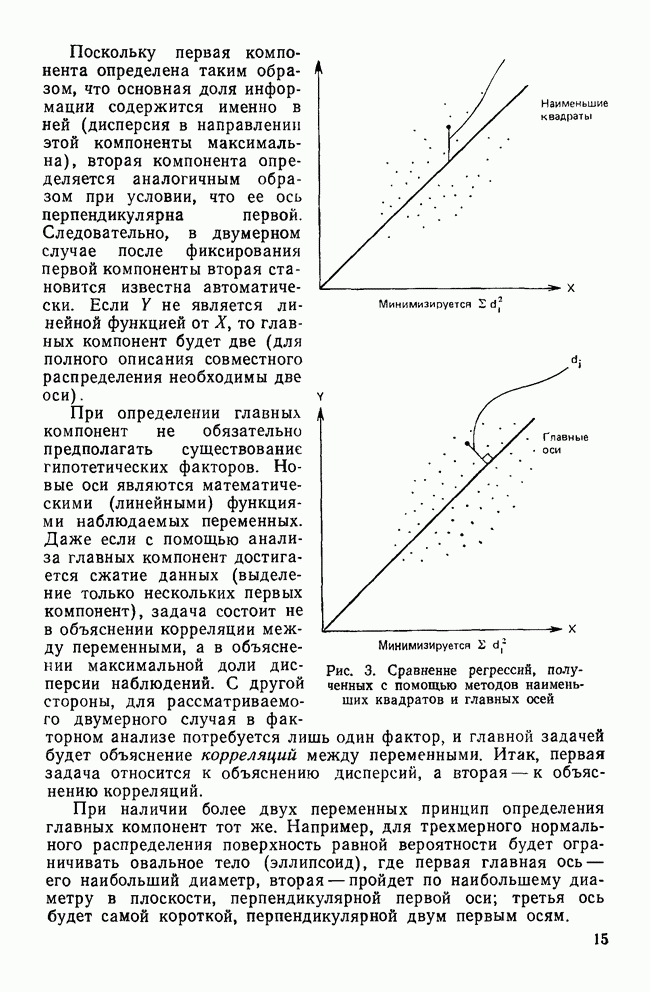
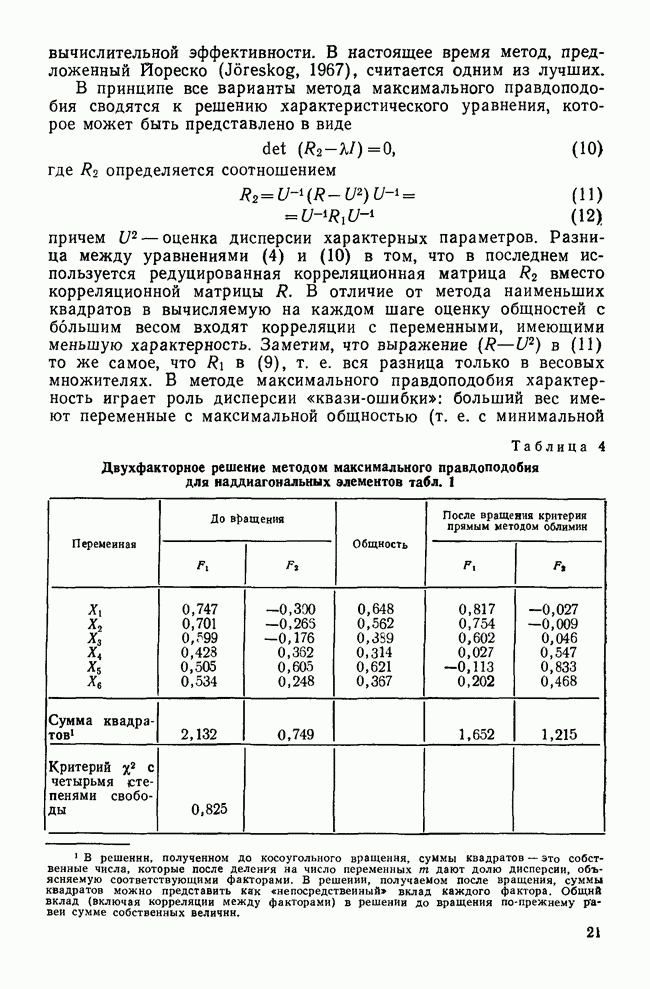
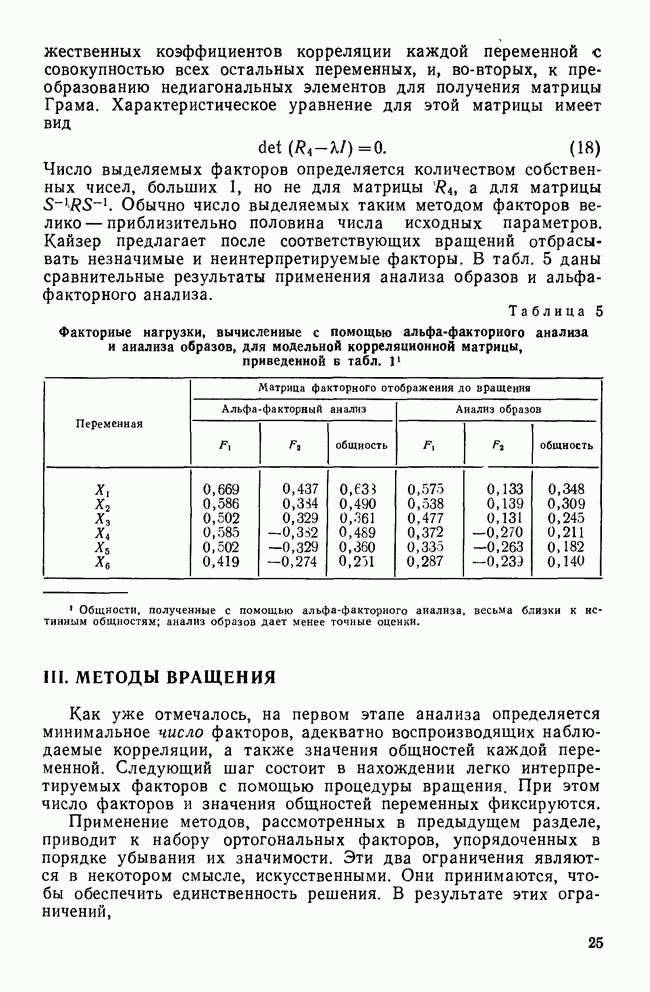
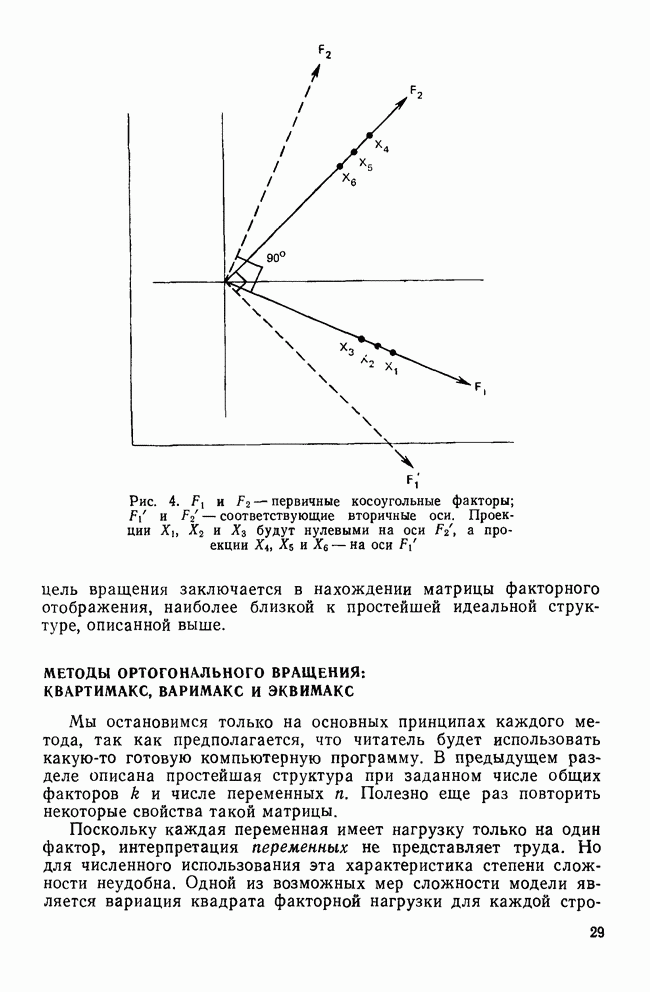
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
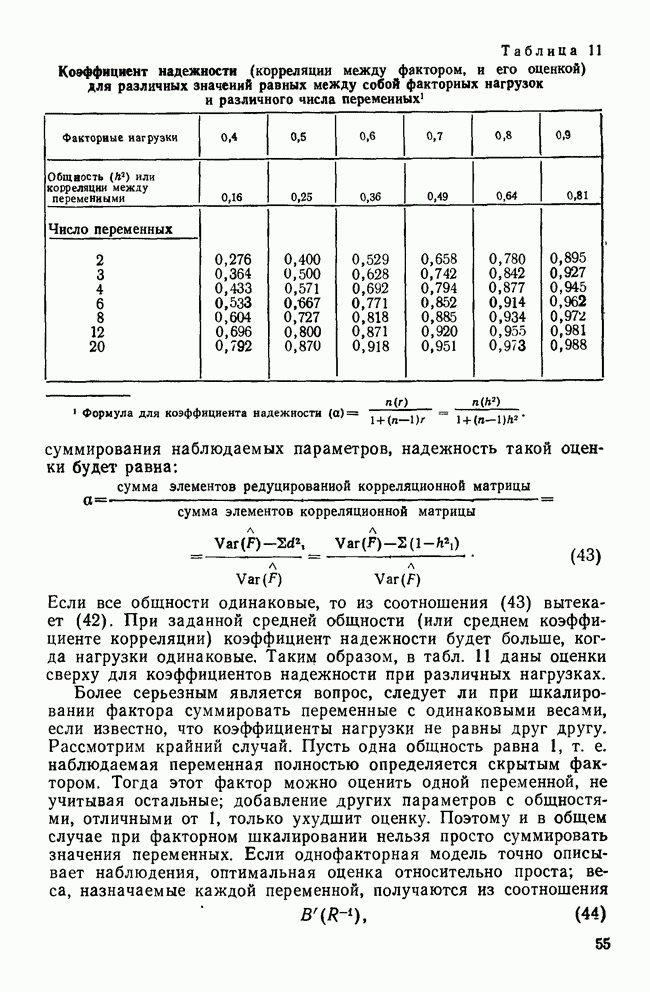
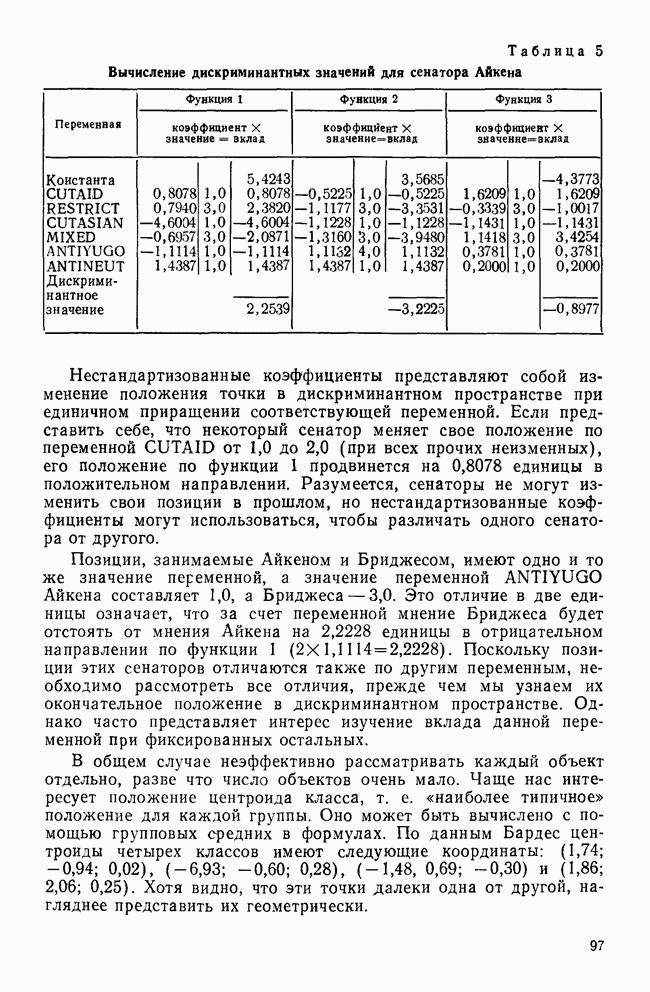
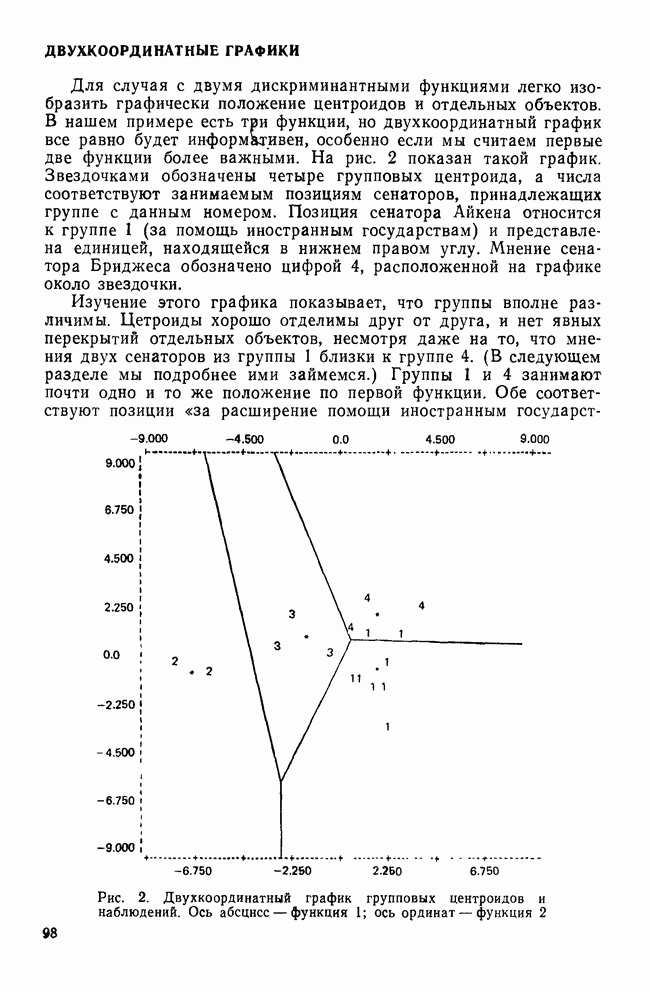
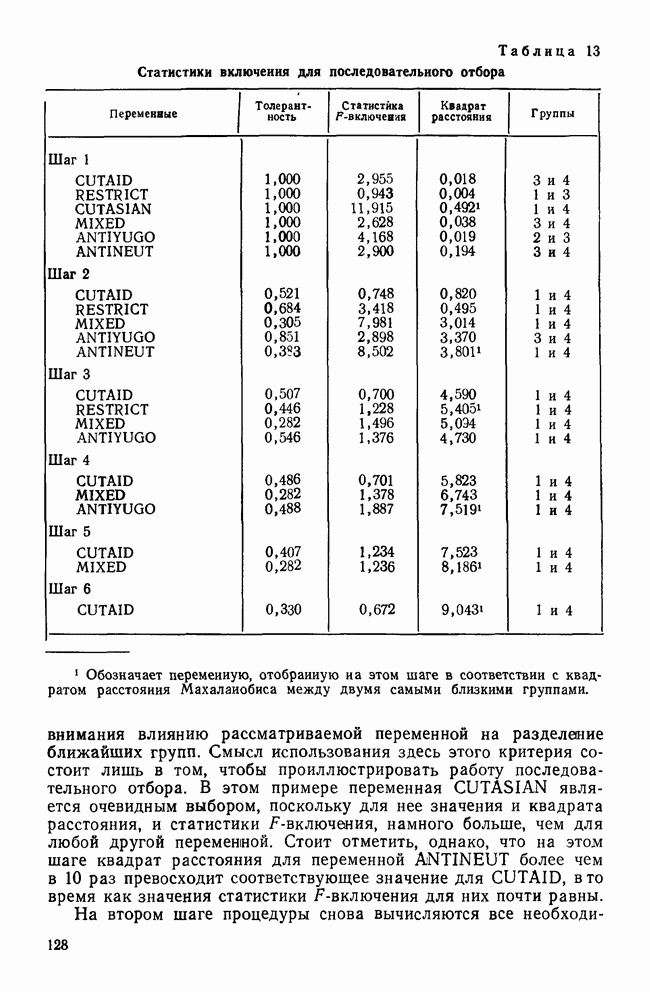
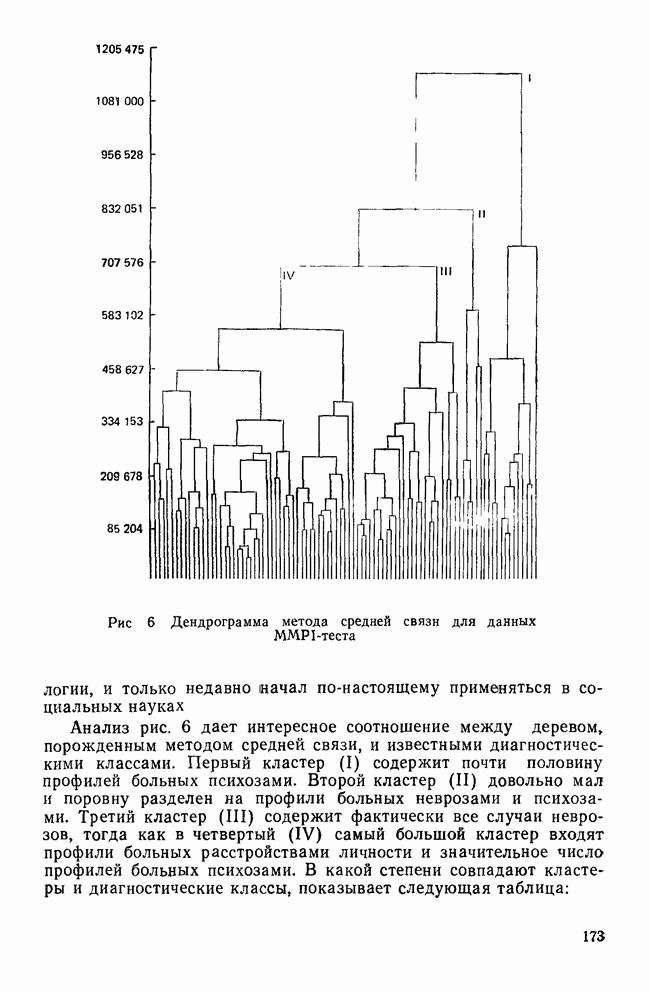
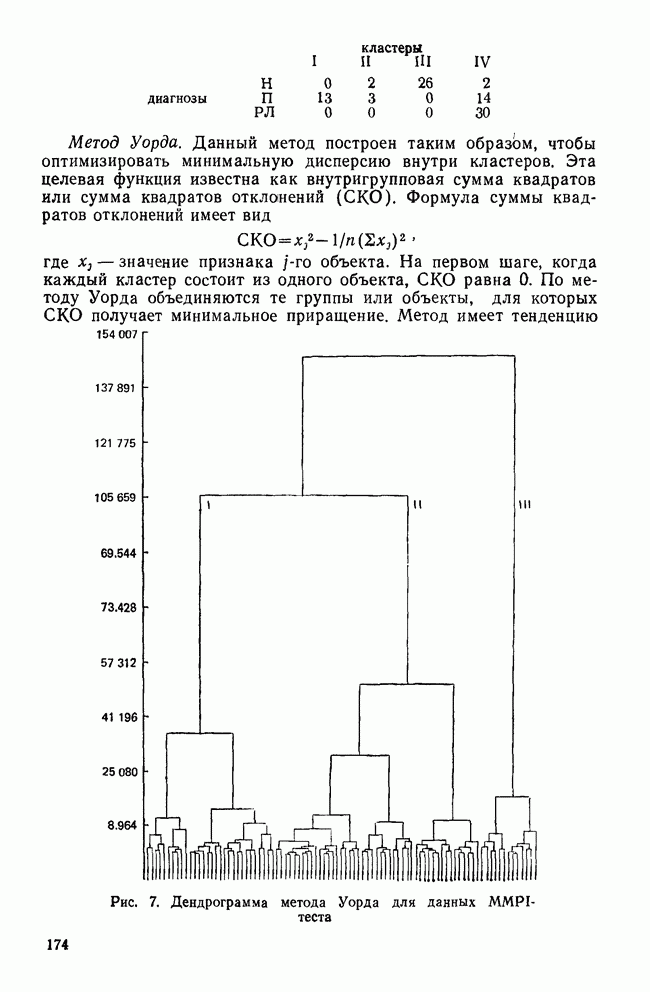
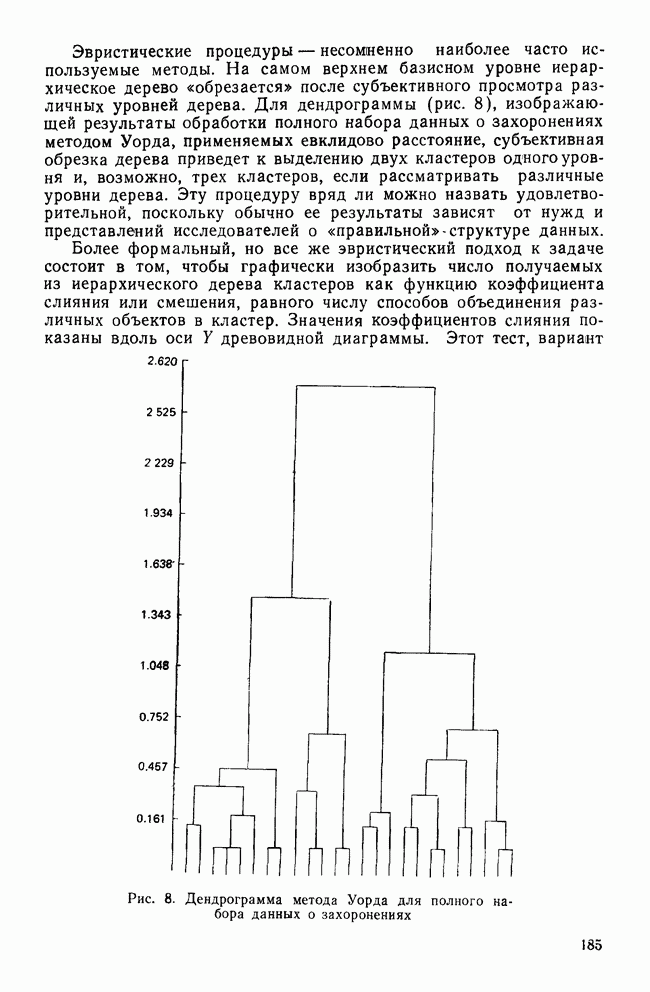
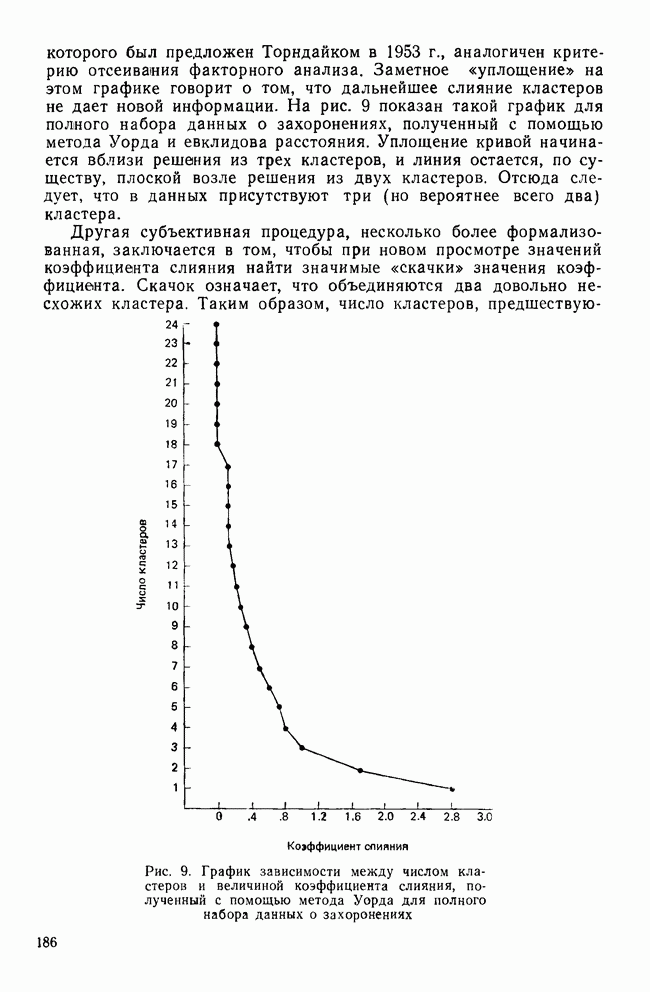
VII. КРАТКИЕ ОТВЕТЫ НА ЧАСТО ВОЗНИКАЮЩИЕ ВОПРОСЫПРИРОДА ПЕРЕМЕННЫХ И ИХ ИЗМЕРЕНИЕа) Какой способ измерений необходим в факторном, анализе? В факторном анализе требуется, чтобы переменные измерялись по крайней мере на уровне шкалы интервалов (Stevens, 1946). Это требование обусловлено тем, что входной информацией для факторного анализа являются элементы ковариационной матрицы. Кроме того, представление переменных в виде линейной комбинации скрытых факторов и использование оценок факторов через линейные комбинации наблюдаемых переменных для порядковых переменных невозможны. б) Возможно ли использование тау-статистики Кендалла или гамма-статистики Гудмана и Крускала вместо обычных корреляций? Нет, невозможно. Как уже отмечалось, операции сложения для порядковых переменных не определены, поэтому не существует факторных моделей с порядковыми статистиками. Допускается лишь эвристическое использование таких моделей без статистической интерпретации результатов. (Существуют некоторые неметрические методы шкалирования, специально разработанные для оперирования с нечисловыми переменными.) в) Должен ли исследователь, учитывая данные выше ответы, всегда избегать использования факторного анализа в случаях, когда метризуемость пространства переменных не вполне ясна? Не обязательно. Многие переменные, такие, как меры отношений и мнений в социологии, различные переменные при обработке результатов тестирования, не имеют точно определенной метрической основы. Тем не менее часто предполагается, что порядковым переменным можно давать числовые значения, не нарушая их внутренних свойств. Окончательный ответ на этот вопрос основан на двух моментах: 1) насколько хорошо вспомогательные числовые значения отражают скрытые истинные расстояния и 2) велико ли искажение, вносимое в корреляции между параметрами (являющимися входными данными в факторном анализе) при введении шкалирования. К счастью, коэффициенты корреляции обладают свойством робастности по отношению к порядковым искажениям в измеряемых данных (Labovitz, 1967, 1970; Kim, 1975). Поэтому, если искажения корреляций, вносимые при шкалировании порядковых переменных, не слишком велики, вполне законно использовать эти переменные в качестве числовых. Тем не менее следует быть готовыми к появлению пусть даже незначительных, систематических ошибок в факторном решении. г) Расскажите о дихотомических переменных. Существует мнение, что факторный анализ вполне применим для таких переменных, во-первых, поскольку при использовании дихотомических переменных не требуется предположение об измерениях и, во-вторых, поскольку Поэтому, возможно ли применение факторного анализа к матрице значений Нет. Дихотомические переменные нельзя представить в рамках факторной модели. Действительно, вспомним о предположении, что каждая переменная является взвешенной суммой по крайней мере двух скрытых факторов (одного общего и одного характерного). Даже если эти факторы принимают лишь 2 значения (что вряд ли встретится на практике), наблюдаемая переменная будет принимать уже 4 возможных значения. Следовательно, никакие соображения, кроме чисто эвристических, не могут обосновать применение факторного анализа к дихотомическим переменным. д) Ответ на предыдущий вопрос озадачивает. Поскольку мы обычно предполагаем факторную модель непрерывной, следует ожидать и непрерывности измеряемых переменных. Однако переменные, с которыми мы имеем дело на практике, часто принимают лишь весьма ограниченный набор значений — да или нет; согласие или несогласие; в лучшем случае — целиком согласен, согласен, безразличен, полностью не согласен и т. д. Означает ли это, что мы применяем факторный анализ к данным, которые с ним не согласуются? В некотором смысле — да. Переменные, принимающие ограниченный набор значений, строго говоря, несовместимы с факторной моделью. Если предположить, что наблюдаемые переменные представляют собой результаты неточных измерений или результаты, полученные при объединении в одну группу близких значений, вопрос будет состоять не в том, применима ли факторная модель к данным, а в том, насколько неслучайные ошибки измерений искажают результаты факторного анализа. Группирование близких значений, безусловно, сказывается на корреляциях, но степень этого влияния зависит от законов распределений, шага дескритизации и т. д. Тем не менее имеются некоторые обнадеживающие соображения по поводу использования факторного анализа как эвристического метода при наличии больших ошибок измерений (см. следующий вопрос). е) В каких случаях возможно применение факторного анализа к данным, содержащим дихотомические переменные или переменные с конечным множеством значений? В общем случае, чем шире множество значений, тем точнее результаты. В случае дихотомических переменных использование коэффициента При переходе от непрерывных переменных к дихотомическим переменным корреляции уменьшаются. При этом на величину уменьшения влияет выбор точек деления. Если корреляции не очень велики, эффект, связанный с выбором точек деления, не столь значителен. Таким образом, группирование (дихо-томизация) переменных в целом уменьшает корреляции между ними, но не влияет на кластерную структуру данных, поскольку факторный анализ основан на относительной величине корреляций. Если цель исследования состоит в нахождении кластерной структуры, использование факторного анализа оправдано (Kim, Nie, Verba, 1977). ж) Если отклонения, возникающие в решении из-за введения точек деления более значительны, чем. отклонения, связанные с уменьшением корреляций при группировании, то почему бы не использовать относительные величины Такой подход целесообразен только в том случае, когда распределение имеет какую-то особую (негауссову) форму (Carrol, 1961) или когда непрерывные переменные связаны функциональной зависимостью. В последнем случае не нужно применять факторный анализ. Поэтому данный подход нерационален (Kim, Nie, Verba, 1977). з) Существуют ли какие-либо более прямые методы решения этих задач? В литературе предложены два подхода. В каждом из них предполагается, что переменные, принимающие два либо несколько значений, являются индикаторными переменными для скрытых непрерывных переменных, к которым, безусловно, применима факторная модель. Соответственно для нахождения факторной структуры необходимо определить корреляции между скрытыми переменными. Первый путь связан с использованием тетрахорических корреляций вместо
|
 |
Оглавление
|


































































































































































































 равное коэффициенту корреляции Пирсона, является адекватной мерой зависимости для факторного анализа.
равное коэффициенту корреляции Пирсона, является адекватной мерой зависимости для факторного анализа.
 ?
?
 может быть оправдано, если решается задача нахождения кластеров переменных и если корреляции между исходными переменными невелики, скажем, не превосходят 0,6 или 0,7.
может быть оправдано, если решается задача нахождения кластеров переменных и если корреляции между исходными переменными невелики, скажем, не превосходят 0,6 или 0,7.
 или R/Rmax вместо Ф и R?
или R/Rmax вместо Ф и R?
 . Этот подход является эвристическим, поскольку вычисление таких корреляций не всегда возможно, и корреляционная матрица может не быть матрицей Грама (Bock, Lieberman, 1970). Другой подход непосредственно применяет скрытое многомерное распределение вместо вычисления тетрахорических корреляций исходя из двумерных таблиц. Данный метод является многообещающим, однако требует чрезмерно большого объема вычислений даже для современных компьютеров (Christoffersson, 1975).
. Этот подход является эвристическим, поскольку вычисление таких корреляций не всегда возможно, и корреляционная матрица может не быть матрицей Грама (Bock, Lieberman, 1970). Другой подход непосредственно применяет скрытое многомерное распределение вместо вычисления тетрахорических корреляций исходя из двумерных таблиц. Данный метод является многообещающим, однако требует чрезмерно большого объема вычислений даже для современных компьютеров (Christoffersson, 1975).