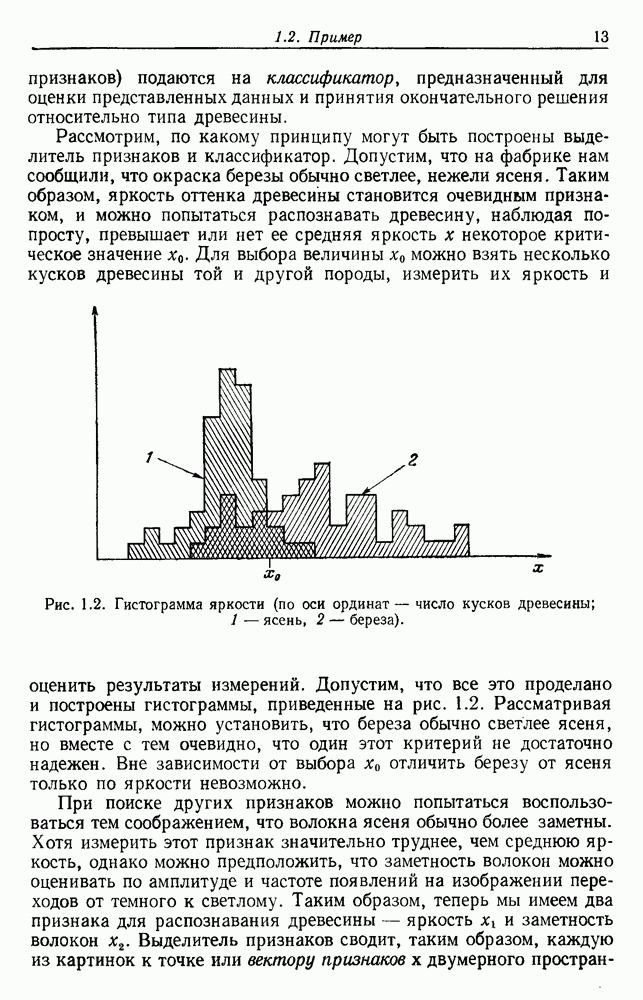
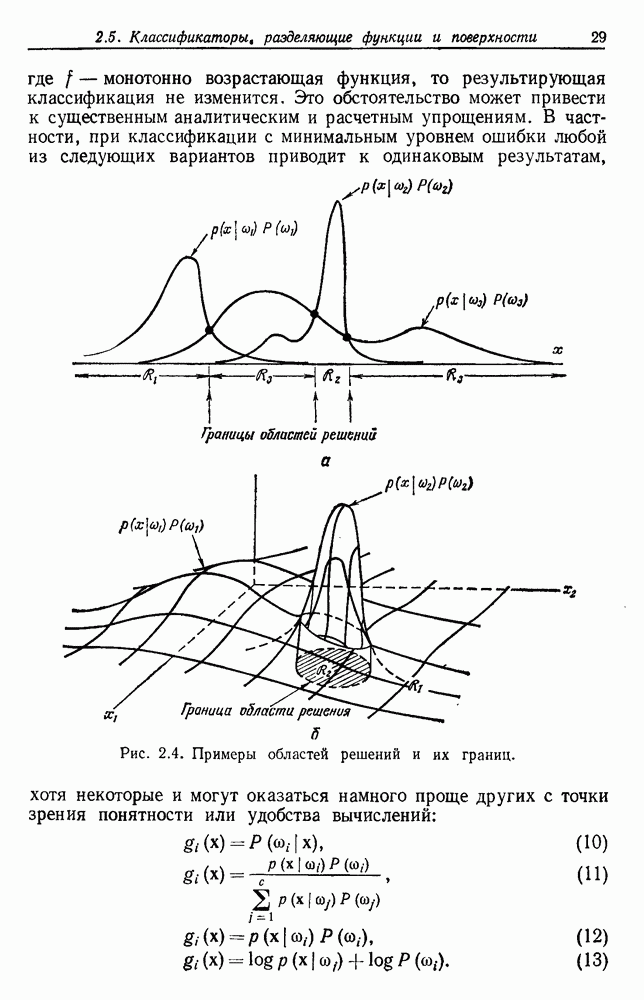
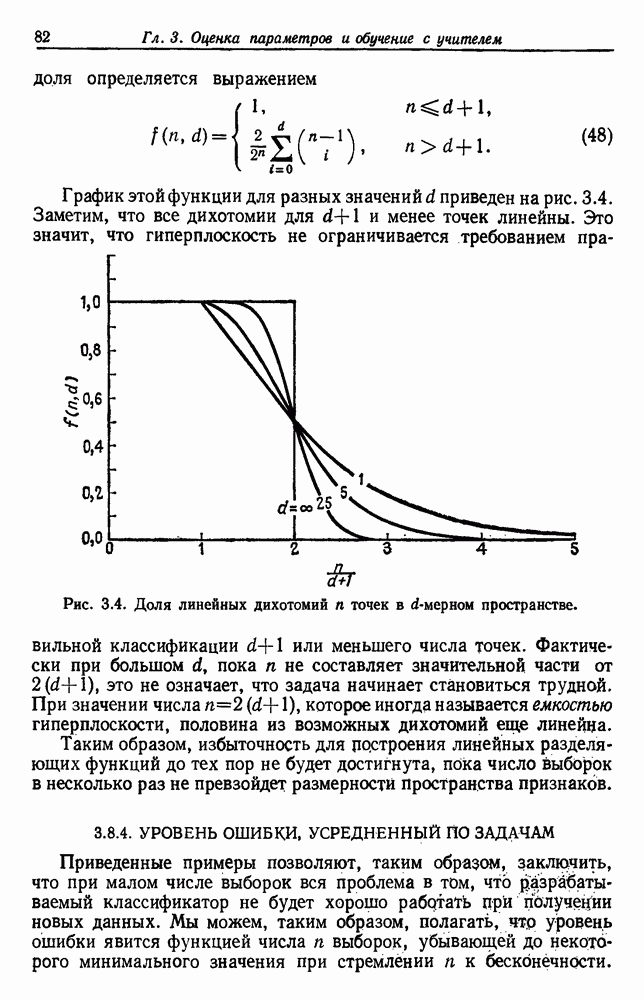
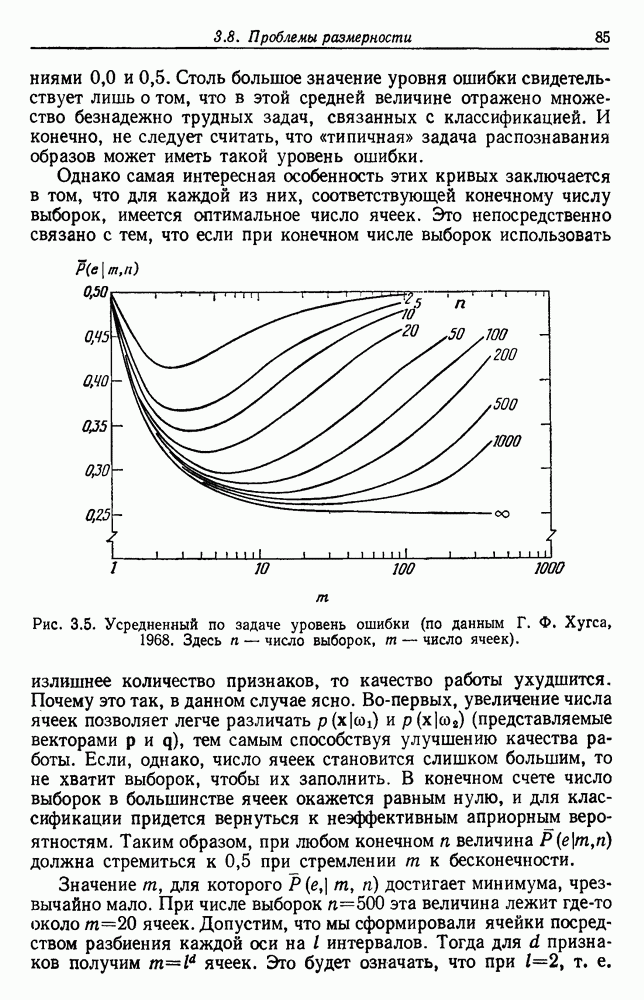
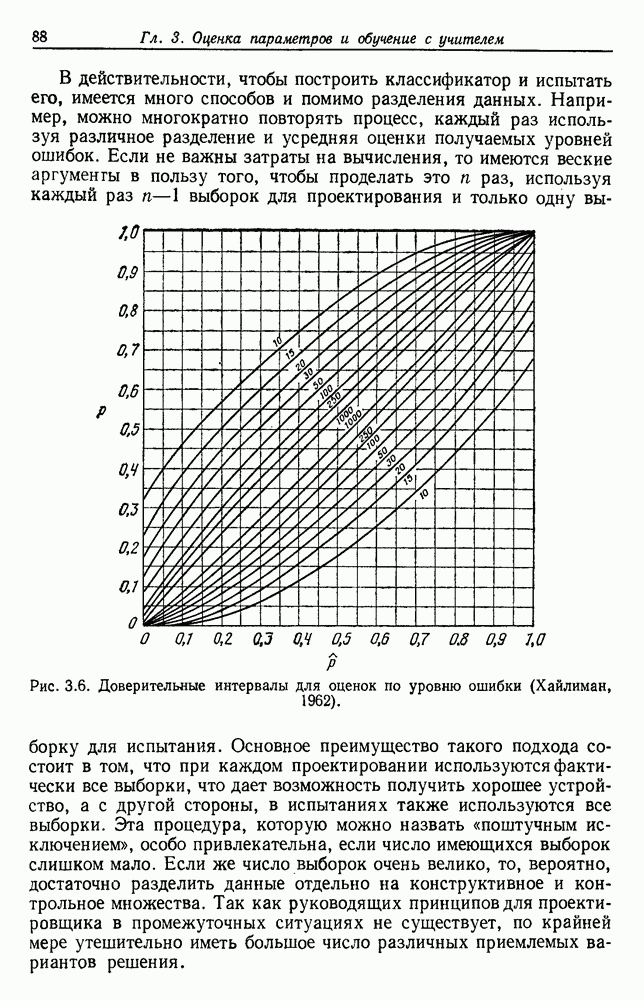
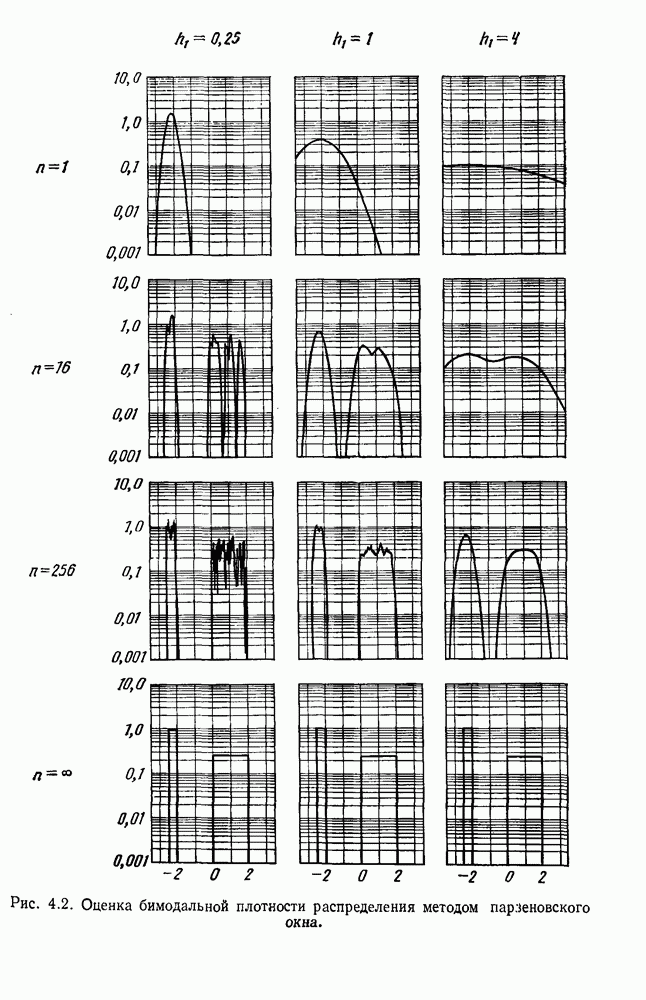
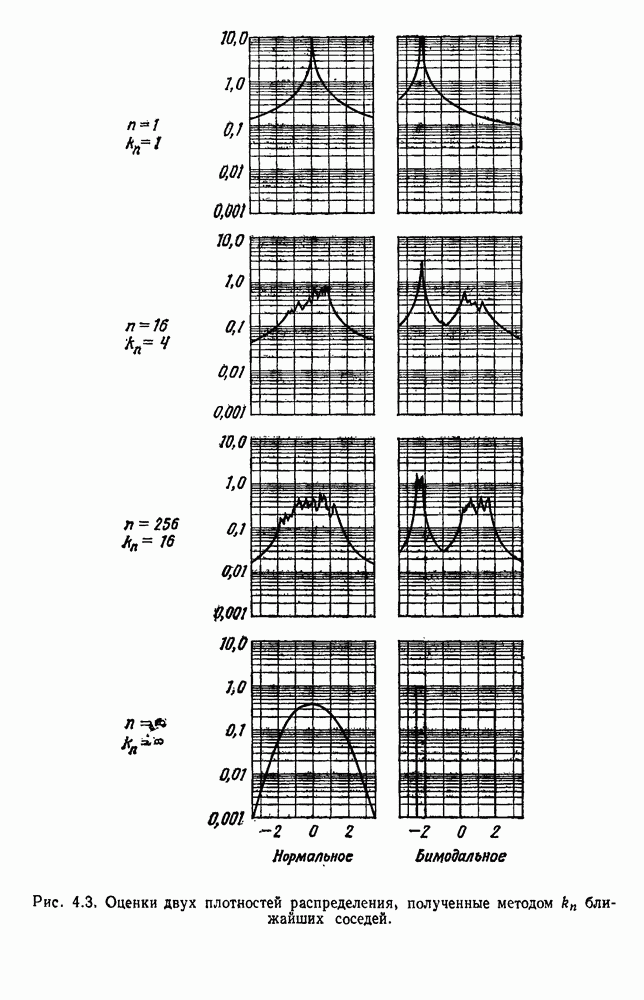
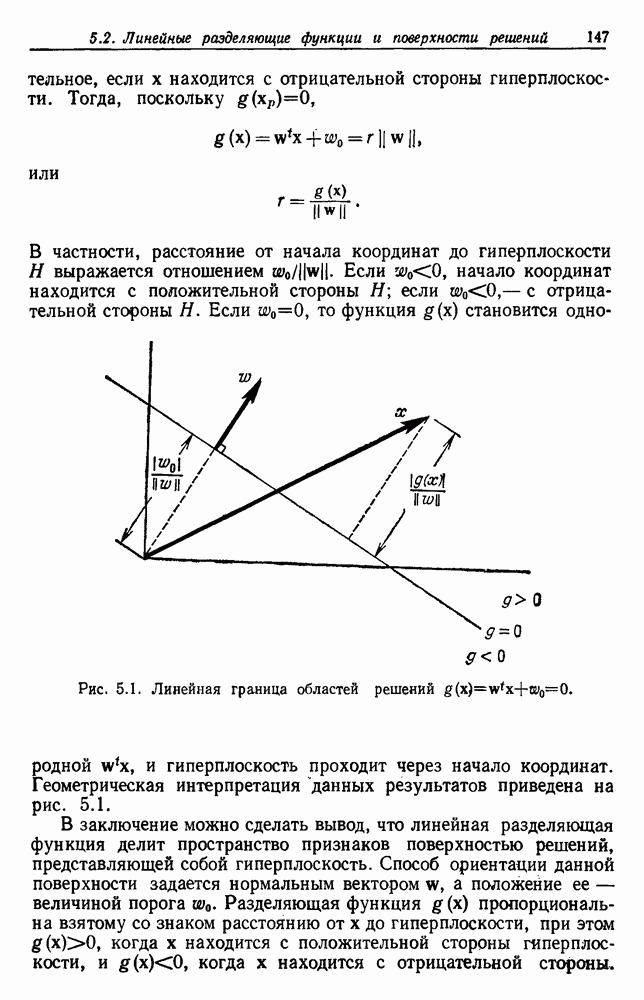
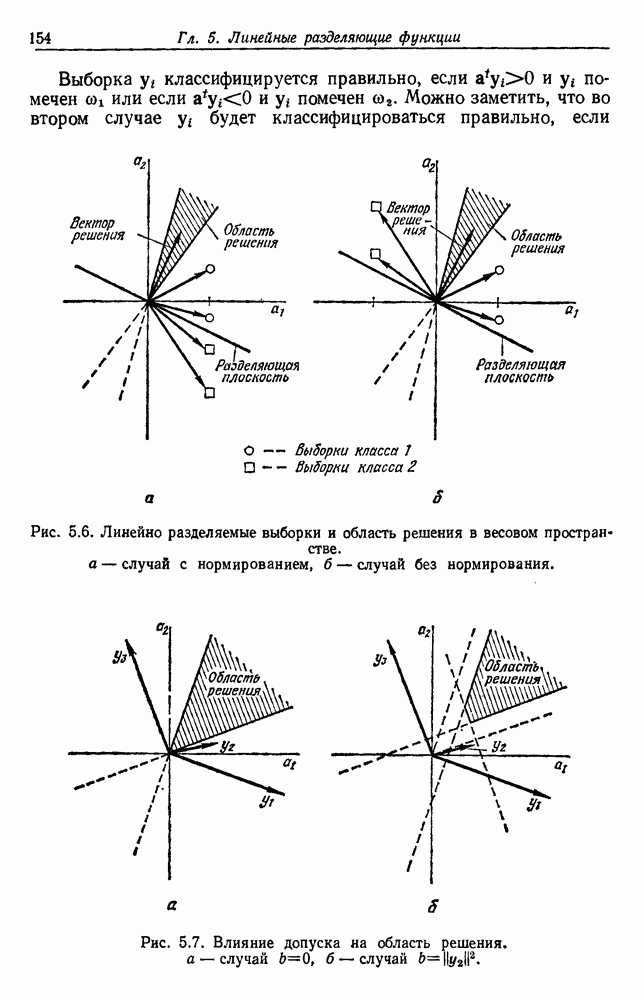
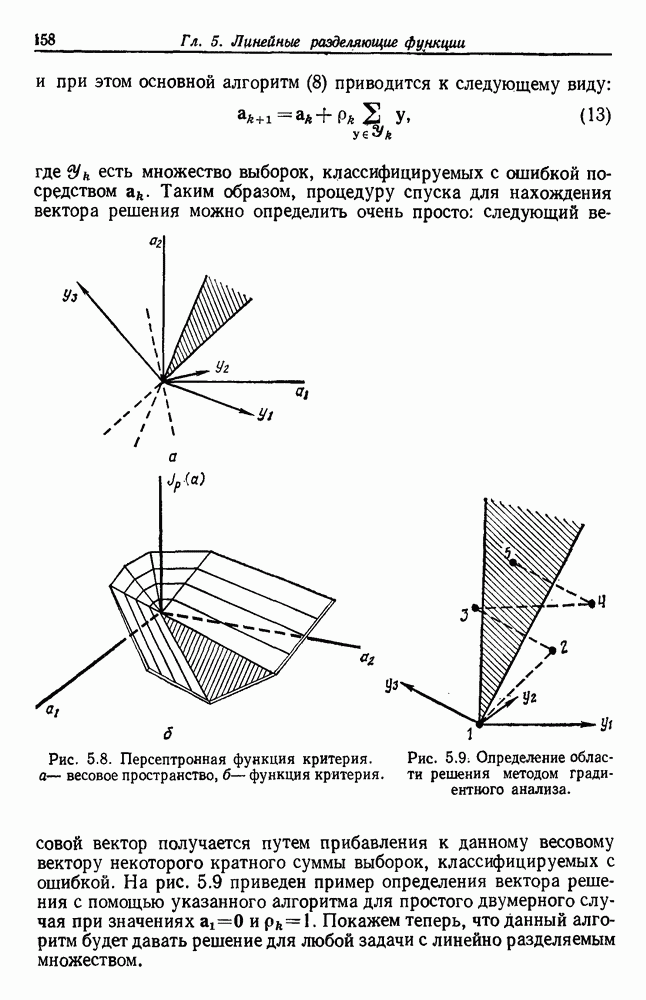
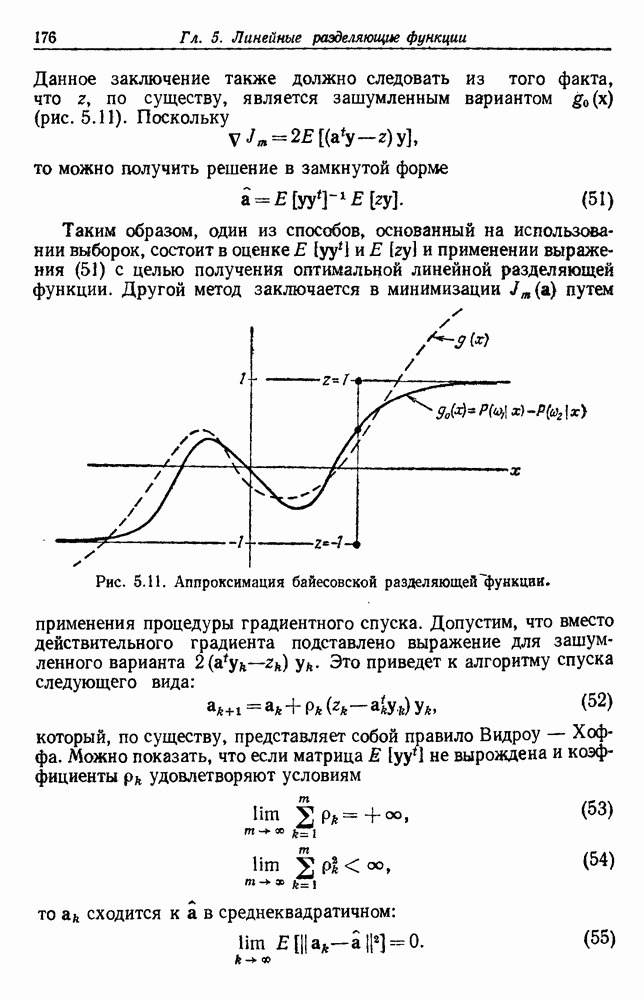
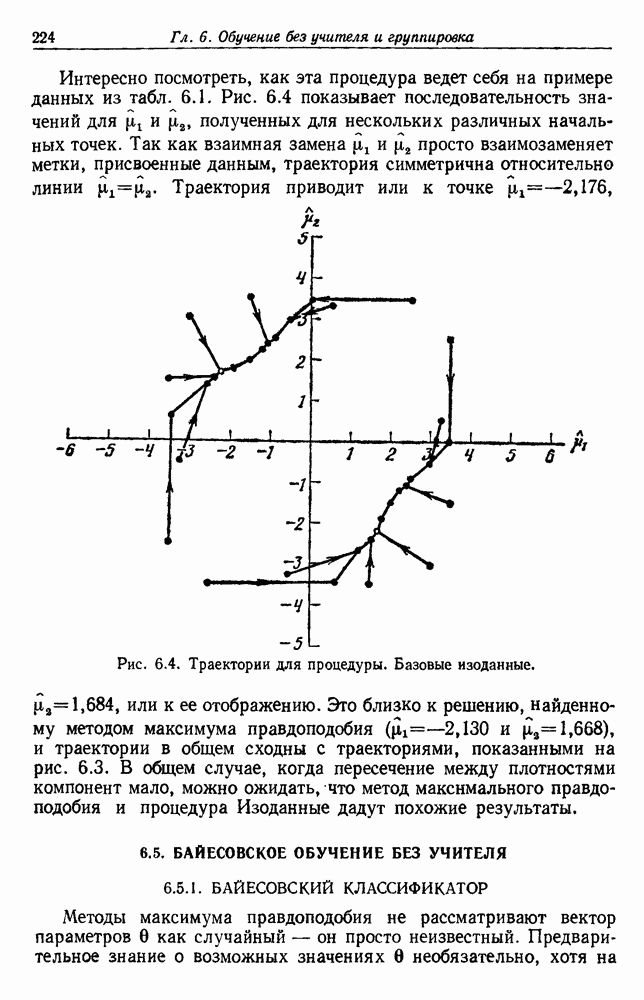
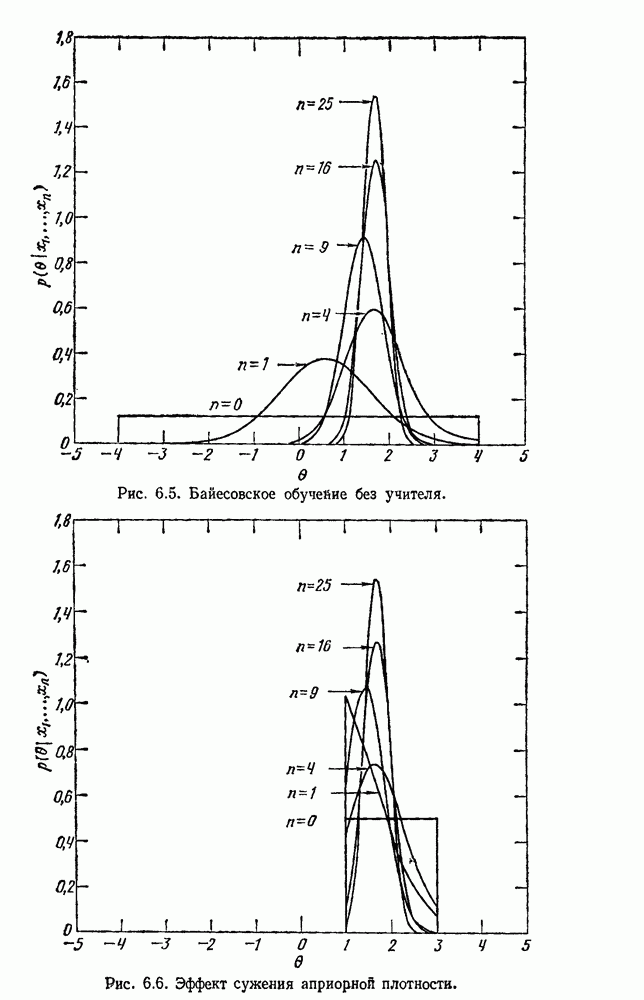
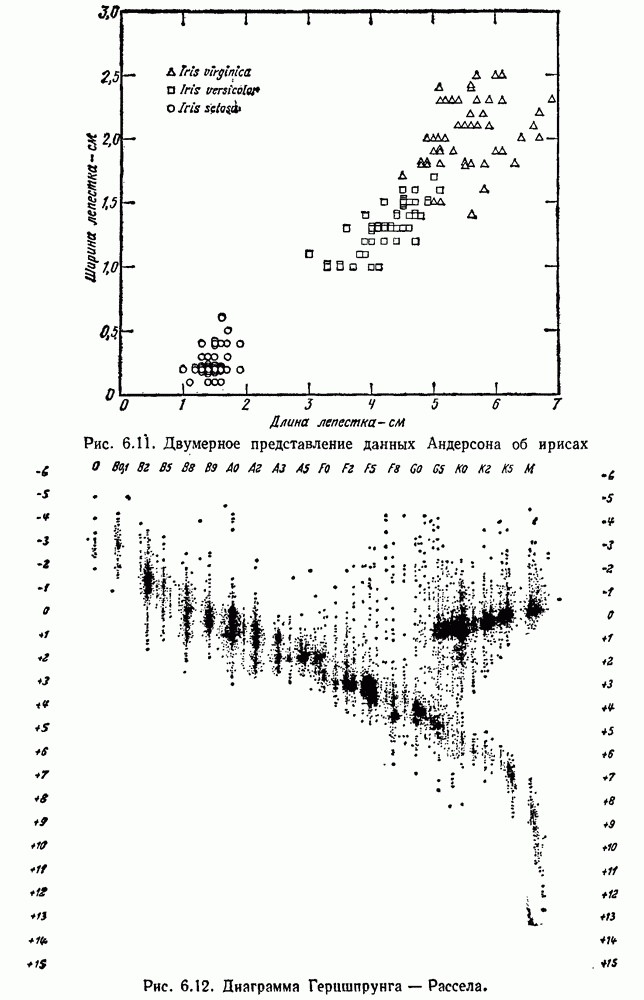
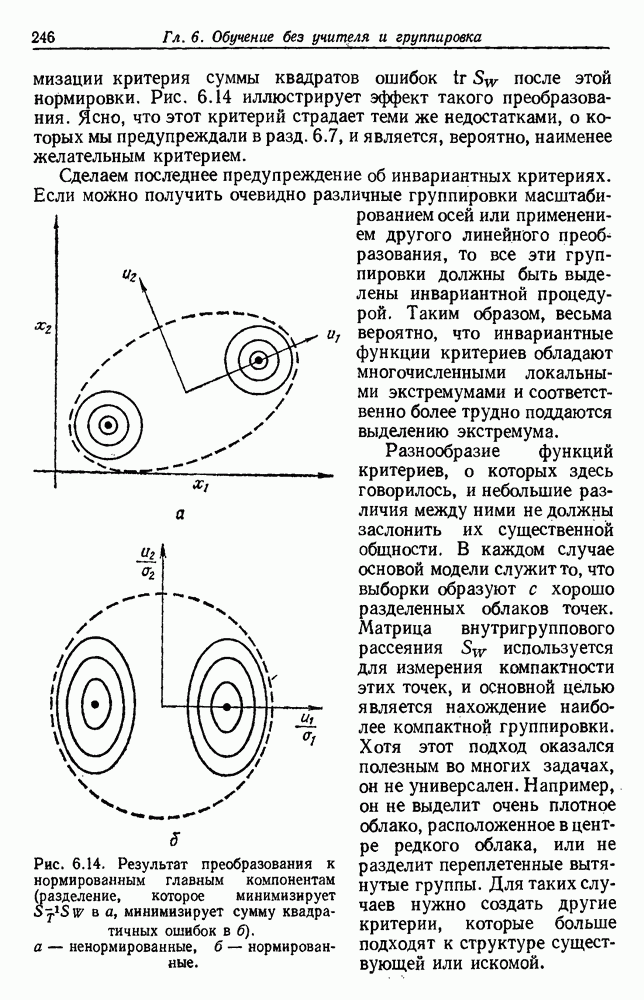
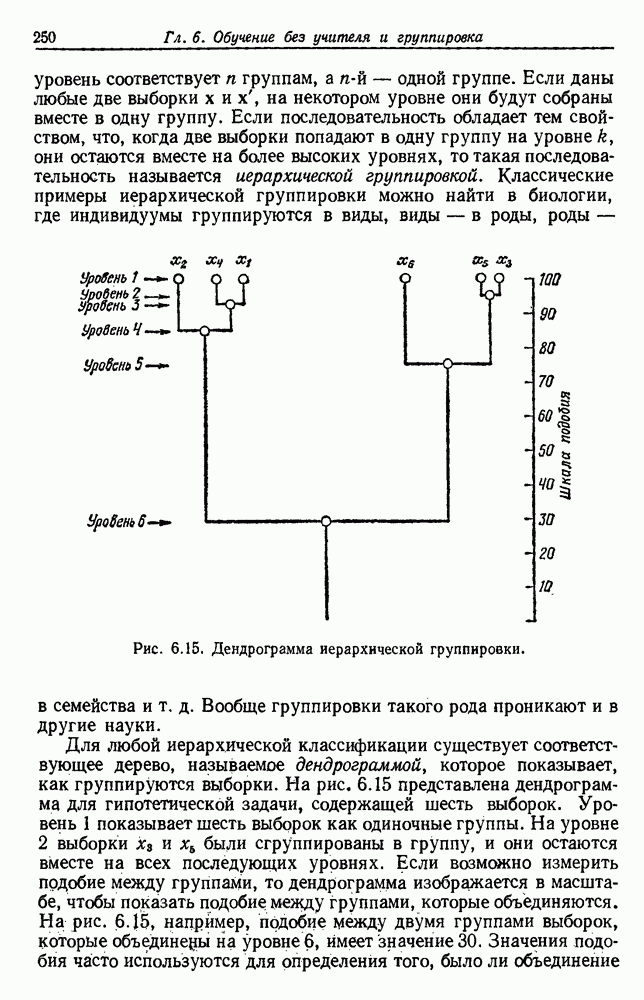
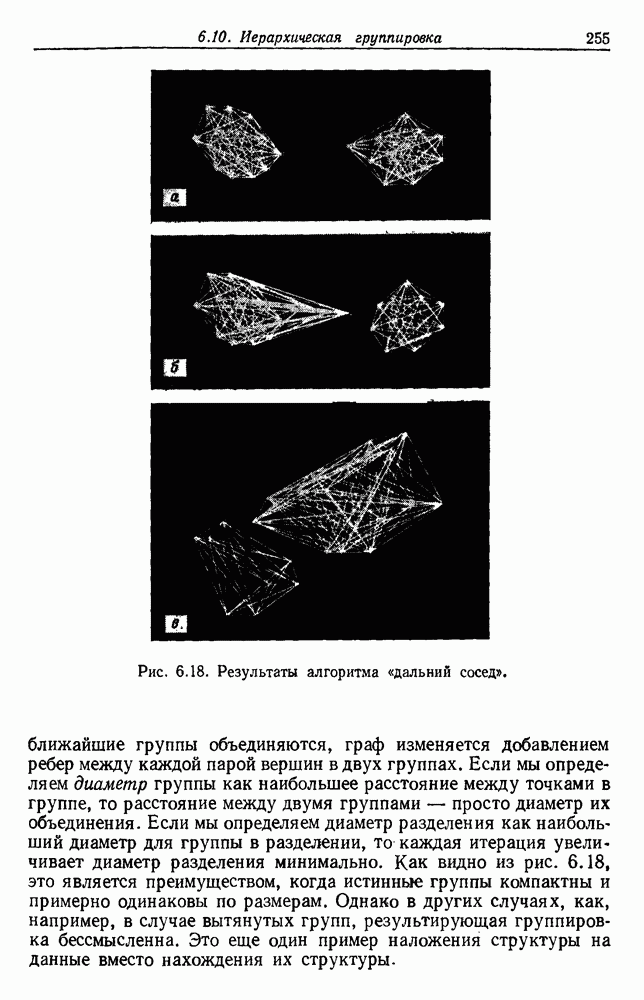
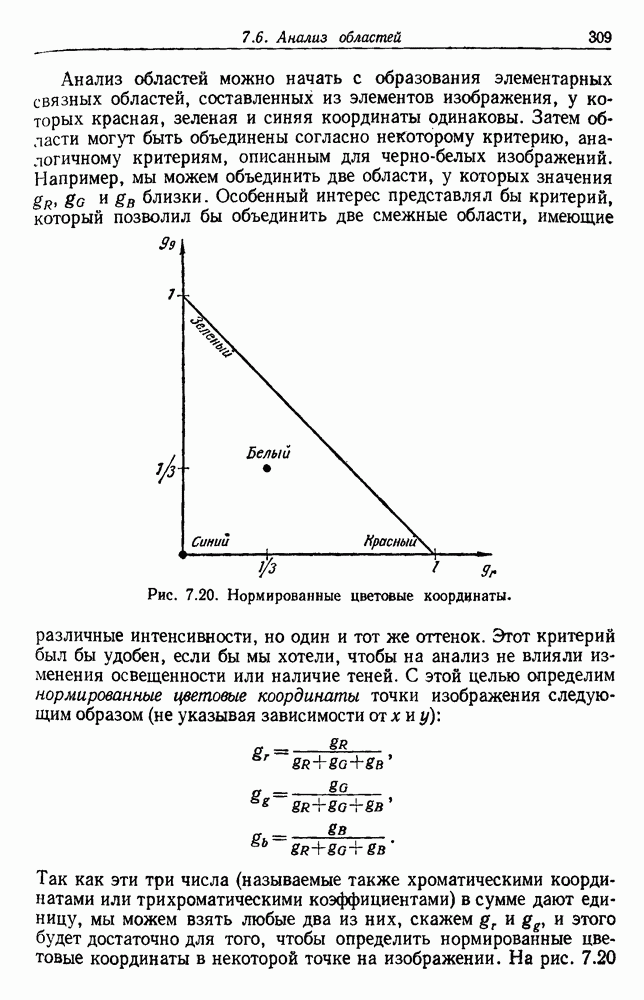
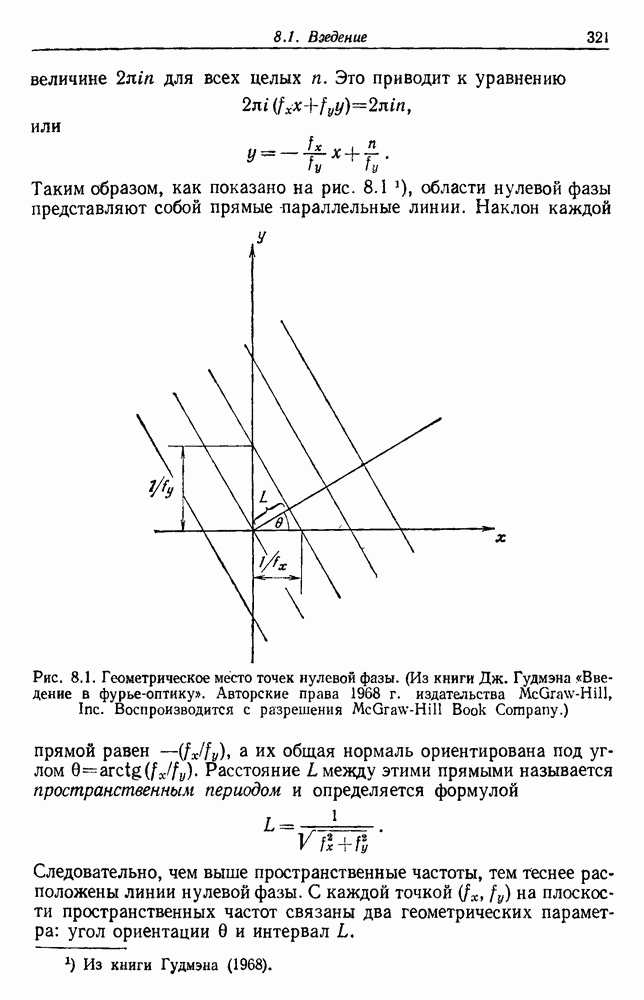
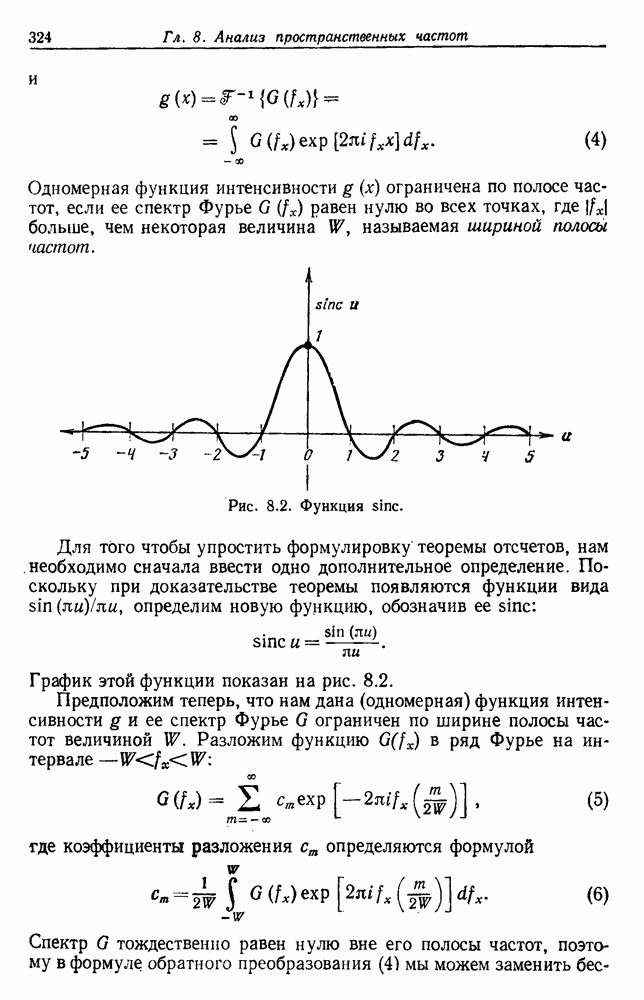
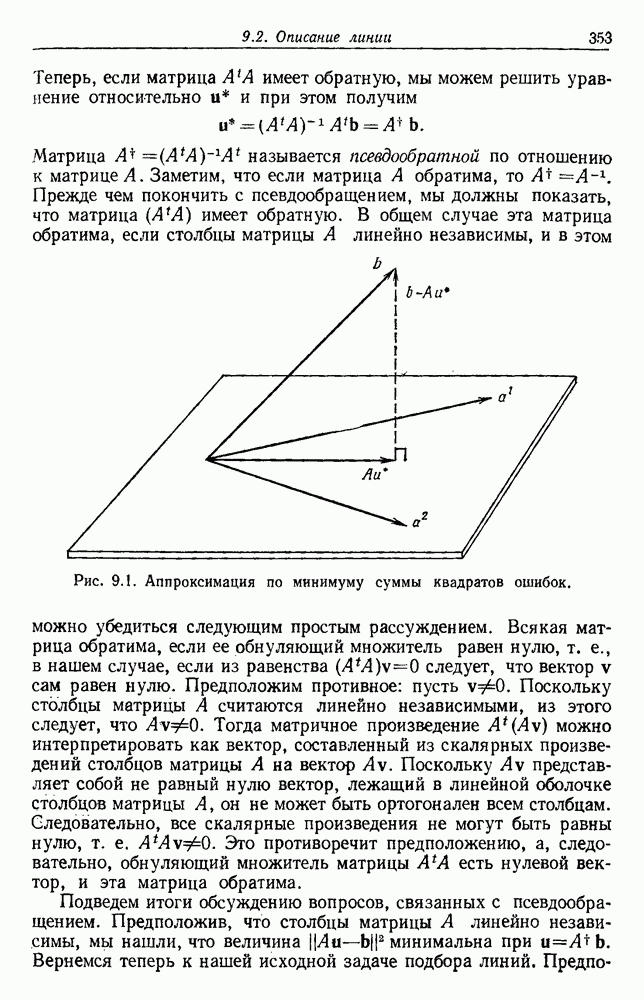
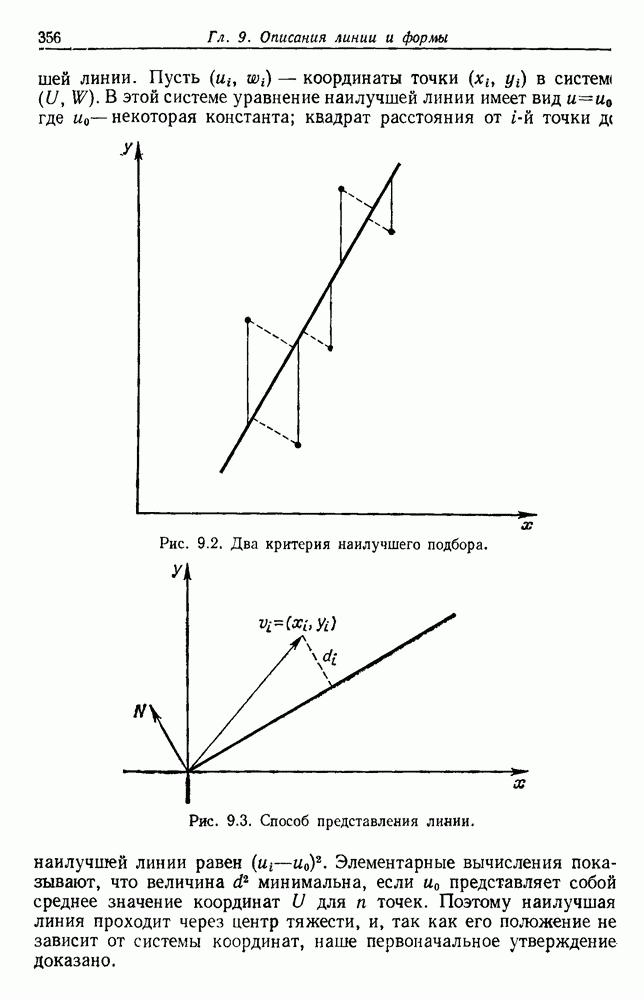
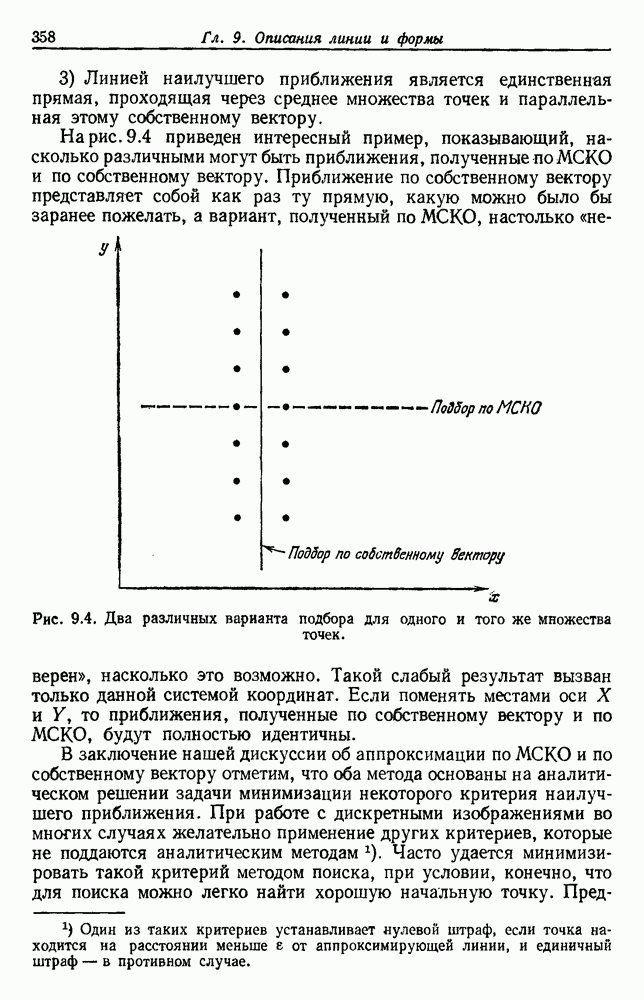
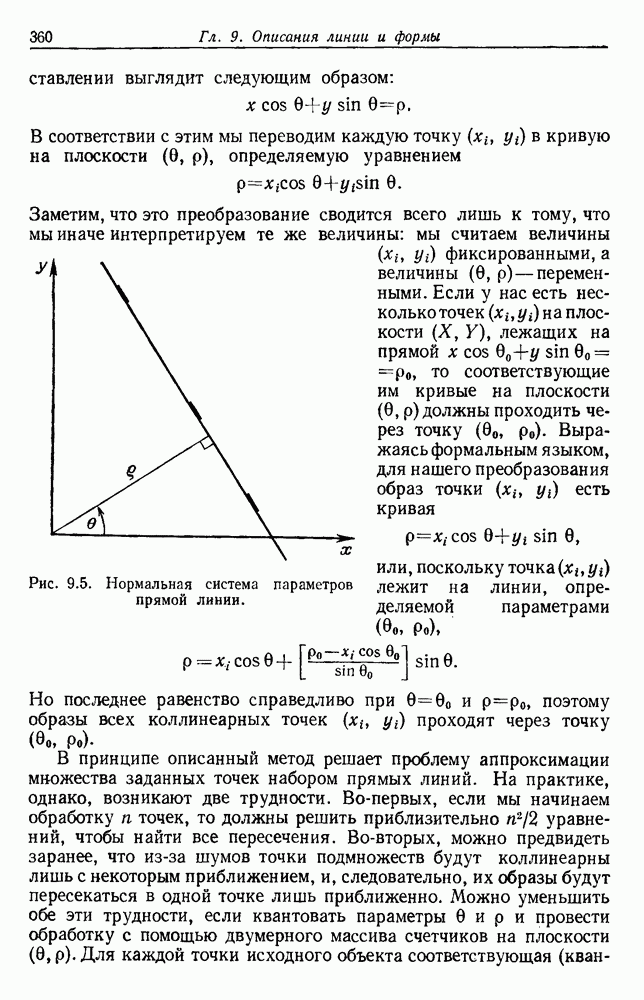
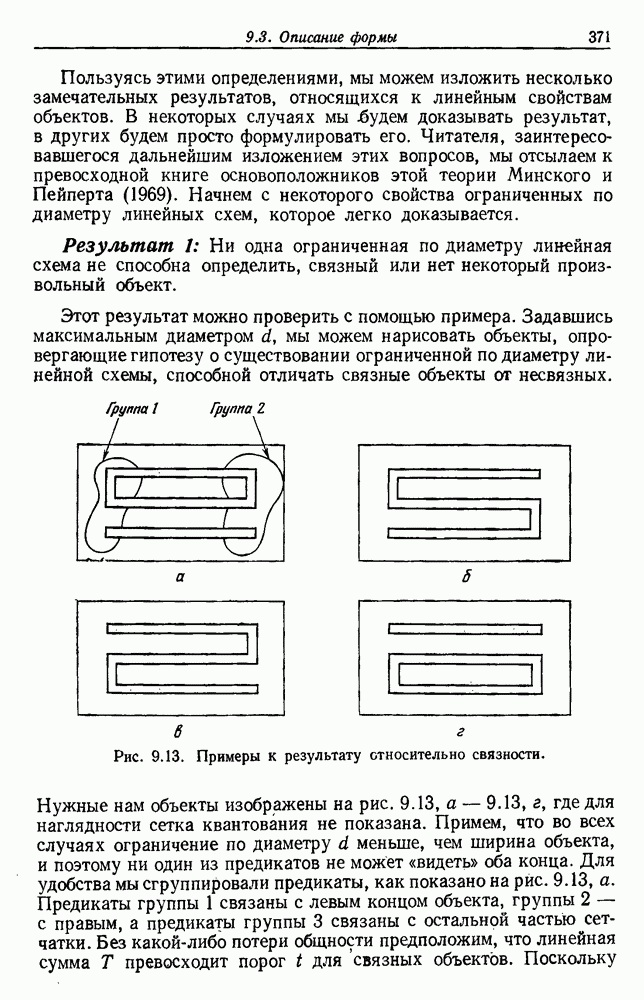
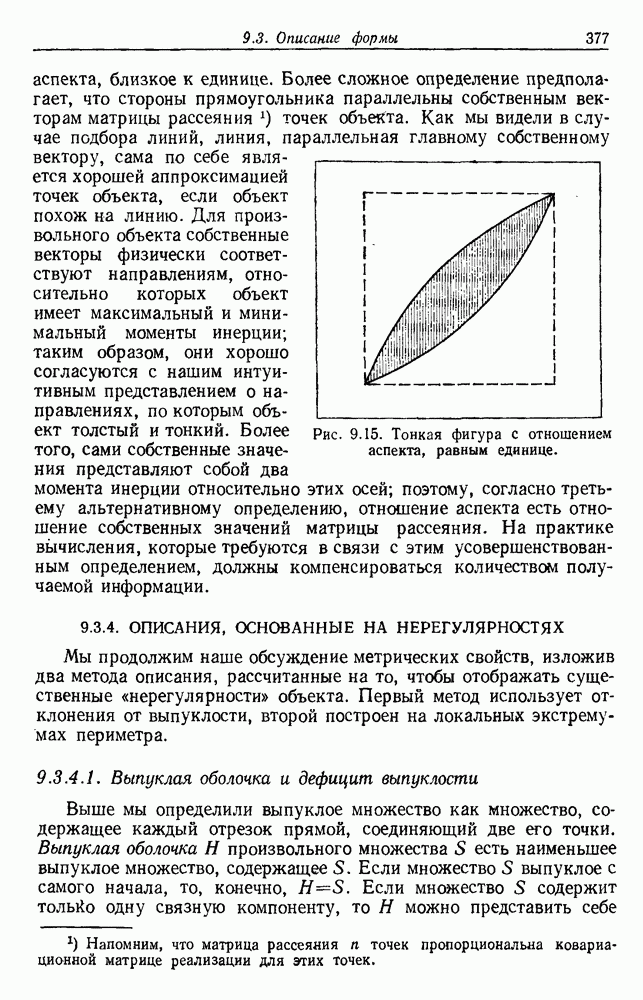
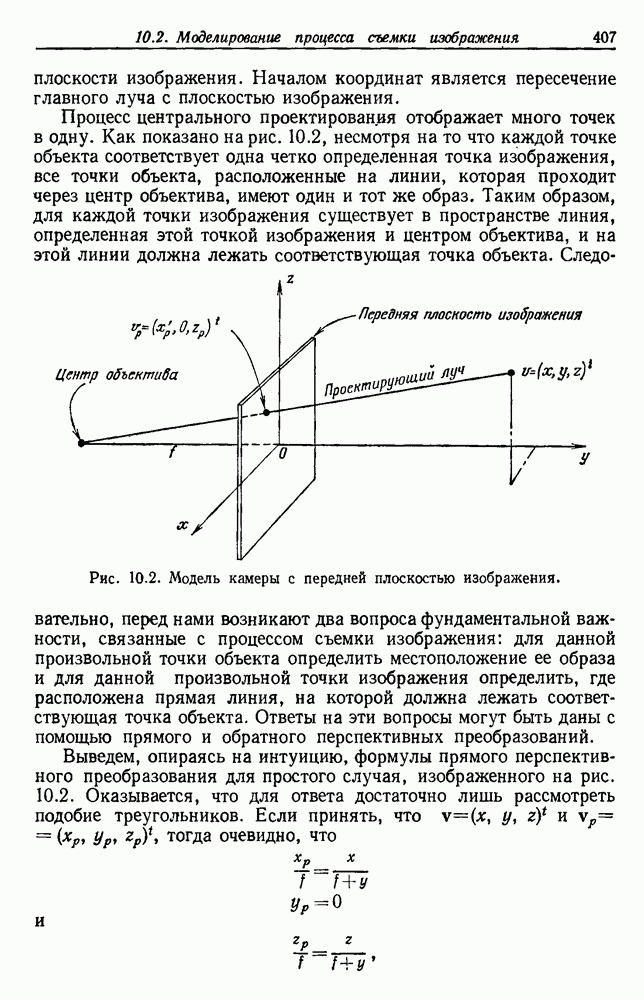
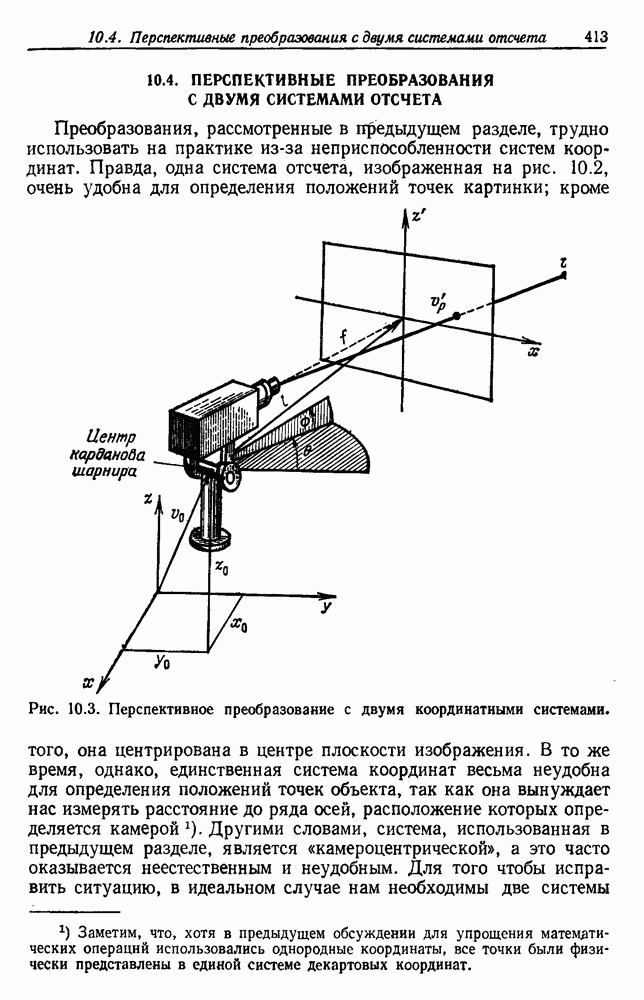
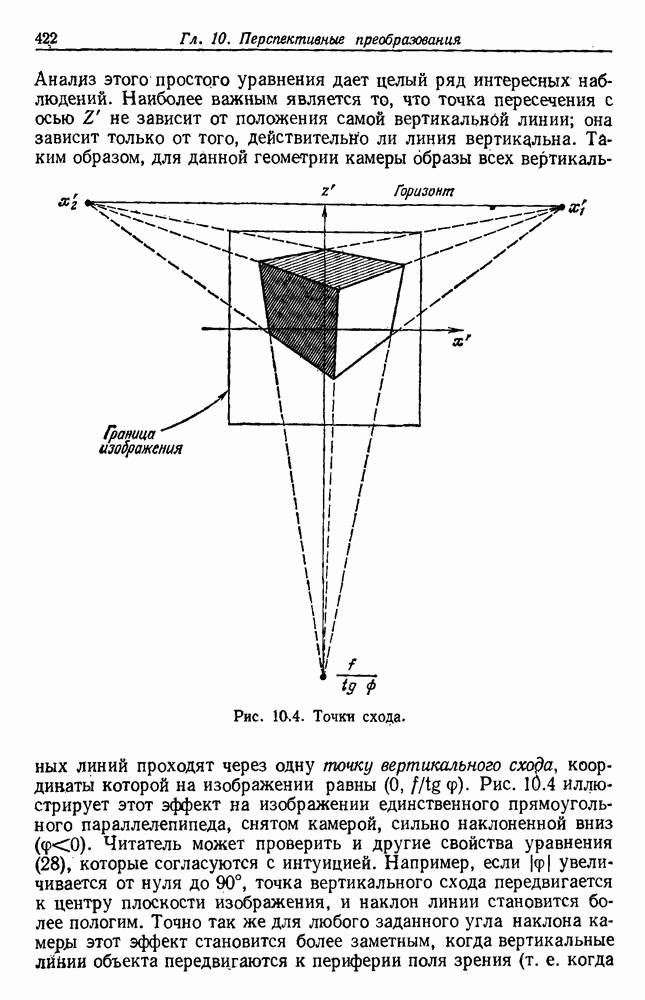
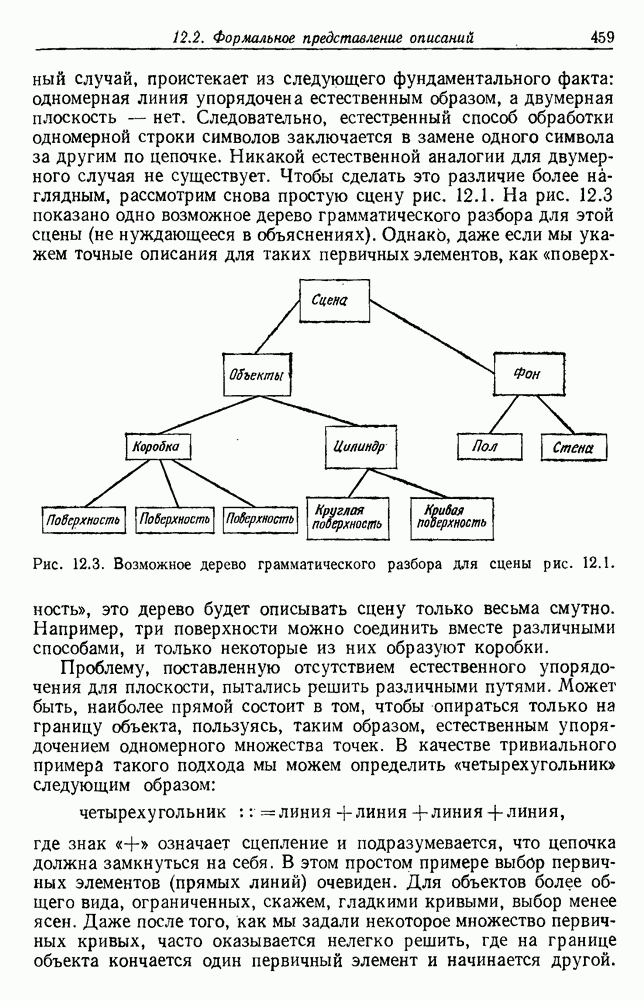
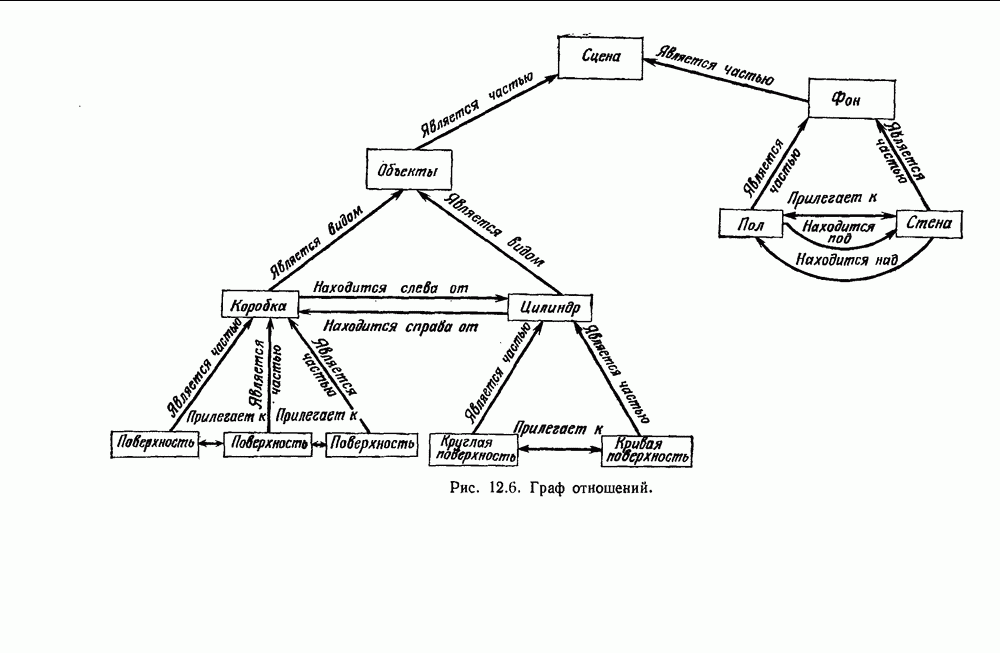
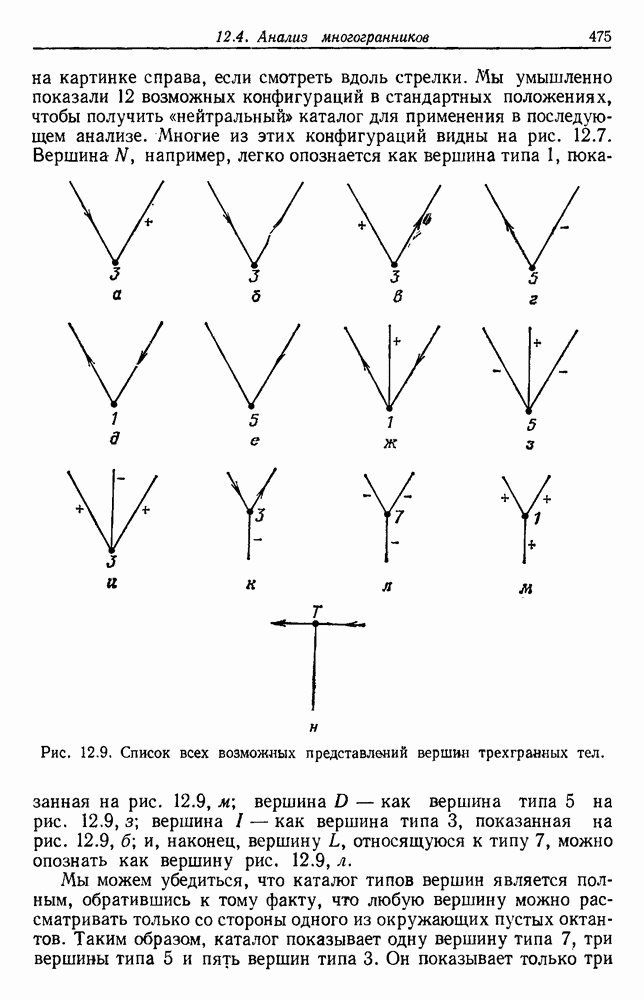
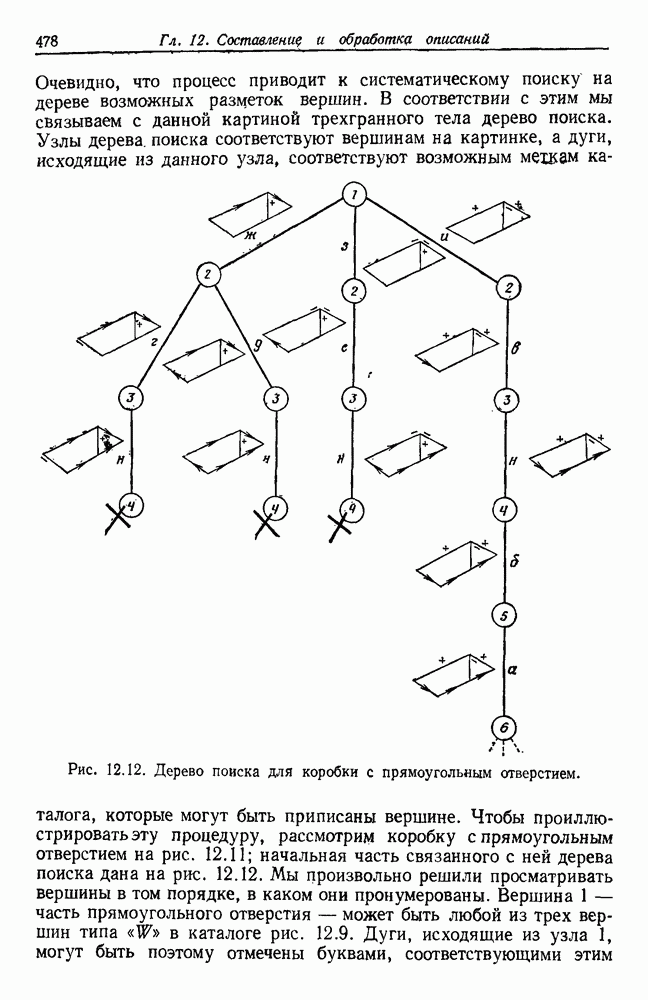
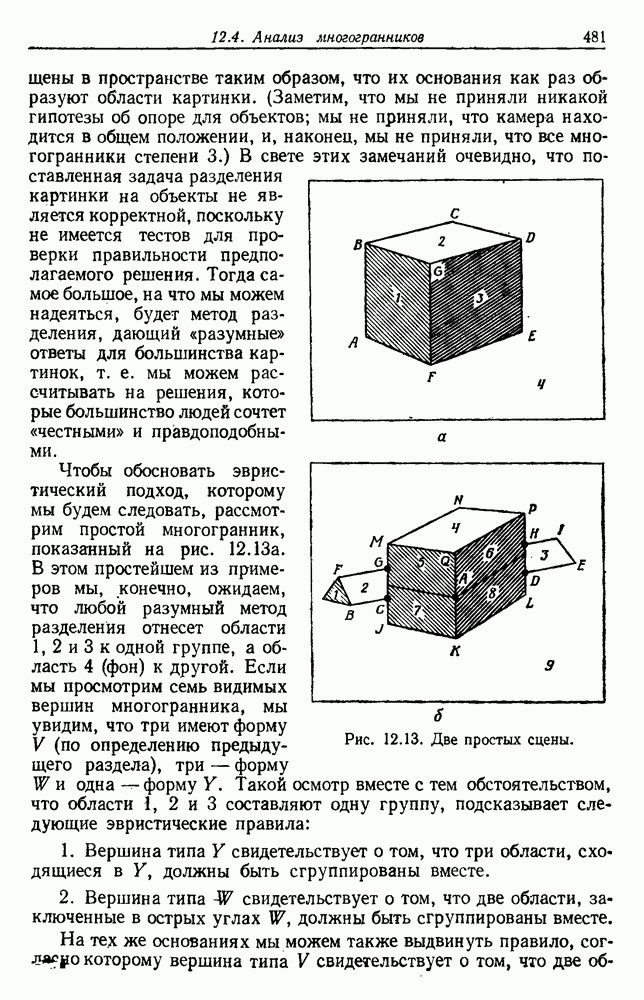
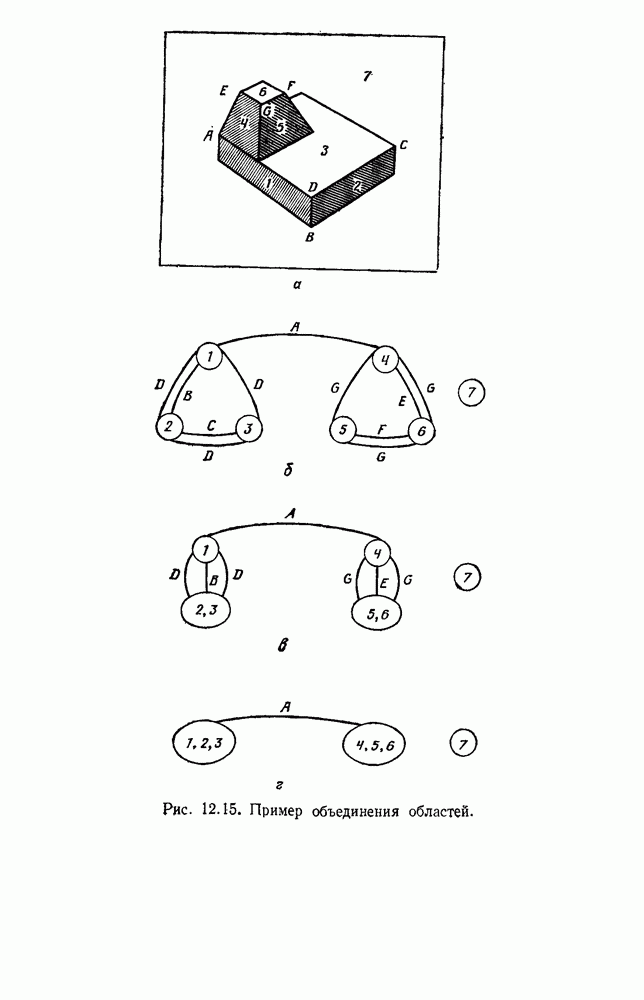
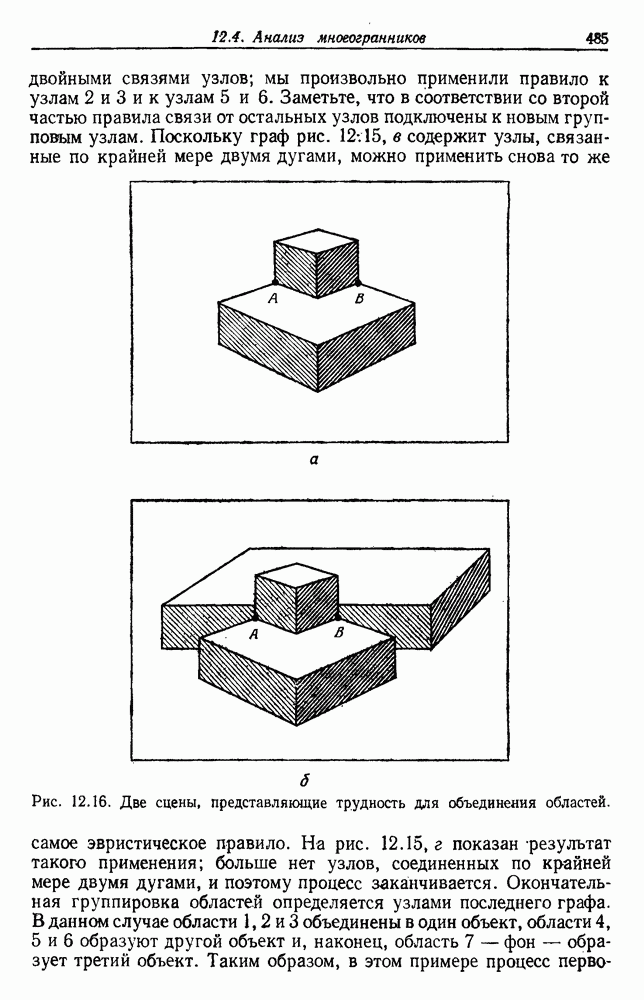
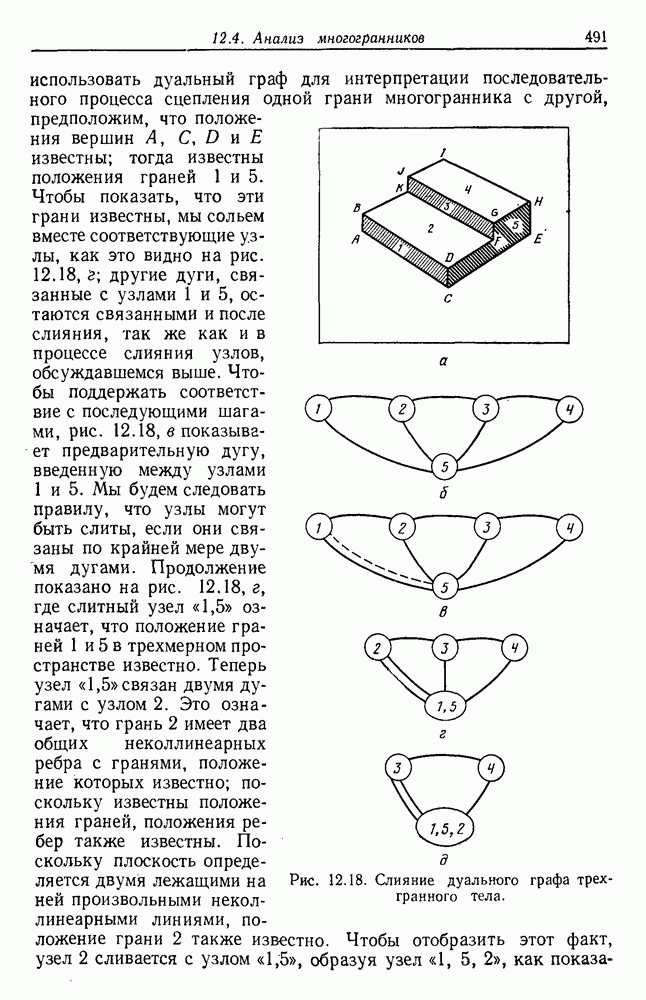
4.7. ПРАВИЛО k БЛИЖАЙШИХ СОСЕДЕЙ
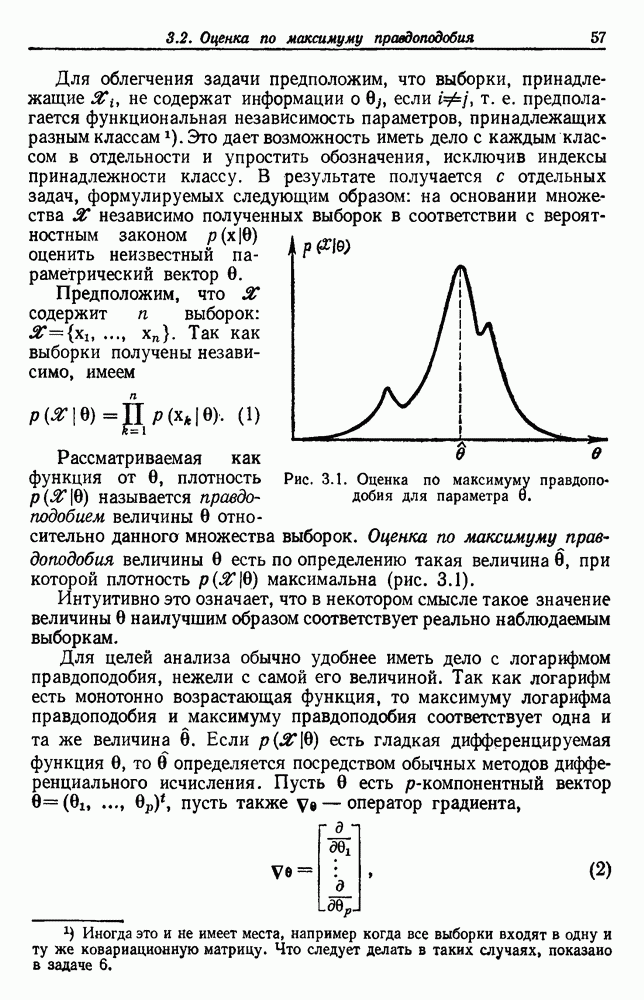
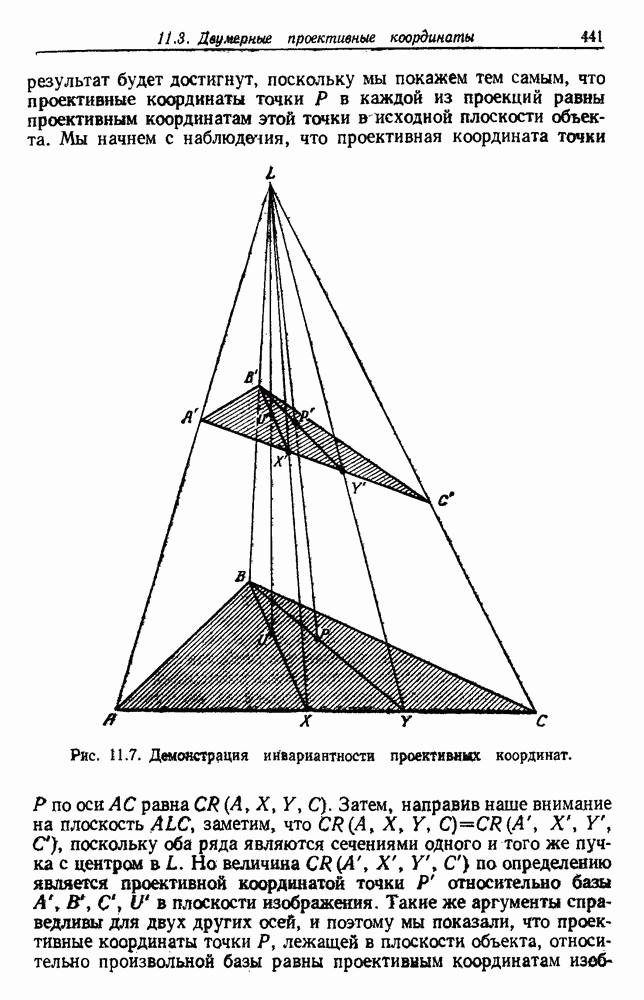
Явным расширением правила ближайшего соседа является правило k ближайших соседей. Как видно из названия, это правило классифицирует х, присваивая ему метку, наиболее часто представляемую среди k ближайших выборок; другими словами, решение принимается после изучения меток k ближайших соседей. Мы не будем подробно анализировать это правило. Однако можно получить некоторые дополнительные представления об этих процедурах, рассмотрев случай с двумя классами при нечетном числе k (чтобы избежать совпадений).
Основным поводом к рассмотрению правила k ближайших соседей послужило сделанное нами ранее наблюдение о согласовании вероятностей с реальностью. Сначала мы заметили, что если k фиксировано и количеству выборок  позволить стремиться к бесконечности, то все k ближайших соседей сойдутся к X. Следовательно, Как и в случае с единственным ближайшим соседом, метками каждого из k ближайших соседей будут случайные величины, независимо принимающие значение
позволить стремиться к бесконечности, то все k ближайших соседей сойдутся к X. Следовательно, Как и в случае с единственным ближайшим соседом, метками каждого из k ближайших соседей будут случайные величины, независимо принимающие значение  - с вероятностью
- с вероятностью  . Если
. Если  является самой большой апостериорной вероятностью, то решающее правило Байеса всегда выбирает сот. Правило единственного ближайшего соседа выбирает
является самой большой апостериорной вероятностью, то решающее правило Байеса всегда выбирает сот. Правило единственного ближайшего соседа выбирает  с вероятностью
с вероятностью  . Правило k ближайших соседей выбирает
. Правило k ближайших соседей выбирает  если большинство из
если большинство из
k ближайших соседей имеют метку  с вероятностью
с вероятностью

В общем чем больше значение  тем больше вероятность, что будет выбрана
тем больше вероятность, что будет выбрана 
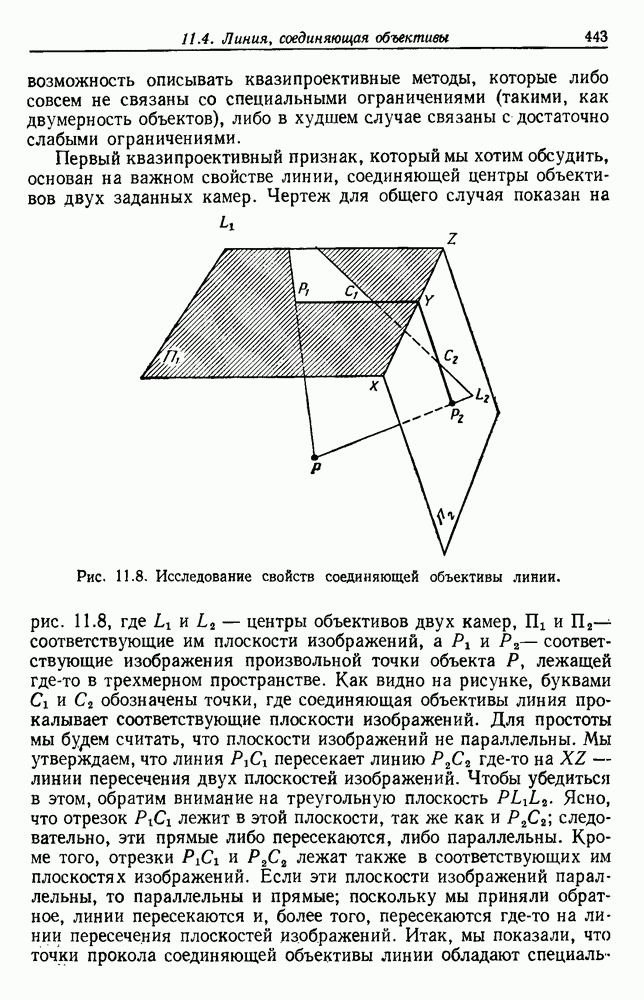
Мы могли бы проанализировать правило k ближайших соседей так же, как мы анализировали правило единственного ближайшего соседа.

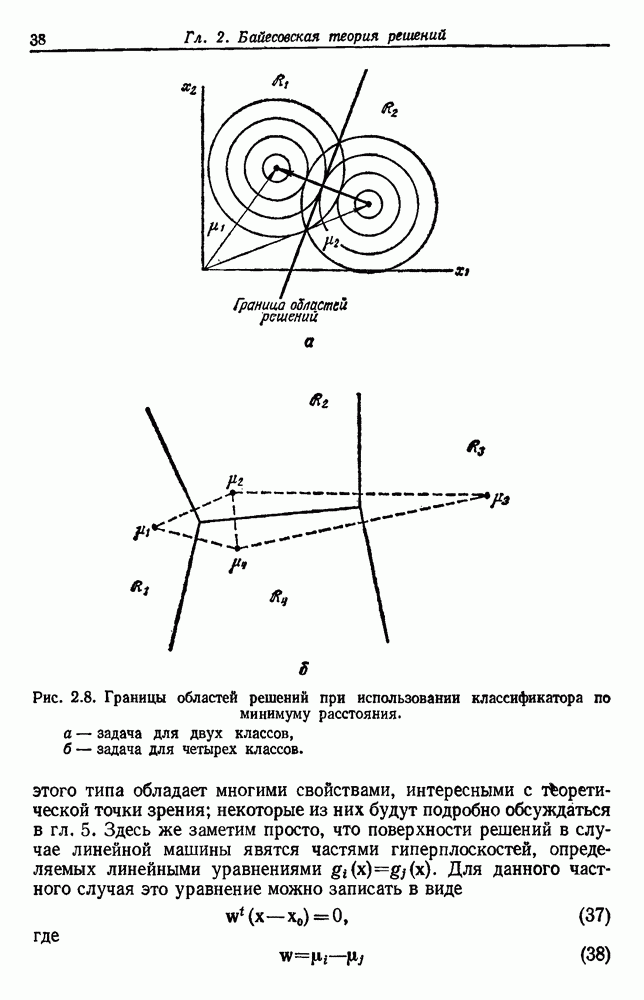
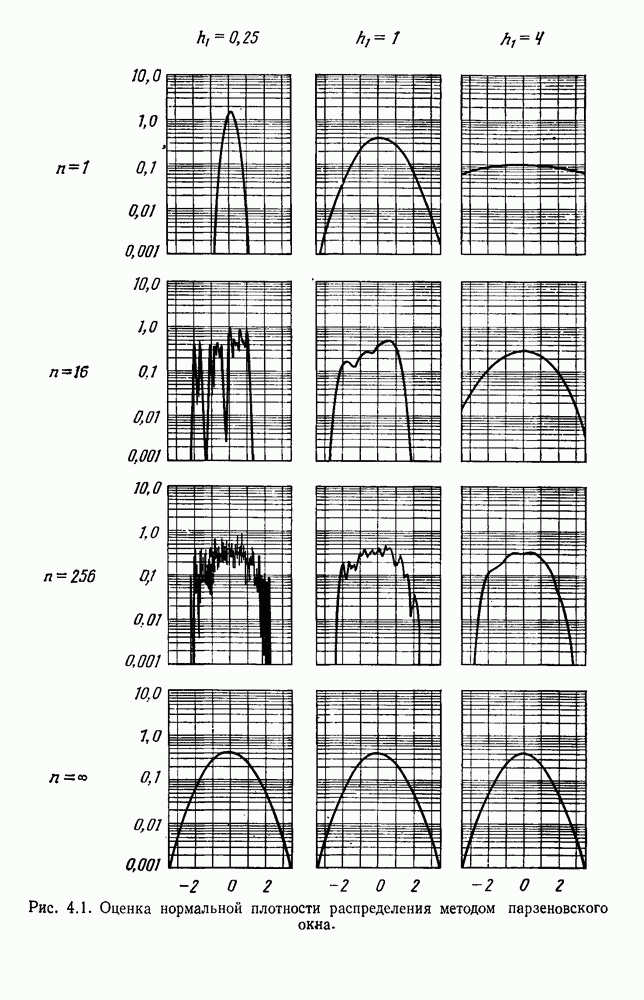
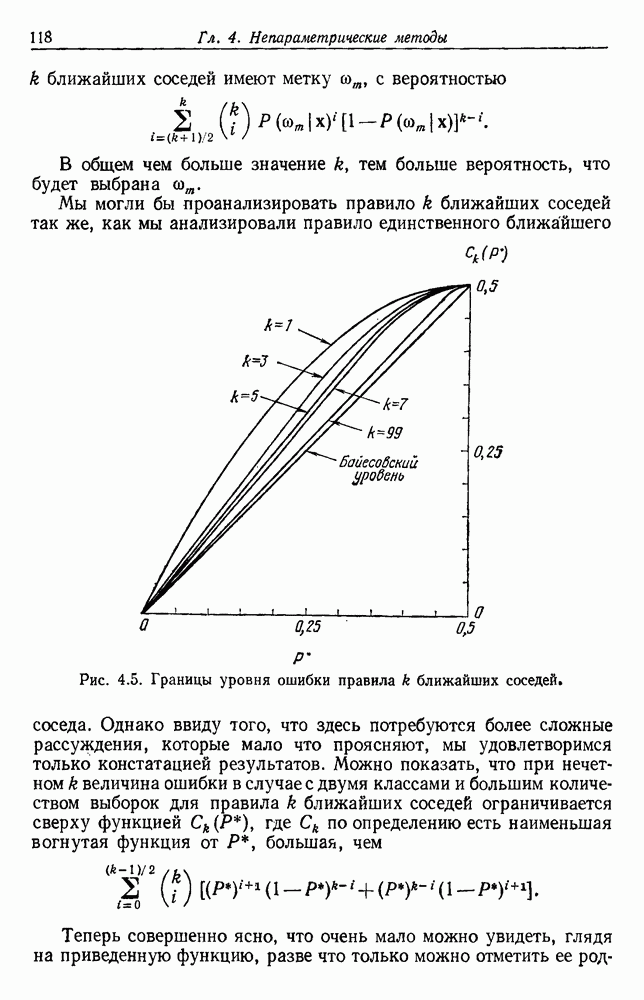
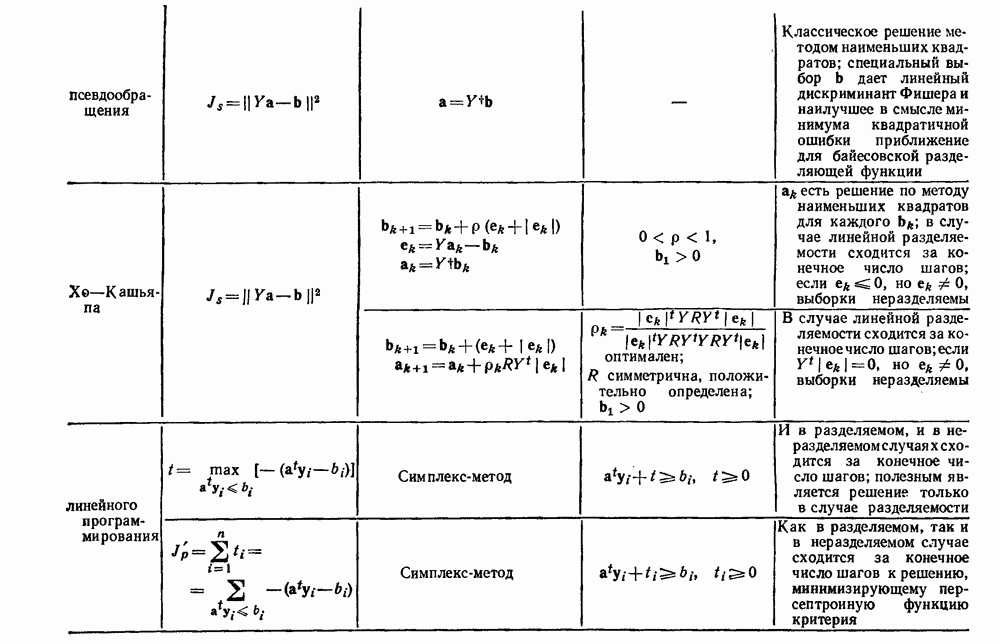
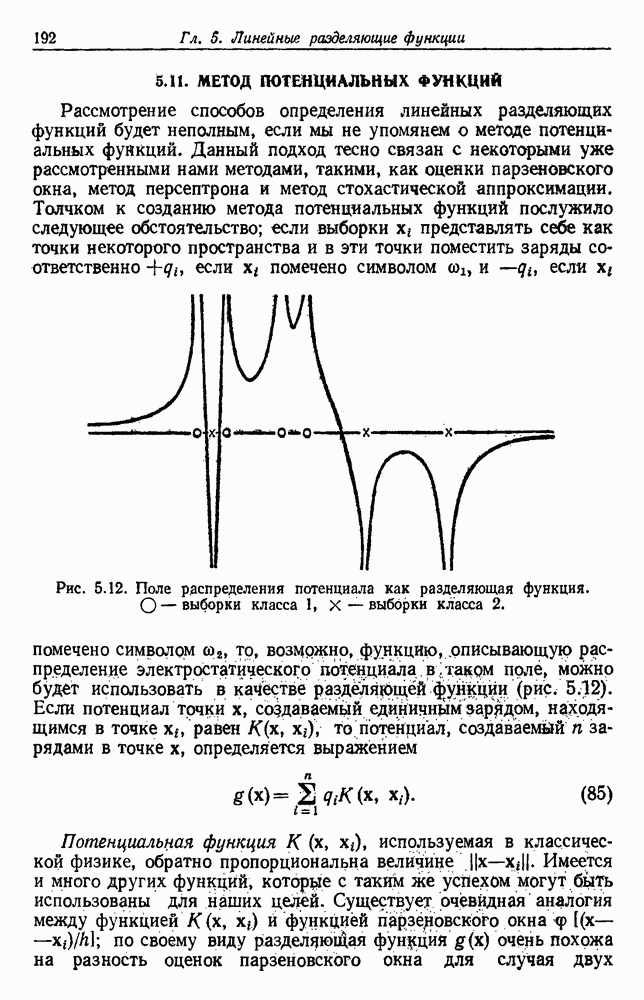
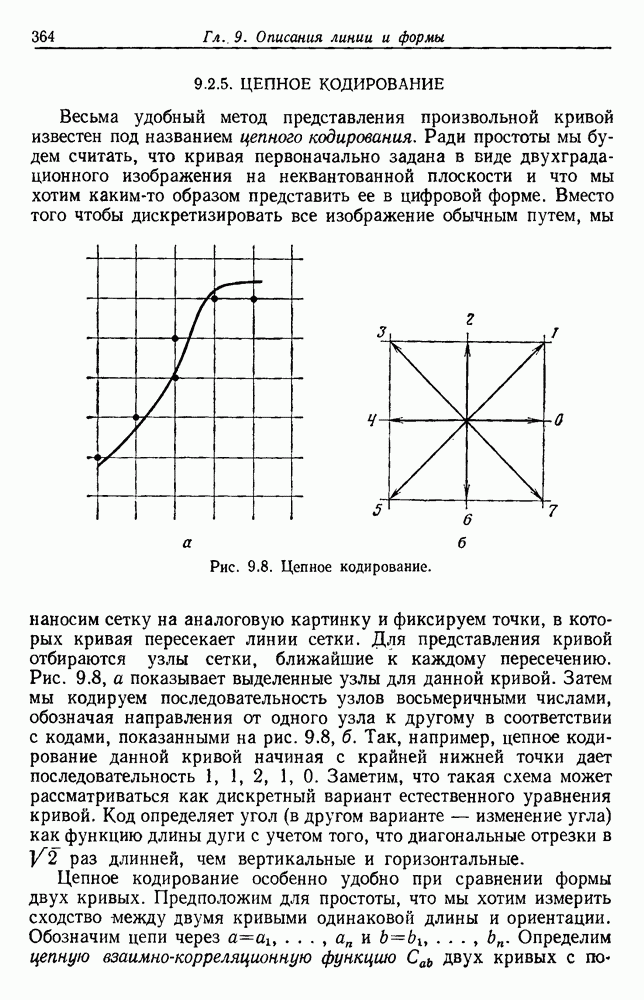
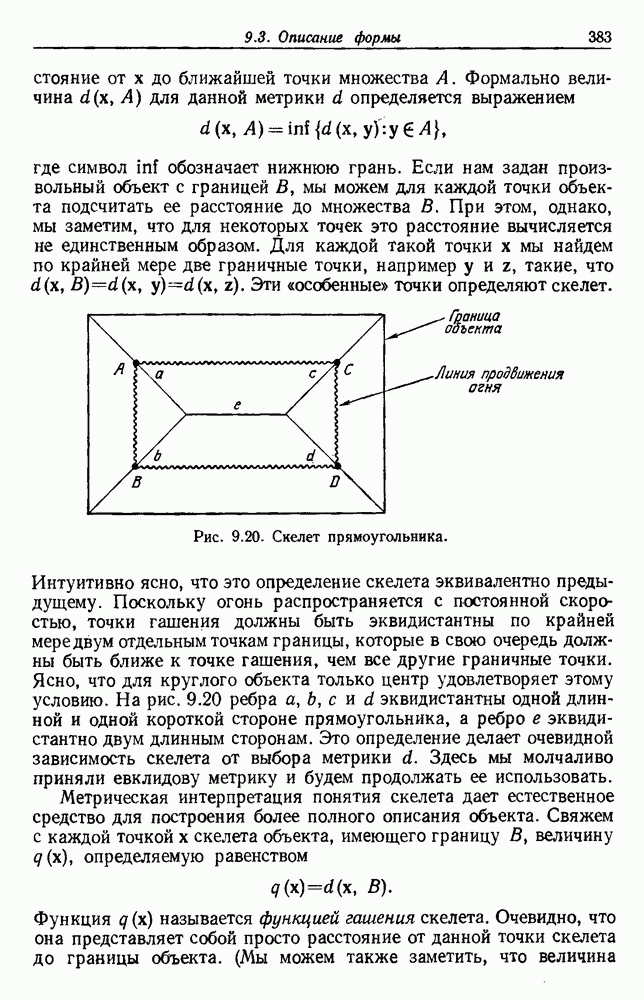
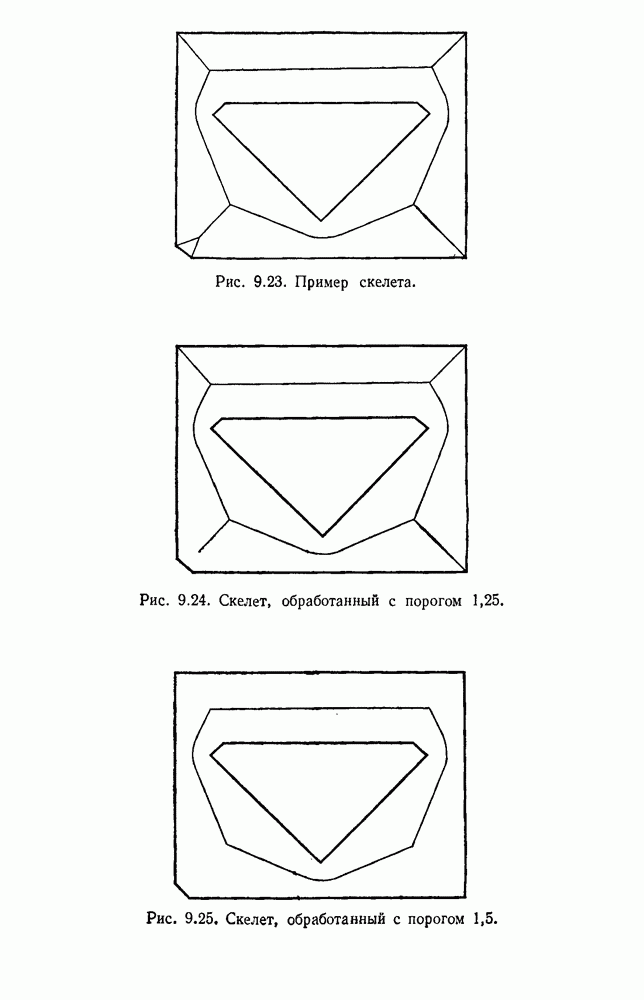
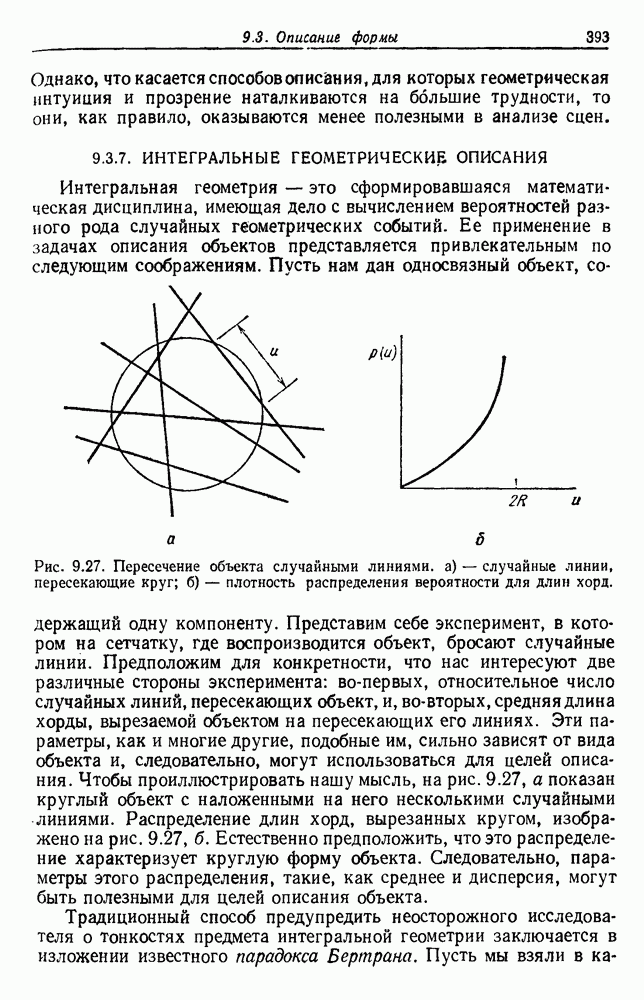
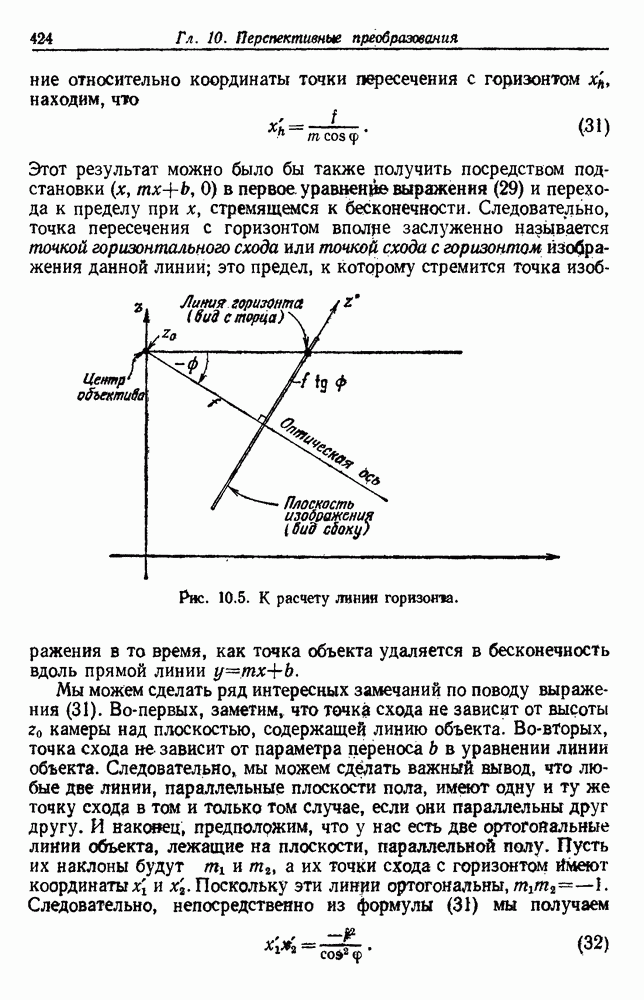
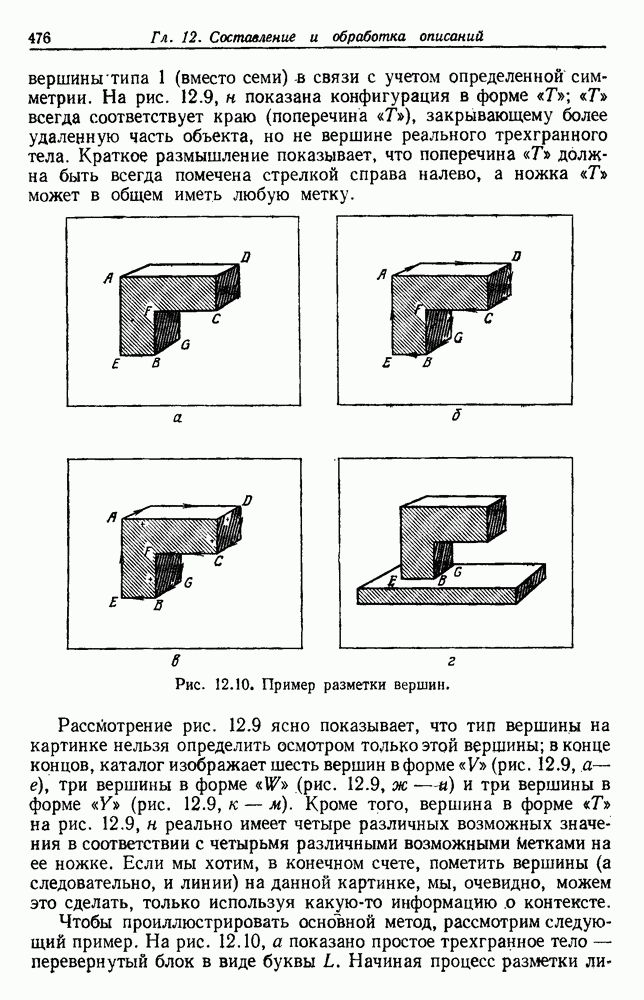
Рис. 4.5. Границы уровня ошибки правила k ближайших соседей.
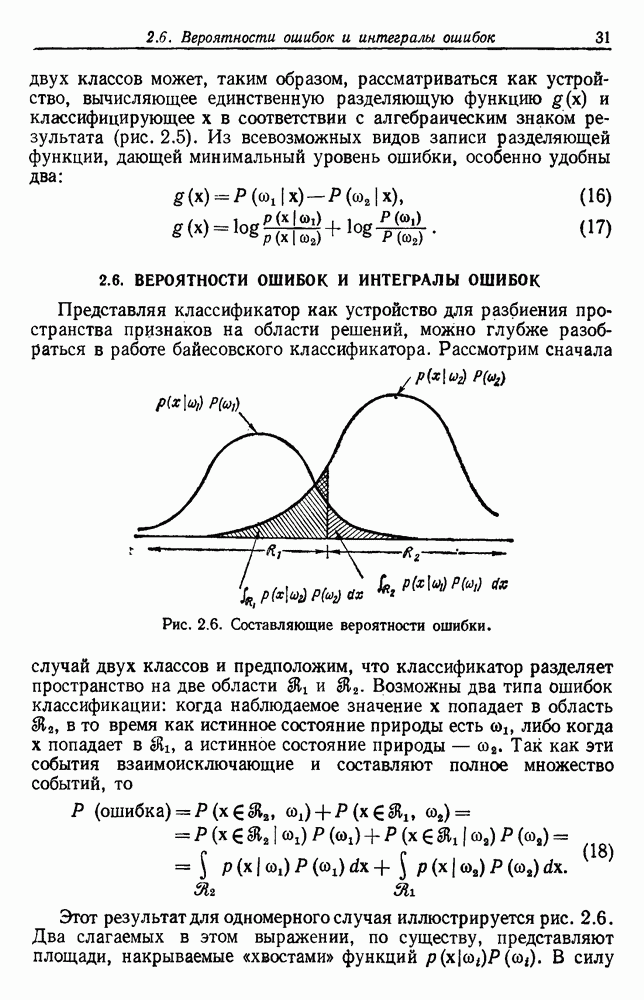
Однако ввиду того, что здесь потребуются более сложные рассуждения, которые мало что проясняют, мы удовлетворимся только констатацией результатов. Можно показать, что при нечетном k величина ошибки в случае с двумя классами и большим количеством выборок для правила k ближайших соседей ограничивается сверху функцией  , где
, где  по определению есть наименьшая вогнутая функция от Р, большая, чем
по определению есть наименьшая вогнутая функция от Р, большая, чем

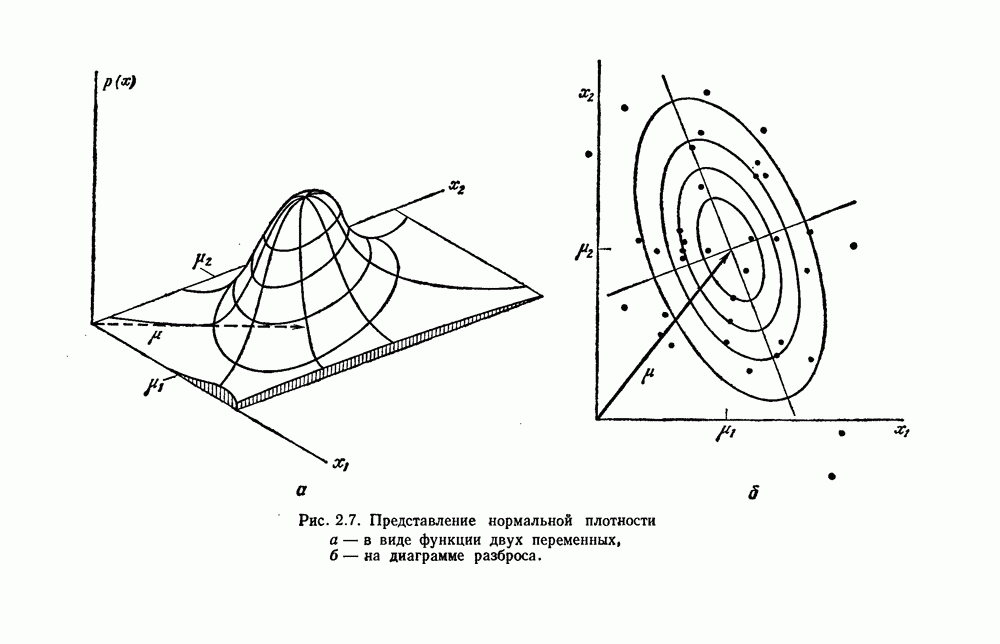
Теперь совершенно ясно, что очень мало можно увидеть, глядя на приведенную функцию, разве что только можно отметить ее родство
с биномиальным распределением. К счастью, можно легко вычислить  и изучить результаты. На рис. 4.5 показаны границы уровней ошибок правила k ближайших соседей для нескольких значений k. Случай с
и изучить результаты. На рис. 4.5 показаны границы уровней ошибок правила k ближайших соседей для нескольких значений k. Случай с  соответствует случаю с двумя классами из рис. 4.4. С возрастанием k верхние границы все более приближаются к нижней границе, уровню Байеса. В пределе, когда k стремится к бесконечности, две границы встречаются и правило k ближайших соседей становится оптимальным.
соответствует случаю с двумя классами из рис. 4.4. С возрастанием k верхние границы все более приближаются к нижней границе, уровню Байеса. В пределе, когда k стремится к бесконечности, две границы встречаются и правило k ближайших соседей становится оптимальным.
Рискуя произвести впечатление, что мы повторяемся, закончим снова упоминанием о ситуации с конечным числом выборок, встречаемой на практике. Правило k ближайших соседей можно рассматривать как еще одну попытку оценить апостериорные вероятности  на основании выборок. Чтобы получить надежную оценку, нам желательно использовать большое значение k. С другой стороны, мы хотим, чтобы все k ближайших соседей х были очень близки к х с тем, чтобы быть уверенными, что
на основании выборок. Чтобы получить надежную оценку, нам желательно использовать большое значение k. С другой стороны, мы хотим, чтобы все k ближайших соседей х были очень близки к х с тем, чтобы быть уверенными, что  приблизительно такая же, как
приблизительно такая же, как  . Это заставляет нас выбрать среднее значение k, являющееся небольшой частью всего количества выборок. Только в пределе при устремлении k к бесконечности можем мы быть уверены в почти оптимальном поведении правила k ближайших соседей.
. Это заставляет нас выбрать среднее значение k, являющееся небольшой частью всего количества выборок. Только в пределе при устремлении k к бесконечности можем мы быть уверены в почти оптимальном поведении правила k ближайших соседей.