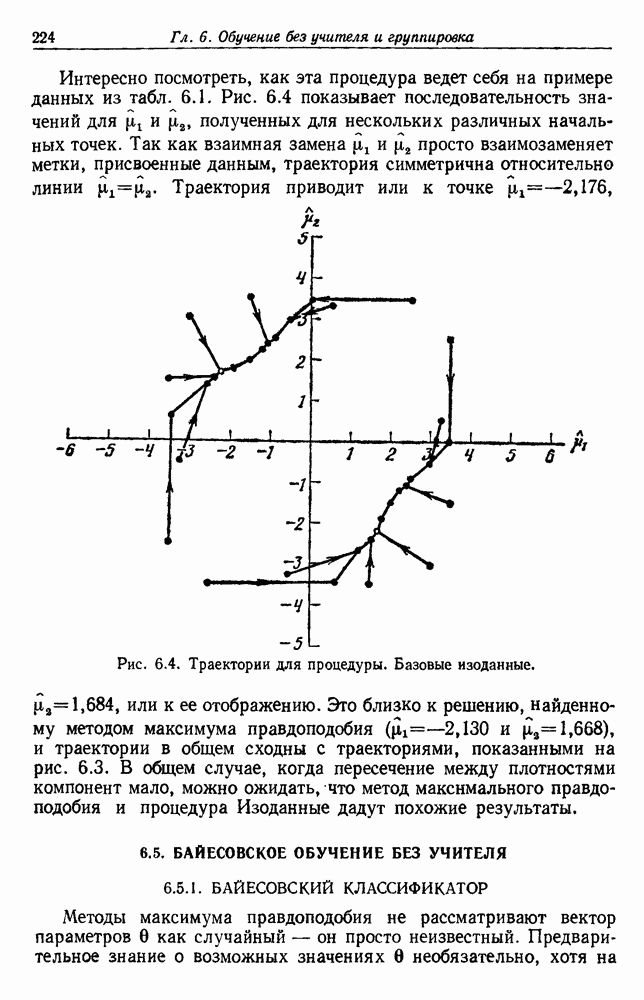
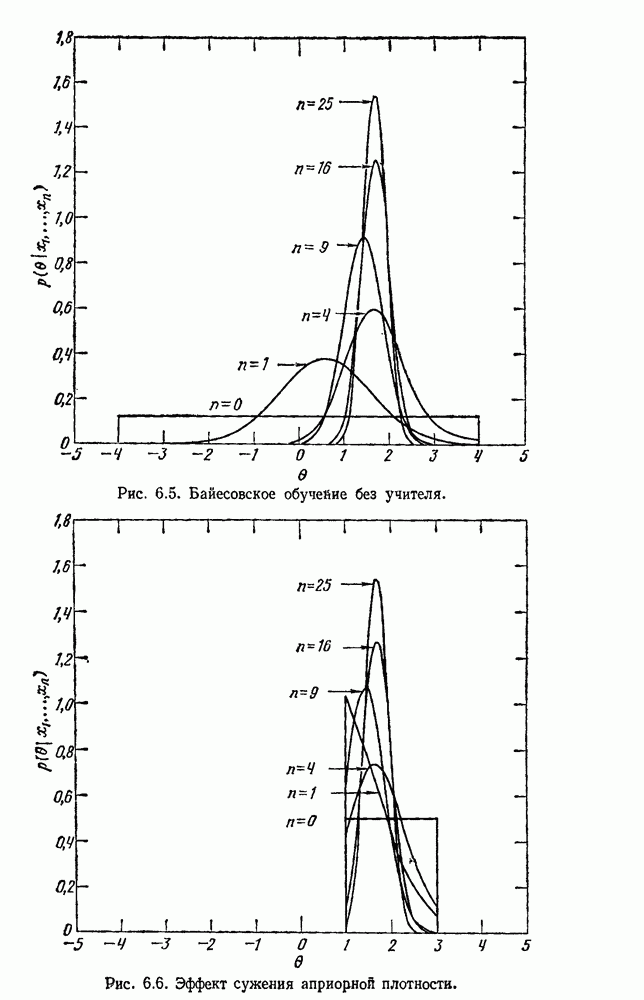
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
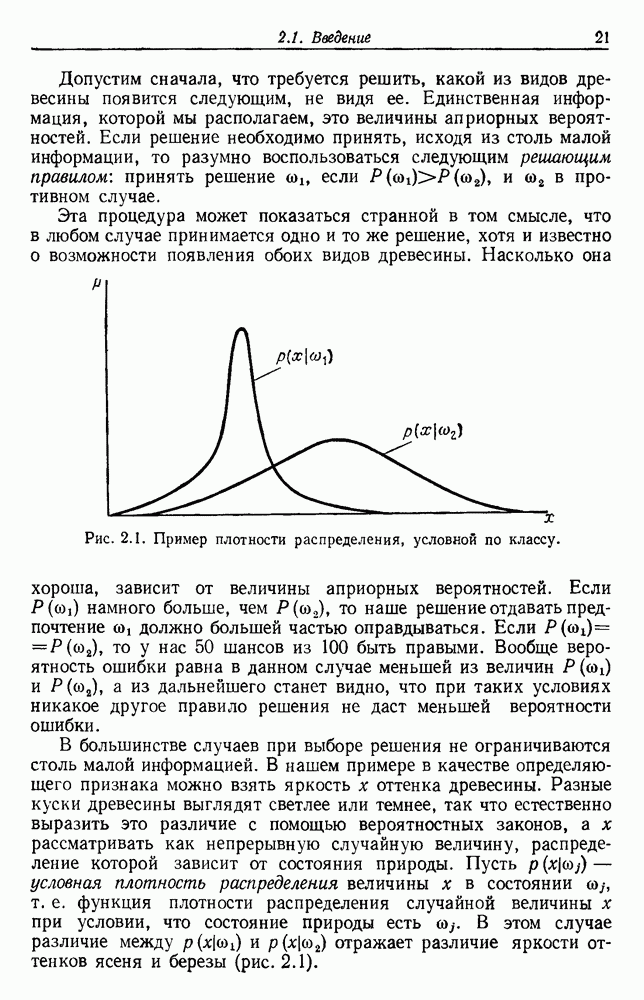
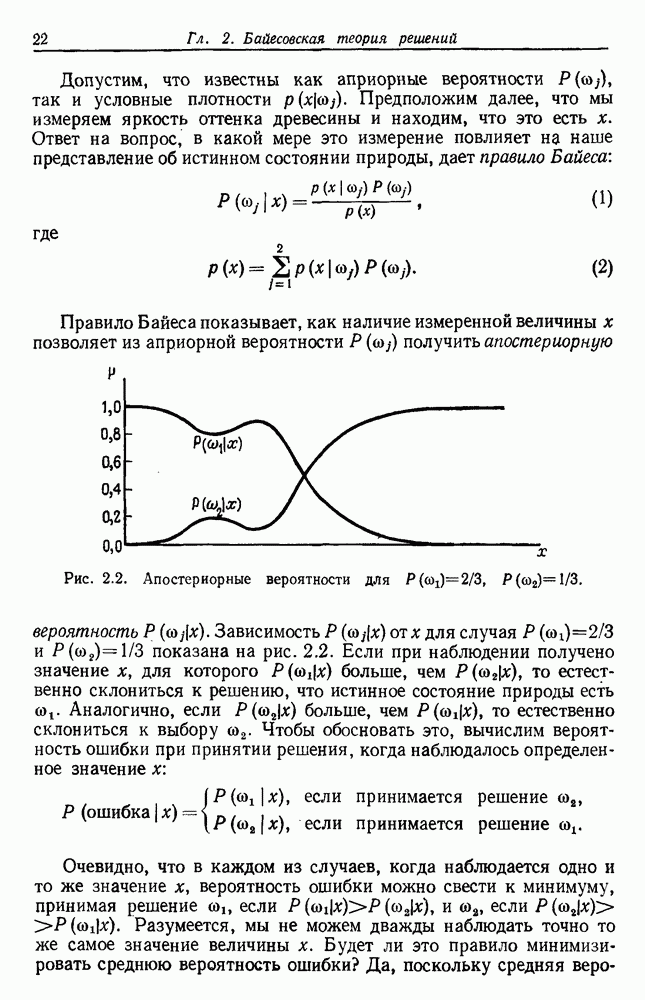
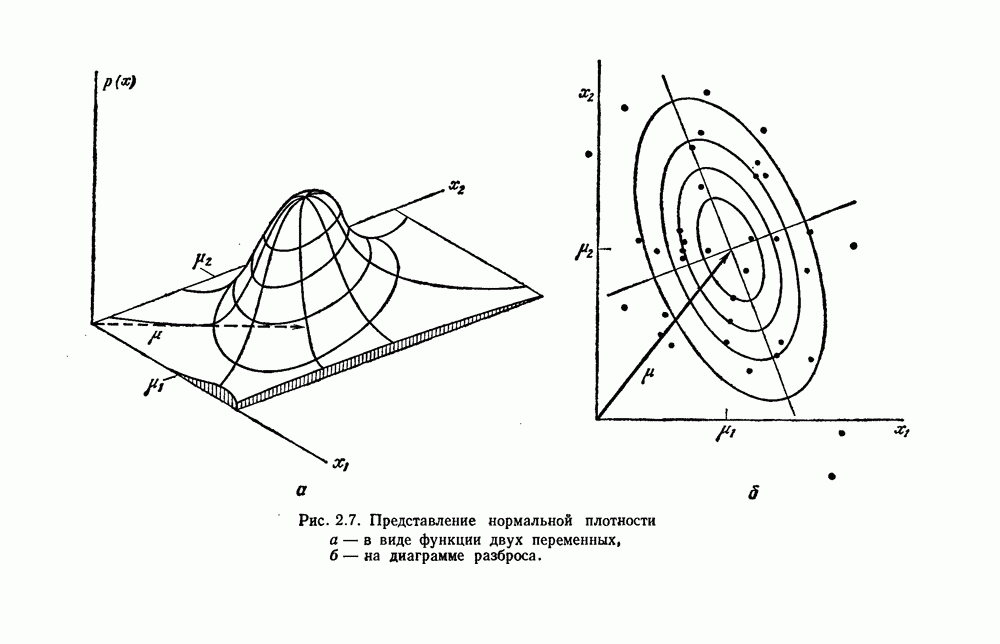
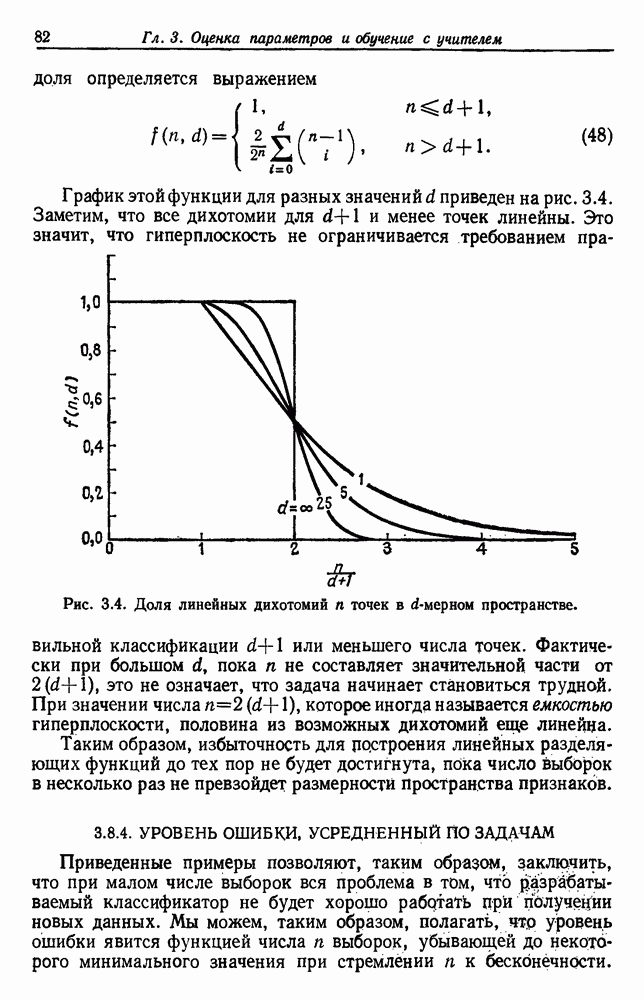
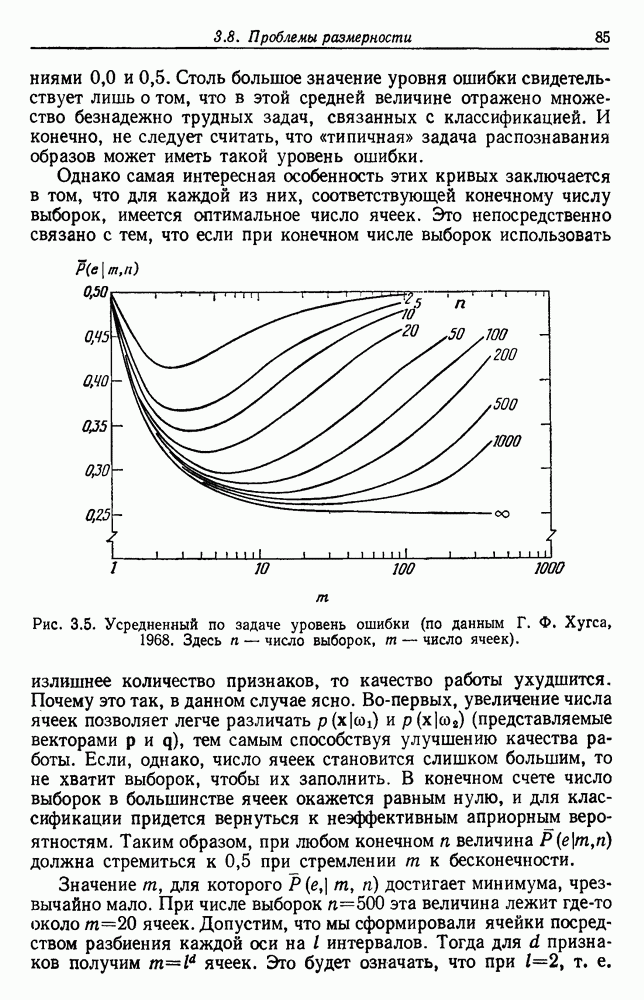
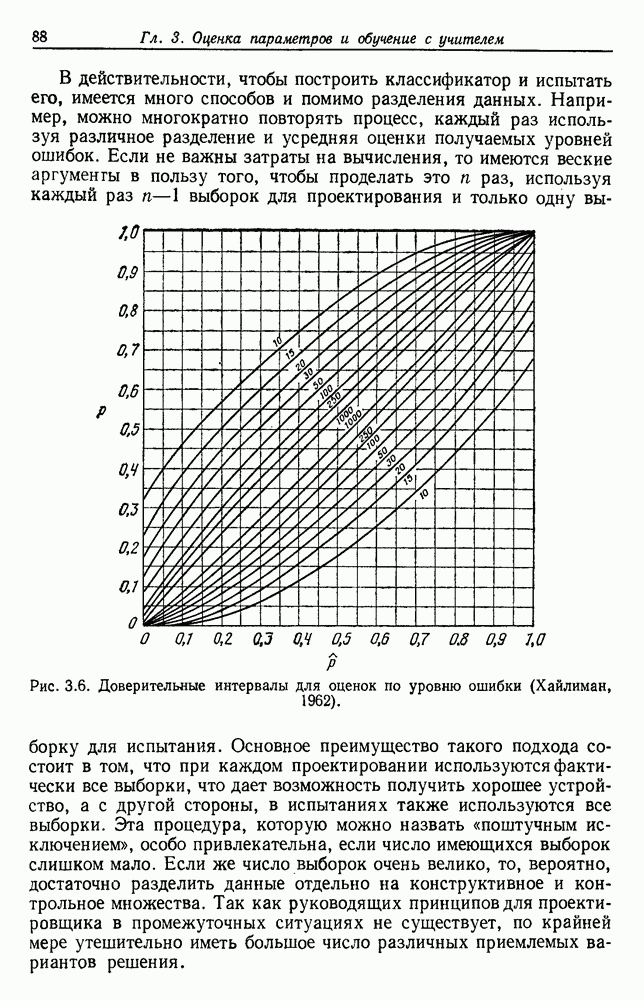
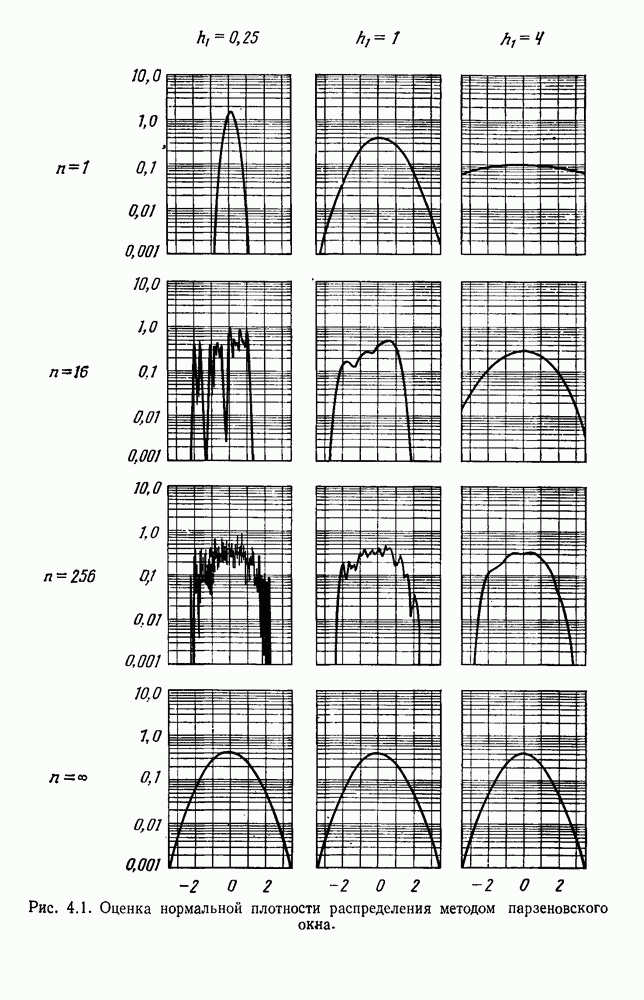
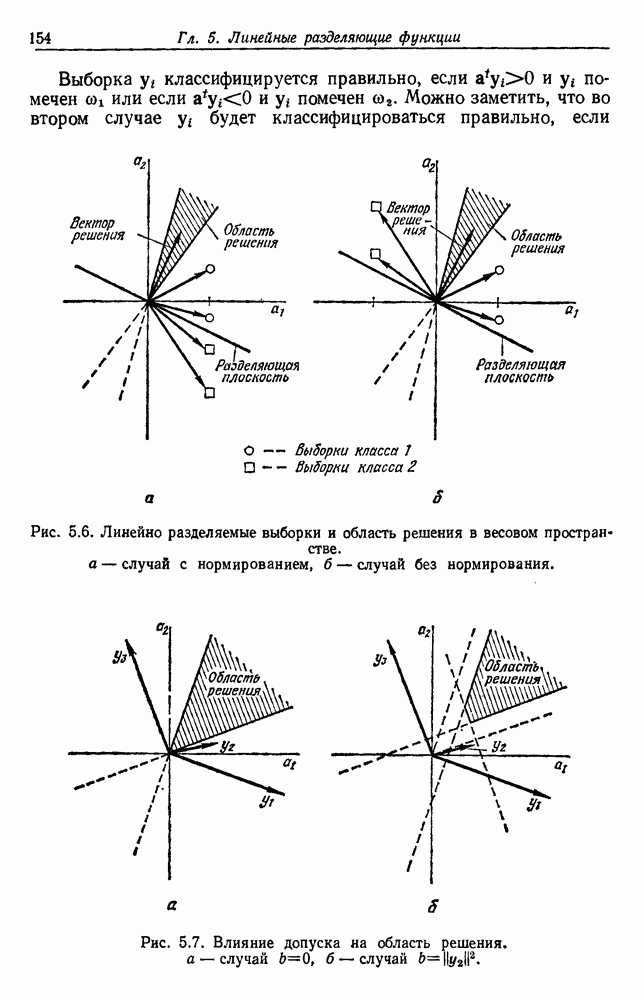
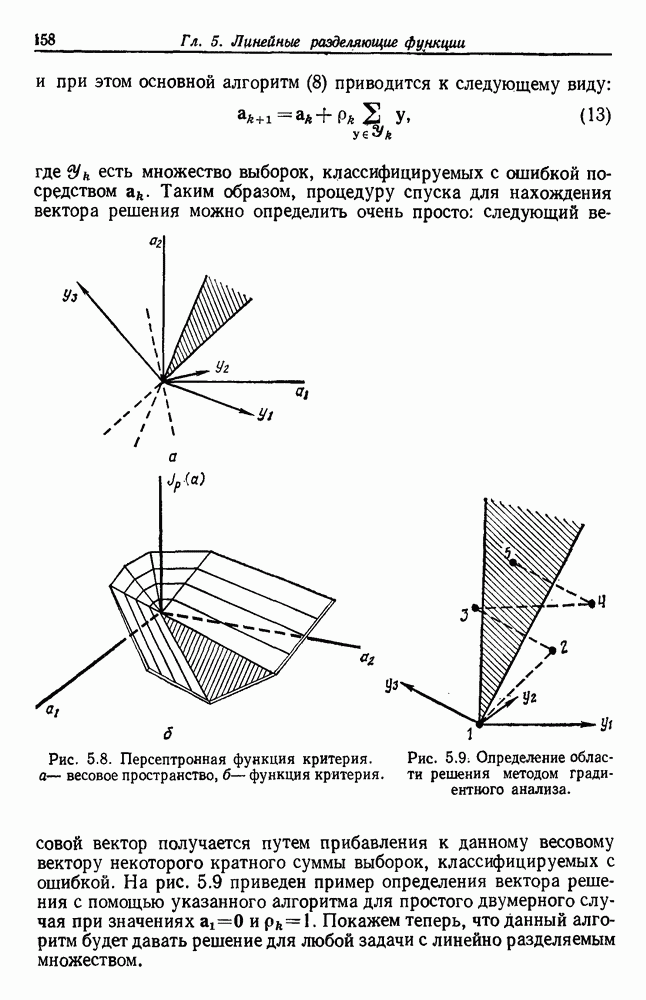
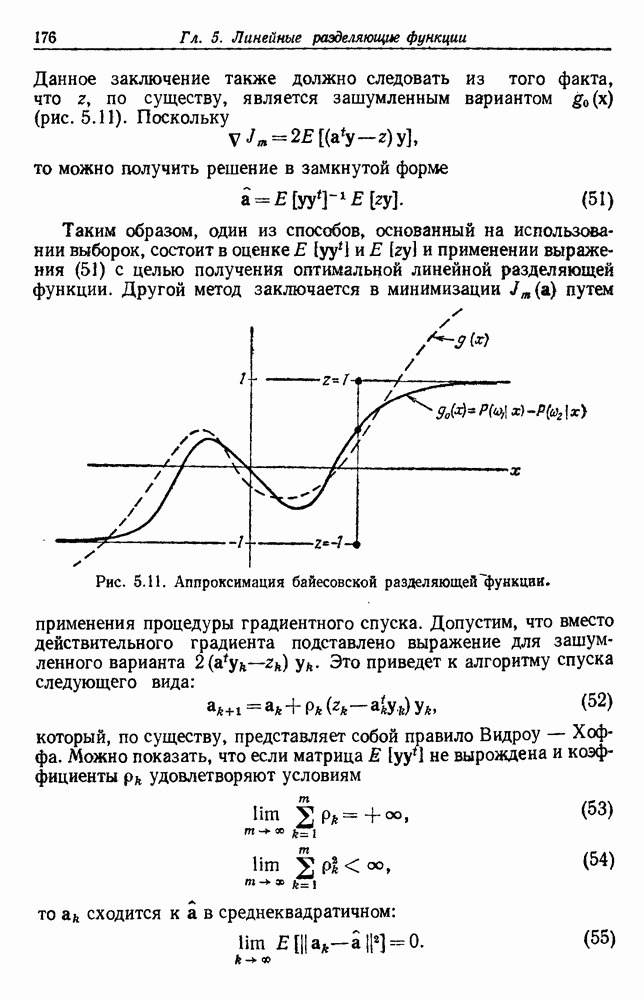
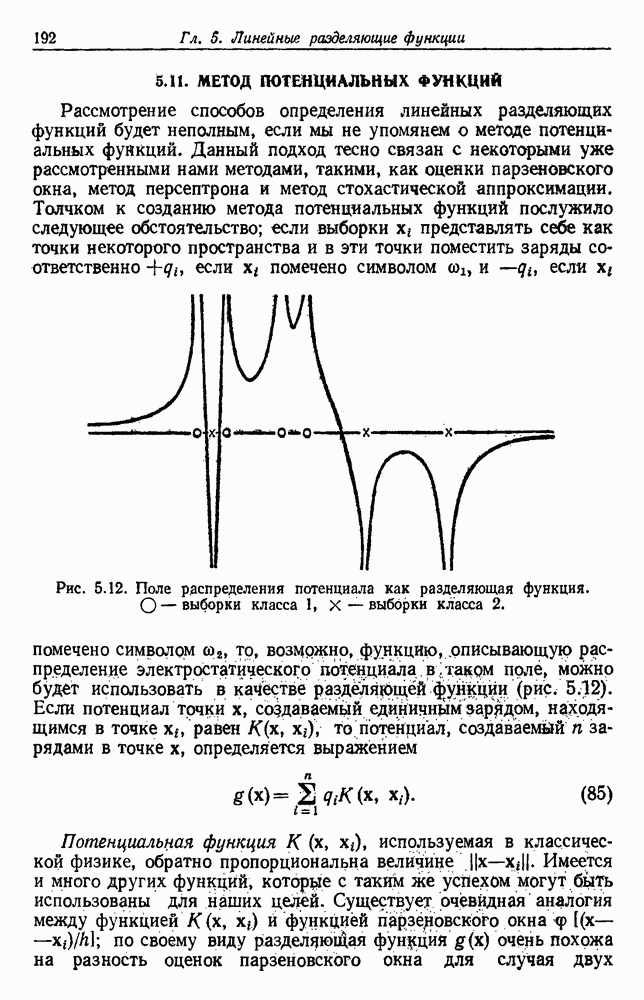
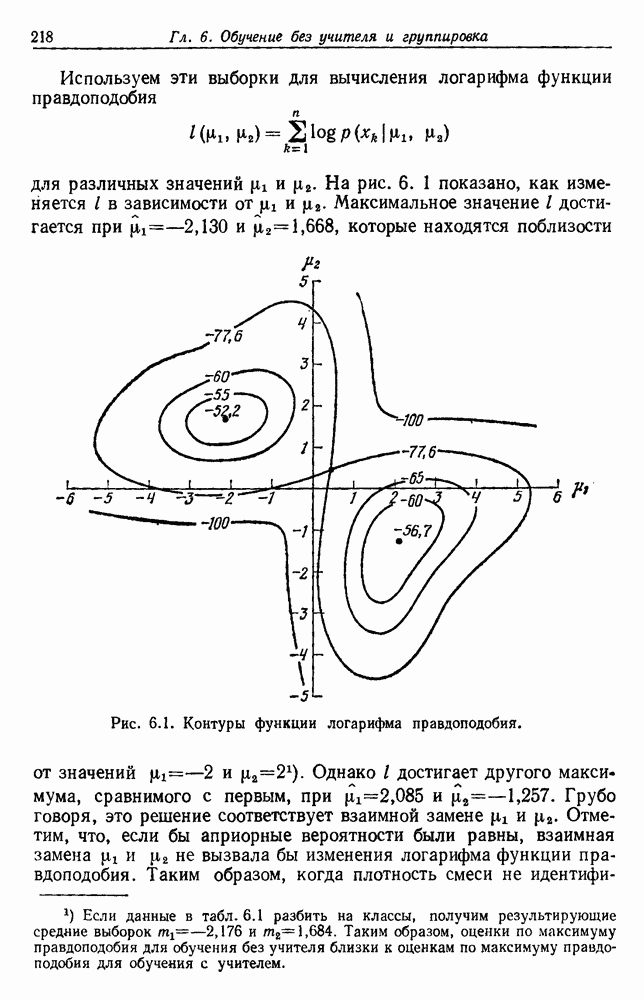
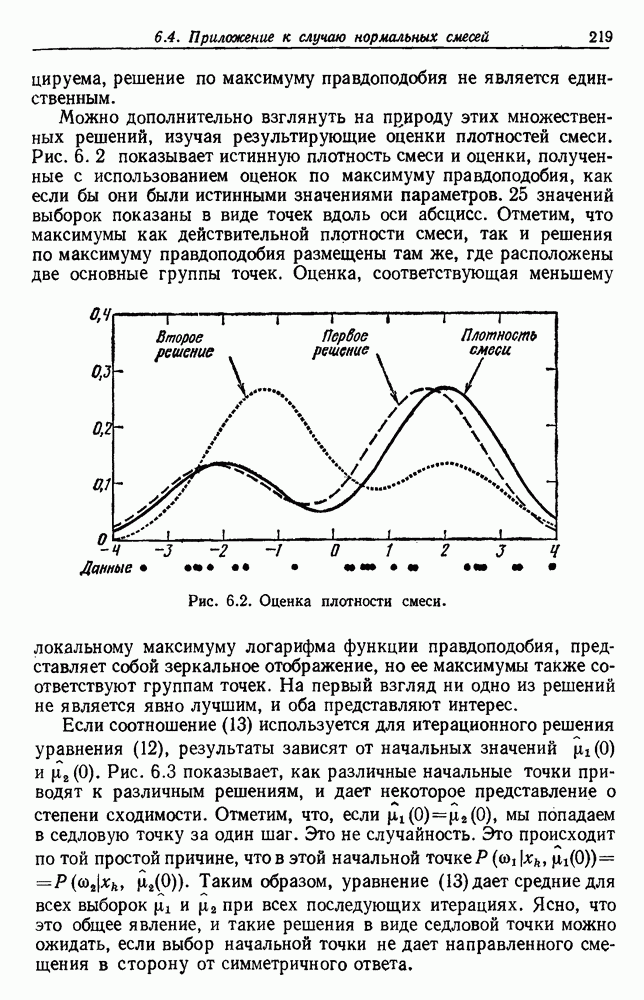
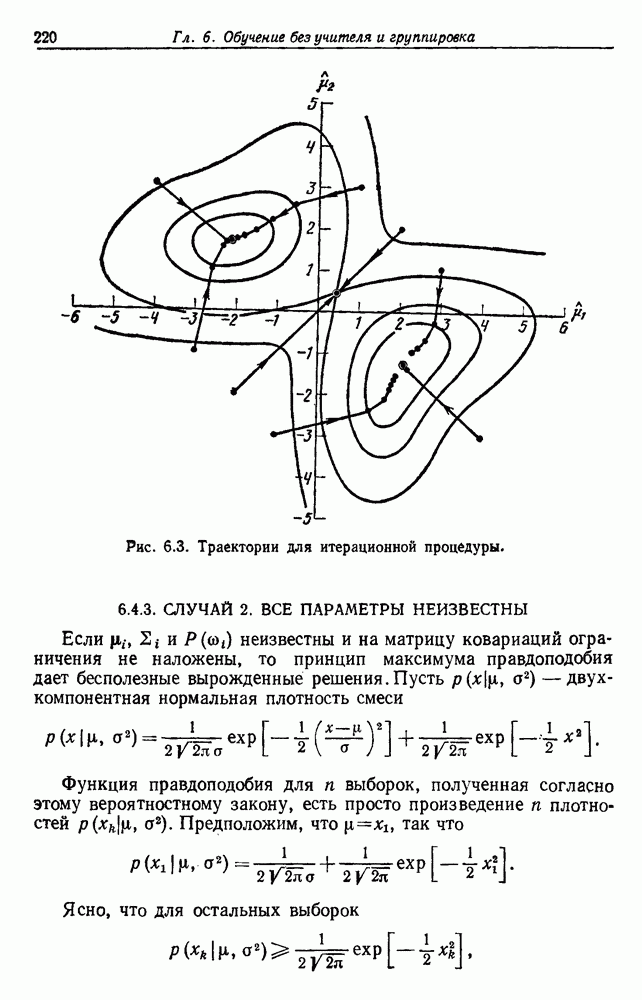
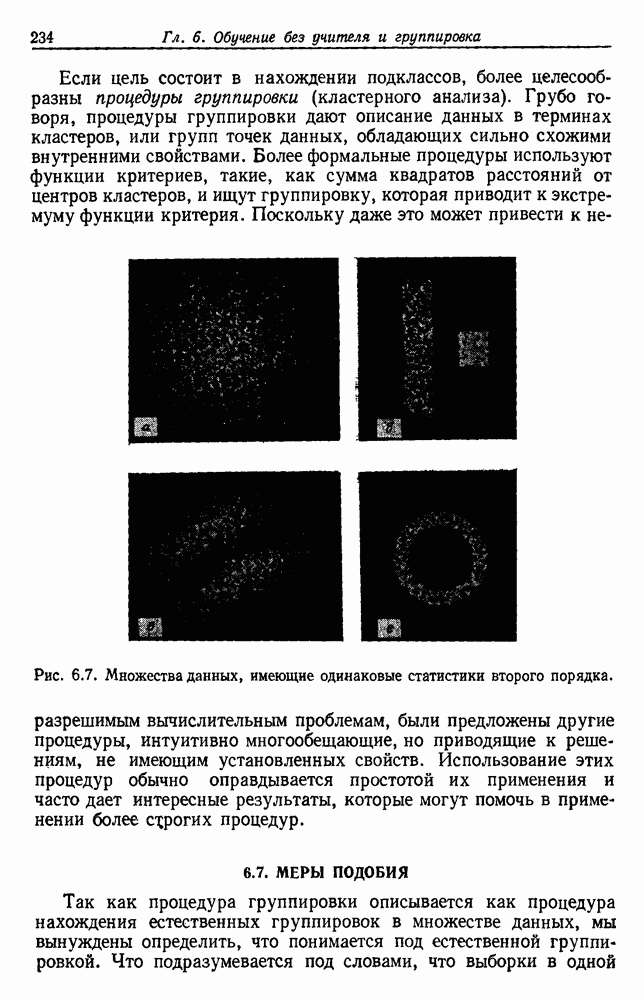
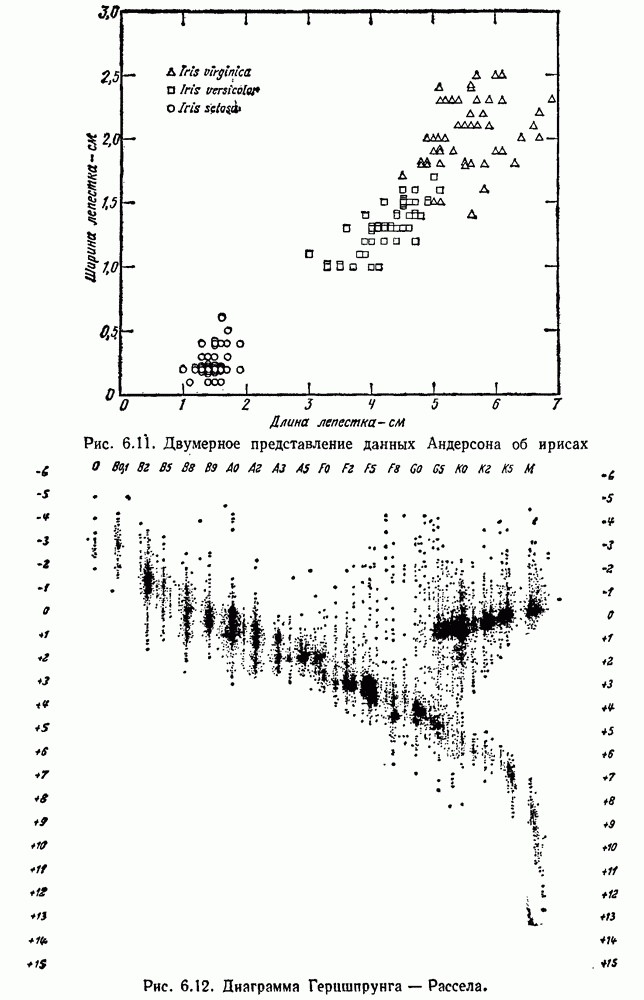
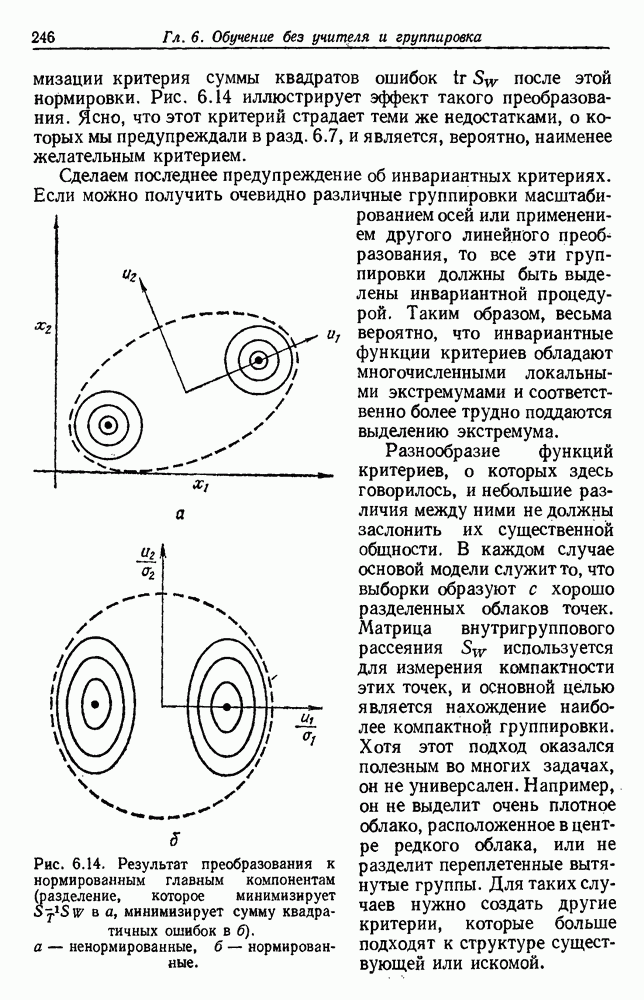
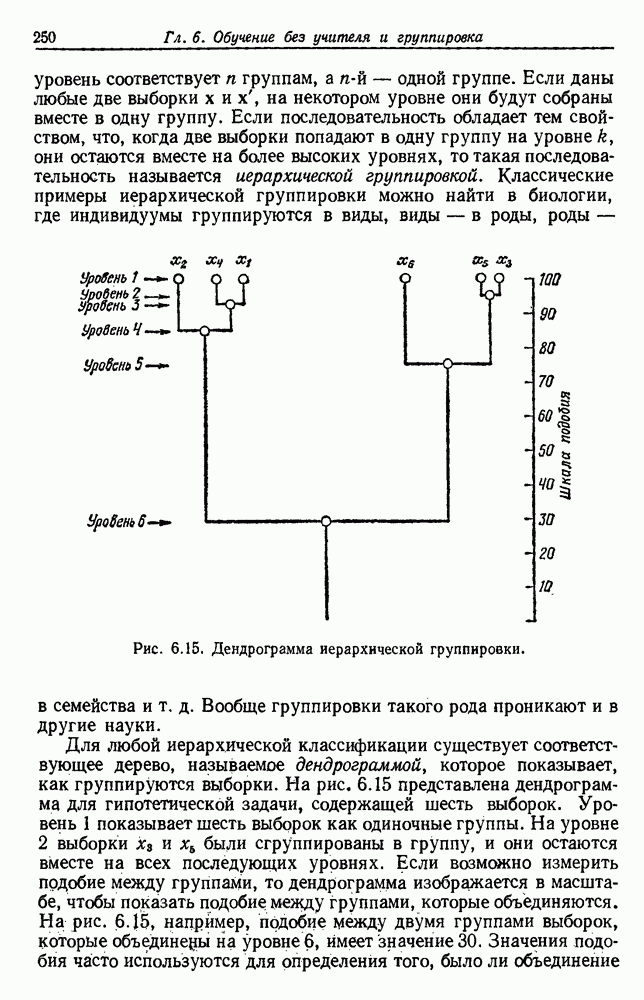
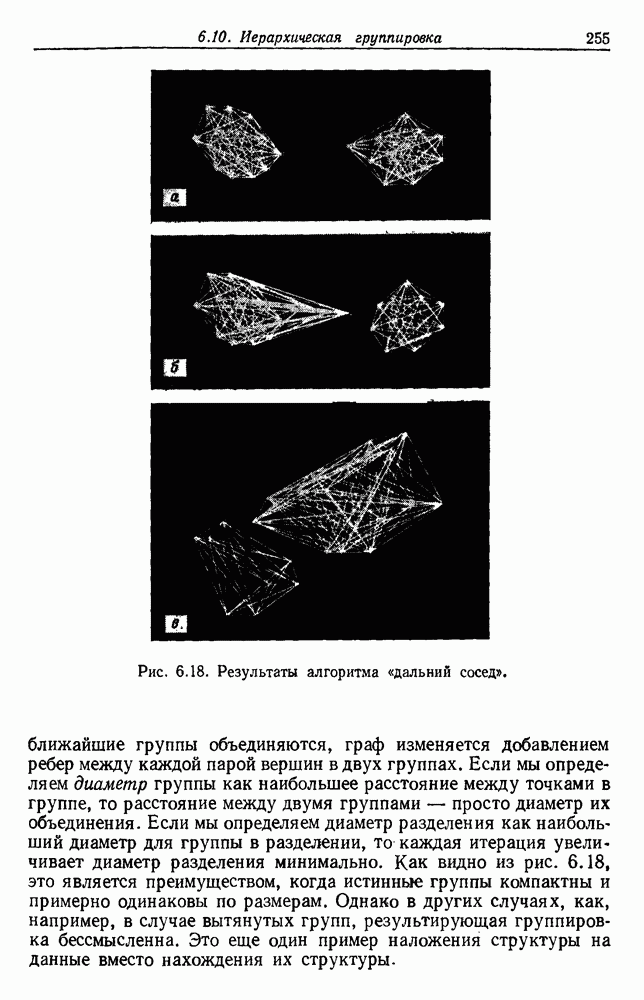
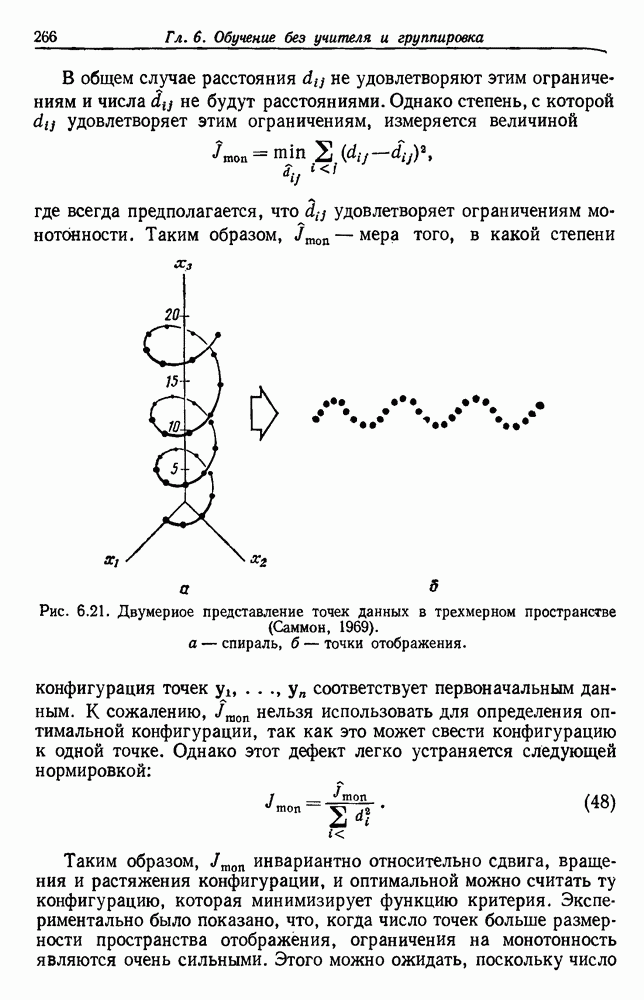
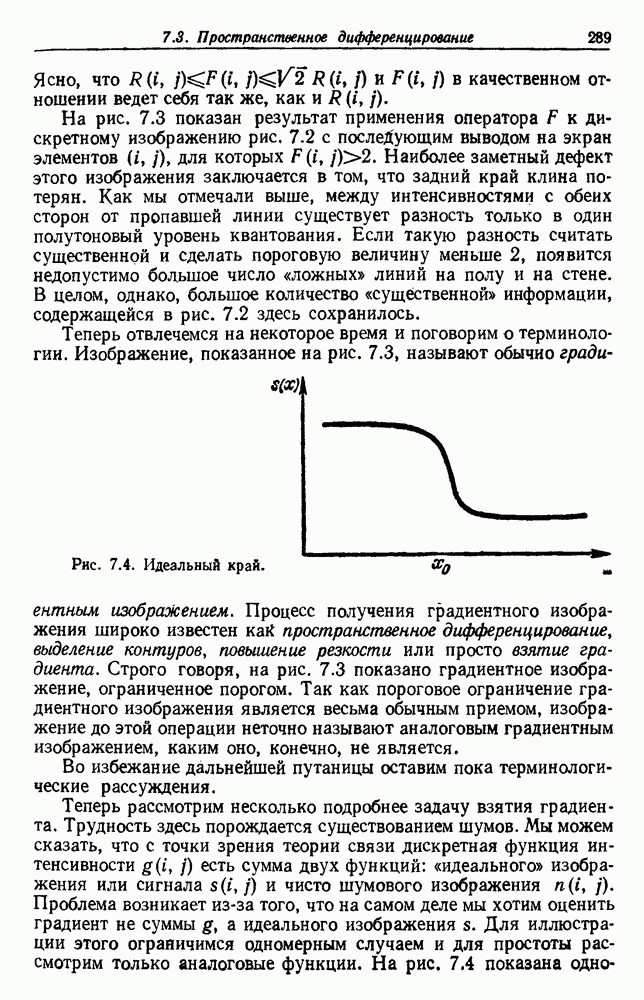
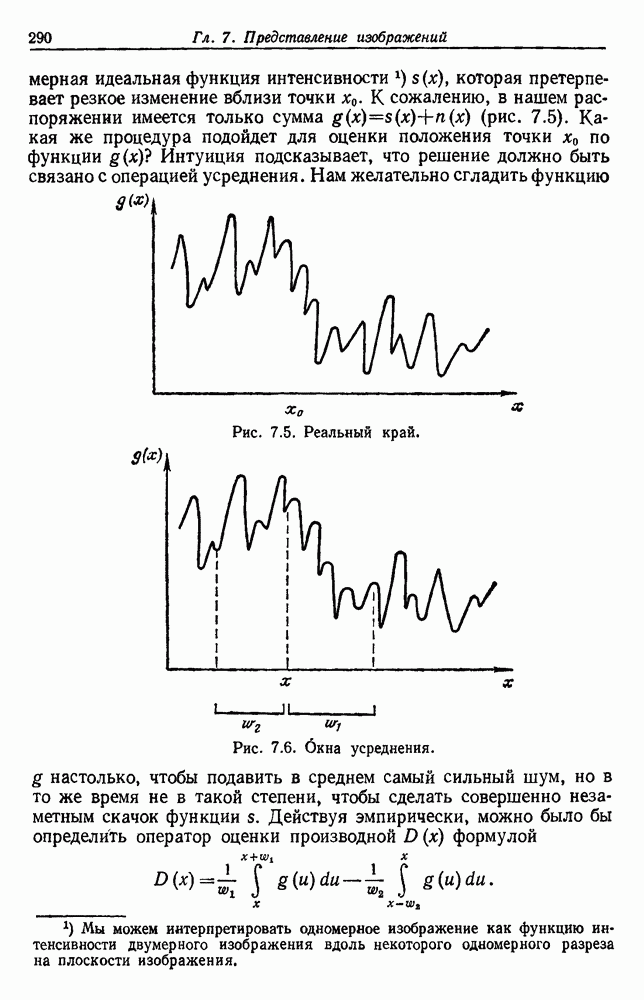
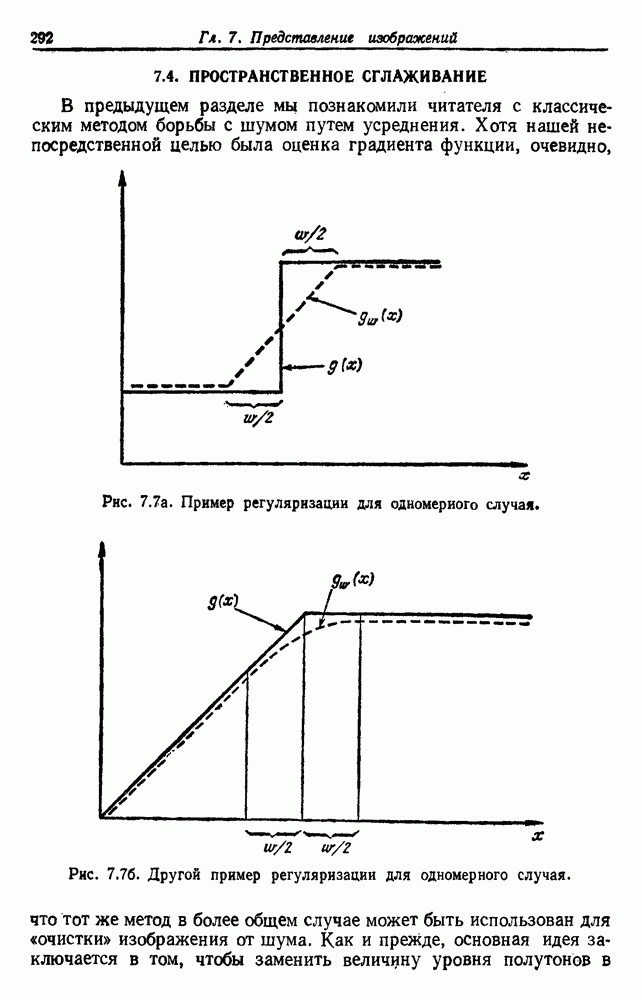
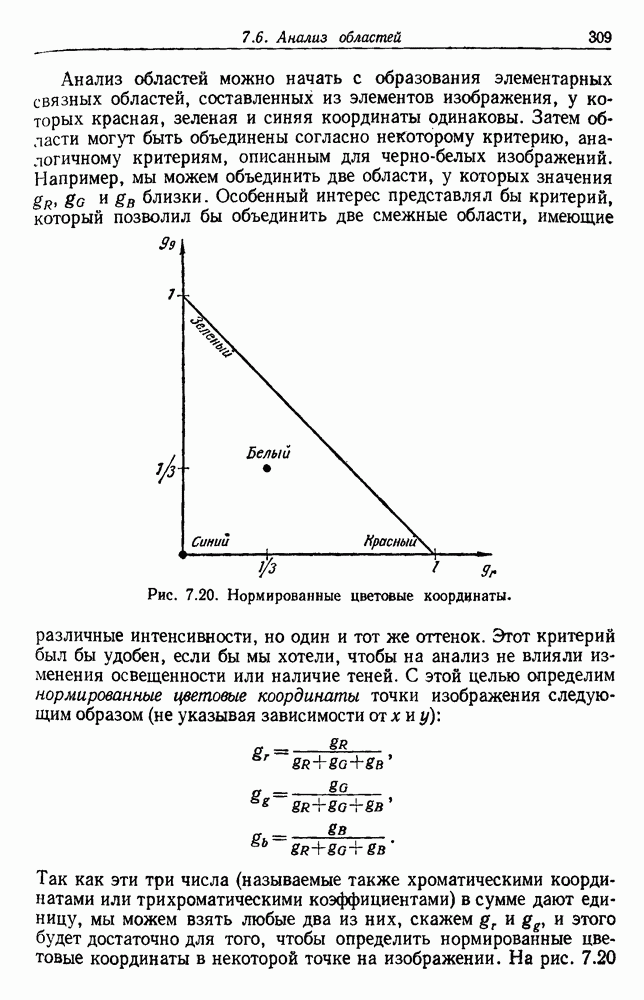
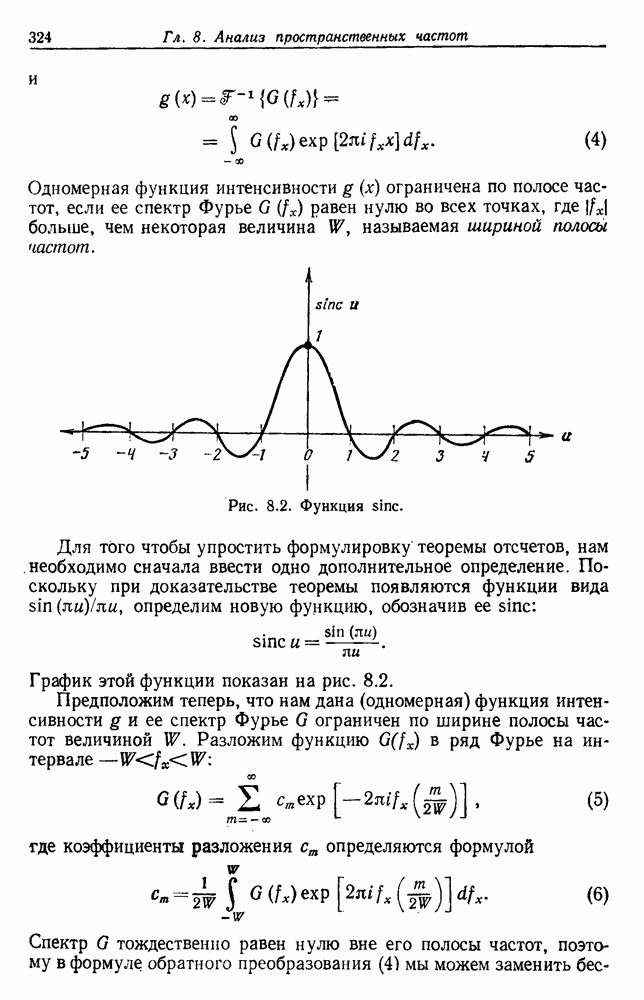
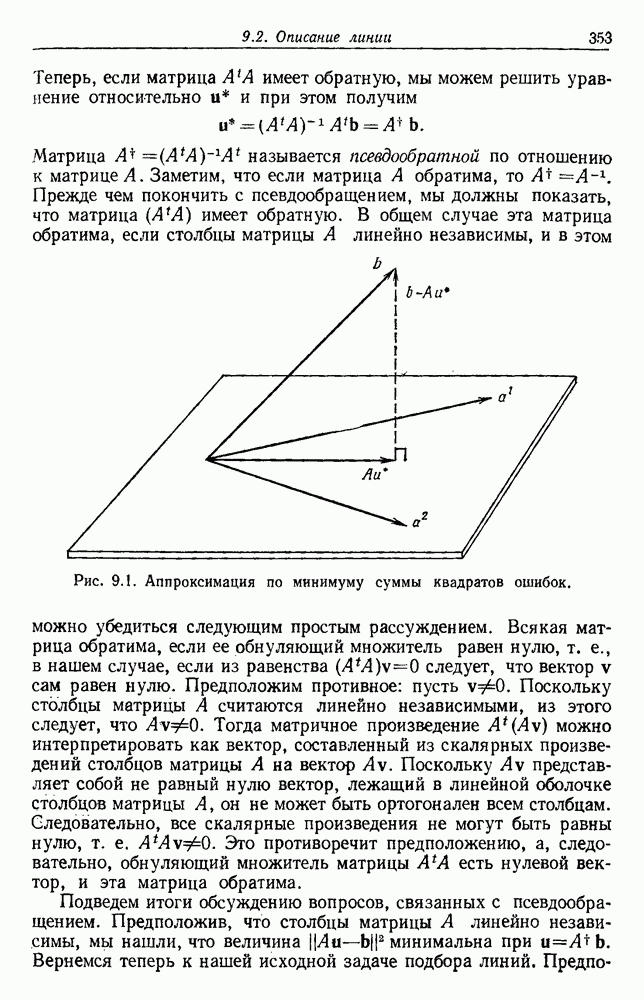
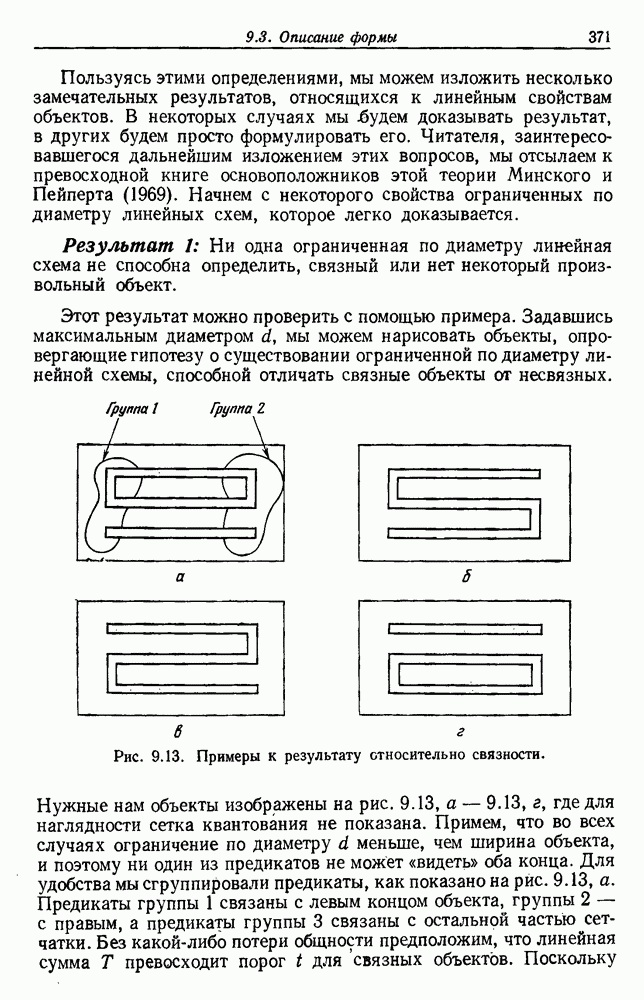
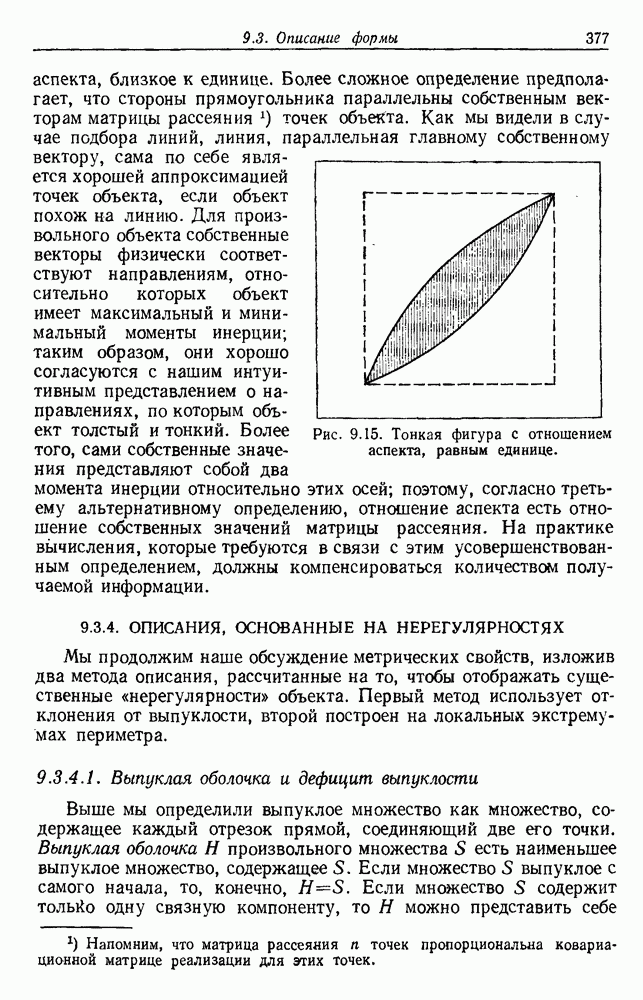
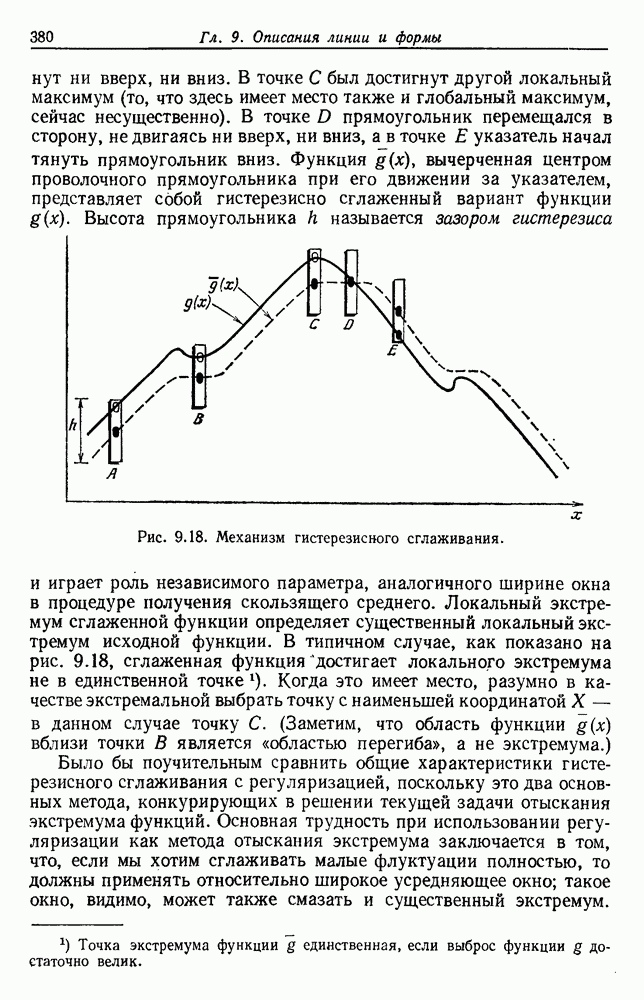
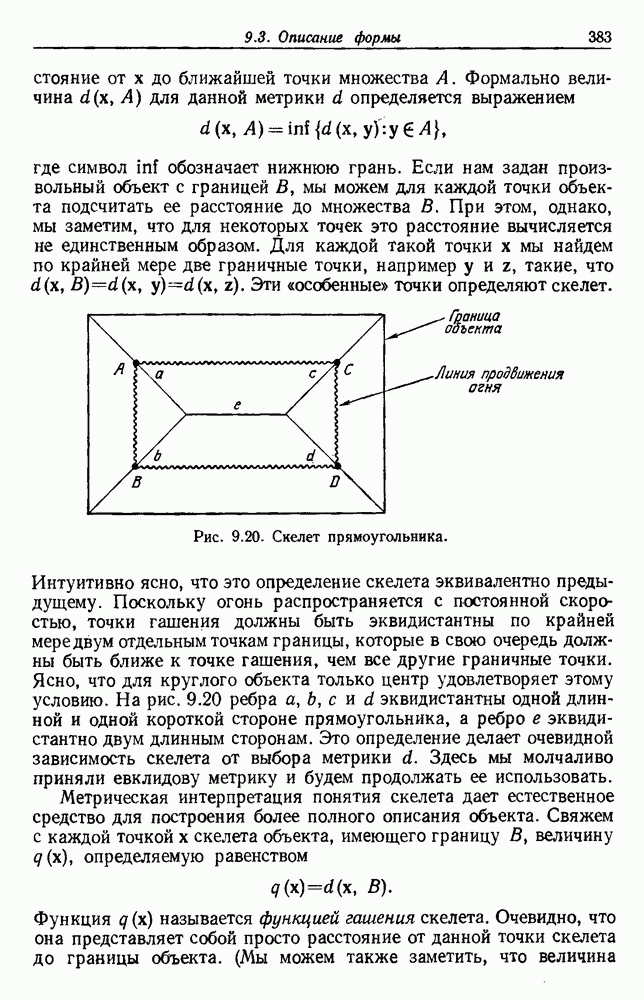
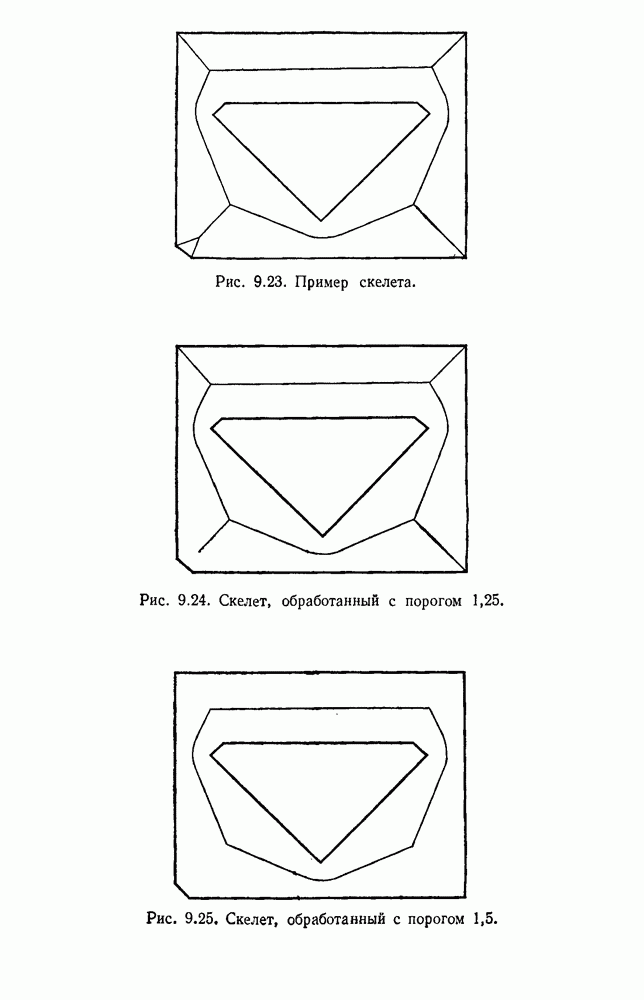
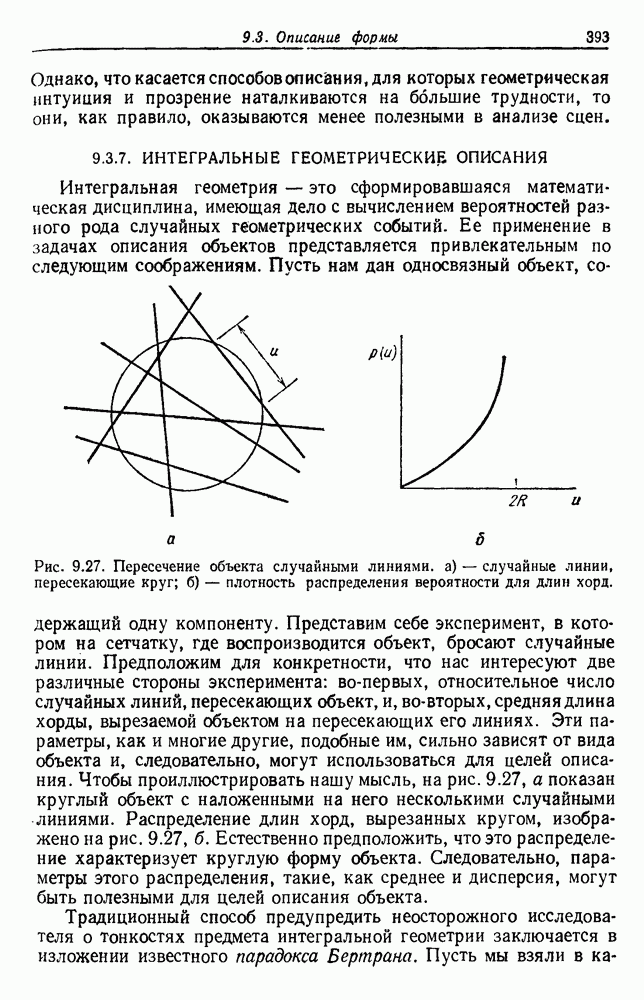
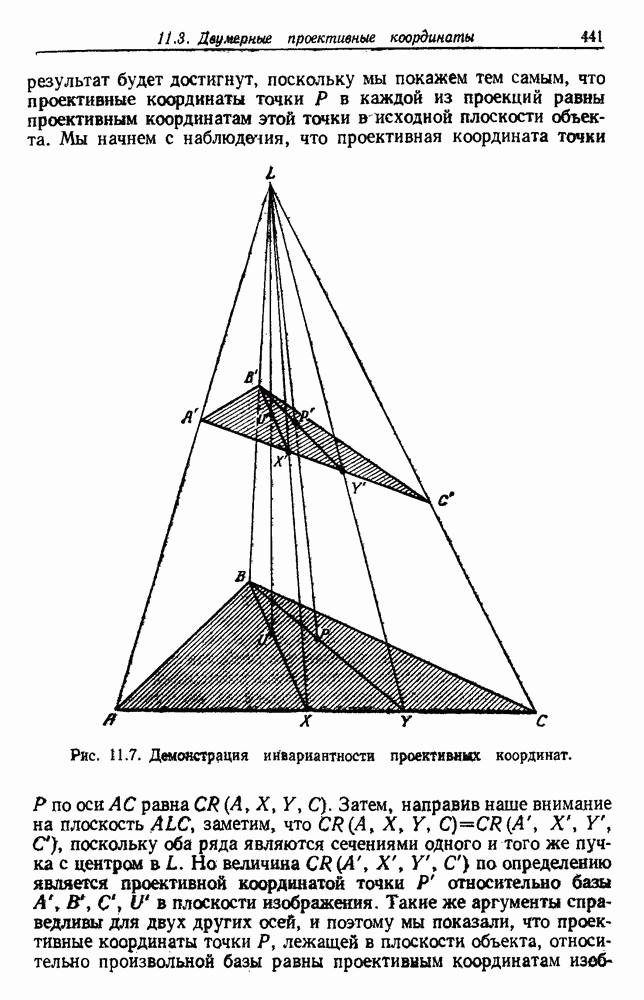
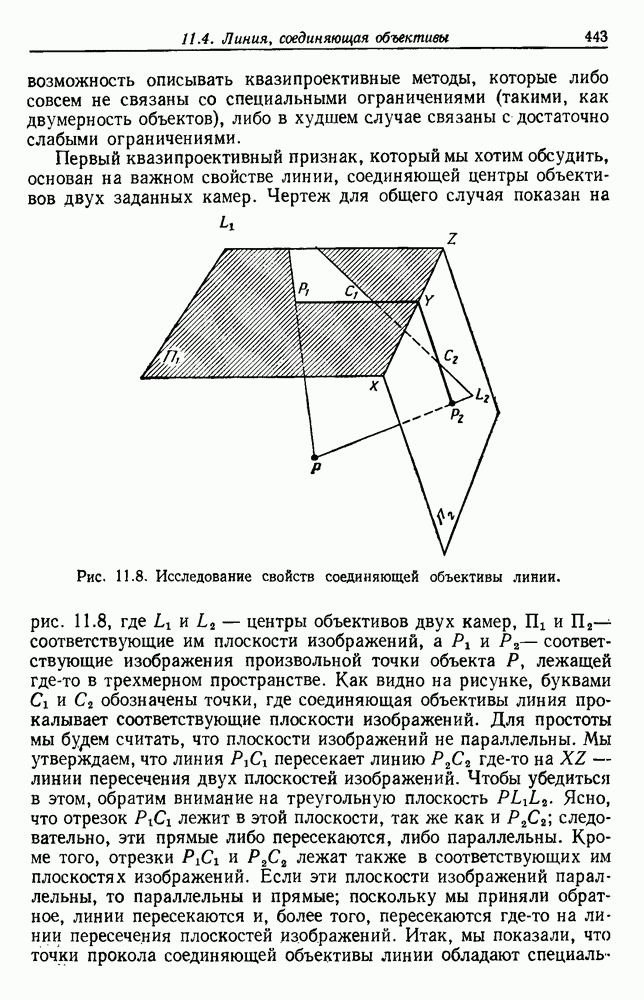
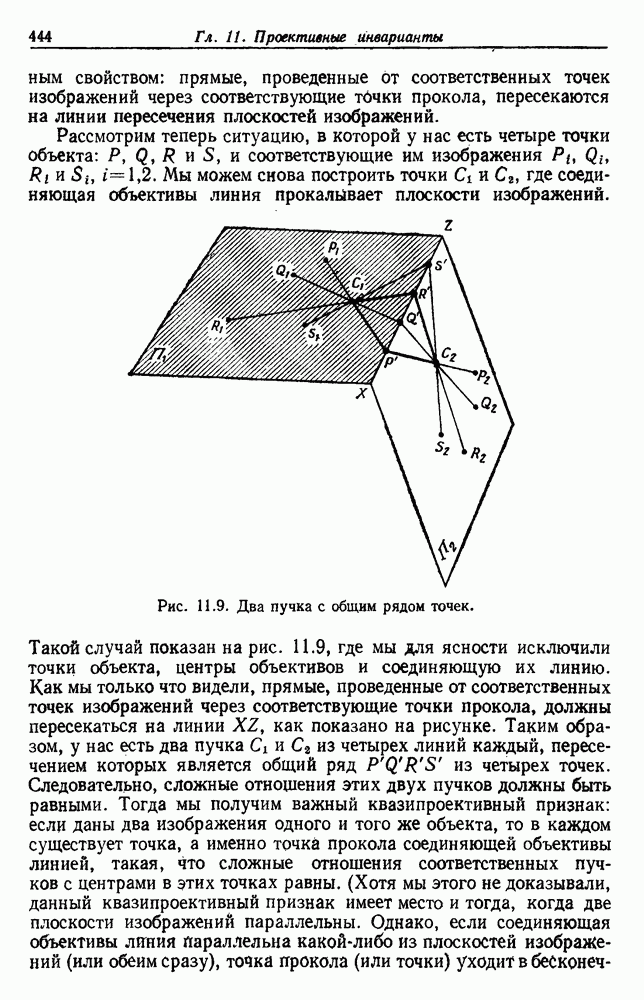
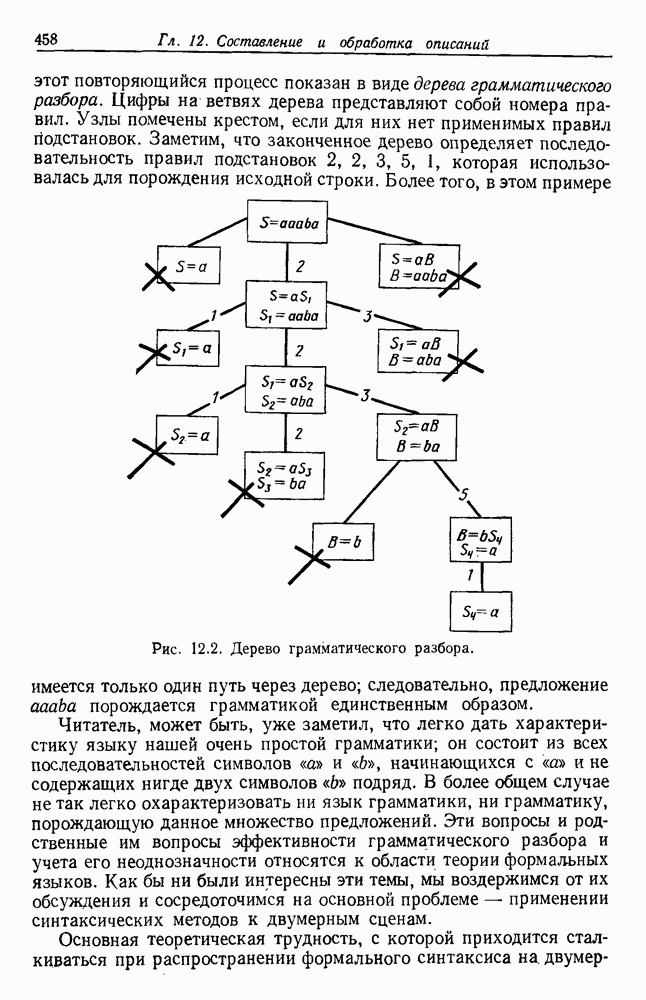
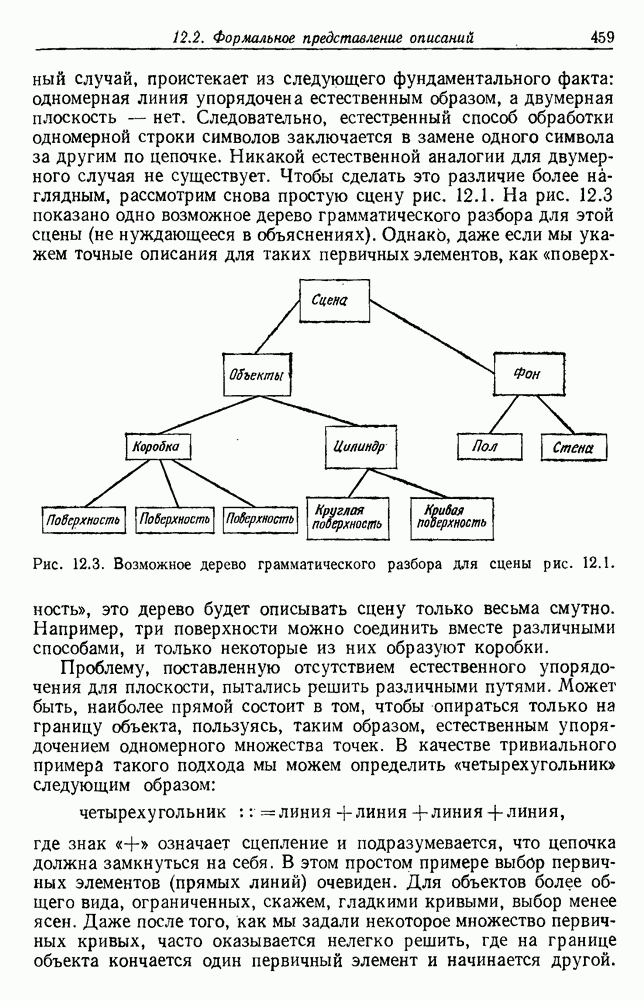
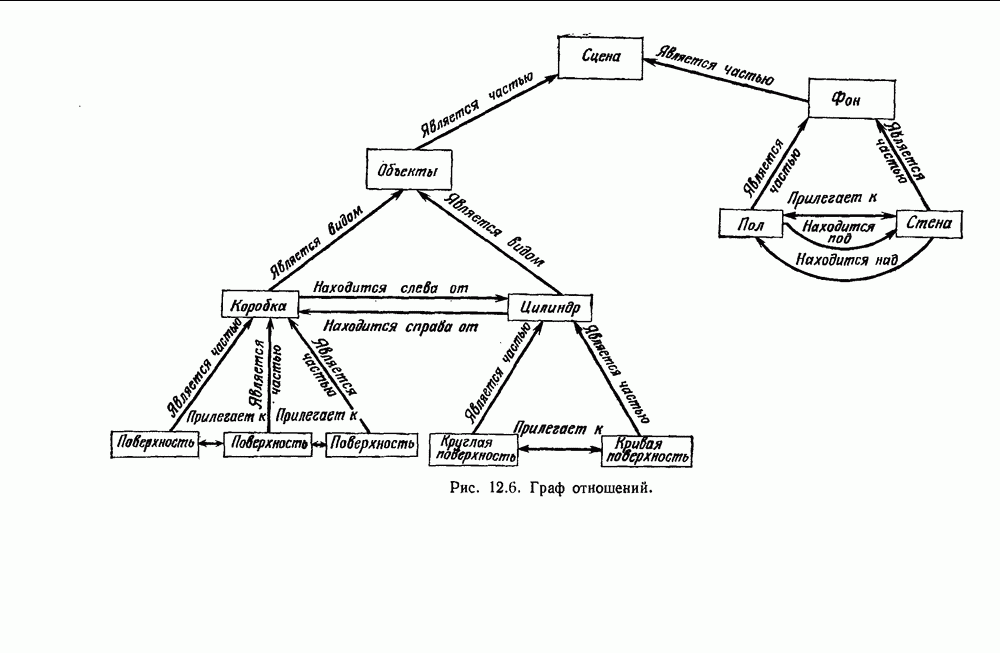
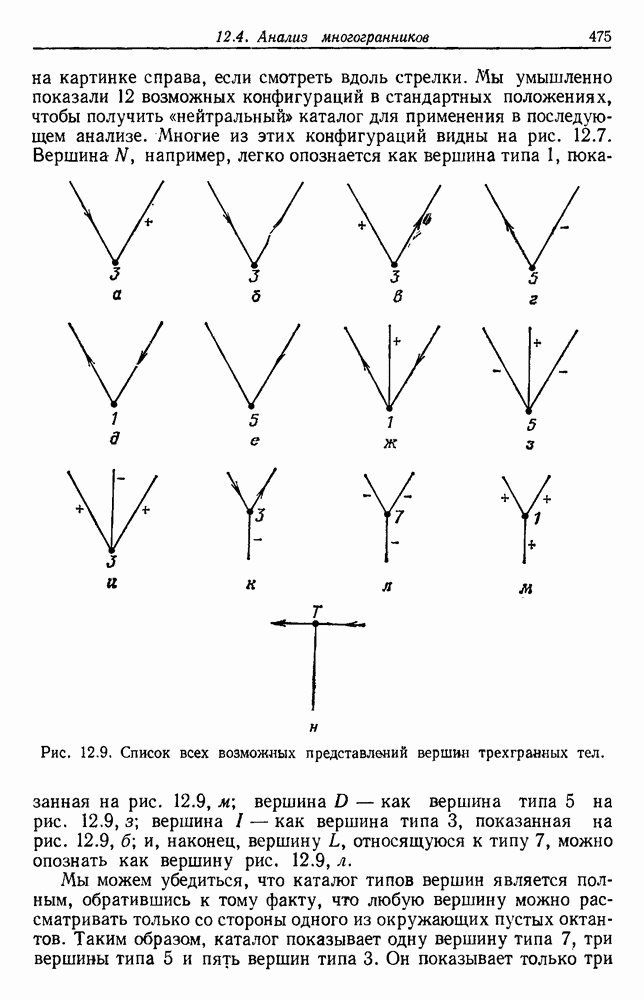
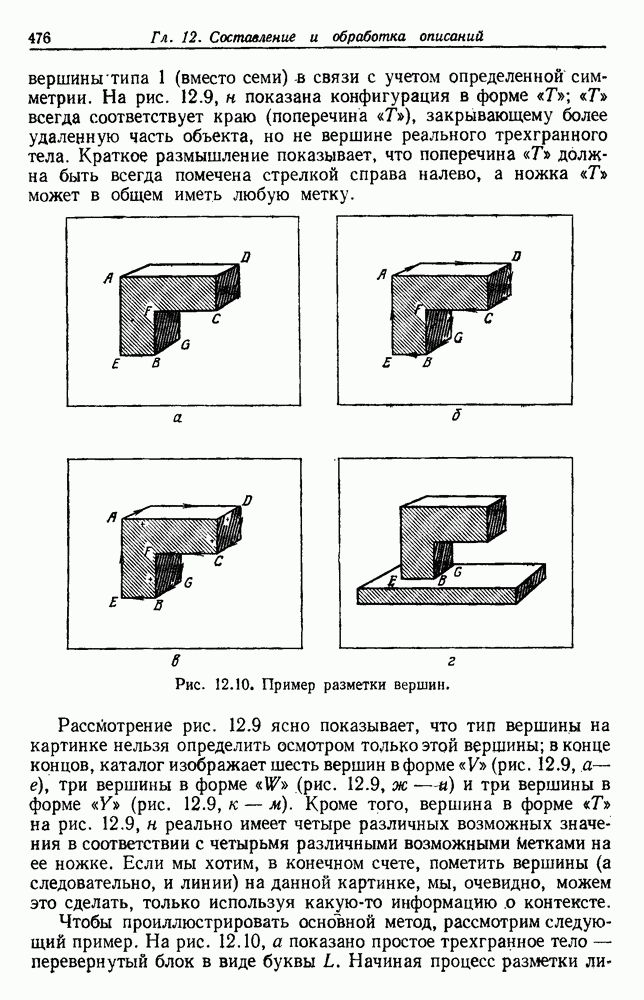
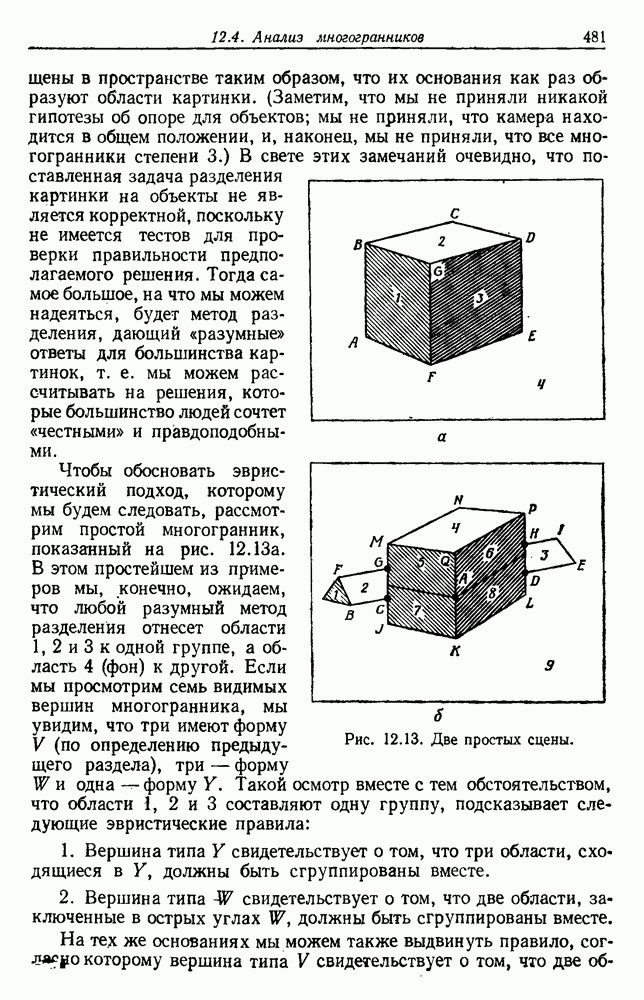
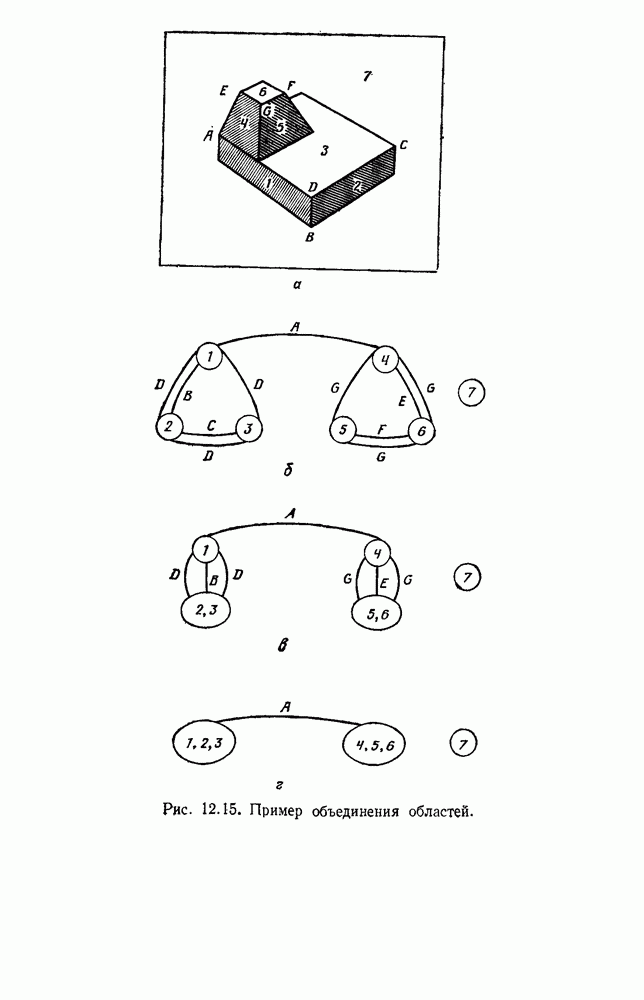
6.7. МЕРЫ ПОДОБИЯТак как процедура группировки описывается как процедура нахождения естественных группировок в множестве данных, мы вынуждены определить, что понимается под естественной группировкой. Что подразумевается под словами, что выборки в одной группе более схожи, чем выборки в другой? Этот вопрос в действительности содержит две отдельные части: как измерять сходство между выборками и как нужно оценивать разделение множества выборок на группы? В этом разделе рассмотрим первую из этих частей. Наиболее очевидной мерой подобия (или различия) между двумя выборками является расстояние между ними. Один из путей, по которому можно начать исследование группировок, состоит в определении подходящей функции расстояния и вычислении матрицы расстояний между всеми парами выборок. Если расстояние является хорошей мерой различия, то можно ожидать, что расстояние между выборками в одной и той же группе будет значительно меньше, чем расстояние между выборками из разных групп. Предположим на минуту, что две выборки принадлежат одной и той же группе, если евклидово расстояние между ними меньше, чем некоторое пороговое расстояние Менее очевидным является факт, что результаты группировки зависят от выбора евклидова расстояния как меры различия. Этот выбор предполагает, что пространство признаков изотропно. Следовательно, группы, определенные евклидовым расстоянием, будут инвариантны относительно сдвигов или вращений — движений точек данных, не меняющих их взаимного расположения. Однако они, вообще говоря, не будут инвариантны линейным или другим преобразованиям, которые искажают расстояния. Таким образом как показано на рис. 6.9, простое масштабирование координатных осей может привести к различному разбиению данных на группы. Конечно, это не относится к задачам, в которых произвольное масштабирование является неестественным или бессмысленным преобразованием. Однако, если группы должны иметь какое-либо значение, они должны быть инвариантны преобразованиям, естественным для задачи. Один из путей достижения инвариантности состоит в нормировании данных перед группировкой. Например, чтобы добиться инвариантности к сдвигу и изменению масштаба, нужно так перенести оси и выбрать такой масштаб, чтобы все признаки имели нулевое среднее значение и единичную дисперсию. Чтобы добиться инвариантности к вращению, нужно так повернуть оси, чтобы они совпали с собственными векторами матрицы ковариаций выборок. Это преобразование к главным компонентам может проводиться до масштабной нормировки или после нее. (см. скан) Рис. 6.8. Действие порога расстояния на группировку (линиями соединены точки с расстояниями, меньшими чем (см. скан) Рис. 6.9. Влияние масштабирования на вид группировки. Однако читатель не должен делать вывода, что такого рода нормировка обязательно нужна. Рассмотрим, например, вопрос переноса и масштабирования осей так, чтобы каждый признак имел нулевое среднее значение и единичную дисперсию. Смысл такой нормировки состоит в том, что она предотвращает превосходство некоторых признаков при вычислении расстояний только потому, что они выражаются большими числовыми значениями. Вычитание среднего и деление на стандартное отклонение являются подходящей нормировкой, если разброс значений соответствует нормальной случайной дисперсии. Однако она может быть совсем неподходящей, если разброс происходит благодаря наличию подклассов (рис. 6.10).
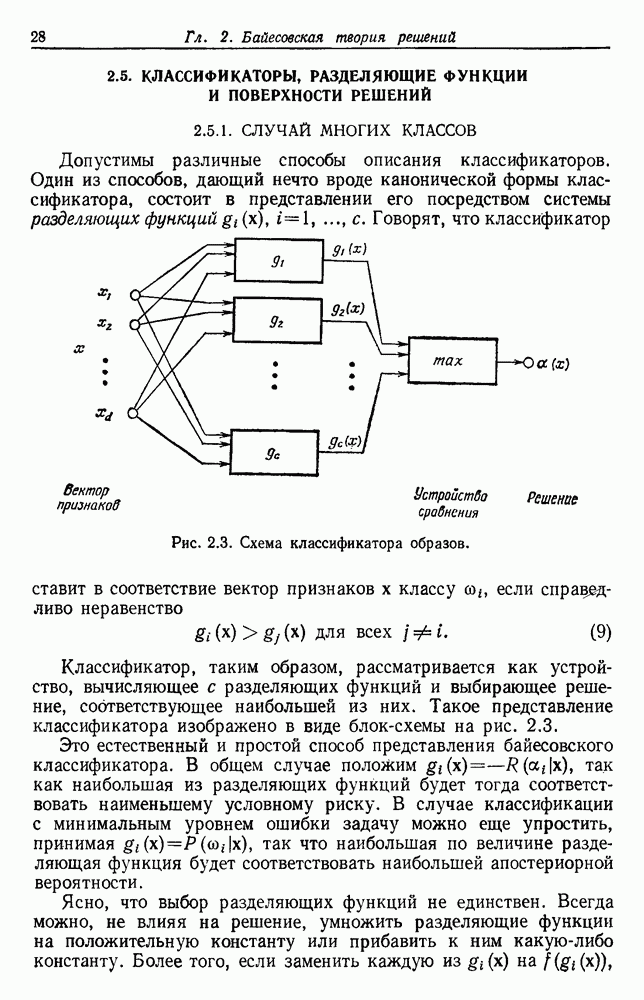
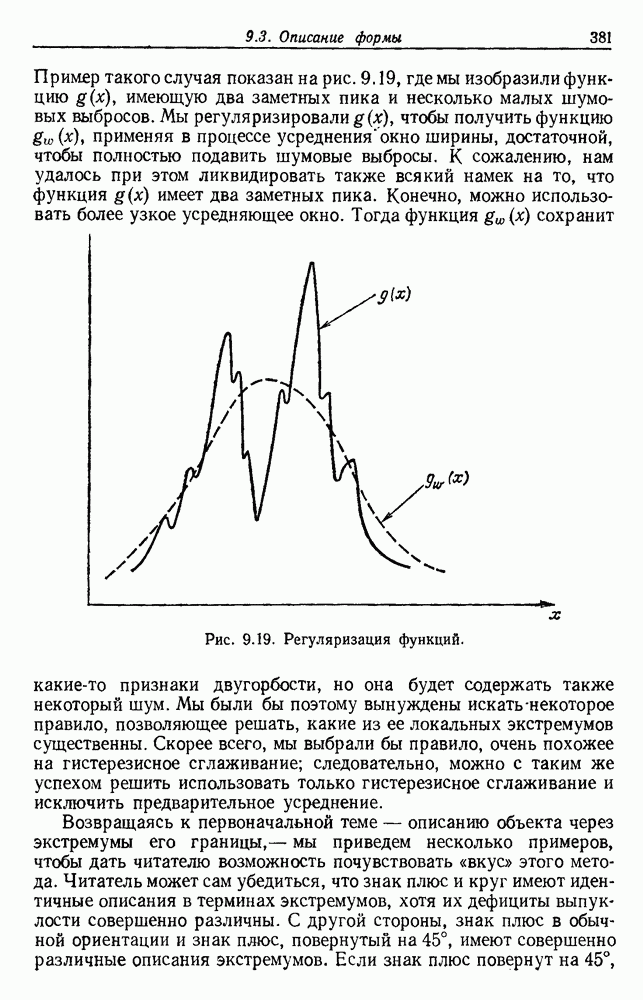
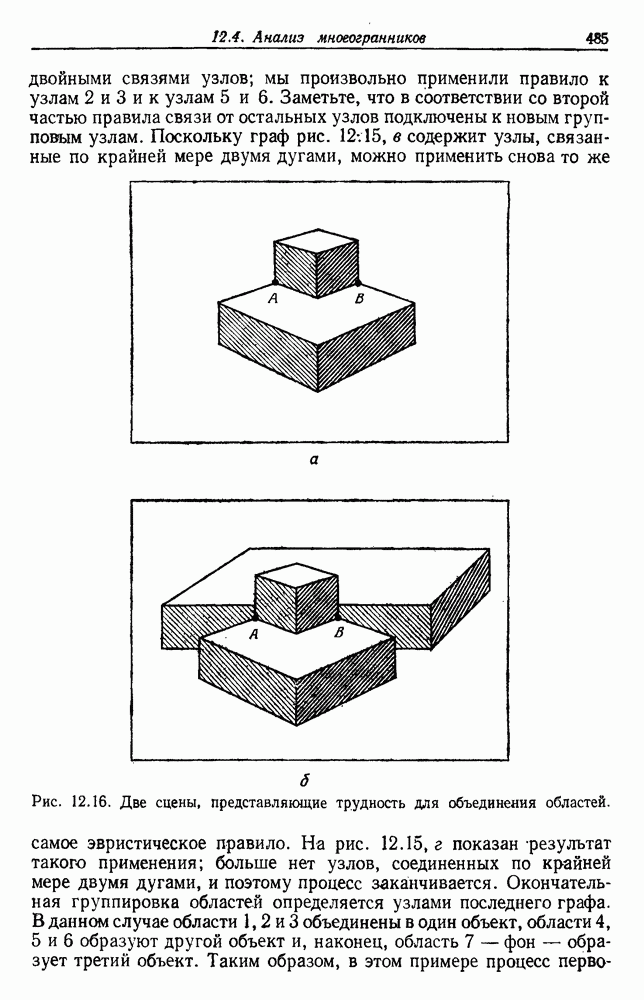
Рис. 6.10. Нежелательные эффекты нормирования. а — ненормированные, б — нормированные. Таким образом, такая обычная нормировка может быть совсем бесполезной в наиболее интересных случаях. В п. 6.8.3 описаны лучшие способы достижения инвариантности относительно масштабирования. Вместо нормировки данных и использования евклидова расстояния можно применить некоторое нормированное расстояние, такое, как махаланобисово. В более общем случае мы можем вообще избавиться от использования расстояния и ввести неметрическую функцию подобия
может быть подходящей функцией подобия. Эта мера — косинус угла между Когда признаки бинарны (0 или 1), функция подобия имеет простую негеометрическую интерпретацию в терминах меры обладания общими признаками или же атрибутами. Будем говорить, что выборка х обладает
(доля общих атрибутов) и
(отношение числа общих атрибутов к числу атрибутов, принадлежащих х или х). Последняя мера (иногда называемая коэффициентом Танимото) часто встречается в области информационного поиска и биологической таксономии. В других приложениях встречаются самые разнообразные меры подобия. Считаем нужным упомянуть, что фундаментальные понятия теории измерений необходимы при использовании любой функции подобия или расстояния. Вычисление подобия между двумя векторами всегда содержит в себе комбинацию значений их компонент. Однако в большинстве случаев применения распознавания образов компоненты вектора признаков являются результатом измерения очевидно несравнимых величин. Каким образом, используя наш прежний пример о классификации пород древесины, можно сравнивать яркость с ровностью волокон? Должно ли сравнение зависеть оттого, как измеряется яркость — в свечах на квадратный метр или в футламбертах? Как нужно обрабатывать векторы, чьи компоненты содержат смесь из номинальных, порядковых, интервальных и относительных
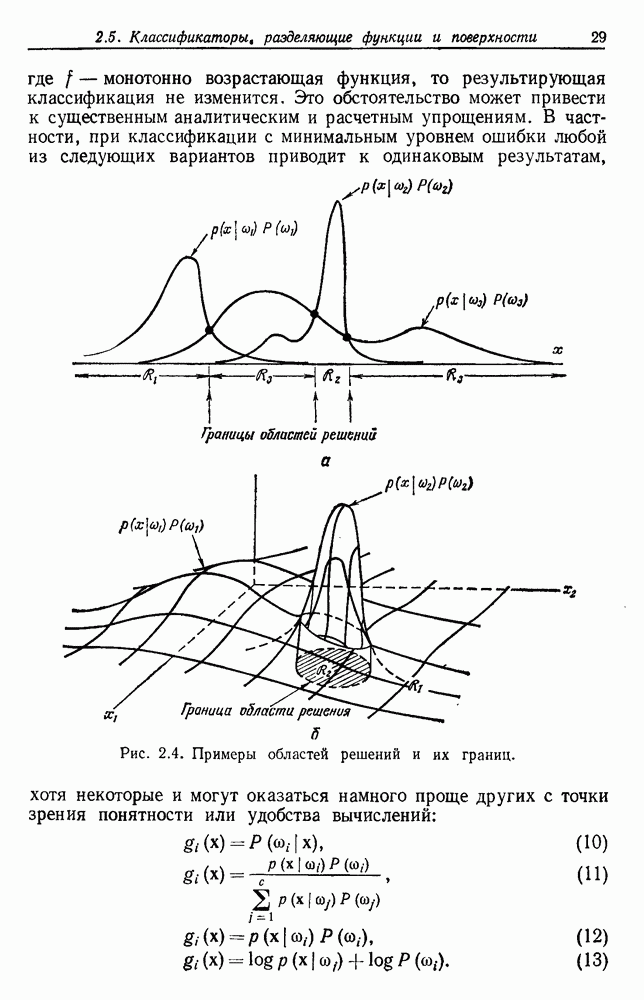
|
 |
Оглавление
|








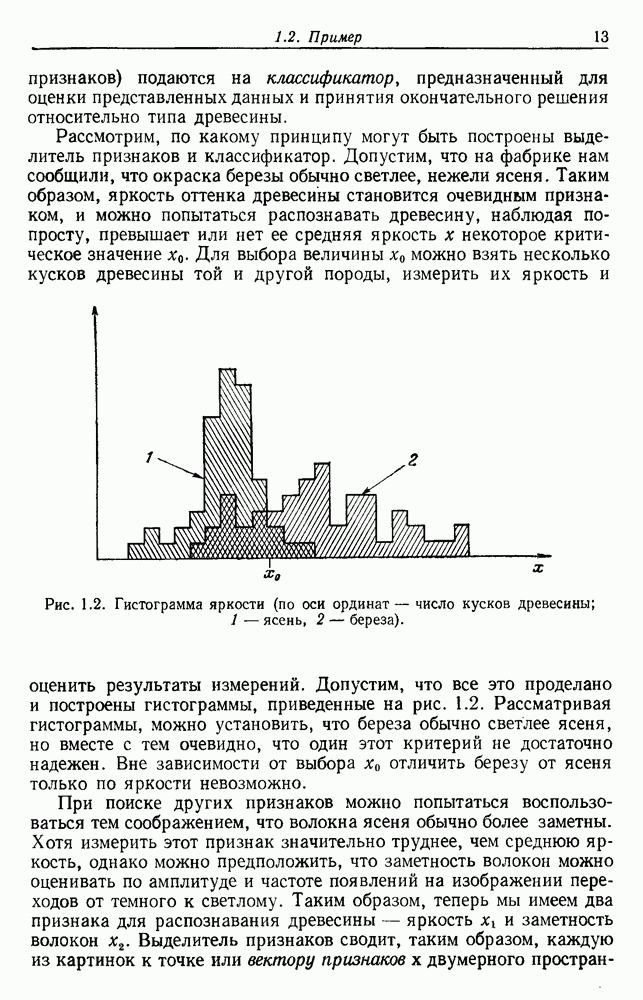














































































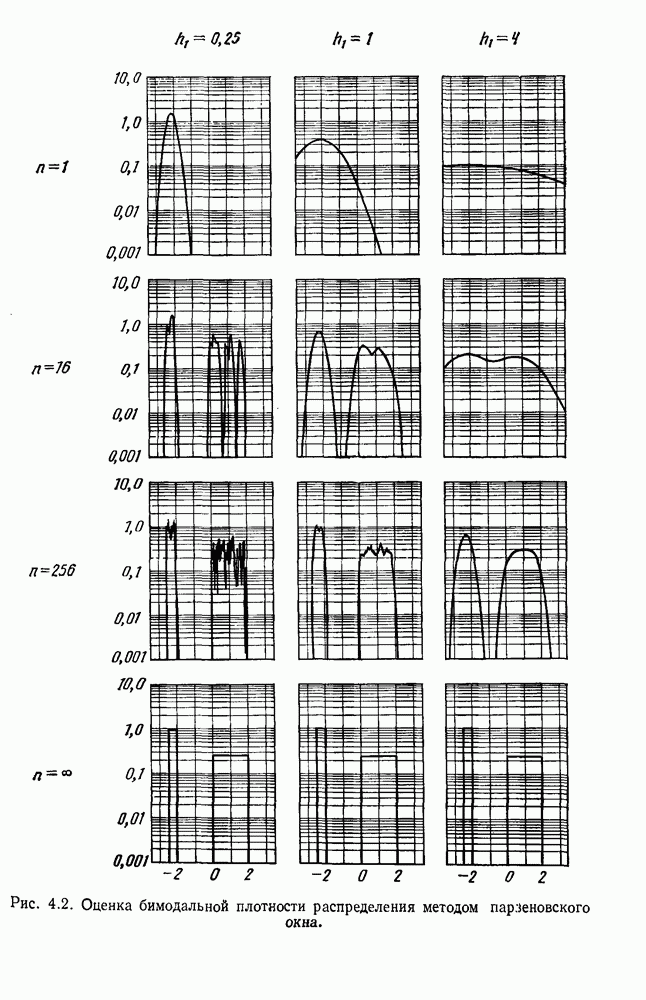

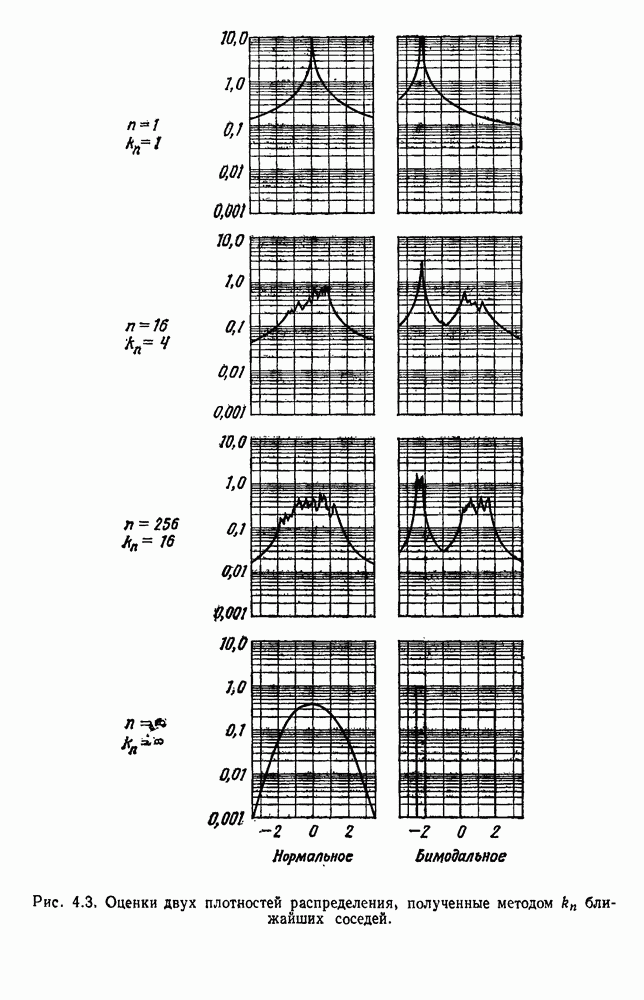








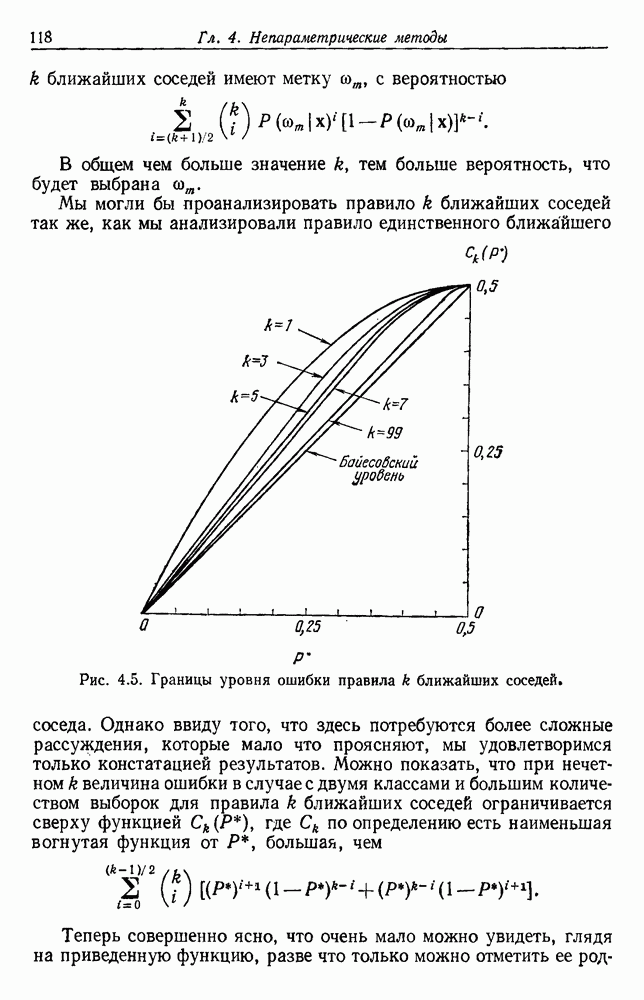





































































































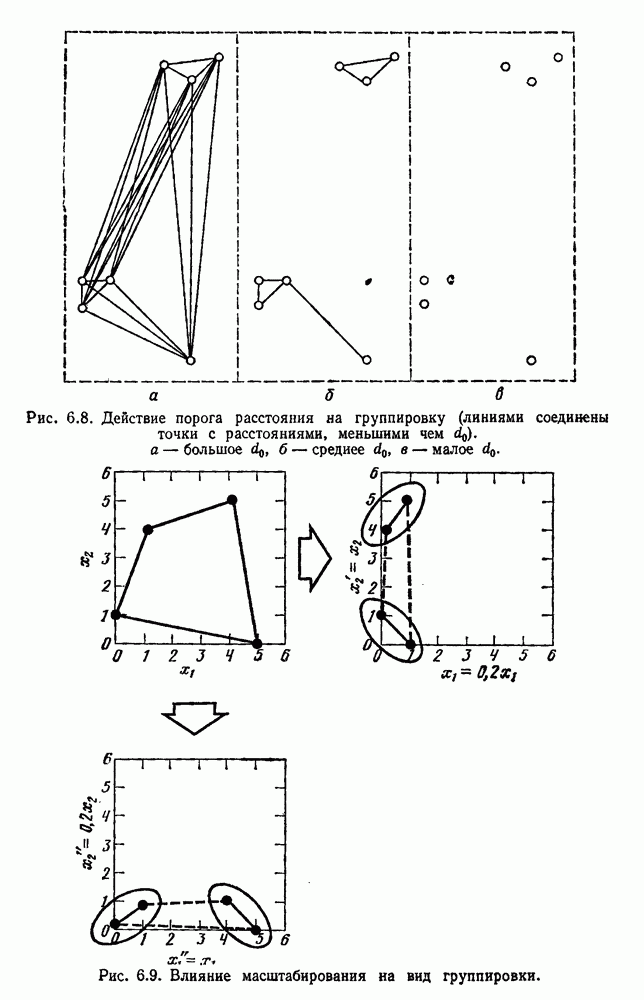







































































































































































































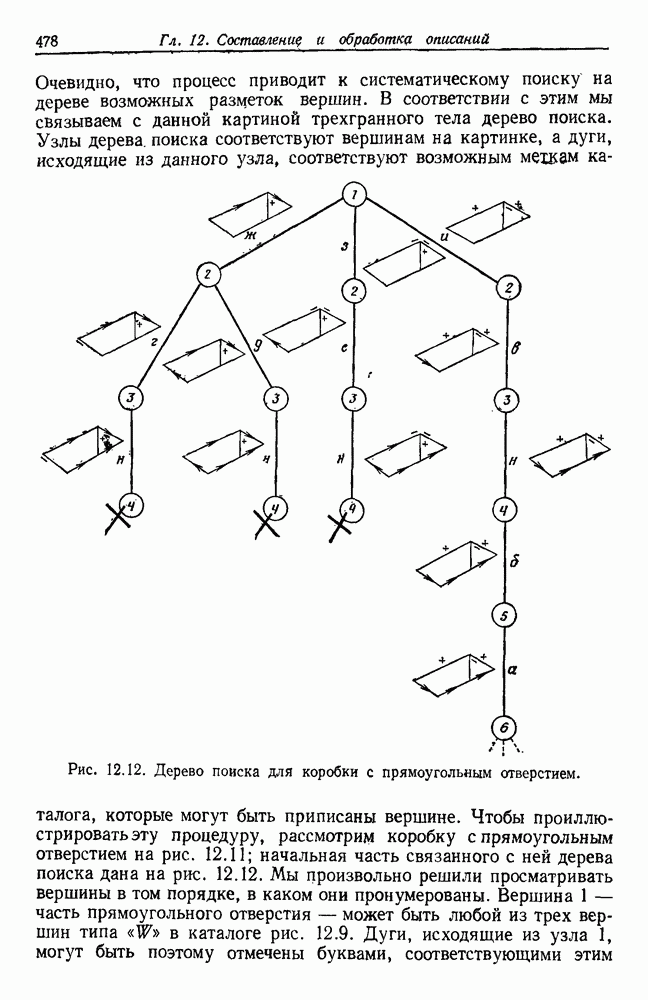















 Сразу очевидно, что выбор
Сразу очевидно, что выбор  очень важен. Если расстояние
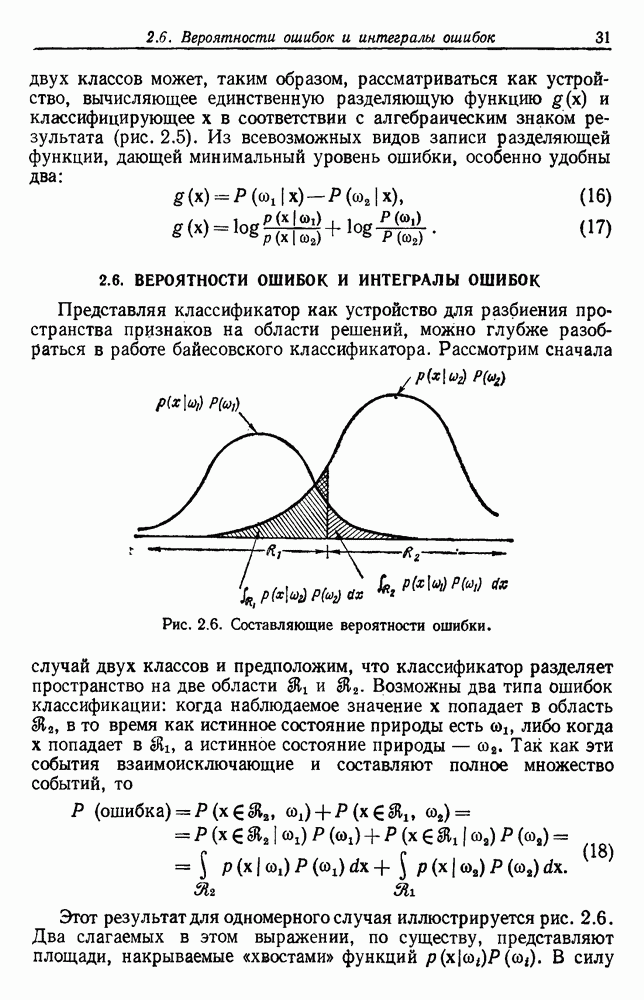
очень важен. Если расстояние  очень большое, все выборки будут собраны в одну группу. Если
очень большое, все выборки будут собраны в одну группу. Если  очень мало, каждая выборка образует отдельную группу. Для получения «естественных» групп расстояние
очень мало, каждая выборка образует отдельную группу. Для получения «естественных» групп расстояние  должно быть больше, чем типичные внутригрупповые расстояния, и меньше, чем типичные межгрупповые расстояния (рис. 6.8).
должно быть больше, чем типичные внутригрупповые расстояния, и меньше, чем типичные межгрупповые расстояния (рис. 6.8).
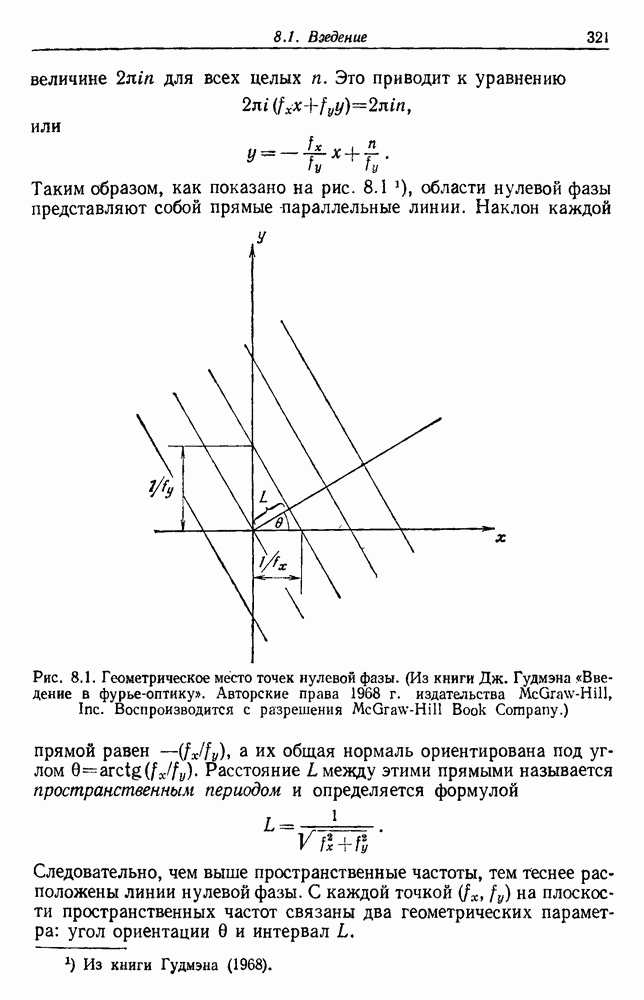
 . а — большое
. а — большое  б — среднее
б — среднее  в — малое
в — малое 

 для сравнения двух векторов
для сравнения двух векторов  Обычно это симметрическая функция, причем ее значение велико, когда
Обычно это симметрическая функция, причем ее значение велико, когда  подобны. Например, когда угол между двумя векторами выбран в качестве меры их подобия, тогда нормированное произведение
подобны. Например, когда угол между двумя векторами выбран в качестве меры их подобия, тогда нормированное произведение

 — инвариантна относительно вращения и расширения, хотя она не инвариантна относительно сдвига и обычных линейных преобразований.
— инвариантна относительно вращения и расширения, хотя она не инвариантна относительно сдвига и обычных линейных преобразований.
 атрибутом, если
атрибутом, если  . Тогда
. Тогда  — это просто число атрибутов, которыми обладают
— это просто число атрибутов, которыми обладают  есть среднее геометрическое числа атрибутов х и числа атрибутов
есть среднее геометрическое числа атрибутов х и числа атрибутов  . Таким образом,
. Таким образом,  это мера относительного обладания общими атрибутами. Некоторые простые варианты этой формулы представляют
это мера относительного обладания общими атрибутами. Некоторые простые варианты этой формулы представляют


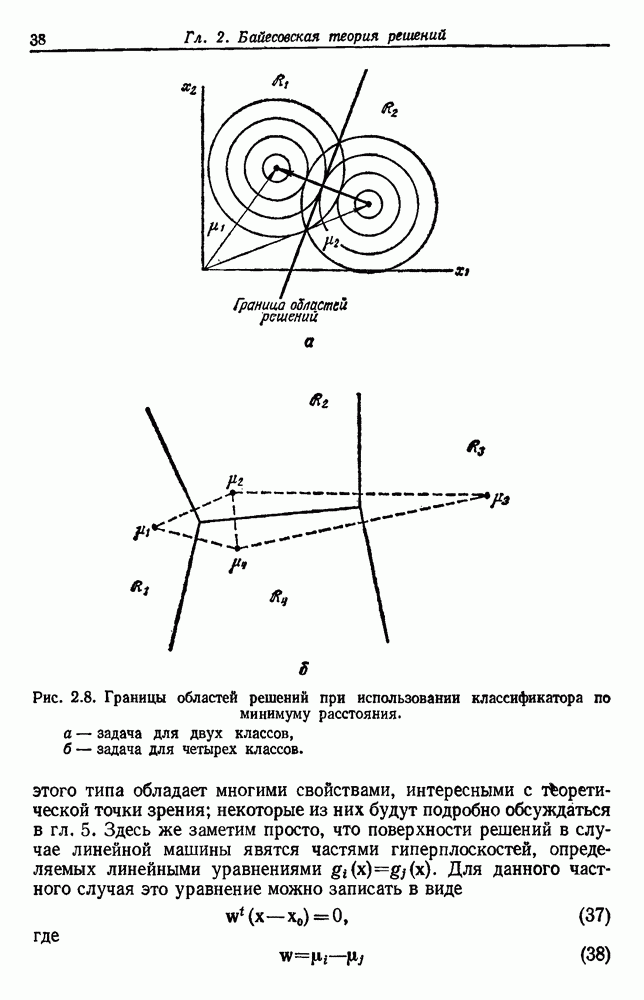
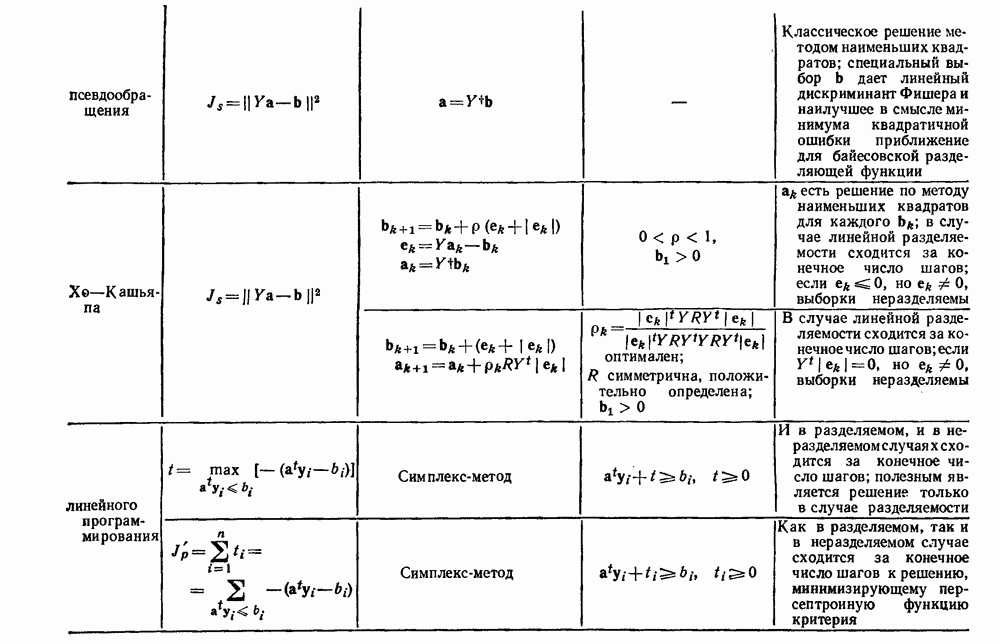
 . В конечном счете, нет методологического ответа на эти вопросы. Когда пользователь выбирает некоторую функцию подобия или нормирует свои данные каким-либо конкретным методом, он вводит информацию, которая задает процедуру. Мы приводили примеры альтернатив, которые могли бы оказаться полезными. Впрочем, мы можем только предупредить начинающего об этих подводных камнях в методах группировок.
. В конечном счете, нет методологического ответа на эти вопросы. Когда пользователь выбирает некоторую функцию подобия или нормирует свои данные каким-либо конкретным методом, он вводит информацию, которая задает процедуру. Мы приводили примеры альтернатив, которые могли бы оказаться полезными. Впрочем, мы можем только предупредить начинающего об этих подводных камнях в методах группировок.