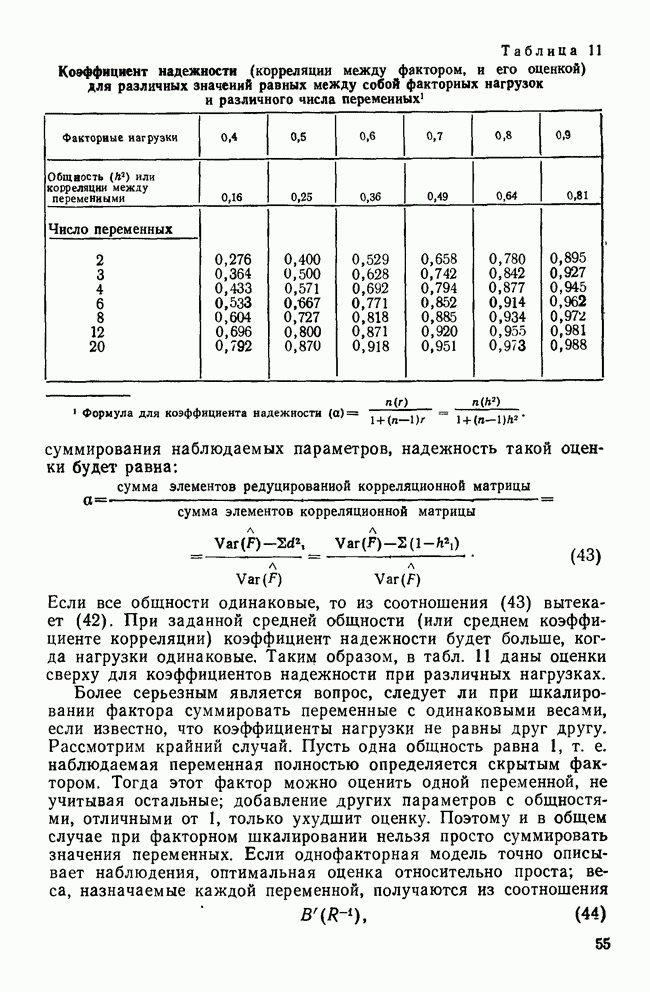
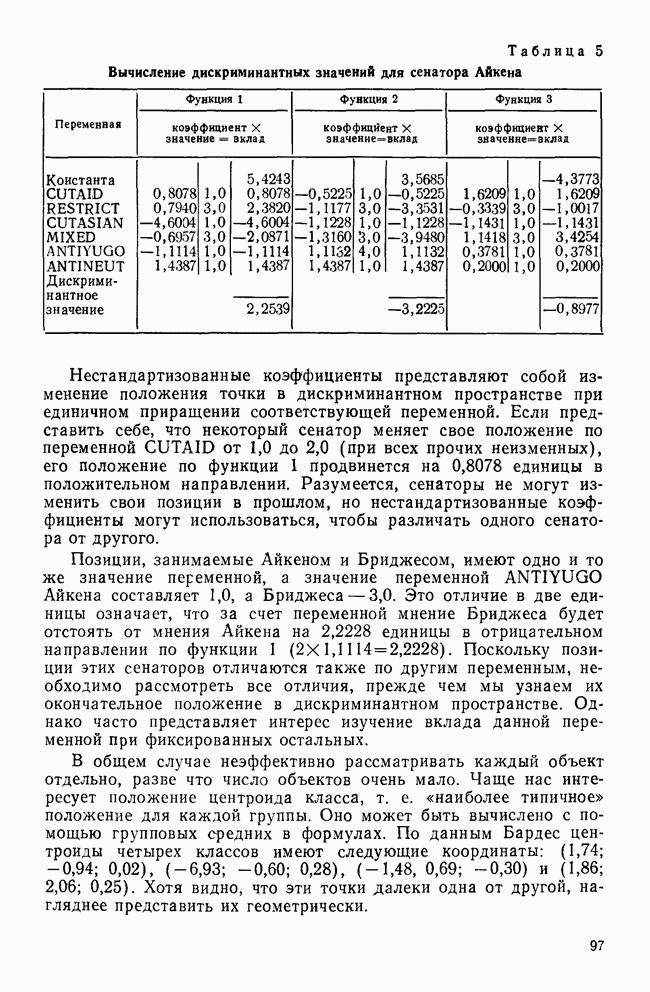
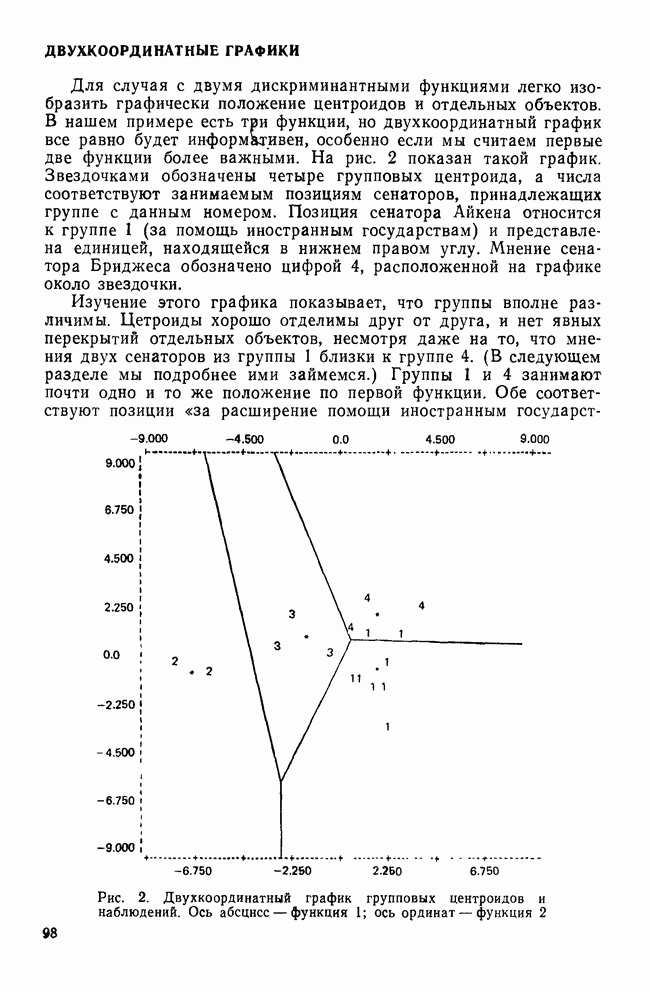
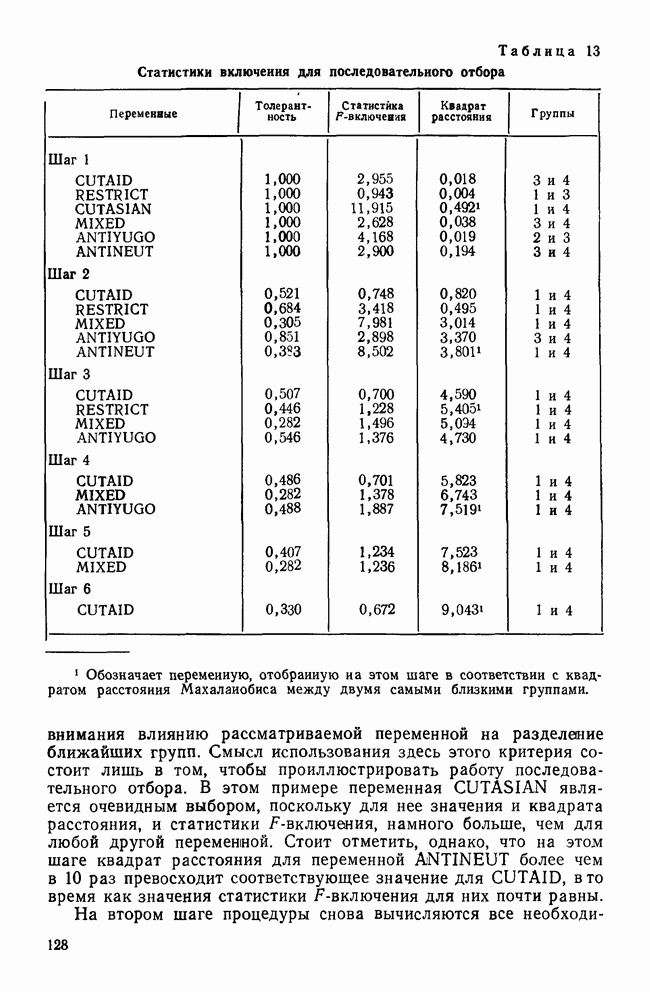
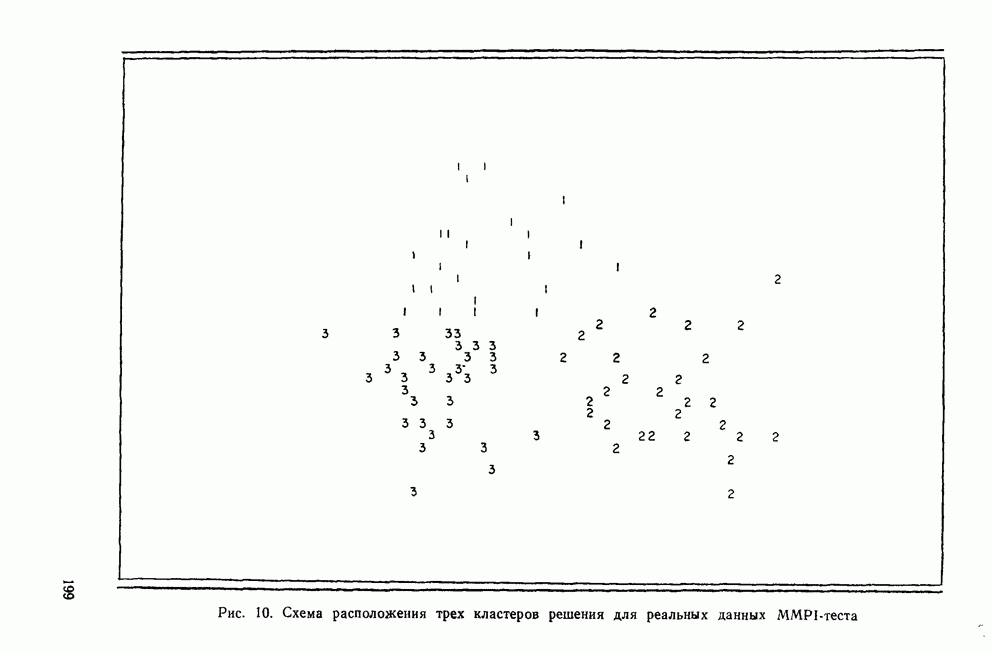
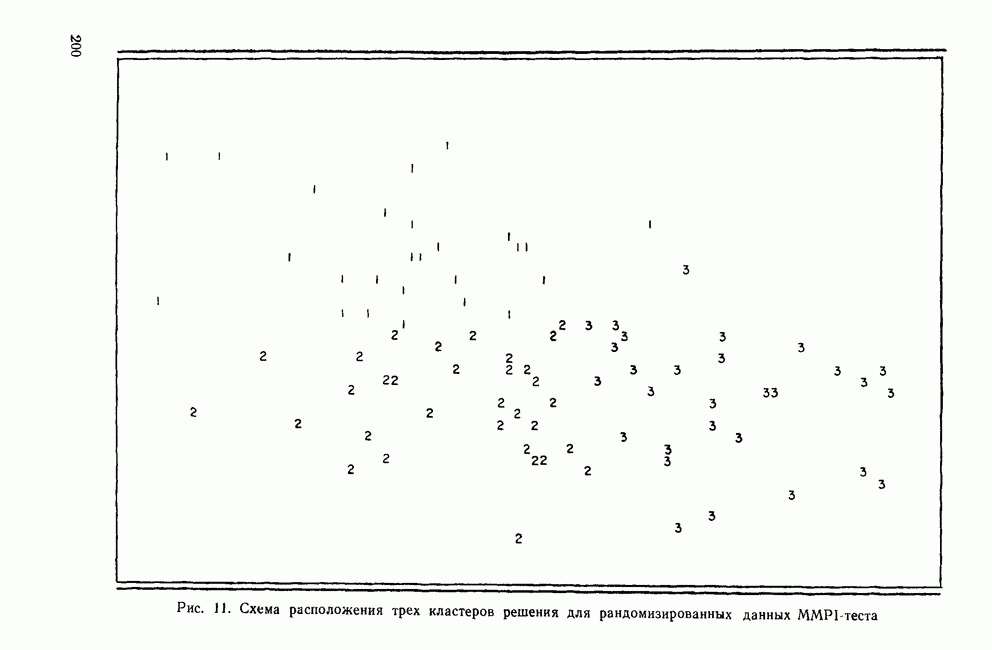
КЛАСТЕРНЫЙ АНАЛИЗ
Mark S. Aidenderfer, Roger К. Biasfifield. Cluster Analysis (Second Printing, 1985).
ПРЕДИСЛОВИЕ
Классификация объектов по осмысленным группам — кластеризация — является важной процедурой в области социологических исследований. Несмотря на широкое применение понятий кластеризации, кластерный анализ как формальная многомерная статистическая процедура понимается все еще плохо. Отчасти это объясняется тем, что последние десять лет техника кластеризации разрабатывалась особенно быстро, поскольку стали доступны вычислительные машины, способные выполнить большое число необходимых операций. Данный метод разрабатывается и применяется археологами, психологами, специалистами по государственному праву и социологии, поэтому часто приходится пользоваться нестандартизовамной, приводящей к путанице терминологией. В связи с этим новые разработки медленно распространяются на другие дисциплины.
Настоящая работа была задумана как введение в кластерный анализ для тех, кто не имеет соответствующей подготовки и нуждается в современном и систематическом путеводителе по «лабиринту» понятий, методов и алгоритмов, связанных с идеей кластеризации. Вначале обсуждаются меры сходства — обязательная отправная точка любого анализа процесса кластеризации. Авторы отмечают расхождения в теоретических значениях этого понятия и рассматривают ряд эмпирических мер, чаще всего применяемых для измерения сходства. Затем описываются различные методы для фактической идентификации кластеров, а также процедуры обоснования и проверки адекватности результатов кластерного анализа, на что часто не обращается внимание.
В работе проводятся сравнение и оценка различных понятий и методов.
Поскольку вычислительные машины почти всегда позволяют провести кластерный анализ больших множеств данных, авторы рассматривают ряд стандартных и специализированных программ. Кроме того, после каждого раздела помещены библиографические замечания. В приложении приводятся первичные данные, использованные в примерах, так что читатель может проверить, правильно ли он разобрался в описанных процедурах.
Поскольку книга сводит воедино сведения из очень обширного круга источников, читатель получит довольно полное руководство по современному применению статистических методов и вычислительных программ.
Ричард Ними, редактор серии