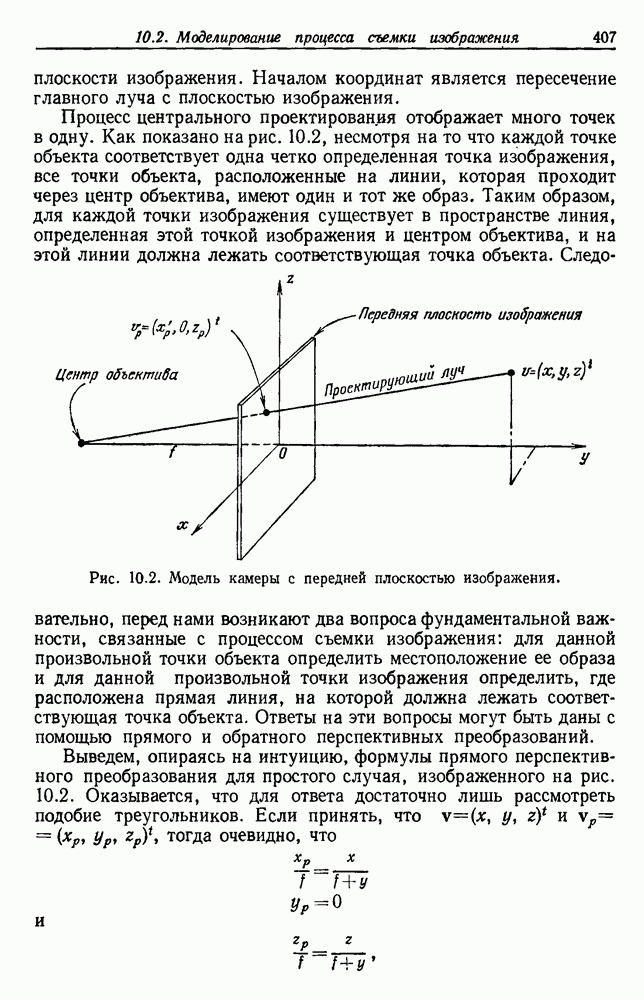
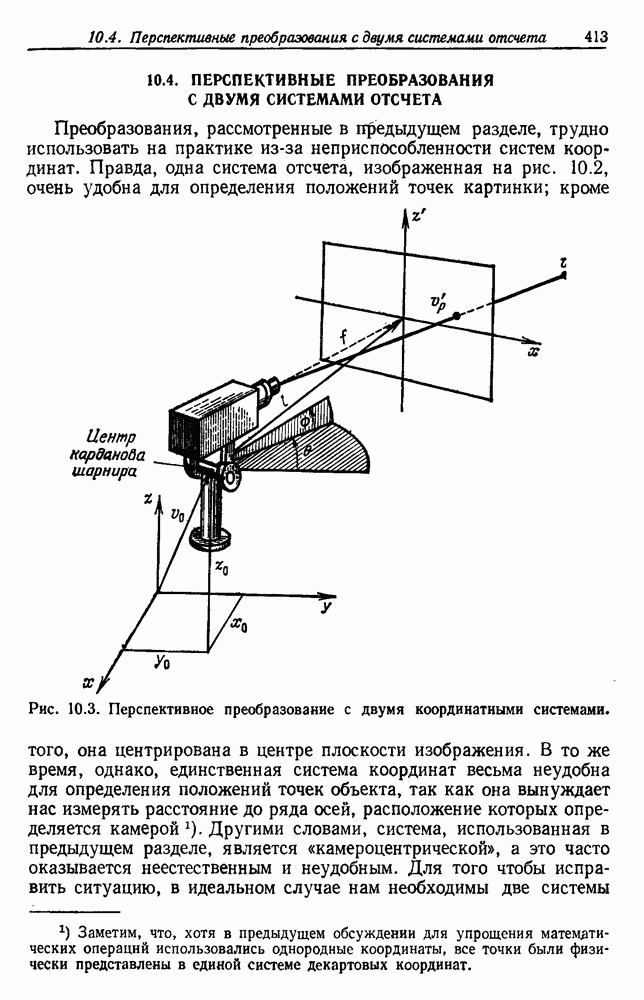
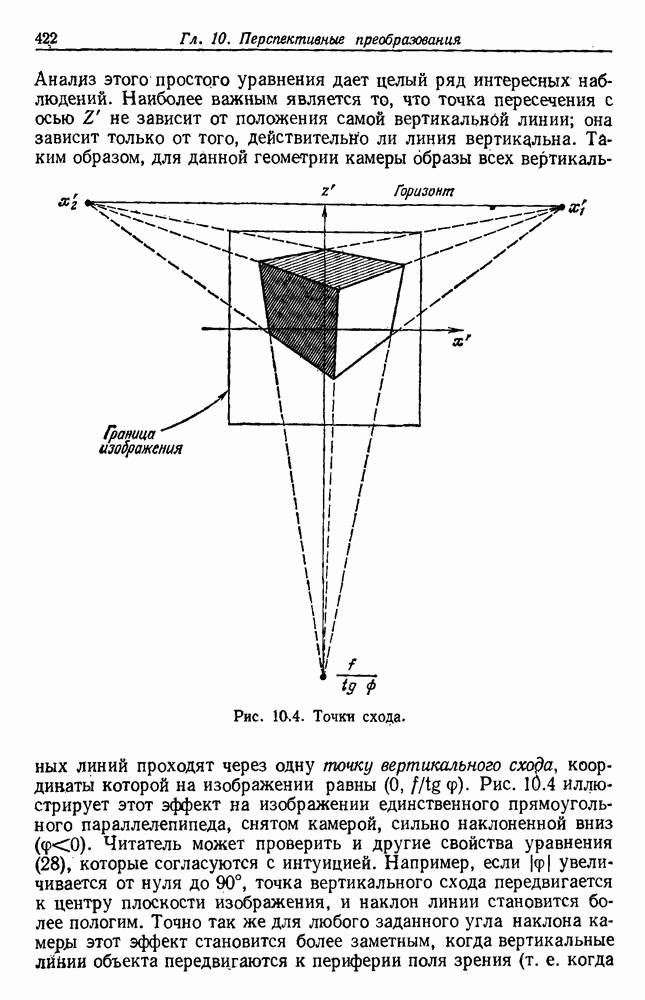
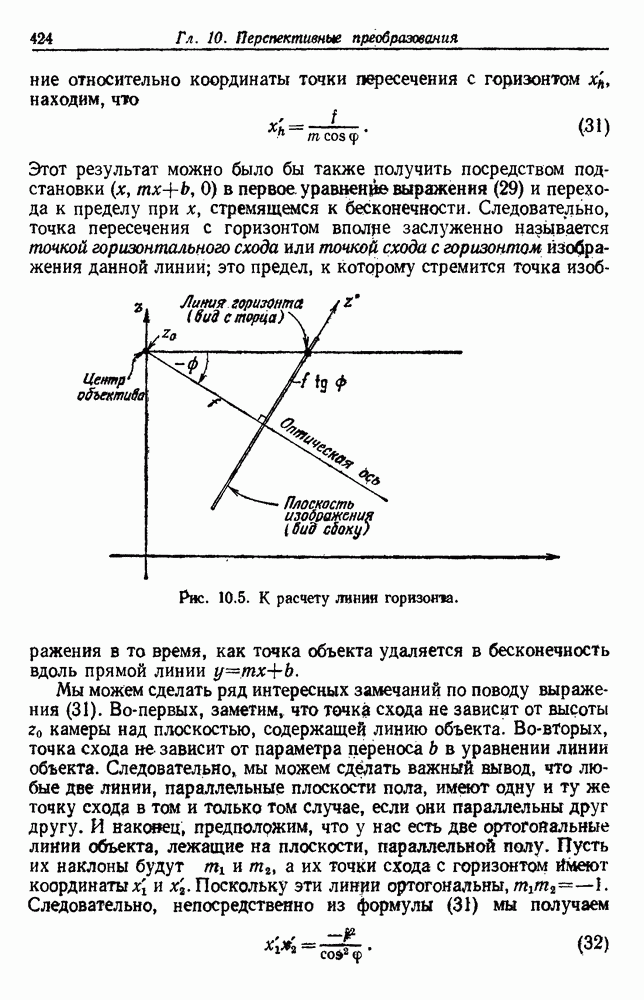
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
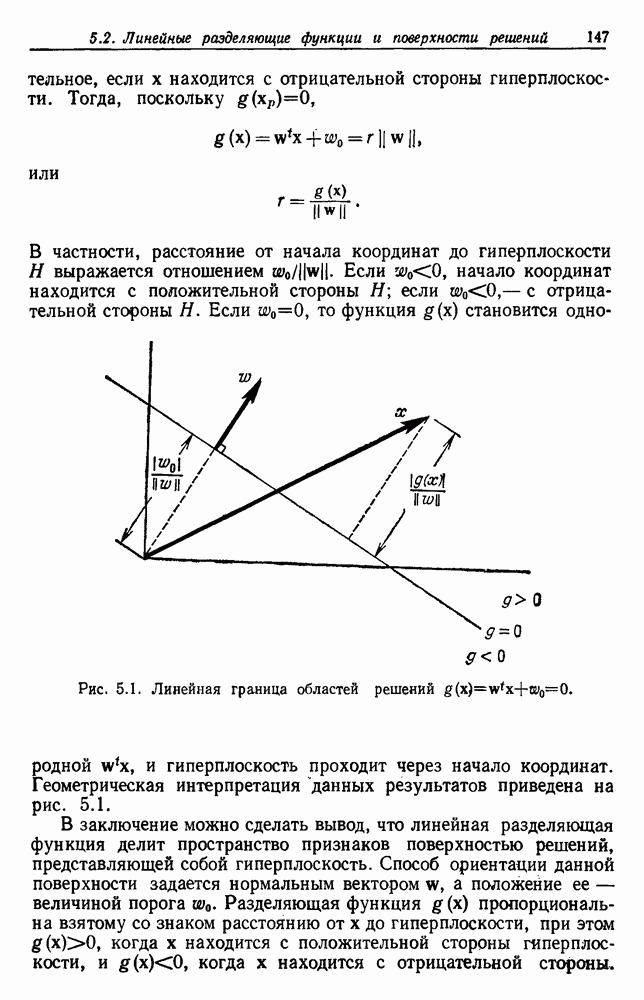
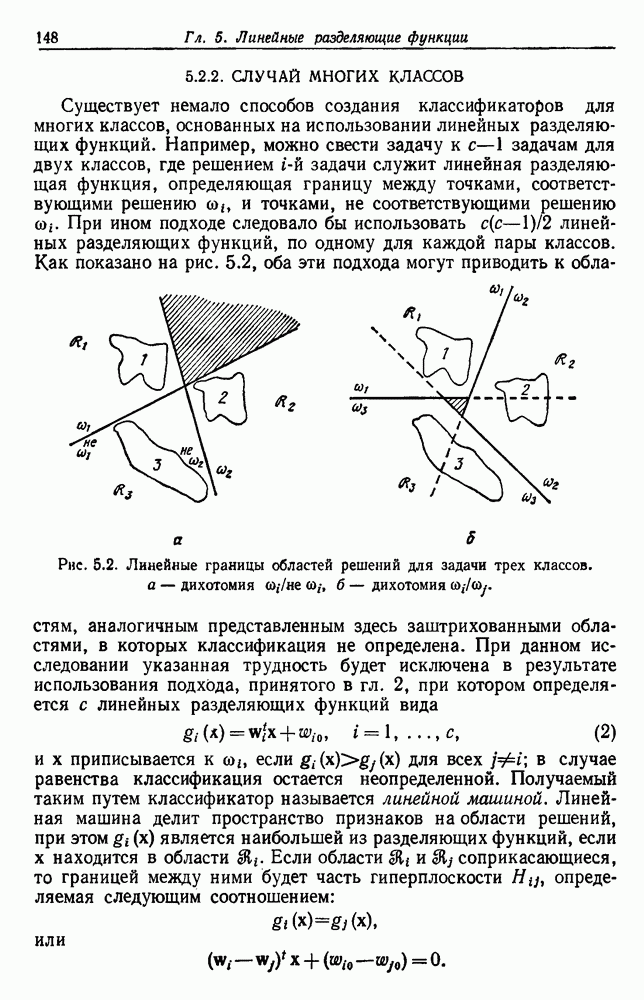
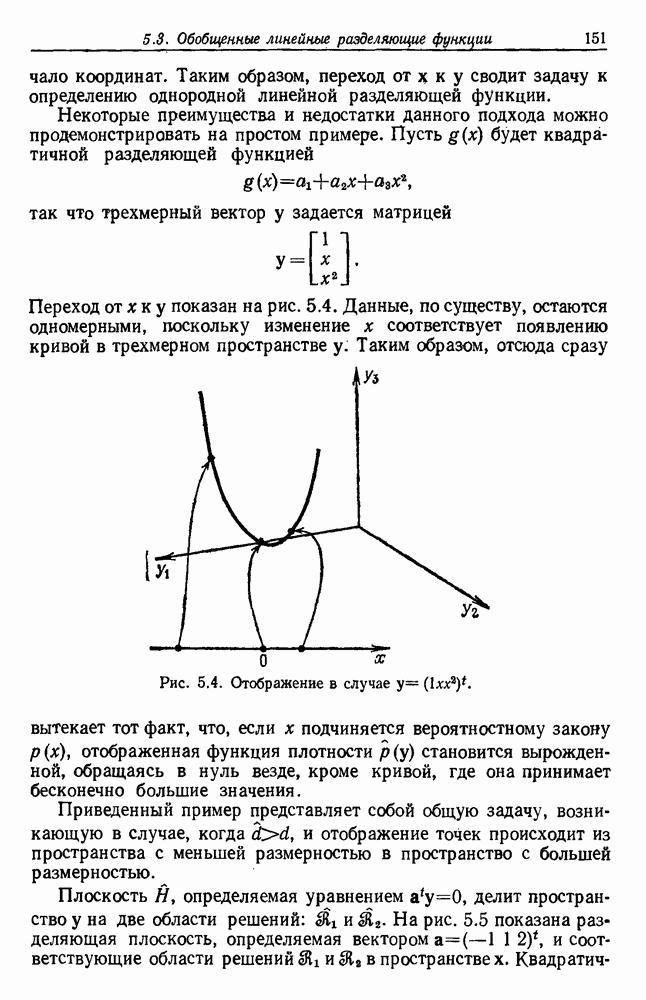
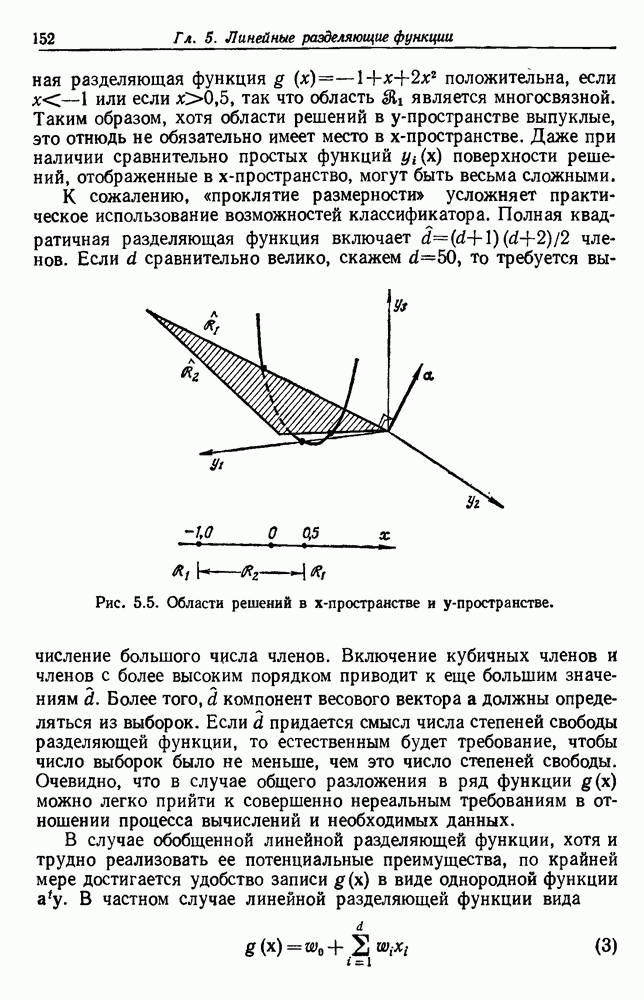
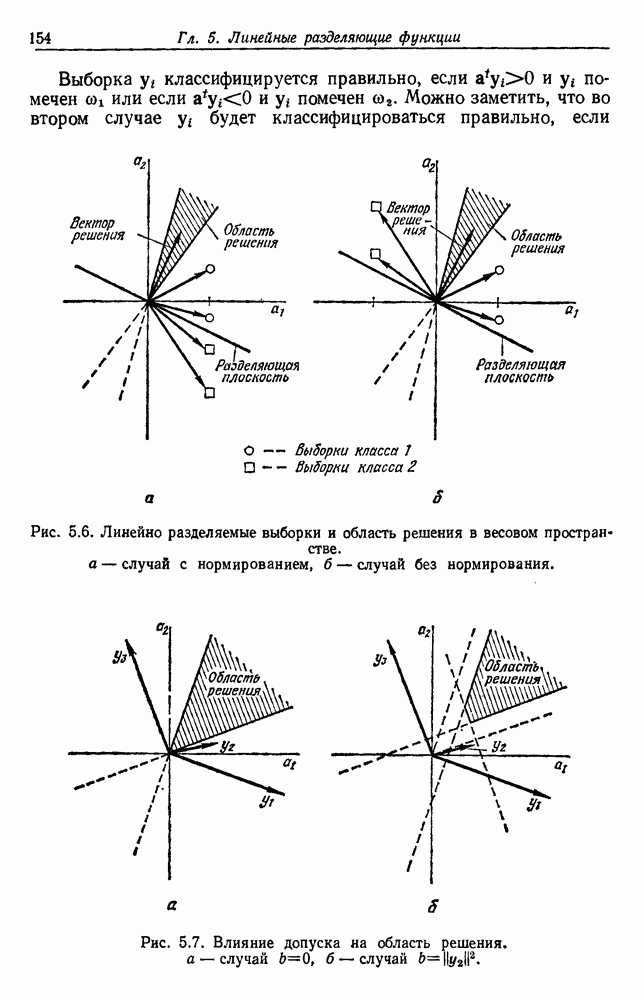
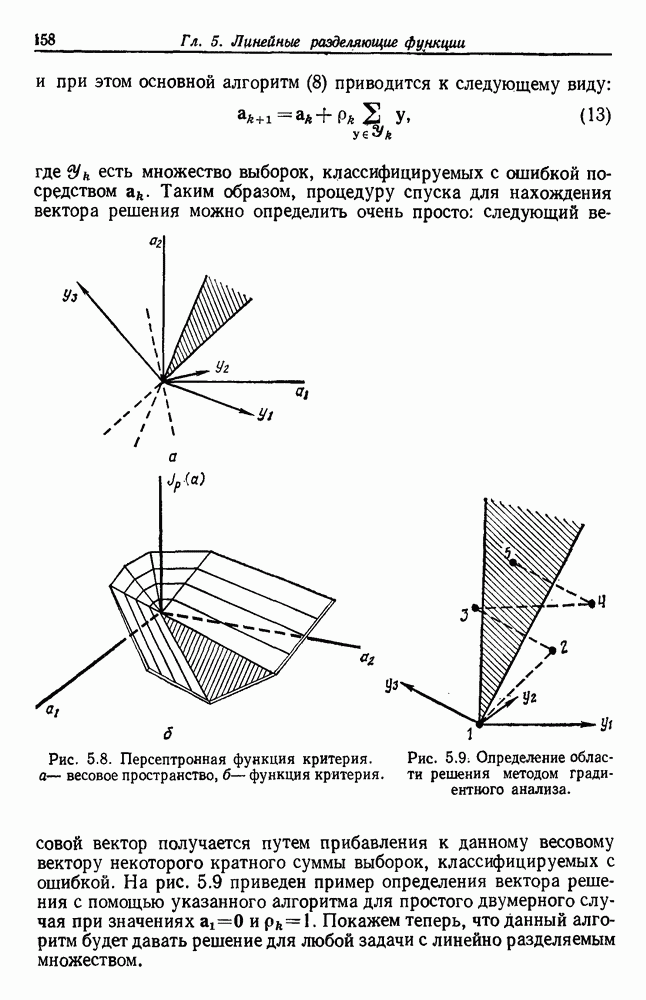
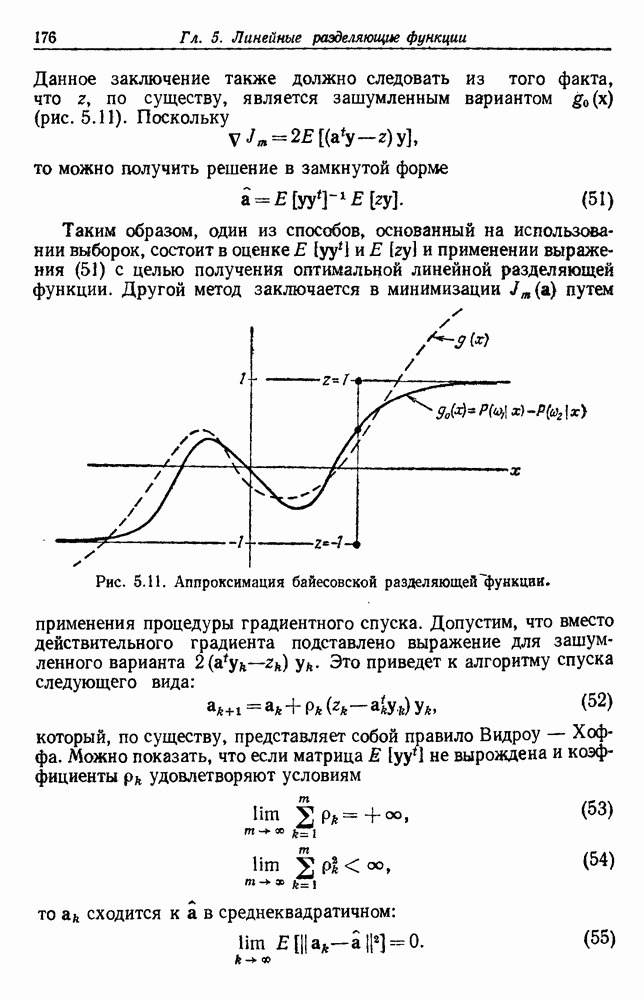
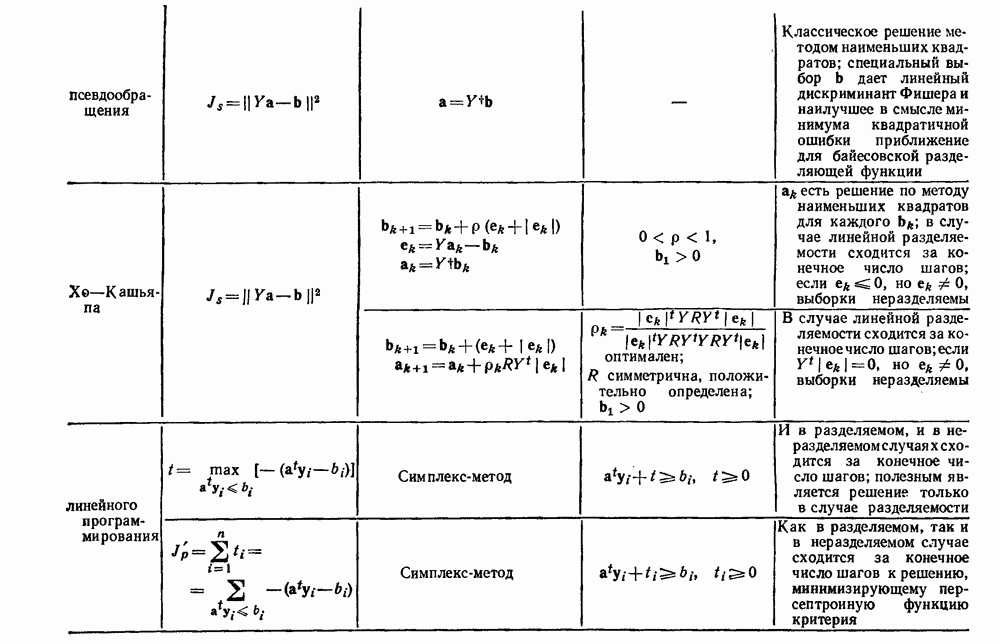
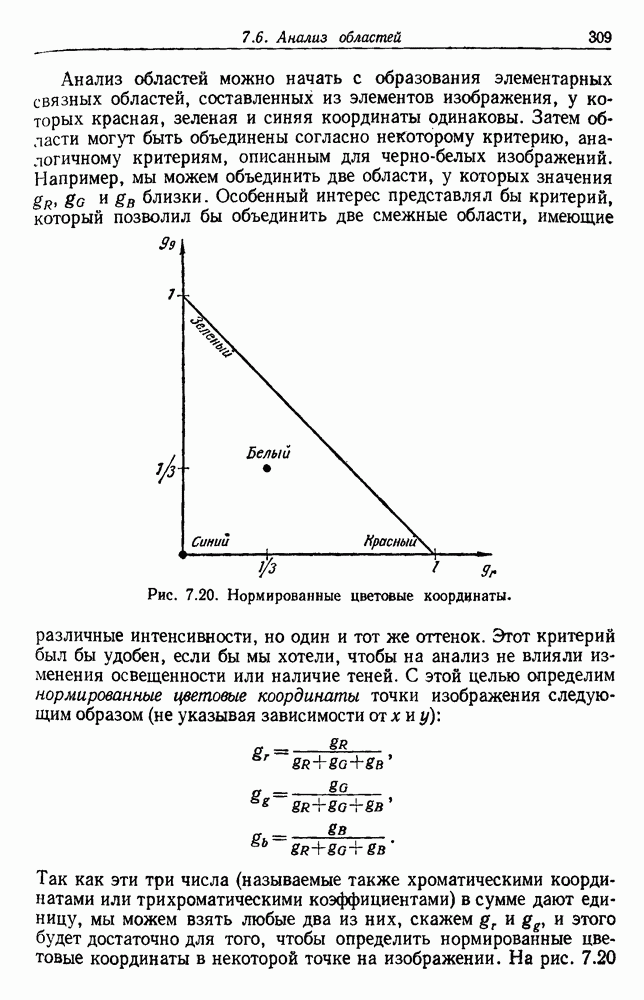
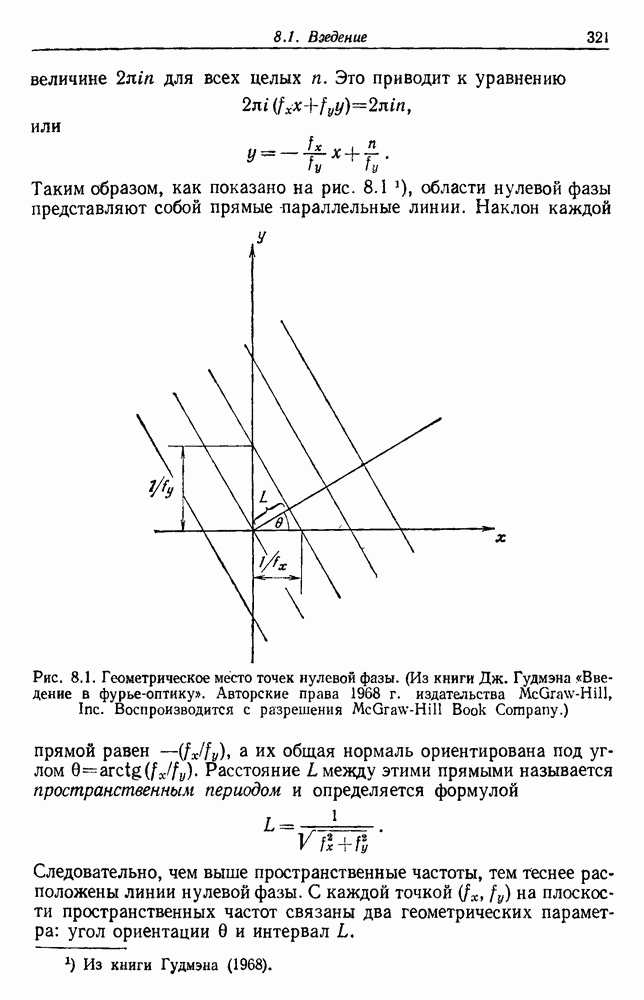
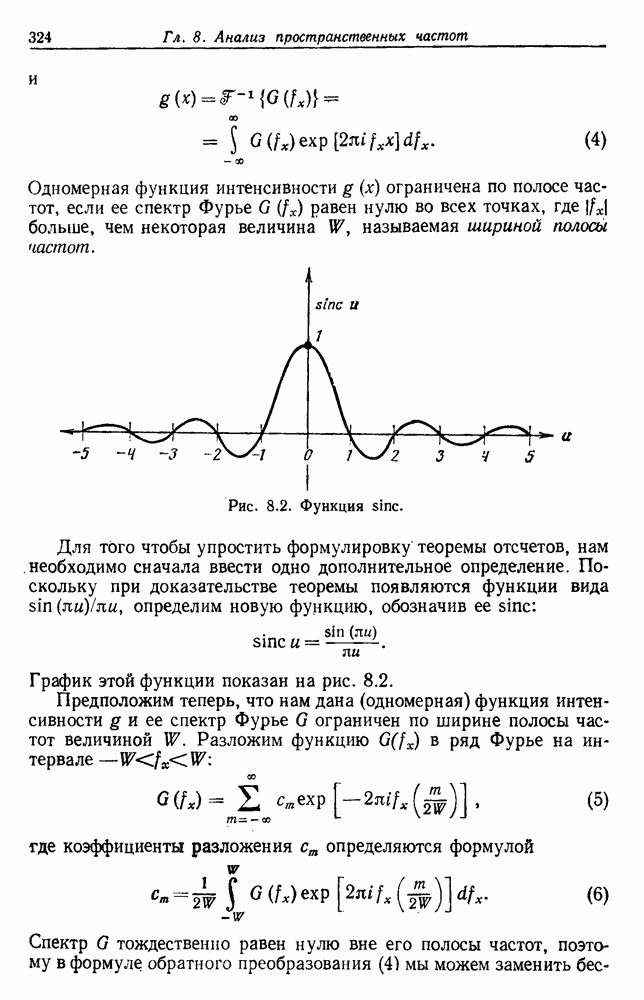
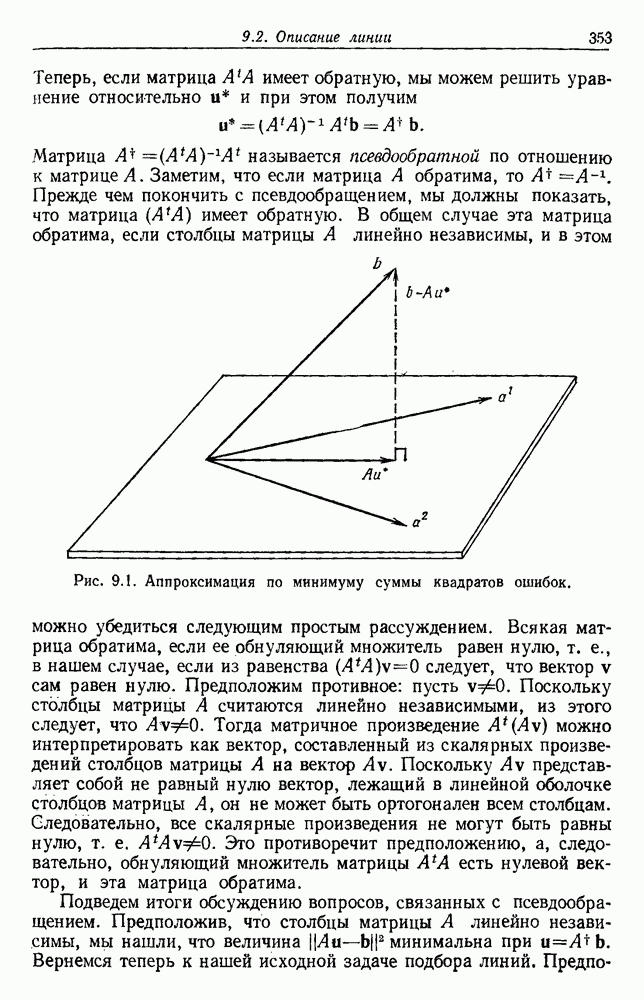
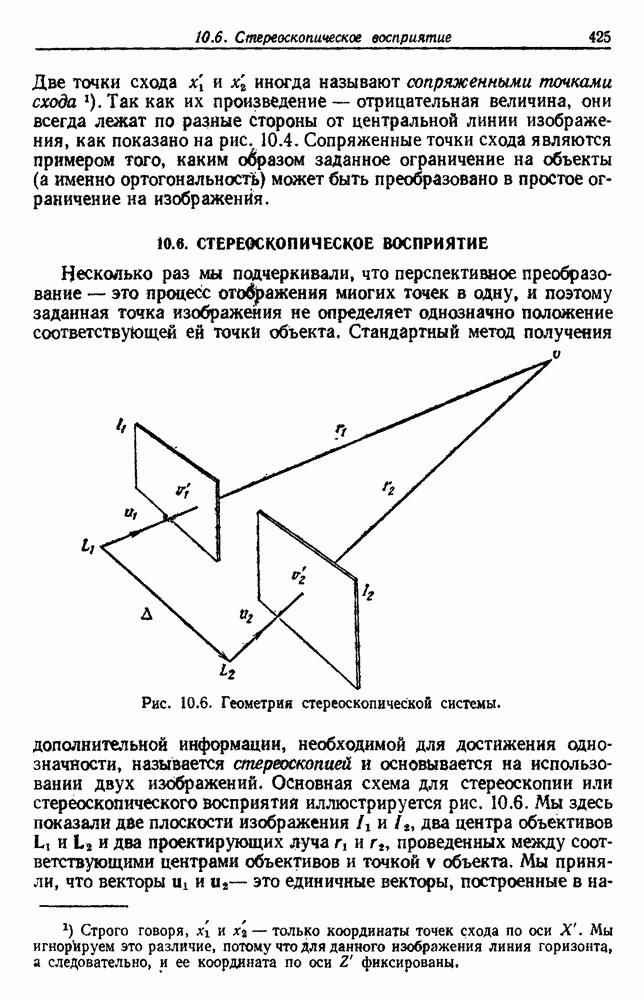
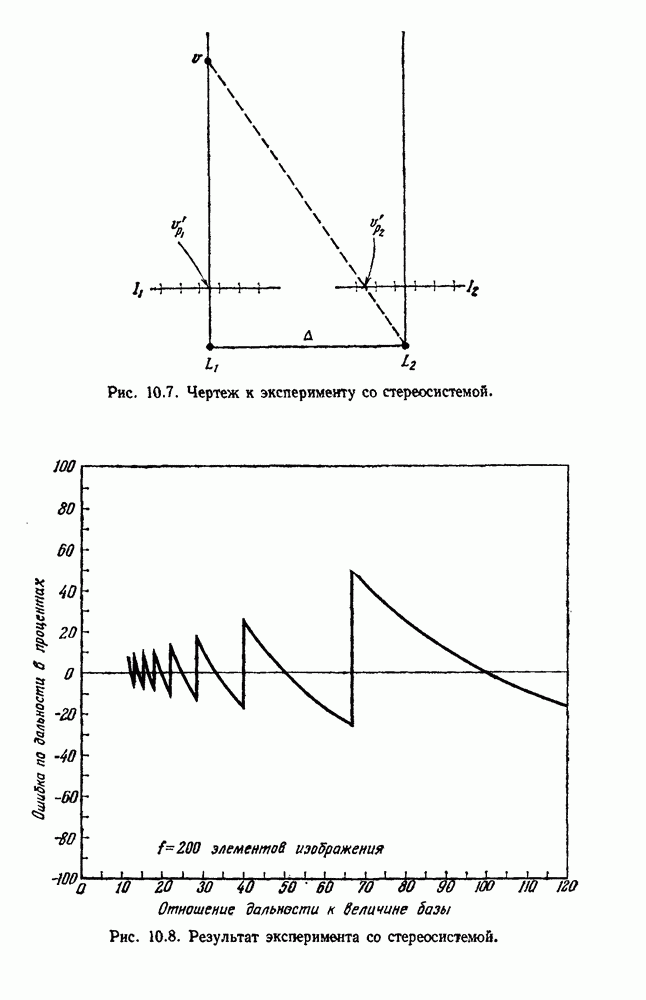
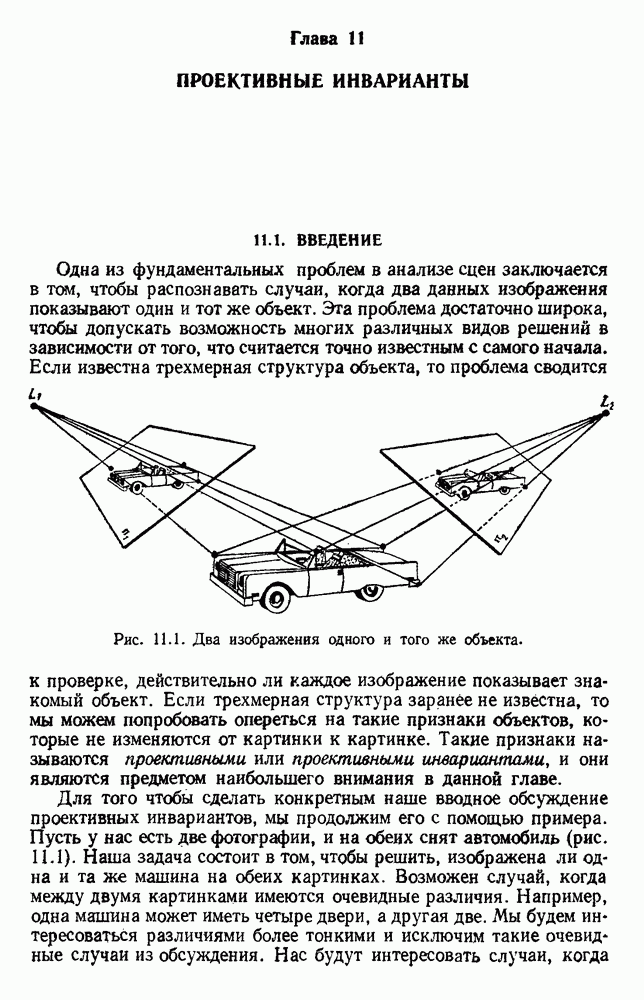
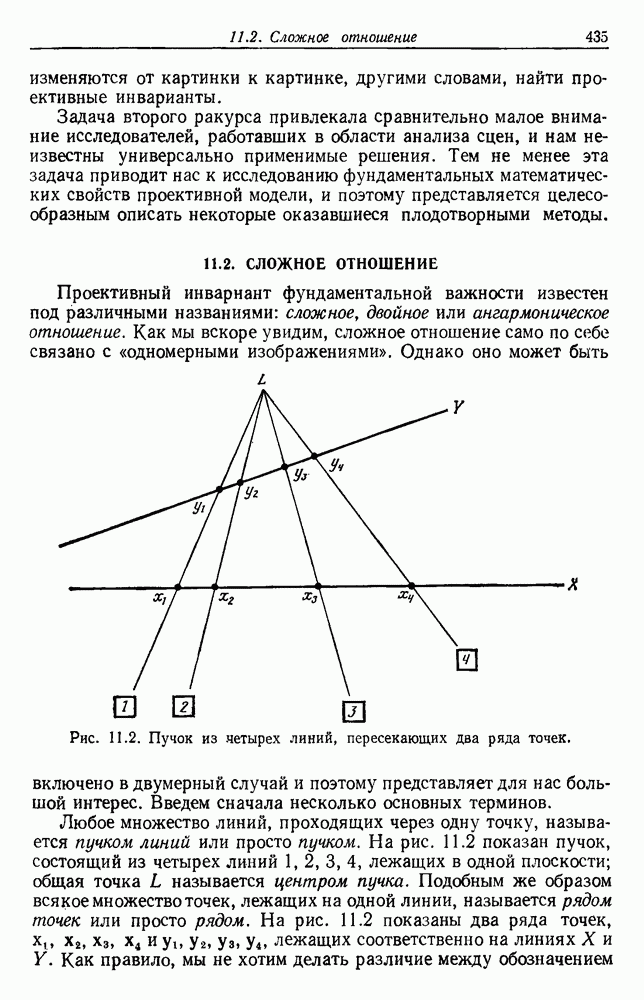
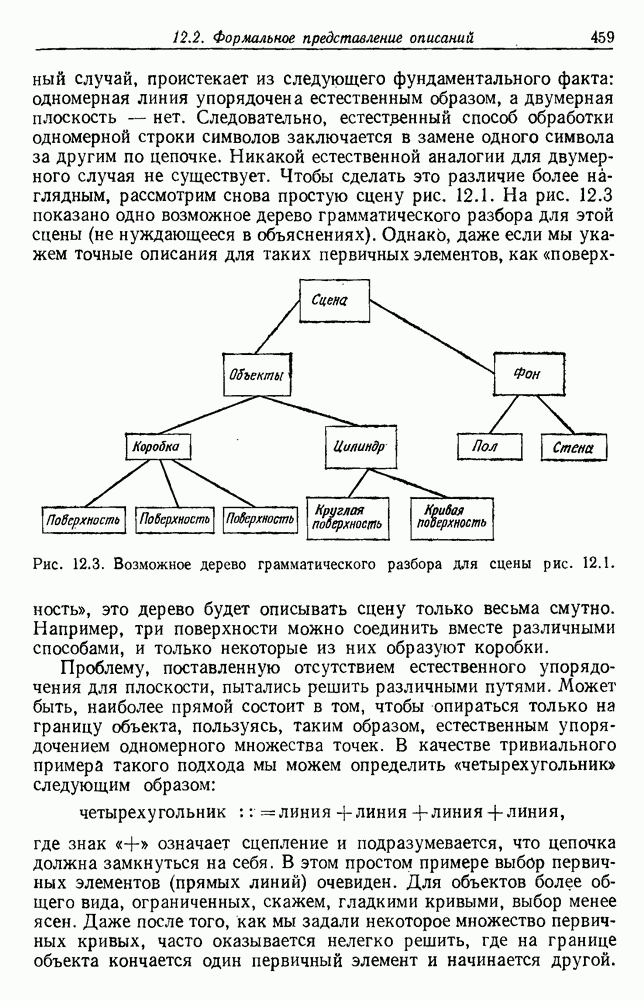
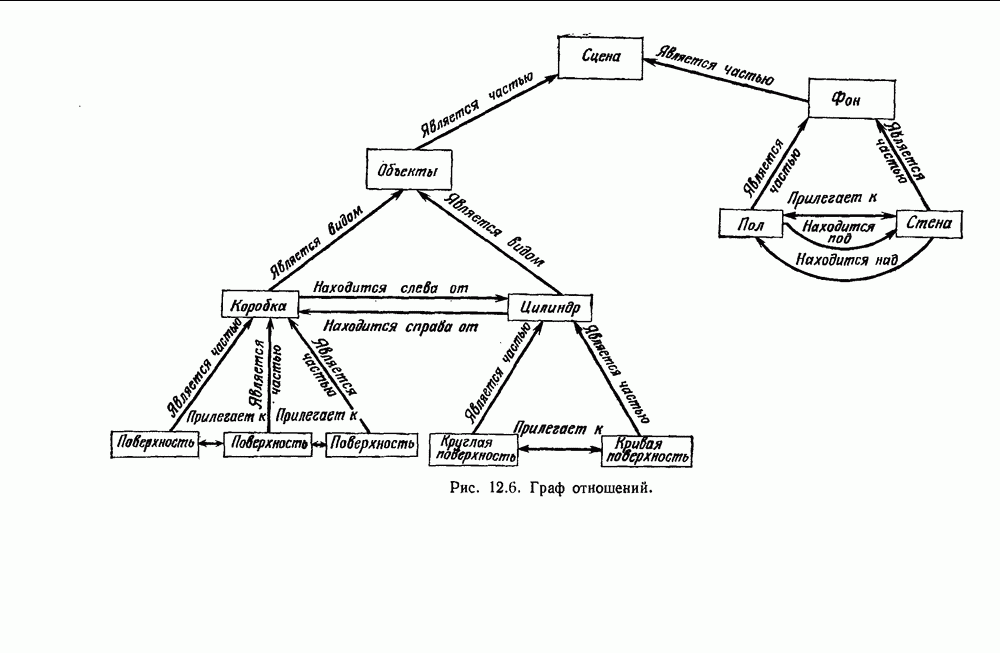
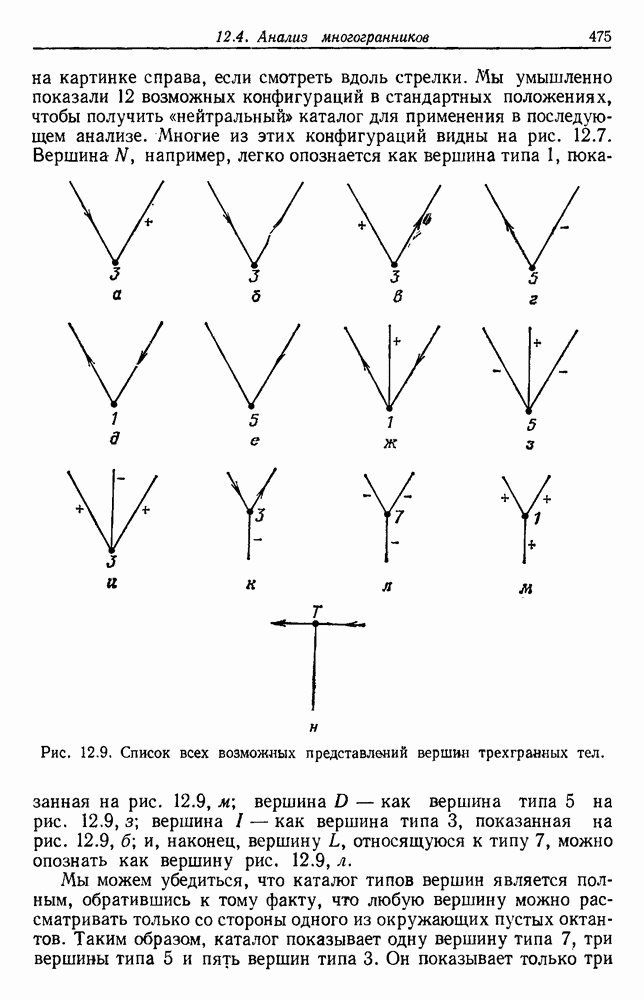
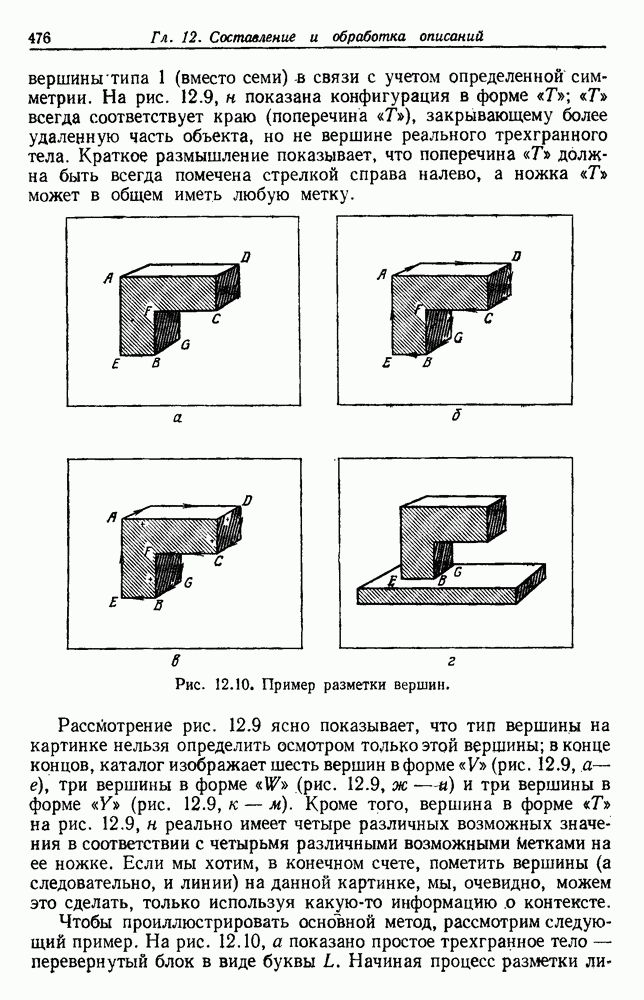
6.12. ПРОБЛЕМА ОБОСНОВАННОСТИПочти для всех процедур, которые мы пока что рассмотрели, предполагалось, что число групп известно. Это разумное предположение, если мы обновляем классификатор, который был создан на малом множестве выборок, или если следим за образами, медленно меняющимися во времени. Однако это очень неестественное предположение в случае, когда мы исследуем совершенно неизвестное множество данных. Поэтому в кластерном анализе постоянно присутствует проблема: сколько групп имеется в множестве выборок? Когда группировка производится достижением экстремума функции критерия, обычный подход состоит в том, что необходимо повторить процедуры группировки для Более формальным подходом к задаче является попытка найти некоторую меру качества, которая показывает, насколько хорошо данное описание из с групп соответствует данным. Традиционными мерами качества являются хи-квадрат и статистики Колмогорова — Смирнова, но размерность данных обычно требует использования более простых мер, таких, как функция критерия J(с). Так как мы предполагаем, что описание на основании чем на основании с групп, то хотелось бы знать, что дает статистически значимое улучшение Формальным способом является выдвижение нулевой гипотезы, что имеются только с групп, и вычисление выборочного распределения для К сожалению, обычно очень трудно сделать что-либо большее, кроме грубой оценки такого распределения для Сумма квадратов ошибок
где Предположим теперь, что мы разделяем множество выборок на два подмножества
здесь m — среднее выборок в решения для распределения выборок. Однако можно получить приблизительную оценку, получив проведением гиперплоскости через среднее выборок разделение, близкое к оптимальному. Для больших Результат совпадает с нашим предположением, что
Конечный результат можно сформулировать следующим образом: отбрасываем нулевую гипотезу с
где а определяется из выражения
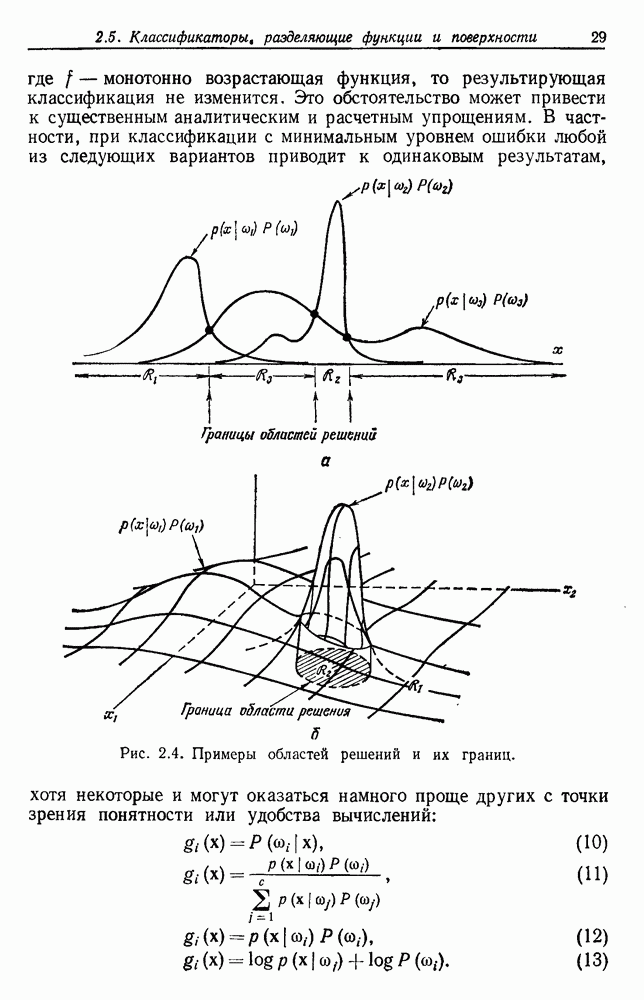
Таким образом, мы получим тест для решения, оправданно или нет разбиение группы. Ясно, что задачу с с группами можно решать, применив те же тесты для всех найденных групп.
|
 |
Оглавление
|








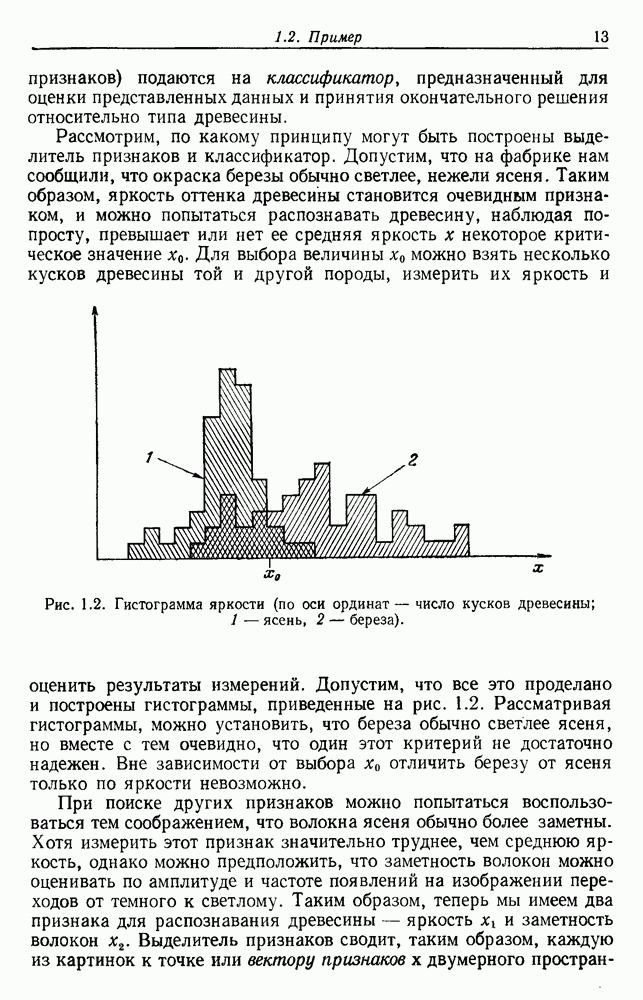







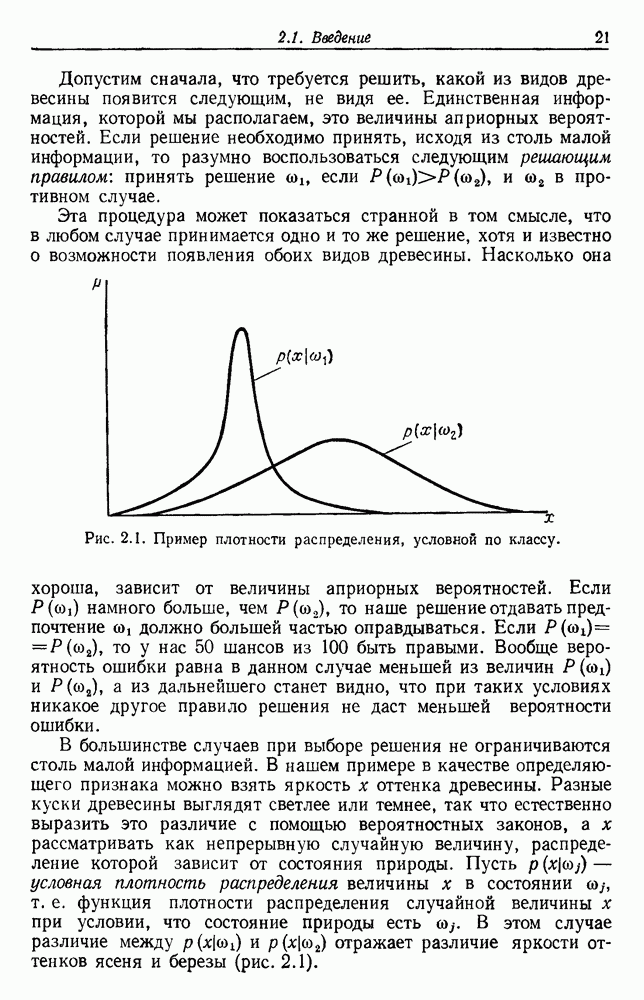
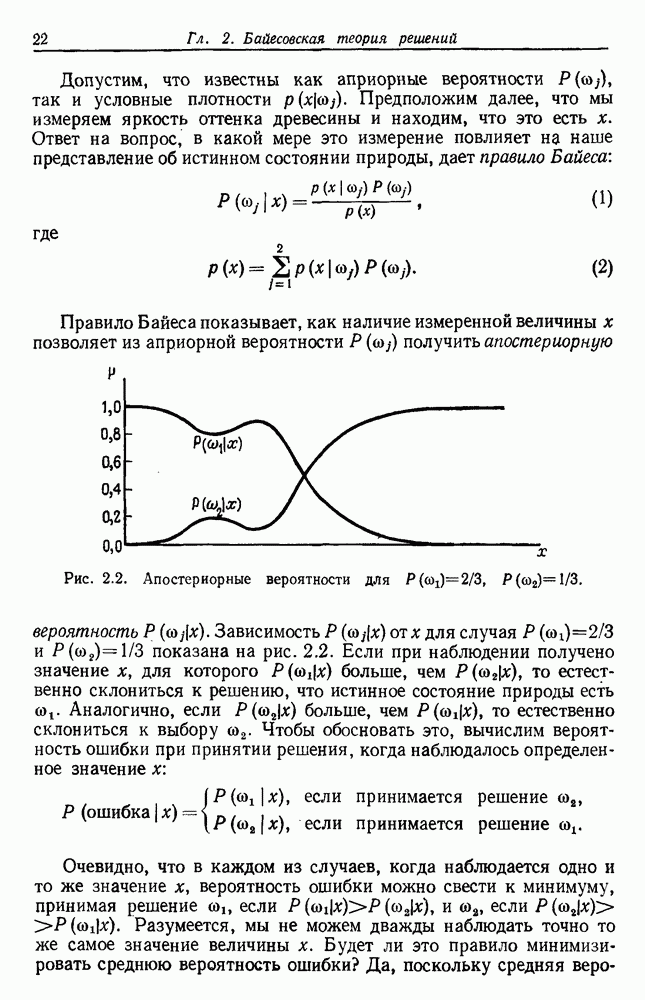





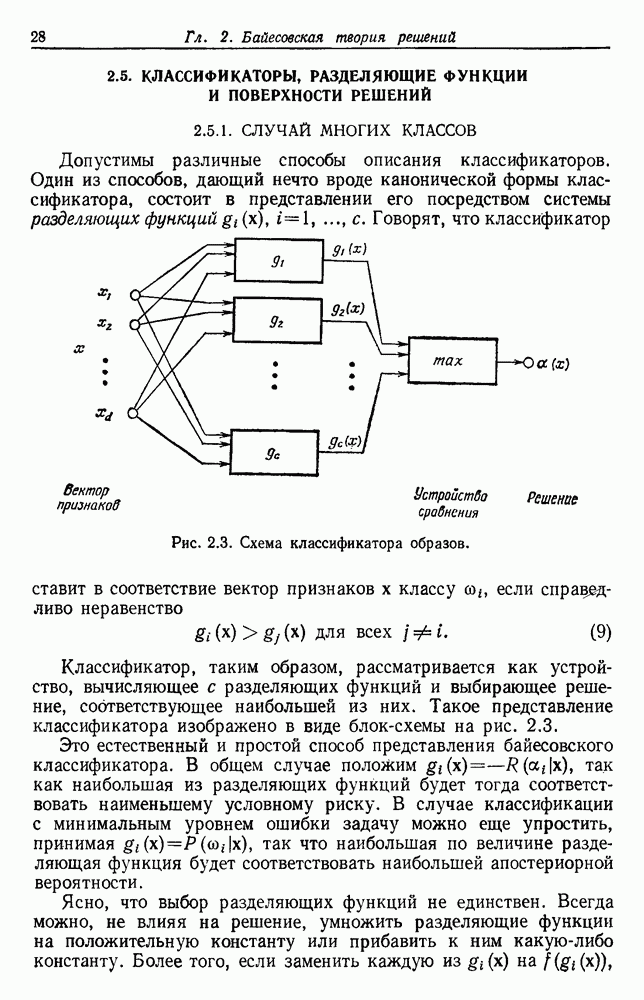


































































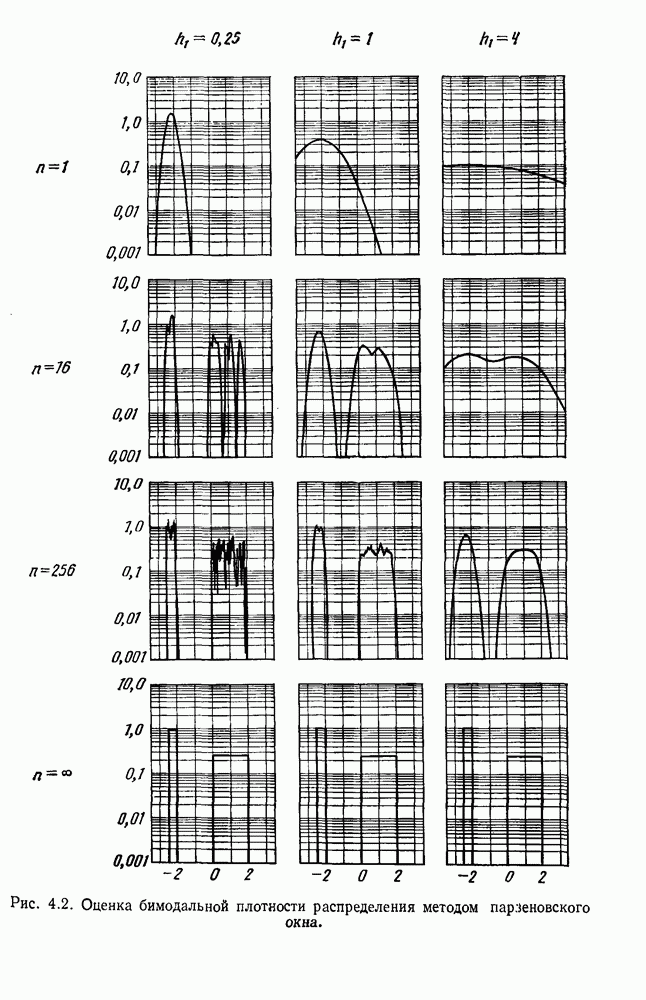

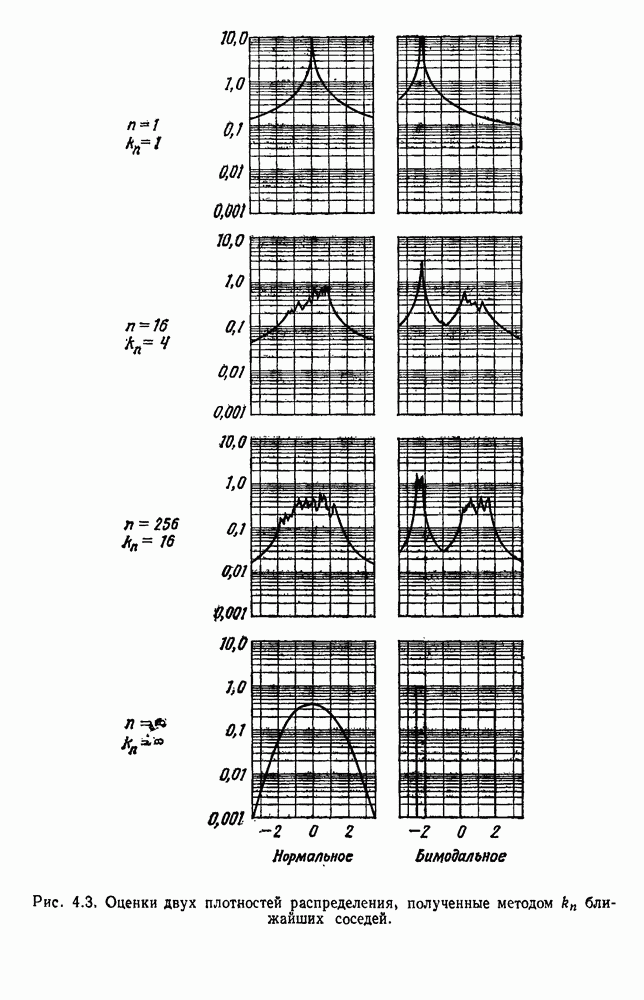








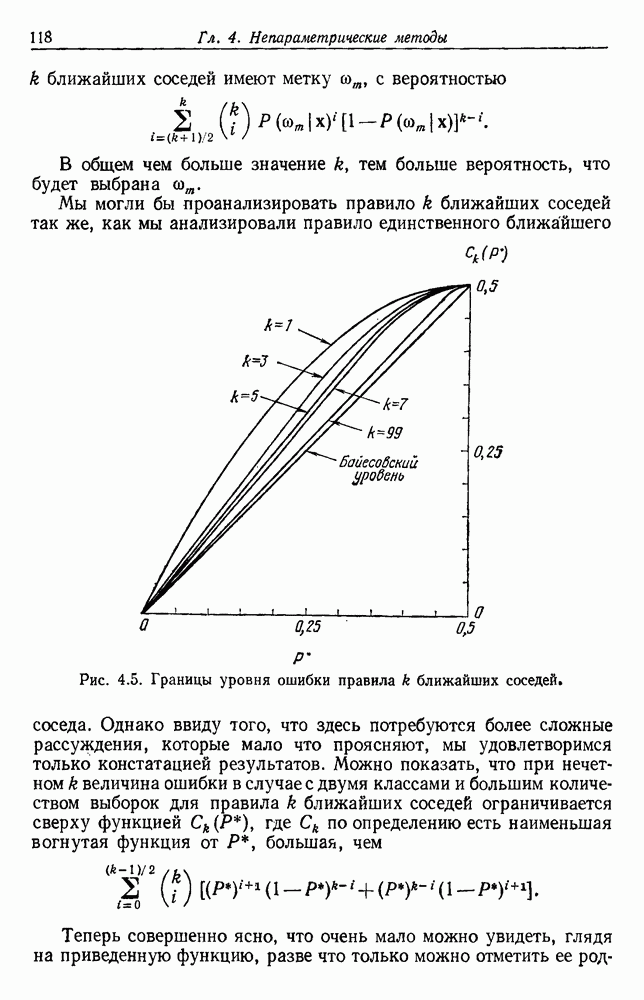






























































































































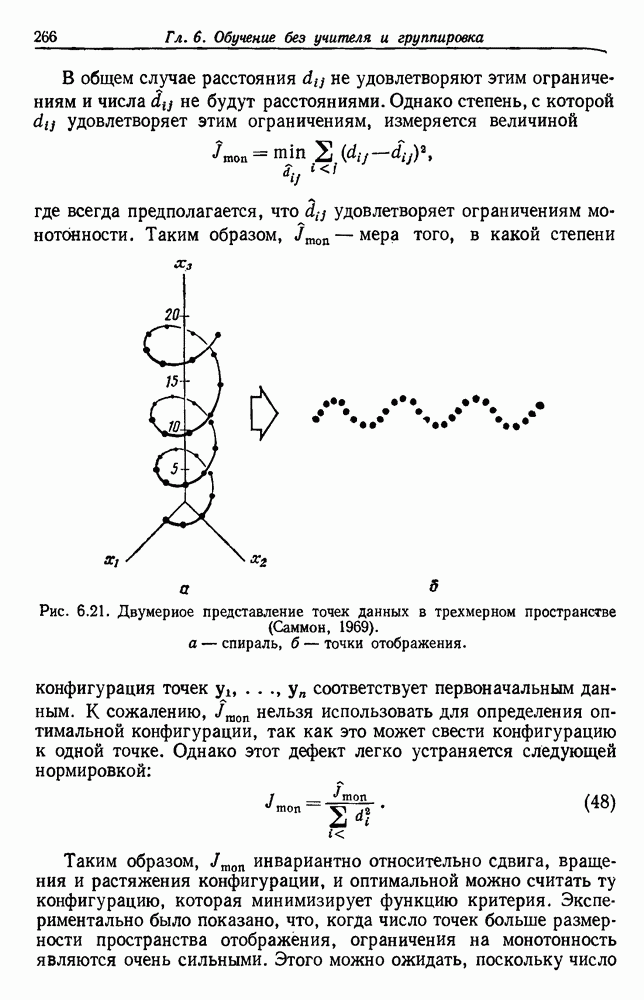




















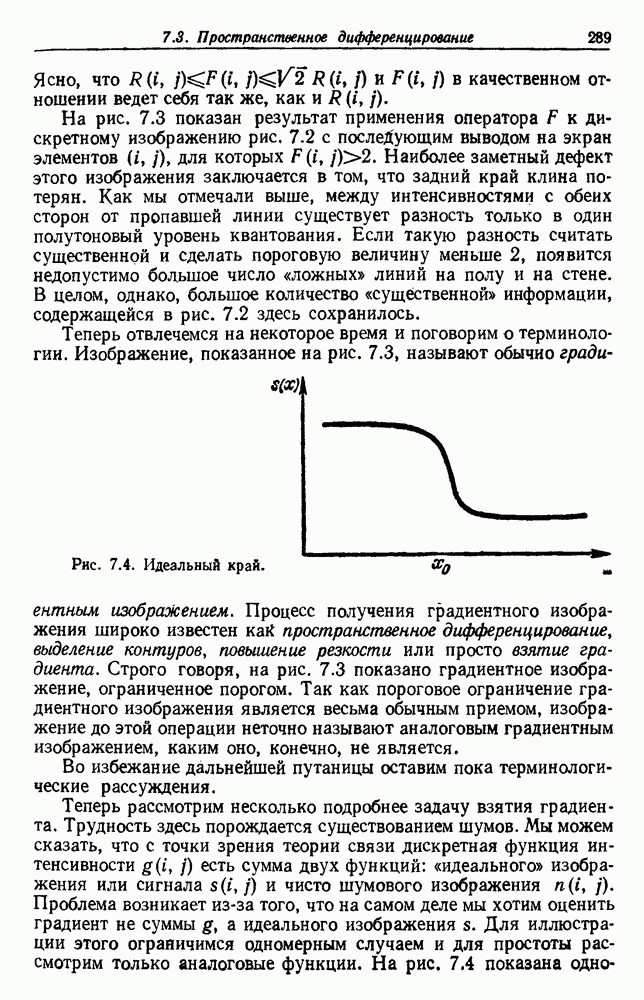
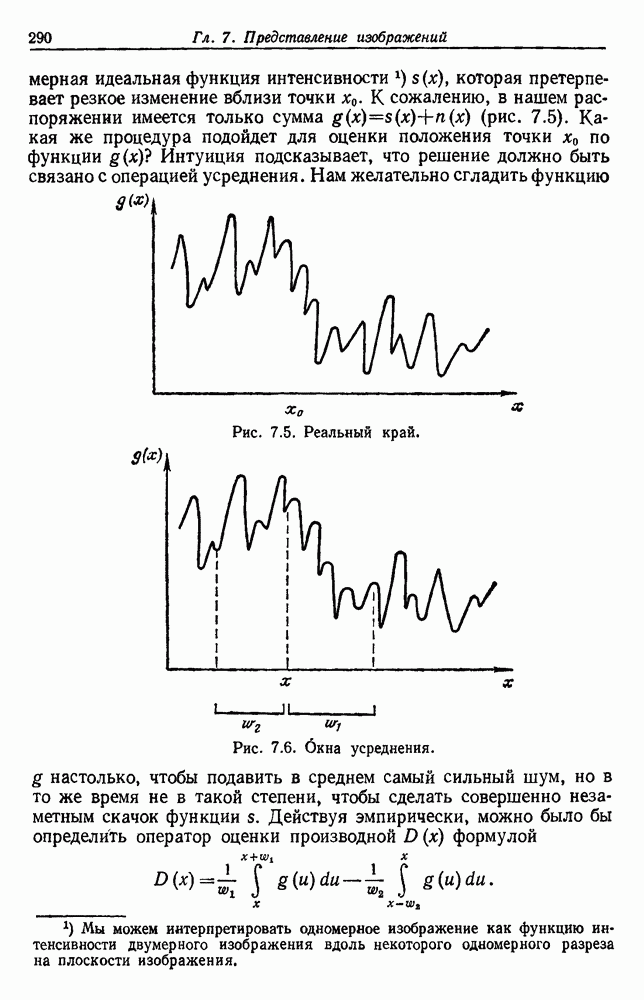

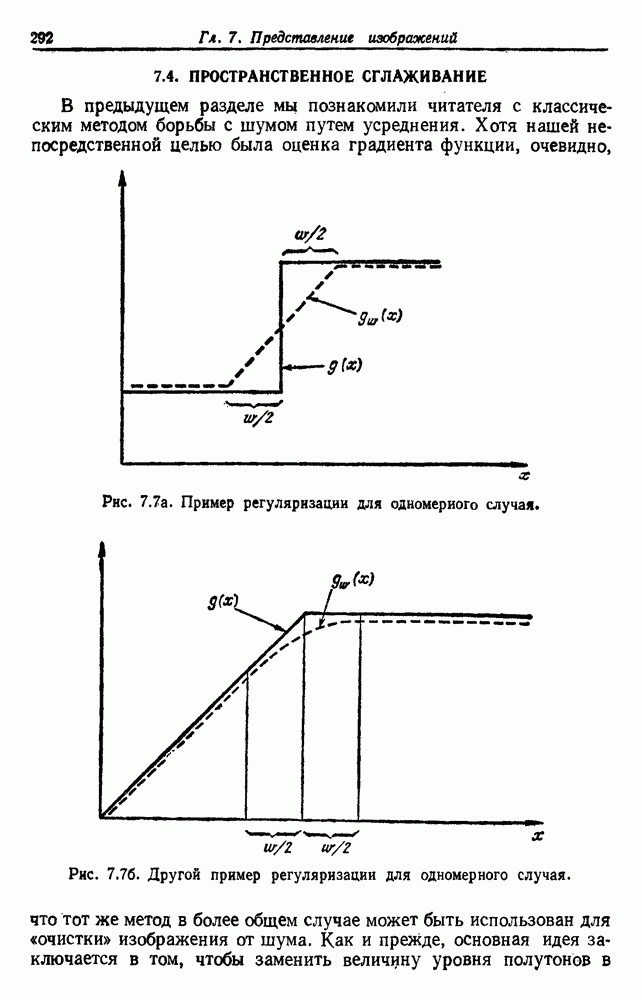






































































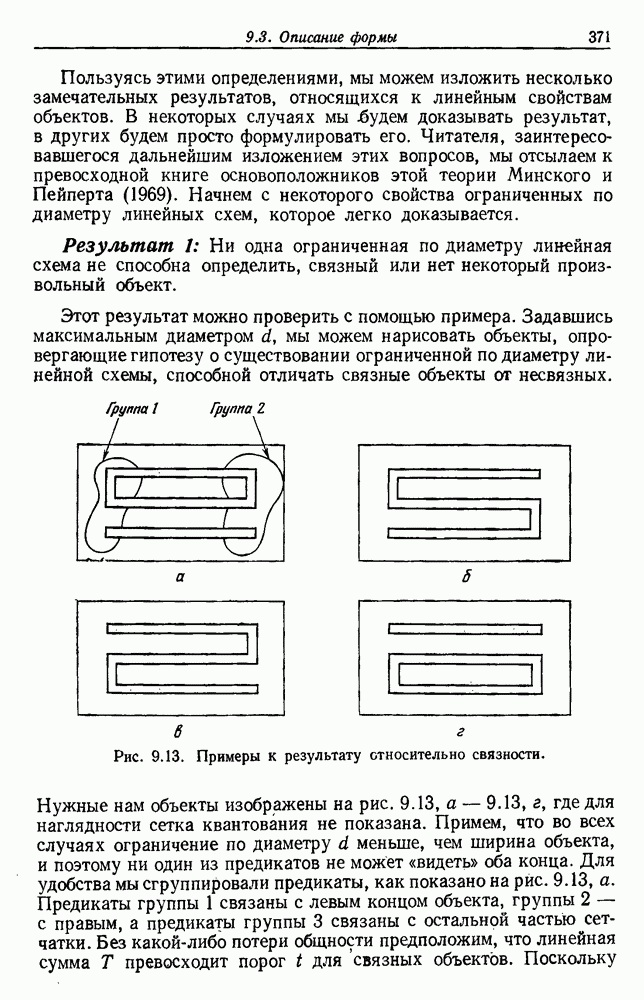





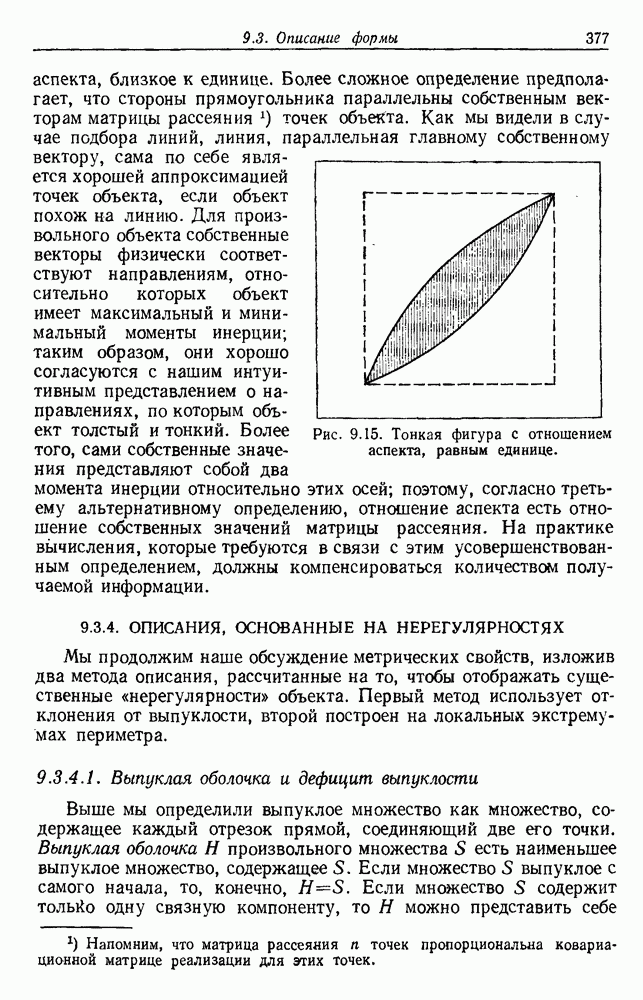


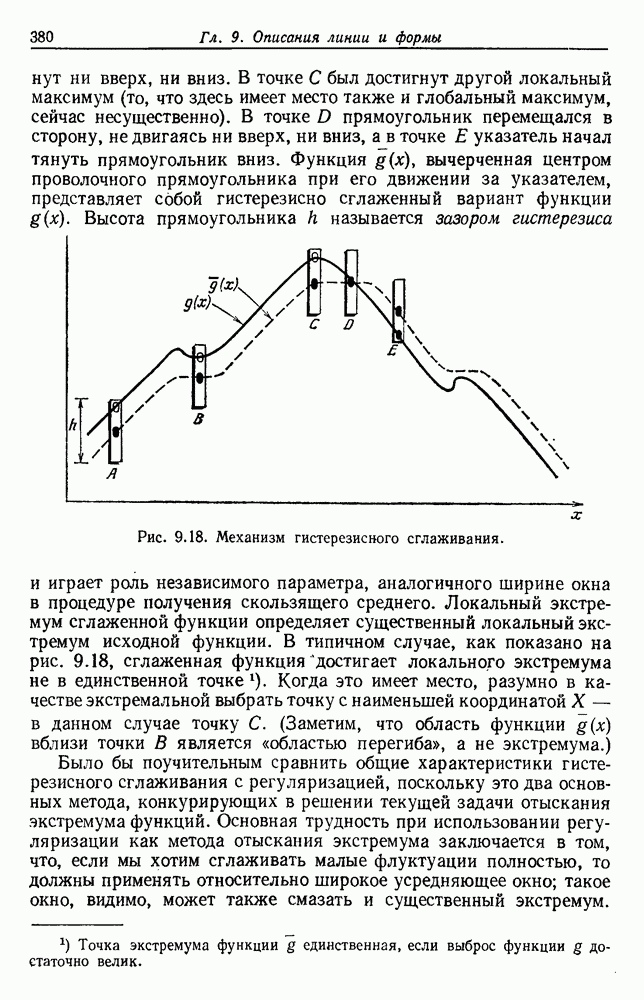
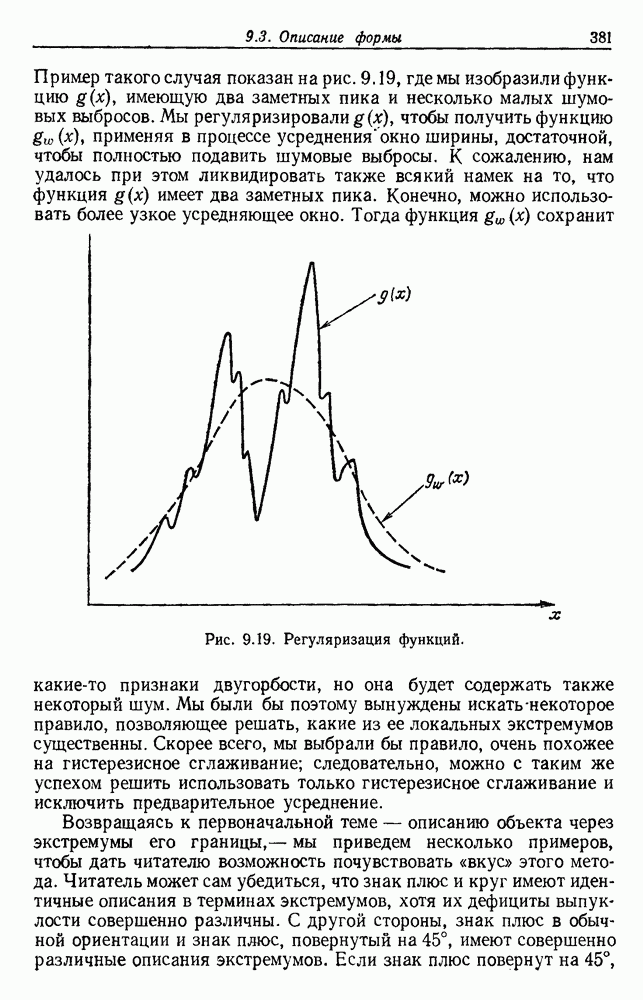












































































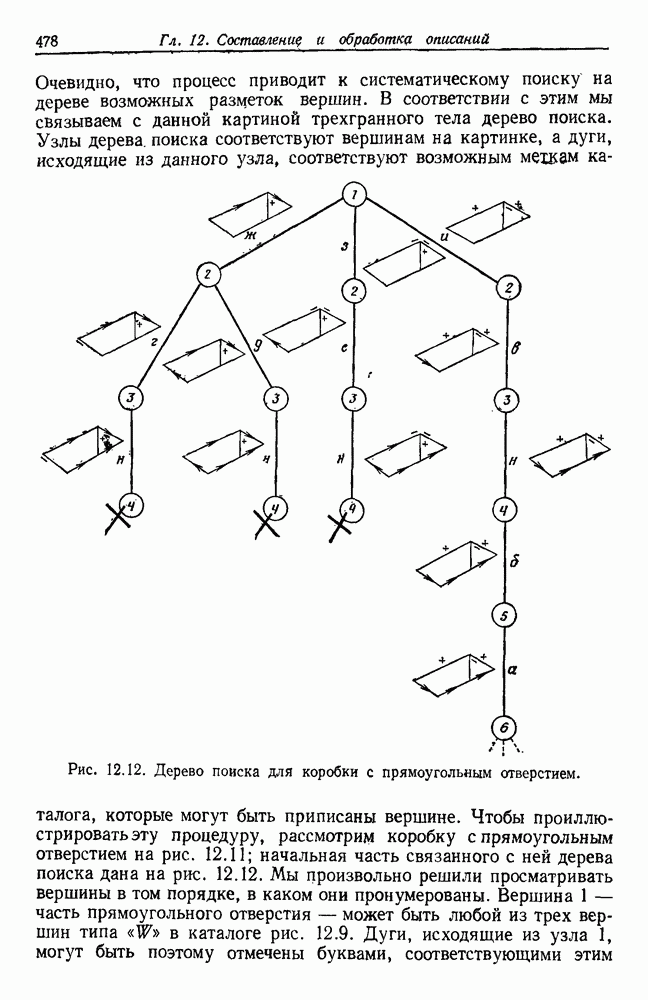


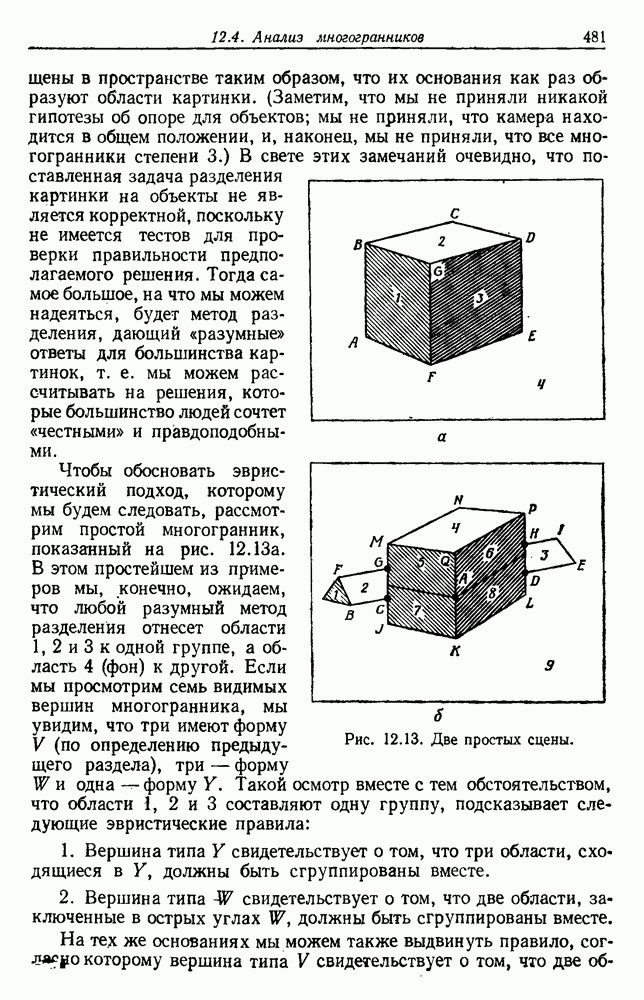


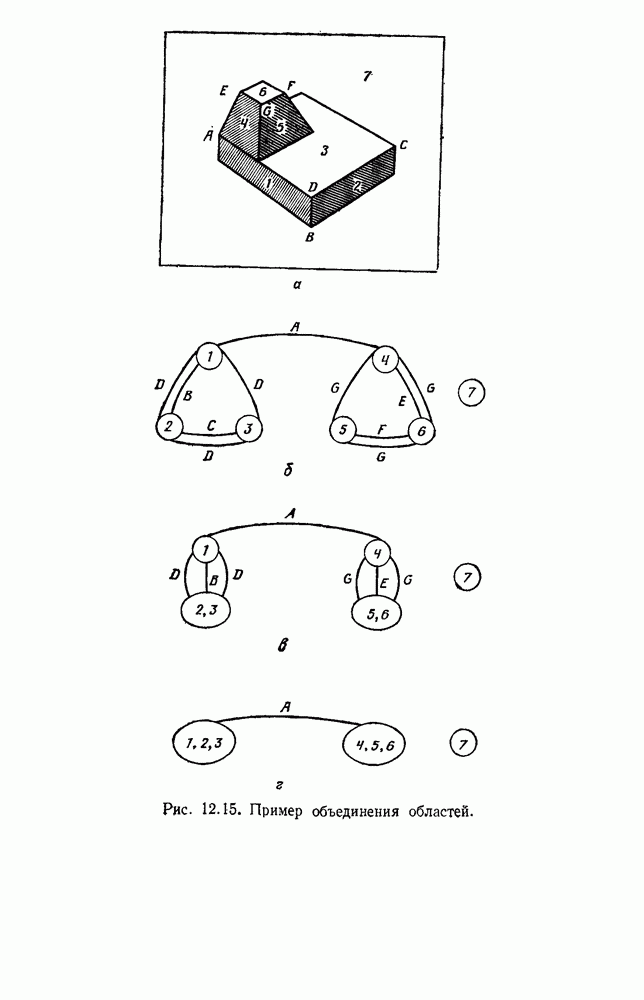
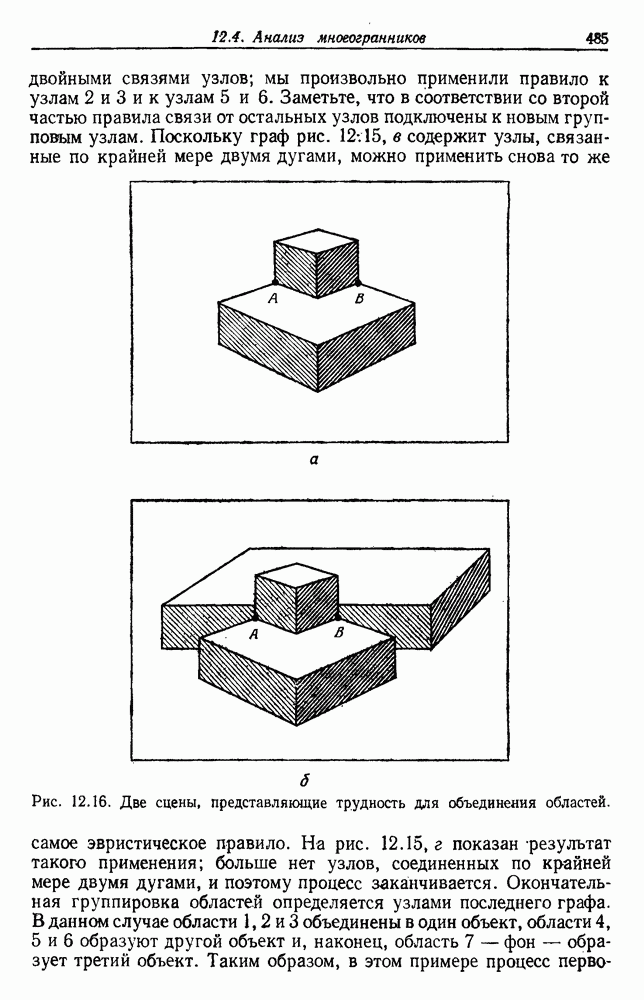











 и т. д. и проследить за изменением функции в зависимости от с. Например, ясно, что критерий по сумме квадратов ошибок
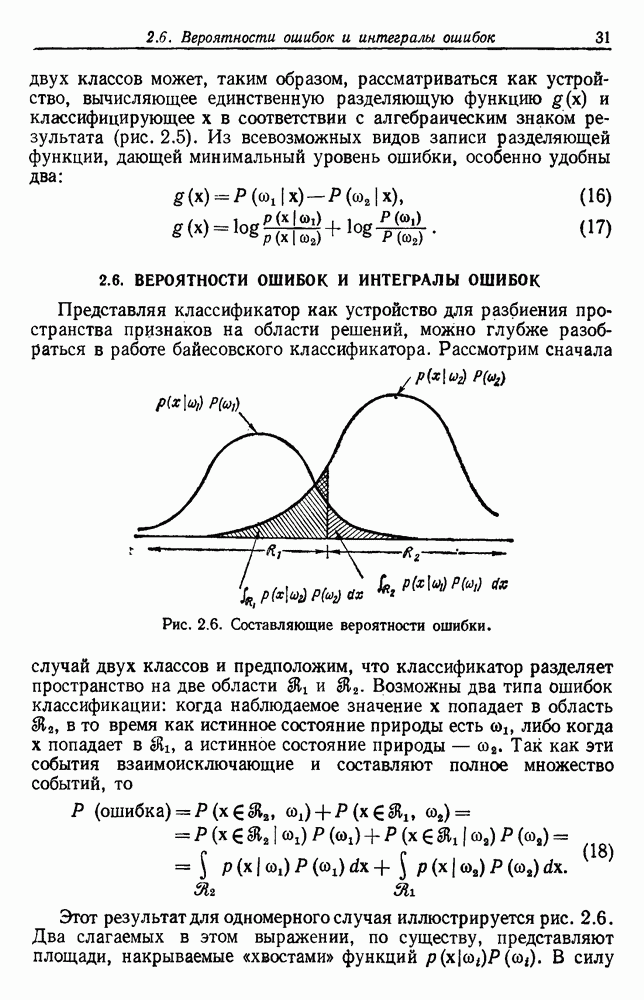
и т. д. и проследить за изменением функции в зависимости от с. Например, ясно, что критерий по сумме квадратов ошибок  должен монотонно уменьшаться в зависимости от с, так как квадратичную ошибку можно уменьшать каждый раз, когда с увеличивается, за счет пересылки одной выборки в новую группу. Если
должен монотонно уменьшаться в зависимости от с, так как квадратичную ошибку можно уменьшать каждый раз, когда с увеличивается, за счет пересылки одной выборки в новую группу. Если  выборок разделены на с компактных, хорошо разделенных групп, можно ожидать, что
выборок разделены на с компактных, хорошо разделенных групп, можно ожидать, что  будет уменьшаться быстро до момента, когда
будет уменьшаться быстро до момента, когда  после этого уменьшение должно замедлиться, а при
после этого уменьшение должно замедлиться, а при  станет равным нулю. Подобные аргументы можно выдвинуть и для процедуры иерархической группировки, причем обычно предполагается, что большие различия в уровнях, на которых группы объединяются, указывают на наличие естественных группировок.
станет равным нулю. Подобные аргументы можно выдвинуть и для процедуры иерархической группировки, причем обычно предполагается, что большие различия в уровнях, на которых группы объединяются, указывают на наличие естественных группировок.
 групп будет точнее,
групп будет точнее,
 .
.
 этой гипотезы. Это распределение показывает, какого улучшения надо ожидать, когда описание из с групп является правильным. Процедура принятия решений должна принять нулевую гипотезу, если полученное значение
этой гипотезы. Это распределение показывает, какого улучшения надо ожидать, когда описание из с групп является правильным. Процедура принятия решений должна принять нулевую гипотезу, если полученное значение  попадает внутрь пределов, соответствующих приемлемой вероятности ложного отказа.
попадает внутрь пределов, соответствующих приемлемой вероятности ложного отказа.
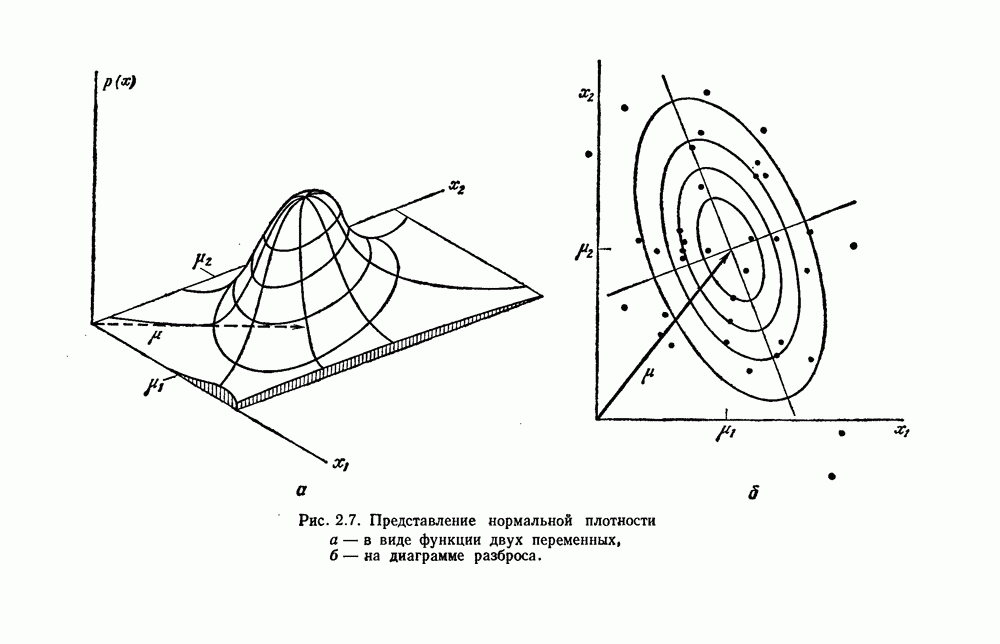
 Конечное решение не всегда достоверно, и статистическая задача проверки правильности группировки в основном не решена. Однако, предполагая, что даже некачественная проверка лучше, чем никакая, мы проведем следующий приблизительный анализ для простого критерия суммы квадратов ошибок. Предположим, что мы имеем множество
Конечное решение не всегда достоверно, и статистическая задача проверки правильности группировки в основном не решена. Однако, предполагая, что даже некачественная проверка лучше, чем никакая, мы проведем следующий приблизительный анализ для простого критерия суммы квадратов ошибок. Предположим, что мы имеем множество  из
из  выборок и хотим решить, есть ли какое-либо основание для предположения, что они образуют более одной группы. Выдвинем нулевую гипотезу, что все
выборок и хотим решить, есть ли какое-либо основание для предположения, что они образуют более одной группы. Выдвинем нулевую гипотезу, что все  выборок получены из нормального распределения со средним
выборок получены из нормального распределения со средним  и матрицей ковариаций
и матрицей ковариаций  Если эта гипотеза правильна, то любые обнаруженные группы были сформированы случайно, и любое замеченное уменьшение суммы квадратов ошибок, полученное при группировке, не имеет значения.
Если эта гипотеза правильна, то любые обнаруженные группы были сформированы случайно, и любое замеченное уменьшение суммы квадратов ошибок, полученное при группировке, не имеет значения.
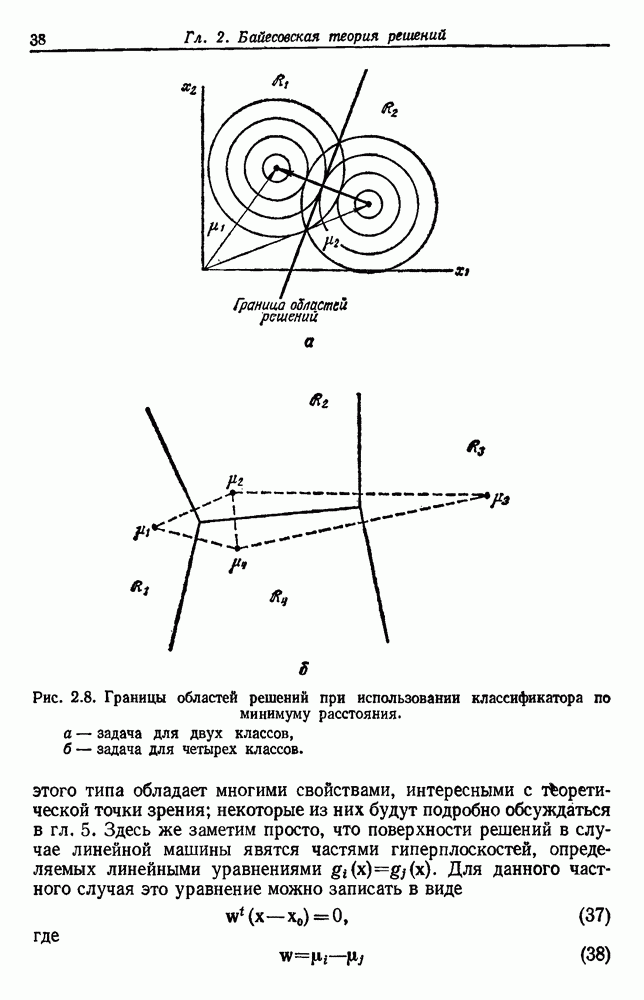
 — случайная переменная, так как она зависит от определенного множества выборок:
— случайная переменная, так как она зависит от определенного множества выборок:

 — среднее всех
— среднее всех  выборок. Согласно нулевой гипотезе, распределение для
выборок. Согласно нулевой гипотезе, распределение для  приблизительно нормальное со средним
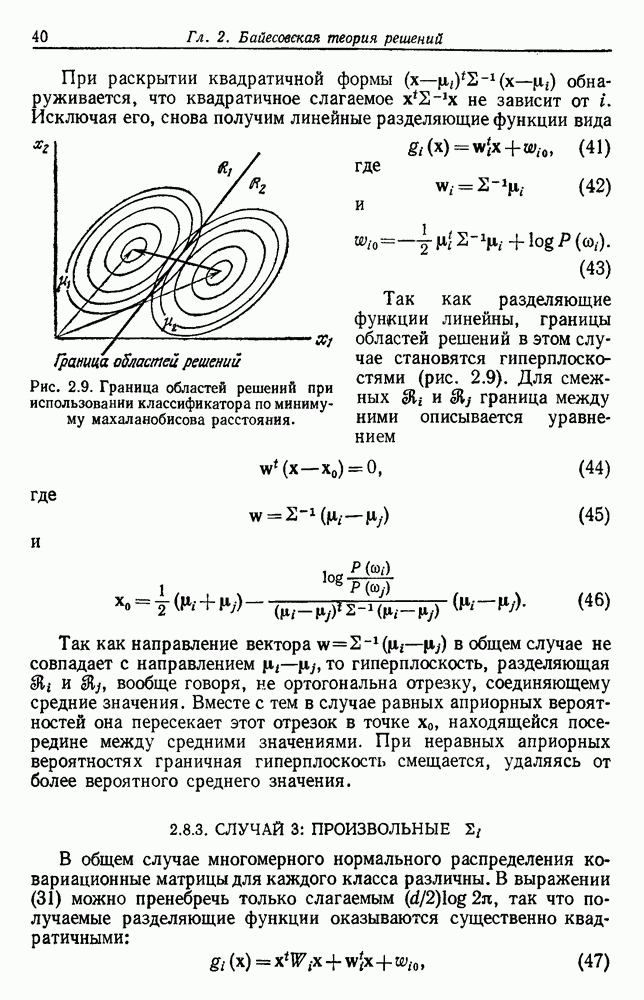
приблизительно нормальное со средним  и дисперсией
и дисперсией 
 так, чтобы минимизировать
так, чтобы минимизировать  где
где

 Согласно нулевой гипотезе, такое разделение ложно, но тем не менее дает в результате значение
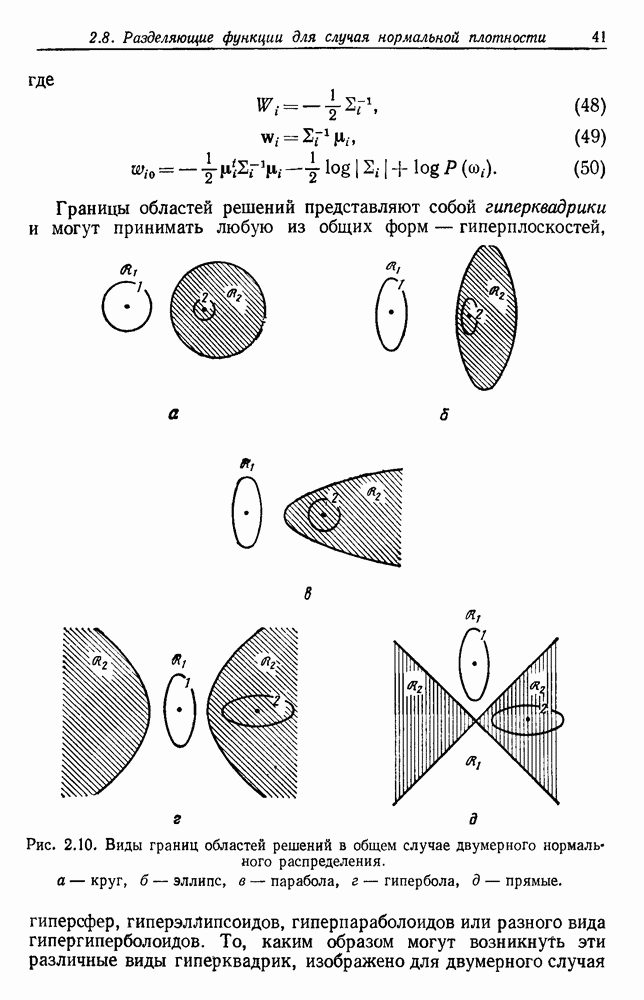
Согласно нулевой гипотезе, такое разделение ложно, но тем не менее дает в результате значение  меньшее
меньшее  Если бы мы знали выборочное распределение для
Если бы мы знали выборочное распределение для  то могли бы определить, насколько мало должно быть
то могли бы определить, насколько мало должно быть  до того, как будем вынуждены отказаться от нулевой гипотезы одногруппового разделения. Так как аналитическое решение для оптимального разделения отсутствует, мы не можем вывести точного
до того, как будем вынуждены отказаться от нулевой гипотезы одногруппового разделения. Так как аналитическое решение для оптимального разделения отсутствует, мы не можем вывести точного
 можно показать, что сумма квадратов ошибок для такого разделения приблизительно нормальна со средним
можно показать, что сумма квадратов ошибок для такого разделения приблизительно нормальна со средним  и дисперсией
и дисперсией 
 меньше, чем
меньше, чем  так как среднее
так как среднее  для
для  для близкого к оптимальному разделению меньше, чем среднее для
для близкого к оптимальному разделению меньше, чем среднее для  Чтобы стать значимым, уменьшение суммы квадратов ошибок должно быть больше, чем этот результат. Мы можем получить приблизительное критическое значение для
Чтобы стать значимым, уменьшение суммы квадратов ошибок должно быть больше, чем этот результат. Мы можем получить приблизительное критическое значение для  предположив, что близкое к оптимальному разделение почти оптимально, используя нормальную аппроксимацию для распределения выборок и оценивая
предположив, что близкое к оптимальному разделение почти оптимально, используя нормальную аппроксимацию для распределения выборок и оценивая  как
как

 -процентным уровнем значимости, если
-процентным уровнем значимости, если

