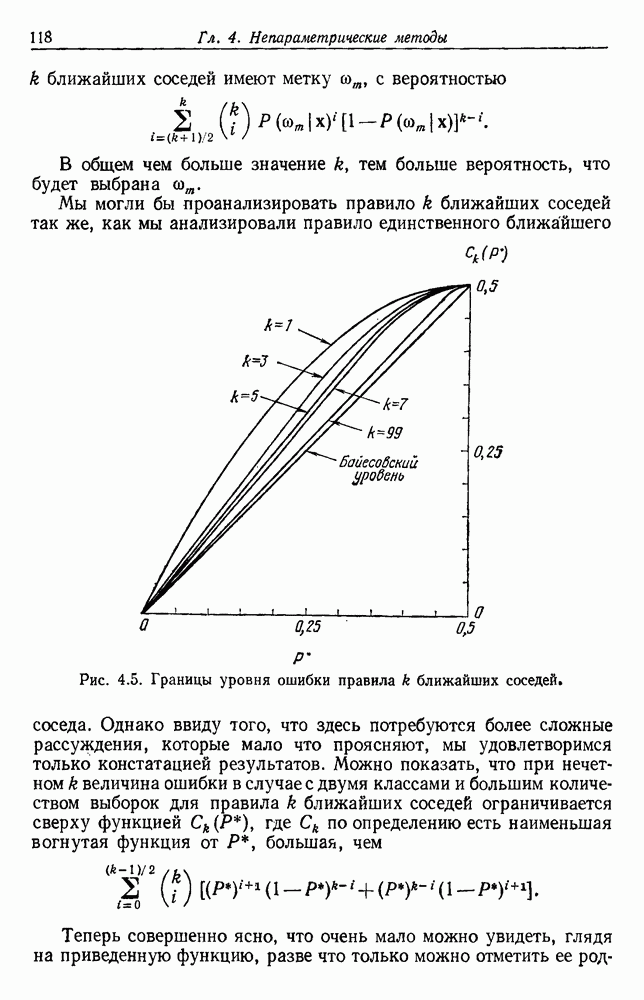
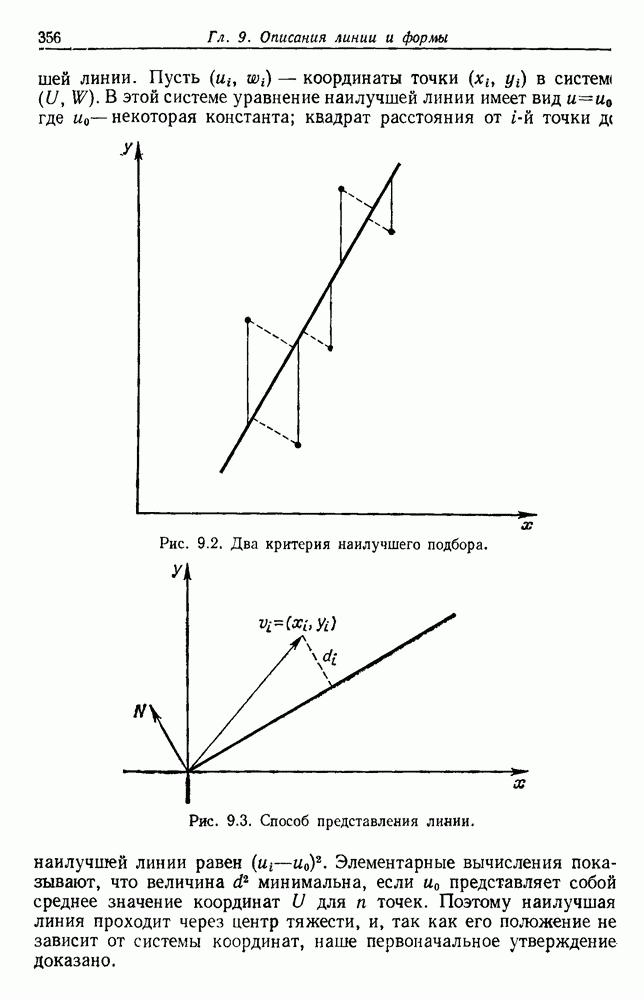
Прежде чем вдаваться в детали, давайте попытаемся эвристически разобраться в том, почему правило ближайшего соседа дает такие хорошие результаты. Для начала отметим, что метка  ассоциированная с ближайшим соседом, является случайной величиной, а вероятность того, что
ассоциированная с ближайшим соседом, является случайной величиной, а вероятность того, что  есть просто апостериорная вероятность
есть просто апостериорная вероятность  . Когда количество выборок очень велико, следует допустить, что
. Когда количество выборок очень велико, следует допустить, что  расположено достаточно близко к х, чтобы
расположено достаточно близко к х, чтобы  . В этом случае можем рассматривать правило ближайшего соседа как рандомизированное решающее правило, которое классифицирует х путем выбора класса
. В этом случае можем рассматривать правило ближайшего соседа как рандомизированное решающее правило, которое классифицирует х путем выбора класса  с вероятностью
с вероятностью  . Поскольку это точная вероятность того, что природа находится в состоянии
. Поскольку это точная вероятность того, что природа находится в состоянии  значит, правило ближайшего соседа эффективно согласует вероятности с реальностью.
значит, правило ближайшего соседа эффективно согласует вероятности с реальностью.
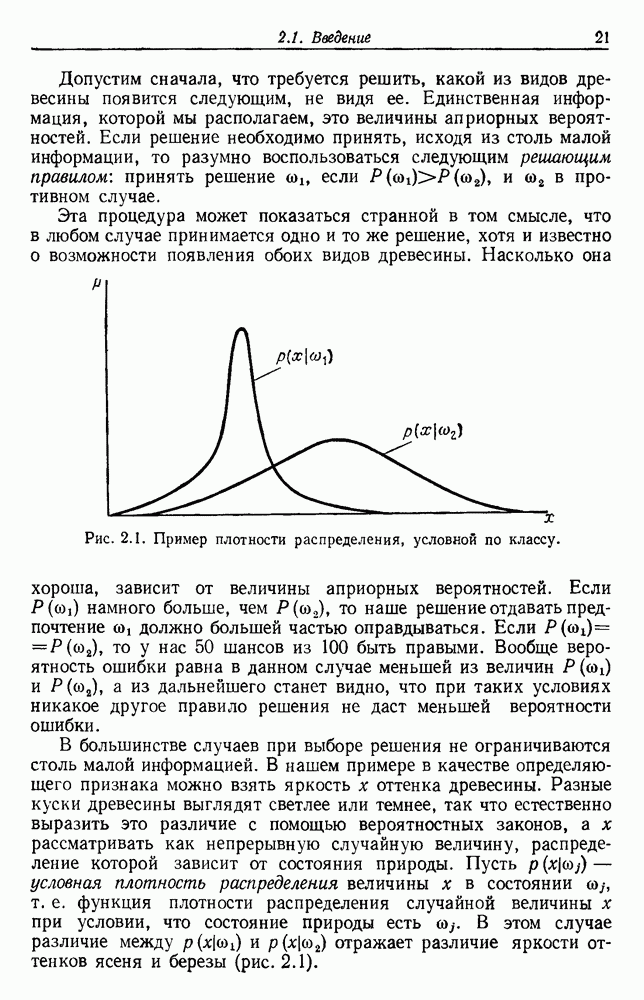
Если мы определяем  как
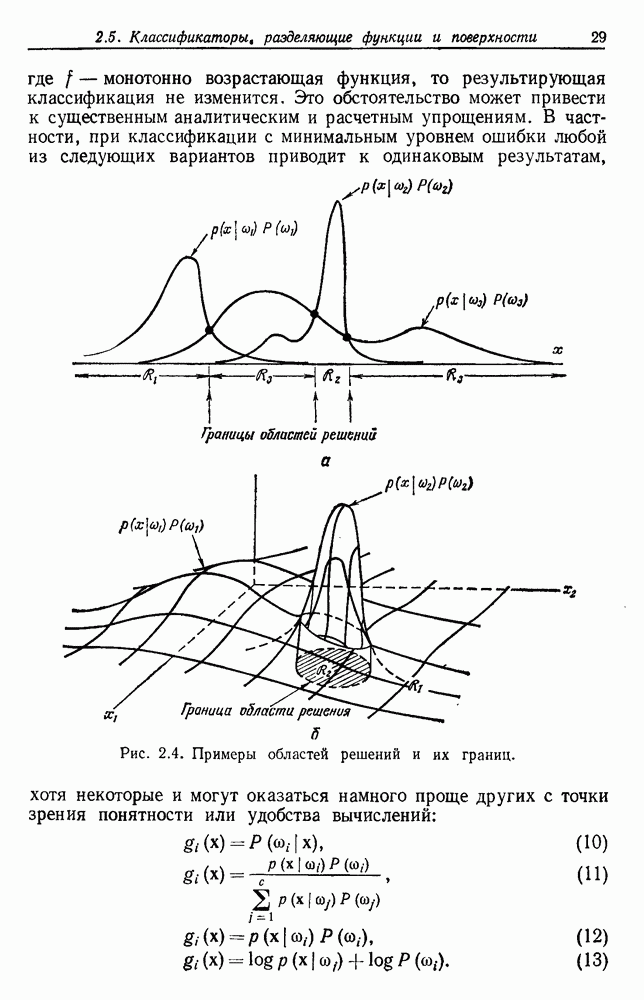
как

то байесовское решающее правило всегда выбирает  Когда вероятность
Когда вероятность  близка к единице, выбор с помощью правила ближайшего соседа почти всегда будет таким же, как и байесовский, это значит, что когда минимальная вероятность ошибки мала, то вероятность ошибки правила ближайшего соседа также мала. Когда
близка к единице, выбор с помощью правила ближайшего соседа почти всегда будет таким же, как и байесовский, это значит, что когда минимальная вероятность ошибки мала, то вероятность ошибки правила ближайшего соседа также мала. Когда  близка к
близка к  так что все классы одинаково правдоподобны, то выборы, сделанные с помощью этих двух правил, редко бывают одинаковыми, но вероятность ошибки в обоих случаях составляет приблизительно
так что все классы одинаково правдоподобны, то выборы, сделанные с помощью этих двух правил, редко бывают одинаковыми, но вероятность ошибки в обоих случаях составляет приблизительно  Не исключая необходимости в более тщательном анализе, эти замечания позволяют меньше удивляться хорошим результатам правила ближайшего соседа.
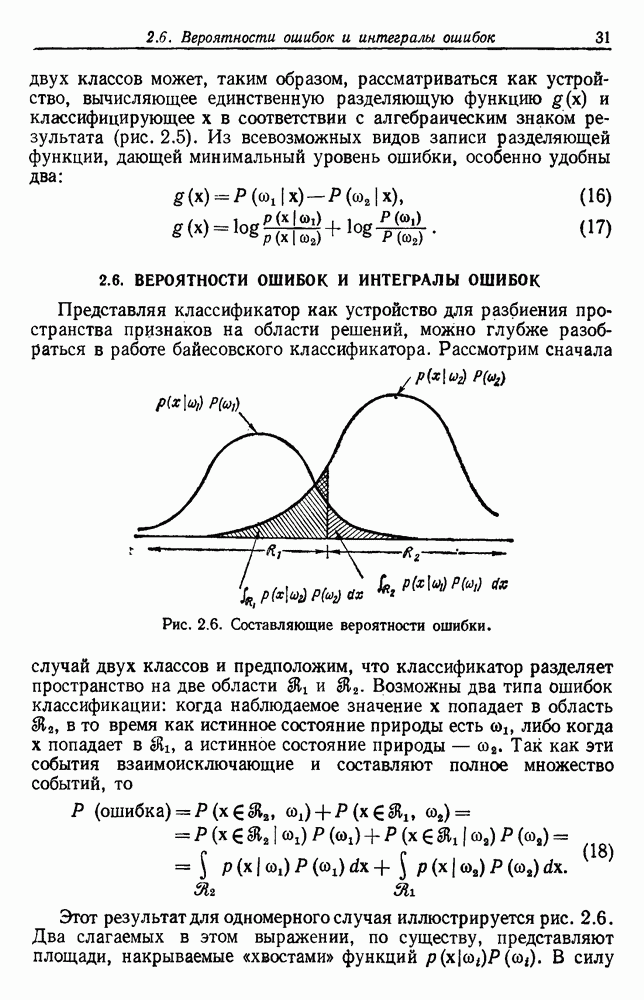
Не исключая необходимости в более тщательном анализе, эти замечания позволяют меньше удивляться хорошим результатам правила ближайшего соседа.
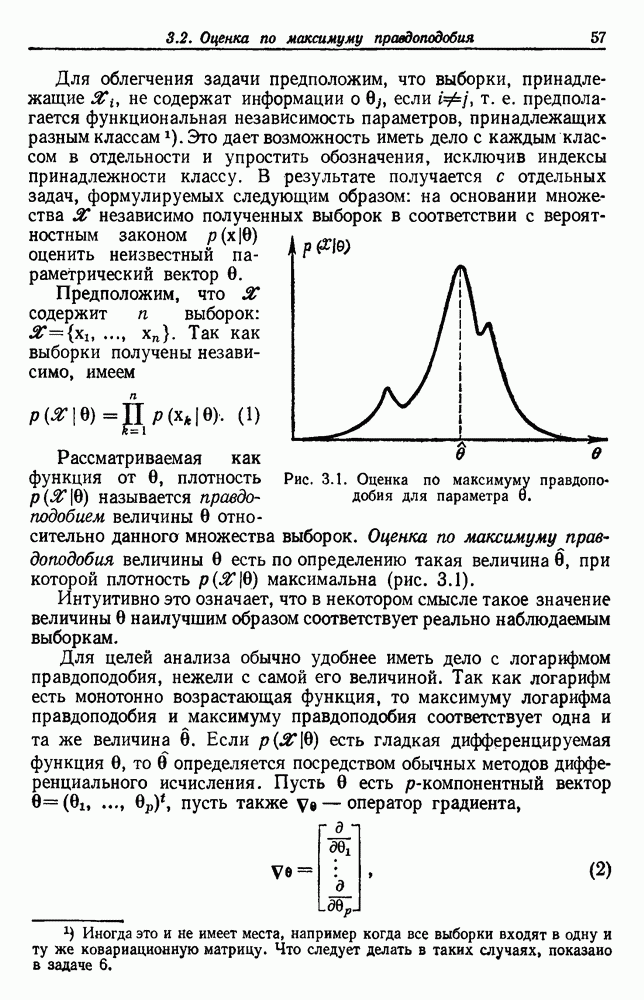
Наш анализ поведения правила ближайшего соседа будет направлен на получение условной средней вероятности ошибки  при большом количестве выборок, где усреднение производится по выборкам. Безусловная средняя вероятность ошибки будет найдена путем усреднения
при большом количестве выборок, где усреднение производится по выборкам. Безусловная средняя вероятность ошибки будет найдена путем усреднения  по всем
по всем 

Заметим, что решающее правило Байеса минимизирует  путем минимизации
путем минимизации  для каждого х.
для каждого х.
Если  является минимально возможным значением
является минимально возможным значением  минимально возможным значением
минимально возможным значением  , то
, то

и

4.6.2. СХОДИМОСТЬ ПРИ ИСПОЛЬЗОВАНИИ МЕТОДА БЛИЖАЙШЕГО СОСЕДА
Теперь мы хотим оценить среднюю вероятность ошибки для правила ближайшего соседа. В частности, если  есть уровень ошибки с
есть уровень ошибки с  выборками и если
выборками и если

то мы хотим показать, что

Начнем с замечания, что при использовании правила ближайшего соседа с конкретным множеством  выборок результирующий уровень ошибки будет зависеть от случайных характеристик выборок. В частности, если для классификации х используются различные множества
выборок результирующий уровень ошибки будет зависеть от случайных характеристик выборок. В частности, если для классификации х используются различные множества  выборок, то для ближайшего соседа вектора х будут получены различные векторы
выборок, то для ближайшего соседа вектора х будут получены различные векторы  . Так как решающее правило зависит от ближайшего соседа, мы имеем условную вероятность ошибки
. Так как решающее правило зависит от ближайшего соседа, мы имеем условную вероятность ошибки  которая зависит как от х, так и от
которая зависит как от х, так и от  Усредняя по
Усредняя по  получаем
получаем

Обычно очень трудно получить точное выражение для условной плотности распределения  Однако, поскольку
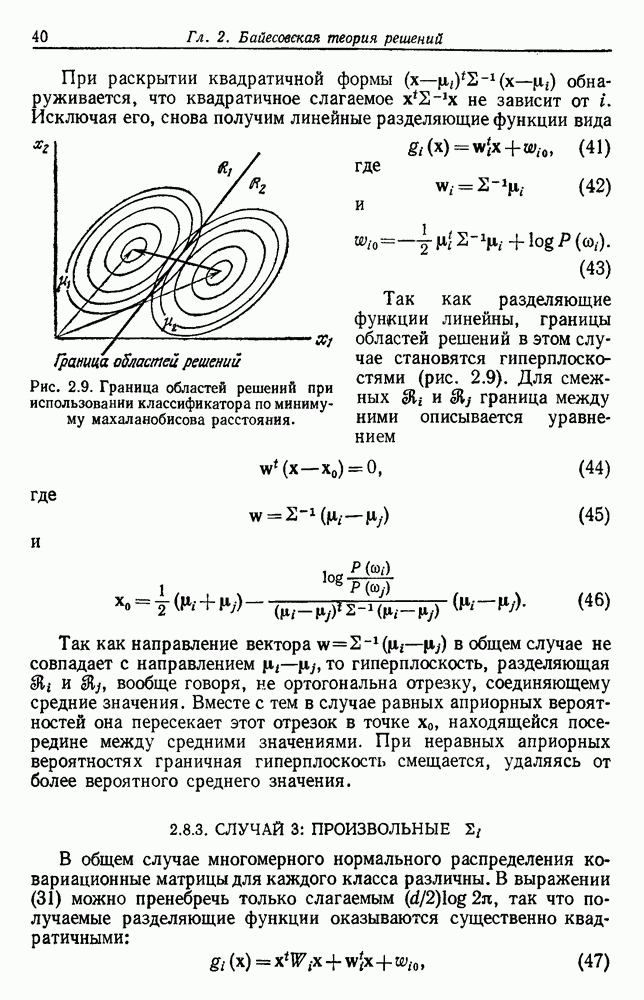
Однако, поскольку  по определению является ближайшим соседом х, мы ожидаем, что эта плотность будет очень большой в непосредственной близости от х и очень малой во всех других случаях. Более того, мы ожидаем, что по мере устремления
по определению является ближайшим соседом х, мы ожидаем, что эта плотность будет очень большой в непосредственной близости от х и очень малой во всех других случаях. Более того, мы ожидаем, что по мере устремления  к бесконечности
к бесконечности  будет стремиться к дельта-функции с центром в х, что делает оценку, задаваемую (29), тривиальной. Для того чтобы показать, что это действительно так, мы должны допустить, что плотность
будет стремиться к дельта-функции с центром в х, что делает оценку, задаваемую (29), тривиальной. Для того чтобы показать, что это действительно так, мы должны допустить, что плотность  для заданного х непрерывна и не равна нулю. При таких условиях вероятность попадания любой выборки в гиперсферу S с центром в х есть некое положительное число
для заданного х непрерывна и не равна нулю. При таких условиях вероятность попадания любой выборки в гиперсферу S с центром в х есть некое положительное число

Таким образом, вероятность попадания всех  независимо взятых выборок за пределы этой гиперсферы будет
независимо взятых выборок за пределы этой гиперсферы будет  стремящейся к нулю по мере устремления
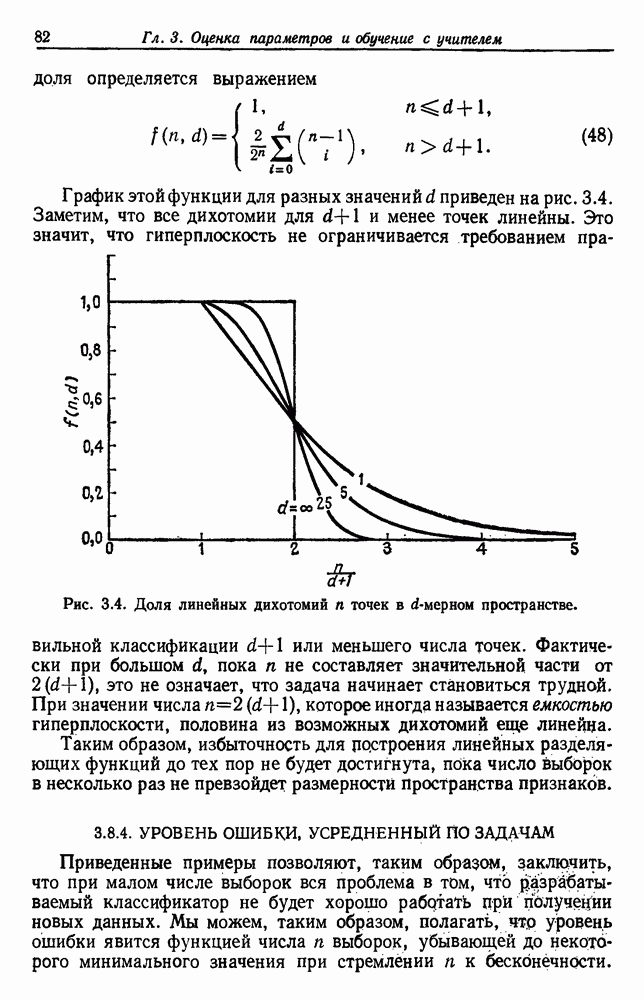
стремящейся к нулю по мере устремления  к бесконечности. Итак,
к бесконечности. Итак,  сходится к х по вероятности
сходится к х по вероятности  приближается к дельта-функции, как и ожидалось. Вообще говоря, применяя методы теории
приближается к дельта-функции, как и ожидалось. Вообще говоря, применяя методы теории 
можно получить более убедительные (и более строгие) доказательства сходимости  , но для наших целей достаточно полученного результата.
, но для наших целей достаточно полученного результата.
4.6.3. УРОВЕНЬ ОШИБКИ ДЛЯ ПРАВИЛА БЛИЖАЙШЕГО СОСЕДА
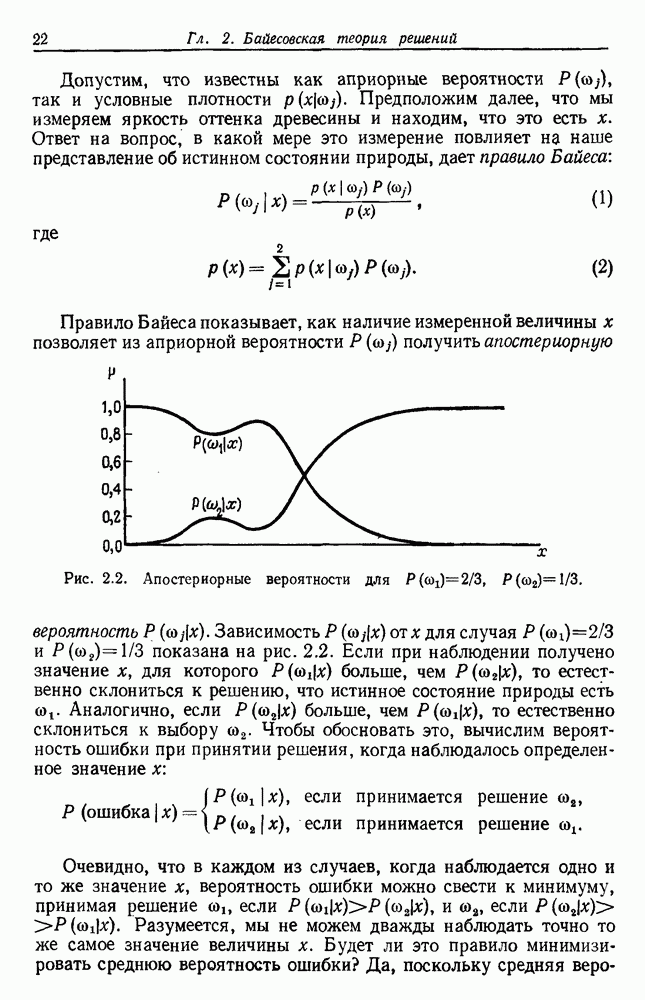
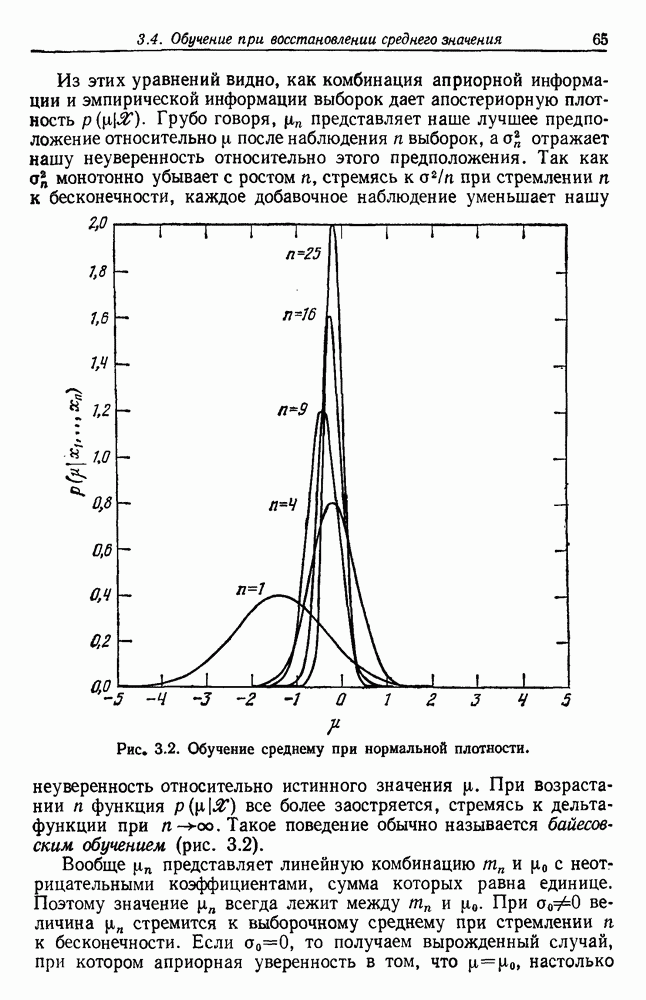
Обратимся теперь к вычислению условной вероятности ошибки  Чтобы избежать недоразумений, необходимо поставить задачу более тщательно, чем это делалось до сих пор. Когда мы говорим, что у нас имеется
Чтобы избежать недоразумений, необходимо поставить задачу более тщательно, чем это делалось до сих пор. Когда мы говорим, что у нас имеется  независимо сделанных помеченных выборок, то мы имеем в виду
независимо сделанных помеченных выборок, то мы имеем в виду  пар случайных переменных
пар случайных переменных  , где
, где  может быть любым из с состояний природы
может быть любым из с состояний природы  . Мы полагаем, что эти пары получались путем выбора состояния природы
. Мы полагаем, что эти пары получались путем выбора состояния природы  для
для  с вероятностью
с вероятностью  а затем путем выбора
а затем путем выбора  в соответствии с вероятностным законом
в соответствии с вероятностным законом  причем каждая пара выбирается независимо. Положим теперь, что природа выбирает пару
причем каждая пара выбирается независимо. Положим теперь, что природа выбирает пару  и что
и что  помеченное
помеченное  есть ближайшая к х выборка. Поскольку состояние природы при выборе х не зависит от состояния при выборе х, то
есть ближайшая к х выборка. Поскольку состояние природы при выборе х не зависит от состояния при выборе х, то

Теперь, если применяется решающее правило ближайшего соседа, мы совершаем ошибку всякий раз, когда  Таким образом, условная вероятность ошибки
Таким образом, условная вероятность ошибки  задается в виде
задается в виде

Чтобы получить  , надо подставить это выражение в (29) вместо
, надо подставить это выражение в (29) вместо  , а затем усреднить результат по х. Вообще это очень трудно сделать, но, как мы уже замечали ранее, интегрирование в (29) становится тривиальным по мере устремления
, а затем усреднить результат по х. Вообще это очень трудно сделать, но, как мы уже замечали ранее, интегрирование в (29) становится тривиальным по мере устремления  к бесконечности, а
к бесконечности, а  к дельта-функции. Если
к дельта-функции. Если  непрерывна в х, получаем
непрерывна в х, получаем

Так что асимптотический уровень ошибки правила ближайшего соседа, если можно поменять местами интегрирование и переход
к пределу, задается выражением

4.6.4. ГРАНИЦЫ ОШИБКИ
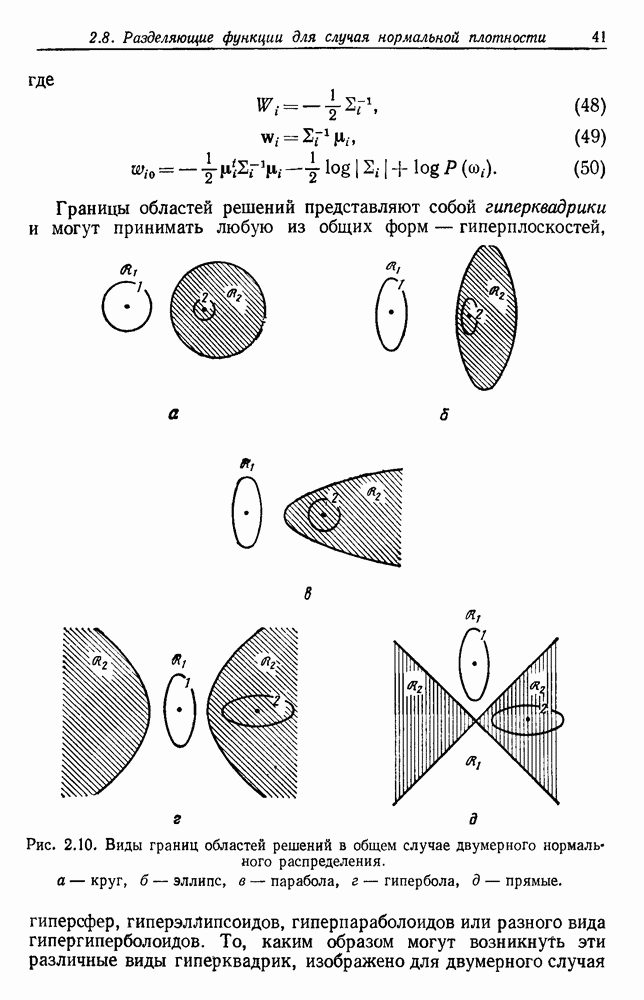
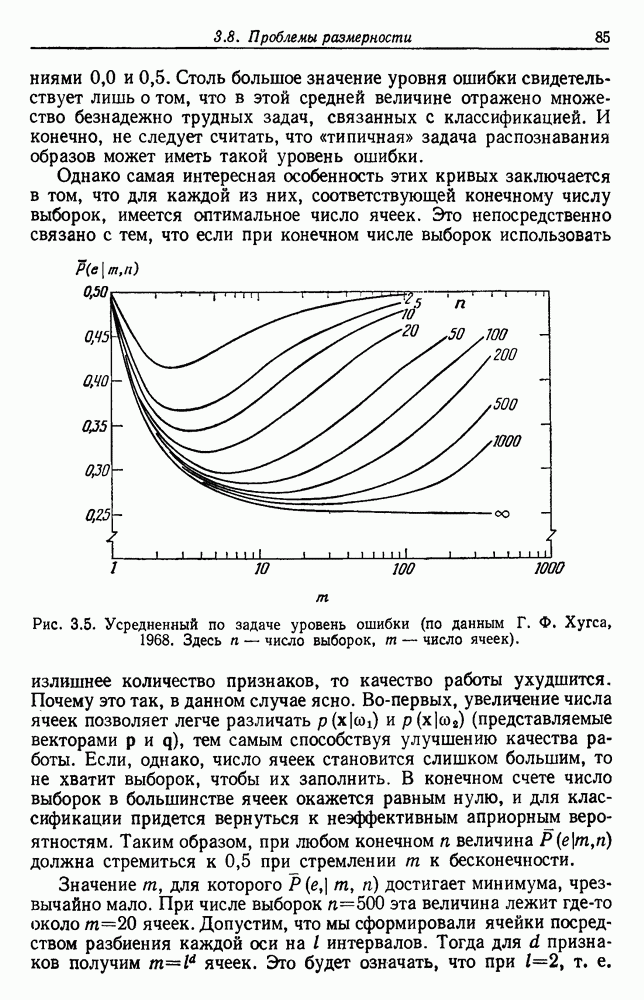
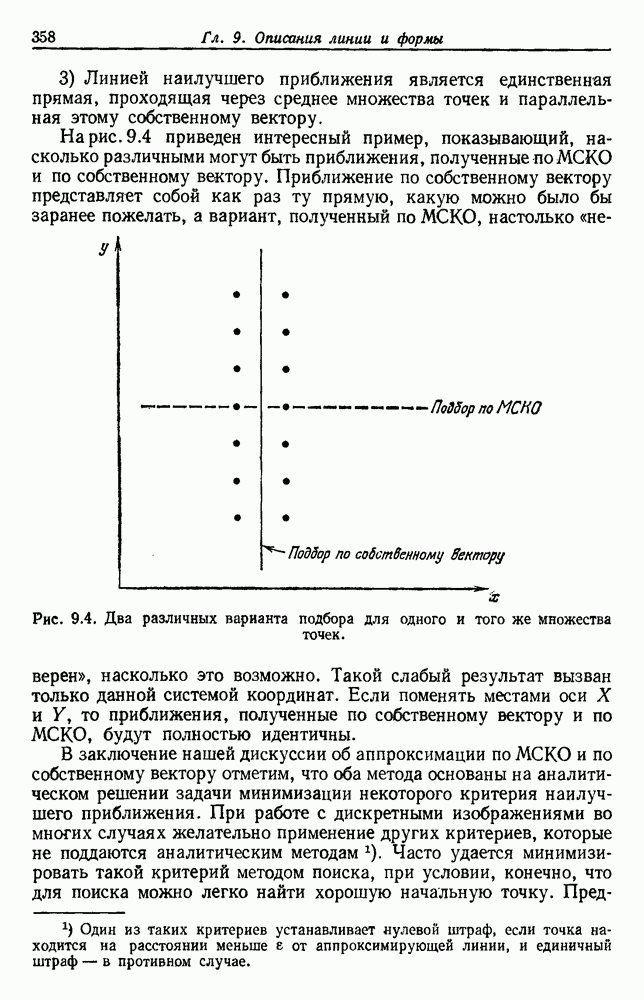
Хотя уравнение (33) дает точный результат, еще показательнее получить границы для Р, выраженные посредством байесовского уровня Р. Очевидной нижней границей для Р является сам уровень Р. Кроме того, можно показать, что при любом Р существует множество условных и априорных вероятностей, для которых эта граница достигается. Так что в этом смысле это точная нижняя граница.
Еще интереснее задача определения точной верхней границы. Следующее соображение позволяет надеяться на низкую верхнюю границу: если байесовский уровень небольшой, то  близка к единице для некоторого i, скажем
близка к единице для некоторого i, скажем  Таким образом, подынтегральное выражение в (33) будет приближенно
Таким образом, подынтегральное выражение в (33) будет приближенно  и поскольку
и поскольку

то интегрирование по х может дать уровень, в два раза превышающий байесовский, но являющийся все еще низким. Чтобы получить точную верхнюю границу, мы должны определить, насколько большим может стать уровень Р ошибки правила ближайшего соседа для заданного байесовского уровня Р. Таким образом, выражение (33) вынуждает нас задаться вопросом, насколько малой может стать  для заданной
для заданной  . Записав
. Записав

мы можем получить границу этой суммы, минимизируя второй член при следующих ограничениях:

Несколько поразмыслив, мы видим, что  минимизируется, если все апостериорные вероятности, кроме
минимизируется, если все апостериорные вероятности, кроме  равны, и второе ограничение дает
равны, и второе ограничение дает

Таким образом,

и

Сразу же видим, что  поэтому можем подставить этот результат в (33) и просто опустить второй член выражения. Однако более точную границу можно получить на основании
поэтому можем подставить этот результат в (33) и просто опустить второй член выражения. Однако более точную границу можно получить на основании

так что

причем равенство сохраняется тогда и только тогда, Когда дисперсия  равна нулю. Пользуясь этим результатом и подставляя соотношение (36) в (33), получаем желаемые границы
равна нулю. Пользуясь этим результатом и подставляя соотношение (36) в (33), получаем желаемые границы

Легко показать, что такая верхняя граница достигается в случае так называемой нулевой информации, в котором плотности распределения  тождественны, так что
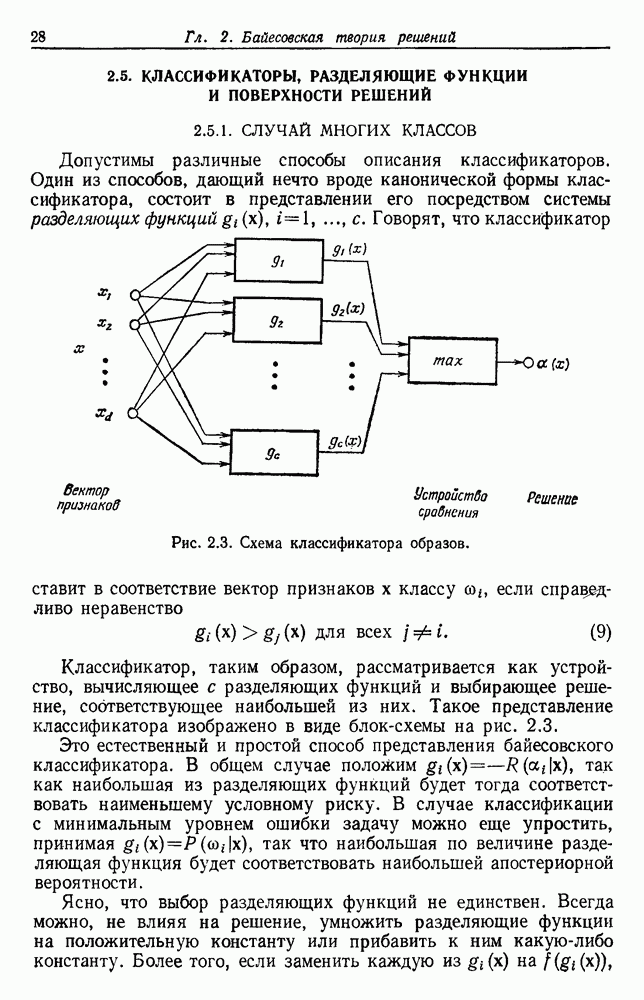
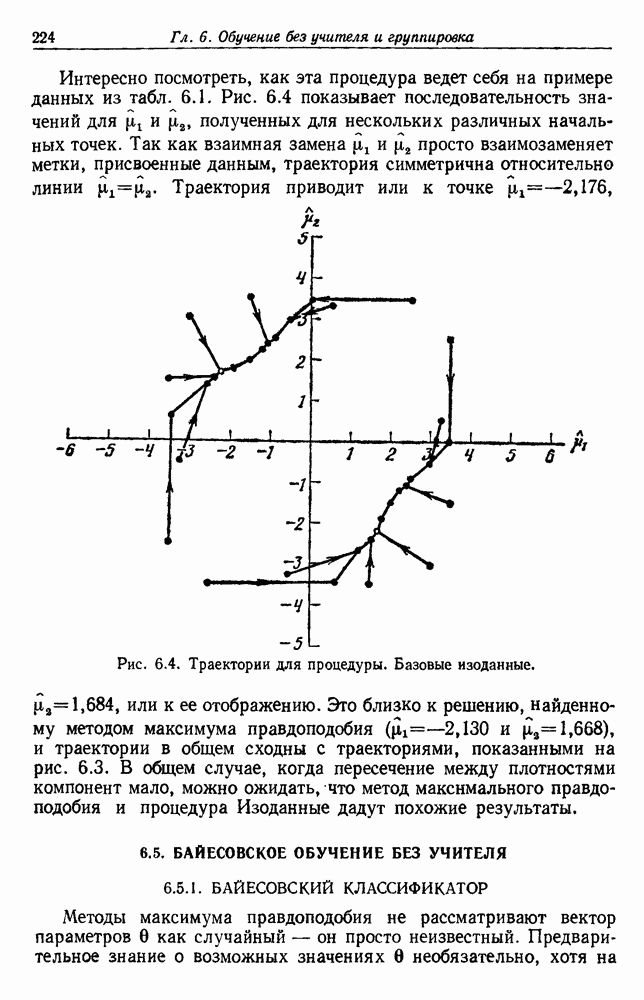
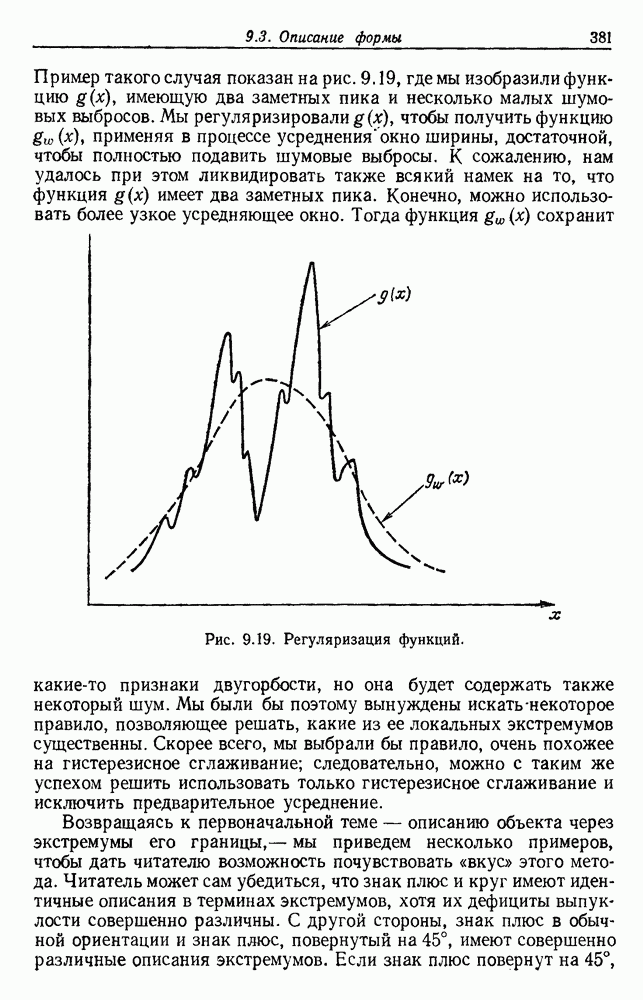
тождественны, так что  не зависит от х. Таким образом, Границы, заданные (28), являются максимально близкими в том смысле, что для любой Р существуют условные и априорные вероятности, для которых эти границы Достигаются. На рис. 4.4 графически представлены эти границы. Байесовский уровень Р может находиться в любом месте между
не зависит от х. Таким образом, Границы, заданные (28), являются максимально близкими в том смысле, что для любой Р существуют условные и априорные вероятности, для которых эти границы Достигаются. На рис. 4.4 графически представлены эти границы. Байесовский уровень Р может находиться в любом месте между  Границы сходятся В этих двух крайних точках. Когда байесовский уровень мал, верхняя граница превышает его почти в два раза. В общем значение ошибки правила ближайшего соседа должно находиться в заштрихованной области.
Границы сходятся В этих двух крайних точках. Когда байесовский уровень мал, верхняя граница превышает его почти в два раза. В общем значение ошибки правила ближайшего соседа должно находиться в заштрихованной области.
Поскольку Р всегда меньше или равна  то, если имеется бесконечный набор данных и используется сложное решающее правило,
то, если имеется бесконечный набор данных и используется сложное решающее правило,

Рис. 4.4. Границы ошибки правила ближайшего соседа.
можно по крайней мере в два раза сократить уровень ошибки.
В этом смысле по крайней мере половина классифицирующей информации бесконечного набора данных находится по соседству.
Естественно задаться вопросом, насколько хорошо правило ближайшего соседа в случае конечного числа выборок и как быстро результат сходится к асимптотическому значению. К сожалению, ответы для общего случая неблагоприятны. Можно показать, что сходимость может быть бесконечно медленной и уровень ошибки  даже не должен монотонно убывать с ростом и. Так же, как это происходит с другими непараметрическими методами, трудно получить какие-либо еще результаты, кроме асимптотических, не делая дальнейших допущений о вероятностных свойствах.
даже не должен монотонно убывать с ростом и. Так же, как это происходит с другими непараметрическими методами, трудно получить какие-либо еще результаты, кроме асимптотических, не делая дальнейших допущений о вероятностных свойствах.









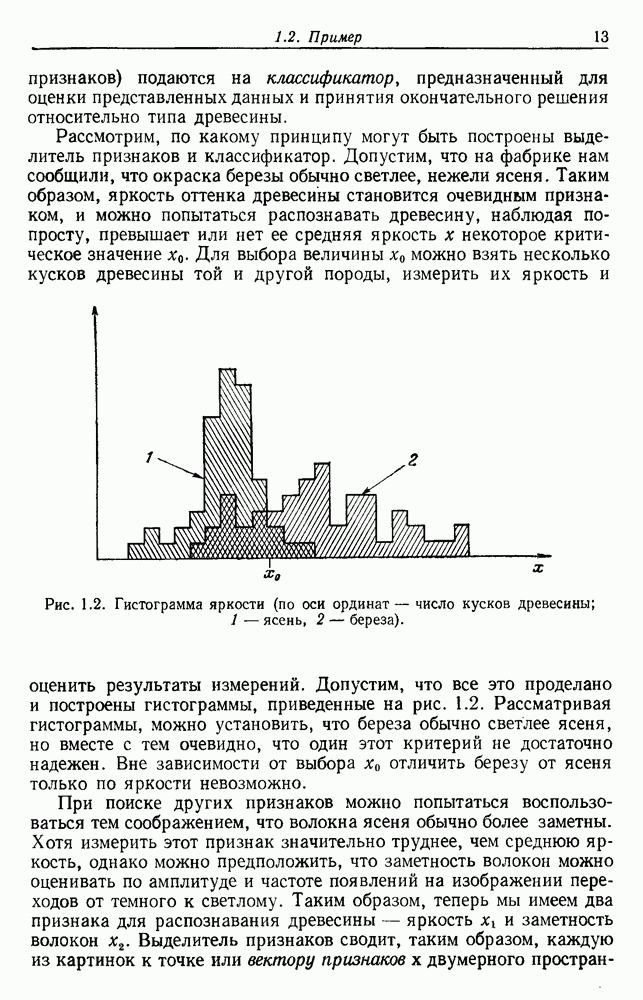














































































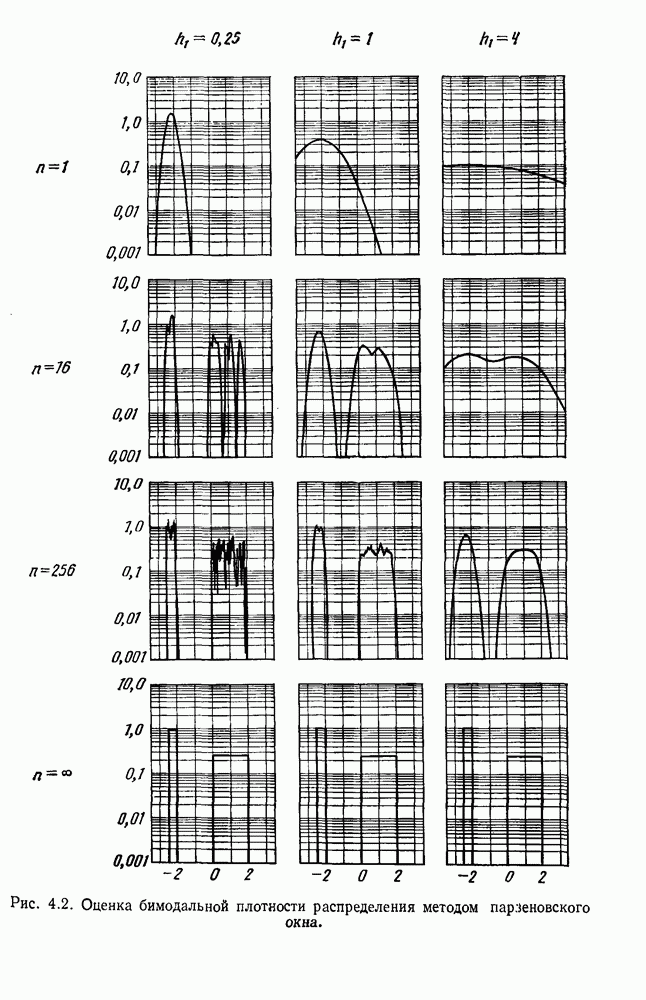

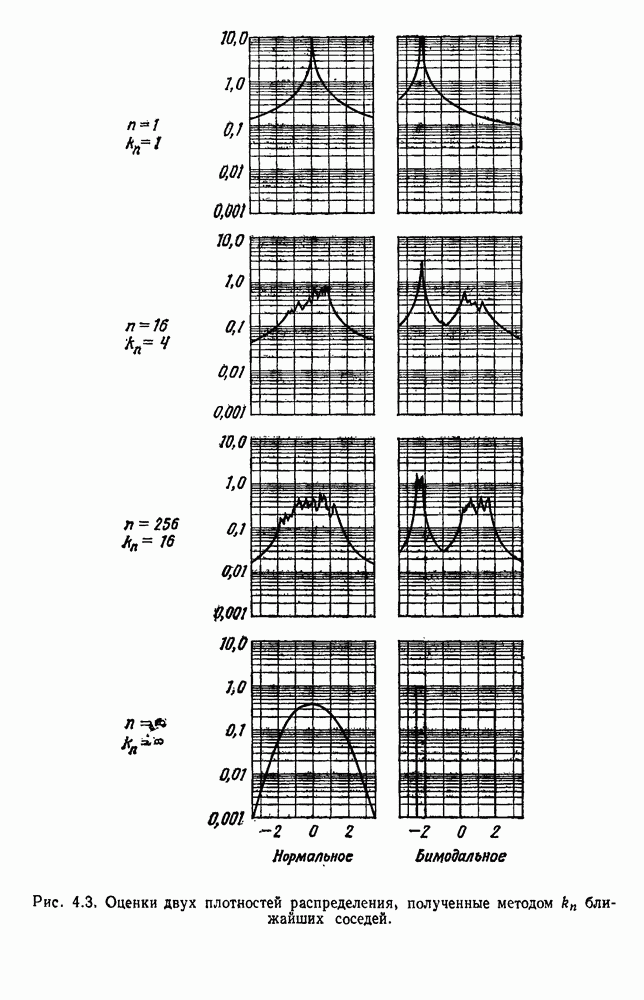



































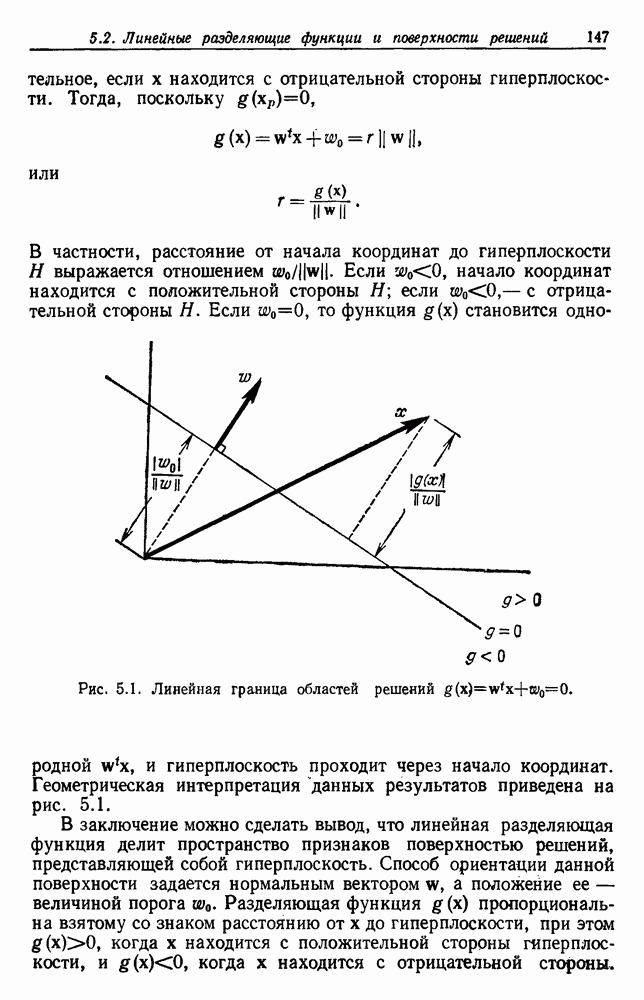



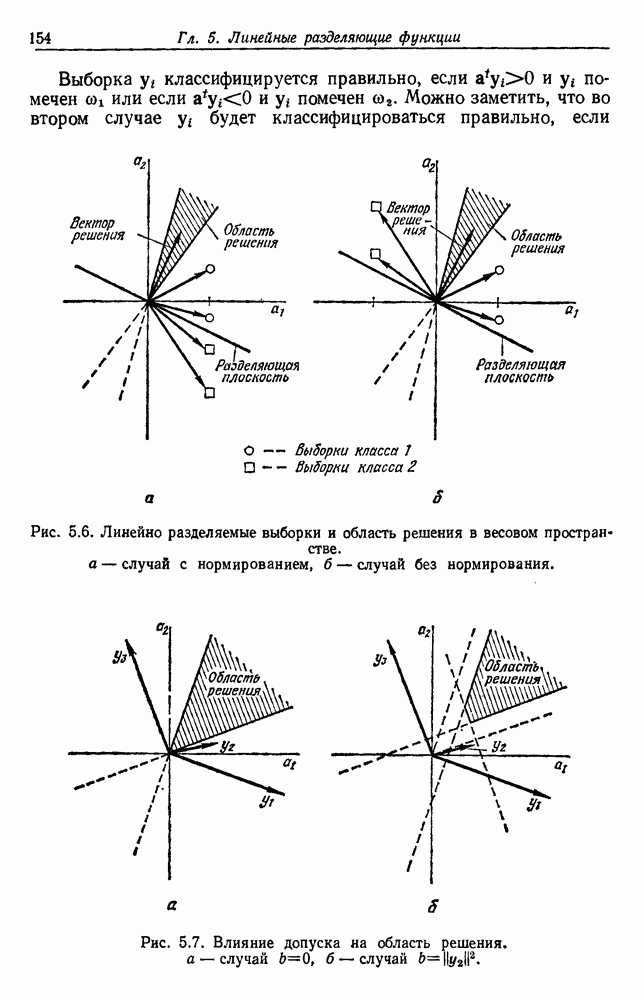



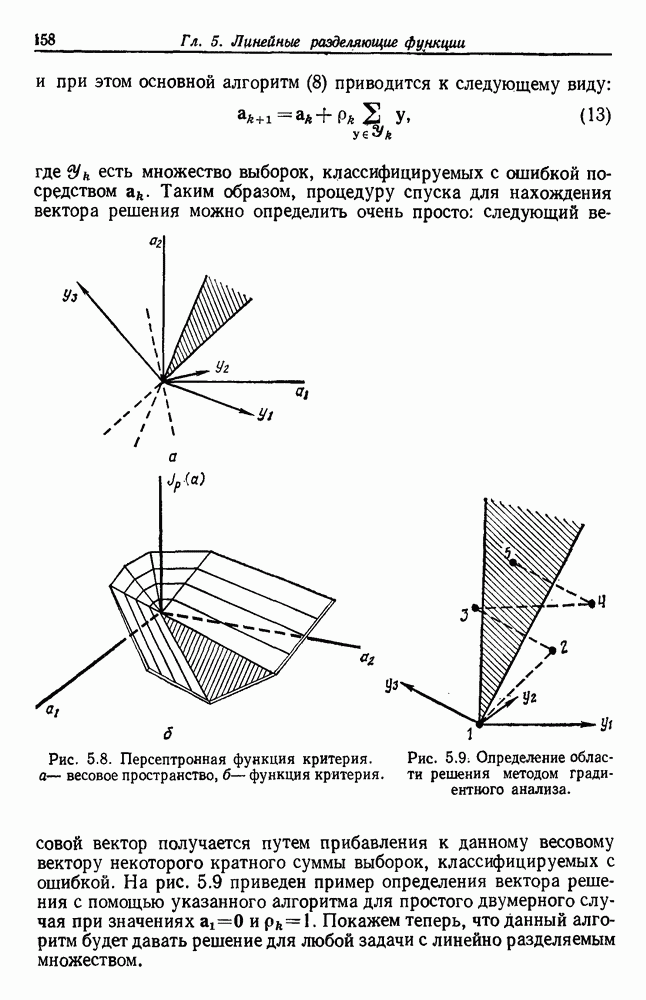

















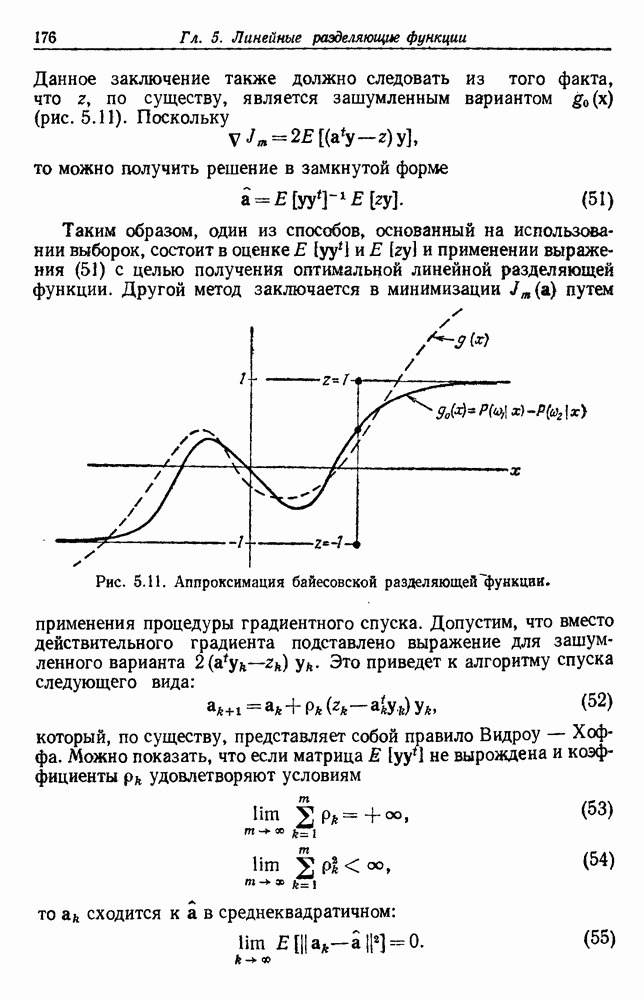














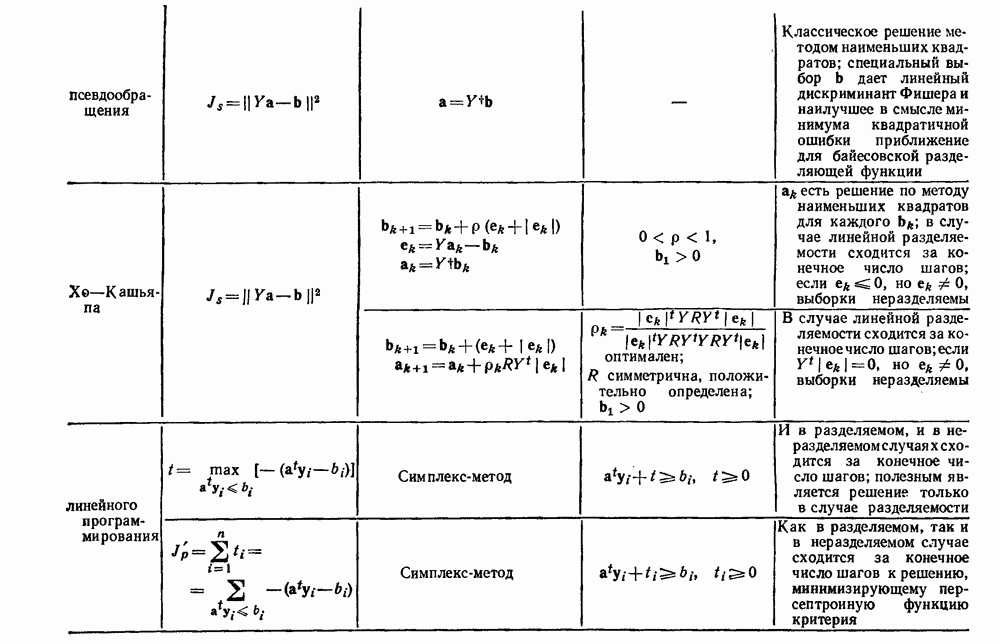
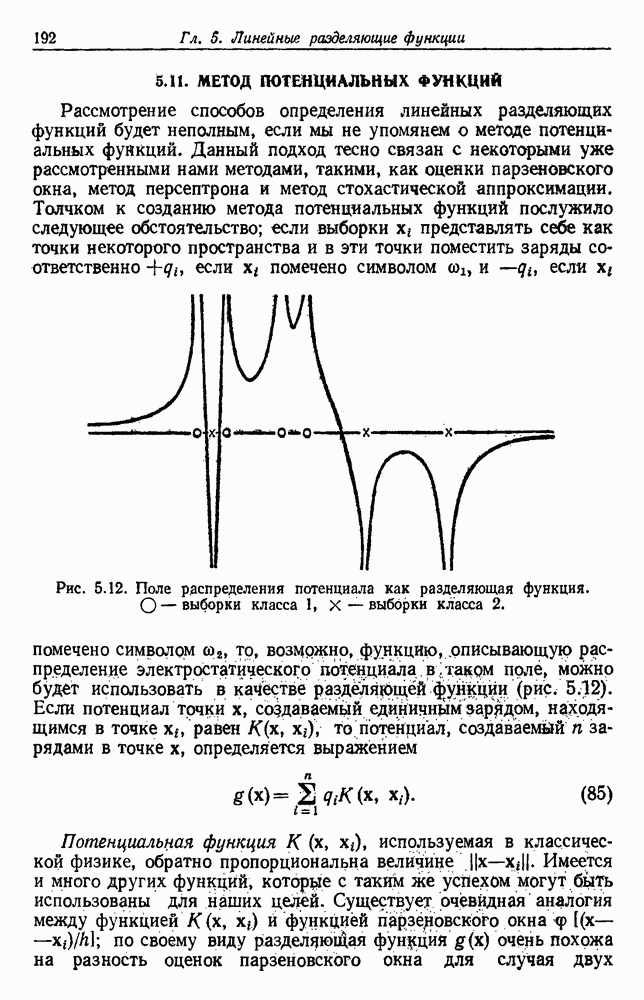

























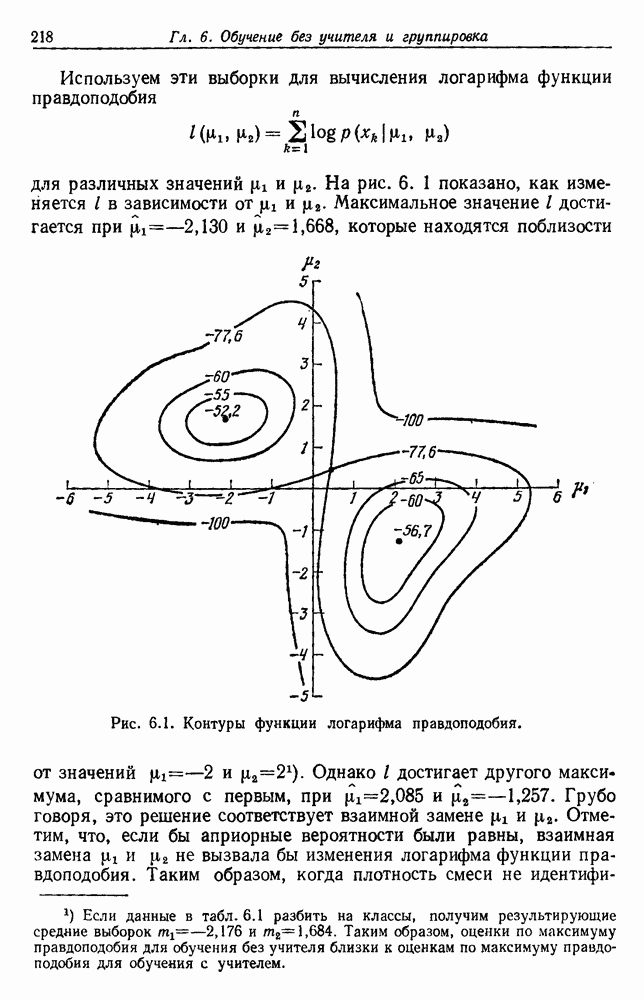
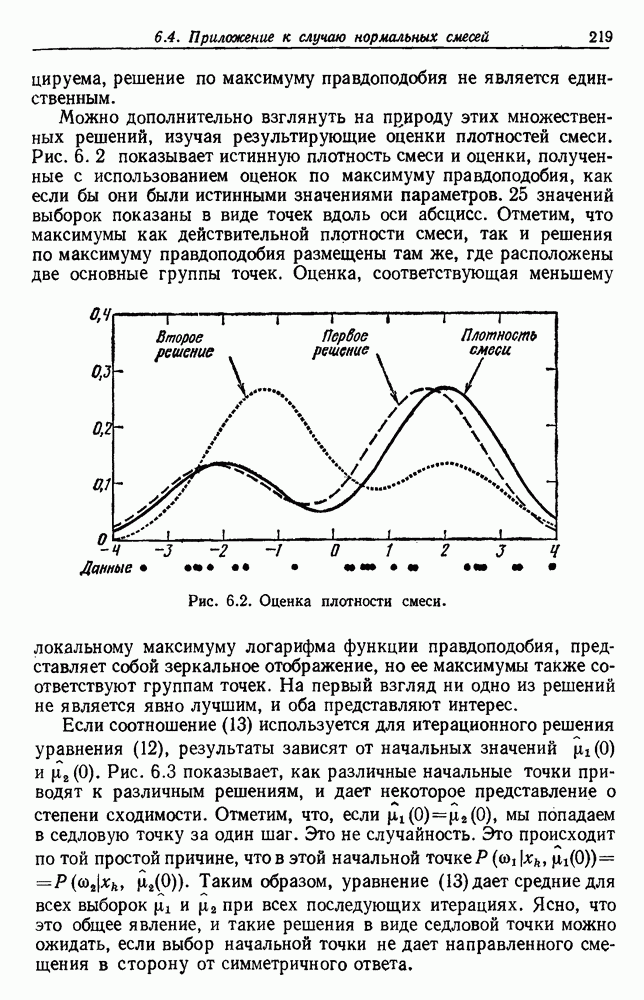
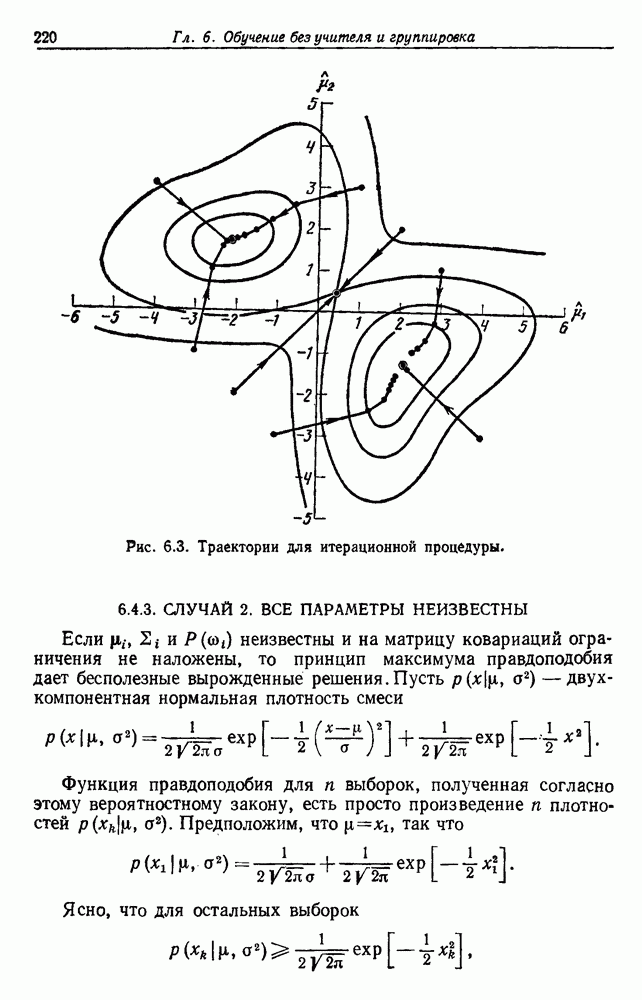





































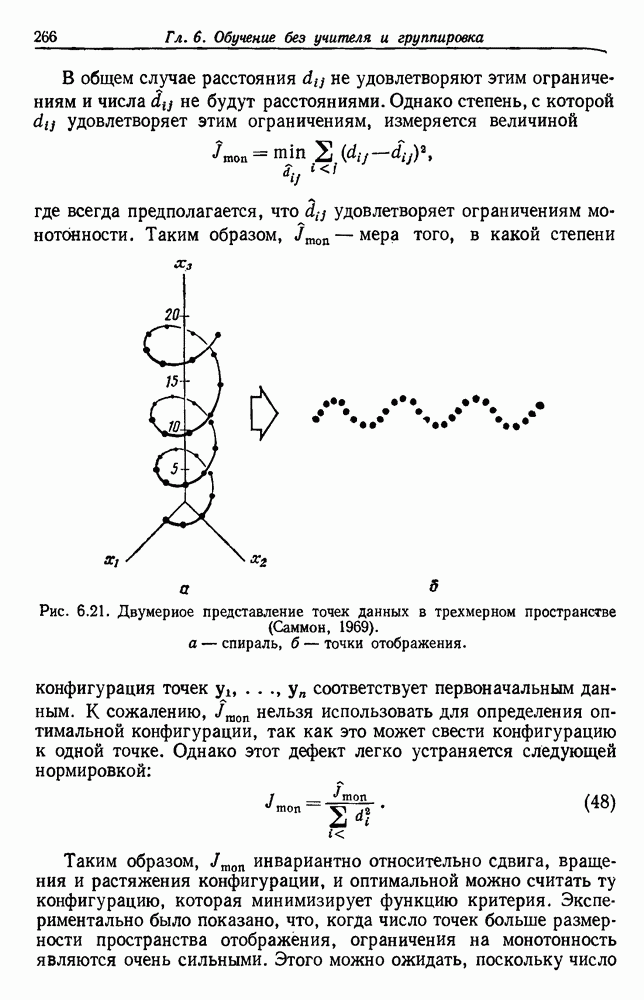



























































































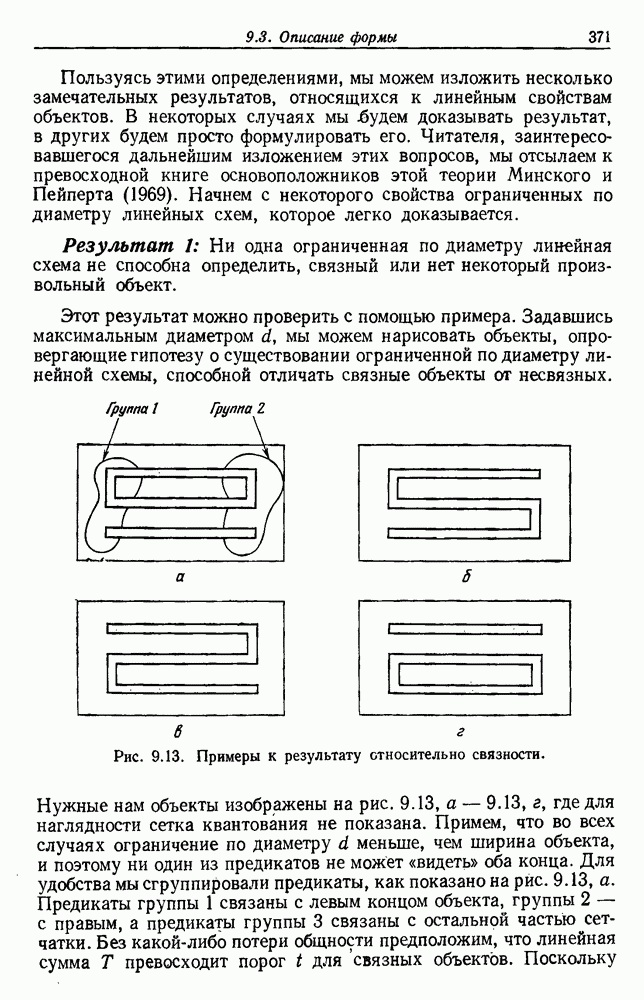








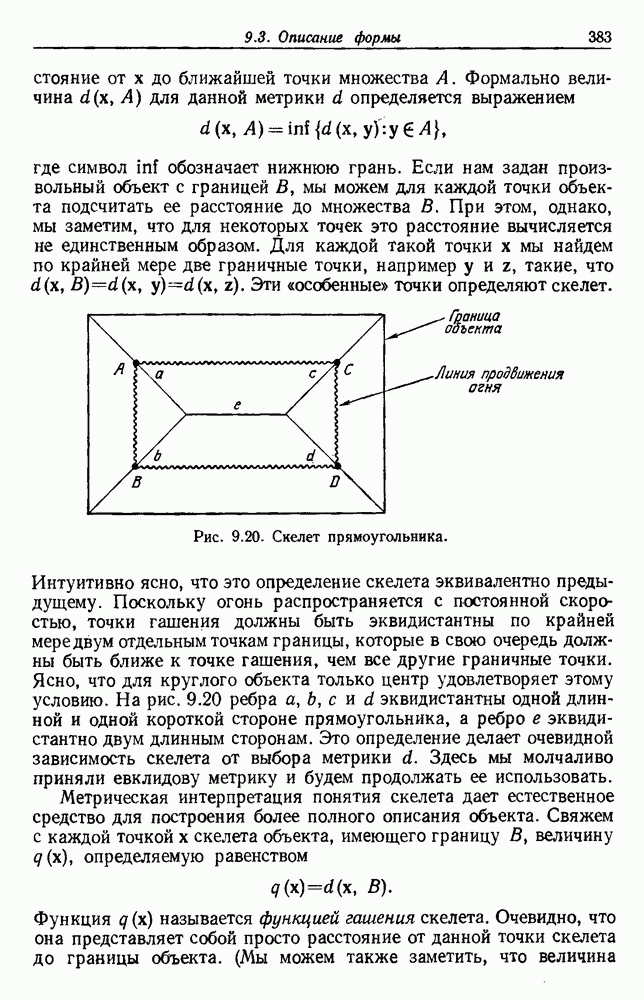


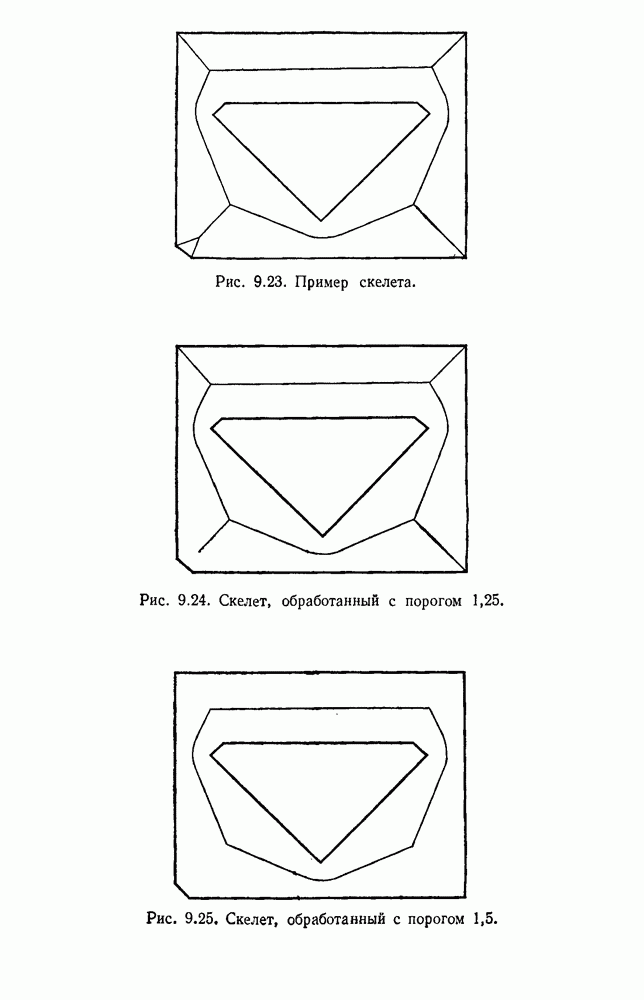






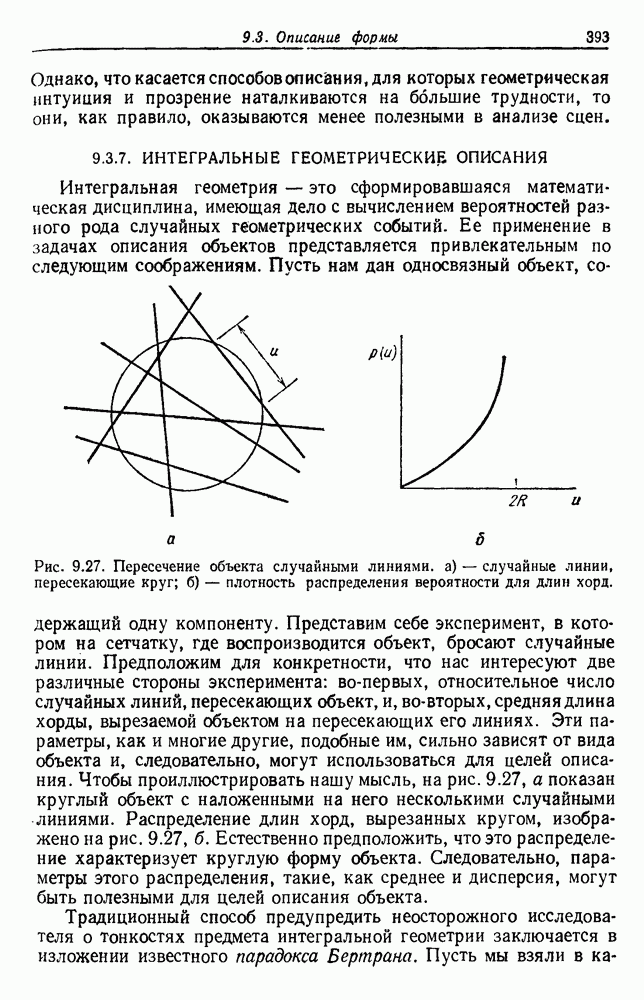


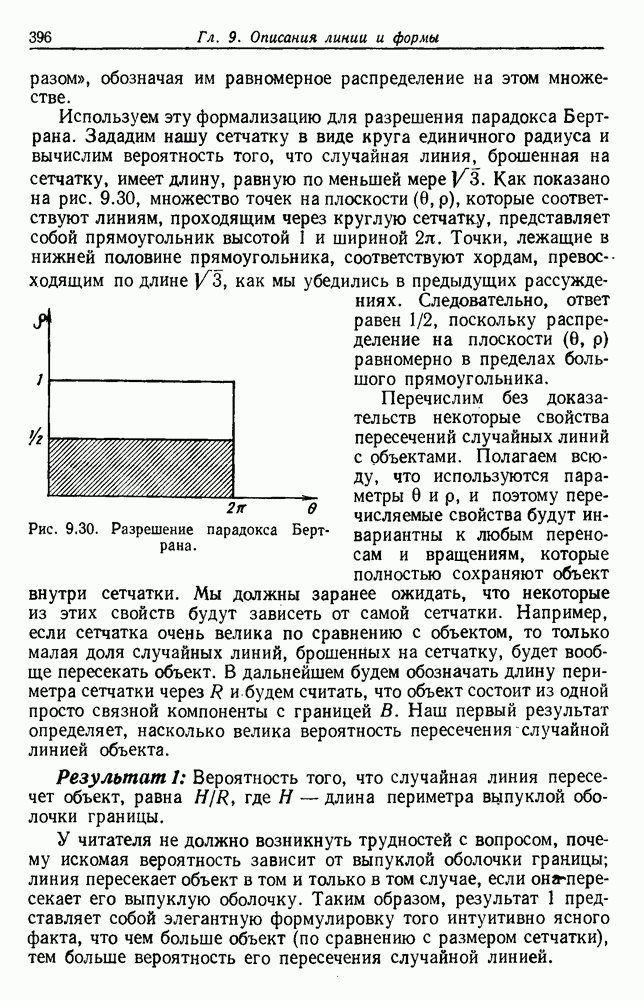
























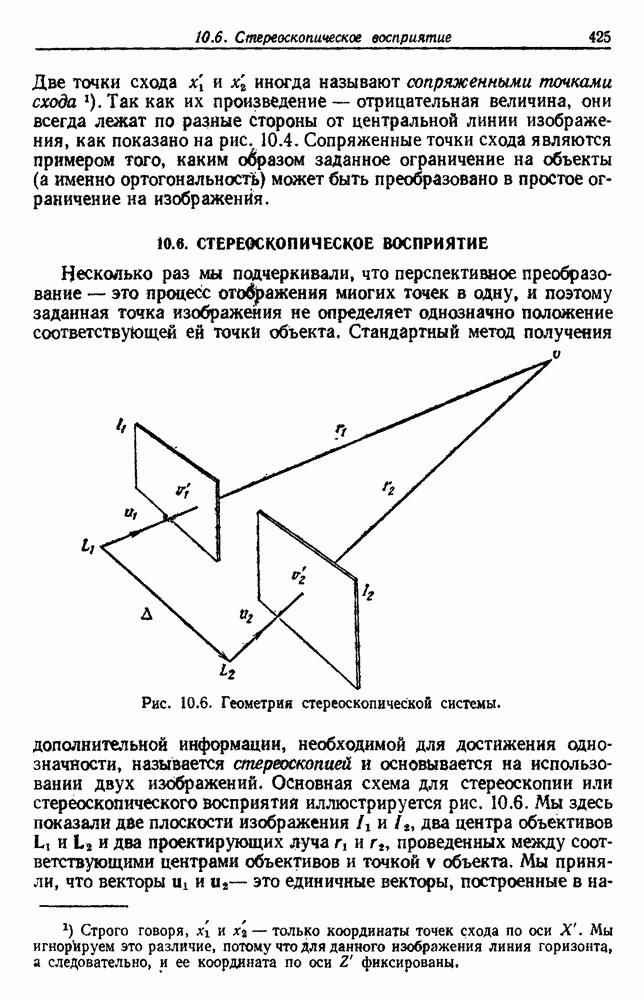












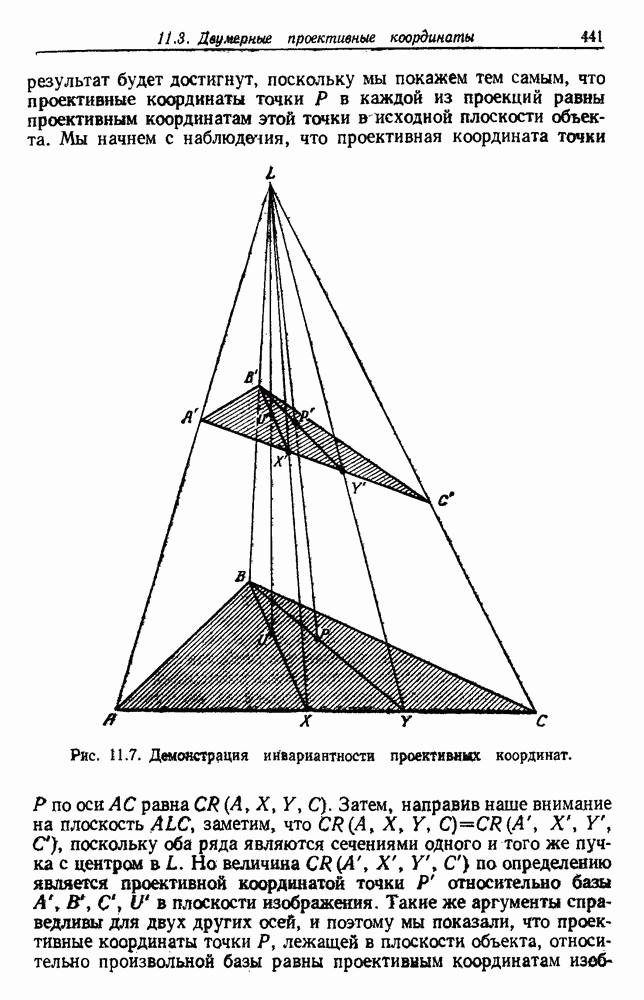

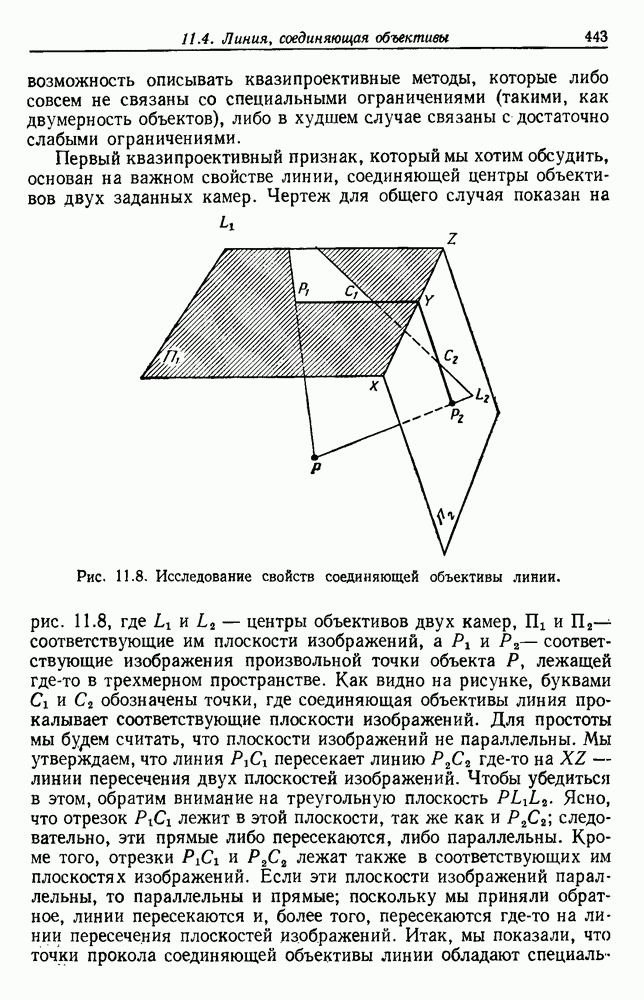
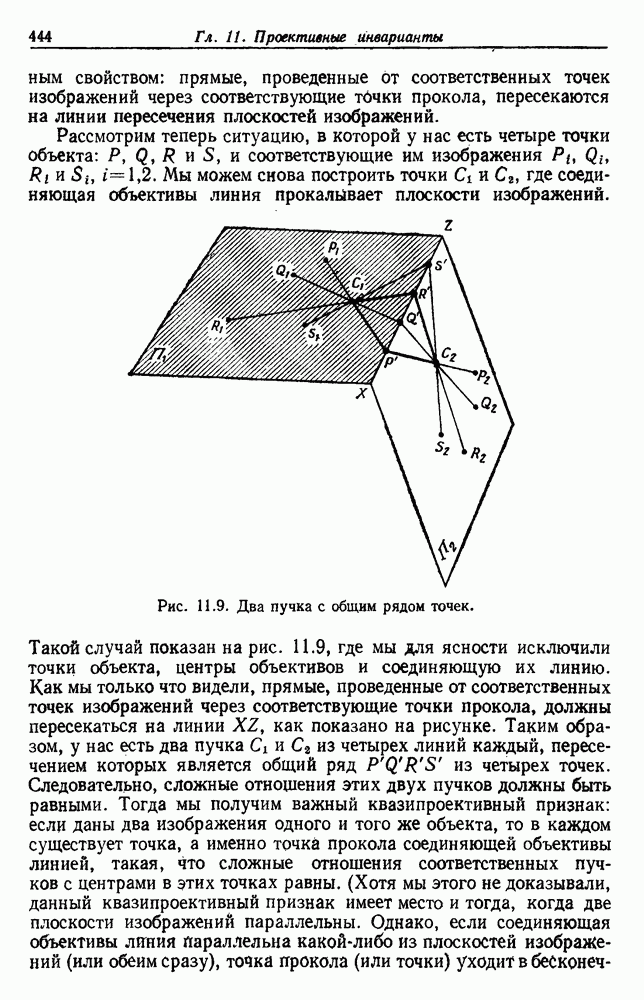













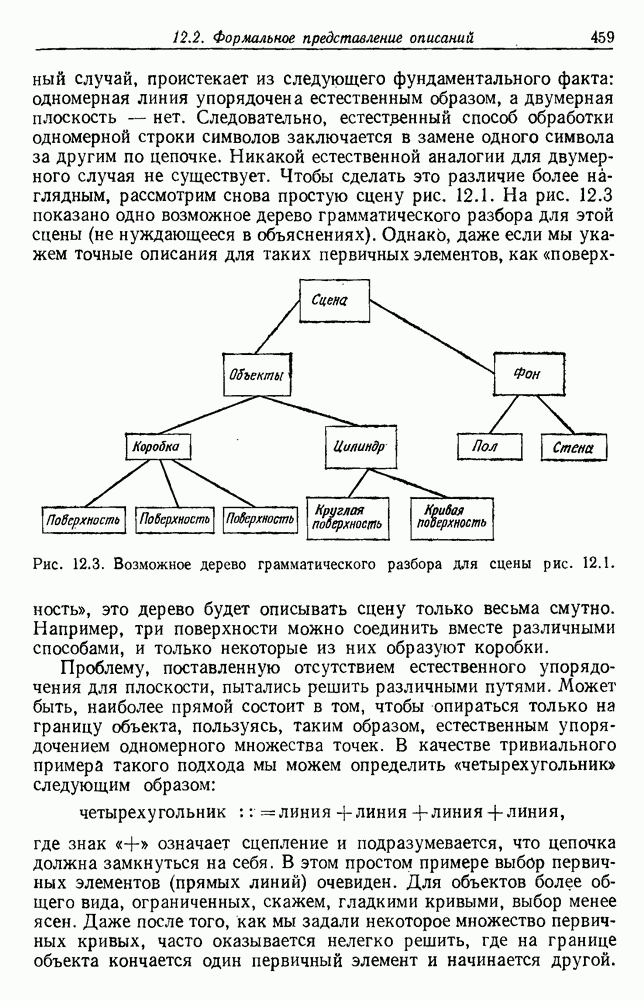















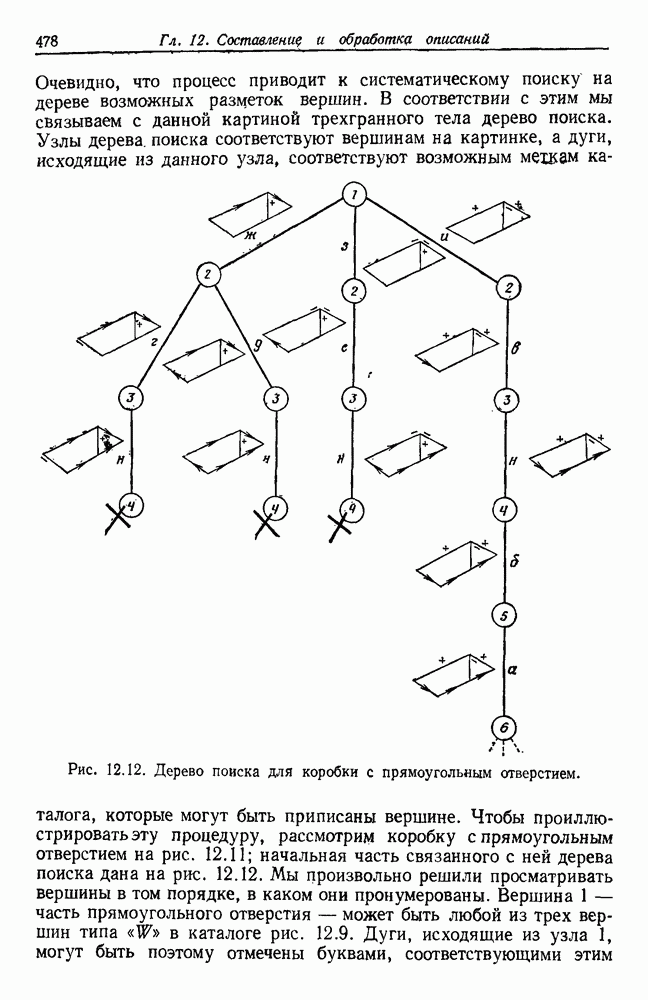


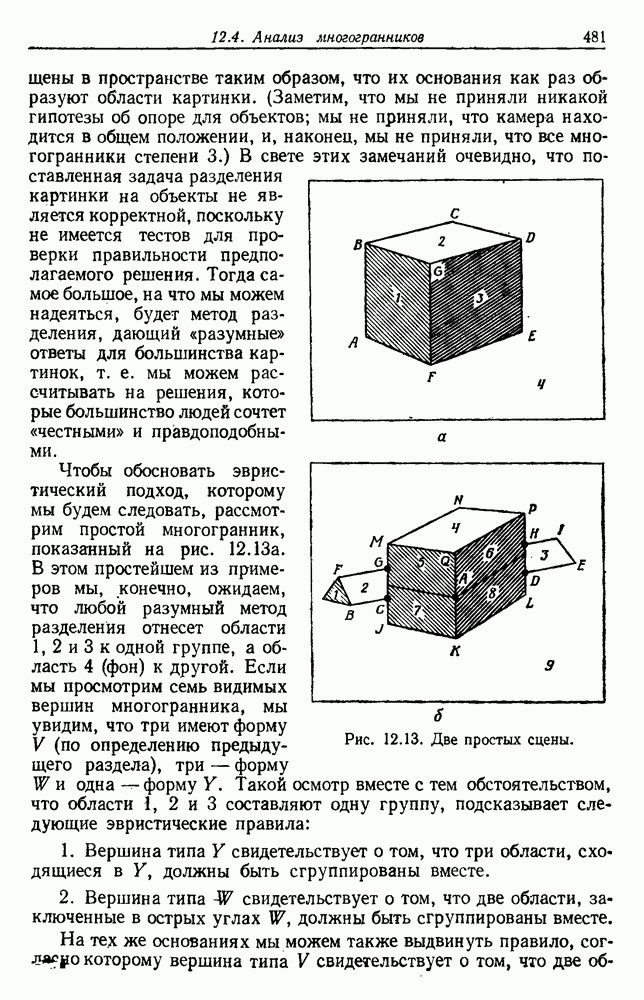


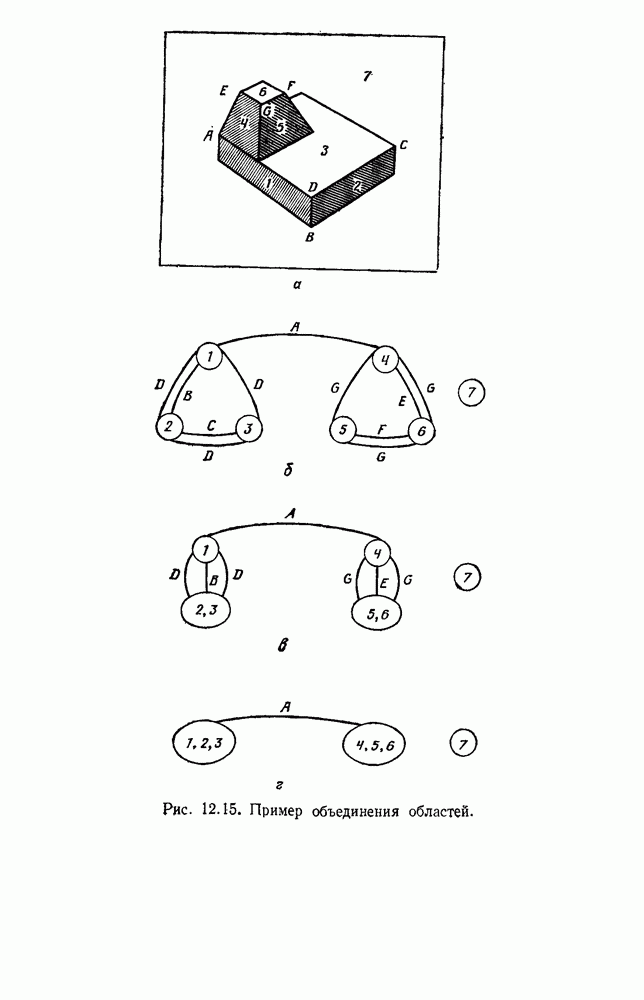
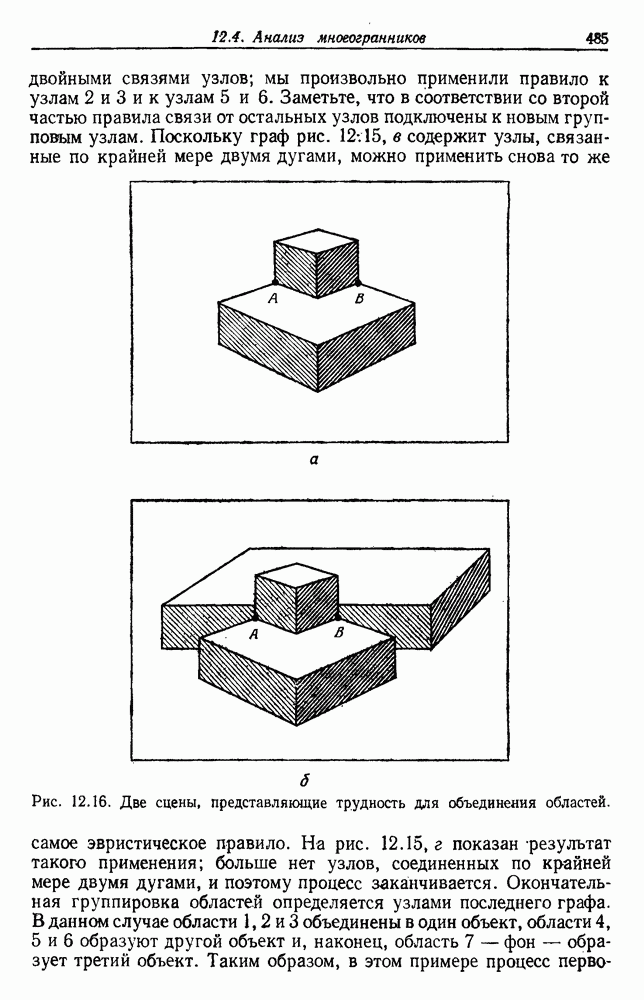











 будет множеством
будет множеством  помеченных выборок, и пусть х будет выборкой, ближайшей к х. Тогда правило ближайшего соседа для классификации х заключается в том, что х присваивается метка, ассоциированная с
помеченных выборок, и пусть х будет выборкой, ближайшей к х. Тогда правило ближайшего соседа для классификации х заключается в том, что х присваивается метка, ассоциированная с  Правило ближайшего соседа является почти оптимальной процедурой; его применение обычно приводит к уровню ошибки, превышающему минимально возможный байесовский. Как мы увидим, однако, при неограниченном количестве выборок уровень ошибки никода не будет хуже байесовского более чем в два раза.
Правило ближайшего соседа является почти оптимальной процедурой; его применение обычно приводит к уровню ошибки, превышающему минимально возможный байесовский. Как мы увидим, однако, при неограниченном количестве выборок уровень ошибки никода не будет хуже байесовского более чем в два раза.