Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
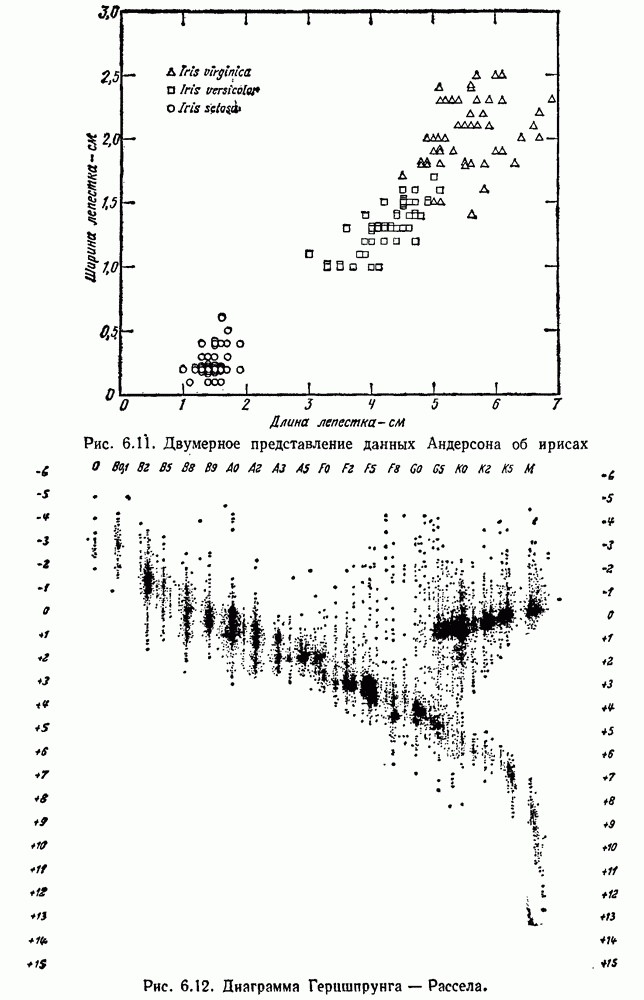
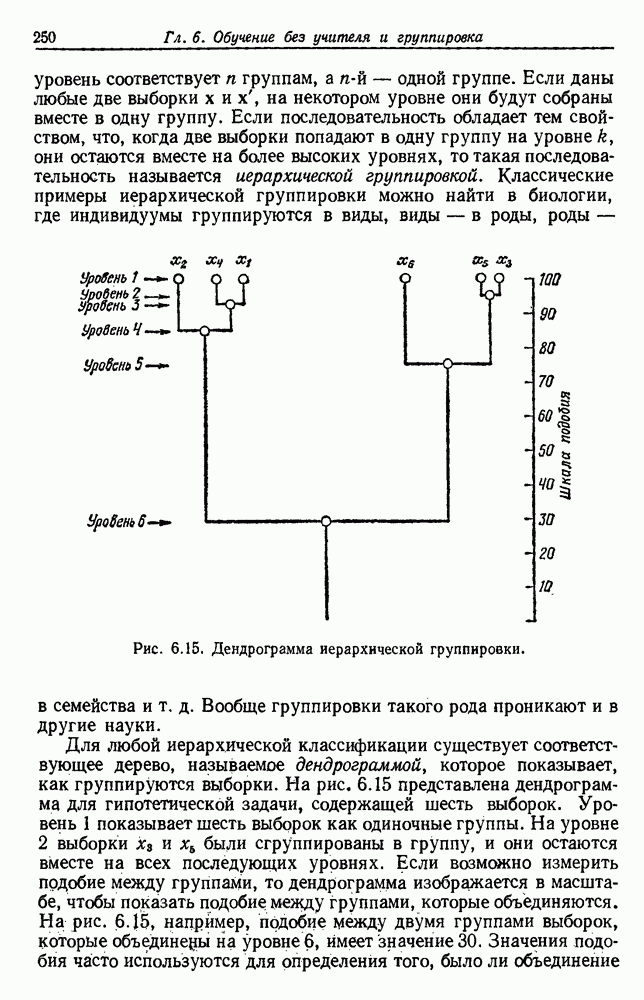
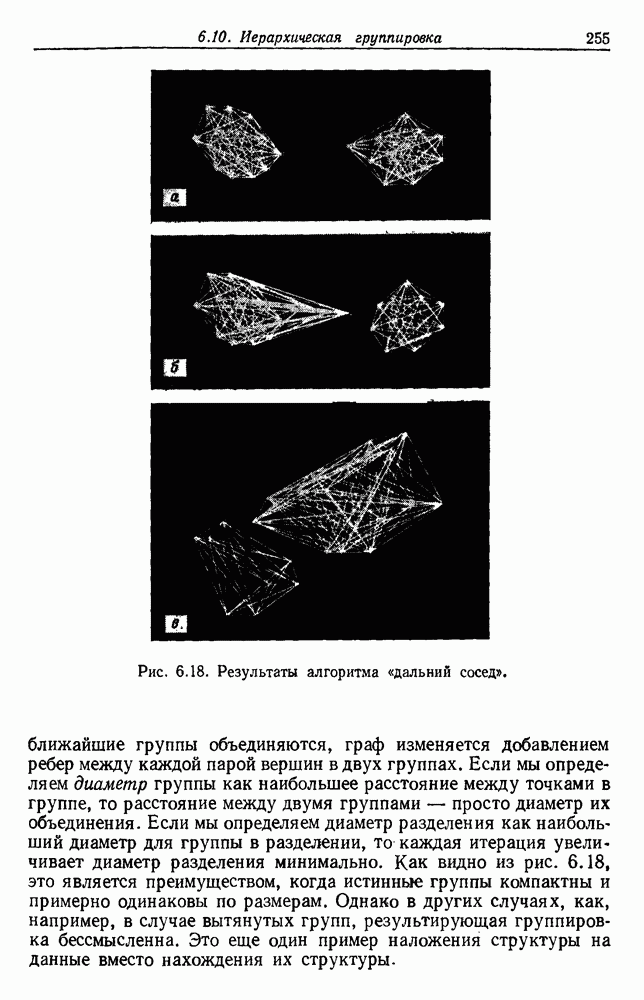
6.15. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ СВЕДЕНИЯЛитература по обучению без учителя и группировкам так обширна и рассеяна среди различных областей науки, что предлагаемый список можно рассматривать как случайную выборку. К счастью, некоторые из источников имеют обширную библиографию, что облегчает нашу задачу. Исторически дата первых источников восходит по меньшей мере к 1894 году, когда Карл Пирсон использовал выборки для определения параметров смеси двух нормальных плотностей одной переменной. Предполагая точное знание значений плотности смеси, Дёч (1936) использовал преобразование Фурье для разложения нормальных смесей. Меджисси (1961) распространил этот подход на другие классы смесей, в процессе решения поставив задачу идентифицируемости. Тэйчер (1961, 1963) и затем Якович и Спреджинс (1968) продемонстрировали идентифицируемость нескольких семейств смесей, причем последние авторы показали эквивалентность идентифицируемости и линейной независимости плотности компонент. Фразы «обучение без учителя» или «самообучение» обычно относятся к определению параметров плотностей компонент по выборкам, извлеченным из смеси плотностей. Спреджинс (1966) и Купер (1969) дают ценный обзор этой области, а ее связь с последовательным байесовским обучением дана Ковером (1969). Некоторые из этих работ достаточно общие, в первую очередь касающиеся теоретических возможностей. Например, Стейнат (1968) показывает, как метод Дёча можно применить для изучения многомерных нормальных смесей и многомерных смесей Бернулли, а Якович (1970) демонстрирует возможность распознавания практически любой идентифицируемой смеси. Удивительно мало работ касаются оценок по максимуму правдоподобия. Хесселблад (1966) вывел формулы максимума правдоподобия для оценки параметров нормальных смесей в случае одной переменной. Дей (1969) вывел формулы для случая многомерной матрицы равных ковариаций и указал на существование вырожденных решений с общими нормальными смесями. Наш подход к случаю многих переменных Основан непосредственно на исключительно доступной статье Вольфа (1970), который также вывел формулы для многомерных смесей Бернулли. Формулировка байесовского подхода к обучению без учителя обычно приписывается Дэйли (1962); более общие формулировки с тех пор были даны несколькими авторами (см. Хилборн и Лейниотис, 1968). Дэйли отметил экспоненциальный рост оптимальной системы и необходимость приближенных решений. Обзор Спреджинса дает ссылки на литературу по аппроксимациям на основе принятия решений, написанную до 1966 г., ссылки на последующие работы можно найти у Патрика, Костелло и Мондса (1970). Приближенные решения были получены с помощью гистограмм (Патрик и Хенкок, 1966), квантованных параметров (Фрелик, 1967) и рандомизированных решений (Агреула, 1970). Мы не упомянули все способы, которые можно применить для оценки неизвестных параметров. В частности, мы не рассмотрели испытанных временем и надежных методов, использующих моменты выборок, в первую очередь из-за того, что ситуация становится довольно сложной, когда в смеси имеется больше двух компонент. Однако некоторые интересные решения для особых случаев были получены Дэвидом и Полем Куперами (1964) и усовершенствованы далее Полем Купером (1967). Из-за медленной сходимости мы не упомянули об использовании стохастической аппроксимации; заинтересованному читателю можно рекомендовать статью Янга и Коралуппи (1970). Первоначально по группировке была проделана большая работа в биологических науках при изучении численной таксономии. Здесь основной интерес вызвала иерархическая группировка. Монография Сокаля и Снифа (1963) является отличным источником библиографии по этой литературе. Психологи и социологи также внесли вклад в группировку, хотя они обычно заинтересованы в группировке признаков, а не в группировке выборок (Трайон, 1939, и Трайон и Бейли, 1970). Появление вычислительных машин сделало кластерный анализ практической наукой и вызвало распространение литературы во многие области науки. Хорошо известная работа Болла (1965) дает исчерпывающий обзор этих работ и широко рекомендуется. Взгляды Болла имеют большое влияние на нашу разработку этой темы. Мы также воспользовались диссертацией Линга (1971), в которой приведен список трудов из 140 названий. Обзоры Большева (1961) и Дорофеюка (1971) дают обширную библиографию советской литературы по разбиению на группы. Сокаль и Сниф (1963) и Болл (1965) приводят много используемых мер подобия и функций критериев. Стивенс (1968) осветил вопросы масштабов измерения, критериев инвариантности и необходимых статистических операций, а Ватанабе (1969) разработал фундаментальные философские проблемы, касающиеся группировки. Критика группировки Флешом и Зубином (1969) указывает на неприятные последствия небрежности в этих вопросах. Джонс (1968) приписывает Торндайку (1953) первенство в использовании критерия по сумме квадратов ошибок, который часто появляется в литературе. Инвариантные критерии, о которых мы говорили, были выведены Фридманом и Рубином (1967), указавшими, что эти критерии связаны со следовым критерием Хотеллинга и В тексте мы привели основные этапы ряда стандартных программ оптимизации и группировки. Эти описания были намеренно упрощены, так как даже более строгие и полные описания, имеющиеся в литературе, не всегда упоминают о разрешении неоднозначностей или об исключении случайных «всплесков». Алгоритм Изоданные Болла и Холла (1967) отличается от нашего упрощенного описания в основном расщеплением групп, имеющих слишком большую изменчивость внутри группы, и слиянием групп, которые имеют слишком малую изменчивость между группами. Наше описание элементарной процедуры минимальных квадратичных ошибок получено на основе неопубликованной программы для ЭВМ, написанной Р. Синглтоном и У. Каутцом в Станфордском исследовательском институте в 1965 г. Эта процедура тесно связана с адаптивной последовательной процедурой Себестьяна (1962) и так называемой процедурой Сокаль и Сниф (1963) приводят список ранних работ по иерархическому группированию, и Вишарт (1969) дает обширную библиографию источников по процедурам единственной связи, ближайшего соседа, полных связей, дальнего соседа, минимальной квадратичной ошибки и других. Ланс и Вильямс (1967) показывают, как можно получить большинство из этих процедур путем уточнения различными способами общей функции расстояния; кроме этого, они дают библиографию основных работ по делимым иерархическим группировкам. Связь между процедурами единственной связи и минимальным покрывающим деревом была показана Говером и Россом (1969), которые рекомендовали простой, эффективный алгоритм для нахождения минимального покрывающего дерева, предложенного Примом (1957). Эквивалентность между иерархической группировкой и функцией расстояния, удовлетворяющей ультраметрическому неравенству, показана Джонсоном (1967). Большинство статей о группировках явно или неявно принимает критерий минимальной дисперсии. Вишарт (1969) указал на серьезные ограничения, присущие этому подходу, и в качестве альтернативы предложил процедуру, напоминающую оценку методом дисперсии подвергались критике также со стороны Лина (1971) и Цаня (1971), причем оба они предлагали для группировки использовать теорию графов. Работа Цаня, хотя и предназначенная для данных любой размерности, была мотивирована желанием найти; математическую процедуру, которая группирует множество данных в двух измерениях наиболее естественно для глаза. (Хэрэлик и Келли (1969) и Хэрэлик и Динштейн (1971) также рассматривают операции обработки изображений как процедуры группировок. Эта точка зрения применима ко многим процедурам, описанным в части II этой книги.) Большинство ранних работ по методам теории графов было сделано для целей информационного поиска. Августсон и Минкер (1970) считают, что впервые теорию графов к группировке применил Кунс (1959). Они же дают экспериментальное сравнение некоторых методов теории графов, предназначенных для целей информационного поиска, и обширную библиографию работ в этой области. Интересно, что среди статей с ориентацией на теорию графов мы находим три, рассматривающие статистические тесты для оценки значимости групп, — это статьи Боннера (1964), Хартигана (1967) и Лина (1971). Холл, Теппинг и Болл (1971) вычислили, как сумма квадратов ошибок изменяется в зависимости от размерности данных и предполагаемого числа групп для однородных данных, и предложили эти распределения в качестве полезного стандарта для сравнения. Вольф (1970) предлагает тест для оценки значимости групп, основанный на предполагаемом распределении хи-квадрат для логарифмической функции правдоподобия. Грин и Кармон (1970), чья ценная монография о многомерном масштабировании содержит обширную библиографию, прослеживают происхождение многомерного масштабирования до статьи Ричардсона (1938). Недавно возникший интерес к этой теме был стимулирован двумя разработками — неметрическим многомерным масштабированием и применением графических устройств ЭВМ. Неметрический подход, разработанный Шепардом (1962) и развитый Крускалом (1964а), хорошо подходит для многих задач психологии и социологии. Вычислительные аспекты минимизации критерия Интерес к человеко-машинным системам возник частично из-за трудностей определения функций критериев и процедур группировок, которые приводят к желаемым результатам. Матсон и Дамман (1965) одни из первых предложили человеко-машинное решение этой задачи. Широкие возможности диалоговых систем хорошо описаны Боллом и Холлом (1970) в статье о системе PROMENADE. Другие хорошо известные системы — ВС TRY (Трайон и Бейли, 1966, 1970), SARF (Стэнли, Лендэрис и Найноу, 1967), INTERSPACE (Патрик, 1969) и OLPARS (Саммон, 1970). Ни автоматические, ни человеко-машинные системы для распознавания образов не могут избежать проблем, связанных с большой размерностью данных. Были предложены различные процедуры уменьшения размерности путем либо отбора наилучшего подмножества имеющихся признаков, либо получения комбинаций признаков (обычно линейных). Для избежания серьезных вычислительный проблем большинство из этих процедур использует некоторый критерий, отличный от критерия вероятности ошибки при выборе. Например, Миллер (1962) использовал критерий
|
 |
Оглавление
|








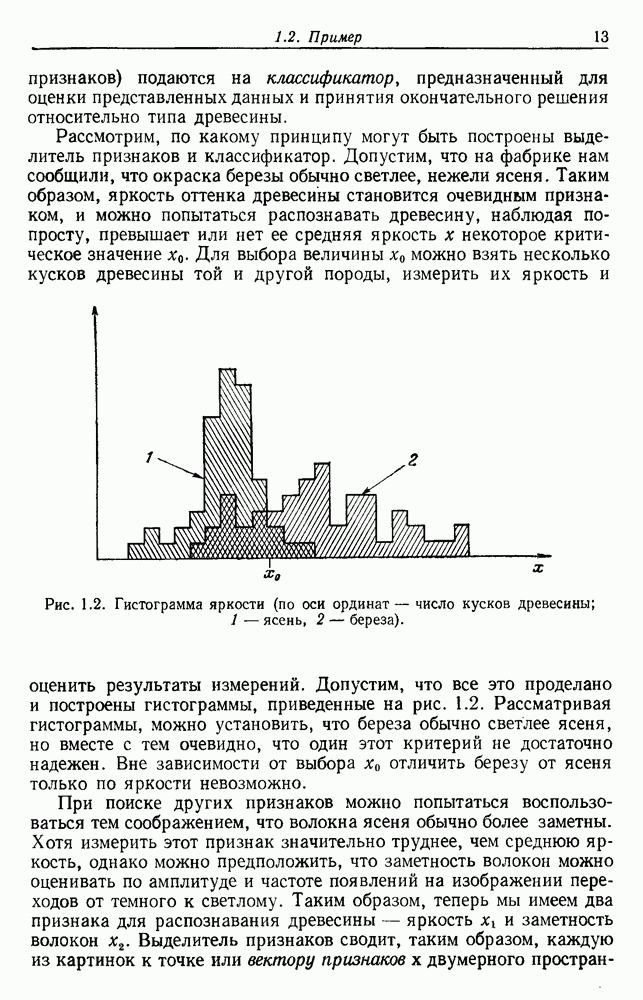







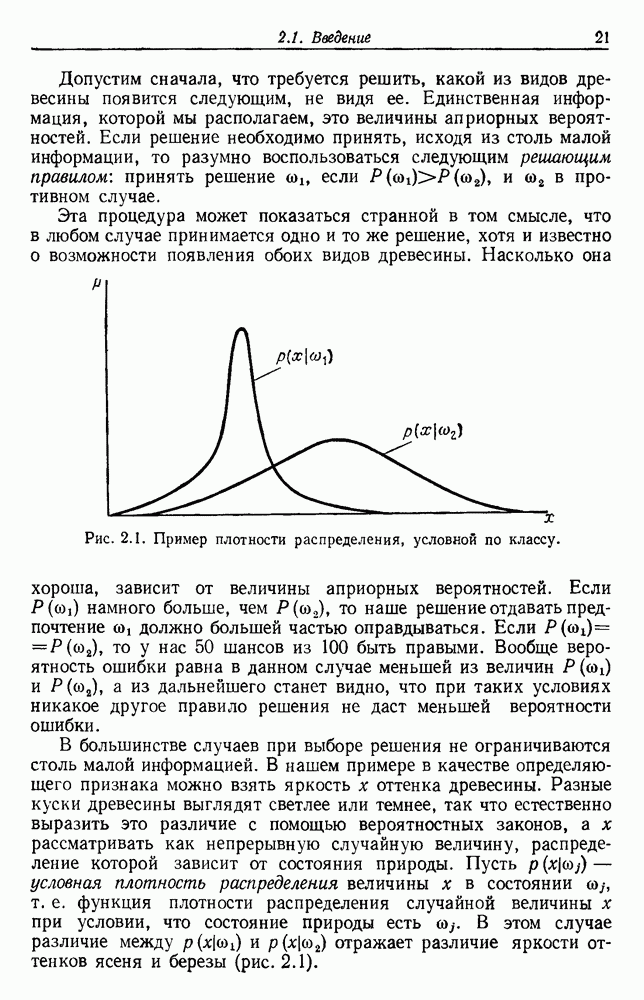
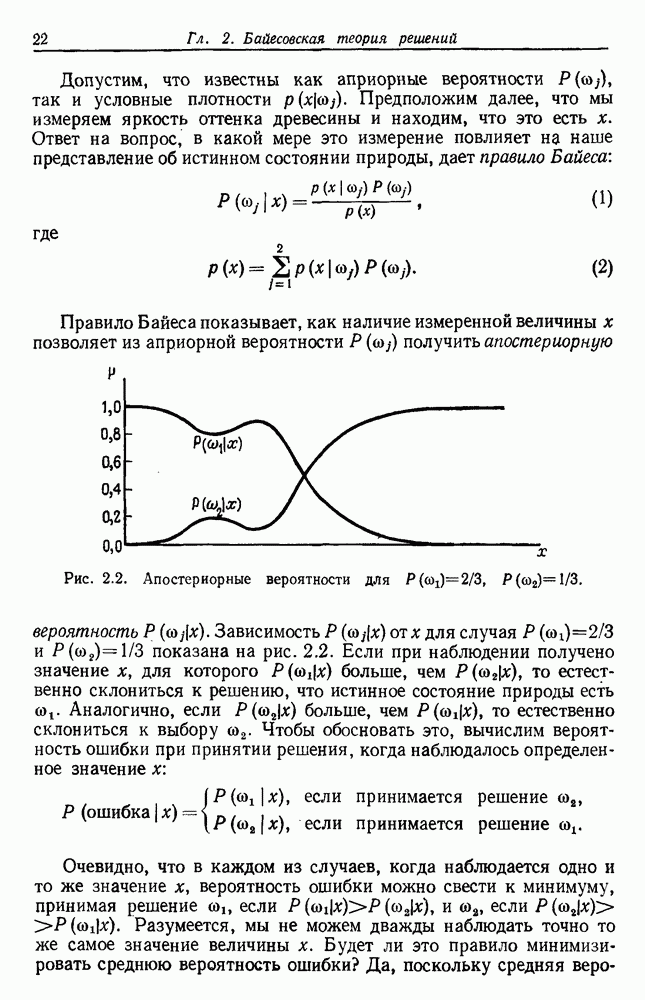





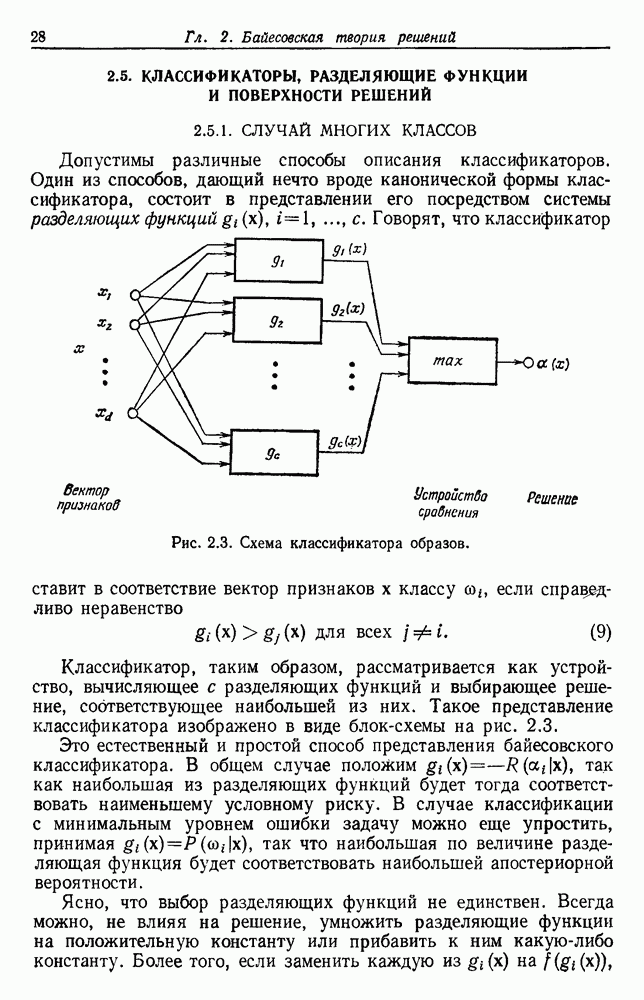









































































































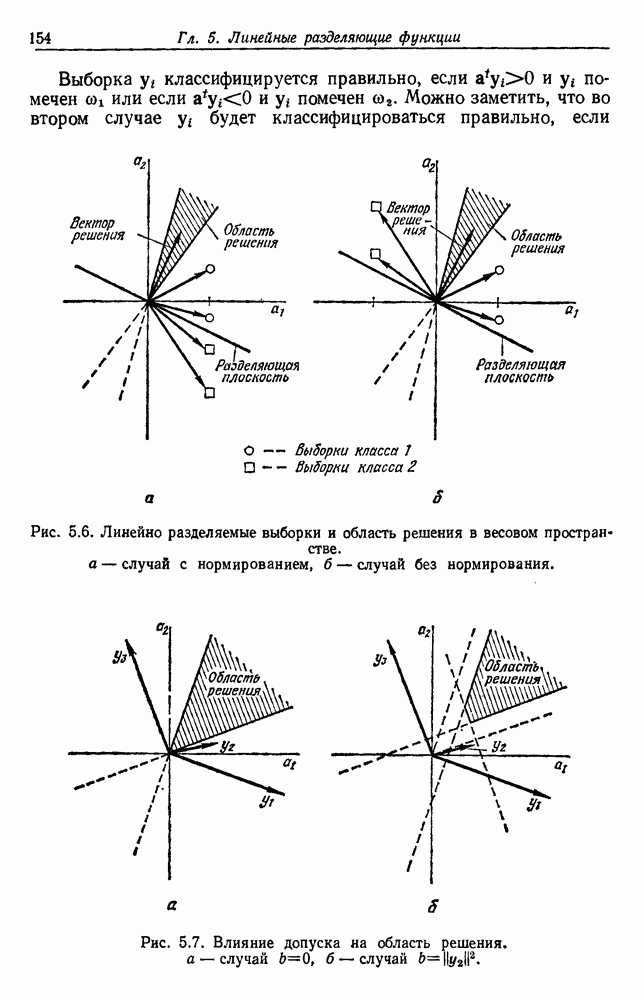



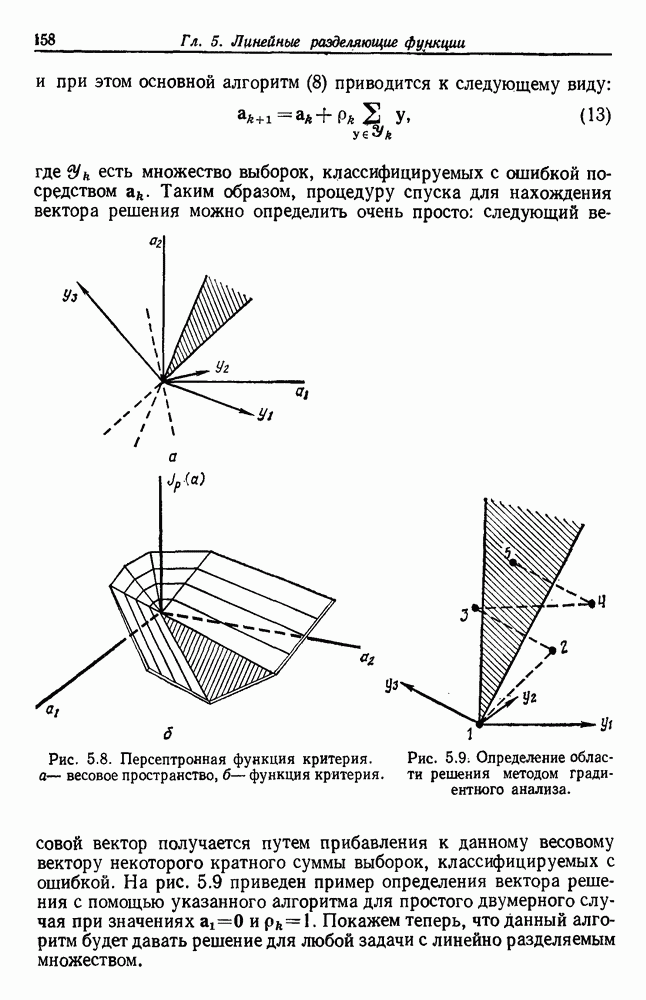

















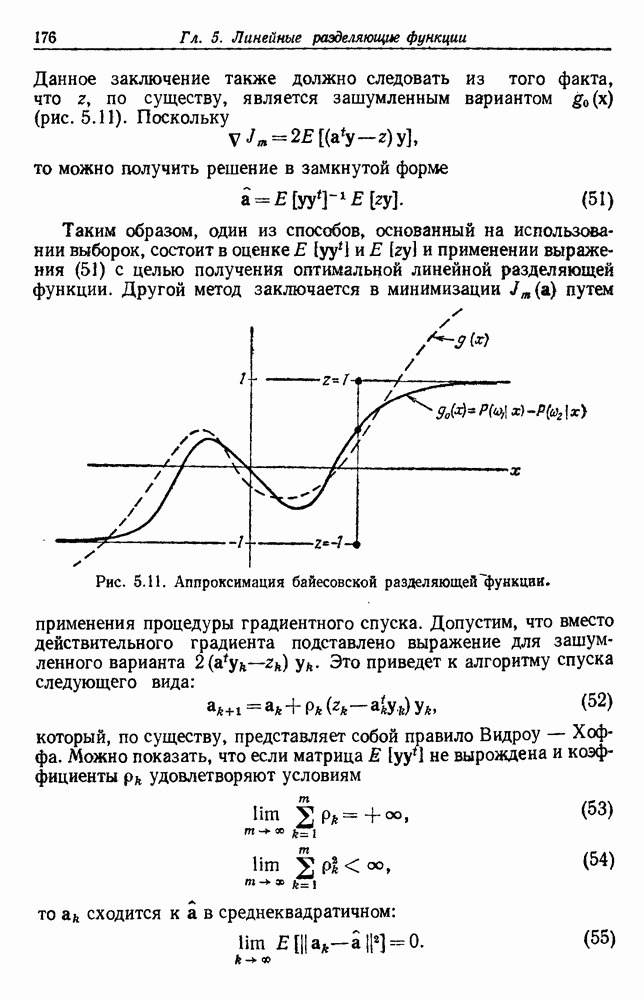














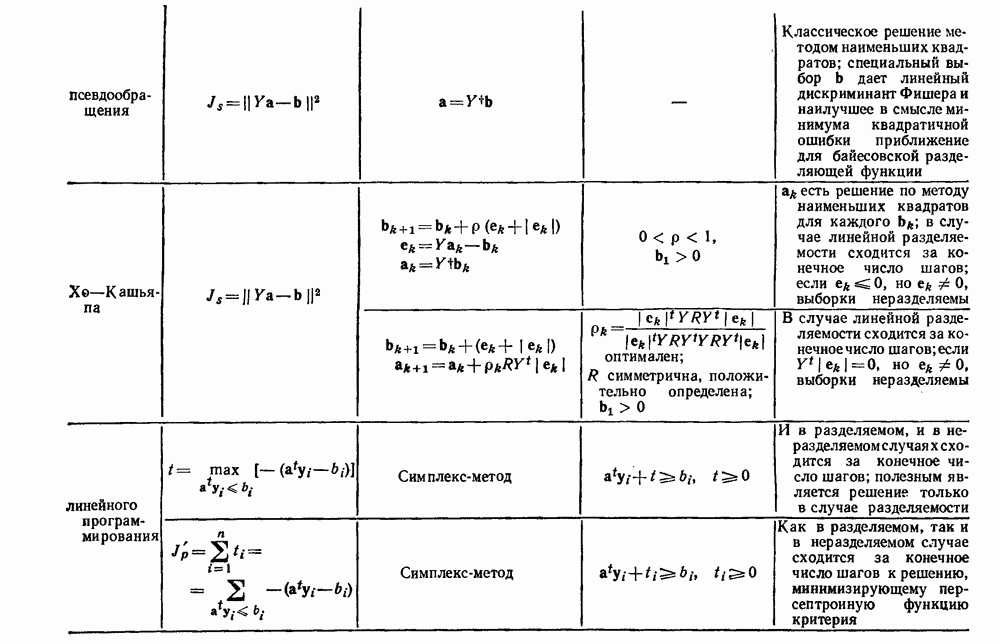




























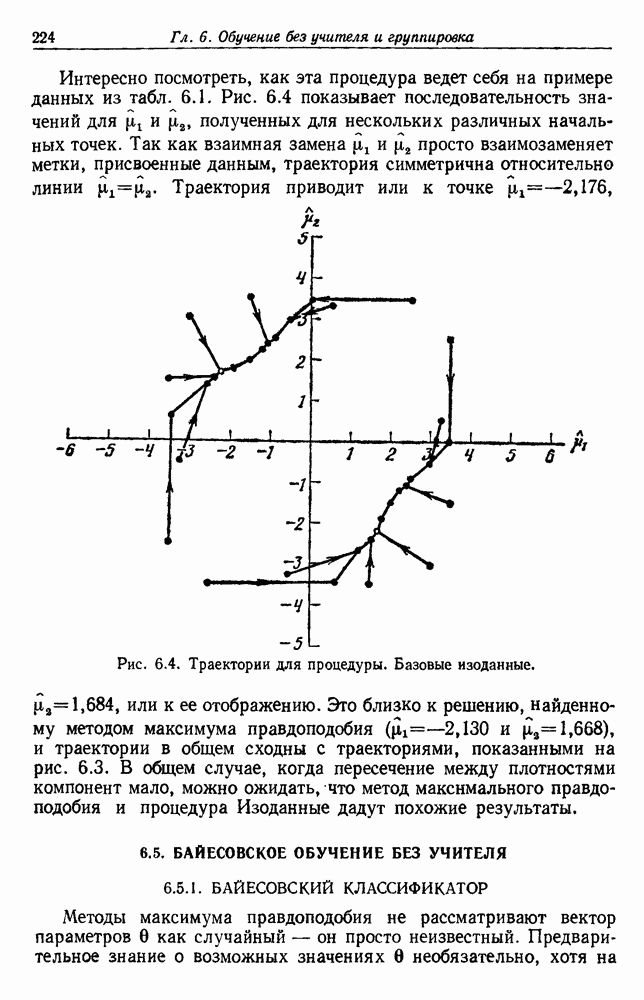


































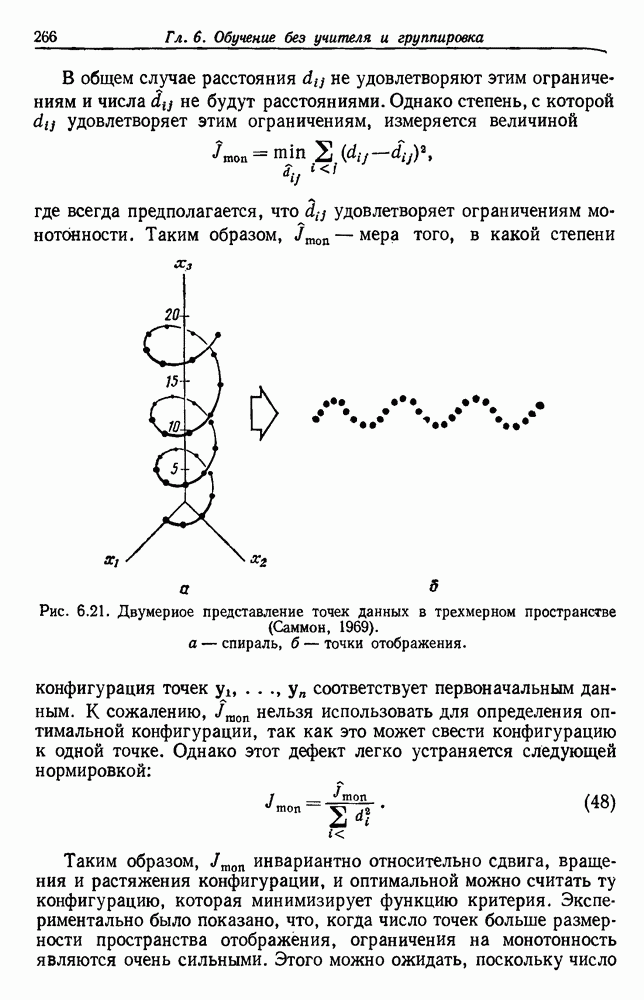




















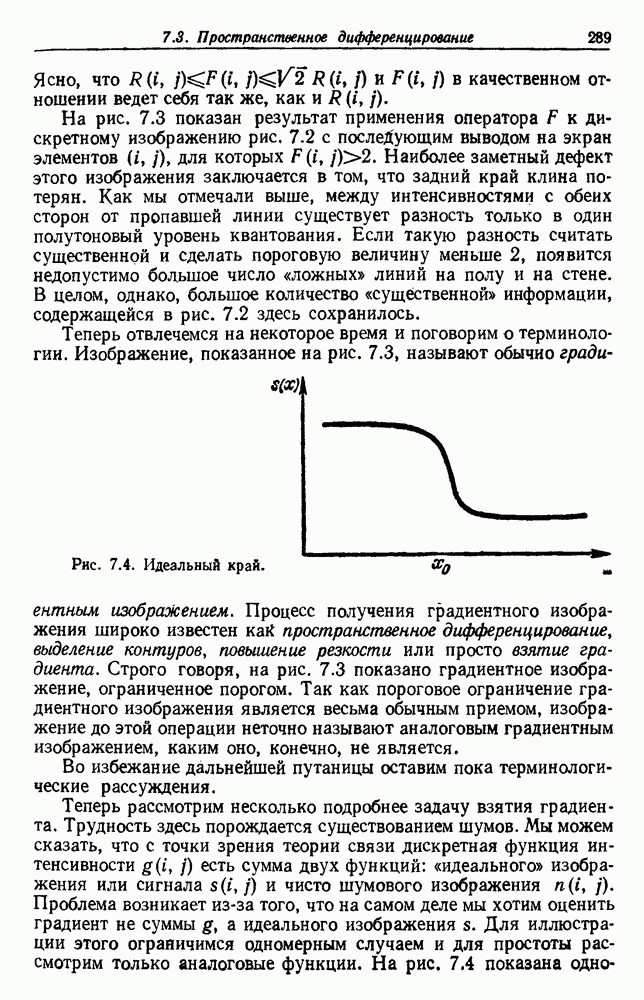
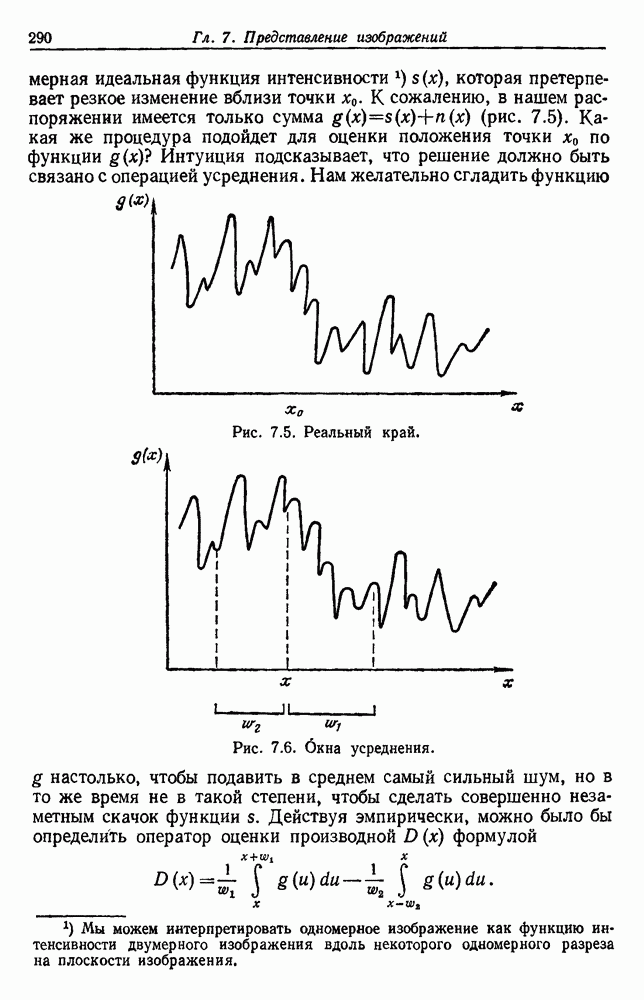

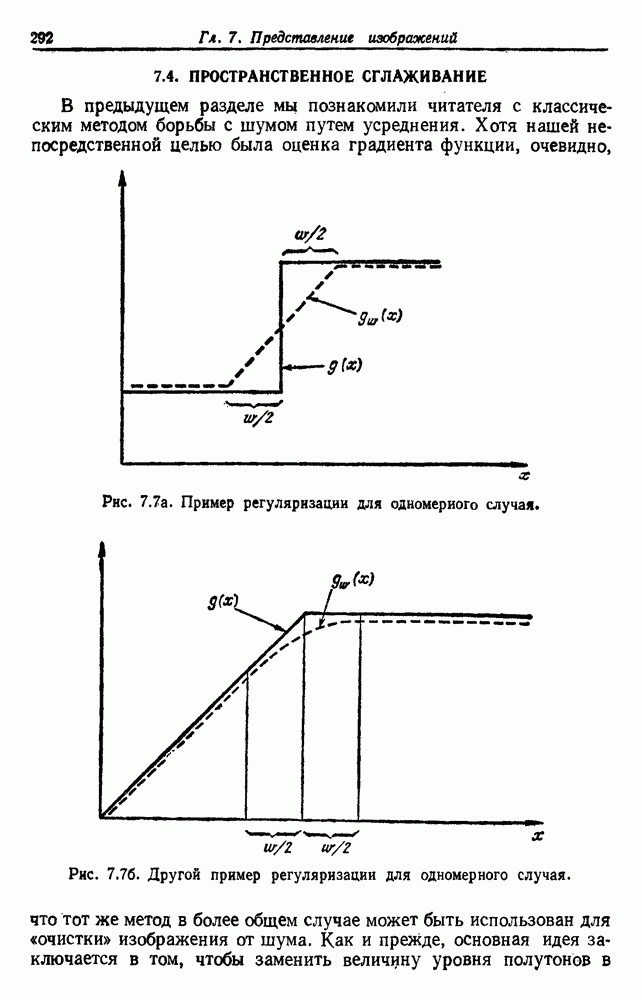
















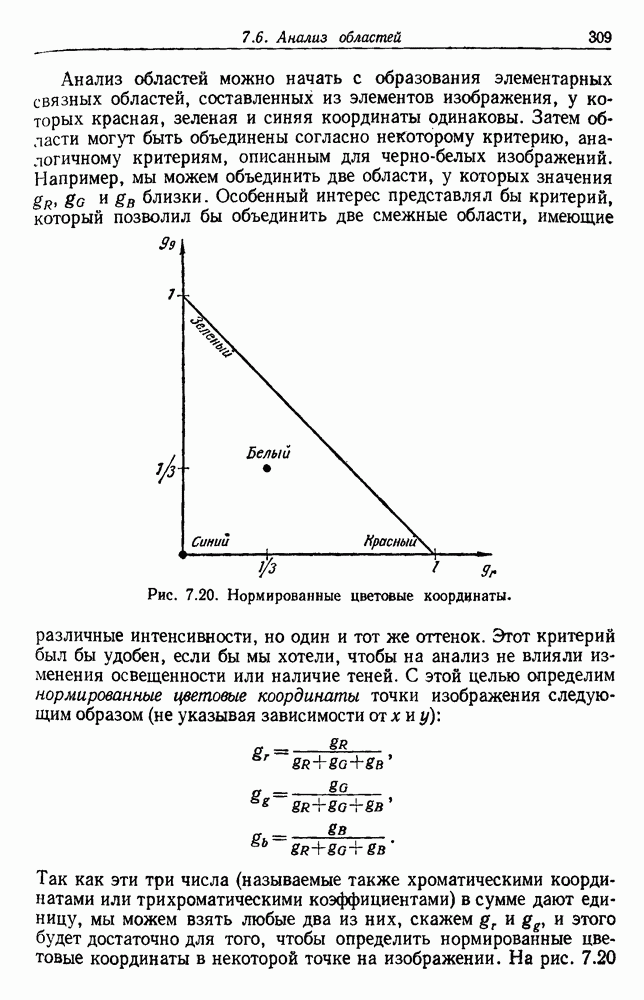











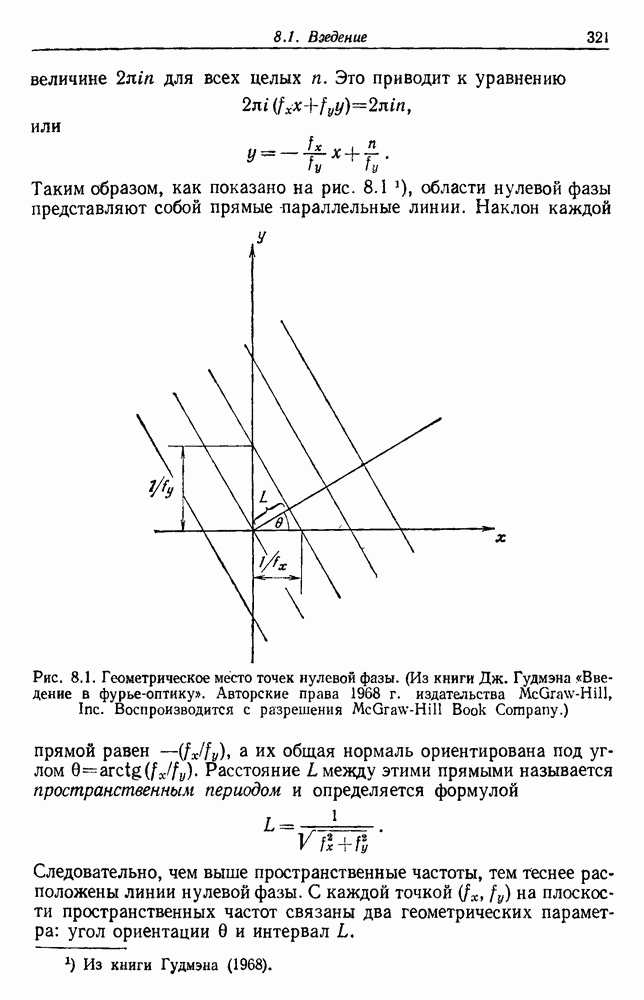


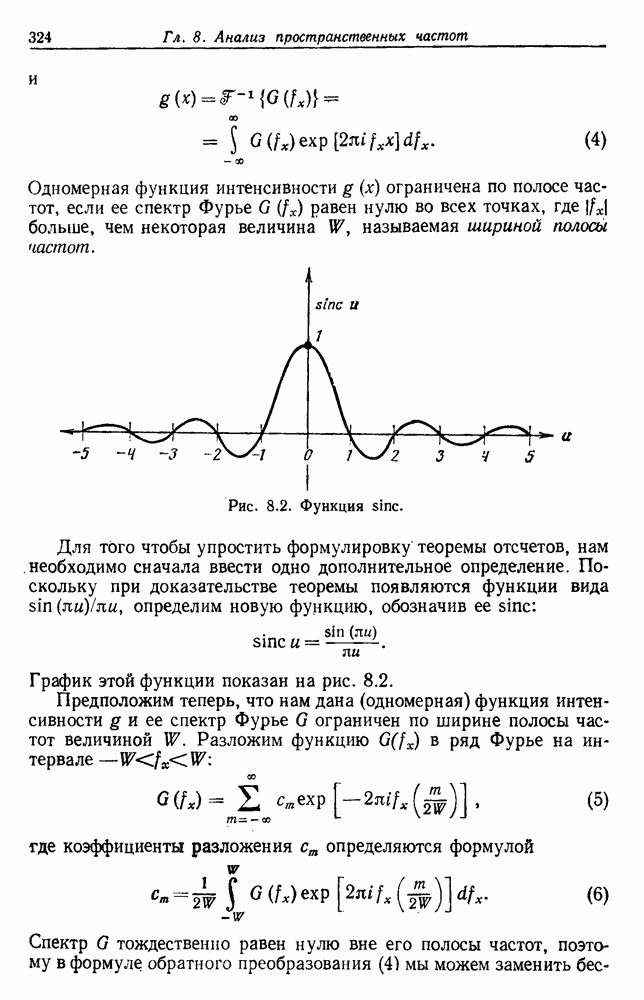




























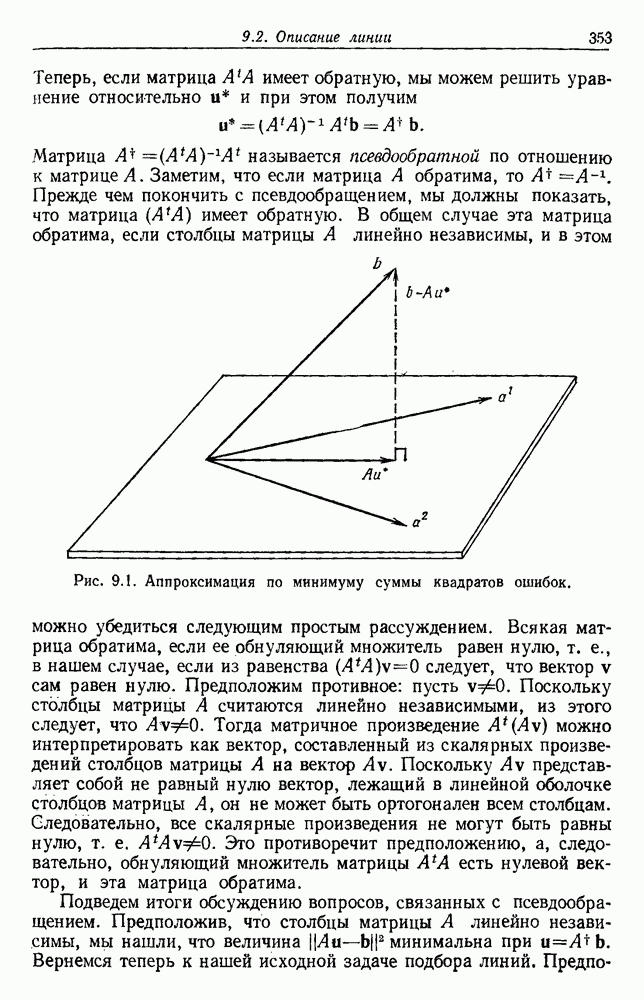


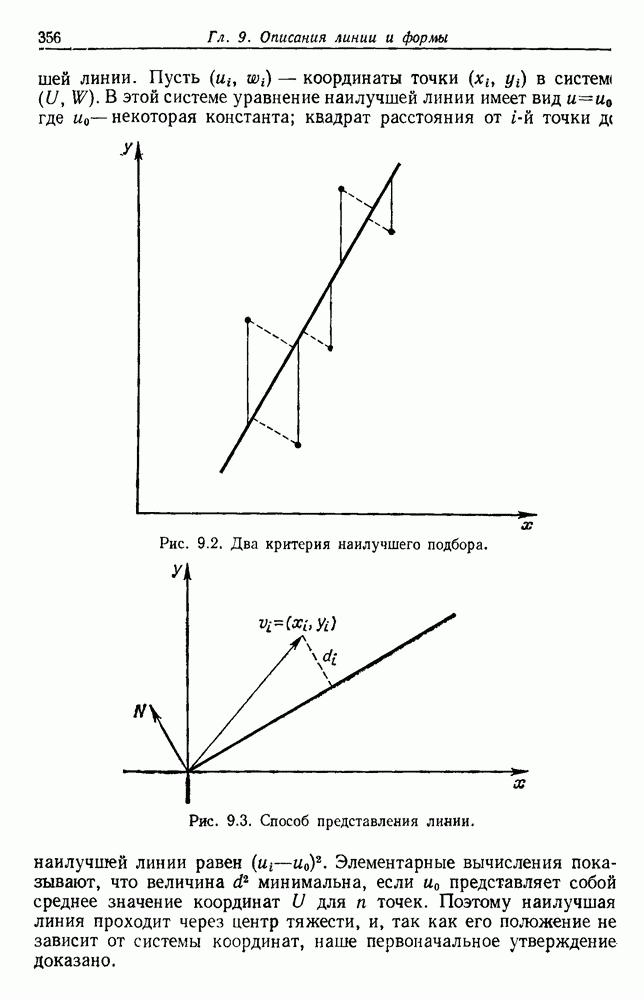

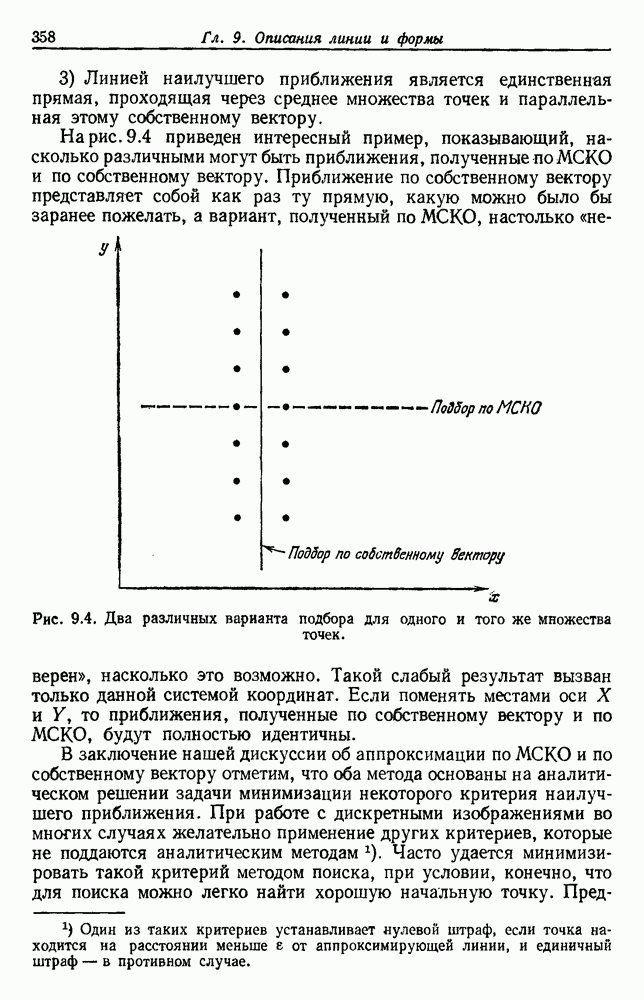

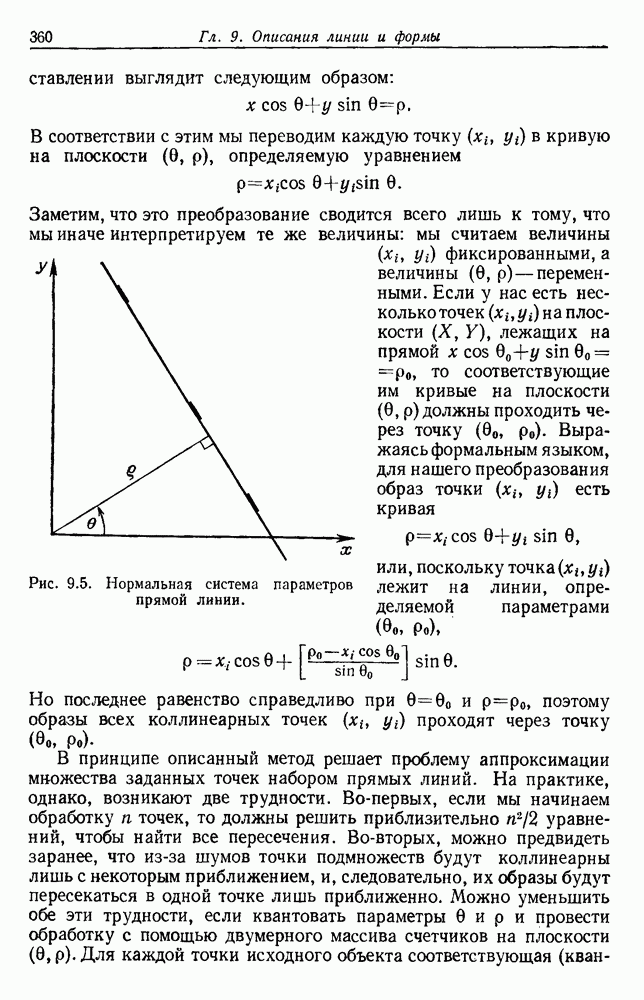



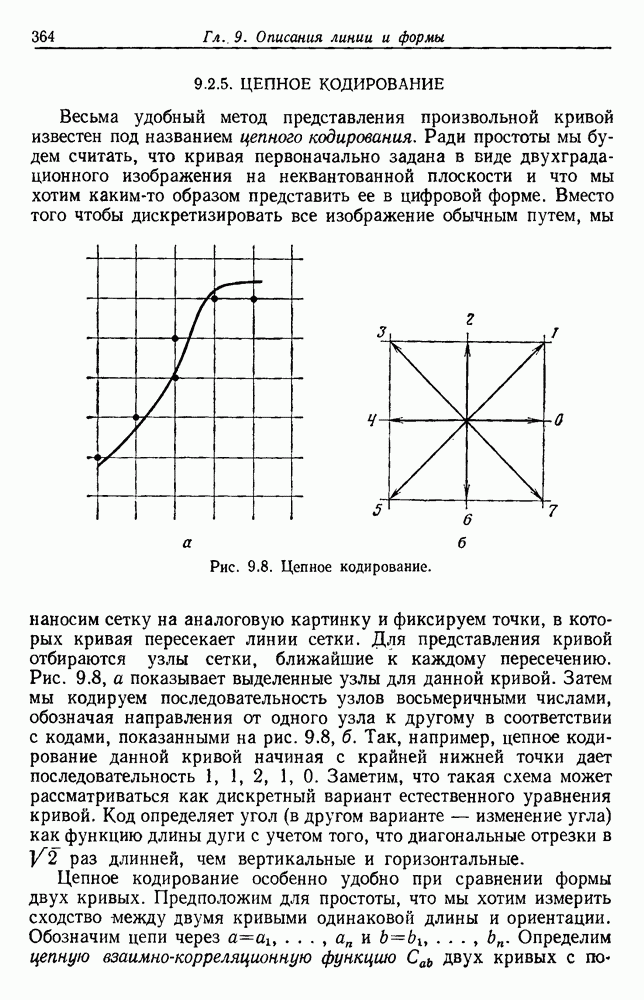


































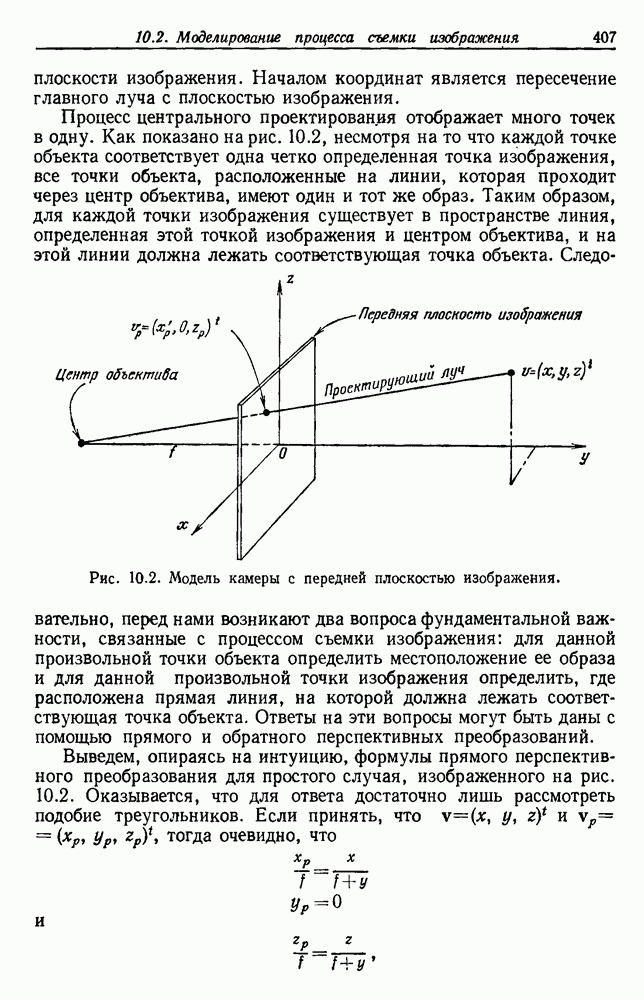





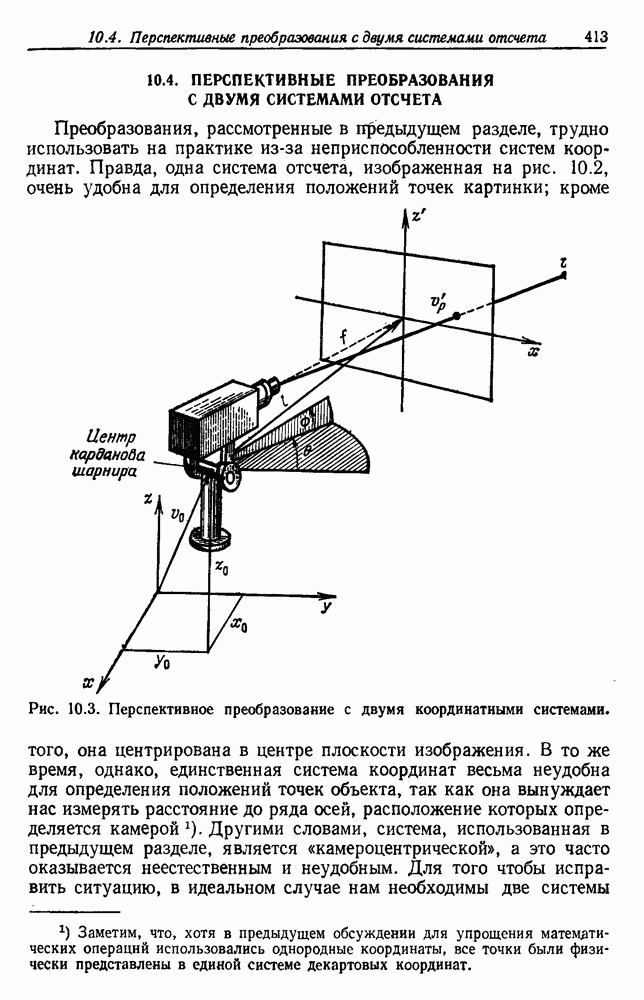








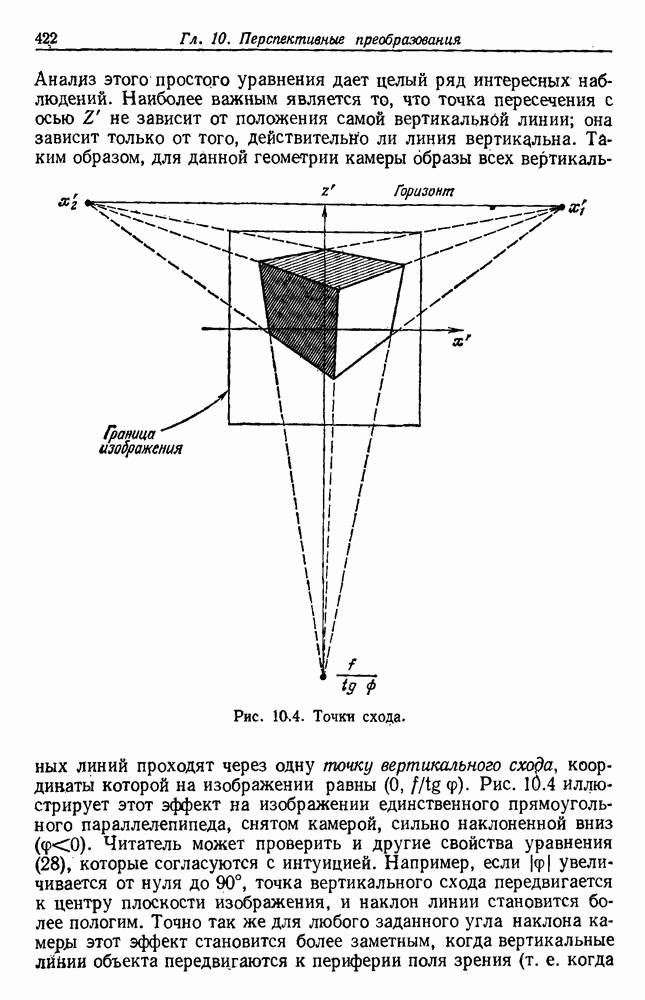

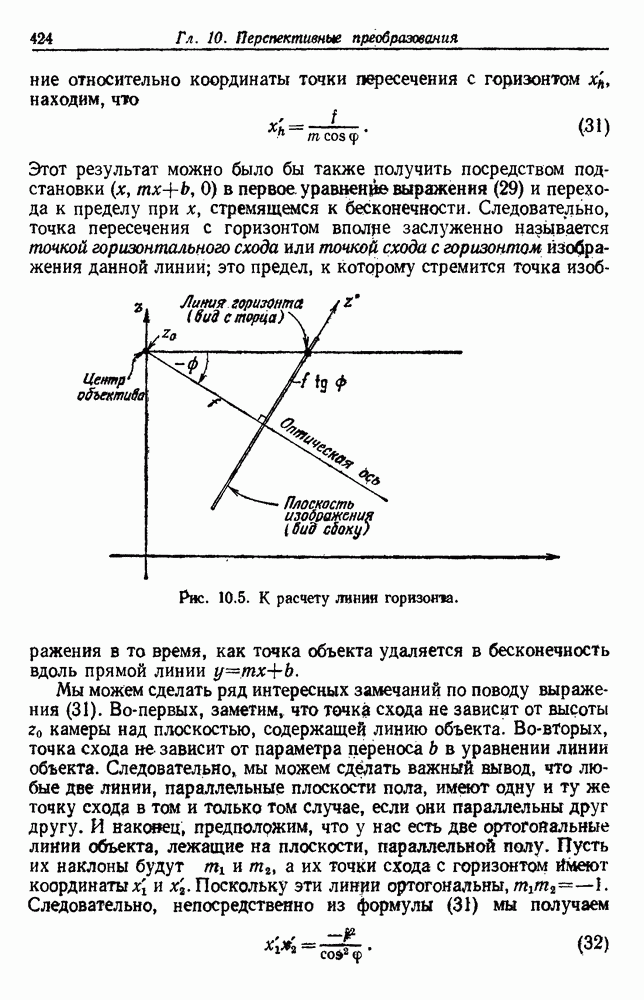
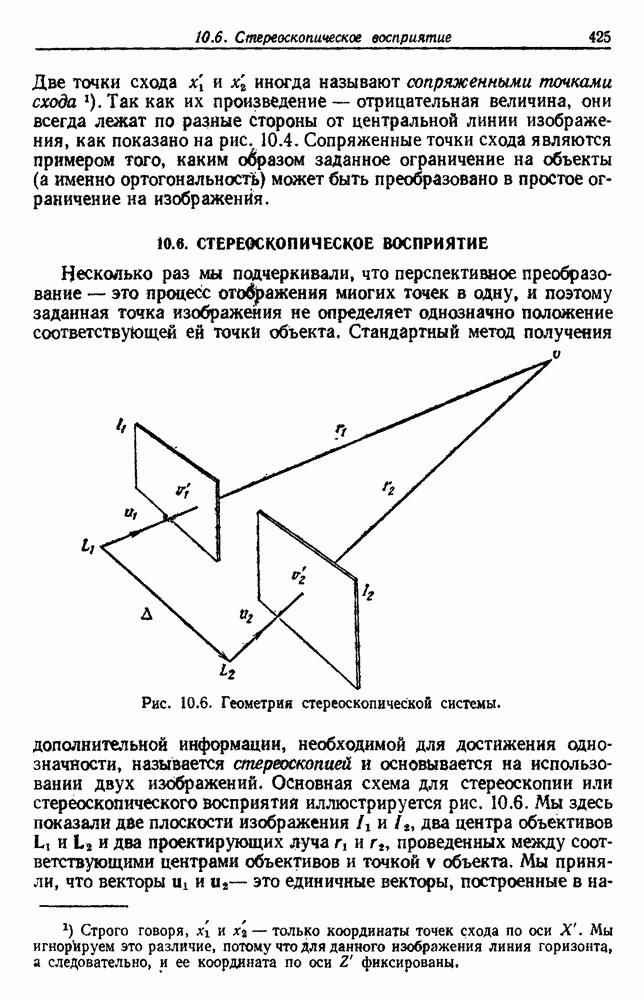









































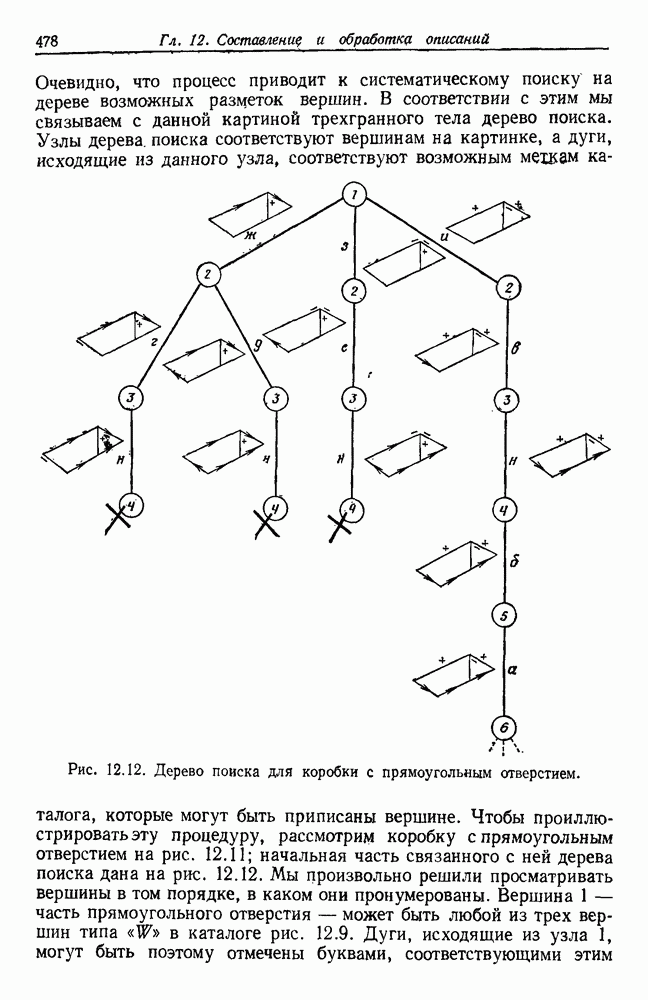


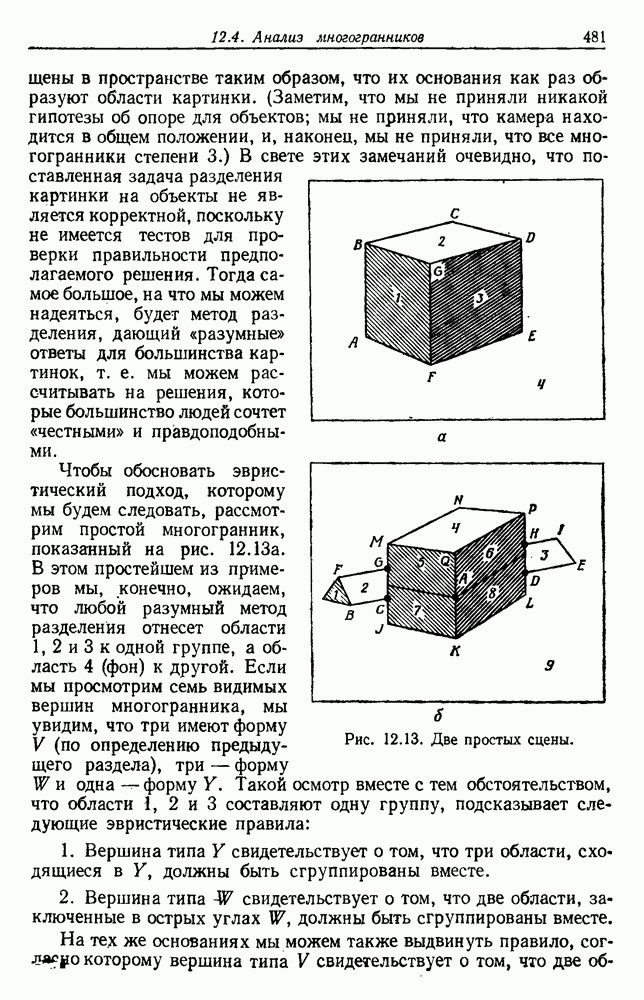


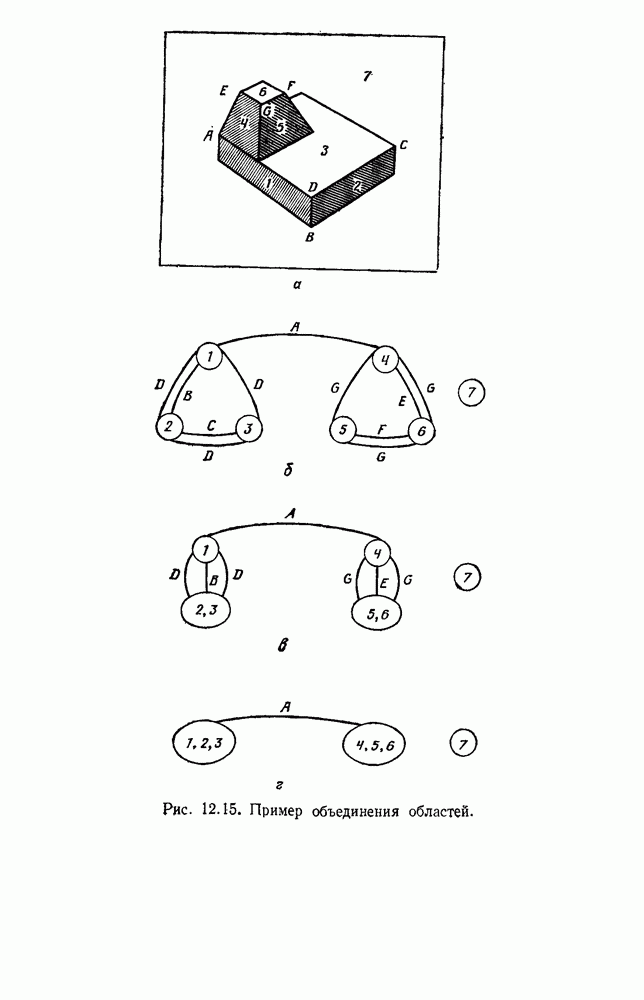
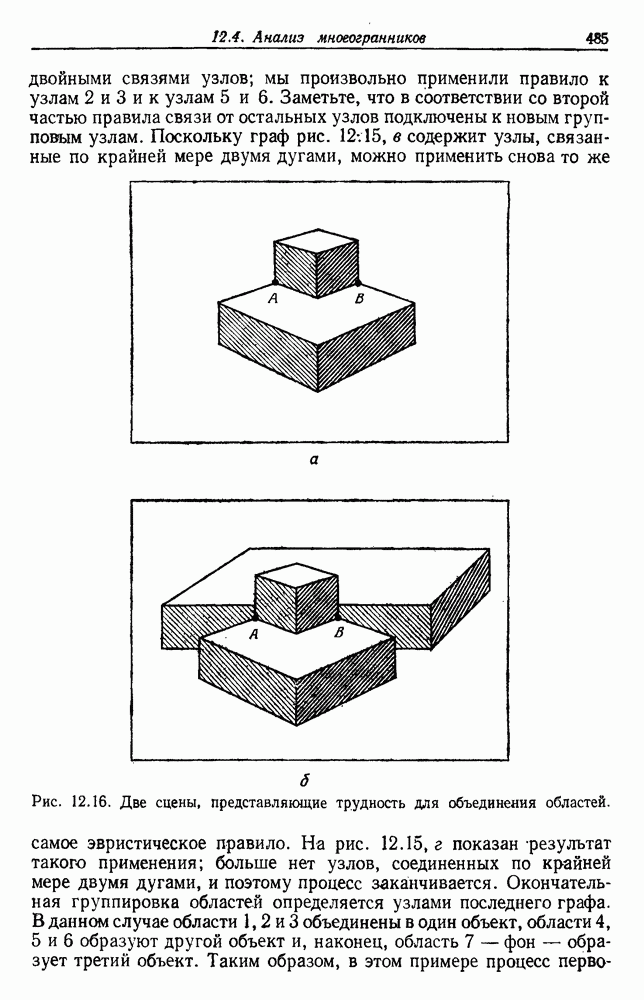











 -соотношением в классической статистике. Фукунага и Кунц (1970) показали, что эти критерии дают одинаковые оптимальные разделения в случае двух групп. Из критериев, которых мы не упоминали, критерий «сцепления» Ватанабе (1969, гл. 8) представляет особый интерес, так как он учитывает не только меру подобия между парами.
-соотношением в классической статистике. Фукунага и Кунц (1970) показали, что эти критерии дают одинаковые оптимальные разделения в случае двух групп. Из критериев, которых мы не упоминали, критерий «сцепления» Ватанабе (1969, гл. 8) представляет особый интерес, так как он учитывает не только меру подобия между парами.
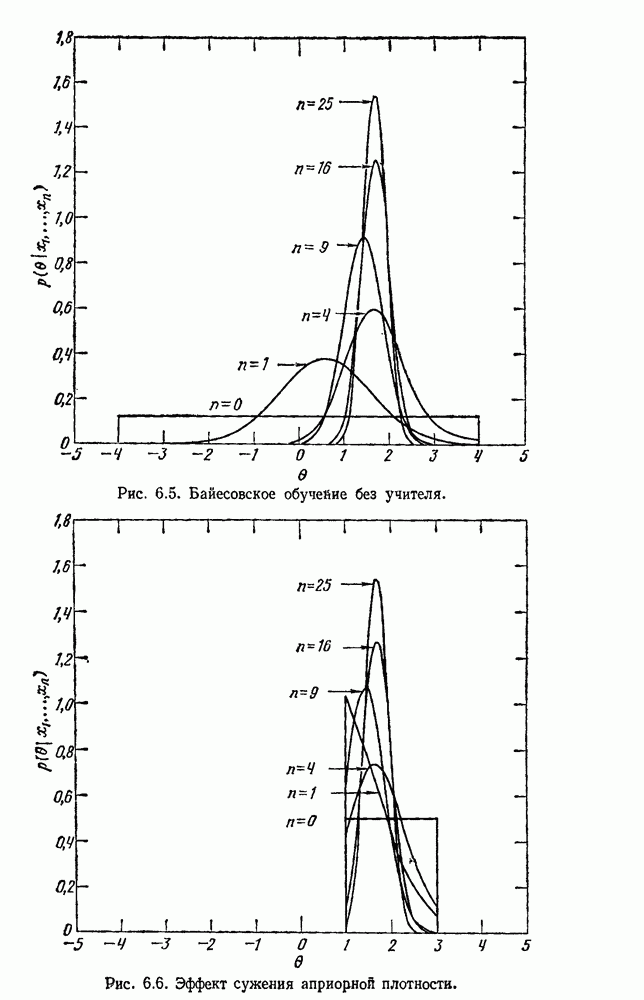
 -средних, свойства сходимости которой изучались Маккуином (1967). Интересные применения этой процедуры к распознаванию символов описаны Эндрюсом, Атрубином и Ху (1968) и Кейзи и Надь (1968).
-средних, свойства сходимости которой изучались Маккуином (1967). Интересные применения этой процедуры к распознаванию символов описаны Эндрюсом, Атрубином и Ху (1968) и Кейзи и Надь (1968).
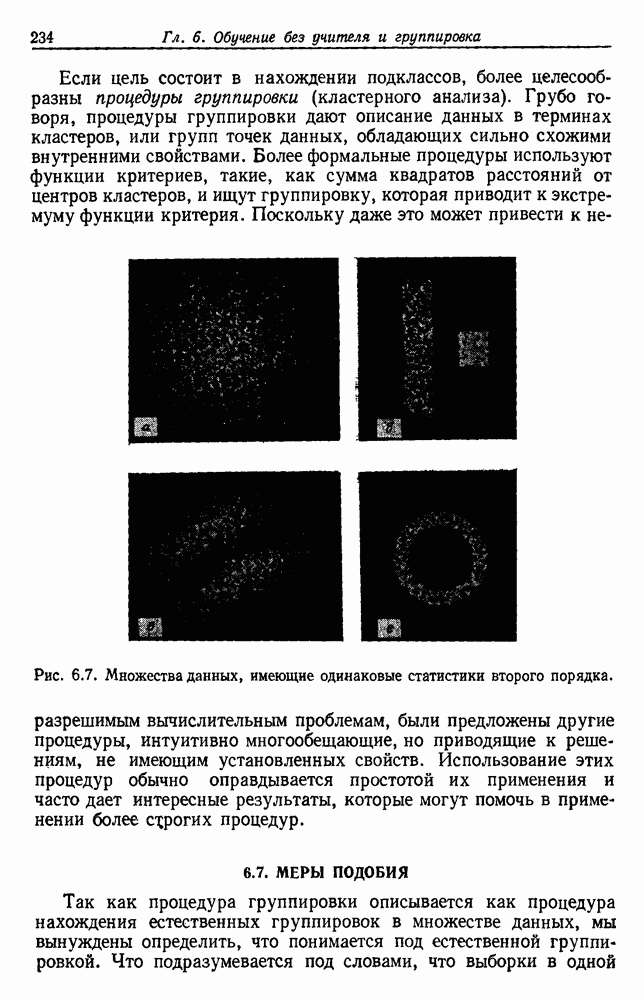
 ближайших соседей моды плотности смеси. Методы минимальной
ближайших соседей моды плотности смеси. Методы минимальной
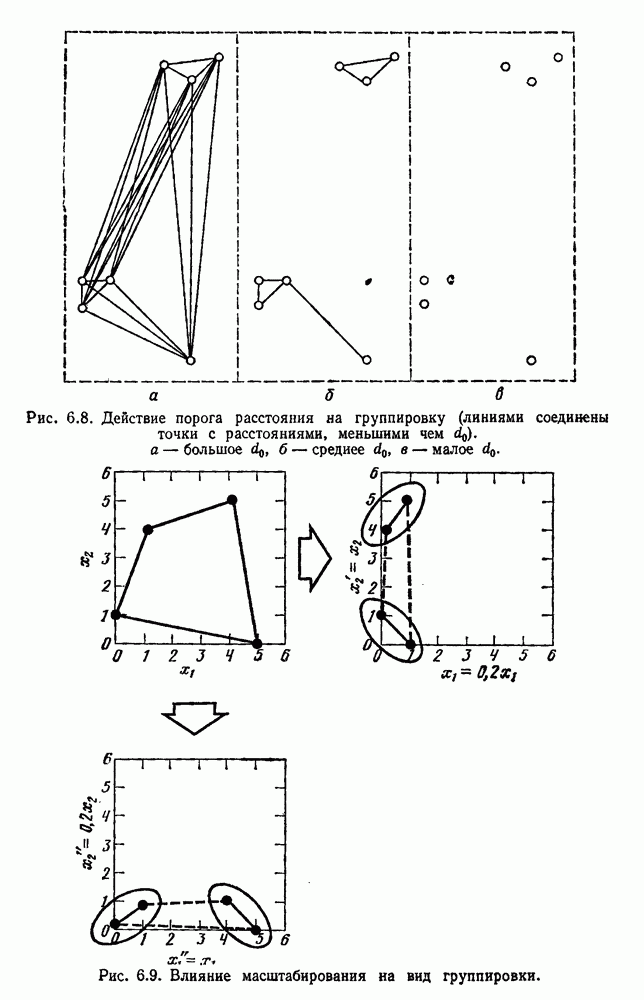
 при ограничениях на монотонность детально описаны Крускалом (19646). Колверт (1968) использует модификацию критерия Шепарда для обеспечения двумерного отображения на ЭВМ многомерных данных. Более простой для вычислений критерий
при ограничениях на монотонность детально описаны Крускалом (19646). Колверт (1968) использует модификацию критерия Шепарда для обеспечения двумерного отображения на ЭВМ многомерных данных. Более простой для вычислений критерий  был предложен и использован Саммоном (1969) для отображения данных при диалоговом режиме анализа.
был предложен и использован Саммоном (1969) для отображения данных при диалоговом режиме анализа.
 , Льюис (1962) — критерий энтропии, а Мерилл и Грин (1963) использовали критерий дивергенции. В некоторых случаях можно ограничить вероятность ошибки более легко вычисляемыми функциями, но окончательной проверкой всегда является реальное функционирование. В тексте мы ограничились простой процедурой Кинга (1967), выбрав ее прежде всего из-за ее близкой связи с группировкой. Отличное представление математических методов уменьшения размерности дано Мейзелом (1972).
, Льюис (1962) — критерий энтропии, а Мерилл и Грин (1963) использовали критерий дивергенции. В некоторых случаях можно ограничить вероятность ошибки более легко вычисляемыми функциями, но окончательной проверкой всегда является реальное функционирование. В тексте мы ограничились простой процедурой Кинга (1967), выбрав ее прежде всего из-за ее близкой связи с группировкой. Отличное представление математических методов уменьшения размерности дано Мейзелом (1972).