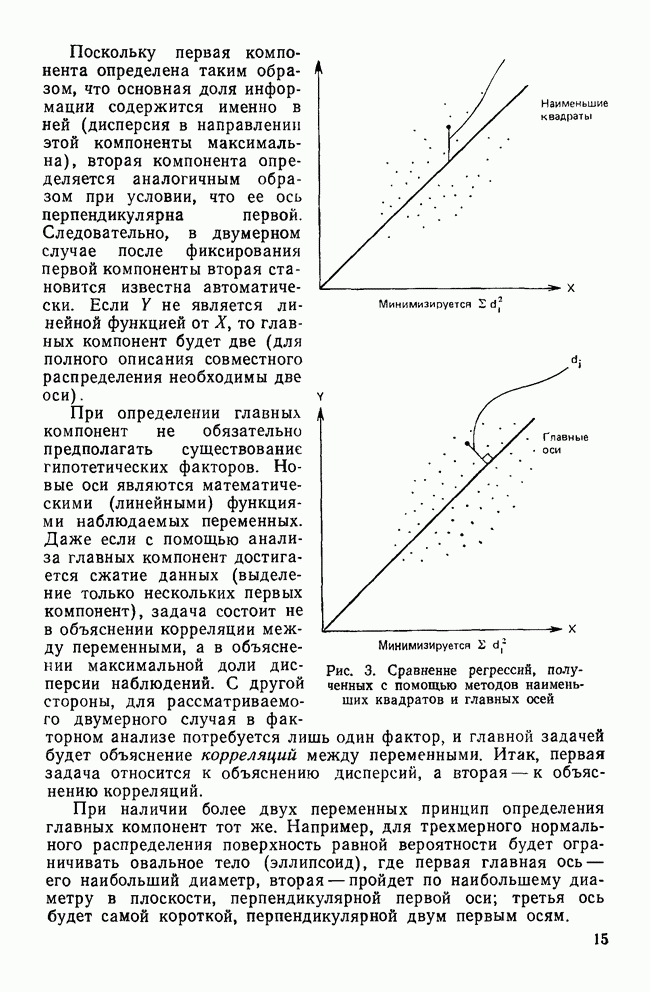
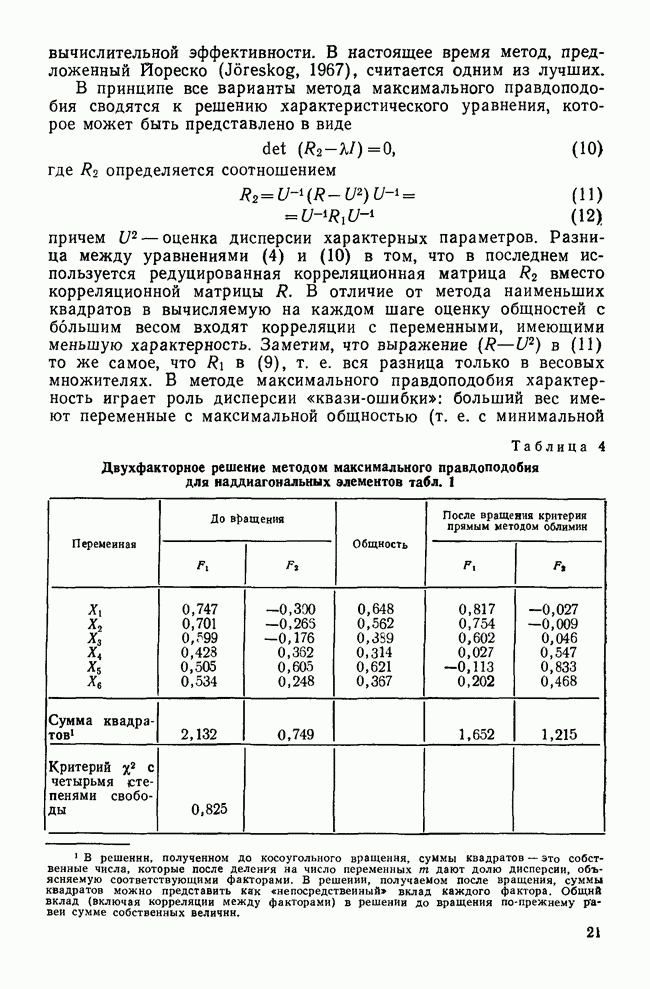
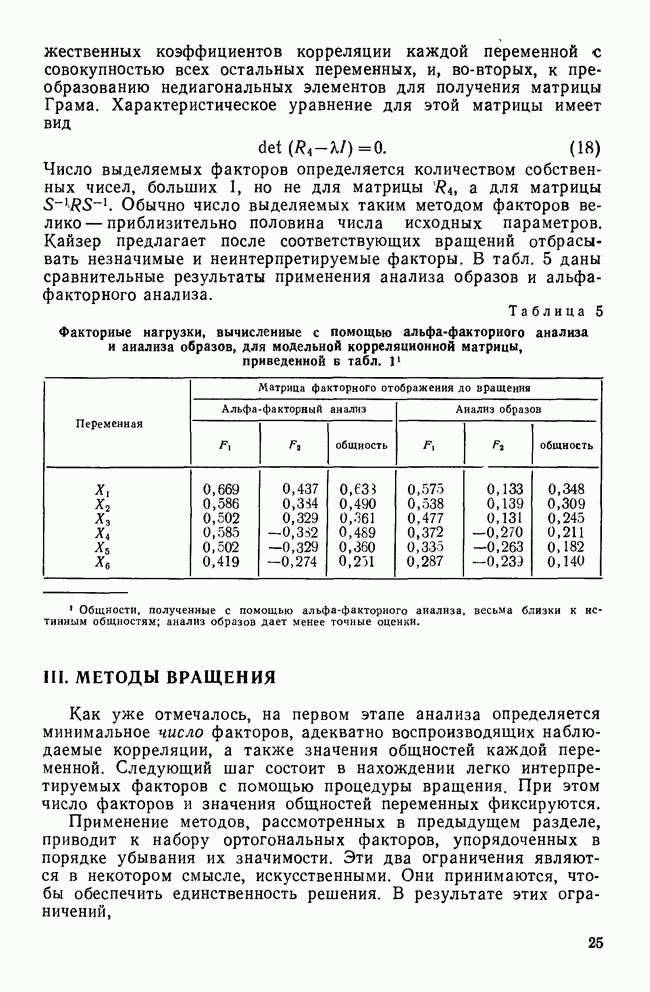
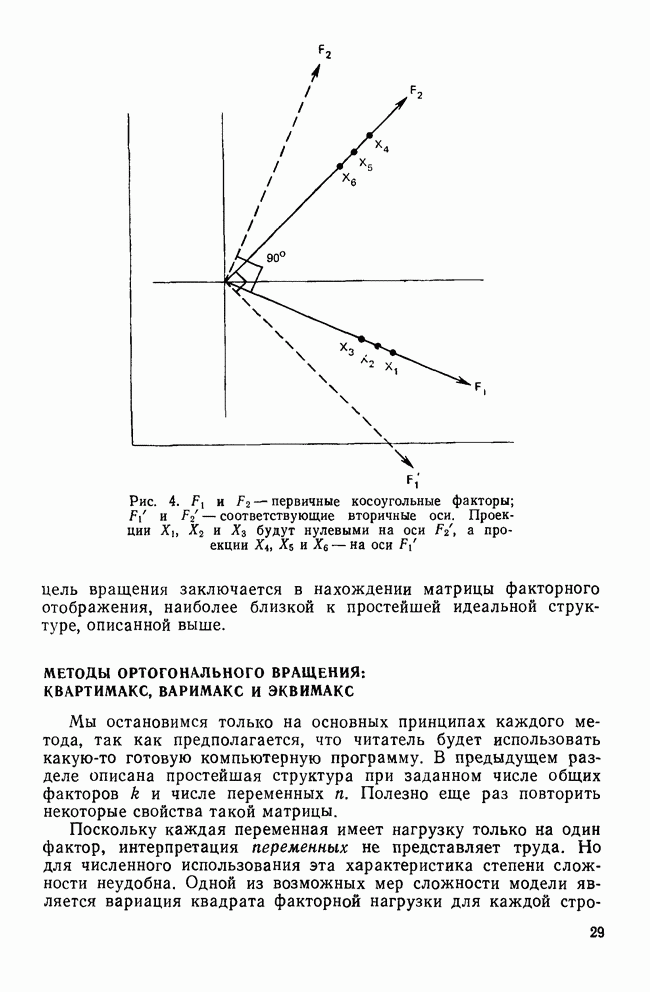
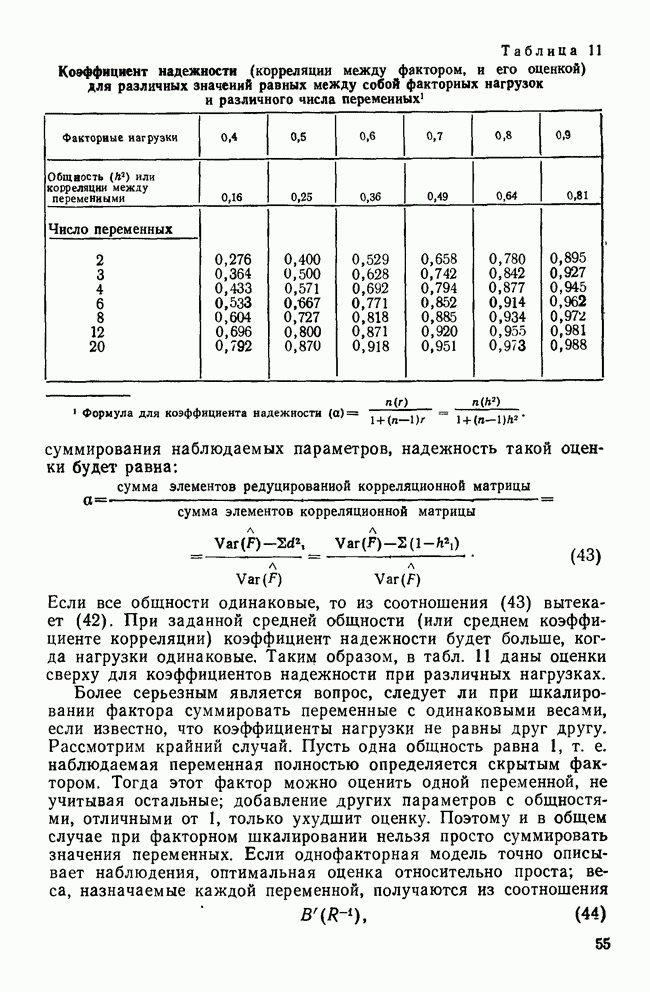
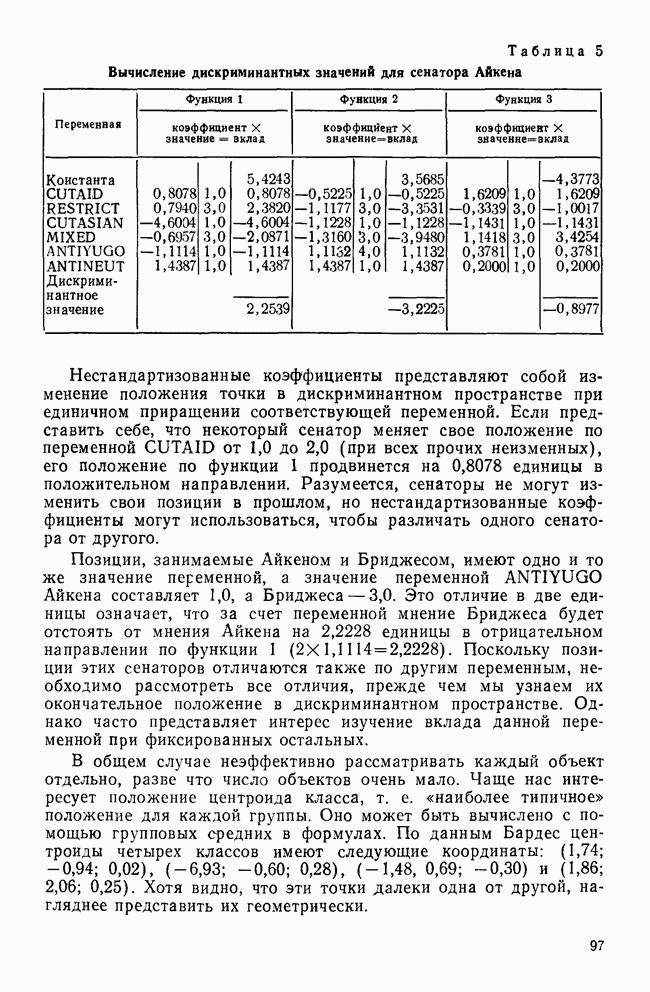
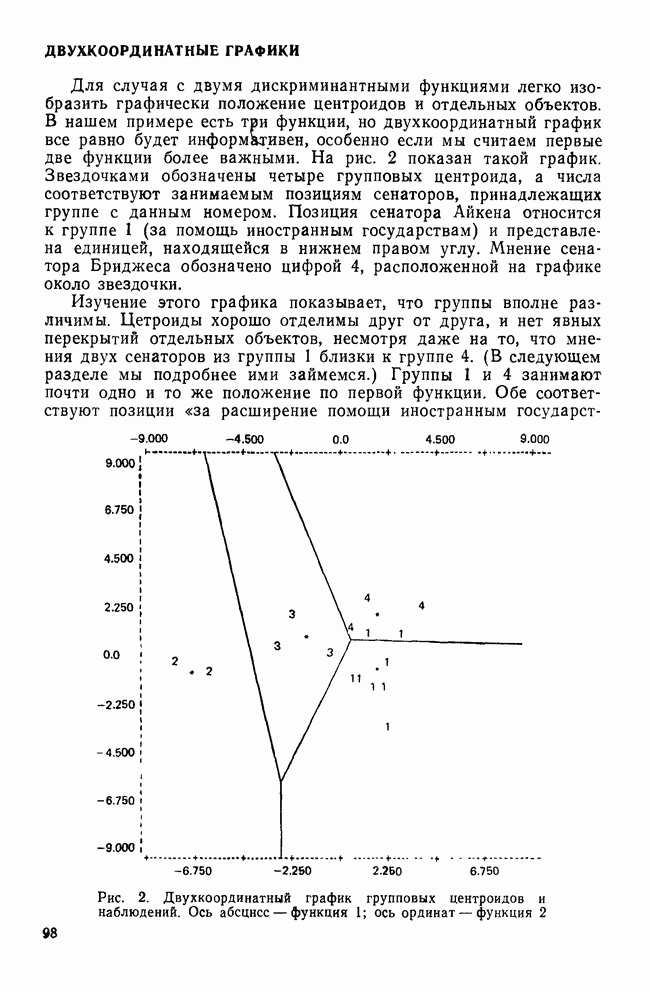
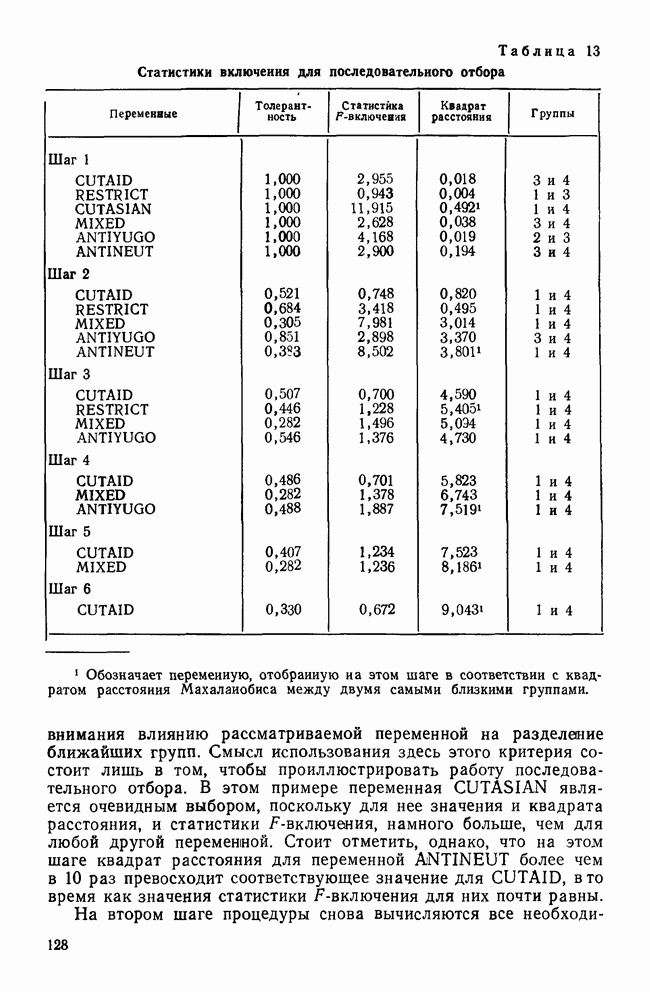
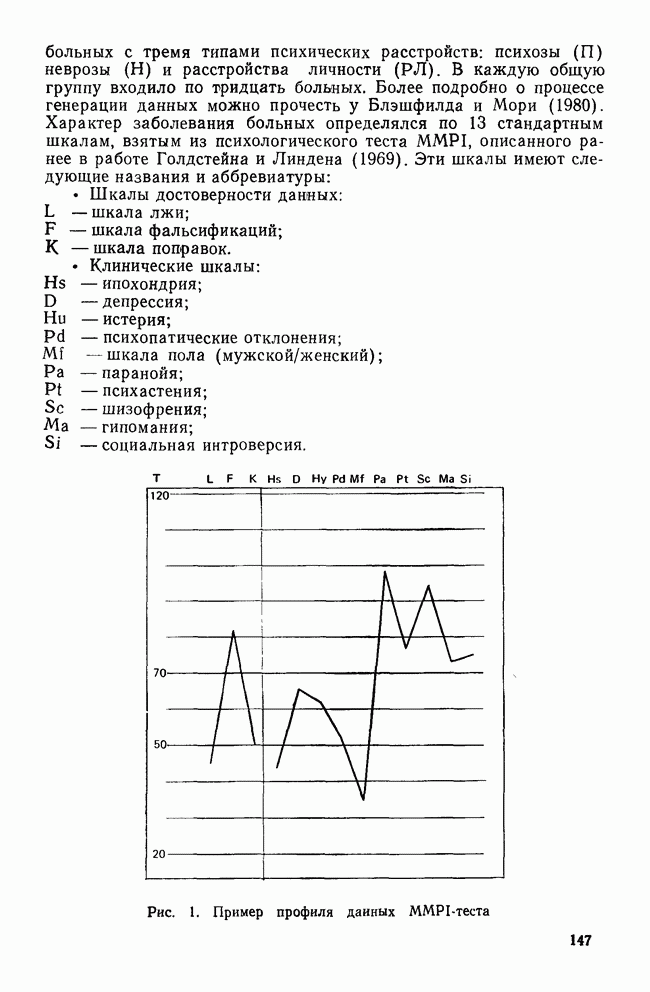
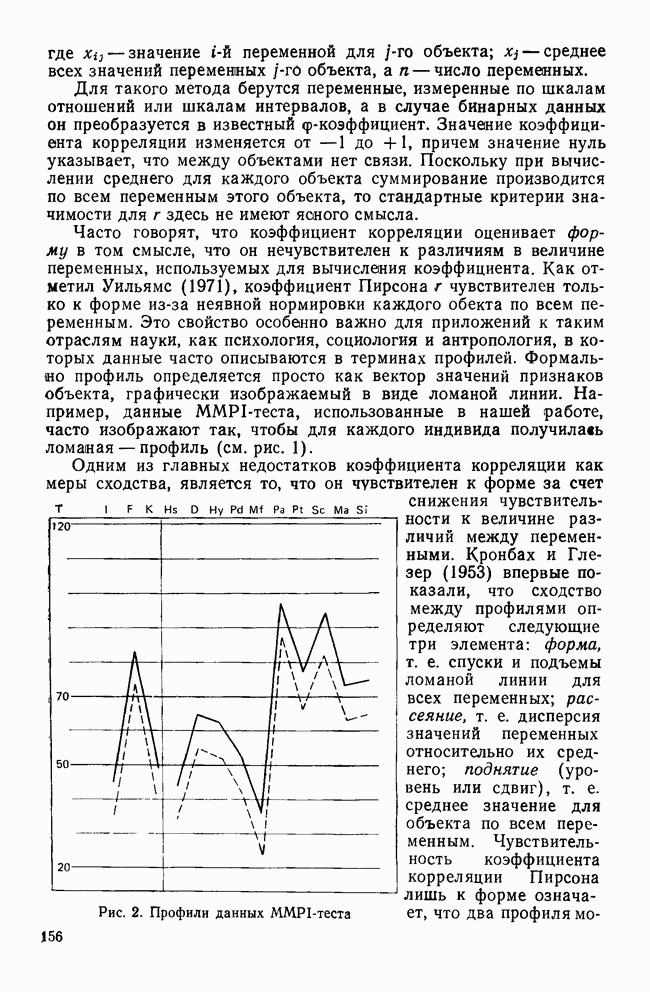
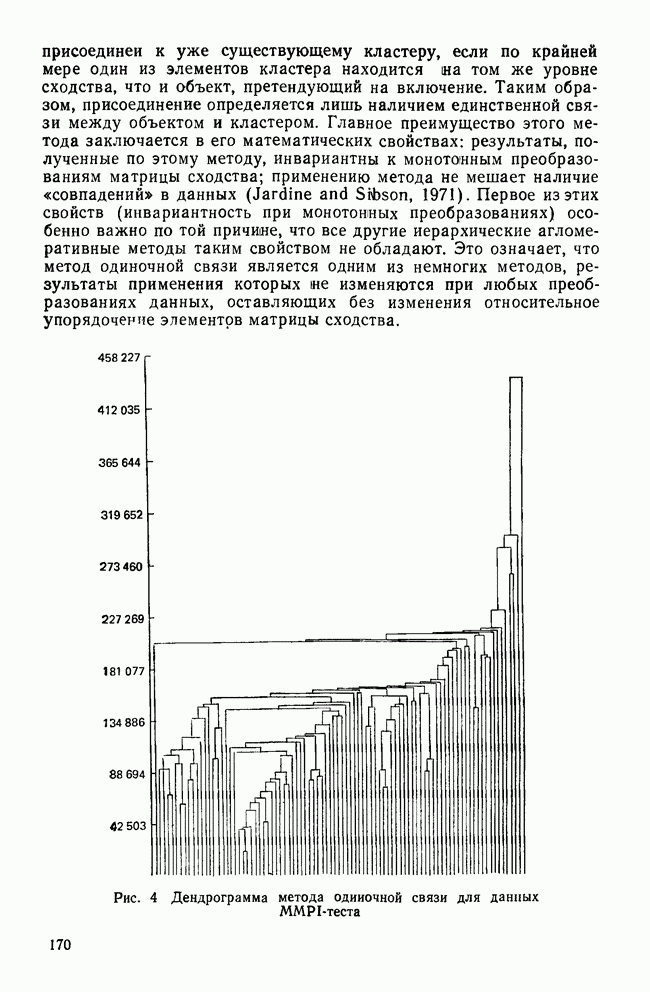
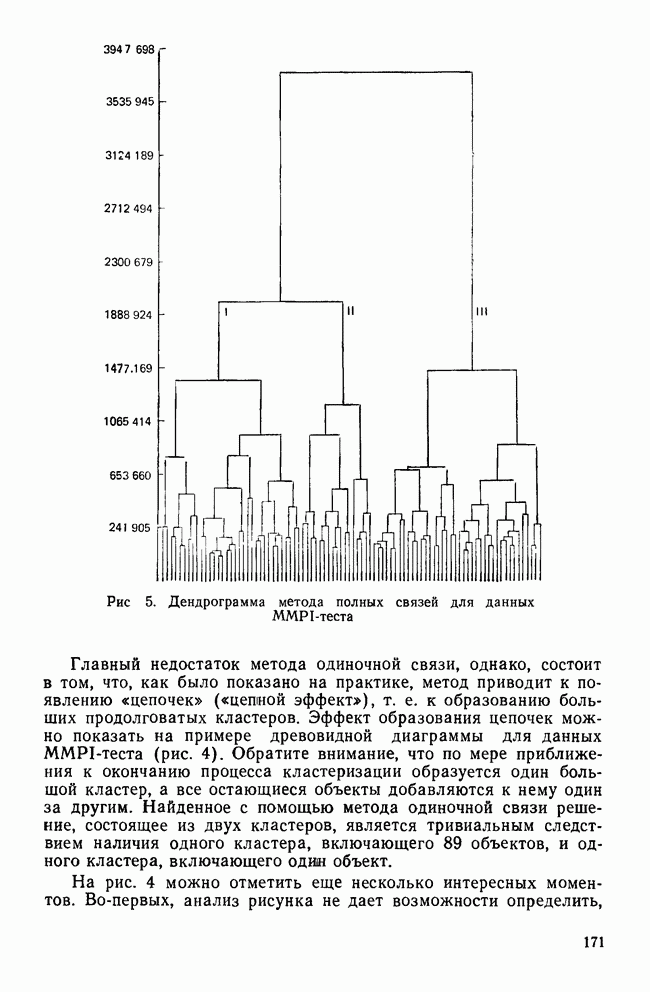
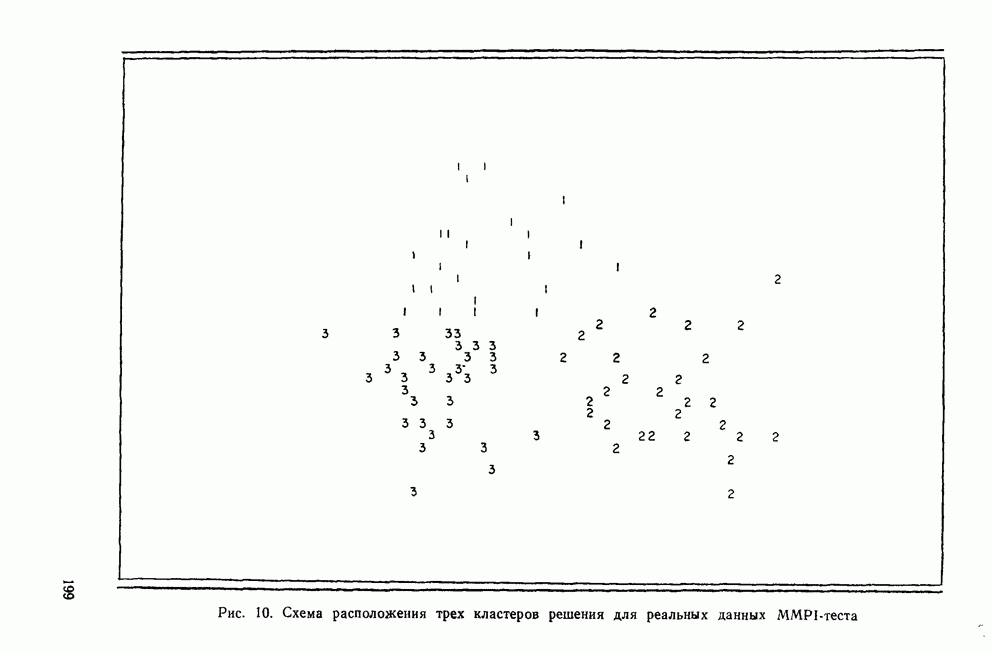
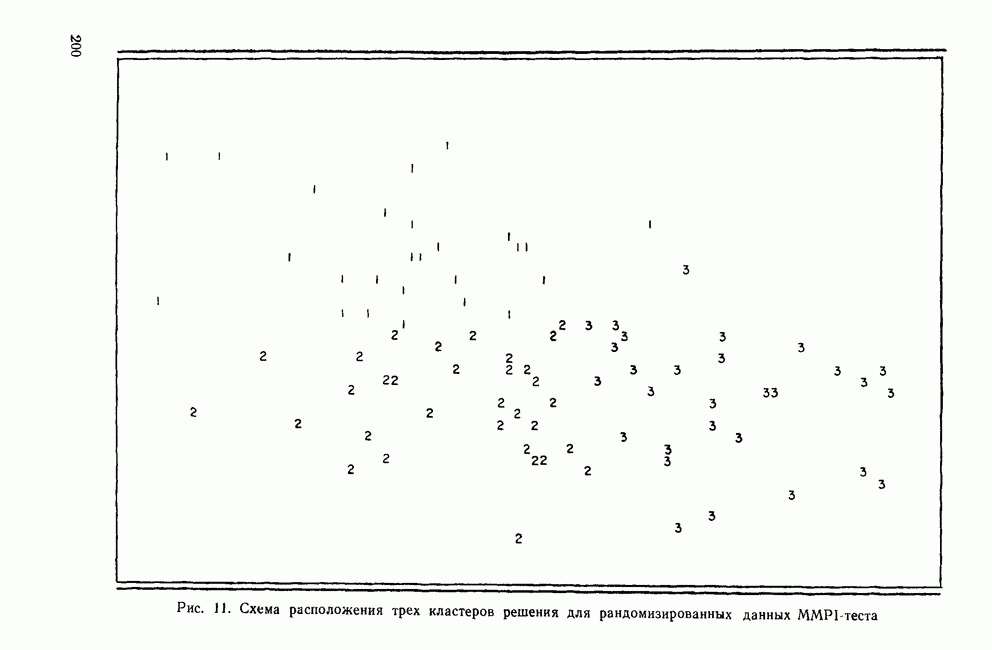
ОБОСНОВАНИЕ С ПОМОЩЬЮ РАЗБИЕНИЯ ВЫБОРКИ
Как и все методы вывода, основанные на выборочных данных, процент правильных предсказаний и  -статистика имеют тенденцию к переоценке эффективности процедуры классификации. Это происходит потому, что обоснование решения производится по той же выборке, которая применялась для получения классифицирующих функций. Выражения, использованные при создании этих функций, чувствительны к выборочным погрешностям. Таким образом, функции отражают свойства конкретной выборки более точно, чем свойства всей генеральной совокупности.
-статистика имеют тенденцию к переоценке эффективности процедуры классификации. Это происходит потому, что обоснование решения производится по той же выборке, которая применялась для получения классифицирующих функций. Выражения, использованные при создании этих функций, чувствительны к выборочным погрешностям. Таким образом, функции отражают свойства конкретной выборки более точно, чем свойства всей генеральной совокупности.
Если выборка достаточно велика, то мы можем при обосновании процедуры классификации взять случайное разбиение выборки на два подмножества. Одно подмножество необходимо для получения функций, а другое — только для проверки классификаций. Поскольку подмножества имеют различные выборочные ошибки, тестовое подмножество даст лучшую оценку способности предсказания свойств генеральной совокупности.
Статистики расходятся во мнениях о целесообразных размерах двух подмножеств Одни рекомендуют выбирать их равными, тогда как другие предпочитают брать большими размеры того или другого подмножества.
Однако главное внимание необходимо уделять тому, чтобы подмножество, используемое для вывода функций, было достаточно велико для обеспечения стабильности коэффициентов, иначе проверка будет обречена на неудачу с самого начала.
Мы рассмотрели различные процедуры классификации, которые позволяют предсказать принадлежность конкретных объектов к определенным классам, дают нам полезную информацию: 1) об отдельных объектах; 2) о различиях между классами и 3) о способности переменных как целого точно различать классы. В нашем обсуждении до сих пор предполагалось, что выбор множества дискриминантных переменных является оптимальным. Теперь перейдем к выделению некоторых подмножеств этих переменных, которые оказываются более экономичными, но столь же эффективными, как все множество.