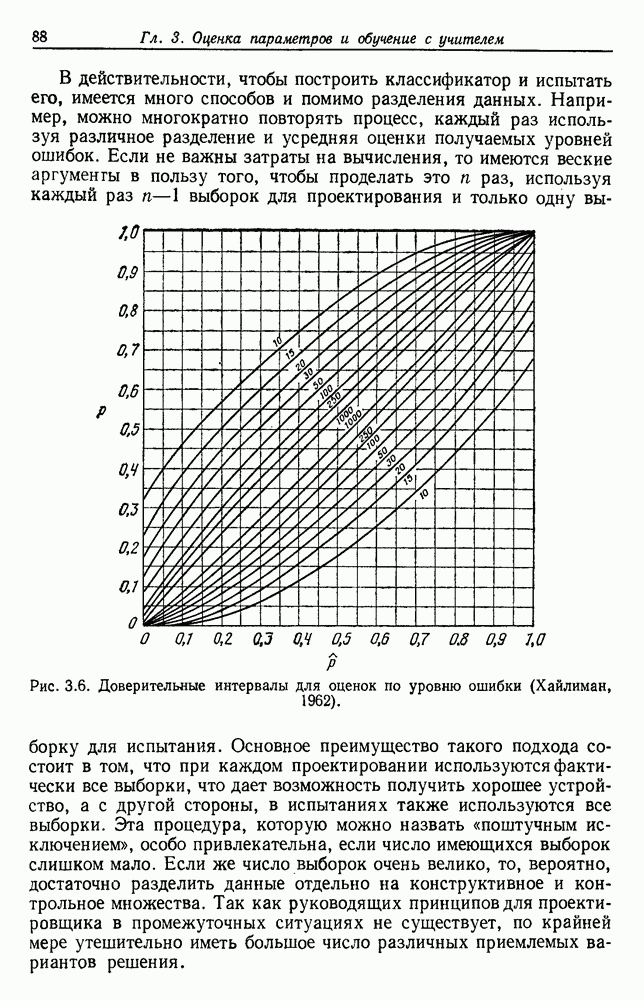
Пред.
След.
Макеты страниц
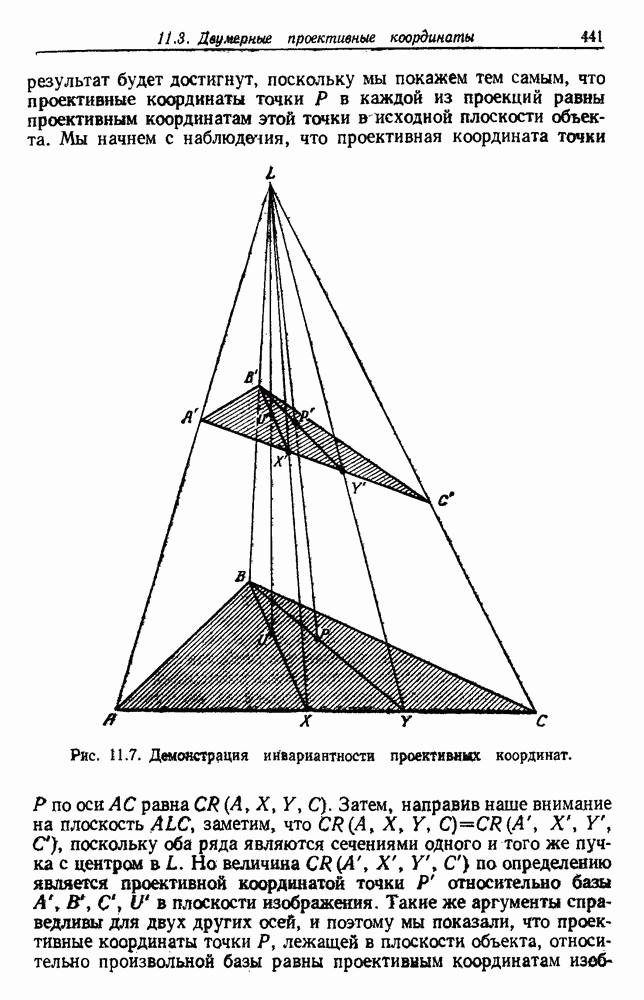
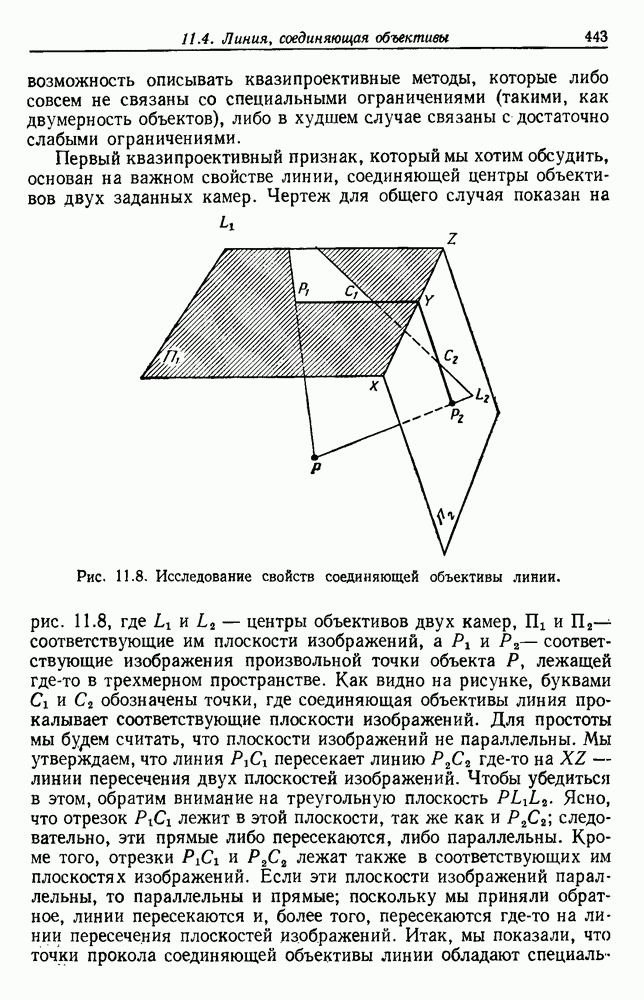
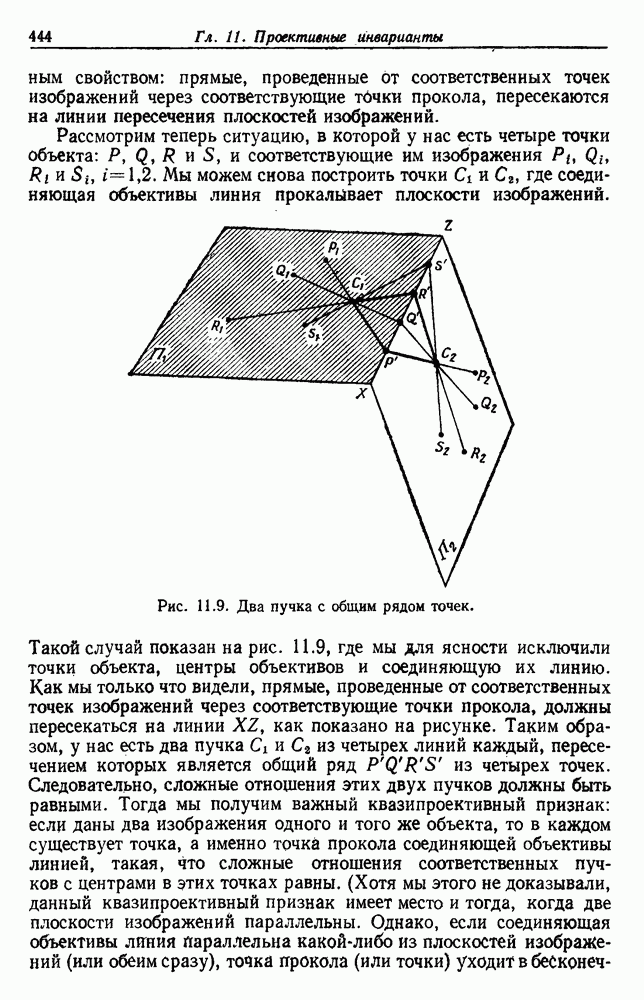
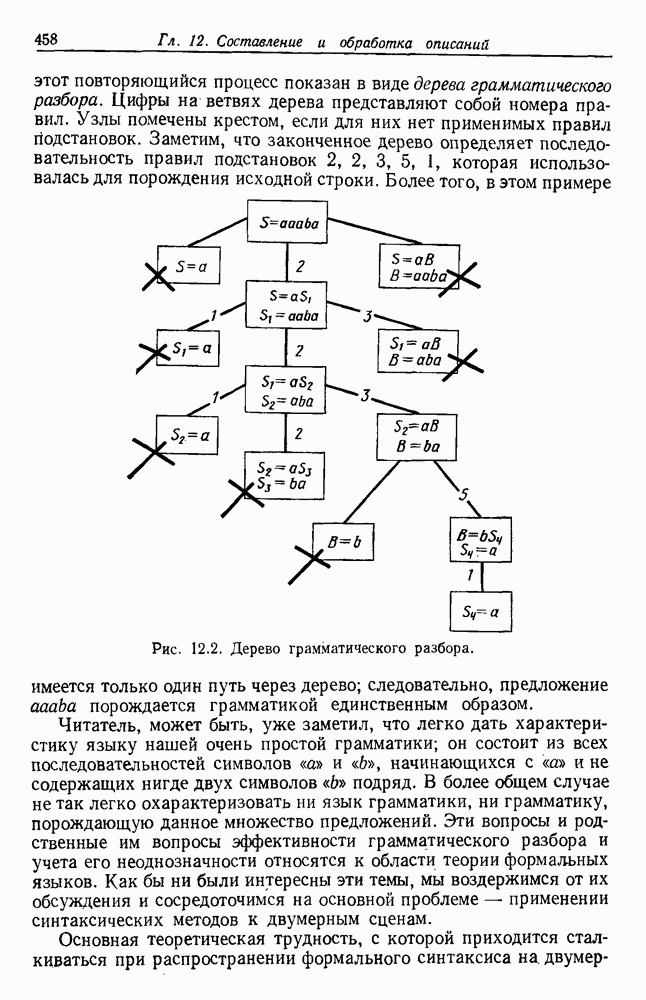
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
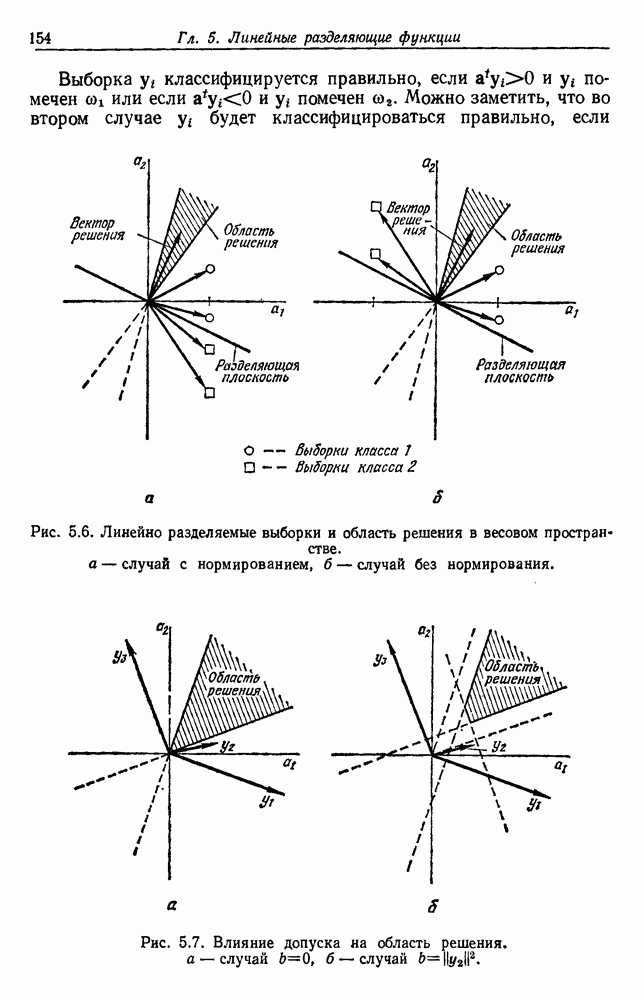
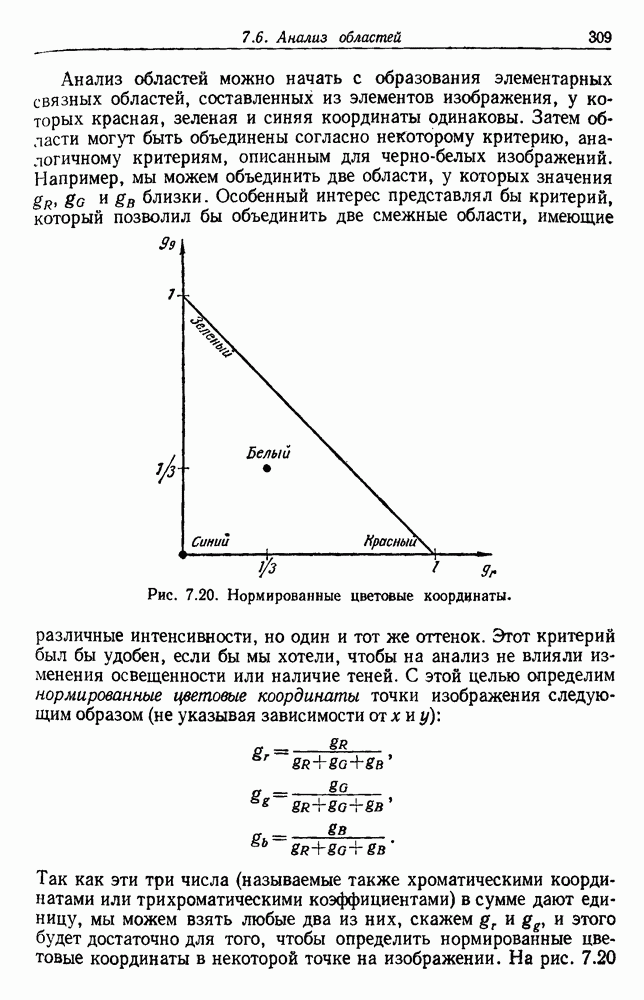
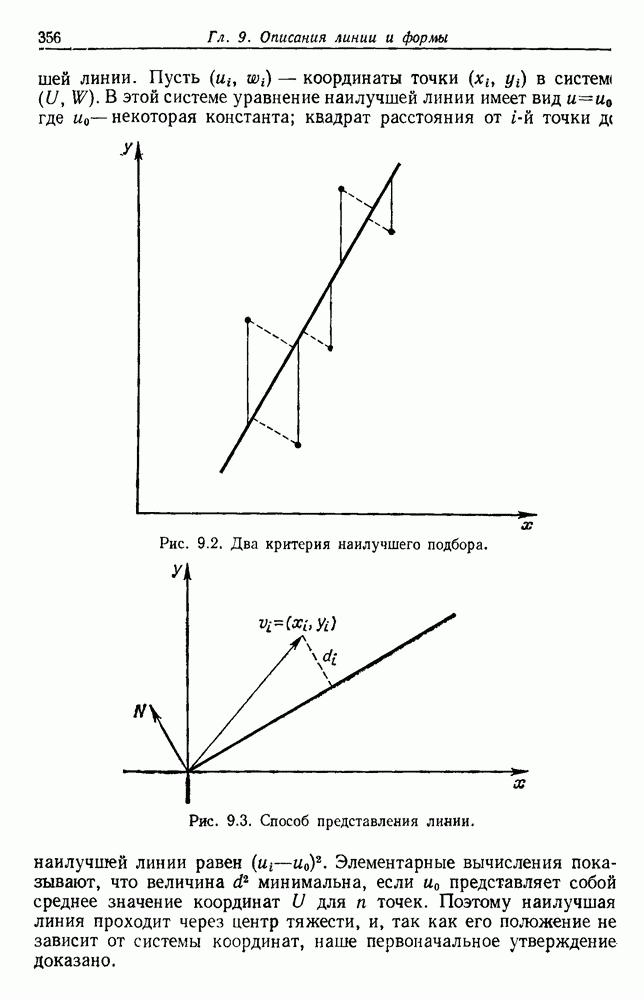
3.8. ПРОБЛЕМЫ РАЗМЕРНОСТИ3.8.1. НЕОЖИДАННАЯ ТРУДНОСТЬВ применении к случаям многих классов нередко приходится сталкиваться с задачами, содержащими до ста признаков, особенно если эти признаки бинарные. Исследователь обычно полагает, что каждый признак может быть полезен хотя бы для одного разделения. Он может и сомневался, что каждый из признаков обеспечивает независимую информацию, но заведомо излишние признаки им не привлекались. Для случая статистически независимых признаков имеются результаты некоторых теоретических исследований, которые подсказывают нам, как поступить наилучшим образом. Рассмотрим, например, многомерный нормальный случай для двух классов, когда
где
Таким образом, вероятность ошибки убывает с ростом
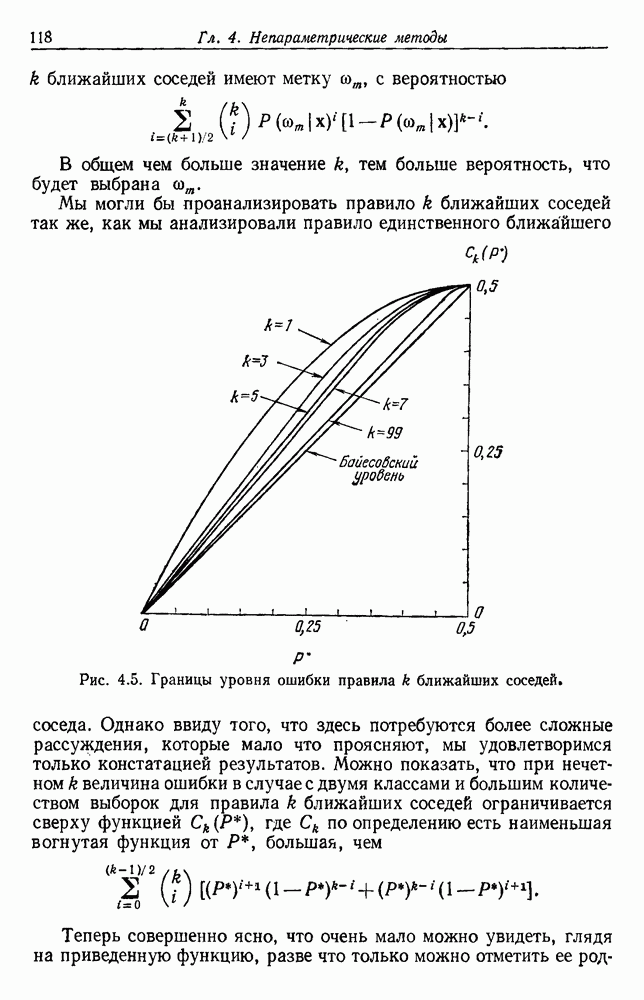
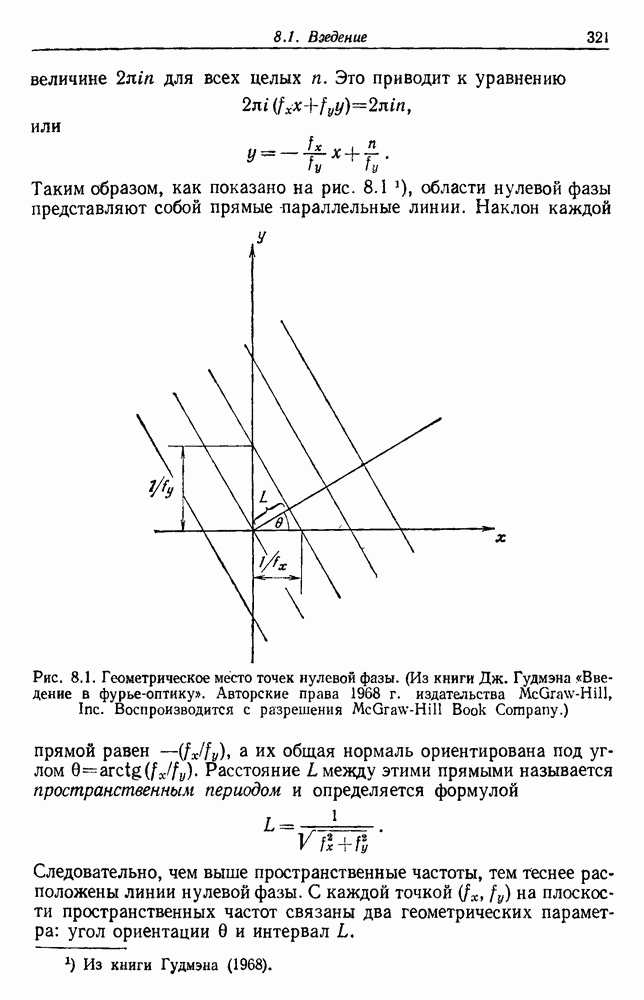
Отсюда видно, что каждый из признаков влияет на уменьшение вероятности ошибки. Наилучшими в этом смысле являются те признаки, у которых разность средних значений велика по сравнению со стандартными отклонениями. Вместе с тем ни один из признаков не бесполезен, если его средние значения для разных классов различны. Поэтому для дальнейшего уменьшения уровня ошибки надо, очевидно, ввести новые, независимые признаки. Хотя вклад каждого нового признака и не очень велик, однако если беспредельно увеличивать Естественно, если результаты, получаемые при использовании данного множества признаков, нас не устраивают, можно попытаться добавить новые признаки, особенно такие, которые способствуют разделению пар классов, с которыми чаще всего происходила путаница. Хотя увеличение числа признаков удорожает и усложняет выделитель признаков и классификатор, оно приемлемо, если есть уверенность в улучшении качества работы. При всем этом, если вероятностная структура задачи полностью известна, добавление новых признаков не увеличит байесовский риск и в худшем случае байесовский классификатор не примет их во внимание, а если эти признаки все же несут дополнительную информацию, то качество работы должно улучшиться. К сожалению, на практике часто наблюдается, что, вопреки ожиданиям, добавление новых признаков ухудшает, а не улучшает качество работы. Это явное противоречие составляет весьма серьезную проблему при разработке классификатора. Главный источник этого можно усмотреть в конечности числа исходных выборок. В целом же данный вопрос требует сложного и тонкого анализа. Простейшие случаи не дают возможности экспериментального наблюдения указанного явления, тогда как случаи, близкие к реальным, оказываются сложными для анализа. С целью внести некоторую ясность, обсудим ряд вопросов, относящихся к проблемам размерности и объема выборки. В связи с тем что большинство результатов анализа будет дано без доказательств, заинтересованный читатель найдет соответствующие ссылки в библиографических и исторических замечаниях. 3.8.2. ОЦЕНКА КОВАРИАЦИОННОЙ МАТРИЦЫНачнем наш анализ с задачи оценки ковариационной матрицы. Для этого требуется оценить
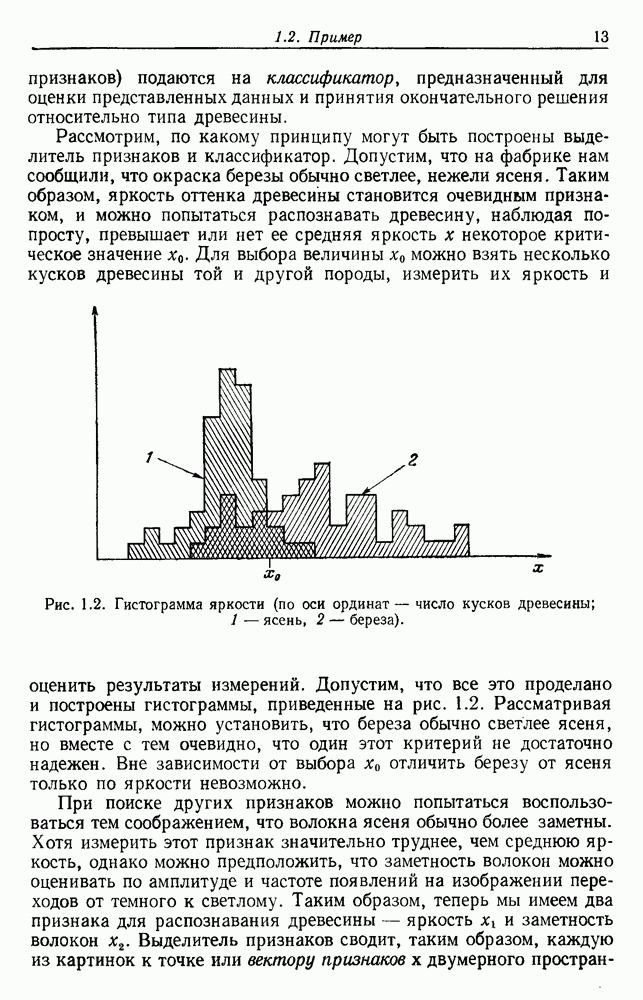
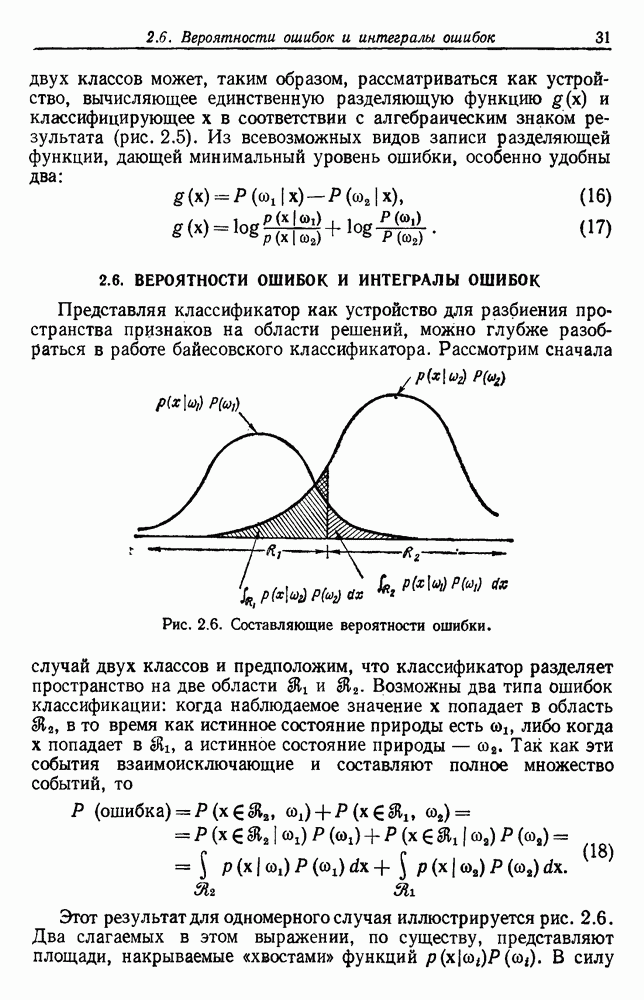
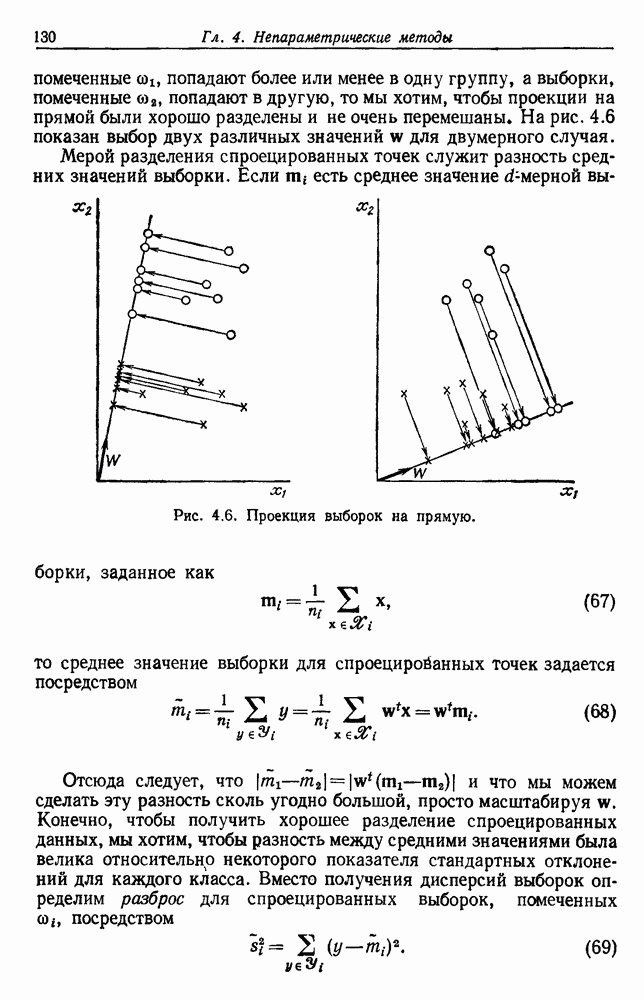
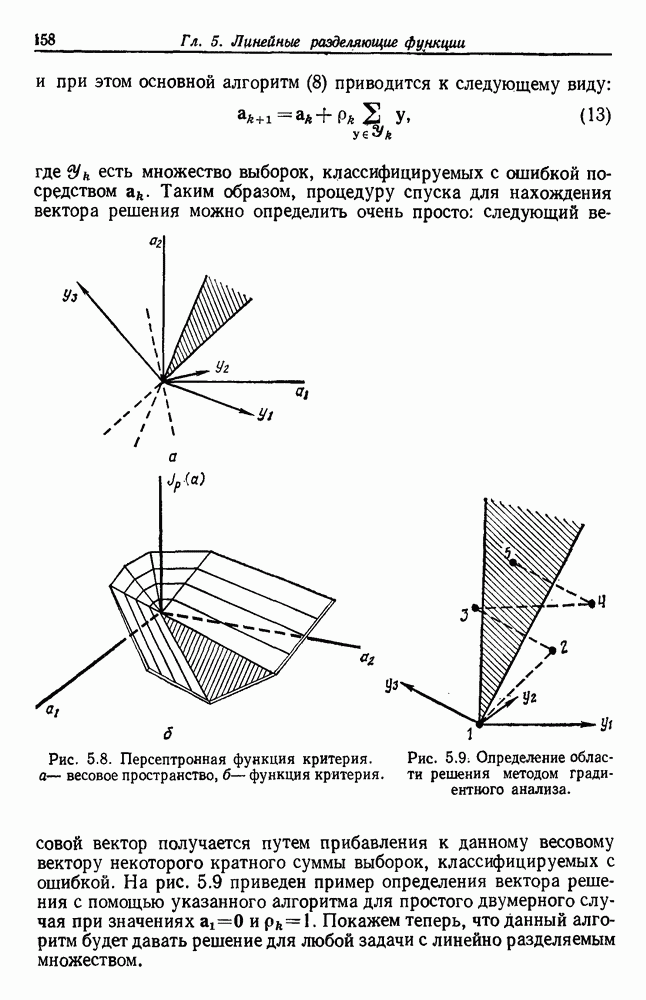
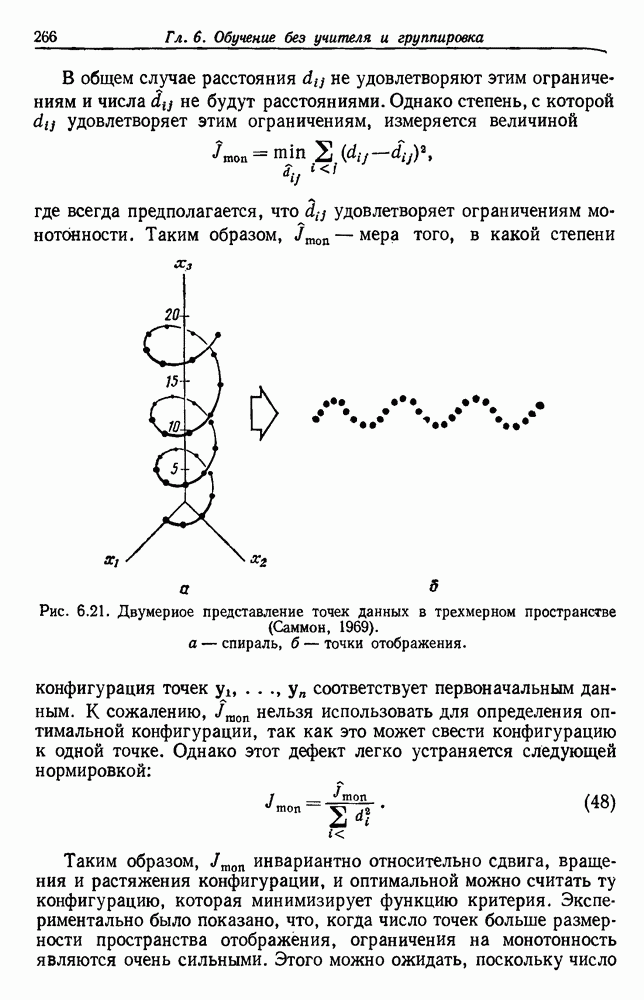
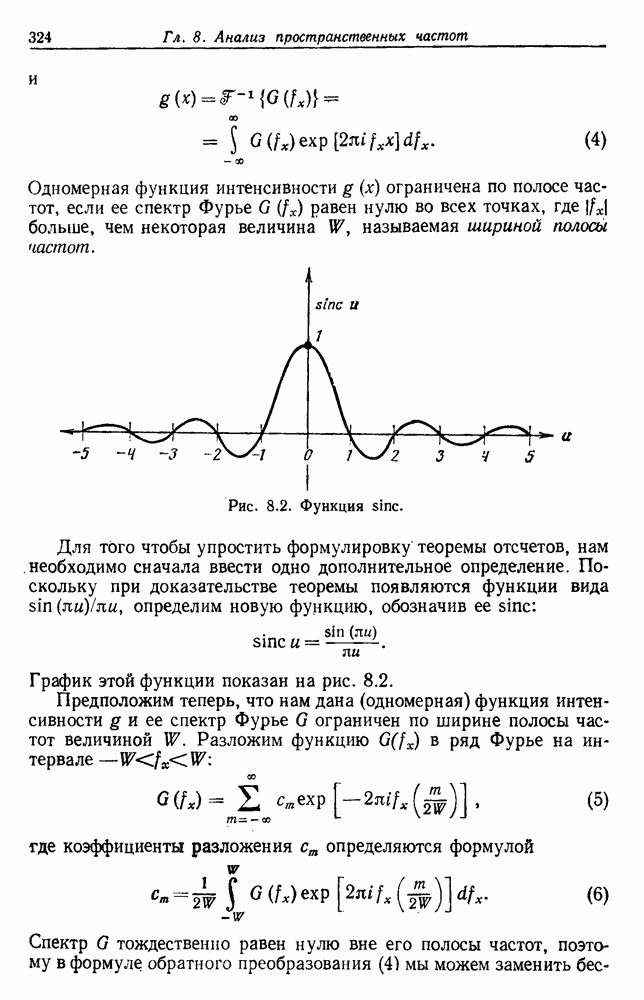
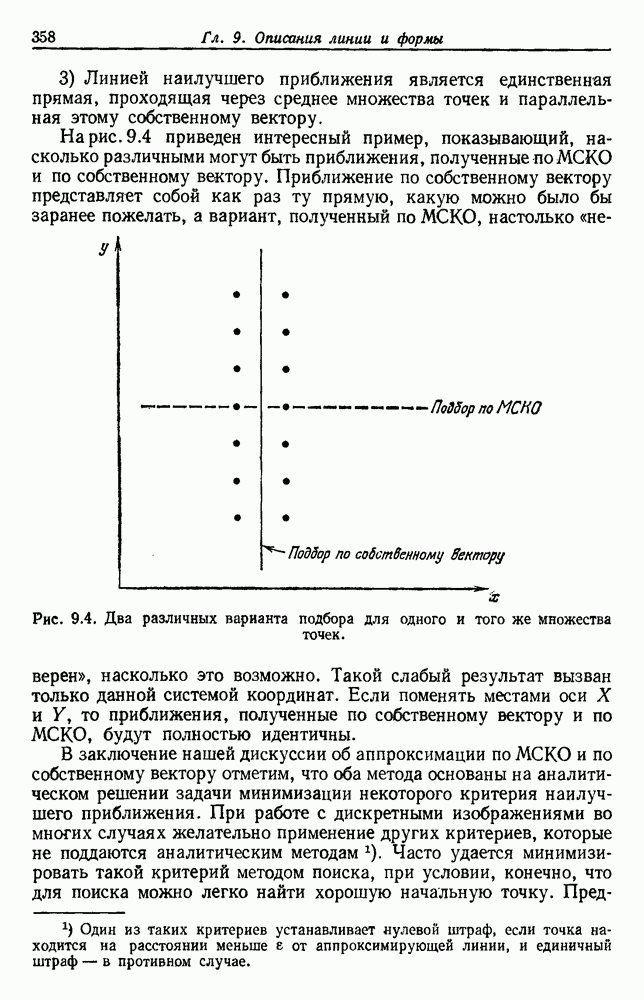
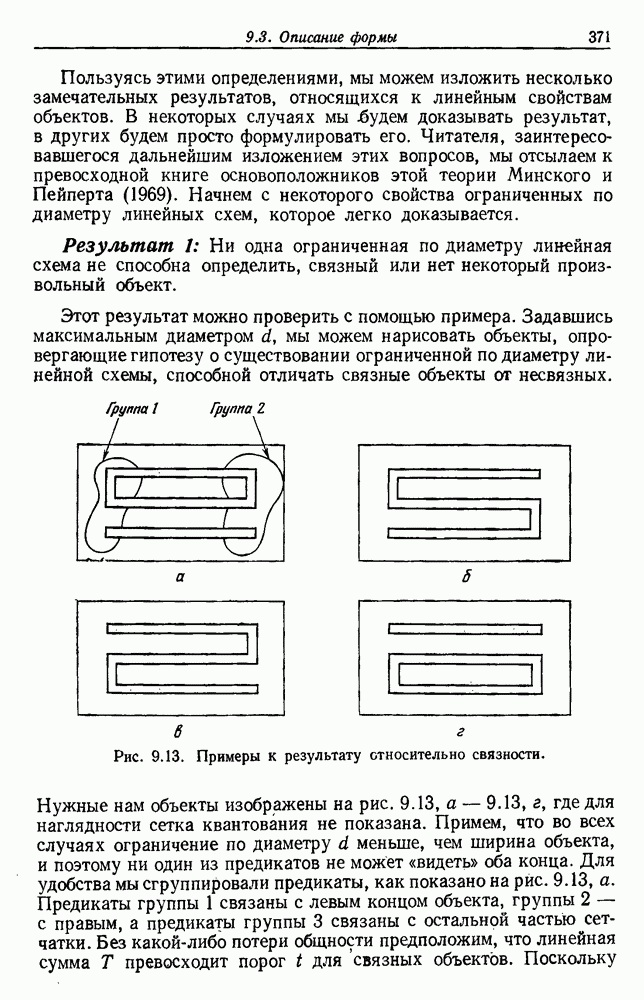
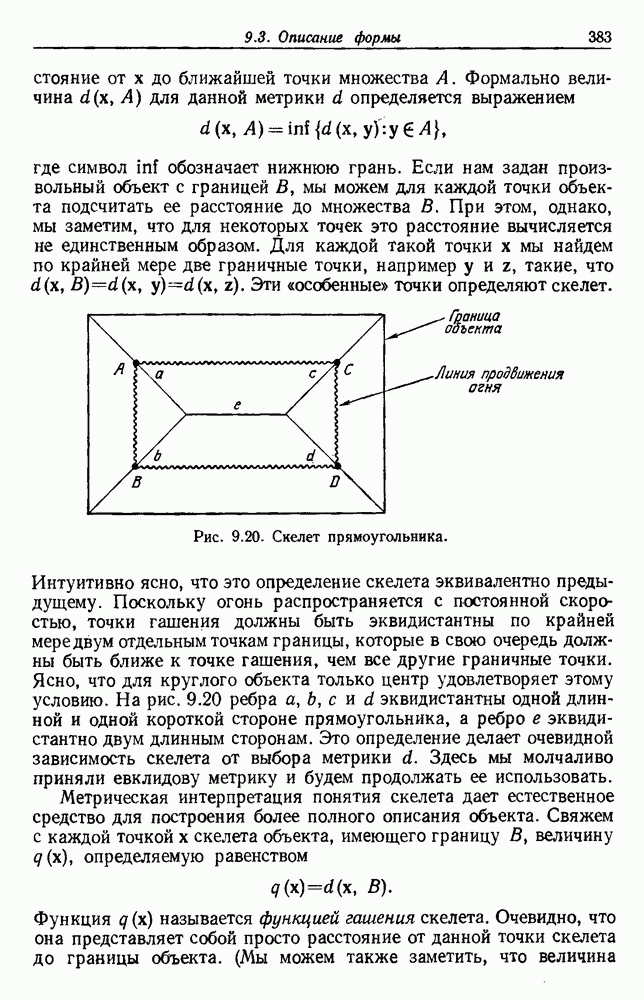
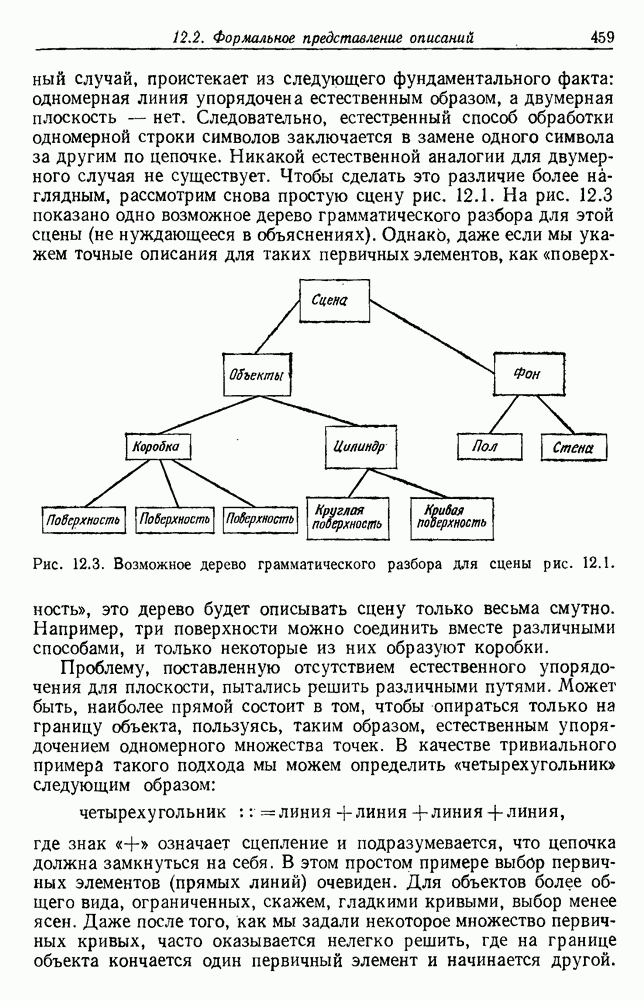
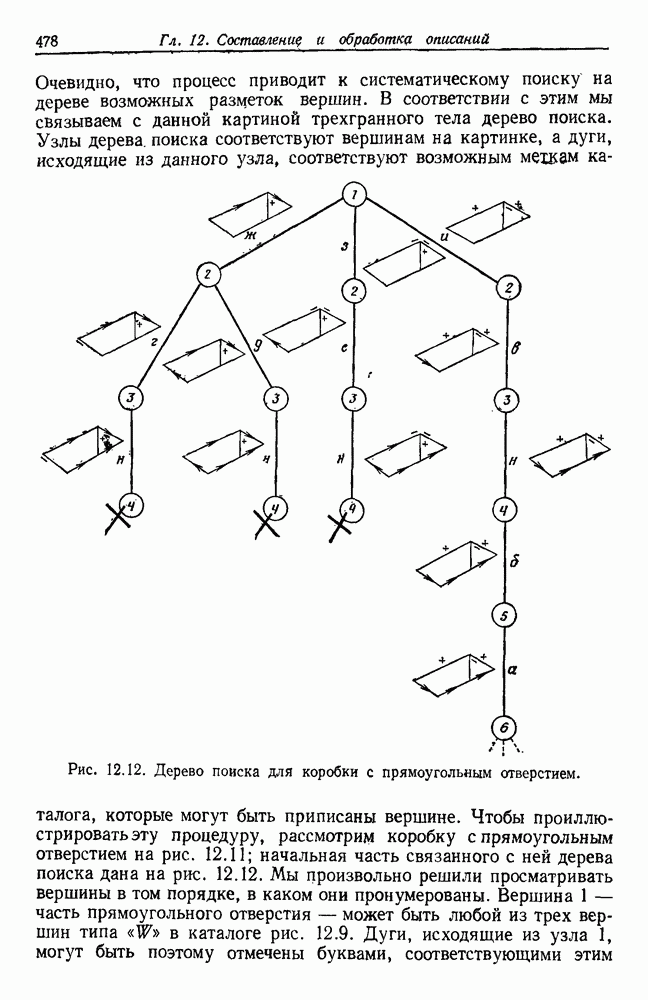
представляет собой сумму Часто встает вопрос, как быть, если число имеющихся в распоряжении выборок недостаточно. Одна из возможностей — уменьшить размерность, либо перестраивая выделитель признаков, либо выбирая подходящее подмножество из имеющихся признаков, либо некоторым образом комбинируя имеющиеся признаки. Другая возможность — это предположить, что все с классов входят в одну ковариационную матрицу, т. е. объединить имеющиеся данные. Можно также попробовать найти лучшую оценку для 2. Если есть какая-нибудь возможность получить приемлемую априорную оценку Здебь мы приходим к другому явному противоречию. Можно быть почти уверенным, что классификатор, который строится в предположении независимости, не будет оптимальным. Понятно, что он будет работать лучше в случаях, когда признаки в самом деле независимы, но как улучшить его работу, когда это предположение неверно? Ответ на это связан с проблемой недостаточности данных, и пояснить ее сущность в какой-то мере можно, если рассмотреть аналогичную поставленной задачу подбора кривой по точкам. На рис. 3.3 показана группа из пяти экспериментальных точек и некоторые кривые, предлагаемые для их аппроксимации. Экспериментальные точки были получены добавлением к исходной параболе независимого шума с нулевым средним значением. Следовательно, если считать, что последующие данные будут получаться таким же образом, то среди всех полиномов парабола должна обеспечить наилучшее приближение. Вместе с тем неплохое приближение к имеющимся данным обеспечивает и приведенная прямая. Однако мы знаем, что парабола дает лучшее приближение, и возникает вопрос, достаточно ли исходных данных, чтобы можно было это предположить. Парабола, наилучшая для большого числа данных, может оказаться совершенно отличной от исходной, а за пределами приведенного интервала легко может одержать верх и прямая линия.
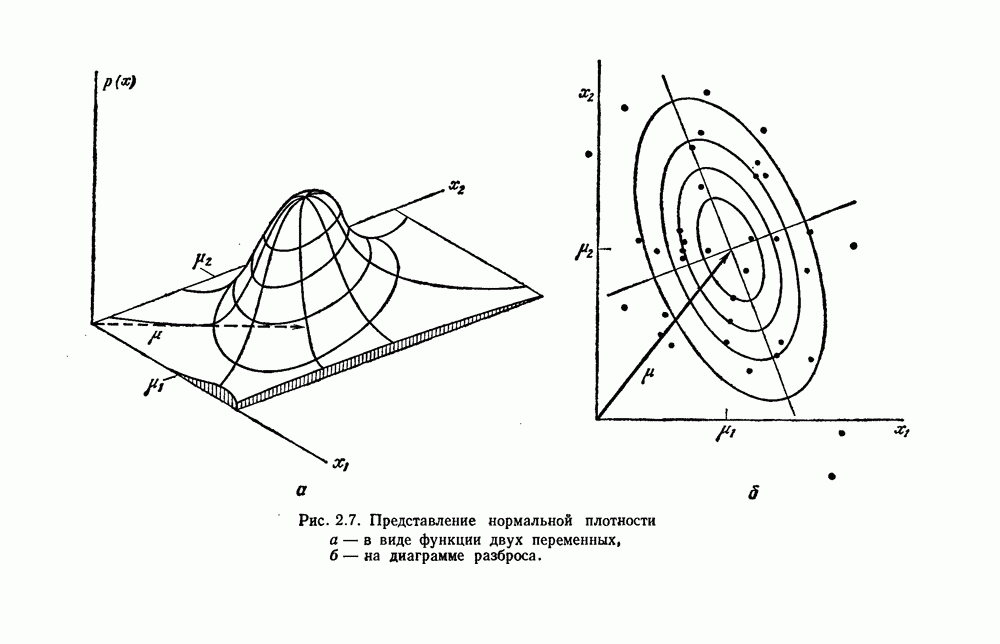
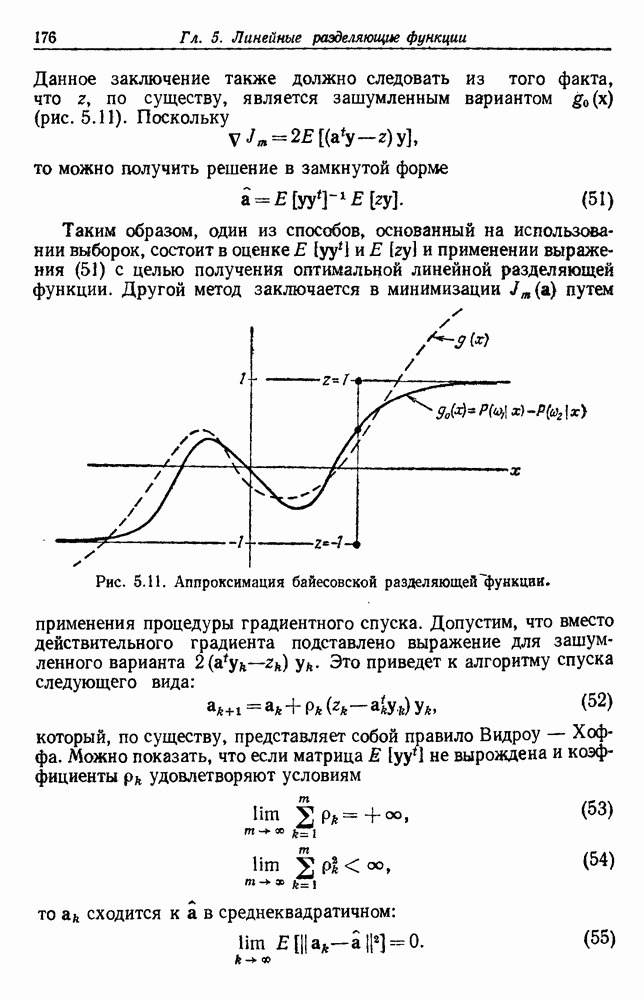
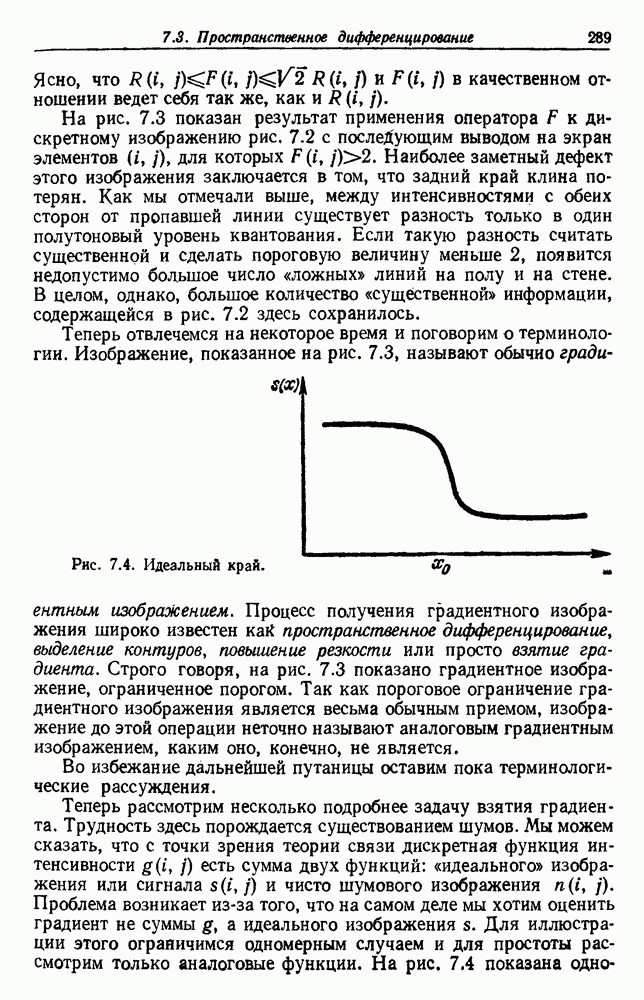
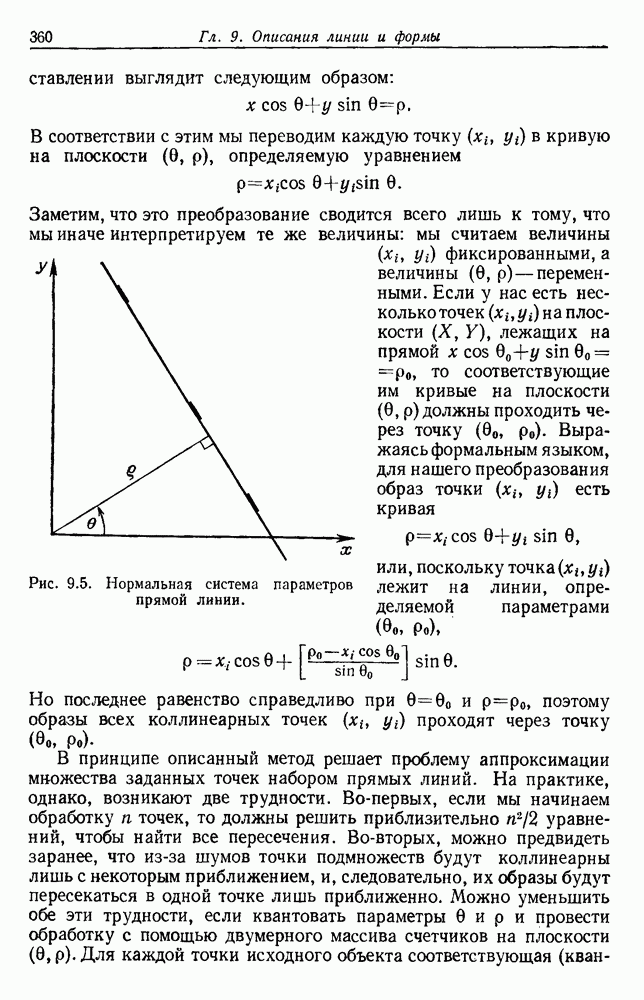
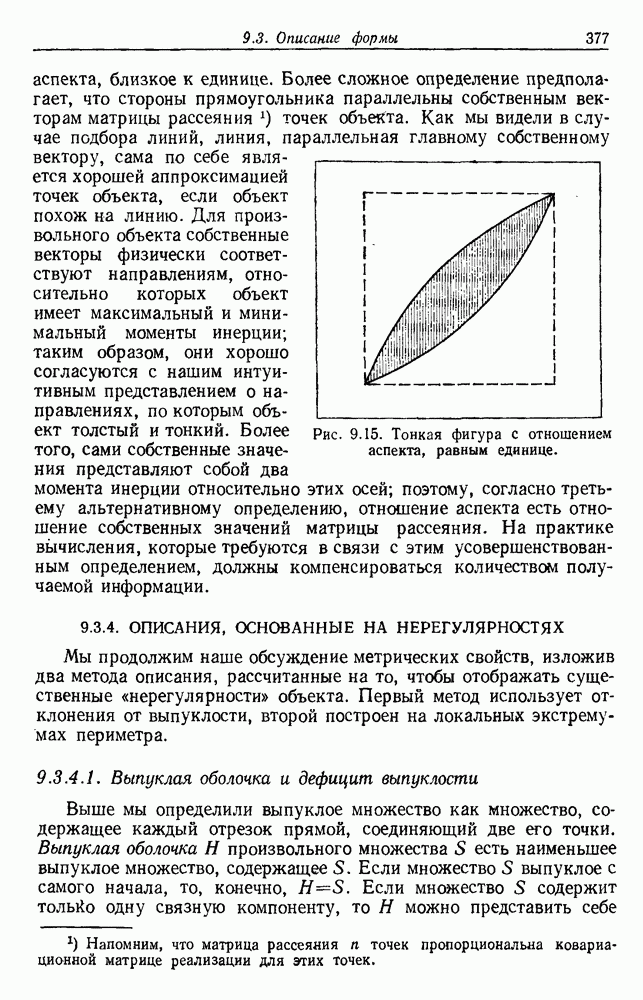
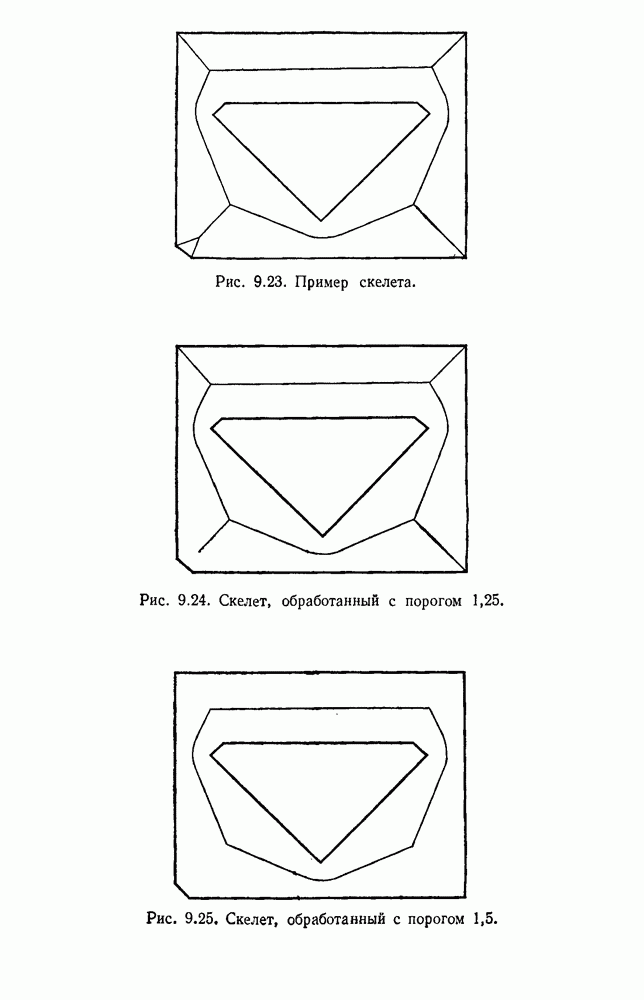
Рис. 3.3. Подбор кривых по заданным точкам. Отлично аппроксимируются приведенные данные кривой десятого порядка. Тем не менее никто не будет ожидать, что полученное таким образом предполагаемое решение окажется в хорошем соответствии с вновь получаемыми данными. И действительно, для получения хорошей аппроксимации посредством кривой десятого порядка потребуется намного больше выборок, чем для кривой второго порядка, хотя последняя и является частным случаем той. Вообще надежная интерполяция или экстраполяция не может быть достигнута, если она не опирается на избыточные данные. 3.8.3. ЕМКОСТЬ РАЗДЕЛЯЮЩЕЙ ПЛОСКОСТИНаличие избыточных данных для классификации столь же важно, как и для оценки. В качестве сравнительно простого примера рассмотрим разбиение доля определяется выражением
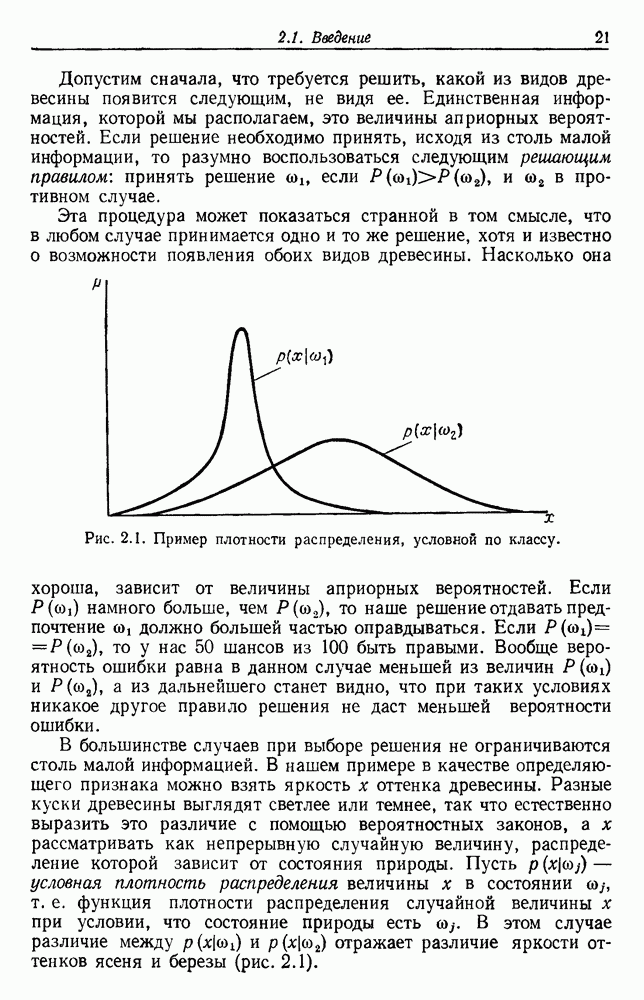
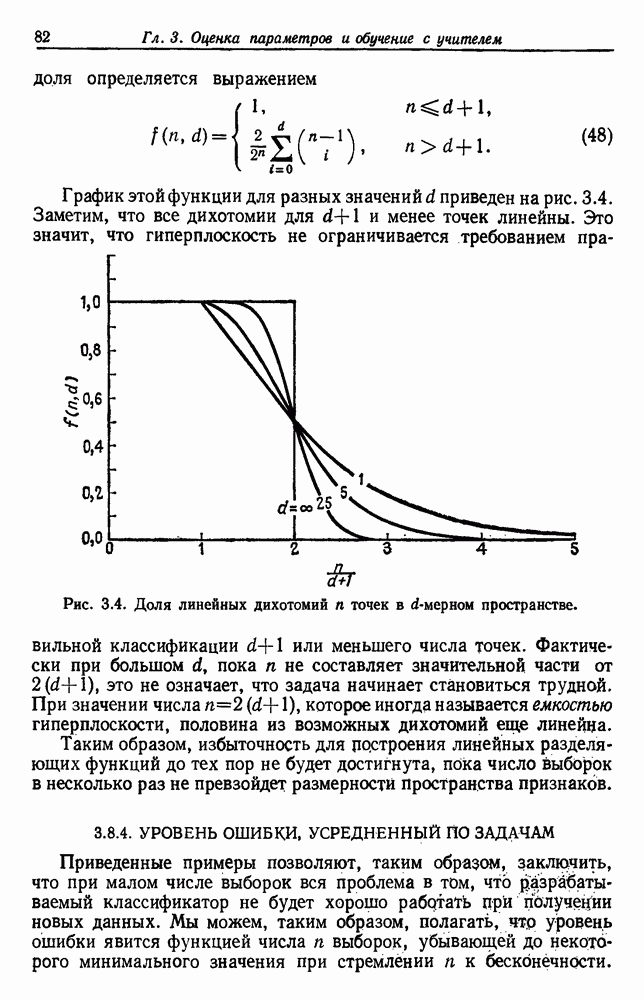
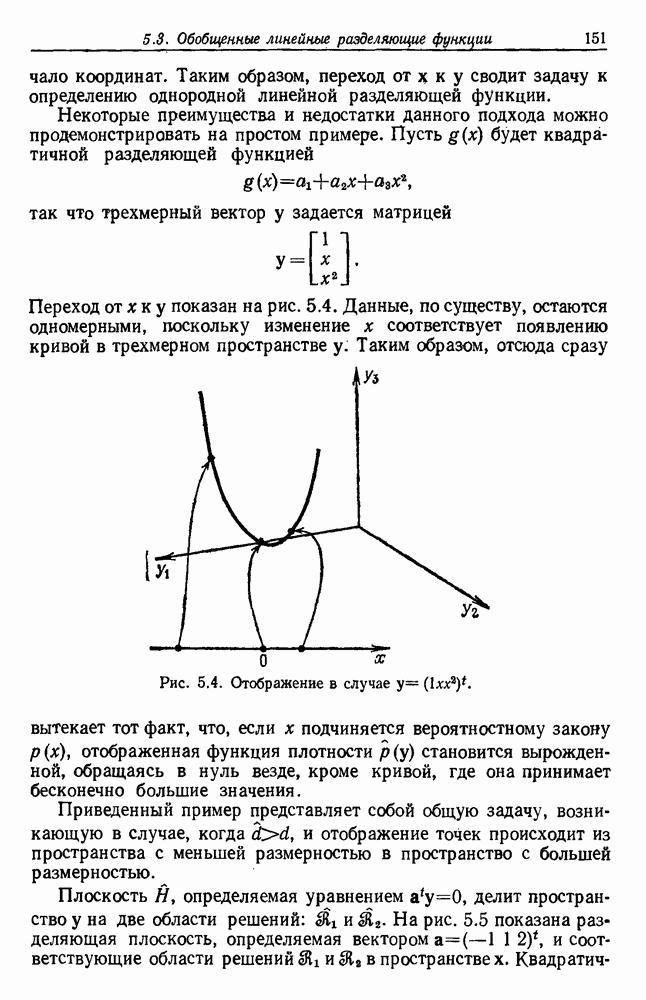
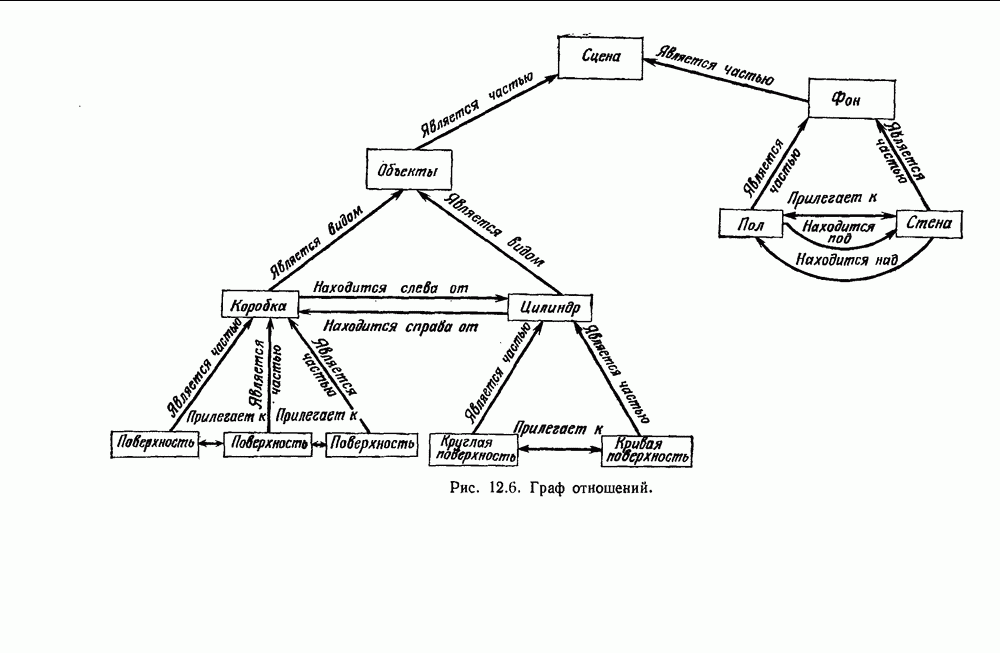
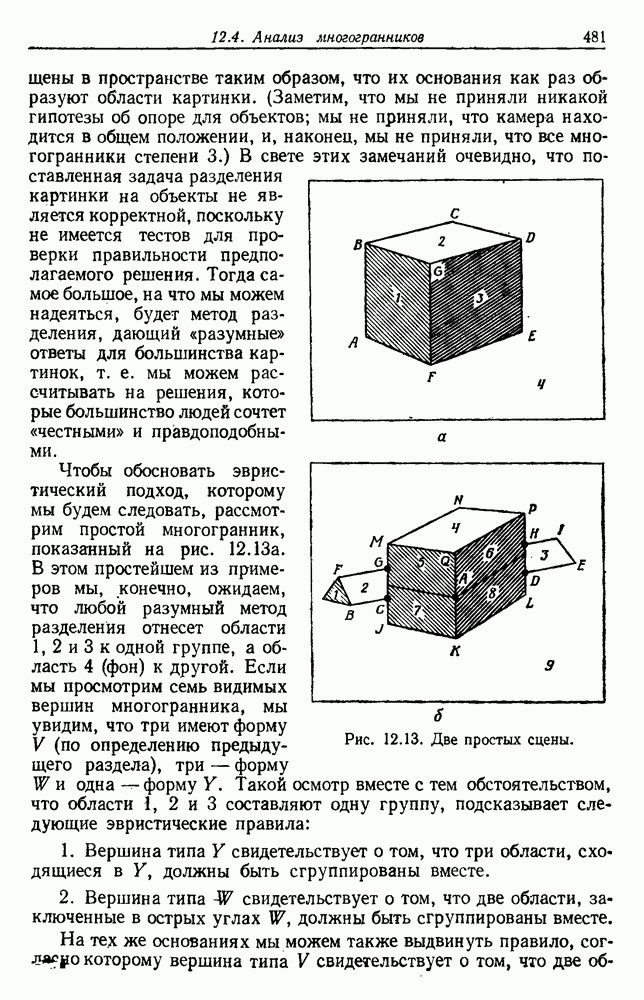
График этой функции для разных значений d приведен на рис. 3.4. Заметим, что все дихотомии для
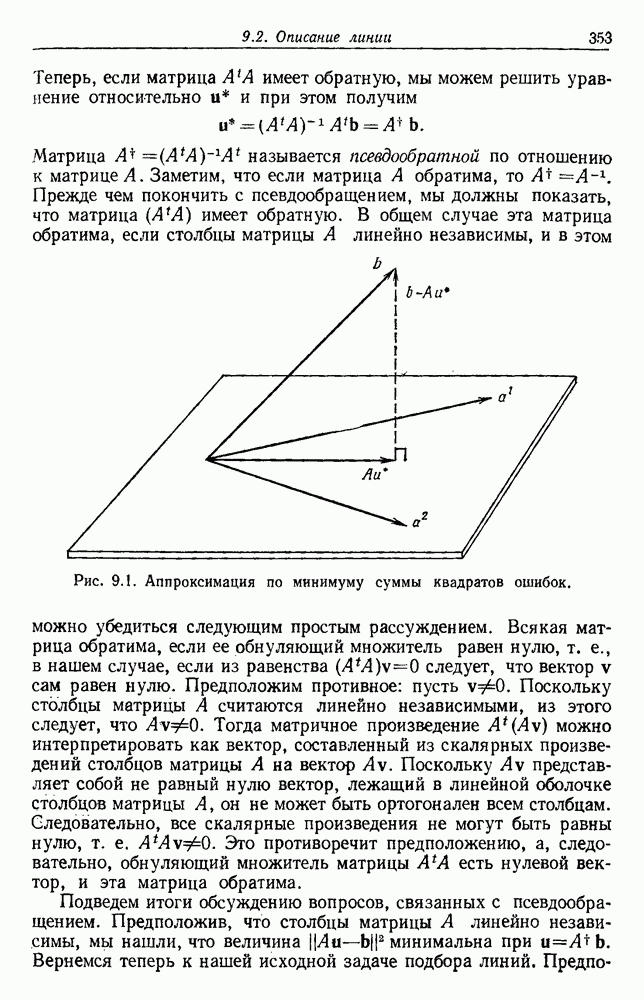
Рис. 3.4. Доля линейных дихотомий Фактически при большом d, пока Таким образом, избыточность для построения линейных разделяющих функций до тех пор не будет достигнута, пока число выборок в несколько раз не превзойдет размерности Пространства признаков. 3.8.4. УРОВЕНЬ ОШИБКИ, УСРЕДНЕННЫЙ ПО ЗАДАЧАМПриведенные примеры позволяют, таким образом, заключить, что при малом числе выборок вся проблема в том, что разрабатываемый классификатор не будет хорошо работать при получении новых данных. Мы можем, таким образом, полагать, что уровень ошибки явится функцией числа Чтобы исследовать это теоретически, требуется выполнить следующие действия: 1) произвести оценку неизвестных параметров по выборкам; 2) применить эти оценки для определения классификатора; 3) вычислить уровень ошибки полученного классификатора. В целом такой анализ очень сложен. Проведение его зависит от многих причин — частных значений получаемых выборок, способа их использования для определения классификатора и неизвестной вероятностной структуры, положенной в основание расчетов. Однако аппроксимируя неизвестные плотности гистограммами и усредняя их соответствующим образом, можно прийти к некоторым интересным выводам. Рассмотрим случай с двумя классами, предполагаемыми равновероятными. Предположим, что пространство признаков мы разбили на некоторое число
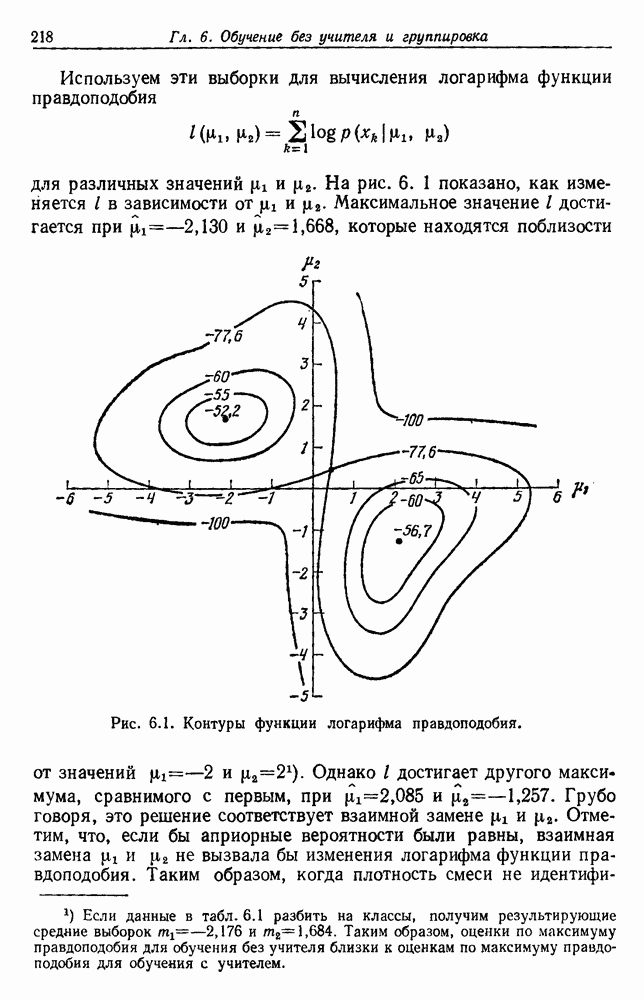
Если параметры
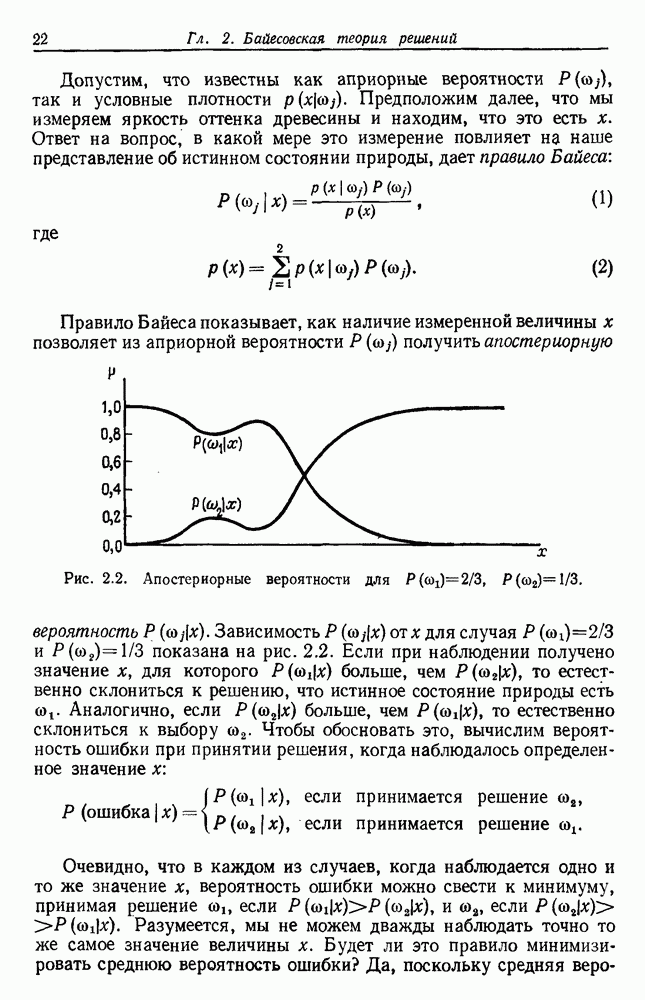
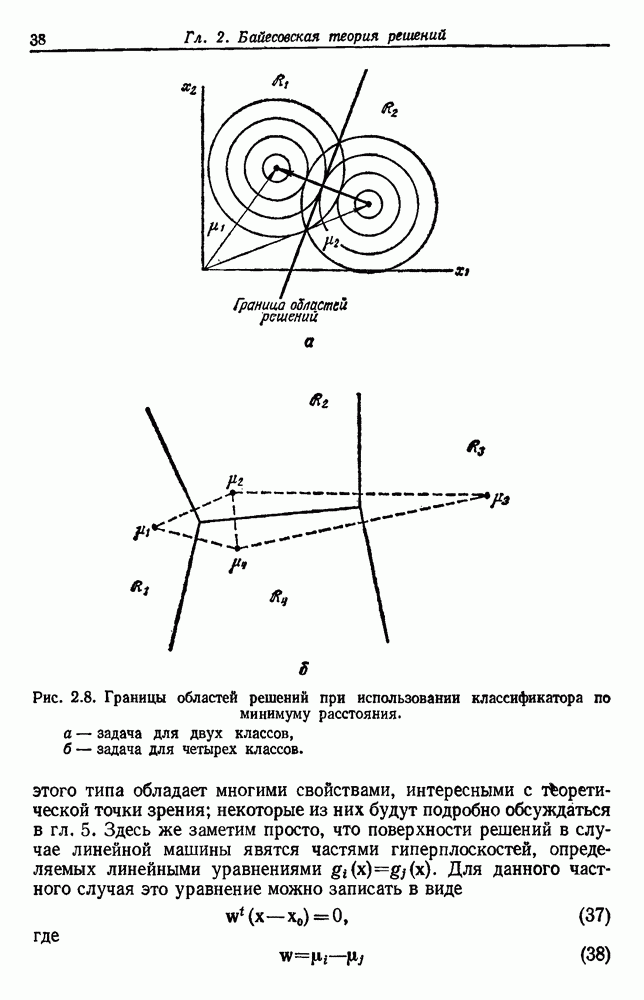
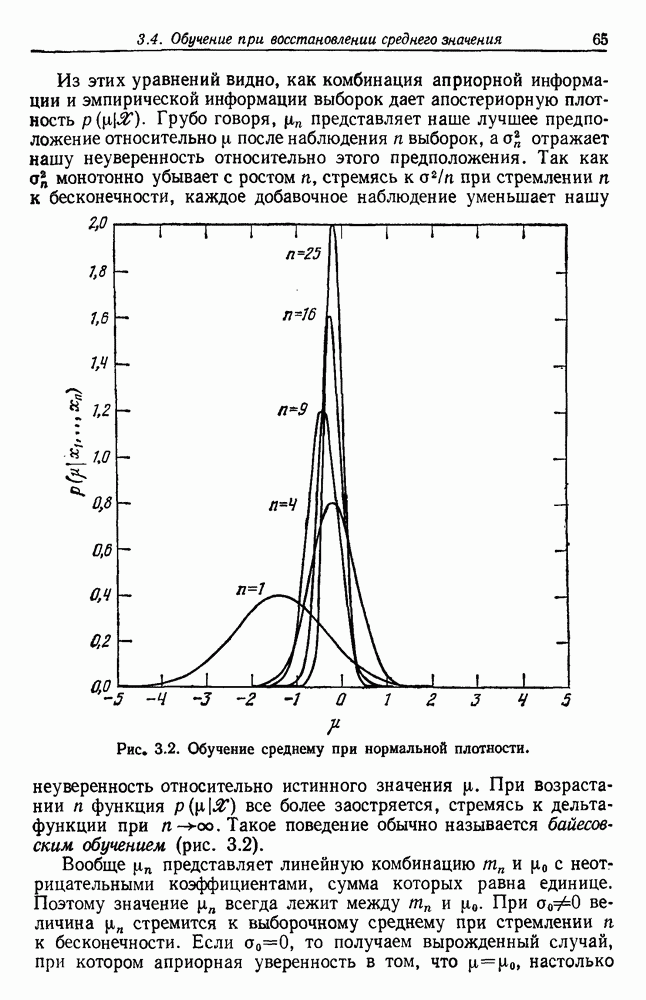
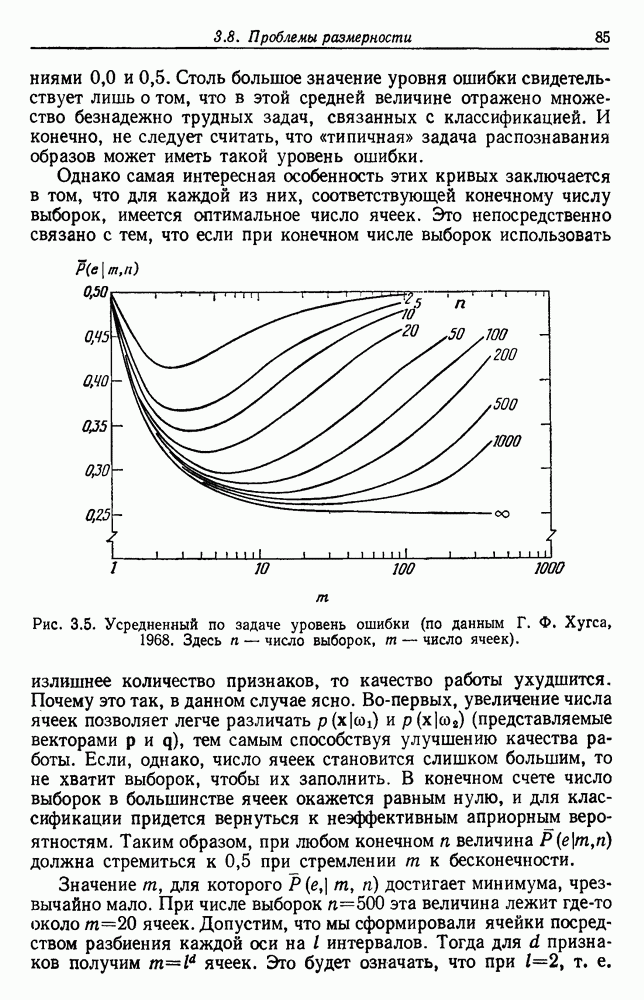
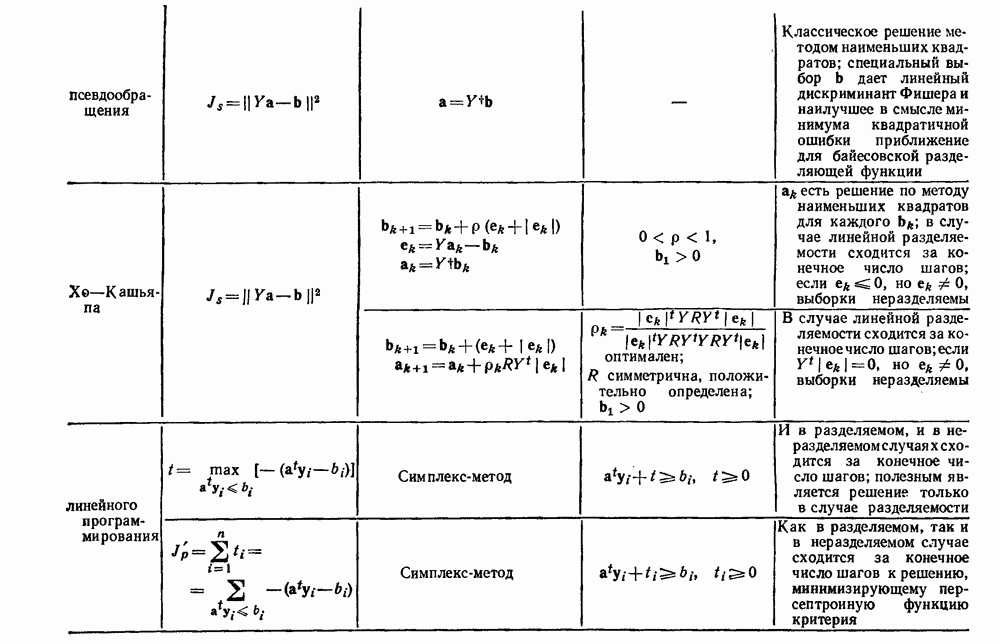
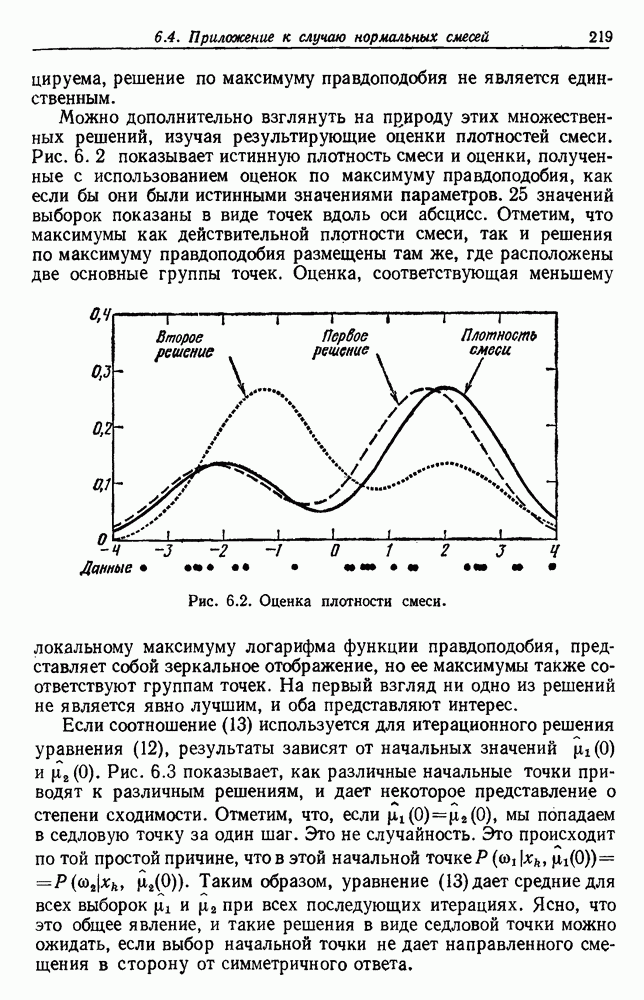
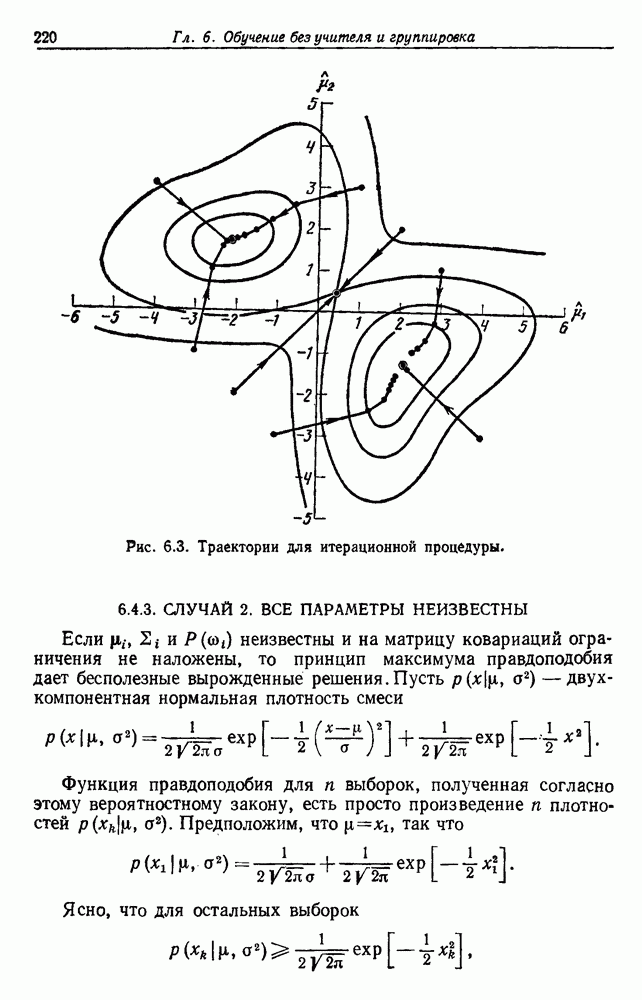
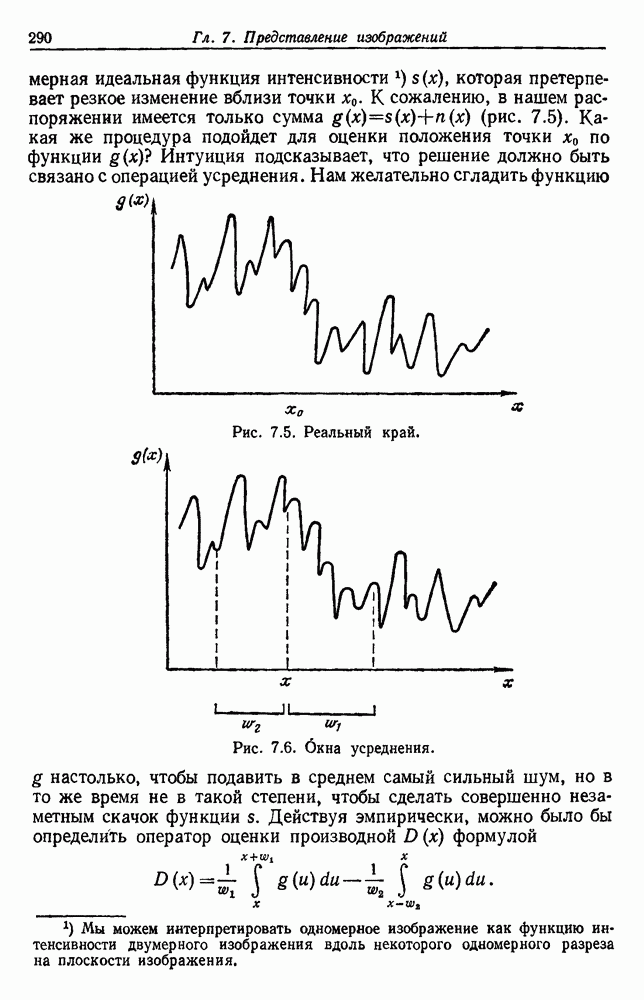
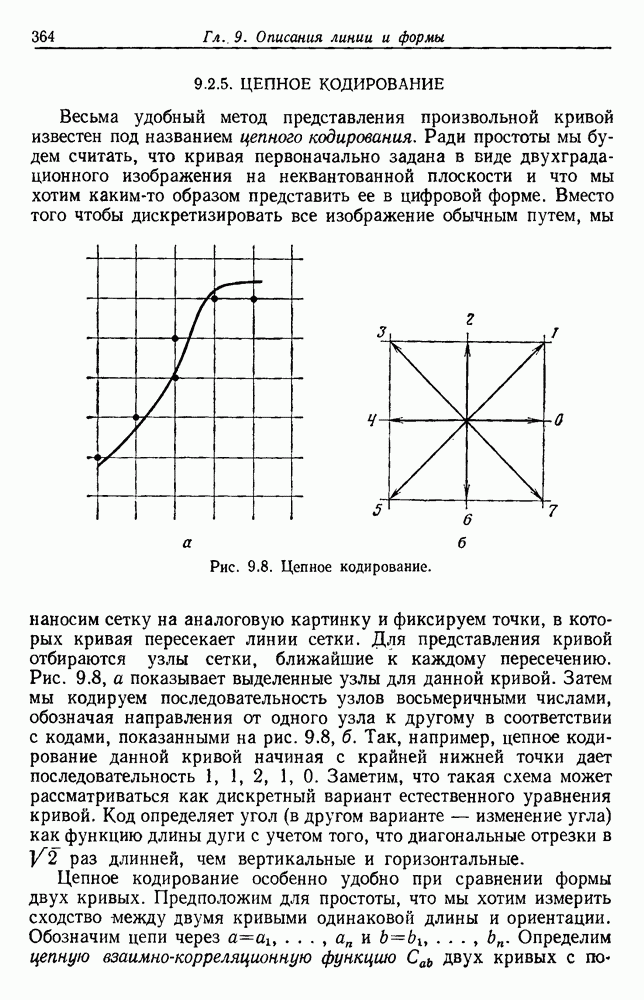
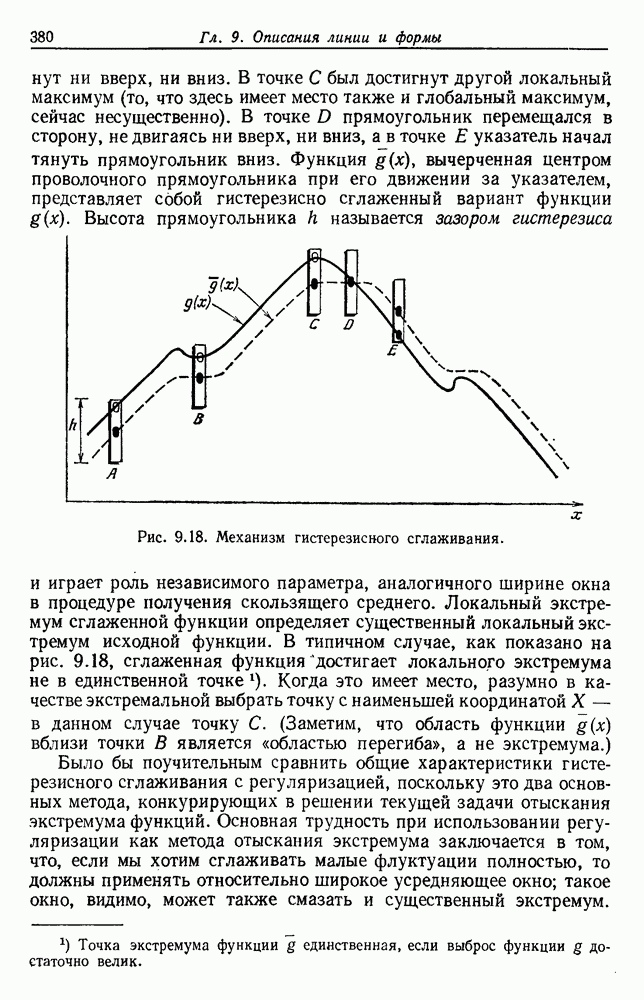
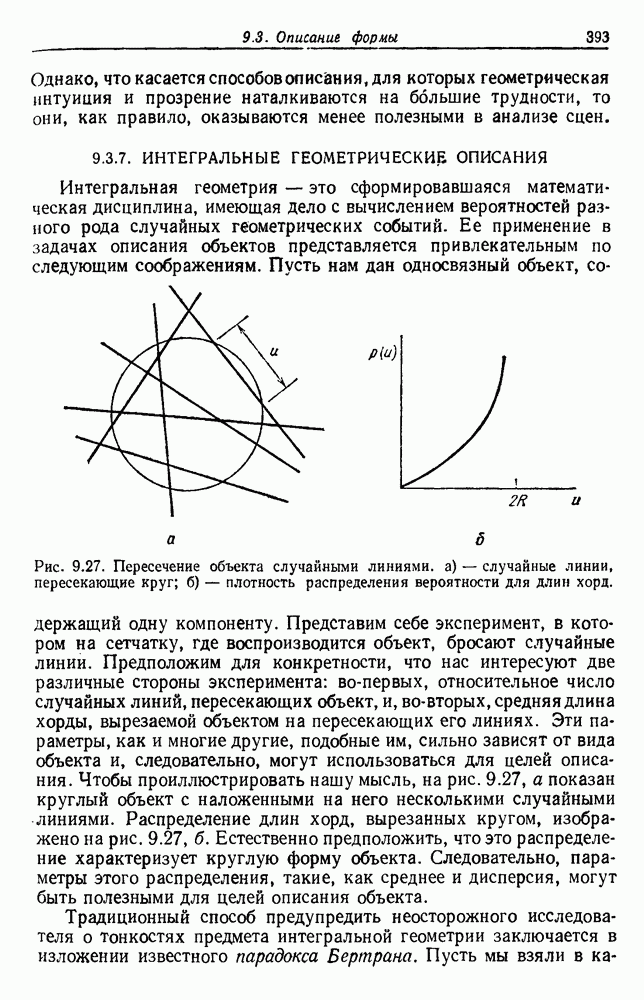
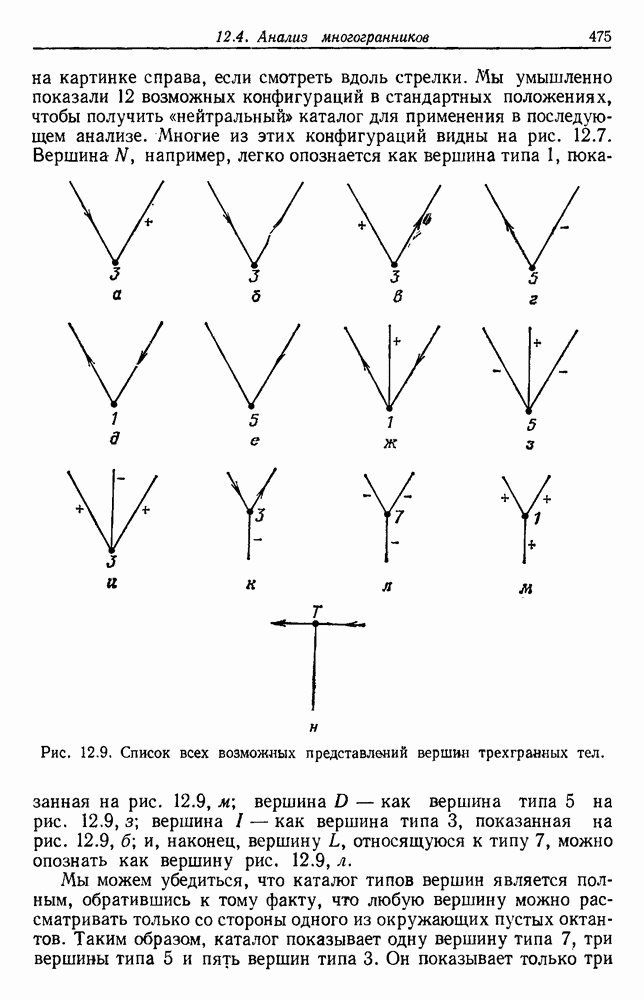
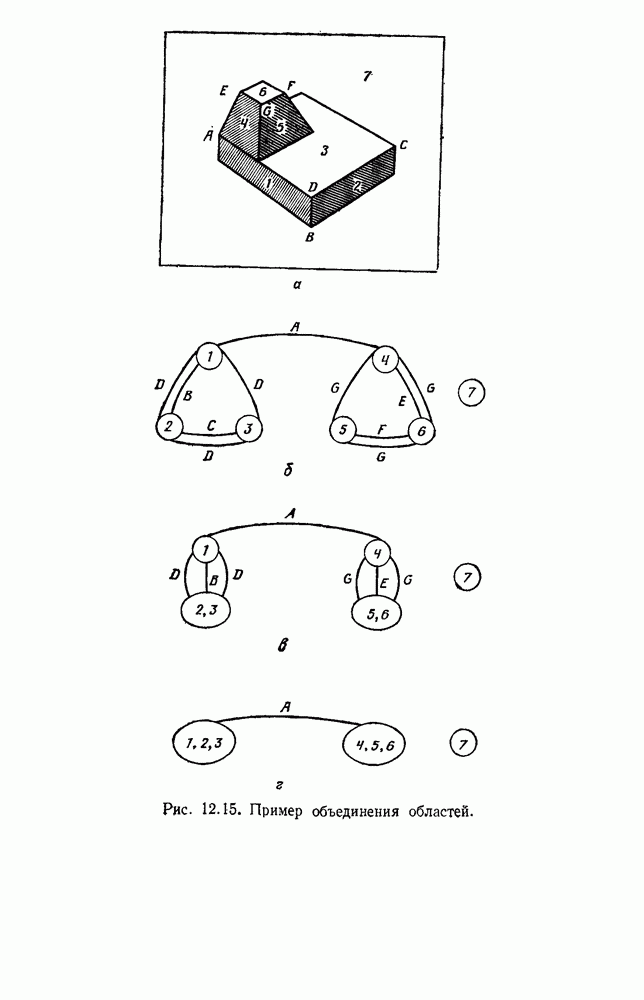
Чтобы оценить вероятность ошибки, надо знать истинные значения условных вероятностей Для усреднения Радикальным путем устранения этой зависимости решения от задачи будет усреднение результатов решения всех возможных задач. Для этого следует выбрать некоторое априорное распределение неизвестных параметров Выбор априорного распределения является, несомненно, тонким моментом. Стараясь облегчить задачу, мы можем принять величину Р близкой к Заметим сначала, что эти кривые представляют Р как функцию числа ячеек для постоянного числа выборок. Если число выборок бесконечно, то становятся верны оценки по максимуму правдоподобия, и Р для любой задачи будет средним значением байесовского уровня ошибки. Кривая, соответствующая 0,0 и 0,5. Столь большое значение уровня ошибки свидетельствует лишь о том, что в этой средней величине отражено множество безнадежно трудных задач, связанных с классификацией. И конечно, не следует считать, что «типичная» задача распознавания образов может иметь такой уровень ошибки. Однако самая интересная особенность этих кривых заключается в том, что для каждой из них, соответствующей конечному числу выборок, имеется оптимальное число ячеек. Это непосредственно связано с тем, что если при конечном числе выборок использовать излишнее количество признаков, то качество работы ухудшится.
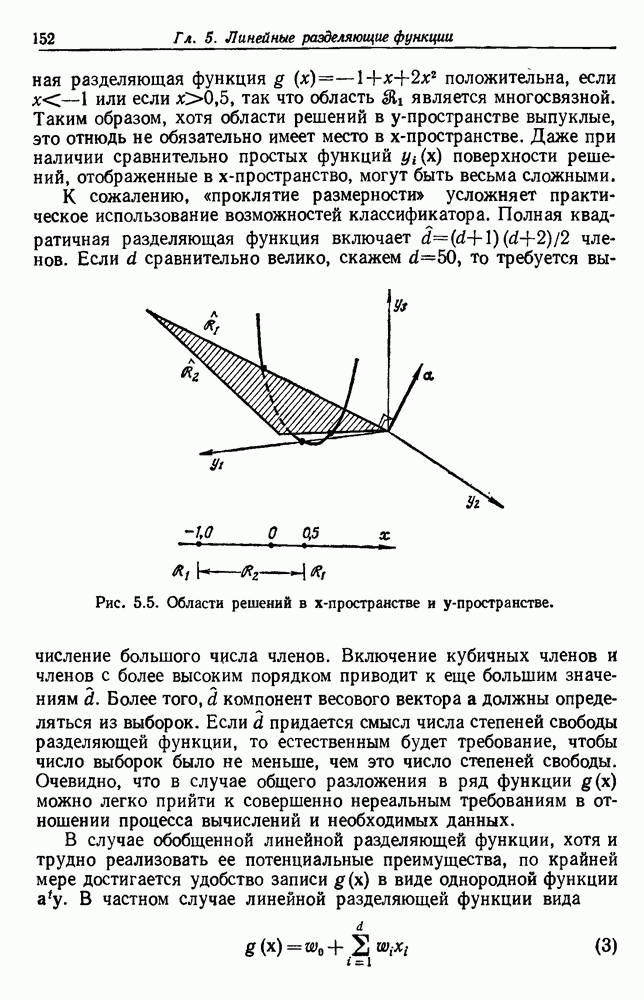
Рис. 3.5. Усредненный по задаче уровень ошибки (по данным Г. Ф. Хугса, 1968. Здесь Почему это так, в данном случае ясно. Во-первых, увеличение числа ячеек позволяет легче различать Значение предельно грубом квантовании, использование более четырех-пяти бинарных признаков ухудшит, а не улучшит качество работы. Такой результат весьма пессимистичен, но не более чем утверждение о том, что средний уровень ошибки равен 0,25. Приведенные численные значения получены в соответствии с априорным распределением, выбранным для конкретной задачи, и могут не иметь отношения к частным задачам, с которыми можно еще столкнуться. Основной замысел проведенного анализа состоит в том, чтобы усвоить, что качество работы классификатора безусловно зависит от числа конструктивных выборок и что при заданном числе выборок увеличение числа признаков сверх определенного может оказаться вредным.
|
 |
Оглавление
|




















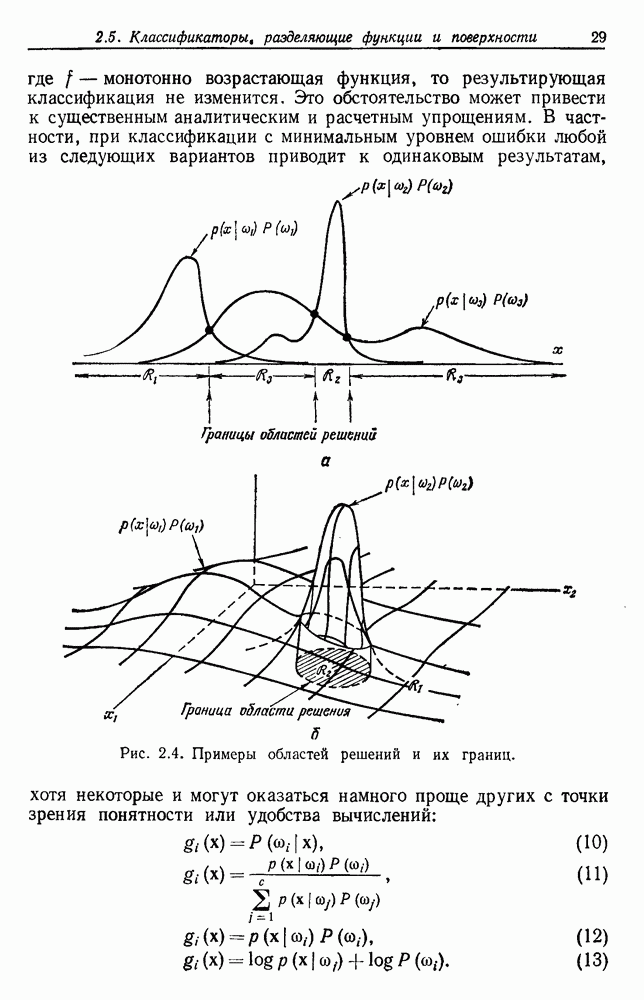


































































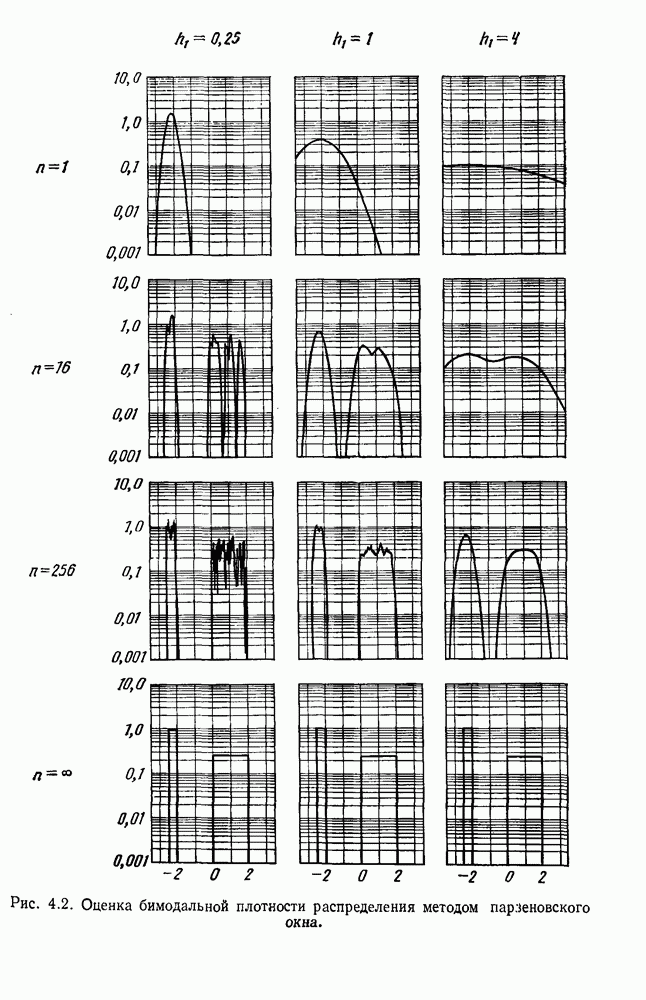

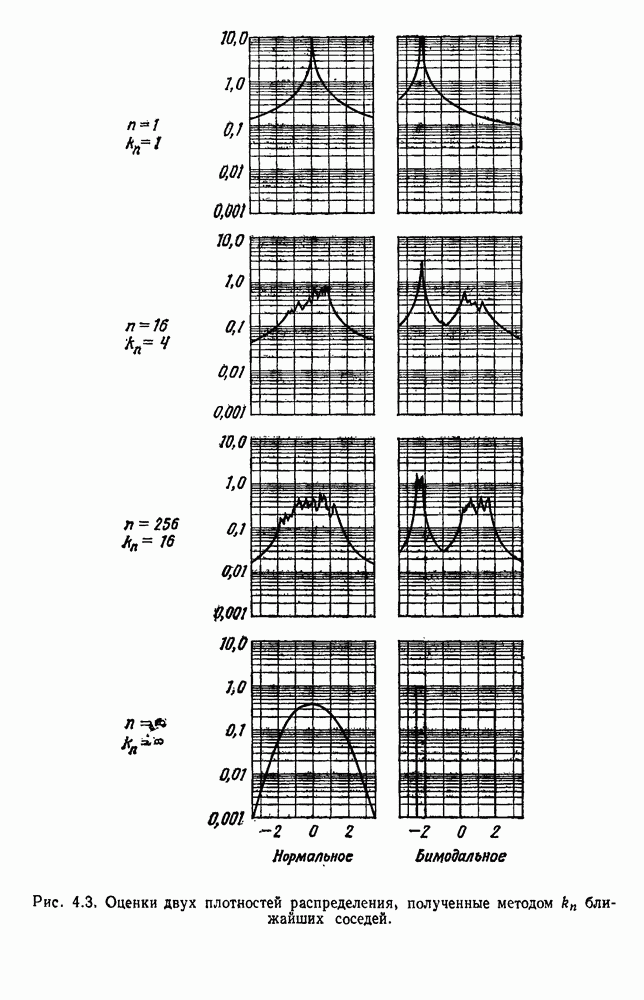



































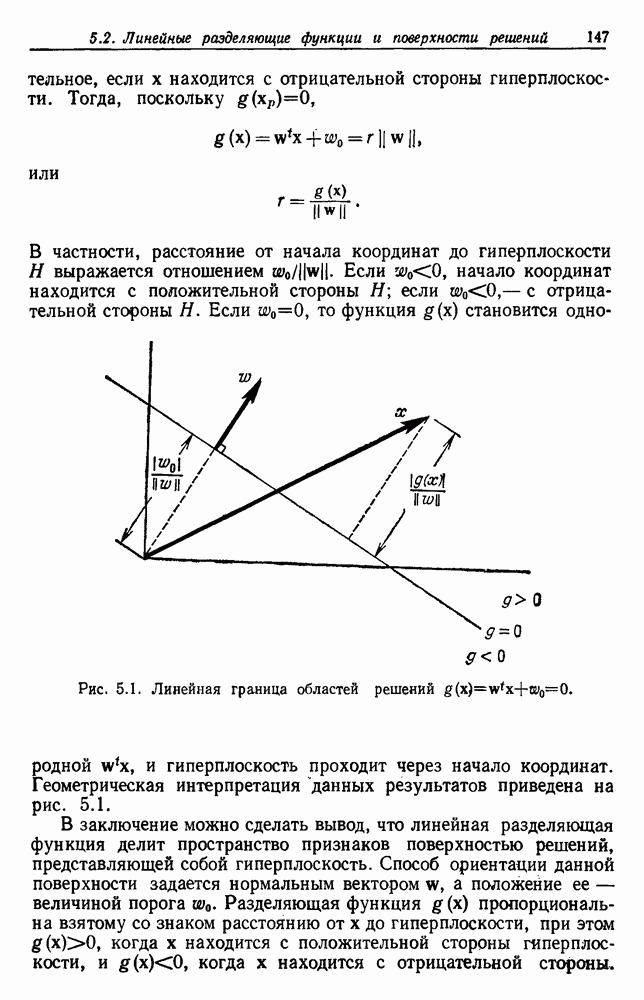





































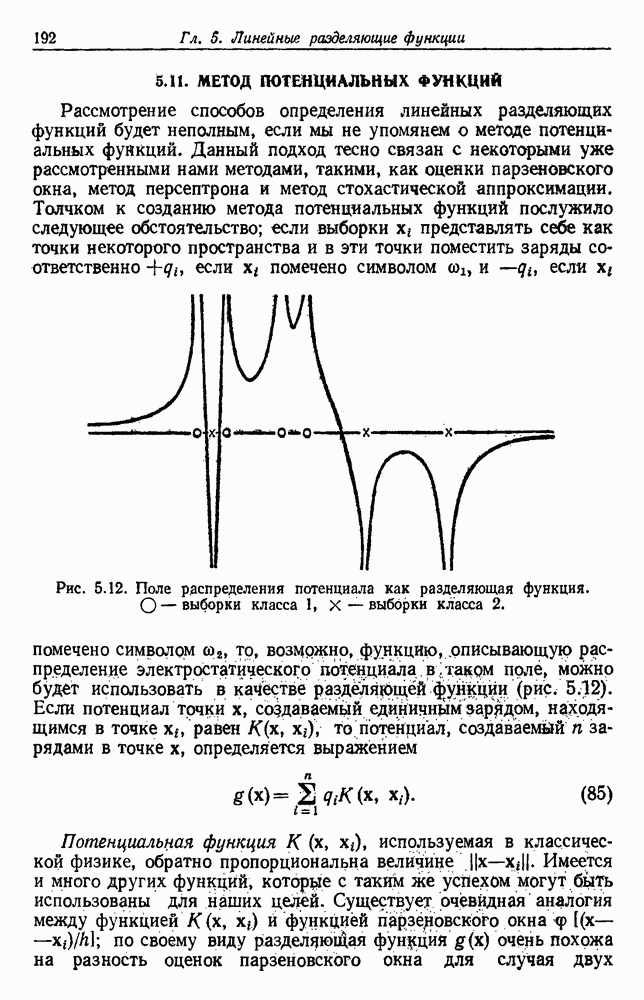





















































































































































































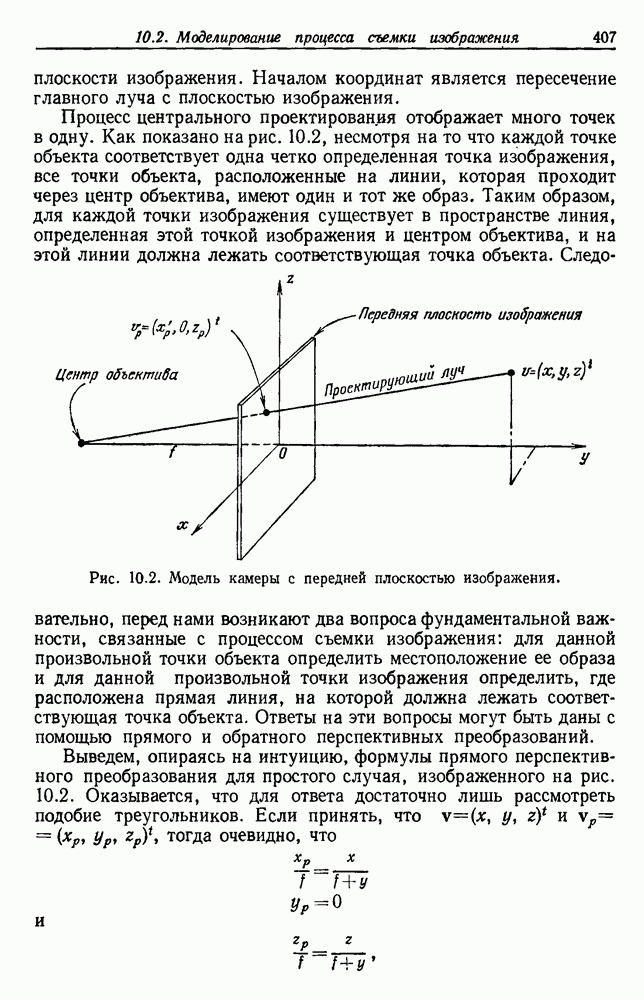
































































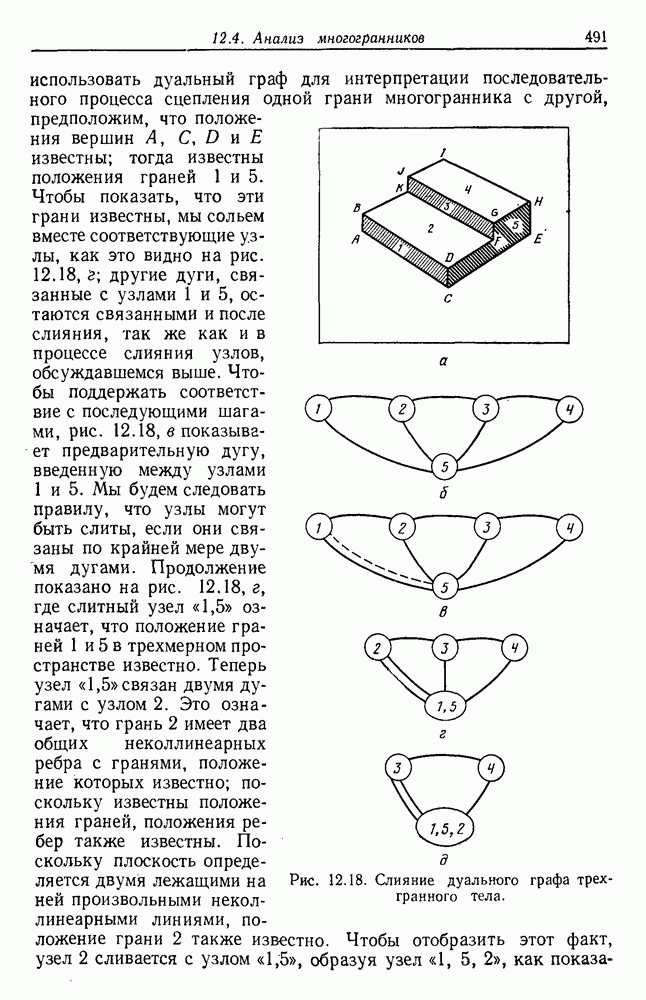






 . Когда априорные вероятности равны, то нетрудно показать, что байесовский уровень ошибки определяется выражением
. Когда априорные вероятности равны, то нетрудно показать, что байесовский уровень ошибки определяется выражением

 есть квадратичное махалонобисово расстояние
есть квадратичное махалонобисово расстояние

 , стремясь к нулю при стремлении
, стремясь к нулю при стремлении  к бесконечности. В случае независимых переменных
к бесконечности. В случае независимых переменных  и
и

 , то вероятность ошибки можно сделать сколь угодно-малой.
, то вероятность ошибки можно сделать сколь угодно-малой.
 параметров, из которых d диагональных элементов и
параметров, из которых d диагональных элементов и  независимых недиагональных элементов. Сначала мы видим, что оценка по максимуму правдоподобия
независимых недиагональных элементов. Сначала мы видим, что оценка по максимуму правдоподобия

 независимых матриц размера
независимых матриц размера  единичного ранга, чем гарантируется, что она является вырожденной при
единичного ранга, чем гарантируется, что она является вырожденной при  . Так как для нахождения разделяющих функций необходимо получить величину, обратную
. Так как для нахождения разделяющих функций необходимо получить величину, обратную  , у нас уже есть алгебраические условия, связывающие по крайней мере
, у нас уже есть алгебраические условия, связывающие по крайней мере  выборок. Неудивительно, что сглаживание случайных отклонений для получения вполне приемлемой оценки потребует в несколько раз большего числа выборок.
выборок. Неудивительно, что сглаживание случайных отклонений для получения вполне приемлемой оценки потребует в несколько раз большего числа выборок.
 , то можно воспользоваться байесовской или псевдобайесовской оценкой вида
, то можно воспользоваться байесовской или псевдобайесовской оценкой вида  . Если матрица
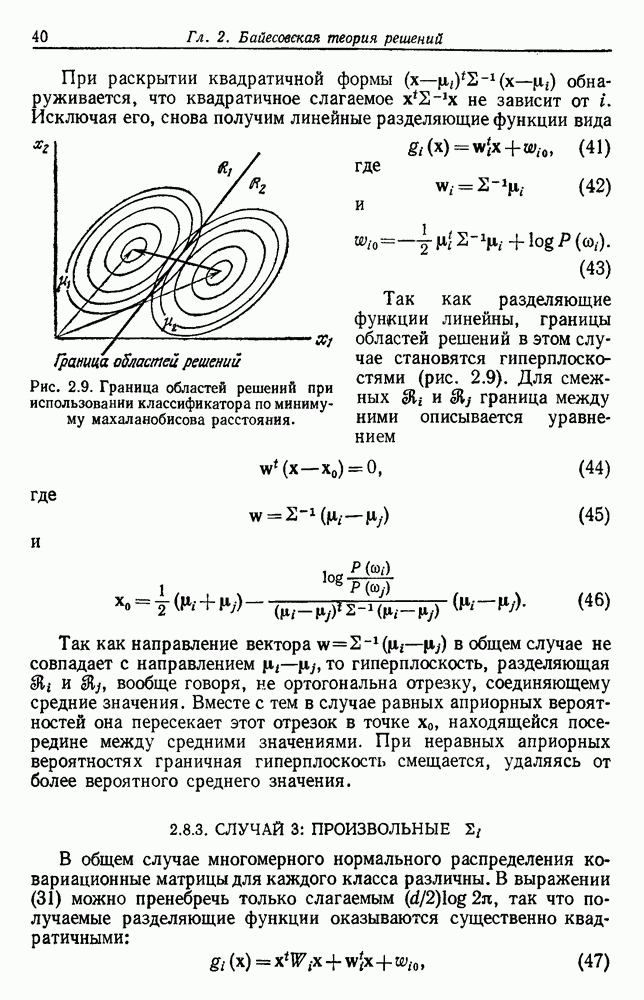
. Если матрица  диагональная, то уменьшается вредное влияние «побочных» корреляций. С другой стороны, от случайных корреляций можно избавиться эвристически, взяв за основу ковариационную матрицу выборок. Например, можно положить все ковариации, величина коэффициента корреляции в которых не близка к единице, равными нулю. В предельном случае при таком подходе предполагается статистическая независимость, означающая, что все недиагональные элементы равны нулю, хотя это и может противоречить опытным данным. Даже при полной неуверенности в правильности такого рода предположений получаемые эвристические оценки часто обеспечивают лучший образ действий, нежели при оценке по максимуму правдоподобия.
диагональная, то уменьшается вредное влияние «побочных» корреляций. С другой стороны, от случайных корреляций можно избавиться эвристически, взяв за основу ковариационную матрицу выборок. Например, можно положить все ковариации, величина коэффициента корреляции в которых не близка к единице, равными нулю. В предельном случае при таком подходе предполагается статистическая независимость, означающая, что все недиагональные элементы равны нулю, хотя это и может противоречить опытным данным. Даже при полной неуверенности в правильности такого рода предположений получаемые эвристические оценки часто обеспечивают лучший образ действий, нежели при оценке по максимуму правдоподобия.

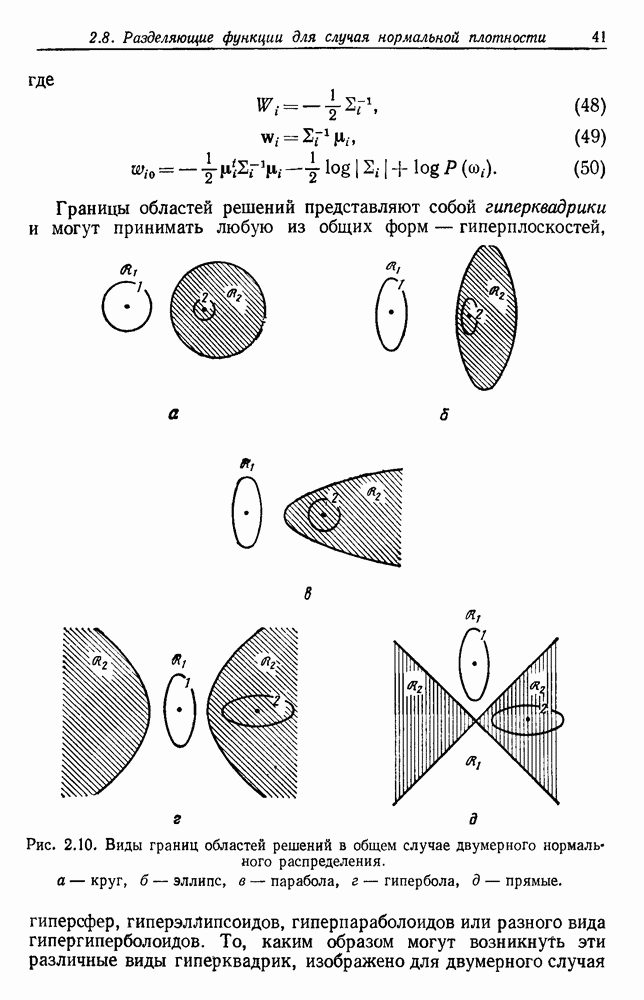
 -мерного пространства признаков гиперплоскостью
-мерного пространства признаков гиперплоскостью  . Допустим, что имеется общее расположение
. Допустим, что имеется общее расположение  выборочных точек, с каждой из которых можно сопоставить метку
выборочных точек, с каждой из которых можно сопоставить метку  или
или  Среди
Среди  возможных дихотомий (разделений на два класса)
возможных дихотомий (разделений на два класса)  точек в
точек в  -мерном пространстве имеется некоторая доля
-мерном пространстве имеется некоторая доля  так называемых линейных дихотомий. Это такая маркировка точек, при которой существует гиперплоскость, отделяющая точки, помеченные
так называемых линейных дихотомий. Это такая маркировка точек, при которой существует гиперплоскость, отделяющая точки, помеченные  от точек, помеченных
от точек, помеченных  Можно показать, что эта
Можно показать, что эта

 и менее точек линейны. Это значит, что гиперплоскость не ограничивается требованием правильной классификации
и менее точек линейны. Это значит, что гиперплоскость не ограничивается требованием правильной классификации  или меньшего числа точек.
или меньшего числа точек.

 точек в
точек в  -мерном пространстве.
-мерном пространстве.
 не составляет значительной части от
не составляет значительной части от  это не означает, что задача начинает становиться трудной. При значении числа
это не означает, что задача начинает становиться трудной. При значении числа  которое иногда называется емкостью гиперплоскости, половина из возможных дихотомий еще линейна.
которое иногда называется емкостью гиперплоскости, половина из возможных дихотомий еще линейна.
 выборок, убывающей до некоторого минимального значения при стремлении
выборок, убывающей до некоторого минимального значения при стремлении  к бесконечности.
к бесконечности.
 отдельных ячеек
отдельных ячеек  Если в пределах каждой из ячеек условные плотности
Если в пределах каждой из ячеек условные плотности  заметно не изменяются, то вместо того, чтобы отыскивать точное значение х, потребуется лишь определить, в какую из ячеек попадает х. Это упрощает задачу, сводя ее к дискретной. Пусть
заметно не изменяются, то вместо того, чтобы отыскивать точное значение х, потребуется лишь определить, в какую из ячеек попадает х. Это упрощает задачу, сводя ее к дискретной. Пусть  Тогда, поскольку мы предположили, что
Тогда, поскольку мы предположили, что  векторы
векторы  определят вероятностную структуру задачи. Если х попадает в то байесовское решающее правило выразится в принятии решения
определят вероятностную структуру задачи. Если х попадает в то байесовское решающее правило выразится в принятии решения  если
если  Получаемый байесовский уровень ошибки определится выражением
Получаемый байесовский уровень ошибки определится выражением

 и q неизвестны и должны быть оценены по множеству выборок, то получаем уровень ошибки, больший, чем байесовский. Точный ответ будет зависеть от взятого множества выборок и способа построения по ним классификатора. Допустим, что одна половина выборок помечена
и q неизвестны и должны быть оценены по множеству выборок, то получаем уровень ошибки, больший, чем байесовский. Точный ответ будет зависеть от взятого множества выборок и способа построения по ним классификатора. Допустим, что одна половина выборок помечена  а другая
а другая  причем
причем  представляет число выборок с пометкой
представляет число выборок с пометкой  попавших в ячейку Допустим далее, что мы строим классификатор, пользуясь оценками по максимуму правдоподобия
попавших в ячейку Допустим далее, что мы строим классификатор, пользуясь оценками по максимуму правдоподобия  как если бы они и были истинными значениями. Тогда новый вектор признаков, попадающий в
как если бы они и были истинными значениями. Тогда новый вектор признаков, попадающий в  будет отнесен к если
будет отнесен к если  Со всеми этими предположениями вероятность ошибки для получаемого классификатора определится выражением
Со всеми этими предположениями вероятность ошибки для получаемого классификатора определится выражением

 и q и множество выборок или по меньшей мере числа
и q и множество выборок или по меньшей мере числа  Различные множества из
Различные множества из  случайных выборок приведут к различным значениям
случайных выборок приведут к различным значениям 
 случайных выборок по всем возможным множествам и получения средней вероятности ошибки
случайных выборок по всем возможным множествам и получения средней вероятности ошибки  можно использовать тот факт, что числа
можно использовать тот факт, что числа  распределены по полиномиальному закону. Грубо говоря, это даст типичный уровень ошибки, который можно ожидать для
распределены по полиномиальному закону. Грубо говоря, это даст типичный уровень ошибки, который можно ожидать для  выборок. Однако оценка этого среднего уровня потребует еще решения второстепенной задачи — оценки величин
выборок. Однако оценка этого среднего уровня потребует еще решения второстепенной задачи — оценки величин  и q. Если
и q. Если  и q различаются сильно, то средний уровень ошибки будет близок к нулю; при сходных
и q различаются сильно, то средний уровень ошибки будет близок к нулю; при сходных  и q он приближается к 1/2.
и q он приближается к 1/2.
 и q, а затем усреднить
и q, а затем усреднить  в соответствии с этими
в соответствии с этими  и q. Получаемая усредненная по задачам вероятность ошибки
и q. Получаемая усредненная по задачам вероятность ошибки  будет зависеть только от числа
будет зависеть только от числа  ячеек, числа
ячеек, числа  выборок и вида априорного распределения.
выборок и вида априорного распределения.
 , а стараясь ее усложнить — близкой к 1/2. Априорное распределение следовало бы выбирать соответствующим тому классу задач, с которым мы обычно встречаемся, однако не ясно, как это сделать. Можно просто предположить эти задачи «равномерно распределенными», т. е. предположить, что векторы
, а стараясь ее усложнить — близкой к 1/2. Априорное распределение следовало бы выбирать соответствующим тому классу задач, с которым мы обычно встречаемся, однако не ясно, как это сделать. Можно просто предположить эти задачи «равномерно распределенными», т. е. предположить, что векторы  распределены равномерно на симплексах
распределены равномерно на симплексах  Г. Ф. Хугсом, предположившим такой подход, проведены необходимые вычисления, результаты которых представлены графиками рис. 3.5. Рассмотрим некоторые приложения его результатов.
Г. Ф. Хугсом, предположившим такой подход, проведены необходимые вычисления, результаты которых представлены графиками рис. 3.5. Рассмотрим некоторые приложения его результатов.
 быстро убывает от 0,5 при
быстро убывает от 0,5 при  до асимптотического значения 0,25 при стремлении
до асимптотического значения 0,25 при стремлении  к бесконечности. Не удивительно, что
к бесконечности. Не удивительно, что  при
при  , так как в случае всего лишь одного элемента решение должно основываться только на априорных вероятностях. Эффектно и то, что Р стремится к 0,25 при стремлении
, так как в случае всего лишь одного элемента решение должно основываться только на априорных вероятностях. Эффектно и то, что Р стремится к 0,25 при стремлении  к бесконечности, так как эта величина находится как раз посередине между предельными значениями
к бесконечности, так как эта величина находится как раз посередине между предельными значениями

 — число выборок,
— число выборок,  — число ячеек).
— число ячеек).
 (представляемые векторами
(представляемые векторами  и
и  , тем самым способствуя улучшению качества работы. Если, однако, число ячеек становится слишком большим, то не хватит выборок, чтобы их заполнить. В конечном счете число выборок в большинстве ячеек окажется равным нулю, и для классификации придется вернуться к неэффективным априорным вероятностям. Таким образом, при любом конечном
, тем самым способствуя улучшению качества работы. Если, однако, число ячеек становится слишком большим, то не хватит выборок, чтобы их заполнить. В конечном счете число выборок в большинстве ячеек окажется равным нулю, и для классификации придется вернуться к неэффективным априорным вероятностям. Таким образом, при любом конечном  величина
величина  должна стремиться к 0,5 при стремлении т. к бесконечности.
должна стремиться к 0,5 при стремлении т. к бесконечности.
 , для которого
, для которого  достигает минимума, чрезвычайно мало. При числе выборок
достигает минимума, чрезвычайно мало. При числе выборок  эта величина лежит где-то около
эта величина лежит где-то около  ячеек. Допустим, что мы сформировали ячейки посредством разбиения каждой оси на I интервалов. Тогда для d признаков получим
ячеек. Допустим, что мы сформировали ячейки посредством разбиения каждой оси на I интервалов. Тогда для d признаков получим  ячеек. Это будет означать, что при
ячеек. Это будет означать, что при  , т. е.
, т. е.