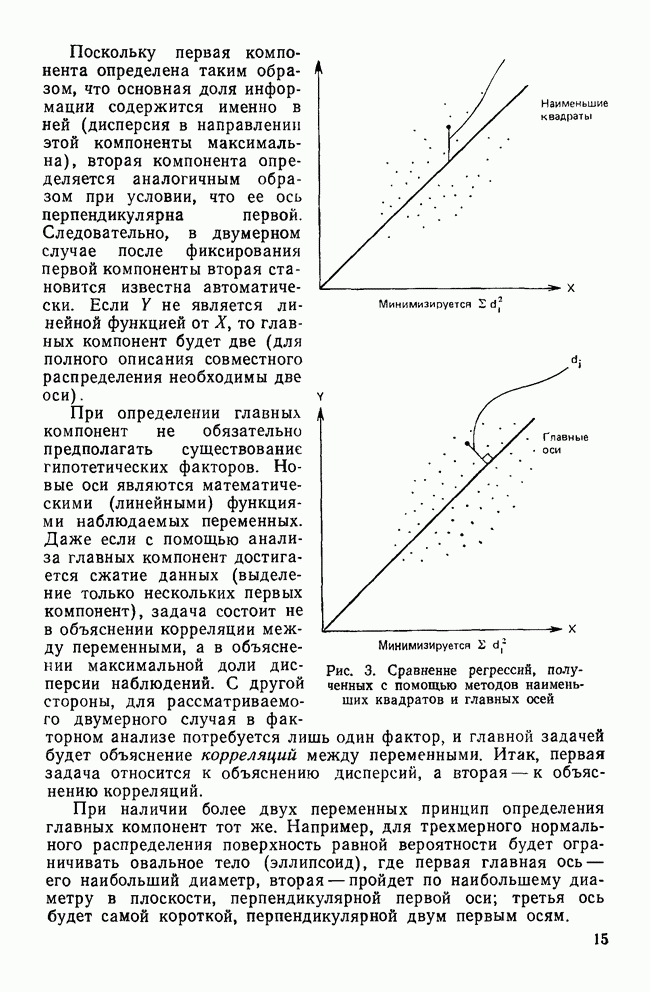
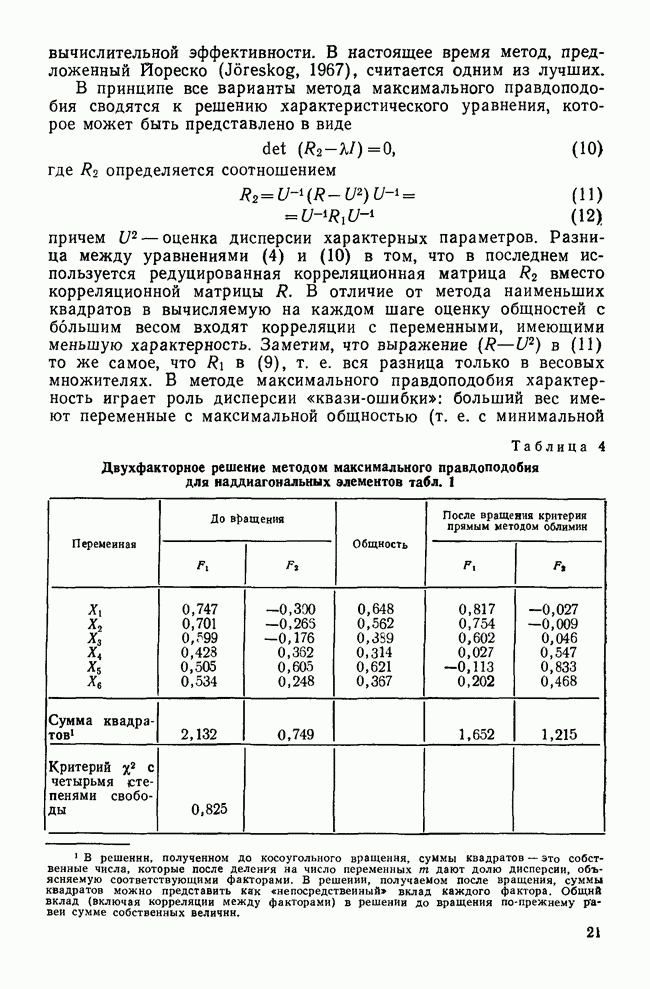
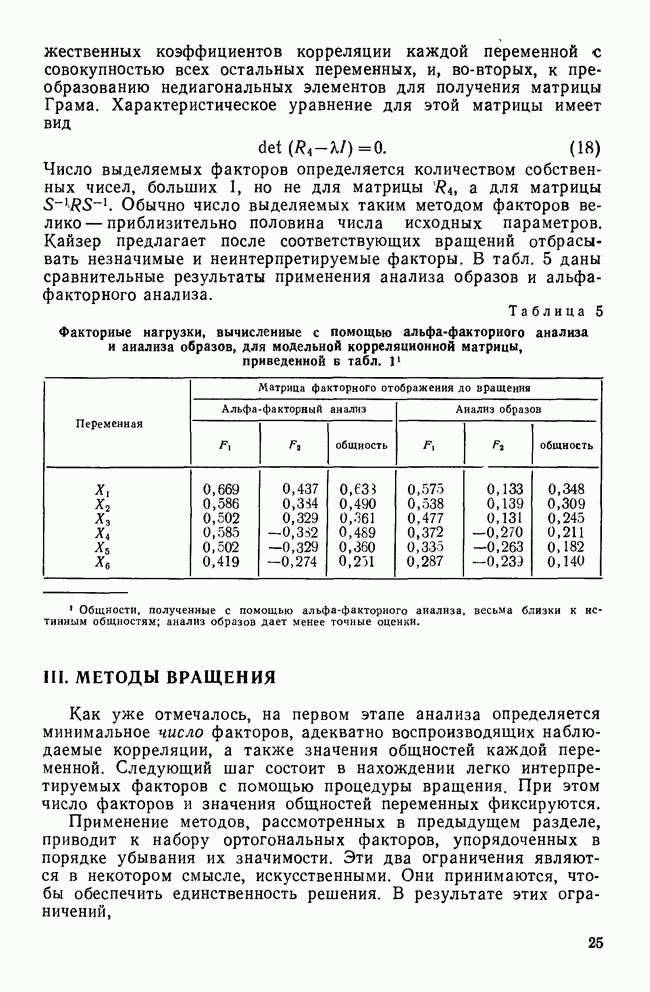
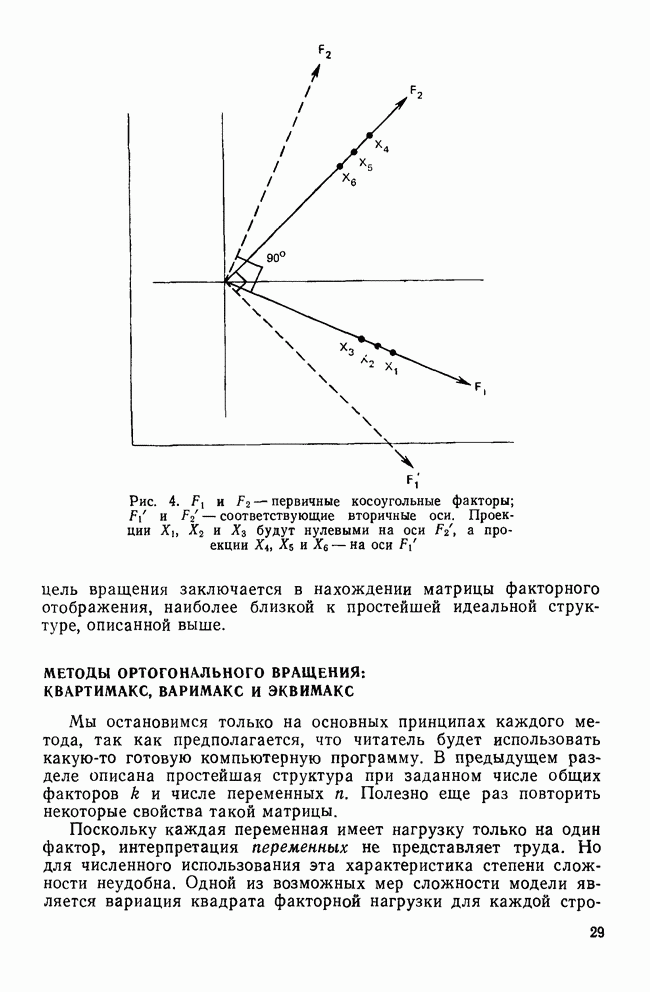
Пред.
След.
Макеты страниц
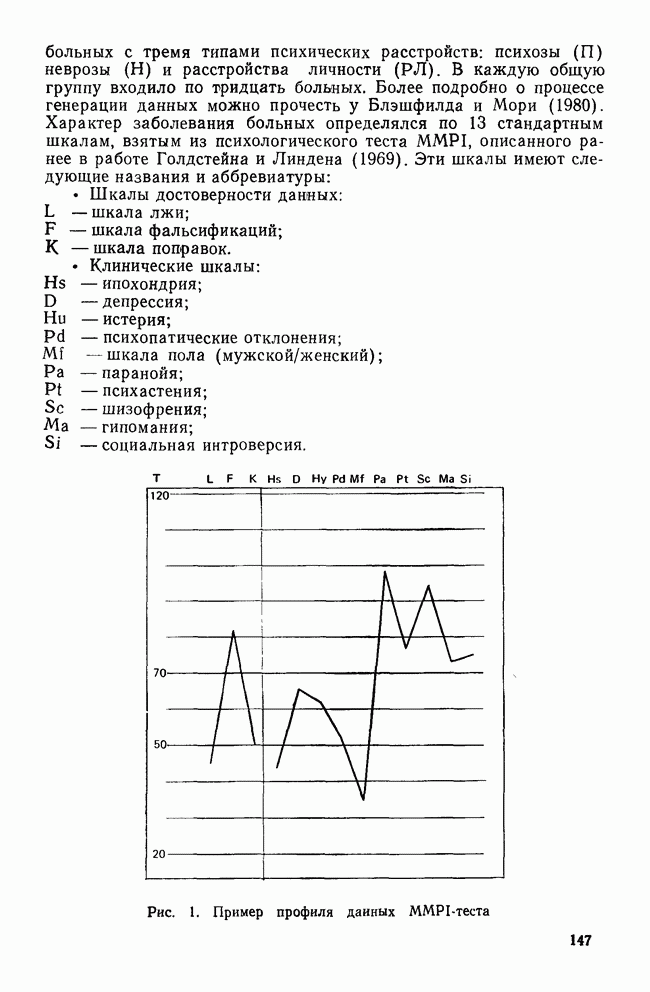
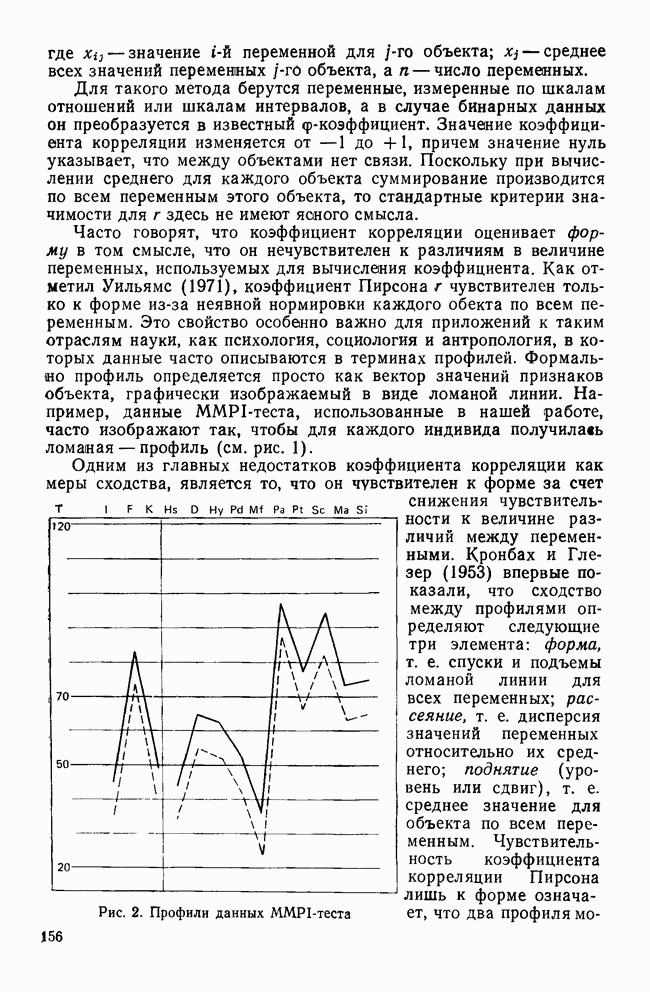
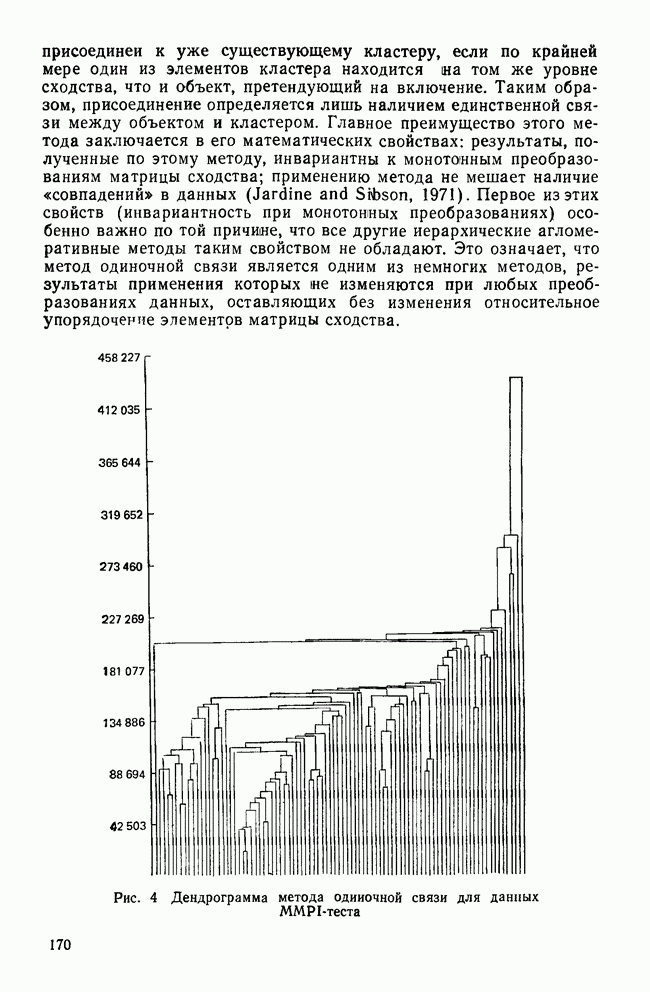
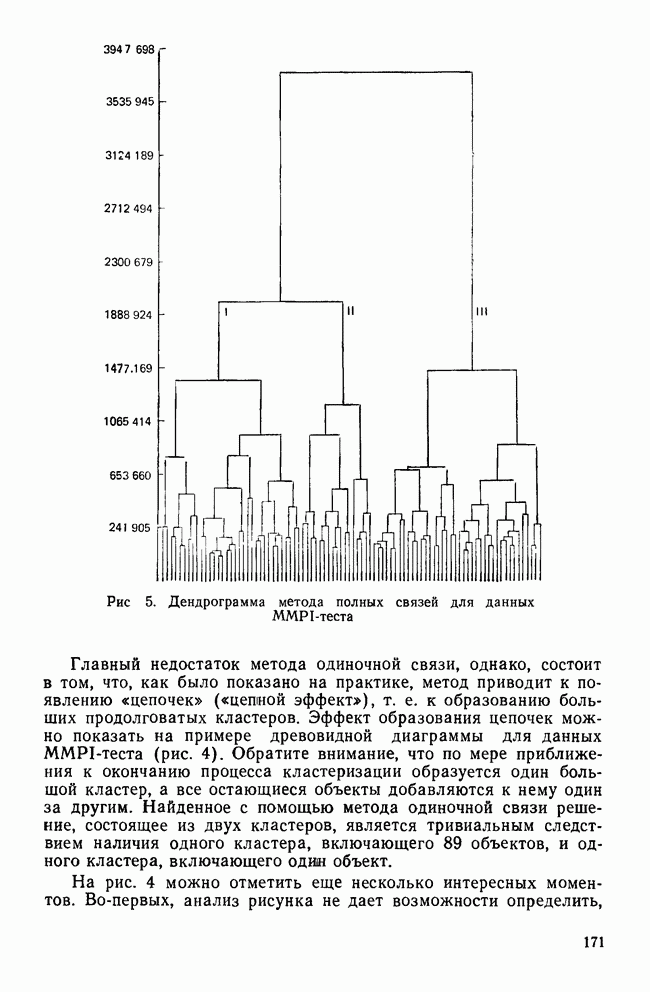
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
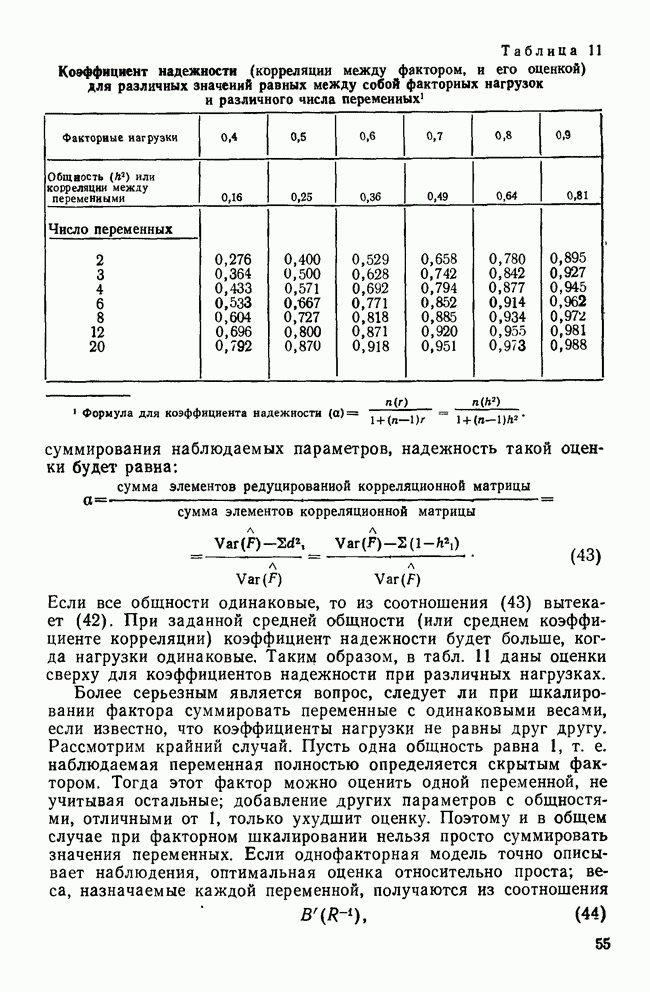
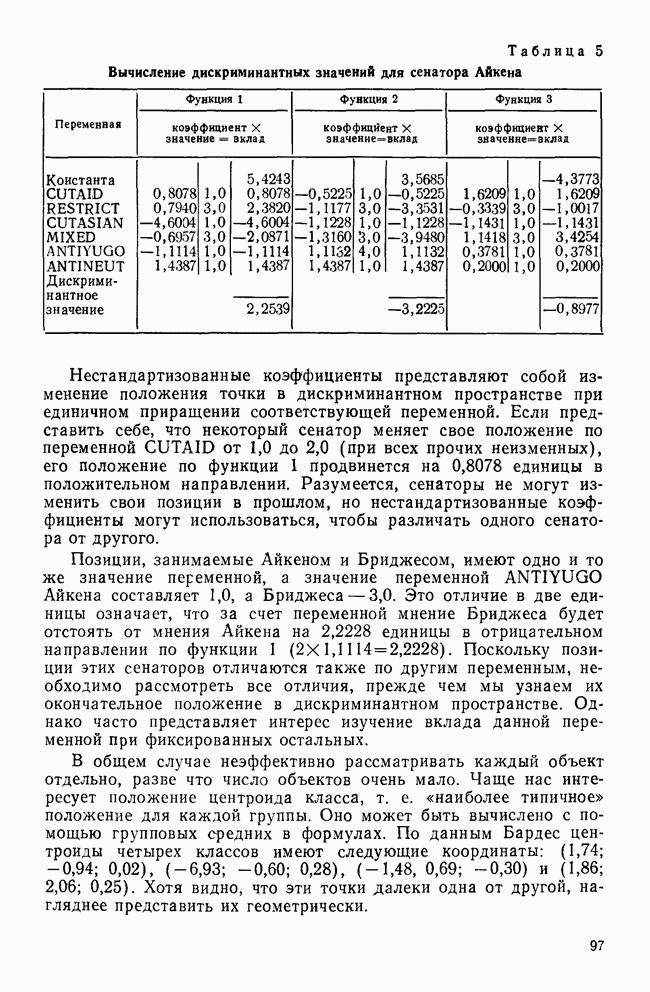
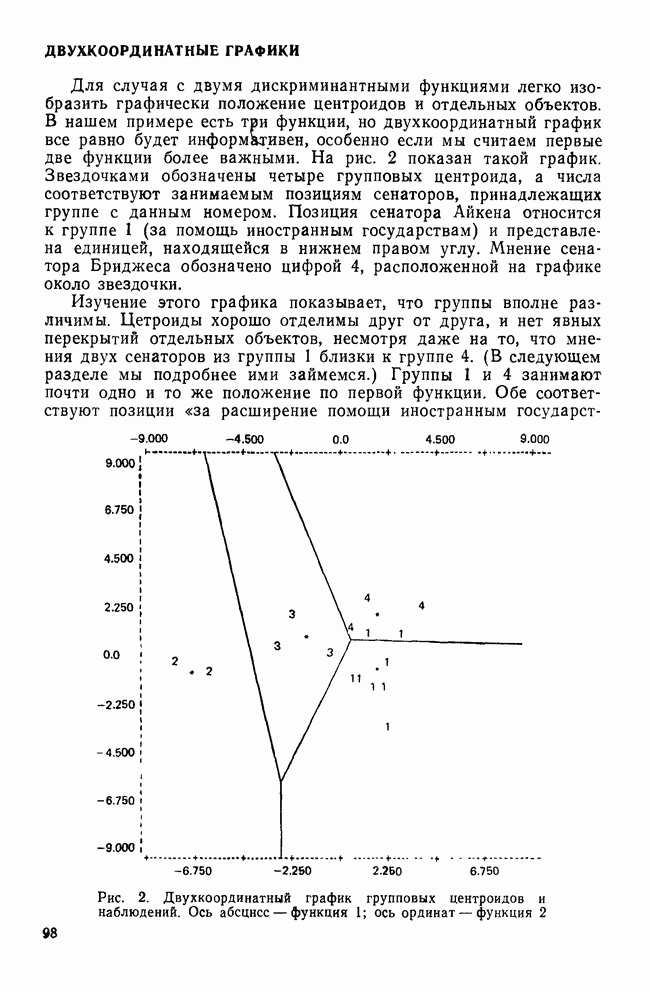
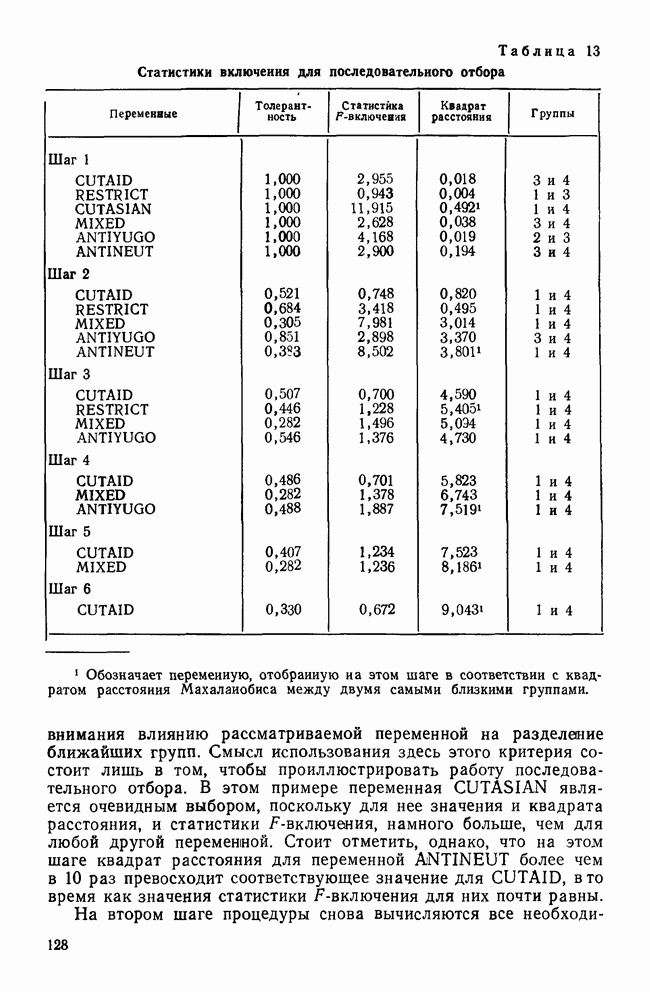
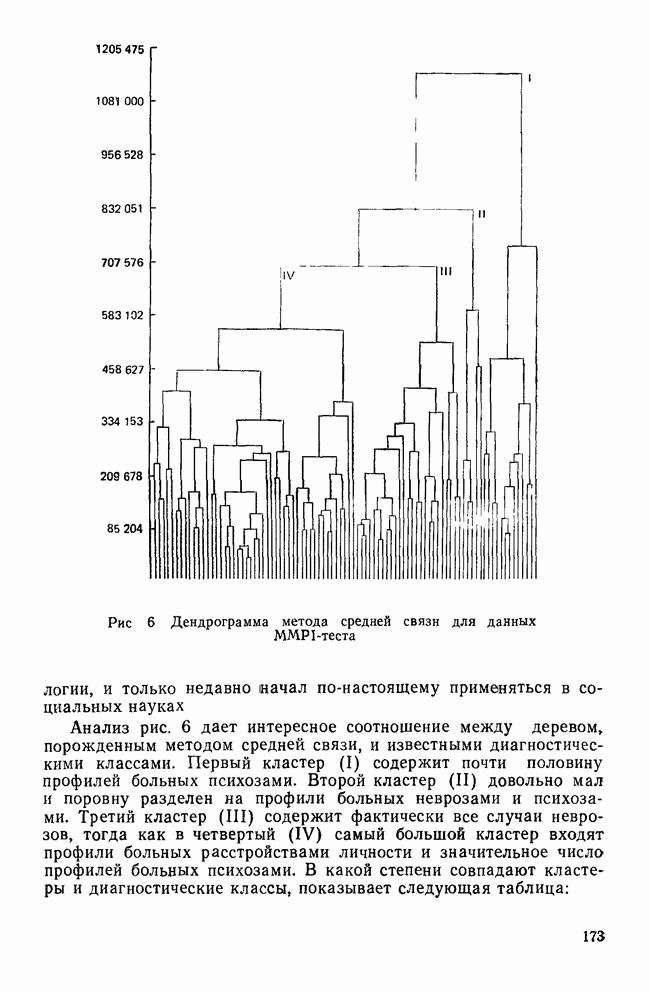
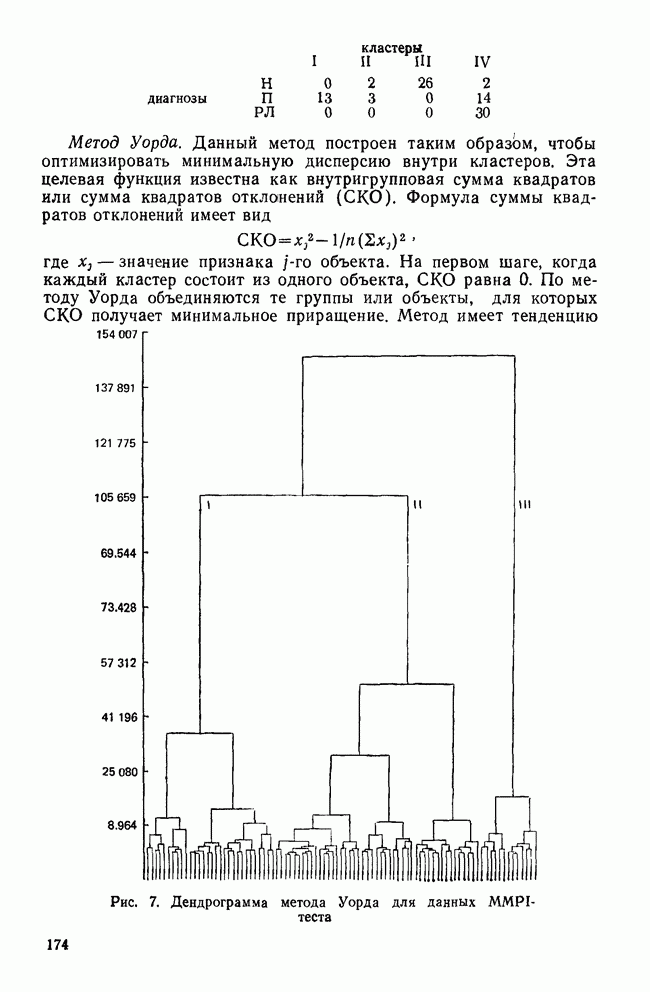
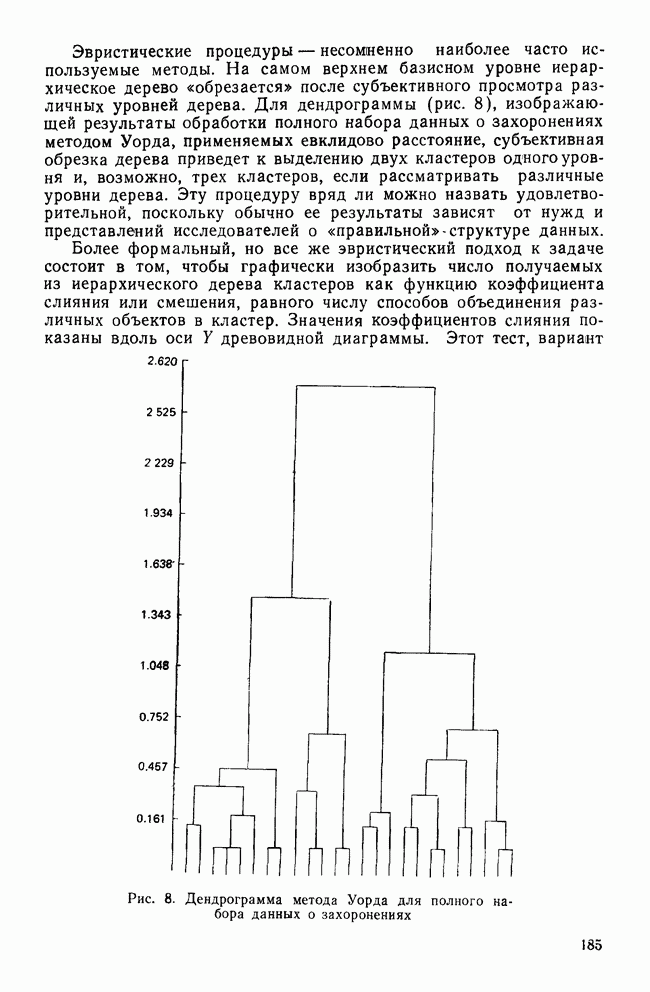
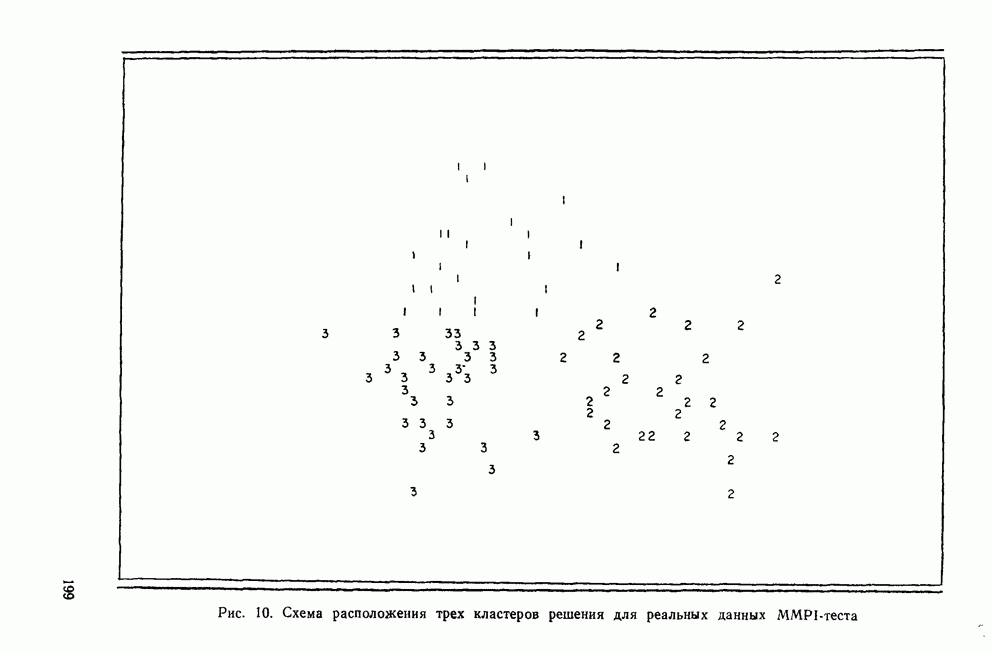
ОПРЕДЕЛЕНИЕ ЧИСЛА КЛАСТЕРОВПоскольку кластерный анализ предназначен для создания однородных групп, естественно рассмотреть процедуры, позволяющие определить число полученных групп. Например, вложенная древовидная структура дендрограммы указывает на то, что в данных может находиться много различных групп, и правомерен вопрос: где нужно «обрезать» дерево, чтобы получить оптимальное число групп? Точно так же и при работе с итеративными методами пользователь должен указать число групп, присутствующих в данных, еще до создания этих групп. К сожалению, эта проблема до сих пор находится среди нерешенных задач кластерного анализа из-за отсутствия подходящей нулевой гипотезы и сложной природы многомерных выборочных распределений. Затруднения в создании работоспособной нулевой гипотезы вызывает отсутствие непротиворечивого и универсального определения кластерной структуры. Но, как мы уже указывали, появление такого определения маловероятно. Понятие «отсутствие структуры» в наборе данных (одна из возможных нулевых гипотез) весьма далеко от ясности, и непонятно, каким должен быть тест, позволяющий определить, есть ли в данных структура или нет. Уже созданные нулевые гипотезы (такие, как гипотеза случайного графа и гипотеза случайного положения), возможно, и полезны, но исчерпывают далеко не все возможности и должны еще найти свое место в практическом анализе данных. В любом случае «отклонение нулевой гипотезы не имеет особого значения, потому что разумные альтернативные гипотезы еще не разработаны; практичного и математически полезного определения «кластерной структуры» нет до сих пор» (Dubes and Jain, 1980). В той же степени не поддается решению задача о разделении смеси многомерных распределений в анализе реальных данных. Хотя многие вопросы многомерных нормальных распределений хорошо разработаны, все же реальные данные не будут соответствовать этому стандарту; более того, многие выборки реальных данных являются сложными смесями, имеющими различные многомерные выборочные распределения неизвестной структуры. Поскольку не существует статистической теории и теории распределений, которые помогли бы в разделении этих смесей, также неразумно ожидать появления формальных тестов для целей кластерного анализа. Реакция на эти ограничения была различной. В некоторых отраслях, особенно в биологии, задача определения числа кластеров не имеет первостепенной важности просто потому, что целью анализа является предварительное исследование общей картины зависимостей между объектами, представленной в виде иерархического дерева. Однако в социальных науках развиваются два основных подхода к определению числа присутствующих кластеров: эвристические процедуры и формальные тесты. Эвристические процедуры — несомненно наиболее часто используемые методы. На самом верхнем базисном уровне иерархическое дерево «обрезается» после субъективного просмотра различных уровней дерева. Для дендрограммы (рис. 8), изображающей результаты обработки полного набора данных о захоронениях методом Уорда, применяемых евклидово расстояние, субъективная обрезка дерева приведет к выделению двух кластеров одного уровня и, возможно, трех кластеров, если рассматривать различные уровни дерева. Эту процедуру вряд ли можно назвать удовлетворительной, поскольку обычно ее результаты зависят от нужд и представлений исследователей о « Более формальный, но все же эвристический подход к задаче состоит в том, чтобы графически изобразить число получаемых из иерархического дерева кластеров как функцию коэффициента слияния или смешения, равного числу способов объединения различных объектов в кластер. Значения коэффициентов слияния показаны вдоль оси У древовидной диаграммы.
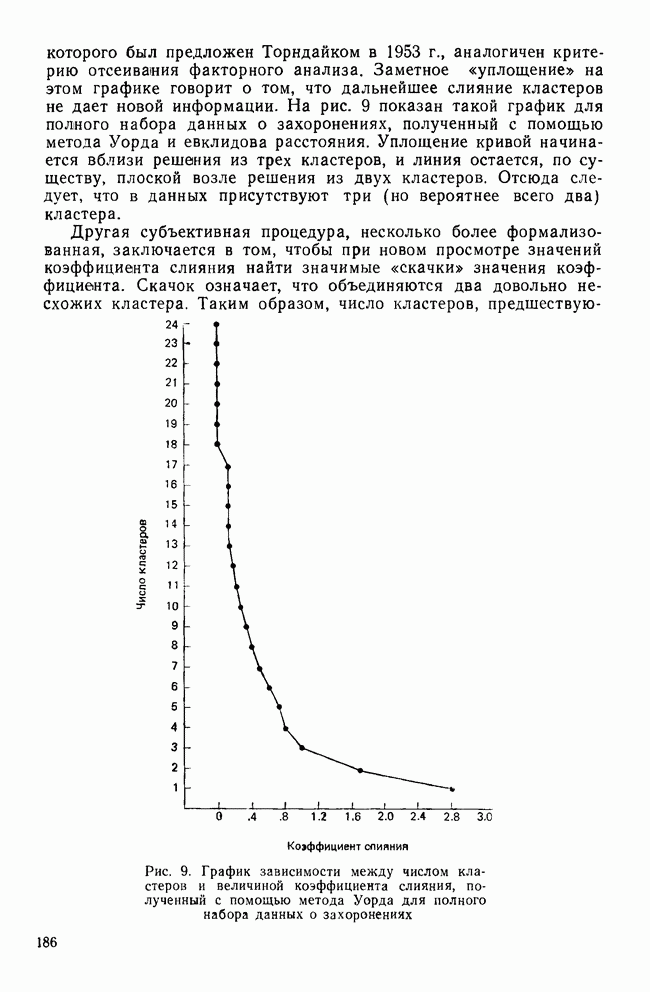
Рис. 8. Дендрограмма метода Уорда для полного набора данных о захоронениях Этот тест, вариант которого был предложен Торндайком в 1953 г., аналогичен критерию отсеивания факторного анализа. Заметное «уплощение» на этом графике говорит о том, что дальнейшее слияние кластеров не дает новой информации. На рис. 9 показан такой график для полного набора данных о захоронениях, полученный с помощью метода Уорда и евклидова расстояния. Уплощение кривой начинается вблизи решения из трех кластеров, и линия остается, по существу, плоской возле решения из двух кластеров. Отсюда следует, что в данных присутствуют три (но вероятнее всего два) кластера. Другая субъективная процедура, несколько более формализованная, заключается в том, чтобы при новом просмотре значений коэффициента слияния найти значимые «скачки» значения коэффициента. Скачок означает, что объединяются два довольно несхожих кластера.
Рис. 9. График зависимости между числом кластеров и величиной коэффициента слияния, полученный с помощью метода Уорда для полного набора данных о захоронениях Таким образом, число кластеров, предшествующее этому объединению, является наиболее вероятным решением. Ниже показаны коэффициенты слияния, соответствующие числу кластеров, которое для полного множества данных о захоронениях принимает значения от 10 до 1.
Как видим, между решениями из четырех и трех кластеров есть скачок, что приводит к выводу о допустимости решения из четырех кластеров. Одна из трудностей, связанная с этой процедурой, состоит в том, что можно найти много малых скачков значения коэффициента слияния, но совершенно невозможно исходя лишь из простого визуального обследования указать, какой из этих скачков «правильный». Этот тест был обобщен в работах (Mojena, 1977, Mojena and Wishart, 1980). Там же была разработана эвристическая процедура, позволяющая лучше определить «значимый скачок» коэффициента. «Правило остановки № 1», как его определил Мойена, предписывает, что групповой уровень или оптимальное разбиение иерархической) кластерного решения получается, если удовлетворяется неравенство
где На практике стандартное отклонение может быть вычислено на каждом этапе кластерного процесса, где k равно:
Значения коэффициента слияния для полного набора данных о захоронениях, обработанного методом кластеризации Уорда с использованием евклидова расстояния, были рассмотрены выше. Теперь приведем значения стандартного отклонения для решений, содержащих от 1 до 4 кластеров:
В этом случае согласно правилу остановки оптимальным считается решение из трех кластеров. Уишарт (1982) отметил, что можно оценить статистическую значимость результатов, полученных с помощью этого правила, используя Процедура заключается в перемножении квадратного корня из Трудности, связанные с составными многомерными выборочными распределениями, мало сказались на разработке формальных статистических тестов, но широкое распространение получило лишь небольшое число этих тестов. Нулевая гипотеза, наиболее часто применяемая в статистических тестах, предполагает, что исследуемые данные являются случайной выборкой из генеральной совокупности с многомерным нормальным распределением. Вульф (1971), считая, что это предположение верно, предложил тест отношения правдоподобия для проверки гипотезы, что имеется
|
 |
Оглавление
|


































































































































































































 -структуре данных.
-структуре данных.




 — величина коэффициента слияния;
— величина коэффициента слияния;  — величина коэффициента на
— величина коэффициента на  этапе кластерного процесса; k — стандартное отклонение, a
этапе кластерного процесса; k — стандартное отклонение, a  — среднее и стандартное отклонение коэффициентов слияния. Невыполнение неравенства говорит о том, что в данных имеется только один кластер.
— среднее и стандартное отклонение коэффициентов слияния. Невыполнение неравенства говорит о том, что в данных имеется только один кластер.


 -статистику с
-статистику с  степенями свободы, где
степенями свободы, где  — число коэффициентов слияния.
— число коэффициентов слияния.
 и значения стандартного отклонения к. В данном примере значения 4,79 (квадратный корень из 23) умножается на 9,74, в результате получаем 4,67. Значение значимо с уровнем 0,01 при 22 степенях свободы. Сейчас этот метод вместе с более сложным правилом встроен в процедуру CLUSTAN2.
и значения стандартного отклонения к. В данном примере значения 4,79 (квадратный корень из 23) умножается на 9,74, в результате получаем 4,67. Значение значимо с уровнем 0,01 при 22 степенях свободы. Сейчас этот метод вместе с более сложным правилом встроен в процедуру CLUSTAN2.
 , а не
, а не  групп. Альтернативная гипотеза, разработанная Ли (1979), заключается в следующем: данные — это выборка из генеральной совокупности с равномерным распределением. Тест, основанный на альтернативной гипотезе, использует критерий внутригрупповой суммы квадратов. Он является полезной отправной точкой в определении возможных различий между кластерами. К сожалению, тест может работать только с одним признаком. Какая бы процедура ни была выбрана, пользователь должен постоянно сознавать, что лишь малая часть этих тестов подверглась широкому изучению. Таким образом, поскольку большинство тестов плохо изучено и эвристично, то результаты их использования должны приниматься с большой осторожностью. В идеале правила определения числа имеющихся в наличии кластеров должны использоваться совместно с подходящей процедурой проверки достоверности результатов (см. разд. IV), так как может случиться, что правило остановки рекомендует такое число кластеров, которое не подтверждается результатами измерений по другим критериям.
групп. Альтернативная гипотеза, разработанная Ли (1979), заключается в следующем: данные — это выборка из генеральной совокупности с равномерным распределением. Тест, основанный на альтернативной гипотезе, использует критерий внутригрупповой суммы квадратов. Он является полезной отправной точкой в определении возможных различий между кластерами. К сожалению, тест может работать только с одним признаком. Какая бы процедура ни была выбрана, пользователь должен постоянно сознавать, что лишь малая часть этих тестов подверглась широкому изучению. Таким образом, поскольку большинство тестов плохо изучено и эвристично, то результаты их использования должны приниматься с большой осторожностью. В идеале правила определения числа имеющихся в наличии кластеров должны использоваться совместно с подходящей процедурой проверки достоверности результатов (см. разд. IV), так как может случиться, что правило остановки рекомендует такое число кластеров, которое не подтверждается результатами измерений по другим критериям.