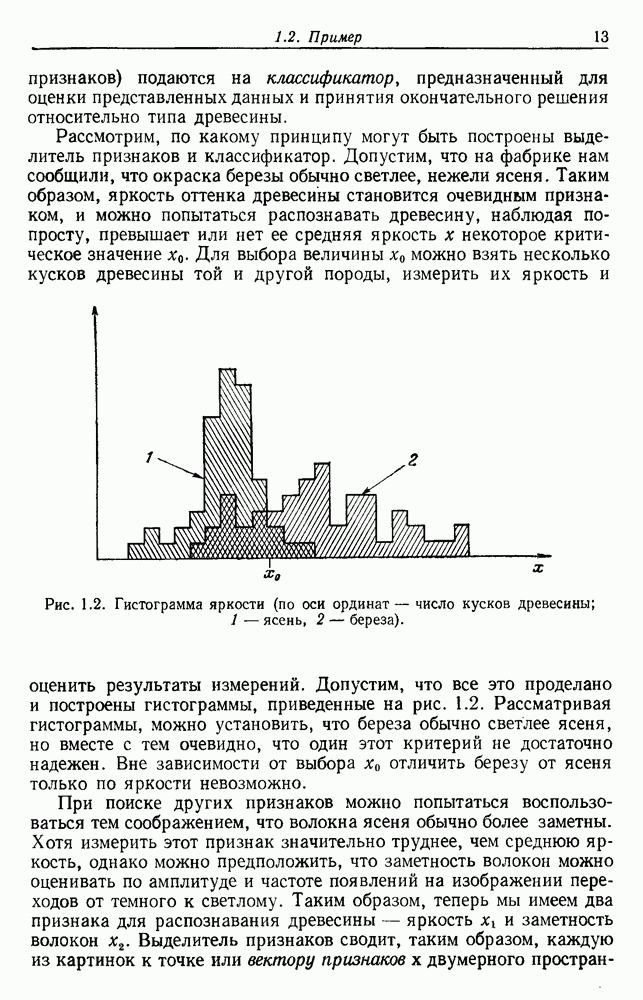
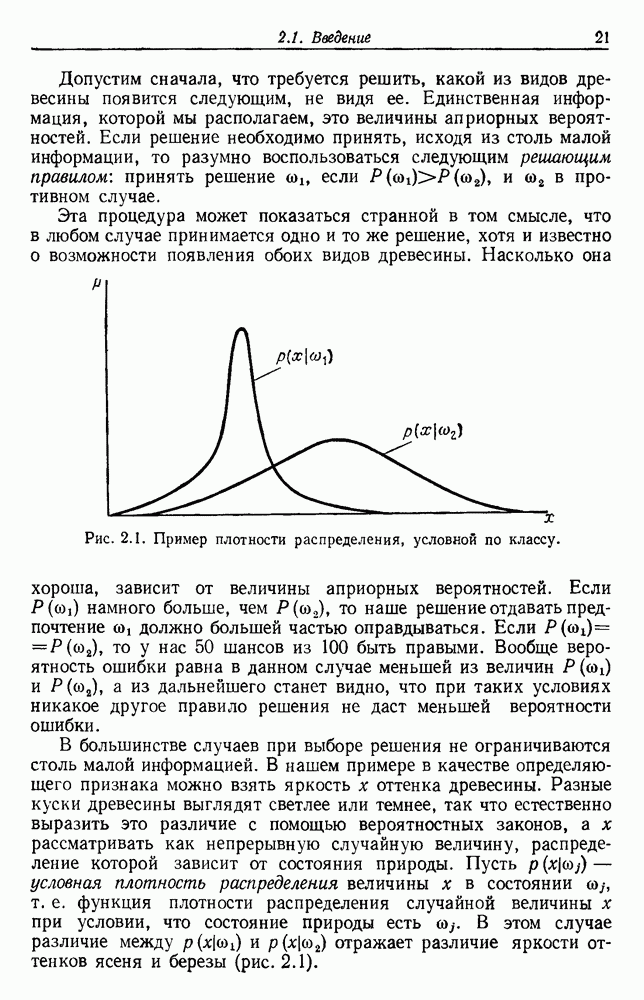
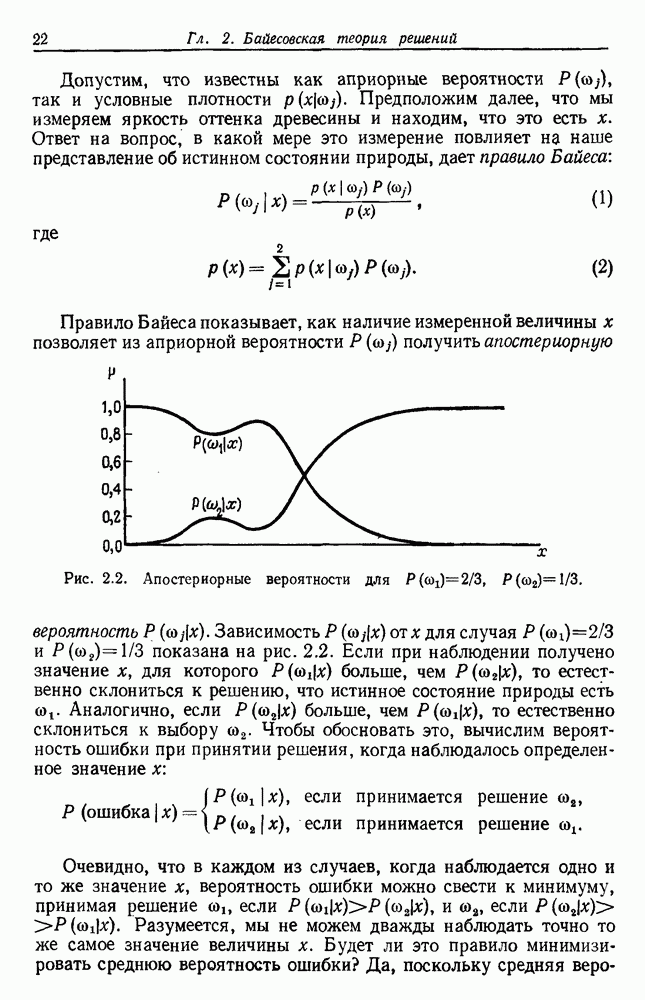
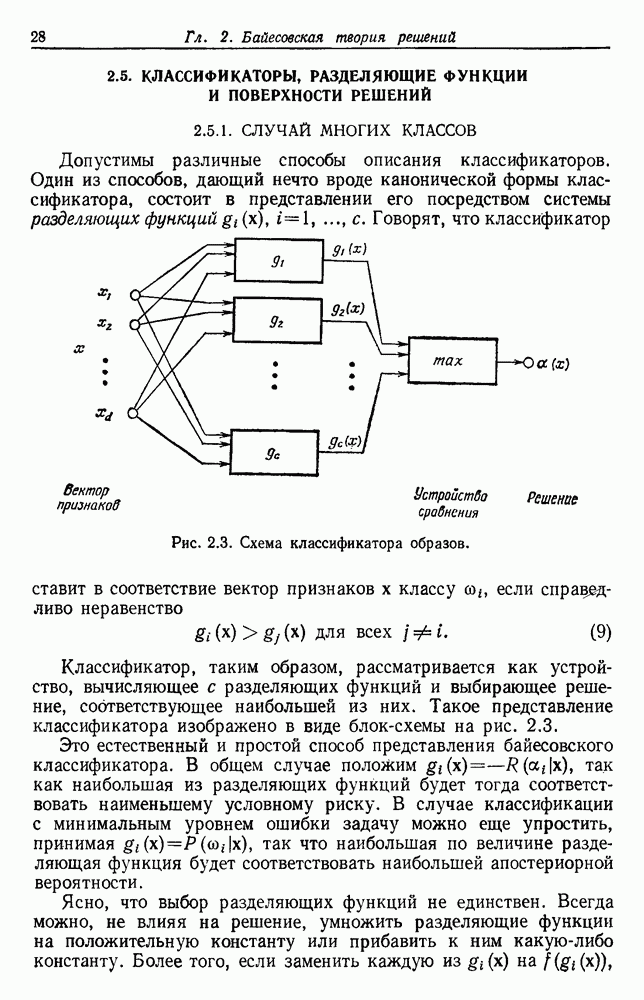
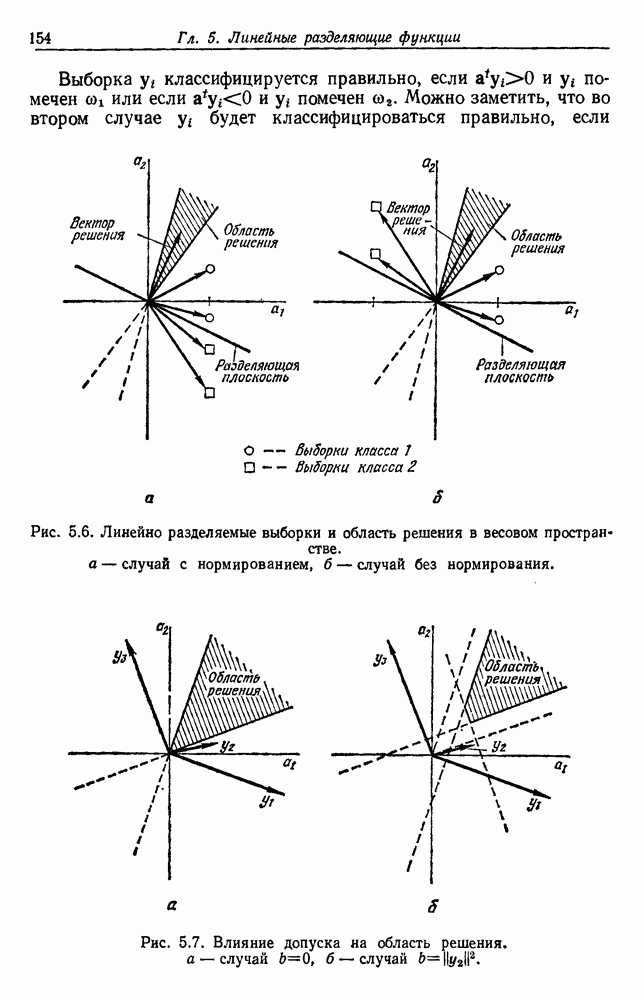
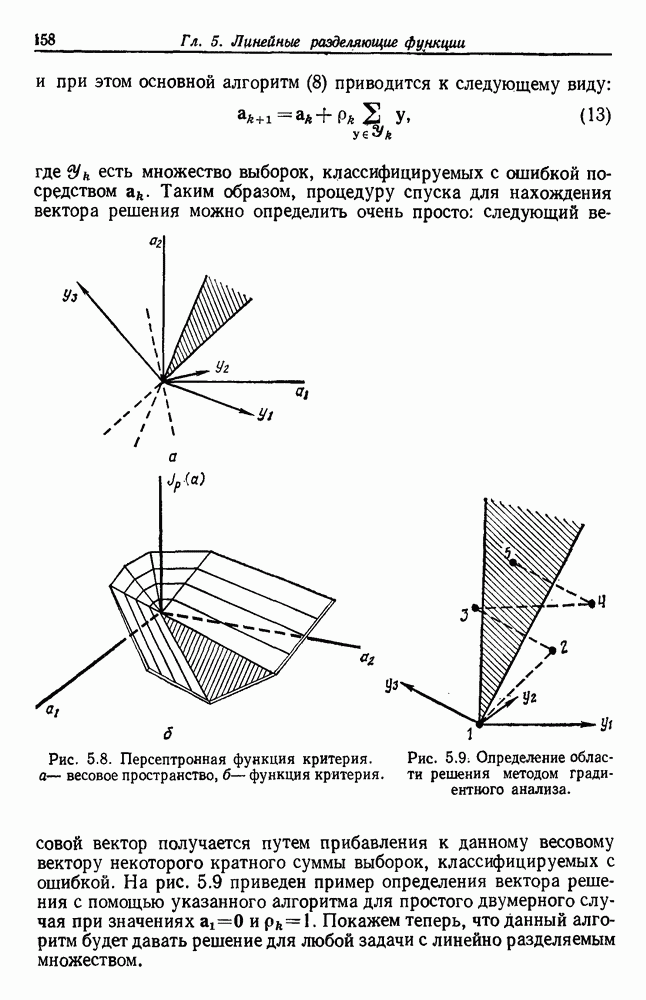
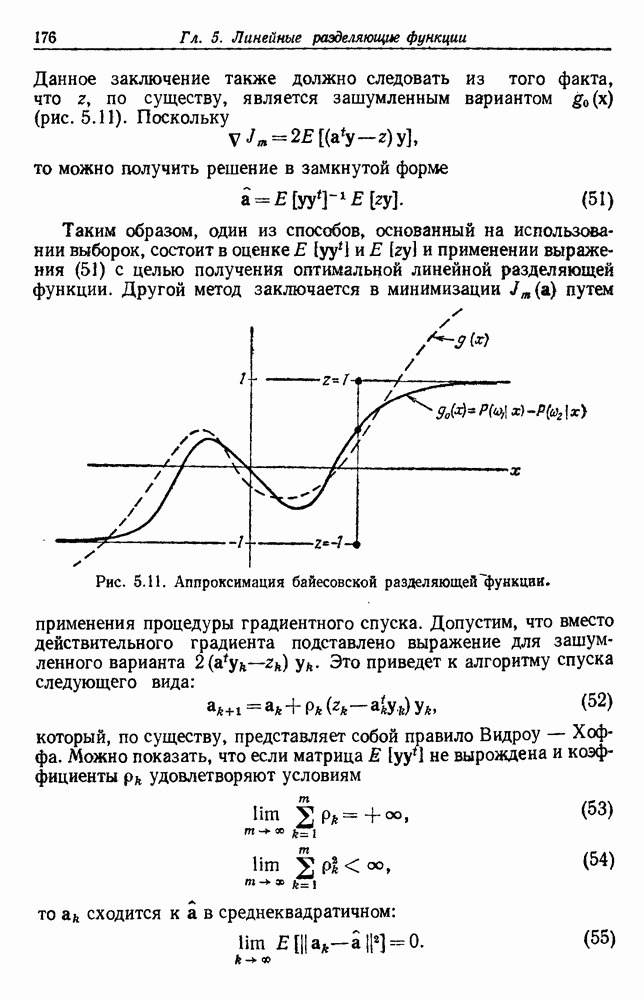
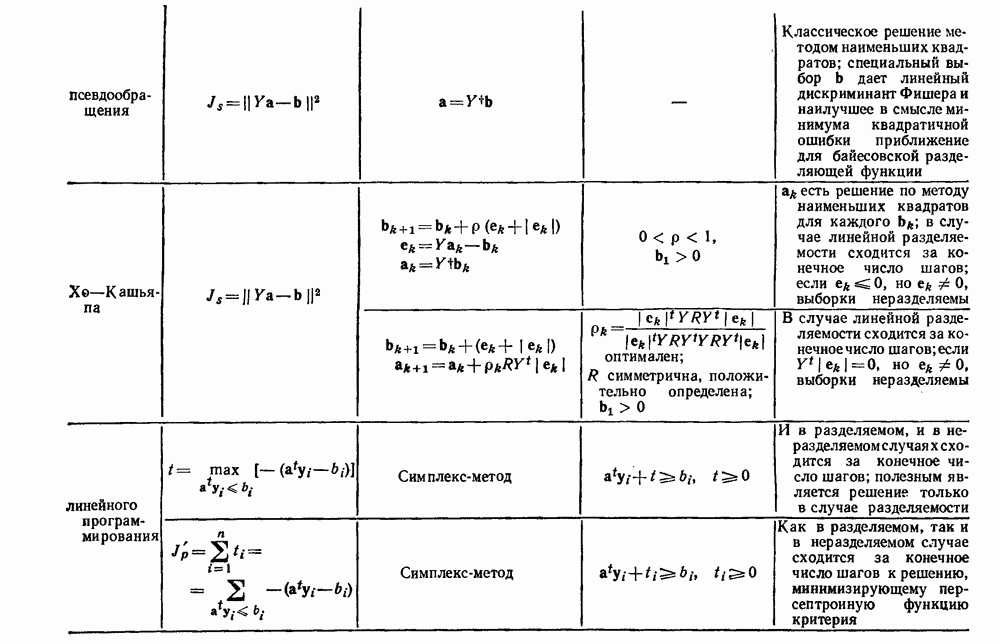
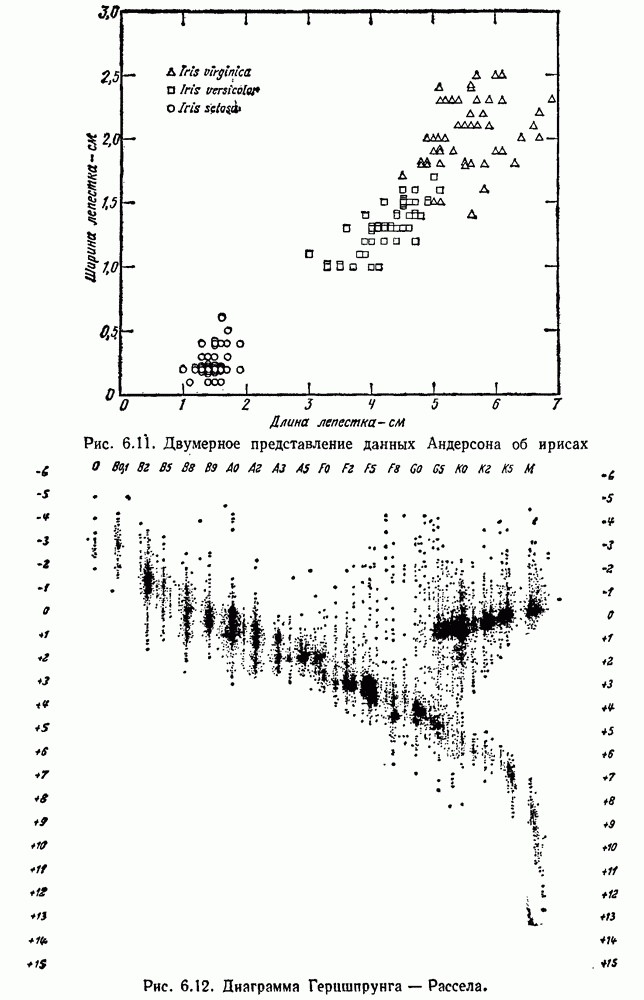
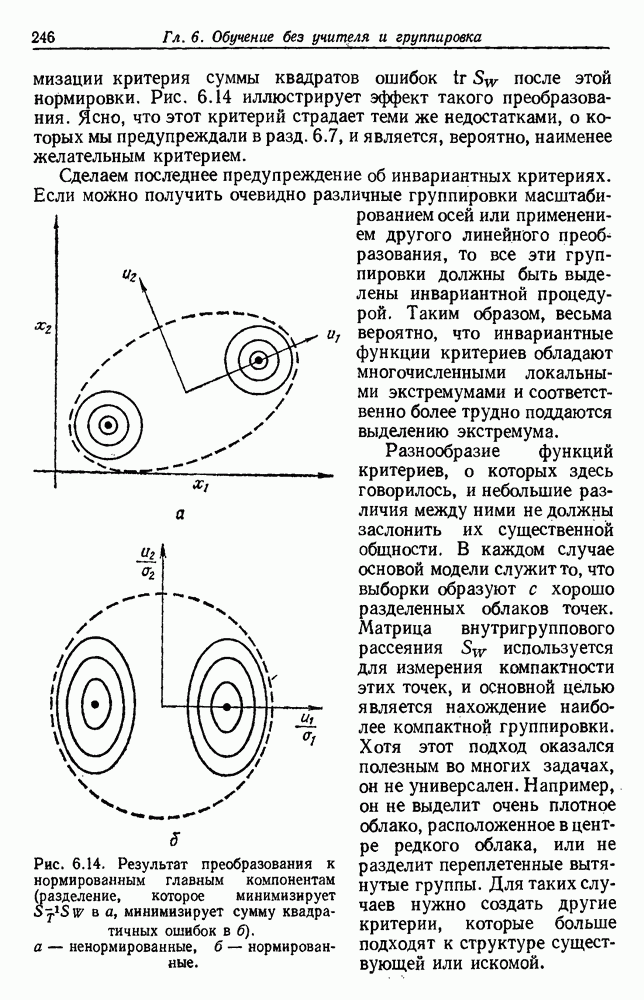
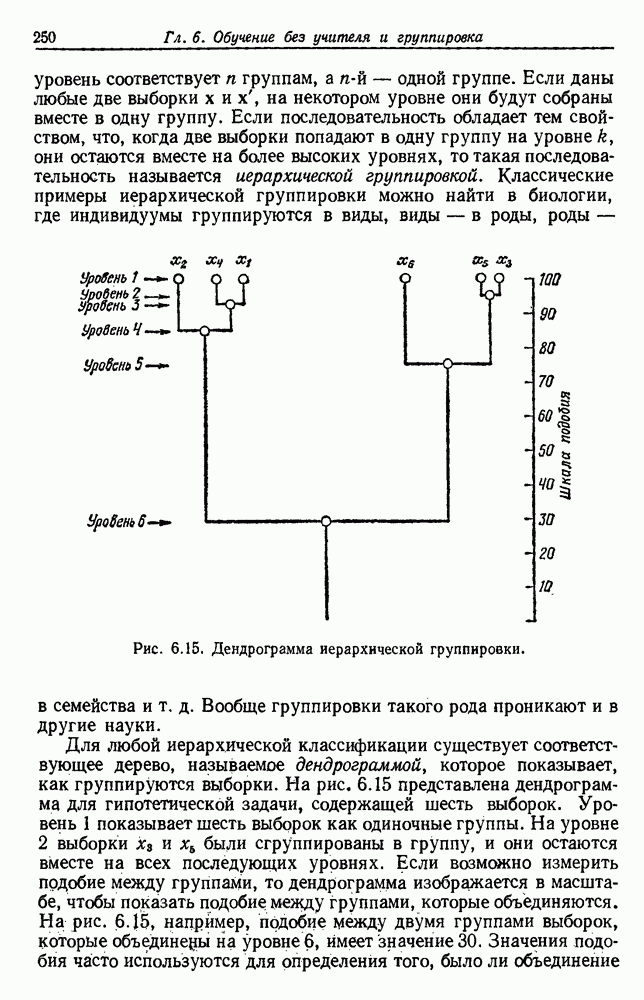
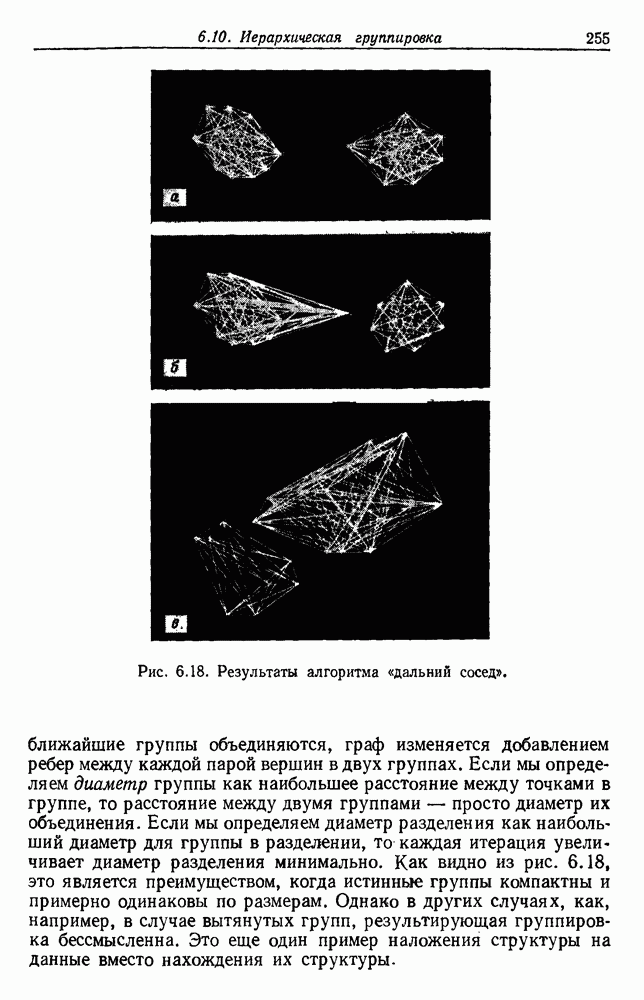
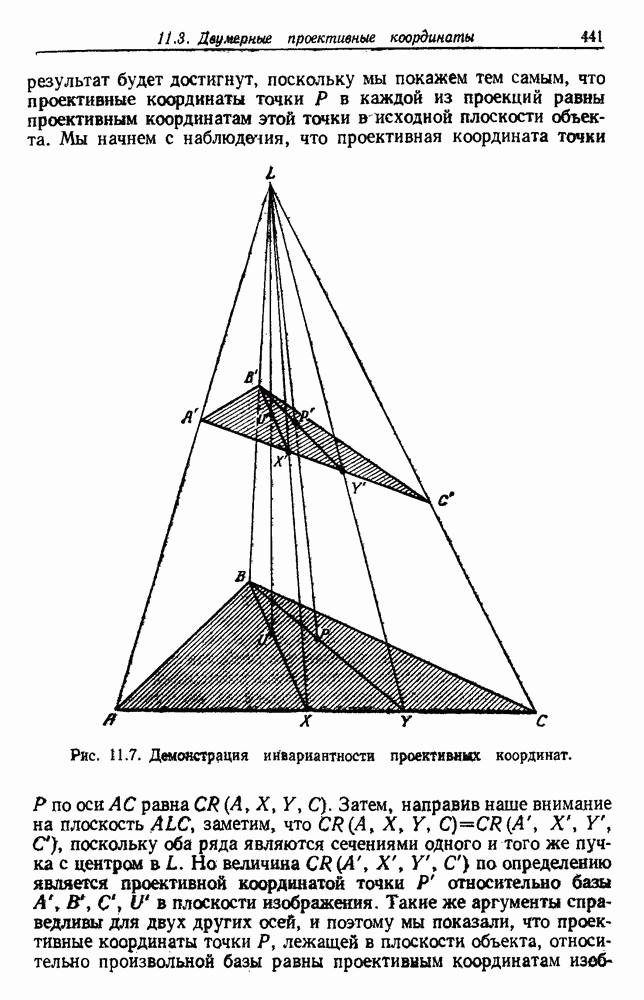
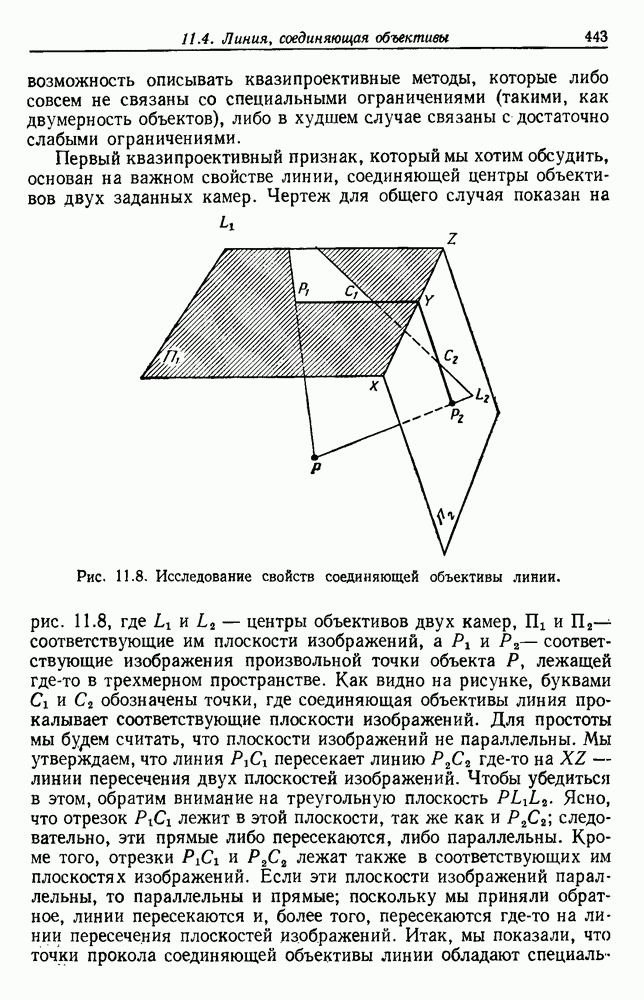
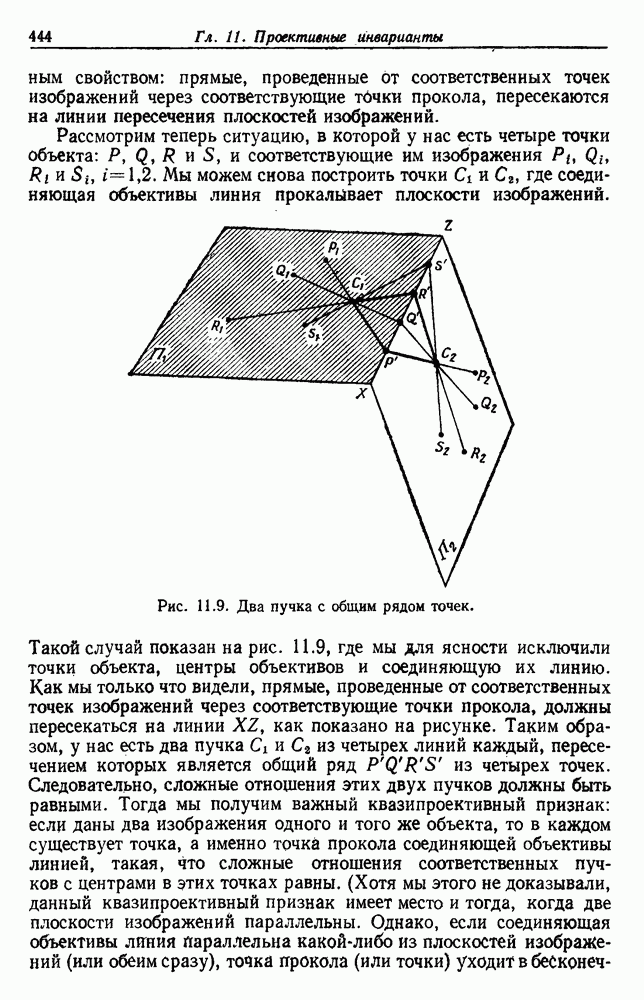
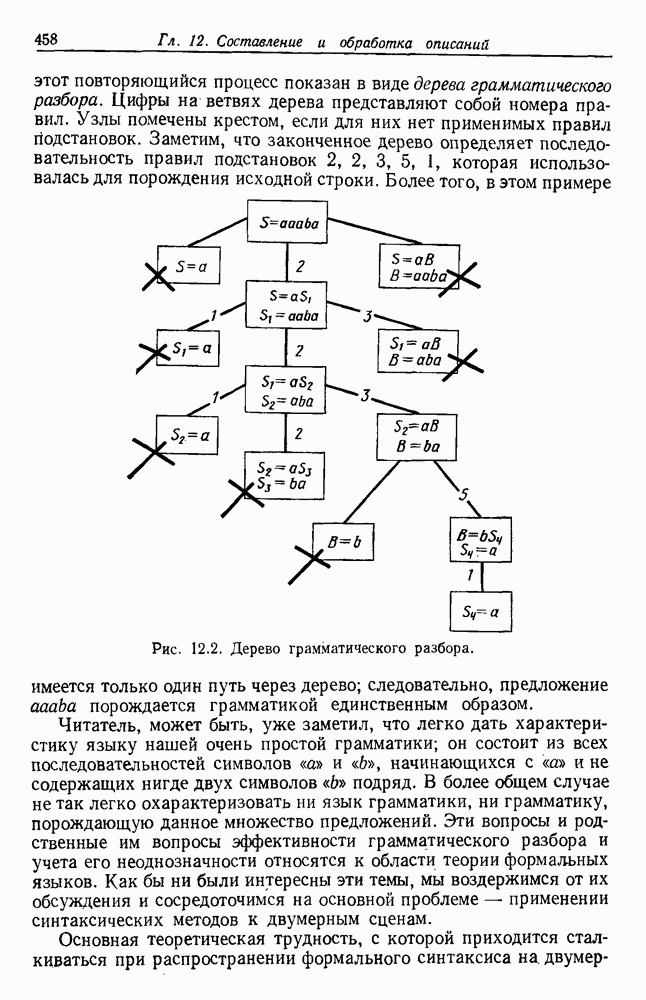
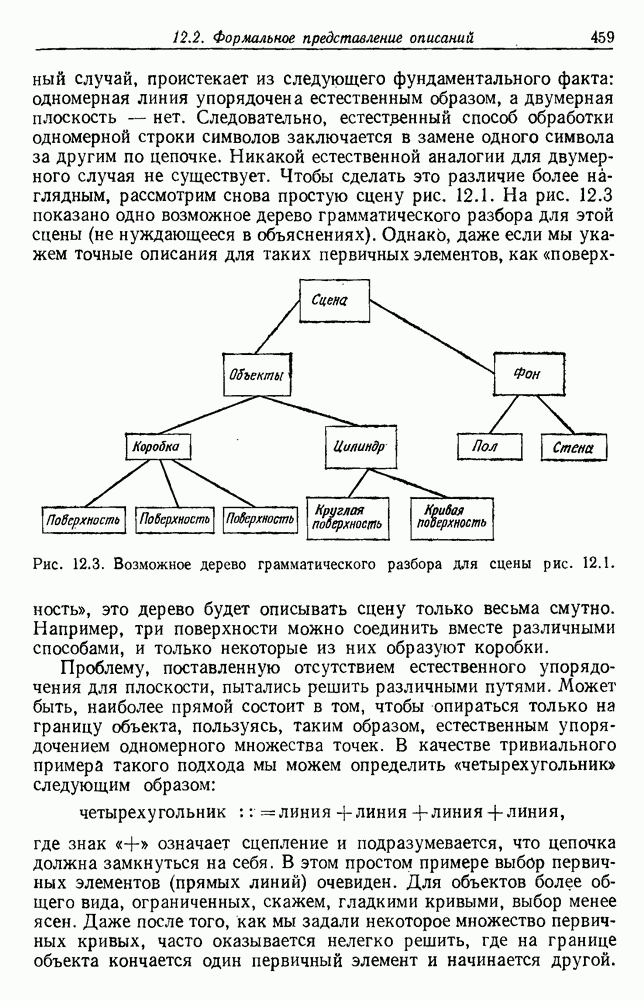
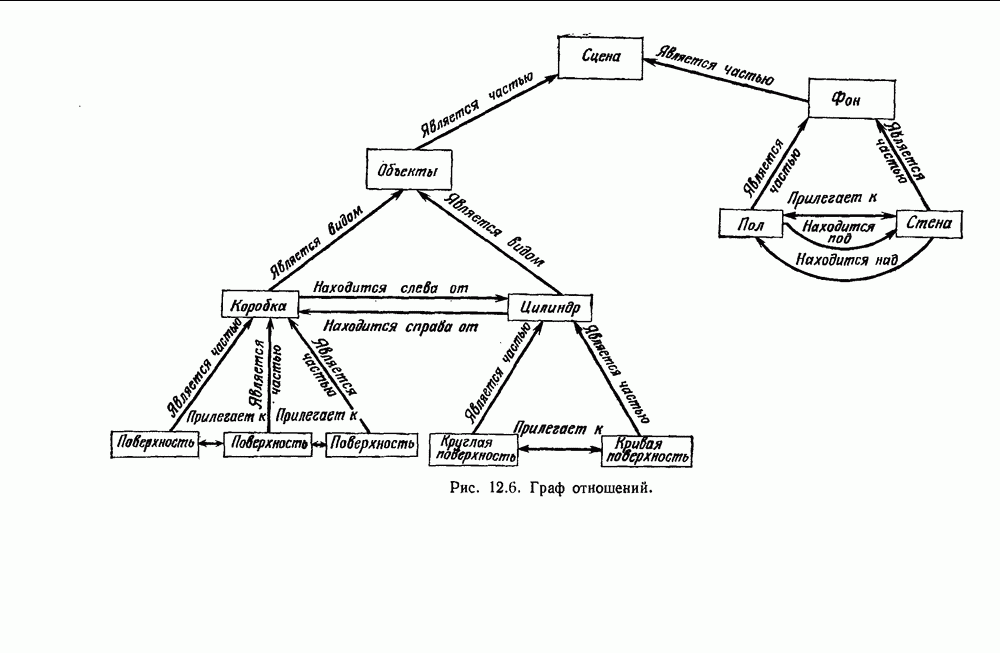
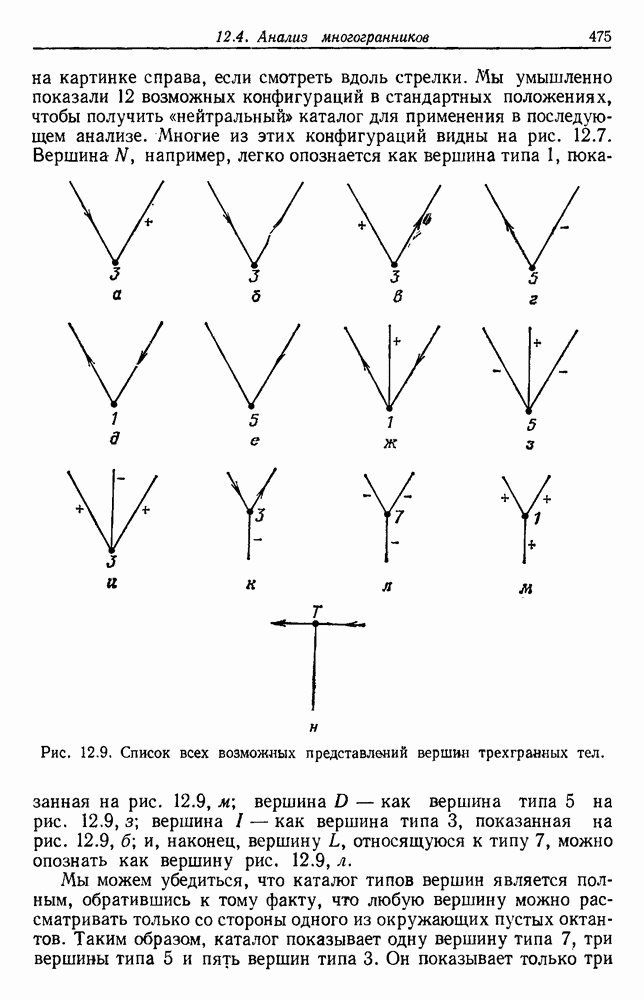
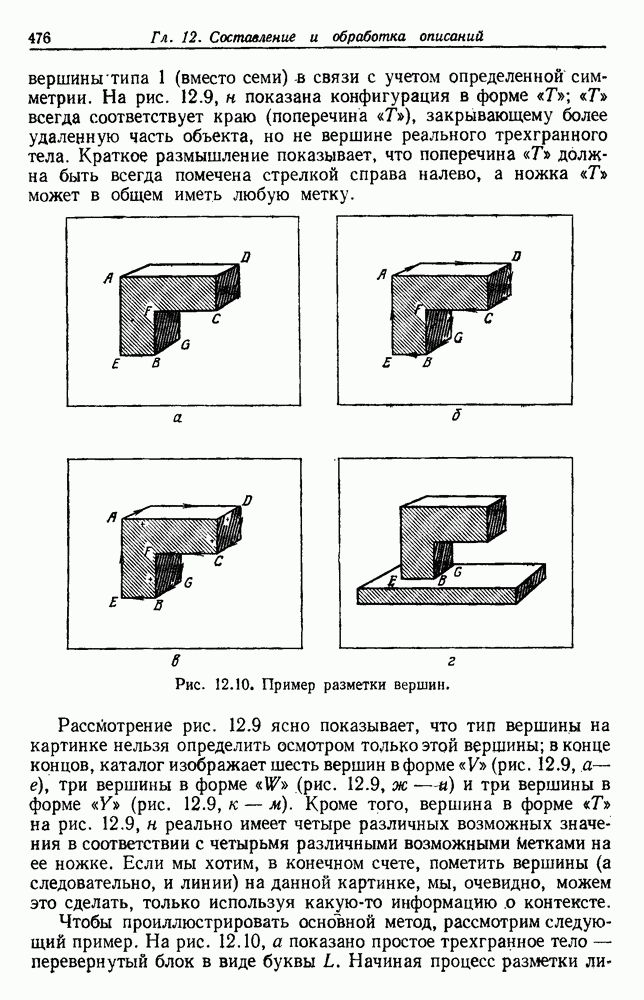
6.2. ПЛОТНОСТЬ СМЕСИ И ИДЕНТИФИЦИРУЕМОСТЬ
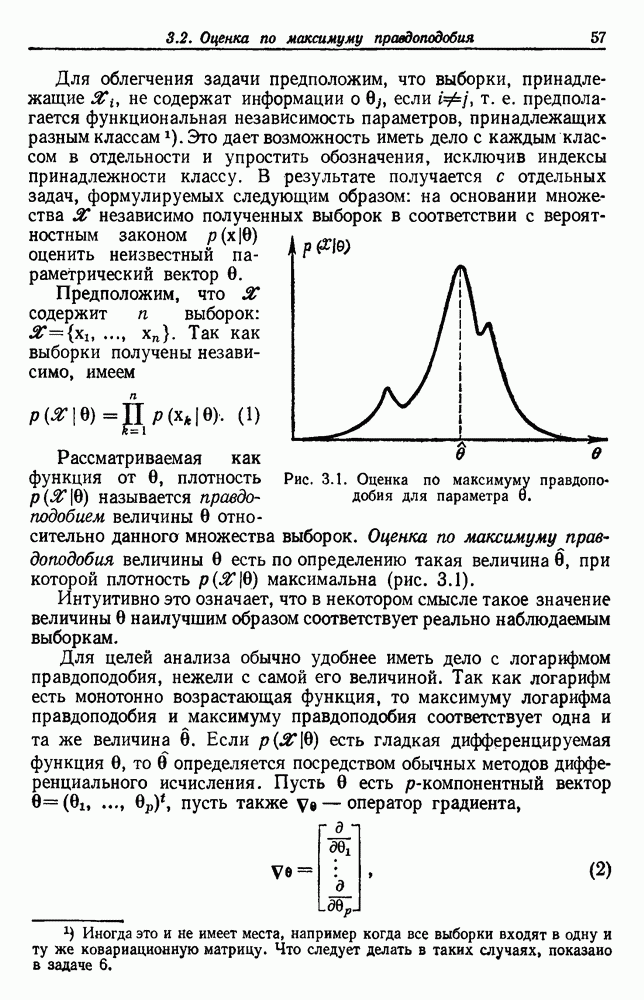
Начнем с предположения, что мы знаем полную вероятностную структуру задачи, за исключением лишь значений некоторых параметров. Более точно, мы делаем следующие предположения:
1. Выборки производятся из известного числа с классов.
2. Априорные вероятности  для каждого класса известны,
для каждого класса известны,  .
.
3. Вид условных по классам плотностей  известен,
известен,  .
.
4. Единственные неизвестные — это значения с параметрических векторов 
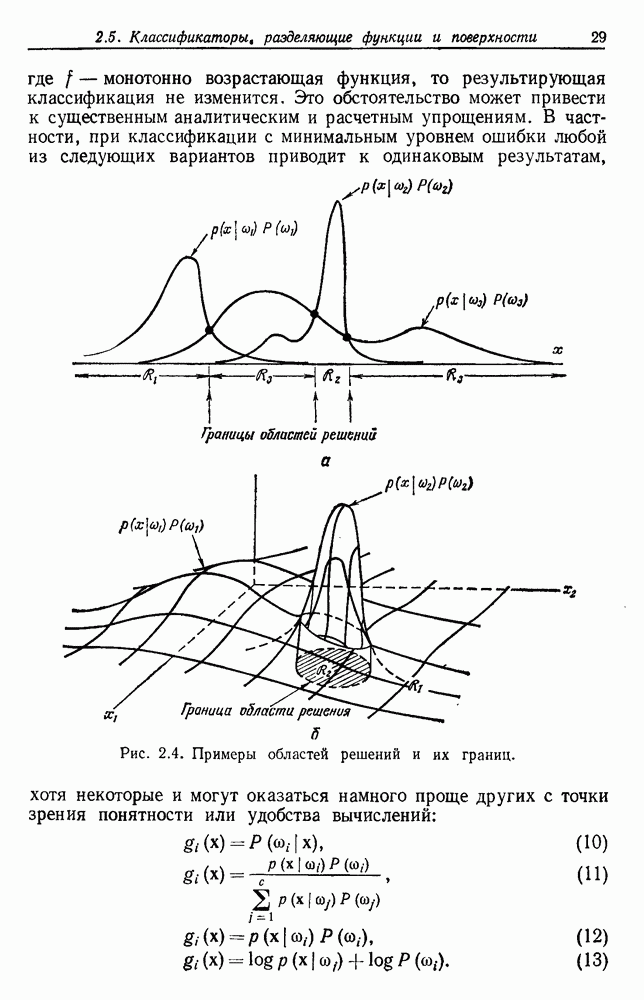
Предполагается, что выборки получены выделением состояния природы  с вероятностью
с вероятностью  и последующим выделением х в соответствии с вероятностным законом
и последующим выделением х в соответствии с вероятностным законом  .
.
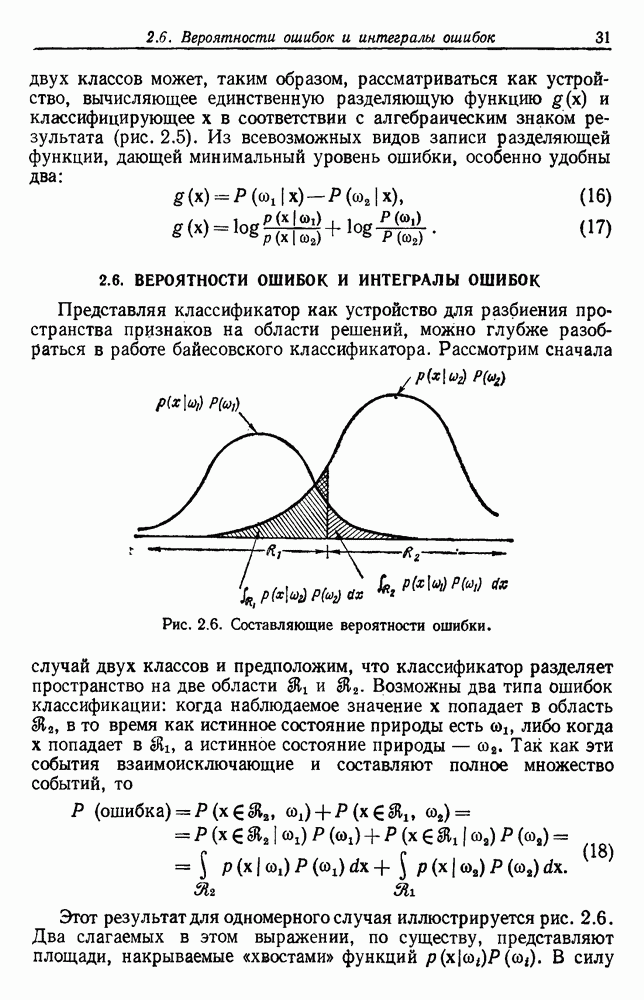
Таким образом, функция плотности распределения выборок определяется как

где  Функция плотности такого вида называется плотностью смеси. Условные плотности
Функция плотности такого вида называется плотностью смеси. Условные плотности  называются плотностями компонент, а априорные вероятности
называются плотностями компонент, а априорные вероятности  — параметрами смеси. Параметры смеси можно включить и в неизвестные параметры, но на данный момент мы предположим, что неизвестно только
— параметрами смеси. Параметры смеси можно включить и в неизвестные параметры, но на данный момент мы предположим, что неизвестно только  .
.
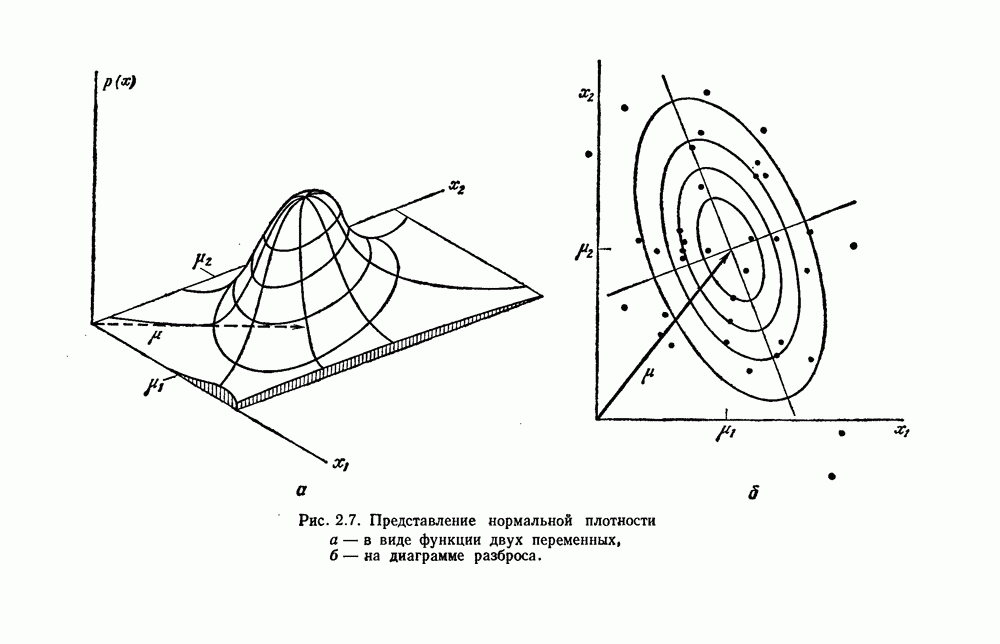
Наша основная цель — использовать выборки, полученные согласно плотности смеси, для оценки неизвестного вектора параметров  . Если мы знаем
. Если мы знаем  , мы можем разложить смесь на компоненты, и задача решена. До получения явного решения задачи выясним, однако, возможно ли в принципе извлечь
, мы можем разложить смесь на компоненты, и задача решена. До получения явного решения задачи выясним, однако, возможно ли в принципе извлечь  из смеси. Предположим, что мы имеем неограниченное число выборок и используем один из непараметрических методов гл. 4 для определения значения
из смеси. Предположим, что мы имеем неограниченное число выборок и используем один из непараметрических методов гл. 4 для определения значения  для каждого х. Если имеется только одно значение
для каждого х. Если имеется только одно значение  , которое дает наблюденные значения для
, которое дает наблюденные значения для  то в принципе решение возможно. Однако если несколько различных значений
то в принципе решение возможно. Однако если несколько различных значений  могут дать одни и те же значения для
могут дать одни и те же значения для  то нет надежды получить единственное решение.
то нет надежды получить единственное решение.
Эти рассмотрения приводят нас к следующему определению: плотность  считается идентифицируемой, если из
считается идентифицируемой, если из 
следует, что существует х, такой, что  Как можно ожидать, изучение случая обучения без учителя значительно упрощается, если мы ограничиваемся идентифицируемыми смесями. К счастью, большинство смесей с обычно встречающимися функциями плотности идентифицируемо. Смеси с дискретным распределением не всегда так хороши. В качестве простого примера рассмотрим случай, где х бинарен и
Как можно ожидать, изучение случая обучения без учителя значительно упрощается, если мы ограничиваемся идентифицируемыми смесями. К счастью, большинство смесей с обычно встречающимися функциями плотности идентифицируемо. Смеси с дискретным распределением не всегда так хороши. В качестве простого примера рассмотрим случай, где х бинарен и  смесь:
смесь:

Если мы знаем, например, что  и, следовательно,
и, следовательно,  , то мы знаем функцию
, то мы знаем функцию  но не можем определить
но не можем определить  и поэтому не можем извлечь распределение компонент. Самое большее, что мы можем сказать, — это что
и поэтому не можем извлечь распределение компонент. Самое большее, что мы можем сказать, — это что  Таким образом, мы имеем случай, в котором распределение смеси неидентифицируемо, и, следовательно, это случай, в котором обучение без учителя в принципе невозможно.
Таким образом, мы имеем случай, в котором распределение смеси неидентифицируемо, и, следовательно, это случай, в котором обучение без учителя в принципе невозможно.
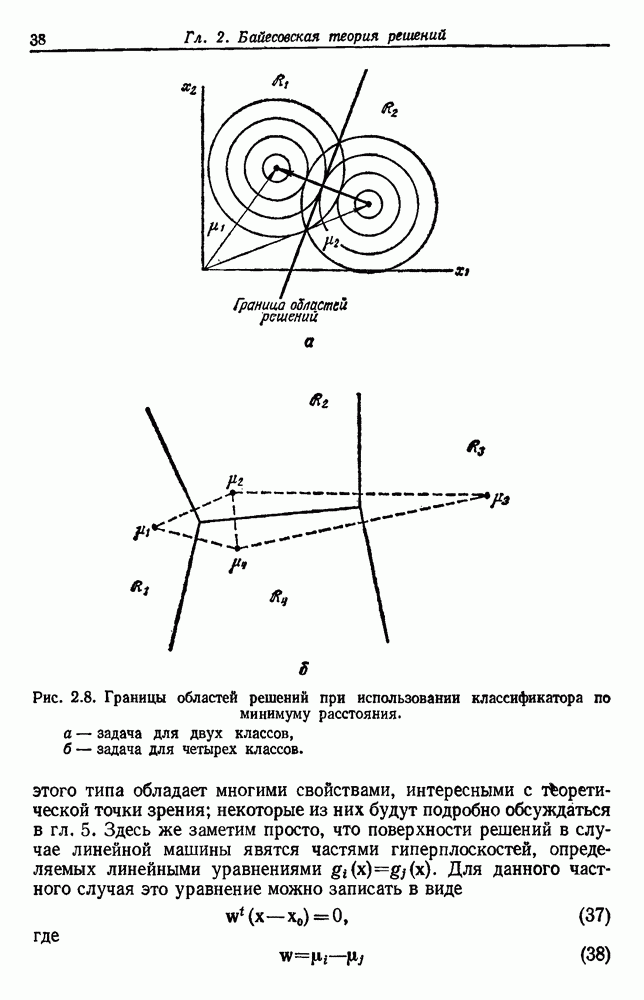
Как правило, при дискретных распределениях возникает такого рода проблема. Если в смеси имеется слишком много компонент, то неизвестных может быть больше, чем независимых уравнений, и идентифицируемость становится сложной задачей. Для непрерывного случая задачи менее сложные, хотя иногда и могут возникнуть небольшие трудности. Таким образом, в то время как можно показать, что смеси с нормальной плотностью обычно идентифицируемы, параметры в простой плотности смеси

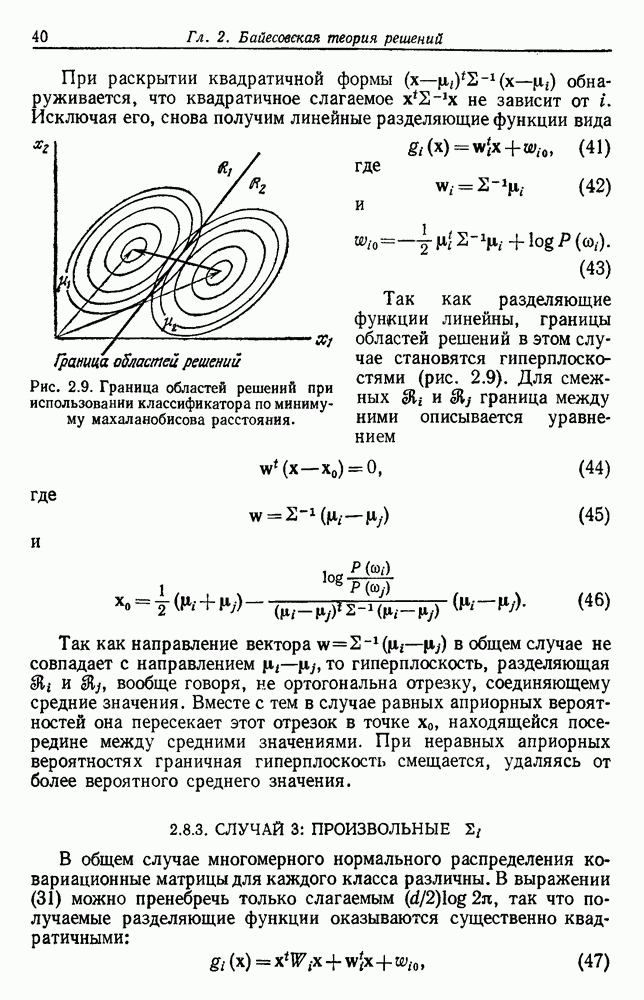
не могут быть идентифицированы однозначно, если  так как тогда
так как тогда  могут взаимно заменяться, не влияя на
могут взаимно заменяться, не влияя на  Чтобы избежать таких неприятностей, мы признаем, что идентифицируемость является самостоятельной задачей, но в дальнейшем предполагаем, что плотности смеси, с которыми мы работаем, идентифицируемы.
Чтобы избежать таких неприятностей, мы признаем, что идентифицируемость является самостоятельной задачей, но в дальнейшем предполагаем, что плотности смеси, с которыми мы работаем, идентифицируемы.