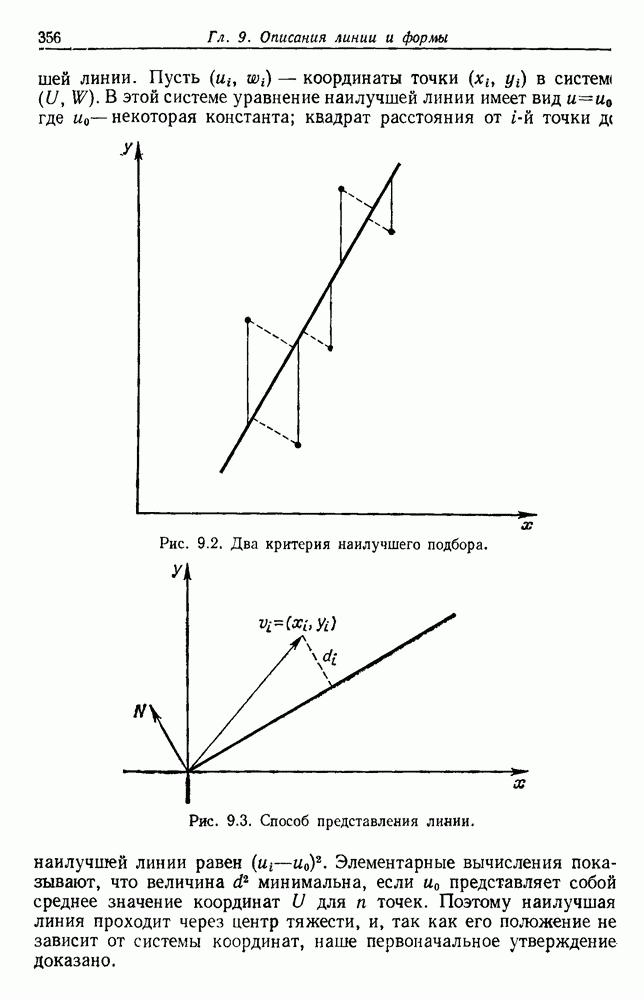
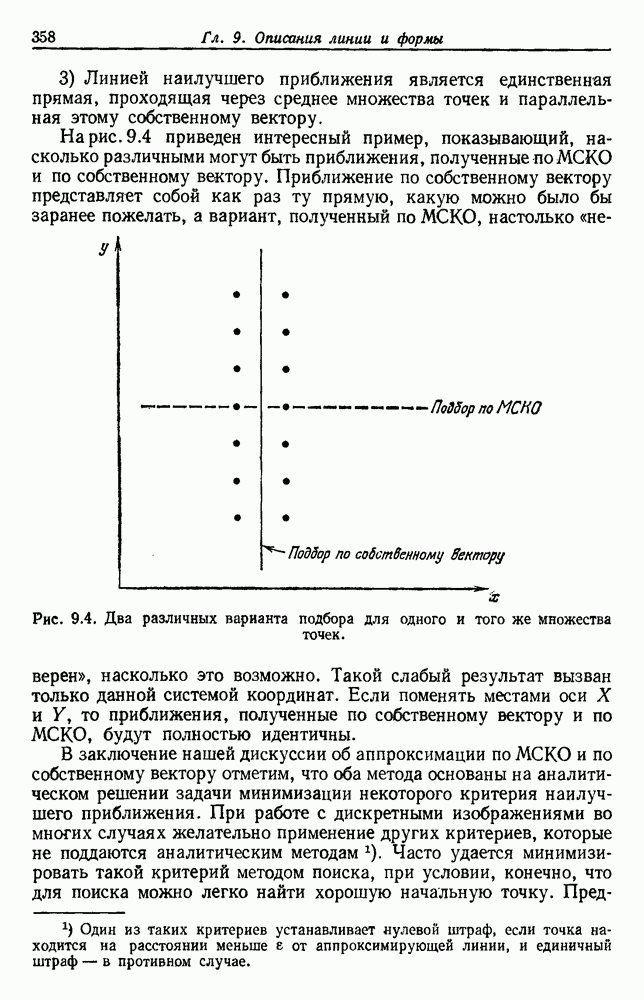
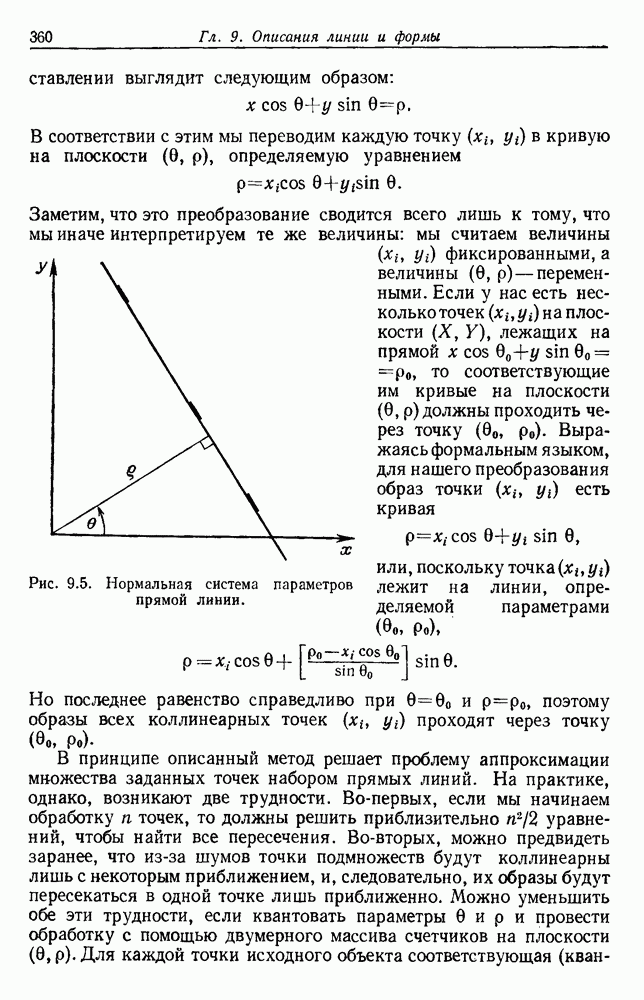
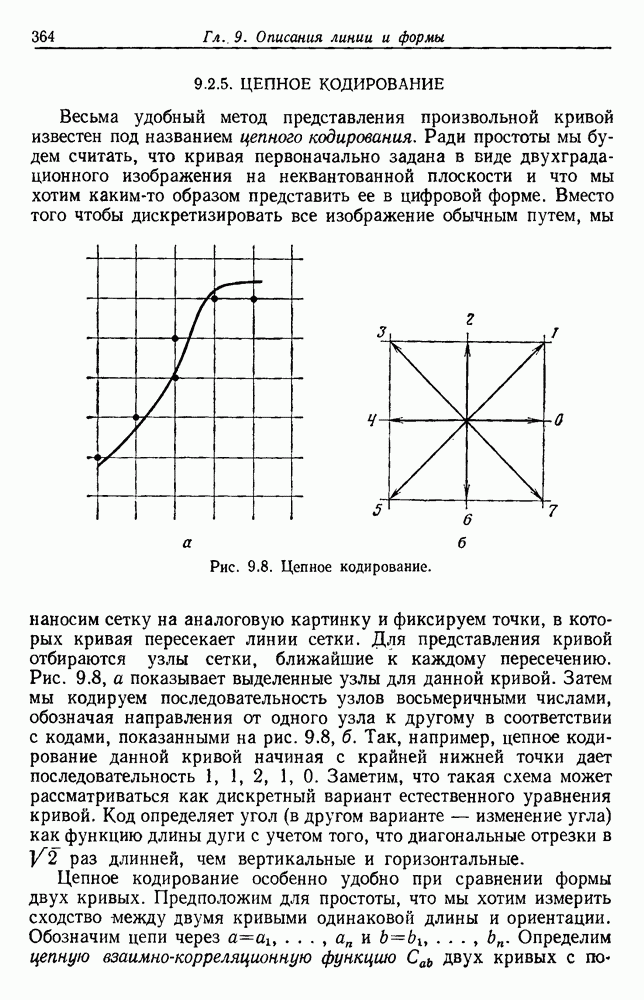
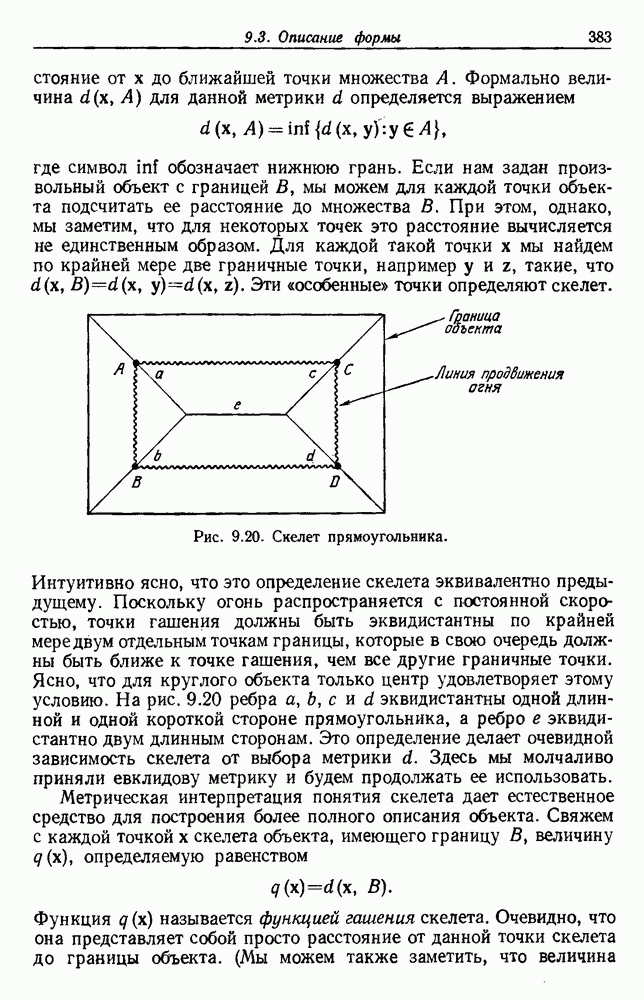
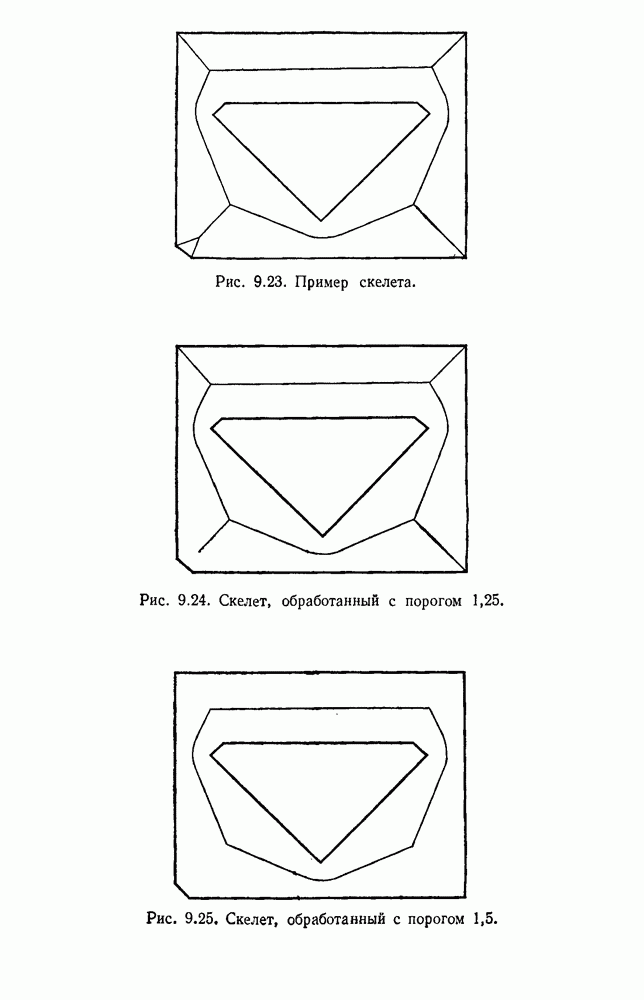
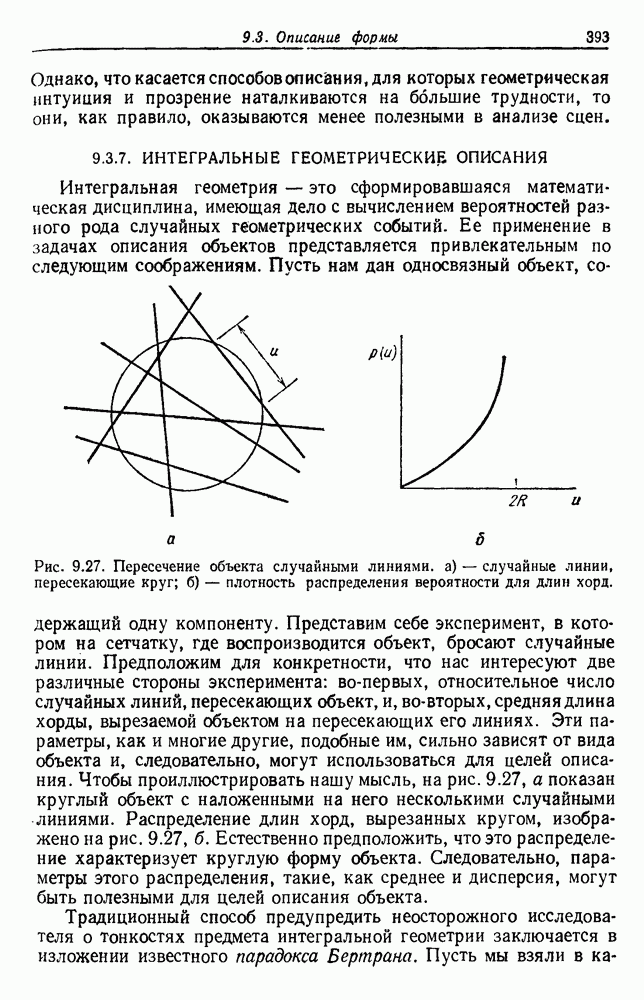
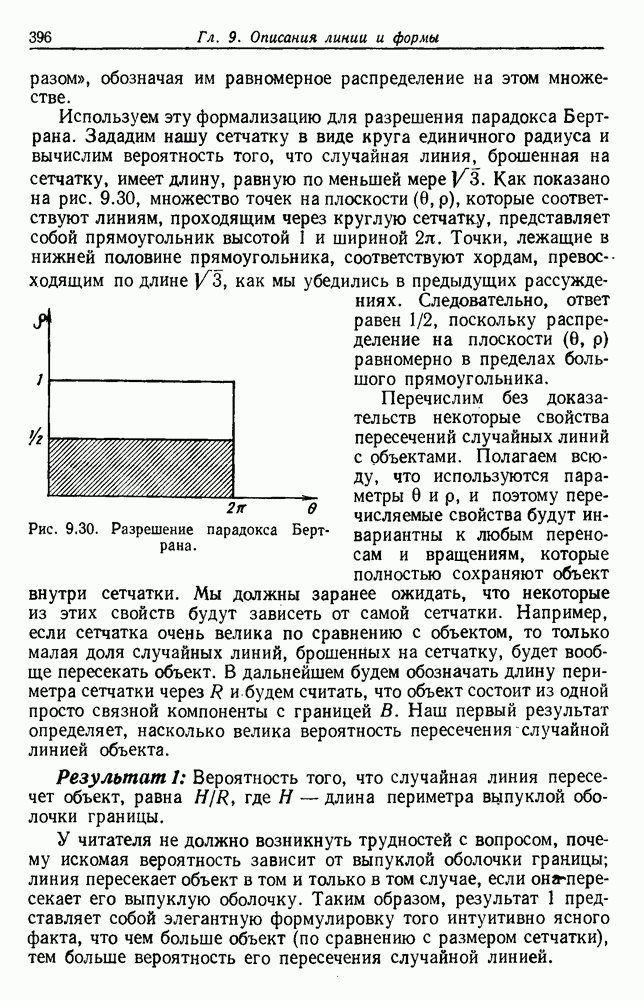
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
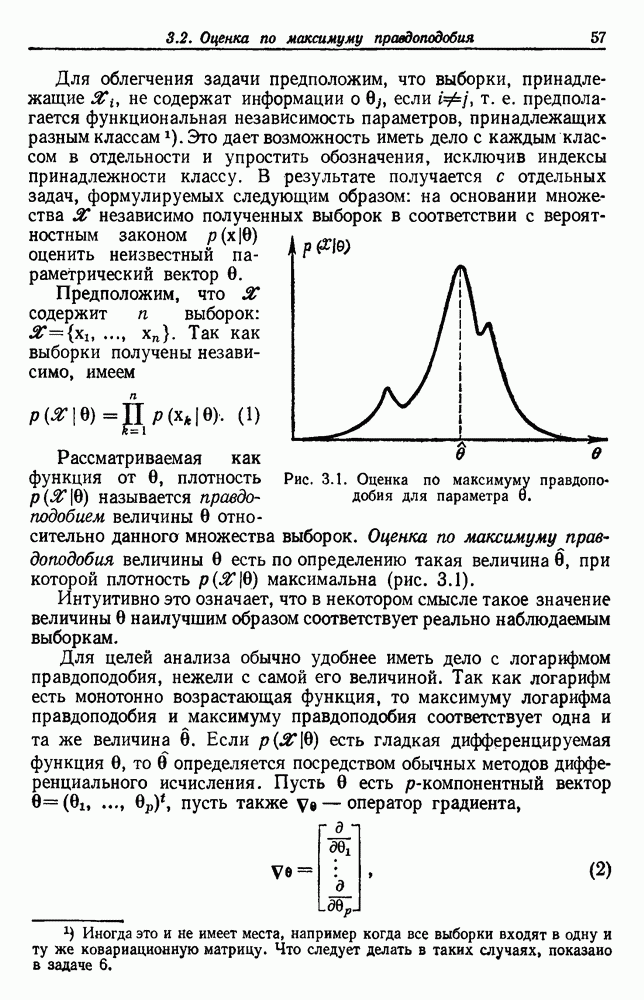
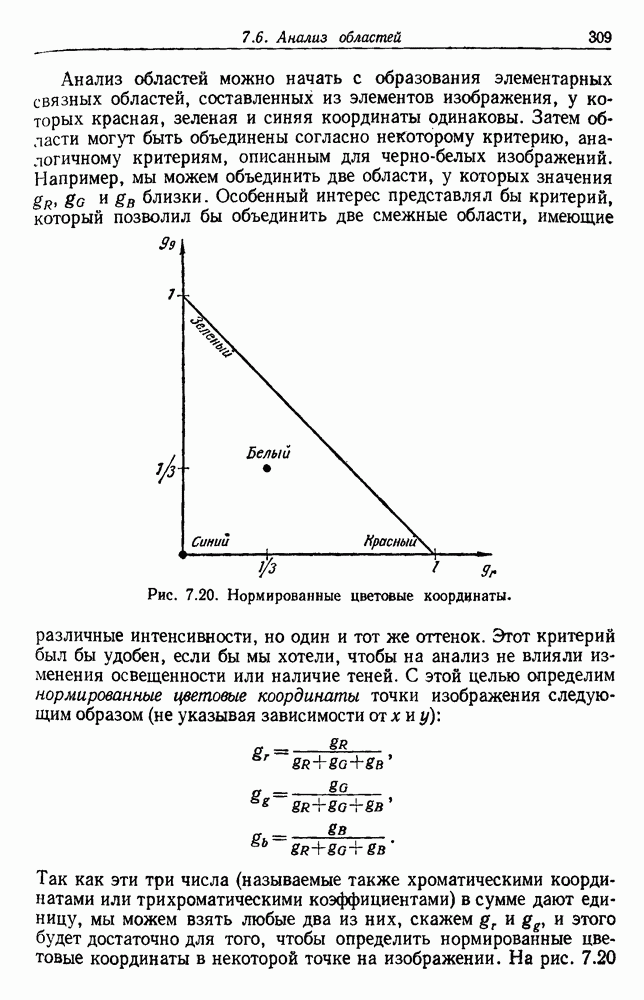
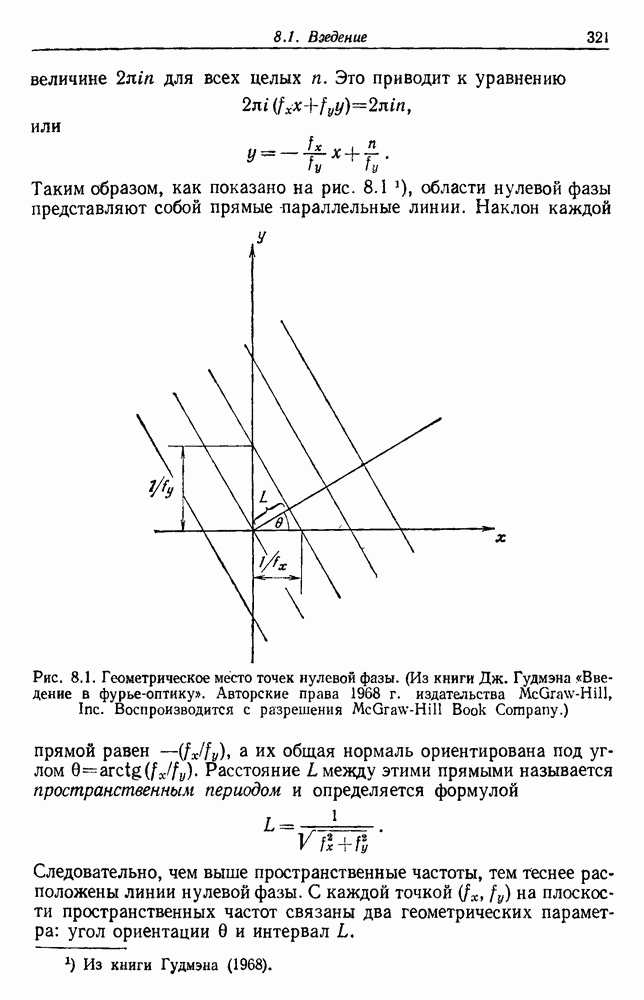
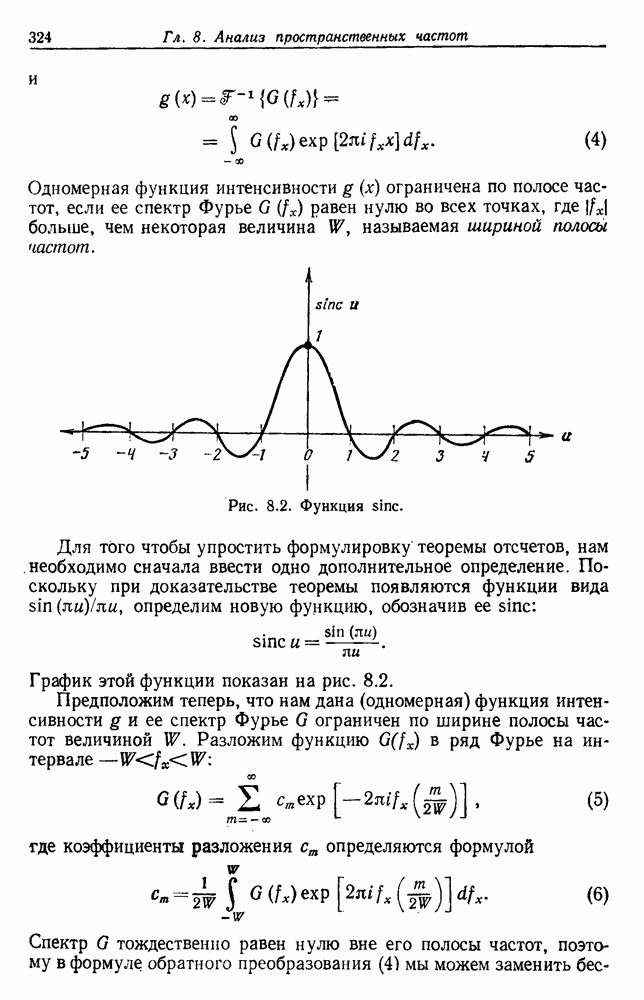
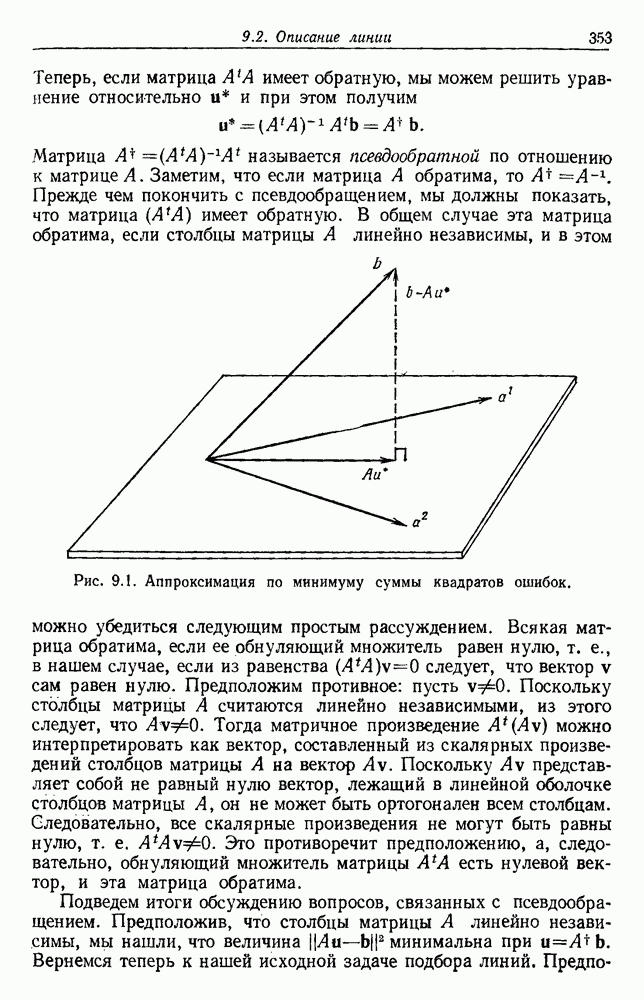
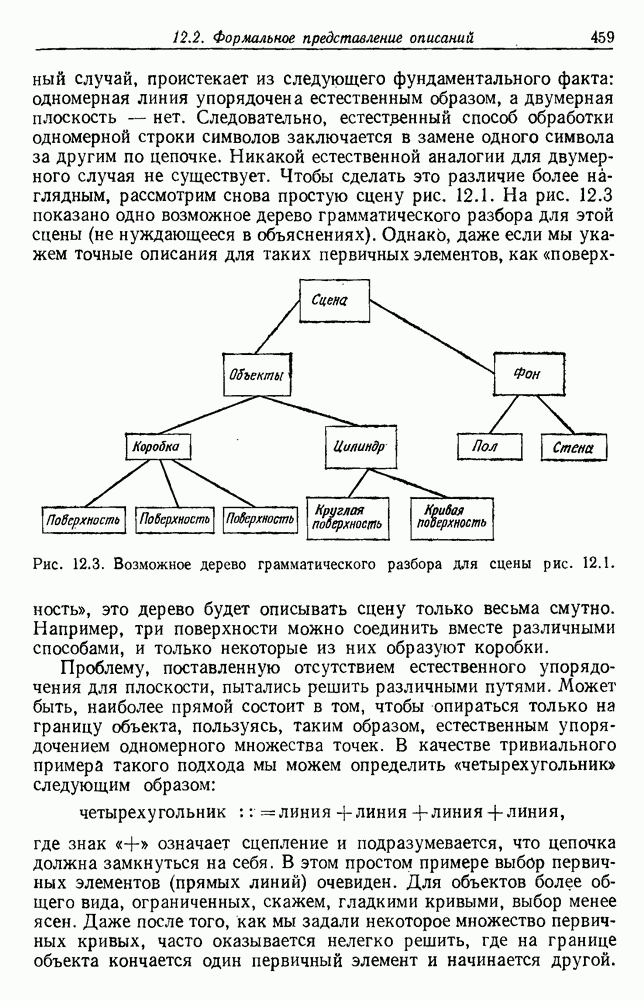
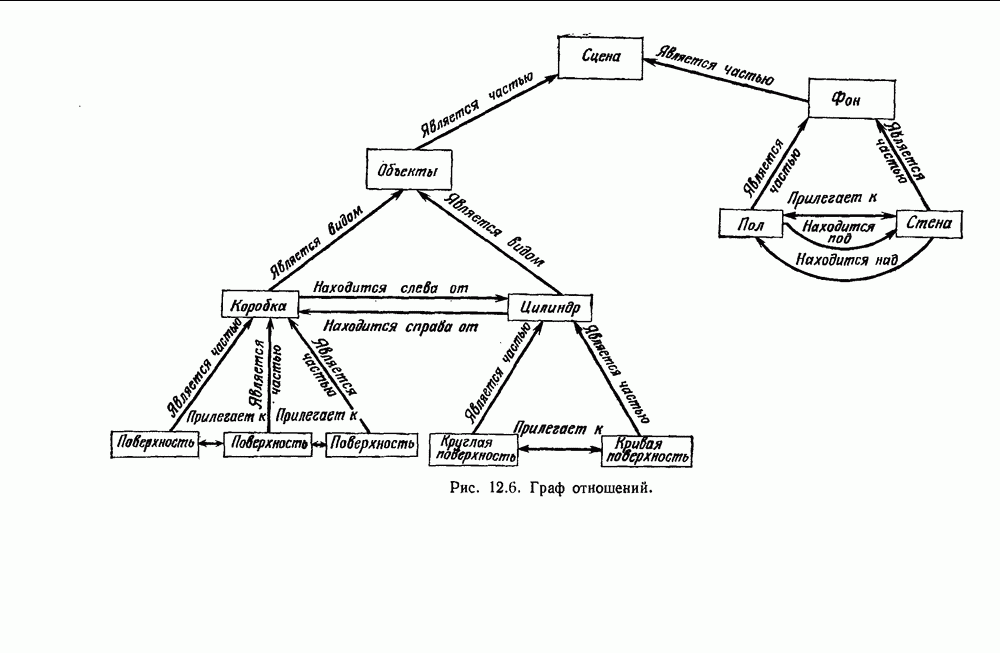
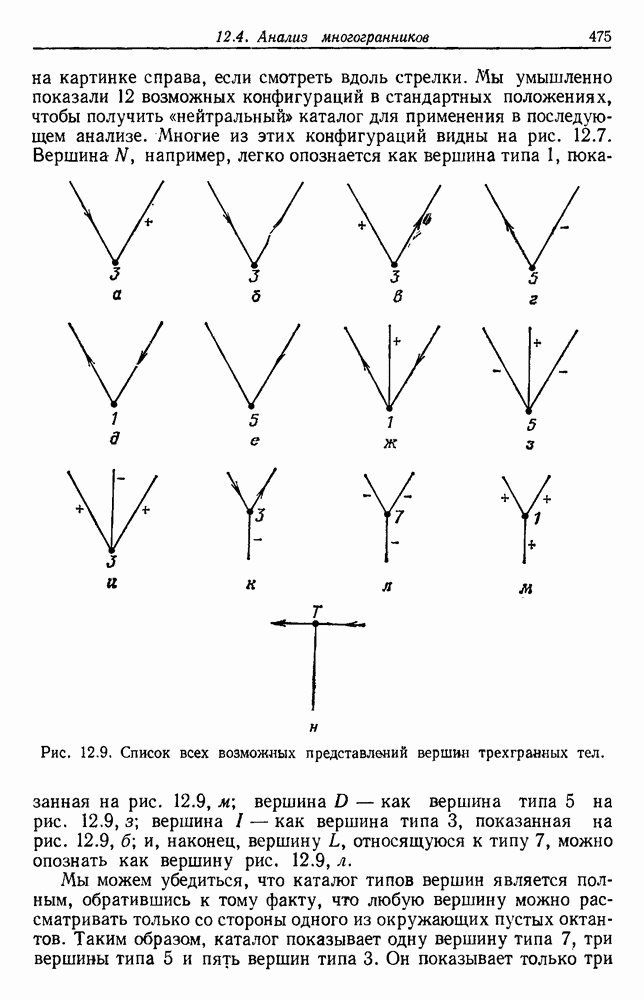
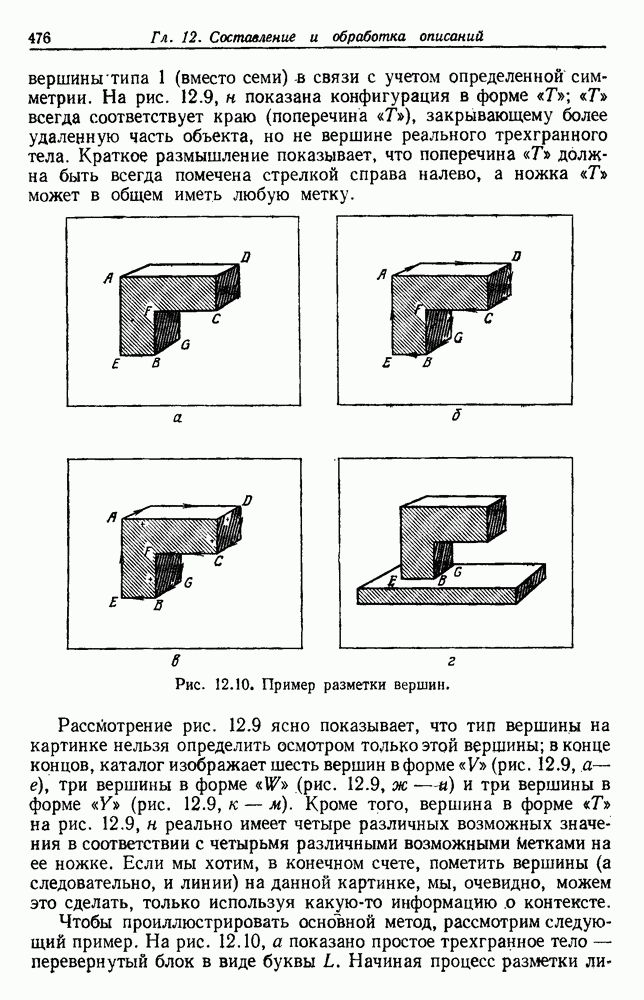
6.5. БАЙЕСОВСКОЕ ОБУЧЕНИЕ БЕЗ УЧИТЕЛЯ6.5.1. БАЙЕСОВСКИЙ КЛАССИФИКАТОРМетоды максимума правдоподобия не рассматривают вектор параметров практике такое знание можно использовать для выбора хорошей начальной точки при процедуре подъема на вершину. В этом разделе мы используем байесовский подход к обучению без учителя. Предположим, что Начнем с четкого определения основных предположений. Предполагаем, что 1. Число классов известно. 2. Априорные вероятности 3. Вид условных по классу плотностей 4. Часть знаний о 5. Остальная часть знаний о
После этого мы могли бы непосредственно начать вычисление Покажем явно роль выборок, записав это в виде
Так как выбор состояния природы
Введем вектор неизвестных параметров, написав
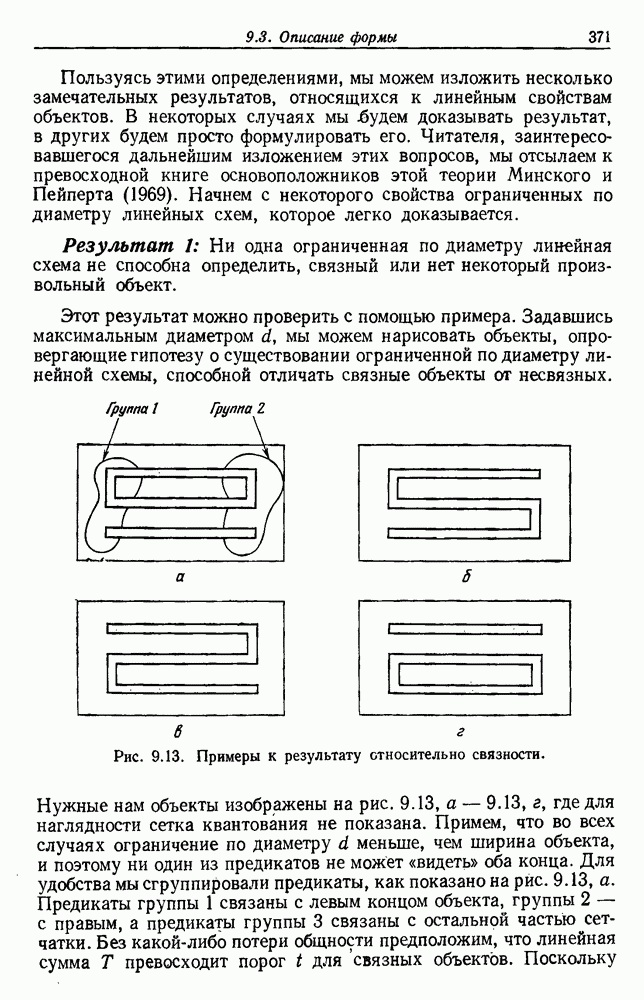
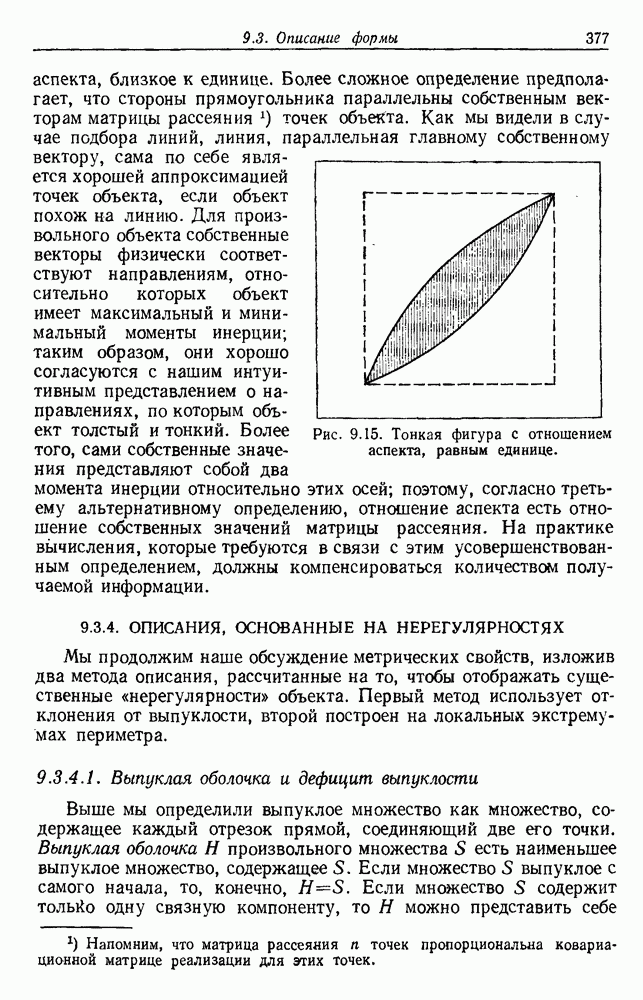
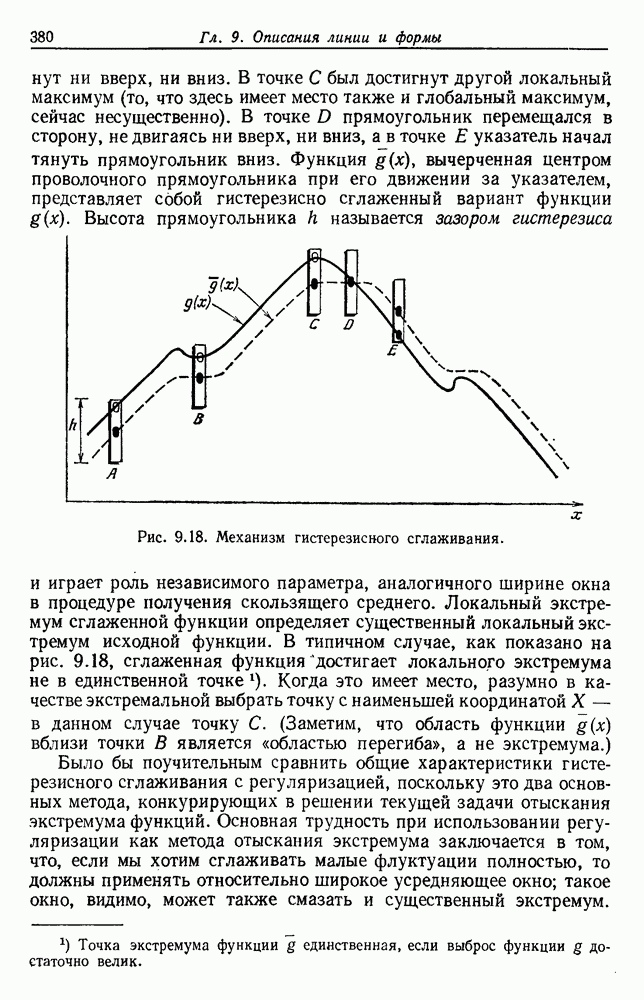
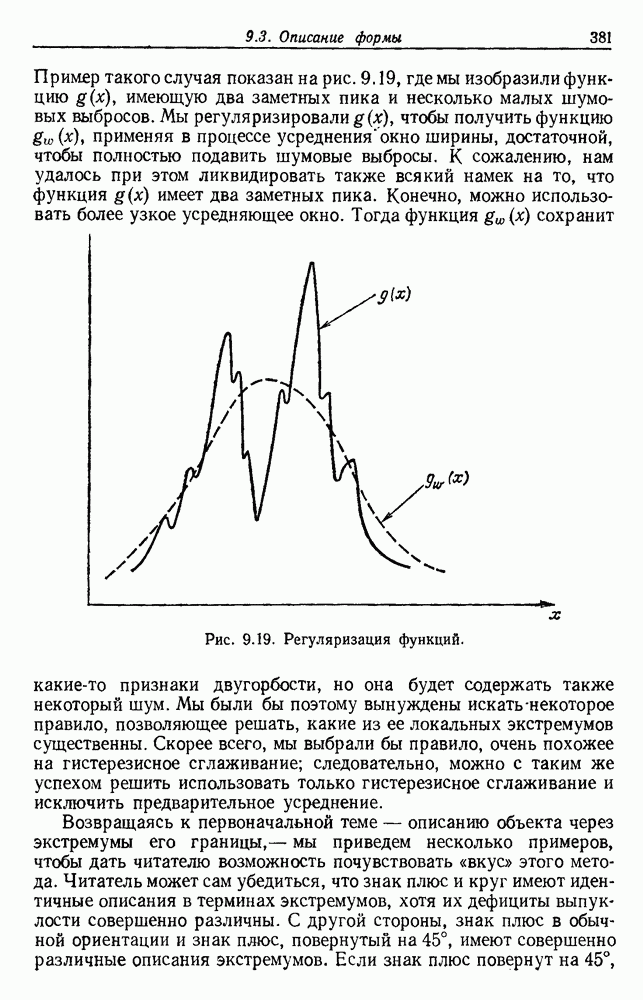
Поскольку сам х не зависит от выборок, то Таким образом, получаем
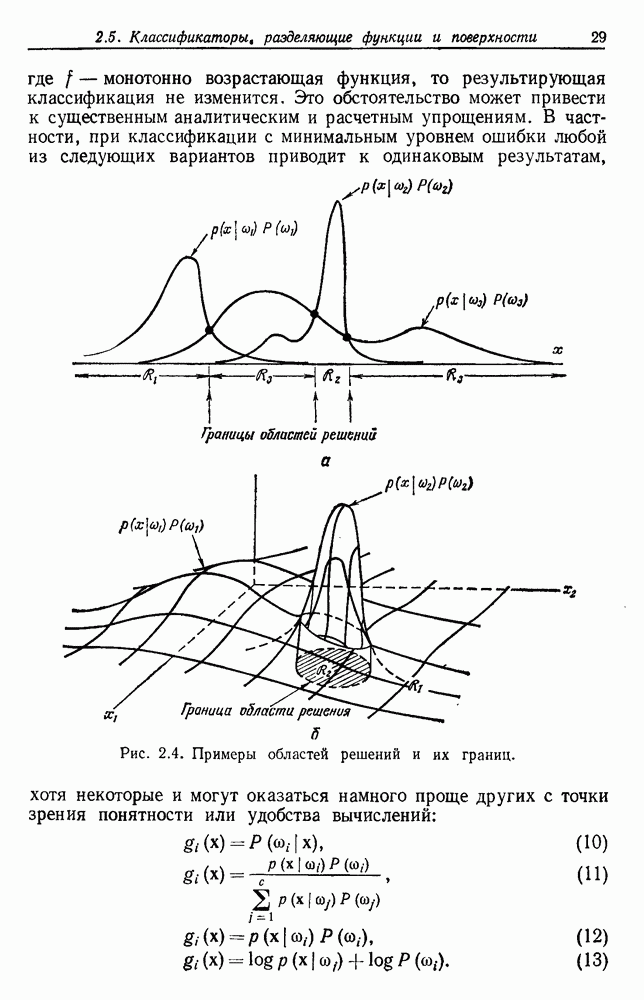
То есть наша наилучшая оценка для 6.5.2. ОБУЧЕНИЕ ВЕКТОРУ ПАРАМЕТРОВИспользуя правило Байеса, можем написать
где независимость выборок приводит к
С другой стороны, обозначив через
Это основные соотношения для байесовского обучения без учителя. Уравнение (20) подчеркивает связь между байесовским решением и решением по максимуму правдоподобия. Если
То есть эти условия оправдывают использование оценки по максимуму правдоподобия, используя ее в качестве истинного значения 0 при создании байесовского классификатора. Естественно, если плотность она будет далека от равномерной и это решающим образом повлияет на Тогда это и есть формальное байесовское решение задачи обучения без учителя. В ретроспективе тот факт, что обучение без учителя параметрам плотности смеси тождественно обучению с учителем параметрам плотности компонент, не является удивительным. Действительно, если плотность компонент сама по себе является смесью, то тогда действительно не будет существенной разницы между этими двумя задачами. Однако существуют значительные различия между обучениями с учителем и без учителя. Одно из главных различий касается вопроса идентифицируемости. При обучении с учителем отсутствие идентифицируемости просто означает, что вместо получения единственного вектора параметров мы получаем эквивалентный класс векторов параметров. Однако, поскольку все это приводит к той же плотности компонент, отсутствие идентифицируемости представляет теоретических трудностей. При обучении без учителя отсутствие идентифицируемости представляет более серьезные трудности. Когда 0 нельзя определить единственным образом, смесь нельзя разложить на ее истинные компоненты. Таким образом, в то время как Другая серьезная проблема для обучения без учителя —
и поэтому остается мало надежды найти простые точные решения для представления
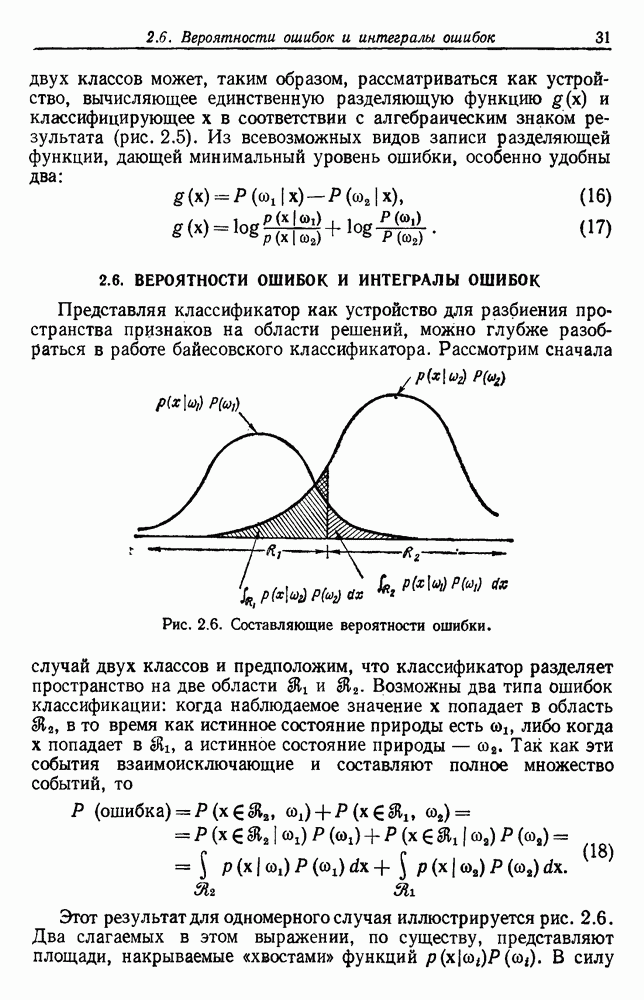
Но по формулам (21) и (1) имеем
Таким образом, Другой способ сравнения обучения с учителем и без учителя состоит в подстановке плотности смеси
Если мы рассматриваем особый случай, где
Сравним уравнения (23) и (24), чтобы увидеть, как дополнительная выборка изменяет нашу оценку 0. В каждом случае мы можем пренебречь знаменателем, который не зависит от Предполагая, что выборка действительно принадлежит классу 1, мы видим, что незнание принадлежности какому-либо классу в случае обучения без учителя приводит к уменьшению влияния изменение 6.5.3. ПРИМЕРРассмотрим одномерную двухкомпонентную смесь с
Рассматриваемая как функция от х, эта плотность смеси представляет собой суперпозицию двух нормальных плотностей, причем одна имеет пик при
где С добавлением второй выборки
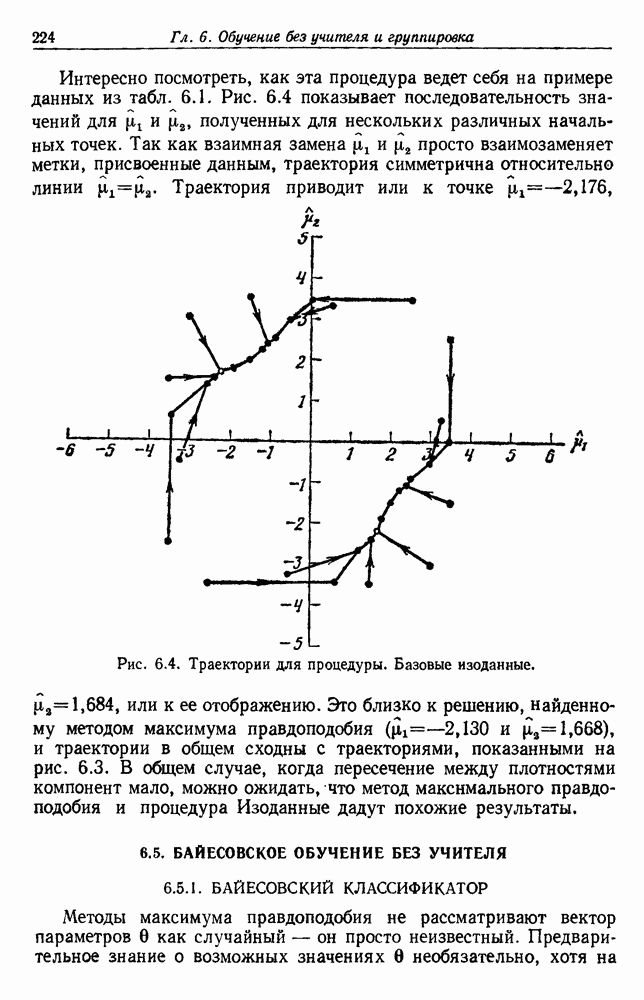
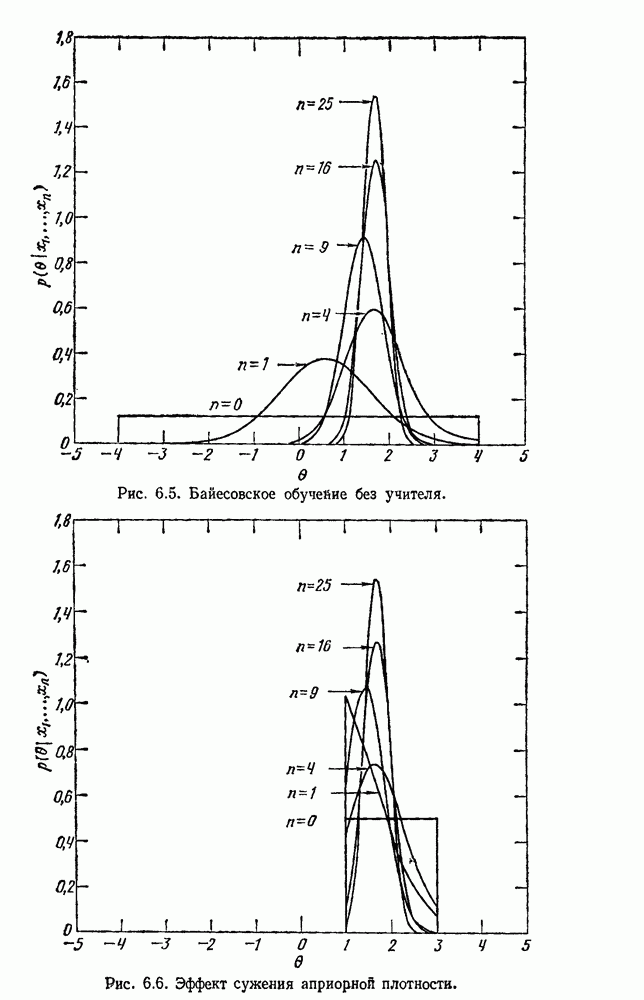
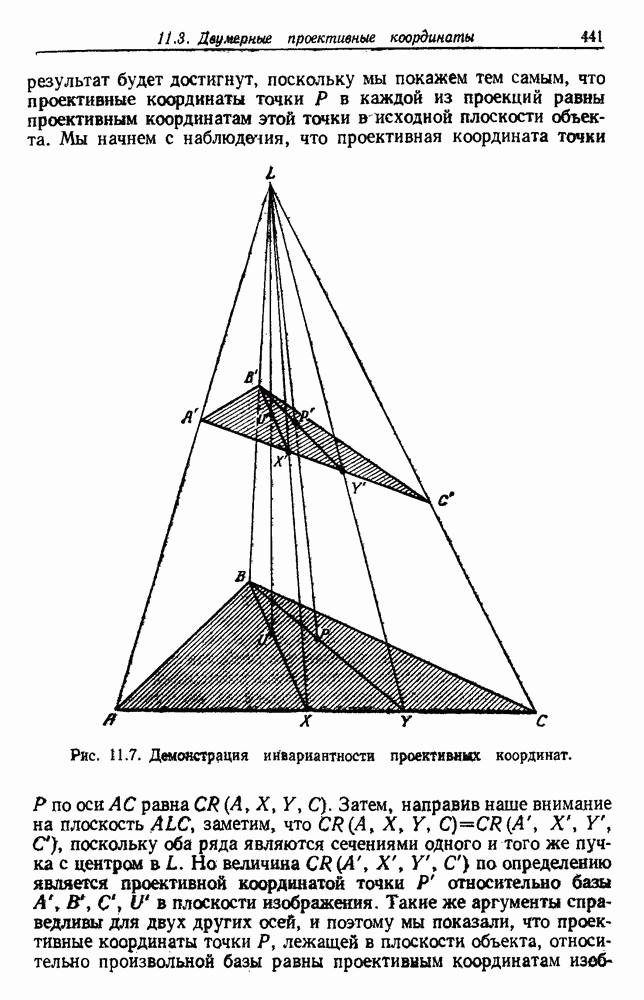
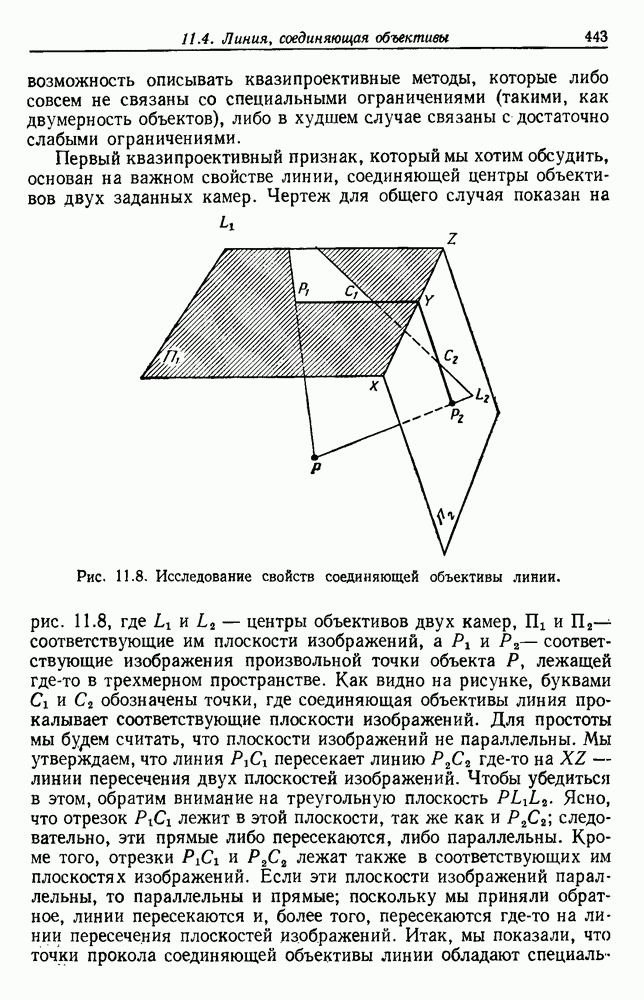
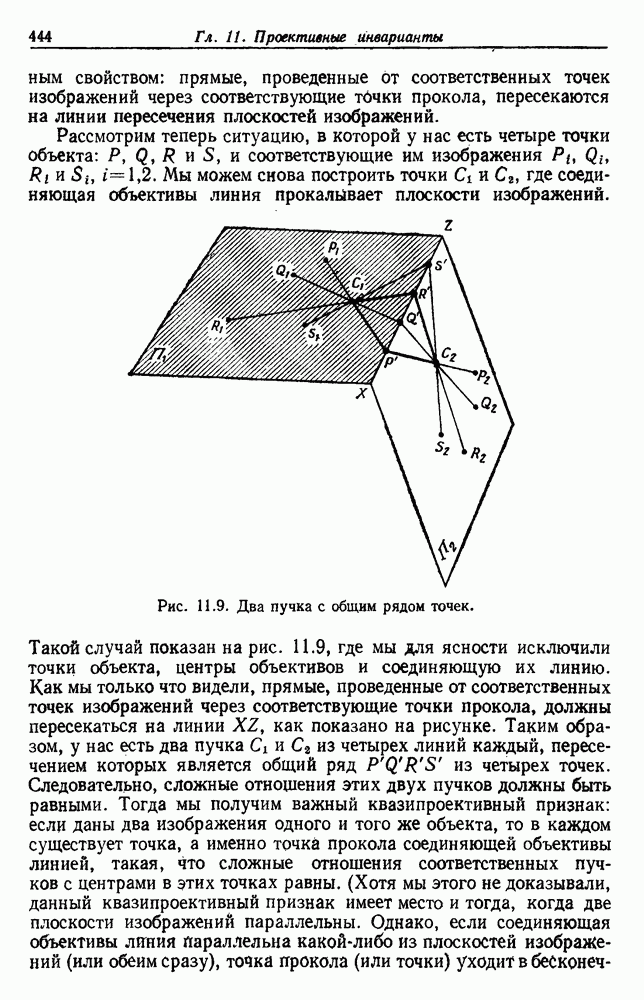
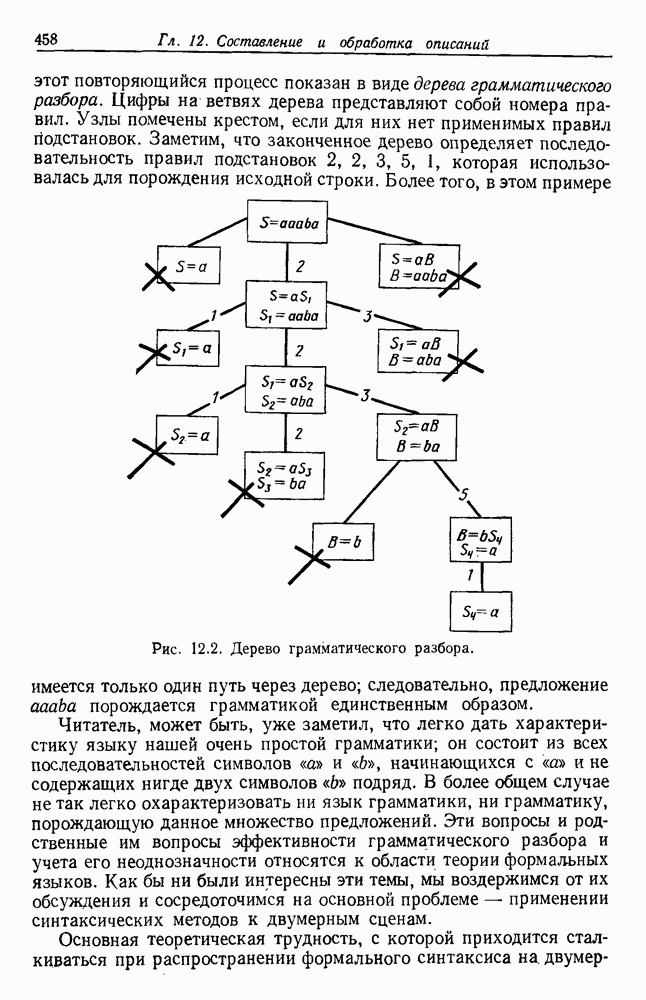
(см. скан) Рис. 6.5. Байесовское обучение без учителя. (см. скан) Рис. 6.6. Эффект сужения априорной плотности. К сожалению, первое, что мы узнаем из этого выражения, — это то, что Возможно использование соотношения
и численного интегрирования для того, чтобы получить приближенное числовое решение Одно из основных различий между байесовским и подходом по максимуму правдоподобия при обучении без учителя связано с априорной плотностью 6.5.4. АППРОКСИМАЦИЯ НА ОСНОВЕ ПРИНЯТИЯ НАПРАВЛЕННЫХРЕШЕНИЙ Хотя задачу обучения без учителя можно поставить просто как задачу определения параметров плотности смеси, ни метод максимума правдоподобия, ни байесовский подход не дают простых аналитических результатов. Точные решения даже простейших нетривиальных примеров ведут к необходимости применения численных методов; объем вычислений при этом растет экспоненциально в зависимости от числа выборок. Задача обучения без учителя слишком важна, чтобы отбросить ее только из-за того, что точные решения слишком трудно найти, и поэтому были предложены многочисленные процедуры получения приближенных решений. Так как основное различие между обучением с учителем и без учителя состоит в наличии или отсутствии меток для выборок, очевидным подходом к обучению без учителя является использование априорной информации для построения классификатора и использования решений этого классификатора для пометки выборок. Такой подход называется подходом принятия направленных решений при обучении без учителя и составляет основу для различных вариаций. Его можно применять последовательно путем обновления классификатора каждый раз, когда классифицируется непомеченная выборка. С другой стороны, его можно применить при параллельной классификации, то есть подождать, пока все С подходом принятия направленных решений связаны некоторые очевидные опасности. Если начальный классификатор не достаточно хорош или если встретилась неудачная последовательность выборок, ошибки классификации непомеченных выборок могут привести к неправильному построению классификатора, что в свою очередь приведет к решению, очень приблизительно соответствующему одному из меньших максимумов функции правдоподобия. Даже если начальный классификатор оптимален, результат пометки не будет соответствовать истинной принадлежности классам; классификация исключит выборки из хвостов желаемого распределения и включит выборки из хвостов других распределений. Таким образом, если имеется существенное перекрытие между плотностями компонент, можно ожидать смещения оценок и неоптимальных результатов. Несмотря на эти недостатки, простота процедур направленных решений делает байесовский подход доступным для численных методов, а решение с изъянами чаще лучше, чем отсутствие решения. При благоприятных условиях можно получить почти оптимальный результат при небольших вычислительных затратах. В литературе имеется несколько довольно сложных методов анализа специальных процедур направленных решений и сообщения о результатах экспериментов. Основной вывод состоит в том, что большинство этих процедур работает хорошо, если параметрические предположения правильны, если перекрытие между плотностями компонент невелико и если начальный классификатор составлен хотя бы приблизительно правильно.
|
 |
Оглавление
|








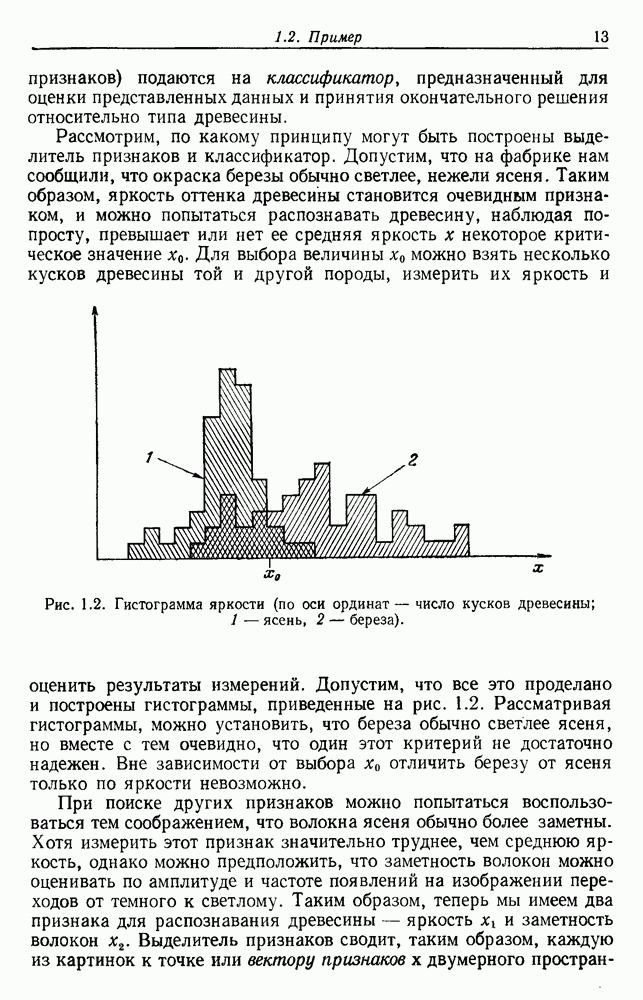







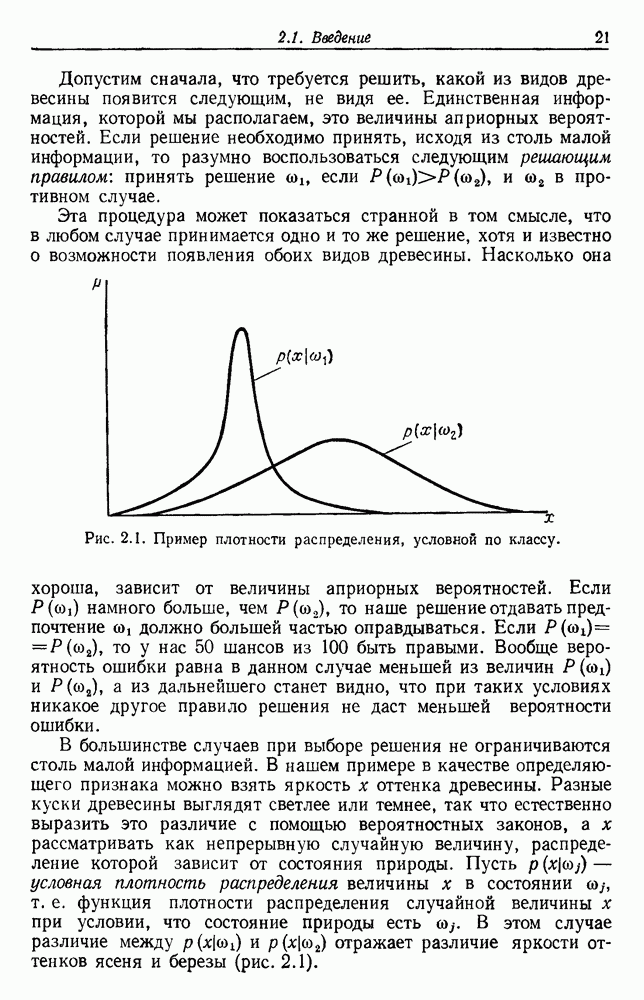
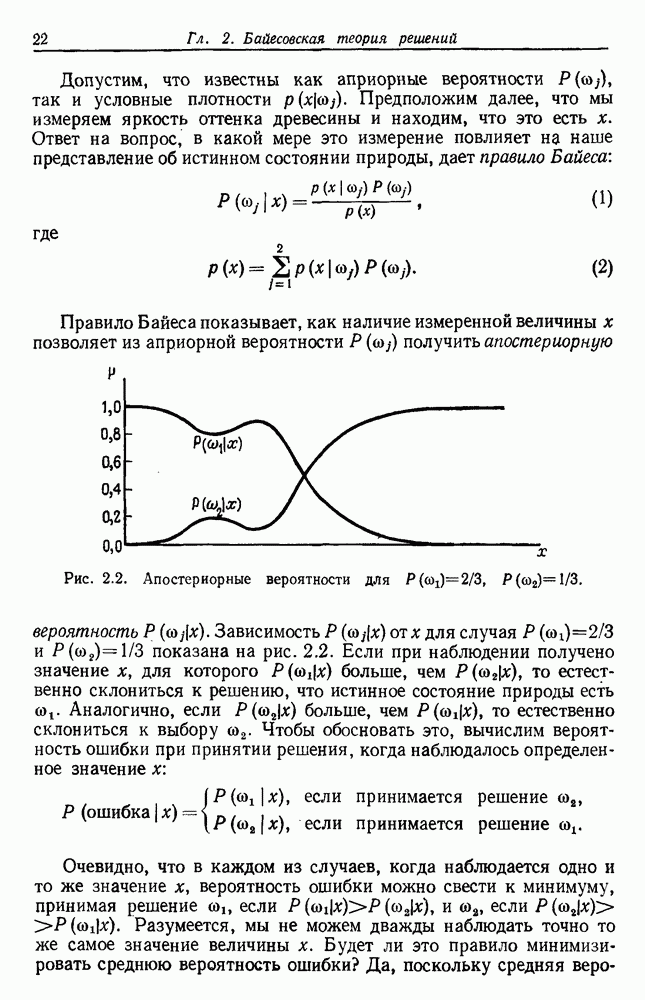





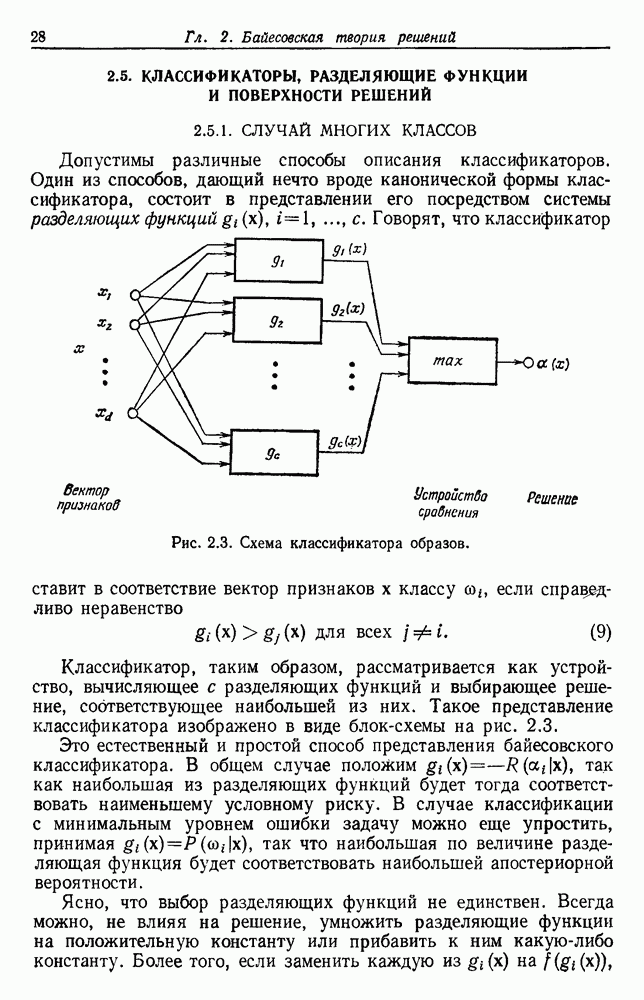


































































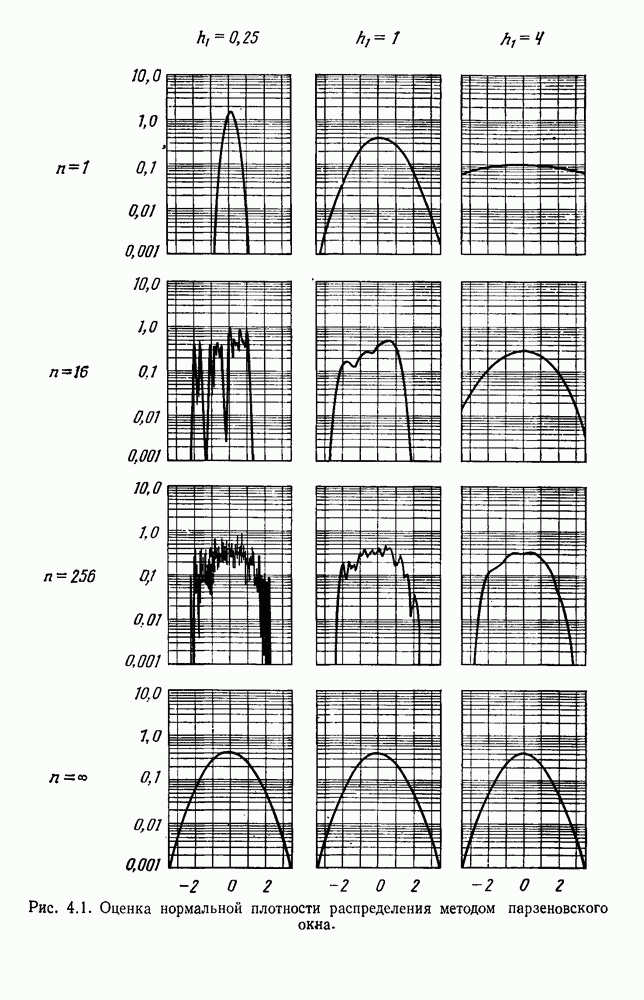
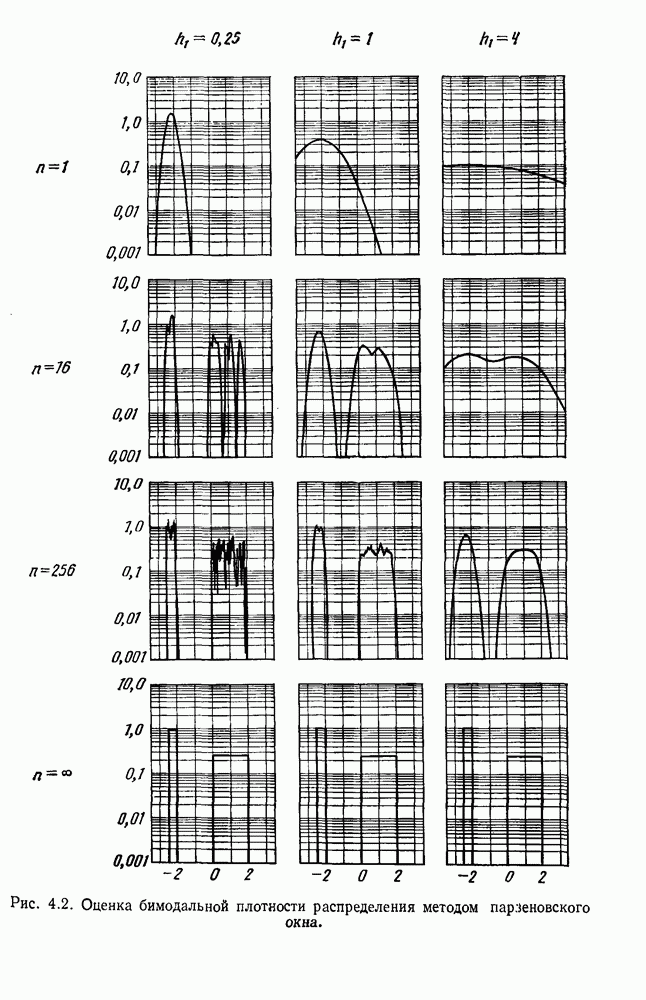

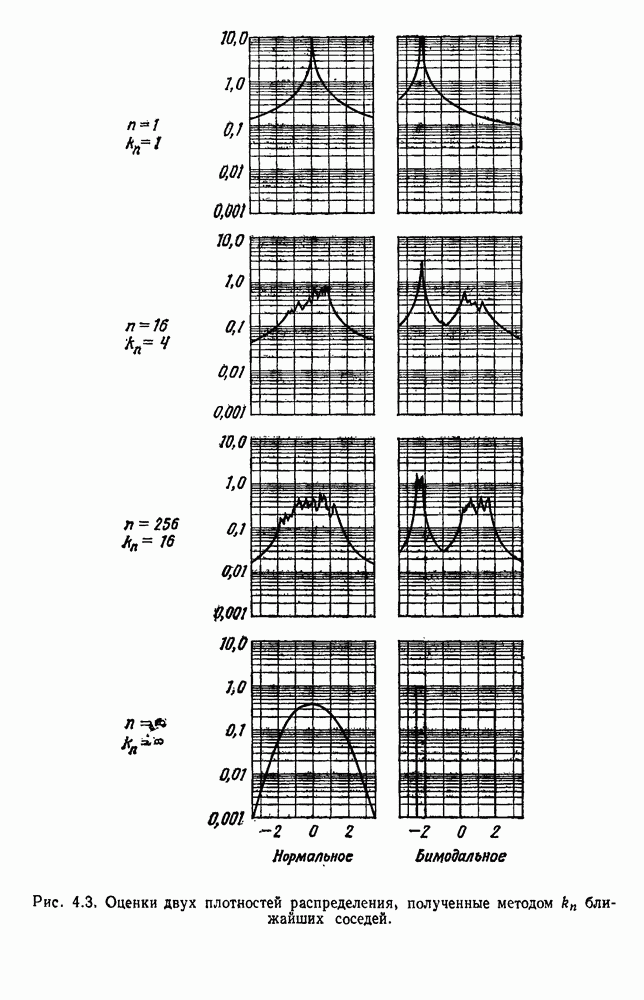








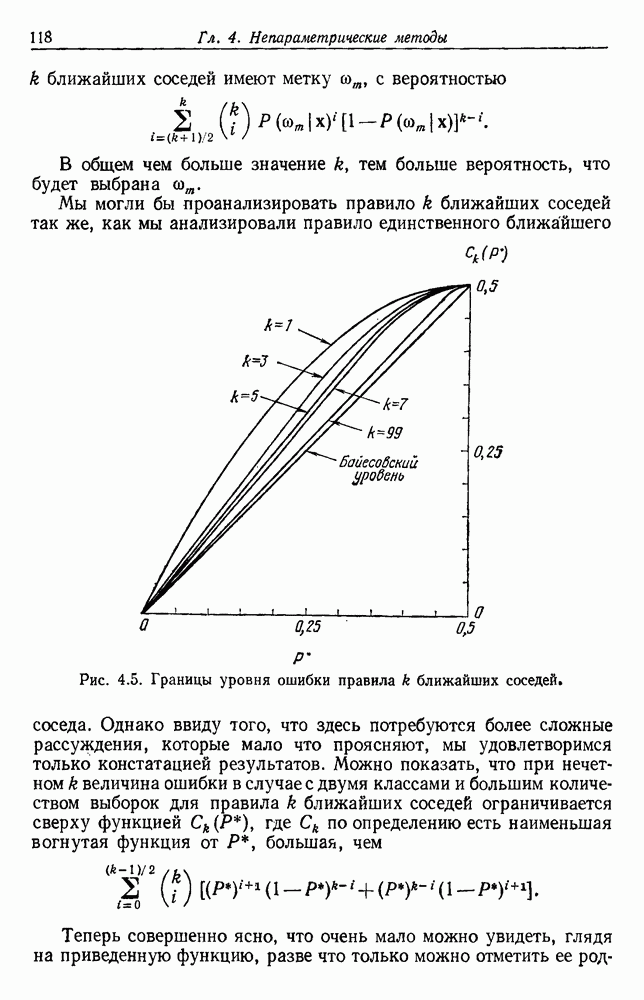











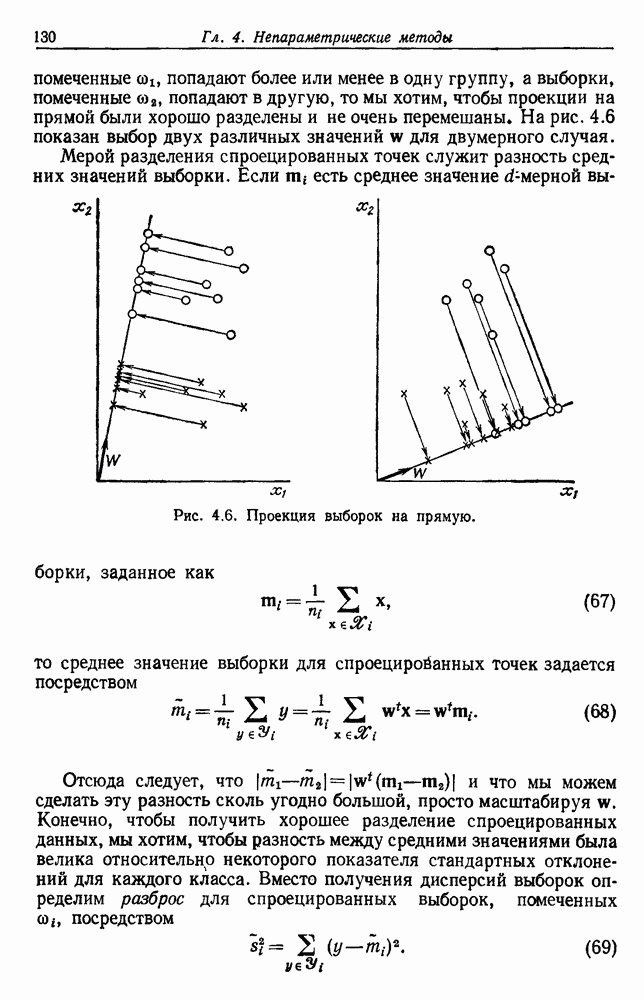
















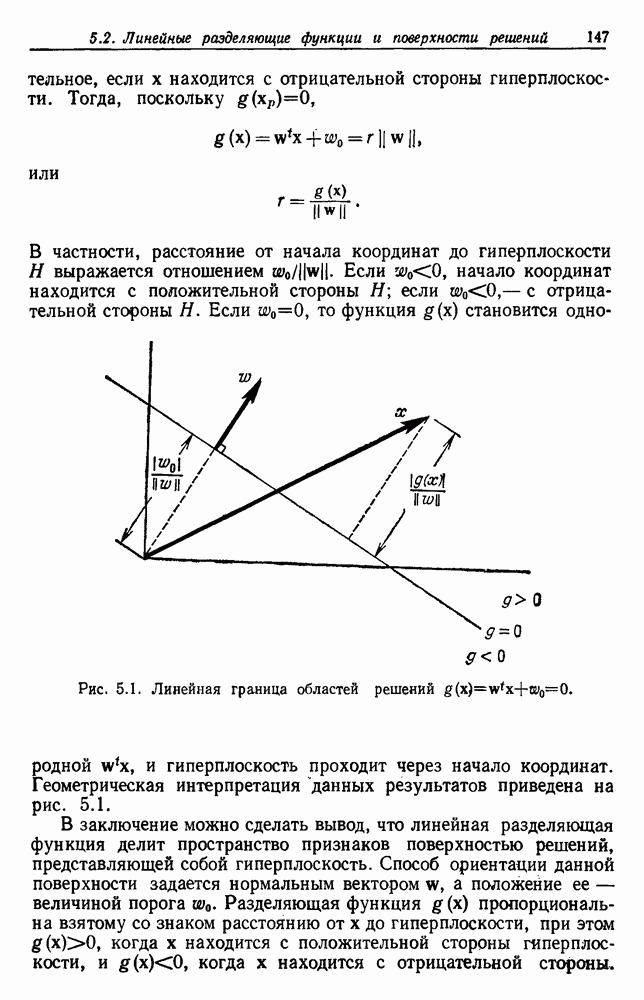
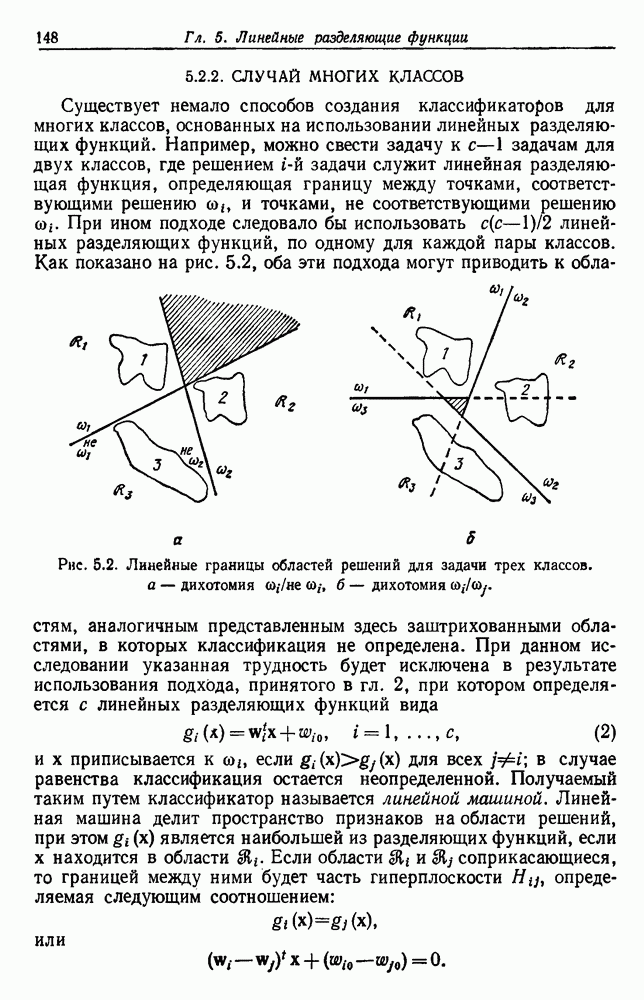


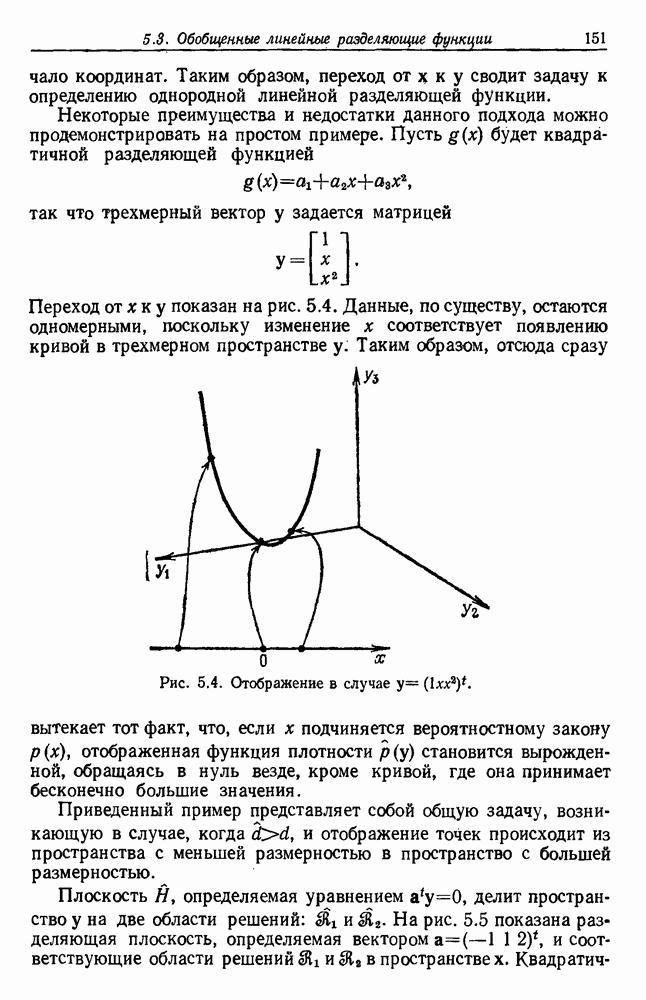
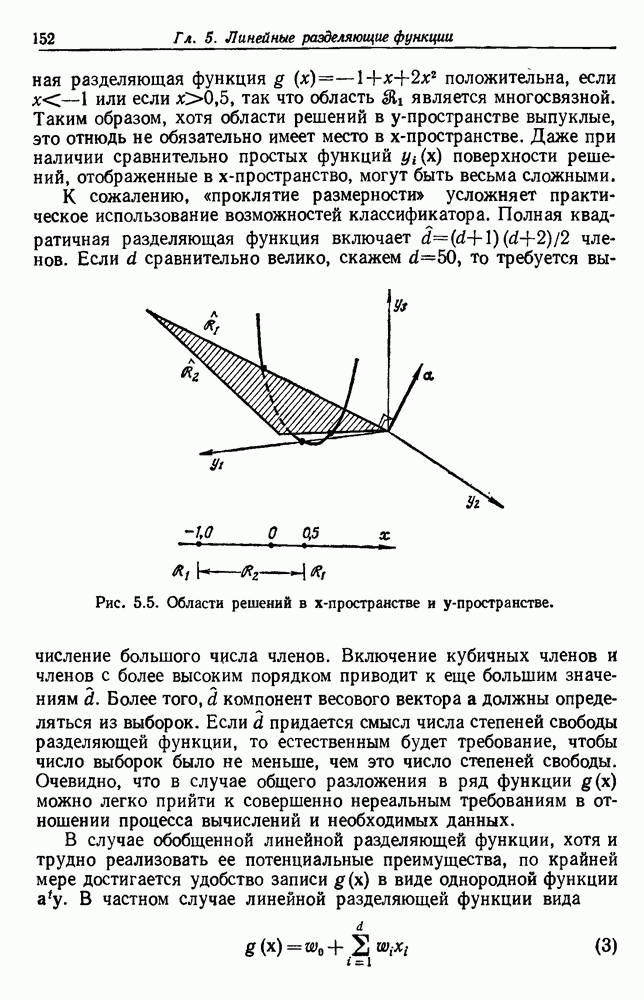

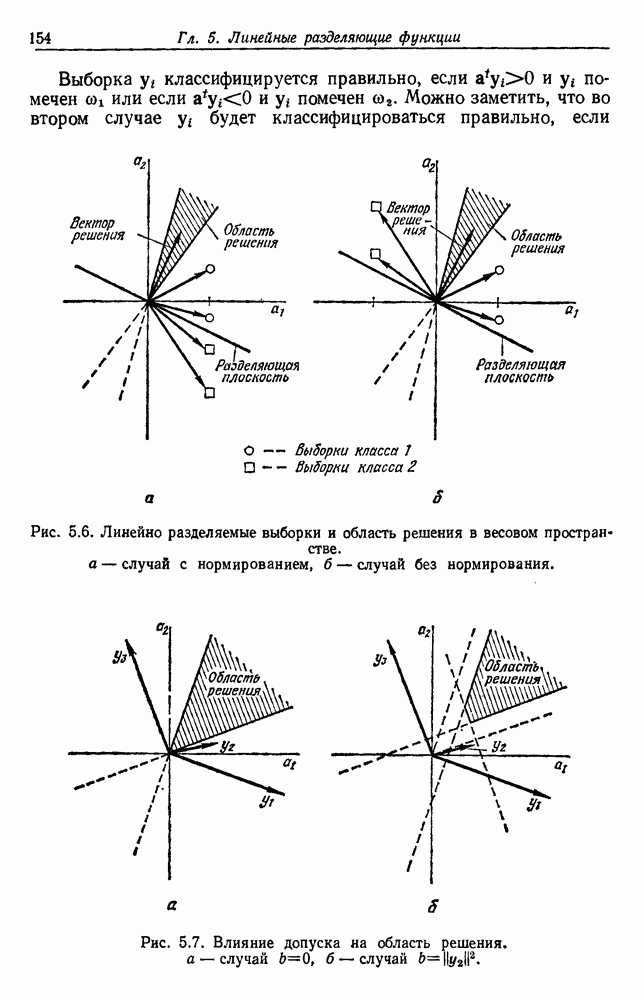



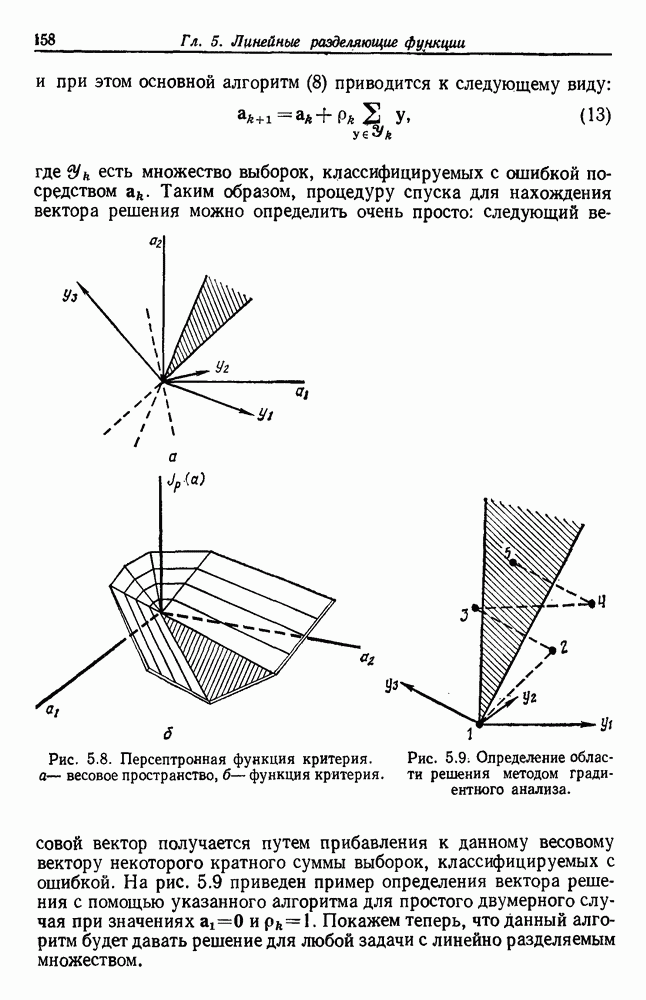

















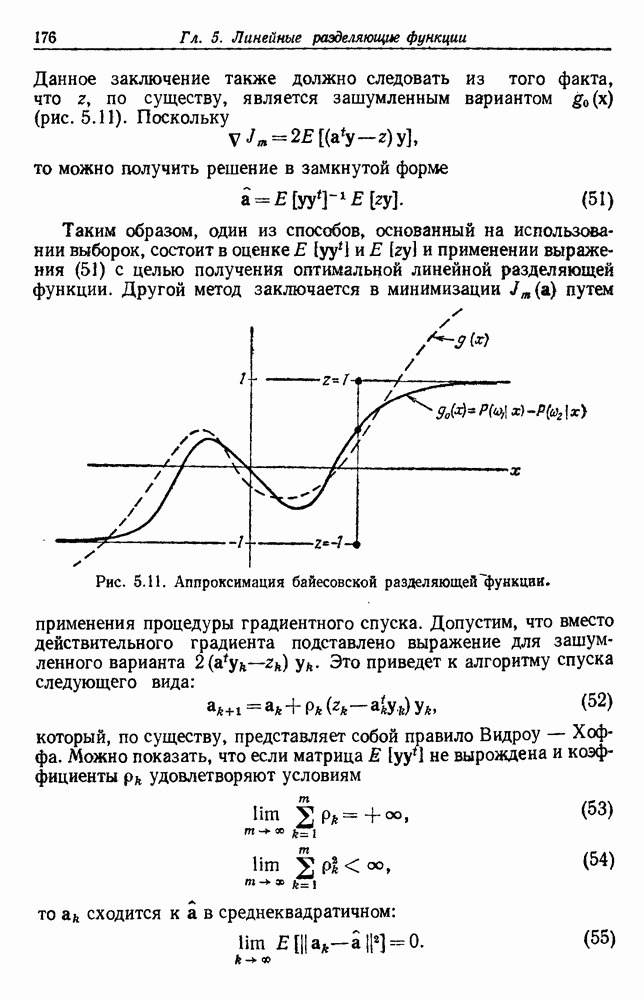






















































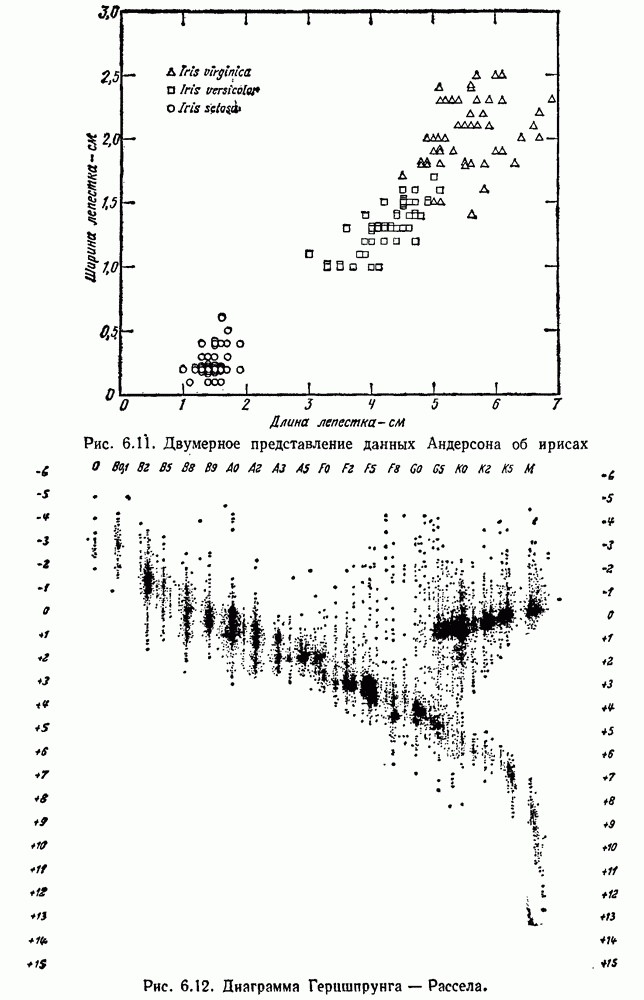








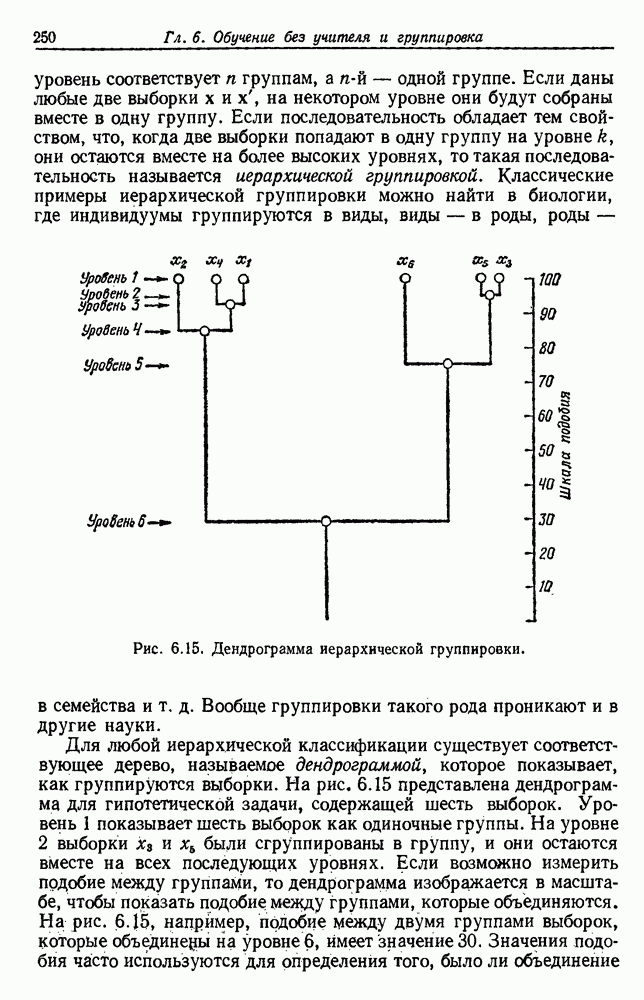




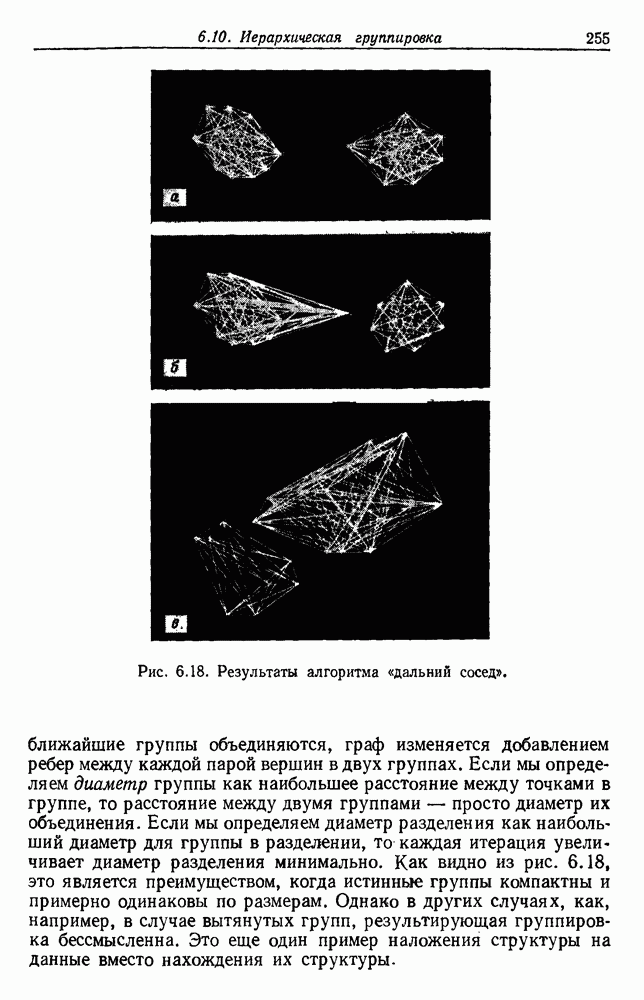










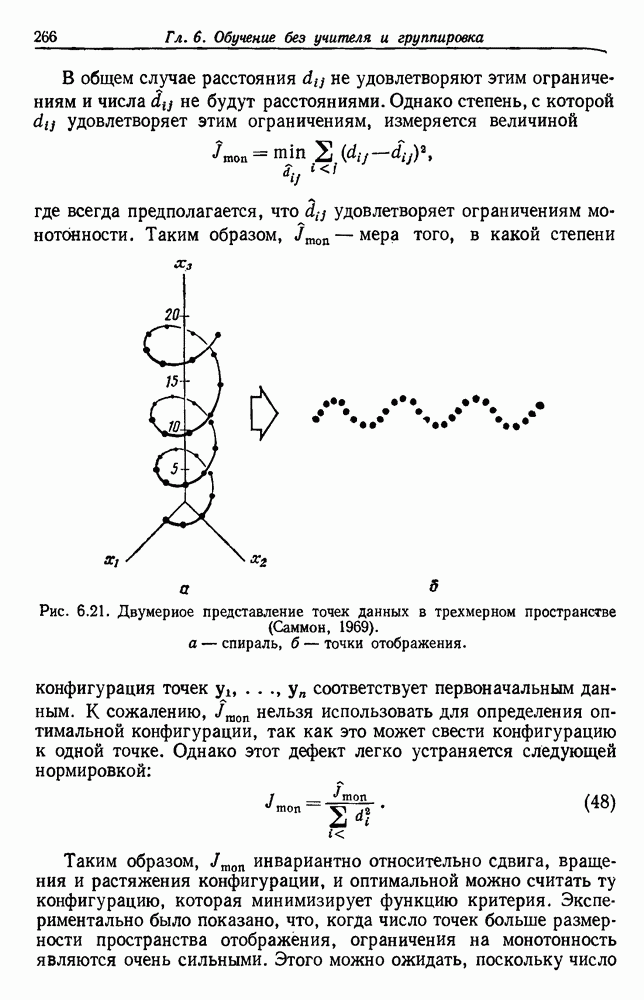




















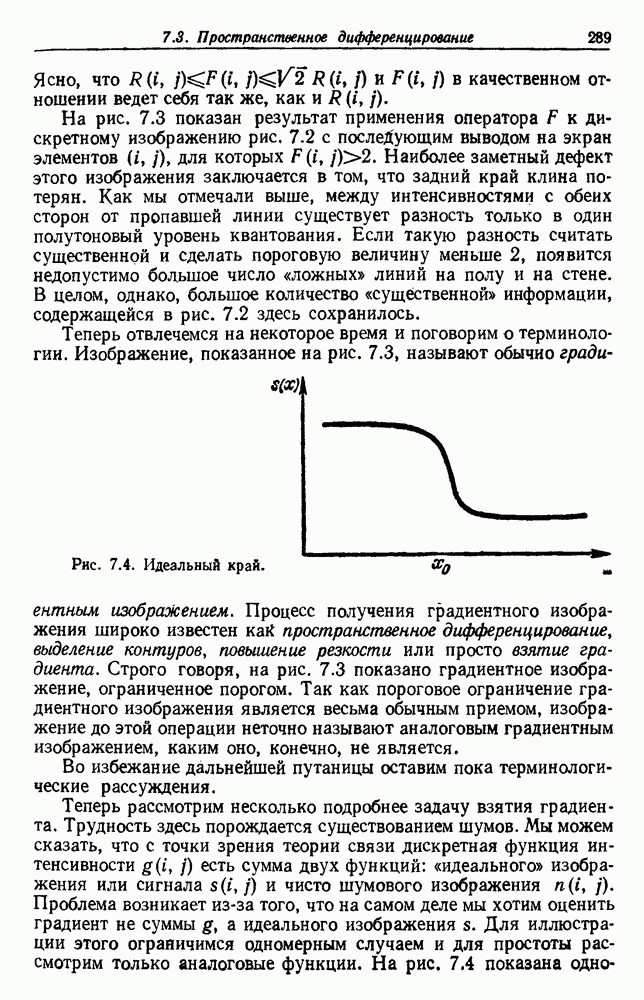

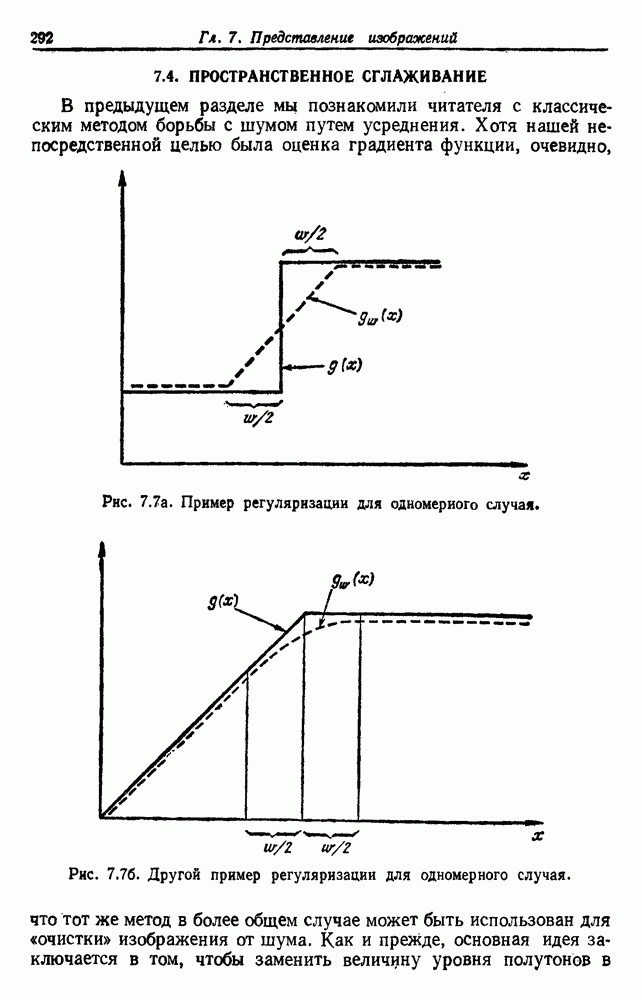


































































































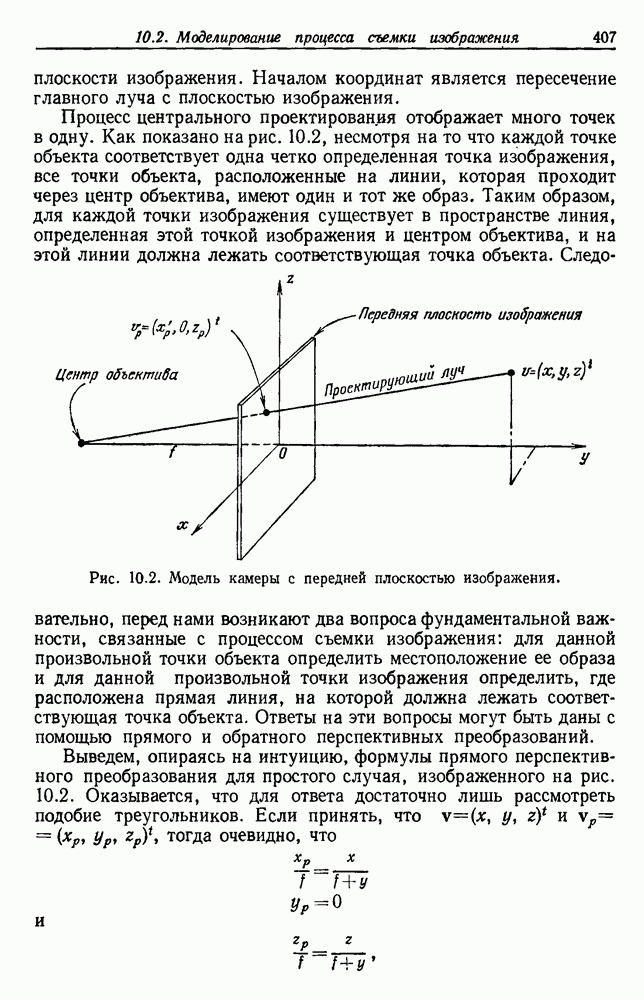





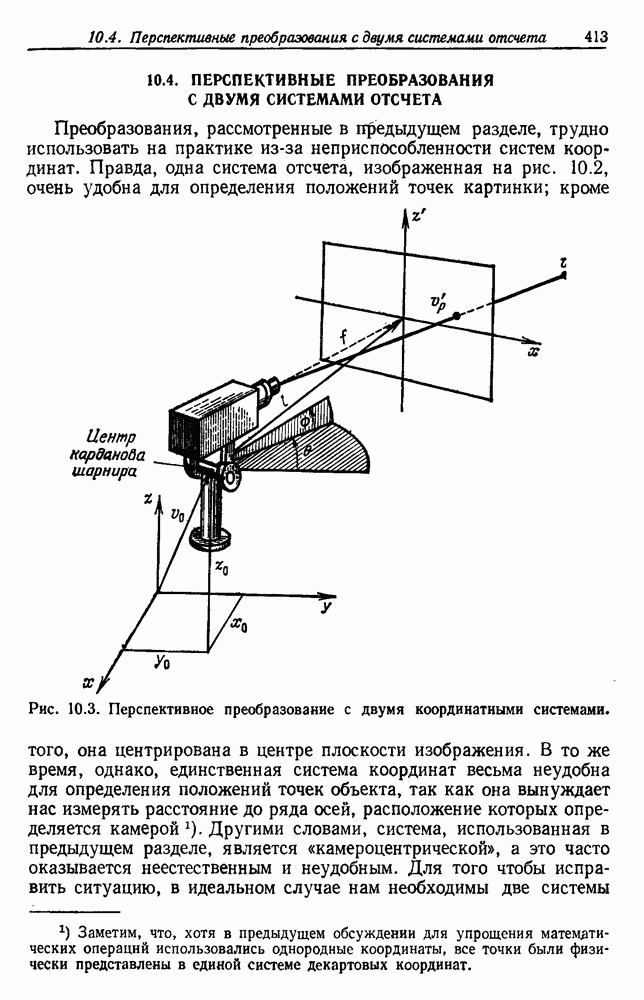








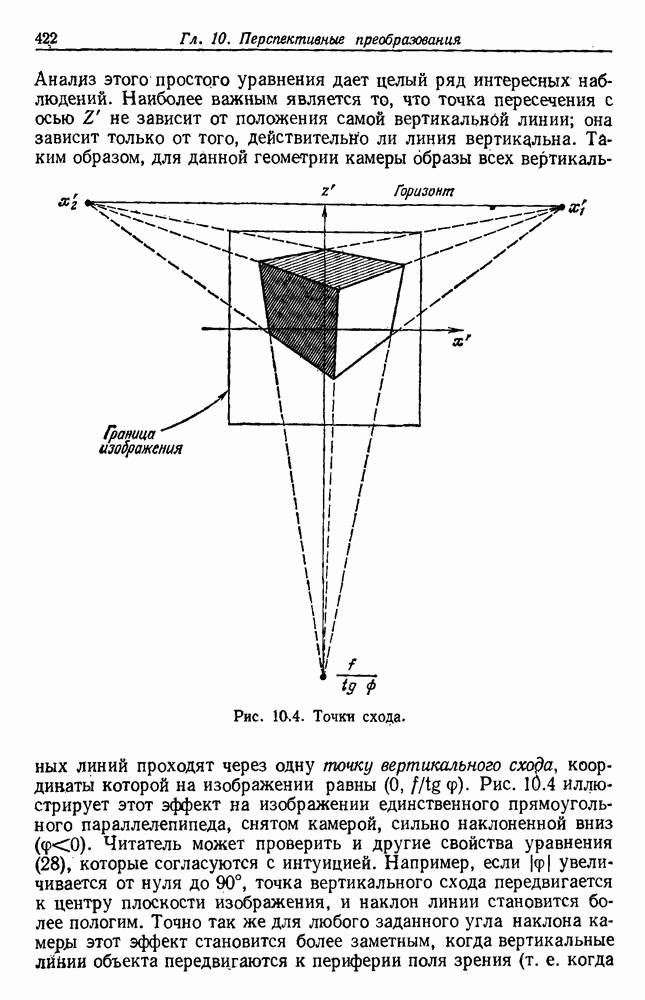

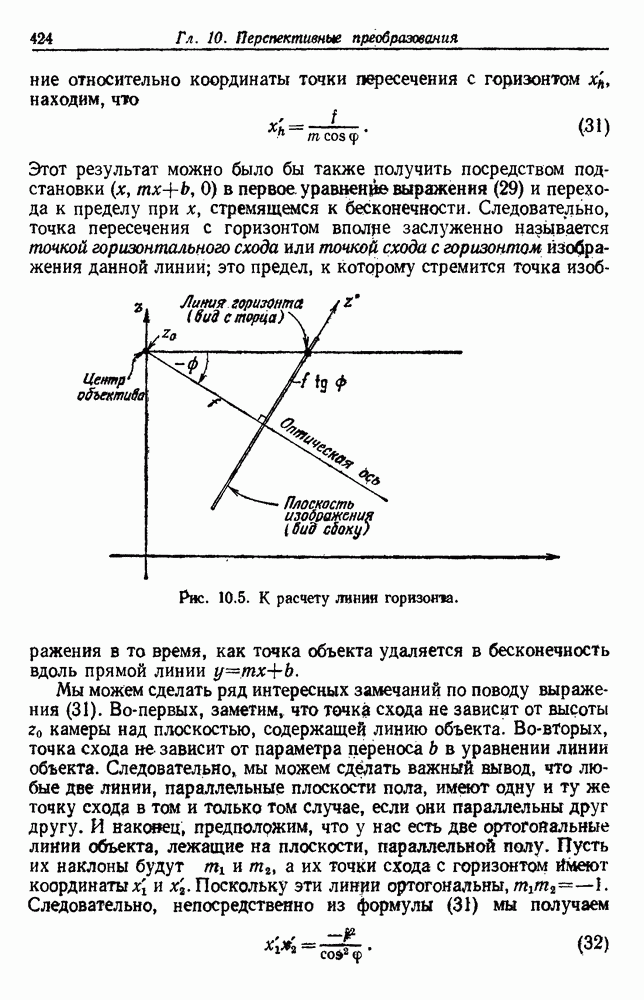
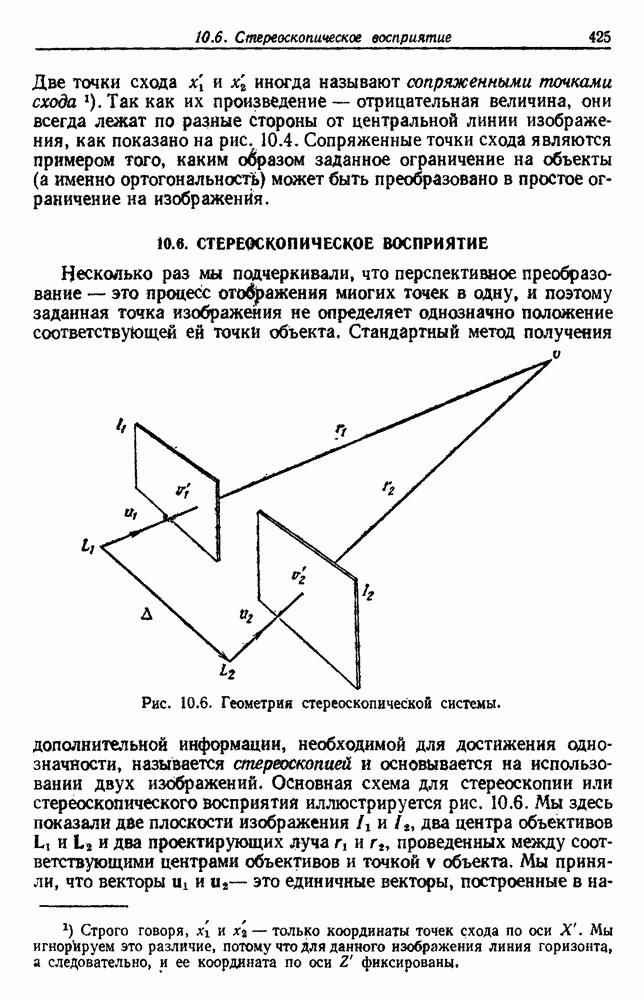


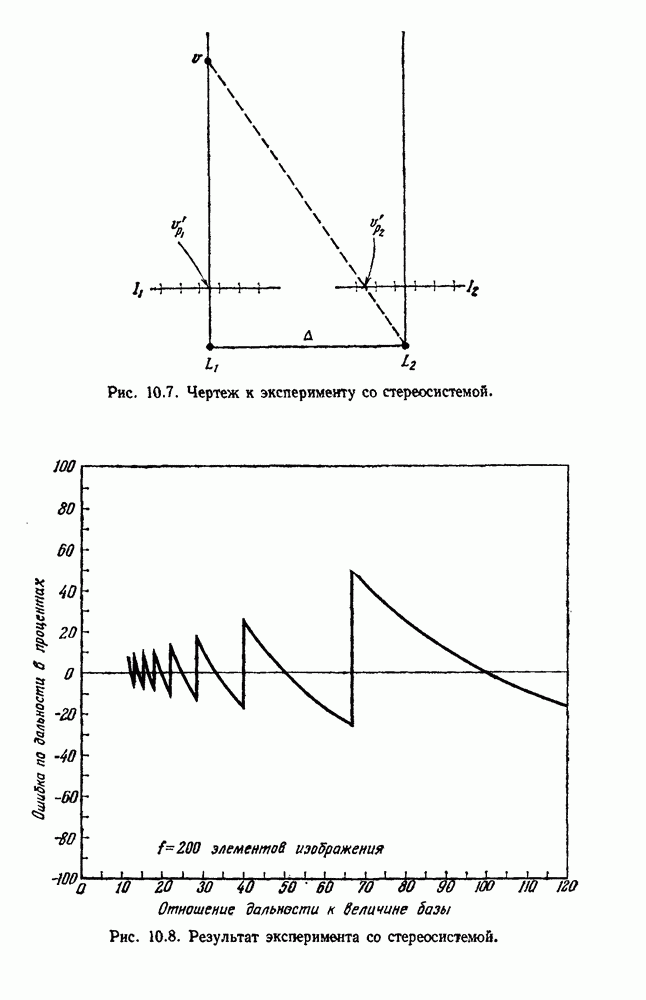







































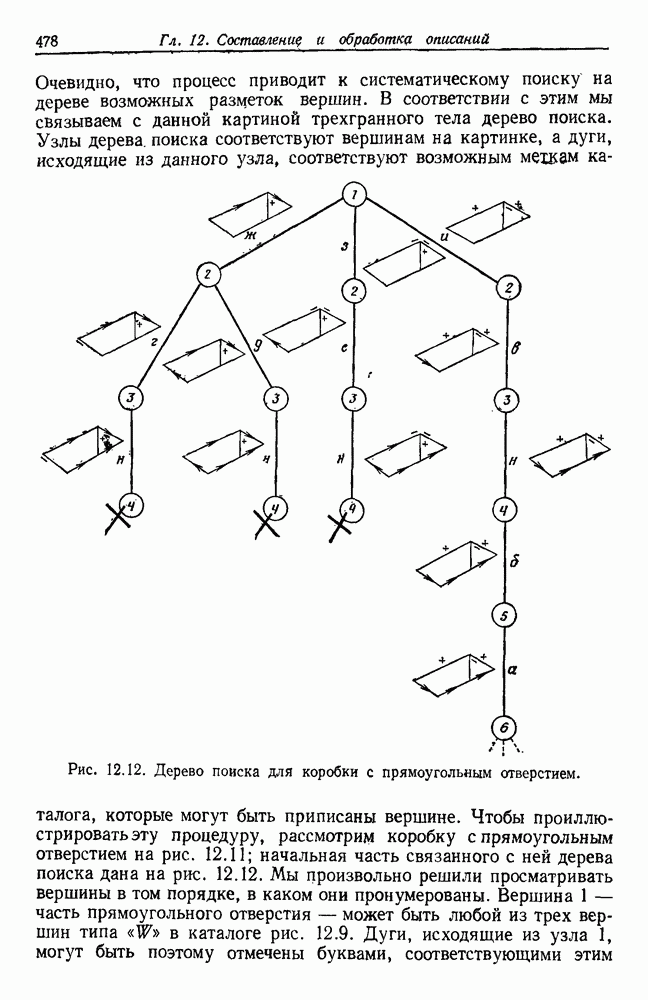


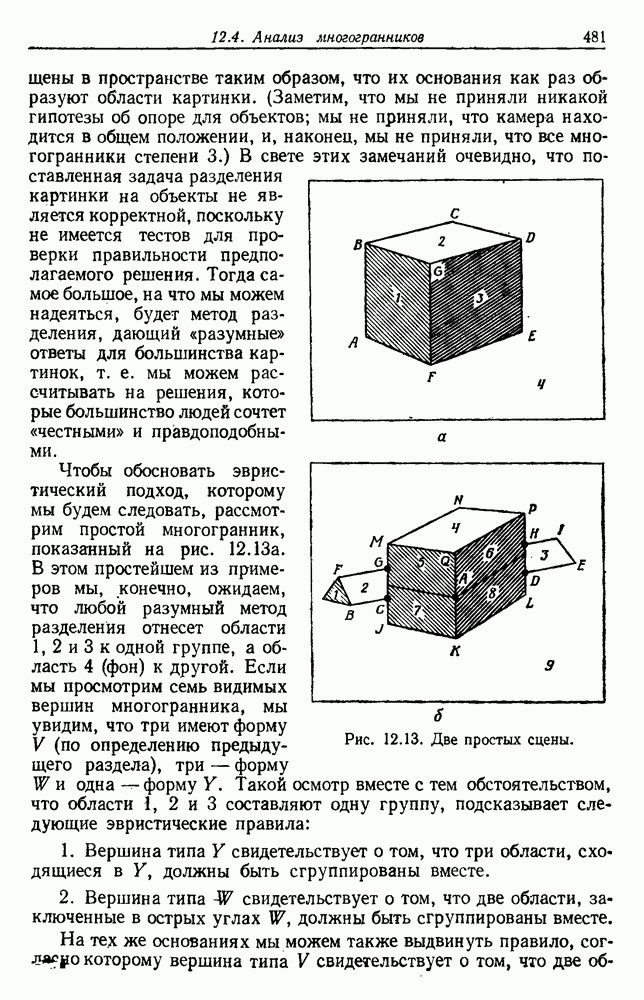


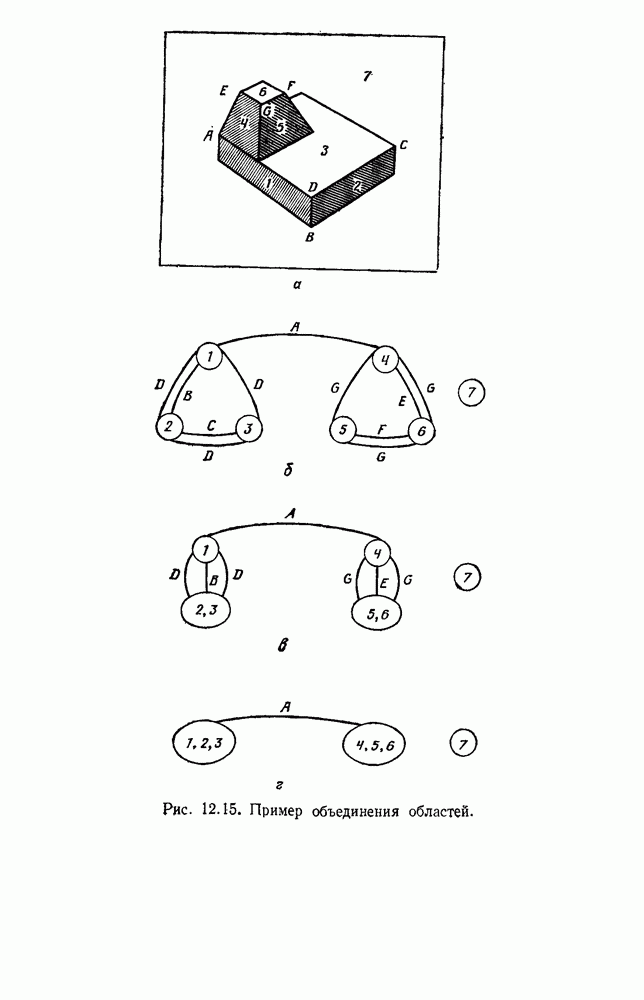
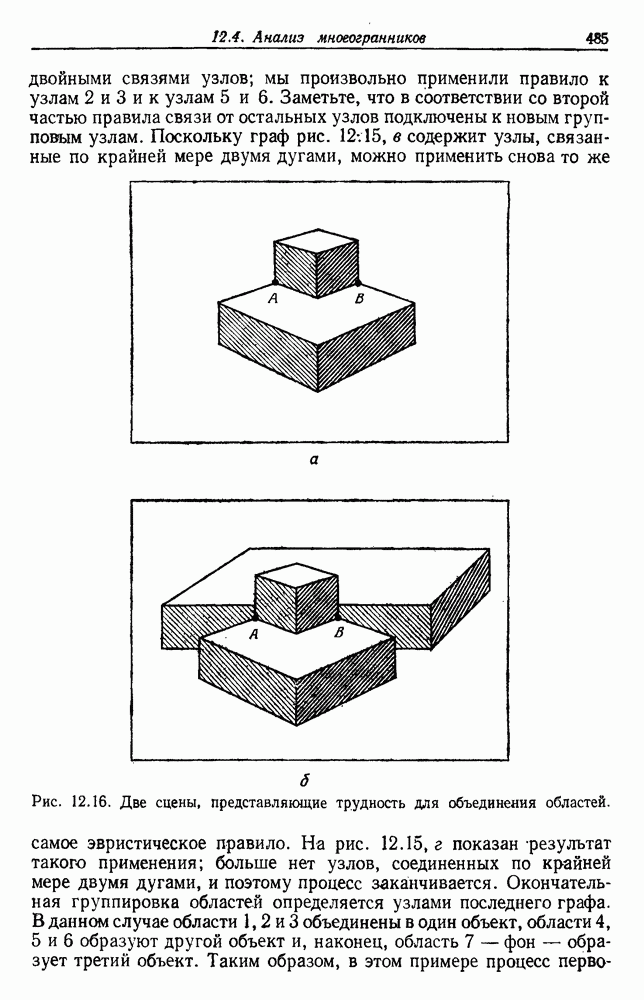











 как случайный — он просто неизвестный. Предварительное знание о возможных значениях 0 необязательно, хотя на
как случайный — он просто неизвестный. Предварительное знание о возможных значениях 0 необязательно, хотя на
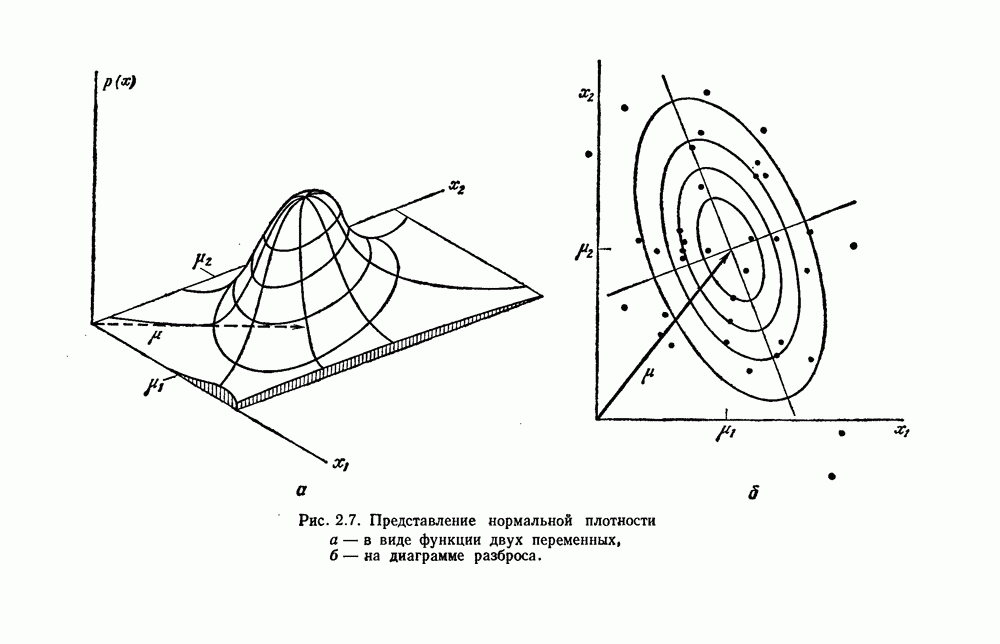
 — случайная величина с известным априорным распределением
— случайная величина с известным априорным распределением  , и будем использовать выборки для вычисления апостериорной плотности
, и будем использовать выборки для вычисления апостериорной плотности  . Весьма интересно, что такой анализ в основном будет подобен анализу байесовского обучения с учителем, что указывает на большое формальное сходство задач.
. Весьма интересно, что такой анализ в основном будет подобен анализу байесовского обучения с учителем, что указывает на большое формальное сходство задач.
 для каждого класса известны,
для каждого класса известны,  .
.
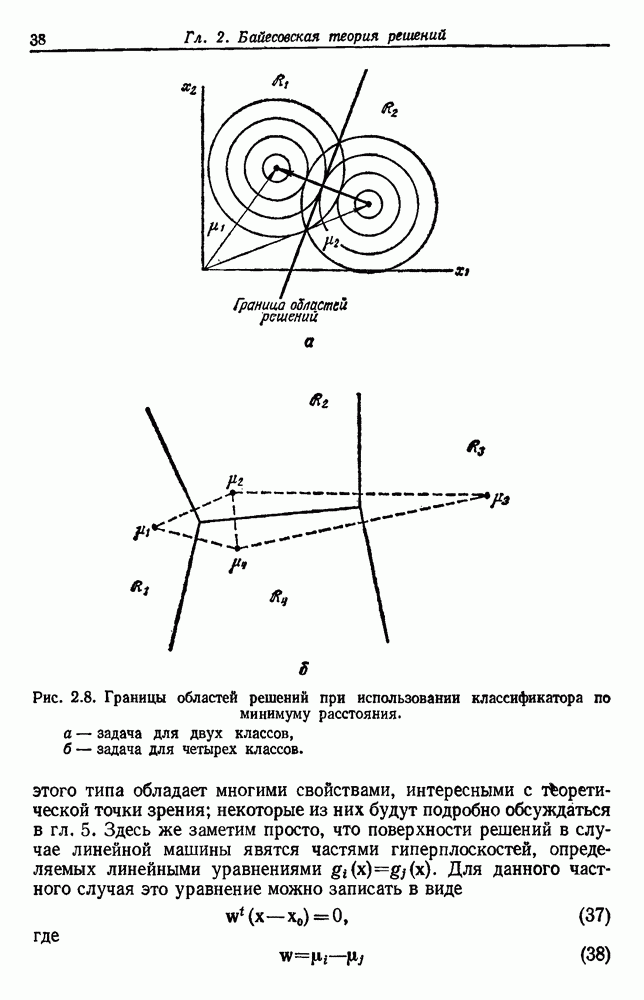
 известен,
известен,  с, но вектор параметров
с, но вектор параметров  неизвестен.
неизвестен.
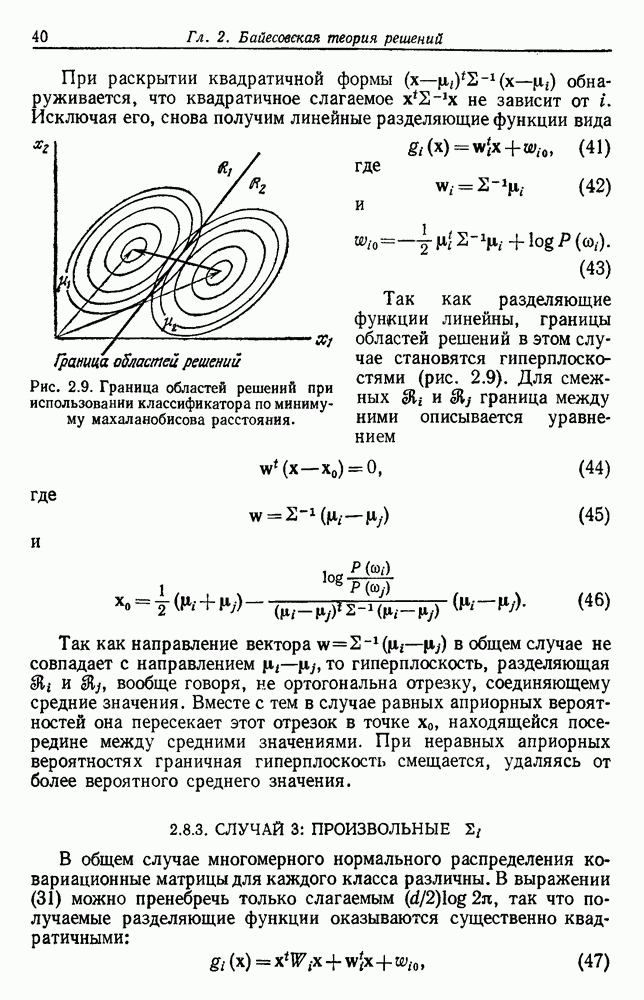
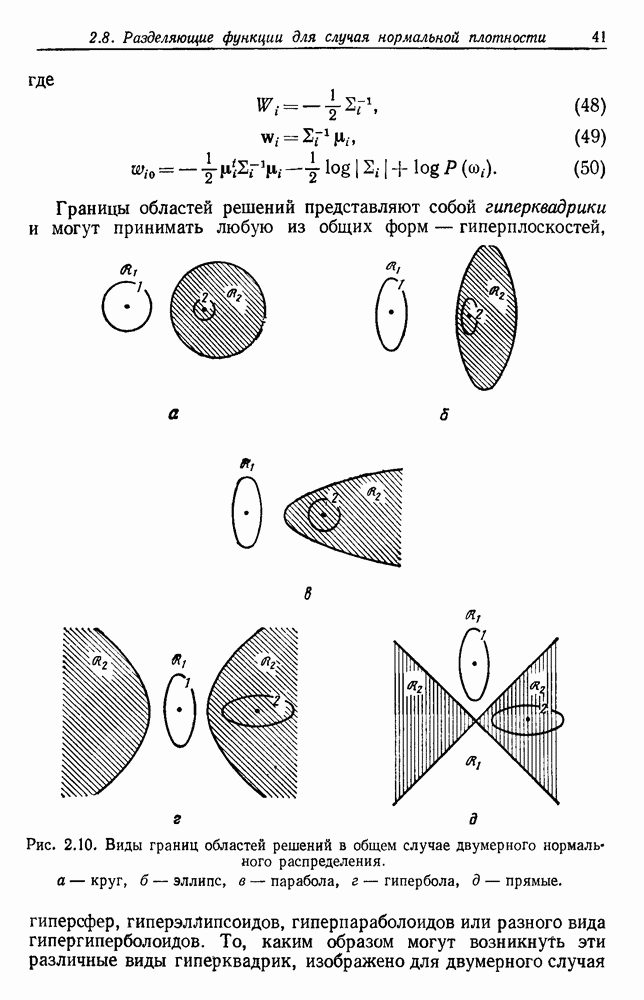
 заключена в известной априорной плотности
заключена в известной априорной плотности 
 содержится в множестве S из
содержится в множестве S из  выборок
выборок  извлеченных независимо из смеси с плотностью
извлеченных независимо из смеси с плотностью

 Однако давайте сначала посмотрим, как эта плотность используется для определения байесовского классификатора. Предположим, что состояние природы выбирается с вероятностью
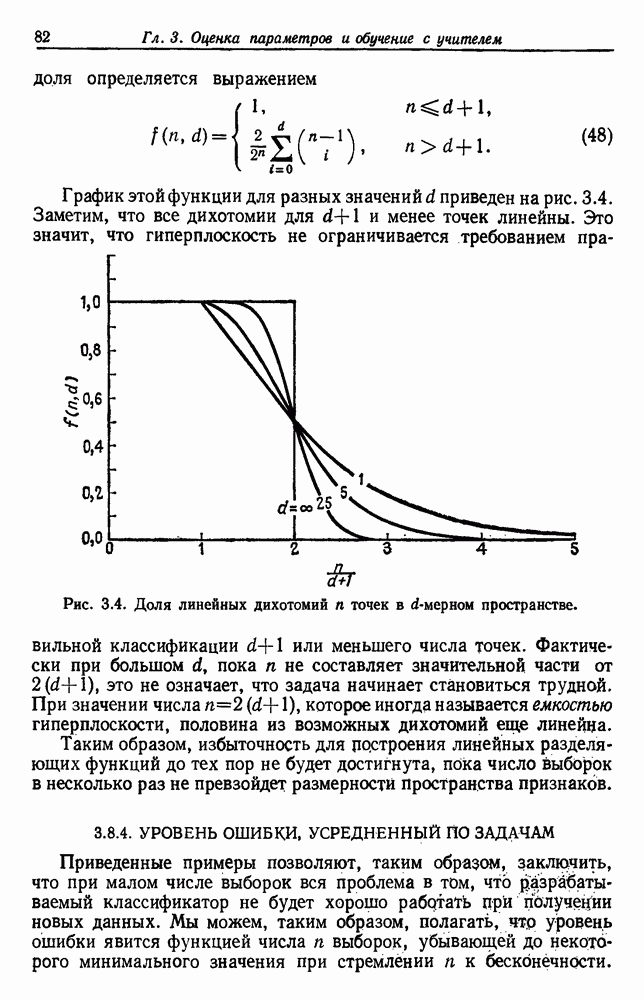
Однако давайте сначала посмотрим, как эта плотность используется для определения байесовского классификатора. Предположим, что состояние природы выбирается с вероятностью  и вектор признаков х выбран в соответствии с вероятностным законом
и вектор признаков х выбран в соответствии с вероятностным законом  . Чтобы вывести байесовский классификатор, мы должны использовать всю имеющуюся информацию для вычисления апостериорной вероятности
. Чтобы вывести байесовский классификатор, мы должны использовать всю имеющуюся информацию для вычисления апостериорной вероятности 
 По правилу Байеса
По правилу Байеса

 был сделан независимо от ранее полученных выборок:
был сделан независимо от ранее полученных выборок:  то мы получим
то мы получим


 Аналогично, так как знание состояния природы при выбранном х нам ничего не говорит о распределении
Аналогично, так как знание состояния природы при выбранном х нам ничего не говорит о распределении  , имеем
, имеем 

 получена усреднением
получена усреднением  по
по  . Хорошая это или плохая оценка, зависит от природы
. Хорошая это или плохая оценка, зависит от природы  и мы должны, наконец, заняться этой плотностью.
и мы должны, наконец, заняться этой плотностью.


 множество
множество  выборок, мы можем записать соотношение (20) в рекуррентной форме
выборок, мы можем записать соотношение (20) в рекуррентной форме

 существенно равномерна в области, где имеется пик
существенно равномерна в области, где имеется пик  , то
, то  имеется пик в том же самом месте. Если имеется только один существенный пик при
имеется пик в том же самом месте. Если имеется только один существенный пик при  и этот пик очень острый, то соотношения (19) и (18) дают
и этот пик очень острый, то соотношения (19) и (18) дают

 была получена при обучении с учителем с использованием большого множества помеченных выборок,
была получена при обучении с учителем с использованием большого множества помеченных выборок,
 когда
когда  мало. Соотношение (22) показывает, как при наблюдении дополнительных непомеченных выборок изменяется наше мнение об истинном значении
мало. Соотношение (22) показывает, как при наблюдении дополнительных непомеченных выборок изменяется наше мнение об истинном значении  и особое значение приобретают идеи модернизации и обучения. Если плотность смеси
и особое значение приобретают идеи модернизации и обучения. Если плотность смеси  идентифицируема, то с каждой дополнительной выборкой
идентифицируема, то с каждой дополнительной выборкой  становится все более острой, и при достаточно общих условиях можно показать, что
становится все более острой, и при достаточно общих условиях можно показать, что  сходится (по вероятности) к дельта-функции Дирака с центром в истинном значении 0. Таким образом, даже если мы не знаем класса выборок, идентифицируемость дает нам возможность узнать вектор неизвестных параметров
сходится (по вероятности) к дельта-функции Дирака с центром в истинном значении 0. Таким образом, даже если мы не знаем класса выборок, идентифицируемость дает нам возможность узнать вектор неизвестных параметров  и вместе с этим узнать плотности компонент
и вместе с этим узнать плотности компонент 
 может все еще сходиться к
может все еще сходиться к  величина
величина  описываемая выражением (19), в общем не сойдется к
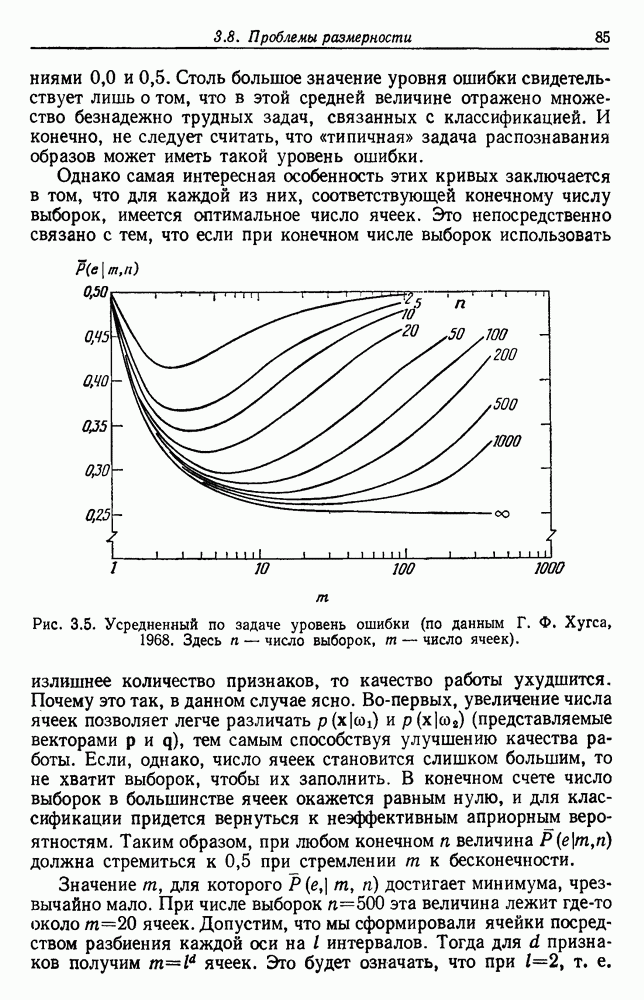
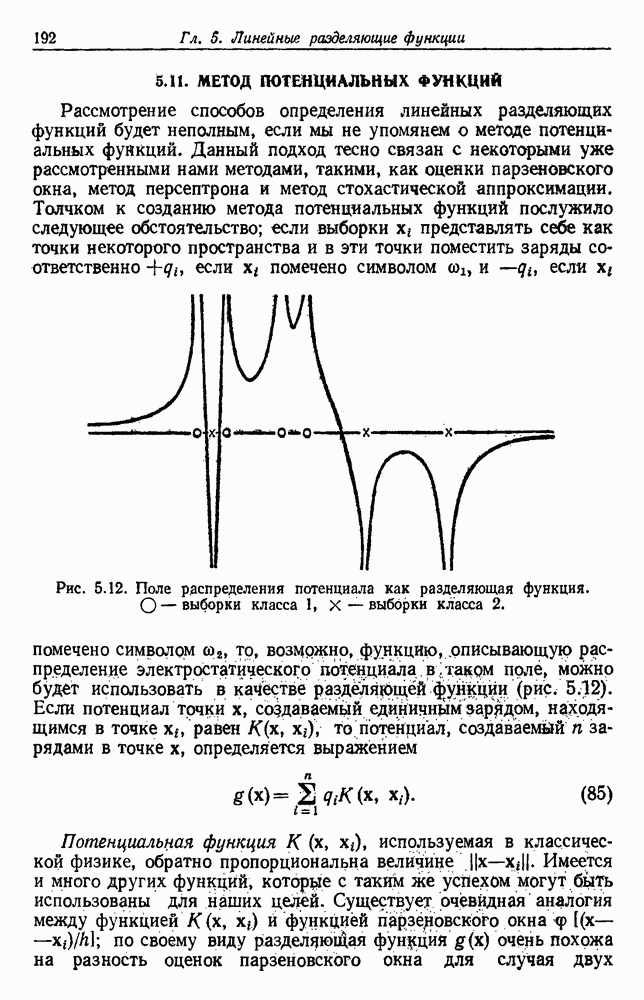
описываемая выражением (19), в общем не сойдется к  , т. е. существует теоретический барьер в обучении.
, т. е. существует теоретический барьер в обучении.
 вычислительная сложность. При обучении с учителем возможность нахождения достаточной статистики дает возможность получить решения, которые решаются как аналитическими, так и численными методами. При обучении без учителя нельзя забывать, что выборки получены из плотности смеси
вычислительная сложность. При обучении с учителем возможность нахождения достаточной статистики дает возможность получить решения, которые решаются как аналитическими, так и численными методами. При обучении без учителя нельзя забывать, что выборки получены из плотности смеси

 Такие решения связаны с существованием простой достаточной статистики, и теорема факторизации требует возможности
Такие решения связаны с существованием простой достаточной статистики, и теорема факторизации требует возможности
 следующим образом:
следующим образом:


 есть сумма с произведений плотностей компонент. Каждое слагаемое суммы можно интерпретировать как общую вероятность получения выборок
есть сумма с произведений плотностей компонент. Каждое слагаемое суммы можно интерпретировать как общую вероятность получения выборок  с определенными метками, причем сумма охватывает все возможные способы пометки выборок. Ясно, что это приводит к общей смеси
с определенными метками, причем сумма охватывает все возможные способы пометки выборок. Ясно, что это приводит к общей смеси  и всех х, и нельзя ожидать простой факторизации. Исключением является случай, когда плотности компонент не перекрываются, так что, как только в 0 изменяется один член, плотность смеси не равна нулю. В этом случае
и всех х, и нельзя ожидать простой факторизации. Исключением является случай, когда плотности компонент не перекрываются, так что, как только в 0 изменяется один член, плотность смеси не равна нулю. В этом случае  есть произведение
есть произведение  ненулевых членов и может обладать простой достаточной статистикой. Однако, поскольку здесь допускается возможность определения класса любой выборки, это сводит задачу к обучению с учителем и, таким образом, не является существенным исключением.
ненулевых членов и может обладать простой достаточной статистикой. Однако, поскольку здесь допускается возможность определения класса любой выборки, это сводит задачу к обучению с учителем и, таким образом, не является существенным исключением.
 в (22) и получении
в (22) и получении

 а все остальные априорные вероятности равны нулю, соответствующий случаю обучения с учителем, в котором все выборки из класса 1, то формула (23) упрощается до
а все остальные априорные вероятности равны нулю, соответствующий случаю обучения с учителем, в котором все выборки из класса 1, то формула (23) упрощается до

 . Таким образом, единственное значительное различие состоит в том, что в случае обучения с учителем мы умножаем априорную плотность для 0 на плотность компоненты
. Таким образом, единственное значительное различие состоит в том, что в случае обучения с учителем мы умножаем априорную плотность для 0 на плотность компоненты  , в то время как в случае обучения без учителя мы умножаем на плотность смеси
, в то время как в случае обучения без учителя мы умножаем на плотность смеси 
 на
на
 . Поскольку
. Поскольку  может принадлежать любому из с классов, мы не можем использовать его с полной эффективностью для изменения компонент (компоненты)
может принадлежать любому из с классов, мы не можем использовать его с полной эффективностью для изменения компонент (компоненты)  , связанных с каким-нибудь классом. Более того, это влияние мы должны распределить на различные классы в соответствии с вероятностью каждого класса.
, связанных с каким-нибудь классом. Более того, это влияние мы должны распределить на различные классы в соответствии с вероятностью каждого класса.
 где
где  известны. Здесь
известны. Здесь

 а другая при
а другая при  Рассматриваемая как функция от
Рассматриваемая как функция от  , плотность
, плотность  имеет один пик при
имеет один пик при  Предположим, что априорная плотность
Предположим, что априорная плотность  равномерна в интервале от а до b. Тогда после одного наблюдения
равномерна в интервале от а до b. Тогда после одного наблюдения

 — нормирующие константы, независимые от
— нормирующие константы, независимые от  . Если выборка
. Если выборка  находится в пределах
находится в пределах  , то
, то  имеет пик при
имеет пик при  . В противном случае она имеет пики либо при
. В противном случае она имеет пики либо при  если
если  либо при
либо при  если
если  Отметим, что прибавляемая константа
Отметим, что прибавляемая константа  велика, если
велика, если  близок к
близок к  Это соответствует тому факту, что если
Это соответствует тому факту, что если  близок к
близок к  то более вероятно, что он принадлежит компоненте
то более вероятно, что он принадлежит компоненте  и, следовательно, его влияние на нашу оценку для
и, следовательно, его влияние на нашу оценку для  уменьшается.
уменьшается.
 плотность
плотность  обращается в
обращается в

 усложняется уже при
усложняется уже при  Четыре члена суммы соответствуют четырем способам, которыми можно извлекать выборки из двухкомпонентных популяций. При
Четыре члена суммы соответствуют четырем способам, которыми можно извлекать выборки из двухкомпонентных популяций. При  выборках будет
выборках будет  членов, и нельзя найти простых достаточных статистик, чтобы облегчить понимание или упростить вычисления.
членов, и нельзя найти простых достаточных статистик, чтобы облегчить понимание или упростить вычисления.

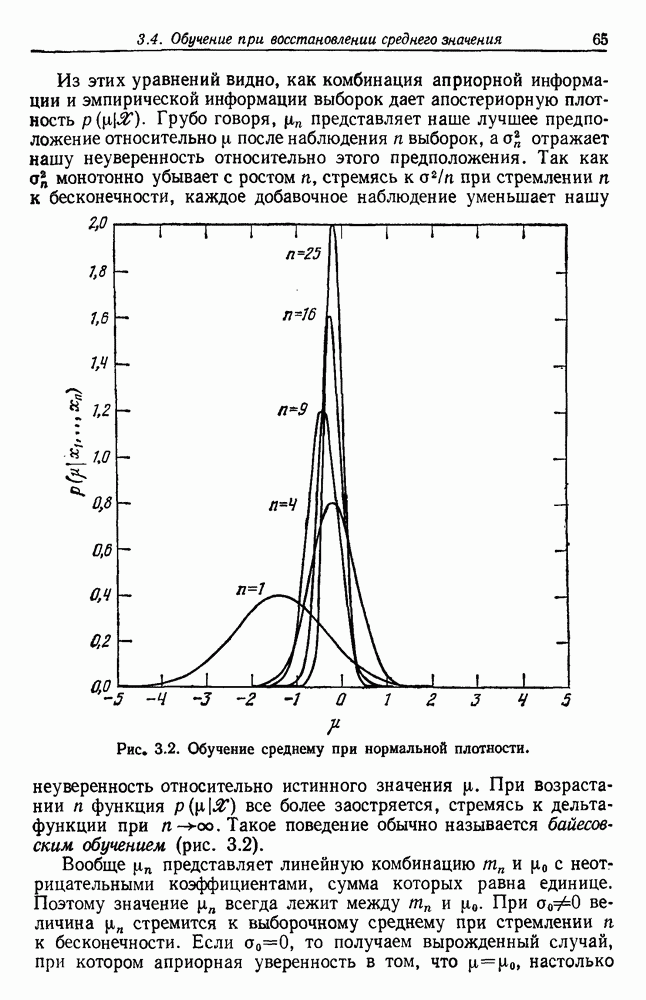
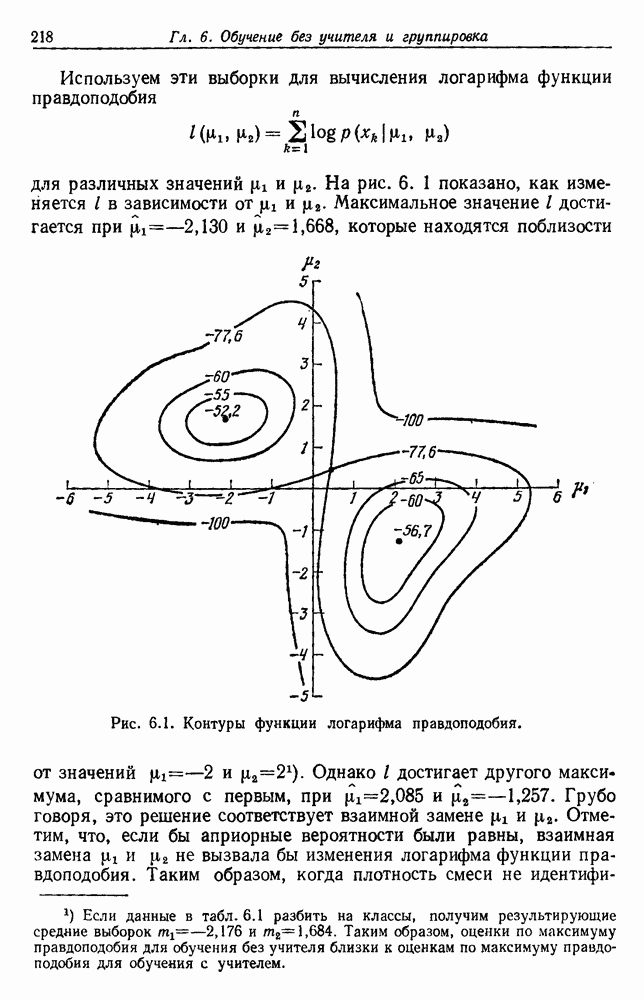
 . Это было сделано для данных табл. 6.1 при зйачениях
. Это было сделано для данных табл. 6.1 при зйачениях  . Априорная плотность
. Априорная плотность  равномерная на интервале от —4 до 4, Включает данные этой таблица. Эти данные были использованы для рекуррентного вычисления
равномерная на интервале от —4 до 4, Включает данные этой таблица. Эти данные были использованы для рекуррентного вычисления  Полученные результаты представлены на рис. 6.5. Когда
Полученные результаты представлены на рис. 6.5. Когда  стремится к бесконечности, мы с уверенностью можем ожидать, что
стремится к бесконечности, мы с уверенностью можем ожидать, что  будет стремиться к всплеску в точке
будет стремиться к всплеску в точке  График дает некоторое представление о скорости сходимости.
График дает некоторое представление о скорости сходимости.
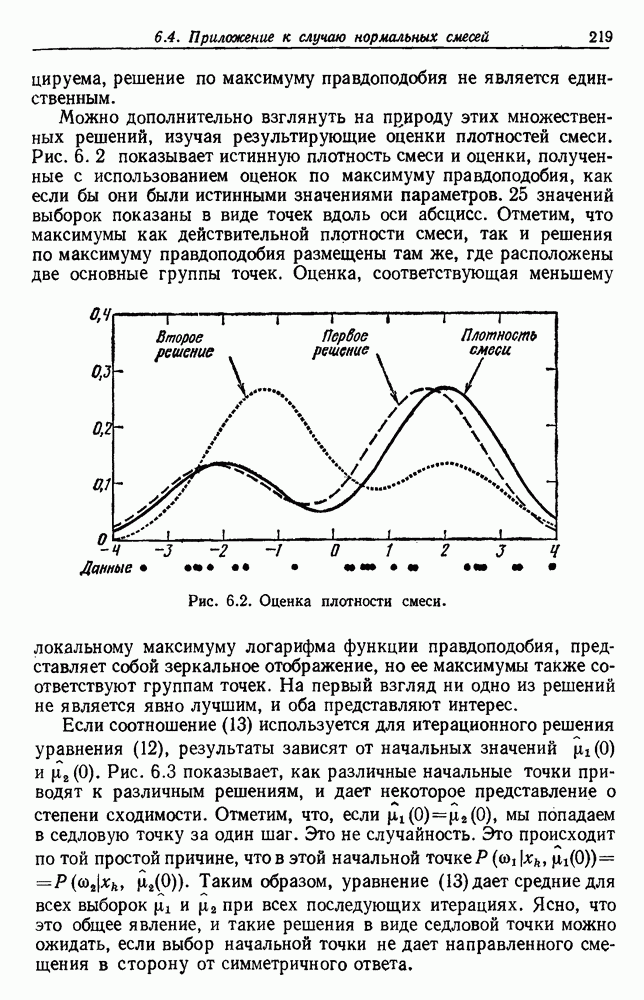
 . Рис. 6.6 показывает, как изменяется
. Рис. 6.6 показывает, как изменяется  , когда предполагается, что
, когда предполагается, что  равномерна на интервале от 1 до 3, в зависимости от более четкого начального знания о 0. Результаты этого изменения больше всего проявляются, когда
равномерна на интервале от 1 до 3, в зависимости от более четкого начального знания о 0. Результаты этого изменения больше всего проявляются, когда  мало. Именно здесь различия между байесовским подходом и подходом по максимуму правдоподобия наиболее значительны. При увеличении
мало. Именно здесь различия между байесовским подходом и подходом по максимуму правдоподобия наиболее значительны. При увеличении  важность априорного знания уменьшается, и в этом частном случае кривые для
важность априорного знания уменьшается, и в этом частном случае кривые для  практически идентичны. В общем случае можно ожидать, что различие будет мало, когда число непомеченных выборок в несколько раз больше эффективного числа помеченных выборок, используемых для определения
практически идентичны. В общем случае можно ожидать, что различие будет мало, когда число непомеченных выборок в несколько раз больше эффективного числа помеченных выборок, используемых для определения  .
.
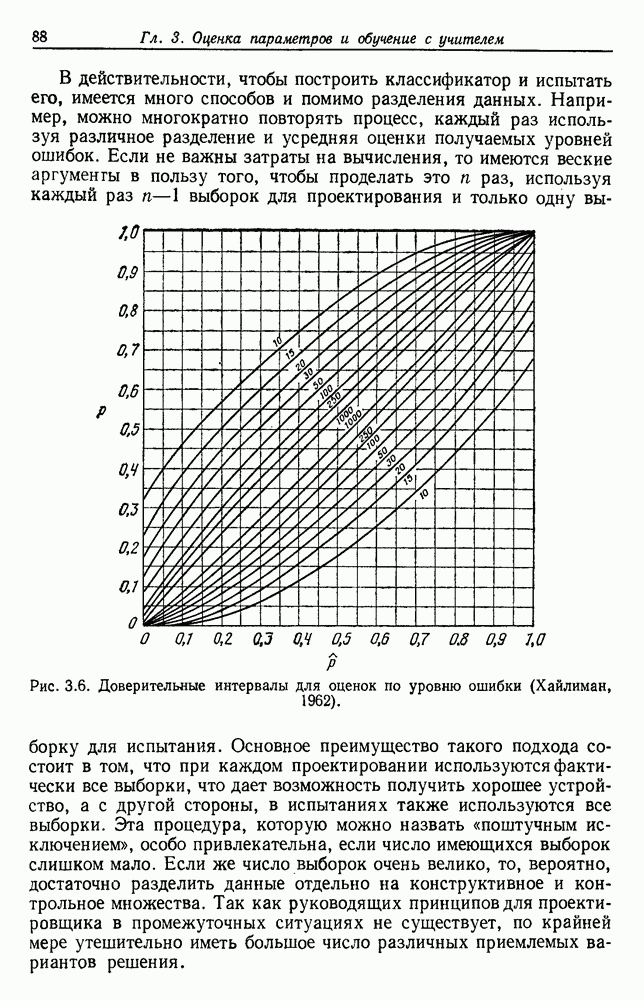
 выборок будут классифицированы, и затем обновить классификатор. При желании процесс можно повторять до тех пор, пока не будет больше изменений при пометке выборок. Можно ввести различные эвристические процедуры, обеспечивающие зависимость любых коррекций от достоверности решения классификатора.
выборок будут классифицированы, и затем обновить классификатор. При желании процесс можно повторять до тех пор, пока не будет больше изменений при пометке выборок. Можно ввести различные эвристические процедуры, обеспечивающие зависимость любых коррекций от достоверности решения классификатора.