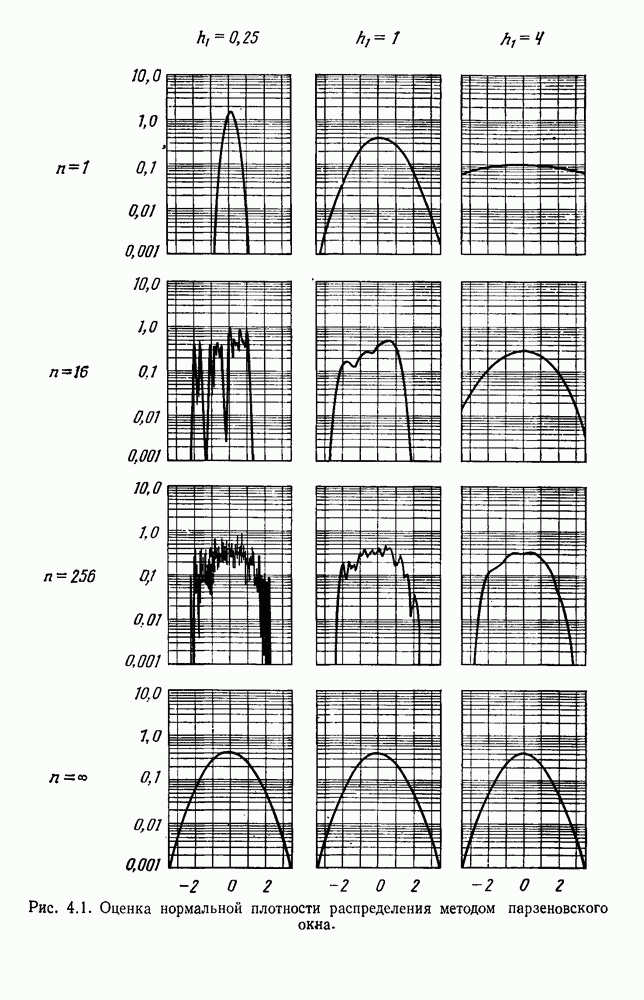
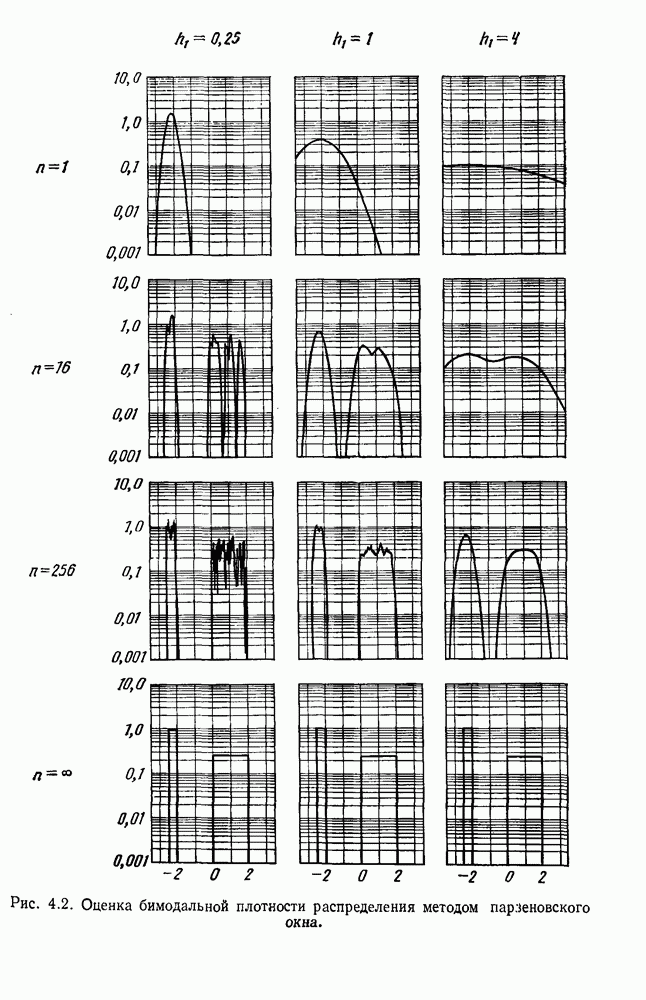
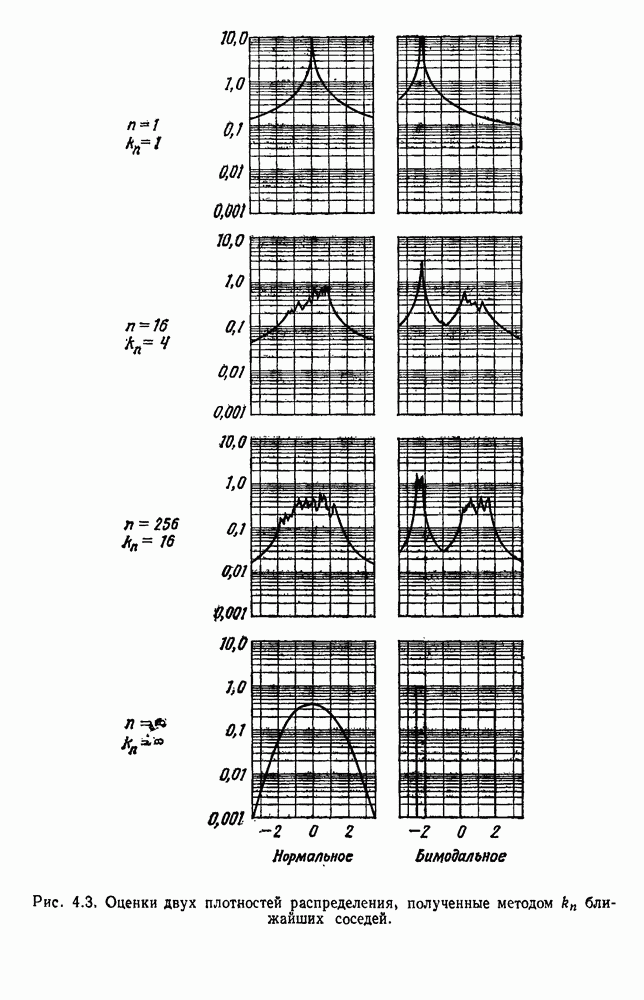
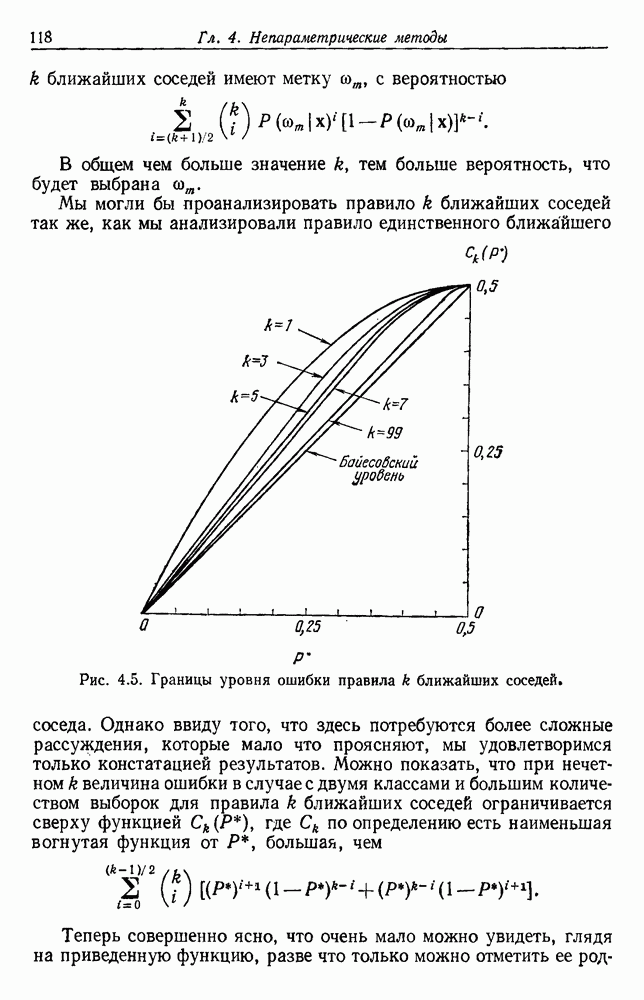
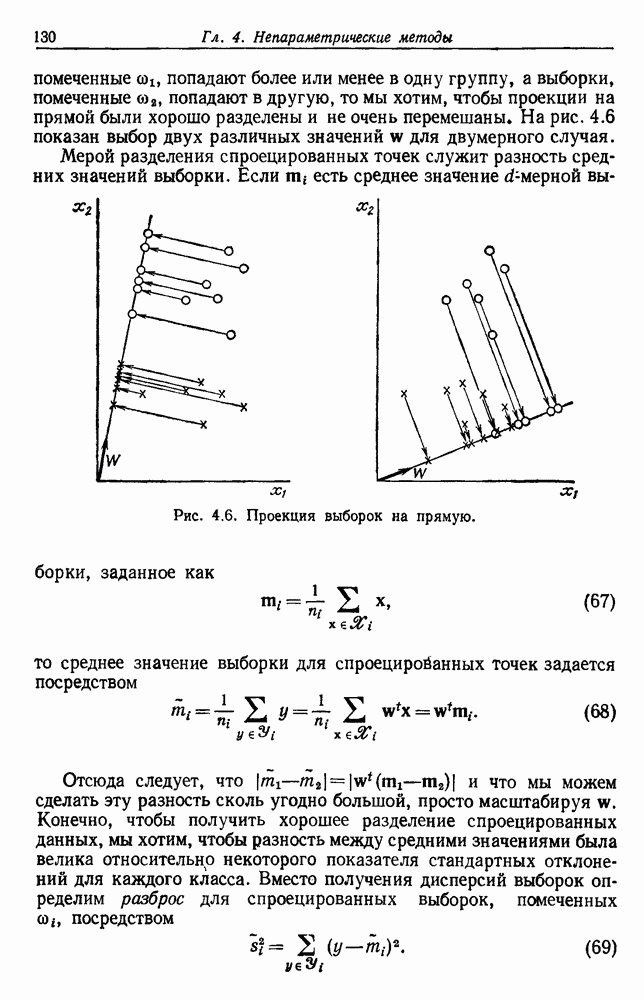
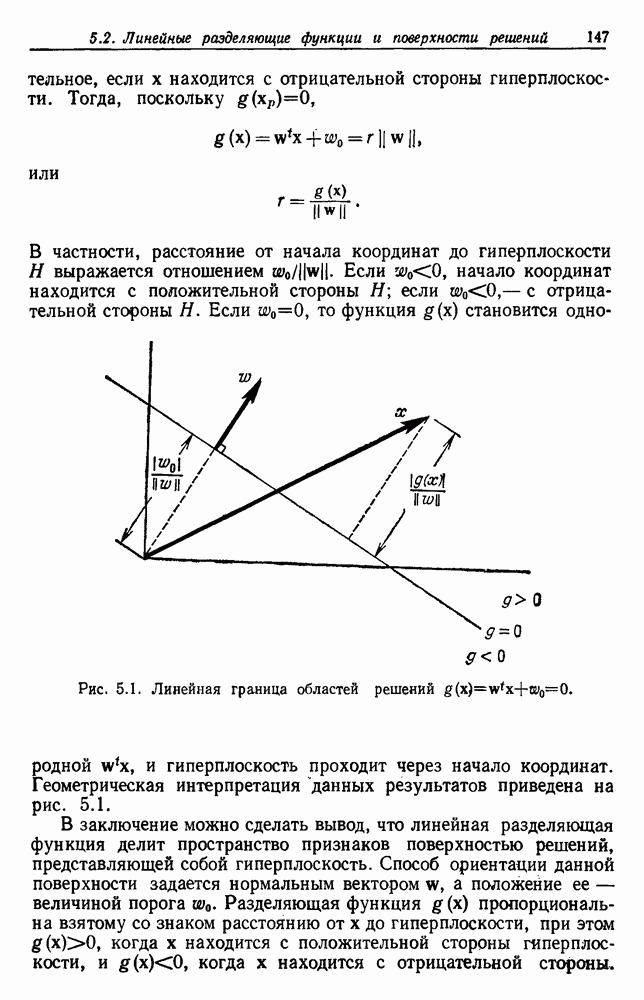
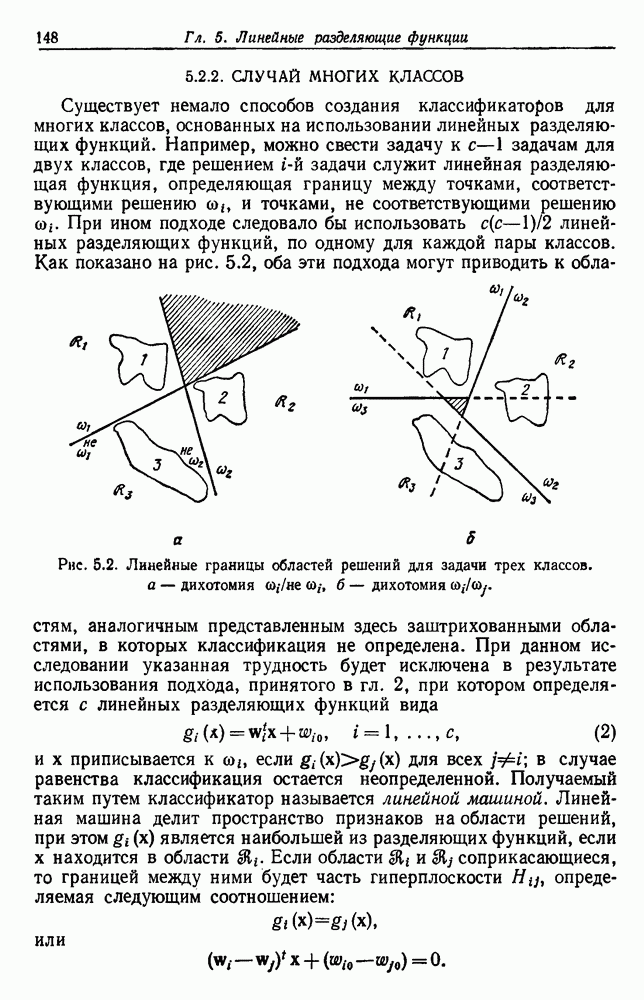
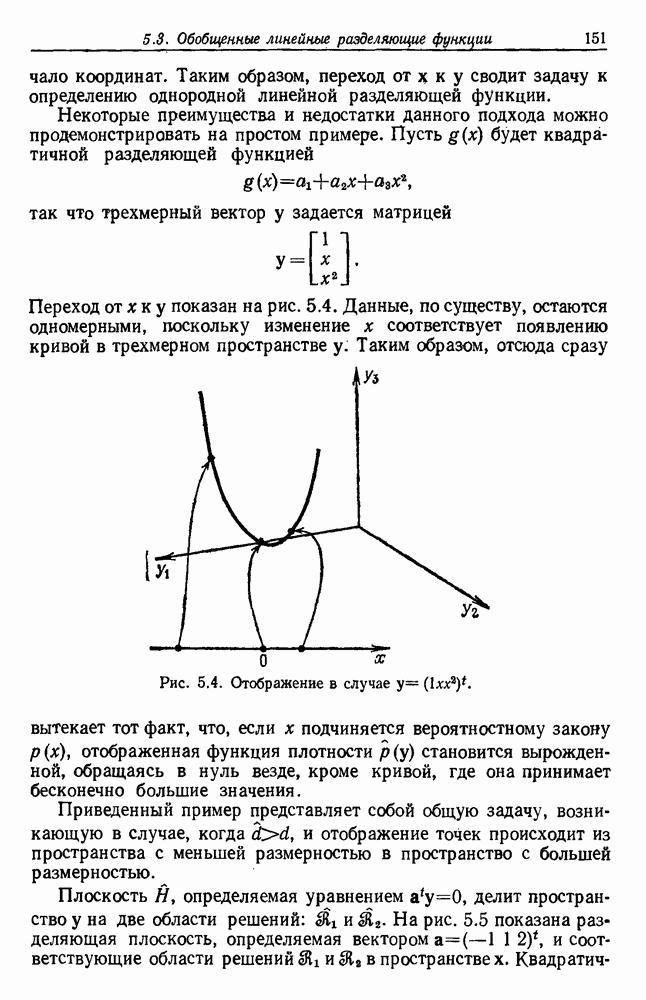
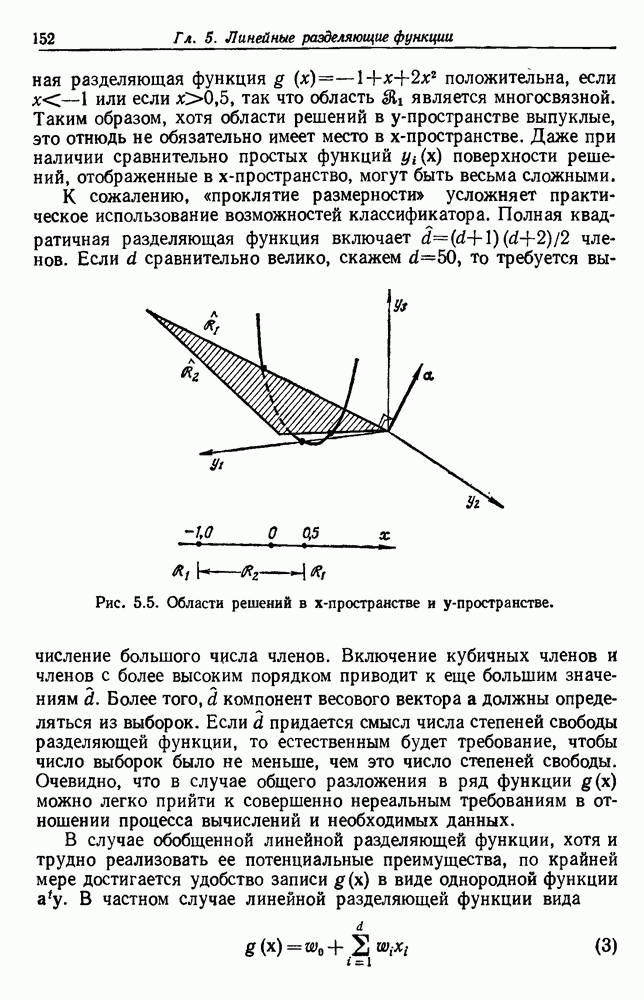
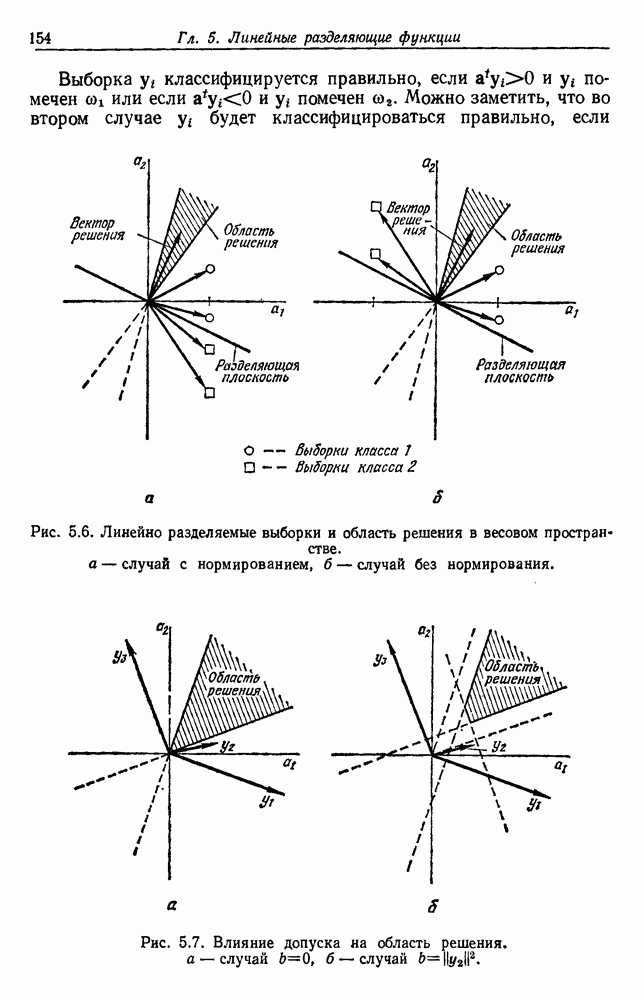
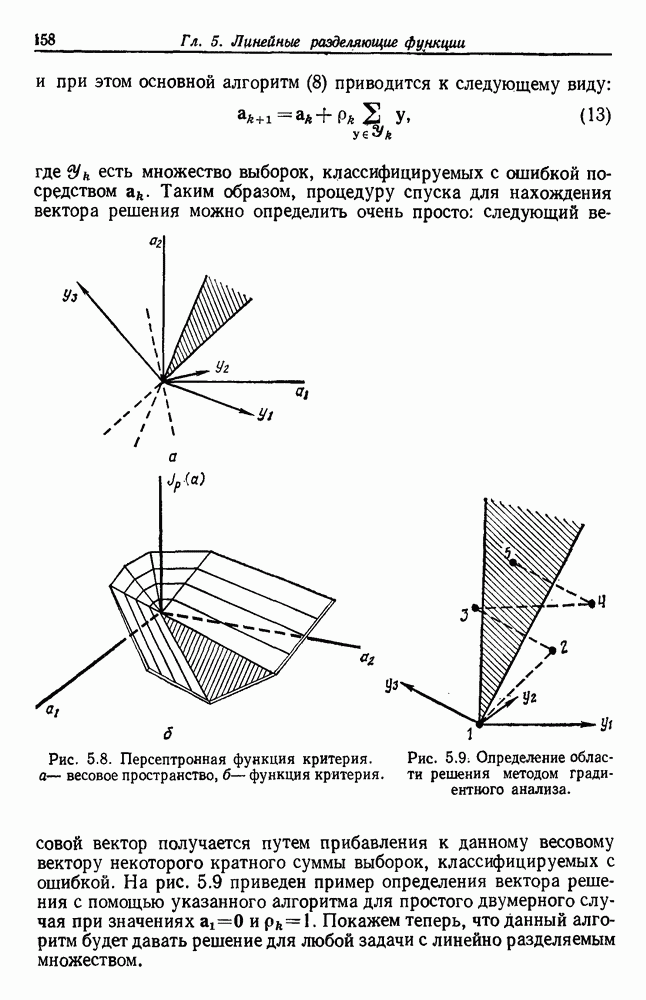
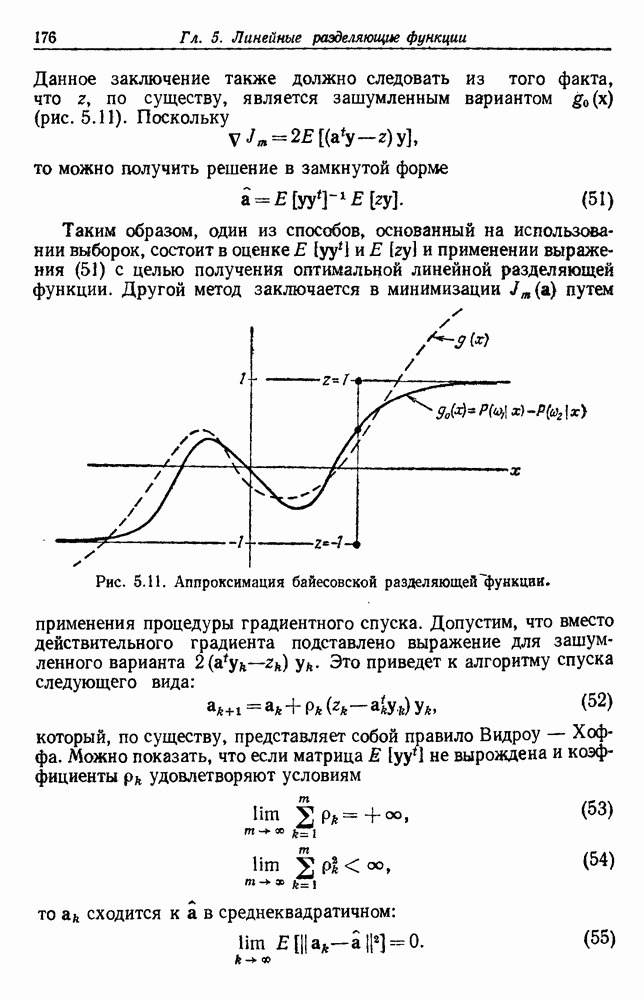
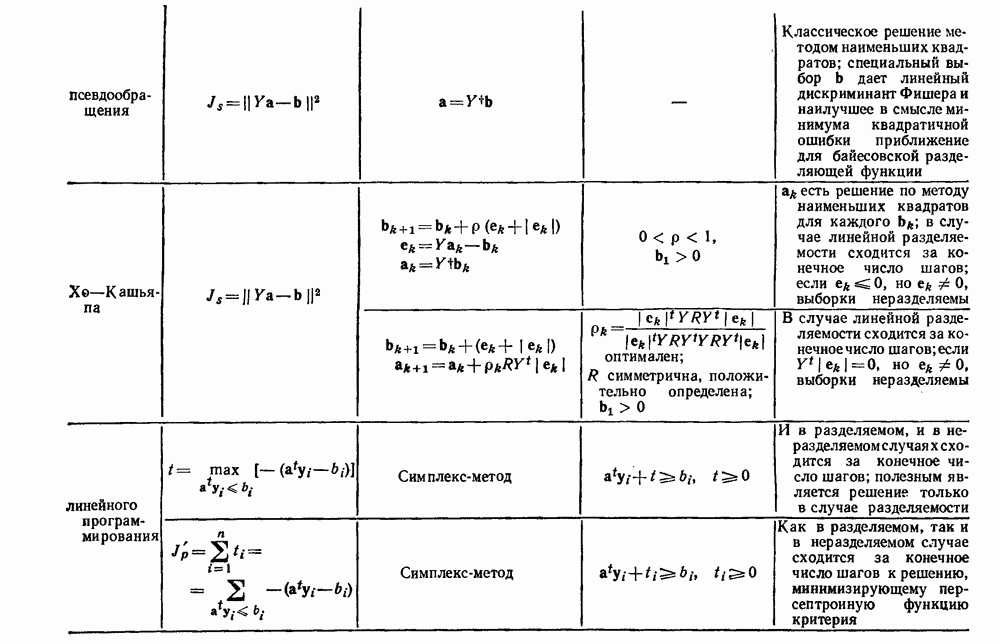
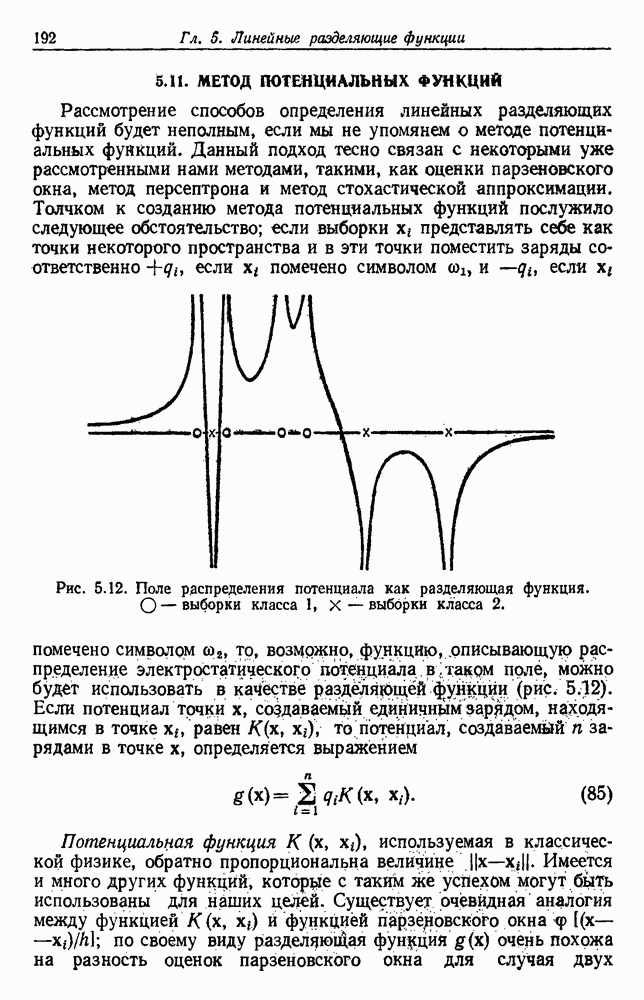
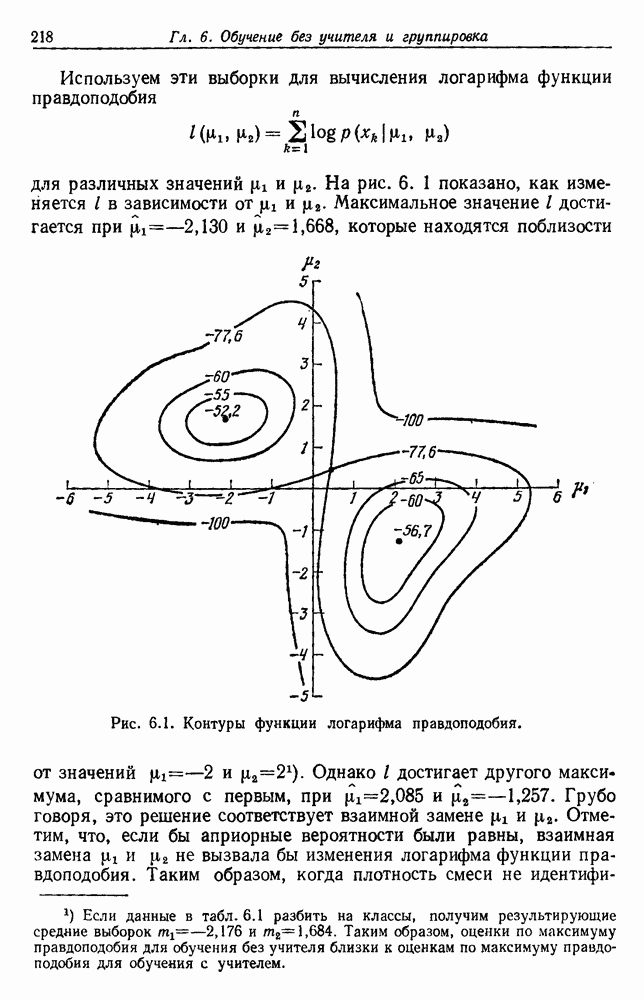
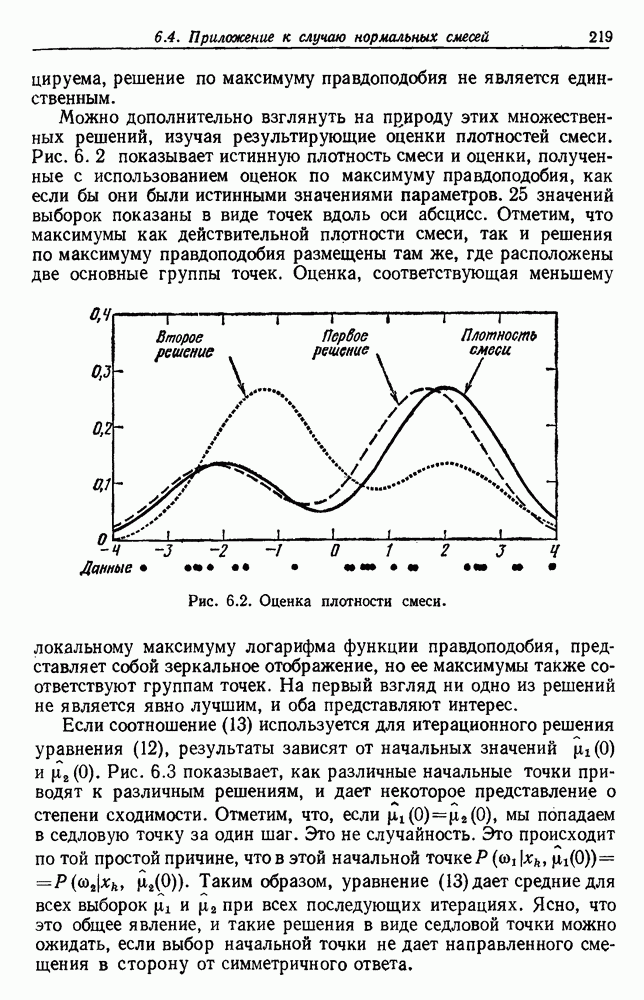
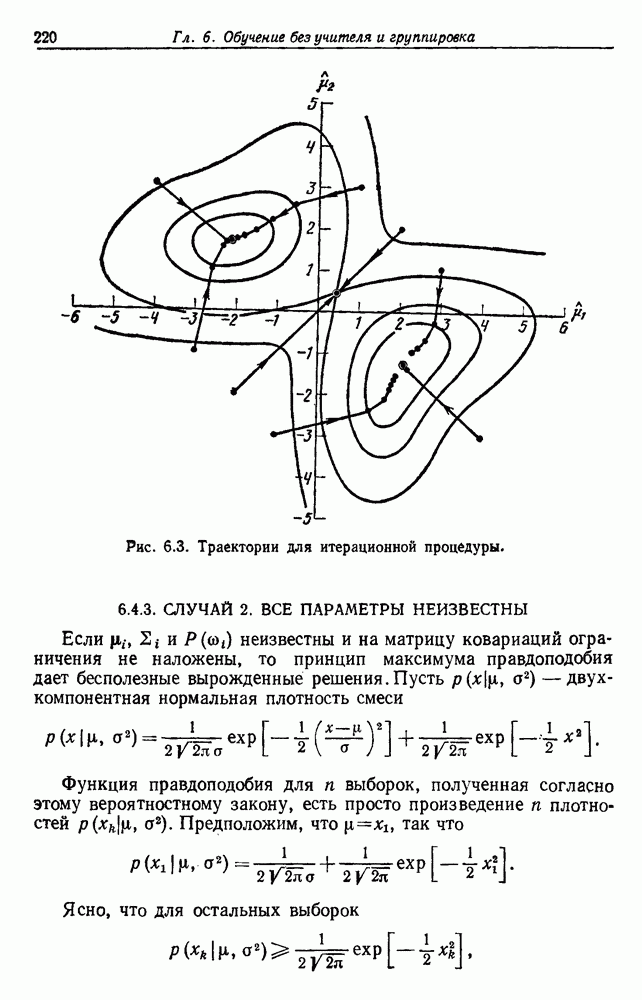
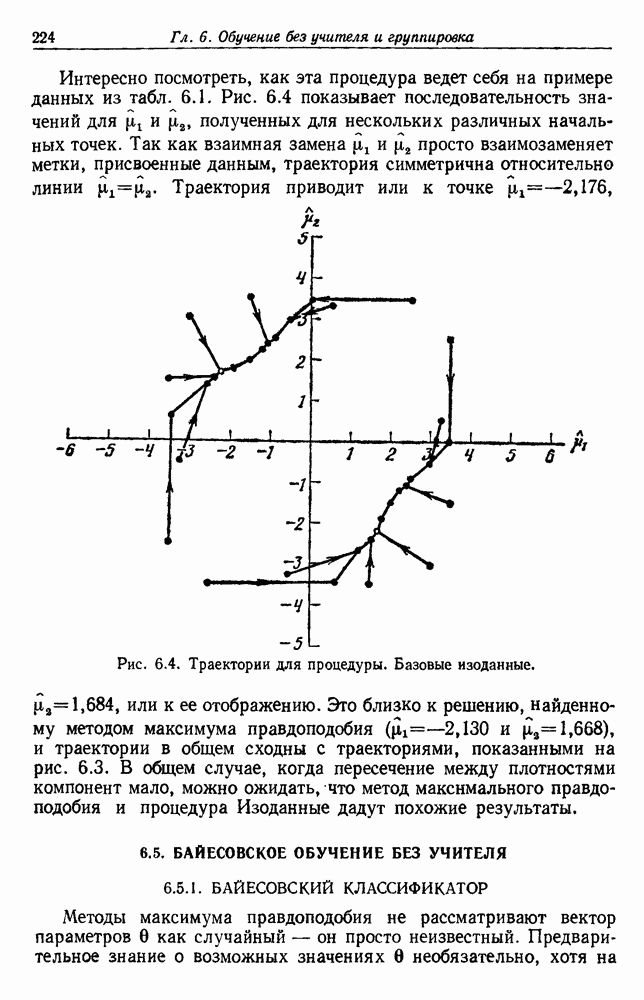
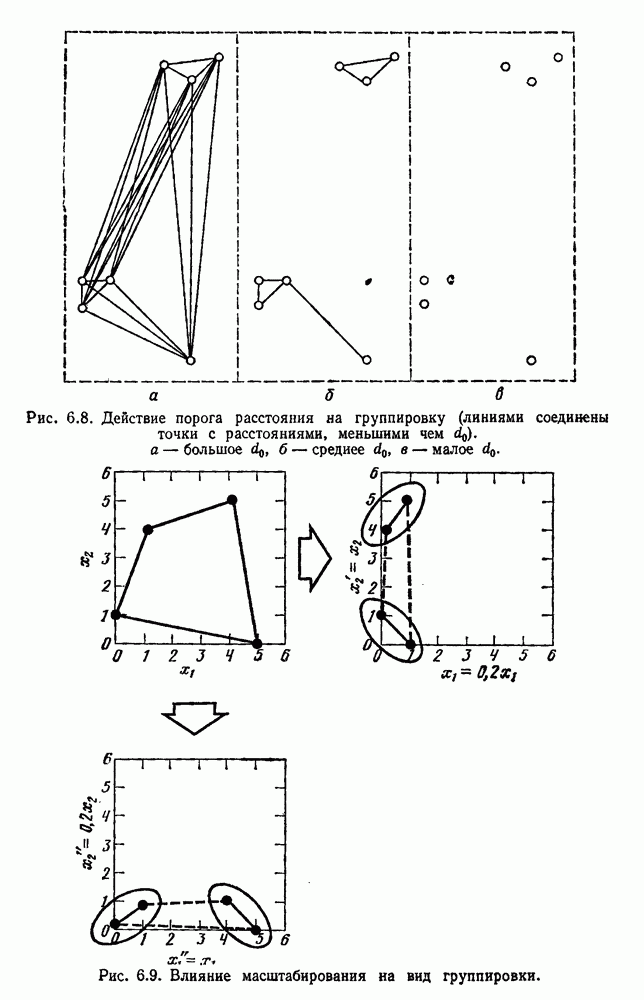
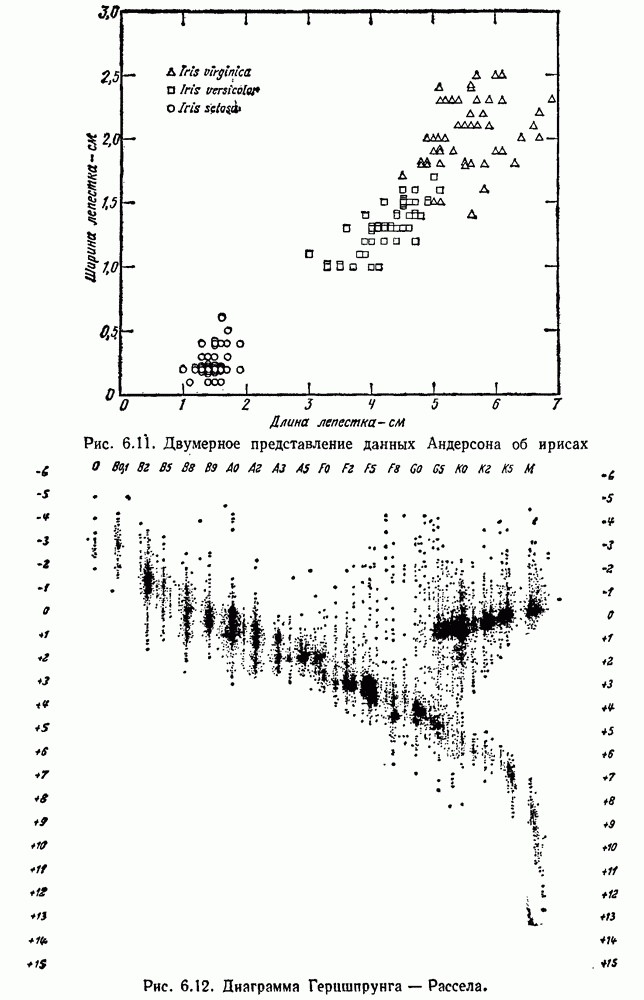
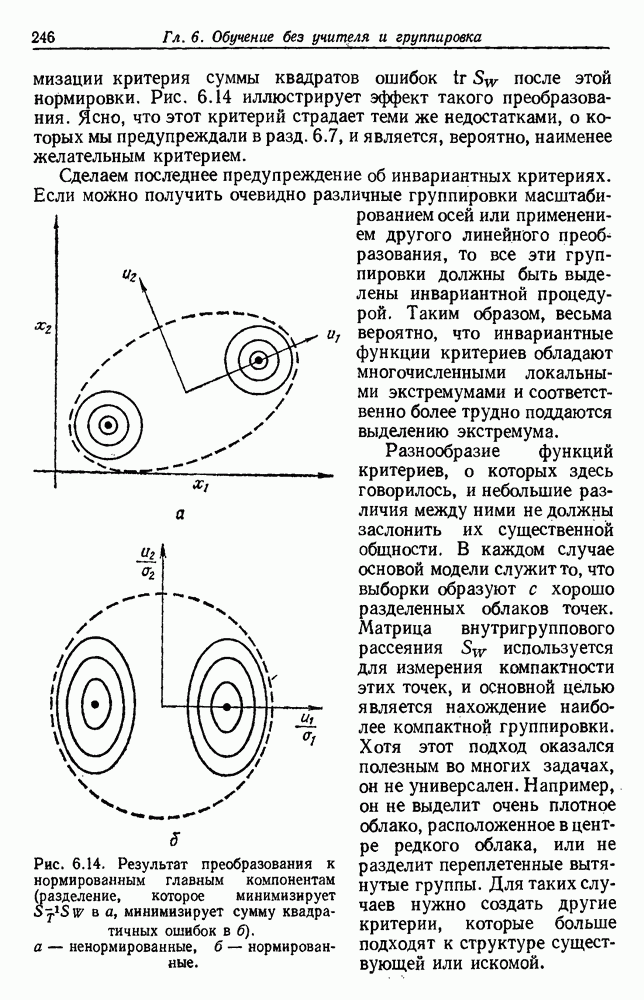
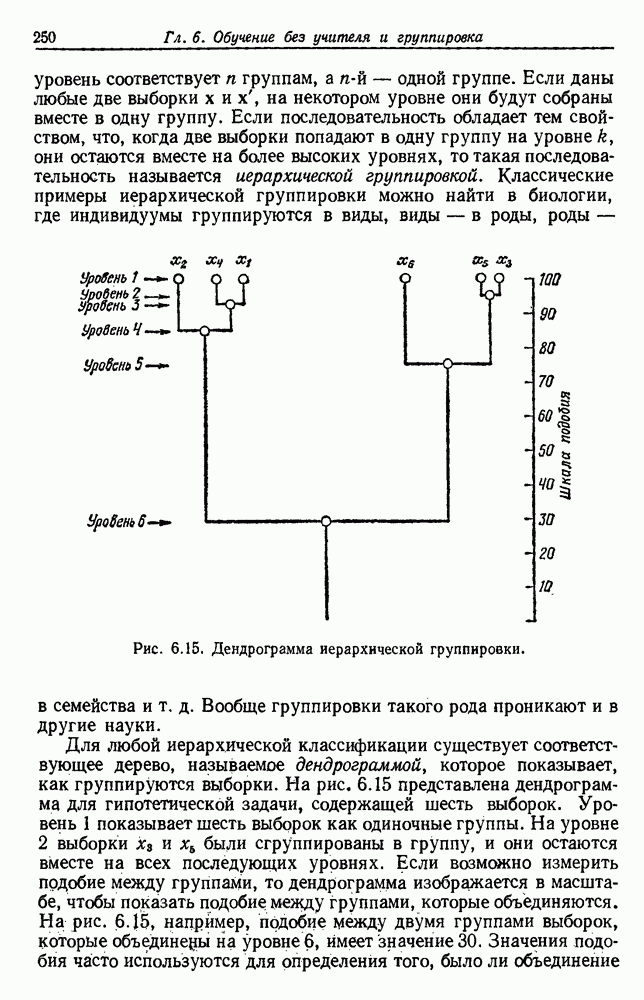
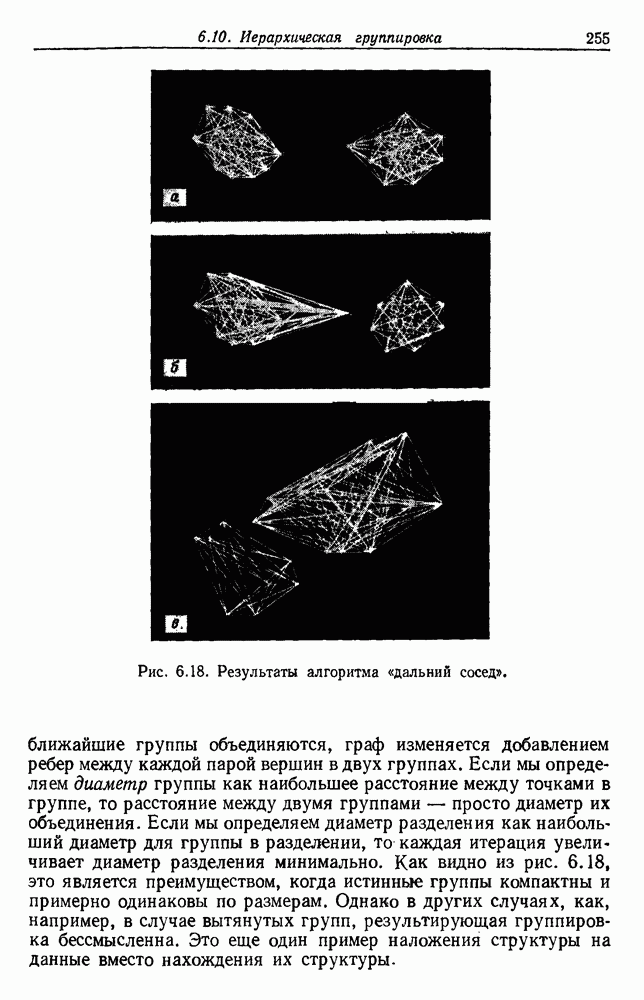
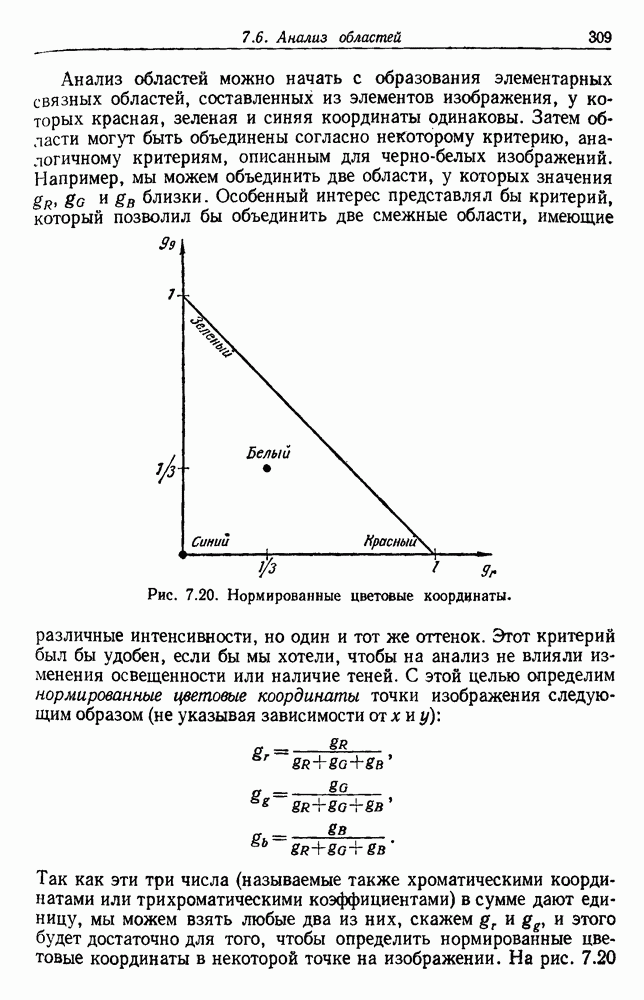
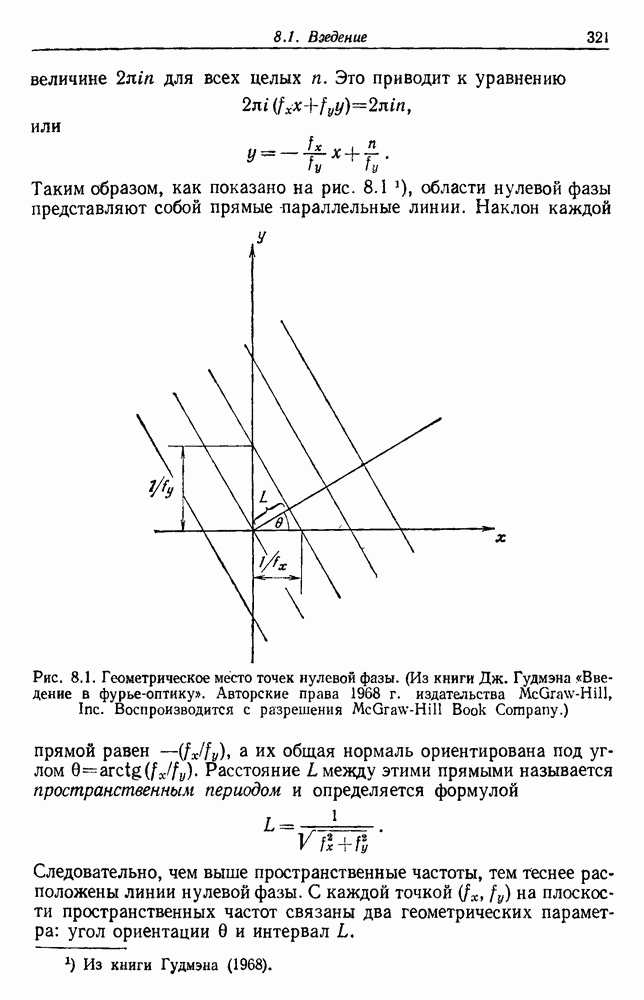
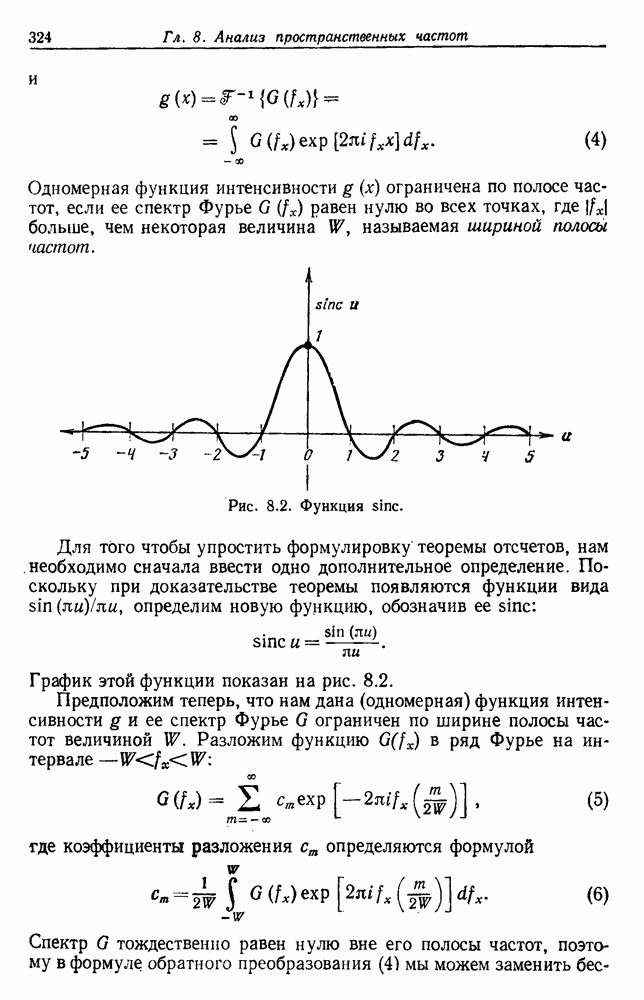
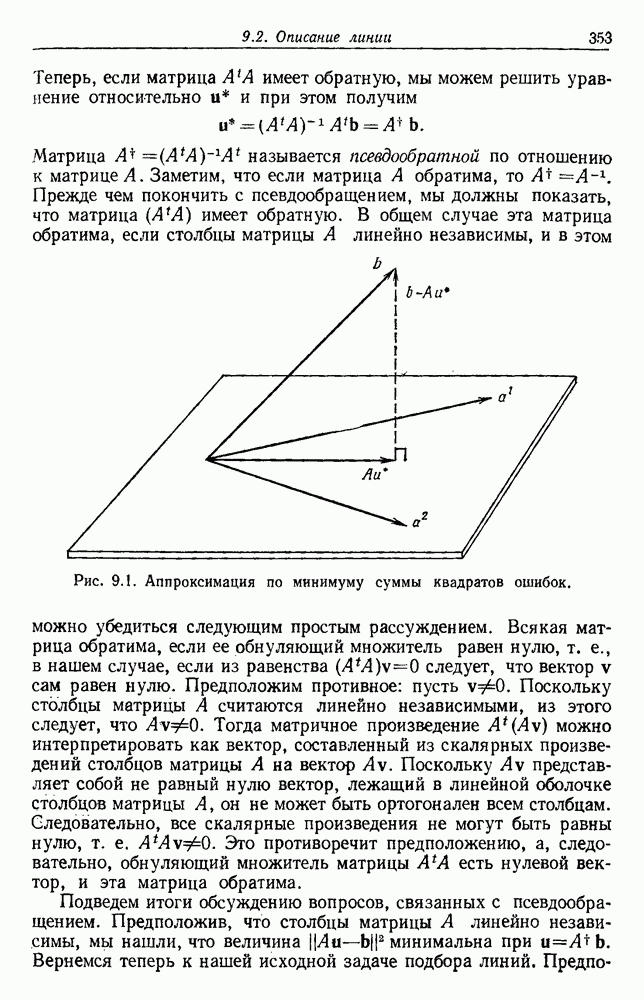
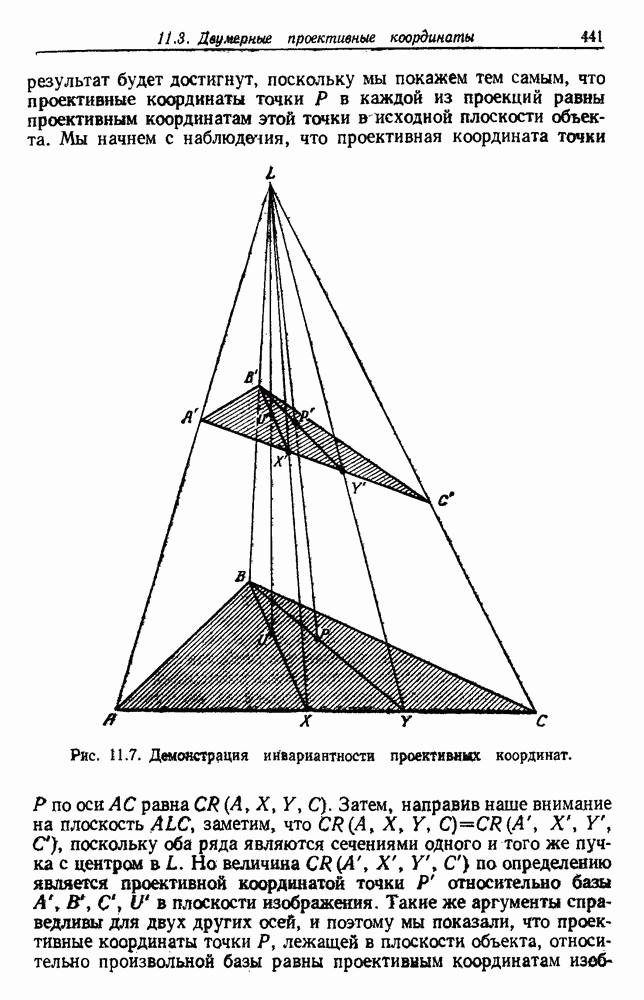
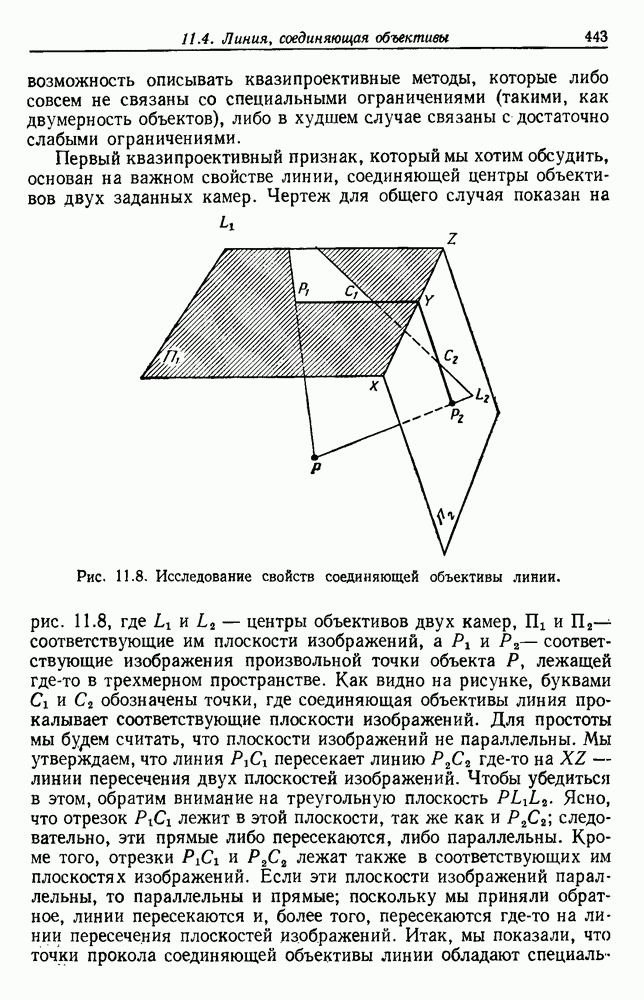
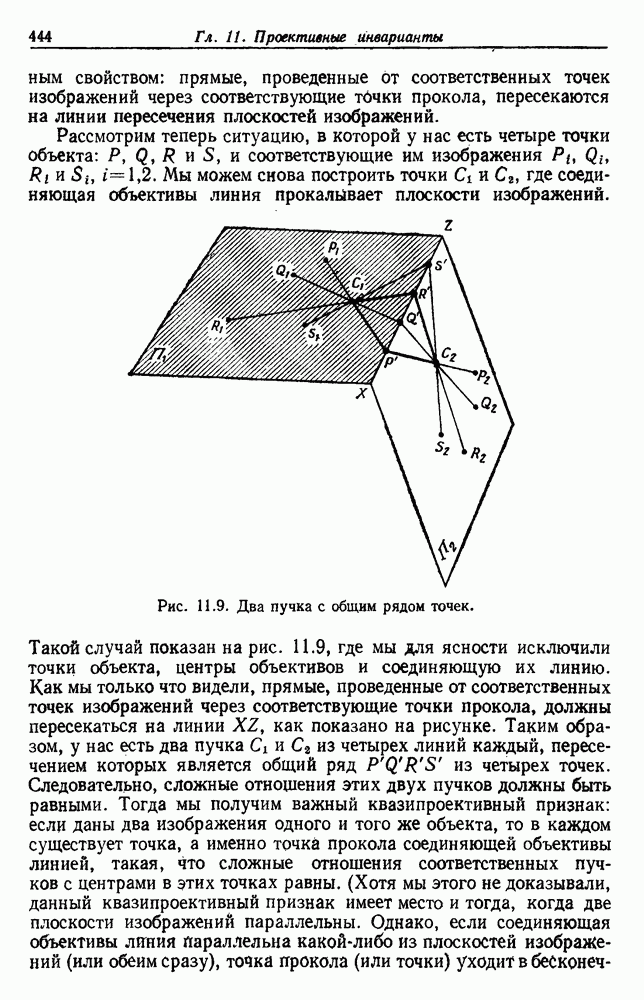
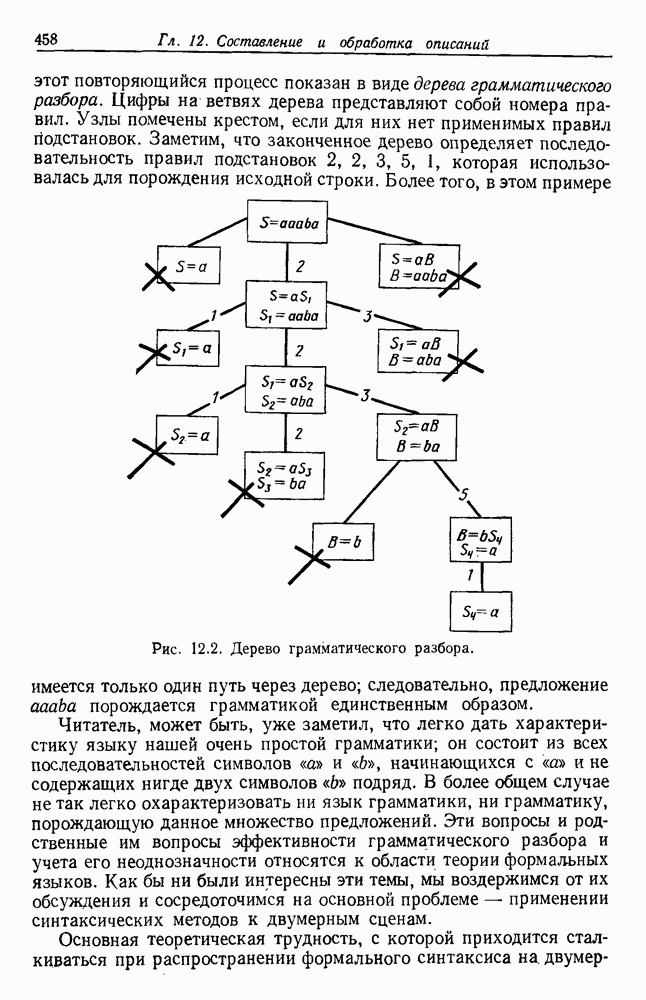
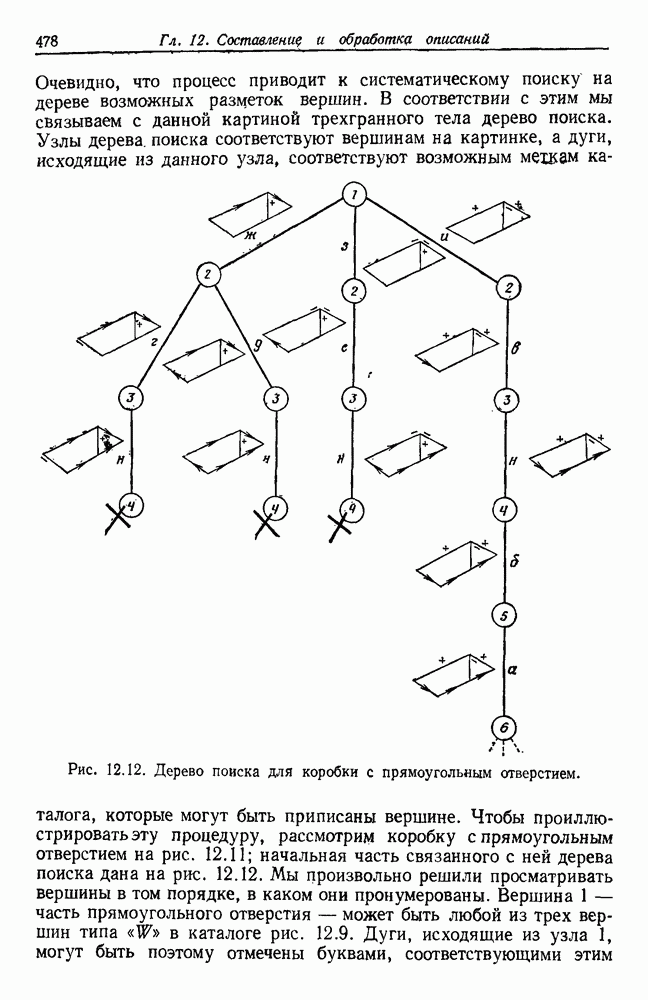
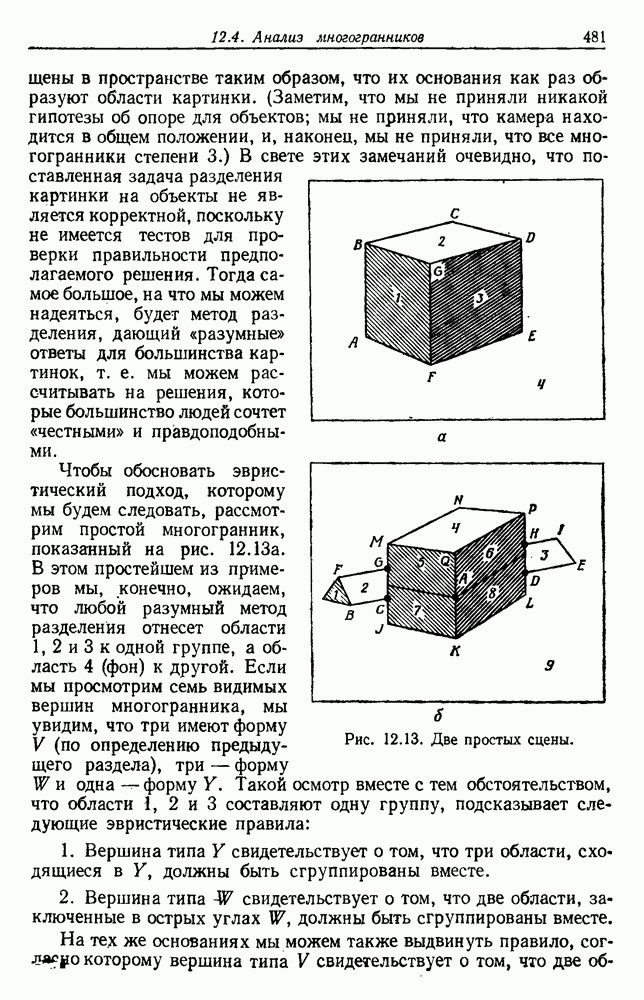
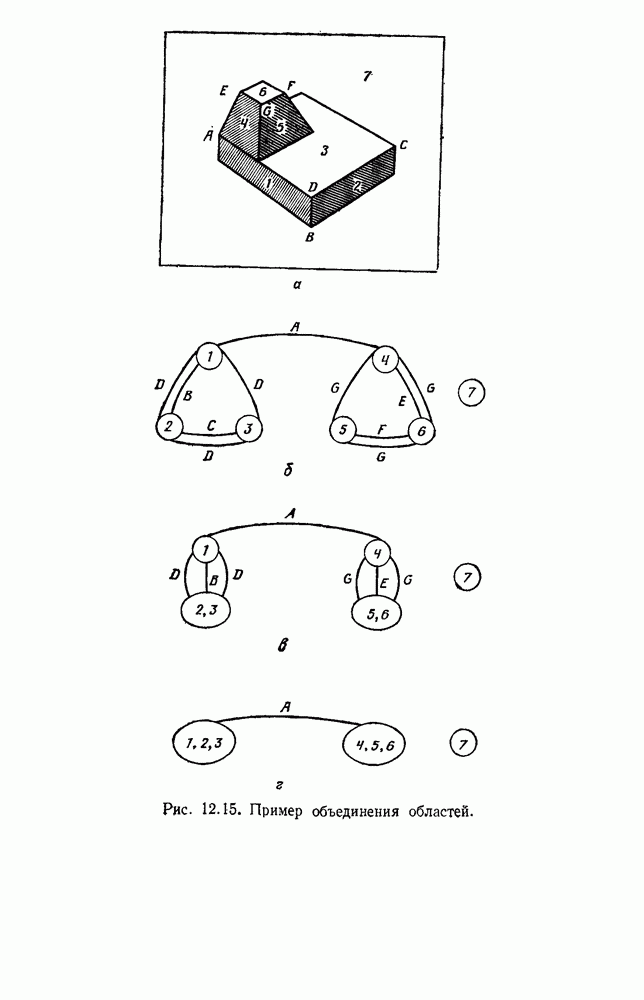
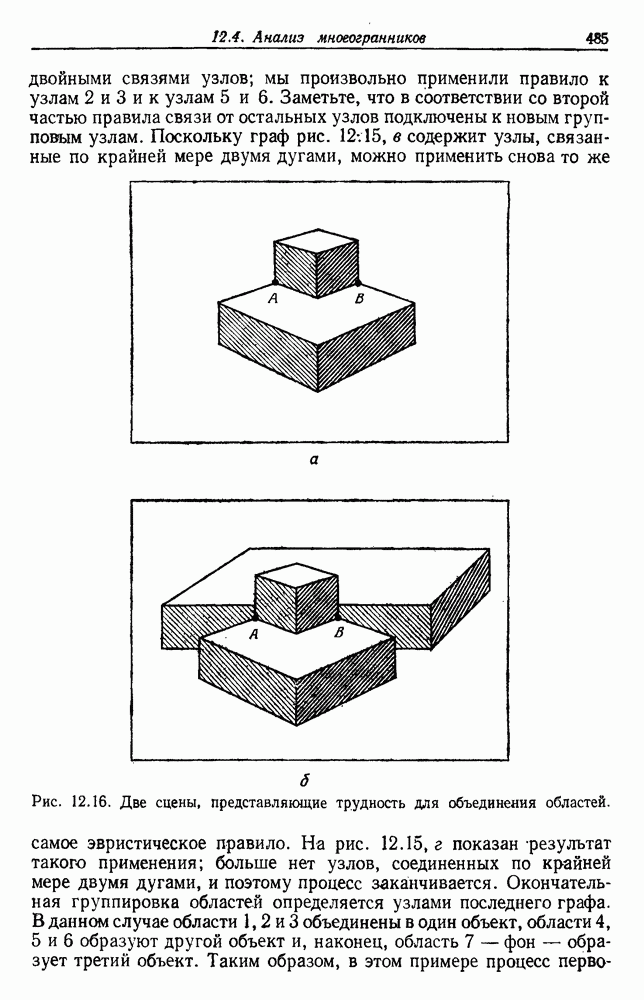
Глава 6. ОБУЧЕНИЕ БЕЗ УЧИТЕЛЯ И ГРУППИРОВКА
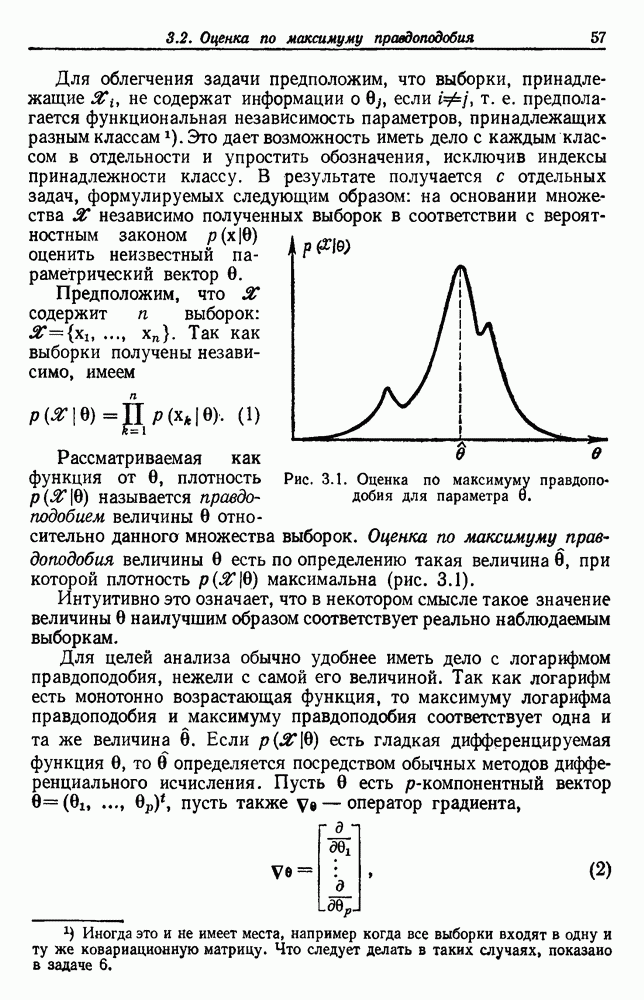
6.1. ВВЕДЕНИЕ
До сих пор мы предполагали, что обучающие выборки, используемые для создания классификатора, были помечены, чтобы показать, к какой категории они принадлежат. Процедуры, использующие помеченные выборки, называются процедурами с учителем. Теперь рассмотрим процедуры без учителя, использующие непомеченные выборки. То есть мы посмотрим, что можно делать, имея набор выборок без указания их классификации.
Возникает вопрос: целесообразна ли такая малообещающая задача и возможно ли в принципе обучить чему-либо по непомеченным выборкам. Имеются три основные причины, по которым мы интересуемся процедурами без учителя. Во-первых, сбор и пометка большого количества выборочных образов требуют много средств и времени. Если классификатор можно в первом приближении создать на небольшом помеченном наборе выборок и после этого его «настроить» на использование без учителя на большом непомеченном наборе, мы сэкономим много труда и времени. Во-вторых, во многих практических задачах характеристики образов медленно изменяются во времени. Если такие изменения можно проследить классификатором, работающим в режиме обучения без учителя, это позволяет повысить качество работы. В-третьих, на ранних этапах исследования иногда бывает интересно получить сведения о внутренней природе или структуре данных. Выделение четких подклассов или основных отклонений от ожидаемых характеристик может значительно изменить подход, принятый при создании классификатора.
Ответ на вопрос, можно или нельзя в принципе обучить чему-либо по непомеченным данным, зависит от принятых предположений — теорему нельзя доказать без предпосылок. Мы начнем с очень ограниченного предположения, что функциональный вид плотностей распределения известен, и единственное, что надо узнать, — это значение вектора неизвестных параметров. Интересно, что формальное решение этой задачи оказывается почти идентичным решению задачи об обучении с учителем, данному в гл. 3. К сожалению, в случае обучения без учителя решение наталкивается на обычные проблемы, связанные с параметрическими предположениями, не способствующими простоте вычислений. Это приводит нас к различным
попыткам дать новую формулировку задачи как задачи разделения данных в подгруппы, или кластеры. Хотя некоторые из результирующих процедур группировки и не имеют большого теоретического значения, они являются одним из наиболее полезных средств решения задач распознавания образов.