Пред.
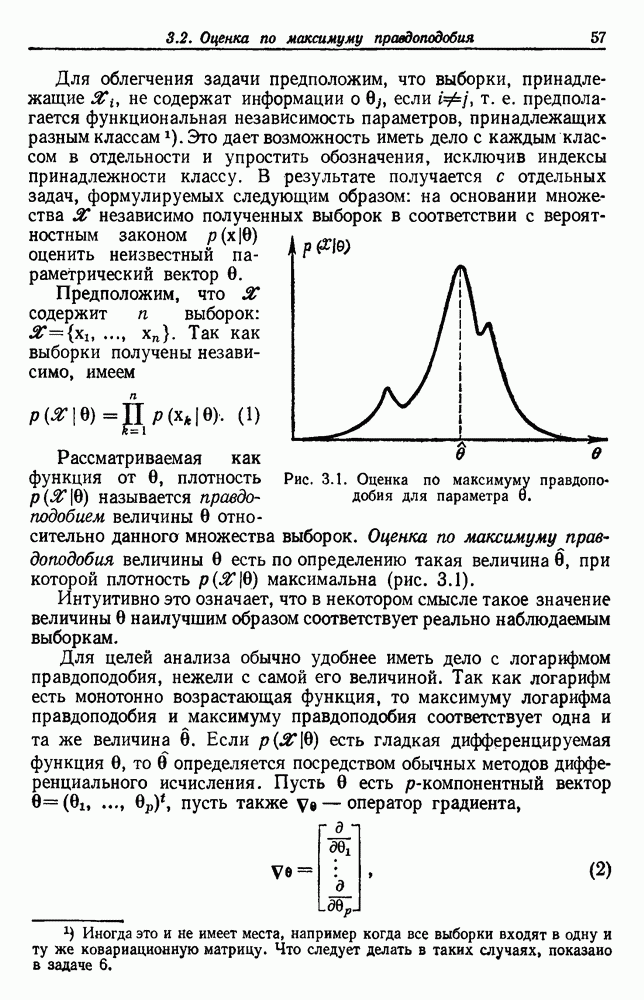
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
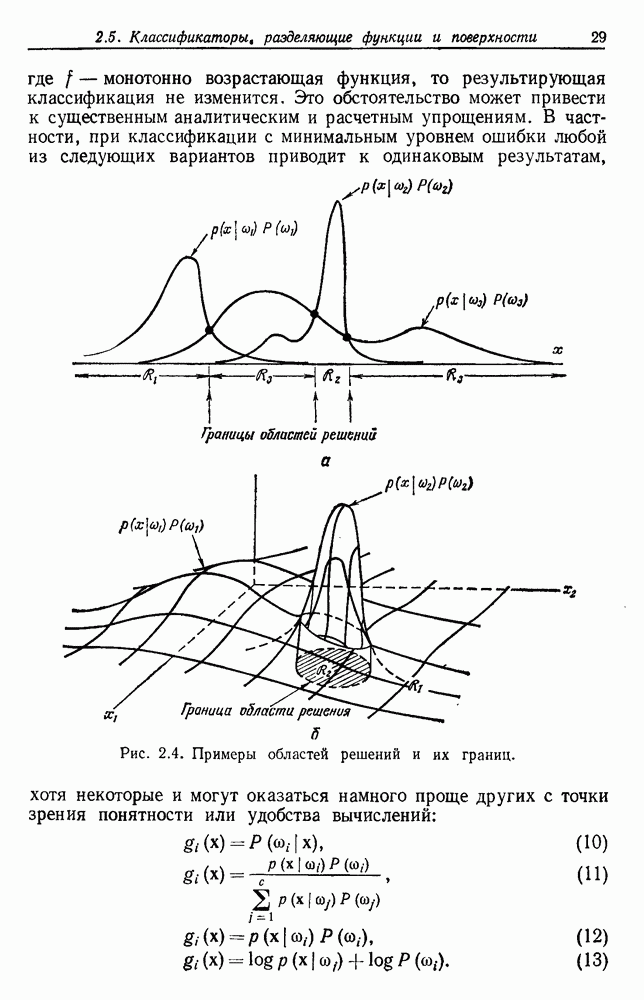
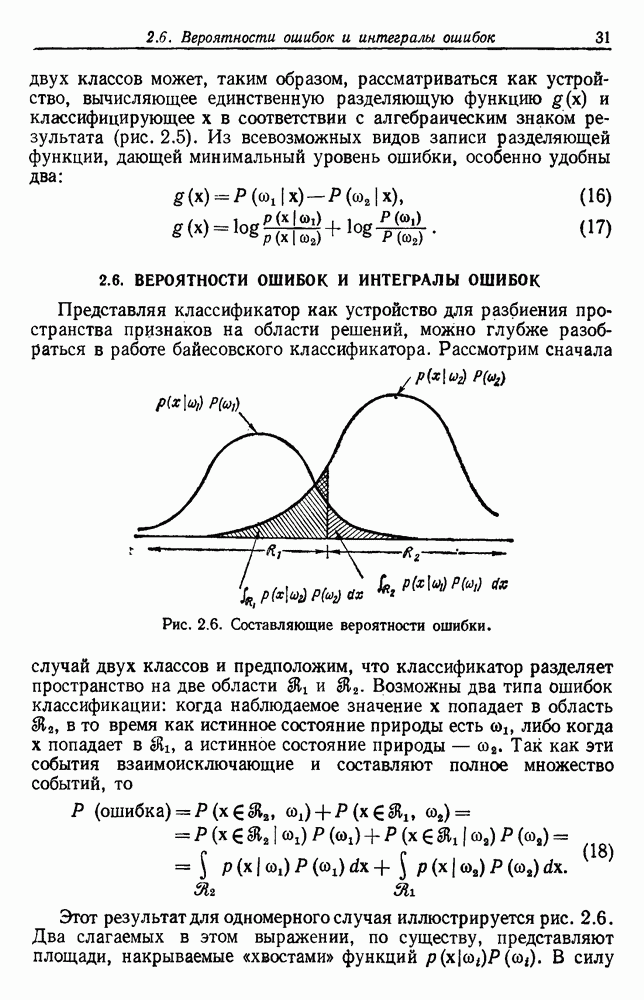
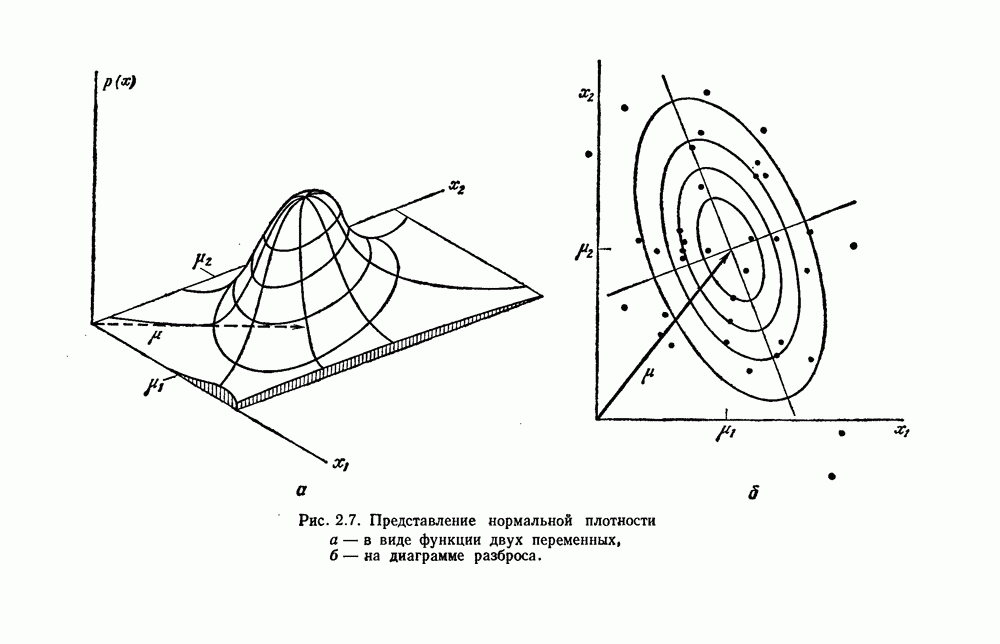
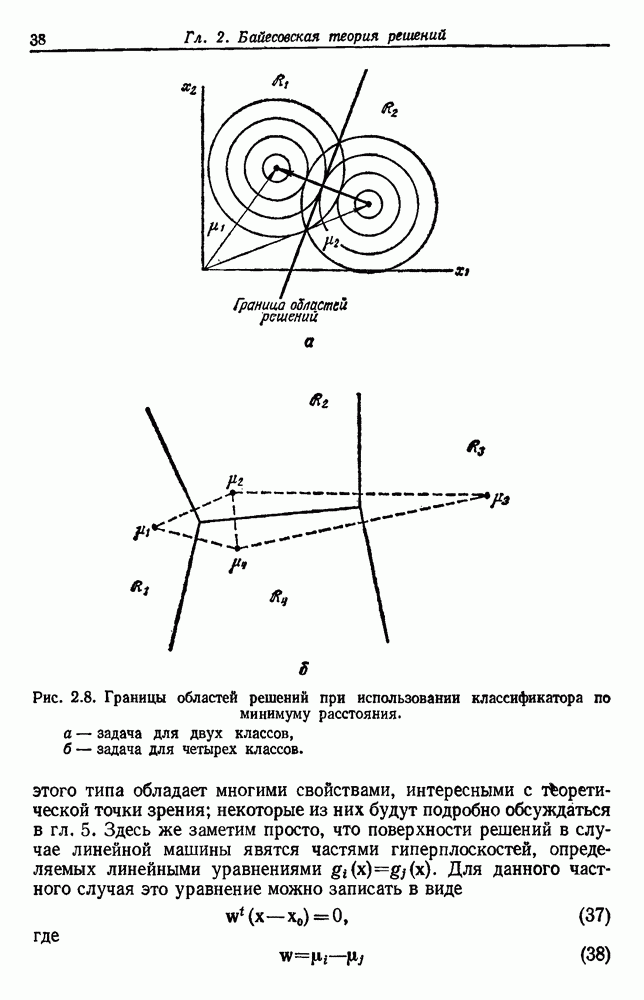
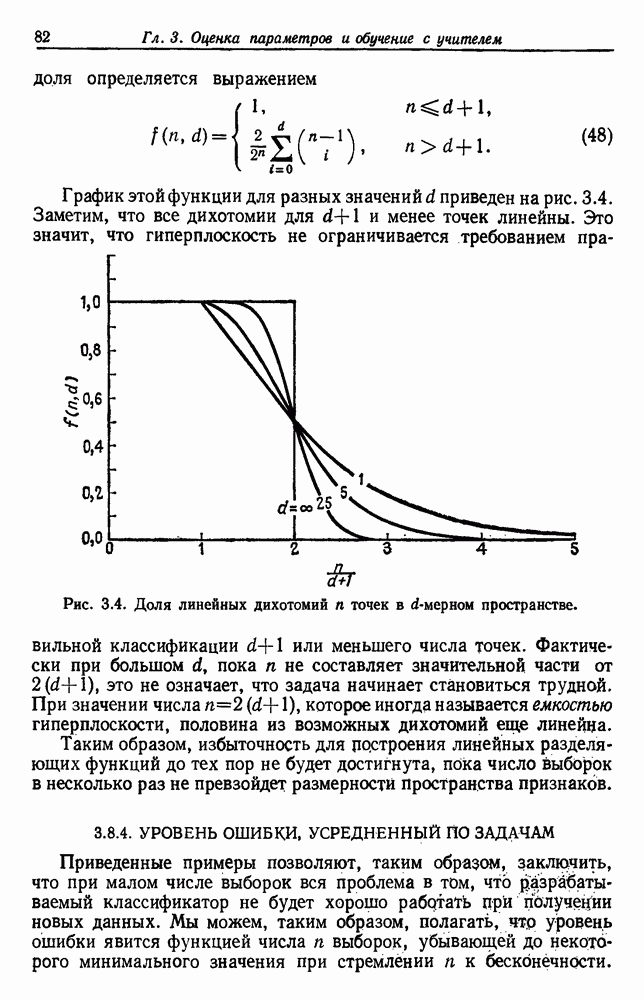
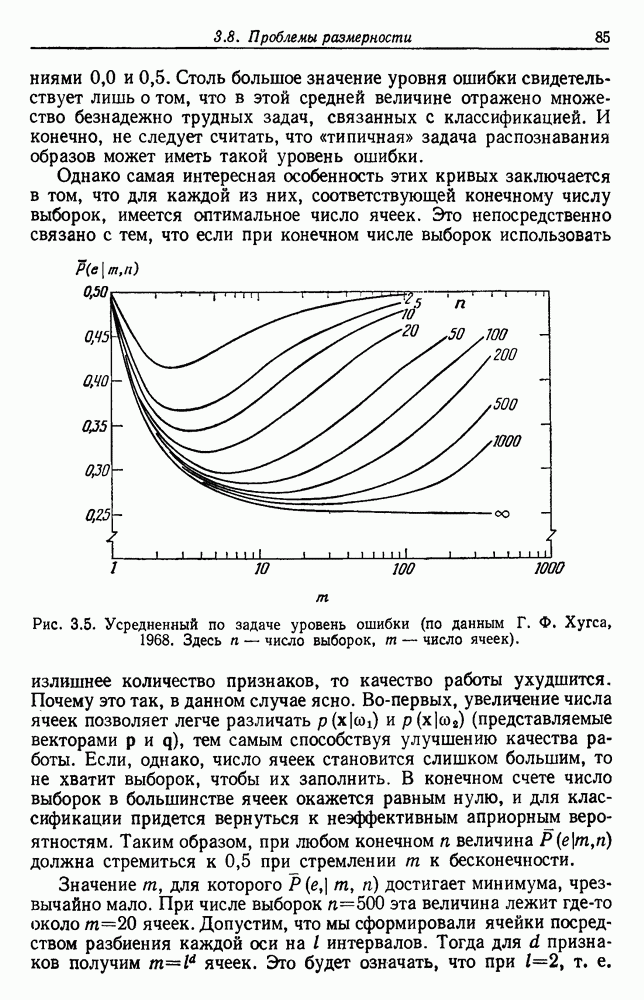
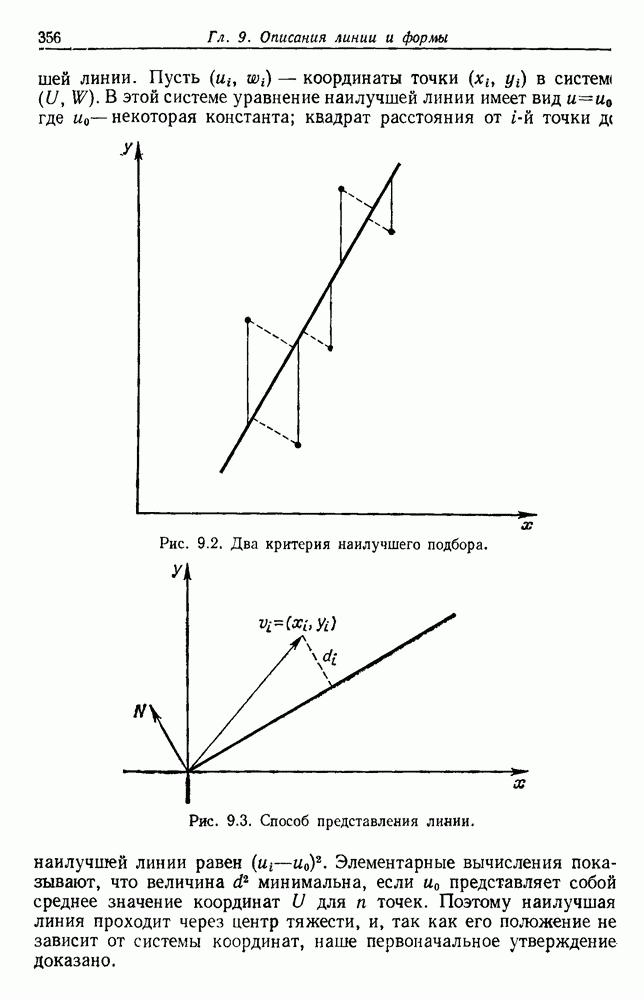
3.9. ОЦЕНКА УРОВНЯ ОШИБКИСуществуют по меньшей мере две причины, чтобы пожелать узнать уровень ошибки классификатора. Первая причина — это оценить, достаточно ли хорошо работает классификатор, чтобы считать его работу удовлетворительной. Вторая состоит в сравнении качества его работы с неким конкурирующим устройством. Один из подходов к оценке уровня ошибки состоит в вычислении его, исходя из предполагаемой параметрической модели. Например, при разделении на два класса в случае многих нормально распределенных величин можно вычислить Эмпирический подход, позволяющий избежать указанных трудностей, состоит в экспериментальных испытаниях классификатора. На практике это часто осуществляется подачей на классификатор системы контрольных выборок с оценкой уровня ошибки по части выборок, классификация которых оказалась неверной. Излишне говорить, что контрольные выборки должны быть отличными от конструктивных, иначе оцениваемый уровень ошибок окажется излишне оптимистичным. Если истинный, но неизвестный уровень ошибки классификатора равен
Таким образом, неверно классифицированная часть пробных выборок и есть в точности оценка
Свойства этой оценки для параметра Потребность в данных для построения классификатора и добавочных данных для его оценки представляет дилемму для проектировщика. Если большую часть своих данных он оставит для проектирования, то у него не будет уверенности в результатах испытаний. Если большую часть данных он оставит для испытаний, то не получит хорошего устройства. Хотя вопрос о том, как лучше разделить множество выборок на конструктивное и контрольное подмножества, в какой-то мере исследовался и много раз обсуждался, однако окончательного ответа на него все еще нет. В действительности, чтобы построить классификатор и испытать его, имеется много способов и помимо разделения данных. Например, можно многократно повторять процесс, каждый раз используя различное разделение и усредняя оценки получаемых уровней ошибок. Если не важны затраты на вычисления, то имеются веские аргументы в пользу того, чтобы проделать это
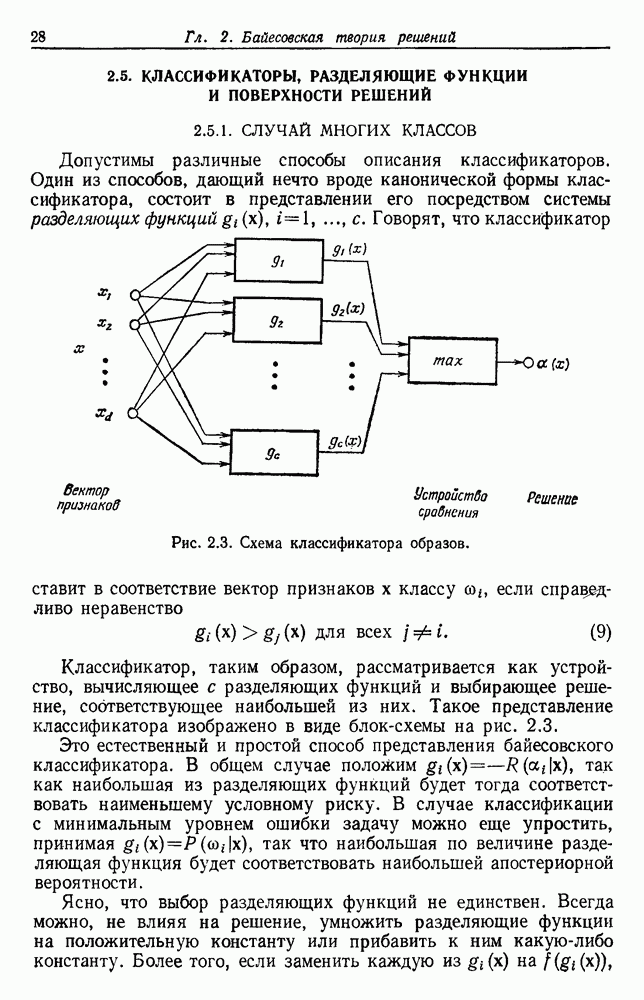
Рис. 3.6. Доверительные интервалы для оценок по уровню ошибки (Хайлиман, 1962). Основное преимущество такого подхода состоит в том, что при каждом проектировании используются фактически все выборки, что дает возможность получить хорошее устройство, а с другой стороны, в испытаниях также используются все выборки. Эта процедура, которую можно назвать «поштучным исключением», особо привлекательна, если число имеющихся выборок слишком мало. Если же число выборок очень велико, то, вероятно, достаточно разделить данные отдельно на конструктивное и контрольное множества. Так как руководящих принципов для проектировщика в промежуточных ситуациях не существует, по крайней мере утешительно иметь большое число различных приемлемых вариантов решения.
|
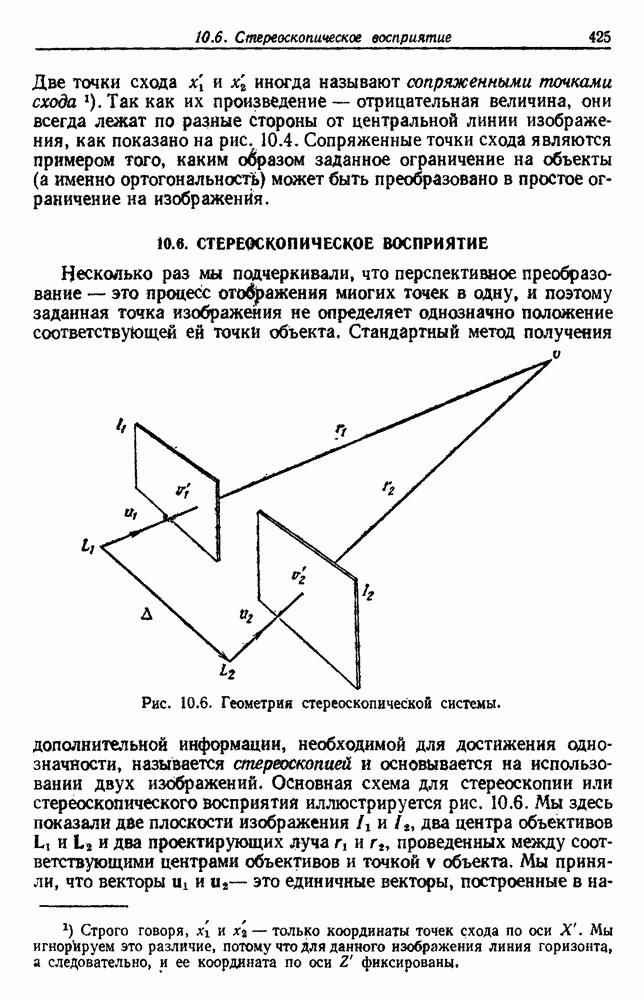
 |
Оглавление
|








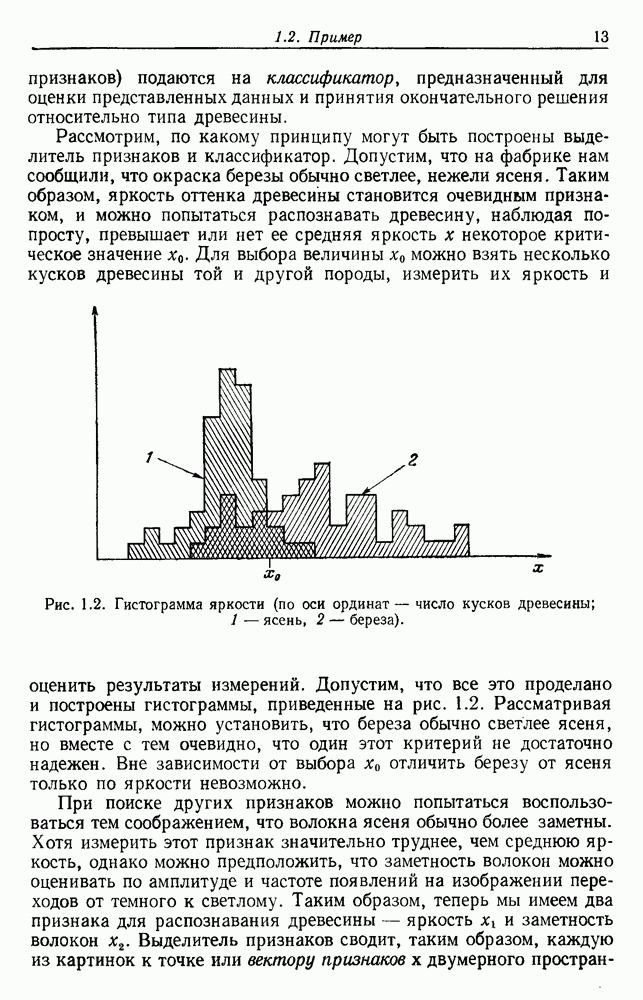














































































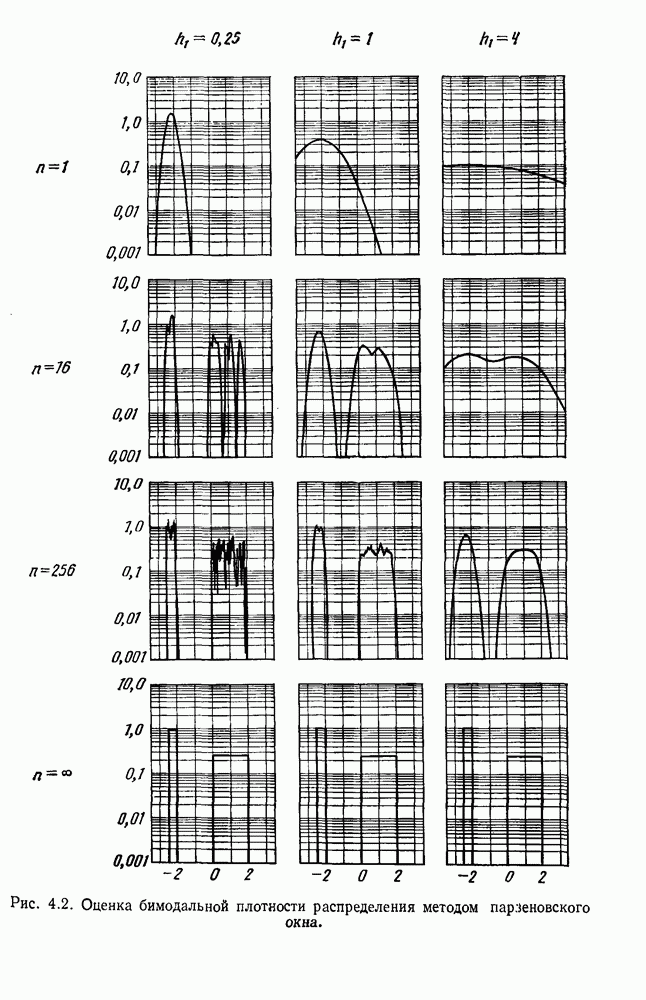

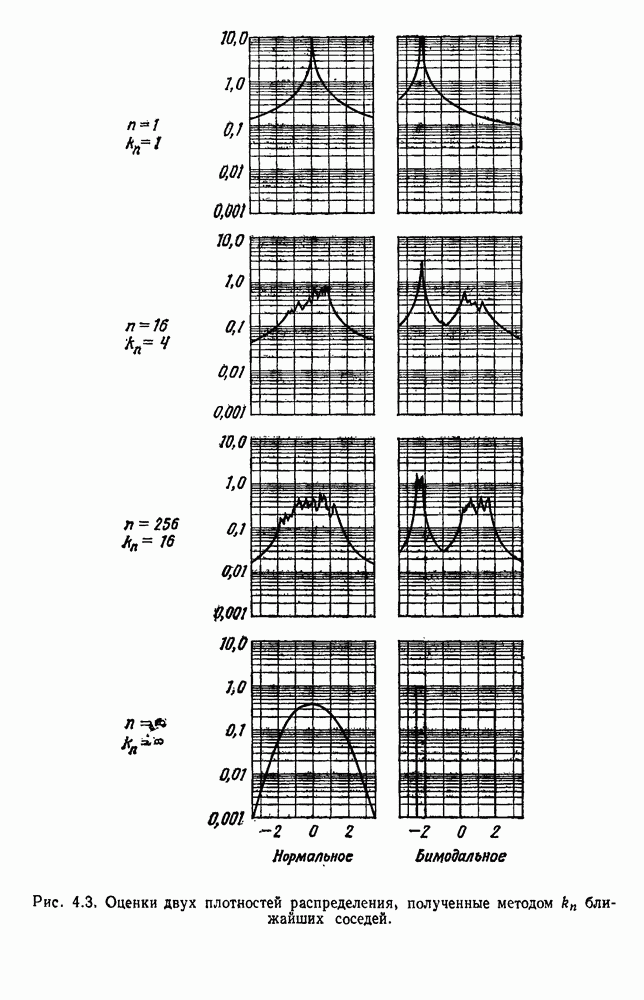








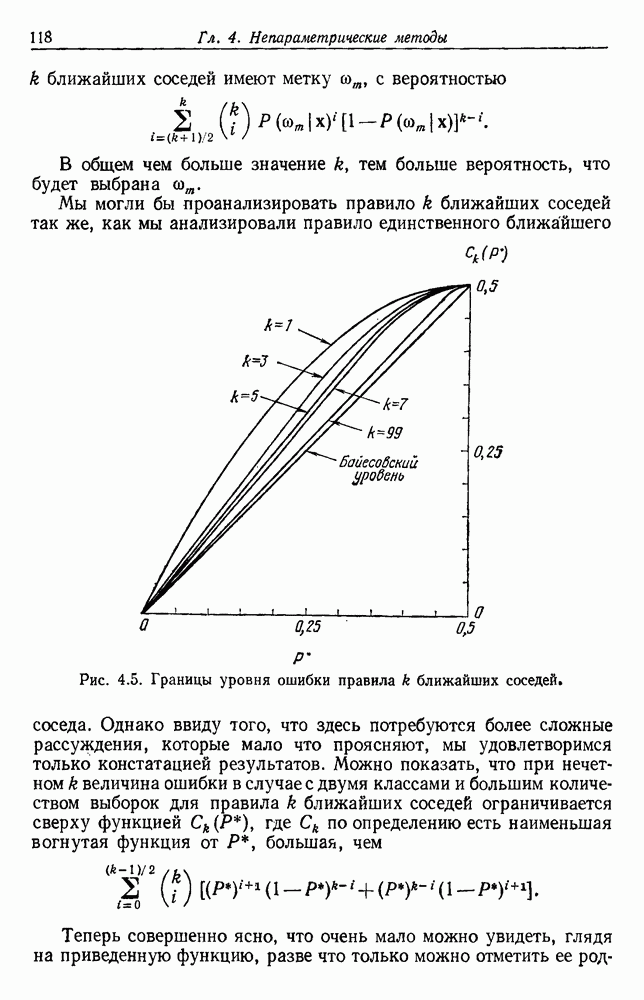



























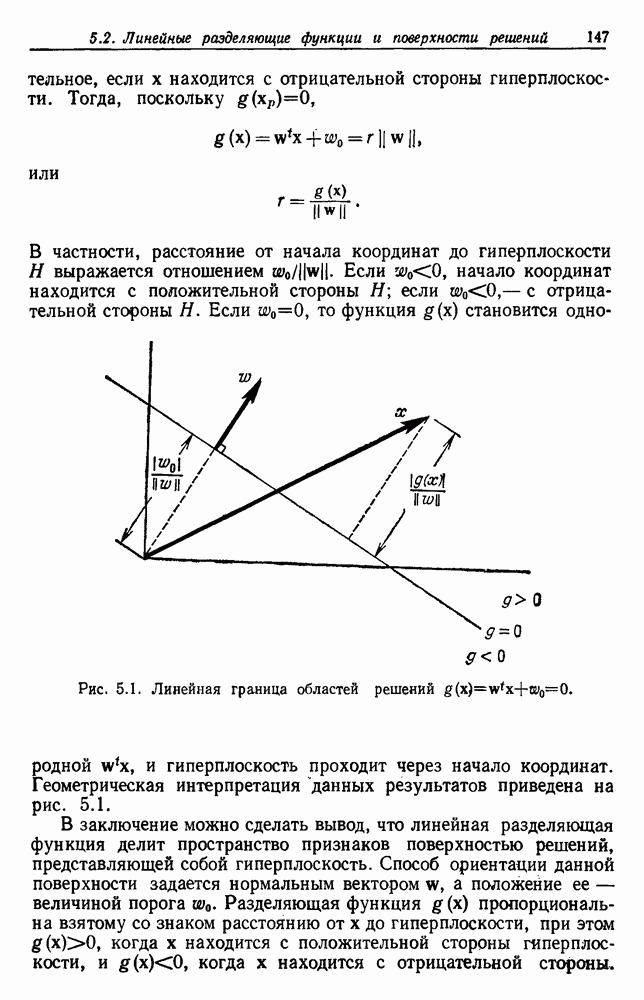
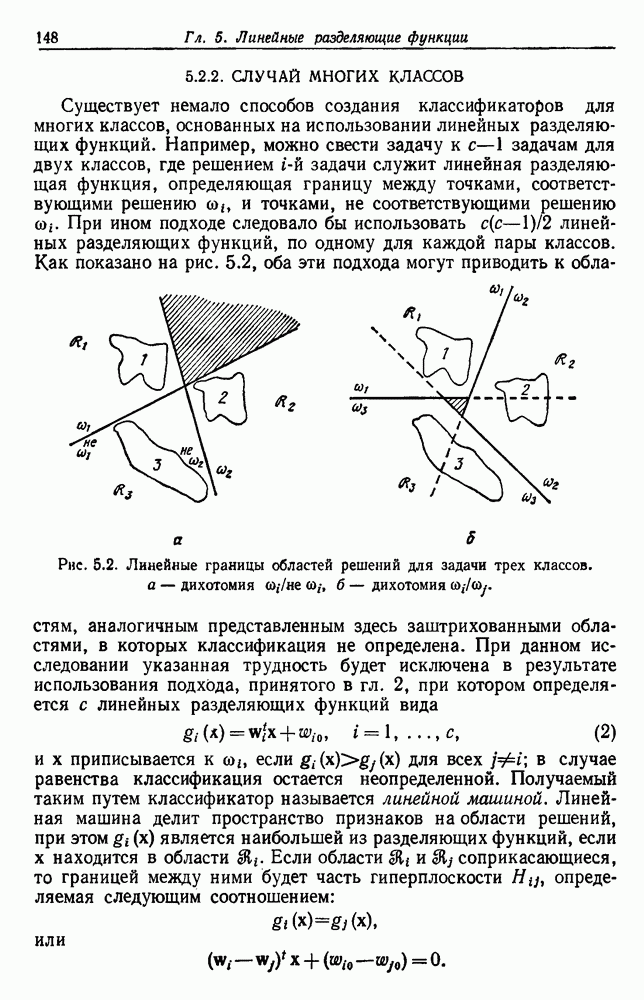


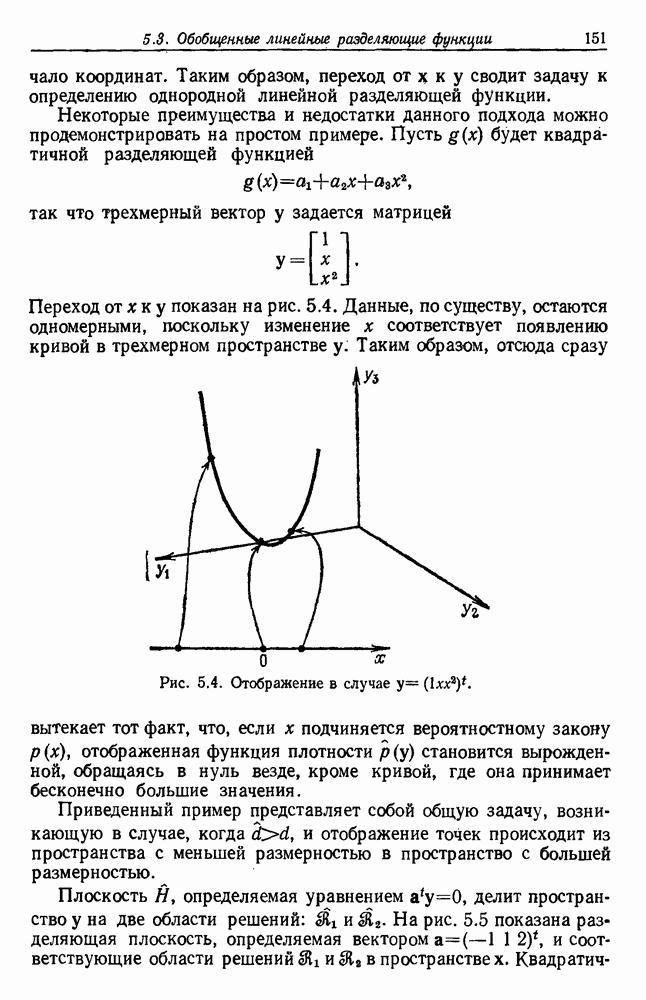
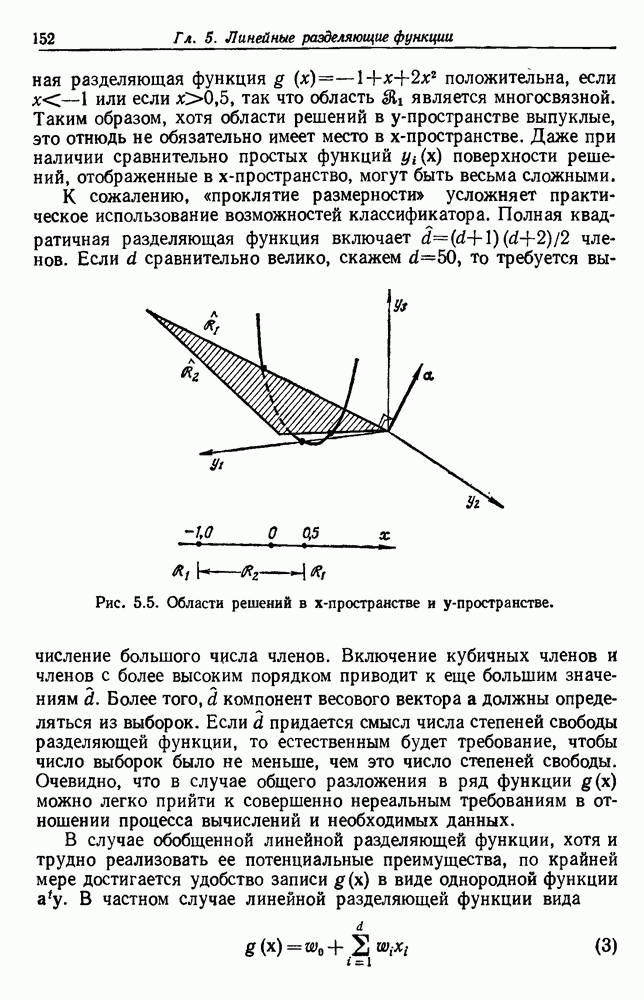

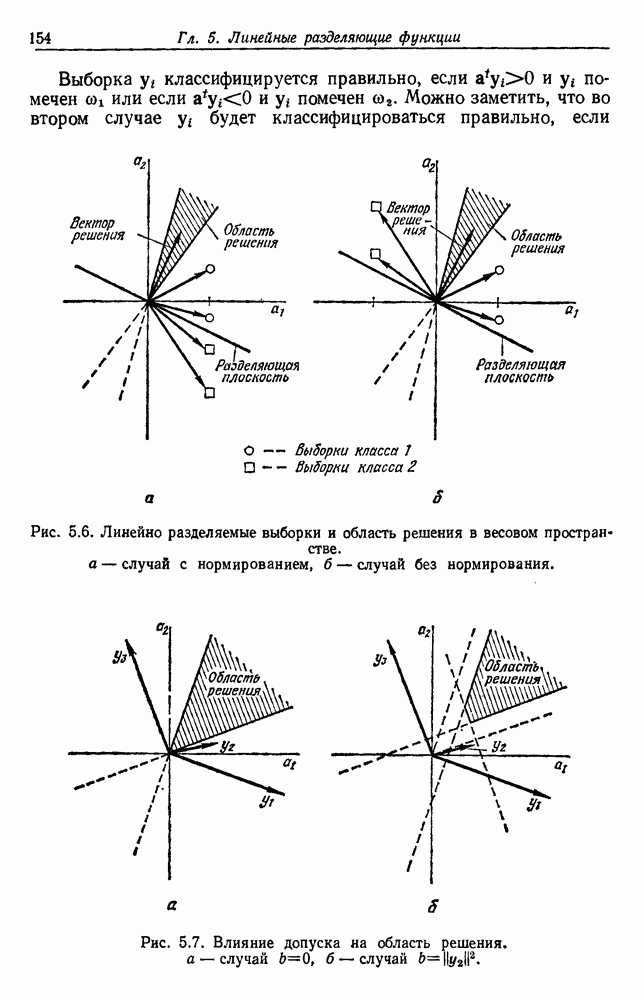



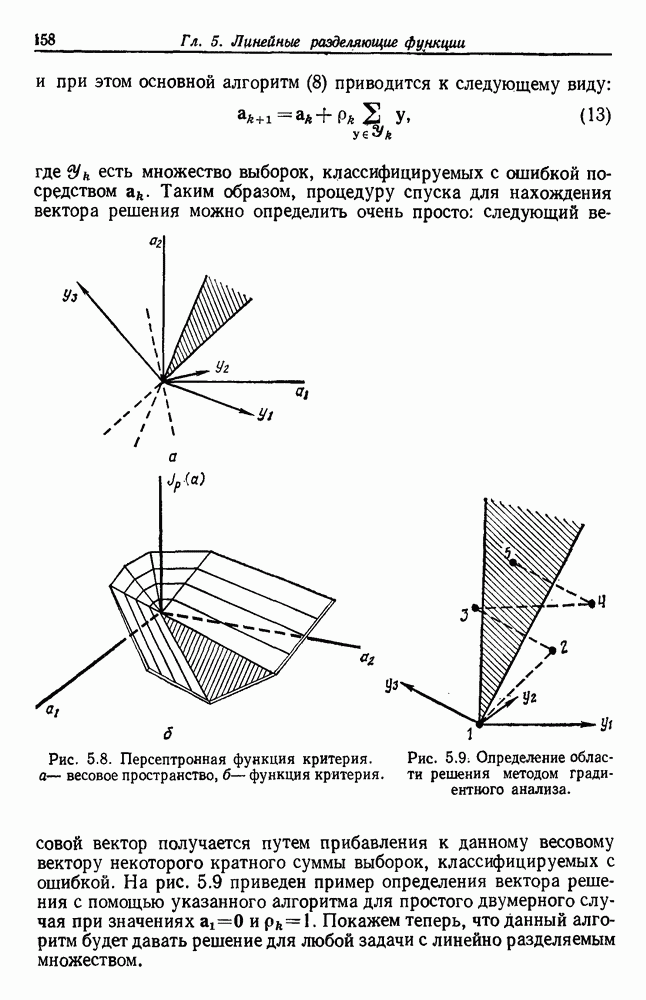

















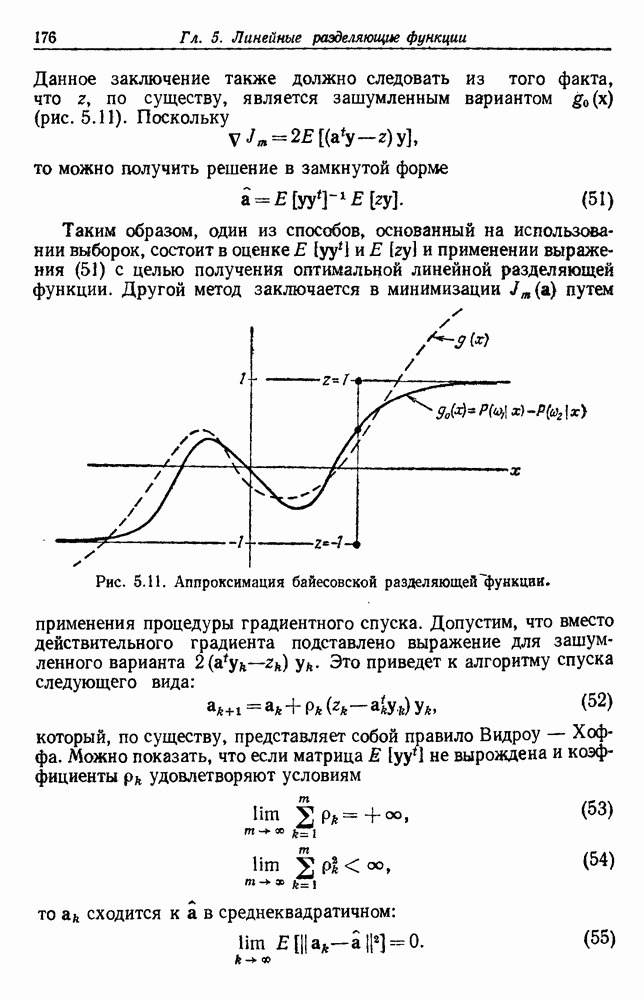














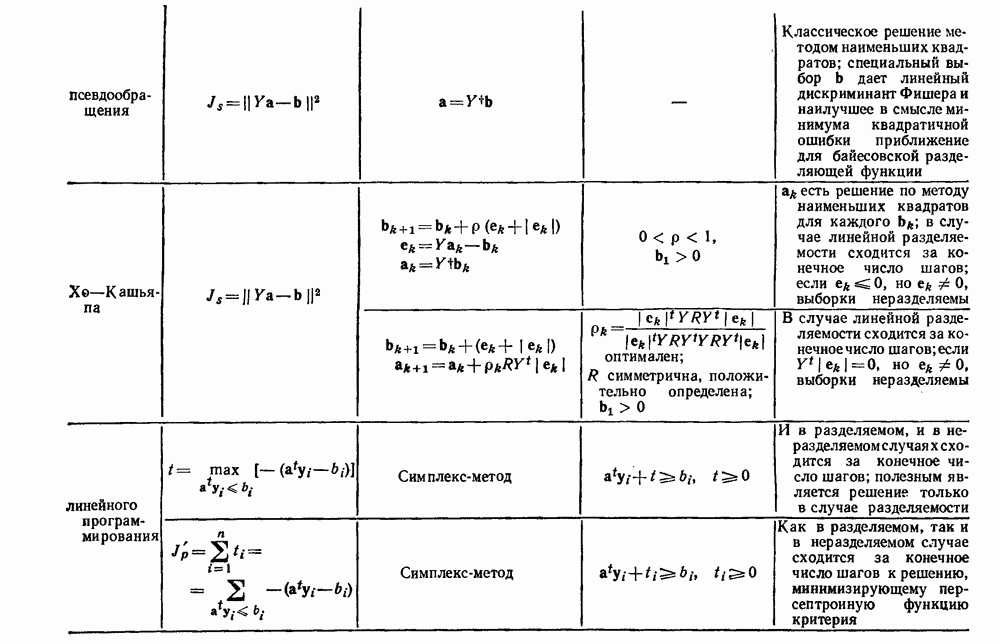




























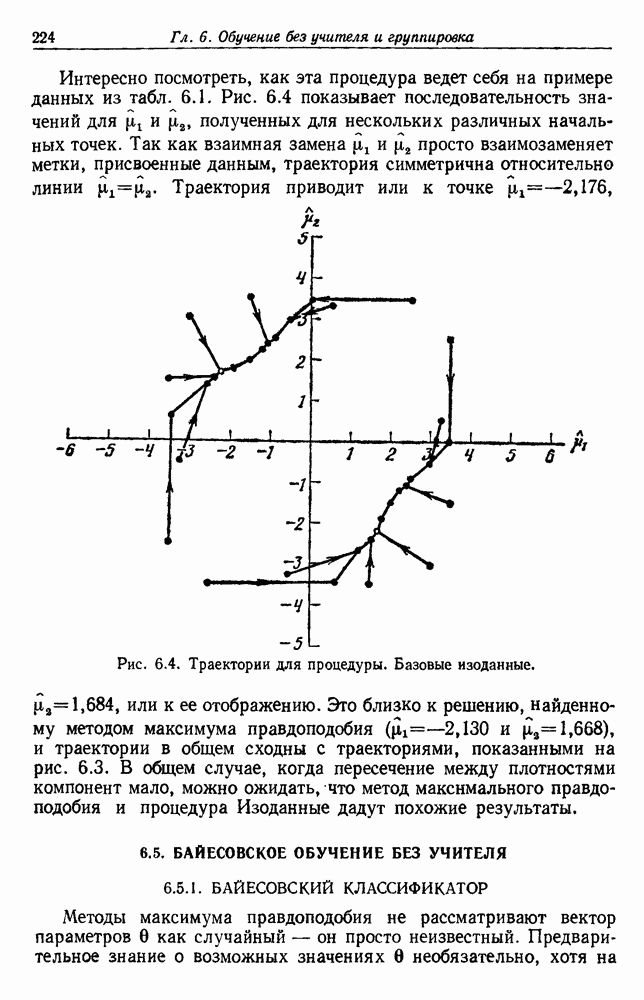





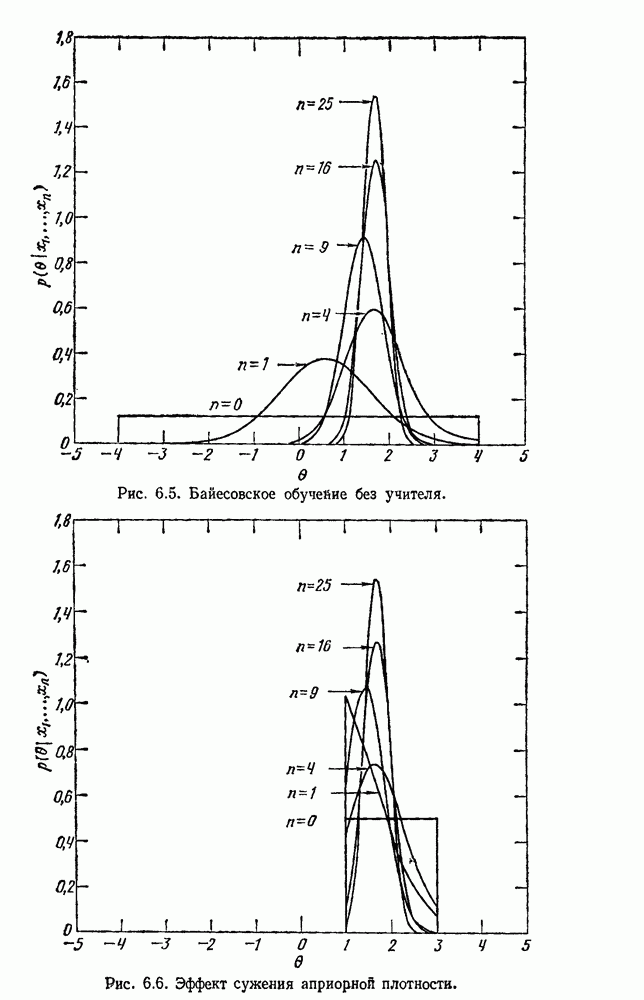





























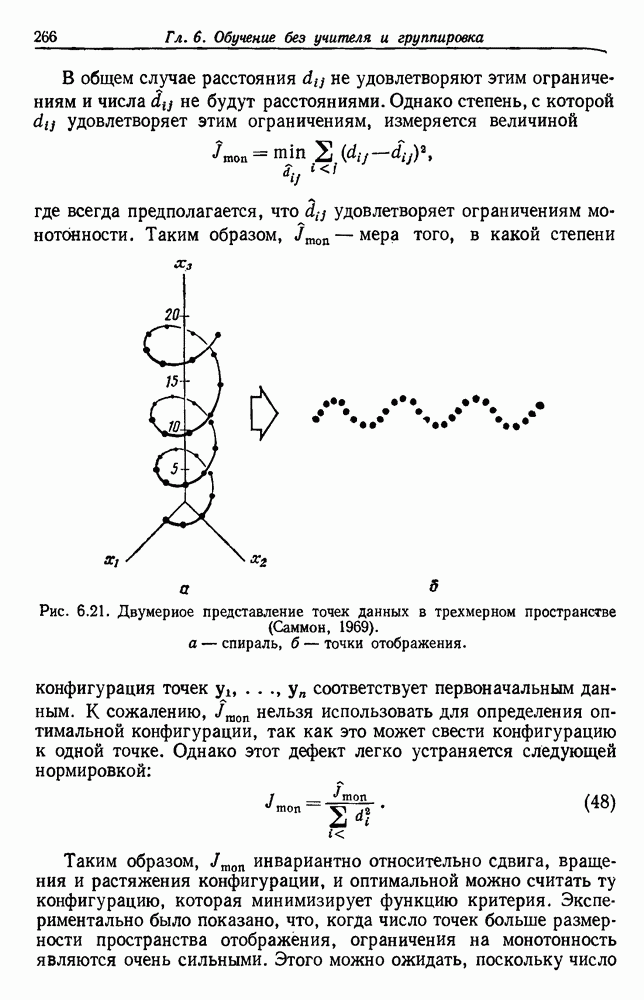




















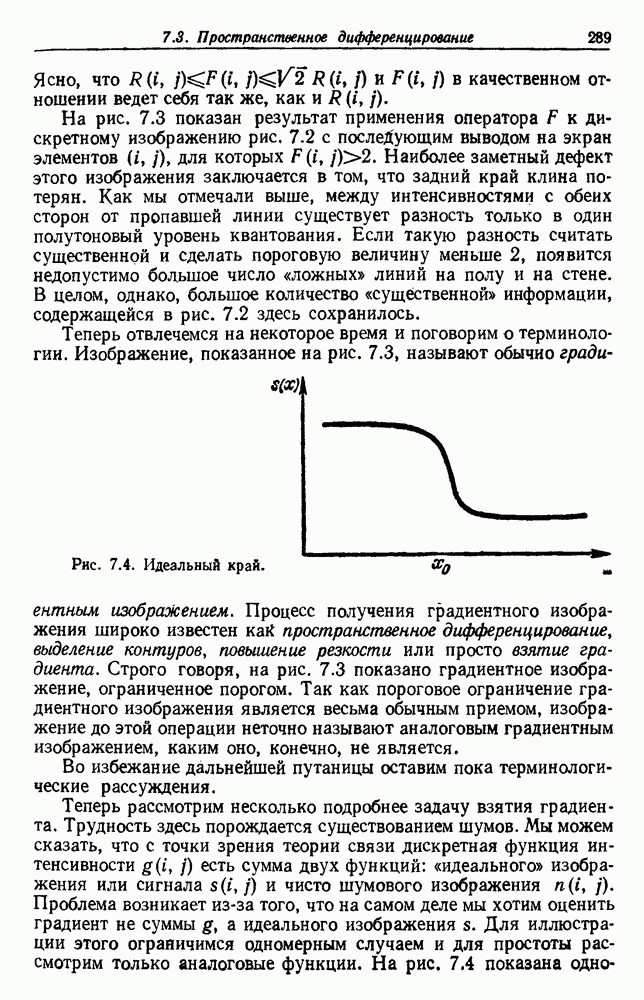
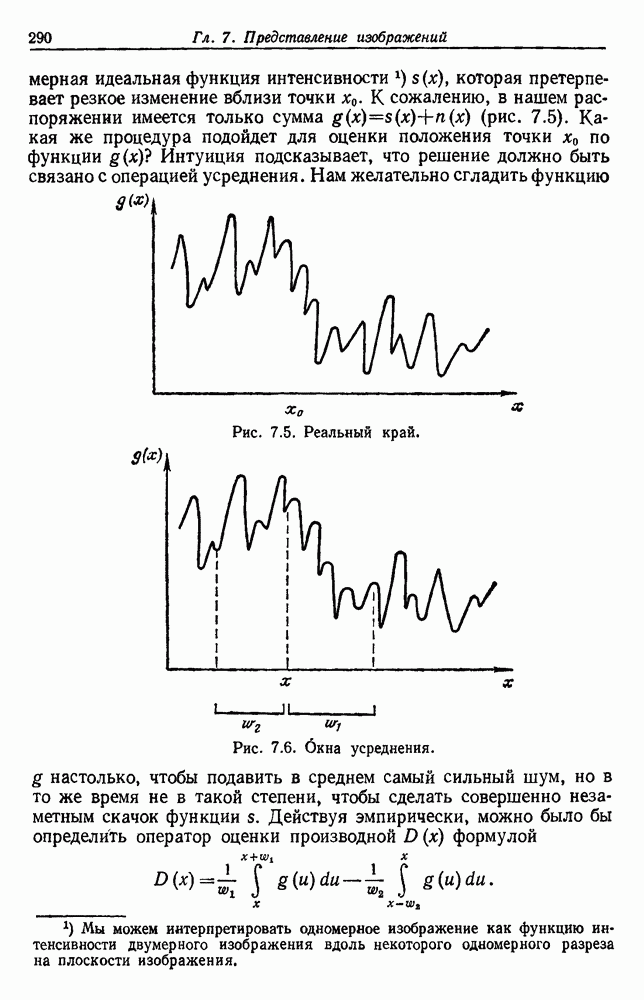

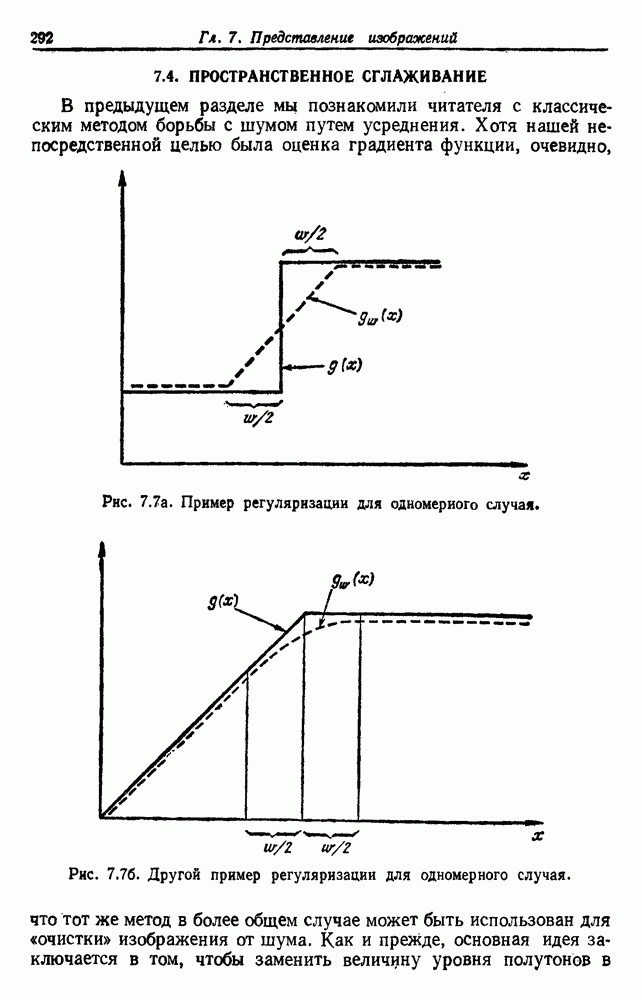
















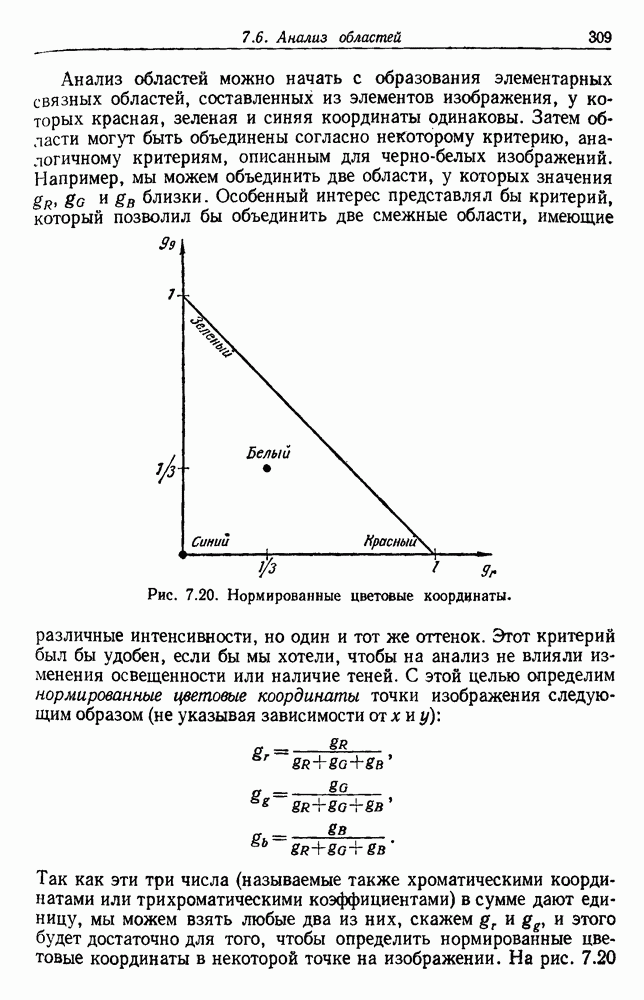






























































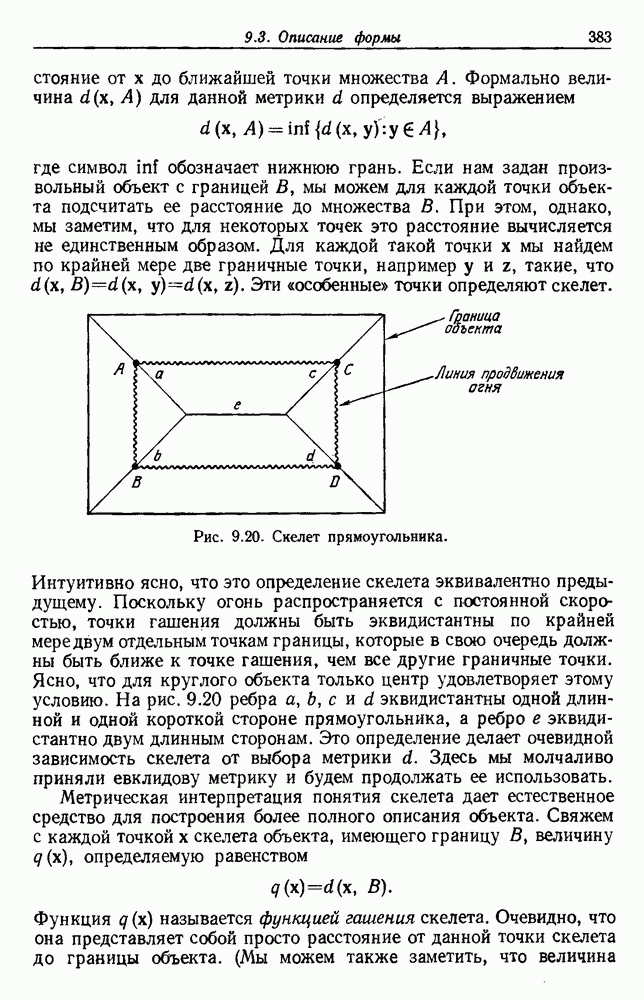


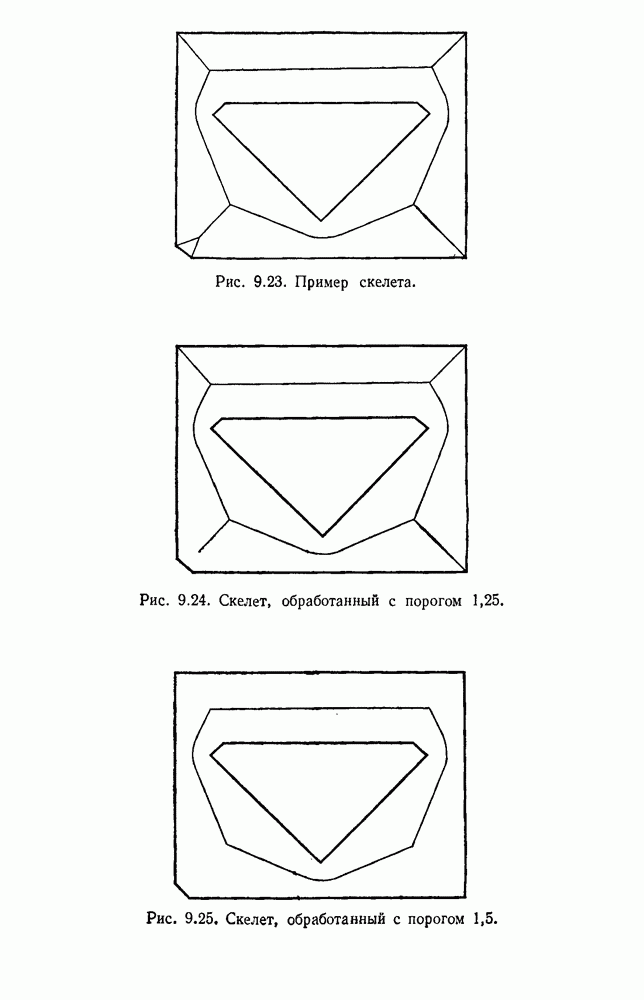






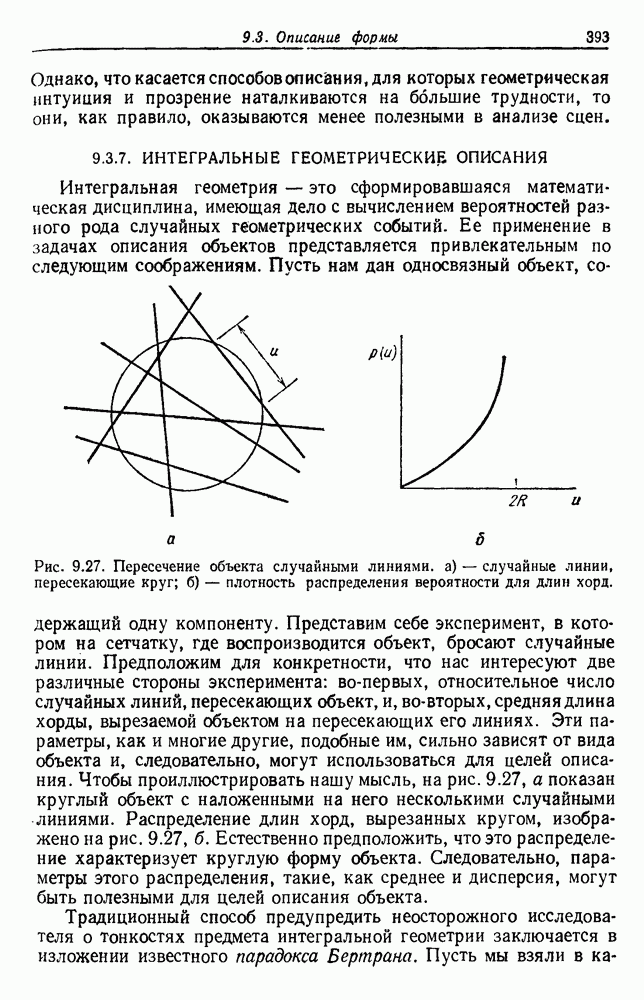












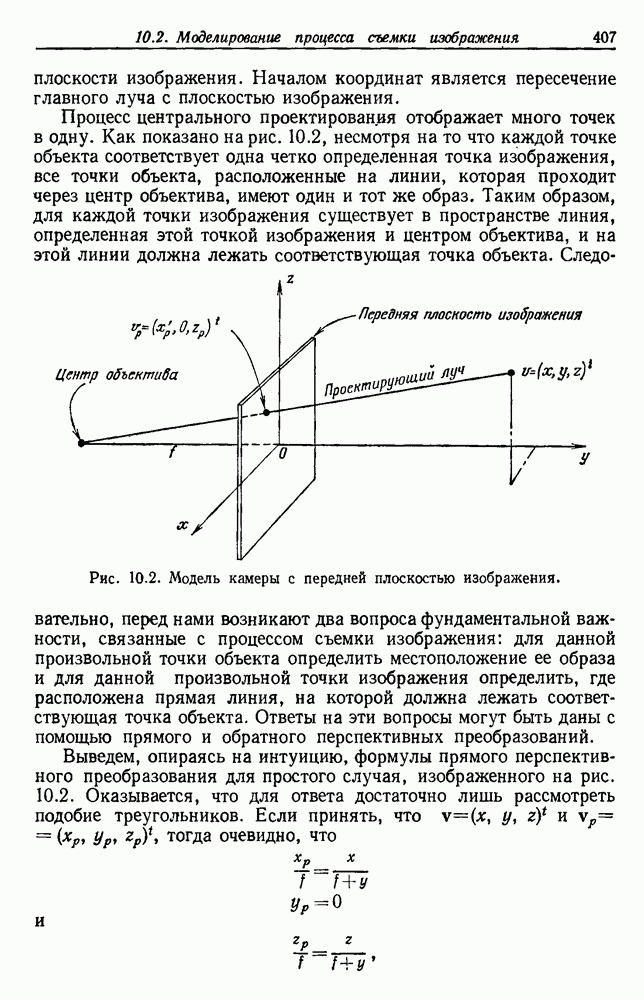





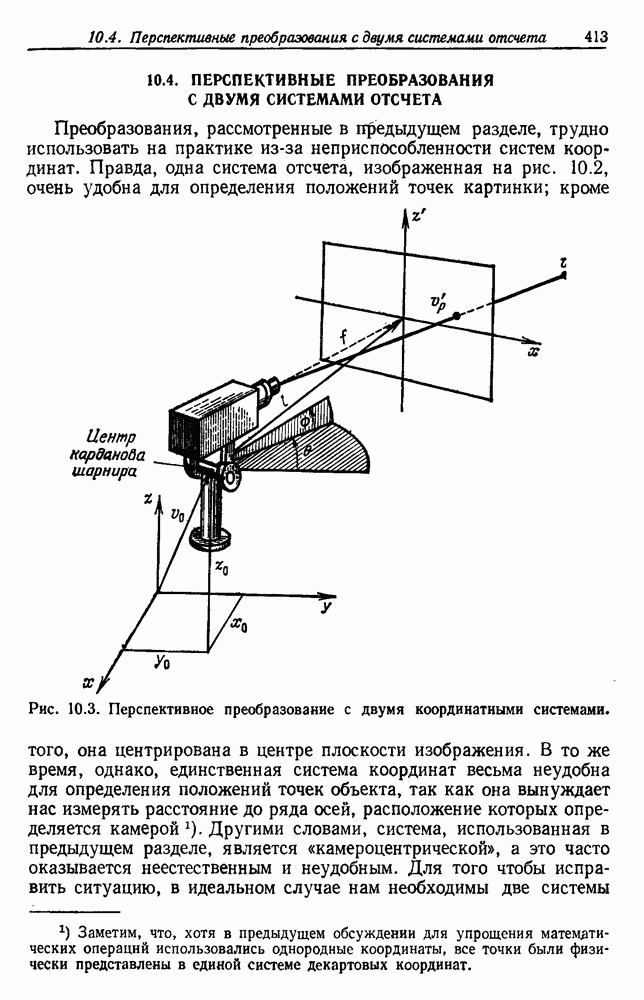









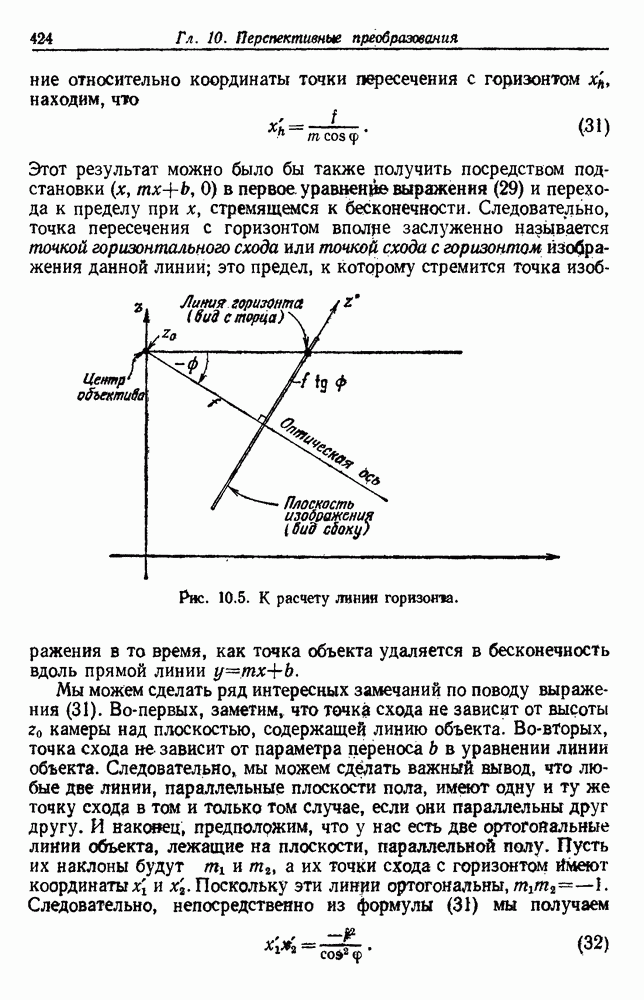












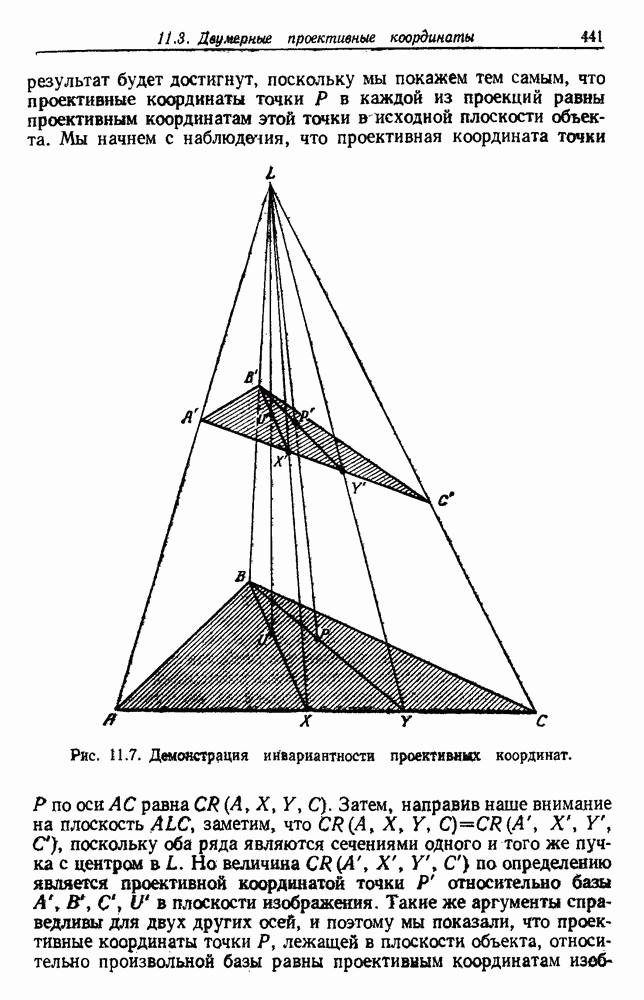

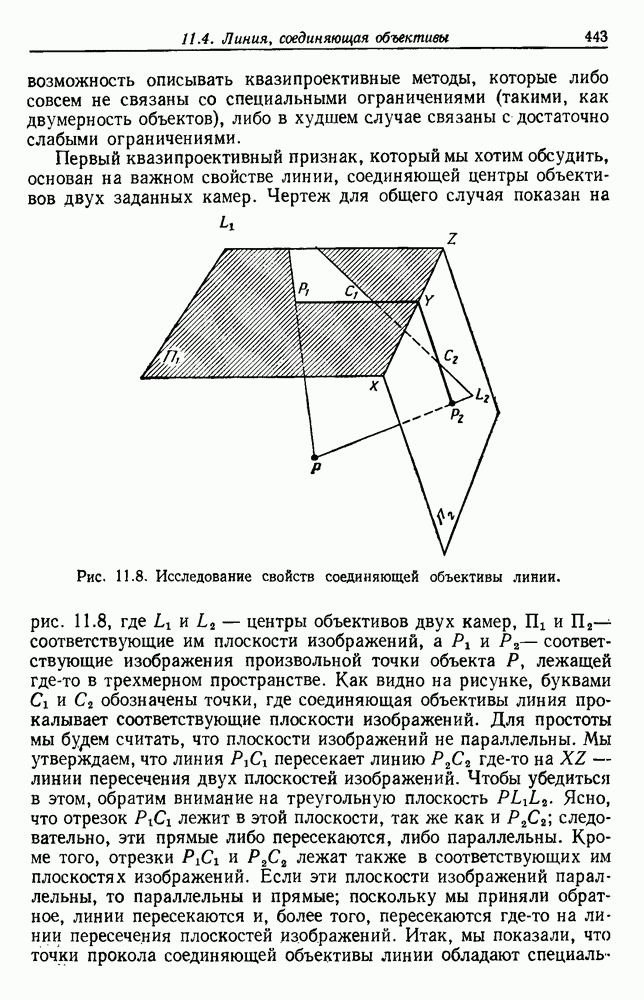
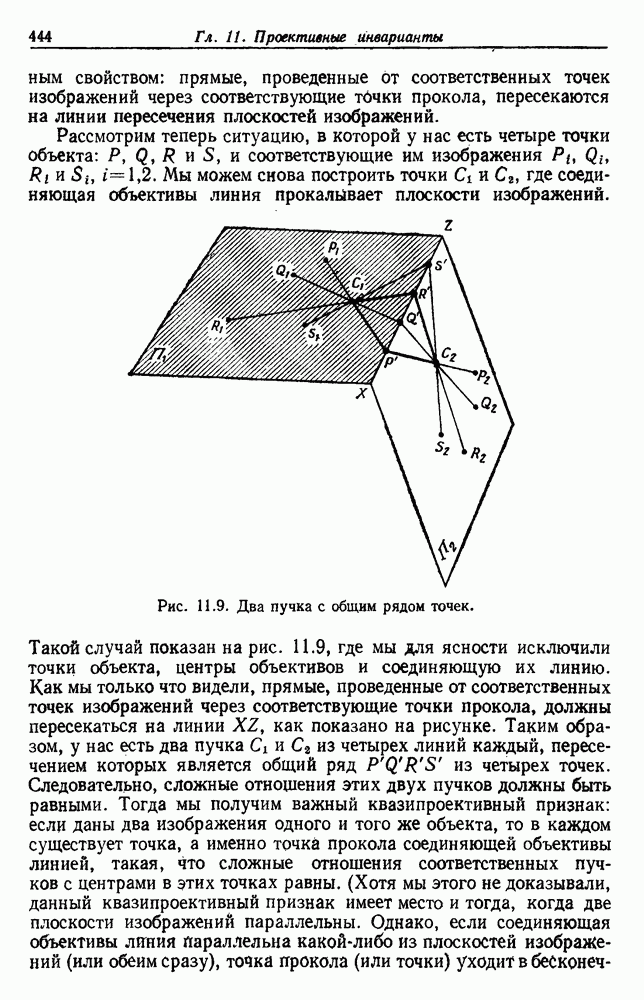











































 посредством уравнений (45) и (46), подставляя оценки средних значений и ковариационных матриц неизвестных параметров. Такой подход связан, однако, с тремя серьезными трудностями. Во-первых, оценка таким способом
посредством уравнений (45) и (46), подставляя оценки средних значений и ковариационных матриц неизвестных параметров. Такой подход связан, однако, с тремя серьезными трудностями. Во-первых, оценка таким способом  почти всегда оказывается излишне оптимистичной, так как при этом будут скрыты особенности, связанные со своеобразием и нецредставительностью конструктивных выборок. Вторая трудность заключается в том, что всегда следует сомневаться в справедливости принятой параметрической модели; оценка работы, основанная на той же самой модели, не внушает доверия, за исключением случаев, когда она неблагоприятна. И наконец, в большинстве общих случаев точное вычисление уровня ошибки очень трудно, даже если полностью известна вероятностная структура задачи.
почти всегда оказывается излишне оптимистичной, так как при этом будут скрыты особенности, связанные со своеобразием и нецредставительностью конструктивных выборок. Вторая трудность заключается в том, что всегда следует сомневаться в справедливости принятой параметрической модели; оценка работы, основанная на той же самой модели, не внушает доверия, за исключением случаев, когда она неблагоприятна. И наконец, в большинстве общих случаев точное вычисление уровня ошибки очень трудно, даже если полностью известна вероятностная структура задачи.
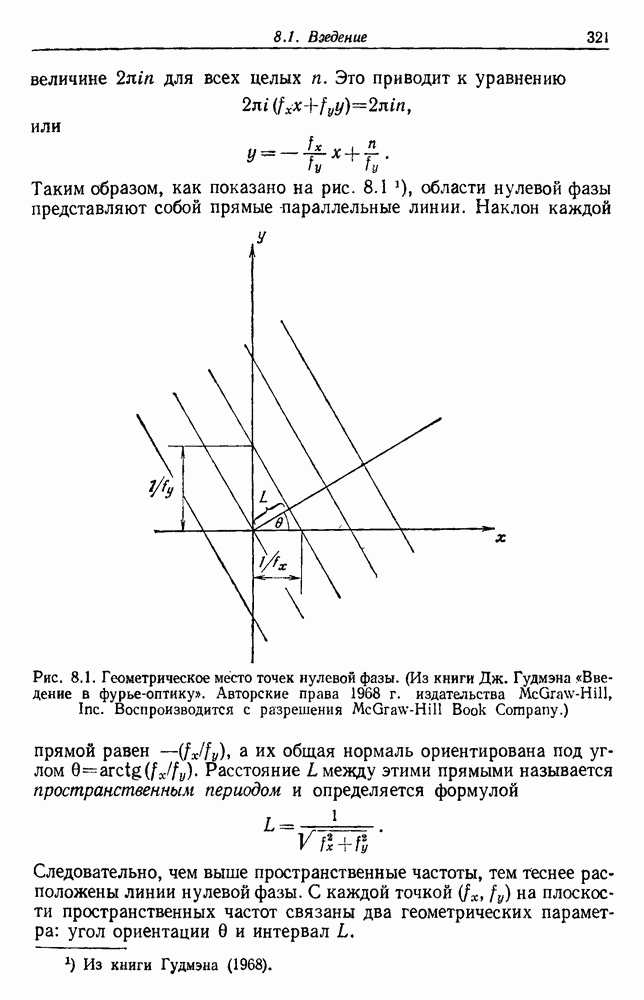
 и если классификация k из
и если классификация k из  независимых, случайно взятых контрольных выборок неверна, то распределение k биномиально:
независимых, случайно взятых контрольных выборок неверна, то распределение k биномиально:

 по максимуму правдоподобия:
по максимуму правдоподобия:

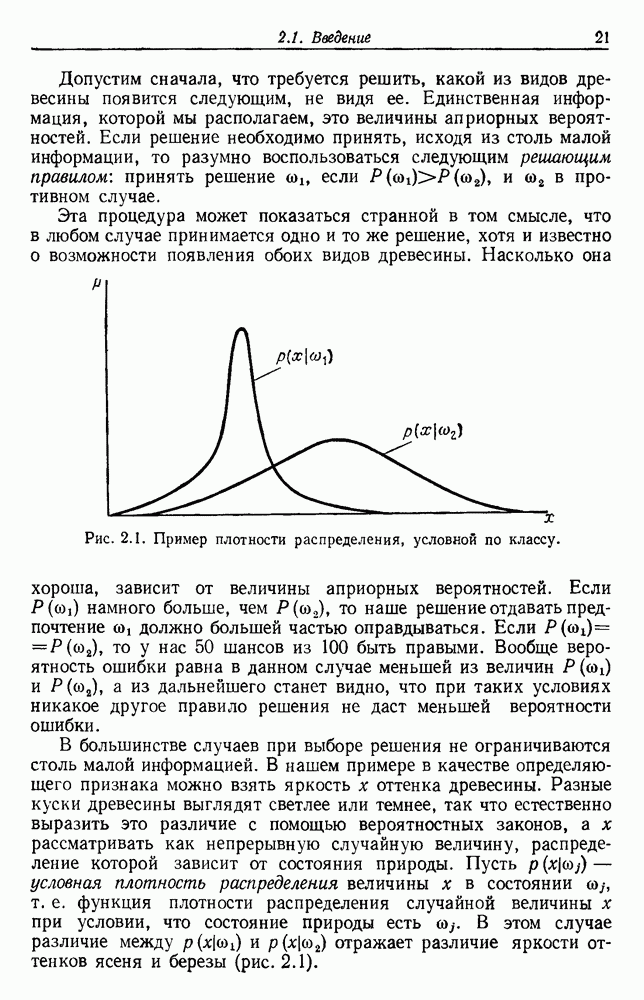
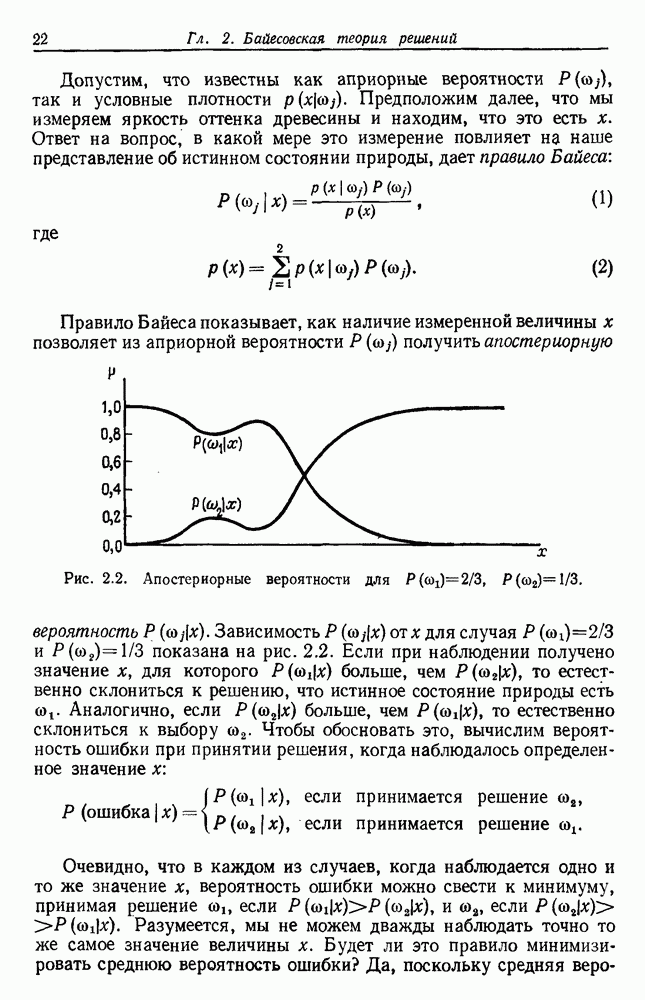
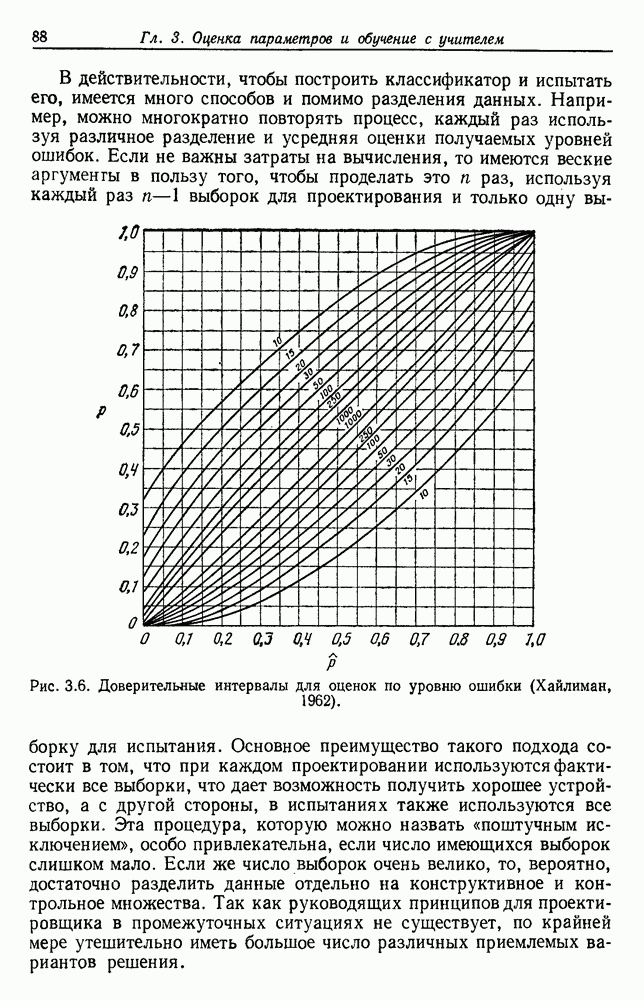
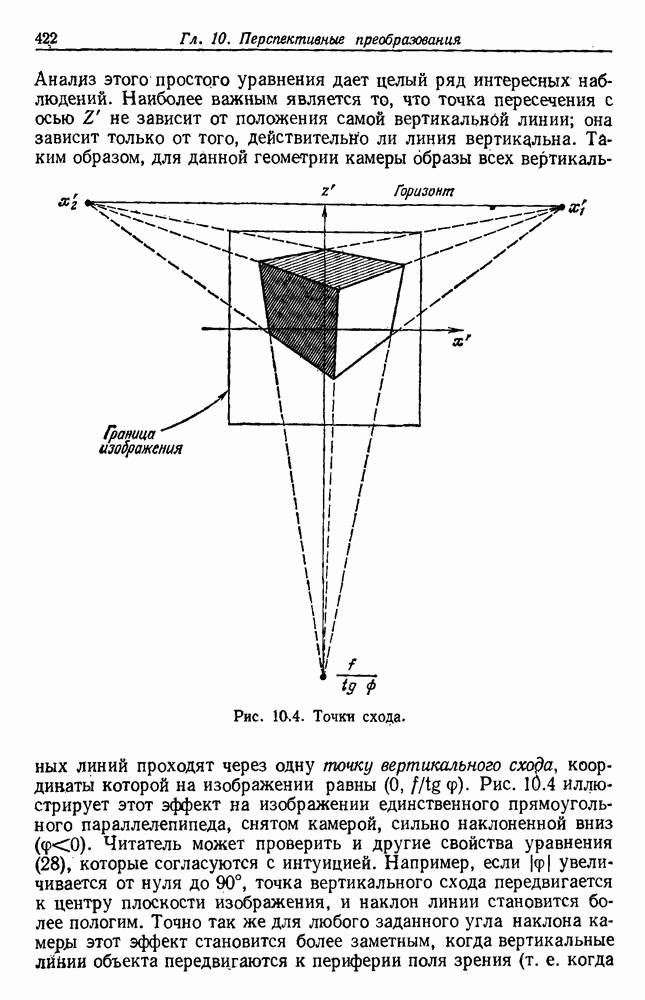
 биномиального распределения хорошо известны. В частности, на рис. 3.6 изображены графики зависимости величины
биномиального распределения хорошо известны. В частности, на рис. 3.6 изображены графики зависимости величины  -ного доверительного интервала от
-ного доверительного интервала от  . Для заданного значения
. Для заданного значения  вероятность того, что истинное значение
вероятность того, что истинное значение  лежит в интервале между нижней и верхней кривыми при заданном числе
лежит в интервале между нижней и верхней кривыми при заданном числе  пробных выборок, равна 0,95. Из кривых видно, что, пока
пробных выборок, равна 0,95. Из кривых видно, что, пока  не очень велико, оценку по максимуму правдоподобия следует принимать с осторожностью. Например, если не было ошибок на 50 пробных выборках, то истинный уровень ошибок лежит в пределах от 0 до 8%. Чтобы быть вполне уверенным в том, что истинный уровень ошибок менее 2%, классификатор не должен ошибиться более чем на 250 пробных выборках.
не очень велико, оценку по максимуму правдоподобия следует принимать с осторожностью. Например, если не было ошибок на 50 пробных выборках, то истинный уровень ошибок лежит в пределах от 0 до 8%. Чтобы быть вполне уверенным в том, что истинный уровень ошибок менее 2%, классификатор не должен ошибиться более чем на 250 пробных выборках.
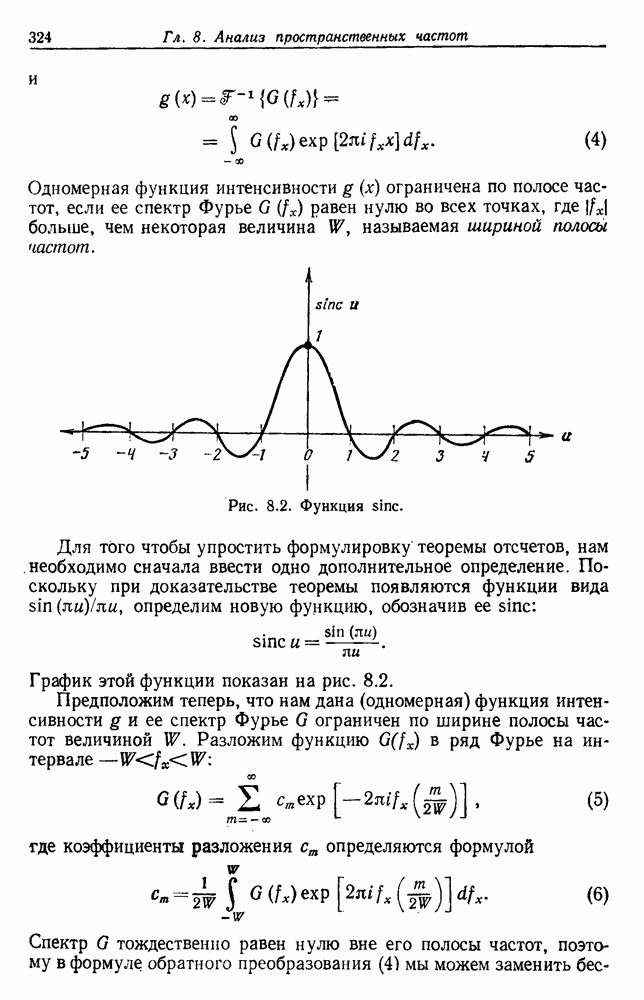
 раз, используя каждый раз
раз, используя каждый раз  выборок для проектирования и только одну выборку для испытания.
выборок для проектирования и только одну выборку для испытания.
