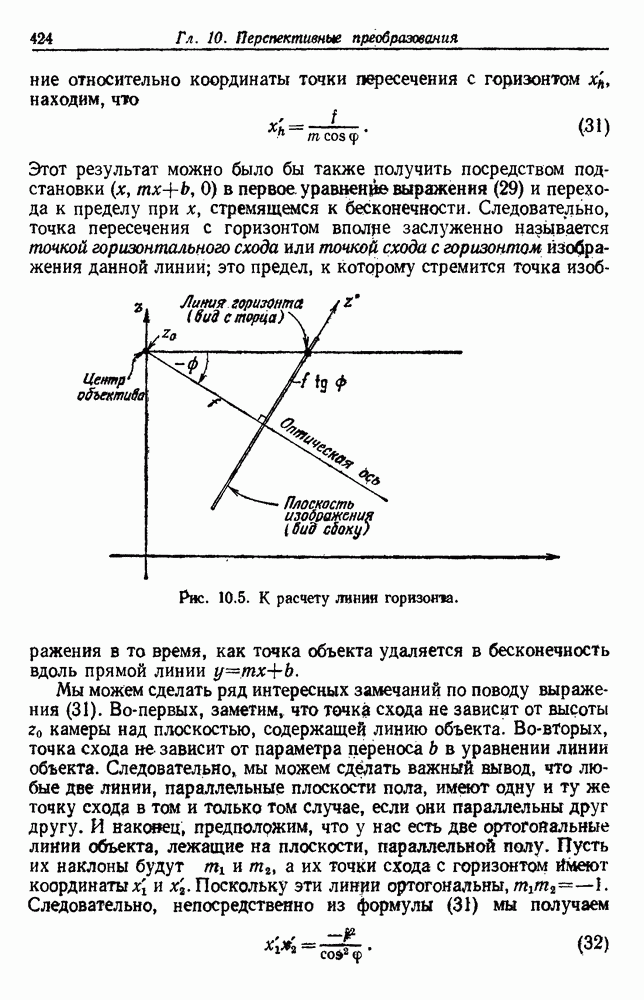












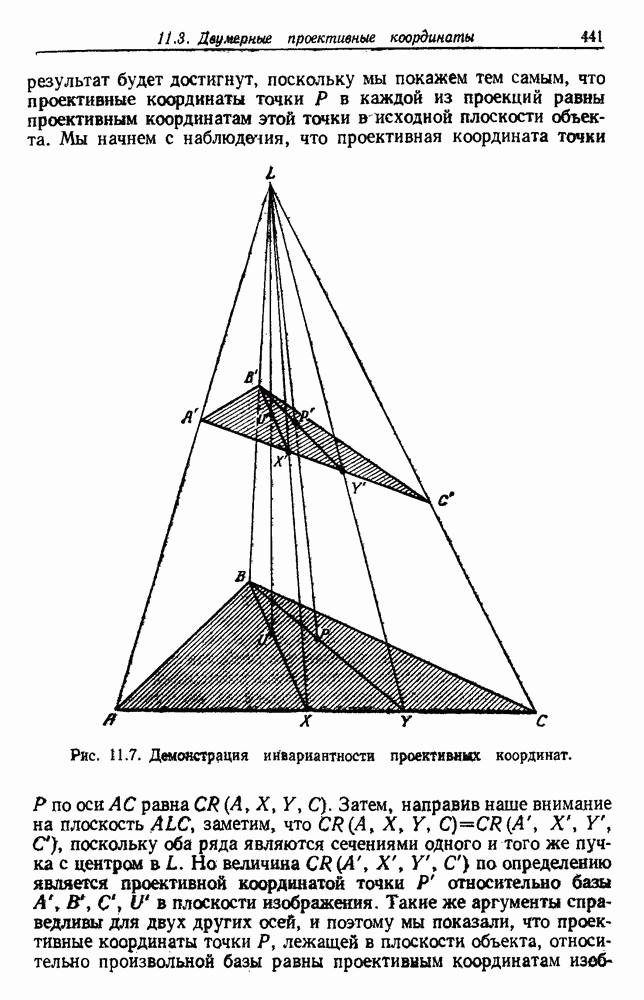

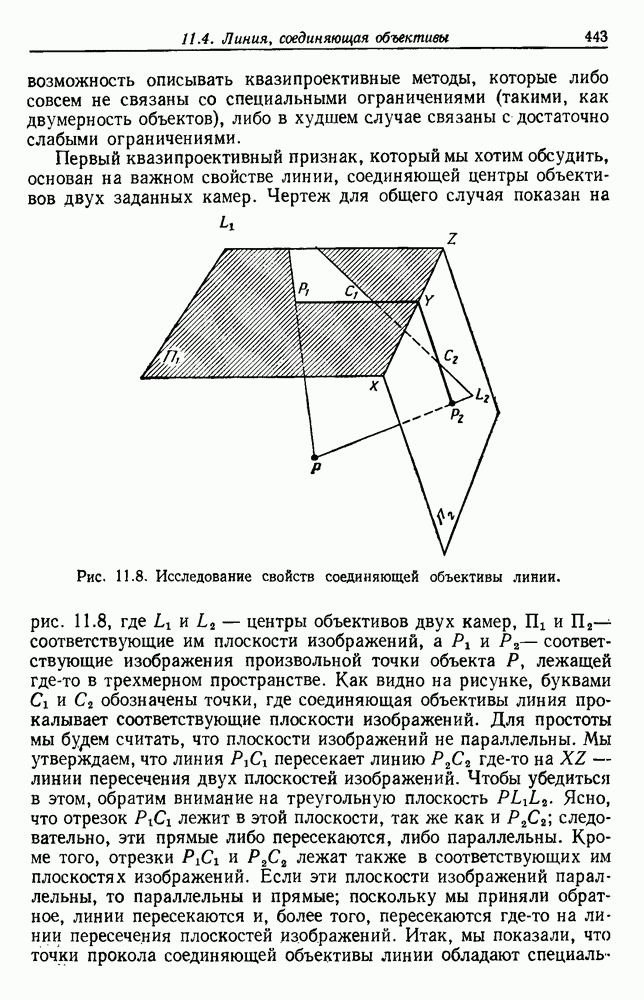
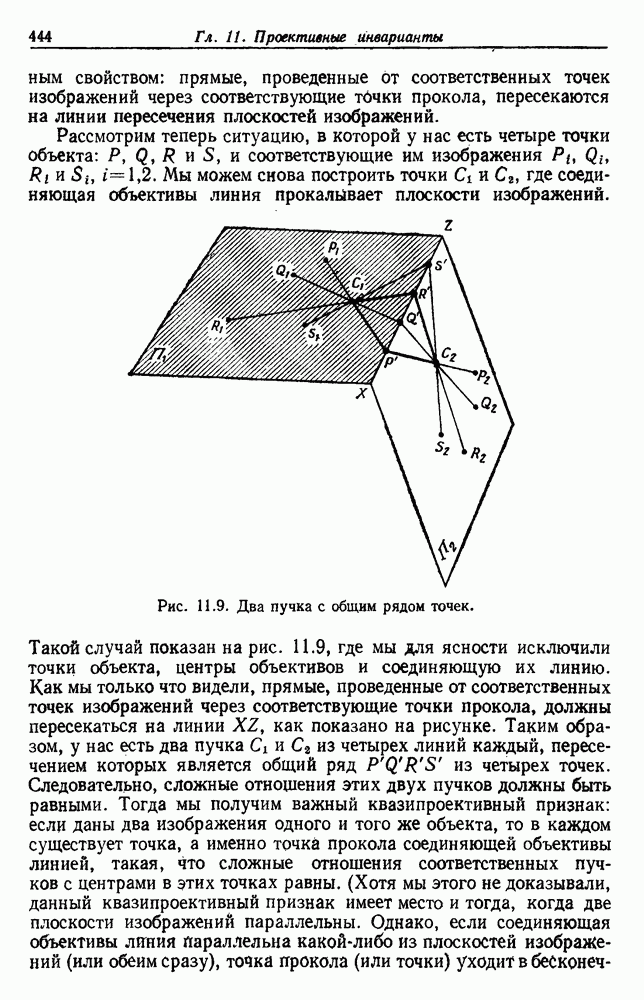













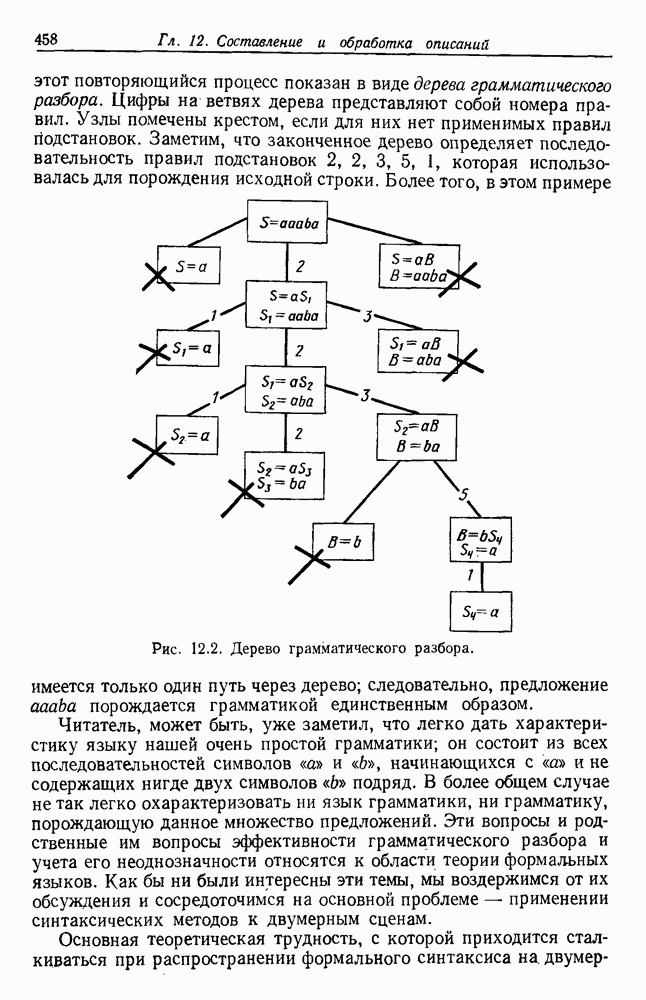















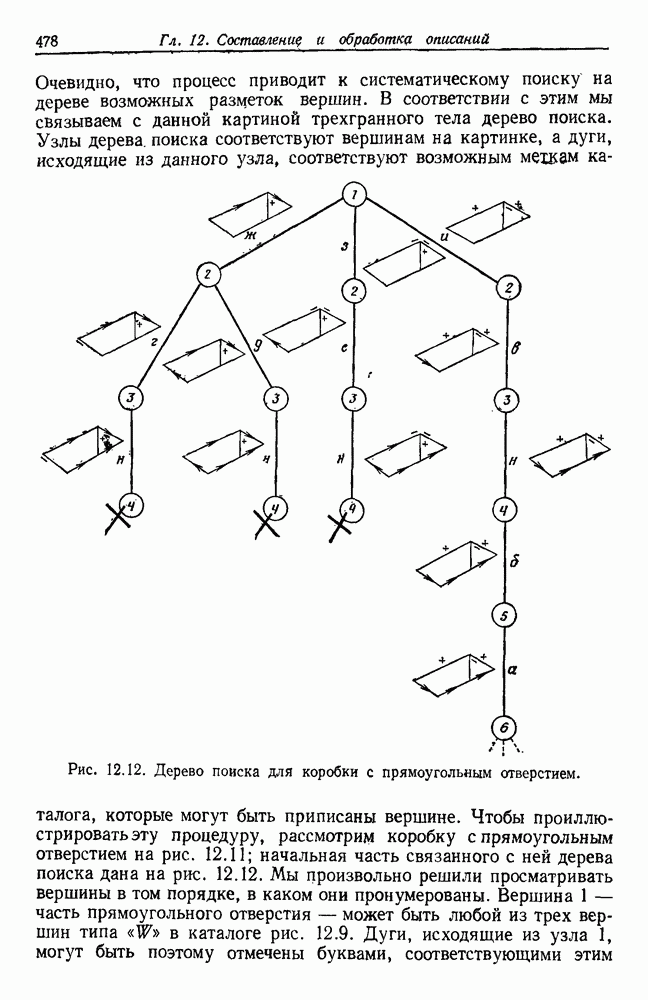















 по возможным значениям 0. Таким образом, в случае, когда неизвестные плотности имеют известный параметрический вид, выборки влияют на
по возможным значениям 0. Таким образом, в случае, когда неизвестные плотности имеют известный параметрический вид, выборки влияют на  через апостериорную плотность
через апостериорную плотность 