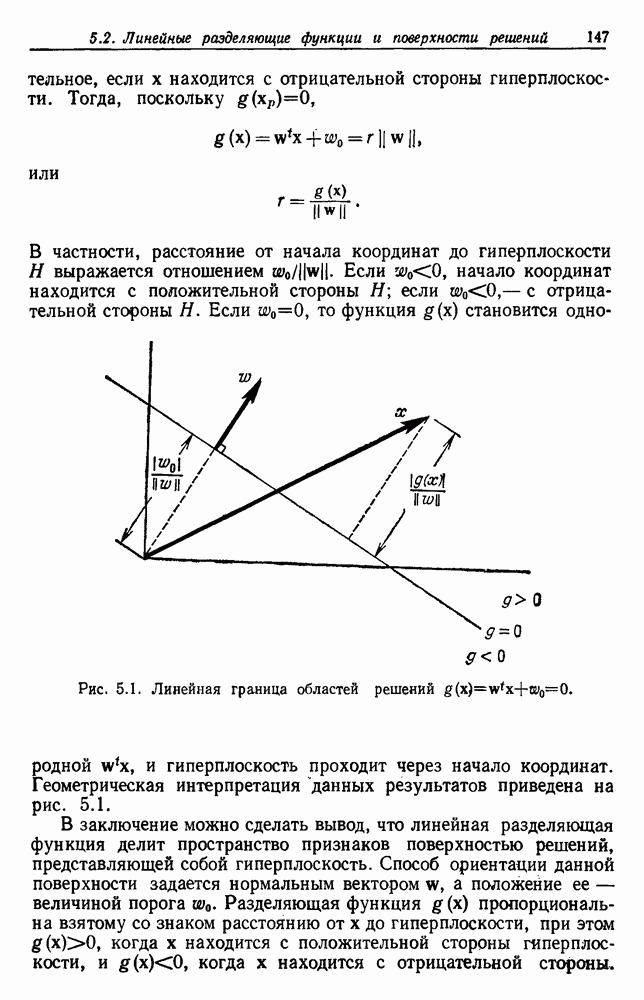
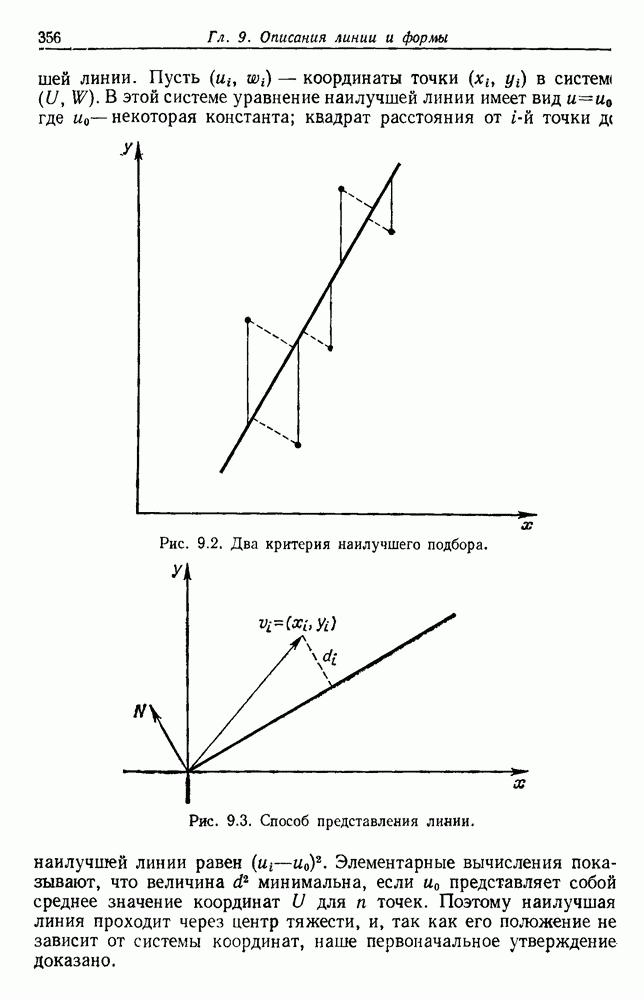
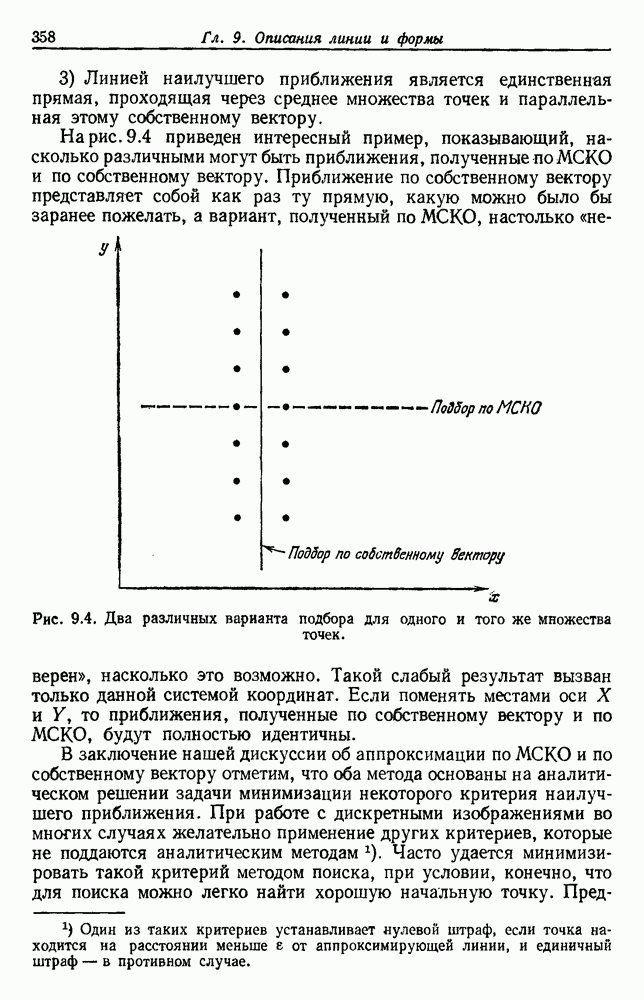
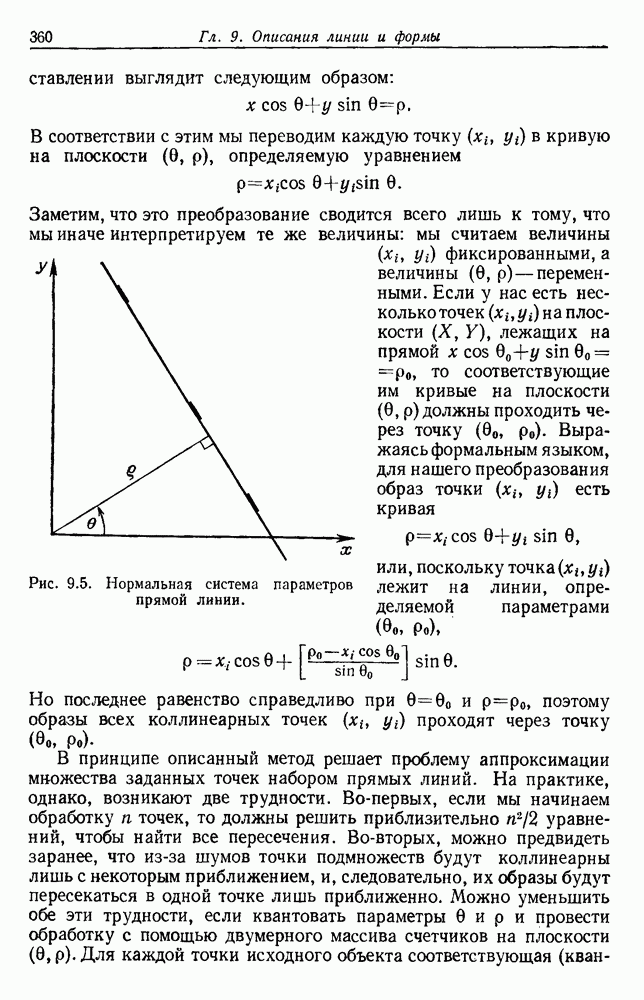
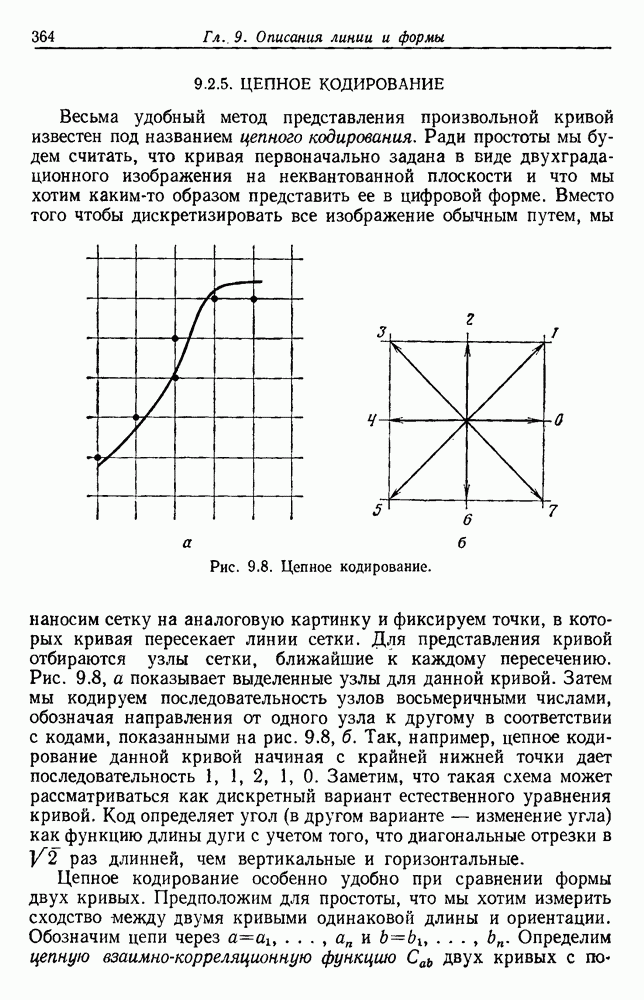
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
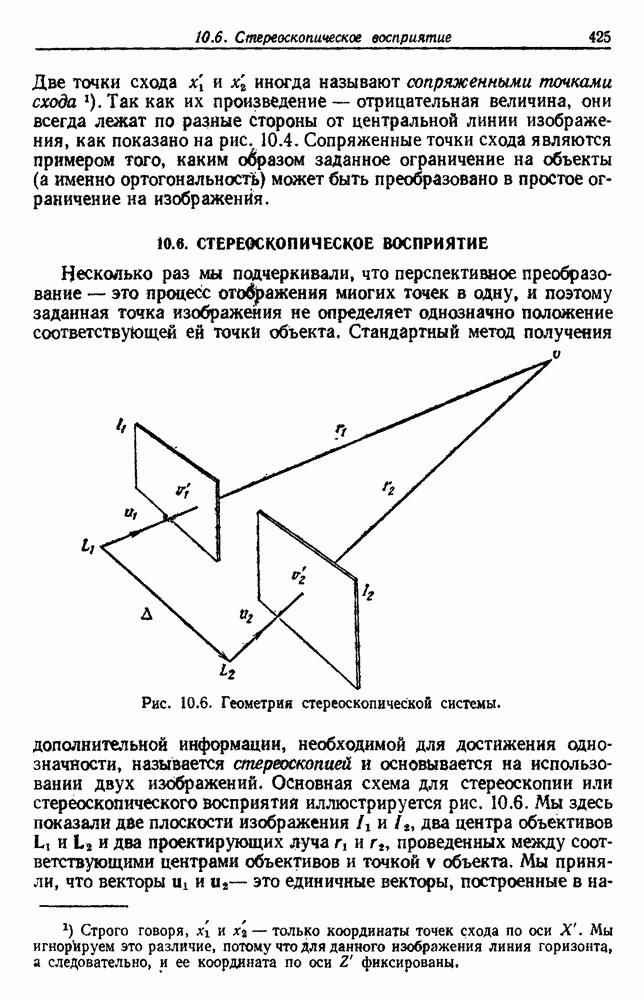
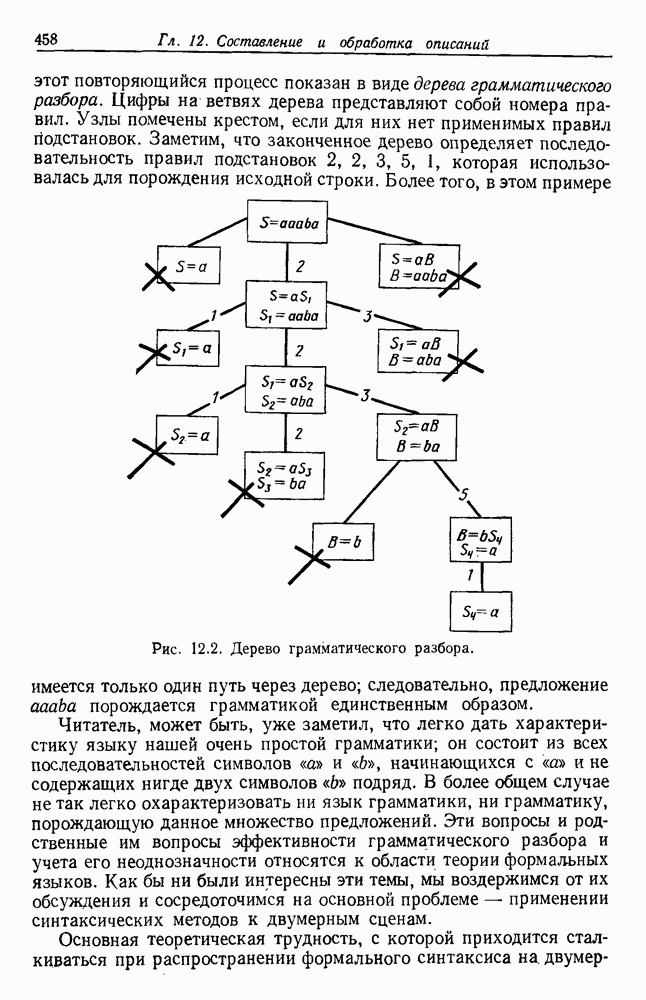
6.10. ИЕРАРХИЧЕСКАЯ ГРУППИРОВКА6.10.1. ОПРЕДЕЛЕНИЯРассмотрим последовательность разделений уровень соответствует
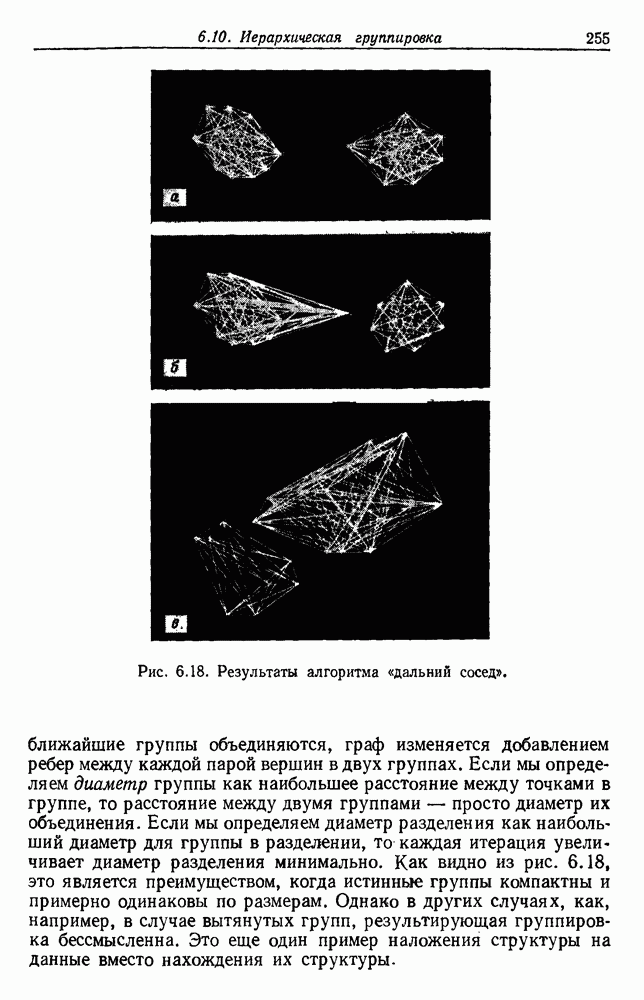
Рис. 6.15. Дендрограмма иерархической группировки. Вообще группировки такого рода проникают и в другие науки. Для любой иерархической классификации существует соответствующее дерево, называемое дендрограммой, которое показывает, как группируются выборки. На рис. 6.15 представлена дендрограмма для гипотетической задачи, содержащей шесть выборок. Уровень 1 показывает шесть выборок как одиночные группы. На уровне 2 выборки естественным или вынужденным. Для нашего гипотетического примера можно сказать, что объединения на уровнях 4 и 5 естественны, но значительное уменьшение подобия, необходимое для перехода на уровень 6, делает объединение на этом уровне вынужденным. Мы вскоре увидим, как получить такие значения подобия. Благодаря простоте понятий иерархические процедуры группировки находятся среди наиболее известных методов. Процедуры можно разделить на два различных класса: агломеративный и делимый. Агломеративные (процедуры снизу-вверх, объединяющие) процедуры начинают с с одиночных групп и образуют последовательность постепенно объединяемых групп. Делимые (сверху-вниз, разделяемые) процедуры начинают с одной группы, содержащей все выборки, и образуют последовательность постепенно расщепляемых групп. Вычисления, необходимые для перехода с одного уровня на другой, обычно проще для агломеративных процедур. Однако, когда имеется много выборок, а нас интересует только небольшое число групп, такое вычисление должно повториться много раз. Для простоты ограничимся агломеративными процедурами, отсылая читателя к литературе по делимым процедурам. 6.10.2. АГЛОМЕРАТИВНАЯ ИЕРАРХИЧЕСКАЯ ГРУППИРОВКАОсновные шаги в агломеративной группировке содержатся в следующей процедуре: Процедура: Базовая Агломеративная Группировка 1. Пусть Цикл: 2. Если 3. Найти ближайшую пару групп, скажем и 4. Объединить 5. Перейти к Цикл. Описанная процедура заканчивается, когда достигнуто заданное число групп. Однако, если мы продолжим до читателя:
Все эти меры напоминают минимальную дисперсию, и они обычно дают одинаковые результаты, если группы компактные и хорошо разделены. (см. скан) Рис. 6.16. Три примера. Однако, если группы близки друг к другу или их форма в основном не гиперсферическая, могут получиться разные результаты. Мы используем двумерные множества точек, показанные на рис. 6.16, для иллюстрации этих различий. 6.10.2.1. Алгоритм «ближайший сосед»Рассмотрим сначала случай, когда используется Рис. 6.17 показывает результат применения этой процедуры к данным из рис. 6.16. Во всех случаях процедура заканчивалась при (см. скан) Рис. 6.17. Результаты алгоритма «ближайший сосед». 6.10.2.2. Алгоритм «дальний сосед»Когда для измерения расстояния между группами используются (см. скан) Рис. 6.18. Результаты алгоритма «дальний сосед». ближайшие группы объединяются, граф изменяется добавлением ребер между каждой парой вершин в двух группах. Если мы определяем диаметр группы как наибольшее расстояние между точками в группе, то расстояние между двумя группами — просто диаметр их объединения. Если мы определяем диаметр разделения как наибольший диаметр для группы в разделении, то каждая итерация увеличивает диаметр разделения минимально. Как видно из рис. 6.18, это является преимуществом, когда истинные группы компактны и примерно одинаковы по размерам. Однако в других случаях, как, например, в случае вытянутых групп, результирующая группировка бессмысленна. Это еще один пример наложения структуры на данные вместо нахождения их структуры. 6.10.2.3. КомпромиссыМинимальная и максимальная меры представляют два крайних подхода в измерении расстояния между группами. Как все процедуры, содержащие максимумы и минимумы, они оказываются слишком чувствительными к различным отклонениям. Использование усреднения — очевидный путь по возможности избежать этого, и 6.10.3. ПОШАГОВАЯ ОПТИМАЛЬНАЯ ИЕРАРХИЧЕСКАЯ ГРУППИРОВКАМы заметили раньше, что, если группы растут за счет слияния ближайшей пары групп, результат напоминает минимальную дисперсию. Однако, когда мера расстояния между группами выбран а произвольно, редко можно утверждать, что результирующее разделение приводит к экстремуму какой-либо конкретной функции критерия. В действительности иерархическая группировка определяет группу как какой-то результат после применения процедуры группировки. Однако простая модификация позволяет получить пошаговую процедуру оптимизации для получения экстремума функции критерия. Это делается простой заменой шага 3 в элементарной агломеративной процедуре группировки (разд. 6.10.2) на 3. Найти пару разделенных групп Это гарантирует нам, что на каждой итерации мы сделали лучший шаг, даже если окончательное разделение не будет оптимальным. Мы видели ранее, что использование
минимально. Следовательно, при выборе групп для слияния этот критерий учитывает как число выборок в каждой группе, так и расстояние между группами. В общем случае использование приведет к тенденции увеличения размера групп за счет присоединения одиночных или малых групп к большим, а не за счет слияния групп средних размеров. Хотя окончательное разделение может не минимизировать 6.10.4. ИЕРАРХИЧЕСКАЯ ГРУППИРОВКА И СООТВЕТСТВУЮЩАЯ МЕТРИКАПредположим, что мы не имеем возможности снабдить метрикой наши данные, но что можем измерить степень различия
или
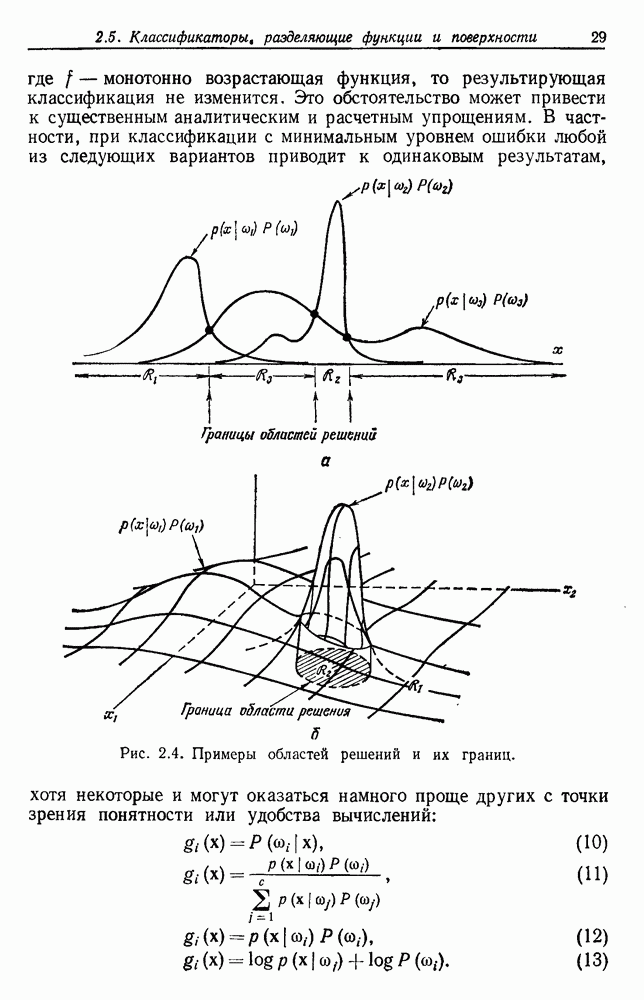
то иерархическая процедура группировки даст функцию расстояния для данного множества из Чтобы увидеть, как это происходит, начнем с определения величины При внимательном рассмотрении станет ясно, что как с Теперь можно определить расстояние
Легко видеть, что первое требование удовлетворяется. Самый низкий уровень, на котором Обратно, если
Но так как значения
Это называется ультраметрическим неравенством. Оно даже сильнее, чем неравенство треугольника, так как
|
 |
Оглавление
|


























































































































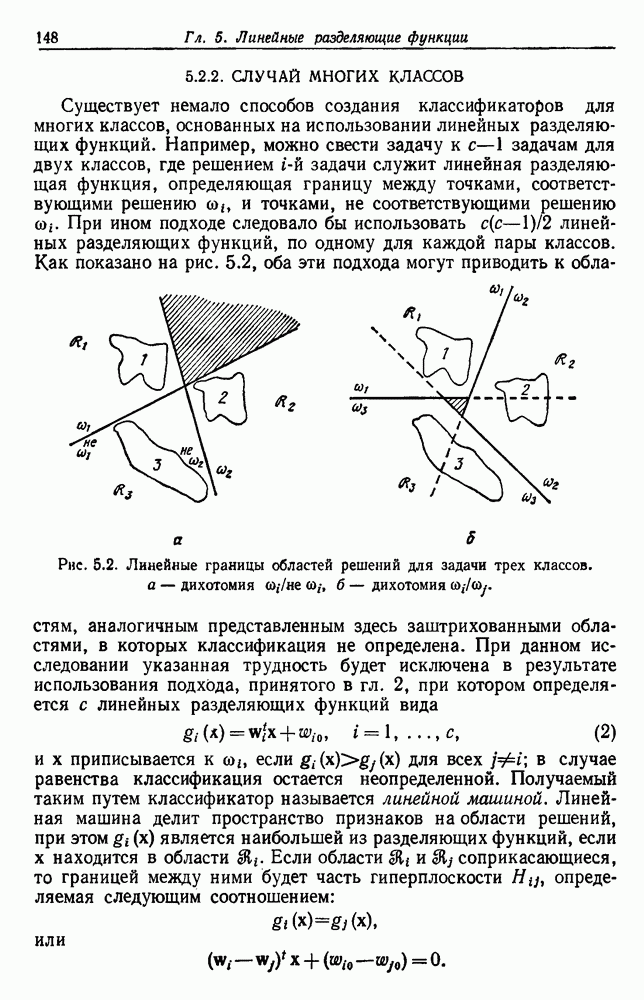



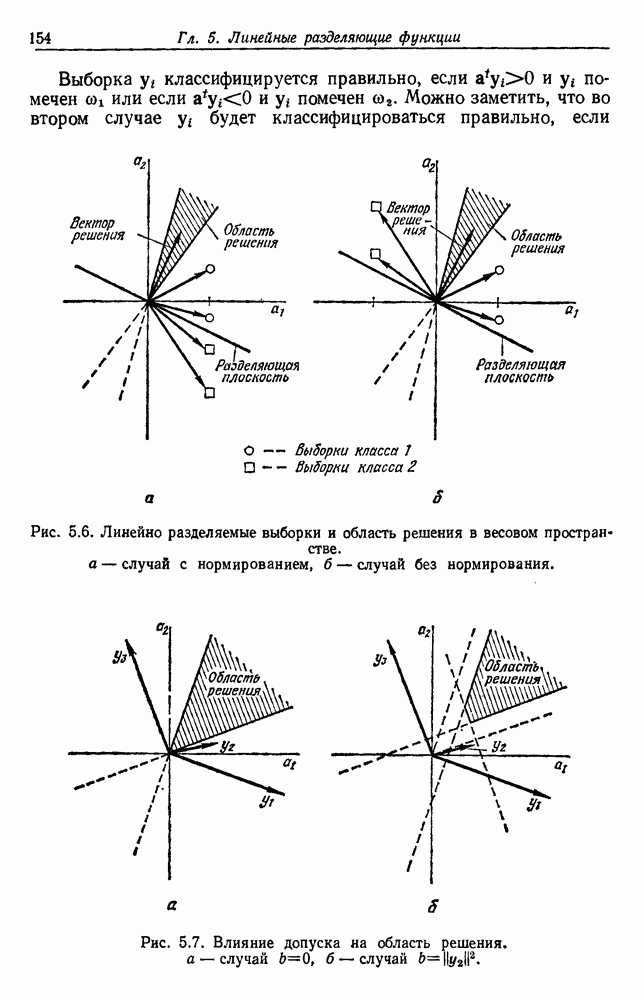



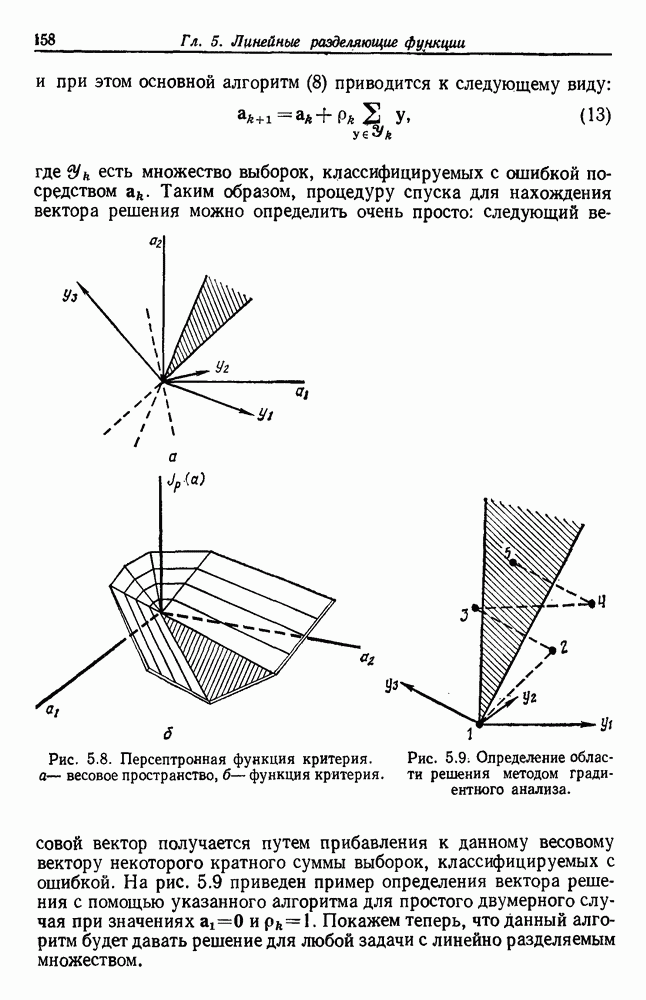

















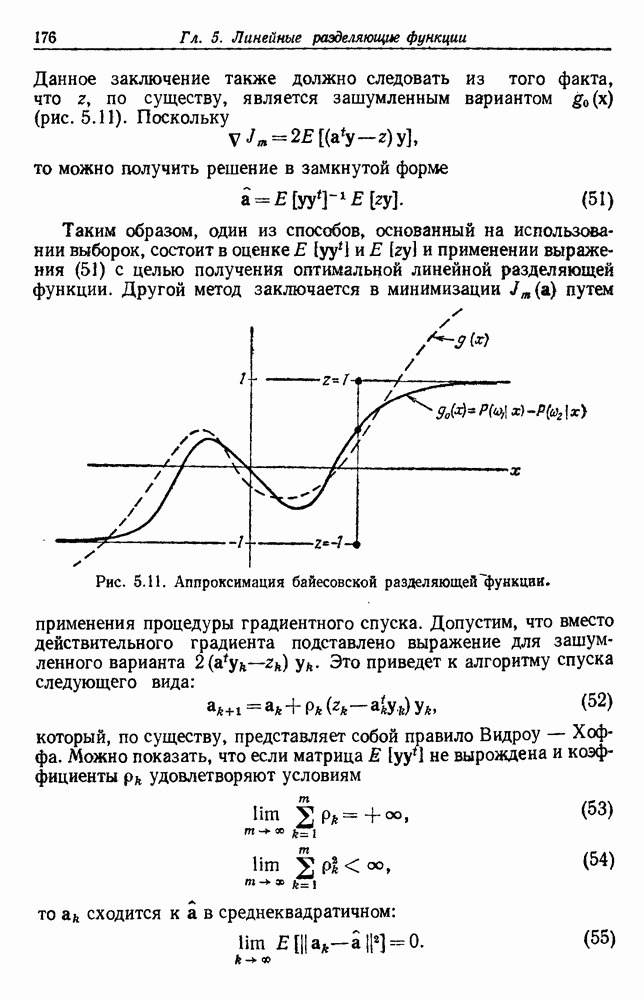














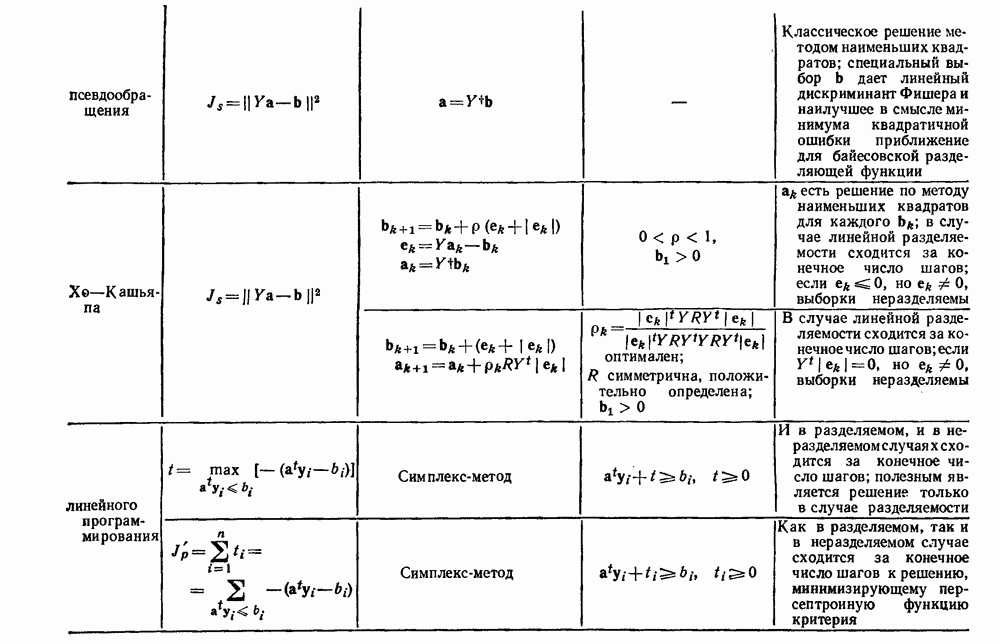

























































































































































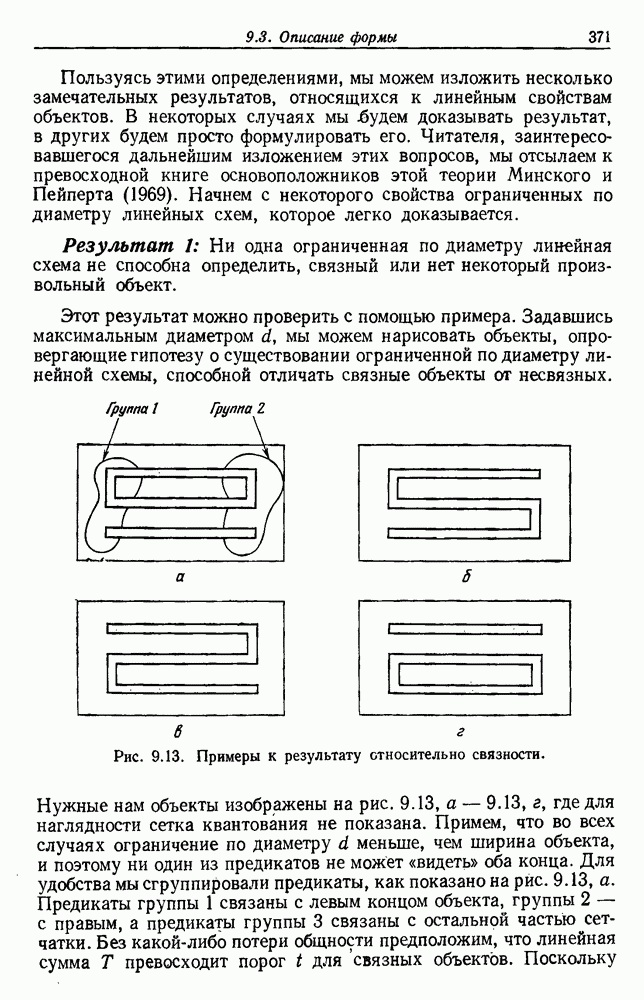






















































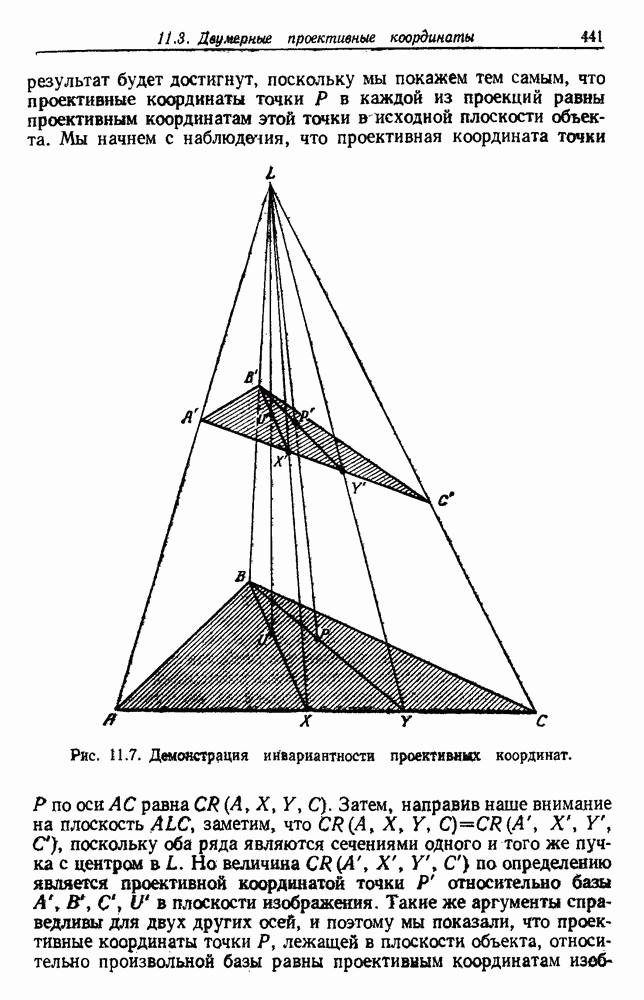














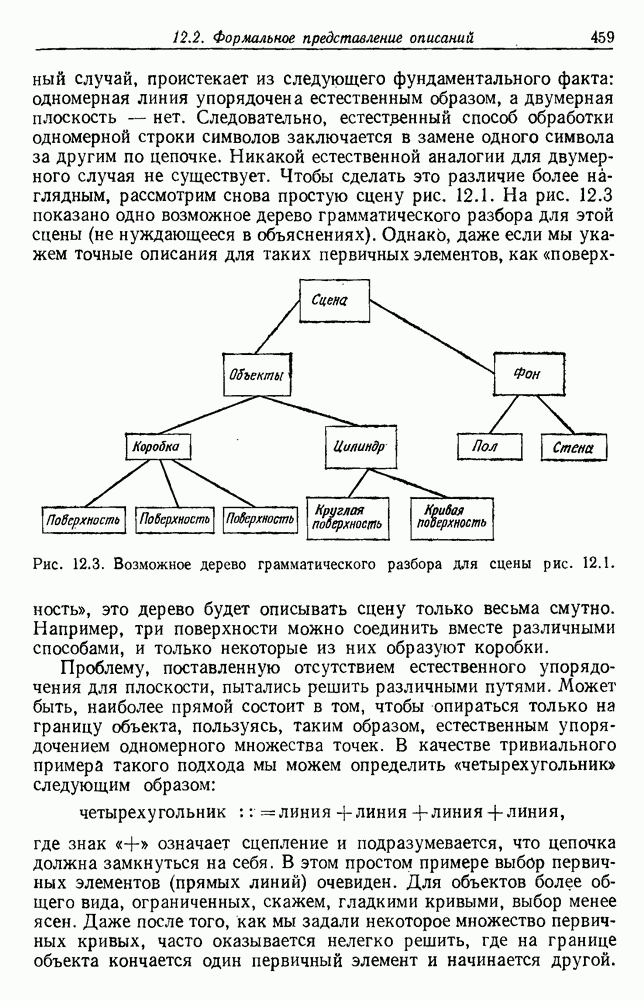




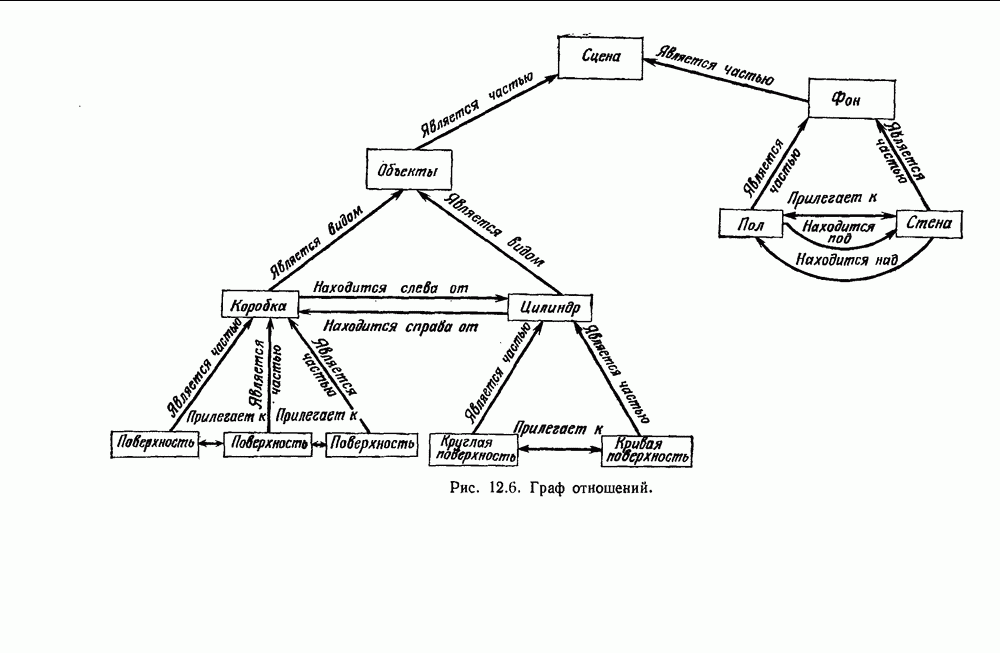










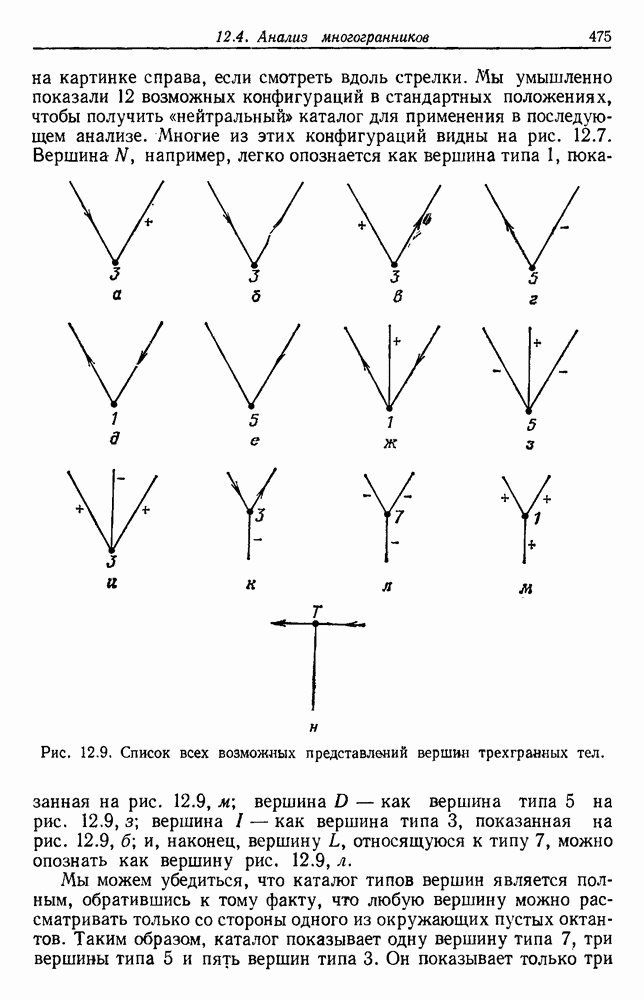
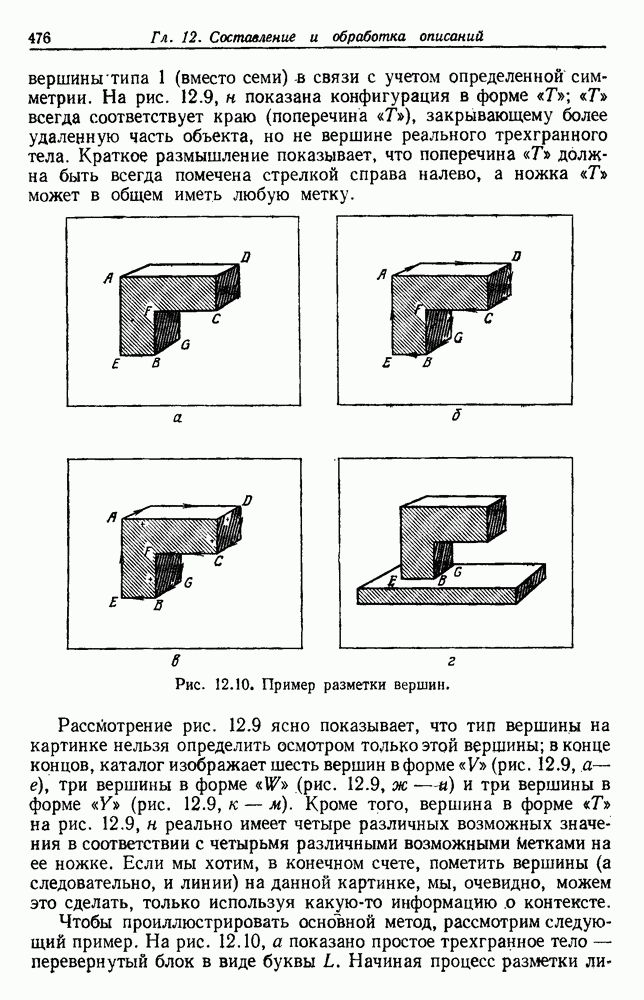










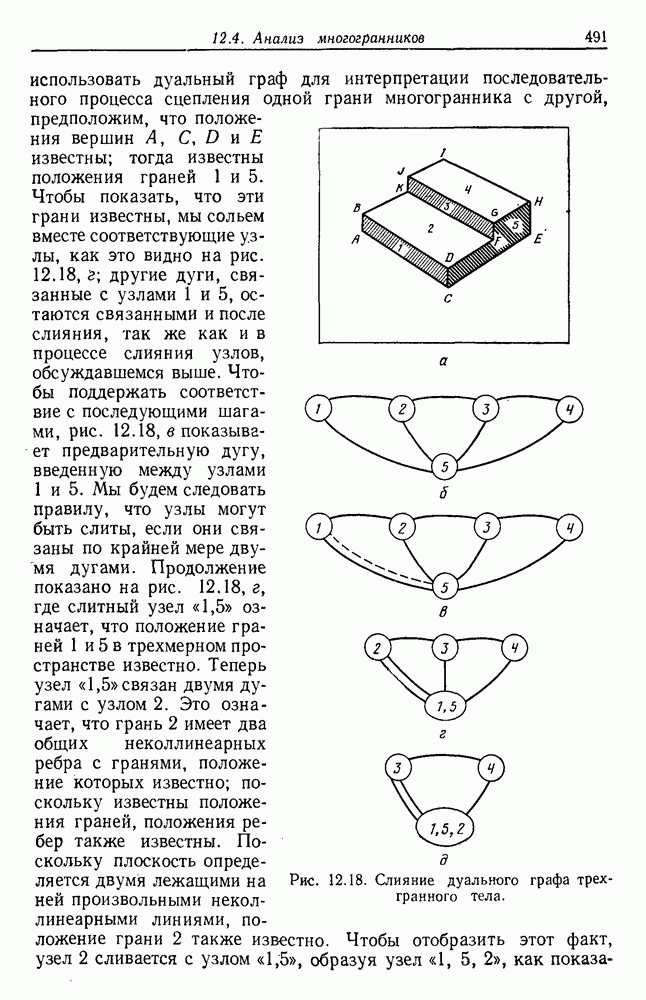






 выборок на с групп. Первое из них — это разделение на
выборок на с групп. Первое из них — это разделение на  групп, причем каждая из групп содержит точно по одной выборке. Следующее разделение на
групп, причем каждая из групп содержит точно по одной выборке. Следующее разделение на  групп, затем на
групп, затем на  и т. д. до
и т. д. до  в котором все выборки образуют одну группу. Будем говорить, что находимся на
в котором все выборки образуют одну группу. Будем говорить, что находимся на  уровне в последовательности, когда
уровне в последовательности, когда  Таким образом, первый
Таким образом, первый
 группам, а
группам, а  одной группе. Если даны любые две выборки
одной группе. Если даны любые две выборки  на некотором уровне они будут собраны вместе в одну группу. Если последовательность обладает тем свойством, что, когда две выборки попадают в одну группу на уровне k, они остаются вместе на более высоких уровнях, то такая последовательность называется иерархической группировкой. Классические примеры иерархической группировки можно найти в биологии, где индивидуумы группируются в виды, виды — в роды, роды — в семейства и т. д.
на некотором уровне они будут собраны вместе в одну группу. Если последовательность обладает тем свойством, что, когда две выборки попадают в одну группу на уровне k, они остаются вместе на более высоких уровнях, то такая последовательность называется иерархической группировкой. Классические примеры иерархической группировки можно найти в биологии, где индивидуумы группируются в виды, виды — в роды, роды — в семейства и т. д.

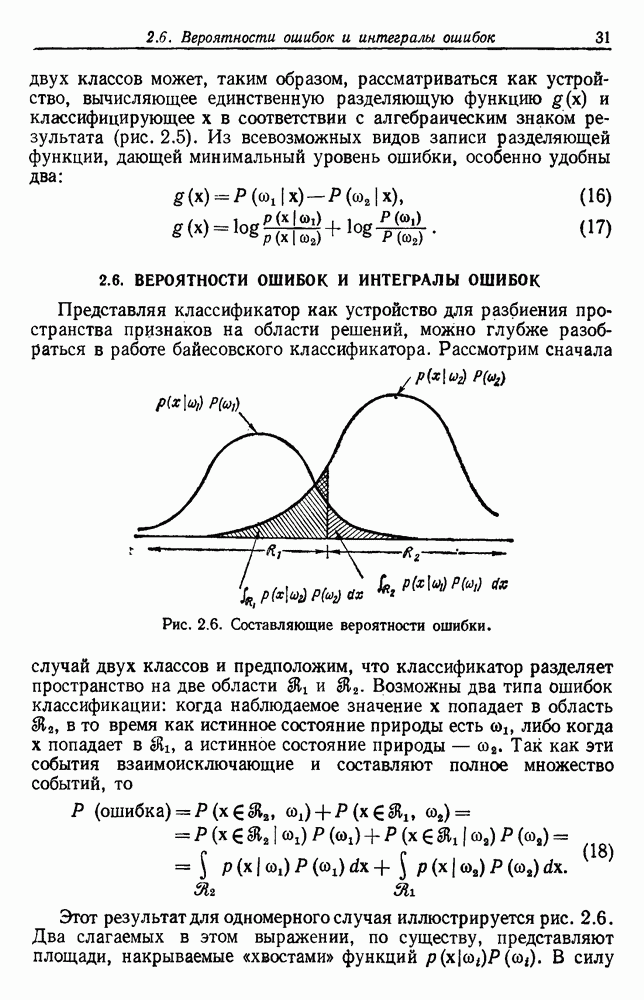
 были сгруппированы в группу, и они остаются вместе на всех последующих уровнях. Если возможно измерить подобие между группами, то дендрограмма изображается в масштабе, чтобы показать подобие между группами, которые объединяются. На рис. 6.15, например, подобие между двумя группами выборок, которые объединены на уровне 6, имеет значение 30. Значения подобия часто используются для определения того, было ли объединение
были сгруппированы в группу, и они остаются вместе на всех последующих уровнях. Если возможно измерить подобие между группами, то дендрограмма изображается в масштабе, чтобы показать подобие между группами, которые объединяются. На рис. 6.15, например, подобие между двумя группами выборок, которые объединены на уровне 6, имеет значение 30. Значения подобия часто используются для определения того, было ли объединение
 .
.
 останов.
останов.

 уничтожить
уничтожить  и уменьшить с на единицу.
и уменьшить с на единицу.
 то можем получить дендрограмму, подобную изображенной на рис. 6.15. На любом уровне расстояние между ближайшими группами может дать значение различия на этом уровне. Читатель обратит внимание на то, что мы не сказали, как измерять расстояние между двумя группами. Рассуждения здесь очень схожи с рассуждениями при выборе функции критерия. Для простоты ограничимся следующими мерами расстояния, предоставляя другие возможные меры воображению
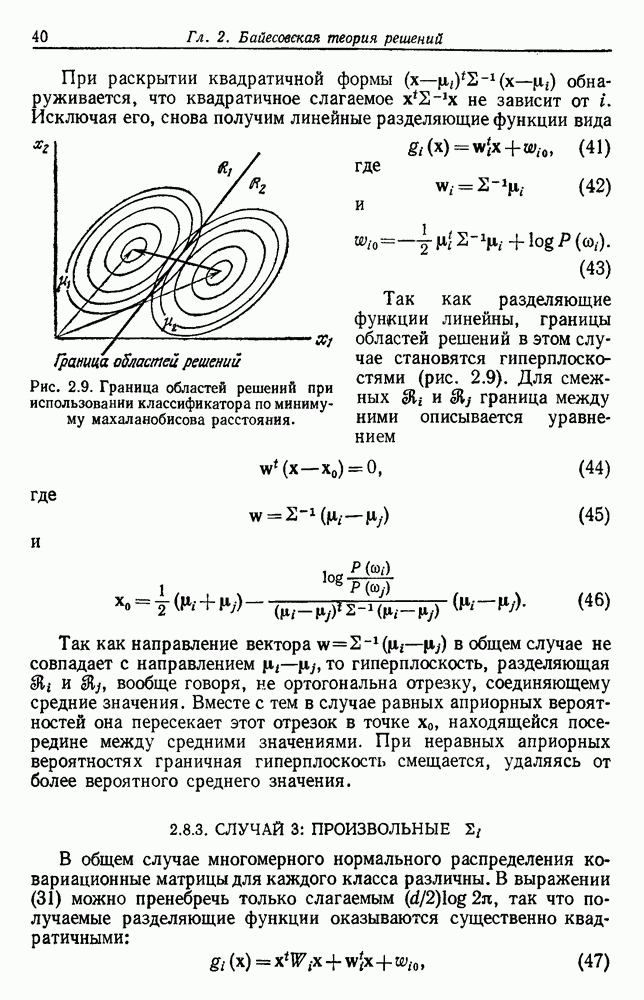
то можем получить дендрограмму, подобную изображенной на рис. 6.15. На любом уровне расстояние между ближайшими группами может дать значение различия на этом уровне. Читатель обратит внимание на то, что мы не сказали, как измерять расстояние между двумя группами. Рассуждения здесь очень схожи с рассуждениями при выборе функции критерия. Для простоты ограничимся следующими мерами расстояния, предоставляя другие возможные меры воображению

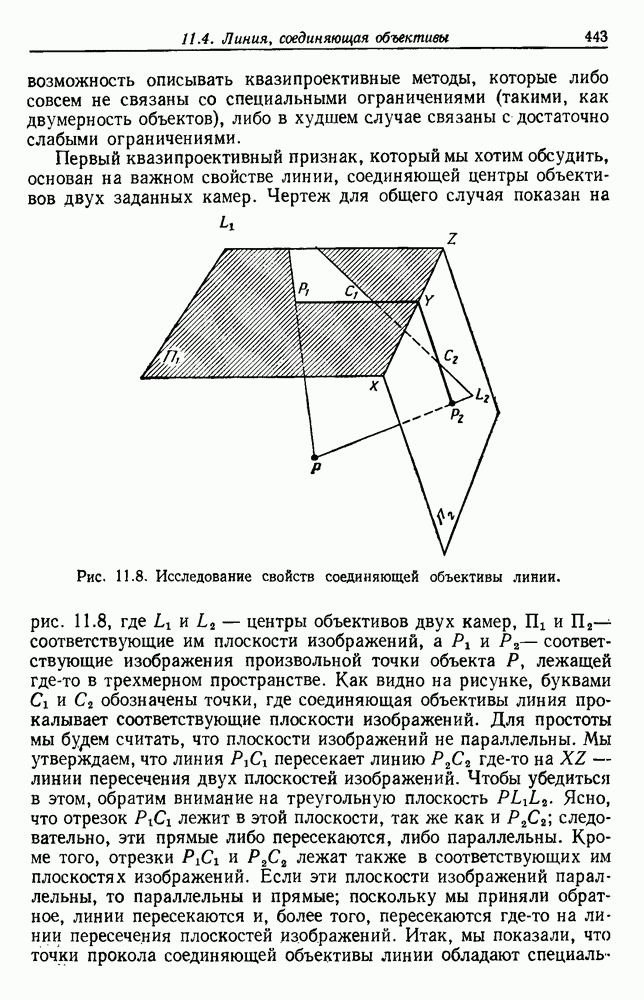
 Предположим, что мы рассматриваем точки данных как вершины графа, причем ребра графа образуют путь между вершинами в том же подмножестве
Предположим, что мы рассматриваем точки данных как вершины графа, причем ребра графа образуют путь между вершинами в том же подмножестве  Когда для измерения расстояния между подмножествами используется
Когда для измерения расстояния между подмножествами используется  ближайшие соседи определяют ближайшие подмножества. Слияние.
ближайшие соседи определяют ближайшие подмножества. Слияние.  соответствует добавлению ребра между двумя ближайшими вершинами в
соответствует добавлению ребра между двумя ближайшими вершинами в  и Поскольку ребра, соединяющие группы, всегда проходят между различными группами, результирующий граф никогда не имеет замкнутых контуров или цепей; пользуясь терминологией теории графов, можно сказать, что эта процедура генерирует дерево. Если так продолжать, пока все подмножества не будут соединены, в результате получим покрывающее дерево (остов) — дерево с путем от любой вершины к любой другой вершине. Более того, можно показать, что сумма длин ребер результирующего дерева не будет превышать суммы длин ребер для любого другого покрывающего дерева для данного множества выборок. Такйм образом, используя
и Поскольку ребра, соединяющие группы, всегда проходят между различными группами, результирующий граф никогда не имеет замкнутых контуров или цепей; пользуясь терминологией теории графов, можно сказать, что эта процедура генерирует дерево. Если так продолжать, пока все подмножества не будут соединены, в результате получим покрывающее дерево (остов) — дерево с путем от любой вершины к любой другой вершине. Более того, можно показать, что сумма длин ребер результирующего дерева не будет превышать суммы длин ребер для любого другого покрывающего дерева для данного множества выборок. Такйм образом, используя  в качестве меры расстояния, агломеративная процедура группировки превращается в алгоритм для генерирования минимального покрывающего дерева.
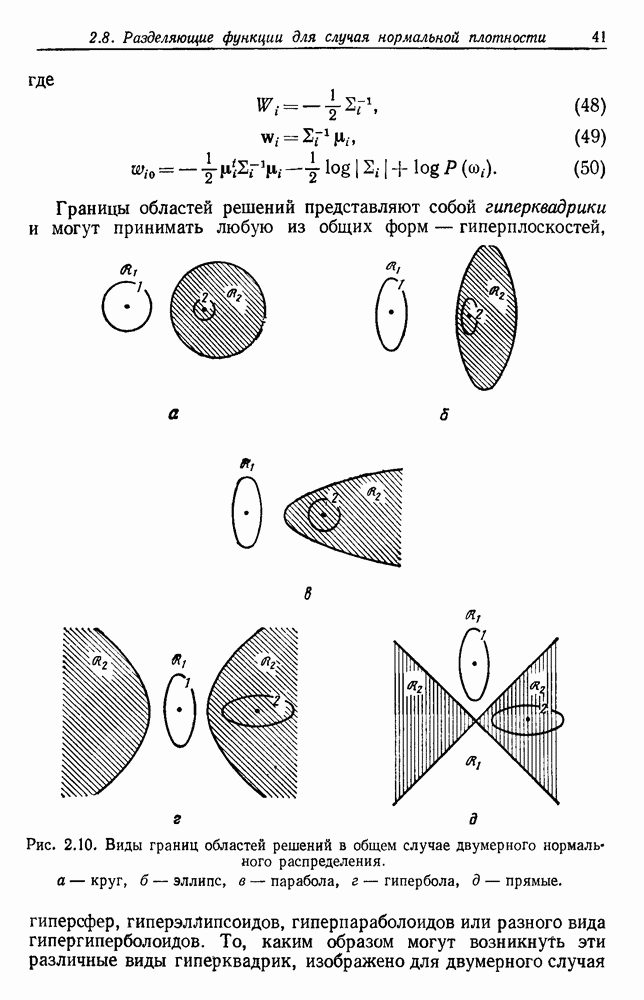
в качестве меры расстояния, агломеративная процедура группировки превращается в алгоритм для генерирования минимального покрывающего дерева.
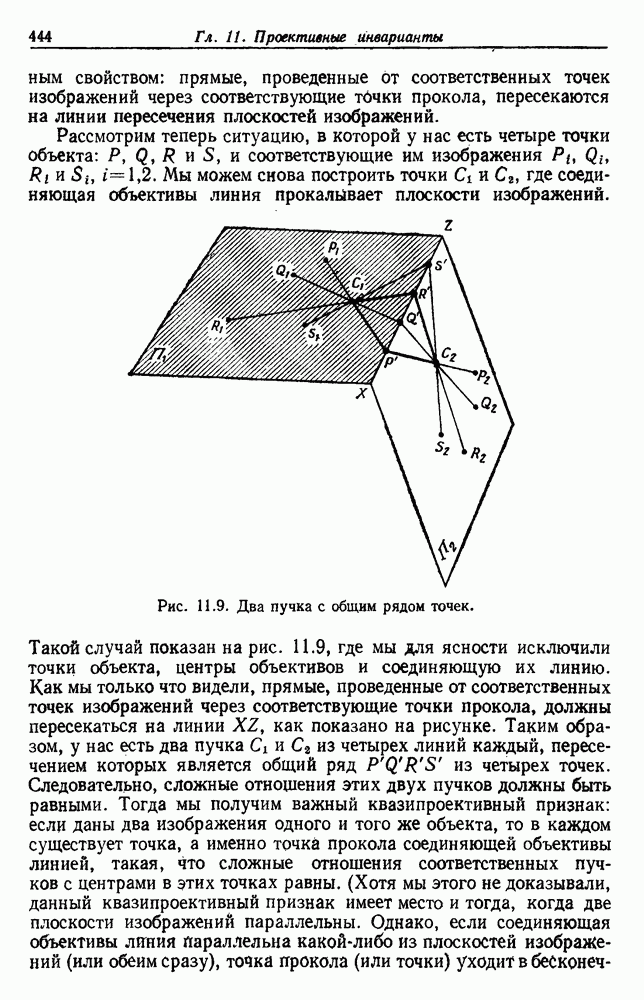
 Минимальное покрывающее дерево можно получить, добавляя самое короткое ребро между двумя группами. В первом случае, где группы компактны и хорошо разделены, найдены явные группы. Во втором случае наличие некоторых точек, расположенных так, что между группами создан некоторый мост, приводит к довольно неожиданной группировке в одну большую продолговатую группу и в одну маленькую компактную группу. Такое поведение часто называют «цепным эффектом» и иногда относят к недостаткам этой меры расстояния. В случае, когда результаты очень чувствительны к шуму или к небольшим изменениям в положении точек данных, такая критика вполне законна. Однако, как иллюстрирует третий случай, та же тенденция формирования цепей может считаться преимуществом, если группы сами по себе вытянуты или имеют вытянутые отростки.
Минимальное покрывающее дерево можно получить, добавляя самое короткое ребро между двумя группами. В первом случае, где группы компактны и хорошо разделены, найдены явные группы. Во втором случае наличие некоторых точек, расположенных так, что между группами создан некоторый мост, приводит к довольно неожиданной группировке в одну большую продолговатую группу и в одну маленькую компактную группу. Такое поведение часто называют «цепным эффектом» и иногда относят к недостаткам этой меры расстояния. В случае, когда результаты очень чувствительны к шуму или к небольшим изменениям в положении точек данных, такая критика вполне законна. Однако, как иллюстрирует третий случай, та же тенденция формирования цепей может считаться преимуществом, если группы сами по себе вытянуты или имеют вытянутые отростки.
 возникновение вытянутых групп является нежелательным
возникновение вытянутых групп является нежелательным  Применение процедуры можно рассматривать как получение графа, в котором ребра соединяют все вершины в группу. Пользуясь терминологией теории графов, можно сказать, что каждая группа образует полный подграф. Расстояние между двумя группами определяется наиболее удаленными вершинами в этих двух группах. Когда
Применение процедуры можно рассматривать как получение графа, в котором ребра соединяют все вершины в группу. Пользуясь терминологией теории графов, можно сказать, что каждая группа образует полный подграф. Расстояние между двумя группами определяется наиболее удаленными вершинами в этих двух группах. Когда
 являются естественным компромиссом между
являются естественным компромиссом между  . С вычислительной точки зрения
. С вычислительной точки зрения  — наиболее простая из всех мер, так как все другие требуют вычисления всех
— наиболее простая из всех мер, так как все другие требуют вычисления всех  пар расстояний
пар расстояний  Однако такую меру, как
Однако такую меру, как  , можно использовать, когда расстояния
, можно использовать, когда расстояния  заменены на меру подобия, а меру подобия между средними векторами трудно или невозможно определить. Мы оставляем читателю разобраться, как использование
заменены на меру подобия, а меру подобия между средними векторами трудно или невозможно определить. Мы оставляем читателю разобраться, как использование  или
или  может изменить группировку точек на рис. 6.16.
может изменить группировку точек на рис. 6.16.
 и слияние которых увеличит (или уменьшит) функцию критерия минимально.
и слияние которых увеличит (или уменьшит) функцию критерия минимально.
 вызывает наименьшее возможное увеличение диаметра разделения на каждом шаге. Приведем еще один простой пример с функцией критерия суммы квадратичных ошибок
вызывает наименьшее возможное увеличение диаметра разделения на каждом шаге. Приведем еще один простой пример с функцией критерия суммы квадратичных ошибок  . С помощью анализа, очень сходного с использованным в разд. 6.9, мы находим, что пара групп, слияние которых увеличивает
. С помощью анализа, очень сходного с использованным в разд. 6.9, мы находим, что пара групп, слияние которых увеличивает  на минимально возможную величину, это такая пара, для которой «расстояние»
на минимально возможную величину, это такая пара, для которой «расстояние»

 оно обычно дает хорошую начальную точку для дальнейшей итерационной оптимизации.
оно обычно дает хорошую начальную точку для дальнейшей итерационной оптимизации.
 для каждой пары выборок, где
для каждой пары выборок, где  причем равенство нулю выполняется тогда и только тогда, когда
причем равенство нулю выполняется тогда и только тогда, когда  Тогда все еще можно использовать агломеративную процедуру, учитывая, что пара ближайших групп — это пара с наименьшими различиями. Интересно, что если мы определяем различия между двумя группами как
Тогда все еще можно использовать агломеративную процедуру, учитывая, что пара ближайших групп — это пара с наименьшими различиями. Интересно, что если мы определяем различия между двумя группами как


 выборок. Более того, упорядочение расстояний между выборками будет инвариантно относительно любого монотонного преобразования величин различий.
выборок. Более того, упорядочение расстояний между выборками будет инвариантно относительно любого монотонного преобразования величин различий.
 для группировки на уровне k. Для уровня 1 имеем
для группировки на уровне k. Для уровня 1 имеем  . Для всех более высоких уровней
. Для всех более высоких уровней  равна минимальному различию между парами разных групп на уровне
равна минимальному различию между парами разных групп на уровне 
 так и
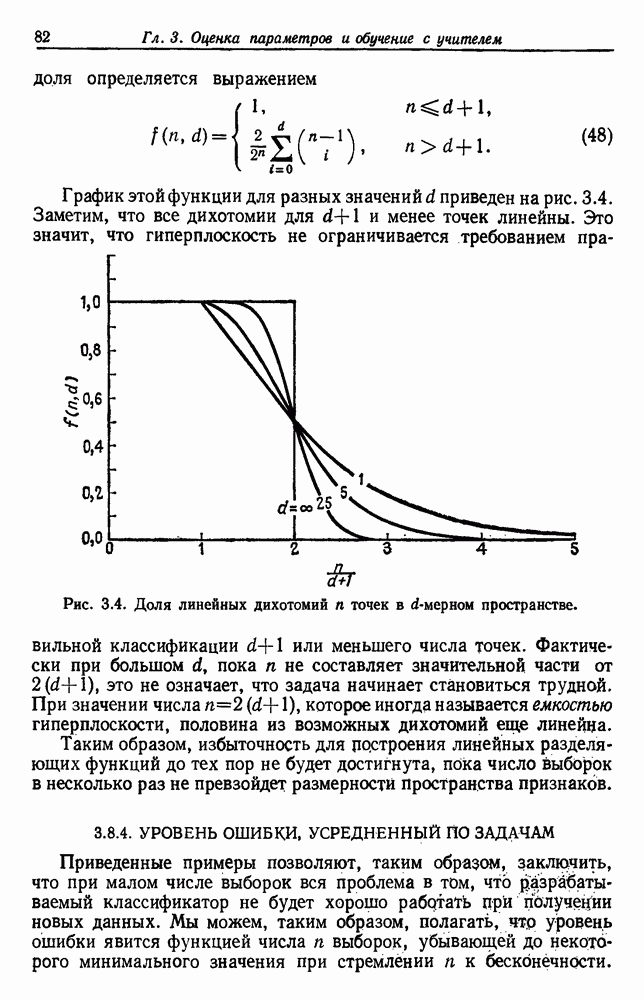
так и  величина
величина  либо остается такой же, либо увеличивается при увеличении k. Более того, мы предполагаем, что нет двух одинаковых выборок в множестве, так что
либо остается такой же, либо увеличивается при увеличении k. Более того, мы предполагаем, что нет двух одинаковых выборок в множестве, так что  . Следовательно,
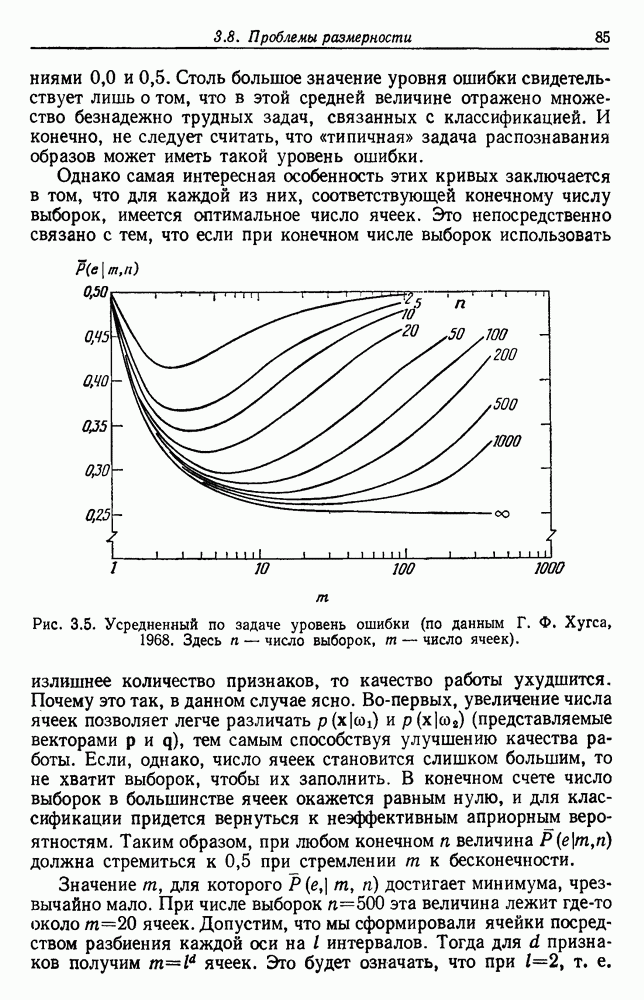
. Следовательно, 
 между
между  как величину группировки на нижнем уровне, для которой х их находятся в одной группе. Чтобы убедиться, что это действительно функция расстояния, или метрит, мы должны показать следующее:
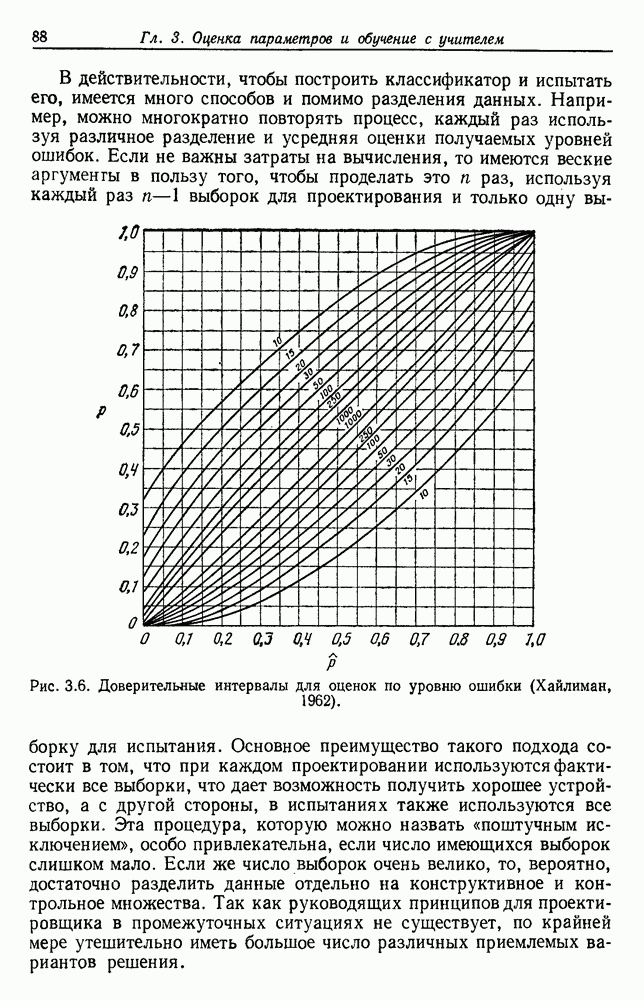
как величину группировки на нижнем уровне, для которой х их находятся в одной группе. Чтобы убедиться, что это действительно функция расстояния, или метрит, мы должны показать следующее:

 могут быть в одной группе, это уровень 1, так что
могут быть в одной группе, это уровень 1, так что 
 то из
то из  следует, что
следует, что  должны быть в одной группе на уровне 1, и поэтому
должны быть в одной группе на уровне 1, и поэтому  Правильность второго требования немедленно следует из определения
Правильность второго требования немедленно следует из определения  Остается третье требование — неравенство треугольника. Пусть
Остается третье требование — неравенство треугольника. Пусть  так что
так что  находятся в одной группе на уровне
находятся в одной группе на уровне  , а
, а  — в одной группе на уровне
— в одной группе на уровне  Из-за иерархического объединения групп одна из этих групп включает другую. Если
Из-за иерархического объединения групп одна из этих групп включает другую. Если  ясно, что на уровне
ясно, что на уровне  находятся в одной группе, и, следовательно, что
находятся в одной группе, и, следовательно, что

 монотонно не уменьшаются, то
монотонно не уменьшаются, то  и поэтому
и поэтому

 Таким образом, удовлетворяются все условия, и мы получили подлинную метрику для сравнения
Таким образом, удовлетворяются все условия, и мы получили подлинную метрику для сравнения  выборок.
выборок.