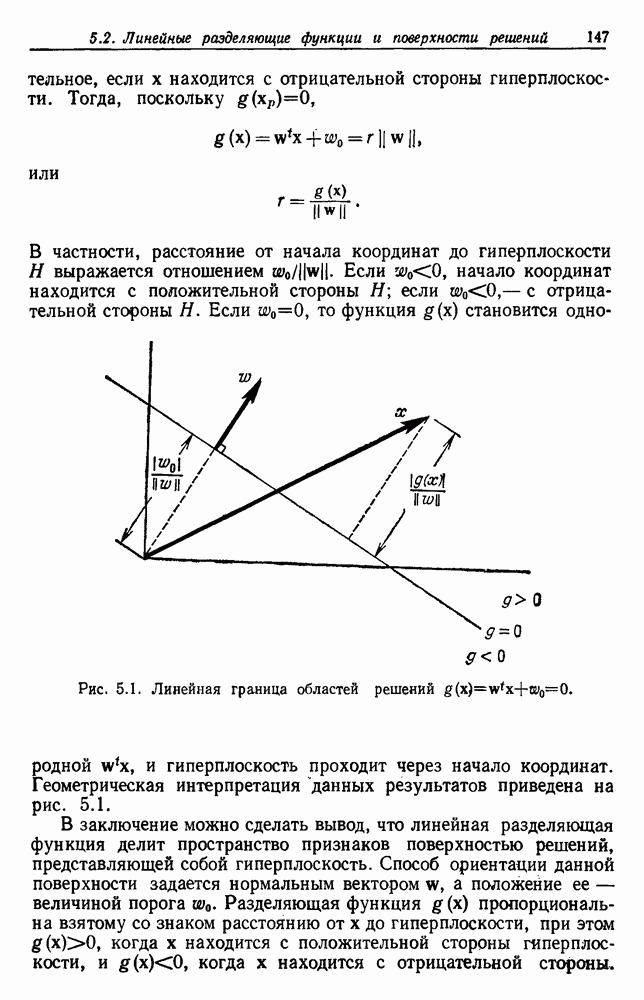
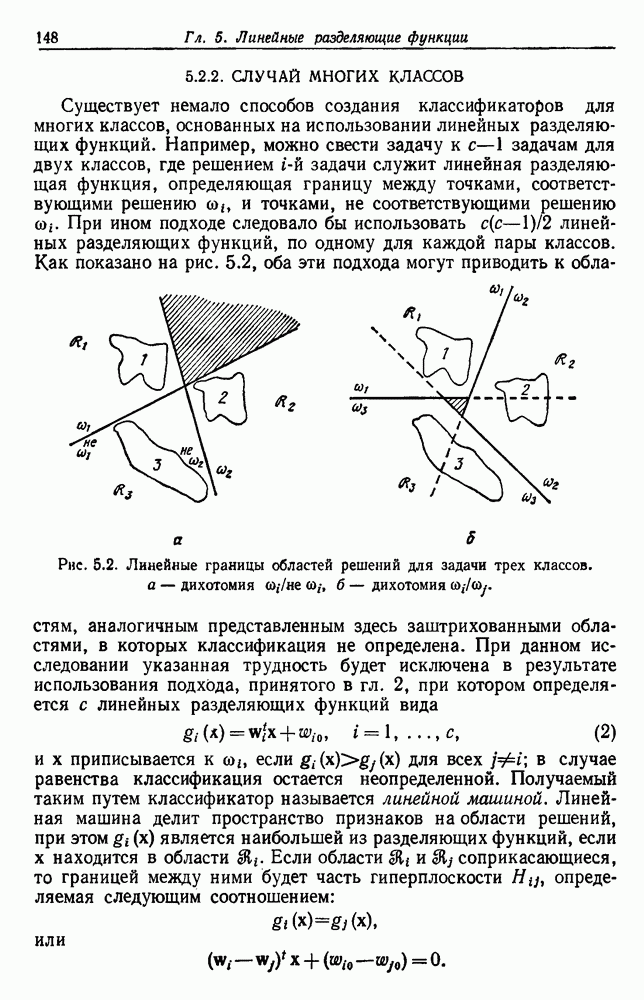
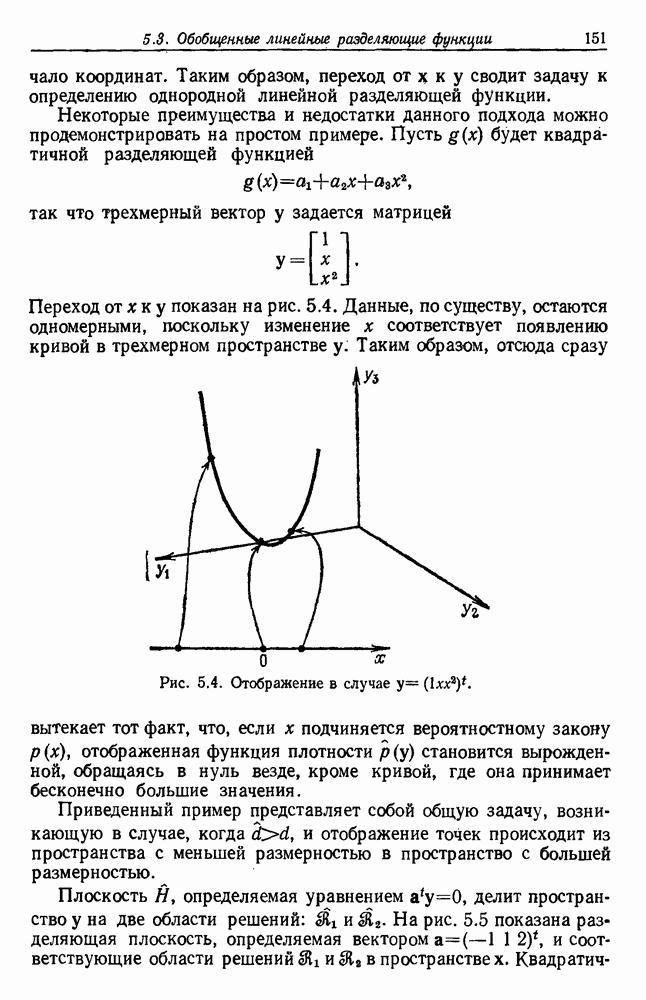
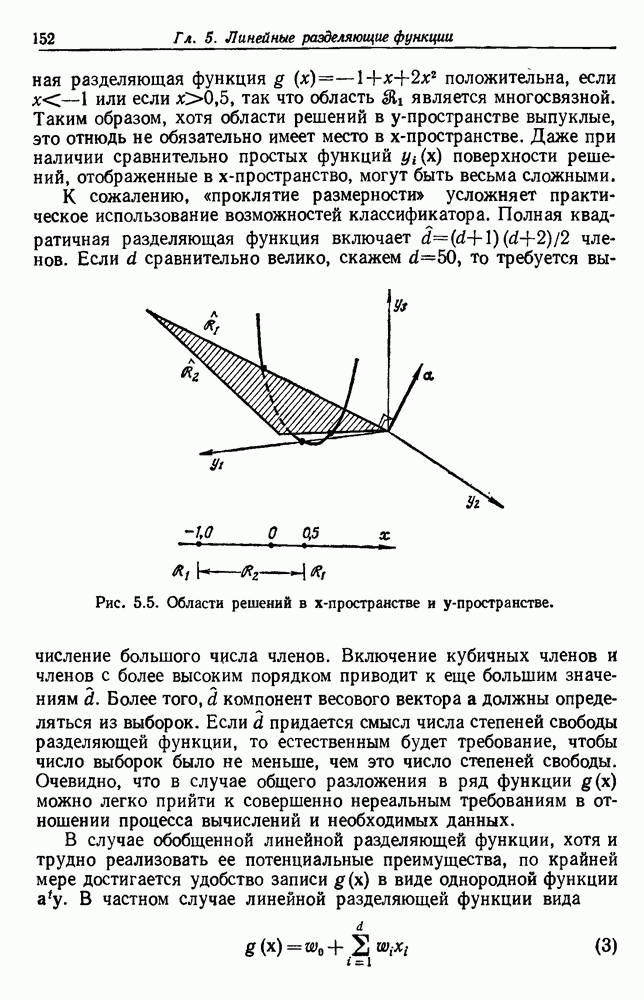
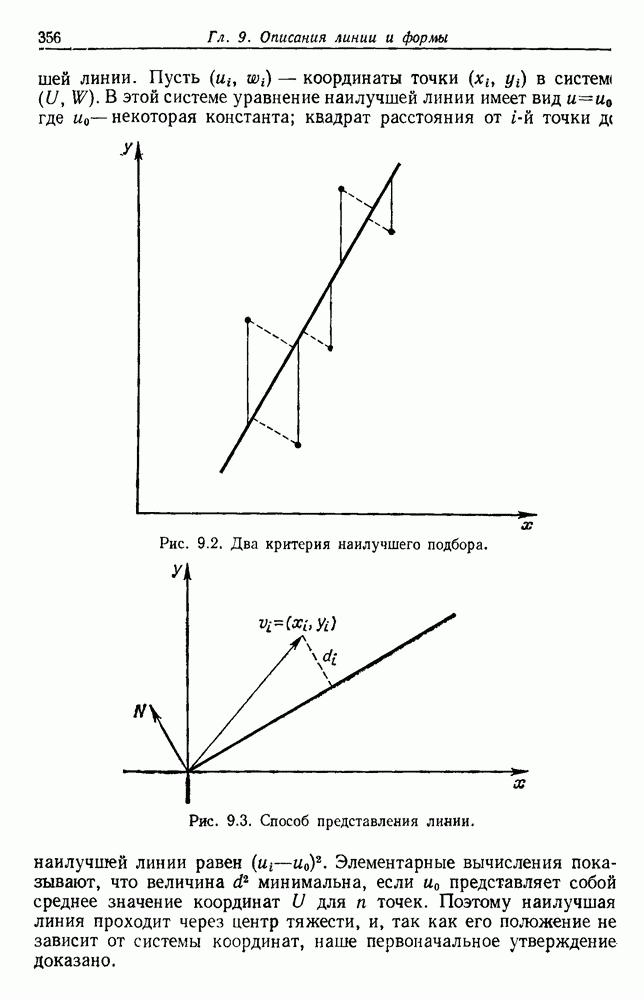
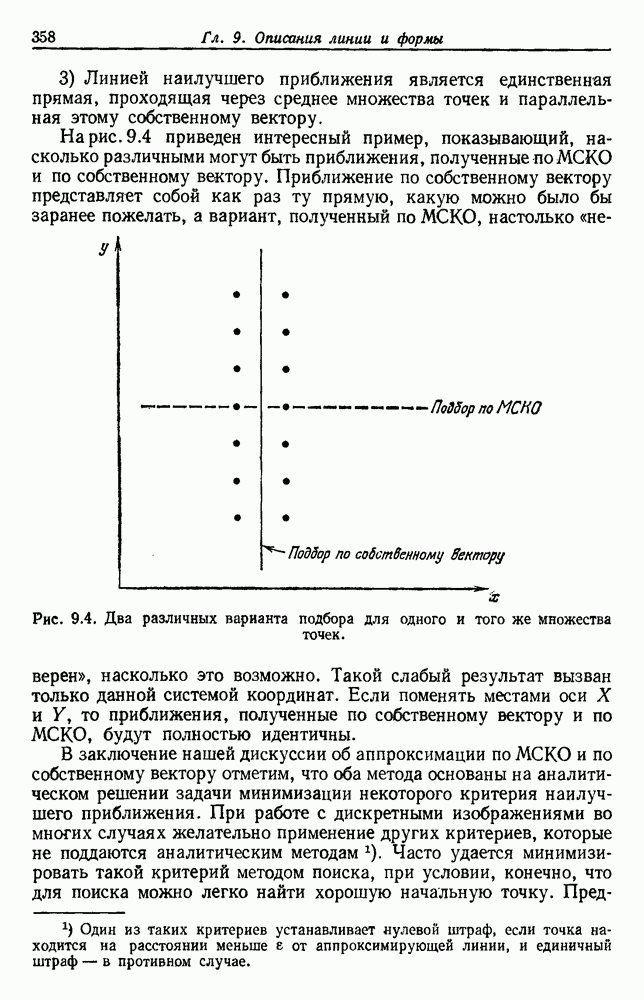
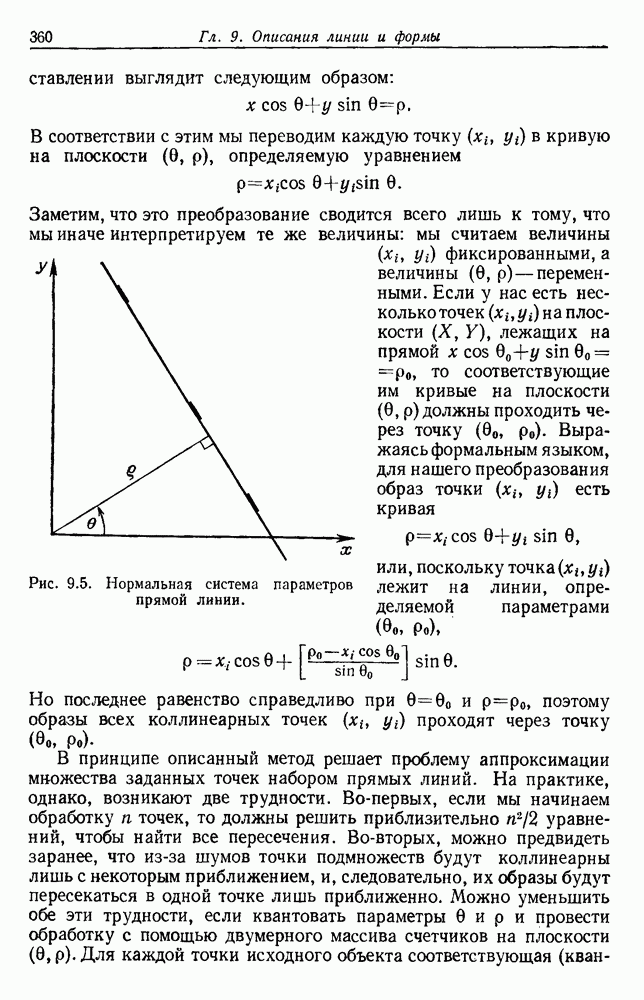
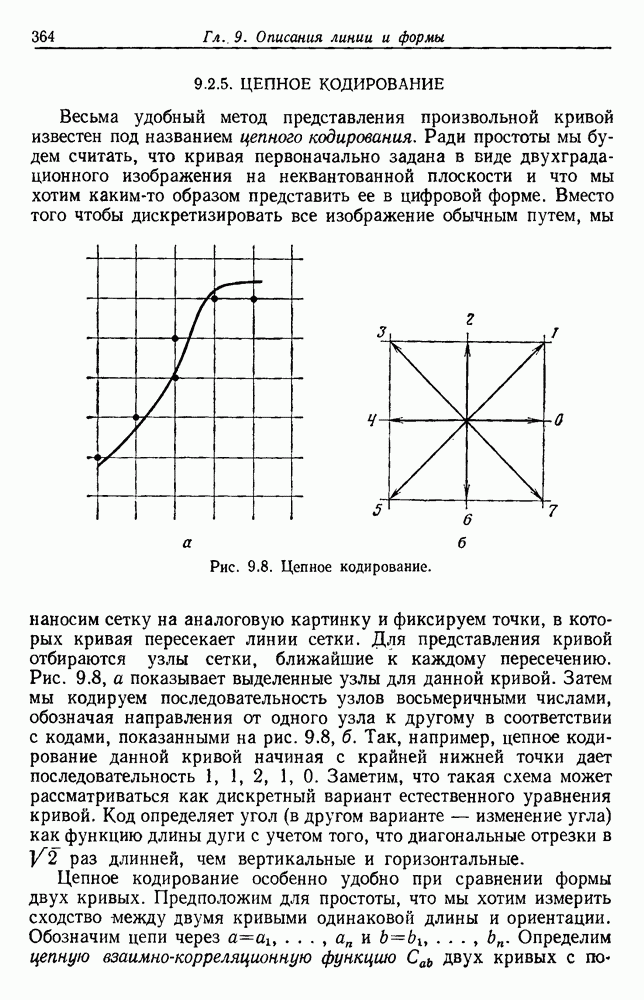
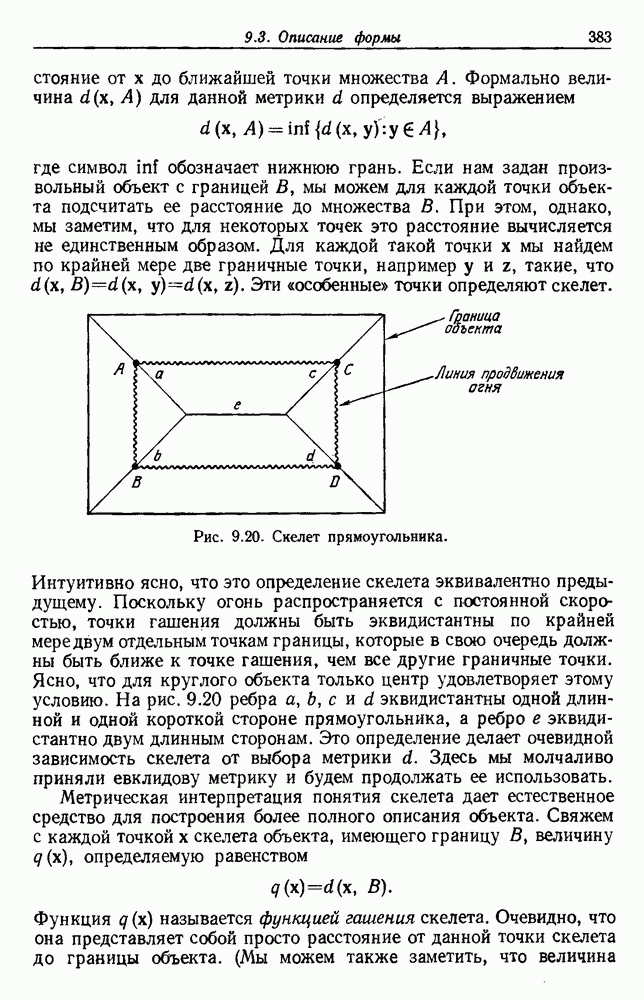
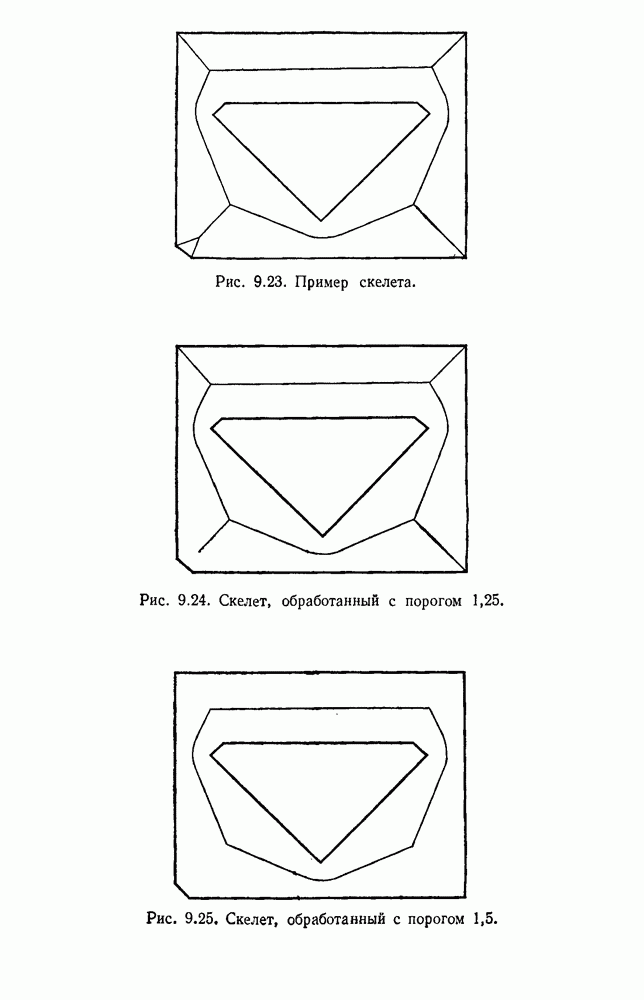
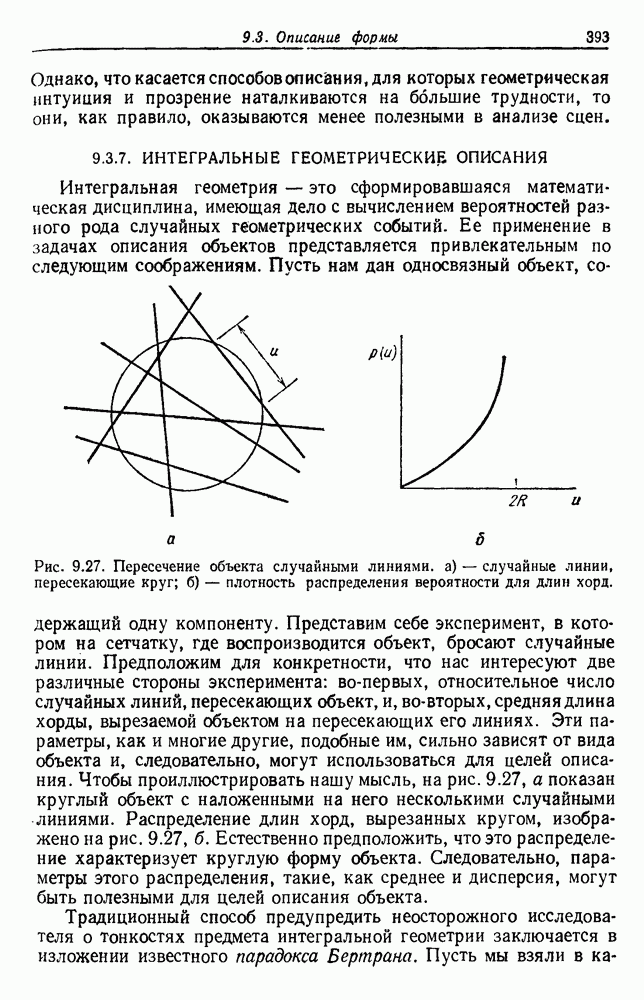
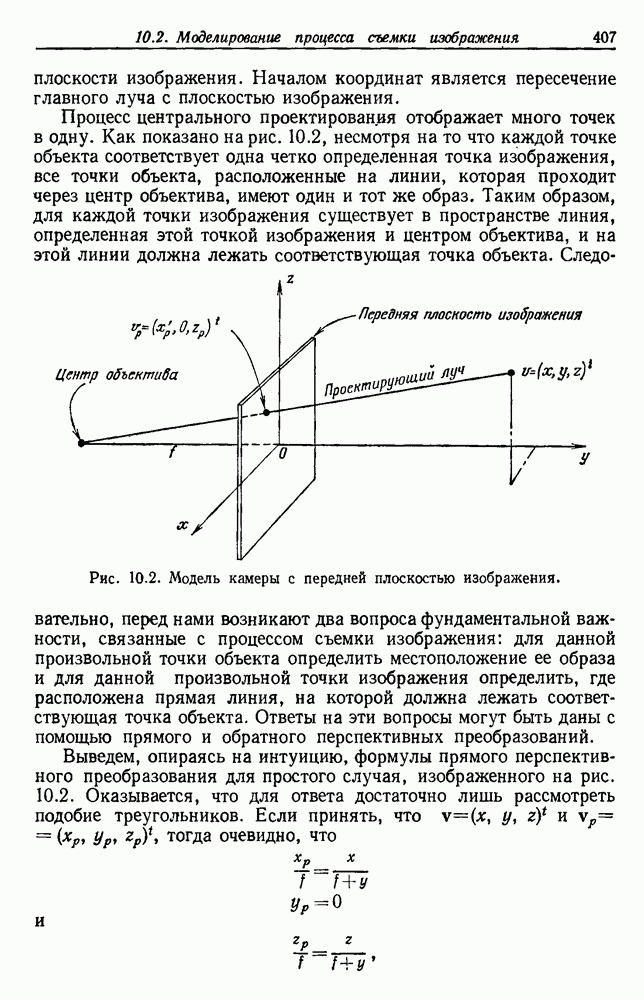
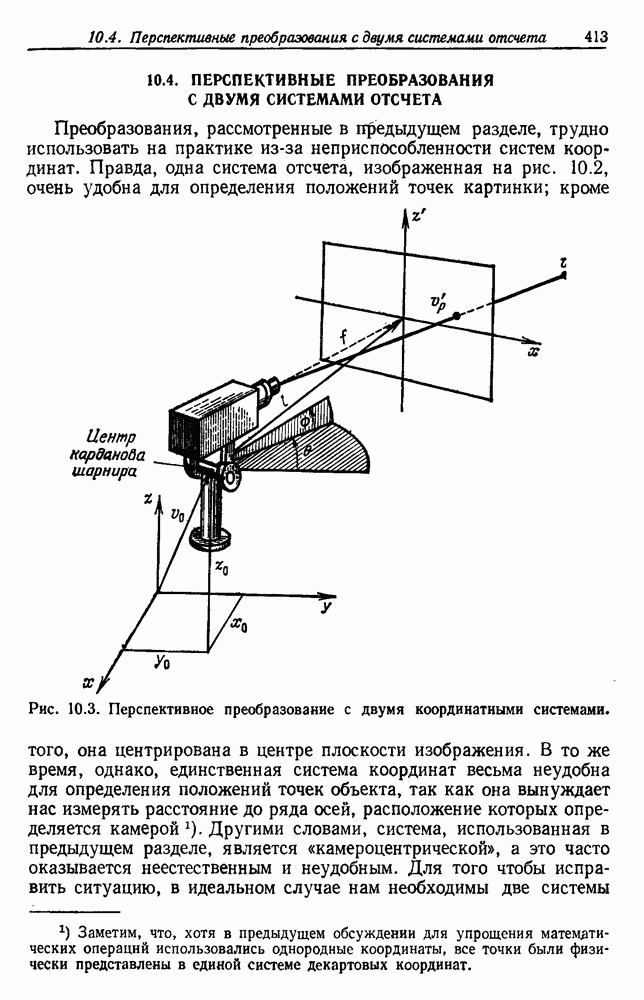
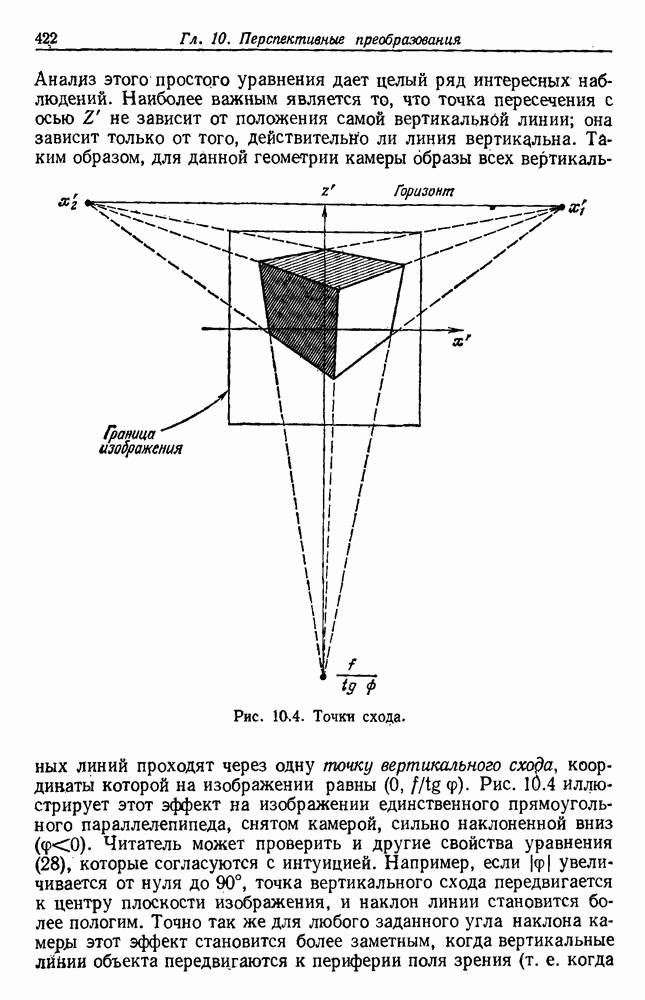
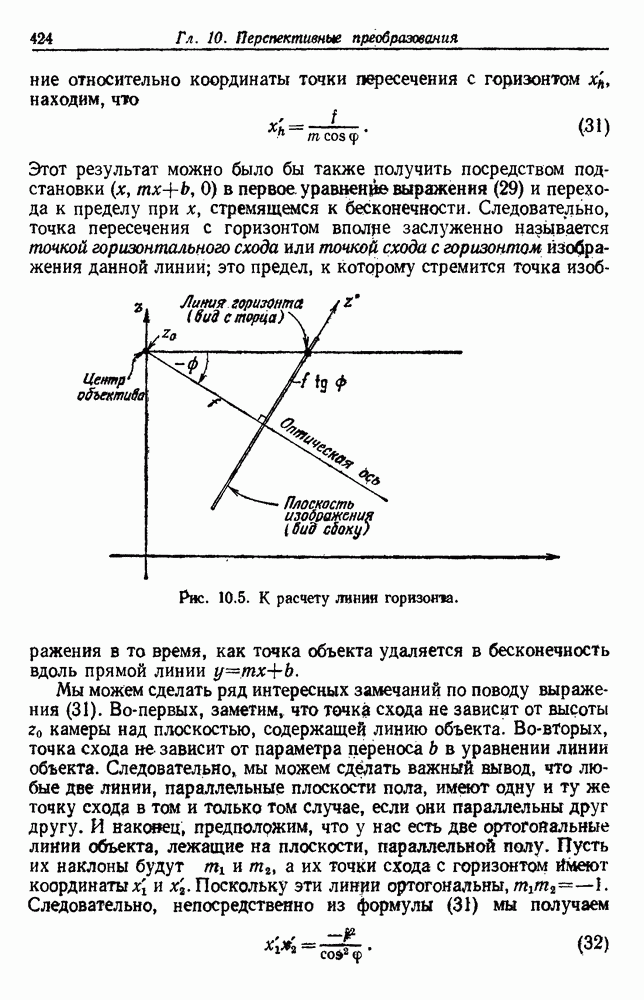
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
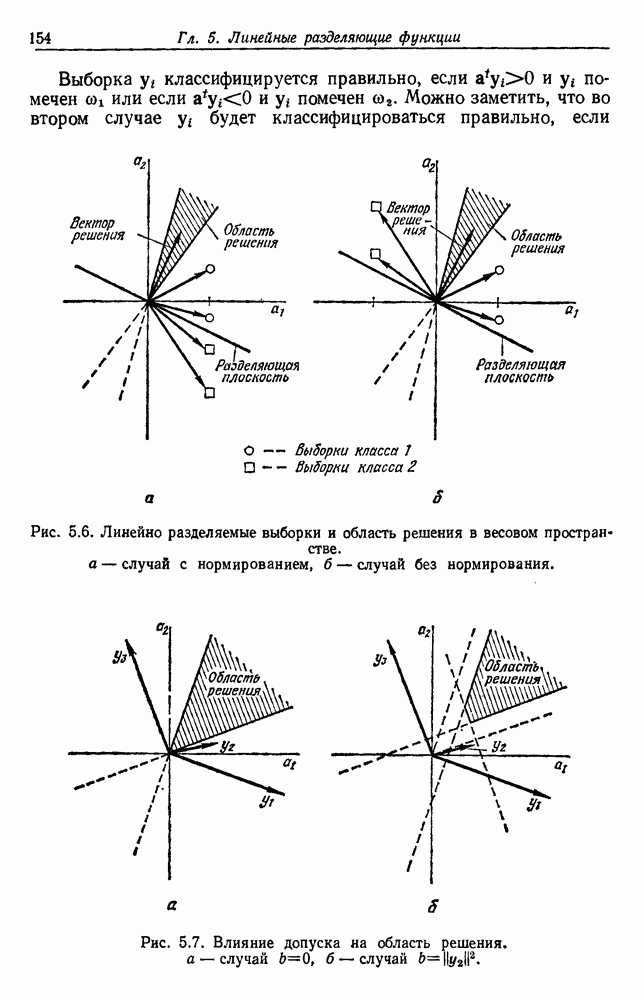
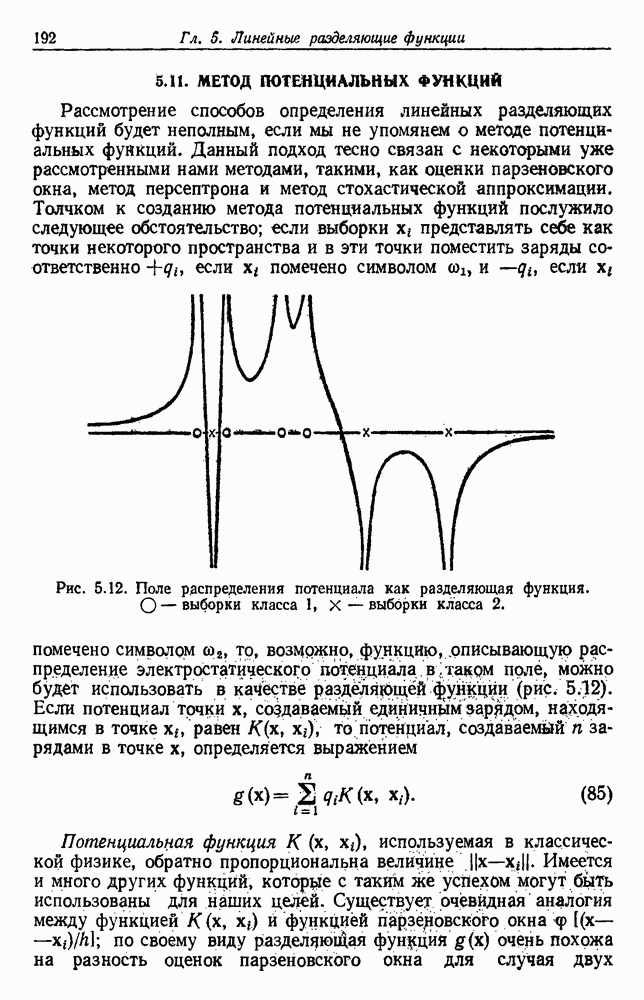
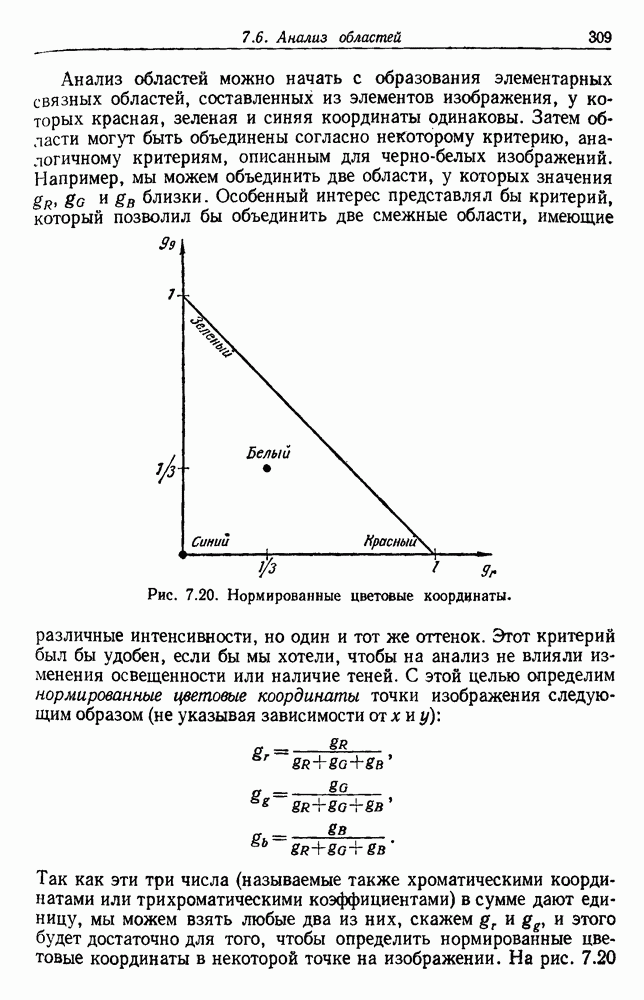
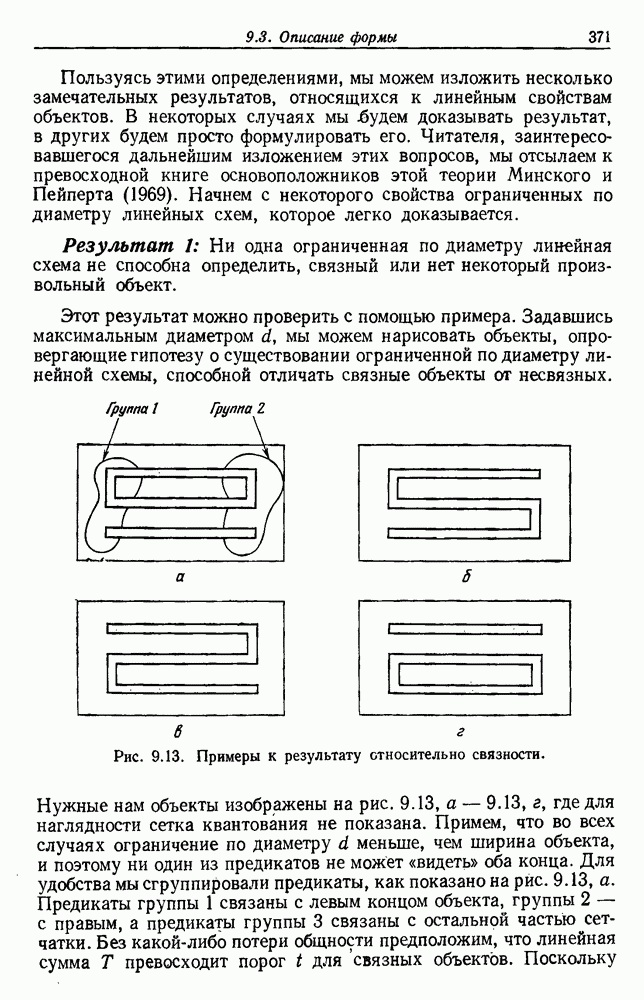
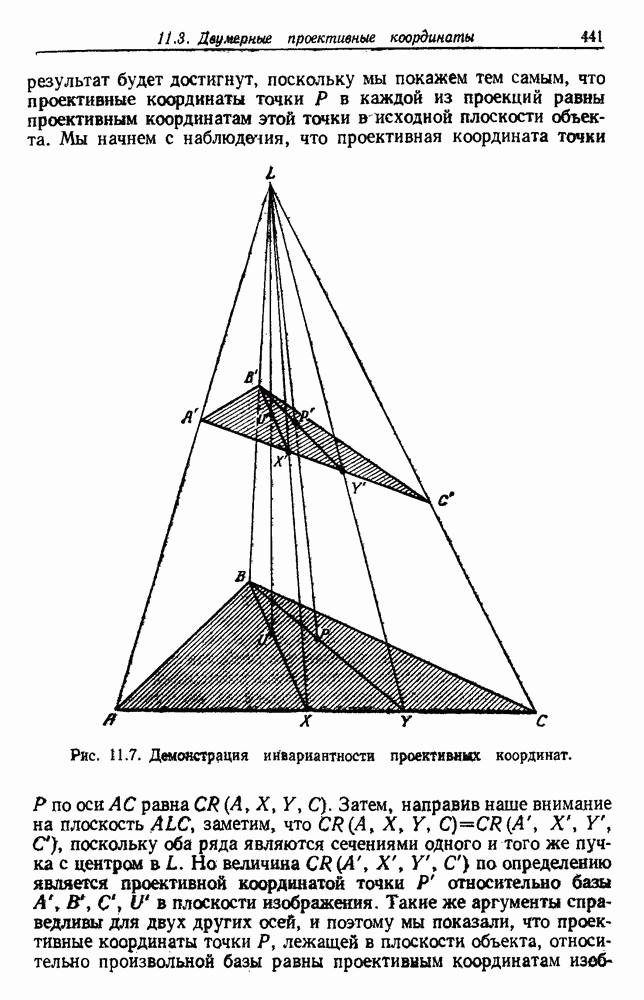
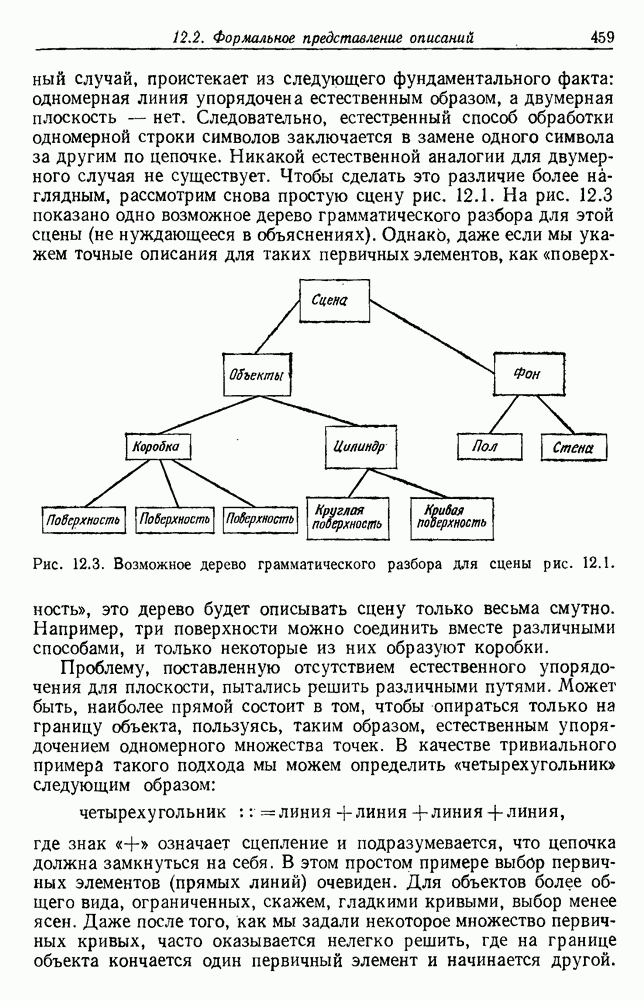
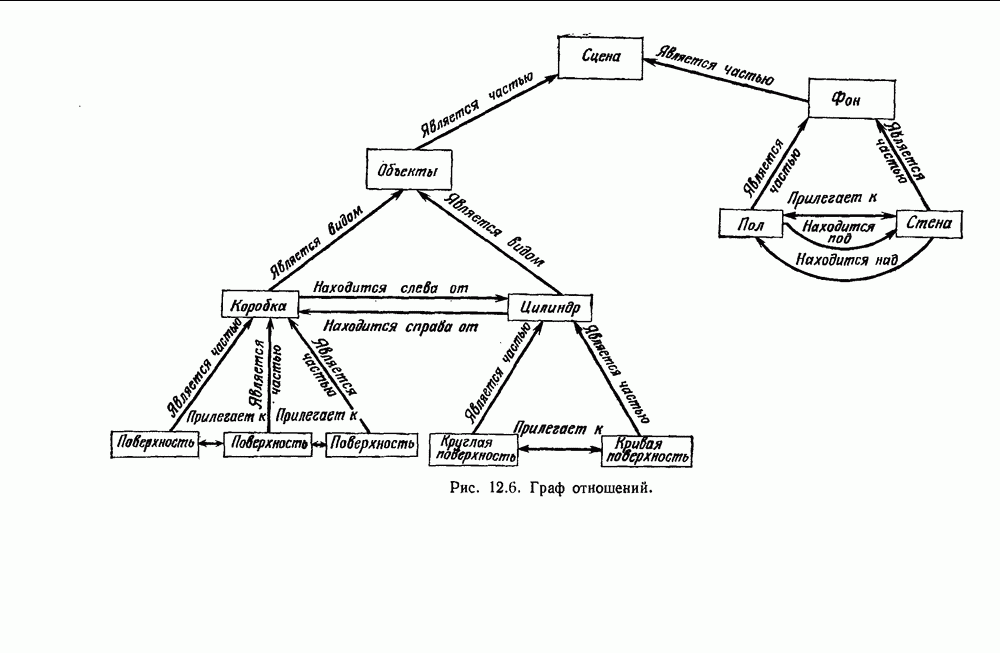
6.8. ФУНКЦИИ КРИТЕРИЕВ ДЛЯ ГРУППИРОВКИПредположим, что мы имеем множество
6.8.1. КРИТЕРИЙ СУММЫ КВАДРАТОВ ОШИБОКСамая простая и наиболее используемая функция критерия — это сумма квадратов ошибок. Пусть
Тогда сумма квадратов ошибок определяется как
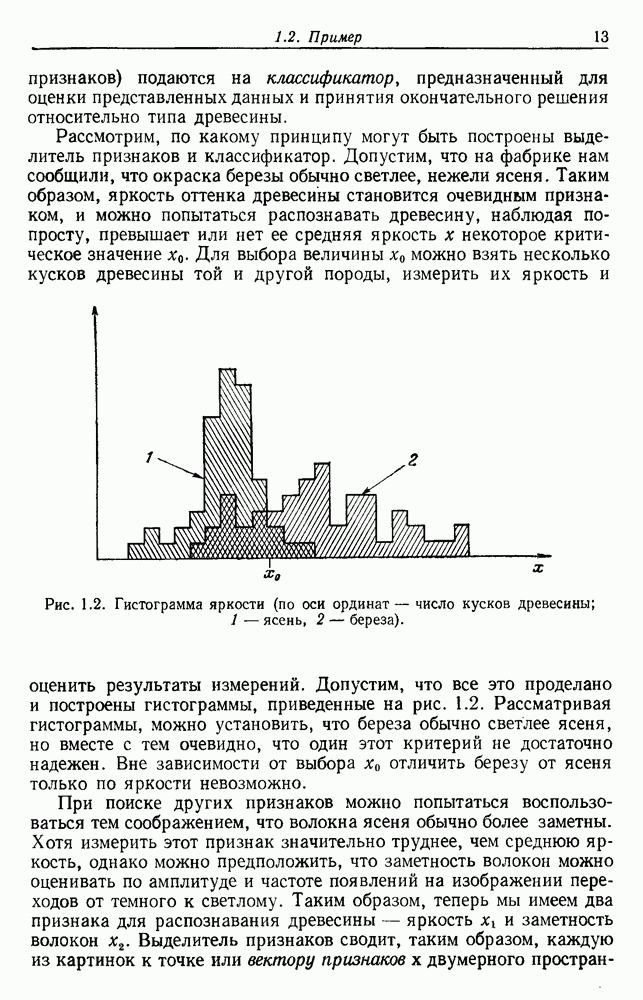
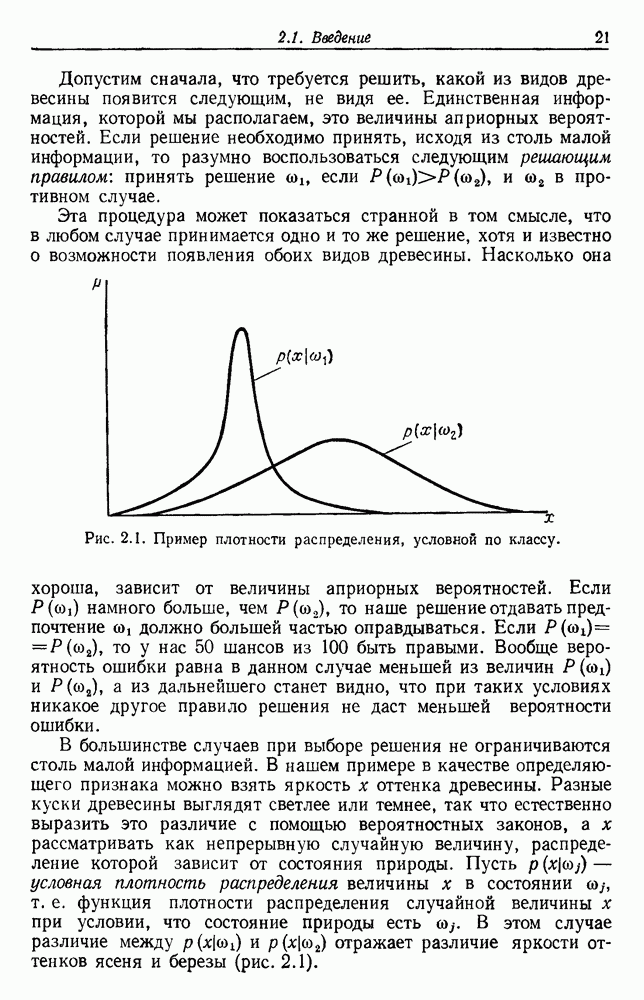
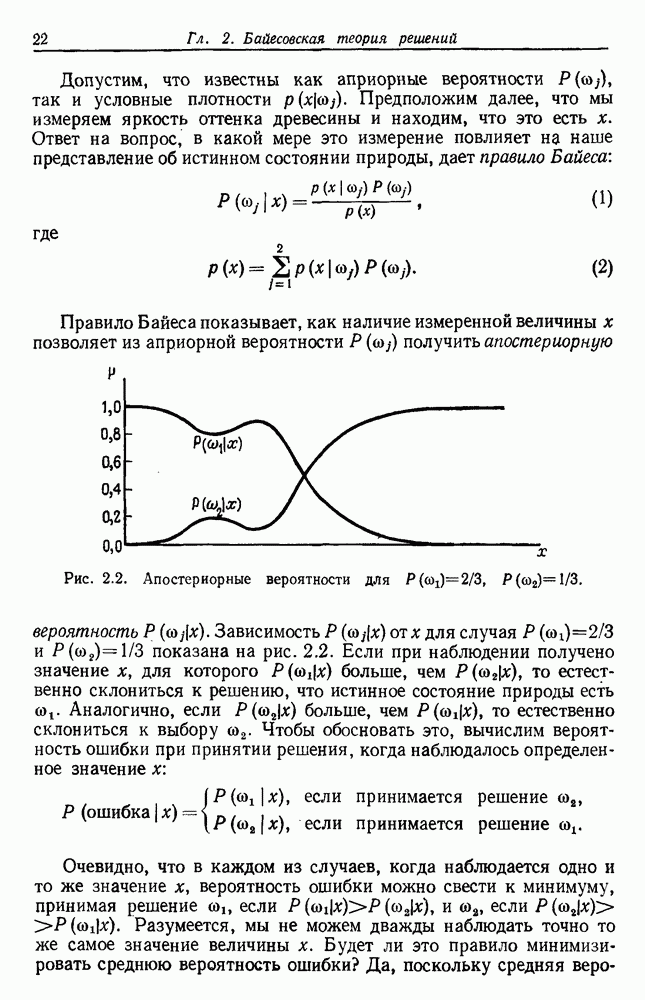
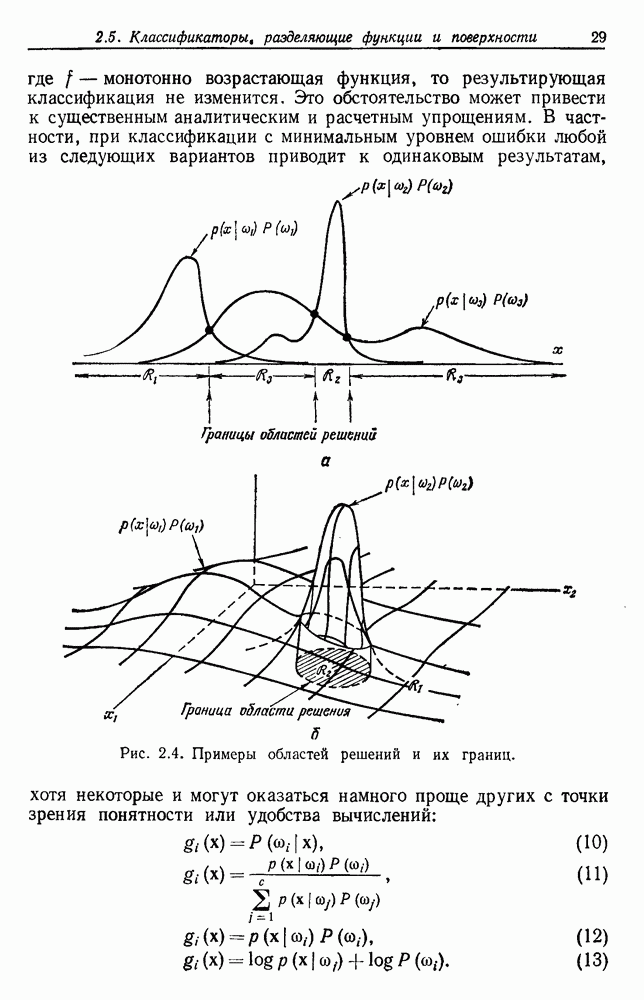
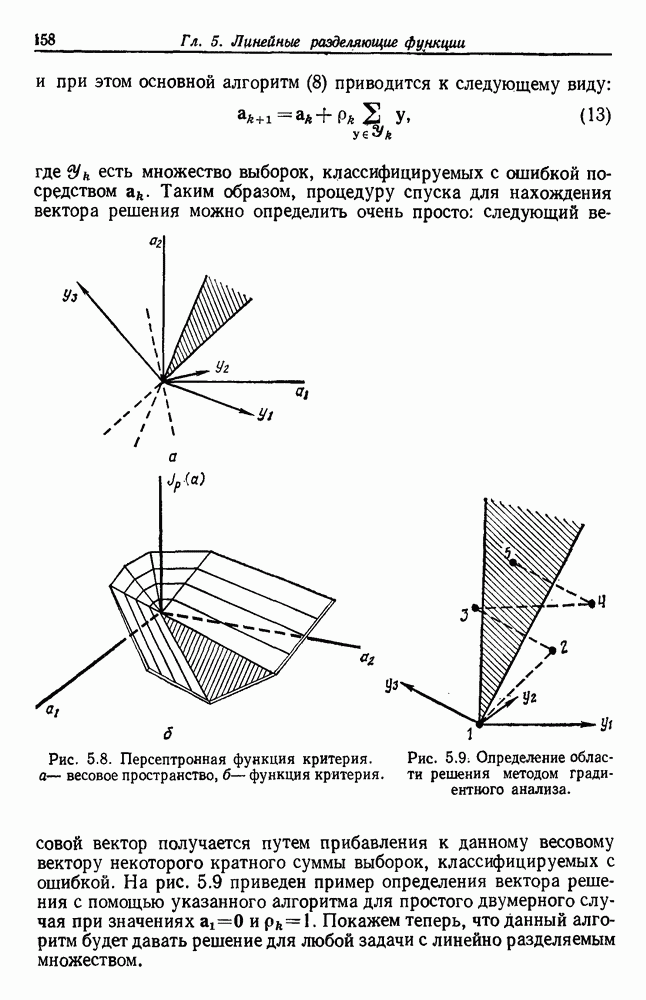
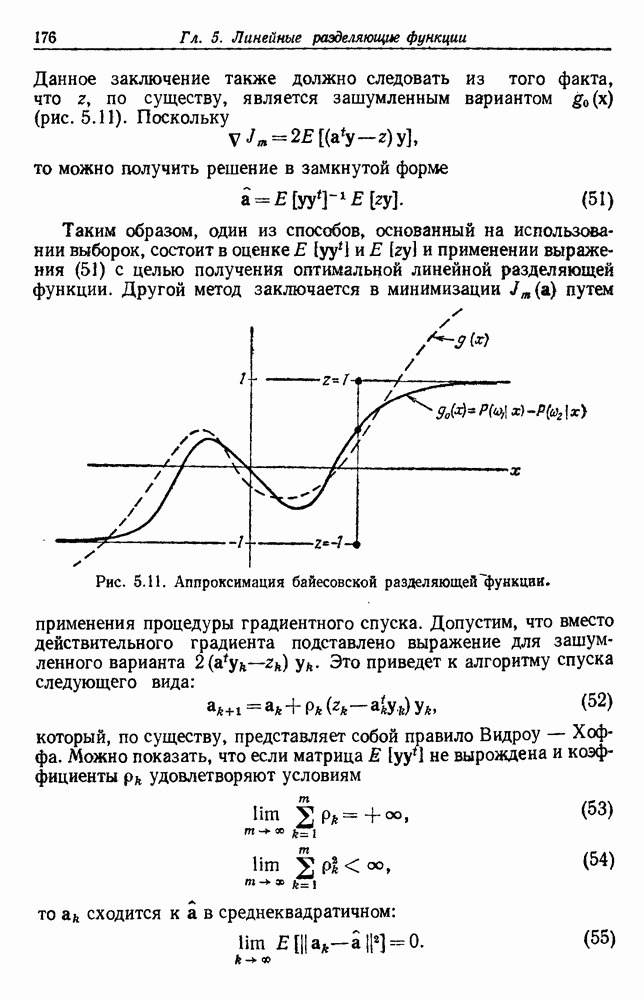
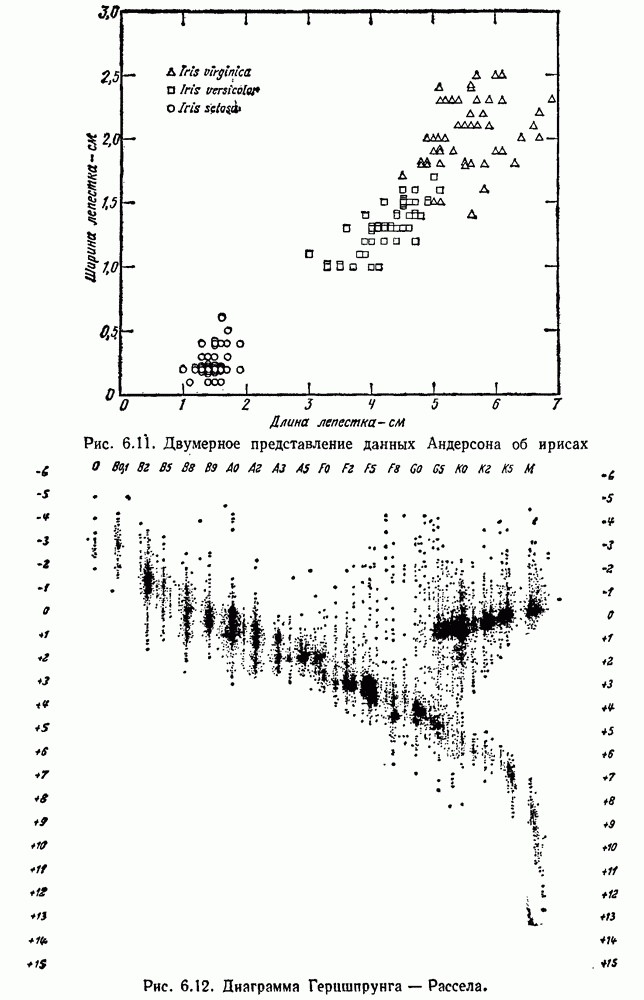
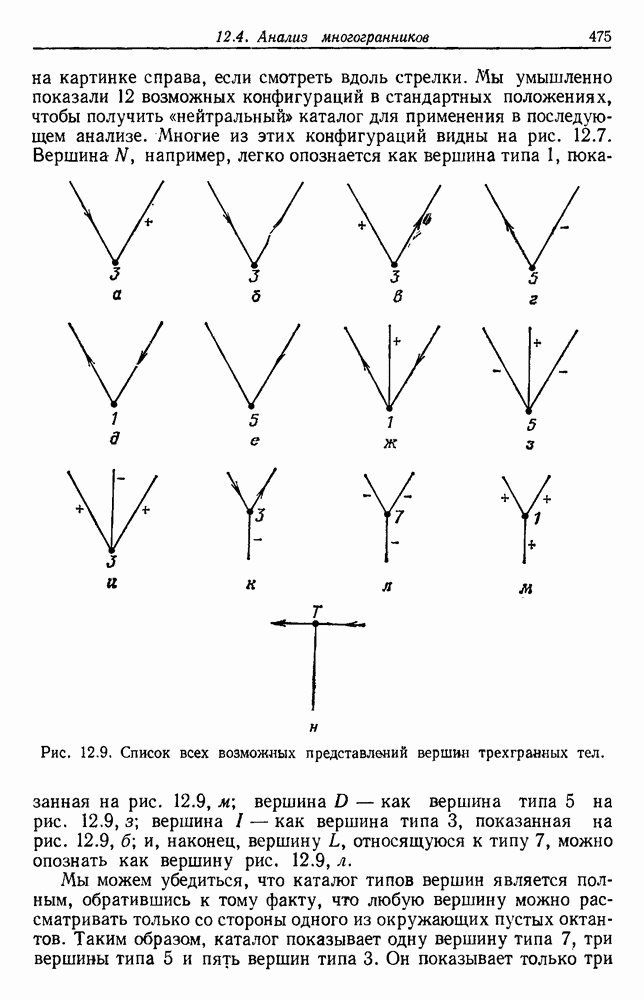
Эта функция имеет простую интерпретацию. Для данной группы Какого типа задачи группировки подходят для критерия в виде суммы квадратов ошибок? В основном (см. скан) Рис. 6.11. Двумерное представление данных Андерсона об ирисах (см. скан) Рис. 6.12. Диаграмма Герцшпрунга — Рассела. когда имеется большое различие между числом выборок из разных групп. В этом случае может случиться, что группировка, которая разделяет большую группу, имеет преимущество перед группировкой, сохраняющей единство группы, только потому, что достигнутое уменьшение квадратичной ошибки умножается на число членов этой суммы (рис. 6.13). Такая ситуация часто вызывается наличием случайных, далеко отстоящих выборок, и возникает проблема интерпретации и оценки результатов группировок. Так как об этом трудно что-либо сказать, мы просто отметим, что если дополнительные условия приводят к тому, что результат минимизации 6.8.2. РОДСТВЕННЫЕ КРИТЕРИИ МИНИМУМА ДИСПЕРСИИПростыми алгебраическими преобразованиями мы можем избавиться от средних векторов в выражении
где
В уравнении (28) s, интерпретируется как среднеквадратичное расстояние между точками
Рис. 6.13. Задача расщепления больших групп: сумма квадратов ошибок меньше для а, чем для б. функциями, как
или
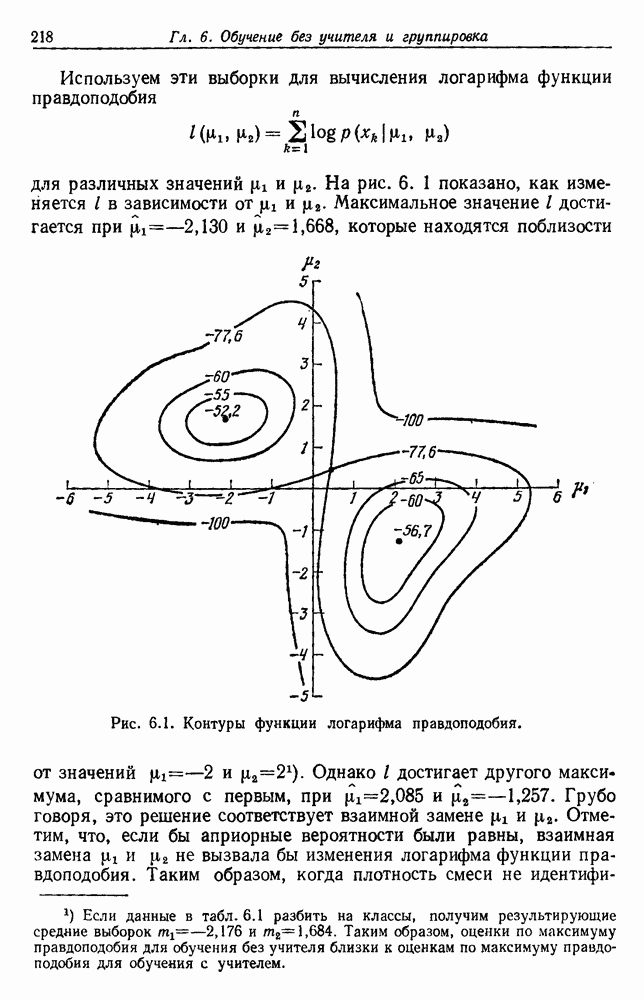
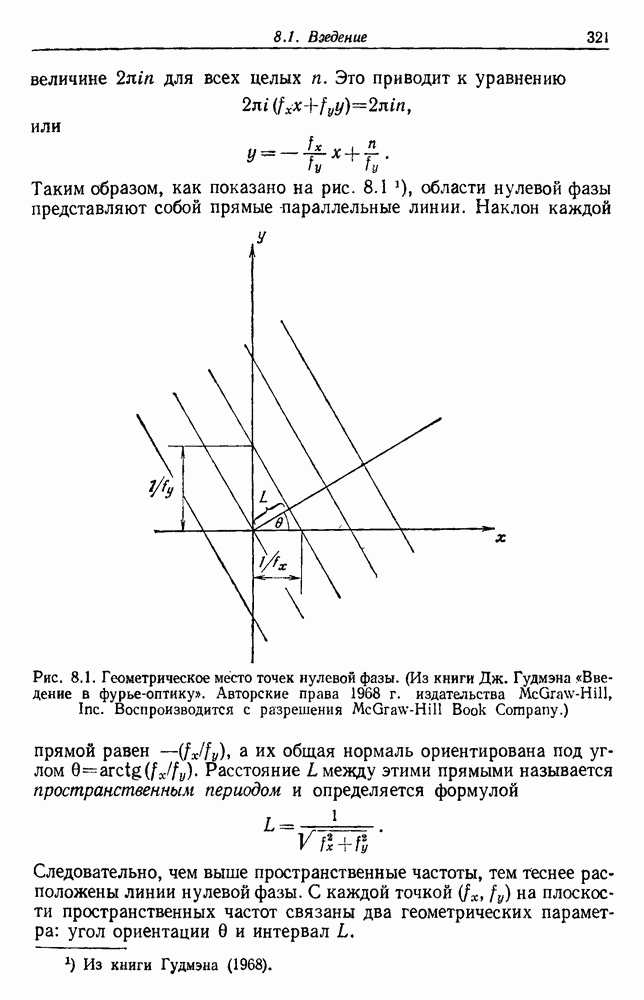
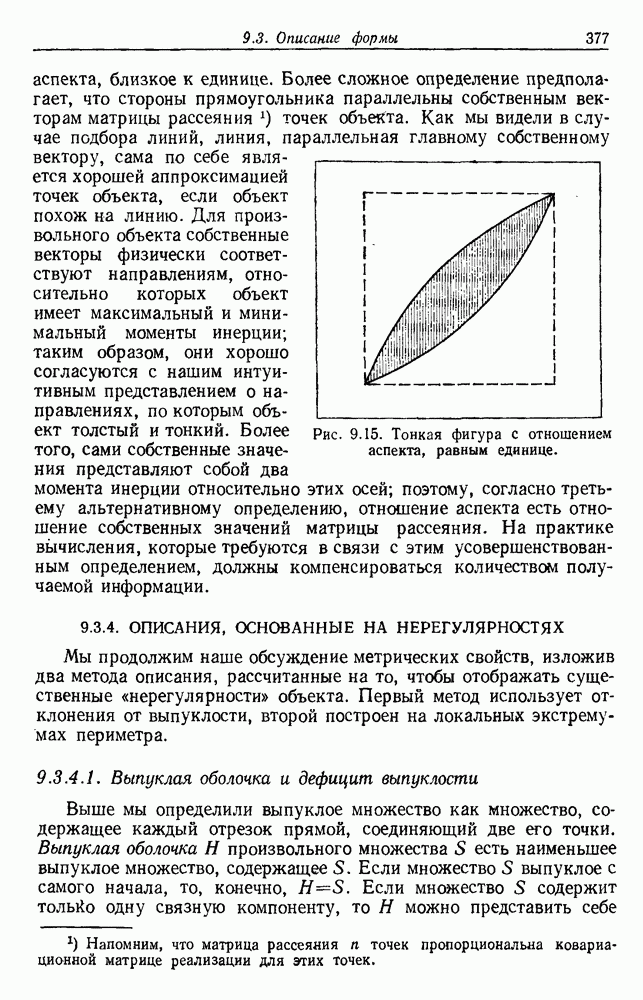
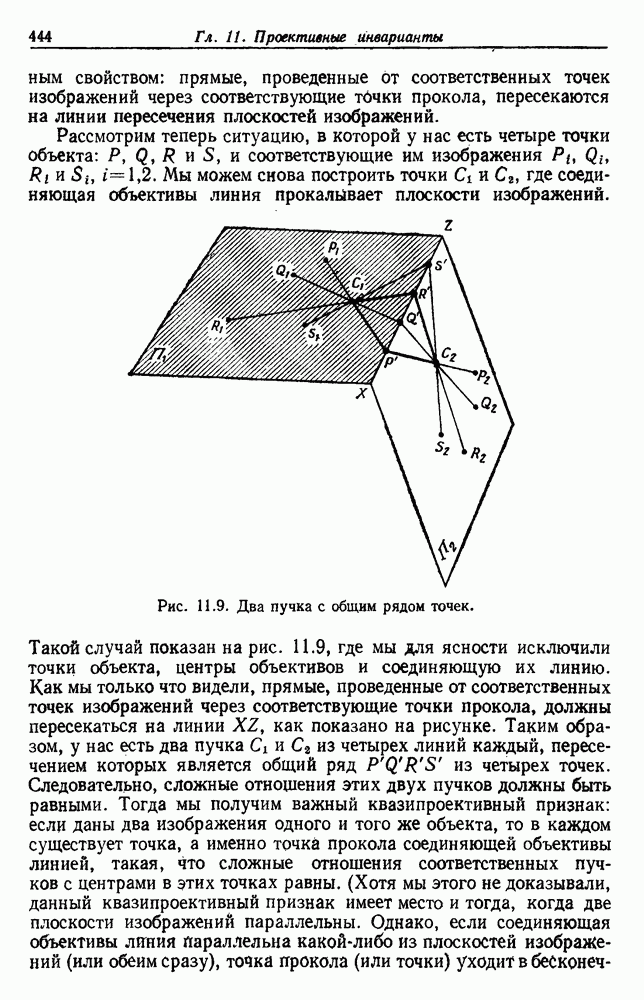
Как и раньше, мы считаем оптимальным такое разделение, которое дает экстремум критерия. Это приводит к корректно поставленной задаче, и есть надежда, что ее решение вскроет внутреннюю структуру данных. 6.8.3. КРИТЕРИИ РАССЕЯНИЯ6.8.3.1. Матрицы рассеянияДругой интересный класс функций критериев можно получить из матриц рассеяния, используемых в множественном дискриминантном анализе. Следующие определения непосредственно вытекают из определений, данных в разд. 4.11. Средний вектор
Общий средний вектор
Матрица рассеяния для
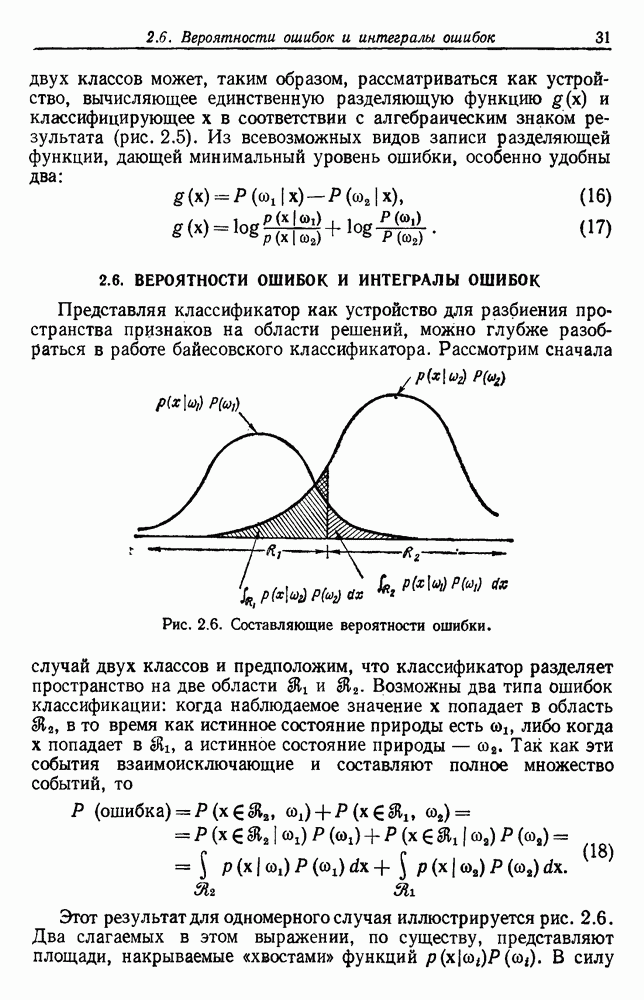
Матрица рассеяния внутри группы
Матрица рассеяния между группами
Общая матрица рассеяния
Как и раньше, из этих определений следует, что общая матрица рассеяния представляет собой сумму матрицы рассеяния внутри группы и матрицы рассеяния между группами:
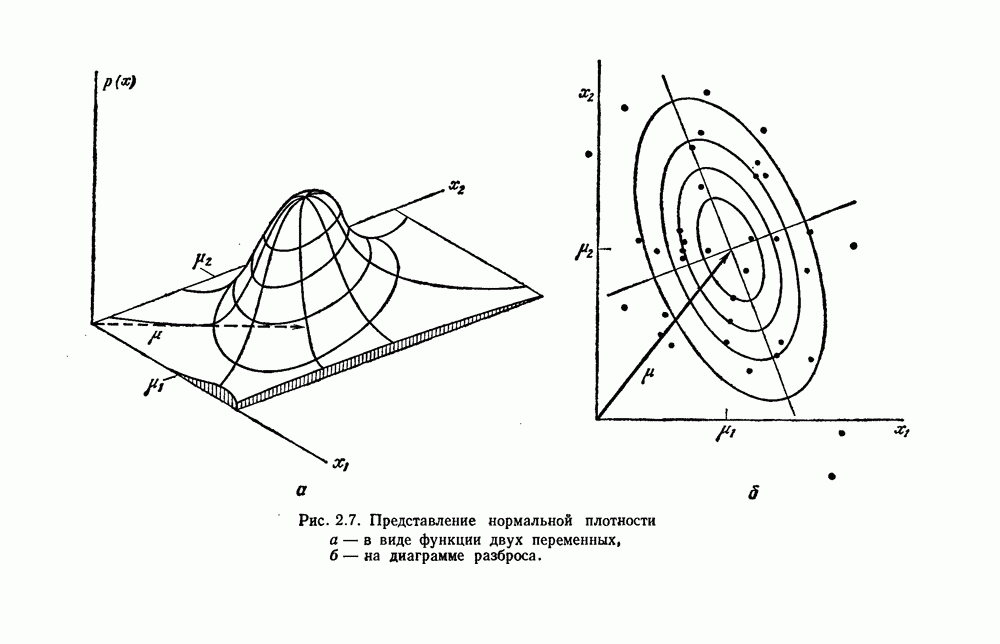
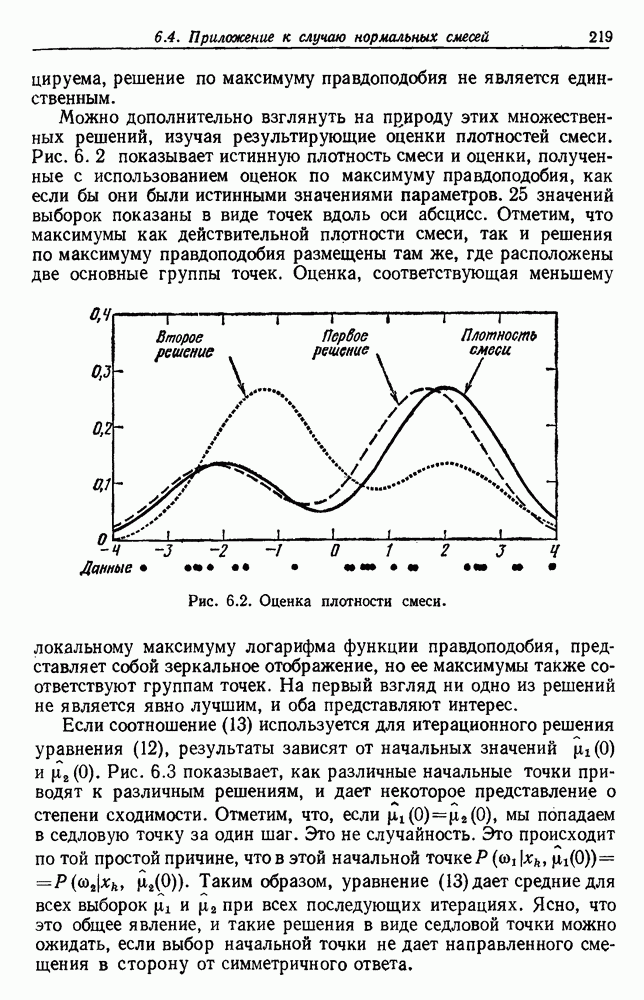
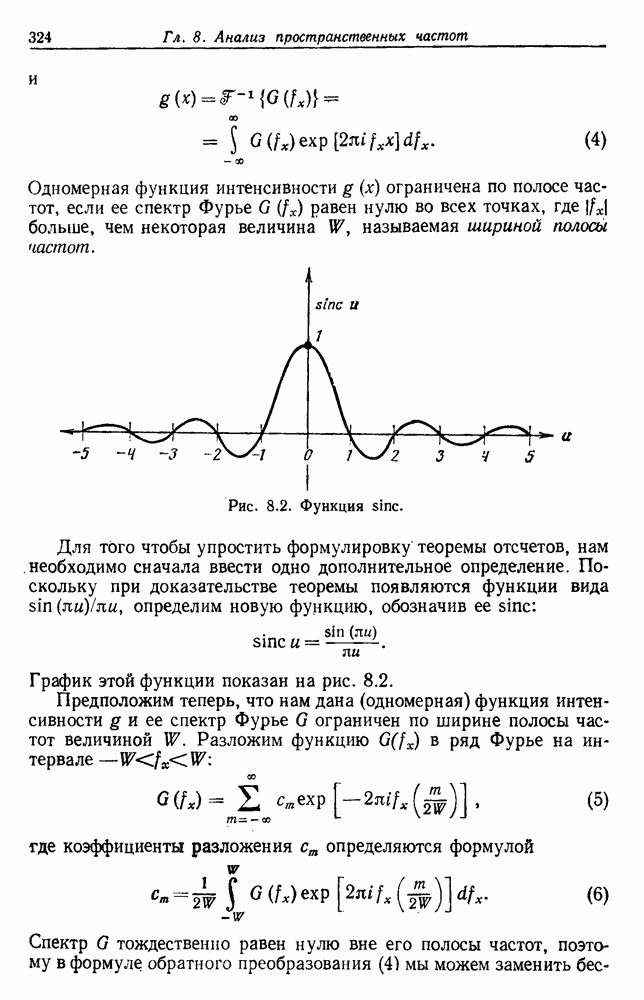
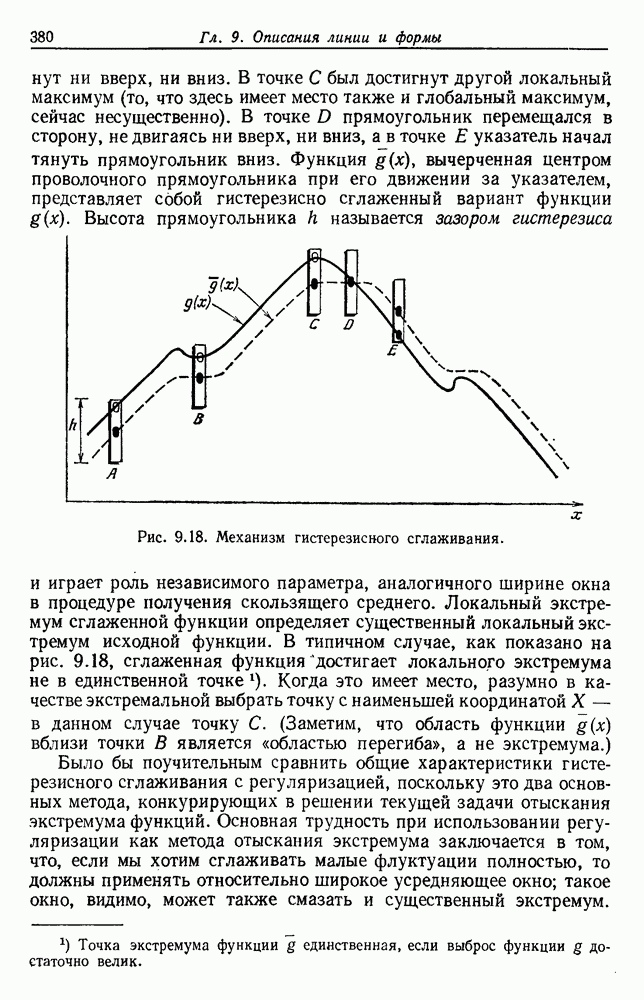
Отметим, что общая матрица рассеяния не зависит от того, как множество выборок разделено на группы. Она зависит только от общего множества выборок. Матрицы рассеяния, внутригрупповые и межгрупповые, все же зависят от разделения. Грубо говоря, существует взаимный обмен между этими двумя матрицами, при этом межгрупповое рассеяние увеличивается, если внутригрупповое уменьшается. Это удобно, потому что, минимизируя внутригрупповую матрицу, мы максимизируем межгрупповую. Чтобы более точно говорить о степени внутригруппового и межгруппового рассеяния, нам нужно ввести скалярную меру матрицы рассеяния. Рассмотрим две меры — след и определитель. В случае одной переменной эти величины эквивалентны, и мы можем определить оптимальное разделение как такое, которое минимизирует 6.8.3.2. След в качестве критерияСамой простой скалярной мерой матрицы рассеяния является ее след — сумма ее диагональных элементов. Грубо говоря, след измеряет квадрат радиуса рассеяния, так как он пропорционален сумме дисперсий по направлениям координат. Таким образом, очевидной функцией критерия для минимизации является след
Так как
6.8.3.3. Определитель в качестве критерияВ разд. 4.11 мы использовали определитель матрицы рассеяния для получения скалярной меры рассеяния. Грубо говоря, он измеряет квадрат величины рассеяния, поскольку пропорционален произведению дисперсий в направлении главных осей. Так как S будет вырожденной матрицей, если число групп меньше или равно размерности, то
Разделение, которое минимизирует
Из того, что масштабный множитель 6.8.3.4. Инвариантные критерииНетрудно показать, что собственные значения желательно, чтобы разделение давало большие значения. Конечно, как мы отметили в разд. 4.11, тот факт, что ранг SB не может превышать Можно изобрести большое число инвариантных критериев группировки с помощью компоновки соответствующих функций этих собственных значений. Некоторые из них естественно вытекают из стандартных матричных операций. Например, поскольку след матрицы — это сумма ее собственных значений, можно выбрать для максимизации функцию критерия
Используя соотношение
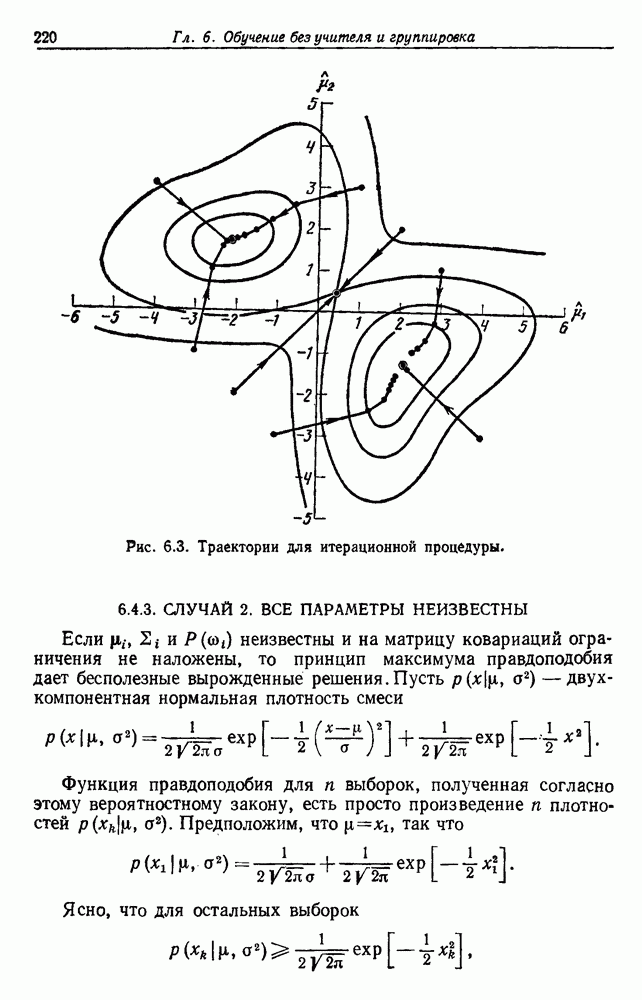
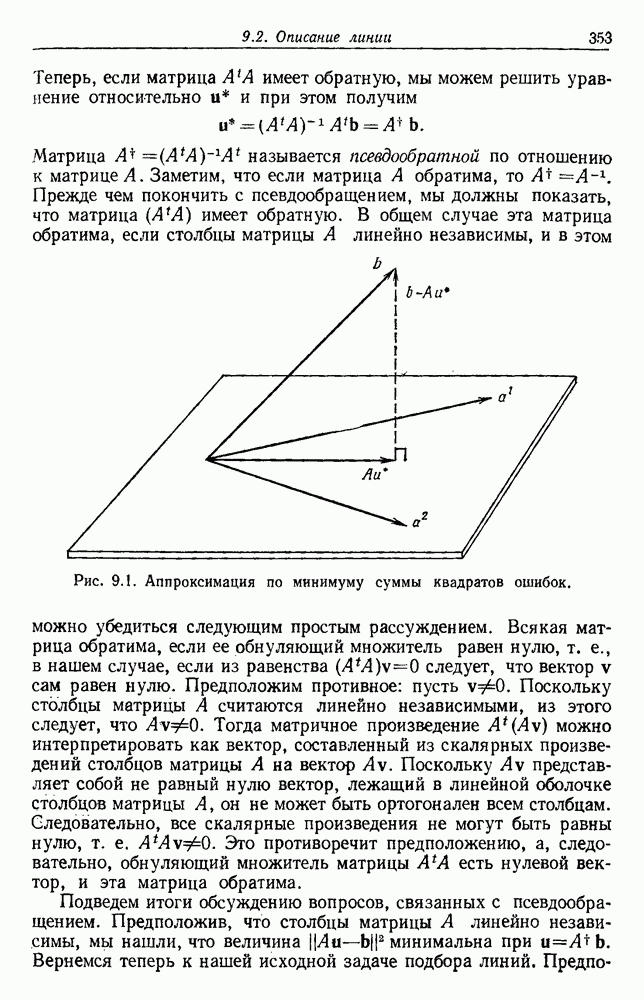
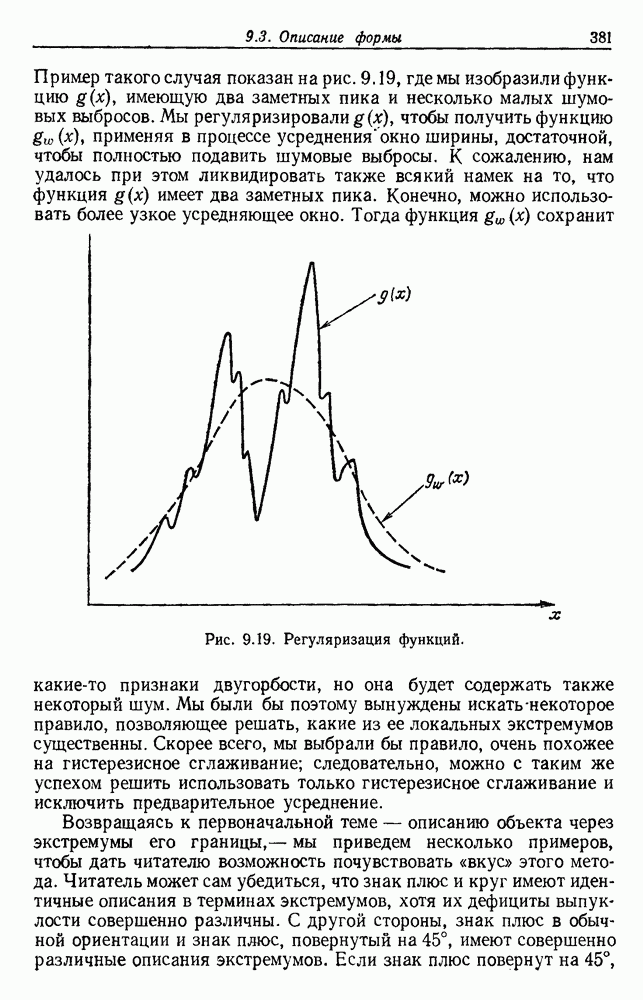
Так как все эти функции критериев инвариантны относительно линейных преобразований, это же верно для разделений, которые приводят функцию к экстремуму. В частном случае двух групп только одно собственное значение не равно нулю, и все эти критерии приводят к одной и той же группировке. Однако, когда выборки разделены более чем на две группы, оптимальные разделения, хотя часто и подобные, необязательно одинаковы. По отношению к функциям критерия, включающим S, отметим, что критерия суммы квадратов ошибок Сделаем последнее предупреждение об инвариантных критериях. Если можно получить очевидно различные группировки масштабированием осей или применением другого линейного преобразования, то все эти группировки должны быть выделены инвариантной процедурой. Таким образом, весьма вероятно, что инвариантные функции критериев обладают многочисленными локальными экстремумами и соответственно более трудно поддаются выделению экстремума. Разнообразие функций критериев, о которых здесь говорилось, и небольшие различия между ними не должны заслонить их существенной общности. В каждом случае основой модели служит то, что выборки образуют с хорошо разделенных облаков точек. Матрица внутригруппового рассеяния
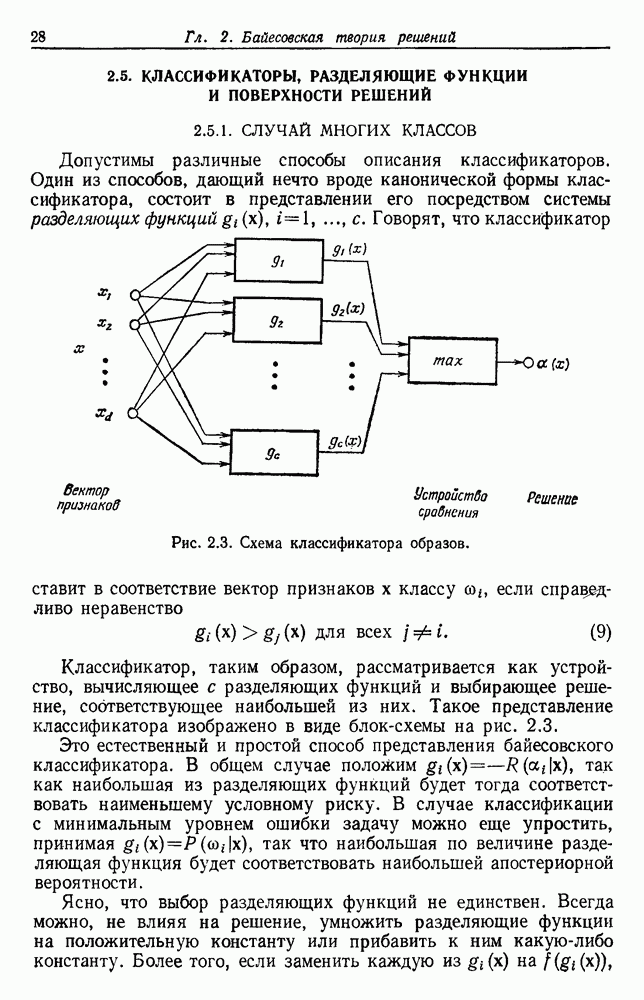
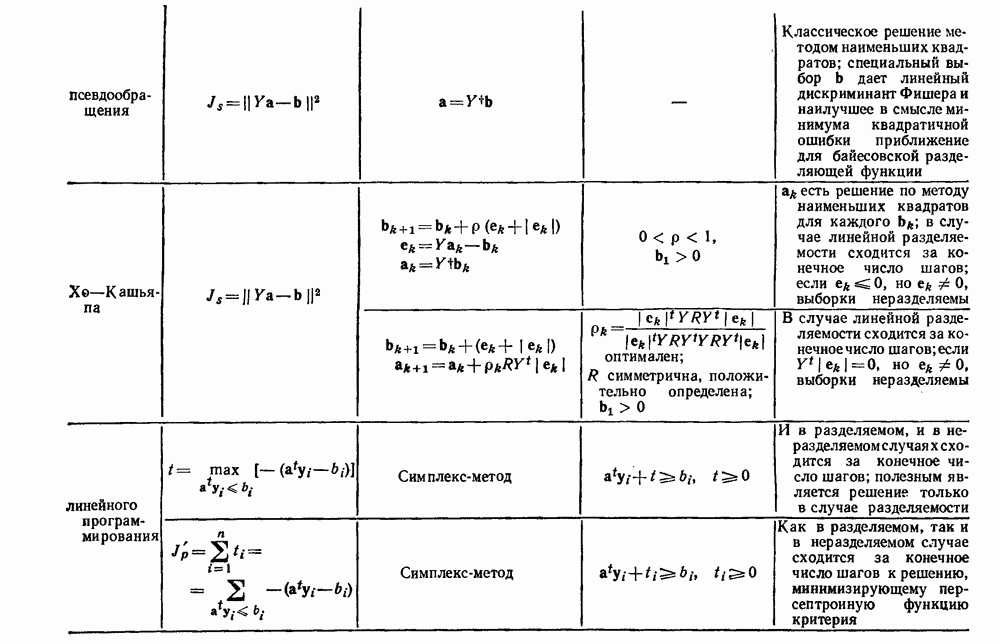
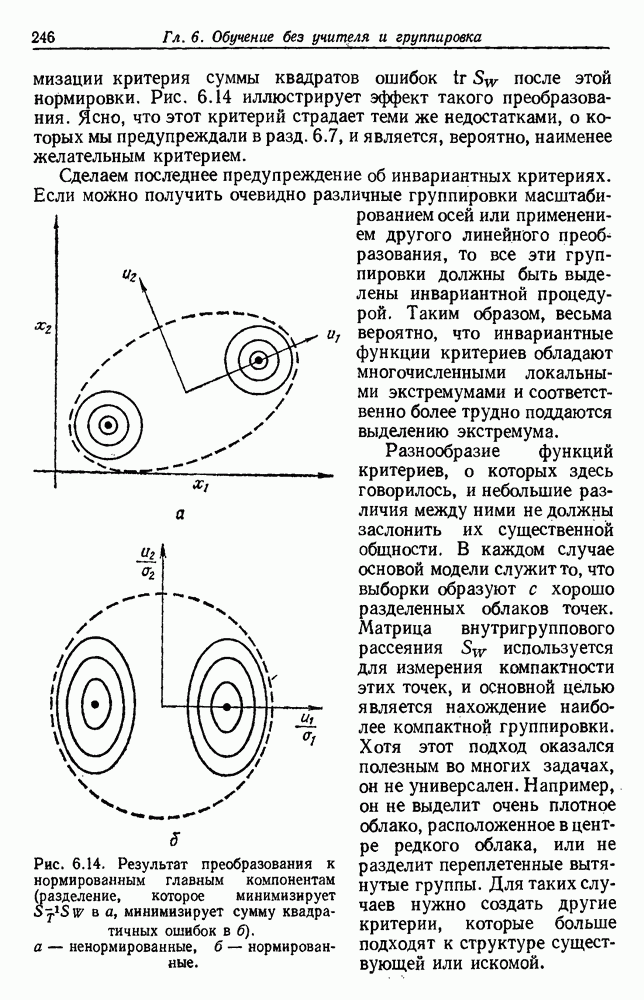
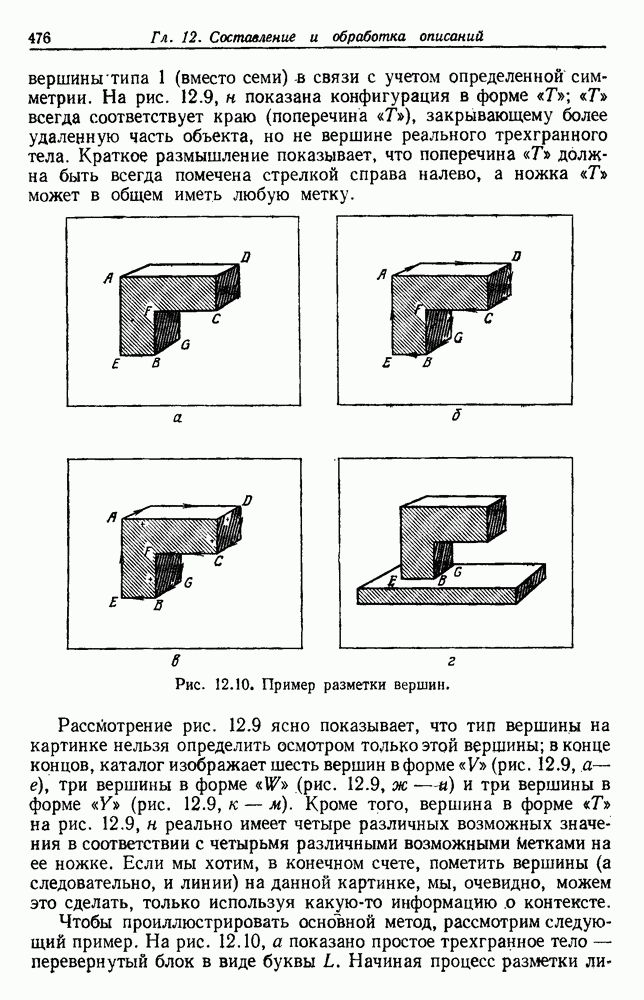
Рис. 6.14. Результат преобразования к нормированным главным компонентам (разделение, которое минимизирует
|
 |
Оглавление
|





























































































































































































































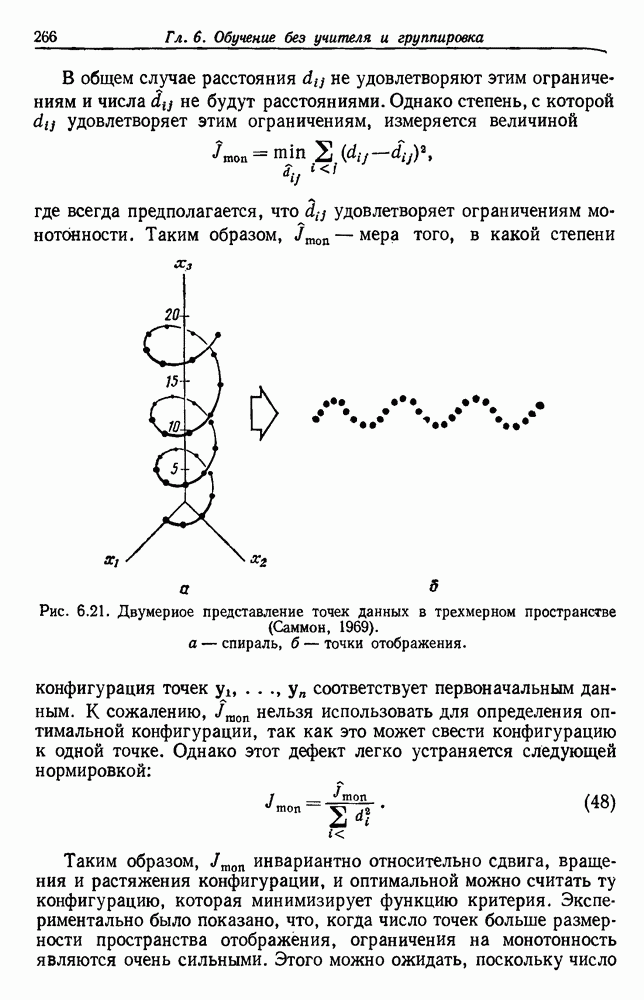




















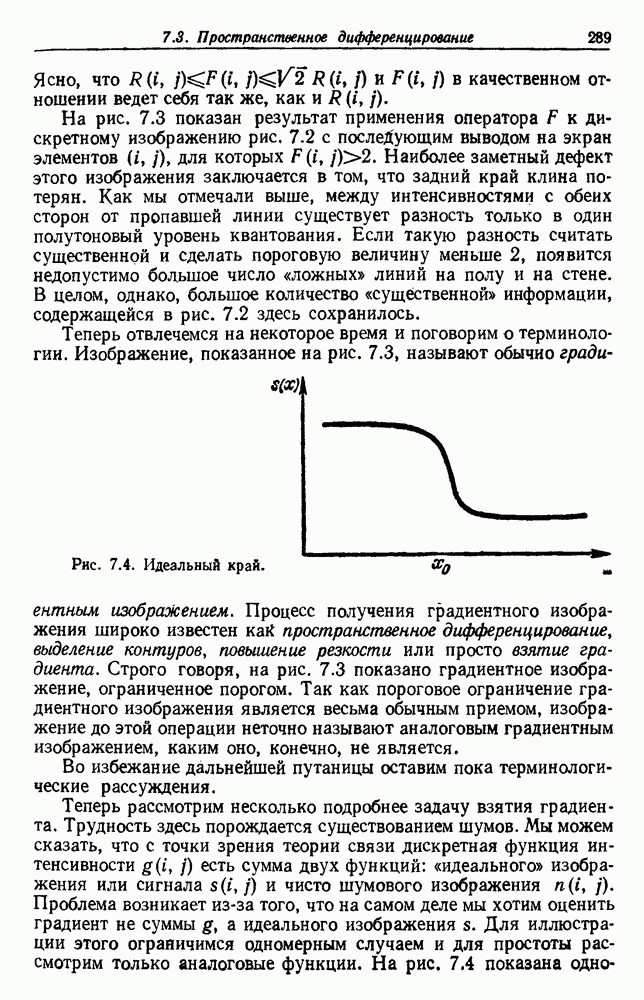
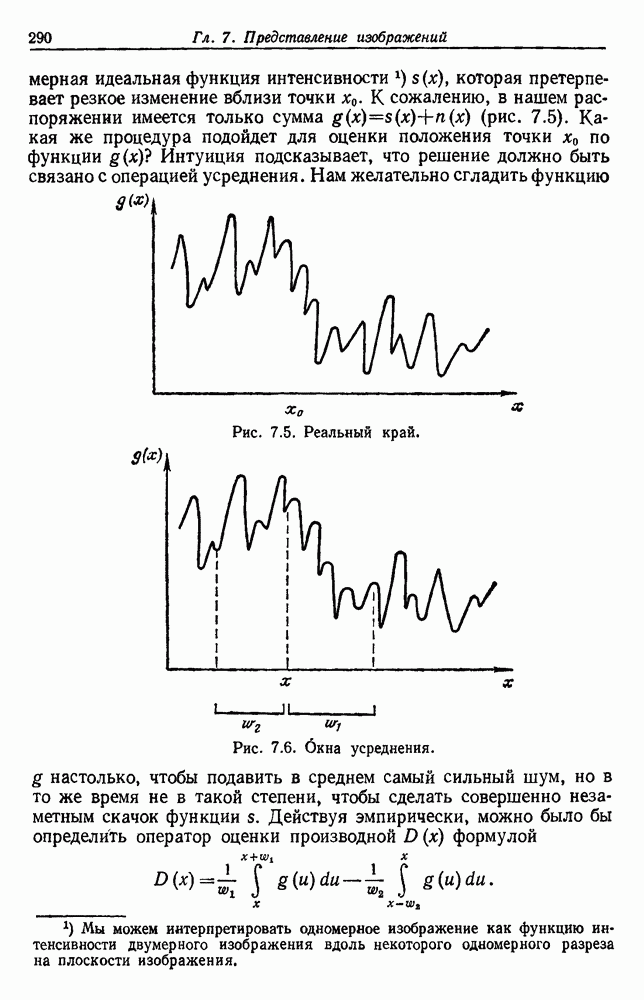

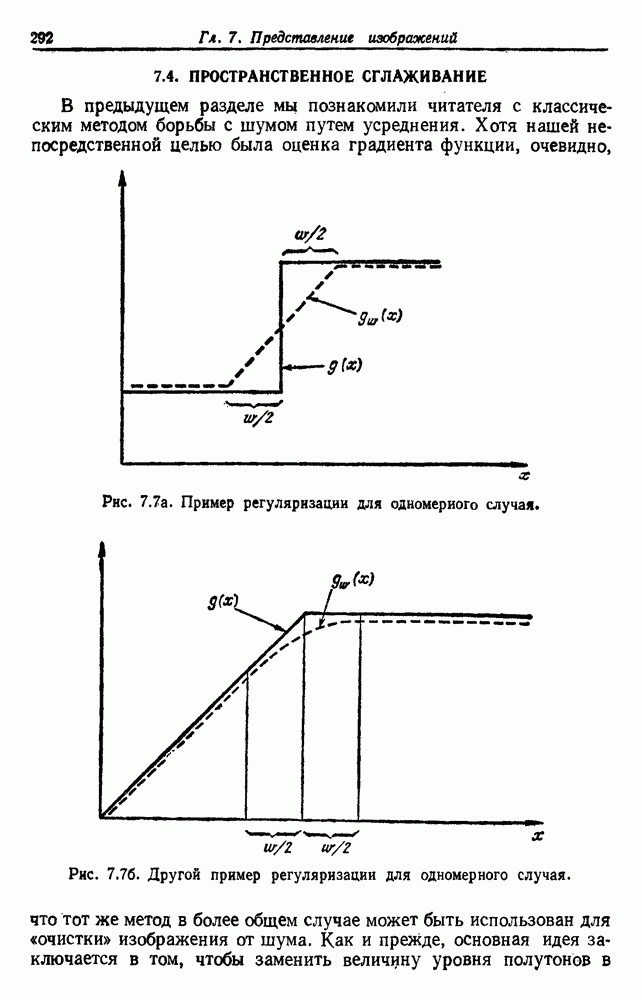








































































































































































 из
из  выборок
выборок  которые хотим разделить на точно с непересекающихся подмножеств
которые хотим разделить на точно с непересекающихся подмножеств
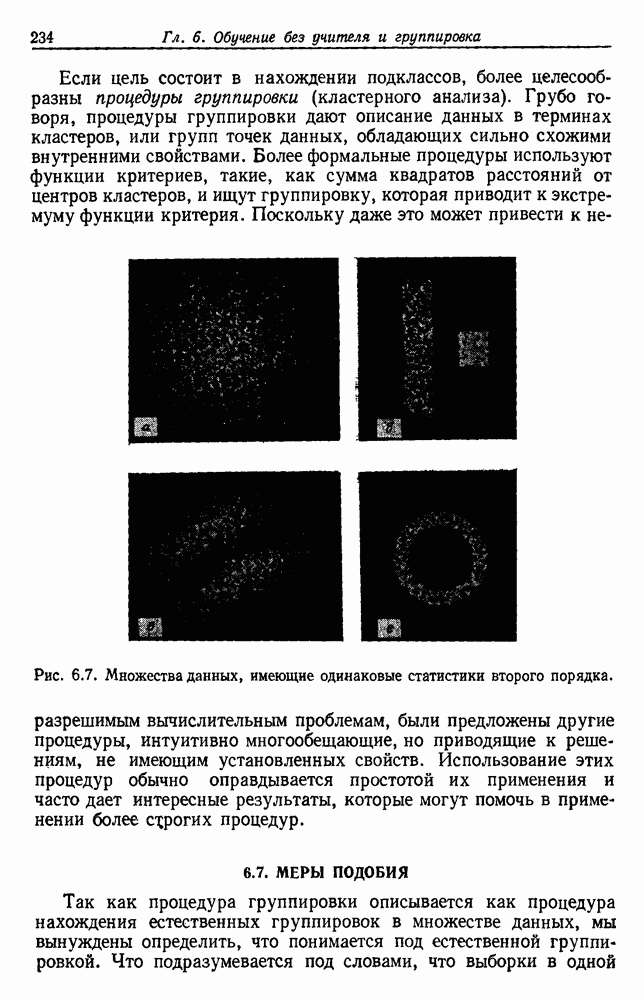
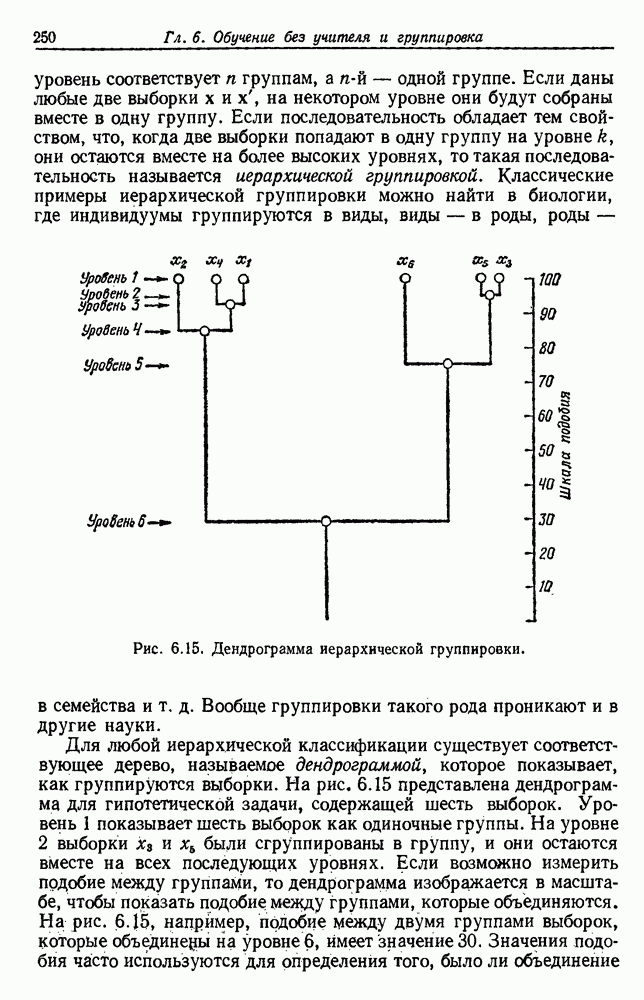
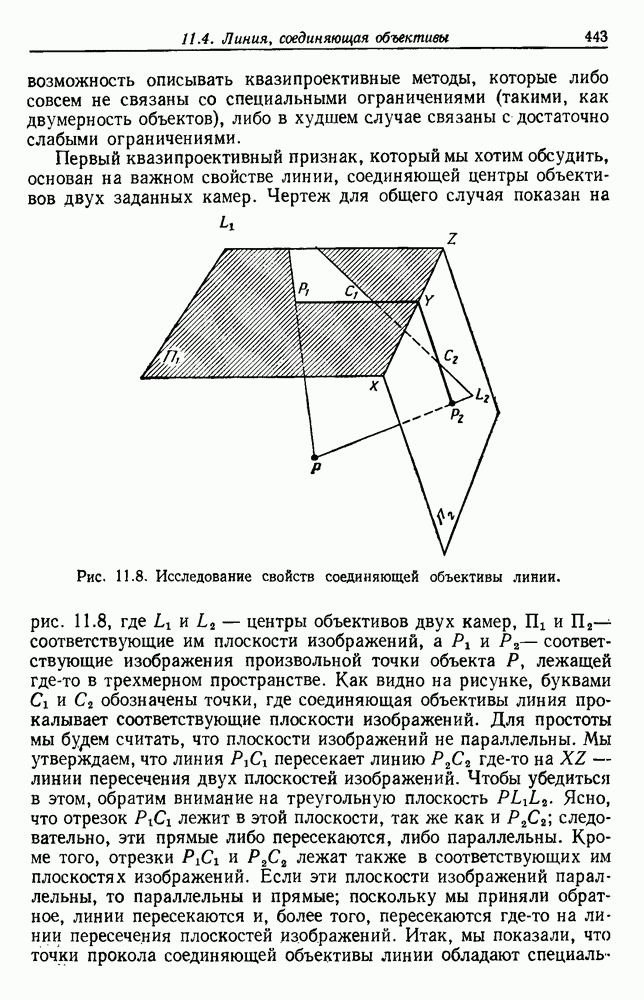
 Каждое подмножество должно представлять группу, причем выборки из одной группы более подобны между собой, чем выборки из разных групп. Чтобы хорошо поставить задачу, единственный путь — это определить функцию критерия, которая измеряет качество группировки любой части данных. Тогда задача заключается в определении такого разделения, которое максимизирует функцию критерия. В этом разделе мы рассмотрим характеристики некоторых в основном подобных функций критериев, отложив временно вопрос о нахождении оптимального разделения.
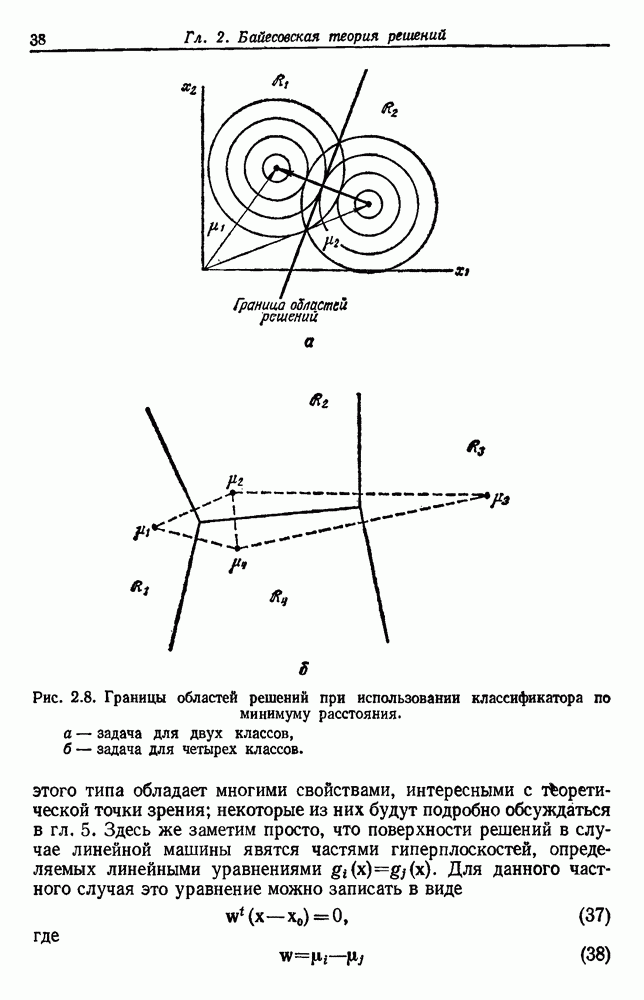
Каждое подмножество должно представлять группу, причем выборки из одной группы более подобны между собой, чем выборки из разных групп. Чтобы хорошо поставить задачу, единственный путь — это определить функцию критерия, которая измеряет качество группировки любой части данных. Тогда задача заключается в определении такого разделения, которое максимизирует функцию критерия. В этом разделе мы рассмотрим характеристики некоторых в основном подобных функций критериев, отложив временно вопрос о нахождении оптимального разделения.
 — число выборок в
— число выборок в  и пусть
и пусть  — среднее этих выборок:
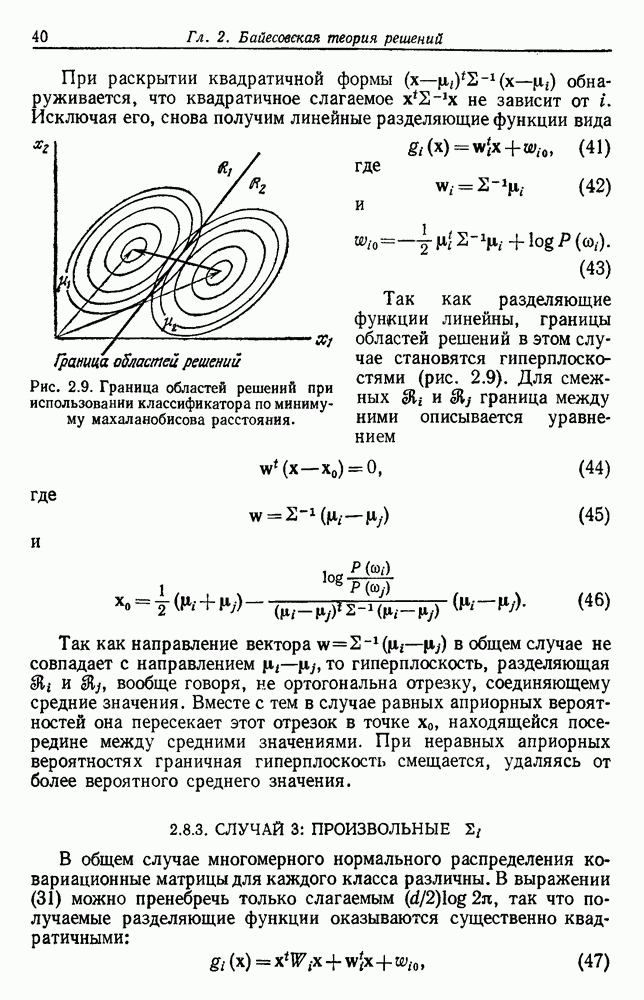
— среднее этих выборок:


 средний вектор
средний вектор  лучше всего представляет выборки в
лучше всего представляет выборки в  так как он минимизирует сумму квадратов длин векторов «ошибок»
так как он минимизирует сумму квадратов длин векторов «ошибок»  . Таким образом,
. Таким образом,  измеряет общую квадратичную ошибку, вносимую при представлении
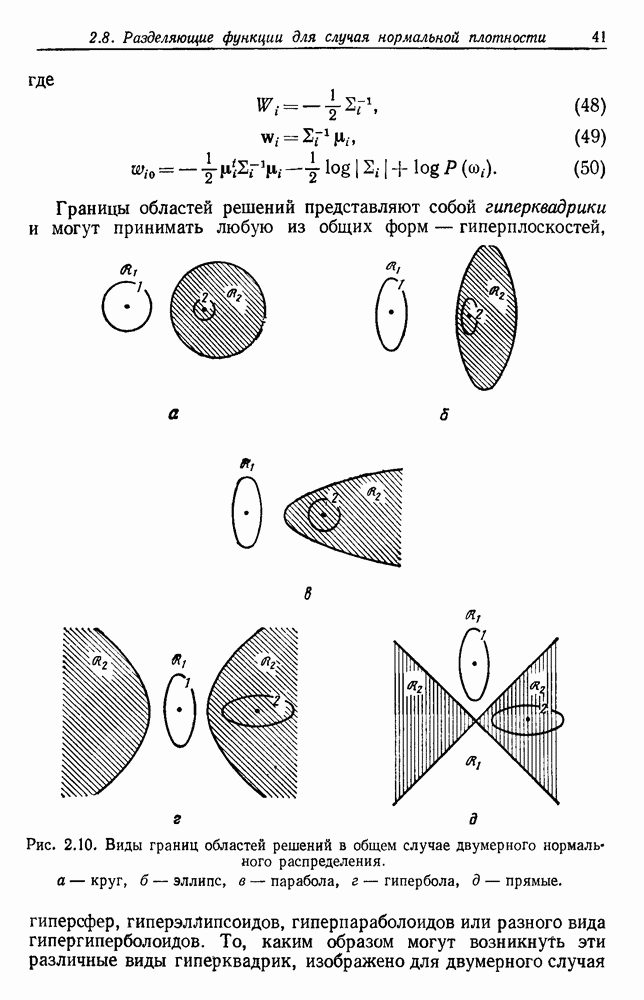
измеряет общую квадратичную ошибку, вносимую при представлении  выборок
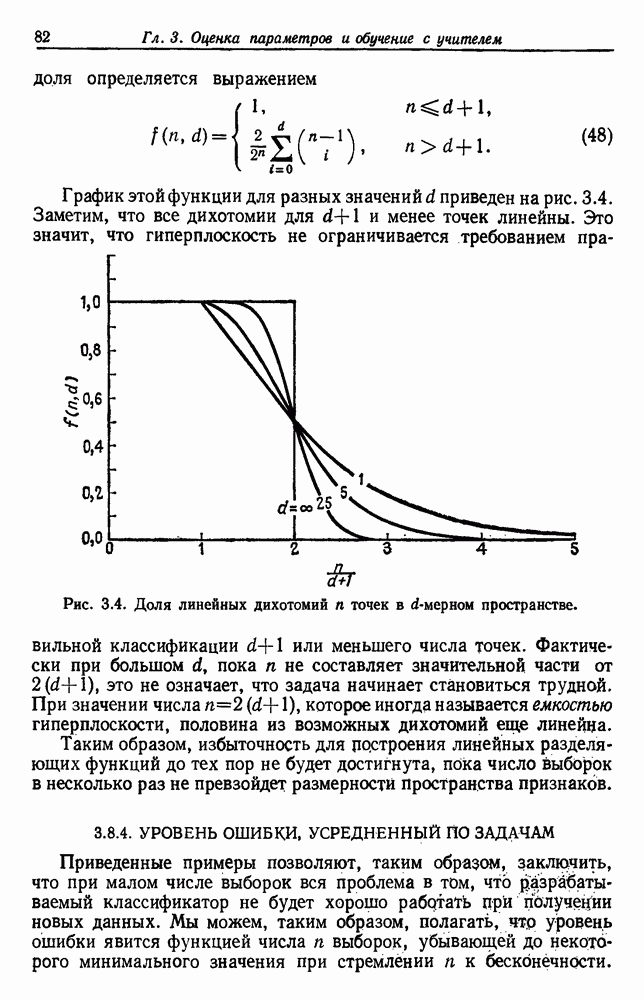
выборок  центрами с групп
центрами с групп  Значение
Значение  зависит от того, как выборки сгруппированы в группы, и оптимальным разделением считается то, которое минимизирует
зависит от того, как выборки сгруппированы в группы, и оптимальным разделением считается то, которое минимизирует  . Группировки такого типа называют разделением с минимальной дисперсией.
. Группировки такого типа называют разделением с минимальной дисперсией.
 — подходящий критерий в случае, когда выборки образуют облака, которые достаточно хорошо отделены друг от друга. Он хорошо будет работать для двух или трех групп рис. 6.11, но для данных на рис. 6.12 не даст удовлетворительных результатов. Менее явные проблемы возникают,
— подходящий критерий в случае, когда выборки образуют облака, которые достаточно хорошо отделены друг от друга. Он хорошо будет работать для двух или трех групп рис. 6.11, но для данных на рис. 6.12 не даст удовлетворительных результатов. Менее явные проблемы возникают,
 неудовлетворителен, то эти условия должны быть использованы для формулировки лучшей функции критерия.
неудовлетворителен, то эти условия должны быть использованы для формулировки лучшей функции критерия.
 и получить эквивалентное выражение
и получить эквивалентное выражение


 группы и подчеркивает тот факт, что критерий по сумме квадратов ошибок использует как меру подобия евклидово расстояние. Оно также подсказывает очевидный путь получения других функций критериев. Например, можно заменить s средним значением, медианой или, может быть, максимальным расстоянием между точками в группе. В более общем случае можно ввести соответствующую функцию подобия
группы и подчеркивает тот факт, что критерий по сумме квадратов ошибок использует как меру подобия евклидово расстояние. Оно также подсказывает очевидный путь получения других функций критериев. Например, можно заменить s средним значением, медианой или, может быть, максимальным расстоянием между точками в группе. В более общем случае можно ввести соответствующую функцию подобия  и заменить
и заменить  такими
такими



 группы
группы


 группы
группы





 или максимизирует
или максимизирует  . В случае многих переменных возникают сложности, и было предложено несколько критериев оптимальности.
. В случае многих переменных возникают сложности, и было предложено несколько критериев оптимальности.
 . В действительности это не что иное, как критерий в виде суммы квадратов ошибок, поскольку из (33) и (34) следует
. В действительности это не что иное, как критерий в виде суммы квадратов ошибок, поскольку из (33) и (34) следует

 не зависит от разделения выборок, мы не получаем никаких новых результатов при попытке максимизировать
не зависит от разделения выборок, мы не получаем никаких новых результатов при попытке максимизировать  Однако нас должно утешать то, что при попытке минимизировать внутригрупповой критерий
Однако нас должно утешать то, что при попытке минимизировать внутригрупповой критерий  мы максимизируем межгрупповой критерий
мы максимизируем межгрупповой критерий

 — явно плохой выбор для функции критерия. Матрица
— явно плохой выбор для функции критерия. Матрица  может быть вырожденной и непременно будет таковой в случае, если
может быть вырожденной и непременно будет таковой в случае, если  меньше, чем размерность d. Однако, если мы предполагаем, что
меньше, чем размерность d. Однако, если мы предполагаем, что  невырожденна, то приходим к функции критерия
невырожденна, то приходим к функции критерия

 обычно подобно разделению, которое минимизирует
обычно подобно разделению, которое минимизирует  но они не обязательно одинаковы. Мы заметили ранее, что разделение, которое минимизирует квадратичную ошибку, может изменяться, если изменяется масштаб по осям. Этого не происходит с
но они не обязательно одинаковы. Мы заметили ранее, что разделение, которое минимизирует квадратичную ошибку, может изменяться, если изменяется масштаб по осям. Этого не происходит с  Чтобы выяснить, почему это так, рассмотрим невырожденную матрицу Т и преобразование переменных
Чтобы выяснить, почему это так, рассмотрим невырожденную матрицу Т и преобразование переменных  Считая разделение постоянным, мы получаем новые средние векторы
Считая разделение постоянным, мы получаем новые средние векторы  и новые матрицы рассеяния
и новые матрицы рассеяния  Таким образом,
Таким образом,  изменяется на
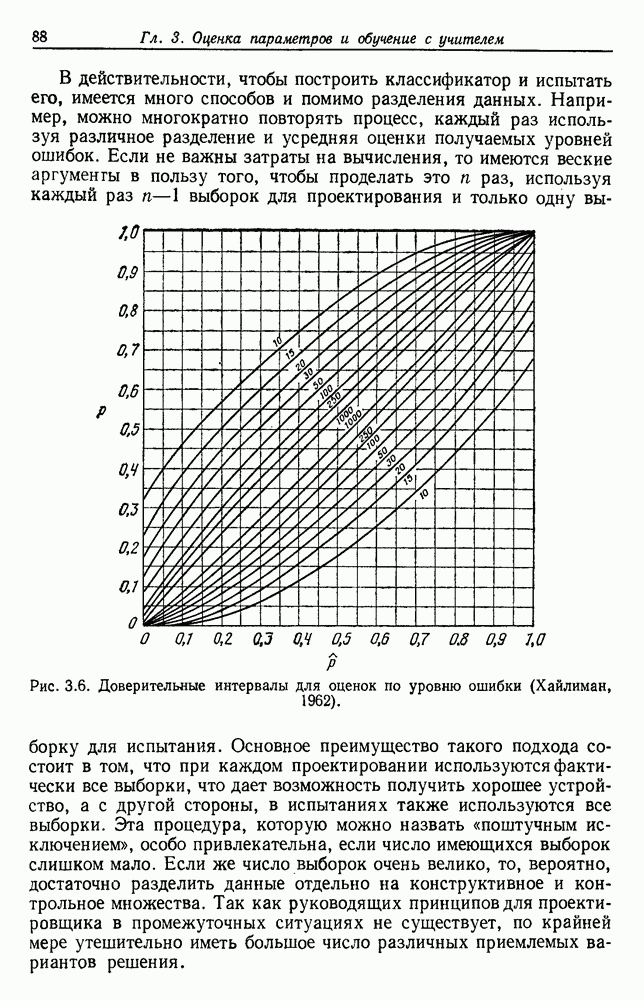
изменяется на

 одинаков для всех разделений, следует, что
одинаков для всех разделений, следует, что  дают одно и то же разделение, и, значит, оптимальная группировка, основанная на
дают одно и то же разделение, и, значит, оптимальная группировка, основанная на  инвариантна относительно линейных невырожденных преобразований данных.
инвариантна относительно линейных невырожденных преобразований данных.
 матрицы инвариантны при невырожденных линейных преобразованиях данных. Действительно, эти собственные значения являются основными линейными инвариантами матриц рассеяния. Их числовые значения выражают отношение межгруппового рассеяния к внутригрупповому в направлении собственных векторов, и обычно
матрицы инвариантны при невырожденных линейных преобразованиях данных. Действительно, эти собственные значения являются основными линейными инвариантами матриц рассеяния. Их числовые значения выражают отношение межгруппового рассеяния к внутригрупповому в направлении собственных векторов, и обычно
 означает, что не более чем
означает, что не более чем  этих собственных значений будут не равны нулю. Тем не менее хброшими считаются такие разделения, у которых ненулевые собственные значения велики.
этих собственных значений будут не равны нулю. Тем не менее хброшими считаются такие разделения, у которых ненулевые собственные значения велики.


 можно вывести следующие инвариантные модификации для
можно вывести следующие инвариантные модификации для 

 не зависит от того, как выборки разделены на группы. Таким образом, группировки, которые минимизируют
не зависит от того, как выборки разделены на группы. Таким образом, группировки, которые минимизируют  в точности те же, которые минимизируют
в точности те же, которые минимизируют  Если мы вращаем и масштабируем оси так, что S становится единичной матрицей, можно видеть, что минимизация
Если мы вращаем и масштабируем оси так, что S становится единичной матрицей, можно видеть, что минимизация  эквивалентна минимизации
эквивалентна минимизации
 после этой нормировки. Рис. 6.14 иллюстрирует эффект такого преобразования. Ясно, что этот критерий страдает теми же недостатками, о которых мы предупреждали в разд. 6.7, и является, вероятно, наименее желательным критерием.
после этой нормировки. Рис. 6.14 иллюстрирует эффект такого преобразования. Ясно, что этот критерий страдает теми же недостатками, о которых мы предупреждали в разд. 6.7, и является, вероятно, наименее желательным критерием.
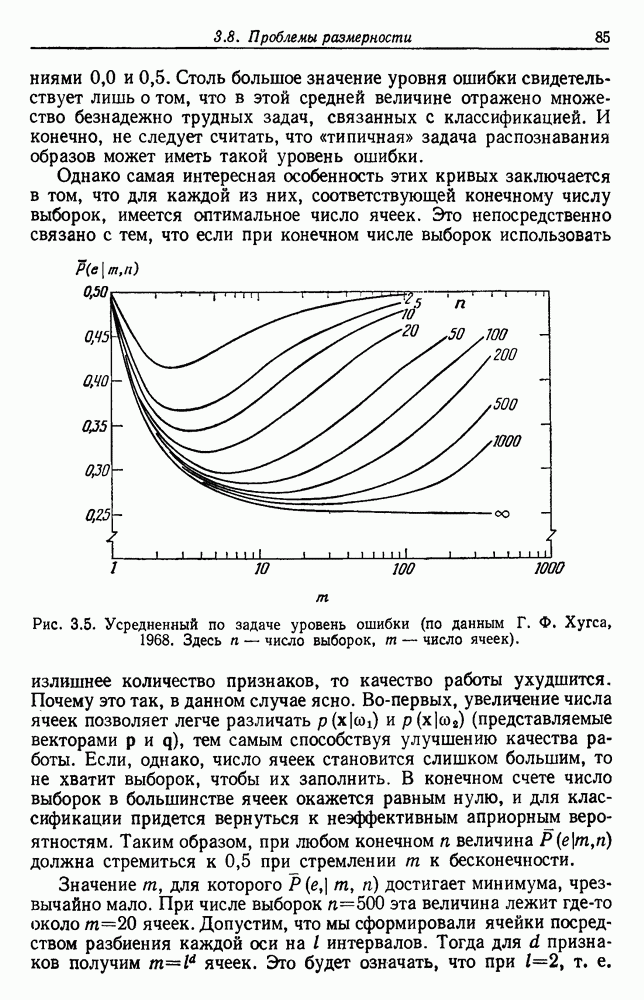
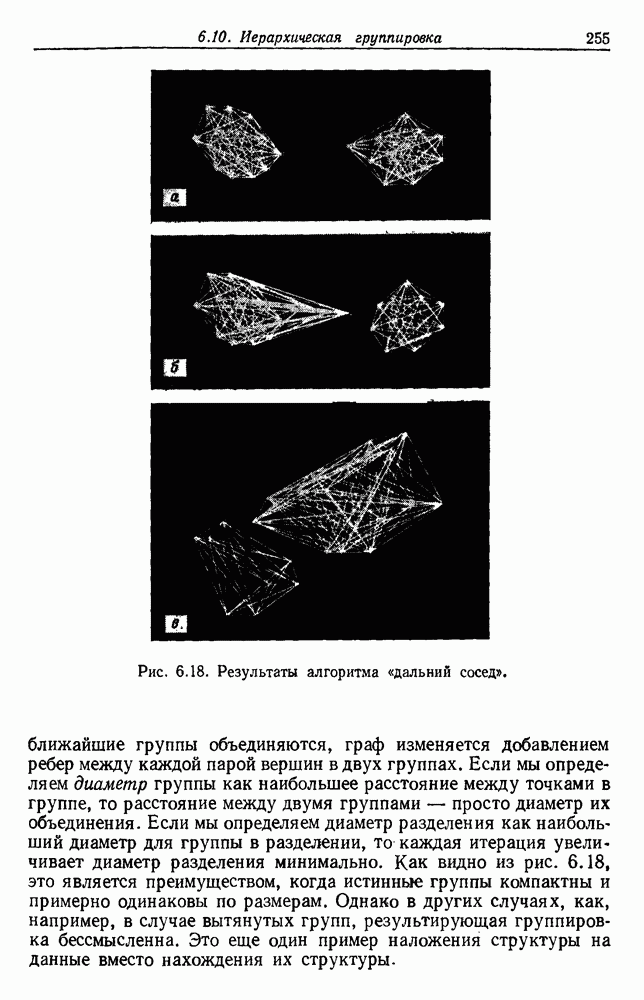
 используется для измерения компактности этих точек, и основной целью является нахождение наиболее компактной группировки. Хотя этот подход оказался полезным во многих задачах, он не универсален. Например, он не выделит очень плотное облако, расположенное в центре редкого облака, или не разделит переплетенные вытянутые группы. Для таких случаев нужно создать другие критерии, которые больше подходят к структуре существующей или искомой.
используется для измерения компактности этих точек, и основной целью является нахождение наиболее компактной группировки. Хотя этот подход оказался полезным во многих задачах, он не универсален. Например, он не выделит очень плотное облако, расположенное в центре редкого облака, или не разделит переплетенные вытянутые группы. Для таких случаев нужно создать другие критерии, которые больше подходят к структуре существующей или искомой.

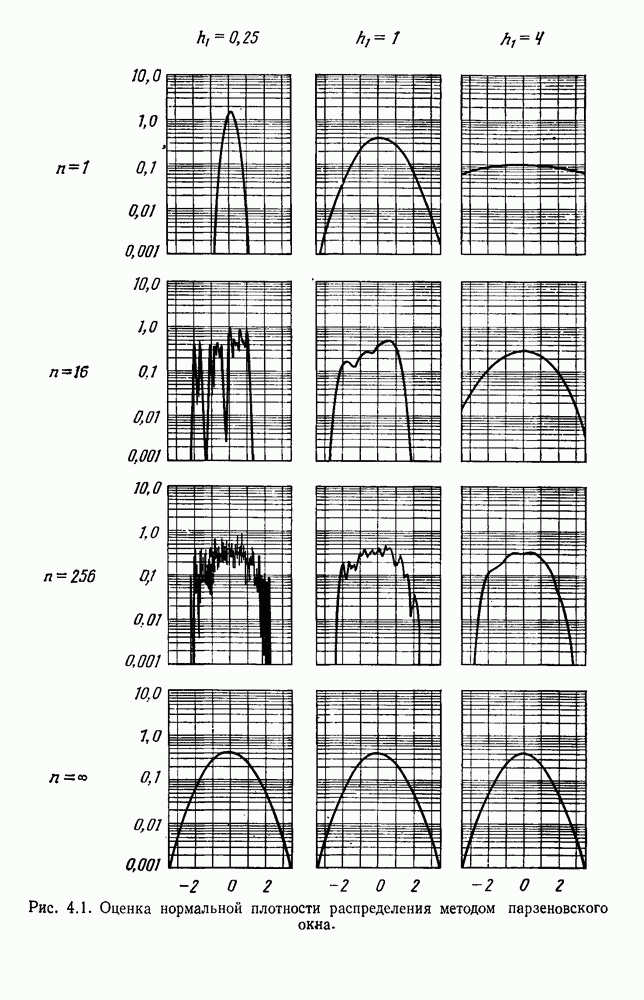
 в а, минимизирует сумму квадратичных ошибок в б), а — ненормированные, б — нормированные.
в а, минимизирует сумму квадратичных ошибок в б), а — ненормированные, б — нормированные.